EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models
Abstract.
Large Language Models (LLMs) such as GPTs and LLaMa have ushered in a revolution in machine intelligence, owing to their exceptional capabilities in a wide range of machine learning tasks. However, the transition of LLMs from data centers to edge devices presents a set of challenges and opportunities. While this shift can enhance privacy and availability, it is hampered by the enormous parameter sizes of these models, leading to impractical runtime costs.
In light of these considerations, we introduce EdgeMoE, the first on-device inference engine tailored for mixture-of-expert (MoE) LLMs, a popular variant of sparse LLMs that exhibit nearly constant computational complexity as their parameter size scales. EdgeMoE achieves both memory and computational efficiency by strategically partitioning the model across the storage hierarchy. Specifically, non-expert weights are stored in the device’s memory, while expert weights are kept in external storage and are fetched into memory only when they are activated. This design is underpinned by a crucial insight that expert weights, though voluminous, are infrequently accessed due to sparse activation patterns. To further mitigate the overhead associated with expert I/O swapping, EdgeMoE incorporates two innovative techniques: (1) Expert-wise bitwidth adaptation: This method reduces the size of expert weights with an acceptable level of accuracy loss. (2) Expert management: It predicts the experts that will be activated in advance and preloads them into the compute-I/O pipeline, thus further optimizing the process. In empirical evaluations conducted on well-established MoE LLMs and various edge devices, EdgeMoE demonstrates substantial memory savings and performance improvements when compared to competitive baseline solutions.
1. Introduction
Large language models (LLMs), e.g., GPTs (radford2018improving, ; radford2019language, ; brown2020language, ; ouyang2022training, ; openai2023gpt4techinicalreport, ; eloundou2023gpts, ) and LLaMa (touvron2023llama, ; touvron2023llama2, ), are reshaping machine intelligence for their remarkable performance on generic multimodal tasks, few-shot ability, and scalability. While born on datacenter warehouse, LLMs will gradually sink to edge devices like personal PCs, smartphones, and even IoTs, for better data privacy, AI function availability, and personalization. In this trend, LLMs not only greatly advance the state-of-the-art performance of edge ML tasks compared to traditional neural networks, but also enable many new, exciting edge applications (chatgpt-googleplay, ). For instance, Qualcomm has deployed a text-to-image generative LLM model with more than 1 billion parameters entirely on smartphones (qualcommstabledef, ). Huawei has embedded a multimodal LLM into its smartphones to facilitate accurate natural language-based content searching (huaweuai, ).
Landing LLMs on mobile devices faces a key challenge of its vast parameter size and consequently unaffordable runtime cost. To alleviate this issue, mixture-of-experts (MoE) architecture (jacobs1991textordfeminineadaptive, ; fedus2022review, ), which allows only part of the LLM to be activated in per-token decoding, has been proposed recently. Intuitively, such sparse activation makes lots of sense as LLMs go larger and serve as a foundation model for various tasks, different tasks or input data could require only a tiny, different portion of the model to work, just as how human brains function (friston2008hierarchical, ). In this work, we target one of the most popular form of MoE design, where the single feed-forward network (FFN) within each transformer block is substituted with many experts (each is an independent FFN). During inference, a trainable function (namely router) within each transformer block routes the input to only Top-K (K=1 or 2) of all experts. More design details of MoE LLMs are presented in 2. Such MoE-based LLMs have been extensively researched (shazeer2017outrageously, ; lepikhin2020gshard, ; fedus2022switch, ; du2022glam, ; lewis2021base, ; roller2021hash, ; zhou2022mixture, ) and adopted in industry (microsoft-moe, ).
Pros and Cons of MoE Through its sparsity design, MoE LLMs are able to scale its parameter size and ability with almost constant computing complexity, making them good fit to edge devices whose storage is much more cost-effective and scalable than the computing capacity. Empirically, to hold a 105B-parameter model like GLaM(1.7B/256E) (du2022glam, ), a device needs 1T (external) storage that costs only less than 100$; yet to execute it in reasonable speed, e.g., 1 sec/token, 10 high-end GPUs are demanded that cost more than 100K$. However, MoE LLMs are too large to fit into device memory as will be shown in 2.2. For instance, Switch Transformers (with 32 experts per layer) requires 54GBs of memory for inference, which is not affordable on most edge devices. Simply scaling down the expert number could significantly degrade the performance capacity (fedus2022switch, ); either, frequently swapping weights between memory and stroage incurs huge overhead due to the autoregressive nature of LLM.
EdgeMoE: an expert-centric inference engine designed for the edge. In this work, we propose EdgeMoE, the first on-device LLM inference engine that is able to scale out the model size (expert number) with both memory and time efficiency. The overall design of EdgeMoE is based on a unique observation: most computations reside in a small portion of weights (non-experts are “hot weights”) that can be held in device memory; while most weights contribute only little computations (experts are “cold weights”). Such characteristics naturally fit the storage hierarchy (faster RAM vs. larger Disk). Based on the observations, EdgeMoE differentiates the positions of experts and non-experts in storage hierarchy. Specifically, it permanently hosts all hot weights in memory since they are used per-token inference; while the rest of the memory budget is used as an expert buffer for the cold expert weights.
With the expert buffer design, EdgeMoE only needs to load the activated experts on demand from storage to memory. However, this I/O overhead is still significant as compared to processing, e.g., up to 4.1 delay on Jetson TX2, as will be shown in 2.1. To address this issue, there are two general approaches: one is to directly reduce the I/O data, e.g., by quantizations; another one is to pipeline the I/O with computing to hide its latency. Both directions are not explored in prior MoE systems and face unique challenges: (1) Sophisticated quantization algorithms (zadeh2020gobo, ; aji2020compressing, ; kim2023squeezellm, ) achieve higher compression ratio, yet incurring significant pre-processing time for deserialization and decompression as discussed in 3.2. More vanilla quantizations (han2015deep, ), on the other hand, cannot effectively reduce the experts I/O. (2) Unlike static models that have a fixed execution pattern, experts in MoE are dynamically activated and system cannot derive a priori knowledge until router function. As such, there is no room for EdgeMoE to pre-load an to-be-activated expert. Disregarding the knowledge of expert activation, one might simply cache the experts that are more frequently activated to increase the expert hit ratio; however, this approach brings limited benefit since the activation frequency across experts are purposely trained to be balanced (fedus2022review, ).
To address above issues, EdgeMoE has two novel designs.
Expert-wise bitwidth adaptation. EdgeMoE augments a preprocessing-lightweight quantization method, per-channel linear quantization (kim2022mixture, ), with expert-level bitwidth adaptation. It is based on a crucial observation that experts across different layers or even in the same layer exhibit different impacts on model accuracy after being quantized. Therefore, EdgeMoE employs a fine-grained, expert-wise bitwidth adaptation to fully leverage the model redundancy. At offline, EdgeMoE progressively lower the bitwidth of a few experts that are most robust to quantization, till the accuracy degradation meets a tolerable threshold specified by users. The selection of which experts to further quantize also jointly considers how much the lower-bitwidth quantization could boost inference speed. Ultimately, EdgeMoE obtains a mixed-precision model that achieves the target accuracy with the smallest possible model size, i.e., the fastest loading time.
In-memory expert management. To enable I/O-compute pipeline, EdgeMoE predicts which expert will be activated before its router function. The design is motivated by a novel observation: the expert activation paths (i.e., the set of sequentially activated experts per token) taken in practice are highly unbalanced and skewed. It indicates significant correlations between expert activations, as further confirmed by our experiments in 3.3.2. Therefore, during the offline phase, EdgeMoE builds a statistic model to estimate the probability of expert activation in the current layer based on the activations of previous layers. In online inference, EdgeMoE queries this model and preloads the most possible expert ahead of activation for I/O-compute pipeline. Additionally, EdgeMoE designs a novel cache eviction policy for the expert buffer, leveraging both the activation frequency and their relative positions to the current executin. Overall, both the predict-then-preload and the eviction techniques are to maximize the expert cache hit ratio when they are activated.
Results We’ve implemented a prototype of EdgeMoE atop PyTorch that fully realizes the above techniques. We then perform extensive experiments to evaluate EdgeMoE’s performance through 7 MoE-based LLMs and 2 embedded platforms including Raspberry Pi 4B (CPU) and Jetson TX2 (GPU). Compared to holding the whole model in device memory, EdgeMoE reduces memory footprint by 1.05–1.18; compared to memory-optimized baselines such as dynamically loading expert and STI (guo2023sti, ), EdgeMoE achieves 1.11–2.78 inference speedup. For the first time, EdgeMoE enables fast inference for 10B-sized LLMs on COTS edge devices like Jetson TX2. The ablation study further shows that each individual technique of EdgeMoE contributes to significant improvements.
Contributions The paper makes following contributions:
-
•
We perform preliminary experiments to demystify the performance of MoE LLMs on edge devices and analyze the implications.
-
•
We present EdgeMoE, an on-device MoE engine with one key design that treats memory as cache for experts that are hold in external storage when not activated.
-
•
We further incorporate two novel techniques, namely expert-wise bitwidth adaptation and in-memory expert management, to reduce the expert I/O overhead of EdgeMoE.
-
•
We demonstrate the effectiveness of EdgeMoE through extensive experiments.
2. Pilot Experiments and Analysis
2.1. A Primer on LLM with Mixture-of-Experts
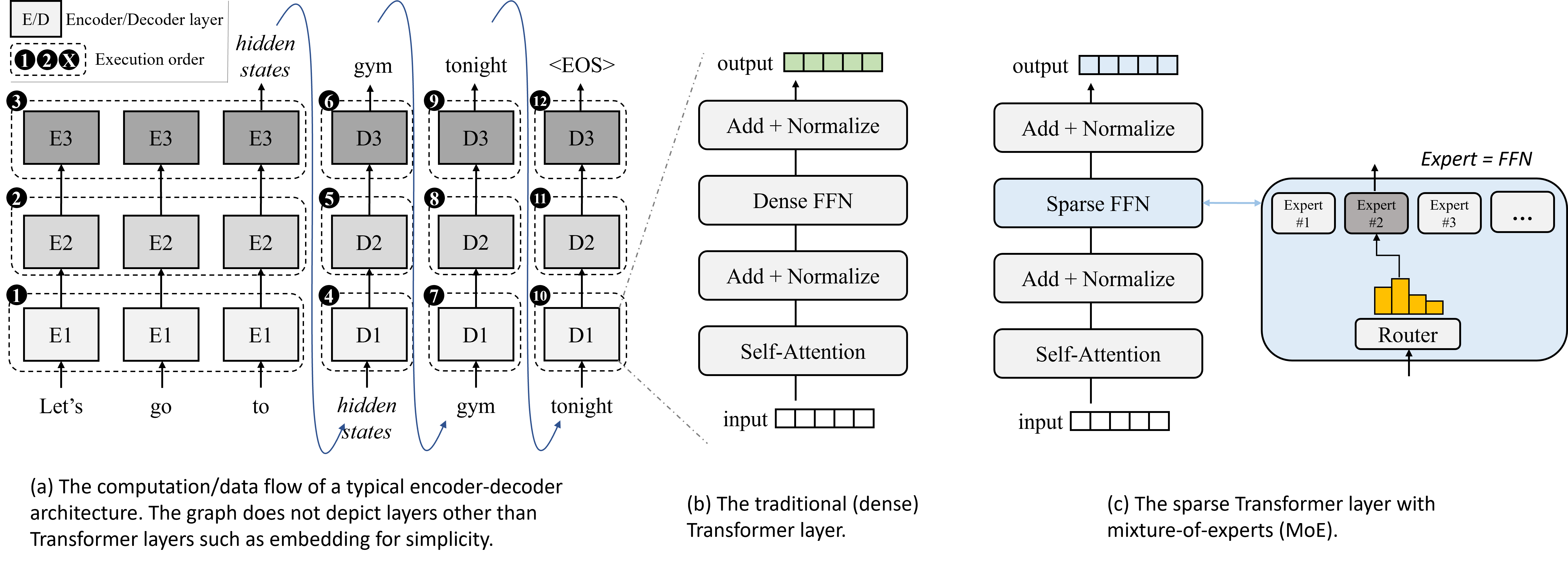
This work focuses on encoder-decoder111Decoder-only LLMs like GPTs (radford2018improving, ; radford2019language, ; brown2020language, ; ouyang2022training, ; openai2023gpt4techinicalreport, ; eloundou2023gpts, ) can be treated as a special case of encoder-decoder therefore is also supported by our system., one of the most popular LLM architecture nowadays. The encoder processes the input sequence and compress this information into a continuous intermediate representation, while the decoder takes this representation and generates (predicts) an output sequence. A unique characteristic of decoder is that it generates tokens in an autoregressive manner, i.e., appending the last output token to the end of the input sequence when generating the next token (token-wise dependency). Figure 1(a) illustrates a simplified computation and dataflow graph of the LLM inference process with three Transformer layers. Both encoder and decoder are underpinned by Transformer layers (vaswani2017attention, ), each consisting a set of attention heads (for extracting word-pair relationships), FFNs (for processing and enhancing information representation with non-linearity), and other minor operators, as shown in Figure 1(b).
