ALECE: An Attention-based Learned Cardinality Estimator for SPJ Queries on Dynamic Workloads (Extended)
Abstract.
For efficient query processing, DBMS query optimizers have for decades relied on delicate cardinality estimation methods. In this work, we propose an Attention-based LEarned Cardinality Estimator (ALECE for short) for SPJ queries. The core idea is to discover the implicit relationships between queries and underlying dynamic data using attention mechanisms in ALECE’s two modules that are built on top of carefully designed featurizations for data and queries. In particular, from all attributes in the database, the data-encoder module obtains organic and learnable aggregations which implicitly represent correlations among the attributes, whereas the query-analyzer module builds a bridge between the query featurizations and the data aggregations to predict the query’s cardinality. We experimentally evaluate ALECE on multiple dynamic workloads. The results show that ALECE enables PostgreSQL’s optimizer to achieve nearly optimal performance, clearly outperforming its built-in cardinality estimator and other alternatives.
PVLDB Reference Format:
Pengfei Li, Wenqing Wei, Rong Zhu, Bolin Ding, Jingren Zhou, and Hua Lu. ALECE: An Attention-based Learned Cardinality Estimator for SPJ Queries on Dynamic Workloads. PVLDB, 17(2): 197 - 210, 2023.
doi:10.14778/3626292.3626302
††
Corresponding authors.
This work is licensed under the Creative Commons BY-NC-ND 4.0 International License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of this license. For any use beyond those covered by this license, obtain permission by emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 17, No. 2 ISSN 2150-8097.
doi:10.14778/3626292.3626302
PVLDB Artifact Availability:
The source code, data, and/or other artifacts have been made available at %leave␣empty␣if␣no␣availability␣url␣should␣be␣sethttps://github.com/pfl-cs/ALECE.
1. Introduction
A cardinality estimator in a DBMS (Selinger et al., 1979; Graefe and McKenna, 1993) estimates the number of result elements of a SQL query before query execution, and thus helps the query optimizer to generate good query plans. In the past, the mainstream of cardinality estimation has always been statistical data-driven methods. Such methods condense information about data into lightweight summaries, e.g., histograms, sketches and data distribution approximation, and adopt analytic functions with the summaries as the input to estimate cardinatilies of SQL queries (Selinger et al., 1979; Kaushik et al., 2005; Zhu et al., 2021). However, real-world datasets are often complex and the analytic functions are usually not powerful enough to build correct mappings between coarse data summaries and SQL query cardinalities. Also, SQL queries often contain join predicates but it is difficult and time-consuming to build particular summaries for each join. Computing joint data distributions is also usually intractable due to high computation and storage overhead.
Recently, traditional cardinality estimators have been disrupted by estimators based on learned models. Data-driven models (Yang et al., 2019; Hilprecht et al., 2020; Yang et al., 2020; Wang et al., 2021a) learn tighter data distributions from the underlying database and use analytic expressions to estimate the cardinalities. In contrast, query-driven models (Kipf et al., 2019; Zhao et al., 2022) utilize the feedback of executed queries in a supervised fashion. The latter learn the relation between cardinalities and query distributions, without paying particular attention to the underlying database. However, neither kind of models can fully make use of both data and queries. It is difficult for them to extract individualized useful information for different queries. A few models (Dutt et al., 2019; Kipf et al., 2019; Negi et al., 2023) consider both data and queries. However, they either only use simple and trivial data information and requires sampling operations over relations (Kipf et al., 2019; Wu and Cong, 2021), or do not support processing queries with joins (Dutt et al., 2019) or complex joins (Negi et al., 2023).
In addition, existing models have a more critical problem: They do not perform well on dynamic workloads that mix queries and data manipulation statements including inserts, deletes and updates. Such statements tend to make estimations difficult as they influence the data distribution and shift the mapping between true cardinalities and query distributions. When the underlying data changes, the joint data distributions among relations and attributes as well as the mapping between queries and true cardinalities also become different. Thus, pure data- or query-driven methods can hardly work on dynamic workloads. Some methods (Kipf et al., 2019; Wu and Cong, 2021), although they consider both data and queries, will also have degraded performance on dynamic workloads as their required featurization or sampling approaches does not support model training and inference with data updates. More importantly, existing methods do not answer how to reasonably link SQL queries and the underlying data and build an appropriate mapping among the true cardinalities, queries and data—especially when data is dynamic.
To address these drawbacks, we design an Attention-based LEarned Cardinality Estimator (ALECE) for select-project-join (SPJ) queries. Fig. 1 depicts ALECE in the context of DBMS’s query execution.
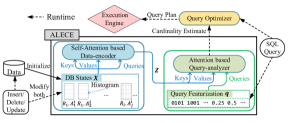
ALECE is both data- and query-driven. When estimating an SPJ query’s cardinality, it losslessly featurizes the query into a vector. Meanwhile, it efficiently featurizes the current underlying data in the database into a set of vectors, called DB states, which ‘compress’ the whole database. Both query and data featurizations are of low space overhead and can be efficiently computed. On top of the DB states and query featurizations, ALECE builds a neural network based model to create reasonable connections between them. The model integrates the information of the DB states and query featurization, and feeds them into a feed-forward regression neural network to make the estimates. Roughly speaking, ALECE first learns to assign different weights to the raw DB states , with each weight showing the correlation between two elements in . This correlation is an useful distribution information to build suitable mapping between the caridinality of a SQL query with the underlying data. Then, is mapped into another set of vectors which are the weighted combinations of and better represent the underlying data. ALECE also learns an another weight for each mapped vector in and the query featurization to measure the influence of on . The weighted combination of is a convolution of the DB states and the query featurization. The combination vector is finally used to generate the cardinality estimate.
Our ALECE’s design encounters two challenges. First, we need to build the DB states suitable for dealing with data changes in dynamic workloads, and meanwhile make them efficient to access. To this end, we propose a simple yet effective data featurization approach that is a good approximation of data distributions, sensitive to data changes, and computation-efficient. This approach constructs succinct summaries of the underlying data, i.e., DB states, based on the histogram of each attribute of the database relations. Each time a record is inserted, deleted or updated, we only need to modify the DB states’ vectors relevant to the changed relation. Also, the basic single attribute distributions and even joint distributions are covered by the DB states. These factors together enable us to process dynamic workloads with the DB states. Besides, depending on the requirement of the distribution approximation precision, the number of bins in a histogram can be flexibly adapted. Moreover, other useful information relevant to underlying data can be seamlessly integrated if needed.
Second, we need to extract the implicit relevance between SQL queries and corresponding DB states, and make the information helpful for cardinality estimation. To this end, we adopt the attention mechanism (Bahdanau et al., 2015; Vaswani et al., 2017; Kim et al., 2017) in our model to draw global dependencies between SQL queries and underlying data. The attention mechanism is widely used in a variety of tasks including question answering (Hermann et al., 2015; Sukhbaatar et al., 2015). Generally, it simulates the process of selection from a set using an attention function that takes as input two main components: a set of queries and a set of key-value pairs. It figures out in an individualized manner which parts of the data play more important roles for different queries, assigns higher weights to the more important and relevant keys for each query, and outputs the combination of the weighted values. Unlike those concepts in a database, a query in attentions is a specific element for which we need to learn a representation, the role of keys is to respond more or less to the query, and the values are used to compose an answer. Nevertheless, the selection process exactly matches our settings where the SQL queries and underlying data are analogies of the queries and key-value pairs in attentions, respectively.
There are two modules in our ALECE where the attentions are used in different ways. On the one hand, the ‘data-encoder’ module uses a self-attention whose inputs of queries, keys and values all come from the DB states. The self-attention allows the DB states, which correspond to different attributes, to interact with each other. By using the self-attention, the data-encoder module learns the implicit joint distribution information among attributes and computes a smarter representation of the underlying data. On the other hand, in the ‘query-analyzer’ module, the queries set of the attention is exactly a set covering only one featurization vector of a SQL query, while the keys and values come from the output of the data-encoder module. The query-analyzer module outputs a fixed-dimensional ‘answering’ vector integrating the information from the query and data representations. We then use a simple linear regression model to map the answering vector to a cardinality estimate.
Compared to the state-of-the-art cardinality estimation methods, ALECE is able to make more reasonable use of both queries and underlying data. With the help of the two attentions, it answers the questions that ‘which parts of data should a SQL query pays more attention to?’ and ‘how to find the more important data?’ A SQL query usually focuses on some local parts of selected attributes. Also, the join conditions make particular tuples contribute more to the cardinality. Moreover, ALECE is able to adapt to dynamic workloads. In practice, learned models need to be trained with past queries and corresponding DB states, and estimate cardinalities for future queries. The performance of existing query-driven models often dramatically degrades when making predictions on a dynamic database. In contrast, ALECE can make immediate and suitable reactions to data changes by modifying the DB states, and learn an appropriate but implicit mapping between the true cardinality and the query featurization accompanied with the corresponding DB states. Our experimental results show that ALECE is able to make accurate estimates even when the distribution of the underlying data changes. Thus, ALECE is less sensitive to data changes.
In our evaluation, ALECE achieves the best cardinality estimation performance on multiple dynamic workloads. Experimental results show ALECE improves the average end-to-end query time by up to faster on the benchmark workload, very close to the optimal results acquired by using true cardinalities. This demonstrates that our ALECE makes more accurate cardinality estimates and helps the query optimizer find better query plans.
We make the following major contributions in this paper:
-
•
We propose necessary principles for a method to featurize the underlying database data and SPJ queries. Accordingly, we design a featurization schema to losslessly featurize an SPJ query and make a reasonable compression of the data. The featurizations can be efficiently updated to support dynamic workloads.
-
•
Based on the featurizations of queries and data, we propose an attention based learned cardinality estimator ALECE, together with detailed analyses.
-
•
ALECE is designed to be a ‘whitebox’ which not only gives estimates but also clear rationale to integrate the SPJ queries and underlying data together in processing dynamic workloads.
-
•
We experimentally validate ALECE ’s advantages over more than half dozen representative alternatives on real datasets.
The rest of the paper is organized as follows. Section 2 gives the preliminaries. Section 3 presents the featurizations of data and queries. Section 4 elaborates on ALECE, followed by an analysis of it in Section 5. Section 6 reports on the experimental studies. Section 7 reviews the related work. Section 8 concludes the paper. In addition, due to space limit, we introduce our developed benchmark, which integrates ALECE into PostgreSQL’s query optimizer, and more experimental analyses in Appendix.
2. Preliminaries and Problem
Table 1 lists important notations used in the paper.
| A relation in the database | |
| The th attribute of the relation | |
| , | The number of relations/attributes in the database |
| The set of data featurizations (a.k.a. DB states) | |
| The number of histogram bins (dimensionality) for a DB state | |
| A SQL query and its vectorized featurization | |
| The dimension of a query featurization vector | |
| , | The number of attention layers in the data-encoder/query-analyzer module |
| The input keys/values/queries of an attention function |
2.1. Cardinality Estimation Problem
Suppose a database has a set of relations . A relation has attributes, i.e., . Each attribute can be either categorical or numerical: the domain of a categorical attribute is a finite set and can be 1-to-1 mapped to an integer set ; the domain of a numerical one is .
Problem Formulation. Given a SQL query and a dynamic database , we want to estimate the cardinality of , denoted as , i.e., the number of resulting tuples when is executed on .
