Retrieval meets Long Context Large Language Models
Abstract
Extending the context window of large language models (LLMs) is getting popular recently, while the solution of augmenting LLMs with retrieval has existed for years. The natural questions are: i) Retrieval-augmentation versus long context window, which one is better for downstream tasks? ii) Can both methods be combined to get the best of both worlds? In this work, we answer these questions by studying both solutions using two state-of-the-art pretrained LLMs, i.e., a proprietary 43B GPT and Llama2-70B. Perhaps surprisingly, we find that LLM with 4K context window using simple retrieval-augmentation at generation can achieve comparable performance to finetuned LLM with 16K context window via positional interpolation on long context tasks, while taking much less computation. More importantly, we demonstrate that retrieval can significantly improve the performance of LLMs regardless of their extended context window sizes. Our best model, retrieval-augmented Llama2-70B with 32K context window, outperforms GPT-3.5-turbo-16k and Davinci003 in terms of average score on nine long context tasks including question answering, query-based summarization, and in-context few-shot learning tasks. It also outperforms its non-retrieval Llama2-70B-32k baseline by a margin, while being much faster at generation. Our study provides general insights on the choice of retrieval-augmentation versus long context extension of LLM for practitioners.
1 Introduction
The long context large language models (LLM) have recently received a lot of attention in production (e.g., Anthropic, 2023; OpenAI, 2023b), research community (e.g., Chen et al., 2023; Liu et al., 2023; Tworkowski et al., 2023), and open source community (e.g., Kaiokendev, 2023). Although the approximate attention methods have been studied for years (e.g., Tay et al., 2022a) (due to the quadratic time and memory complexities of self-attention mechanism in sequence length), the recent advance for long context LLMs with exact attention is mainly driven by the development of faster GPU with more memory and memory-efficient exact attention (Dao et al., 2022; Dao, 2023).
An alternative and long-standing solution for handling long context is retrieval. Specifically, the LLMs only read relevant context retrieved from a standalone retriever (e.g., Karpukhin et al., 2020; Wang et al., 2022; Lin et al., 2023), which is much easier to scale 111The dense embedding retriever can easily retrieve context from billions of tokens using the fast similarity search library (Johnson et al., 2019). and runs orders of magnitudes faster than LLMs for selecting relevant context. Conceptually, the retrieval-augmented decoder-only LLM can be viewed as applying the sparse attention over its long context window, where the sparsity pattern is not predefined as Child et al. (2019) but determined by the standalone retriever. In other words, unretrieved context is treated as irrelevant and has zero-valued attention weights.
Given the surge of interest in long context LLM research and much more required computation at inference 222For example, the price of GPT-4 with 32k context length is twice the 8k context model., it is still unclear for practitioners whether extending the context window of LLM provides higher accuracy than the retrieval-augmentation for downstream tasks with informative queries. Moreover, it would be compelling if we could combine the strength of both methods and achieve even higher accuracies. In this work, we attempt to answer the above questions through a comprehensive study.
Specifically, we make the following contributions:
-
1.
We perform comprehensive study using two state-of-the-art LLMs, a proprietary 43B pretrained GPT and Llama2-70B (Touvron et al., 2023b) on 9 downstream long context tasks, including single and multi document question answering (QA), query-based summarization, and in context few-shot learning tasks.
-
2.
We demonstrate that retrieval-augmentation significantly improves the performance of 4K context LLMs. Perhaps surprisingly, we find this simple retrieval-augmented baseline can perform comparable to 16K long context LLMs, i.e., average score 29.32 vs. 29.45 by using GPT-43B, and 36.02 vs. 36.78 by using Llama2-70B, while using much less computation.
-
3.
Furthermore, we demonstrate that the performance of long context LLM (i.e., 16K or 32K) can still be improved by retrieval, especially for the larger Llama2-70B. As a result, our best model, retrieval augmented Llama2-70B-32k-ret with 32K context window (avg. score 43.6), outperforms GPT-3.5-turbo-16k (avg. score 42.8) and Davinci-003 in terms of average score. It also largely outperforms its non-retrieval Llama2-70B-32k baseline (avg. score 40.9), while can be much faster at generation (e.g., 4 faster on NarrativeQA).
2 Related Work
In this section, we discuss the related work in long context LLM, efficient attention methods, and retrieval-augmented language models.
2.1 Parallel work
When we are preparing this manuscript, we notice that a concurrent work (Bai et al., 2023) (arXived on 28 Aug 2023) also studies the impact of retrieval on long context LLM, including black-box model GPT-3.5-Turbo-16k (OpenAI, 2022), white-box model Llama2-7B-chat-4k (Touvron et al., 2023b), and ChatGLM2-6B-32k (Zeng et al., 2022). Different from our findings, they find that retrieval is only helpful for Llama2-7B-chat-4k with 4K context window, but not helpful for long context model, i.e., GPT-3.5-Turbo-16k and ChatGLM2-6B-32k. We hypothesize the major reasons are: i) it is challenging to do controlled experiments using black-box APIs, ii) the white-box LLMs used in their study are relatively small, thus they have limited zero-shot capability of incorporating context through retrieval. Our conclusions are drawn from much larger LLMs. In particular, our best long context model Llama2-70B-32k performs as well as Davinci003 and GPT-3.5-turbo-16k, while it can still be further enhanced by retrieval (see Table 3).
2.2 Long Context Large Language Models
Over the past few years, pretraining large language models (LLMs) with long context window becomes a viable solution thanks to faster GPU with more memory and memory-efficient exact attention (e.g., Dao et al., 2022). For example, the context window for pretrained LLM have been increased from 1024 of GPT-2 (Radford et al., 2019), 2048 of GPT-3 (Brown et al., 2020), 4096 of Llama 2 (Touvron et al., 2023b), to 8192 of GPT-4 (OpenAI, 2023a). However, further extending the context window in pretraining can be challenging, because, i) pretraining LLM from scratch with long context (e.g., >16K tokens) is very expensive due to the quadratic time and memory complexities of exact attention, and ii) most of documents in pretraining corpus (e.g., Common Crawl) are relatively short.
