Diffusion Variational Autoencoder for Tackling Stochasticity in Multi-Step Regression Stock Price Prediction
Abstract.
Multi-step stock price prediction over a long-term horizon is crucial for forecasting its volatility, allowing financial institutions to price and hedge derivatives, and banks to quantify the risk in their trading books. Additionally, most financial regulators also require a liquidity horizon of several days for institutional investors to exit their risky assets, in order to not materially affect market prices. However, the task of multi-step stock price prediction is challenging, given the highly stochastic nature of stock data. Current solutions to tackle this problem are mostly designed for single-step, classification-based predictions, and are limited to low representation expressiveness. The problem also gets progressively harder with the introduction of the target price sequence, which also contains stochastic noise and reduces generalizability at test-time.
To tackle these issues, we combine a deep hierarchical variational-autoencoder (VAE) and diffusion probabilistic techniques to do seq2seq stock prediction through a stochastic generative process. The hierarchical VAE allows us to learn the complex and low-level latent variables for stock prediction, while the diffusion probabilistic model trains the predictor to handle stock price stochasticity by progressively adding random noise to the stock data. To deal with the additional stochasticity in the target price sequence, we also augment the target series with noise via a coupled diffusion process. We then perform a denoising process to ”clean” the prediction outputs that were trained on the stochastic target sequence data, which increases the generalizability of the model at test-time. Our Diffusion-VAE (D-Va) model is shown to outperform state-of-the-art solutions in terms of its prediction accuracy and variance. Through an ablation study, we also show how each of the components introduced helps to improve overall prediction accuracy by reducing the data noise. Most importantly, the multi-step outputs can also allow us to form a stock portfolio over the prediction length. We demonstrate the effectiveness of our model outputs in the portfolio investment task through the Sharpe ratio metric and highlight the importance of dealing with different types of prediction uncertainties. Our code can be accessed through https://github.com/koa-fin/dva.
1. Introduction
The stock market, an avenue in which investors can purchase and sell shares of publicly-traded companies, have seen a total market capitalization of over $111 trillion in 2022111https://www.sifma.org/resources/research/research-quarterly-equities/. Accurate stock price forecasting help investors to make informed investment decisions, allow financial institutions to price derivatives, and let regulators manage the amount of risk in the financial system. As such, the task of stock market prediction has become an increasingly challenging and important one in the field of finance, which has attracted significant attention from both the academia and industry (Feng et al., 2019b; Lin et al., 2021; Yang et al., 2022).
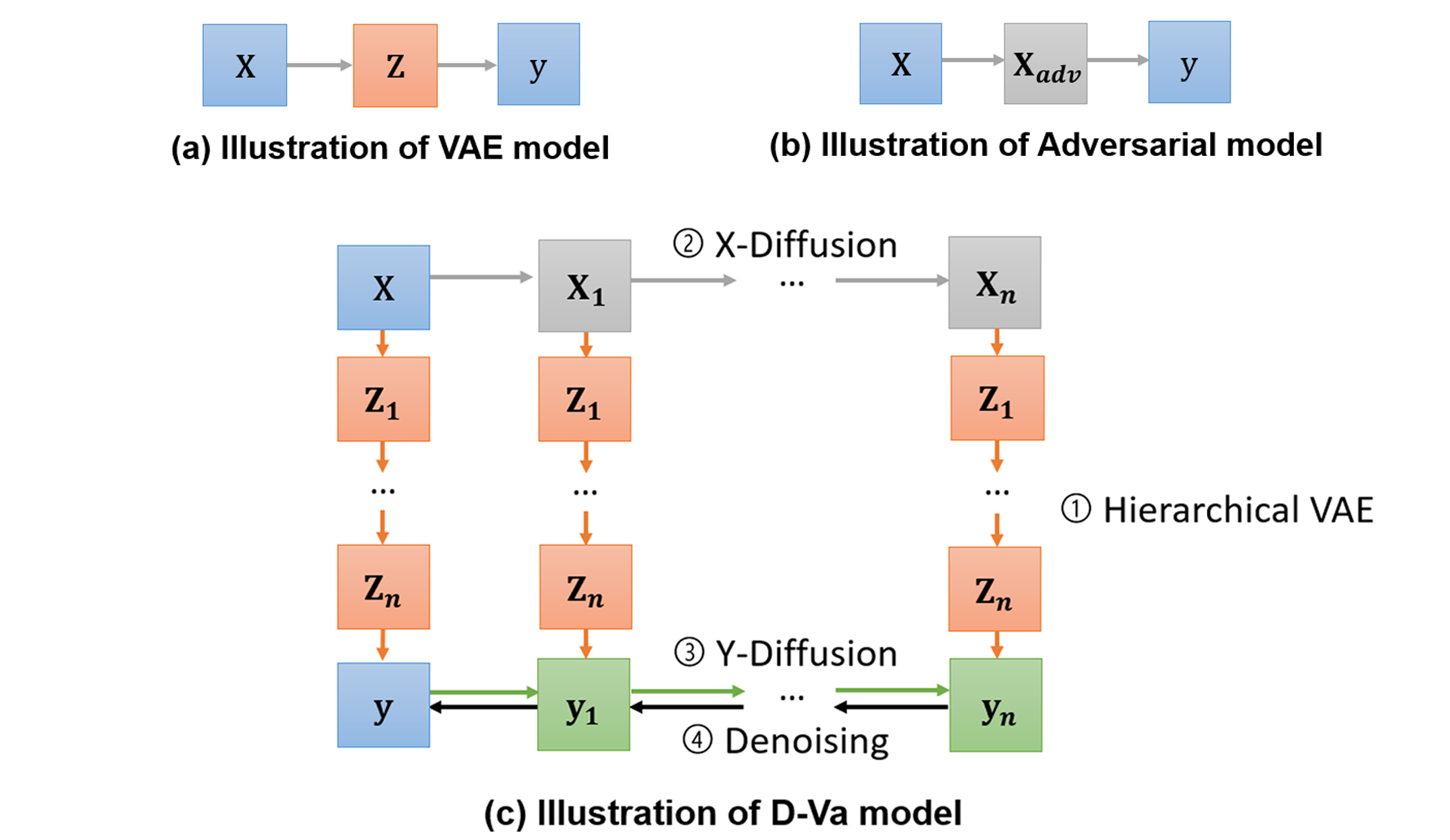
Typically, most current works on stock prediction do single-day prediction (Hu et al., 2018a; Chen et al., 2018), instead of making predictions for the next multiple days. Intuitively, this allows them to make trading decisions on whether to buy or sell a stock to achieve profits for the next day. However, stock prediction over a longer-term horizon is also crucial to forecast its volatility, which allows for applications such as pricing and hedging financial derivatives by financial institutions and quantifying the risk in banks’ trading books (Raunig, 2006). Additionally, most financial regulators require a liquidity horizon of minimum 10 days for institutional investors to exit their risky assets, in order to not materially affect market prices222 Most financial regulatory authorities set a regulatory liquidity horizon chosen from {10, 20, 40, 60, 120} days for different asset classes. Some references can be found at: • https://www.mas.gov.sg/publications/consultations/2021/consultation-paper-on-draft-standards-for-market-risk-capital-and-capital-reporting-requirements • https://www.eba.europa.eu/regulation-and-policy/market-risk/draft-technical-standards-on-the-ima-under-the-frtb . Currently, there is a limited number of works that do multi-step stock price prediction (Dong et al., 2013; Liu and Wang, 2019). Our work fills this gap by designing a method to tackle this task.
For our multi-step stock prediction task, two main challenges are identified. Firstly, it is well-established in previous stock prediction literature that stock prices are highly stochastic and standard prediction models tend not to generalize well when dealing with such data (Xu and Cohen, 2018; Feng et al., 2019a). Given that stock prices are continuous and change at high frequencies, the discrete stock price data used for training models are essentially stochastic “samples” drawn at specific time-steps, e.g., at 12.00am on each day or at the 60-second mark of each minute, which might not fully capture the intrinsic stock price behavior. Currently, existing techniques that tackle this problem include (see Figure 1): learning a continuous, “latent” variable using a VAE model (Kingma and Welling, 2014) as the new independent variable for predicting the stock movement (Xu and Cohen, 2018); and adding adversarial perturbations (Goodfellow et al., 2020) to the stock training data to simulate stock price stochasticity (Feng et al., 2019a). However, these models are designed for single-step classification-based stock movement prediction, and are limited to low representation expressiveness. Secondly, for the multi-step regression task, the problem becomes progressively harder with the introduction of the target price sequence. The target series also contains stochastic noise, and training the model to predict this series directly would also reduce the generalizability of the predictions at test-time.