Recent trend is to deploy sparse FFNs – a set of “experts” which is selected at runtime via small-sized, offline-trained “routers”, as illustrated in Figure 1(c). As a result, MoE architecture is able to scale the model parameter size with sublinearly increased computing complexity. This is because only a fixed set (typically 1 or 2) of experts/weights will be activated for each token. For instance, GLaM (du2022glam, ), a MoE-based LLM, achieves considerably higher accuracy on NLP tasks than GPT-3 with only half of its computation cost. There are also rumors saying that GPT-4 (openai2023gpt4techinicalreport, ), the state-of-the-art LLM, is using MoE as well. Such parameter scalability makes MoE-based LLMs good candidates for edge devices in terms of their constrained computing capacity.
2.2. On-device Sparse LLM Inference
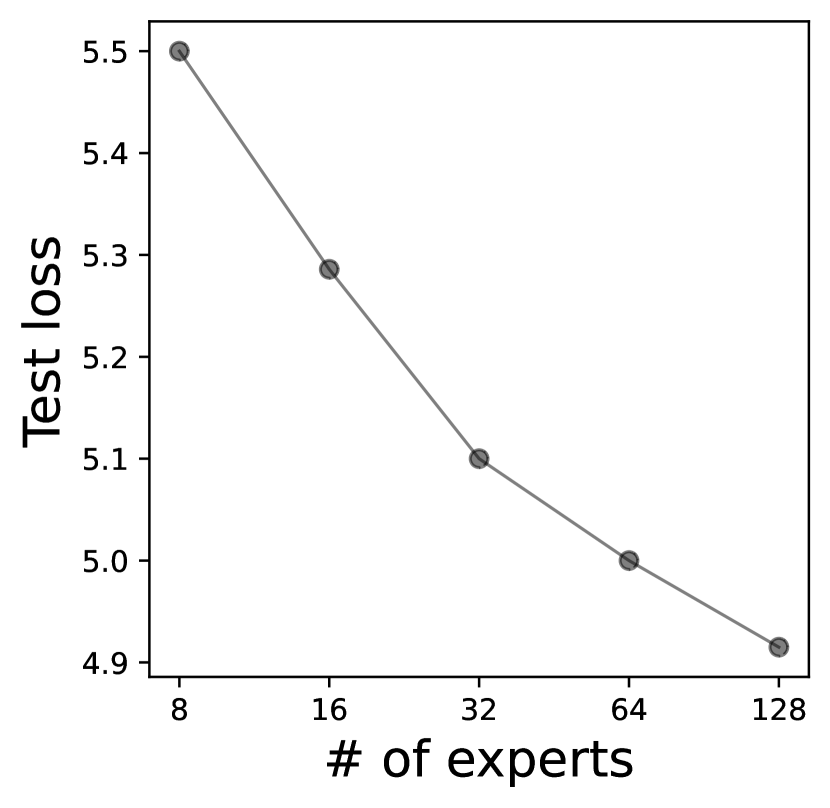
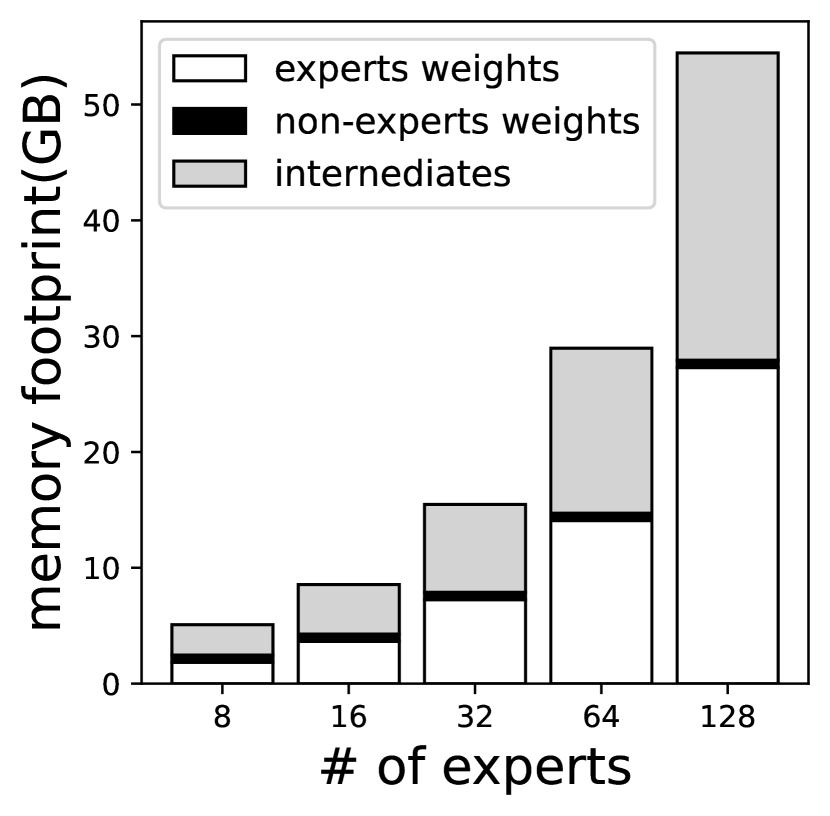
With great sparsity comes great model size. Sparsely scaled-out LLMs stress memory, the key resource on a edge device. To better understand their implications to an edge device, especially the memory/computation tradeoff and execution characteristics, we characterize the execution of Switch Transformer (fedus2022switch, ), one of the most popular MoE-based sparse LLMs by Google, on two COTS SoCs Jetson TX2 and Raspberry Pi 4B. We make following crucial observations as following.
(1) Expert weights bloat device memory. While improving the model accuracy, the expert weights quickly bloat the model sizes as its number increases. Google has shown that by scaling up the expert number per FFN from 8 to 256, the model capacity continuously and remarkably improves (fedus2022switch, ). However, as shown in Figure 2, the increased experts lead to huge peak memory footprint that is unaffordable by edge devices. For instance, Raspberry Pi 4B with 8GB memory can only hold the smallest Switch Transformers variant with 8 experts per FFN. Consequently, the memory wall severely limits the scalability of MoE-based LLMs, which is crucial to its success. Note that even if the device memory is large enough (e.g. Jetson TX2 with 8GB RAM) to hold a whole model in memory, the large model size makes it a likely victim of OS memory management. The result is the model only can serve a few inferences before getting recycled.
One might resort to layer-by-layer swapping strategy (guo2023sti, ) to handle memory inefficacy. However, due to the auto-regressive nature of LLMs, the whole model weights need to be loaded for decoding each token. As a result, the I/O loading time could be 30.9 more than compute, making the inference extremely slow.
(2) Experts weights are bulky but cold. We find that most computations during inference reside in a small portion of weights (non-experts), while most of the weights (experts) contribute to a small portion of computations. This attributes to the sparse activation nature of experts. Taking ST-base-16 as an instance, the experts contribute 86.5% of total memory usage while only 26.4% of the computation.
Intuitively, the above characteristics naturally fit the device storage hierarchy (faster RAM vs. larger Disk). Therefore, we could use a discriminative swapping strategy by holding all non-experts in memory but only swapping in/out experts between memory and disk. Specifically, an expert is loaded into memory only when it is activated by the router; once used, its memory is released immediately. In such a case, the memory usage could be as less as the size of all non-expert weights plus the size of one expert. Meanwhile, the I/O overhead is reduced to one expert’s weights per layer.
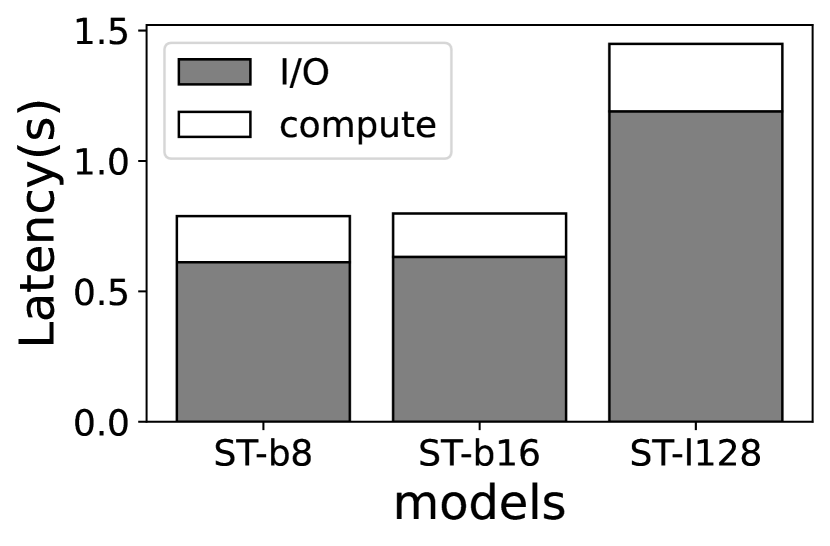
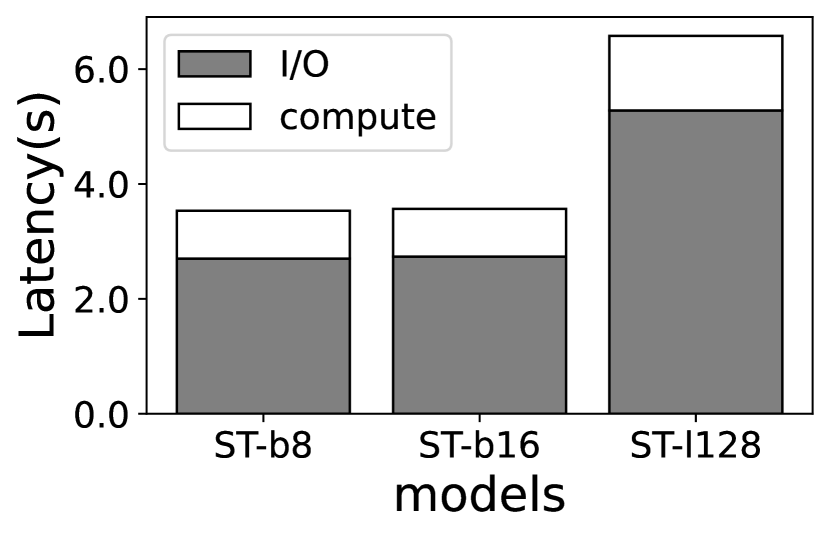
(3) Expert weight computation vs I/O asymmetry. Unfortunately, even loading one expert per layer significantly degrades the execution performance of MoEs. With the above discriminiative swapping strategy, we find that the per-sample inference time (generating a whole sequence with multiple tokens) is slow on Jetson TX2 (e.g., more than 17secs on Jetson TX2 on average), and the decoding time dominates due to its autoregressive nature. We further break down the latency to the compute (inference) and I/O (experts loading) in Figure 3, and find that the latter contributes the most. Compared to an oracle case with infinite memory (so no experts I/O), the per-token decoding time is increased by 3.2–3.9 and 3.3–3.8 on Jetson TX2 and Raspberry Pi 4B, respectively.