In this paper, we focus on select-project-join SQL queries with conjunctive filter predicates; the cardinality is the number of tuples after joins and filters, as the following counting query:
| (1) | ||||
where involves relations , with a set of join predicates which is a conjunction of join conditions each in the form of “”, and a conjunction of filter predicates . This formulation allows us to support not only PK-FK joins but also more general joins by specifying join predicates on pairs of joinable attributes (which may or may not be primary/foreign keys) in . A filter predicate is an relational expression in the form of “” where and is a fixed value. In , an attribute can appear in a join or a filter predicate, or both. The support for predicates is left for future work.
ALECE in the Optimization of SPJ Queries. The estimation results for counting queries in the format of (1) can be used to support the optimization of more complex queries, e.g., widely-used SPJ (select-project-join) queries in the following format:
| (2) | ||||
where each () is an aggregate function over one or multiple attributes which can be , , and , etc, or can be simply omitted. The join predicate set and filter predicate set carry the same meanings with that in (1).
To search for the best execution plan, the query optimizer of a modern DBMS like PostgreSQL first decomposes into a series of sub-queries (implicitly) in some fixed order (Han et al., 2021). The cardinalities of these sub-queries are then estimated with the built-in estimator. Accordingly, candidate query execution plans are enumerated and their estimated execution costs given the cardinality estimates are calculated using also a fixed cost model. The plan with the smallest estimated cost is chosen to execute the query physically. Apparently, the execution performance of a query is basically determined by the cardinality estimates of its sub-queries. The design of our ALECE enables it to provide more accurate estimates. Our developed benchmark can plug external cardinality estimator into the optimizer to replace the built-in one. Thus, ALECE is able to improve the cardinality estimation for ’s sub-queries, and further enable the query optimizer to select a good execution plan.
ALECE is applicable for optimizing even more complex queries. For the sub-queries that it supports, it gives better cardinality estimates; for the sub-queries that ALECE does not support, the optimizer can still use its default cardinality estimator.
Estimation Model on Dynamic Workloads. In reality, the data in a DBMS is seldom static but often keeps being updated. Thus, it is beneficial to design cardinality estimators able to make accurate estimates for a dynamic workload, i.e., a sequence of SQL statements including queries, inserts, deletes and updates. Our ALECE aims to support dynamic workloads and provide up-to-date cardinality estimates for queries at any time during the workload.
For a learned cardinality estimator to work on frequent changes of the underlying data distribution without retraining, a straightforward idea is to use the database itself as part of the input features to train an estimation model. However, this is infeasible as the size of can be huge and varies continuously. Instead, we use succinct summaries of the database (e.g., fixed-size histograms), called DB states, as part of input features to train ALECE. As the database is updated, the DB states should be updated accordingly (and efficiently) such that they can be fed into the trained model to produce cardinality estimates. Details about featurizing as DB states are in Section 3.1. We assume that ’s schema is static. The support for dynamic schema is left for future work.
2.2. Overview of ALECE
An overview of ALECE’s model structure and its role in the query engine is shown in Fig. 1. Features from dynamic data and queries are decoupled and handled by two modules in ALECE. The data-encoder module adopts a self-attention structure on DB states to figure out the correlations among all attributes and to learn their joint distribution, whereas the query-analyzer module employs a data-query cross attention to discover correlation between the data-encoder’s outputs and the cardinalities of (sub-)queries. The cardinality estimates eventually produced by the query-analyzer in ALECE depend on both data (DB states) and queries.
Offline Training. Training ALECE needs a dataset of queries, their true cardinalities, and the corresponding database information when these queries are executed. The training dataset is obtained by collecting the true cardinalities of the historical queries executed on a dynamic database for a period of time. We start from featurizing the initial database by generating a set of vectors with fixed dimensionality, i.e., DB states (Section 3.1). Statements in the SQL workload are sequentially processed. For the insert, delete and update statements, we modify the DB states accordingly. When a query comes, it will also be featurized into a vector with fixed dimensionality (Section 3.2). The query features and the current DB states will be packed together as a training sample with the true cardinality as its label. With sufficient training samples collected, ALECE is trained with gradient descent methods.
Online Estimation. A well-trained ALECE can make online estimates on both static and dynamic workloads. Given a new query, we feed its featurization and the up-to-date DB states into ALECE to get the estimates. If the workload is static, i.e., it contains no data update statements, the DB states are constant. Otherwise, the DB states keep changing and the latest ones will always be used.
3. Featurizations of Data and Queries
The underlying database data and SQL queries are required to be featurized numerically such that our ALECE can deal with. Any featurization method is able to be flexibly adopted by ALECE as long as it satisfies some principles. First, the underlying data needs to be featurized into a set of fixed-dimensional vectors covering enough distribution information. Second, any SPJ query should be losslessly mapped to a fixed-dimensional vector such that ALECE could better understand it. Also, to effectively support the dynamic workloads, the featurization method is supposed to be efficient and of low storage overhead. Following these principles, we propose an method of featurizing the database data and SQL queries numerically. The details are given in Section 3.1 and 3.2, respectively. Moreover, Section 3.3 discusses the properties of our featurization method and how it helps process dynamic workloads. It is noteworthy that our featurization method is specifically designed for our ALECE and it perfectly aligns with the requirements on inputs to ALECE.
3.1. Data Featurization
In our settings, the data featurization , also known as the ‘DB states’, is a compression of the whole database, which can roughly describe the data of each attribute and the relationships among them. Our ALECE requires the data featurization to be a set of vectors of the same dimension. Here we use the set of histograms for each attribute as the DB states, i.e., where is the histogram of the th attribute and is the number of all attributes in the database. How to order the attributes will be introduced in Section 3.2. This featurization method is simple but powerful and we can efficiently access and update the histograms.
In particular, the values of categorical attributes are first converted to consecutive integers numbered from 1. Given an attribute , we use to denote its domain or the converted integer set if is categorical. It is easy to show that where and with . Then, given a time stamp and the database data at , we create a -bin-histogram for each . In particular, let and be the number of ’s values in for , the histogram for attribute could be easily accessed with . Our DB states at any time is simply a set of elements each being a -dim histogram vector. In practice, each in all histogram vectors will be scaled to the range [0, 1] through a suitable affine transformation. The value of can be flexibly modified according to the complexity of the data distribution. Apparently, a larger will make the data featurization capture more distribution information among the attributes but result in extra time and storage overhead. Usually, when strong correlations exist among attributes, a larger value tends to be used for .
3.2. Query Featurization
Following and extending the existing work (Zhao et al., 2022; Wang et al., 2021b), we featurize a SQL query into a fixed length vector 111Without ambiguity, denotes both a SQL query and its vectorized featurization.. It is a simple concatenation of two separately generated parts and , which featurize the join predicates and filter predicates , respectively.
Join featurization. For the relations numbered from 1 to , we use bits to featurize the id of each relation. Similarly, bits can featurize the ids of all attributes in any relation, where is the maximum number of attributes in a relation. Thus, any attribute can be uniquely identified with a binary vector of dimension . The first -dimensional and the last -dimensional sub-vectors identify the relation and the attribute, respectively. Then a join predicate is featurized by a -dim binary vector with the first and second half sub-vectors refer to the left and right hand side of , respectively.
Suppose there are possible join patterns, the join featurization of a SQL query is a -dim binary vector, containing -dim sub-vectors, indicating which join patterns covers and featurizing their referred attributes. If the join predicates of contain the th join pattern , the th sub-vector of equals . Otherwise, this sub-vector is set to zero. Usually, the value of is not large, nearly linearly related to the number of attributes (Wu et al., 2023; Zhu et al., 2021). Unlike existing work (Zhao et al., 2022) that simply featurizes whether each join condition appears in the query, our featurization way is more compact and incorporates more helpful information about the joins.
In practice, we define the attributes in the left and right hand side of a join predicate are ‘equivalent’ and find all equivalence classes in . Afterwords, we re-organize the join predicates based on the equivalence classes. Given an equivalence class containing attributes sorted by their -dim featurizations, we re-create join predicates with the th one to be . By doing this to each equivalence class and packing the corresponding join predicates together, we generate a new join predicate set . The join featurization is actually performed with instead of . In this way, two equivalent join predicate sets in explicitly different forms will be featurized to be the same. For example, in the following formula, join predicate set and both have two same equivalence classes. They will be converted to another set .
Filter featurization. We sort all attributes according to their -dim featurizations and use to denote the th one among attributes. Without loss of generality, we assume is for each attribute . Thus, the product space . Apparently, the filter predicates are equivalent to a hyper-rectangle which is a subset of . In particular, for any filter condition on the attribute , we convert it into an equivalent one in the form like . Then, the values of and are set to and , respectively. Specifically,
Above, denotes the equivalence operator.
Accordingly, the featurization of filter predicates is a -dim vector composed of the boundary points of the search hyper-rectangle, i.e., . In practice, each and will be normalized to [0, 1].
Concatenation. By concatenating and , we get the -dim featurization vector of SQL query . Fig. 2 shows an example.
|
|
3.3. Discussions
3.3.1. Featurization properties.
As we claimed, our way of featurizing database data and SQL queries has the following properties:
1) Efficiency. Building the data featurizations of a static database requires looking over each relation once only. An insert/delete/update statement only influences one relation and modifying the relevant histograms takes time where is the number of the records involved. The time complexity of featurizing a SQL query is , which is small and can often be ignored.
2) Low space overhead. The DB states only contain float numbers. In practice, we usually set smaller than 100. The dimensionality of a query featurization is . Usually, the value of is small. In our experiments, is smaller than 10. Our way of re-generating join predicates based on equivalence classes will usually reduce , the number of possible joins. Also, the joins tends to be performed on attributes with primary keys. According to our observations, is usually less than and featurizing a query on a 8-relation database requires less than 1000 float numbers.
3) Stability. The dimensions of data and query featurizations are fixed, no matter how the database or queries change. This ensures the featurizations can be easily processed with learned models.
3.3.2. Why our featurizations work on dynamic workloads?
It is noteworthy that no matter how the underlying data changes, the featurization of a given query will not change. In contrast, the DB states will vary with the change of the data in the database. It is a compression of the whole database and able to catch the distribution characteristics of each attribute. Our model takes both featurizations as input and is able to ‘convolute’ the query featurizations with the DB states. Thus, when the data changes, it can react properly and give different predictions for the same query with different DB states. The experiments in Section 6 and Section C in Appendix show that our model outperforms other state-of-the-art methods on both static and dynamic workloads.
4. Design of ALECE
Given the DB states and a SQL query featurization , our ALECE can reasonably discover the implicit relations between them that are required for cardinality estimation. The mystery behind lies in the attention mechanisms (Vaswani et al., 2017) twice used in our ALECE. In this section, we will review the motivation of ALECE’s design, introduce the details of ALECE including its two modules processing and , respectively, and the training process of ALECE.
4.1. Motivations and ALECE Overview
An attention function maps a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors (Vaswani et al., 2017). Here, the concepts of key-value pairs and queries can be analogous to retrieval systems. Take a user’s search behavior on an e-commerce platform like Amazon as an analogy. When the search engine receives a query (the text in the search bar), it maps the query against a set of keys (item names, tags and descriptions, etc.) associated with values (candidate items) in the database and outputs the best matched items. The output is a weighted sum of the values, where each weight is computed by a compatibility function that measures the relevance between the query and keys.