To deal with the abovementioned problems, we propose our Diffusion-VAE (D-Va) model, which combines deep hierarchical VAEs (Sønderby et al., 2016; Klushyn et al., 2019; Vahdat and Kautz, 2020) and diffusion probabilistic (Sohl-Dickstein et al., 2015; Song and Ermon, 2019; Ho et al., 2020) techniques to do seq2seq stock prediction (see Figure 1). Firstly, the deep hierarchical VAE increases the expressiveness of the approximate posterior stock price distribution, allowing us to learn more complex and low-level latent variables. Simultaneously, the diffusion probabilistic model trains the predictor to handle stock price stochasticity by progressively adding random noise to the input stock data (X-Diffusion in Figure 1). Secondly, we deal with the stochastic target price sequence by additionally augmenting the target series with noise via a coupled diffusion process (Y-Diffusion in Figure 1). The predicted diffused targets are then ”cleaned” with a denoising process (Da Silva and Shi, 2019; Ma et al., 2022) to obtain the generalized, ”true” target sequence. This is done by performing denoising score-matching on the diffused target predictions with the actual targets during training, then applying a single-step gradient denoising jump at test-time (Saremi and Hyvärinen, 2019; Li et al., 2019; Jolicoeur-Martineau et al., 2021). This process can also be seen as removing the estimated aleatoric uncertainty resulting from the data stochasticity (Li et al., 2022).
To demonstrate the effectiveness of D-Va, we perform extensive experiments, and show that our model is able to outperform state-of-the-art models in overall prediction accuracy and variance. Additionally, we also test the model in a practical investment setting. Having predicted sequences of stock returns allow us to form a stock portfolio across the duration of the prediction length using their means and covariance information. Using standard Markowitz mean-variance optimization, we then calculate the portfolio weights of each stock that can maximize the overall expected returns of the portfolio and minimizes its volatility (Markowitz, 1952). We further regularize the prediction covariance matrix via the graphical lasso (Friedman et al., 2008) in order to reduce the impact of the uncertainty of the prediction model, which can be seen as a form of epistemic uncertainty (Hüllermeier and Waegeman, 2021). We show that tackling both the uncertainties of the data (aleatoric) and the model (epistemic) allow us to achieve the best portfolio performance, in terms of the Sharpe ratio (Sharpe, 1994), over the specified test period.
The main contributions of this paper are summarized as:
-
•
We investigate the problem of generalization in the stock prediction task under the multi-step regression setting, and deal with stochasticity in both the input and target sequences.
-
•
We propose a solution that integrates a hierarchical VAE model, a stochastic diffusion process and a denoising component and implement it in an end-to-end model for stock prediction.
-
•
We conduct extensive experiments on public stock price data across three different time periods, and show that D-Va provide improvements over state-of-the-art methods in prediction accuracy and variance. We further demonstrate the effectiveness of the model in a practical, stock investment setting.
2. Related Works
The task of stock prediction is popular and there is a large amount of literature on this topic. Among the literature, we can classify them into various specific categories in order to position our work:
Technical and Fundamental Analysis. Technical Analysis (TA) methods focus on predicting the future movement of stock prices from quantitative market data, such as the price and volume. Common techniques include using attention-based Long Short-Term Memory (LSTM) networks (Qin et al., 2017), Autoregressive models (Li et al., 2016) or Fourier Decomposition (Zhang et al., 2017). On the other hand, Fundamental Analysis (FA) seeks information from external data sources to predict price, such as news (Hu et al., 2018a), earnings calls (Yang et al., 2022) or relational knowledge graphs (Feng et al., 2019b). For our work, we focus on TA to evaluate our techniques on processing quantitative financial data.
Classification and Regression. The stock prediction task can be formulated as a binary classification task, where the goal is to predict if prices will move up or down in the next time-step (Ding et al., 2020). This is generally considered a more achievable task (Ye et al., 2020) and is sufficient to help retail investors decide whether to buy or sell a stock. On the other hand, one can also formulate it as a regression task and predict the stock price directly. This offers investors more information for decision-making, such as being able to rank stocks based on profits and buying the top percentile stocks (Feng et al., 2019b; Lin et al., 2021). In this work, we tackle the regression task, in order to be able to weigh the amount of each stock for an investment portfolio.
Single and Multiple Steps Prediction. Most current works on stock prediction do single-step prediction for the next time-step (Tuncer et al., 2022), given that it allows one to make immediate trading decisions for the next day. On the other hand, there are very few literature on multi-step prediction, where stock predictions are made for the next multiple time-steps. An example can be found in (Liu and Wang, 2019), where the authors perform multi-step prediction to analyze the impact of breaking news on stock prices over a period of time. For this work, we will deal with the multi-step prediction task, where the motivation is to allow larger institutions to make long-term, volatility-aware investment decisions. Note that this is different from doing a single time-step prediction over a longer-term horizon (Feng et al., 2021), which can be considered as a single-step prediction task.
3. Methodology
In this section, we first formulate the task for the multi-step regression stock prediction. We then present the proposed D-Va model, which is illustrated in Figure 2. There are four main components in the framework: (1) a hierarchical VAE to generate the sequence predictions; (2) a diffusion process that gradually adds Gaussian noise to the input sequence to simulate stock price stochasticity; (3) a coupled diffusion process additionally applied to the target sequence; and (4) a denoising function that is trained to “clean” the predictions by removing the stochasticity from the predicted series. We will elaborate on each of these components in more details.
3.1. Problem Formulation
For each stock s, given an input sequence of trading days , we aim to predict its returns sequence over the next trading days , where refers to its percentage returns at time , i.e. , and is the closing price. The input vector consist of its open price, high price, low price, volume traded, absolute returns and percentage returns, i.e. , making it a multi-variate input to single-variate output prediction task. Additionally, given that we are interested in predicting the percentage returns, the open, high and low prices are normalized by the previous closing price, e.g., , similar to what was done in (Xu and Cohen, 2018; Feng et al., 2019a). The absolute returns is also included as an input feature.
3.2. Deep Hierarchical VAE
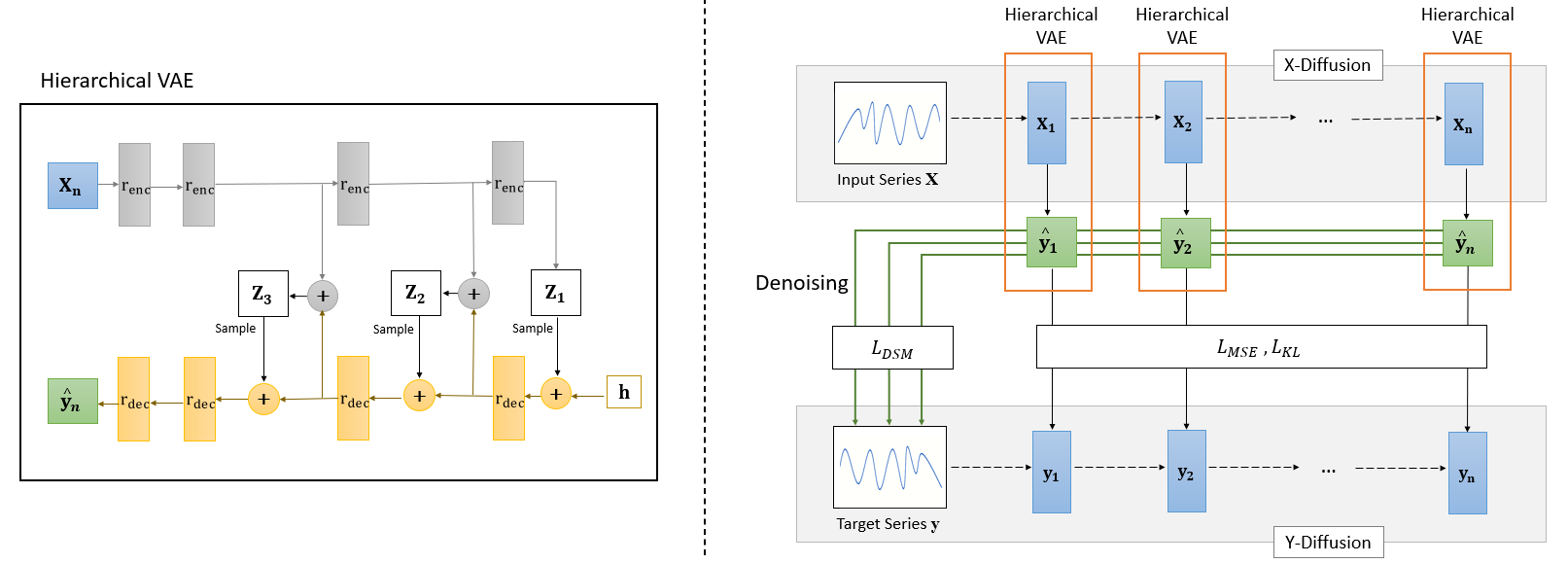
In order to increase the expressiveness of modeling the continuous latent factors that affect stock prices, we leverage deep hierarchical VAEs to learn more complex and low-level latent variables.