(4) Compute/IO pipelining is not feasible. One may further leverage the compute/IO parallelism and overlap the expert loading with weight computation, similar to STI (guo2023sti, ). However, we find such an approach unfeasible due to following reasons.
-
•
Expert activation dependency. Unlike standard Transformer models targeted by STI, which sequentially preload layers, MoE Transformers only decide which experts to load when the prior layer finishes computation. Such expert-level activation dependency prohibits compute/IO pipeline.
-
•
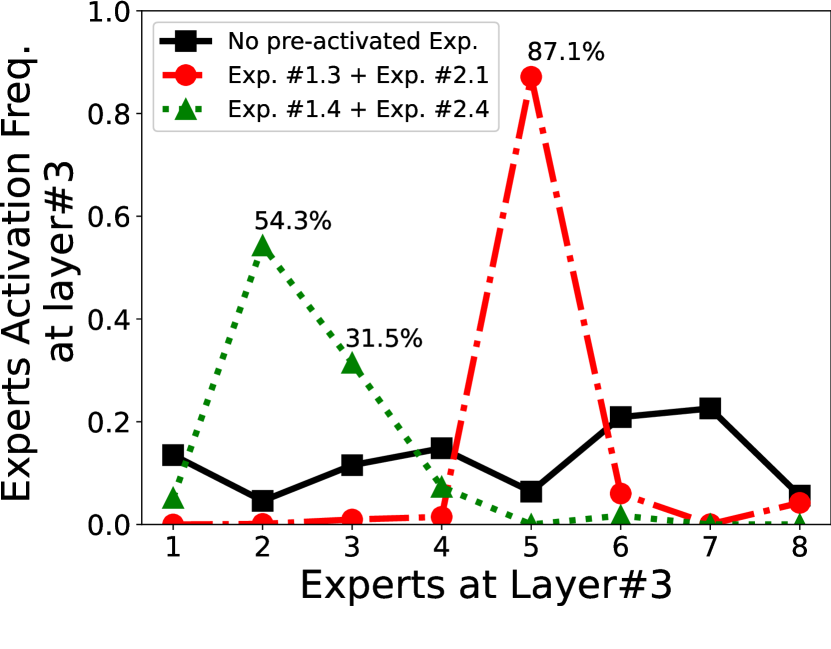
Expert activation frequency. One might preload “hot” experts with higher chance to be activated into memory as pipeline, i.e., a frequency-based cache strategy. However, we find such an approach not beneficial as the experts in the same layer have similar chance to be activated, as demonstrated by our experiments depicted in Figure 8(left). Such a balanced activation phenomenon is not surprising, because the training mechansim designs it to be so to maximize the GPU usage at training time (fedus2022switch, ).
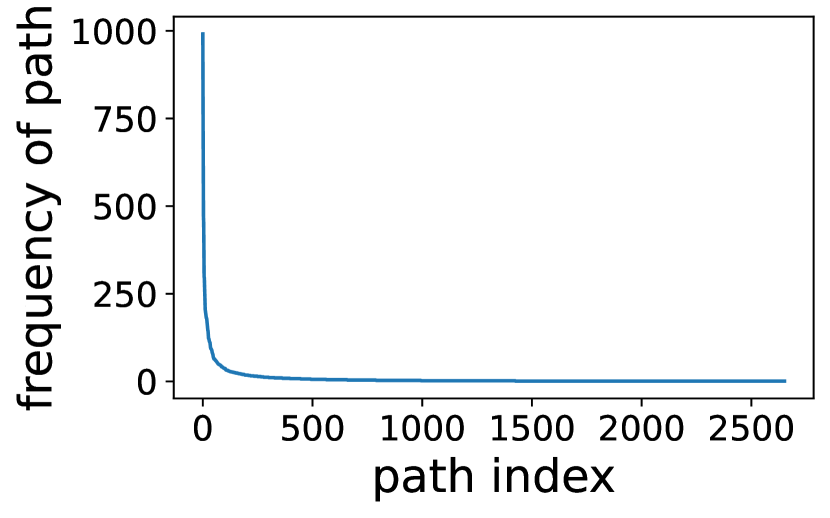
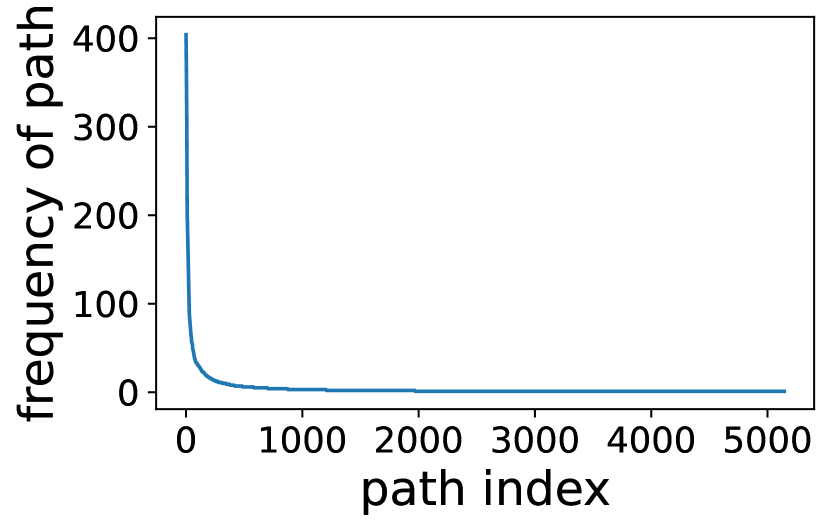
(5) Expert activation path follows power law distribution. While the overall activation frequency of each single expert is well balanced, we find that the activation path, i.e., a vector of the activated experts of all transformer layers for a token, are highly skewed. Figure 4 depicts the distribution of activation path obtained on two MoE models and two datasets. It presents a power law distribution: the 20% most frequently activated paths contribute to more than 99% of the activation cases of all tokens. This observation implies that the expert activation across different layers could be non-iid, which drives us to a deeper analysis of the expert activation correlation later in 3.3.
3. EdgeMoE Design
3.1. Overview
System model
EdgeMoE is the first execution engine to enable fast inference of large MoE Transformer model (e.g. ¿8GB) on an edge device. It supports general MoE Transformer models for interactive tasks such as text generation and summarization.
EdgeMoE incarnates as a runtime library linked to user apps. Along with EdgeMoE, MoE LLMs with experts compressed into different bitwidths are also installed on an edge device. It is configured by two key parameters. First, a memory budget , specified either by users or the OS. The budget ranges from 1.5GB–3GB, which is one to two orders of magnitude smaller than the existing MoE LLMs. The flexible constraint accommodates varying device memory and adapts to system memory pressure. Second, a tolerable accuracy loss chosen by the user. Based on the desired accuracy loss , EdgeMoE tunes the individual bitwidths for the experts for constructing the model to be executed at run time. Note this is a soft goal because existing MoE LLMs are unable to provide accuracy guarantees.
Upon user invocation, EdgeMoE first selects the model satisfiable to accuracy loss and instantiates an expert preload/compute pipeline for reducing inference latency: it sequentially loads all non-expert weights by layers; depending on prior experts activated, it opportunistically load the experts for the next layers, overlapped with the computation of current layers. As a result of the inference, EdgeMoE generates a set of predicted tokens (e.g. in text generation task) or a summary (e.g. in summarization task).
During execution, EdgeMoE maintains two memory buffers: 1) an expert buffer used for managing and caching expert weights.It resides in memory along with EdgeMoE for supporting multiple rounds of inferences. 2) a working buffer that holds all intermediate results. It is only temporary and can be thrown away right after each inference finishes.
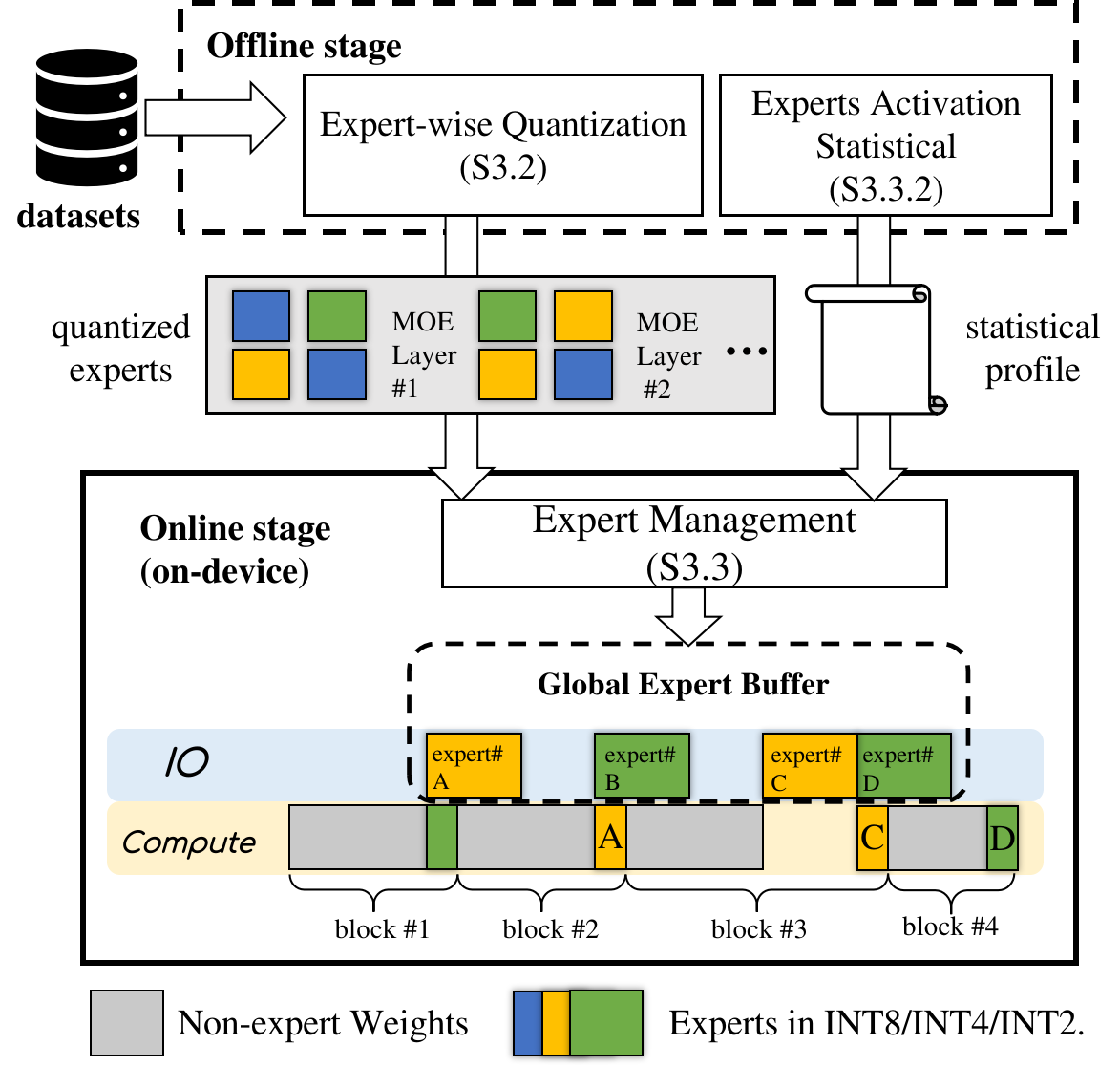
The operation
To use, EdgeMoE works in two main stages as shown in Figure 5.