The idea behind the attention mechanism is to encode the input key-value pairs set, and utilize the most relevant parts of the keys, associated with values, with the query in a flexible manner. Through a weighted combination of all encoded input vectors, this mechanism ‘answers’ the query with the most relevant vectors getting the highest weights. This idea perfectly fits in our research problem as a SQL query’s featurization is a natural query vector. Besides, the DB states can be seen as the item information in the above example and be used as the keys and values in the attention functions. Thus, we extend this idea and design ALECE, which takes full advantage of the attention mechanism to accurately estimate cardinalities of SQL queries on dynamic workloads. Fig. 3 illustrates the structure of ALECE.
Our attention-based model ALECE is designed like a soft lookup table. It fetches information from a better representative of the DB states using features from the transformation of as indices. It is composed of two modules. The left data-encoder module maps to another set of representations . It learns the implicit joint distribution information among all attributes by computing the relevance between any pairs of DB states through a stack of self-attention layers. This distribution information is embodied in the set . Given , the right query-analyzer module adopts another stack of attention layers to measure the relevance between the query featurization and , and generates an ‘answer’ vector . Finally, vector is fed into a linear regression layer and ’s cardinality given DB states is estimated and returned.
| Data-encoder (Self-attention) | Query-analyzer (Data-query cross attention) | ||||||||||||||||||||||
| Input source | What to learn? | Output | Input source | What to learn? | Output | ||||||||||||||||||
|
|
|
|
|
|
||||||||||||||||||
4.2. Attentions in ALECE
Attention background. Before showing the data-encoder and query-analyzer modules in ALECE, it is worth briefly introducing the attention mechanism. In neural networks, attention is a technique that is meant to mimic cognitive attention. Its motivation behind is that the network should devote more focus to the important parts of the data instead of treating all data equally. It uses an attention function to discover which parts of the data should be emphasized. The function maps a query and a set of key-value pairs to an output, which is a weighted sum of the values. Usually, the function computes the similarity (relevance) between each pair of query and key with some metric, and uses it to produce the weight assigned to the corresponding value.
Our ALECE uses the ‘Scaled Dot-Product Attention’ (Vaswani et al., 2017), namely , as the attention functions in the attention layers from both the data-encoder and query-analyzer modules. The input keys and values are packed together into matrices and , of dimension and , respectively, where denotes the size of the original key-value pair set.222In the rest of the paper, we regard a set of vectors as a matrix. In other words, we do not distinguish a set of key/value/query vectors with a key/value/query matrix. The -dim query vector is converted to a matrix . The function computes the dot products of the given query with all keys , divides each by , and applies a softmax function to obtain the weights on the values :
The dot product above is used as the similarity metric. To prevent the dot products from growing too large such that the gradients of the softmax function ‘vanishing’, we divide the dot product by the factor. In practice, the function is computed with batches of queries simultaneously to improve the efficiency. Before feeding the input to , we adopt a multi-head projection mechanism (Vaswani et al., 2017) to first project the queries, keys and values multiple times with different linear projections. This operation is able to enhance the representation ability of ALECE. Due to space limit, more details are given in Section A in Appendix.
Attentions in ALECE’s two modules.The multi-head attention layer appears twice in ALECE. The first is a self-attention layer in the data-encoder module. It is fed with the same query, key and value matrix of dimension , and outputs a matrix that will be later projected to another matrix . Then, is used as the key and value matrix of the other attention layer in the query-analyzer module, where the input query set contains only one SQL query featurization vector. It is noteworthy that the ”queries” set in the self-attention layers does not come from the SQL query. In addition, we do not need to order the vectors in the DB states. Thus, unlike transformer-like models to process sequences (Devlin et al., 2019; Brown et al., 2020), ALECE does not need the positional encodings (Vaswani et al., 2017) or positional embeddings (Gehring et al., 2017) of the attention layers’ inputs.
Table 2 states the input sources and output of the two modules’ attention layers, and what each module is able to learn. The rationale behind them is given in the following two subsections.
4.3. Data-encoder
Suppose a random variable ’s value is taken randomly with an equal possibility from the possible values of an attribute. As a result, the corresponding histogram can be regarded as the rough distribution function of . Thus, the DB states consists of a series of ‘marginal’ distributions describing single attributes. However, SQL queries tend to cover join predicates that need to know the joint distribution information among multiple attributes. Usually, the distributions of different attributes are not independent. It is difficult and impractical to directly derive the joint distribution from the marginal distributions. To address this issue, we design the data-encoder module that makes use of attentions, to establish a bridge between the marginal distributions and the joint distribution.
The data-encoder takes as input the DB states and feeds it into a -stacked layers. Each layer is identical and has two sub-layers. The first is the multi-head self-attention sub-layer which takes the same inputs of keys, values and queries—three matrices equal to or the output of the last layer, and outputs another -element set . On top of , the feed-forward sub-layer uses stacked fully connected networks and nonlinear activation functions, e.g., ReLU, to map into the data representation set . Besides, to address the degradation problem and ease the model training, we employ a residual connection (He et al., 2016) around each sub-layer, followed by layer normalization (Ba et al., 2016), following the settings in (Vaswani et al., 2017). Thus, the output of each sub-layer is LayerNorm(. The sub-layer is either or . The analytic expression of the output representations is described as follows.
Finally, the output matrix will be linearly projected to the representation matrix . This projection is to align the dimensionality of with that of the query featurization .
The keys, values and queries in the attention layers are the same set. They are either the DB states or the output of the previous stacked layer. This setting makes each element in the output set of a layer attend to all outputs in the previous layer and thus attend to all DB states. More importantly, the self-attention layer quantitatively ‘calculates’ the relevance between a pair of elements from any two histograms. It is noteworthy that each element of a histogram describes the local distribution of an attribute. Therefore, the data-encoder module is able to more effectively discover the implicit connections between any pair of DB states, and thus exhibits behavior in relation to the joint distribution of multiple attributes in the output set. Compared to other neural network architectures like multilayer perceptron (MLP) (Hastie et al., 2009), self-attention could yield more interpretability and have higher representative abilities. Through self-attention layers, we create links among all DB states, or equivalently, all attributes in the database. After fine-
tuning the parameters of the self-attention and feed-forward layers, the relationship information helpful to the cardinality estimation task is implicitly covered and encoded into the output of the data-encoder module. This information will be processed and utilized in the query-analyzer module.
4.4. Query-analyzer
The query-analyzer module attempts to discover and measure the relevance, through data-query cross attention layers, between the SQL query and each element of , the output of the data-encoder module covering joint distribution information among attributes.
This module is also a stacked structure composed of identical layers. Similar to the data-encoder module, each layer here is composed of a multi-head attention sub-layer and a fully connected sub-layer. Also, residual connections are employed around each sub-layer, followed by layer normalization. Unlike the data-encoder module, the input sets of key-value pairs and queries to the ‘data-query’ attention sub-layer here are not from the same place. We use , the output of the data-encoder module, as both the input key and value matrices, while the query set here comes from either the query featurization or the output of the previous layer. It is noteworthy that the input query set and the output set of each attention sub-layer have only one -dim element.
The data-query attention sub-layer establishes a bridge between the queries and the data. It individualize each SQL query featurization and presents different ‘answers’ by enhancing the influences of some parts of the input key-value pair set , while diminishing other parts. Learning which part of the data is more important depends on the relations between queries and keys, and this is measured with the attention functions. Suppose a SQL query contains join predicate and filter predicate , and the attributes , and are numbered , and , respectively. The data-query attention sub-layer will pay more attention to the part of the vectors in the set that are relevant to , and . The effect of particular attention can be realized through suitable parameters of different layers in both modules.
After accessing , the output of the final query-analyzer layer, we use a simple linear regression layer to calculate a scalar value as the cardinality estimate . The process of accessing with the input of and is described as follows.
| (3) | ||||
4.5. Training of ALECE
Fine-tuning the parameters of ALECE requires a training dataset of which each element is a 3-tuple , where is the query featurization of a SQL query and is the associated DB states of the dynamic database. By executing on the database of which the DB states is , we will get the true cardinality , which will be used as the label. In practice, we will take the logarithm of to make the range of the labels not too large. Collecting the training dataset is not difficult. Usually, we only need to collect the feedback of executed queries on a dynamic database. Then, we will get the training dataset with three lists , and . They will be split into batches to train our ALECE.
We use the mean-weighted-squared-error function taking input of the batch card predictions and the true cards as well as their weights with batch size as the loss function, i.e., . The parameters of the linear regression layer, the attention and feed-forward sub-layers in both modules are trained by gradient descent with batches in an end-to-end fashion. Here, the value is proportional to that of . In particular, . We use the weight in the loss function because it is usually beneficial to emphasize the queries with larger true cardinalities as their execution times tend to be longer. The procedure of training ALECE using the these lists , and is detailed in Algorithm 1.
In practice, a training dataset is split into two parts: the first part is the three data lists used to fit the parameters in the learning process (lines 7-10); the second part is used as the validation set to choose best parameters for ALECE and avoid overfitting (lines 4-5). Also, we will apply the early stopping strategy (Prechelt, 2012), to stop the training process when the error on the validation set grows.
5. Analysis of ALECE
In this section, we discuss why ALECE is suitable for dynamic workloads and further analyze its properties.
5.1. ALECE on Dynamic Workloads
It is critical for databases to process dynamic workloads, i.e., mixture of queries and data manipulation operations. This requires a DBMS’ query optimizer to be able to accurately predict the cardinalities of the (sub-)queries performed on a continuously changing database. To reduce the related overhead, the DBMS regularly maintains its
cardinality estimators instead of modifying it immediately after each update. Between two model-maintaining time points, the cardinality estimator model is usually fixed but still expected to make accurate estimates.
The traditional histogram-based cardinality estimators (Selinger et al., 1979; Poosala and Ioannidis, 1997; Gunopulos et al., 2000; Deshpande et al., 2001) currently used in systems like PostgreSQL (Group, 1996) make simple and often unreasonable assumptions, like the mutual independence of attributes. Their estimates are inaccurate, especially when the data is dynamic. This renders it difficult for the optimizer to choose good query plans. Existing learned cardinality estimation methods either do not support dynamic workloads (Zhao et al., 2022) or need to completely re-build the model at model-maintaining time points (Zhu et al., 2021; Hilprecht et al., 2020; Yang et al., 2020). This process is often too time-consuming to be feasible.
Compared to existing methods (Hilprecht et al., 2020; Zhu et al., 2021; Yang et al., 2020), the training of ALECE is efficient. Also, it is easily maintained: it can be incrementally updated at model-maintaining time points. Moreover, its architecture design is reasonable and suitable for processing dynamic workloads. It is noteworthy that the SQL queries and underlying data are decoupled in ALECE such that ALECE can learn something whenever the DB states or the query featurization in the training dataset changes. Thus, ALECE is able to avoid overfitting certain datasets. Instead, it applies the attention mechanisms on its two modules to learn the properties of the data distribution which ‘generates’ the underlying data, and how these properties influence the cardinality of a SQL query. It is able to reasonably approximate , the true but implicit mapping among the queries, dynamic data and cardinalities. When either the query featurization or DB states, or both of them, get changed, ALECE can still output accurate results. Our experimental results indicate that ALECE achieves good performance even if there is distribution discrepancy between the training and testing data.