For our backbone model, we use a Noveau Variational Auto-Encoder (NVAE) (Vahdat and Kautz, 2020) that is repurposed as a seq2seq prediction model. NVAE is a state-of-the-art deep hierarchical VAE model that was originally built for image generation through the use of depthwise separable convolutions and batch normalization. The framework can be seen in Figure 2 (left). In the generative network, a series of decoder residual cells , initialized by hidden layer , are trained to generate conditional probability distributions. These are then used to generate the latent variables . The latent variables are further passed on as additional input to the next residual cell, which finally culminates in generating the prediction sequence . At the same time, in the encoder network, a series of encoder residual cells are used to extract the representations from the input sequence , which are also fed to the same generative network to infer the latent variables . Formally, we can define the data density of the prediction sequence as:
| (1) |
where represents the aggregated data density for all latent variables , and is a parameterized function that represents the aggregated decoder network. The prediction sequence can be defined to be generated from the probability distribution .
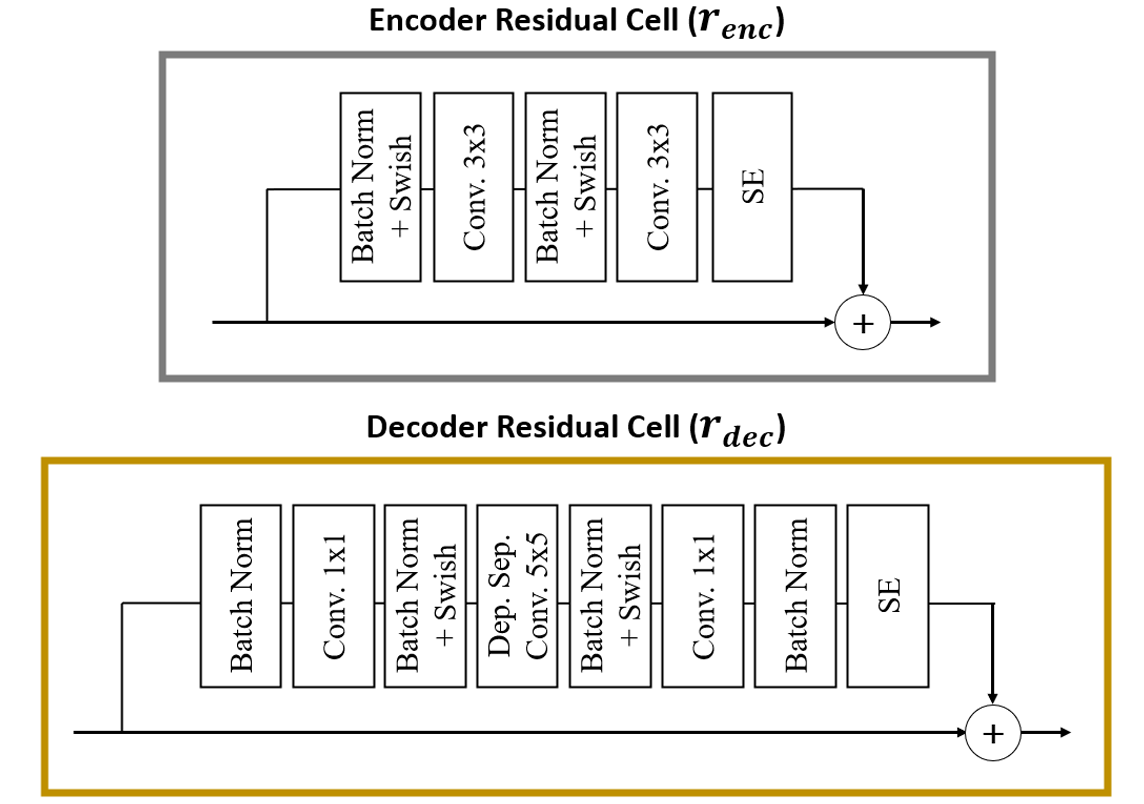
Next, we follow the work done in (Vahdat and Kautz, 2020) to design the two types of residual cells, which can be seen in Figure 3. The encoder residual cells consist of two series of batch normalization, Swish activation and convolution layers, followed by a Squeeze-and-Excitation (SE) layer. The Swish activation (Ramachandran et al., 2017), and the SE layer (Hu et al., 2018b), a gating unit that models the interdependencies between convolutional channels, are both experimentally verified to improve the performance of the hierarchical VAE. For the decoder residual cells , a different combination of these units are used, with the addition of a depthwise separable convolution layer. This layer helps to increase the receptive field of the network while keeping computational complexity low by separately mapping all the cross-channels correlations in the input features (Chollet, 2017). This allows us to capture the long-range dependencies of the data within each cell.
The stack of latent variables in the hierarchical VAE, together with the depthwise separable convolution layer in each residual cell, allow us to capture the complex, low-level dependencies of the stock price data beyond its stochasticity. This lets us generate the target sequence more accurately, resulting in better predictions.
3.3. Input Sequence Diffusion
Next, in order to guide the model in learning from the stochastic stock data, we gradually add random noise to the input stock price sequence, through the use of diffusion probabilistic models.
In the diffusion probabilistic model, we define a Markov chain of diffusion steps that slowly adds random Gaussian noise to the input sequence to obtain the noisy samples , where is the number of diffusion steps. The noise to be added at each step is controlled by a variance schedule, . The noisy samples for each of the diffusion step can then be obtained via:
| (2) |
Here, instead of sampling times for each diffusion step, we use the reparameterization trick (Ho et al., 2020) to allow us to obtain samples at any arbitrary step, in order to be able to train the model in a tractable closed-form. Let . We then have:
| (3) |
This process of generating from is akin to performing gradual augmentation on the input series, which trains the model to generate the target sequence through different levels of noise. This then results in more generalizable and robust predictions.
3.4. Target Sequence Diffusion
Additionally, it is shown in in (Li et al., 2022) that by adding diffusion noise to sequences and concurrently and matching the distributions learnt from a generative model and the diffusion process, it is possible to reduce the overall uncertainty produced by the generative model and the inherent random noise in the data (i.e. the source of aleatoric uncertainty). The relationship can be formulated as:
| (4) |
Here, the first term is the Kullback–Leibler (KL) divergence between the noise distribution after the additive diffusion process , and the noise distribution from the generative process of diffused series, , i.e., the uncertainty after augmentation. The second term is the KL divergence between the inherent data noise distribution and the noise distribution from generating the original series, , i.e., the uncertainty before augmentation. Hence, by coupling the generative and diffusion process, the overall prediction uncertainty of the model can be reduced.
Following this observation, we additionally add coupled Gaussian noise to the target sequences to obtain the noisy samples . Here, the noise to be added at each step is for , where is a scaling hyperparameter. Hence, we have:
| (5) |
Similarly as before, to allow us to obtain samples at any arbitrary step, we let and . Then, we have:
| (6) |
For the coupled diffusion process, we minimize the KL divergence:
| (7) |
where refers to the posterior distribution of the hierarchical VAE that generates the predicted sequence at diffusion step , and is the corresponding distribution from the diffusion model that generates the noisy target sequence .
Here, the diffusion noise applied to target sequence to generate helps to simulate the stochasticity in the target series, similar to what was done for the input sequence . Additionally, following the theorem in Eqn. 4, the coupled diffusion process also allows us to generate the predicted sequence with less uncertainty.
3.5. Denoising Score-Matching
In D-Va, the reverse process of a standard diffusion model (Ho et al., 2020) was replaced by the predictor for , which removes the need to perform denoising of the diffused samples. At test-time, we simply feed input sequence into the hierarchical VAE model, which will predict the target sequence . However, we note that we have previously defined target sequence to be a stochastic series, i.e. , which is not ideal to recover fully. Instead, we aim to capture the ”true” sequence , which lies on the actual data manifold.
