Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space
Abstract
Recent advances in tabular data generation have greatly enhanced synthetic data quality. However, extending diffusion models to tabular data is challenging due to the intricately varied distributions and a blend of data types of tabular data. This paper introduces TabSyn, a methodology that synthesizes tabular data by leveraging a diffusion model within a variational autoencoder (VAE) crafted latent space. The key advantages of the proposed TabSyn include (1) Generality: the ability to handle a broad spectrum of data types by converting them into a single unified space and explicitly capture inter-column relations, (2) Quality: optimizing the distribution of latent embeddings to enhance the subsequent training of diffusion models, which helps generate high-quality synthetic data, (3) Speed: much fewer number of reverse steps and faster synthesis speed than existing diffusion-based methods. Extensive experiments on six datasets with five metrics demonstrate that TabSyn outperforms existing methods. Specifically, it reduces the error rates by 86% and 67% for column-wise distribution and pair-wise column correlation estimations compared with the most competitive baselines. Code has been made available at https://github.com/amazon-science/tabsyn.
1 Introduction
Tabular data synthesis has a wide range of applications, such as augmenting training data (Fonseca & Bacao, 2023), protecting private data instances (Assefa et al., 2021; Hernandez et al., 2022), and imputing missing values (Zheng & Charoenphakdee, 2022). Recent developments in tabular data generation have notably enhanced the quality of synthetic data (Xu et al., 2019; Borisov et al., 2023; Liu et al., 2023b), while the synthetic data is still far from the real one. To further improve the generation quality, researchers have explored adapting diffusion models, which have shown strong performance in image synthesis tasks (Ho et al., 2020; Rombach et al., 2022), for tabular data generation (Kim et al., 2022; Kotelnikov et al., 2023; Kim et al., 2023; Lee et al., 2023). Despite the progress made by these methods, tailoring a diffusion model for tabular data leads to several challenges. Unlike image data, which comprises pure continuous pixel values with local spatial correlations, tabular data features have complex and varied distributions (Xu et al., 2019), making it hard to learn joint probabilities across multiple columns. Moreover, typical tabular data often contains mixed data types, i.e., continuous (e.g., numerical features) and discrete (e.g., categorical features) variables. The standard diffusion process assumes a continuous input space with Gaussian noise perturbation, which leads to additional challenges with categorical features. Existing solutions either transform categorical features into numerical ones using techniques like one-hot encoding (Kim et al., 2023; Liu et al., 2023b) and analog bit encoding (Zheng & Charoenphakdee, 2022) or resort to two separate diffusion processes for numerical and categorical features (Kotelnikov et al., 2023; Lee et al., 2023). However, it has been proven that simple encoding methods lead to suboptimal performance (Lee et al., 2023), and learning separate models for different data types makes it challenging for the model to capture the co-occurrence patterns of different types of data. Therefore, we seek to develop a diffusion model in a joint space of numerical and categorical features that preserves the inter-column correlations.
This paper presents TabSyn, a principled approach for tabular data synthesis. TabSyn first transforms raw tabular data into a continuous embedding space, where well-developed diffusion models with Gaussian noises become feasible. Subsequently, we learn a score-based diffusion model in the embedding space to capture the distribution of latent embeddings. To learn an informative, smoothed latent space while maintaining the decoder’s reconstruction ability, we specifically designed a Variational AutoEncoder (VAE (Kingma & Welling, 2013)) model for tabular-structured data. Our proposed VAE model includes 1) Transformer-architecture encoders and decoders for modeling inter-column relationships and obtaining token-level representations, facilitating token-level tasks. 2) Adaptive loss weighting to dynamically adjust the reconstruction loss weights and KL-divergence weights, allowing the model to improve reconstruction performance gradually while maintaining a regularized embedding space. 3) Finally, when applying diffusion models in the latent space, we adopt a simplified forward diffusion process, which adds Gaussian noises of linear standard deviation with respect to time. We demonstrate through theoretical analysis and empirical justifications that this approach can reduce the errors in the reverse process, thus improving sampling speed. The advantages of TabSyn are three-fold: (1) Generality: Mixed-type Feature Handling - TabSyn transforms diverse input features, encompassing numerical, categorical, etc., into a unified embedding space. (2) Quality: High Generation Quality - with tailored designs of the VAE model, the tabular data is mapped into regularized latent space of good shape, e.g., a standard normal distribution. This will greatly simplify training the subsequent diffusion model (Vahdat et al., 2021), making TabSyn more expressive and enabling it to generate high-quality synthetic data. (3) Speed: With the proposed linear noise schedule, our TabSyn can generate high-quality synthetic data with fewer than reverse steps, which is significantly fewer than existing methods.
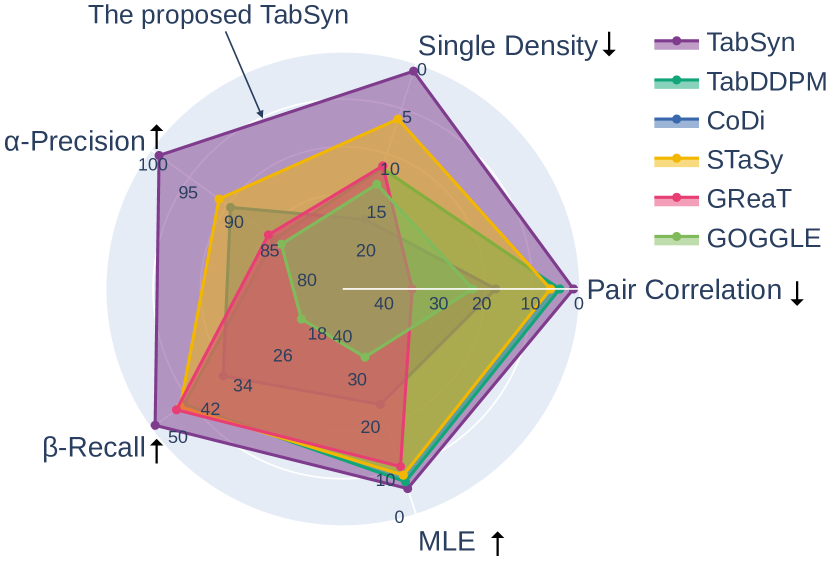
Recognizing the absence of unified and comprehensive evaluations for tabular data synthesis methods, we perform extensive experiments, which involve comparing TabSyn with seven state-of-the-art methods on six mixed-type tabular datasets using over five distinct evaluation metrics. The experimental results demonstrate that TabSyn consistently outperforms previous methods (see Figure 1). Specifically, TabSyn reduces the average errors in column-wise distribution shape estimation (i.e., single density) and pair-wise column correlation estimation (i.e., pair correlation) tasks by and than the most competitive baselines. Furthermore, we demonstrate that TabSyn achieves competitive performance across two downstream tabular data tasks, machine learning efficiency and missing value imputation. Specifically, the well-learned unconditional TabSyn is able to be applied to missing value imputation without retraining. Moreover, thorough ablation studies and visualization case studies substantiate the rationale and effectiveness of our developed approach.
2 Related Works
Deep Generative Models for Tabular Data Generation.