A straightforward baseline without attentions. It is mentioned in Section 3.3 that the DB states will be dynamically modified when data is inserted to/deleted from the database. This renders it possible to use a stable well-trained model to predict the cardinalities of queries on a dynamic workload. As the dimensions of DB states and query featurizations are fixed, we can also adopt a straightforward method without attentions to process them. For example, for each pair of data featurizations and query featurization , we flatten the matrix into a vector and concatenate the vector with to generate another vector . Subsequently, and the associated layer are fed into a common supervised neural network like multilayer perceptron (MLP) (Hastie et al., 2009). However, a straightforward neural network like MLP is usually not powerful enough to discover the implicit relations between SQL queries and the underlying data. Its performance heavily relies on the similarity between the distributions of training and testing datasets. When the workload is static, i.e., the database data never changes, straightforward methods perform well. However, the cardinality estimator model needs to use the current training data it observes to make predictions for ‘future’ data. The distribution of future DB states may be highly different from that of the current data. In contrast, the application of the attention mechanisms in our ALECE make it possible to make accurate estimates even when the distributions of the underlying data change. Experimental results in Section 6 show the great advantages of ALECE over MLP on processing dynamic workloads.
5.2. Overhead of ALECE and Its Extension
Several other good properties make ALECE more practical and attractive as a cardinality estimation method in modern DBMS’s query optimizers. First, the storage and training overhead of ALECE is affordable. On the one hand, the sizes of ALECE on the three datasets in our experiments are both smaller than 23 MB. On the other hand, training ALECE from scratch requires less than 12 minutes. Also, the estimation latency of ALECE is less than 11 ms. These overheads make ALECE able to process real world workloads.
Second, different from FLAT (Zhu et al., 2021) and DeepDB (Hilprecht et al., 2020), ALECE directly estimates the cardinality instead of the selectivity of a SQL query. To get the cardinality, the selectivity estimation methods usually needs to estimate the size of the corresponding join table with sampling-based techniques (Zhao et al., 2018). However, when multiple relations are involved, the statistical variance often becomes large and results in highly inaccurate estimates.
Last but more importantly, ALECE establishes a general framework that is not limited to cardinality estimation tasks. By replacing with with other aggregation functions, the special aggregate analytic queries of Format (2) can be further transformed to more general ones. As a matter of fact, ALECE can be easily extended to approximate the results of more general aggregate analytic queries. When processing queries with other kinds of aggregate functions, we only need to make slight modifications to the data and query featurizations, including featurizing the extra aggregate functions and optional clauses in the query featurizations, and incorporating more data description information specific to the aggregate queries. We left the support of the general aggregate analytic queries for future work.
6. Experimental Studies
This section reports the experiments that compare ALECE with selected alternatives. All methods are implemented in Python 3.9 and evaluated on a Linux server with a 96-core Xeon(R) Platinum 8163 CPU and 376GB memory. The implementation of ALECE is open (cod, line). Due to space limit, we present additional experimental results and analyses in Section C in Appendix.
6.1. Experimental Settings
Datasets. We use three real datasets to evaluate all models.
-
•
STATS contains 8 relations (users, posts, postLinks, postHistory, comments, votes, badges, tags) with 43 attributes (STA, line). There are 1,029,842 records in total. An existing open workload with 146 queries are marked as ‘testing queries’. They are associated with 2,603 sub-queries. We created another 1000 different queries with sub-queries, which are used as the training and validation data.
-
•
Job-light is a subset of the IMDB dataset (imd, line). It contains 6 relations (cast_info, movie_info, movie_companies, movie_keyword, movie_info_idx, title) with 14 attributes. There are 62,118,470 records in total. The testing query set contains 208 queries, associated with 3,248 sub-queries. Similarly, another 2,000 queries as well as their sub-queries are created for training the models.
-
•
TPCH (1 GB) (tpc, line) is a widely-used benchmark dataset of a suite of business oriented relations (customer, lineitem, nation, orders, part, partsupp, region and supplier). We remove the string type ‘comment’ attribute from each relation as it is not supported by ALECE or other methods. We use the remaining 46 attributes. There are 8,661,245 records in total. We randomly create 123 testing queries and 1,554 testing sub-queries for evaluation. Another 2,000 queries and their sub-queries are used for training.
The join information among relations in these datasets are shown in Fig. 5 in Appendix. All joins in the queries on the Job-light dataset are PK-FK joins, while the queries on the other datasets involve more complex many-to-many joins.
Dynamic workloads. For each dataset, we create three different dynamic workloads, each of which is a random mix of inserts, deletes, updates and query statements. These workloads are differ-
entiated according to the ratios among the numbers of inserts, deletes and updates, and the distributions of the inserted records:
-
•
Insert-heavy: #inserts : #deletes : #updates = .
-
•
Update-heavy: #inserts : #deletes : #updates = .
-
•
Dist-shift is a special Insert-heavy workload but having skewed distribution of the inserted records. In particular, the inserted records are selected intentionally such that their first attributes’ values are the first 30% smallest among all data.
To generate a dynamic workload, we randomly select about of the records as the initial datasets to bulk load all the relations. Subsequently, the insert and update statements in a dynamic workload will insert the remaining of the records to the database, while the delete and update statements will remove or change some records. For simplicity and clarity, we assume that each delete or update statement only influences one record. These statements are equally split into two parts: the former ‘training’ part and the latter ‘evaluation’ part. To ensure that ALECE learns from enough features, we make three copies of the training queries and their sub-queries and randomly mix them with the training part. The training part of the workload is used as the training dataset for building all cardinality estimation methods. Note that the true cardinalities of the queries in the training part are also available to all methods.
The way of mixing testing queries with the data manipulation statements in the evaluation part are slightly different. For each testing query, we pack it up with its sub-queries together. Then, those packs are shuffled and randomly mixed with data manipulation statements in the evaluation part. Also, we’d like to know how cardinality estimators perform when a certain amount of data in the database changes. Thus, it is assumed that when each testing query is executed, the associate changing rate of the underlying database data is larger than a pre-defined threshold. We use to denote the set of all records in the database after executing all the statements in the training part. Given any query in the evaluation part, suppose is the set of all records in the database when is executed, and the numbers of inserts, deletes and updates from the evaluation part so far are , and , respectively. The changing rate is defined as , where denotes the symmetric difference operation of two sets. When there is no ambiguity, the subscript is omitted.
Both training and testing queries are randomly generated. In particular, to generate a query, we run a series of Bernoulli tests with to determine which relations appear. Then, we enumerate all possible subsets of the join conditions among the selected relations such that they can be connected by these join conditions. One of the subsets is randomly selected as the join predicate set . The attributes in the filter predicates and their operators (, etc) are determined with the analogous Bernoulli tests. The right hand side values of the filter predicates are randomly sampled from the initial dataset.
Competitors. We include the following representative methods:
-
•
PG is the simplest 1D histogram based cardinality estimation method used in PostgreSQL (Group, 1996).
-
•
Uni-Samp (Liang et al., 2021) uniformly samples a set of tuples with a given probability for each relation. The cardinality estimate of a query equals where is the number of returned tuples by executing on the sample sets and is the number of involved relations in . We tune the value of to make Uni-Samp’s storage overhead or latency is comparable to that of the other methods. The values of the sampling ratio for the STATS, Job-light and TPCH datasets are set to 0.1, 0.06 and 0.04, respectively.
-
•
DeepDB (Hilprecht et al., 2020) is based on a Sum-Product-Network (SPN) (Poon and Domingos, 2011). It learns a pure data-driven model to capture the data’s joint probability distribution. Following the same settings in (Hilprecht et al., 2020), we set the RDC independence threshold to 0.3 and split each SPN node with at least 1% of the input data.
-
•
FLAT (Zhu et al., 2021) improves SPN based on factorize-sum-split-product network (FSPN) (Wu et al., 2020), a graphical model, to adaptively model the joint probability density function of attributes. It is data-driven.
-
•
NeuroCard (Yang et al., 2020) is a data-driven method, extending Naru (Yang et al., 2019) into the multi-table case, while Naru is a Deep Auto-Regression (DAR) (Gregor et al., 2014) based cardinality estimation algorithm for a single table. The sampling size of the NeuroCard model is set to 8,000, following the settings in the paper.
-
•
FactorJoin (Wu et al., 2023) combines classical join-histogram methods with learned single table cardinality estimates into a factor graph.
-
•
MLP (Rumelhart et al., 1986) is the baseline neural network based method introduced in Section 5.1.
-
•
MSCN (Kipf et al., 2019) is a multi-set convolutional network which adopts the information from both queries and data.
-
•
NNGP (Zhao et al., 2022) adopts the Neural Network Gaussian Process (NNGP) model (Lee et al., 2018) to learn from queries as well as their true cardinalities in a supervised manner.
In addition, we also include the comparison with the results generated by true cardinalities. This Optimal method measures the best performance a method can achieve.
These competitors are chosen because they have better overall performance over other statistical and learned cardinality estimators. The comparisons are reported in benchmark and evaluation papers (Han et al., 2021; Sun et al., 2021) and other existing works like (Zhu et al., 2021; Wu and Shaikhha, 2020; Yang et al., 2020). Table 3 summarizes the properties of all methods. The better performance is indicated in bold.
| Method |
|
|
|
|
|
||||||||||
| PG (Group, 1996) | small | low | |||||||||||||
| Uni-Samp (Liang et al., 2021) | small | medium | |||||||||||||
| DeepDB (Hilprecht et al., 2020) | medium | medium | |||||||||||||
| FLAT (Zhu et al., 2021) | large | high | |||||||||||||
| NeuroCard (Yang et al., 2020) | medium | medium | |||||||||||||
| FactorJoin (Wu et al., 2023) | medium | small | |||||||||||||
| MLP (Rumelhart et al., 1986) | small | low | |||||||||||||
| MSCN (Kipf et al., 2019) | small | small | |||||||||||||
| NNGP (Zhao et al., 2022) | small | medium | |||||||||||||
| ALECE (ours) | small | medium |
| Data | Model | Insert-heavy | Update-heavy | |||||||||||||||||||
| E2E Time(S) | Q-error | P-error | Size (MB) | Building Time(Min) | Latency (ms) | E2E Time(S) | Q-error | P-error | ||||||||||||||
| 50% | 90% | 95% | 99% | 50% | 90% | 95% | 99% | 50% | 90% | 95% | 99% | 50% | 90% | 95% | 99% | |||||||
| STATS | PG | - | - | - | ||||||||||||||||||
| Uni-Samp | ¿ | ¿ | ¿ | ¿ | ||||||||||||||||||
| NeuroCard | ¿ | |||||||||||||||||||||
| FLAT | ¿ | |||||||||||||||||||||
| FactorJoin | ¿ | ¿ | ||||||||||||||||||||
| MLP | ¿ | ¿ | ¿ | ¿ | ¿ | ¿ | ¿ | ¿ | ||||||||||||||
| MSCN | ||||||||||||||||||||||
| NNGP | ||||||||||||||||||||||
| ALECE | ||||||||||||||||||||||
| Optimal | - | - | - | |||||||||||||||||||
| Job- light | PG | - | - | - | ||||||||||||||||||
| Uni-Samp | ¿ | ¿ | ||||||||||||||||||||
| DeepDB | ||||||||||||||||||||||
| NeuroCard | ||||||||||||||||||||||
| FLAT | ||||||||||||||||||||||
| FactorJoin | ||||||||||||||||||||||
| MLP | ||||||||||||||||||||||
| MSCN | ||||||||||||||||||||||
| NNGP | ¿ | ¿ | ¿ | |||||||||||||||||||
| ALECE | ||||||||||||||||||||||
| Optimal | - | - | - | |||||||||||||||||||
| TPCH | PG | - | - | - | ||||||||||||||||||
| Uni-Samp | ¿ | ¿ | ¿ | ¿ | ¿ | ¿ | ||||||||||||||||
| NeuroCard | ||||||||||||||||||||||
| FLAT | ||||||||||||||||||||||
| MLP | ¿ | |||||||||||||||||||||
| MSCN | ||||||||||||||||||||||
| NNGP | ¿ | ¿ | ¿ | |||||||||||||||||||
| ALECE | ||||||||||||||||||||||
| Optimal | - | - | - | |||||||||||||||||||
Evaluation Metrics. We use three metrics to evaluate all methods:
-
•
E2E time is the total execution time of all queries in the evaluation part of a workload, in which we feed the query optimizer the estimated cardinalities of all relevant sub-queries. Those estimation results are acquired using cardinality estimation methods. It is the most important evaluation metric as it directly connects to the query optimizer and objectively shows if a cardinality estimation method could help improve the query performance of a DBMS. This type of evaluation requires an improved benchmark over the existing work (Han et al., 2021). This benchmark can integrate the estimation results by an external method to PostgreSQL. We show its details in Section B in Appendix.