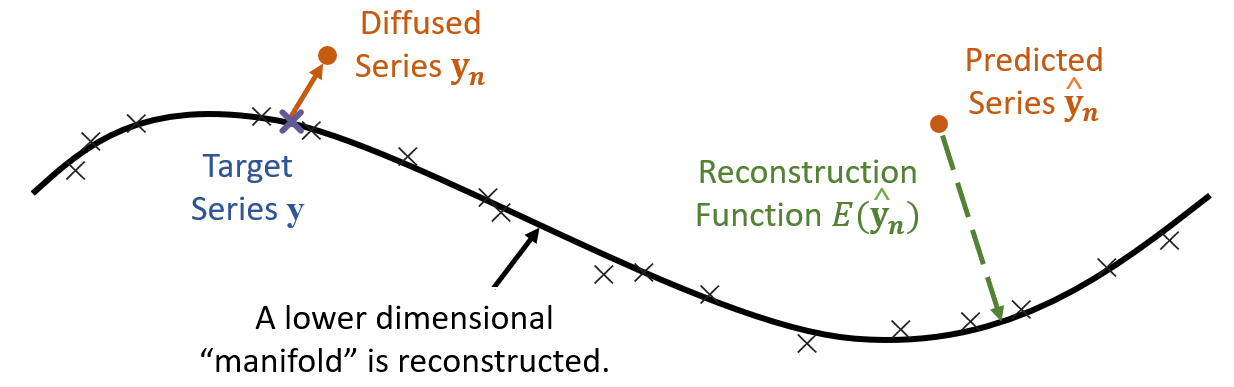
It has been shown in multiple previous works that it is possible to obtain samples closer to the actual data manifold, by adding an extra denoising step on the final sample (Saremi and Hyvärinen, 2019; Kadkhodaie and Simoncelli, 2020; Song and Ermon, 2020). This is akin to helping to remove residual noise, which could be caused by inappropriate sampling steps (Jolicoeur-Martineau et al., 2021), etc. In our case, this step will serve to remove the intrinsic noise from the generated target sequence , further reducing the aleatoric uncertainty of the series prediction. To do so, we first follow the denoising score-matching (DSM) process of a standard diffusion probabilistic model (Song and Ermon, 2019; Li et al., 2019). The process matches the gradient from the noisy prediction to the “clean” with the gradient of an energy function to be learnt, scaled by the amount of noise added from the diffusion process. Note that by doing energy-based learning, the model is not learning to replicate the target y series exactly, but a lower-dimensional manifold, which is closer to the ”true” sequence (see Figure 4). The DSM loss function to be minimized is as follows:
| (8) |
The gradient of the learnt energy function can be seen as a reconstruction step, which is able to recover from a corrupted sequence with any level of Gaussian noise. At test-time, we are then able to perform the one-step denoising jump:
| (9) |
where is the final predicted sequence of our model.
Additionally, this one-step denoising process can also be seen as removing the estimated aleatoric uncertainty resulting from data stochasticity (Li et al., 2022). Here, is an estimation of the sum of the noise produced by the generative VAE and the inherent random noise in the data, which we remove from the prediction series.
3.6. Optimization and Inference
Putting together the loss equations from Eq. 7 and 8, we get:
| (10) |
where and refers to the tradeoff parameters. Additionally, calculate the overall mean squared error (MSE) between the predicted sequence and diffused sequence for all diffusion steps , giving us the overall loss function for our model.
The training procedure is as follows: During training, we first apply the coupled diffusion process to both the input and target sequence and to generate the diffused sequences and . We then train the hierarchical VAE to generate predictions from the diffused input sequence , which are matched to the diffused target sequence . Simultaneously, we also train a denoising energy function to obtain the ”clean” predictions from .
During inference, the trained hierarchical VAE model is used to generate the predictions from the input sequences . The predicted sequences are further ”cleaned” by taking a one-step denoising jump (Eqn. 9) to remove the estimated aleatoric uncertainty. This allows us to obtain our final predicted sequences .
4. Experiment
We extensively evaluate D-Va on real-world stock data across three different time periods from 2014-2022, using two different datasets. Our work aims to answer the following three research questions:
-
•
RQ1: How does D-Va perform against the state-of-the-art methods on the multi-step regression stock prediction task?
-
•
RQ2: How does each of the proposed components (i.e., Hierarchical VAE, X-Diffusion, Y-Diffusion, Denoising) affects the prediction performance of D-Va?
-
•
RQ3: How does the multi-step outputs of D-Va help institutional investors in a practical setting, e.g., portfolio optimization?
4.1. Experiment Settings
4.1.1. Dataset
The first dataset used is the ACL18 StockNet dataset (Xu and Cohen, 2018). It contains the historical prices of 88 high trade volume stocks from the U.S. market, which represents the top 8-10 stocks in capital size across 9 major industries. The duration of data ranges between 01/01/2014 to 01/01/2017. This dataset is a popular benchmark that has been used in many stock prediction works (Feng et al., 2021; Sawhney et al., 2020; Feng et al., 2019a).
Furthermore, we extend this dataset by collecting updated U.S. stock data from 01/01/2017 to 01/01/2023, taking the latest top 10 stocks from the 11 major industries (Note that the list of industries have been expanded since the previous work), giving us a total of 110 stocks. The data is collected from Yahoo Finance333https://finance.yahoo.com/, and is processed in the same manner as the ACL18 dataset.
For this work, in order to maintain a consistent dataset length across the experiments, we further split this dataset into two. This gives us exactly three datasets of 3 years each for evaluation. In the results, each dataset will be labelled by their last year, which also correspond to the year of the testing period, i.e., 2016, 2019, 2022. We summarize the statistics of three datasets in Table 1.
For all datasets, we also split all data into training, validation and test sets in chronological order by the ratio of 7:1:2.
| Dataset | Duration | # Stocks | # Trading Days |
|---|---|---|---|
| 2016 | Jan 01 2014 - Dec 31 2016 | 88 | 756 |
| 2019 | Jan 01 2017 - Dec 31 2019 | 110 | 754 |
| 2022 | Jan 01 2020 - Dec 31 2022 | 110 | 756 |
4.1.2. Baselines
As the multi-step stock price prediction task has not been widely explored, to demonstrate the effectiveness of D-Va, we also include baselines from the general seq2seq task for comparison. This includes both statistical and deep learning methods that have been shown to work well in time series forecasting.
| Model | ARIMA | NBA | VAE | VAE + Adv | Autoformer | D-Va | MSE | SD | |
|---|---|---|---|---|---|---|---|---|---|
| 2016 | 10 | 11.41% | 73.06% | ||||||
| 20 | 7.83% | 76.16% | |||||||
| 40 | 3.04% | 67.56% | |||||||
| 60 | 2.50% | 71.09% | |||||||
| 2019 | 10 | 10.57% | 77.87% | ||||||
| 20 | 9.84% | 79.10% | |||||||
| 40 | 6.58% | 75.40% | |||||||
| 60 | 3.51% | 75.93% | |||||||
| 2022 | 10 | 13.10% | 70.23% | ||||||
| 20 | 10.70% | 78.41% | |||||||
| 40 | 7.83% | 77.12% | |||||||
| 60 | 3.01% | 78.22% | |||||||
-
•
ARIMA (Box et al., 2015) Autoregressive Integrated Moving Average (ARIMA) is a traditional statistical method that combines autoregressive, differencing, and moving average components to do time series forecasting. This is one of the baselines in the M5 accuracy competition, a popular time series forecasting competition (Makridakis et al., 2022).
-
•
NBA (Liu and Wang, 2019): Numerical-Based Attention (NBA) is a baseline model that tackles the multi-step stock price prediction task. It utilizes a long short-term memory (LSTM) network (Hochreiter and Schmidhuber, 1997; Akita et al., 2016) with an additional attention component that captures the text and temporal dependency of stock prices. For this model, we remove the text input component for an equivalent comparison.
-
•
VAE (Kingma and Welling, 2014; Xu and Cohen, 2018) We adapt a vanilla VAE model as a benchmark to compare against the hierarchical VAE. In this model, there is a single dense layer for the encoder, a single latent variable to be generated and a single dense layer for the sampling decoder. The VAE model has been shown to provide improvements in the single-step stock movement classification task (Xu and Cohen, 2018).
-
•
VAE + Adversarial (Goodfellow et al., 2014; Feng et al., 2019a): This is similar to the above model, but adversarial perturbations are added to the input sequence. The perturbation added is equal to the gradient of the loss function of the model, similar to what was done in (Goodfellow et al., 2014; Feng et al., 2019a).
-
•
Autoformer (Wu et al., 2021): The Autoformer is a state-of-the-art seq2seq prediction model that aggregates series-wise dependencies to do long-term forecasting. The model adapts a standard Transformer model with progressive decomposition capacities and an auto-correlation mechanism to find series periodicity.