Generative models for tabular data have become increasingly important and have widespread applications Assefa et al. (2021); Zheng & Charoenphakdee (2022); Hernandez et al. (2022). To deal with the imbalanced categorical features, Xu et al. (2019) proposes CTGAN and TVAE based on the popular Generative Adversarial Networks (Goodfellow et al., 2014) and VAE (Kingma & Welling, 2013), respectively. Multiple advanced methods have been proposed for synthetic tabular data generation in the past year. Specifically, GOGGLE (Liu et al., 2023b) became the first to explicitly model the dependency relationship between columns, proposing a VAE-based model using graph neural networks as the encoder and decoder models. Inspired by the success of large language models in modeling the distribution of natural languages, GReaT transformed each row in a table into a natural sentence and learned sentence-level distributions using auto-regressive GPT2. In recent years, the physical diffusion process has inspired a lot of advanced research in deep learning. For example, DIFFormer (Wu et al., 2023) develops a scalable Transformer model for geometric data via a constrained diffusion process, and the Denoising Diffusion models have achieved great success in image generation (Ho et al., 2020). STaSy (Kim et al., 2023), TabDDPM (Kotelnikov et al., 2023), and CoDi (Lee et al., 2023) concurrently applied the popular diffusion-based generative models for synthetic tabular data generation.
Generative Modeling in the Latent Space.
While generative models in the data space have achieved significant success, latent generative models have demonstrated several advantages, including more compact and disentangled representations, robustness to noise, and greater flexibility in controlling generated styles (van den Oord et al., 2017; Razavi et al., 2019; Esser et al., 2021). For example, the recent GAN literature (Li et al., 2022) has demonstrated superior controllability via adversarial learning in the latent space. Recently, the Latent Diffusion Models (LDM) (Rombach et al., 2022; Vahdat et al., 2021) have achieved great success in image generation as they exhibit better scaling properties and expressivity than the vanilla diffusion models in the data space (Ho et al., 2020; Song et al., 2021b; Karras et al., 2022). The success of LDMs in image generation has also inspired their applications in video (Blattmann et al., 2023) and audio data (Liu et al., 2023a). To the best of our knowledge, the proposed work is the first to explore the application of latent diffusion models for general tabular data generation tasks.
3 Synthetic Tabular Data generation with TabSyn
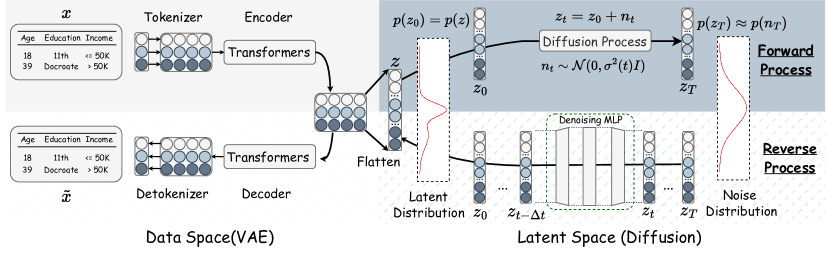
Figure 2 gives an overview of TabSyn. In Section 3.1, we first formally define the tabular data generation task. Then, we introduce the design details of TabSyn’s autoencoding and diffusion process in Section 3.2 and 3.3. We summarize the training and sampling algorithms in Appendix A.
3.1 Problem Definition of Tabular Data Generation
Let and be the number of numerical columns and categorical columns, respectively. Each row is represented as a vector of numerical features and categorical features , where and . Specifically, the -th categorical attribute has finite candidate values, therefore we have . This paper focuses on the unconditional generation task. With a tabular dataset , we aim to learn a parameterized generative model , with which realistic and diverse synthetic tabular data can be generated.
3.2 AutoEncoding for Tabular Data
Tabular data is highly structured of mixed-type column features, with different columns having distinct meanings and being highly dependent on each other. These characteristics make it challenging to design an approximate encoder to model and effectively utilize the rich relationships between columns. Motivated by the successes of Transformers in classification/regression of tabular data (Gorishniy et al., 2021), we first learn a unique tokenizer for each column, and then the token(column)-wise representations are fed into a Transformer for capturing the intricate relationships among columns.
Feature Tokenizer. The feature tokenizer converts each column (both numerical and categorical) into a -dimensional vector. First, we use one-hot encoding to pre-process categorical features, i.e., . Each record is represented as . Then, we apply a linear transformation for numerical columns and create an embedding lookup table for categorical columns, where each category is assigned a learnable -dimensional vector, i.e.,
| (1) |
where , are learnable parameters of the tokenizer, . Now, each record is expressed as the stack of the embeddings of all columns
| (2) |
Transformer Encoding and Decoding. As with typical VAEs, we use the encoder to obtain the mean and log variance of the latent variable. Then, we acquire the latent embeddings with the reparameterization tricks. The latent embeddings are then passed through the decoder to obtain the reconstructed token matrix . The detailed architectures are in Appendix D.
Detokenizer. Finally, we apply a detokenizer to the recovered token representation of each column to reconstruct the column values. The design of the detokenizer is symmetrical to that of the tokenizer:
| (3) |
where , are detokenizer’s parameters.
Training with adaptive weight coefficient.
The VAE model is usually learned with the classical ELBO loss function, but here we use -VAE (Higgins et al., 2016), where a coefficient balances the importance of the reconstruction loss and KL-divergence loss
| (4) |
is the reconstruction loss between the input data and the reconstructed one, and is the KL divergence loss that regularizes the mean and variance of the latent space. In the vanilla VAE model, is set to be because the two loss terms are equally important to generate high-quality synthetic data from Gaussian noises. However, in our model, is expected to be smaller, as we do not require the distribution of the embeddings to precisely follow a standard Gaussian distribution because we have an additional diffusion model. Therefore, we propose to adaptively schedule the scale of in the training process, encouraging the model to achieve lower reconstruction error while maintaining an appropriate embedding shape.
With an initial (maximum) , we monitor the epoch-wise reconstruction loss . When fails to decrease for a predefined number of epochs (which indicates that the KL-divergence dominates the overall loss), the weight is scheduled by . This process continues until approaches a predefined minimum value . This strategy is simple yet very effective, and we empirically justify the effectiveness of the design in Section 4.
3.3 Score-based Generative Modeling in the Latent Space
Training and sampling via denoising.
After the VAE model is well-learned, we extract the latent embeddings through the encoder and flatten the encoder’s output as such that the embedding of a record is a vector rather than a matrix. To learn the underlying distribution of embeddings , we consider the following forward diffusion process and reverse sampling process (Song et al., 2021b; Karras et al., 2022):
| (5) | |||||
| (6) |
where is the initial embedding from the encoder, is the diffused embedding at time , and is the noise level. In the reverse process, is the score function of , and is the standard Wiener process. The training of the diffusion model is achieved via denoising score matching (Karras et al., 2022):
| (7) |
where is a neural network (named denoising function) to approximate the Gaussian noise using the perturbed data and the time . Then . After the model is trained, synthetic data can be obtained via the reverse process in Eq. 6. The detailed algorithm description of TabSyn is provided in Appendix A. Detailed derivations are in Appendix B.
Schedule of noise level .
The noise level defines the scale of noises for perturbing the data at different time steps and significantly affects the final Differential Equation solution trajectories (Song et al., 2021b; Karras et al., 2022). Following the recommendations in Karras et al. (2022), we set the noise level that is linear w.r.t. the time. We show in Proposition 1 that the linear noise level schedule leads to the smallest approximation errors in the reverse process:
Proposition 1.
Consider the reverse diffusion process in Equation (6) from to , the numerical solution has the smallest approximation error to when .
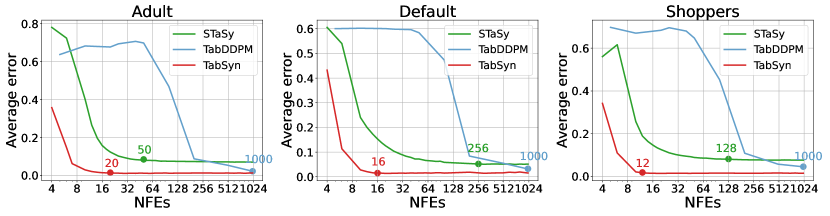
See proof in Appendix C. A natural corollary of Proposition 1 is that a small approximation error allows us to increase the interval between two timesteps, thereby reducing the overall number of sampling steps and accelerating the sampling. In Section 4, we demonstrate that with this design, TabSyn can generate synthetic tabular data of high quality within less than NFEs (number of function evaluations), which is much smaller than other tabular-data synthesis methods based on diffusion (Kim et al., 2023; Kotelnikov et al., 2023).