-
•
P-error (Han et al., 2021) measures the gap between the optimal query plan and the generated plan based on the estimated cardinalities, without executing the given query. In particular, given a query , a query plan and the set of estimated/true cardinalities of ’s all sub-queries, the DBMS will output an estimated cost with a cost function . By feeding the query optimizer , the set of true cardinalities of ’s all sub-queries, we can get the optimal plan for . Similarly, a cardinality estimation method outputs for a set which results in another query plan . Then, , where the denominator is the optimal execution cost, and the numerator is the cost by feeding the true cardinalities of sub-queries to the query plan generated by method . In other words, is the actual execution cost of if method is adopted.
-
•
Q-error (Moerkotte et al., 2009) measures the distance between the estimated cardinality and the true cardinality of a query. In particular, .
-
•
Storage overhead is the memory size used by a method.
-
•
Building time indicates the offline training time of query-driven methods or construction time of data-driven methods.
-
•
Estimation latency is the average estimation time per sub-query used by a cardinality estimation method.
As the optimizer only requires the cardinality estimates of the sub-queries, our evaluations also involve the testing sub-queries only.
Parameter Settings. We use a 40-bin-histogram for each attribute, i.e., . The values of and , i.e., the number of stacked attention layers in the data-encoder and query-analyzer, respectively, are both set to 4. To train our ALECE, we use an Adam optimizer (Kingma and Ba, 2015) with a learning rate of 0.01 and a batch size of 128.
6.2. Performance on Dynamic Workloads
For each dynamic workload, we build all methods using the data in the training part to make estimates for the testing sub-queries in the evaluation part. The featurizations of the training queries and sub-queries as well as the corresponding DB states and true cardinalities in the training part form the training data. We use the training data to train the query-driven models including ALECE, MLP, MSCN and NNGP. The data-driven models, namely DeepDB, NeuroCard, FLAT and FactorJoin, are built with the database data after all the statements in the training part of the workload are executed. This setting is compatible with real world scenarios as the cardinality estimation models are updated at regular intervals. In our experiments, the associated changing rate of each testing query is larger than 20%. In other words, when testing queries are executed, at least 20% of the underlying data are changed, compared
to the database when cardinality estimators are built.
The estimation results by different methods will be fed into our improved benchmark to compare the end-to-end query times (E2E times) of all methods on dynamic workloads. To investigate the performance gap between these methods and the optimal, we also feed the true cardinalities to the benchmark to get the optimal execution time. We do not compare with DeepDB on the STATS and TPCH datasets since it supports PK-FK joins only. The open implementation of Factorjoin is hard-coded for the STATS and Job-light datasets and does not support the TPCH dataset. Thus, Factorjoin is not tested on this dataset. Besides the E2E time, we also record the Q-error and P-error distributions, building time, storage overhead and latency of all methods on different workloads. These results are shown in Table 4. The storage overhead, building time and latency results on the Update-heavy workloads are similar to the counterparts on the Insert-heavy workloads and thus omitted.
End-to-end evaluations. Referring to Table 4, ALECE has clear advantages on the E2E time over the other methods. On the one hand, compared to PostgreSQL’s built-in cardinality estimator, ALECE makes query execution up to 2.7 faster. Its E2E time is only slightly larger than that of PG on TPCH’s Insert-heavy workload. However, there is almost no gap between the performance of PG and Optimal on this workload. Compared to Optimal, ALECE only results in at most 2.2% extra E2E time. Considering the superiority of ALECE on these workloads, we confidently claim that ALECE performs much better than the built-in estimator in PostgreSQL and is able to greatly improve the query execution performance on dynamic workloads. On the other hand, in addition to ALECE, only MLP and Uni-Samp outperform PG on few workloads. The E2E time of DeepDB, NeuroCard, FLAT, FactorJoin and NNGP is larger than that of PG in all cases. Compared to Optimal, these methods results in more than double of E2E time on most workloads. These results indicate that these existing methods cannot make satisfactory estimates for DBMS on the dynamic workloads.
The P-error comparisons demonstrate that ALECE results in ef-
fective query executions from another angle. The P-errors of ALECE on most queries are close to 1. In other words, with ALECE’s outputs, most queries can be executed almost as fast as if they are optimized with true cardinalities. At the 95% quantile, ALECE outperforms PG, Uni-Samp, DeepDB, NeuroCard, FLAT, FactorJoin, MLP, MSCN and NNGP, in terms of P-error, by up to 26, 32, 21, 518, 1,385, 551, 1,443, 463 and 37 times, respectively. All these show that ALECE achieves large superiority over the competitors on helping PostgreSQL process queries more efficiently.
It is noteworthy that ALECE has clearer advantages on the STATS dataset with more complex join patterns. This reflects that our ALECE is able to grasp the implicit relations between complex join patterns and the underlying data significantly better than the alternatives. Besides, ALECE outperforms MLP in terms of E2E time and P-error. The main structure difference of ALECE and MLP is reflected on the adoption of attentions in ALECE’s modules. This verifies the positive effects of the attention mechanisms in extracting useful information from underlying data and SQL queries.
Estimation Accuracy. Table 4 also reports on the Q-error distributions of all methods. In general, ALECE clearly outperforms PG on all three datasets. This verifies that the independence assumption in PG is not reasonable for some scenarios. ALECE still performs best among all methods in all cases. At most quantiles, ALECE results in the smallest maximum Q-error. The median Q-error of ALECE in all cases are all close to 1, the optimal value. At the 95% quantile, the Q-error of ALECE in all cases is smaller than 10. In contrast, none of the other methods can reach this level of performance. Also at the 95% quantile, Uni-Samp, DeepDB, NeuroCard, FLAT, FactorJoin, MLP, MSCN and NNGP result in up to or more than , 84, 1,643, 8,220, , 3,480, , 7,927, larger Q-error than that of ALECE. At other quantiles, these methods are still incomparable with ALECE. These results show that ALECE is more accurate and able to discover the implicit relationships among attributes and those between queries and attributes. Another inter-
esting thing is that smaller Q-error does not necessarily result in smaller E2E time, which is claimed in the existing work (Negi et al., 2021) and shown by the comparisons among NNGP, DeepDB and NeuroCard, etc, on the Job-light dataset. An inaccurate estimate for a single sub-query tends to generate bad query plans and large execution time. It is necessary to ensure accurate estimates for all sub-queries.
Model Construction Efficiency. Referring to Table 4, the training cost of ALECE is small. It requires less than 10, 8 and 13 minutes to fine-tune its parameters for the STATS, Job-light and TPCH datasets, respectively. In contrast, DeepDB, NeuroCard, FLAT and MSCN consume more construction time. Although Uni-Samp and Factorjoin require less construction time in some cases, their E2E time, P-error and Q-error performance are much worse. Compared to ALECE, MLP and NNGP have simpler structures and thus they need less time to train. However, their representation abilities are not so powerful as that of ALECE. The overwhelming advantage of ALECE on E2E time illustrates the necessity of a more complex structure and slightly more training time.
In terms of latency, Uni-Samp achieves the worst performance. FactorJoin, MLP and MSCN require the least average time, less than 10 ms, on making an estimate. ALECE’s latency is slightly larger but smaller than the others. Considering the fact that executing a query on all datasets takes more than 10 seconds on average, estimation latency of less than 10 ms is not crucial in the overall picture.
Storage Overhead. The storage overhead of the query-driven methods is smaller than that of the data-driven ones in general. The query-driven methods only need to maintain a fixed number of parameters whose sizes are usually much smaller than the ‘data summaries’ held by the data-driven methods, e.g., the SPN or FSPN in DeepDB and FLAT, respectively. FactorJoin and MSCN incur the smallest memory costs. ALECE consumes more memory than MLP and NNGP due to its more complex structure. Compared to NeuroCard and FLAT, ALECE saves up to 75.4% and 89.4% memory cost on the STATS dataset, respectively. ALECE results in a little more memory cost than FLAT and DeepDB on the Job-light dataset. Considering the fact that modern computers usually have large memories and ALECE performs better in terms of E2E time, P-error and Q-error, the extra storage overhead pays off highly.
6.3. Effect of Distribution Shifting
To investigate if ALECE still works well when the distribution of the underlying data greatly changes, we carry out experiments to compare the different methods on the Dist-shift workload. It is noteworthy that the evaluation part of the Dist-shift workload covers highly skewed insert statements. Table 5 reports the E2E time, Q-error and P-error distribution comparisons among ALECE, PG, NeuroCard, MSCN, NNGP and Optimal. Those competitors are chosen because they have better overall performance on the Insert-heavy and Update-heavy workloads. Due to space limit, the storage overhead, building time and latency comparisons are omitted. These results are similar to the counterparts on the other two workloads.
| Data | Model | E2E Time(S) | Q-error | P-error | ||||||
| 50% | 90% | 95% | 99% | 50% | 90% | 95% | 99% | |||
| STATS | PG | |||||||||
| Uni-Samp | ¿ | ¿ | ¿ | |||||||
| NeuroCard | ||||||||||
| MSCN | ||||||||||
| NNGP | ||||||||||
| ALECE | ||||||||||
| Optimal | ||||||||||
| Job- light | PG | |||||||||
| Uni-Samp | ¿ | |||||||||
| NeuroCard | ||||||||||
| MSCN | ||||||||||
| NNGP | ¿ | ¿ | ¿ | |||||||
| ALECE | ||||||||||
| Optimal | ||||||||||
| TPCH | PG | |||||||||
| Uni-Samp | ¿ | ¿ | ¿ | |||||||
| NeuroCard | ||||||||||
| MSCN | ||||||||||
| NNGP | ¿ | ¿ | ¿ | |||||||
| ALECE | ||||||||||
| Optimal | ||||||||||
Referring to Table 5, the overall Q-error and P-error performance of all methods on the Dist-shift workloads are worse than the counterparts on the Insert-heavy workloads. This is reasonable because compared to the data upon which these methods are built, the distribution of the underlying data is greatly shifted when testing queries are executed. Nevertheless, ALECE still achieves the best E2E time on all datasets. It needs up to 18.5% less time than PG to execute all testing queries. Its E2E time on all three workloads is close to the optimal results and much smaller than that of other competitors. In terms of Q-error and P-error, ALECE also performs best. At the 95% quantile, the largest Q-error and P-error of ALECE are 11.75 and 1.71, respectively. In contrast, the other competitors’ Q-error and P-error are at least and times larger, respectively. All these demonstrate that ALECE is less sensitive to the distribution shifting and able to make accurate estimates even when the distributions of the underlying data changes significantly.