-
(1)
Offline expert quantization (3.2) With an accuracy loss specified by user (e.g. 5%) on a given task, EdgeMoE first preprocesses a pretrained model offline: it profiles the expert importance and then quantizes the experts to different bitwidths based on their assessed importance. The resultant model comprises a set of experts with different bitwidths, even for those in the same transformer layer.
-
(2)
Online expert management (3.3). At run time, EdgeMoE instantiates a preload/compute pipeline and dynamically manages the experts between device memory and disk via an expert buffer. By leveraging the statistical profile of expert activation, EdgeMoE pre-determines which experts to fetch from disk prior to their router function and which to evict when the buffer is full.
Applicability
The EdgeMoE framework is generic, applicable to both decoder-only and encoder-only transformer architecture. It is compatible with both dynamic (e.g. Switch Transformers (fedus2022switch, ), GLaM (du2022glam, )) and static routing (e.g. Hash layer (roller2021hash, ), expert choice MoE (zhou2022mixture, )) MoE layers. Notably, in static routing layers, expert activation only depends on the original input tokens but not their hidden states. For such layers, EdgeMoE simply preloads experts as instructed by input tokens in the pipeline without prediction.
3.2. Expert-wise Quantization
To fit the expert weights under a set memory budget and to balance the compute/IO asymmetry, we opt for dictionary-based quantization (han2015deep, ), which works with unmodified pretrained models; we do not use quantization-aware training (QAT) (liu2023llm, ) to avoid retraining LLMs, which is tedious and expensive. While the quantization techniques are well-known, EdgeMoE is the first to apply them to individual experts and to exploit accuracy vs bitwidths tradeoffs.
Choosing the algorithm.
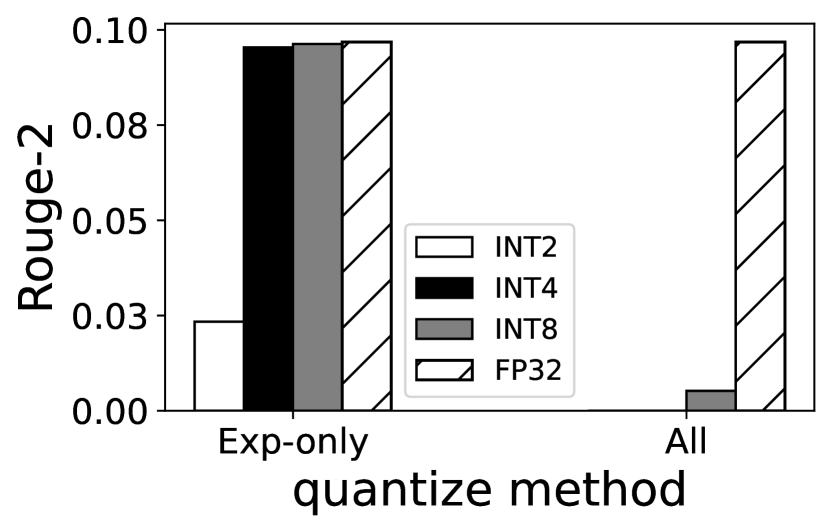
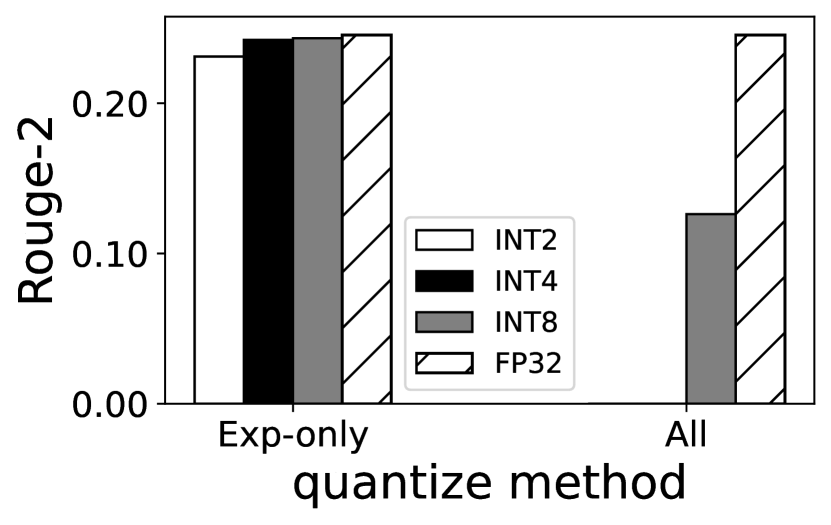
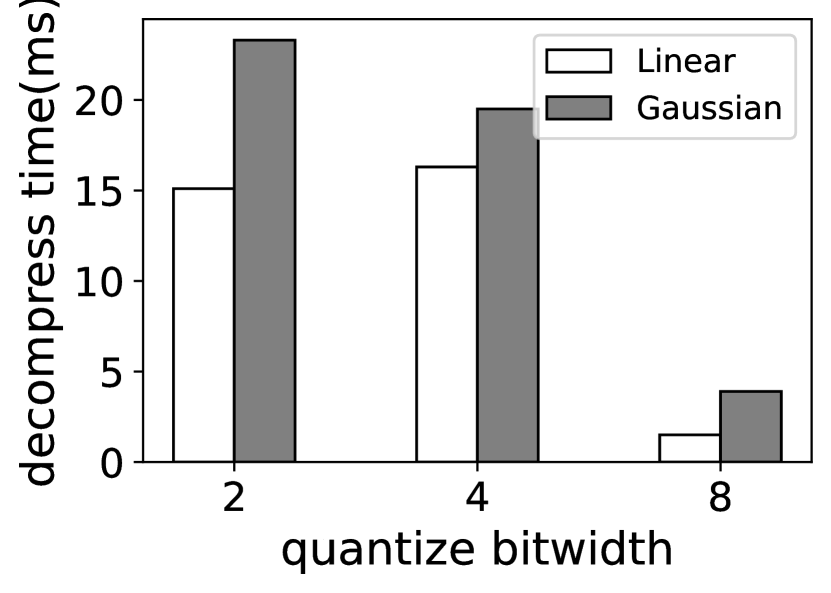
We surveyed a wide range of quantization techniques (e.g. Gaussian outlier-aware quantization (zadeh2020gobo, ) and log-based quantization (aji2020compressing, )) and have chosen channel-wise linear quantization (han2015deep, ) for its good accuracy and fast decompression time. As shown in Figure 6, quantizing all experts weights to 4-bit integers (INT4) only 1.30%–1.44% accuracy degradation; on dataset SAMsum, the experts can be further quantized to 2-bit integers with only 5.82% loss, acceptable to our use. As shown in Figure 7(b), compared with other quantization technique (e.g. Gaussian outlier-aware quantization (zadeh2020gobo, )), channel-wise linear quantization is 1.1%–25% faster, attributed to its simplified decompression process as a straightforward linear mapping.
Channel-wise linear quantization uniformly maps quantized integer values to the original float values using scaling factors. The scaling factor for each channel is determined by the maximum absolute value within that channel and the range expressible by the bitwidth.
Quantized weights are not meant to be used as-is, which is different from QAT (liu2023llm, ). Prior to use, we must decompress them, which is a mirror process of compression.
Profiling expert importance.
For experts we quantize them into different bitwidths, e.g. INT2/4/8. The rationale is experts show different importance to model accuracy;we want the most important experts to have high-bitwidth, hence contributing to the model accuracy more positively.
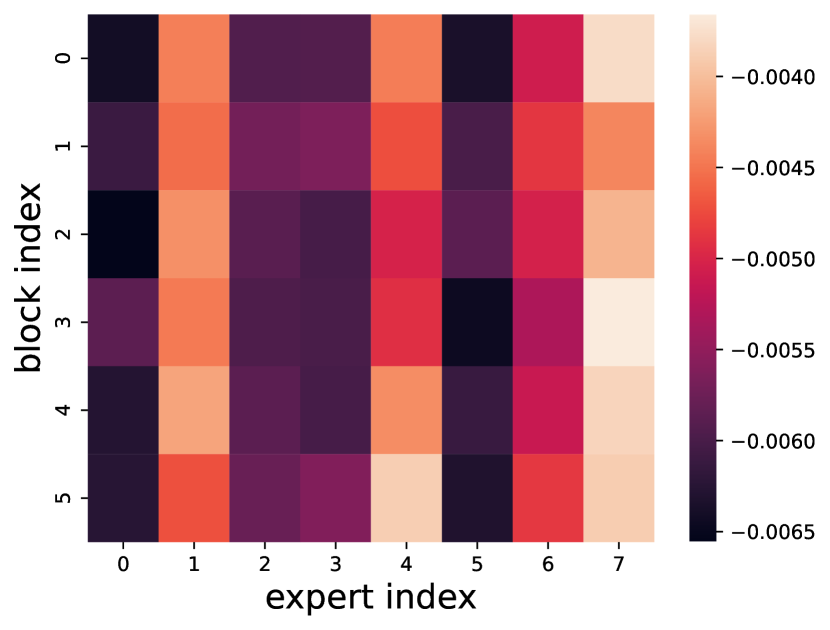
To do so, EdgeMoE enumerate all experts, quantize each to INT2, and profile the resultant accuracy loss on different validation sets (e.g. ST-base-8). The results are shown as a heatmap in Figure 7(a). For instance, quantizing the expert to INT2 at tranformer block degrades the accuracy by 0.44%, while quantizing expert to the same precision causes 0.59% degradation. Therefore, the expert is more sensitive to quantization and more important to model accuracy.
As a result, EdgeMoE obtains the list of expert importance, which is sorted by the model accuracy when a corresponding expert is quantized into INT2. The list will be used for constructing the runtime model, which we will shortly describe.
Note that EdgeMoE does not quantize non-expert weights because quantizing them makes the model unusable, which we have observed in early experiments shown in Figure 6. Our conjecture is: while experts weights are huge, during each inference the activated experts are small so the compressed weights do not cause much difference.
Selecting expert-wise bitwidths.
Based on the user-tolerable accuracy loss, EdgeMoE judiciously selects the bitwidths of individual experts offline as follows.
-
•
First, EdgeMoE decides a bitwidth bound for all experts of the model, which serve as a baseline for EdgeMoE to further tune. To do so, EdgeMoE enumerates through the available bitwidths (e.g. INT2/4/8 and FP32) for all experts and measures the model accuracy, respectively. EdgeMoE then sets the lower and upper bound of bitwidths to those whose accuracies closely approximate the tolerable accuracy loss.
-
•
Second, EdgeMoE tunes individually the bitwidth of experts based on the lower and upper bound of bitwidths. It starts from the top- experts from the list obtained earlier. As they are less important, EdgeMoE quantizes them into lower bitwidth (i.e. INT2) while keeping the rest higher bitwidth (e.g. INT4). EdgeMoE then measures the accuracy of the resultant model. If its accuracy loss is still lower than the desired goal, which means the model can afford more lower-bitwidth experts, EdgeMoE follows the list to gradually increases the parameters until the accuracy loss reaches the goal. Otherwise EdgeMoE decreases the parameters for reducing the accuracy loss, i.e. by lifting more experts to higher bitwidths.
Through above process, EdgeMoE obtains a model with mixed precision, achieving a balance between accuracy and storage.
3.3. In-memory Expert Management
3.3.1. Experts re-batching for encoder
During execution of the MoE layer within encoder, experts are activated token-by-token, where multiple tokens might select the same expert. Without a system view, naively pulling expert weights upon being invoked by tokens leads to repetitive loading, incurring significant delays and I/O bandwidth waste.
To address this, EdgeMoE reorganizes input tokens by re-batching. Specifically, EdgeMoE reorders the encoder computations, shifting it from a token-by-token manner to an expert-by-expert manner. In accordance with the experts’ order, EdgeMoE loads the weight of each expert and following that, concatenates all tokens select that expert for computation. This strategy ensures that each expert’s weights are loaded only once, preventing redundant loading.
3.3.2. Preloading and pipeline
To overlap the expert loading with weight computation, we must predict the expert activation beforehand, instead of passively waiting for the router output of previous MoE layers.