4.1.3. Parameter Settings
To compare performances under different horizons, we evaluate a range of sequence lengths, with 10, 20, 40 and 60 days for both the input and output lengths and . The chosen lengths are typical liquidity horizons required by financial regulators, which follows the motivation of this work.
The Adam optimizer (Kingma and Ba, 2014) was used to optimize the model, with an initial learning rate of 5e-4. The batch size is 16, and we train the model for 20 epochs for each stock separately, taking the iteration with the best validation results for each. For the trade-off hyperparameters, we perform a grid search of step 0.1 within the range of and set and . All experiments are repeated five times for each stock: we report the overall average MSE and standard deviation of all stocks in our results section. We then measure the percentage improvement in MSE and standard deviation of D-Va against the strongest baselines for each experiment setting.
5. Results
Next, we will discuss the performance of D-Va in tackling each of the proposed research questions from the previous section.
5.1. Performance Comparison (RQ1)
Table 2 reports the results on the multi-step regression stock prediction task. From the table, we observe the following:
-
•
The statistical model ARIMA tends to perform better than the other baselines when the sequence length is longer. This can be attributed to it having enough information to capture the auto-correlations within the sequence for forecasting, as opposed to shorter sequences where there are less obvious periodicity and greater noise-to-data ratio. This is also later observed in the Autoformer, which also learns from sequence auto-correlations.
-
•
The VAE models tend to exhibit MSE improvements when the prediction uncertainty is high, as measured by the standard deviation over multiple runs. This can be observed when comparing the performance of the NBA and VAE model. When the predictions of the NBA model display high standard deviation, i.e., above 0.075, the VAE model show clear MSE improvements. On the other hand, when the standard deviation for NBA is low, the VAE model performs worse. In all cases, the standard deviation of the VAE model predictions is much lower. It is likely that the NBA model is unable to learn well when the data is noisy, resulting in predictions that are poor and vary greatly. However, during periods where the data is less noisy, the LSTM + Attention components of the NBA model is able to perform better than the simple dense layers of the encoder/decoder in the VAE models.
-
•
The VAE + Adversarial model does not show much improvements from the VAE model. The difference in MSE is not statistically significant, and could be attributed to the standard deviation of the results. However, the additional adversarial component seems to provide some slight improvements in the standard deviation of its prediction results over the pure VAE model.
-
•
The Autoformer model remarkably outperforms the above three deep learning models across all sequence lengths despite not having a variational component, which highlights the robustness of this method. This trait was also mentioned in the source material (Wu et al., 2021), where the model was able to perform well on the exchange rate prediction task even when there are no obvious periodicity. Our result is able to verify this on the stock prediction task. We also observe that the standard deviation of the predictions of this model increases gradually as the sequence length increases, which goes in an opposite trend to the previous 3 models. This could be attributed to noise accumulating in the captured series periodicity which is used to generate the output sequence.
-
•
Our D-Va model is able to outperform all models in terms of its MSE performance and the standard deviation of the predictions. On average, D-Va achieves an improvement of 7.49% over the strongest baselines (underlined in Table 2) on MSE performance and a strong 75.01% on standard deviation. This showcases the capabilities of D-Va in handling data uncertainty to improve predictions in the multi-step regression stock prediction task.
-
•
Finally, we note that the MSE improvement decreases with increasing prediction length. This is likely due to the fact that there are more chances of unexpected material changes in the market with a longer prediction horizon, which the model cannot foresee. In a practical setting, given a long horizon, it could be better to do a rolling forecast using a shorter-length model instead.
5.2. Model Study (RQ2)
To demonstrate the effectiveness of each additional component in D-Va, we conduct an ablation study over different variants of the model. We remove one additional component for each variant, i.e., no denoising component (D-VaDn); no target series diffusion and denoising components (D-VaYdDn); and no input series diffusion, target series diffusion and denoising components, which leaves only the backbone hierarchical VAE model (D-VaXdYdDn).
5.2.1. Ablation Study
| Model |
|
|
|
D-Va | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2016 |
10 |
||||||||||
|
20 |
|||||||||||
|
40 |
|||||||||||
|
60 |
|||||||||||
| 2019 |
10 |
||||||||||
|
20 |
|||||||||||
|
40 |
|||||||||||
|
60 |
|||||||||||
| 2022 |
10 |
||||||||||
|
20 |
|||||||||||
|
40 |
|||||||||||
|
60 |
|||||||||||
Table 3 reports the results on the ablation study. From the table, we make the following observations:
-
•
The backbone model D-VaXdYdDn, i.e., only the hierarchical VAE, already showcase a strong MSE improvement over the previous baseline models, i.e., ARIMA and Autoformer, which highlights the strength of this method. It is possible that handling the data stochasticity through the latent variables of the hierarchical VAE is more effective than learning from the series auto-correlation, for the stock price prediction task.
-
•
With each additional diffusion component, i.e., in the D-VaYdDn and D-VaDn models, we see can clear improvement in the standard deviation of the predictions. The additional noise augmentation helps to improve the stability of the predictions, which was also previously observed in the VAE + Adversarial model. This also shows that our proposed components help to increase the robustness of the model and decrease the prediction uncertainty.
-
•
The best MSE performances seem to vary across the variant models. However, we can see a visible relationship between the prediction uncertainty of one model, as measured by the standard deviation of their results, against the MSE performance of the next model. When the standard deviation is low, i.e., below 0.050, there seems to be little to no MSE improvement provided by the next additional component. It is likely that the components work by making the model more robust against noise in the data – however, for experimental settings where the data noise is low enough (hence, low standard deviation), there is not much improvements to be made in the predictions. We will explore this observation in more details in the next subsection.
-
•
Interestingly, we note that the denoising component, i.e., from D-VaDn to D-Va, also slightly increase the standard deviation of the predictions. This could be due to it being trained to take the one-step denoising step towards the target series (see Eq. 8), which we had previously defined to be stochastic.
5.2.2. Uncertainty Reduction
A key observation that was made over the results analysis was that the MSE improvements of the variational components seem to be related to the uncertainty, measured by the standard deviation of the results, from the prior models. In this section, we study this observation in more detail.
First, we note that the reported performance was calculated from the average of the results from individual stocks, each of them with their own average MSE and standard deviation over 5 runs. Taking all of their individual results from all 12 experimental settings (i.e., 3 test periods and 4 sequence lengths), we then plot the standard deviation for one model against the percentage change in MSE from the improved variant, given an additional component.
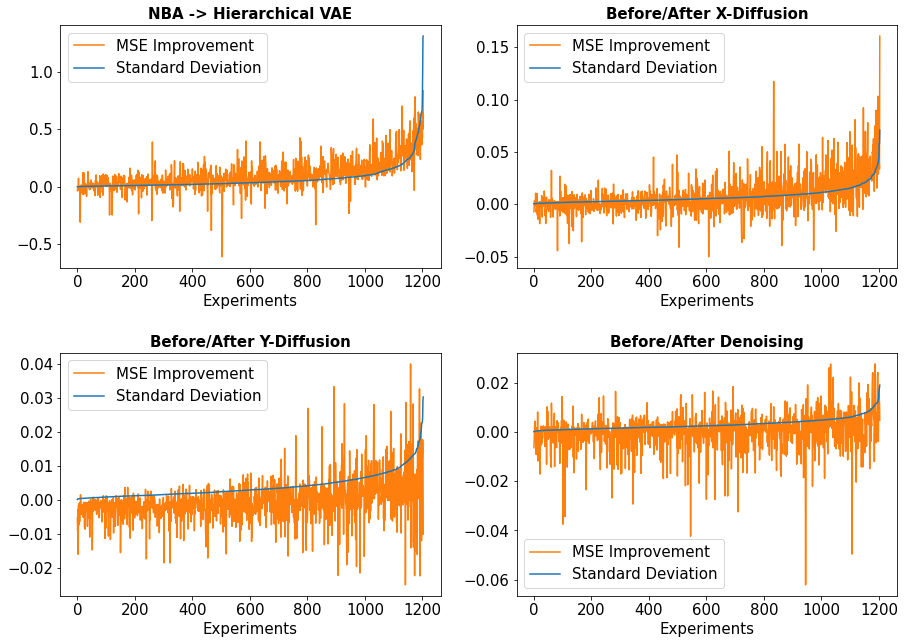
As shown in Figure 5, there is a visible relationship between the prediction uncertainty of the models, as measured by the standard deviation of the prediction results before the introduction of each variational component, with the resulting MSE improvement after each component is introduced. When the model is more uncertain about its predictions, likely due to the stochastic nature of stock data, the additional VAE and diffusion components become more effective given their capabilities to handle data noise and uncertainty. The relationship becomes less pronounced with each additional component, likely due to there being significantly less uncertainty with each component that comes before it (note the reduction in scale of the standard deviation across each subplot in Figure 5).