7. Related Work
Data-driven Cardinality Estimators. Data-driven methods aim to describe the underlying data with statistical or machine learning models. The simple yet efficient 1-D Histogram (Selinger et al., 1979) is used in many well-known DBMS like PostgreSQL. It assumes all attributes are mutually independent and maintains a 1-D (cumulative) histogram for each attribute. To address the problem of unreasonable independence assumption, M-D Histogram based methods (Deshpande et al., 2001; Gunopulos et al., 2000; Poosala and Ioannidis, 1997; Wang and Sevcik, 2003) build multi-dimensional histograms to model attribute dependency. Although such methods improve the accuracy, the decomposition of the joint attributes is still lossy. Also, they hardly work for queries with complex joins. Sampling-based methods (Chaudhuri et al., 1999; Chen and Yi, 2017; Kipf et al., 2019; Qiu et al., 2021; Li et al., 2016) address join queries but they risk high variance and sampling failure when the data distribution or query is complex. Bayesian network (BN) based methods (Chow and Liu, 1968; Getoor et al., 2001; Tzoumas et al., 2011) use a directed acyclic graph to model the dependence among attributes, assuming that each attribute is conditionally independent of the remaining attributes given its parents’ distributions. BayesCard (Wu and Shaikhha, 2020) revitalizes BN using probabilistic programming to improve its inference and model construction speed. Recently, machine learning techniques are adopted in data-driven methods. Deep autoregressive models are adopted in Naru (Yang et al., 2019) and NeuroCard (Yang et al., 2020) to decompose the joint distribution of attributes to a product of conditional distributions. DeepDB (Hilprecht et al., 2020) is built upon Sum-Product Network (SPN) (Poon and Domingos, 2011) which approximates the joint distribution using several local and simple PDFs. FLAT (Zhu et al., 2021) improves SPN by adopting a factorize-split-sum-product network (FSPN) (Wu et al., 2020) to adaptively decompose the joint distribution according to the attribute dependence level.
Query-driven Cardinality Estimators. Such estimators focus on modeling the relationships between queries and their true cardinalities. The feedbacks of past queries are utilized to correct and self-tune histograms (Bruno et al., 2001; Fuchs et al., 2007; Khachatryan et al., 2015; Srivastava et al., 2006) and update statistical summaries (Stillger et al., 2001; Wu et al., 2018). LW-XGB and LW-NN (Dutt et al., 2019) formulate the cardinality estimation as a regression problem and apply gradient boosted trees and neural networks for regression, respectively. UAE-Q (Wu et al., 2022) applies the deep auto-regression models and differentiable progressive sampling via the Gumbel-Softmax trick to learn hidden information from queries. The KDE-based join estimators (Kiefer et al., 2017) combine kernel density estimation (KDE) with a query-driven tuning mechanism to estimate multivariate probability distributions of a relation and cardinalities of joins. Fauce (Liu et al., 2021) and NNGP (Zhao et al., 2022) assume a query’s cardinality follows a Gaussian distribution and adopt Deep Ensemble (Lakshminarayanan et al., 2017) and neural network Gaussian process (Lee et al., 2018) to predict the distribution’s mean and variance.
A few works also consider both data and SQL queries. Wu et. al. (Wu and Cong, 2021) propose a unified deep autoregressive model utilizing both data as unsupervised information and query workload as supervised information. Kipf et. al. (Kipf et al., 2019) concatenate basic relation information and query features together and use a multi-set convolutional neural network to process them and make estimates. Negi et. al. (Negi et al., 2023) propose techniques to build sample tables on the join keys and use neural networks to extract information from queries. However, these methods require either samples over joined attributes which results in high sampling overhead, or unrenewable featurization/samples over static data which are not applicable for dynamic database. Also, compared to ALECE, these methods do not explain the links among data, queries and true cardinalities. Besides, Negi’s work (Negi et al., 2023) supports PK-FK joins only. Dutt et. al. (Dutt et al., 2019) use neural networks and tree-based ensembles to extract information from data and queries to solve the problem of selectivity estimation on a single relation. Thus, their approach does not support joins. In addition, Han et. al. (Han et al., 2021) propose an end-to-end evaluation benchmark for cardinality estimators. Our used benchmark is an improved version of it. Sun et. al. (Sun et al., 2021) make a comprehensive comparison of the existing cardinality estimators.
8. Conclusion and Future Work
In this work, we design ALECE, a versatile learned cardinality estimation model, that makes accurate and high-quality estimates for SQL queries. Based on two delicate methods to featurize the underlying database data and the SQL queries, respectively, ALECE adopts the attention mechanisms in its two modules to understand the implicit relations between data and queries. The self-attention layer in the data-encoder module figures out the links among all database attributes. The query-analyzer takes the input of the query featurization and the output of the data-encoder, and puts attention on the more important parts of the data. Extensive experimental results show that ALECE clearly outperforms the state-of-the-art alternatives in terms of multiple evaluation metrics.
For future work, it is interesting to extend ALECE to more general aggregate analytic queries by replacing with other aggregate functions. Also, it is relevant to explore if better data and query featurization methods exist. Moreover, it makes sense to use other types of attention functions in ALECE.
References
- (1)
- cod (line) https://github.com/pfl-cs/ALECE.
- STA (line) https://relational.fit.cvut.cz/dataset/Stats.
- imd (line) http://homepages.cwi.nl/~boncz/job/imdb.tgz.
- tpc (line) https://www.tpc.org/tpc_documents_current_versions/current_specifications5.asp.
- Ba et al. (2016) Lei Jimmy Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. 2016. Layer Normalization. arXiv preprint abs/1607.06450 (2016). http://arxiv.org/abs/1607.06450
- Bahdanau et al. (2015) Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural Machine Translation by Jointly Learning to Align and Translate. In ICLR.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. In NeurIPS.
- Bruno et al. (2001) Nicolas Bruno, Surajit Chaudhuri, and Luis Gravano. 2001. STHoles: A Multidimensional Workload-Aware Histogram. In SIGMOD. 211–222.
- Chaudhuri et al. (1999) Surajit Chaudhuri, Rajeev Motwani, and Vivek R. Narasayya. 1999. On Random Sampling over Joins. In SIGMOD. 263–274.
- Chen and Yi (2017) Yu Chen and Ke Yi. 2017. Two-Level Sampling for Join Size Estimation. In SIGMOD. 759–774.
- Chow and Liu (1968) C. K. Chow and C. N. Liu. 1968. Approximating discrete probability distributions with dependence trees. IEEE Trans. Inf. Theory 14, 3 (1968), 462–467.
- Deshpande et al. (2001) Amol Deshpande, Minos N. Garofalakis, and Rajeev Rastogi. 2001. Independence is Good: Dependency-Based Histogram Synopses for High-Dimensional Data. In SIGMOD. 199–210.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT. 4171–4186.
- Dutt et al. (2019) Anshuman Dutt, Chi Wang, Azade Nazi, Srikanth Kandula, Vivek R. Narasayya, and Surajit Chaudhuri. 2019. Selectivity Estimation for Range Predicates using Lightweight Models. Proc. VLDB Endow. 12, 9 (2019), 1044–1057.
- Fuchs et al. (2007) Dennis Fuchs, Zhen He, and Byung Suk Lee. 2007. Compressed histograms with arbitrary bucket layouts for selectivity estimation. Inf. Sci. 177, 3 (2007), 680–702.
- Gehring et al. (2017) Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. 2017. Convolutional Sequence to Sequence Learning. In ICML. 1243–1252.
- Getoor et al. (2001) Lise Getoor, Benjamin Taskar, and Daphne Koller. 2001. Selectivity Estimation using Probabilistic Models. In SIGMOD. 461–472.
- Graefe and McKenna (1993) Goetz Graefe and William J. McKenna. 1993. The Volcano Optimizer Generator: Extensibility and Efficient Search. In ICDE. IEEE Computer Society, 209–218.
- Gregor et al. (2014) Karol Gregor, Ivo Danihelka, Andriy Mnih, Charles Blundell, and Daan Wierstra. 2014. Deep AutoRegressive Networks. In ICML, Vol. 32. 1242–1250.
- Group (1996) PostgreSQL Global Development Group. 1996. PostgreSQL. https://www.postgresql.org. (1996). Accessed: 2022-10-28.
- Gunopulos et al. (2000) Dimitrios Gunopulos, George Kollios, Vassilis J. Tsotras, and Carlotta Domeniconi. 2000. Approximating Multi-Dimensional Aggregate Range Queries over Real Attributes. In SIGMOD. 463–474.
- Han et al. (2021) Yuxing Han, Ziniu Wu, Peizhi Wu, Rong Zhu, Jingyi Yang, Liang Wei Tan, Kai Zeng, Gao Cong, Yanzhao Qin, Andreas Pfadler, Zhengping Qian, Jingren Zhou, Jiangneng Li, and Bin Cui. 2021. Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation. Proc. VLDB Endow. 15, 4 (2021), 752–765.
- Hastie et al. (2009) Trevor Hastie, Robert Tibshirani, and Jerome H. Friedman. 2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd Edition. Springer.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In CVPR. 770–778.
- Hermann et al. (2015) Karl Moritz Hermann, Tomás Kociský, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. 2015. Teaching Machines to Read and Comprehend. In NeurIPS. 1693–1701.
- Hilprecht et al. (2020) Benjamin Hilprecht, Andreas Schmidt, Moritz Kulessa, Alejandro Molina, Kristian Kersting, and Carsten Binnig. 2020. DeepDB: Learn from Data, not from Queries! Proc. VLDB Endow. 13, 7 (2020), 992–1005.
- Kaushik et al. (2005) Raghav Kaushik, Jeffrey F. Naughton, Raghu Ramakrishnan, and Venkatesan T. Chakaravarthy. 2005. Synopses for query optimization: A space-complexity perspective. ACM Trans. Database Syst. 30, 4 (2005), 1102–1127.
- Khachatryan et al. (2015) Andranik Khachatryan, Emmanuel Müller, Christian Stier, and Klemens Böhm. 2015. Improving Accuracy and Robustness of Self-Tuning Histograms by Subspace Clustering. IEEE Trans. Knowl. Data Eng. 27, 9 (2015), 2377–2389.
- Kiefer et al. (2017) Martin Kiefer, Max Heimel, Sebastian Breß, and Volker Markl. 2017. Estimating Join Selectivities using Bandwidth-Optimized Kernel Density Models. Proc. VLDB Endow. 10, 13 (2017), 2085–2096.