Estimating expert activation as priori. How to predict expert activation? We exploit a key observation that the expert activations of sequential layers are statistically correlated. That is to say, given the prior knowledge of expert activations of layers, we can estimate the activation probability of each expert at layer with good confidence, formulated as where is the index of the expert and is the layer index. To demonstrate such correlation, we analyze the expert activations running ST-base-8 model on SAMSum dataset. As shown in Figure 8 (left), with two previous layers’ activations observed, at layer there is a high probability (87.1%) that No.5 expert will be activated, i.e., . Figure 8(right) further confirms this observation by statistically summarizing across different activation paths.
Opportunistic preloading. EdgeMoE exploits the previous observation for opportunistically preloading the expert weights and executing the pipeline as follows. In the offline phase, based on the previous observation EdgeMoE executes the model on multiple datasets to build the statistical profile of expert activations. To this end, EdgeMoE generates a dictionary, wherein the key denotes the activation status of experts from two consecutive MoE layers, and the value represents the probabilities of individual experts being activated in the subsequent MoE layer. The statistical profile is then stored for utilization in online inference.
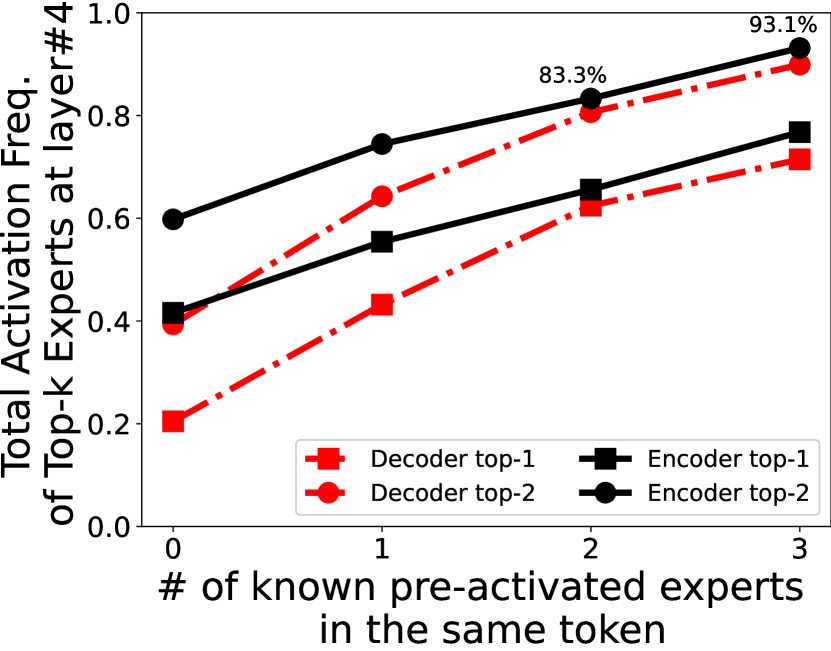
In the online phase, before each MoE layer routing, EdgeMoE employs the activation statuses of experts in the previous layers as the key for querying the statistical profile. Then, it sequentially preloads the experts to experts buffer (if not present) prioritized with their estimated activation probability. The preloading stops until the router is finished and the real activated expert is thereby known. In practice, EdgeMoE is able to preload 1–3 experts each layer for pipeline, depending on the compute-I/O speedup gap.
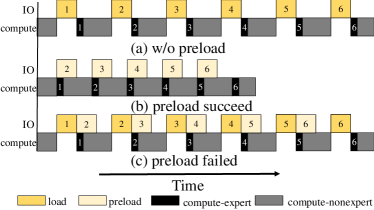
The pipeline scheduling. EdgeMoE instantiates a preload/compute pipeline to concurrently execute computations within the current transformer block and the preloading of the subsequent transformer block, based on the prediction made by the statistical profile. Figure 9 elucidates the pipeline scheduling for situations where prediction is both successful/failed. When EdgeMoE accurately forecast the activation of the next MoE layer’s expert which is a common case, it significantly reduces the end-to-end inference delay, hiding the loading time under computation. As a worst case scenario (which we have never observed), when all predictions fail, the inference time is only as long as loading experts on demand.
3.3.3. Cache eviction policy
EdgeMoE maintains a cache for expert weights in memory, sized by the memory budget . Once an in-cache expert is activated, the weights are directly fetched from the buffer, i.e., a cache hit. Otherwise, EdgeMoE needs to fetch the expert from disk and evicts an old expert when the cache is full. The cache eviction policy – determining which expert to be evicted, is crucial to EdgeMoE performance, since wrongly evicting an expert that will be used in the near future causes significant I/O overhead.
Classic cache policies like FIFO/LRU/LFU are designed for operating system, mainly based on the data access history and frequency. EdgeMoE leverages the expert activation frequency as well, yet incorporates another unique opportunity: since LLMs are built with sequentially stacked transformer layers, each expert’s activation timing co-relates with its position (i.e., layer index). Specifically, if an expert resides in a layer that is going to be executed soon, it shall be endowed with higher score for not being evicted.
Based on this heuristic, EdgeMoE’s eviction policy considers both the frequency of expert usage and MoE layer index. The key idea is to give priority to the eviction of experts stored in the buffer with lower usage frequency and those whose layers are farther away from the current block.We formulate the eviction policy as follows. For the -th expert at -th MoE layer, we define its eviction score as :
where is the index of current MoE layer, is the frequency of the -th expert activated in the -th MoE layer. And indicates the size of MoE layers in this model’s decoder. Therefore, the higher the score is, the more likely the expert will be evicted. For the experts within encoder, we set the frequency to 0. The reason is these experts are loaded only once after re-batching, so they should be prioritized for eviction. When initializing the expert buffer, we load encoder expert weights sequentially. For encoder only models, the expert buffer is initialized with the experts having the highest frequency of usage.
4. Evaluation
4.1. Implementation and Methodology
| Model | Type | EnM/En | DeM/De | Exp. | Top-k | Params. |
|---|---|---|---|---|---|---|
| ST-b-8 | en-de | 6/12 | 6/12 | 8 | 1 | 0.4B |
| ST-b-16 | en-de | 6/12 | 6/12 | 16 | 1 | 0.9B |
| ST-b-32 | en-de | 6/12 | 6/12 | 32 | 1 | 1.8B |
| ST-b-64 | en-de | 6/12 | 6/12 | 32 | 1 | 3.5B |
| ST-b-128 | en-de | 6/12 | 6/12 | 128 | 1 | 7.1B |
| ST-l-128 | en-de | 12/24 | 12/24 | 128 | 1 | 26B |
| GPTSAN | de | 0/0 | 9/9 | 16 | 2 | 0.6B |
EdgeMoE prototype We’ve fully implemented a prototype of EdgeMoE with 1K Python LoC atop transformers. We used Pytorch as transformers’ backend and CUDA backend for its more generic support for different platforms. Note that the techniques of EdgeMoE are compatible with other DL libraries as well.
Models We use 7 popular MoE-based sparse LLMs as summarized in Table 1 to test the performance of EdgeMoE. Most of these models are based on Switch Transformers (fedus2022switch, ) architecture in encoder-decoder structure with top-1 routing, i.e., only 1 expert is activated per layer. Besides, GPTSAN (tanrei-gptsan-jp, ) has a decoder-only structure and works as a shifted Masked Language Model for Prefix Input tokens. It uses top-2 routing. The pre-trained weights of those models are downloaded directly from Hugging Face (huggingfacehubmodels, ).
Datasets We evaluate EdgeMoE with three NLP downstream datasets: (1) Xsum Dataset (huggingface-xsum, ): Comprising a substantial collection of 226,711 news articles, each accompanied by a concise one-sentence summary. (2) SAMsum Dataset (huggingface-samsum, ): This dataset features approximately 16,000 conversation transcripts, reminiscent of messenger exchanges, along with corresponding summaries. (3) Wikipedia-jp Dataset (huggingface-wikipedia-japanese, ): This extensive dataset encompasses the entire corpus of Japanese Wikipedia articles as of August 8, 2022. Datasets Xsum and SAMsum are specifically employed for the summarization task, where the objective is to generate a summary of the input content. We evaluated the performance of the Switch Transformers model on these datasets. Conversely, the Wikipedia-jp dataset serves as the foundation for text generation tasks. We assessed the capabilities of GPTSAN in text generation tasks using this dataset.
Metrics We mainly report the model accuracy, inference speed (per token and sequence), peak memory footprint, and model size of EdgeMoE and baselines. To assess model accuracy, we use the Rouge-2 metric (lin2005recall, ) in our experiments. It comprises a collection of metrics designed for the evaluation of automatic summarization and text generation tasks. In the context of summarization, Rouge-2 quantifies similarity by comparing automatically generated abstracts with a reference set of abstracts, typically manually crafted.
Hardware We evaluate EdgeMoE on two prominent edge devices: the Jetson TX2 (GPU) and the Raspberry Pi 4B (CPU). Both the Jetson TX2 (tx2, ) and Raspberry Pi 4B (rpi4b, ) run Ubuntu 18.04 as their operating system. Since MoE LLMs are large, we need external storage to hold them. For Raspberry Pi 4B, we use SDCards (SanDisk Ultra 128GB (sdcard, )); for Jetson TX2, we use two types of hard drives, namely SSD (default) and HDD. The SSD model is SAMSUNG 860 EVO (samsungssd, ), boasting read/write speed of 550/520 MB/s. and HDD model is MOVE SPEED YSUTSJ-64G2S (movespeed, ) who provide a read/write speed of 50/20 MB/s. The offline stage of EdgeMoE to generate a quantized MoE is performed on a GPU server equipped with 8x NVIDIA A40.
Baselines We compare EdgeMoE with four baselines. (1) IO-FREE assumes all model weights are held in memory so no swapping I/O is needed. This is the most computationally efficient approach but not scalable due to memory constraints. (2) IO-EXP treats memory as cache for experts and dynamically loads them once activated, similar to EdgeMoE. (3) IO-QEXP combines the above method with MoQE (kim2022mixture, ) to quantize experts weights into INT4 and dynamically loading them during inference. Alike EdgeMoE, the quantized weights need to be converted back to FP32 for fast inference on device processors. (4) STI minimizes inference accuracy by model sharding and instantiates an IO/compute pipeline under a tight memory budget (guo2023sti, ). It does not differentiate the weights for experts and non-experts. For a fair comparison, we adjust the size of buffer for preload shards so that STI and EdgeMoE has the same memory footprint.
Configurations If not otherwise specified, we set the expert buffer of EdgeMoE to 10 experts; the tolerable accuracy loss is 5%. Each experiment is conducted systematically with multiple repetitions, and the reported values are based on their respective averages.
4.2. End-to-end Results

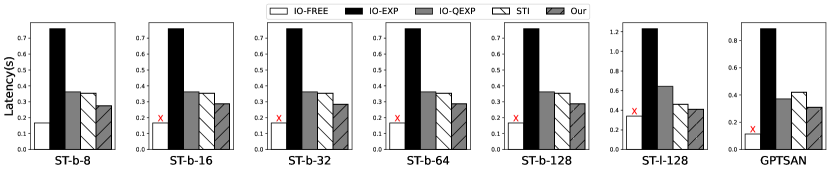
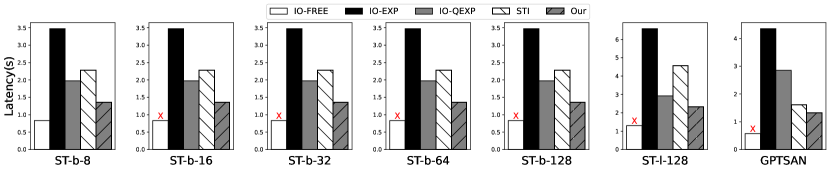
Memory footprint. We conducted a memory footprint evaluation of EdgeMoE and the baselines on edge devices. The results are shown in Figure 10. EdgeMoE significantly outperforms the baselines across all models and platforms, achieving memory savings ranging from 2.6 to 3.2 compared to IO-FREE. This improvement can be attributed to EdgeMoE’s efficient management of inactive expert weights and activations. Additionally, EdgeMoE dynamically loads and caches activated expert weights in memory to reduce memory footprint.