4 Benchmarking Synthetic Tabular Data Generation Algorithms
4.1 Experimental Setups
Datasets. We select six real-world tabular datasets consisting of both numerical and categorical attributes: Adult, Default, Shoppers, Magic, Faults, Beijing, and News. Table 6 provides the overall statistics of these datasets, and the detailed descriptions can be found in Appendix E.1.
Baselines. We compare the proposed TabSyn with seven existing synthetic tabular data generation methods. The first two are classical GAN and VAE models: CTGAN (Xu et al., 2019) and TVAE (Xu et al., 2019). Additionally, we evaluate five SOTA methods introduced recently: GOGGLE (Liu et al., 2023b), a VAE-based method; GReaT (Borisov et al., 2023), a language model variant; and three diffusion-based methods: STaSy (Kim et al., 2023), TabDDPM (Kotelnikov et al., 2023), and CoDi (Lee et al., 2023). Notably, these approaches were nearly simultaneously introduced, limiting opportunities for extensive comparison. For reference, we also compare with the representative interpolation-based method SMOTE (Chawla et al., 2002). Our paper fills this gap by providing the first comprehensive evaluation of their performance in a standardized setting.
Evaluation Methods. We evaluate the quality of the synthetic data from three aspects: 1) Low-order statistics – column-wise density estimation and pair-wise column correlation, estimating the density of every single column and the correlation between every column pair (Section 4.2). We also evaluate if the density estimation performance by testing if the synthetic data can be detected from the real data via a machine learning model (Appendix F.3). 2) High-order metrics – -precision and -recall scores (Alaa et al., 2022) that measure the overall fidelity and diversity of synthetic data (the results are deferred to Appendix F.2), and 3) Performance on downstream tasks – machine learning efficiency (MLE) and missing value imputation. MLE is to compare the testing accuracy on real data when trained on synthetically generated tabular datasets. The performance on privacy protection is measured by MLE tasks that have been widely adopted in previous literature (Section 4.3.1). We also extend TabSyn for the missing value imputation task, which aims to fill in missing features/labels given partial column values (Appendix F.4).
Implementation details. The reported results are averaged over randomly sampled synthetic data. The implementation details are in Appendix E.
4.2 Estimating Low-order Statistics of Data Density
Metrics. We employ the Kolmogorov-Sirnov Test (KST) for numerical columns and the Total Variation Distance (TVD) for categorical columns to quantify column-wise density estimation. For pair-wise column correlation, we use Pearson correlation for numerical columns and contingency similarity for categorical columns. The performance is measured by the difference between the correlations computed from real data and synthetic data. For the correlation between numerical and categorical columns, we first group numerical values into categorical ones via bucketing, then calculate the corresponding contingency similarity. Further details on these metrics are in Appendix E.3.
| Method | Adult | Default | Shoppers | Magic | Beijing | News | Average | |
| SMOTE | ||||||||
| CTGAN | ||||||||
| TVAE | ||||||||
| GOGGLE1 | ||||||||
| GReaT2 | OOM | |||||||
| STaSy | ||||||||
| CoDi | ||||||||
| TabDDPM3 | ||||||||
| TabSyn | ||||||||
| Improv. |
-
1
GOGGLE fixes the random seed during sampling in the official codes, and we follow it for consistency.
-
2
GReaT cannot be applied on News because of the maximum length limit.
-
3
TabDDPM fails to generate meaningful content on the News dataset.
| Method | Adult | Default | Shoppers | Magic | Beijing | News | Average | |
| SMOTE | ||||||||
| CTGAN | ||||||||
| TVAE | ||||||||
| GOGGLE | ||||||||
| GReaT | OOM | |||||||
| STaSy | ||||||||
| CoDi | ||||||||
| TabDDPM | ||||||||
| TabSyn | ||||||||
| Improve. |
Column-wise distribution density estimation.
In Table 1, we note that TabSyn consistently outperforms baseline methods in the column-wise distribution density estimation task. On average, TabSyn surpasses the most competitive baselines by . While STaSy and TabDDPM perform well, STaSy is sub-optimal because it treats one-hot embeddings of categorical columns as continuous features. Additionally, TabDDPM exhibits unstable performance across datasets, failing to generate meaningful content on the News dataset despite a standard training process.
Pair-wise column correlations.
Table 2 displays the results of pair-wise column correlations. TabSyn outperforms the best baselines by an average of . Notably, the performance of GReaT is significantly poorer in this task than in the column-wise task. This indicates the limitations of autoregressive language models in density estimation, particularly in capturing the joint probability distributions between columns.
4.3 Performance on Downstream Tasks
4.3.1 Machine Learning Efficiency
We then evaluate the quality of synthetic data by evaluating their performance in Machine Learning Efficiency tasks. Following established settings (Kotelnikov et al., 2023; Kim et al., 2023; Lee et al., 2023), we first split a real table into a real training and a real testing set. The generative models are learned on the real training set, from which a synthetic set of equivalent size is sampled. This synthetic data is then used to train a classification/regression model (XGBoost Classifier and XGBoost Regressor (Chen & Guestrin, 2016)), which will be evaluated using the real testing set. The performance of MLE is measured by the AUC score for classification tasks and RMSE for regression tasks. The detailed settings of the MLE evaluations are in Appendix E.4.
In Table 3, we demonstrate that TabSyn consistently outperforms all the baseline methods. The performance gap between methods is smaller compared to column-wise density and pair-wise column correlation estimation tasks (Tables 1 and 2). This suggests that some columns may not significantly impact the classification/regression tasks, allowing methods with lower performance in previous tasks to show competitive results in MLE (e.g., GReaT on Default dataset). This underscores the need for a comprehensive evaluation approach beyond just MLE metrics. As shown above, we have incorporated low-order and high-order statistics for a more robust assessment.
| Methods | Adult | Default | Shoppers | Magic | Beijing | News1 | Average Gap |
| AUC | AUC | AUC | AUC | RMSE | RMSE | ||
| Real | |||||||
| SMOTE | |||||||
| CTGAN | |||||||
| TVAE | |||||||
| GOGGLE | |||||||
| GReaT | OOM | ||||||
| STaSy | |||||||
| CoDi | |||||||
| TabDDPM2 | |||||||
| TabSyn |
-
1
Following CoDi (Lee et al., 2023), the continuous targets are standardized to prevent large values.
-
2
TabDDPM collapses on News, leading to an extremely high error on this dataset. We exclude this dataset
when computing the average gap of TabDDPM.
4.3.2 Missing Value Imputation and Privacy Protection
One advantage of the diffusion model is that a well-trained unconditional model can be directly used for data imputation (e.g., image inpainting (Song et al., 2021b; Lugmayr et al., 2022)) without additional training. This paper explores adapting TabSyn for missing value imputation, a crucial task in real-world tabular data. Due to space limitation, the detailed algorithms for missing value imputation and the results are deferred to Appendix F.4. We also evaluate if the synthetic data is randomly sampled according to the distribution density rather than copied from the training data (for privacy protection) via Distance to Closest Records (DCR) in Appendix F.6.