- Kim et al. (2017) Yoon Kim, Carl Denton, Luong Hoang, and Alexander M. Rush. 2017. Structured Attention Networks. In ICLR.
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. In ICLR.
- Kipf et al. (2019) Andreas Kipf, Thomas Kipf, Bernhard Radke, Viktor Leis, Peter A. Boncz, and Alfons Kemper. 2019. Learned Cardinalities: Estimating Correlated Joins with Deep Learning. In CIDR.
- Lakshminarayanan et al. (2017) Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2017. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. In NIPS. 6402–6413.
- Lee et al. (2018) Jaehoon Lee, Yasaman Bahri, Roman Novak, Samuel S. Schoenholz, Jeffrey Pennington, and Jascha Sohl-Dickstein. 2018. Deep Neural Networks as Gaussian Processes. In ICLR.
- Li et al. (2016) Feifei Li, Bin Wu, Ke Yi, and Zhuoyue Zhao. 2016. Wander Join: Online Aggregation via Random Walks. In SIGMOD. 615–629.
- Liang et al. (2021) Xi Liang, Stavros Sintos, Zechao Shang, and Sanjay Krishnan. 2021. Combining Aggregation and Sampling (Nearly) Optimally for Approximate Query Processing. In SIGMOD. 1129–1141.
- Liu et al. (2021) Jie Liu, Wenqian Dong, Dong Li, and Qingqing Zhou. 2021. Fauce: Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation. Proc. VLDB Endow. 14, 11 (2021), 1950–1963.
- Moerkotte et al. (2009) Guido Moerkotte, Thomas Neumann, and Gabriele Steidl. 2009. Preventing Bad Plans by Bounding the Impact of Cardinality Estimation Errors. Proc. VLDB Endow. 2, 1 (2009), 982–993.
- Negi et al. (2021) Parimarjan Negi, Ryan C. Marcus, Andreas Kipf, Hongzi Mao, Nesime Tatbul, Tim Kraska, and Mohammad Alizadeh. 2021. Flow-Loss: Learning Cardinality Estimates That Matter. Proc. VLDB Endow. 14, 11 (2021), 2019–2032.
- Negi et al. (2023) Parimarjan Negi, Ziniu Wu, Andreas Kipf, Nesime Tatbul, Ryan Marcus, Sam Madden, Tim Kraska, and Mohammad Alizadeh. 2023. Robust Query Driven Cardinality Estimation under Changing Workloads. Proc. VLDB Endow. 16, 6 (2023), 1520–1533.
- Poon and Domingos (2011) Hoifung Poon and Pedro M. Domingos. 2011. Sum-Product Networks: A New Deep Architecture. In UAI. 337–346.
- Poosala and Ioannidis (1997) Viswanath Poosala and Yannis E. Ioannidis. 1997. Selectivity Estimation Without the Attribute Value Independence Assumption. In VLDB. 486–495.
- Prechelt (2012) Lutz Prechelt. 2012. Early Stopping - But When? In Neural Networks: Tricks of the Trade - Second Edition. Lecture Notes in Computer Science, Vol. 7700. Springer, 53–67.
- Qiu et al. (2021) Yuan Qiu, Yilei Wang, Ke Yi, Feifei Li, Bin Wu, and Chaoqun Zhan. 2021. Weighted Distinct Sampling: Cardinality Estimation for SPJ Queries. In SIGMOD. 1465–1477.
- Rumelhart et al. (1986) D. E. Rumelhart, G. E. Hinton, and R. J. Williams. 1986. Learning Internal Representations by Error Propagation. 318–362.
- Selinger et al. (1979) Patricia G. Selinger, Morton M. Astrahan, Donald D. Chamberlin, Raymond A. Lorie, and Thomas G. Price. 1979. Access Path Selection in a Relational Database Management System. In SIGMOD. 23–34.
- Srivastava et al. (2006) Utkarsh Srivastava, Peter J. Haas, Volker Markl, Marcel Kutsch, and Tam Minh Tran. 2006. ISOMER: Consistent Histogram Construction Using Query Feedback. In ICDE. 39.
- Stillger et al. (2001) Michael Stillger, Guy M. Lohman, Volker Markl, and Mokhtar Kandil. 2001. LEO - DB2’s LEarning Optimizer. In VLDB. 19–28.
- Sukhbaatar et al. (2015) Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. 2015. End-To-End Memory Networks. In NeurIPS. 2440–2448.
- Sun et al. (2021) Ji Sun, Jintao Zhang, Zhaoyan Sun, Guoliang Li, and Nan Tang. 2021. Learned Cardinality Estimation: A Design Space Exploration and A Comparative Evaluation. Proc. VLDB Endow. 15, 1 (2021), 85–97.
- Tzoumas et al. (2011) Kostas Tzoumas, Amol Deshpande, and Christian S. Jensen. 2011. Lightweight Graphical Models for Selectivity Estimation Without Independence Assumptions. Proc. VLDB Endow. 4, 11 (2011), 852–863.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In NeurIPS. 5998–6008.
- Wang and Sevcik (2003) Hai Wang and Kenneth C. Sevcik. 2003. A multi-dimensional histogram for selectivity estimation and fast approximate query answering. In CASCON. 328–342.
- Wang et al. (2021a) Jiayi Wang, Chengliang Chai, Jiabin Liu, and Guoliang Li. 2021a. FACE: A Normalizing Flow based Cardinality Estimator. Proc. VLDB Endow. 15, 1 (2021), 72–84.
- Wang et al. (2021b) Xiaoying Wang, Changbo Qu, Weiyuan Wu, Jiannan Wang, and Qingqing Zhou. 2021b. Are We Ready For Learned Cardinality Estimation? Proc. VLDB Endow. 14, 9 (2021), 1640–1654.
- Wu et al. (2018) Chenggang Wu, Alekh Jindal, Saeed Amizadeh, Hiren Patel, Wangchao Le, Shi Qiao, and Sriram Rao. 2018. Towards a Learning Optimizer for Shared Clouds. Proc. VLDB Endow. 12, 3 (2018), 210–222.
- Wu and Cong (2021) Peizhi Wu and Gao Cong. 2021. A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation. In SIGMOD. 2009–2022.
- Wu et al. (2023) Ziniu Wu, Parimarjan Negi, Mohammad Alizadeh, Tim Kraska, and Samuel Madden. 2023. FactorJoin: A New Cardinality Estimation Framework for Join Queries. Proc. ACM Manag. Data 1, 1 (2023), 41:1–41:27.
- Wu and Shaikhha (2020) Ziniu Wu and Amir Shaikhha. 2020. BayesCard: A Unified Bayesian Framework for Cardinality Estimation. CoRR abs/2012.14743 (2020). https://arxiv.org/abs/2012.14743
- Wu et al. (2022) Ziniu Wu, Pei Yu, Peilun Yang, Rong Zhu, Yuxing Han, Yaliang Li, Defu Lian, Kai Zeng, and Jingren Zhou. 2022. A Unified Transferable Model for ML-Enhanced DBMS. In CIDR.
- Wu et al. (2020) Ziniu Wu, Rong Zhu, Andreas Pfadler, Yuxing Han, Jiangneng Li, Zhengping Qian, Kai Zeng, and Jingren Zhou. 2020. FSPN: A New Class of Probabilistic Graphical Model. CoRR abs/2011.09020 (2020). https://arxiv.org/abs/2011.09020
- Yang et al. (2020) Zongheng Yang, Amog Kamsetty, Sifei Luan, Eric Liang, Yan Duan, Xi Chen, and Ion Stoica. 2020. NeuroCard: One Cardinality Estimator for All Tables. Proc. VLDB Endow. 14, 1 (2020), 61–73.
- Yang et al. (2019) Zongheng Yang, Eric Liang, Amog Kamsetty, Chenggang Wu, Yan Duan, Xi Chen, Pieter Abbeel, Joseph M. Hellerstein, Sanjay Krishnan, and Ion Stoica. 2019. Deep Unsupervised Cardinality Estimation. Proc. VLDB Endow. 13, 3 (2019), 279–292.
- Zhao et al. (2022) Kangfei Zhao, Jeffrey Xu Yu, Zongyan He, Rui Li, and Hao Zhang. 2022. Lightweight and Accurate Cardinality Estimation by Neural Network Gaussian Process. In SIGMOD. 973–987.
- Zhao et al. (2018) Zhuoyue Zhao, Robert Christensen, Feifei Li, Xiao Hu, and Ke Yi. 2018. Random Sampling over Joins Revisited. In SIGMOD. 1525–1539.
- Zhu et al. (2021) Rong Zhu, Ziniu Wu, Yuxing Han, Kai Zeng, Andreas Pfadler, Zhengping Qian, Jingren Zhou, and Bin Cui. 2021. FLAT: Fast, Lightweight and Accurate Method for Cardinality Estimation. Proc. VLDB Endow. 14, 9 (2021), 1489–1502.
Appendix
Due to space limit, we present some minute details and relatively less important experimental results and analyses in this appendix.
Appendix A Multi-head Attention
To enhance the representation ability of our ALECE, we adopt a multi-head attention mechanism (Vaswani et al., 2017) in both modules instead of performing a single function. Fig. 4 depicts its details.
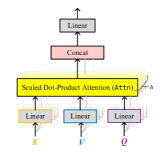
A multi-head attention projects the queries, keys and values multiple times with different linear projections, and then executes the attention function with the input of the projected queries, keys and values in parallel. Compared to a single attention head, it could jointly attend to information from different projected spaces and thus is more powerful. Below is its analytical expressions:
Above, , and project each query, key and value vector into space respectively; projects the output of weighted values back to . In our experiments, the value of is set to 8, following the settings in (Vaswani et al., 2017).
It is noteworthy that the choice of the attention function is not unique and there may be other type of -integrated attention mechanism besides the multi-head attention. The attention layers can be flexibly designed depending on situations.
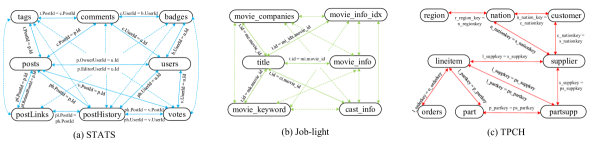
Appendix B An Improved Benchmark
The CardEst benchmark (Han et al., 2021) provides a way to integrate external cardinality estimators into the built-in query optimizer of PostgreSQL. In particular, given a SQL query to be executed, PostgreSQL’s query optimizer needs to get the estimated cardinalities of a series of sub-queries in a fixed order. By enabling a knob, the benchmark provides the function of reading the cardinality estimates from a given file instead of using the estimates by PostgreSQL’s built-in estimator. Thus, if we know what the sub-queries are and feed the corresponding cardinality estimates accessed through external estimators, we can directly compare the quality of their generated query plans by watching the end-to-end query execution time.
The idea above is simple and appealing. However, the original benchmark (Han et al., 2021) cannot produce correct sub-queries for queries on the dynamic workloads and with complex join predicates. In other words, it works on very limited cases only. These drawbacks motivate us to improve the benchmark to support dynamic workloads and more general join schema. Our improved benchmark (cod, line) implements correct sub-queries generations function and inherits the cardinality estimates reading function. We have validated it with numerous queries on the STATS, Job-light and TPCH datasets.