This relationship is least visible in the denoising component. This could be attributed to two possible reasons: Firstly, through the VAE and diffusion components, the data noise has been reduced to the minimal possible, making it difficult for the last component to produce any more improvements. Secondly, it is also plausible that the denoising component works via a different mechanism that does not depend as much on the prior model’s uncertainty. As mentioned, the model is trained to take the one-step denoising step towards the stochastic target series , which increases its information of the targets but reduces its generalizability. This is similar to the bias-variance problem (Kohavi and Wolpert, 1996; von Luxburg and Schölkopf, 2011), whereas our model does not want to overfit to the target data as it also contains stochastic noise.
5.3. Portfolio Optimization (RQ3)
Furthermore, we examine the usefulness of the model in a practical setting. As opposed to a single-day prediction, having multi-step prediction allow us to understand the outlook for the stocks’ returns over the next few days, allowing us to form a portfolio of assets that can maximize our returns and minimize its volatility.
5.3.1. Mean-Variance Optimization
Given the returns sequence prediction for every stock , we first calculate their overall mean and covariance across each individual prediction period :
| (11) |
where and represents the mean vector and covariance matrix of all stocks’ returns across prediction period , and is the total number of stocks. We then form a stock portfolio for the period using Markowitz’ mean-variance optimization (Markowitz, 1952):
| (12) |
where is the portfolio weights vector to be learnt, which sums to 1 representing the overall capital. is the risk-aversion parameter, which can be treated as a hyper-parameter to be tuned by maximizing the portfolio results on the validation set (Peng and Linetsky, 2022). Additionally, we also set a no short-sales constraint, i.e., , which has been shown to reduce the overall portfolio risk (Jagannathan and Ma, 2003; DeMiguel et al., 2009) and is also often restricted by financial institutions (Chang et al., 2014; Beber and Pagano, 2013).
| 2016 | Sharpe Ratio |
|
2019 | Sharpe Ratio |
|
2022 | Sharpe Ratio |
|
|||||||||||
| NBA | 0.0270 | 0.0691 | Handling aleatoric | NBA | 0.0820 | 0.1767 | Handling aleatoric | NBA | 0.0332 | 0.0404 | Handling aleatoric | ||||||||
| Equal | 0.1089 | Equal | 0.2337 | Equal | 0.0437 | ||||||||||||||
| D-Va | 0.0772 | 0.1174 | D-Va | 0.1197 | 0.2767 | D-Va | 0.0600 | 0.0645 | |||||||||||
| Handling epistemic | Handling epistemic | Handling epistemic | |||||||||||||||||
5.3.2. Graphical Lasso Regularization
Additionally, we further perform regularization on the covariance matrix by applying a graphical lasso (Friedman et al., 2008). This is done by maximizing the penalized log-likelihood:
| (13) |
where is the regularized, inverted covariance matrix to be learnt and is a hyper-parameter, which we set to 0.1 in our experiments. The method is akin to performing L1 regularization (Tibshirani, 1996) in machine learning, which increases the generalizability of the predictions by reducing their dimensionalities. It is also similar to performing covariance shrinkage (Ledoit and Wolf, 2004a, b) in finance, where the extreme values are pulled towards more central values. However, the graphical lasso has been shown to work better for the covariances of smaller samples (Belilovsky et al., 2017; Gao et al., 2018), which was also observed in our experiments.
The L1 regularization can also be seen as a way to reduce the impact of model uncertainty, which is a form of epistemic uncertainty (Hüllermeier and Waegeman, 2021). On the other hand, our diffusion-based prediction model deals mainly with data uncertainty, or aleatoric uncertainty (Li et al., 2022). Applying both techniques, we explore the effects of handling each type of uncertainty on the performance of the stock portfolio.
5.3.3. Comparison Method
To compare portfolio performance, we use the Sharpe Ratio (Sharpe, 1994), which is a measure of the ratio of the portfolio returns compared to its volatility. It is defined as the overall expected returns of the portfolio (we set the risk-free interest rate to 0) divided by the returns’ standard deviation , i.e., :
For each prediction period , we first form a portfolio across sequence length using Eq. 12, which allows us to calculate its Sharpe Ratio. We then evaluate the average Sharpe Ratio across all within the test period, and also average across the results of the 5 prediction runs. Additionally, we also include the performance of the equal-weight portfolio, i.e., . The naive equal-weight portfolio have been shown to outperform most existing portfolio methods on look-ahead performance (DeMiguel et al., 2009), which makes it a strong baseline for comparison. We make three comparisons: Firstly, we compare the average 10-day Sharpe ratios of D-Va with the baseline model NBA, with and without using regularization, to analyze the impact of handling each uncertainty type. Next, we compare the average -day Sharpe ratios across the different sequence lengths . Finally, we compare the average -day Sharpe ratios, after regularization, across the benchmark multi-step prediction models.
5.3.4. Portfolio Results
Table 4 compares the average 10-day Sharpe ratios across the different dataset years. We can see that using D-Va as the prediction model and applying regularization both help to improve the Sharpe ratio results, and combining both methods allow us to obtain the best Sharpe ratio performance. The equal-weight portfolio remains a strong baseline against our non-regularized model: this could be due to D-Va not incorporating additional information sources like news, and hence not being able to expect new changes or shocks to the price trends. However, the model was still able to provide enough information to the regularized portfolio method to outperform this benchmark using only historical price data, which is an optimistic sign for its prediction ability.
Figure 6 compares the average -day Sharpe ratios across the different prediction lengths. As observed previously, using the predictions from D-Va, together with covariance regularization, we are able to form portfolios that consistently achieve the best Sharpe ratios, even across difference sequence lengths . We note that there are settings where D-Va with regularization does not outperform the equal-weight portfolio e.g., test period 2019 and . This might be attributed to D-Va not being able to capture any information on possible shocks to the price trends over the next days. However, for such cases, its performance often lies close to the equal-weight portfolio, showing that the regularization method is able to spread the risk out well when there are limited information.
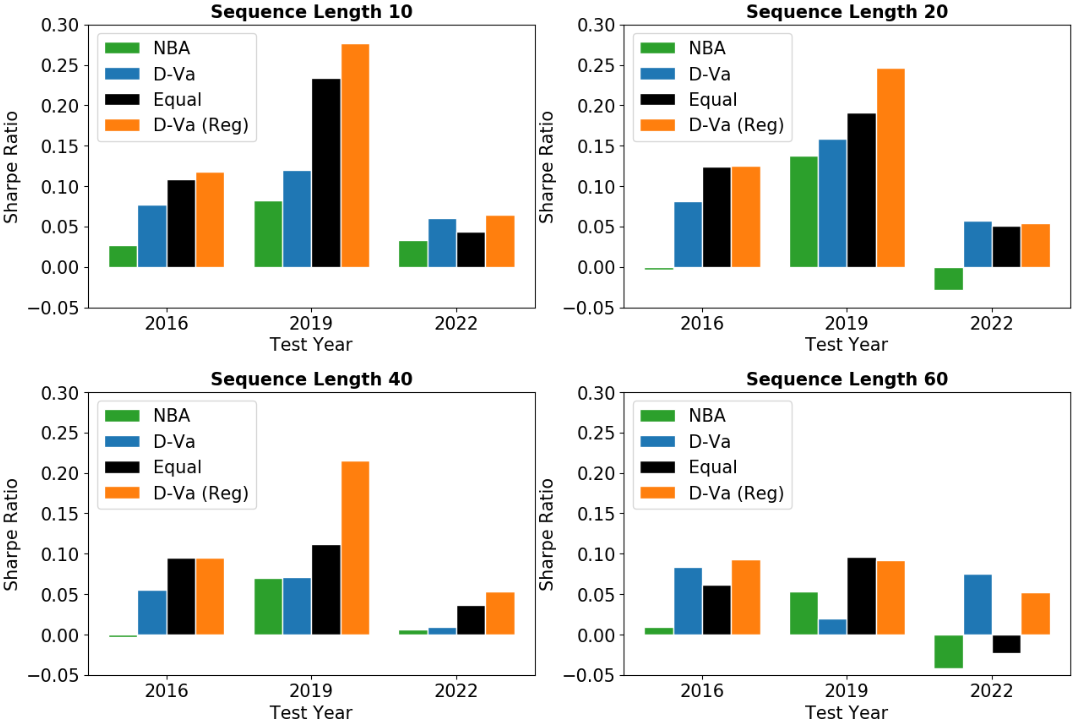
Finally, Table 5 compares the average -day Sharpe ratios across the three benchmark models, after the graphical lasso regularization is applied. We see that our D-Va model is able to obtain the best results on Sharpe ratio, and results close to that of the equal-weight portfolio when it does not, which was observed previously. One important observation is that the Sharpe ratio results are not directly proportional to the prediction MSE results in Table 2. This is likely because the forming of portfolios take into account the volatility direction of the predictions – for example, for a true value of 0.0, a prediction of -0.01 and 0.01 would contribute the same impact to the MSE but would result in different trading decisions when forming a portfolio. However, our D-Va model was still able to achieve state-of-the-art results in both metrics. It is possible that dealing with the stochasticity of the target series allows the model to make ”cleaner” predictions, which allows the MSE to accurately reflect its actual closeness to the target series and not its noise.