4.4 Ablation Studies
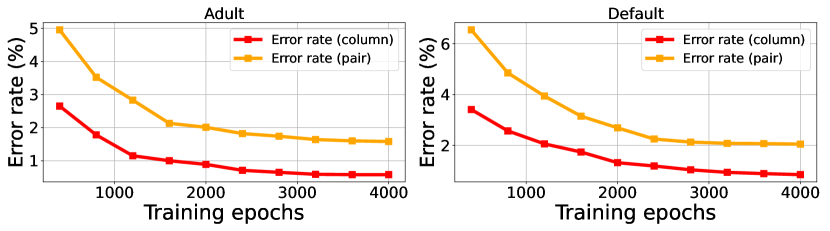
The effect of adaptive -VAE.
We assess the effectiveness of scheduling the weighting coefficient in the VAE model. Figure 3 presents the trends of the reconstruction loss and the KL-divergence loss with the scheduled and constant values (from to ) across 4,000 training epochs. Notably, a large value leads to subpar reconstruction, while a small value results in a large divergence between the embedding distribution and the standard Gaussian, making the balance hard to achieve. In contrast, by dynamically scheduling during training (), we not only prevent excessive KL divergence but also enhance quality. Table 4 further evaluates the learned embeddings from various values of the VAE model via synthetic data quality (single-column density and pair-wise column correlation estimation tasks). This demonstrates the superior performance of our proposed scheduled approach to train the VAE model.

| Single | Pair | |
| Scheduled |
The effect of linear noise levels.
We evaluate the effectiveness of using linear noise levels, , in the diffusion process. As Section 3.3 outlines, linear noises lead to linear trajectories and faster sampling speed. Consequently, we compare TabSyn and two other diffusion models (STaSy and TabDDPM) in terms of the single-column density and pair-wise column correlation estimation errors relative to the number of function evaluations (NFEs), i.e., denoising steps to generate the real data. As continuous-time diffusion models, the proposed TabSyn and STaSy are flexible in choosing NFEs. For TabDDPM, we use the DDIM sampler (Song et al., 2021a) to adjust NFEs. Figure 4 shows that TabSyn not only significantly improves the sampling speed but also consistently yields better performance (with fewer than 20 NFEs for optimal results). In contrast, STaSy requires 50-200 NFEs, varying by datasets, and achieves sub-optimal performance. TabDDPM achieves competitive performance with 1,000 NFEs but significantly drops in performance when reducing NFEs.
| Variants | Single | Pair |
| TabDDPM | ||
| TabSyn-OneHot | ||
| TabSyn-DDPM | ||
| TabSyn |
Comparing different encoding/diffusion methods.
We assess the effectiveness of learning the diffusion model in the latent space learned by VAE by creating two TabSyn variants: 1) TabSyn-OneHot: replacing VAE with one-hot encodings of categorical variables and 2) TabSyn-DDPM: substituting the diffusion process in Equation (5) with DDPM as used in TabDDPM. Results in Table 5 demonstrate: 1) One-hot encodings for categorical variables plus continuous diffusion models lead to the worst performance, indicating that it is not appropriate to treat categorical columns simply as continuous features; 2) TabSyn-DDPM in the latent space outperforms TabDDPM in the data space, highlighting the benefit of learning high-quality latent embeddings for improved diffusion modeling; 3) TabSyn surpasses TabSyn-DDPM, indicating the advantage of employing tailored diffusion models in the continuous latent space for better data distribution learning.
4.5 Visualization
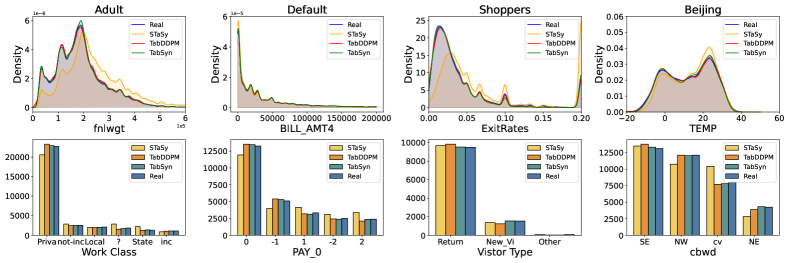
In Figure 5, we compare column density across eight columns from four datasets (one numerical and one categorical per dataset). TabDDPM matches TabSyn’s accuracy on numerical columns but falls short on categorical ones. Figure 6 displays the divergence heatmap between estimated pair-wise column correlations and real correlations. TabSyn gives the most accurate correlation estimation, while other methods exhibit suboptimal performance. These results justify that employing generative modeling in latent space enhances the learning of categorical features and joint column distributions.
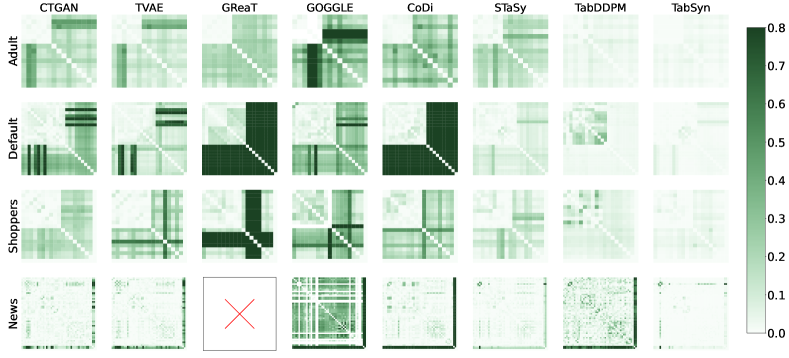
5 Conclusions
In this paper, we have proposed TabSyn for synthetic tabular data generation. The TabSyn framework leverages a VAE to map tabular data into a latent space, followed by utilizing a diffusion-based generative model to learn the latent distribution. This approach presents the dual advantages of accommodating numerical and categorical features within a unified latent space, thus facilitating a more comprehensive understanding of their interrelationships and enabling the utilization of advanced generative models in a continuous embedding space. To address potential challenges, TabSyn proposes a model design and training methods, resulting in a highly stable generative model. In addition, TabSyn rectifies the deficiency in prior research by employing a diverse set of evaluation metrics to comprehensively compare the proposed method with existing approaches, showcasing the remarkable quality and fidelity of the generated samples in capturing the original data distribution.
References
- Alaa et al. (2022) Ahmed Alaa, Boris Van Breugel, Evgeny S Saveliev, and Mihaela van der Schaar. How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. In International Conference on Machine Learning, pp. 290–306. PMLR, 2022.
- Assefa et al. (2021) Samuel A. Assefa, Danial Dervovic, Mahmoud Mahfouz, Robert E. Tillman, Prashant Reddy, and Manuela Veloso. Generating synthetic data in finance: Opportunities, challenges and pitfalls. In Proceedings of the First ACM International Conference on AI in Finance, ICAIF ’20. Association for Computing Machinery, 2021. ISBN 9781450375849.
- Ba et al. (2016) Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- Blattmann et al. (2023) Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 22563–22575, 2023.
- Borisov et al. (2023) Vadim Borisov, Kathrin Sessler, Tobias Leemann, Martin Pawelczyk, and Gjergji Kasneci. Language models are realistic tabular data generators. In The Eleventh International Conference on Learning Representations, 2023.
- Chawla et al. (2002) Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16:321–357, 2002.
- Chen & Guestrin (2016) Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 785–794, 2016.
- Esser et al. (2021) Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 12873–12883, 2021.
- Fonseca & Bacao (2023) Joao Fonseca and Fernando Bacao. Tabular and latent space synthetic data generation: a literature review. Journal of Big Data, 10(1):115, 2023.
- Goodfellow et al. (2014) Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, pp. 2672–2680, 2014.
- Gorishniy et al. (2021) Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data. In Proceedings of the 35th International Conference on Neural Information Processing Systems, pp. 18932–18943, 2021.