Usage guidance. Our benchmark mainly provides two functions: sub-queries generation and cardinality estimates replacement. We leave multiple knobs to let users decide when to generate sub-queries and which method’s estimation results used to generate the query plans for the queries on a workload .
1) Sub-queries generation. This function is related with only one knob: print_sub_queries. Given a query, the optimizer needs the cardinality estimations of the sub-queries of two types: the single sub-queries only involve single tables whereas the join sub-queries cover join conditions. By setting the value of the knob to True and executing the Explain statement for each query on , two files will be generated in the data directory of PostgreSQL: ‘single_sub_queries.txt’ and ‘join_sub_queries.txt’. They record the above two types of sub-queries, respectively. Each line of either file is a sub-query of a query on . Also, the line will include the appearance ranking of among all queries. This information help users know the ties between queries and sub-queries.
2) Cardinality estimates replacement. After estimating the cardinalities of the sub-queries in both files using an external method, e.g. ALECE, we can ‘inject’ them into PostgreSQL to replace the built-in results. First, we need to save the estimation results into two files with each file corresponds to one type of sub-queries, and copy them into the data directory of PostgreSQL. Then, two knobs, namely read_single_cards and read_join_cards, are supposed to be turned on. Meanwhile, we should set the configuration parameters single_cards_fname an join_cards_fname to be the names of the above two files, respectively. After these settings, we can run the workload in the usual way. It is noteworthy that the query optimizer will use the cardinality estimates by the external method to generate the query plans. Suppose the files for the single and join sub-queries are named ‘single_cards.txt’ and ‘join_cards.txt’, respectively. The setting statements for the knobs and configuration parameters are shown as follows.
Usually, PostgreSQL’s built-in estimator is able to give sufficiently accurate cardinality estimates for the single sub-queries. Thus, we only need to estimate the cardinalities of the join sub-queries, turn on the knob read_join_cards and set the parameter join_cards_fname in most cases.
Please also refer to our github repository (cod, line) for more details.
Appendix C Additional Experimental Results
This section presents the additional experimental results that cannot be put in the main body of the paper due to the space limit.
C.1. Join Information among Relations
Fig. 5 shows the join information among relations in the STATS, Job-light and TPCH datasets. For clearity, only part of the joins are exhibited.
C.2. Performance on Static Workloads
We also conduct experiments to compare all methods on the static workloads that consist of query statements only. In particular, we use the whole STATS, Job-light and TPCH datasets to build the data-driven methods. On top of the whole dataset, the training queries and sub-queries as well as their true cardinalities are used as the training and validation data for the query-driven methods. Accordingly, all data-driven and query-driven methods estimate the cardinalities for the testing sub-queries. These estimates are in turn used to generate the E2E evaluation results, Q-error, etc. Table 6 reports the relevant comparative results.
| Data | Model | E2E Time(S) | Q-error | Size (MB) | Building Time(Min) | Latency (ms) | |||
| 50% | 90% | 95% | 99% | ||||||
| STATS | PG | - | - | - | |||||
| Uni-Samp | ¿ | ¿ | |||||||
| NeuroCard | |||||||||
| MLP | |||||||||
| MSCN | |||||||||
| NNGP | |||||||||
| ALECE | |||||||||
| Optimal | - | - | - | ||||||
| Job- light | PG | - | - | - | |||||
| Uni-Samp | ¿ | ||||||||
| NeuroCard | |||||||||
| MLP | |||||||||
| MSCN | |||||||||
| NNGP | ¿ | ||||||||
| ALECE | |||||||||
| Optimal | - | - | - | ||||||
| TPCH | PG | - | - | - | |||||
| Uni-Samp | ¿ | ¿ | |||||||
| NeuroCard | |||||||||
| MLP | |||||||||
| MSCN | |||||||||
| NNGP | |||||||||
| ALECE | |||||||||
| Optimal | - | - | - | ||||||
As shown in Table 6, the end-to-end performance of cardinality estimators on the static workloads is different from the counterparts on the dynamic workloads. Overall, the performance of the methods on static workloads is better than that on the dynamic workloads. Nevertheless, ALECE still performs best among all methods. ALECE results in up to 1.66, 2.00, 2.58, 1.97 and at least 3 times faster query execution than PG, Uni-Samp, NeuroCard, MSCN and NNGP, respectively. The E2E time of ALECE is only at most 1.1% larger than that of Optimal. Next, at most quantiles, ALECE’s Q-error is smaller than that of the others on all datasets. At the 95% quantile, ALECE achieves up to or more than , , , and smaller Q-error compared to PG, Uni-Samp, NeuroCard, MSCN and NNGP, respectively. ALECE is not the best in terms of training time, latency and memory cost. However, ALECE incurs comparable results with the competitors. Considering the much better E2E time and estimation accuracy that ALECE achieves, the slightly extra overhead is acceptable.
ALECE vs. MLP on static workloads. Referring to Table 6, MLP achieves E2E time and Q-error comparable with the counterparts of ALECE, and even less storage overhead, latency and training time. The reason behind is that ALECE is almost equivalent to MLP when processing queries on static workloads, where the DB states for the queries are constant. In this case, only one element exists in the input sets of keys, values and queries of the self-attention layers in the data-encoder module. This is the same to the three sets of the attention layers in the query-analyzer module. Consequently, both attention layers make almost no effects, and the whole ALECE network degenerates to an MLP. Therefore, if there is no underlying data change, we can simply train an MLP to estimate cardinalities.
C.3. Effect of
Parameter is used to control the amount of distribution information covered by data featurizations. A larger usually implies more informative featurizations but results in more storage and latency overhead. To investigate the effect of , we build four ALECE versions with different values and observe their performance on the Insert-heavy workload of the STATS dataset. The results on the other datasets and other workloads are similar and thus omitted. Table 7 shows the results of ALECE with different values of . As ’s value increases, ALECE is able to make more accurate estimates. Meanwhile, the building time does not changes much. The storage overhead and latency increase slightly. In particular, when the value of increases from to , the memory cost of ALECE increases by only MB. Also, the value of does not influence the cost of updating DB states when an data manipulation statement is executed. Thus, we suggest to use a larger to build the DB states within affordable memory and latency costs.
| Q-error | Size (MB) | Building Time(Min) | Latency (ms) | ||||
| 50% | 90% | 95% | 99% | ||||
| 10 | |||||||
| 20 | |||||||
| 40 | |||||||
| 80 | |||||||
C.4. Hyperparameter Studies
To study the effects of more hyperparameters, we build different ALECE versions and observe their performance. Similarly, we only show the comparison results on the Insert-heavy workload of the STATS dataset. The results on the other datasets and other workloads are similar and thus omitted.
Effects of and . and are the numbers of stacked multi-head attention layers in ALECE’s data-encoder and query-analyzer modules, respectively. To investigate if they affect ALECE’s performance, we train a series of ALECE with different and values. Table 8 reports the comparison results.
| Q-error | Size (MB) | Building Time(Min) | Latency (ms) | |||||
| 50% | 90% | 95% | 99% | |||||
| 2 | 2 | |||||||
| 2 | 4 | |||||||
| 4 | 2 | |||||||
| 4 | 4 | |||||||
| 4 | 6 | |||||||
| 6 | 4 | |||||||
| 6 | 6 | |||||||
As shown in Table 8, the storage overhead of ALECE is clearly influenced by and . When the values of and get larger, ALECE will also result in larger memory costs. However, the Q-error performance of ALECE is not necessarily positively correlated to the numbers of attention layers in its two modules. When the values of and are set to 2, a smaller number, ALECE achieves the worst estimation accuracy. When both and equal 4 or 6, ALECE has the overall best Q-error performance. However, larger or will result in larger storage and latency overhead. Thus, we set the values of both parameters to 4.
Effects of join condition featurization ways. In Section 3.2, we mention that compared to simply featurize whether each join predicate appears in the SQL query, our way of additionally featurizing the relations involved in joins are more compact, informative and helpful to the estimations. To verify this claim, we carry out an ablation study by building two ALECE versions with different join predicate featurization ways and observing their performance. The comparison results are reported in Table 9.
| Featurization way | Q-error | Size (MB) | Building Time(Min) | Latency (ms) | |||
| 50% | 90% | 95% | 99% | ||||
| Simple (Zhao et al., 2022) | |||||||
| Ours | |||||||
Apparently, our method of featurizing join predicates result in better Q-error performance, at the very slightly extra expense of memory cost and latency.
C.5. Effect of Number of Relations in Join
We also investigate the effect of the number of relations involved in a query on ALECE and the alternatives. According to the number of relations involved, the testing sub-queries on STATS’s Insert-heavy workload are divided into two categories. The sub-queries in both categories covers and join predicates, respectively. Then, we observe each method’s Q-error distributions on different categories. As the results in Fig. 6 show, ALECE is able to achieve the best overall performance. All methods have better Q-error distribution performance on queries involving less relations. However, the gap between ALECE’s achieved Q-error on queries with less and more relations is far smaller than that of the competitors. This implies that ALECE is effective at understanding the implicit relationships between true cardinalities and complex join patterns.
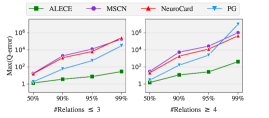
C.6. Effect of DB State Types
We have conducted additional experiments to investigate the effects of the DB state types. We build three ALECE-variants with different types of the DB states:
-
•
Histogram is of our used DB state type in the paper.
-
•
Sample is built by uniformly sampling from the underlying data. For each relation , we maintain a sample set of fixed size . may gets updated when a data manipulation statement referred to the relation comes in. It is guaranteed that each tuple in is equal-possibly sampled. In our experiments, the value of is set to 512. In other words, the dimension of each DB state vector is 512.
-
•
NE-Hist is the set of histograms over unequally sized partitions over the value ranges of all attributes. Specifically, we first extract all values of an attribute from the initial dataset. Then the range of is partitioned into parts, with each part covering the same number of values. Each element of NE-Hist data featurzations is a vector generated by aligning the value frequency for each , where refers to the number of values falling in the th partition. It is noteworthy that the values of all are the same initially. With the data manipulation statements in the workload are executed, the value of will keep changing.
Table 10 shows the Q-error distributions, storage overhead and latency of three ALECE-variants with different types of the DB states on the Insert-heavy workload of the STATS datasets. The results on the other datasets and other workloads are similar and thus omitted.
| DB state type | Q-error | Size (MB) | Latency (ms) | |||
| 50% | 90% | 95% | 99% | |||
| Histogram | ||||||
| Sample | ||||||
| NE-hist | ||||||
Referring to Table 10, all of the three DB state types are able to help ALECE achieve accurate estimates. It is noteworthy that all of these features can be regarded as the marginal distribution approximation of single attributes. The data-encoder module of ALECE establishes a bridge between the marginal distributions and the joint distribution. It can quantitatively ‘calculate’ the relevance between a pair of elements from any two DB states. Thus, it can effectively discover the implicit connections between any pair of attributes, which is helpful to the cardinality estimation task.
Nevertheless, the cost of updating histograms when data manipulation statements come in is smaller than that of updating other types of DB states. Thus, our ALECE adopts the simple histograms as the DB states in the paper. In the future, we will investigate more types of DB states.