Most recently, researchers start to extend the context window of LLMs with continued training or fine-tuning (e.g., Kaiokendev, 2023; Nijkamp et al., 2023; Chen et al., 2023; Tworkowski et al., 2023; Mohtashami & Jaggi, 2023). Tworkowski et al. (2023) introduced LongLLaMA by fine-tuning the 3B and 7B OpenLLaMA checkpoints with contrastive training on 8K context length. Landmark attention (Mohtashami & Jaggi, 2023) extends the context length of LLaMA 7B from 4K to 32K by introducing “landmark tokens” to represent blocks of the context and fine-tuning the attention to use landmark tokens for selecting relevant blocks. Chen et al. (2023) and Kaiokendev (2023) introduced positional interpolation to extend the context window sizes of RoPE-based (Su et al., 2021) pretrained LLMs. In particular, Chen et al. (2023) demonstrates promising results on LLaMA 7B to 65B (Touvron et al., 2023a) with minimal fine-tuning effort (within 1000 steps). ALiBi (Press et al., 2021) extrapolates context window length by removing the positional embeddings while simply biasing the key-query attention scores with a linear penalty that is proportional to their distance, so one does not need finetuning for context window extrapolation. Ratner et al. (2023) chunks long context into multiple sub-windows and re-use the positional embeddings across these windows, thus can handle longer context without any further finetuning. In this work, we apply positional interpolation method to extend the 4K context window of a proprietary 43B pretrained LLM and Llama2-70B (Touvron et al., 2023b) to 16K and 32K, as they both use rotary position embedding at pretraining. In terms of evaluation, we focus on downstream task performance (e.g., Shaham et al., 2023; Bai et al., 2023) after instruction tuning (Wei et al., 2021).
There are other studies showing the interplay between retrieval-augmentation and long context LLM. Liu et al. (2023) performs the black-box evaluation for the long context capability of existing LLM products, including ChatGPT 3.5 (OpenAI, 2022), GPT-4 (OpenAI, 2023a), Claude (Anthropic, 2023), in retrieval-augmented setting, and identify the “lost in the middle” phenomenon in these models.
2.3 Efficient Attention Methods
In previous study, many approximate attention methods (Tay et al., 2022a) have been introduced for dealing with the quadratic complexity of self-attention that becomes a computational bottleneck for long context. They can be grouped into the following categories: i) Sparse attention mechanisms with predefined sparsity patterns (e.g., Child et al., 2019; Parmar et al., 2018; Ho et al., 2019; Beltagy et al., 2020; Zaheer et al., 2020; Zhu et al., 2021), ii) recurrence-based method (Dai et al., 2019; Bulatov et al., 2022), iii) low-rank projection attention (e.g., Wang et al., 2020; Xiong et al., 2021; Tay et al., 2021; Zhu et al., 2021), iv) memory-based mechanisms (e.g., Rae et al., 2020; Liu et al., 2018), v) similarity and clustering based methods (e.g., Kitaev et al., 2020; Tay et al., 2020; Roy et al., 2021). These approximate methods introduce inductive bias (e.g., predefined sparsity) that can fit well for specific domain, but may reduce model quality in general LLM training.
Most recently, FlashAttention (Dao et al., 2022; Dao, 2023) is introduced to speed up the exact attention computation by accounting for reads and writes between levels of GPU memory. FlashAttention is particularly useful for handling longer sequences.
2.4 Retrieval-augmented Language Models
Retrieval has been integrated into language models for years to improve perplexity (Borgeaud et al., 2022; Wang et al., 2023), factual accuracy (Nakano et al., 2021), downstream task accuracy (Guu et al., 2020; Izacard & Grave, 2021; Izacard et al., 2022; Lewis et al., 2020), and in-context learning capability (Huang et al., 2023). Combined with a standalone retriever (Karpukhin et al., 2020; Wang et al., 2022; Lin et al., 2023), retrieval-augmented LLM is well established for handling question answering with long document and in open-domain. In previous study, language models have been augmented with retrieval at inference (Khandelwal et al., 2019; Yogatama et al., 2021), fine-tuning (Izacard et al., 2022; Lewis et al., 2020; Guu et al., 2020), and pretraining (Borgeaud et al., 2022; Izacard et al., 2022; Wang et al., 2023). There are also methods that try to integrate LLM and retriever in a single model and build the end-to-end solution (e.g., Jiang et al., 2022; Shi et al., 2023). However, most of previous works mainly study retrieval-augmentation for LLMs that have around 10 billion parameters, except a few recent ones (e.g., Shi et al., 2023).
In this work, we focus on decoder-only LLMs with 43B and 70B parameters trained on trillions of tokens, because the LLMs at such scale exhibit strong zero-shot capability to incorporate context after instruction tuning (Wei et al., 2021; 2022).
3 Experimental Setup
In this section, we present the details of our experimental setup.
3.1 Large Language Models
We focus on comparing the zero-shot capability of integrating long context information for generative QA or summarization tasks via retrieval or LLM’s own self-attention mechanism. In contrast to most existing works that focus on relatively small models (e.g., 3B or 7B) (Kaiokendev, 2023; Nijkamp et al., 2023; Tworkowski et al., 2023; Mohtashami & Jaggi, 2023), we gather the insights by exploring model sizes that are larger than 40B after instruction tuning, as previous study suggests that instruction tuning becomes effective when the decoder-only LLM has around 50B parameters (Wei et al., 2021; 2022).
Specifically, we experimented with two pretrained GPT models, a proprietary Nemo GPT-43B and Llama2-70B. GPT-43B is a 43 billion parameter model that is trained with 1.1T tokens with 70% English corpus and the other 30% for multilingual and code data. For the English pretraining corpus, GPT-43B used Common Crawl web archive (WARC), Wikipedia, Reddit, Books, Gutenberg, ArXiv, StackExchange, PubMed, etc. It contains 48 layers with the hidden dimension of 8,192. It is trained with a sequence length of 4,096 and RoPE embeddings (Su et al., 2021). The other Llama2-70B is a public available 70B GPT model trained on 2T tokens using around 90% English data. It contains 80 layers with the hidden dimension of 8,192. It also has the context window size of 4,096 and trained with RoPE embeddings.
3.2 Datasets and Metrics
In this study, we include seven datasets ranging from single document QA, multi document QA, to query-based summarization for our zero shot evaluations. Specifically, we include four datasets from the validation set of the Scroll benchmark (Shaham et al., 2022).
-
•
QMSum (QM) (Zhong et al., 2021) is a query-based summarization dataset, consisting of meetings’ transcripts and their corresponding summaries from multiple domains such as academic, industrial product. In this task, a meeting dialogue transcript is given, and a question to summarize certain topic is raised about the dialogue, such as “what is agreed between them”. The answer generally contains a few sentences.
-
•
Qasper (QASP) (Dasigi et al., 2021) is a question answering dataset over NLP papers filtered from the Semantic Scholar Open Research Corpus (S2ORC) (Lo et al., 2020). Qasper contains abstractive, extractive, and yes/no questions, as well as unanswerable ones. In this task, one script is provided together with an information seeking question, such as “which multilingual approaches do they compare with?”. A model needs to give a short answer by reasoning over the given context.
-
•
NarrativeQA (NQA) (Kočiský et al., 2018) is an established question answering dataset over entire books from Project Gutenberg333https://www.gutenberg.org/ and movie scripts from a list of websites. In this task, the given passage is transcribed from books and is usually noisy. A model is required to generate a short phrase by reasoning over the long and noisy text.