- Hernandez et al. (2022) Mikel Hernandez, Gorka Epelde, Ane Alberdi, Rodrigo Cilla, and Debbie Rankin. Synthetic data generation for tabular health records: A systematic review. Neurocomputing, 493:28–45, 2022.
- Higgins et al. (2016) Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. In The Forth International Conference on Learning Representations, 2016.
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Proceedings of the 34th International Conference on Neural Information Processing Systems, pp. 6840–6851, 2020.
- Hoogeboom et al. (2021) Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. Argmax flows and multinomial diffusion: Learning categorical distributions. In Proceedings of the 35th International Conference on Neural Information Processing Systems, pp. 12454–12465, 2021.
- Karras et al. (2022) Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, pp. 26565–26577, 2022.
- Kim et al. (2022) Jayoung Kim, Chaejeong Lee, Yehjin Shin, Sewon Park, Minjung Kim, Noseong Park, and Jihoon Cho. Sos: Score-based oversampling for tabular data. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 762–772, 2022.
- Kim et al. (2023) Jayoung Kim, Chaejeong Lee, and Noseong Park. Stasy: Score-based tabular data synthesis. In The Eleventh International Conference on Learning Representations, 2023.
- Kingma & Ba (2015) Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations, 2015.
- Kingma & Welling (2013) Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- Kotelnikov et al. (2023) Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. Tabddpm: Modelling tabular data with diffusion models. In International Conference on Machine Learning, pp. 17564–17579. PMLR, 2023.
- Lee et al. (2023) Chaejeong Lee, Jayoung Kim, and Noseong Park. Codi: Co-evolving contrastive diffusion models for mixed-type tabular synthesis. In International Conference on Machine Learning, pp. 18940–18956. PMLR, 2023.
- Li et al. (2022) Yang Li, Yichuan Mo, Liangliang Shi, and Junchi Yan. Improving generative adversarial networks via adversarial learning in latent space. Advances in Neural Information Processing Systems, 35:8868–8881, 2022.
- Liu et al. (2023a) Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. Audioldm: Text-to-audio generation with latent diffusion models. arXiv preprint arXiv:2301.12503, 2023a.
- Liu et al. (2023b) Tennison Liu, Zhaozhi Qian, Jeroen Berrevoets, and Mihaela van der Schaar. Goggle: Generative modelling for tabular data by learning relational structure. In The Eleventh International Conference on Learning Representations, 2023b.
- Lugmayr et al. (2022) Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11461–11471, 2022.
- Razavi et al. (2019) Ali Razavi, Aäron van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with vq-vae-2. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, pp. 14866–14876, 2019.
- Rombach et al. (2022) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022.
- Song et al. (2021a) Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In The Ninth International Conference on Learning Representations, 2021a.
- Song et al. (2021b) Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In The Ninth International Conference on Learning Representations, 2021b.
- Vahdat et al. (2021) Arash Vahdat, Karsten Kreis, and Jan Kautz. Score-based generative modeling in latent space. In Proceedings of the 35th International Conference on Neural Information Processing Systems, pp. 11287–11302, 2021.
- van den Oord et al. (2017) Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 6309–6318, 2017.
- Wu et al. (2023) Qitian Wu, Chenxiao Yang, Wentao Zhao, Yixuan He, David Wipf, and Junchi Yan. Difformer: Scalable (graph) transformers induced by energy constrained diffusion. In The Eleventh International Conference on Learning Representations, 2023.
- Xu et al. (2019) Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni. Modeling tabular data using conditional gan. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, pp. 7335–7345, 2019.
- Zheng & Charoenphakdee (2022) Shuhan Zheng and Nontawat Charoenphakdee. Diffusion models for missing value imputation in tabular data. arXiv preprint arXiv:2210.17128, 2022.
Appendix A Algorithms
In this section, we provide an algorithmic illustration of the proposed TabSyn. Algorithm 1 and Algorithm 2 present the algorithms of the VAE and Diffusion phases of the training process of TabSyn, respectively. Algorithm 3 presents TabSyn’s sampling algorithm.
Appendix B Diffusion Models Basics
Diffusion models are often presented as a pair of two processes.
-
•
A fixed forward process governs the training of the model, which adds Gaussian noises of increasing scales to the original data.
-
•
A corresponding backward process involves utilizing the trained model iteratively to denoise the samples starting from a fully noisy prior distribution.
B.1 Forward Process
Although there are different mathematical formulations (discrete or continuous) of the diffusion model, Song et al. (2021b) provides a unified formulation via the Stochastic Differential Equation (SDE) and defines the forward process of Diffusion as (note that in this paper, the independent variable is denoted as )
| (8) |
where and are the drift and diffusion coefficients and are selected differently for different diffusion processes, e.g., the variance preserving (VP) and variance exploding (VE) formulations. is the standard Wiener process. Usually, is of the form . Thus, the SDE can be equivalently written as
| (9) |
Let be a function of the time , i.e., , then the conditional distribution of given (named as the perturbation kernel of the SDE) could be formulated as:
| (10) |
where
| (11) |
Therefore, the forward diffusion process could be equivalently formulated by defining the perturbation kernels (via defining appropriate and ).
Variance Preserving (VP) implements the perturbation kernel Eq. 10 by setting , and (). Denoising Diffusion Probabilistic Models (DDPM, Ho et al. (2020)) belong to VP-SDE by using discrete finite time steps and giving specific functional definitions of .
Variance Exploding (VE) implements the perturbation kernel Eq. 10 by setting , indicating that the noise is directly added to the data rather than weighted mixing. Therefore, The noise variance (the noise level) is totally decided by . The diffusion model used in TabSyn belongs to VE-SDE, but we use linear noise level (i.e., ) rather than in the vanilla VE-SDE (Song et al., 2021b). When , the perturbation kernels become:
| (12) |
which aligns with the forward diffusion process in Eq. 5.
B.2 Reverse Process
B.3 Training
As are all known, if (named the score function) is also available, we can sample synthetic data via the reverse process from random noises. Diffusion models train a neural network (named the denoising function) to approximate . However, itself is intractable, as the marginal distribution is intractable. Fortunately, the conditional distribution is tractable. Therefore, we can train the denoising function to approximate the conditional score function instead , and the training process is called denoising score matching:
| (16) |
where has analytical solution according to Eq. 10:
| (17) |
Therefore, Eq. 16 becomes
| (18) |
where . After the training ends, sampling is enabled by solving Eq. 13 (replacing with ).
Appendix C Proofs
C.1 Proof for Proposition 1
We first introduce Lemma 1 (from (Karras et al., 2022)), which introduces a family of SDEs sharing the same solution trajectories with different forwarding processes:
Lemma 1.
Let be a free parameter functional of , and the following family of (forward) SDEs have the same marginal distributions of the solution trajectories with noise levels for any choice of :
| (19) |
The reverse family of SDEs of Eq. 19 is given by changing the sign of the first term:
| (20) |
Lemma 1 indicates that for a specific (forward) SDE following Eq. 19, we can obtain its solution trajectory by solving Eq. 20 of any .
Since our forwarding diffusion process (Eq. 5) lets (see derivations in Appendix B), its solution trajectory can be solved via letting in Eq. 20:
| (21) |
Eq. 21 is usually named the Probability-Flow ODE, since it depicts a deterministic reverse process without noise terms. Based on Lemma 1, we can study the solution of Eq. 6 using Eq. 21.
To prove Proposition 1, we only have to study the absolute error between the ground-truth the approximated one by solving Eq. 6 from , where :
| (22) |
Since , there is .
The solution of from can be obtained using 1st-order Euler method:
| (23) |
| (24) |
Specifically, if , there is
| (25) |
Comparably, setting (as in VE-SDE Song et al. (2021b)) leads to
| (26) |
Therefore, the proof is complete.