In contrast, EdgeMoE exhibits a memory footprint similar to that of IO-EXP and IO-QEXP. Since these two baselines do not require caching prior expert weights, EdgeMoE incurs a slightly higher memory footprint in comparison. For example, when the expert buffer is set to 10 the expert’s memory footprint, ST-base models consume approximately 180MB more memory than IO-EXP and IO-QEXP. According to the settings outlined in 4.1, the baseline STI shares the same memory footprint as EdgeMoE.
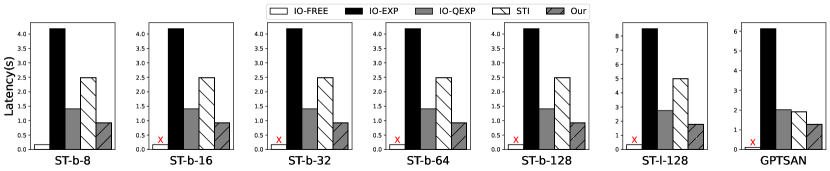
Per-token inference latency. Figure 11 presents a comprehensive comparison of per-token inference latency between EdgeMoE and the baselines on edge devices. The results highlight a significant performance improvement achieved by EdgeMoE across all models and platforms. In Jetson TX2, EdgeMoE demonstrates a speedup ranging from 2.63 to 3.01 compared to IO-EXP, and in Raspberry Pi 4B, the speedup ranges from 4.49 to 5.43. This notable performance gain can be attributed to several key factors. Firstly, EdgeMoE employs weight quantization for the experts, effectively reducing loading latency. Additionally, EdgeMoE adopts an efficient strategy for preloading expert weights, intelligently overlapping this preload process with computation, thereby effectively masking most of the latency. Consequently, EdgeMoE achieves a commendable speedup of 1.35–1.5 compared to IO-QEXP and 1.11–2.78 inference speedup over STI.
However, a performance gap still exists between EdgeMoE and IO-FREE because EdgeMoE’s preloading stage doesn’t always predict which expert to activate for the next MoE layer. Some experts still need to load dynamically.
Impact of hard drive read speed. Figure 11 also compares per-token inference latency between SSD and HDD on Jetson TX2. Notably, EdgeMoE achieves a higher acceleration rate on lower-cost HDDs compared to SSDs, especially when compared to baselines IO-EXP. For example, compared to IO-EXP, EdgeMoE achieves a speedup ranging from 4.49 to 4.76 on HDDs and from 2.63 to 3.01 on SSDs. This difference is due to the relatively slower read speeds of HDDs, resulting in longer expert weight loading times compared to SSDs. EdgeMoE demonstrates a more significant improvement in expert loading, leading to a more pronounced enhancement in per-token inference latency.
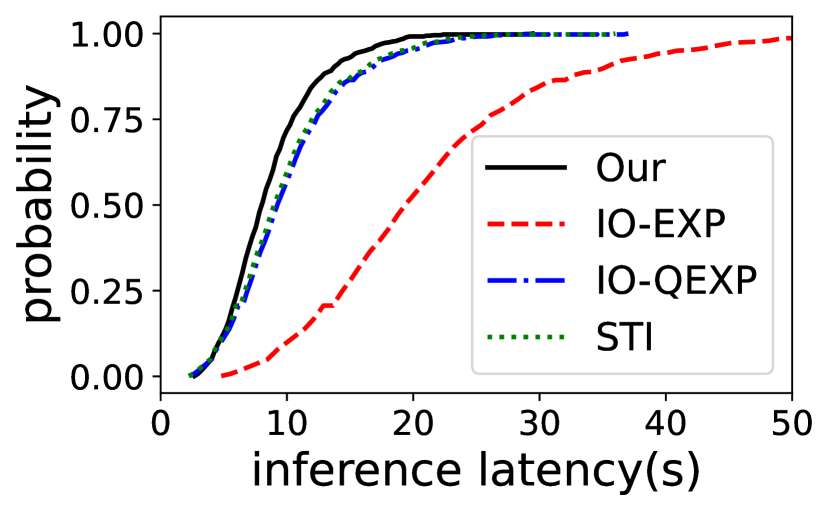
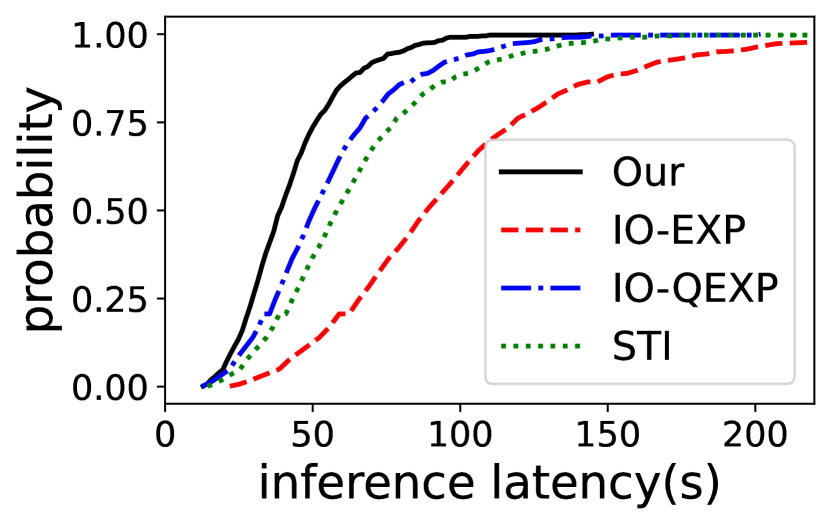
Per-sample inference latency. We also evaluate the per-sample inference latency of EdgeMoE compared to the baselines on both Jetson TX2 and Raspberry Pi 4B. The cumulative distribution function (CDF) for the ST-base-8 model is depicted in Figure 12. The results shows that EdgeMoE consistently outperforms the baselines. For instance, on the Raspberry Pi 4B, 50% of the samples processed by EdgeMoE exhibit a latency of less than 46 seconds, whereas with IO-FREE, 50% of the samples experience a latency of less than 106 seconds.
| baseline | Storage(GB) | Loss(%) |
|---|---|---|
| IO-FREE | 2.43 | 0.00 |
| IO-EXP | 2.53 | 0.00 |
| IO-QEXP | 0.85 | 2.04 |
| STI | 0.85 | 20.0 |
| Our | 0.81 | 4.89 |
| baseline | Storage(GB) | Loss(%) |
|---|---|---|
| IO-FREE | 4.12 | 0.00 |
| IO-EXP | 4.12 | 0.00 |
| IO-QEXP | 1.03 | 3.15 |
| STI | 1.03 | 25.1 |
| Our | 0.95 | 4.95 |
Storage and accuracy. We also compared the storage requirements of EdgeMoE and the baselines while measuring their accuracy loss. Table 2 presents the experimental results for ST-base-8 and ST-base-16. Notably, EdgeMoE significantly outperforms the baselines in terms of storage, achieving a 3.03 improvement over IO-FREE and a 1.11 improvement over IO-QEXP for ST-base-8. This superiority stems from EdgeMoE’s utilization of a mixed-precision quantization method for expert weights.
Furthermore, the accuracy loss aligns with our expectations. EdgeMoE exhibits an accuracy loss that closely approximates the tolerable 5% threshold. IO-FREE, IO-EXP, and IO-QEXP models similarly show accuracy losses consistent with their respective bitwidth configurations. Unlike the other baselines, STI quantizes both non-expert weights and expert weights, leading to a significant accuracy loss.
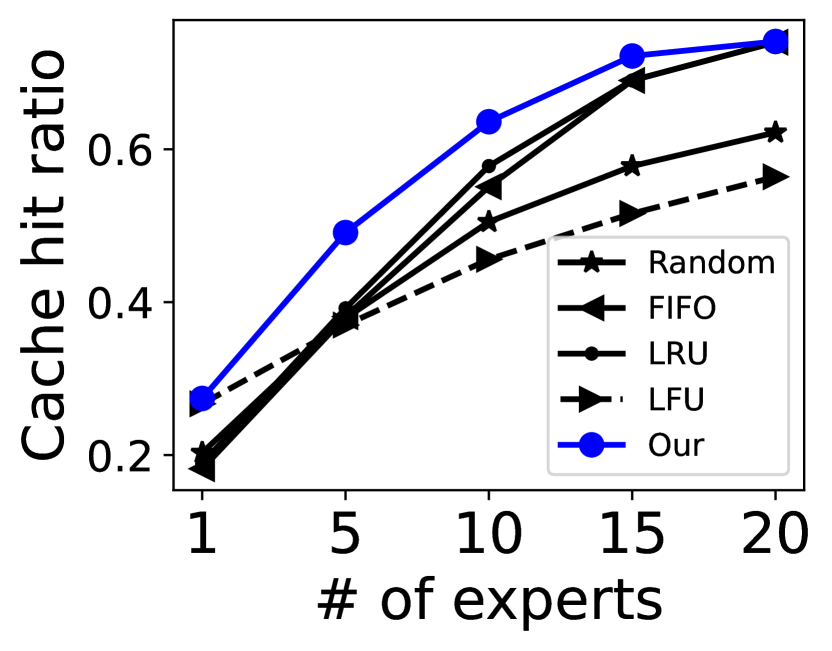
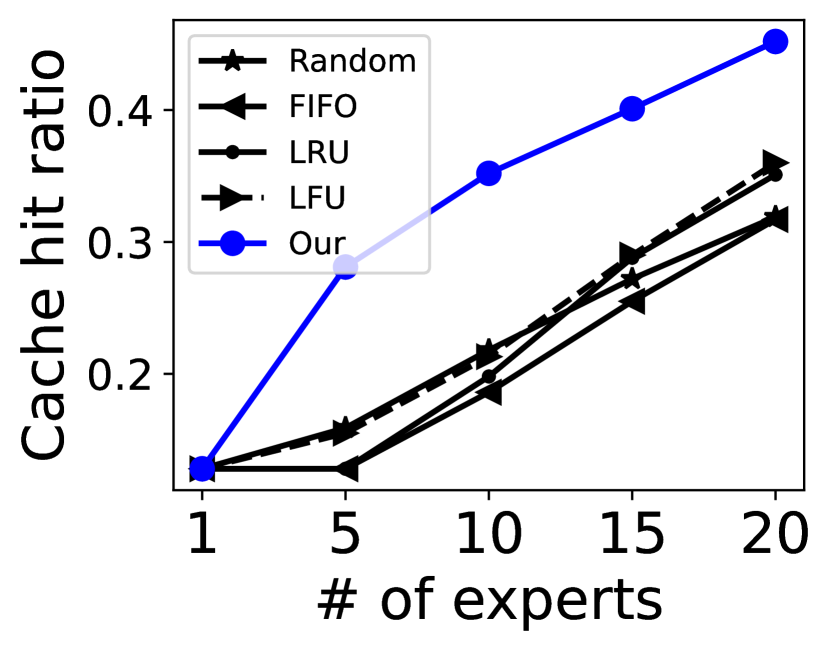
Cache eviction policy. We perform a comparative analysis of cache hit ratios between our novel cache eviction policy and other policies with varying exeprt buffer sizes. To mitigate the influence of preloading on the hit ratio, we disable the preloading functionality in these experiments. The results are shown in Figure 13. Our novel eviction policy exhibits superior efficacy compared to several other policies.