-
•
QuALITY (QLTY) (Pang et al., 2022) is a question answering dataset over stories and articles collected from several resources, such as Project Gutenberg and the Open American National Corpus444https://anc.org/. Different from all the other tasks, this is a multi-choices dataset and a model is required to select one among four given choices.
We take another three datasets from LongBench (Bai et al., 2023).
-
•
HotpotQA (HQA) (Yang et al., 2018) is a Wikipedia-based question-answer dataset. Different from above single hot datasets, HQA is a multi-hop dataset where multiple supporting documents are required to be read for answering and reasoning and the questions are diverse and not constrained to any pre-existing knowledge bases.
-
•
MuSiQue (MSQ) (Trivedi et al., 2022) is another multi-hop question answering dataset. Compared to HQA, MSQ requires connected reasoning by reducing potential reasoning shortcuts, minimizing train-test leakage, and including harder distractor contexts. Thus, MSQ is much harder task than HQA and significantly less cheatable.
-
•
MultiFieldQA-en (MFQA) (Bai et al., 2023) was manually curated to better test the model’s long context understanding ability across diverse fields. The evidences from multiple sources, including legal documents, government reports, encyclopedias, and academic papers, are fairly randomly located in the documents to avoid biases that might occur at the beginning or ending of the documents.
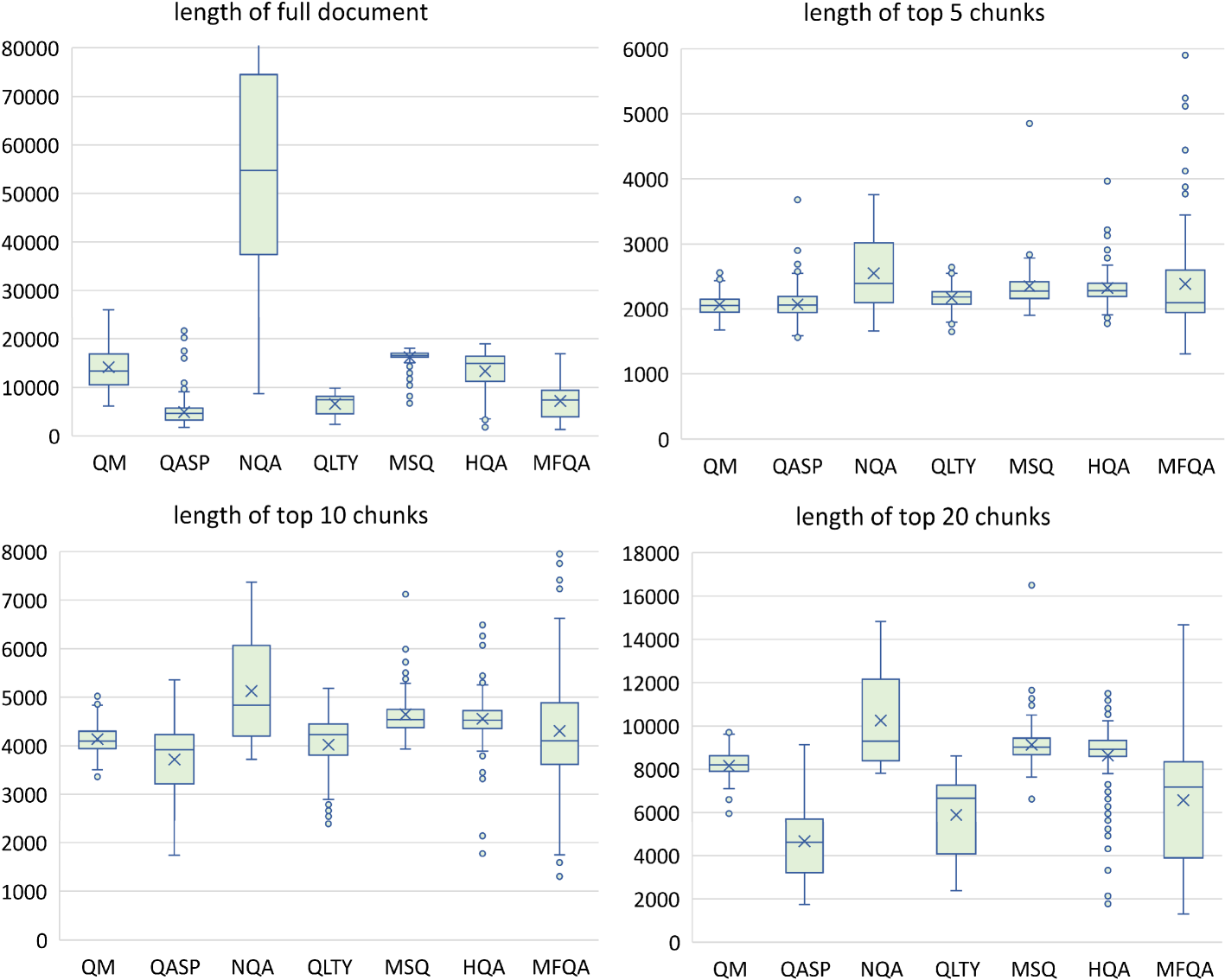
The full details of the dataset can be found in Table 1. We can see that our evaluation datasets have a wide range of average document length from 4.9k (QASP) to 84k (NQA). Therefore, for the baseline model without retrieval, we truncate the document accordingly to fit into the input sequence length.
| QM | QASP | NQA | QLTY | MSQ | HQA | MFQA | |
|---|---|---|---|---|---|---|---|
| # of samples | 200 | 1,726 | 2,000 | 2,000 | 200 | 200 | 150 |
| avg doc length | 14,140 | 4,912 | 84,770 | 6,592 | 16,198 | 13,319 | 7,185 |
| avg top-5 chunks | 2,066 | 2,071 | 2,549 | 2,172 | 2,352 | 2,322 | 2,385 |
| avg top-10 chunks | 4,137 | 3,716 | 5,125 | 4,018 | 4,644 | 4,554 | 4,305 |
| avg top-20 chunks | 8,160 | 4,658 | 10,251 | 5,890 | 9,133 | 8,635 | 6,570 |
Following the official metrics, we report the geometric mean of ROUGE scores (i.e., ROUGE-1/2/L) (Lin, 2004) for QM, the exact matching (EM) score for QLTY, and F1 scores for the remaining five datasets QASP, NQA, MSQ, HQA and MFQA.