| Model | ARIMA | NBA | Autoformer | Equal | D-Va | |
|---|---|---|---|---|---|---|
| 2016 | 10 | 0.0953 | 0.0691 | 0.1114 | 0.1089 | 0.1174 |
| 20 | 0.0815 | 0.1075 | 0.0921 | 0.1243 | 0.1246 | |
| 40 | 0.0683 | 0.0717 | 0.0438 | 0.0950 | 0.0953 | |
| 60 | 0.0544 | 0.0803 | 0.0235 | 0.0614 | 0.0929 | |
| 2019 | 10 | 0.2736 | 0.1767 | 0.2350 | 0.2337 | 0.2767 |
| 20 | 0.2455 | 0.1443 | 0.1672 | 0.1912 | 0.2467 | |
| 40 | 0.2152 | 0.1252 | 0.1031 | 0.1113 | 0.2152 | |
| 60 | 0.0732 | 0.0826 | 0.0804 | 0.0965 | 0.0914 | |
| 2022 | 10 | 0.0173 | 0.0404 | 0.0544 | 0.0437 | 0.0645 |
| 20 | 0.0408 | 0.0404 | 0.0141 | 0.0505 | 0.0540 | |
| 40 | 0.0287 | -0.0223 | -0.0016 | 0.0365 | 0.0527 | |
| 60 | -0.0329 | -0.0179 | -0.0630 | -0.0230 | 0.0524 | |
6. Conclusion and Future Work
In this paper, we explained the importance of the multi-step regression stock price prediction task, which is often overlooked in current literature. For this task, we highlighted two challenges: the limitations of existing methods in handling the stochastic noise in stock price input data, and the additional problem of noise in the target sequence for the multi-step task. To tackle these challenges, we propose a deep-learning framework, D-Va, that integrates hierarchical VAE and diffusion probabilistic techniques to do multi-step predictions. We conducted extensive experiments on two benchmark datasets, one of which is collected by us by extending a popular stock prediction dataset (Xu and Cohen, 2018). We found that our D-Va model outperforms state-of-the-art methods in both its prediction accuracy and the standard deviation of the results. Furthermore, we also demonstrated the effectiveness of the model outputs in a practical investment setting. The portfolios formed from D-Va’s predictions are also able to outperform those formed from the other benchmark prediction models and also the equal-weight portfolio, which is a known strong baseline in finance literature (DeMiguel et al., 2009).
The results of this work open up some possible future directions for research. On data augmentation, we have explored perturbing the data by the gradient of the loss function (Feng et al., 2019a) and Gaussian diffusion noise in this work. Other possibilities include adding noise between the range of the high and low prices, which represent the maximum observed price movements for each time-step. A recent work (Liu et al., 2022) also proposed theoretically that augmenting stock data with noise of strength is the most optimal to achieve the best Sharpe ratio. Additionally, there has also been numerous existing research on predicting stock movements with alternative data, such as text (Hu et al., 2018a; Feng et al., 2021) or audio (Yang et al., 2022). This could be incorporated into D-Va, which currently only uses the historical price data. However, instead of simply looking at prediction accuracy, one can also explore how the additional information sources help to reduce the uncertainty of the predictions. This will be greatly helpful for the case of predicting highly stochastic data, such as stock prices. Finally, given the sequence prediction outputs from D-Va, other state-of-the-art portfolio techniques can also be explored, such as the Hierarchical Risk Parity (HRP) approach (De Prado, 2016), or the most recent Partially Egalitarian Portfolio Selection (PEPS) technique (Peng and Linetsky, 2022), to evaluate the synergy of our model with different financial techniques.
7. Acknowledgement
This research is supported by the Defence Science and Technology Agency, and the NExT Research Centre.
References
- (1)
- Akita et al. (2016) Ryo Akita, Akira Yoshihara, Takashi Matsubara, and Kuniaki Uehara. 2016. Deep learning for stock prediction using numerical and textual information. In ICIS. IEEE Computer Society, 1–6.
- Beber and Pagano (2013) Alessandro Beber and Marco Pagano. 2013. Short-selling bans around the world: Evidence from the 2007–09 crisis. J. Finance 68, 1 (2013), 343–381.
- Belilovsky et al. (2017) Eugene Belilovsky, Kyle Kastner, Gaël Varoquaux, and Matthew B. Blaschko. 2017. Learning to Discover Sparse Graphical Models. In ICML (Proceedings of Machine Learning Research, Vol. 70). PMLR, 440–448.
- Box et al. (2015) George EP Box, Gwilym M Jenkins, Gregory C Reinsel, and Greta M Ljung. 2015. Time series analysis: forecasting and control. John Wiley & Sons.
- Chang et al. (2014) Eric C Chang, Yan Luo, and Jinjuan Ren. 2014. Short-selling, margin-trading, and price efficiency: Evidence from the Chinese market. J. Bank. Finance 48 (2014), 411–424.
- Chen et al. (2018) Yingmei Chen, Zhongyu Wei, and Xuanjing Huang. 2018. Incorporating Corporation Relationship via Graph Convolutional Neural Networks for Stock Price Prediction. In CIKM. ACM, 1655–1658.
- Chollet (2017) François Chollet. 2017. Xception: Deep Learning with Depthwise Separable Convolutions. In CVPR. IEEE Computer Society, 1800–1807.
- Da Silva and Shi (2019) Brandon Da Silva and Sylvie Shang Shi. 2019. Style transfer with time series: Generating synthetic financial data. arXiv preprint arXiv:1906.03232 (2019).
- De Prado (2016) Marcos Lopez De Prado. 2016. Building diversified portfolios that outperform out of sample. The Journal of Portfolio Management 42, 4 (2016), 59–69.
- DeMiguel et al. (2009) Victor DeMiguel, Lorenzo Garlappi, and Raman Uppal. 2009. Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy? Rev. Financ. Stud. 22, 5 (2009), 1915–1953.
- Ding et al. (2020) Qianggang Ding, Sifan Wu, Hao Sun, Jiadong Guo, and Jian Guo. 2020. Hierarchical Multi-Scale Gaussian Transformer for Stock Movement Prediction. In IJCAI. ijcai.org, 4640–4646.
- Dong et al. (2013) Guanqun Dong, Kamaladdin Fataliyev, and Lipo Wang. 2013. One-step and multi-step ahead stock prediction using backpropagation neural networks. In ICICS. IEEE, 1–5.
- Feng et al. (2019a) Fuli Feng, Huimin Chen, Xiangnan He, Ji Ding, Maosong Sun, and Tat-Seng Chua. 2019a. Enhancing Stock Movement Prediction with Adversarial Training. In IJCAI. ijcai.org, 5843–5849.
- Feng et al. (2019b) Fuli Feng, Xiangnan He, Xiang Wang, Cheng Luo, Yiqun Liu, and Tat-Seng Chua. 2019b. Temporal Relational Ranking for Stock Prediction. ACM TOIS 37, 2 (2019), 27:1–27:30.
- Feng et al. (2021) Fuli Feng, Xiang Wang, Xiangnan He, Ritchie Ng, and Tat-Seng Chua. 2021. Time horizon-aware modeling of financial texts for stock price prediction. In ICAIF. ACM, 51:1–51:8.
- Friedman et al. (2008) Jerome Friedman, Trevor Hastie, and Robert Tibshirani. 2008. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 9, 3 (2008), 432–441.
- Gao et al. (2018) Xu Gao, Weining Shen, Chee-Ming Ting, Steven C Cramer, Ramesh Srinivasan, and Hernando Ombao. 2018. Modeling brain connectivity with graphical models on frequency domain. arXiv preprint arXiv:1810.03279 (2018).
- Goodfellow et al. (2020) Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. 2020. Generative adversarial networks. Commun. ACM 63, 11 (2020), 139–144.
- Goodfellow et al. (2014) Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. 2014. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014).
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. In NeurIPS.