Appendix D Network Architectures
D.1 Architectures of VAE
In Sec. 3.2, we introduce the general architecture of our VAE module, which consists of a tokenizer, a Transformer encoder, a Transformer decoder, and a detokenizer. Figure 7 is a detailed illustration of the architectures of the Transformer encoder and decoder.
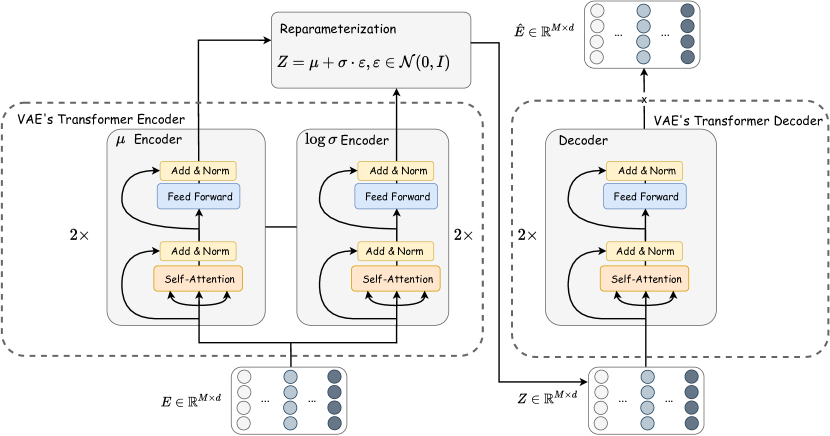
The VAE’s encoder takes the tokenizer’s output as input. As we are using the Variational AutoEncoder, the encoder module consists of a encoder and a encoder of the same architecture. Each encoder is implemented as a two-layer Transformer, each with a Self-Attention (without multi-head) module and a Feed Forward Neural Network (FFNN). The FFNN used in TabSyn is a simple two-layer MLP with ReLU activation(the input of the FFNN is denoted by ):
| (27) |
where FC denotes the fully-connected layer, and is FFNN’s hidden dimension. In this paper, we set and for all datasets. "Add & Norm" in Figure 7 denotes residual connection and Layer Normalization (Ba et al., 2016), respectively.
The VAE encoder outputs two matrixes: mean matrix and log standard deviation matrix . Then, the latent variables are obtained via the parameterization trick:
| (28) |
The VAE’s decoder is another two-layer Transformer of the same architecture as the encoder, and it takes as input. The decoder is expected to output for the detokenizer.
D.2 Architectures of Denoising MLP
In Figure 7, we present the architecture of the denoising neural networks in Eq. 7, which is a simple MLP of the similar architecture as used in TabDDPM (Kotelnikov et al., 2023).
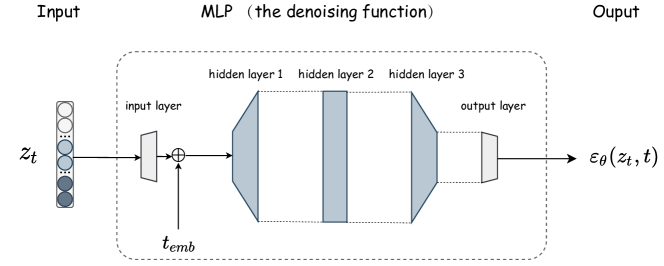
The denoising MLP takes the current time step and the corresponding latent vector as input. First, is fed into a linear projection layer that converts the vector dimension to be :
| (29) |
where is the transformed vector, and is the output dimension of the input layer.
Then, following the practice in TabDDPM (Kotelnikov et al., 2023), the sinusoidal timestep embeddings is added to to obtain the input vector :
| (30) |
The hidden layers are three fully connected layers of the size , with SiLU activation functions (in consistency with TabDDPM (Kotelnikov et al., 2023)):
| (31) |
The estimated score is obtained via the last linear layer:
| (32) |
Finally, is applied to Eq. 7 for model training.
Appendix E Details of Experimental Setups
We implement TabSyn and all the baseline methods with PyTorch. All the methods are optimized with Adam (Kingma & Ba, 2015) optimizer. All the experiments are conducted on an Nvidia RTX 4090 GPU with 24G memory.
E.1 Datasets
We use tabular datasets from UCI Machine Learning Repository111https://archive.ics.uci.edu/datasets: Adult, Default, Shoppers, Magic, Beijing, and News, where each tabular dataset is associated with a machine-learning task. Classification: Adult, Default, Magic, and Shoppers. Regression: Beijing and News. The statistics of the datasets are presented in Table 6.
| Dataset | # Rows | # Num | # Cat | # Train | # Validation | # Test | Task |
| Adult | Classification | ||||||
| Default | Classification | ||||||
| Shoppers | Classification | ||||||
| Magic | Classification | ||||||
| Beijing | Regression | ||||||
| News | Regression |
In Table 6, # Rows denote the number of rows (records) in the table. # Num and # Cat denote the number of numerical features and categorical features, respectively. Note that the target column is counted as either a numerical or a categorical feature, depending on the task type. Specifically, the target column belongs to the categorical column if the task is classification; otherwise, it is a numerical column. Each dataset is split into training, validation, and testing sets for the Machine Learning Efficiency experiments. As Adult has its official testing set, we directly use it as the testing set. The original training set of Adult is further split into training and validation split with the ratio . The remaining datasets are split into training/validation/testing sets with the ratio with a fixed seed.
Below is a detailed introduction to each dataset:
-
•
Adult222https://archive.ics.uci.edu/dataset/2/adult: The "Adult Census Income" dataset contains the demographic and employment-related features people. The task is to predict whether an individual’s income exceeds .
-
•
Default333https://archive.ics.uci.edu/dataset/350/default+of+credit+card+clients: The "Default of Credit Card Clients Dataset" dataset contains information on default payments, demographic factors, credit data, history of payment, and bill statements of credit card clients in Taiwan from April 2005 to September 2005. The task is to predict whether the client will default payment next month.
-
•
Shoppers444https://archive.ics.uci.edu/dataset/468/online+shoppers+purchasing+intention+dataset: The "Online Shoppers Purchasing Intention Dataset" contains information of user’s webpage visiting sessions. The task is to predict if the user’s session ends with the shopping behavior.
-
•
Magic555https://archive.ics.uci.edu/dataset/159/magic+gamma+telescope: The "Magic Gamma Telescope" dataset is to simulate registration of high energy gamma particles in a ground-based atmospheric Cherenkov gamma telescope using the imaging technique. The task is to classify high-energy Gamma particles in the atmosphere.
-
•
Beijing666https://archive.ics.uci.edu/dataset/381/beijing+pm2+5+data: The "Beijing PM2.5 Data" dataset contains the hourly PM2.5 data of US Embassy in Beijing and the meteorological data from Beijing Capital International Airport. The task is to predict the PM2.5 value.
-
•
News777https://archive.ics.uci.edu/dataset/332/online+news+popularity: The "Online News Popularity" dataset contains a heterogeneous set of features about articles published by Mashable in two years. The goal is to predict the number of shares in social networks (popularity).
E.2 Baselines
In this section, we introduce and compare the properties of the baseline methods used in this paper.
-
•
CTGAN and TVAE are two methods for synthetic tabular data generation proposed in one paper (Xu et al., 2019), using the same techniques proposed but based on different basic generative models – GAN for CTGAN while VAE for TVAE. The two methods contain two important designs: 1) Mode-specific Normalization to deal with numerical columns with complicated distributions. 2) Conditional Generation of numerical columns based on categorical columns to deal with class imbalance problems.