3.3 Context Window Extension
We extend the context window length with position interpolation method (Chen et al., 2023), as it is simple and effective for RoPE embeddings. We extend the 4K context window to 16K for GPT-43B. For Llama2, we extend its 4K context window to 32k for Llama2-7B and both 16K and 32K for Llama2-70B. We follow Chen et al. (2023) and finetune both LLMs on the Pile dataset (Gao et al., 2021) with batch size as 128, constant learning rate of 5e-6 to adapt the position embeddings.
3.4 Retrieval
For the retriever, we experimented with three retrievers: 1) Dragon (Lin et al., 2023) as it achieves state-of-the-art results on both supervised and zero-shot information retrieval benchmarks (Thakur et al., 2021). Dragon is a dual encoder model that consists of a query encoder and a context encoder. 2) a widely used Contriever model (Izacard et al., 2021). Following the MoCo technique (He et al., 2020), Contriever used a simple contrastive learning framework to pre-train models for information retrieval. It was trained without supervision and achieved competitive results with BM25 for R@100 on the BEIR benchmark (Thakur et al., 2021), and 3) OpenAI embedding555https://platform.openai.com/docs/guides/embeddings. For the OpenAI embedding model, we use the latest “text-embedding-ada-002” as recommended by OpenAI. It accepts 8,191 maximum input tokens for one sequence with an output vector of 1,536 dimensions. The cosine similarities are then computed between the questions and the list of contexts for retrieval ranking.
To use these retrievers, we first chunk each context document with 300 words, and then we encode both the questions and all chunks independently with corresponding encoders. The most relevant N chunks, ranked by the dot product of the question embedding and chunk embedding, are then concatenated together (following the left to right order from the most relevant to least relevant) as the context of the prompt for generation. Table 1 shows the statistics of the top N retrieved chunks while Figure 2 in the Appendix gives more details of the token length distribution of all seven datasets. We can see that top-5 chunks can all fit into 4k sequence length (except few outliers) while top-10 and top-20 chunks can fit into 16k sequence length.
3.5 Instruction Tuning
To train the pretrained LLMs to follow instructions for question answering or text summarization, we also performed instruction tuning. We first construct a blend of instruction tuning datasets consisting of 102K training samples from the Soda dataset (Kim et al., 2022), ELI5 dataset (Fan et al., 2019), FLAN dataset (Wei et al., 2021) , Open Assistatant dataset (Köpf et al., 2023), Dolly (Conover et al., 2023) and a proprietary sourced conversational dataset, to adapt all foundation models to follow instructions. In terms of the template, we use "System: {System}\n\nUser: {Question}\n\nAssistant: {Answer}" as the format to support multi-turn dialogue training. As all of the tasks contain the context information for reasoning over at inference time, we add the context before the dialogue, i.e. "System: {System}\n\n{Context}\n\nUser: {Question}\n\nAssistant: {Answer}".
We finetune the LLM by taking the loss only on the {Answer} part with batch size 128 and learning rate of 5e-6 for 1000 steps. For the rest of the paper, results are all reported using the instruction tuned chat model on top of the foundational GPT-43B, Llama2-7B, and Llama2-70B.
| Model | Seq len. | Avg. | QM | QASP | NQA | QLTY | MSQ | HQA | MFQA |
| GPT-43B | 4k | 26.44 | 15.56 | 23.66 | 15.64 | 49.35 | 11.08 | 28.91 | 40.90 |
| + ret | 4k | 29.32 | 16.60 | 23.45 | 19.81 | 51.55 | 14.95 | 34.26 | 44.63 |
| GPT-43B | 16k | 29.45 | 16.09 | 25.75 | 16.94 | 50.05 | 14.74 | 37.48 | 45.08 |
| + ret | 16k | 29.65 | 15.69 | 23.82 | 21.11 | 47.90 | 15.52 | 36.14 | 47.39 |
| Llama2-70B | 4k | 31.61 | 16.34 | 27.70 | 19.07 | 63.55 | 15.40 | 34.64 | 44.55 |
| + ret | 4k | 36.02 | 17.41 | 28.74 | 23.41 | 70.15 | 21.39 | 42.06 | 48.96 |
| Llama2-70B | 16k | 36.78 | 16.72 | 30.92 | 22.32 | 76.10 | 18.78 | 43.97 | 48.63 |
| + ret | 16k | 37.23 | 18.70 | 29.54 | 23.12 | 70.90 | 23.28 | 44.81 | 50.24 |
| Llama2-70B | 32k | 37.36 | 15.37 | 31.88 | 23.59 | 73.80 | 19.07 | 49.49 | 48.35 |
| + ret | 32k | 39.60 | 18.34 | 31.27 | 24.53 | 69.55 | 26.72 | 53.89 | 52.91 |
| Llama2-7B | 4k | 22.65 | 14.25 | 22.07 | 14.38 | 40.90 | 8.66 | 23.13 | 35.20 |
| + ret | 4k | 26.04 | 16.45 | 22.97 | 18.18 | 43.25 | 14.68 | 26.62 | 40.10 |
| Llama2-7B | 32k | 28.20 | 16.09 | 23.66 | 19.07 | 44.50 | 15.74 | 31.63 | 46.71 |
| + ret | 32k | 27.63 | 17.11 | 23.25 | 19.12 | 43.70 | 15.67 | 29.55 | 45.03 |
4 Results
In this section, we report the results and provide detailed analysis.
4.1 Main Results
In Table 2, we compare different model variants with context lengths ranging from 4K to as long as 32K using GPT-43B and Llama2-70B. First, we find that baseline models without retrieval of 4k sequence length achieve the worst results for both GPT-43B and Llama2-70B. This is because the minimum average sequence length of all seven tasks exceeds 4096, the context window of the foundation models and therefore valuable texts get truncated randomly. As a result, retrieval is especially helpful for 4K LLMs e.g., Llama2-70B-4K is improved from 31.61 to 35.73 while GPT-43B-4K is improved from 26.44 to 29.32. Second, we observe that HotpotQA (HQA) especially favors long sequence models as the score improves from 34.64 to 43.97 for Llama2-70B and from 28.91 to 37.48 for GPT-43B when the sequence length increases from 4k to 16k. This is because Hotpot QA is a multi-hop dataset where the questions are not hard to answer but all intermediate hops are necessary to get correct answer. Therefore, long context are beneficial to increase the recall of incorporating all intermediate hops.