4.3. Sensitivity Analysis
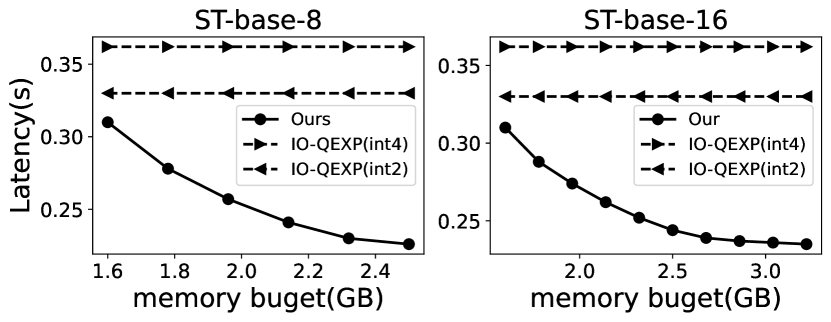
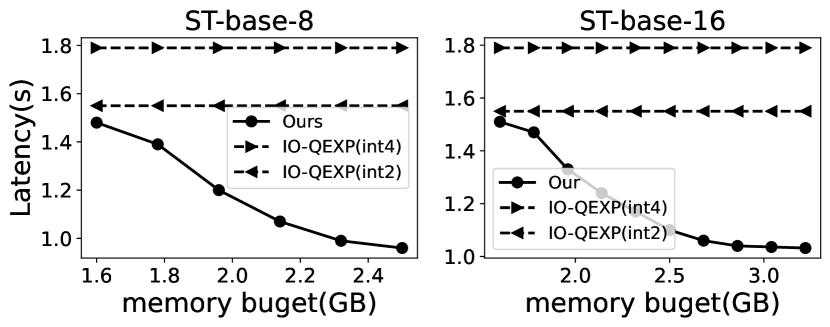
Various memory budget. EdgeMoE adapts to various edge devices with diverse device memory sizes by tailoring the expert buffer, based on the memory budget (3.3). In our experiments, we configured memory budgets from 1.6GB to 3.5GB, reflecting real-world edge device memory profiles. We extensively evaluated EdgeMoE’s per-token inference latency compared to baselines across these memory budgets, and the results are shown in Figure 14. Notably, as the size of expert buffer increases, inference latency decreases. This is because the expanded expert buffer can retain more previously activated expert weights, leading to higher cache hit ratios and saving weights loading time.
Figure 14 compares EdgeMoE to IO-QEXP on two devices. The results consistently show that EdgeMoE has lower inference latency across all memory budget configurations compared to both INT4 and INT2 versions of IO-QEXP.
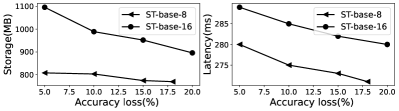
Impact of tolerable accuracy loss. Figure 15 provides a comparison across different desired accuracy loss . During these experiments, we evaluated inference latency and model storage across accuracy loss levels ranging from 5% to 20% on Jetson TX2, running ST-base-8 and ST-base-16 models. The results show accuracy loss scales with model sizes and inference latency. It confirm EdgeMoE effectively adapts to available resources (storage and latency) by tuning individual bitwidths of experts.
4.4. Ablation Study
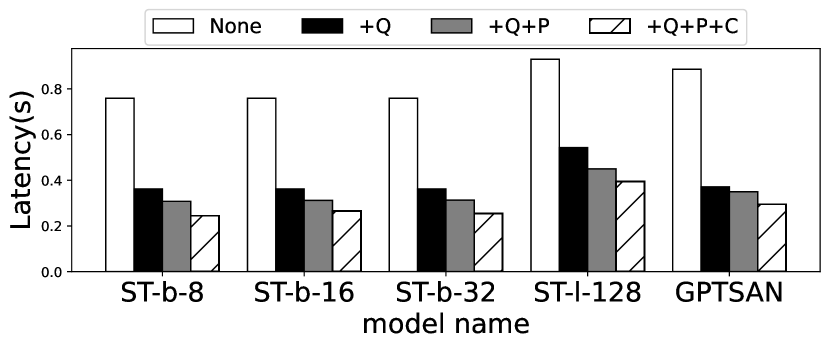
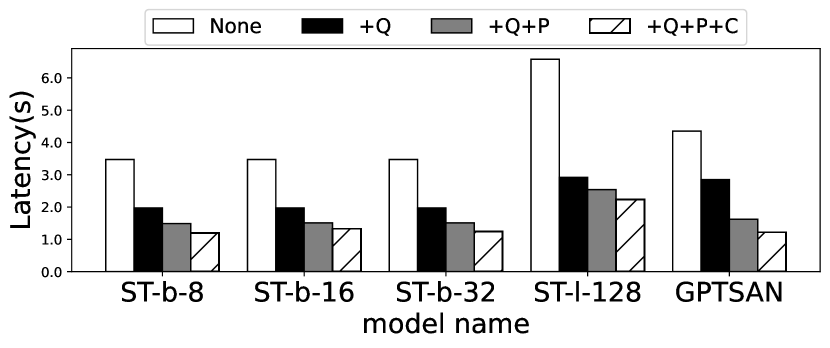
We then evaluate the benefits brought by EdgeMoE’s each key technique separately. The results of per-token inference latency evaluation are illustrated in Figure 16. Our major observation is that each of EdgeMoE’s key techniques contributes noticeably to the inference speedup. For example, with ST-base-8 and Jetson TX2, the expert-wise quantization first reduces the inference latency from 0.789s to 0.392s. Preloading and pipeline further reduce the latency to 0.305s, and by using expert buffer, the latency finally becomes 0.245s.
5. Related Work
Resource-efficient LLMs Research on resource-efficient LLMs is very popular. Prior works have used methods such as knowledge distillation (wu2023lamini, ; li2023symbolic, ; fu2023specializing, ; tan2023industry, ; yuan2023distilling, ; wang2023scott, ), network pruning (frantar2023sparsegpt, ; ma2023llm, ; sun2023simple, ), quantization (frantar2022gptq, ; xiao2023smoothquant, ; lin2023awq, ; yuan2023rptq, ; liu2023llm, ; chee2023quip, ), architecture design (liu2023deja, ; miao2023specinfer, ; spector2023accelerating, ; del2023skipdecode, ; ning2023skeleton, ; li2023losparse, ; xu2023tensorgpt, ), efficient structure design (dao2022flashattention, ; dao2023flashattention, ), and text compression (valmeekam2023llmzip, ; chevalier2023adapting, ; ge2023context, ) to achieve resource-efficient LLMs. However, the scenarios for this type of work differ from EdgeMoE. On the one hand, these works can achieve efficient deployment of LLMs in the cloud, but they often cannot accommodate edge devices with extremely limited resources for LLMs. On the other hand, these works often do not focus on MoE-based LLMs. MoE-based LLMs have been widely adopted in the industry. Specifically, EdgeMoE is built for efficient on-device MoE LLMs inference and is orthogonal to most of the above techniques.
On-device ML optimizations There are two main categories of on-device DNN inference optimizations. One is at system level, e.g., by exploiting heterogeneous processors (cao2017mobirnn, ; fu2017crnn, ; huynh2017deepmon, ; lane2016deepx, ), cache (mathur2017deepeye, ; xu2018deepcache, ), generating high-performance GPUs kernels (liang2022romou, ), or adaptive offloading (laskaridis2020spinn, ; xu2019deepwear, ). The other is model level, e.g., quantization (joo2011fast, ; liu2018demand, ) or sparsifiction (bhattacharya2016sparsification, ; niu2020patdnn, ). They reduce the execution time and/or the weights to be read from the disk. These works can optimize small ML models, but they cannot optimize large language models with running memory that is a hundred times greater than that of edge devices. EdgeMoE is built for resource-efficient MoE-based sparse LLMs and is orthogonal to them.
DNN memory optimizations Given that memory is a crucial and scarce resource of mobile devices, memory saving has long been a concern research direction of a mobile community. There are two main categories of DNN memory optimizations. One is general memory management of on-device OSes. Existing studies mainly focus on app-level memory management. The other one is a customized memory optimization method for DNN. Split-CNN (jin2019split, ) proposed splitting the weights of a single layer into multiple sub-windows, on which memory offloading and prefetching are applied to reduce activation memory and the weight memory. Melon (wang2022melon, ) incorporates novel techniques to deal with the high memory fragmentation and memory adaptation to fit into resource-constrained mobile devices, i.e., recomputation and micro-batch. these researches mostly focus on on-device training and traditional smaller DNN models, not LLM. EdgeMoE is built to optimaize memory footprint of LLMs and is orthogonal to the above techniques.
Non-autoregressive MoE models optimizations Some work focuses on optimizing non-autoregressive MoE-based models on device. Edge-MoE (sarkar2023edge, ) is designed to enhance the performance of Non-autoregressive transformer-based models on edge devices. In the case of MoE-based models, it introduces an expert-by-expert computation in order to maximize the reuse of loaded experts. However, it is essential to note that Edge-MoE primarily accelerates non-autoregressive transformer-based models, such as ViT (dosovitskiy2020image, ). These works can only optimize memory footprints that approximate the device’s capabilities. In contrast, for autoregressive large language models with a decoder, EdgeMoE demonstrates strong performance. Specifically, EdgeMoE is built for autoregressive MoE-based LLMs, and is orthogonal to them.
6. Conclusions
In this work, we propose EdgeMoE, the first on-device inference engine for mixture-of-expert (MoE) LLMs. EdgeMoE integrates two innovative techniques: expert-specific bitwidth adaptation, reducing expert sizes with acceptable accuracy loss, and expert preloading, which anticipates activated experts and preloads them using a compute-I/O pipeline. Extensive experiments demonstrate that EdgeMoE enables real-time inference for MoE LLMs on edge CPU and GPU platforms while maintaining tolerable accuracy loss.
References
- [1] Microsoft translator enhanced with z-code mixture of experts models. https://www.microsoft.com/en-us/research/blog/microsoft-translator-enhanced-with-z-code-mixture-of-experts-models/, 2022.
- [2] Beating google and apple, huawei brings large ai model to mobile voice assistant - huawei central. https://www.huaweicentral.com/beating-google-and-apple-huawei-brings-large-ai-model-to-mobile-voice-assistant/, 2023.
- [3] c4 · datasets at hugging face. https://huggingface.co/datasets/c4, 2023.
- [4] Chatgpt - google play. https://play.google.com/store/apps/details?id=com.openai.chatgpt, 2023.
- [5] Jetson tx2 module — nvidia developer. https://developer.nvidia.com/embedded/jetson-tx2, 2023.
- [6] Model card for tanrei/gptsan-japanese. https://huggingface.co/Tanrei/GPTSAN-japanese, 2023.
- [7] Models - hugging face. https://huggingface.co/models, 2023.
- [8] Move speed usb2.0. http://www.movespeed.com/productinfo/1162939.html, 2023.
- [9] Raspberry pi 4 model b – raspberry pi. https://www.raspberrypi.com/products/raspberry-pi-4-model-b/2, 2023.
- [10] samsum · datasets at hugging face. https://huggingface.co/datasets/samsum, 2023.
- [11] Samsung 860 evo — consumer ssd — specs & features — samsung semiconductor global. https://semiconductor.samsung.com/consumer-storage/internal-ssd/860evo/, 2023.
- [12] Sandisk ultra® microsd, uhs-i card, full hd store — western digital. https://www.westerndigital.com/products/memory-cards/sandisk-ultra-uhs-i-microsd#SDSQUNC-016G-AN6MA, 2023.
- [13] wikipedia-japanese · datasets at hugging face. https://huggingface.co/datasets/inarikami/wikipedia-japanese, 2023.
- [14] World’s 1st on-device stable diffusion on android — qualcomm. https://www.qualcomm.com/news/onq/2023/02/worlds-first-on-device-demonstration-of-stable-diffusion-on-android, 2023.
- [15] xsum · datasets at hugging face. https://huggingface.co/datasets/xsum, 2023.
- [16] Alham Fikri Aji and Kenneth Heafield. Compressing neural machine translation models with 4-bit precision. In Proceedings of the Fourth Workshop on Neural Generation and Translation, pages 35–42, 2020.