-
•
GOGGLE (Liu et al., 2023b) is a recently proposed synthetic tabular data generation model based on VAE. The primary motivation of GOGGLE is that the complicated relationships between different columns are hardly exploited by previous literature. Therefore, it proposes to learn a graph adjacency matrix to model the dependency relationships between different columns. The encoder and decoder of the VAE model are both implemented as Graph Neural Networks (GNNs), and the graph adjacent matrix is jointly optimized with the GNNs parameters.
-
•
GReaT (Borisov et al., 2023) treats a row of tabular data as a sentence and applies the Auto-regressive GPT model to learn the sentence-level row distributions. GReaT involves a well-designed serialization process to transform a row into a natural language sentence of a specific format and a corresponding deserialization process to transform a sentence back to the table format. To ensure the permutation invariant property of tabular data, GReaT shuffles each row several times before serialization.
-
•
STaSy (Kim et al., 2023) is a recent diffusion-based model for synthetic tabular data generation. STaSy treats the one-hot encoding of categorical columns as continuous features, which are then processed together with the numerical columns. STaSy adopts the VP/VE SDEs from Song et al. (2021b) as the diffusion process to learn the distribution of tabular data. STaSy further proposes several training strategies, including self-paced learning and fine-tuning, to stabilize the training process, increasing sampling quality and diversity.
-
•
CoDi (Lee et al., 2023) proposes to utilize two diffusion models for numerical and categorical columns, respectively. For numerical columns, it uses the DDPM (Ho et al., 2020) model with Gaussian noises. For categorical columns, it uses the multinominal diffusion model (Hoogeboom et al., 2021) with categorical noises. The two diffusion processes are inter-conditioned on each other to model the joint distribution of numerical and categorical columns. In addition, CoDi adopts contrastive learning methods to further bind the two diffusion methods.
-
•
TabDDPM (Kotelnikov et al., 2023). Like CoDi, TabDDPM introduces two diffusion processes: DDPM with Gaussian noises for numerical columns and multinominal diffusion with categorical noises for categorical columns. Unlike CoDi, which introduces many additional techniques, such as co-evolved learning via inter-conditioning and contrastive learning, TabDDPM concatenates the numerical and categorical features as input and output of the denoising function (an MLP). Despite its simplicity, our experiments have shown that TabDDPM performs even better than CoDi.
We further compare the properties of these baseline methods and the proposed TabSyn in Table 7. The compared properties include: 1) Compatibility: if the method can deal with mixed-type data columns, e.g., numerical and categorical. 2) Robustness: if the method has stable performance across different datasets (measured by the standard deviation of the scores ( or not) on different datasets (from Table 1 and Table 2). 3) Quality: Whether the synthetic data can pass column-wise Chi-Squared Test (). 4) Efficiency: Each method can generate synthetic tabular data of satisfying quality within less than steps.
| Method | Base Model | Compatibility | Robustness | Quality | Efficiency | |
| CTGAN | GAN | ✓ | ✗ | ✗ | ✓ | |
| TVAE | VAE | ✓ | ✓ | ✗ | ✓ | |
| GOGGLE | VAE | ✗ | ✗ | ✗ | ✓ | |
| GReaT | AR | ✓ | ✗ | ✗ | ✗ | |
| STaSy | Diffusion | ✗ | ✓ | ✓ | ✗ | |
| CoDi | Diffusion | ✓ | ✗ | ✗ | ✗ | |
| TabDDPM | Diffusion | ✓ | ✗ | ✓ | ✗ | |
| TabSyn | Diffusion | ✓ | ✓ | ✓ | ✓ |
E.3 Metrics of Low-order Statistics
In this section, we give a detailed introduction of the metrics used in Sec. 4.2.
E.3.1 Column-wise Density Estimation
Kolmogorov-Sirnov Test (KST): Given two (continuous) distributions and ( denotes real and denotes synthetic), KST quantifies the distance between the two distributions using the upper bound of the discrepancy between two corresponding Cumulative Distribution Functions (CDFs):
| (33) |
where and are the CDFs of and , respectively:
| (34) |
Total Variation Distance (TVD): TVD computes the frequency of each category value and expresses it as a probability. Then, the TVD score is the average difference between the probabilities of the categories:
| (35) |
where describes all possible categories in a column . and denotes the real and synthetic frequencies of these categories.
E.3.2 Pair-wise Column Correlation
Pearson Correlation Coefficient: The Pearson correlation coefficient measures whether two continuous distributions are linearly correlated and is computed as:
| (36) |
where and are two continuous columns. Cov is the covariance, and is the standard deviation.
Then, the performance of correlation estimation is measured by the average differences between the real data’s correlations and the synthetic data’s corrections:
| (37) |
where and denotes the Pearson correlation coefficient between column and column of the real data and synthetic data, respectively. As , the average score is divided by to ensure that it falls in the range of , then the smaller the score, the better the estimation.
Contingency similarity: For a pair of categorical columns and , the contingency similarity score computes the difference between the contingency tables using the Total Variation Distance. The process is summarized by the formula below:
| (38) |
where and describe all the possible categories in column and column , respectively. and are the joint frequency of and in the real data and synthetic data, respectively.
E.4 Details of Machine Learning Efficiency Experiments
As preliminarily illustrated in Sec. 4.3.1 and Appendix E.1, each dataset is first split into the real training and testing set. The generative models are learned on the real training set. After the models are learned, a synthetic set of equivalent size is sampled.
The performance of synthetic data on MLE tasks is evaluated based on the divergence of test scores using the real and synthetic training data. Therefore, we first train the machine learning model on the real training set, split into training and validation sets with a ratio. The classifier/regressor is trained on the training set, and the optimal hyperparameter setting is selected according to the performance on the validation set. After the optimal hyperparameter setting is obtained, the corresponding classifier/regressor is retrained on the training set and evaluated on the real testing set. We create 20 random splits for training and validation sets, and the performance reported in Table 3 is the mean and std of the AUC/RMSE score over the random trails. The performance of synthetic data is obtained in the same way.
Below is the hyperparameter search space of the XGBoost Classifier/Regressor used in MLE tasks, and we select the optimal hyperparameters via grid search.
-
•
Number of estimators: [10, 50, 100]
-
•
Minimum child weight: [5, 10, 20].
-
•
Maximum tree depth: [1,10].
-
•
Gamma: [0.0, 1.0].
We use the implementations of these metrics from SDMetric888https://docs.sdv.dev/sdmetrics.
Appendix F Addition Experimental Results
In this section, we compare the training and sampling time of different methods, taking the Adult dataset as an example.
F.1 Training / Sampling Time
| Method | Training | Sampling |
| CTGAN | 1029.8s | 0.8621s |
| TVAE | 352.6s | 0.5118s |
| GOGGLE | 1h 34min | 5.342s |
| GReaT | 2h 27min | 2min 19s |
| STaSy | 2283s | 8.941s |
| CoDi | 2h 56min | 4.616s |
| TabDDPM | 1031s | 28.92s |
| TabSyn | 1758s + 664s | 1.784s |
As shown in Fig. 8, though having an additional VAE training process, the proposed TabSyn has a similar training time to most of the baseline methods. In regard to the sampling time, TabSyn requires merely s to generate synthetic data of the same size as Adult’s training data, which is close to the one-step sampling methods CTGAN and TVAE. Other diffusion-based methods take a much longer time for sampling. E.g., the most competitive method TabDDPM (Kotelnikov et al., 2023) takes s for sampling. The proposed TabSyn reduces the sampling time by , and achieves even better synthesis quality.