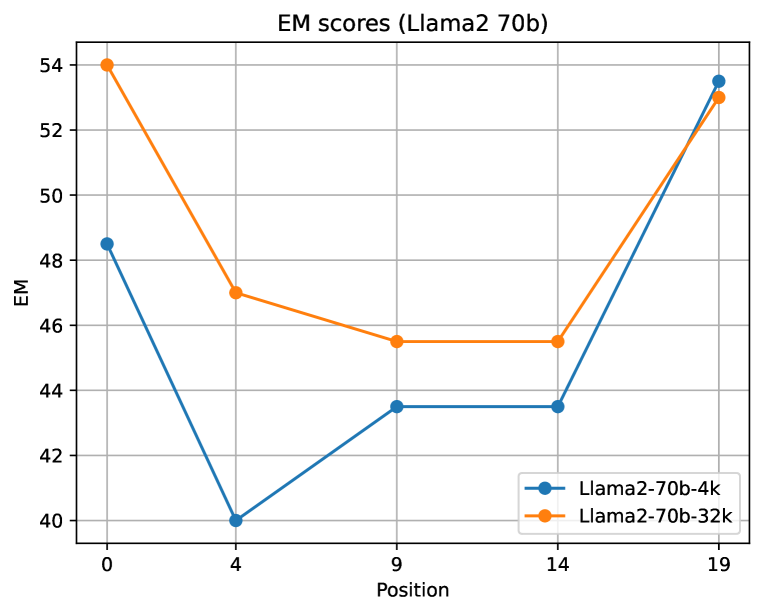
It is quite interesting that the retrieval-augmented long context LLM (e.g., 16K and 32K) can obtain better results than retrieval-augmented 4K context LLM, even they are feed with the same top 5 chunks of evidence. We hypothesize this interesting observation is related to the “lost in the middle” phenomenon (Liu et al., 2023), where the LLMs has such “U-shaped” performance curve. Specifically, LLMs are better at utilizing relevant information that occurs at the beginning or end of its input context window. To further verify the hypothesis, we conduct the “lost-in-the-middle” study following Liu et al. (2023) for Llama2-70B-4k and Llama2-70B-32k. As show in Figure 1, we confirm that the phenomenon also exists in Llama2-70B with different context lengths. In particular, the comparison of the curves from Llama2-70B-4k and Llama2-70B-32k suggests that the long context model has better accuracy for incorporating top-5 retrieved context.
| Model | Avg-7 | Avg-4* | QM* | QASP* | NQA* | QLTY* | MSQ | HQA | MFQA |
|---|---|---|---|---|---|---|---|---|---|
| Davinci003 (175B) | 39.2 | 40.8* | 16.9* | 52.7* | 24.6* | 69.0* | 22.1 | 41.2 | 47.8 |
| GPT-3.5-turbo (4k) | 38.4 | 39.2* | 15.6* | 49.3* | 25.1* | 66.6* | 21.2 | 40.9 | 49.2 |
| +ret | 24.4 | 49.5 | 49.5 | ||||||
| GPT-3.5-turbo-16k | 42.8 | 42.4 | 17.6 | 50.5 | 28.8 | 72.6 | 26.9 | 51.6 | 52.3 |
| +ret | 30.4 | 46.6 | 52.8 | ||||||
| Llama2-70B-32k | 40.9 | 42.4 | 15.6 | 45.9 | 28.4 | 79.6 | 19.1 | 49.5 | 48.4 |
| Llama2-70B-32k-ret | 43.6 | 43.0 | 18.5 | 46.3 | 31.5 | 75.6 | 26.7 | 53.9 | 52.9 |
Note that, we have very different observation from the conclusion drawn from LongBench work (Bai et al., 2023): “Retrieval brings improvement for model with weak ability on long contexts, but the performance still lags behind models that have strong long context understanding capability”. Here, we demonstrate retrieval can significantly improve the performance of both GPT-43B and Llama2-70B regardless their context window size. For example, our best retrieval-augmented Llama2-70B-32k-ret outperforms its baseline w/o retrieval by a margin, i.e., 39.60 vs. 37.36. We think the major reason for such different conclusion is that Bai et al. (2023) uses much smaller LLM with 6B and 7B parameters, which usually has relatively worse zero-shot capability to incorporate the retrieved chunked context. To further validate the hypothesis, we also report the results using Llama2-7B in Table 5. One can actually draw similar conclusions to Bai et al. (2023) . We think the underlying reasons are: i) For Llama2-7B-chat-4k, its short context length is the bottleneck for long context tasks. Thus, retrieval-augmentation largely improves the results. ii) For Llama2-7B-chat-32 and ChatGLM2-6B-32k, the context length bottleneck has been mostly removed. However, their retrieval-augmented models have limited zero-shot capability of incorporating retrieved chunks of context, due to the smaller size. As a result, retrieval is not helpful for both Llama2-7B-32k and ChatGLM2-6B-32k, which is different from large LLMs like Llama2-70B-32k in our case.
In contrast, the larger instruction tuned LLMs like Llama2-70B has much stronger zero-shot capability to incorporate retrieved evidence. This observation is becoming more clear when one compares the gain of retrieval-augmentation between GPT-43B and Llama2-70B, where Llama2-70B enjoys larger benefit of incorporating context through retrieval.
4.2 Comparing to OpenAI models
To further understand how good is our best model, i.e., augmenting Llama2-70B-32k with retrieval, we also compare it to GPT-3.5-turbo(4k), GPT-3.5-turbo-16k and Davinci-003 on those seven datasets.666For QMSum (QM), Qasper (QASP), NarrativeQA (NQA), QuALITY (QLTY), we used the test set from the ZeroSCROLLS leaderboard as the organizers have prepared the scores of GPT-3.5-turbo (4k) and Davinci-003 there. We found that Llama2-70B-32k-ret achieves better results than GPT-3.5-turbo-16k in terms of the average accuracy over seven datasets, while better than Davinci-003 (w/ 175B parameters) on the average over 4 tasks. This indicates Llama2-70B-32k with retrieval is a strong model for these long context tasks, and our conclusion is built on the state-of-the-art results.
We also report the retrieval augmented results for GPT3.5-turbo on MSQ, HQA and MFQA. For GPT3.5-turbo-4k, retrieval significantly improves the performance (avg from 37.08 to 41.15). For GPT3.5-turbo-16k, the average scores for retrieval (43.27) and non-retrieval (43.60) scores are close to each other which are both lower than our Llam2-70B-32k-ret results (44.51). Note that GPT3.5-turbo-16k is a blackbox API, we don’t know how it is implemented, the model size as well as any preprocessing steps.