- Hochreiter and Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long Short-Term Memory. Neural Comput. 9, 8 (1997), 1735–1780.
- Hu et al. (2018b) Jie Hu, Li Shen, and Gang Sun. 2018b. Squeeze-and-Excitation Networks. In CVPR. Computer Vision Foundation / IEEE Computer Society, 7132–7141.
- Hu et al. (2018a) Ziniu Hu, Weiqing Liu, Jiang Bian, Xuanzhe Liu, and Tie-Yan Liu. 2018a. Listening to Chaotic Whispers: A Deep Learning Framework for News-oriented Stock Trend Prediction. In WSDM. ACM, 261–269.
- Hüllermeier and Waegeman (2021) Eyke Hüllermeier and Willem Waegeman. 2021. Aleatoric and epistemic uncertainty in machine learning: an introduction to concepts and methods. Mach. Learn. 110, 3 (2021), 457–506.
- Jagannathan and Ma (2003) Ravi Jagannathan and Tongshu Ma. 2003. Risk reduction in large portfolios: Why imposing the wrong constraints helps. J. Finance 58, 4 (2003), 1651–1683.
- Jolicoeur-Martineau et al. (2021) Alexia Jolicoeur-Martineau, Rémi Piché-Taillefer, Ioannis Mitliagkas, and Remi Tachet des Combes. 2021. Adversarial score matching and improved sampling for image generation. In ICLR. OpenReview.net.
- Kadkhodaie and Simoncelli (2020) Zahra Kadkhodaie and Eero P Simoncelli. 2020. Solving linear inverse problems using the prior implicit in a denoiser. arXiv preprint arXiv:2007.13640 (2020).
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Kingma and Welling (2014) Diederik P. Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes. In ICLR.
- Klushyn et al. (2019) Alexej Klushyn, Nutan Chen, Richard Kurle, Botond Cseke, and Patrick van der Smagt. 2019. Learning Hierarchical Priors in VAEs. In NeurIPS. 2866–2875.
- Kohavi and Wolpert (1996) Ron Kohavi and David H. Wolpert. 1996. Bias Plus Variance Decomposition for Zero-One Loss Functions. In ICML. Morgan Kaufmann, 275–283.
- Ledoit and Wolf (2004a) Olivier Ledoit and Michael Wolf. 2004a. Honey, I shrunk the sample covariance matrix. J. Portf. Manag. 30, 4 (2004), 110–119.
- Ledoit and Wolf (2004b) Olivier Ledoit and Michael Wolf. 2004b. A well-conditioned estimator for large-dimensional covariance matrices. J. Multivar. Anal. 88, 2 (2004), 365–411.
- Li et al. (2016) Lili Li, Shan Leng, Jun Yang, and Mei Yu. 2016. Stock market autoregressive dynamics: a multinational comparative study with quantile regression. Mathematical Problems in Engineering 2016 (2016).
- Li et al. (2022) Yan Li, Xinjiang Lu, Yaqing Wang, and Dejing Dou. 2022. Generative time series forecasting with diffusion, denoise, and disentanglement. In NeurIPS.
- Li et al. (2019) Zengyi Li, Yubei Chen, and Friedrich T Sommer. 2019. Learning energy-based models in high-dimensional spaces with multi-scale denoising score matching. arXiv preprint arXiv:1910.07762 (2019).
- Lin et al. (2021) Hengxu Lin, Dong Zhou, Weiqing Liu, and Jiang Bian. 2021. Learning Multiple Stock Trading Patterns with Temporal Routing Adaptor and Optimal Transport. In KDD. ACM, 1017–1026.
- Liu and Wang (2019) Guang Liu and Xiaojie Wang. 2019. A Numerical-Based Attention Method for Stock Market Prediction With Dual Information. IEEE Access 7 (2019), 7357–7367.
- Liu et al. (2022) Ziyin Liu, Kentaro Minami, and Kentaro Imajo. 2022. Theoretically Motivated Data Augmentation and Regularization for Portfolio Construction. In ICAIF. ACM, 273–281.
- Ma et al. (2022) Yanqing Ma, Carmine Ventre, and Maria Polukarov. 2022. Denoised Labels for Financial Time Series Data via Self-Supervised Learning. In ICAIF. ACM, 471–479.
- Makridakis et al. (2022) Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. 2022. M5 accuracy competition: Results, findings, and conclusions. Int. J. Forecast. 38, 4 (2022), 1346–1364.
- Markowitz (1952) Harry Markowitz. 1952. Portfolio Selection. J. Finance 7, 1 (1952), 77–91.
- Peng and Linetsky (2022) Yiming Peng and Vadim Linetsky. 2022. Portfolio Selection: A Statistical Learning Approach. In ICAIF. ACM, 257–263.
- Qin et al. (2017) Yao Qin, Dongjin Song, Haifeng Chen, Wei Cheng, Guofei Jiang, and Garrison W. Cottrell. 2017. A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction. In IJCAI. ijcai.org, 2627–2633.
- Ramachandran et al. (2017) Prajit Ramachandran, Barret Zoph, and Quoc V Le. 2017. Searching for activation functions. arXiv preprint arXiv:1710.05941 (2017).
- Raunig (2006) Burkhard Raunig. 2006. The longer-horizon predictability of German stock market volatility. Int. J. Forecast. 22, 2 (2006), 363–372.
- Saremi and Hyvärinen (2019) Saeed Saremi and Aapo Hyvärinen. 2019. Neural Empirical Bayes. J. Mach. Learn. Res. 20 (2019), 181:1–181:23.
- Sawhney et al. (2020) Ramit Sawhney, Shivam Agarwal, Arnav Wadhwa, and Rajiv Ratn Shah. 2020. Deep Attentive Learning for Stock Movement Prediction From Social Media Text and Company Correlations. In EMNLP (1). ACL, 8415–8426.
- Sharpe (1994) William F Sharpe. 1994. The sharpe ratio. J. Portf. Manag. 21 (1994), 49–58.
- Sohl-Dickstein et al. (2015) Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. 2015. Deep Unsupervised Learning using Nonequilibrium Thermodynamics. In ICML (JMLR Workshop and Conference Proceedings, Vol. 37). JMLR.org, 2256–2265.
- Sønderby et al. (2016) Casper Kaae Sønderby, Tapani Raiko, Lars Maaløe, Søren Kaae Sønderby, and Ole Winther. 2016. Ladder Variational Autoencoders. In NIPS. 3738–3746.
- Song and Ermon (2019) Yang Song and Stefano Ermon. 2019. Generative Modeling by Estimating Gradients of the Data Distribution. In NeurIPS. 11895–11907.
- Song and Ermon (2020) Yang Song and Stefano Ermon. 2020. Improved Techniques for Training Score-Based Generative Models. In NeurIPS.
- Tibshirani (1996) Robert Tibshirani. 1996. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological) 58, 1 (1996), 267–288.
- Tuncer et al. (2022) Tuna Tuncer, Uygar Kaya, Emre Sefer, Onur Alacam, and Tugcan Hoser. 2022. Asset Price and Direction Prediction via Deep 2D Transformer and Convolutional Neural Networks. In ICAIF. ACM, 79–86.
- Vahdat and Kautz (2020) Arash Vahdat and Jan Kautz. 2020. NVAE: A Deep Hierarchical Variational Autoencoder. In NeurIPS.
- von Luxburg and Schölkopf (2011) Ulrike von Luxburg and Bernhard Schölkopf. 2011. Statistical Learning Theory: Models, Concepts, and Results. In Inductive Logic. Handbook of the History of Logic, Vol. 10. Elsevier, 651–706.
- Wu et al. (2021) Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. 2021. Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting. In NeurIPS. 22419–22430.
- Xu and Cohen (2018) Yumo Xu and Shay B. Cohen. 2018. Stock Movement Prediction from Tweets and Historical Prices. In ACL (1). ACL, 1970–1979.
- Yang et al. (2022) Linyi Yang, Jiazheng Li, Ruihai Dong, Yue Zhang, and Barry Smyth. 2022. NumHTML: Numeric-Oriented Hierarchical Transformer Model for Multi-Task Financial Forecasting. In AAAI. AAAI Press, 11604–11612.
- Ye et al. (2020) Jiexia Ye, Juanjuan Zhao, Kejiang Ye, and Chengzhong Xu. 2020. Multi-Graph Convolutional Network for Relationship-Driven Stock Movement Prediction. In ICPR. IEEE, 6702–6709.
- Zhang et al. (2017) Liheng Zhang, Charu C. Aggarwal, and Guo-Jun Qi. 2017. Stock Price Prediction via Discovering Multi-Frequency Trading Patterns. In KDD. ACM, 2141–2149.