- [17] Sourav Bhattacharya and Nicholas D Lane. Sparsification and separation of deep learning layers for constrained resource inference on wearables. In Proceedings of the 14th ACM Conference on Embedded Network Sensor Systems CD-ROM, pages 176–189, 2016.
- [18] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [19] Qingqing Cao, Niranjan Balasubramanian, and Aruna Balasubramanian. Mobirnn: Efficient recurrent neural network execution on mobile gpu. In Proceedings of the 1st International Workshop on Deep Learning for Mobile Systems and Applications, pages 1–6, 2017.
- [20] Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher De Sa. Quip: 2-bit quantization of large language models with guarantees. arXiv preprint arXiv:2307.13304, 2023.
- [21] Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. Adapting language models to compress contexts. arXiv preprint arXiv:2305.14788, 2023.
- [22] Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
- [23] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
- [24] Luciano Del Corro, Allie Del Giorno, Sahaj Agarwal, Bin Yu, Ahmed Awadallah, and Subhabrata Mukherjee. Skipdecode: Autoregressive skip decoding with batching and caching for efficient llm inference. arXiv preprint arXiv:2307.02628, 2023.
- [25] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [26] Nan Du, Yanping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, et al. Glam: Efficient scaling of language models with mixture-of-experts. In International Conference on Machine Learning, pages 5547–5569. PMLR, 2022.
- [27] Tyna Eloundou, Sam Manning, Pamela Mishkin, and Daniel Rock. Gpts are gpts: An early look at the labor market impact potential of large language models. arXiv preprint arXiv:2303.10130, 2023.
- [28] William Fedus, Jeff Dean, and Barret Zoph. A review of sparse expert models in deep learning. arXiv preprint arXiv:2209.01667, 2022.
- [29] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. The Journal of Machine Learning Research, 23(1):5232–5270, 2022.
- [30] Elias Frantar and Dan Alistarh. Sparsegpt: Massive language models can be accurately pruned in one-shot. 2023.
- [31] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022.
- [32] Karl Friston. Hierarchical models in the brain. PLoS computational biology, 4(11):e1000211, 2008.
- [33] Xinyu Fu, Eugene Ch’ng, Uwe Aickelin, and Simon See. Crnn: a joint neural network for redundancy detection. In 2017 IEEE international conference on smart computing (SMARTCOMP), pages 1–8. IEEE, 2017.
- [34] Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, and Tushar Khot. Specializing smaller language models towards multi-step reasoning. arXiv preprint arXiv:2301.12726, 2023.
- [35] Tao Ge, Jing Hu, Xun Wang, Si-Qing Chen, and Furu Wei. In-context autoencoder for context compression in a large language model. arXiv preprint arXiv:2307.06945, 2023.
- [36] Liwei Guo, Wonkyo Choe, and Felix Xiaozhu Lin. Sti: Turbocharge nlp inference at the edge via elastic pipelining. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, pages 791–803, 2023.
- [37] Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015.
- [38] Loc N Huynh, Youngki Lee, and Rajesh Krishna Balan. Deepmon: Mobile gpu-based deep learning framework for continuous vision applications. In Proceedings of the 15th Annual International Conference on Mobile Systems, Applications, and Services, pages 82–95, 2017.
- [39] RA Jacobs, MI Jordan, SJ Nowlan, and GE Hinton. ªadaptive mixtures of local experts, º neural computation, vol. 3. 1991.
- [40] Tian Jin and Seokin Hong. Split-cnn: Splitting window-based operations in convolutional neural networks for memory system optimization. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, pages 835–847, 2019.
- [41] Yongsoo Joo, Junhee Ryu, Sangsoo Park, and Kang G Shin. FAST: Quick application launch on Solid-State drives. In 9th USENIX Conference on File and Storage Technologies (FAST 11), 2011.
- [42] Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W Mahoney, and Kurt Keutzer. Squeezellm: Dense-and-sparse quantization. arXiv preprint arXiv:2306.07629, 2023.
- [43] Young Jin Kim, Raffy Fahim, and Hany Hassan. Mixture of quantized experts (moqe): Complementary effect of low-bit quantization and robustness. 2022.
- [44] Nicholas D Lane, Sourav Bhattacharya, Petko Georgiev, Claudio Forlivesi, Lei Jiao, Lorena Qendro, and Fahim Kawsar. Deepx: A software accelerator for low-power deep learning inference on mobile devices. In 2016 15th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), pages 1–12. IEEE, 2016.
- [45] Stefanos Laskaridis, Stylianos I Venieris, Mario Almeida, Ilias Leontiadis, and Nicholas D Lane. Spinn: synergistic progressive inference of neural networks over device and cloud. In Proceedings of the 26th annual international conference on mobile computing and networking, pages 1–15, 2020.
- [46] Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668, 2020.
- [47] Mike Lewis, Shruti Bhosale, Tim Dettmers, Naman Goyal, and Luke Zettlemoyer. Base layers: Simplifying training of large, sparse models. In International Conference on Machine Learning, pages 6265–6274. PMLR, 2021.
- [48] Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai-Wei Chang, and Yejin Choi. Symbolic chain-of-thought distillation: Small models can also” think” step-by-step. arXiv preprint arXiv:2306.14050, 2023.
- [49] Yixiao Li, Yifan Yu, Qingru Zhang, Chen Liang, Pengcheng He, Weizhu Chen, and Tuo Zhao. Losparse: Structured compression of large language models based on low-rank and sparse approximation. arXiv preprint arXiv:2306.11222, 2023.
- [50] Rendong Liang, Ting Cao, Jicheng Wen, Manni Wang, Yang Wang, Jianhua Zou, and Yunxin Liu. Romou: Rapidly generate high-performance tensor kernels for mobile gpus. In Proceedings of the 28th Annual International Conference on Mobile Computing And Networking, pages 487–500, 2022.
- [51] C Lin. Recall-oriented understudy for gisting evaluation (rouge). Retrieved August, 20:2005, 2005.
- [52] Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration. arXiv preprint arXiv:2306.00978, 2023.
- [53] Sicong Liu, Yingyan Lin, Zimu Zhou, Kaiming Nan, Hui Liu, and Junzhao Du. On-demand deep model compression for mobile devices: A usage-driven model selection framework. In Proceedings of the 16th annual international conference on mobile systems, applications, and services, pages 389–400, 2018.
- [54] Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, and Vikas Chandra. Llm-qat: Data-free quantization aware training for large language models. arXiv preprint arXiv:2305.17888, 2023.
- [55] Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, et al. Deja vu: Contextual sparsity for efficient llms at inference time. In International Conference on Machine Learning, pages 22137–22176. PMLR, 2023.
- [56] Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models. arXiv preprint arXiv:2305.11627, 2023.
- [57] Akhil Mathur, Nicholas D Lane, Sourav Bhattacharya, Aidan Boran, Claudio Forlivesi, and Fahim Kawsar. Deepeye: Resource efficient local execution of multiple deep vision models using wearable commodity hardware. In Proceedings of the 15th Annual International Conference on Mobile Systems, Applications, and Services, pages 68–81, 2017.
- [58] Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. Specinfer: Accelerating generative llm serving with speculative inference and token tree verification. arXiv preprint arXiv:2305.09781, 2023.
- [59] Xuefei Ning, Zinan Lin, Zixuan Zhou, Huazhong Yang, and Yu Wang. Skeleton-of-thought: Large language models can do parallel decoding. arXiv preprint arXiv:2307.15337, 2023.
- [60] Wei Niu, Xiaolong Ma, Sheng Lin, Shihao Wang, Xuehai Qian, Xue Lin, Yanzhi Wang, and Bin Ren. Patdnn: Achieving real-time dnn execution on mobile devices with pattern-based weight pruning. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, pages 907–922, 2020.
- [61] OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774v2, 2023.
- [62] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- [63] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018.
- [64] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [65] Stephen Roller, Sainbayar Sukhbaatar, Jason Weston, et al. Hash layers for large sparse models. Advances in Neural Information Processing Systems, 34:17555–17566, 2021.
- [66] Rishov Sarkar, Hanxue Liang, Zhiwen Fan, Zhangyang Wang, and Cong Hao. Edge-moe: Memory-efficient multi-task vision transformer architecture with task-level sparsity via mixture-of-experts. arXiv preprint arXiv:2305.18691, 2023.
- [67] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
- [68] Benjamin Spector and Chris Re. Accelerating llm inference with staged speculative decoding. arXiv preprint arXiv:2308.04623, 2023.
- [69] Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models. arXiv preprint arXiv:2306.11695, 2023.
- [70] Shicheng Tan, Weng Lam Tam, Yuanchun Wang, Wenwen Gong, Shu Zhao, Peng Zhang, and Jie Tang. [industry] gkd: A general knowledge distillation framework for large-scale pre-trained language model. In The 61st Annual Meeting Of The Association For Computational Linguistics, 2023.
- [71] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [72] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [73] Chandra Shekhara Kaushik Valmeekam, Krishna Narayanan, Dileep Kalathil, Jean-Francois Chamberland, and Srinivas Shakkottai. Llmzip: Lossless text compression using large language models. arXiv preprint arXiv:2306.04050, 2023.
- [74] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [75] Peifeng Wang, Zhengyang Wang, Zheng Li, Yifan Gao, Bing Yin, and Xiang Ren. Scott: Self-consistent chain-of-thought distillation. arXiv preprint arXiv:2305.01879, 2023.
- [76] Qipeng Wang, Mengwei Xu, Chao Jin, Xinran Dong, Jinliang Yuan, Xin Jin, Gang Huang, Yunxin Liu, and Xuanzhe Liu. Melon: Breaking the memory wall for resource-efficient on-device machine learning. In Proceedings of the 20th Annual International Conference on Mobile Systems, Applications and Services, pages 450–463, 2022.
- [77] Minghao Wu, Abdul Waheed, Chiyu Zhang, Muhammad Abdul-Mageed, and Alham Fikri Aji. Lamini-lm: A diverse herd of distilled models from large-scale instructions. arXiv preprint arXiv:2304.14402, 2023.
- [78] Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning, pages 38087–38099. PMLR, 2023.
- [79] Mengwei Xu, Feng Qian, Mengze Zhu, Feifan Huang, Saumay Pushp, and Xuanzhe Liu. Deepwear: Adaptive local offloading for on-wearable deep learning. IEEE Transactions on Mobile Computing, 19(2):314–330, 2019.
- [80] Mengwei Xu, Mengze Zhu, Yunxin Liu, Felix Xiaozhu Lin, and Xuanzhe Liu. Deepcache: Principled cache for mobile deep vision. In Proceedings of the 24th annual international conference on mobile computing and networking, pages 129–144, 2018.
- [81] Mingxue Xu, Yao Lei Xu, and Danilo P Mandic. Tensorgpt: Efficient compression of the embedding layer in llms based on the tensor-train decomposition. arXiv preprint arXiv:2307.00526, 2023.
- [82] Siyu Yuan, Jiangjie Chen, Ziquan Fu, Xuyang Ge, Soham Shah, Charles Robert Jankowski, Deqing Yang, and Yanghua Xiao. Distilling script knowledge from large language models for constrained language planning. arXiv preprint arXiv:2305.05252, 2023.
- [83] Zhihang Yuan, Lin Niu, Jiawei Liu, Wenyu Liu, Xinggang Wang, Yuzhang Shang, Guangyu Sun, Qiang Wu, Jiaxiang Wu, and Bingzhe Wu. Rptq: Reorder-based post-training quantization for large language models. arXiv preprint arXiv:2304.01089, 2023.
- [84] Ali Hadi Zadeh, Isak Edo, Omar Mohamed Awad, and Andreas Moshovos. Gobo: Quantizing attention-based nlp models for low latency and energy efficient inference. In 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 811–824. IEEE, 2020.
- [85] Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, Quoc V Le, James Laudon, et al. Mixture-of-experts with expert choice routing. Advances in Neural Information Processing Systems, 35:7103–7114, 2022.