| Seq len | Setting | Avg. | QM | QASP | NQA | QLTY | MSQ | HQA | MFQA |
|---|---|---|---|---|---|---|---|---|---|
| 4k | baseline (w/o ret) | 31.61 | 16.34 | 27.70 | 19.07 | 63.55 | 15.40 | 34.64 | 44.55 |
| Dragon | 35.73 | 18.14 | 29.20 | 23.39 | 70.30 | 20.09 | 41.54 | 47.45 | |
| Contriever | 36.02 | 17.41 | 28.74 | 23.41 | 70.15 | 21.39 | 42.06 | 48.96 | |
| OpenAI-embedding | 35.79 | 17.76 | 28.85 | 23.57 | 70.70 | 19.92 | 41.76 | 47.99 | |
| 32k | baseline (w/o ret) | 37.36 | 15.37 | 31.88 | 23.59 | 73.80 | 19.07 | 49.49 | 48.35 |
| Dragon | 39.60 | 18.34 | 31.27 | 24.53 | 69.55 | 26.72 | 53.89 | 52.91 | |
| Contriever | 38.85 | 17.60 | 31.56 | 23.88 | 69.00 | 26.61 | 49.65 | 53.66 | |
| OpenAI-embedding | 39.34 | 18.24 | 32.07 | 24.36 | 69.45 | 24.90 | 51.64 | 54.75 |
| Seq len | Setting | Avg. | QM | QASP | NQA | QLTY | MSQ | HQA | MFQA |
|---|---|---|---|---|---|---|---|---|---|
| 4k | base | 31.61 | 16.34 | 27.70 | 19.07 | 63.55 | 15.40 | 34.64 | 44.55 |
| top-5 | 35.73 | 18.14 | 29.20 | 23.39 | 70.30 | 20.09 | 41.54 | 47.45 | |
| top-10 | 34.62 | 16.54 | 28.67 | 24.38 | 68.70 | 19.00 | 42.18 | 42.84 | |
| top-20 | 34.61 | 16.52 | 28.67 | 24.38 | 68.70 | 19.00 | 42.18 | 42.84 | |
| 16k | base | 36.78 | 16.72 | 30.92 | 22.32 | 76.10 | 18.78 | 43.97 | 48.63 |
| top-5 | 37.23 | 18.70 | 29.54 | 23.12 | 70.90 | 23.28 | 44.81 | 50.24 | |
| top-10 | 38.31 | 18.41 | 30.20 | 25.53 | 73.60 | 22.78 | 47.72 | 49.91 | |
| top-20 | 36.61 | 17.26 | 29.60 | 25.81 | 72.30 | 22.69 | 41.36 | 47.23 | |
| 32k | base | 37.36 | 15.37 | 31.88 | 23.59 | 73.80 | 19.07 | 49.49 | 48.35 |
| top-5 | 39.60 | 18.34 | 31.27 | 24.53 | 69.55 | 26.72 | 53.89 | 52.91 | |
| top-10 | 38.98 | 17.71 | 30.34 | 25.94 | 70.45 | 22.80 | 55.73 | 49.88 | |
| top-20 | 38.38 | 16.36 | 30.42 | 24.42 | 69.60 | 24.51 | 54.67 | 48.65 |
4.3 Ablation on Different Retrievers
To investigate the impacts of different retrievers on top of Llama2-70B, we compare Dragon, Contriever, and OpenAI embeddings on top of Llama2-70B-4k and Llama2-70B-32k. The results in Table 4 confirms that our finding, i.e., retrieval can boost the performance of both short context and long context LLMs, is consistent across different retrievers.
4.4 Increasing the number of retrieved chunks
To study the impact of adding more retrieved chunks to the context, we increase the number of retrieved chunks from 5 to 20 using Dragon retriever and the results can be found in Table 5. We observe that for different sequence lengths, the best averaged results are obtained either from top 5 or top 10. Even if 20 chunks can still fit into the 16K and 32K context window (as shown in Figure 2), adding more chunks up to 20 is not helpful and will sometime hurt the performance. We believe this is related to the “lost in the middle” phenomenon (Liu et al., 2023) or the model is getting distracted by irrelevant information and therefore needs further research.
4.5 Retrieval for Few-shot Tasks
| Model | Trec | SAMSum |
|---|---|---|
| GPT-3.5-turbo-16k | 68 | 41.7 |
| Llama2-70B | 73 | 46.5 |
| Llama2-70B-ret | 76 | 47.3 |
In addition to the zero-shot tasks of query-based summarization tasks and question answering tasks mentioned above, we further investigate the benefits of long context models for few-shot tasks using two additional datasets (Trec and SAMSum) from LongBench. We take the question from each dataset as the query and use it to search relevant QA pairs provided in the given few-shot examples. Table 6 shows that our best model Llama2-70B-32k-ret outperforms its non-retrieval Llama2-70B-32k baseline as well as GPT-3.5-turbo-16k by a large margin. It again confirms the benefits on using retrieval together with long context models.
5 Conclusion
In this work, we systematically study the retrieval-augmentation versus long context extension using the state-of-the-art LLMs after instruction tuning for various long context QA and query-based summarization tasks. After study, we have the following interesting findings: i) Retrieval largely boosts the performance of both 4K short context LLM and 16K/32K long context LLMs. ii) The 4K context LLMs with simple retrieval-augmentation can perform comparable to 16K long context LLMs, while being more efficient at inference. iii) After context window extension and retrieval-augmentation, the best model Llama2-70B-32k-ret can outperform GPT-3.5-turbo-16k and Davinci003 in terms of average score on a suit of downstream tasks with informative queries. Our study shed light on the promising direction of combining retrieval and long context techniques together to build better LLM.
6 Future Directions
There are many potential research directions that can be extended from this work. One direction is to develop advanced methods (e.g. memory or hierarchical attention) for existing pretrained large language models e.g. Llama2-70B, which is itself non-trivial. Also, further extending the context window to 64k and even longer would be a very interesting study for large 70B parameter models even though pre-training longer sequence requires much more computation. Lastly, how to mitigate the “lost-in-the-middle” phenomenon is an open research topic and continue pretraining with UL2 loss (Tay et al., 2022b) could be one potential solution.
References
- Anthropic (2023) Anthropic. Introducing 100k context windows. https://www.anthropic.com/index/100k-context-windows, 2023.
- Bai et al. (2023) Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508, 2023.
- Beltagy et al. (2020) Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
- Borgeaud et al. (2022) Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. In ICML, 2022.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. NeurIPS, 2020.
- Bulatov et al. (2022) Aydar Bulatov, Yury Kuratov, and Mikhail Burtsev. Recurrent memory transformer. NeurIPS, 2022.
- Chen et al. (2023) Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation. arXiv preprint arXiv:2306.15595, 2023.
- Child et al. (2019) Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
- Conover et al. (2023) Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. Free dolly: Introducing the world’s first truly open instruction-tuned llm, 2023. URL https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm.
- Dai et al. (2019) Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-XL: Attentive language models beyond a fixed-length context. In ACL, 2019.
- Dao (2023) Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
- Dao et al. (2022) Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. NeurIPS, 2022.
- Dasigi et al. (2021) Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 4599–4610, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.365. URL https://aclanthology.org/2021.naacl-main.365.
- Fan et al. (2019) Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. Eli5: Long form question answering. arXiv preprint arXiv:1907.09190, 2019.
- Gao et al. (2021) Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The pile: An 800gb dataset of diverse text for language modeling. CoRR, abs/2101.00027, 2021. URL https://arxiv.org/abs/2101.00027.
- Guu et al. (2020) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. REALM: Retrieval augmented language model pre-training. In ICML, 2020.
- He et al. (2020) Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- Ho et al. (2019) Jonathan Ho, Nal Kalchbrenner, Dirk Weissenborn, and Tim Salimans. Axial attention in multidimensional transformers. arXiv preprint arXiv:1912.12180, 2019.
- Huang et al. (2023) Jie Huang, Wei Ping, Peng Xu, Mohammad Shoeybi, Kevin Chen-Chuan Chang, and Bryan Catanzaro. Raven: In-context learning with retrieval augmented encoder-decoder language models. arXiv preprint arXiv:2308.07922, 2023.
- Izacard & Grave (2021) Gautier Izacard and Édouard Grave. Leveraging passage retrieval with generative models for open domain question answering. In EACL, 2021.
- Izacard et al. (2021) Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. Unsupervised dense information retrieval with contrastive learning, 2021. URL https://arxiv.org/abs/2112.09118.
- Izacard et al. (2022) Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. Few-shot learning with retrieval augmented language models. arXiv preprint arXiv:2208.03299, 2022.
- Jiang et al. (2022) Zhengbao Jiang, Luyu Gao, Jun Araki, Haibo Ding, Zhiruo Wang, Jamie Callan, and Graham Neubig. Retrieval as attention: End-to-end learning of retrieval and reading within a single transformer. In EMNLP, 2022.
- Johnson et al. (2019) Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547, 2019.
- Kaiokendev (2023) Kaiokendev. Things I’m learning while training SuperHOT. https://kaiokendev.github.io/til#extending-context-to-8k, 2023.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In EMNLP, 2020.
- Khandelwal et al. (2019) Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Generalization through memorization: Nearest neighbor language models. arXiv preprint arXiv:1911.00172, 2019.
- Kim et al. (2022) Hyunwoo Kim, Jack Hessel, Liwei Jiang, Ximing Lu, Youngjae Yu, Pei Zhou, Ronan Le Bras, Malihe Alikhani, Gunhee Kim, Maarten Sap, et al. Soda: Million-scale dialogue distillation with social commonsense contextualization. arXiv preprint arXiv:2212.10465, 2022.
- Kitaev et al. (2020) Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In ICLR, 2020.
- Köpf et al. (2023) Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, et al. Openassistant conversations–democratizing large language model alignment. arXiv preprint arXiv:2304.07327, 2023.
- Kočiský et al. (2018) Tomáš Kočiský, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Edward Grefenstette. The NarrativeQA Reading Comprehension Challenge. Transactions of the Association for Computational Linguistics, 6:317–328, 05 2018. ISSN 2307-387X. doi: 10.1162/tacl_a_00023. URL https://doi.org/10.1162/tacl_a_00023.
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. NeurIPS, 2020.
- Lin (2004) Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pp. 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL https://aclanthology.org/W04-1013.
- Lin et al. (2023) Sheng-Chieh Lin, Akari Asai, Minghan Li, Barlas Oguz, Jimmy Lin, Yashar Mehdad, Wen-tau Yih, and Xilun Chen. How to train your dragon: Diverse augmentation towards generalizable dense retrieval. arXiv preprint arXiv:2302.07452, 2023.
- Liu et al. (2023) Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172, 2023.
- Liu et al. (2018) Peter J Liu, Mohammad Saleh, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, and Noam Shazeer. Generating wikipedia by summarizing long sequences. In ICLR, 2018.
- Lo et al. (2020) Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel Weld. S2ORC: The semantic scholar open research corpus. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 4969–4983, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.447. URL https://aclanthology.org/2020.acl-main.447.
- Mohtashami & Jaggi (2023) Amirkeivan Mohtashami and Martin Jaggi. Landmark attention: Random-access infinite context length for transformers. arXiv preprint arXiv:2305.16300, 2023.
- Nakano et al. (2021) Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. WebGPT: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021.
- Nijkamp et al. (2023) Erik Nijkamp, Hiroaki Hayashi, Tian Xie, Congying Xia, Bo Pang, Congying Xia, and et al. Long sequence modeling with XGen: A 7b LLM trained on 8k input sequence length. https://blog.salesforceairesearch.com/xgen/, 2023.
- OpenAI (2022) OpenAI. Introducing chatgpt. https://openai.com/blog/chatgpt, 2022.
- OpenAI (2023a) OpenAI. Gpt-4. https://openai.com/research/gpt-4, 2023a.
- OpenAI (2023b) OpenAI. Function calling and other API updates (longer context). https://openai.com/blog/function-calling-and-other-api-updates, 2023b.
- Pang et al. (2022) Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh Padmakumar, Johnny Ma, Jana Thompson, He He, and Samuel Bowman. QuALITY: Question answering with long input texts, yes! In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 5336–5358, Seattle, United States, July 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl-main.391. URL https://aclanthology.org/2022.naacl-main.391.
- Parmar et al. (2018) Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. Image transformer. In ICML, pp. 4055–4064, 2018.
- Press et al. (2021) Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. In ICLR, 2021.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. 2019.
- Rae et al. (2020) Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, and Timothy P Lillicrap. Compressive Transformers for long-range sequence modelling. In ICLR, 2020.
- Ratner et al. (2023) Nir Ratner, Yoav Levine, Yonatan Belinkov, Ori Ram, Inbal Magar, Omri Abend, Ehud Karpas, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. Parallel context windows for large language models. In ACL, 2023.
- Roy et al. (2021) Aurko Roy, Mohammad Saffar, Ashish Vaswani, and David Grangier. Efficient content-based sparse attention with routing transformers. Transactions of the Association for Computational Linguistics, 2021.
- Shaham et al. (2022) Uri Shaham, Elad Segal, Maor Ivgi, Avia Efrat, Ori Yoran, Adi Haviv, Ankit Gupta, Wenhan Xiong, Mor Geva, Jonathan Berant, and Omer Levy. SCROLLS: Standardized CompaRison over long language sequences. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 12007–12021, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.emnlp-main.823.
- Shaham et al. (2023) Uri Shaham, Maor Ivgi, Avia Efrat, Jonathan Berant, and Omer Levy. Zeroscrolls: A zero-shot benchmark for long text understanding. arXiv preprint arXiv:2305.14196, 2023.
- Shi et al. (2023) Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. RePlug: Retrieval-augmented black-box language models. arXiv preprint arXiv:2301.12652, 2023.
- Su et al. (2021) Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864, 2021.
- Tay et al. (2020) Yi Tay, Dara Bahri, Liu Yang, Donald Metzler, and Da-Cheng Juan. Sparse sinkhorn attention. In ICML, 2020.
- Tay et al. (2021) Yi Tay, Dara Bahri, Donald Metzler, Da-Cheng Juan, Zhe Zhao, and Che Zheng. Synthesizer: Rethinking self-attention for transformer models. In ICML, 2021.
- Tay et al. (2022a) Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. Efficient transformers: A survey. ACM Computing Surveys, 2022a.
- Tay et al. (2022b) Yi Tay, Mostafa Dehghani, Vinh Q Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Dara Bahri, Tal Schuster, Steven Zheng, et al. Ul2: Unifying language learning paradigms. In The Eleventh International Conference on Learning Representations, 2022b.
- Thakur et al. (2021) Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models. In NeurIPS, 2021.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
- Trivedi et al. (2022) Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. MuSiQue: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10:539–554, 2022. doi: 10.1162/tacl_a_00475. URL https://aclanthology.org/2022.tacl-1.31.
- Tworkowski et al. (2023) Szymon Tworkowski, Konrad Staniszewski, Mikołaj Pacek, Yuhuai Wu, Henryk Michalewski, and Piotr Miłoś. Focused transformer: Contrastive training for context scaling. arXiv preprint arXiv:2307.03170, 2023.
- Wang et al. (2023) Boxin Wang, Wei Ping, Peng Xu, Lawrence McAfee, Zihan Liu, Mohammad Shoeybi, Yi Dong, Oleksii Kuchaiev, Bo Li, Chaowei Xiao, et al. Shall we pretrain autoregressive language models with retrieval? a comprehensive study. arXiv preprint arXiv:2304.06762, 2023.
- Wang et al. (2022) Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022.
- Wang et al. (2020) Sinong Wang, Belinda Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
- Wei et al. (2021) Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
- Wei et al. (2022) Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682, 2022.
- Xiong et al. (2021) Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, and Vikas Singh. Nyströmformer: A nyström-based algorithm for approximating self-attention. AAAI, 2021.
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2369–2380, Brussels, Belgium, October-November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-1259. URL https://aclanthology.org/D18-1259.
- Yogatama et al. (2021) Dani Yogatama, Cyprien de Masson d’Autume, and Lingpeng Kong. Adaptive semiparametric language models. Transactions of the Association for Computational Linguistics, 9:362–373, 2021.
- Zaheer et al. (2020) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big Bird: Transformers for longer sequences. In NeurIPS, 2020.
- Zeng et al. (2022) Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, et al. Glm-130b: An open bilingual pre-trained model. arXiv preprint arXiv:2210.02414, 2022.
- Zhong et al. (2021) Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli Celikyilmaz, Yang Liu, Xipeng Qiu, and Dragomir Radev. QMSum: A new benchmark for query-based multi-domain meeting summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 5905–5921, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.472. URL https://aclanthology.org/2021.naacl-main.472.
- Zhu et al. (2021) Chen Zhu, Wei Ping, Chaowei Xiao, Mohammad Shoeybi, Tom Goldstein, Anima Anandkumar, and Bryan Catanzaro. Long-short transformer: Efficient transformers for language and vision. NeurIPS, 2021.
We show an example below where the smaller model Llama2-7B fails to incorporate relevant context, while larger models with retrieval could successfully predict the correct answer.
Appendix A Appendix
| Chunk 1 |
On September 18, 2015, the deluxe edition of the album was released containing live and instrumental tracks from the standard edition album, in addition to the single "Light" featuring Little Dragon. Critical reception … Angelspit has toured with Angel Theory, Ayria, Ikon, KMFDM, Tankt and The Crüxshadows, and have also shared the stage with bands such as The Sisters of Mercy, Nitzer Ebb, Skinny Puppy and Front Line Assembly. They performed with Lords of Acid during a 22-date U.S. tour in March 2011 and toured the United States with Blood on the Dance Floor in October 2011. History Karl Learmont (ZooG) and Amelia Tan (Destroyx) met on an online zine forum. They shared an interest in zines and started the distro Vox Populis in 2002. |
|---|---|
| Chunk 2 |
They then started making zines for themselves which became the lyrical inspiration for releases to follow. Angelspit was formed in 2003, and the duo then self-released their debut EP, Nurse Grenade on 3 October 2004. … A video for the remix of "Sleep Now" was released on 2 October 2010. They released their third remix album, Carbon Beauty on 8 March 2011. This new remix album contains 3 new tracks as well as 10 remixes of tracks from the Hideous and Perfect album. A video for "Toxic Girl" was released on 13 April 2011, and a video for "Like It? |
| Chunk 3 |
Passage 1: Blood on the Dance Floor (band) Blood on the Dance Floor was an American electronic music group from Orlando, Florida, formed in 2006. The group’s longest standing lineup, from 2009 to 2016, consisted of Jesus David Torres also known as Dahvie Vanity (born 1984) and Jayy Von Monroe (born 1991). … The CD was self-released in October 2008. Only 300 copies were made.Vanity and Ecstasy recorded the singles "Siq With a Q" and "Suicide Club" as a duo in 2008, and released three extended plays over the first half of 2009, I Scream I Scream, OMFG Sneak Peak, and Extended Play. |
| Chunk 4 |
title: , source: Lick It!" was released on 27 July 2011. On 15 April 2011, Angelspit announced the addition of three new members: guitarist Valerie Gentile (Black Tape for a Blue Girl, The Crüxshadows), drummer Chris Kling (Hanzel und Gretyl, Mortiis) and videojammer The Liar. The new line-up of Angelspit released their fourth studio album, Hello My Name Is on 11 October 2011. Matt James replaced Chris Kling in early 2012, and former Crüxshadows guitarist George Bikos filled in for Valerie Gentile on the band’s 2012 tour… |
| Chunk 5 |
Vanity denied these allegations in a video.In April 2017, Vanity announced that there would be a new member, and that Blood on the Dance Floor would be returning on May 5 of that year without Jayy Von Monroe. … On January 1, 2021, Vanity released a new version of Blood on the Dance Floor’s "Bewitched" as "Bewitched Reimagined" featuring singer Sammy Beare. As of 2016, Jayy Von Monroe has continued to work as a drag monster under the name "The Dahli" and Vanity has continued to release music and merchandise by himself under both "The Most Vivid Nightmares" and "Dark Arts Official". |
| Question: |
Angelspit toured the United States with an American electronic music duo from Orlando, Florida, that formed in what year? |
| LLaMA2-7b-32k |
Angelspit toured the United States with Blood on the Dance Floor in October 2011. |
| LLaMA2-7b-32k-ret |
Angelspit toured the United States with Blood on the Dance Floor in October 2011. |
| LLaMA2-70b-32k |
2011 |
| LLaMA2-70b-32k-ret |
2006 |
| Ground truth |
2006 |