F.2 Sample-wise Quality score of Synthetic Data (-Precison and -Recall)
Experiments in Sec. 4 have evaluated the performance of synthetic data generated from different models using low-order statistics, including the column-wise density estimation (Table 1) and pair-wise column correlation estimation (Table 2). However, these results are insufficient to evaluate synthetic data’s overall density estimation performance, as the generative model may simply learn to estimate the density of each single column individually rather than the joint probability of all columns. Furthermore, the MLE tasks also cannot reflect the overall density estimation performance since some unimportant columns might be overlooked. Therefore, in this section, we adopt higher-order metrics that focus more on the entire data distribution, i.e., the joint distribution of all the columns.
Following Liu et al. (2023b) and Alaa et al. (2022), we adopt the -Precision and -Recall proposed in Alaa et al. (2022), two sample-level metric quantifying how faithful the synthetic data is. In general, -Precision evaluates the fidelity of synthetic data – whether each synthetic example comes from the real-data distribution, -Recall evaluates the coverage of the synthetic data, e.g., whether the synthetic data can cover the entire distribution of the real data (In other words, whether a real data sample is close to the synthetic data). Liu et al. (2023b) also adopts the third metric, Authenticity – whether the synthetic sample is generated randomly or simply copied from the real data. However, we found that authenticity score and beta-recall exhibit a predominantly negative correlation – their sum is nearly constant, and an improvement in beta-recall is typically accompanied by a decrease in authenticity score (we believe this is the reason for the relatively small differences in quality scores among the various models in GOGGLE (Liu et al., 2023b)). Therefore, we believe that beta-recall and authenticity are not suitable for simultaneous use.
In Table 9 and Table 10 we report the scores of -Precision and -Recall, respectively. TabSyn obtains the best -Precision scores on all the datasets, demonstrating the superior capacity of TabSyn in generating synthetic data that is close to the real ones. In Table 10, we observe that TabSyn consistently achieves high -Recall scores across six datasets. Although some baseline methods obtain higher -recall scores on specific datasets, it can hardly be concluded that the synthetic data generated by these methods are of better quality since 1) their synthetic data has poor -Precision scores (e.g., GReaT on Adult, and STaSy on Magic), indicating that the synthetic data is far from the real data’s manifold; 2) they fail to demonstrate stably competitive performance on other datasets (e.g., GReaT has high -Recall scores on Adult but poor scores on Magic). We believe that to assess the quality of generation, the first consideration is whether the generated data is sufficiently authentic (-Precision), and the second is whether the generated data can cover all the modes of the real dataset (-Recall). According to this criterion, the quality of data generated by TabSyn is the highest. It not only possesses the highest fidelity score but also consistently demonstrates remarkably high coverage on every dataset.
| Methods | Adult | Default | Shoppers | Magic | Beijing | News | Average | Ranking |
| CTGAN | ||||||||
| TVAE | ||||||||
| GOGGLE | 8 | |||||||
| GReaT | - | |||||||
| STaSy | ||||||||
| CoDi | ||||||||
| TabDDPM | ||||||||
| TabSyn |
| Methods | Adult | Default | Shoppers | Magic | Beijing | News | Average | Ranking |
| CTGAN | ||||||||
| TVAE | ||||||||
| GOGGLE | ||||||||
| GReaT | - | |||||||
| STaSy | ||||||||
| CoDi | ||||||||
| TabDDPM | ||||||||
| TabSyn |
F.3 Detection: Classifier Two Sample Tests (C2ST)
We further study how difficult it is to tell apart the real data from the synthetic data, therefore evaluating if the synthetic data can recover the real data distribution. To this end, we employ the detection metric provided by sdmetrics 999https://docs.sdv.dev/sdmetrics/metrics/metrics-in-beta/detection-single-table. In Table 11, we present the results obtained using logistic regression as the detection method.
| Method | Adult | Default | Shoppers | Magic | Beijing | News |
| SMOTE | ||||||
| CTGAN | ||||||
| TVAE | ||||||
| GOGGLE | ||||||
| GReaT | - | |||||
| STaSy | ||||||
| CoDi | ||||||
| TabDDPM | ||||||
| TabSyn |
As indicated in the table, the Detection score exhibits superior discriminative power compared to other metrics, such as single-column density estimation, pair-wise column shape estimation, and MLE. The detection score shows significant variations across different models for synthetic data generation. As indicated in the table, the Detection score exhibits superior discriminative power compared to other metrics, such as single-column density estimation, pair-wise column shape estimation, and MLE. The detection score shows significant variations across different models for synthetic data generation. The proposed TabSyn consistently achieves notably high scores across all datasets (SMOTE (Chawla et al., 2002) directly interpolates within the training set, so it is not surprising that it achieves high scores in the detection metric.).
F.4 Missing Value Imputation
Adapting TabSyn for missing value imputation
An essential advantage of the Diffusion Model is that an unconditional model can be directly used for missing data imputation tasks (e.g., image inpainting (Song et al., 2021b; Lugmayr et al., 2022) and missing value imputation) without retraining. Following the inpainting methods proposed in Lugmayr et al. (2022), we apply the proposed TabSyn in Missing Value Imputation Tasks.
For a row of tabular data , , . Assume the index set of masked numerical columns is , and of masked categorical columns is , we first preprocess the masked columns as follows:
-
•
The value of a masked numerical column is set as the averaged value of this column, i.e., .
-
•
The masked categorical column is set as .
The updated (we omit the subscript in the remaining parts) is fed to TabSyn’s frozen VAE’s encoder to obtain the embedding . As TabSyn’s VAE employs the Transformer architecture, there is a deterministic mapping from the masked indexes in the data space and to the masked indexes in the latent space. For example, the first dimension of the numerical column is mapped to dimension to in . Therefore, we can create a masking vector indicating whether each dimension is masked. Then, the known and unknown part of could be expressed as and , respectively.
Following Lugmayr et al. (2022), the reverse step is modified as a mixture of the known part’s forwarding and the unknown part’s denoising:
| (39) |
The reverse imputation from time to also involves resampling in order to reduce the error brought by each step (Lugmayr et al., 2022). Resampling indicates that Eq. 39 will be repeated for steps from to . After completing the reverse steps, we obtain the imputed latent vector , which could be put into TabSyn’s VAE decoder to recover the original input data.
The algorithm for missing value imputation is presented in Algorithm 4.
Classification/Regression as missing value imputation.
With Algorithm 4, we are able to use TabSyn for imputation with any missing columns. In this section, we consider a more interesting application – treating classification/regression as missing value imputation tasks directly. As illustrated in Section E.1, each dataset is assigned a machine learning task, either a classification or regression on the target column in the dataset. Therefore, we can mask the values of the target columns, then apply TabSyn to impute the masked values, completing the classification or regression tasks.
In Table 12, we present TabSyn’s performance in missing value imputation tasks on the target column of each dataset. The performance is compared with directly training a classifier/regressor, using the remaining columns to predict the target column (the ’Real’ row in Machine Learning Efficiency tasks, Table 3). Surprisingly, imputing with TabSyn shows highly competitive results on all datasets. On four of six datasets, TabSyn outperforms training a discriminate ML classifier/regressor on real data. We suspect that the reason for this phenomenon may be that discriminative ML models are more prone to overfitting on the training set. In contrast, by learning the smooth distribution of the entire data, generative models significantly reduce the risk of overfitting. The excellent results on the missing value imputation task further highlight the significant importance of our proposed TabSyn for real-world applications.
Our TabSyn is not trained conditionally on other columns for the missing value imputation tasks, and the performance can be further improved by training a separate conditional model specifically for this task. We leave it for future work.
| Methods | Adult | Default | Shoppers | Magic | Beijing | News |
| AUC | AUC | AUC | AUC | RMSE | RMSE | |
| Real with XGBoost | ||||||
| Impute with TabSyn |
F.5 Impacts of the quality of VAEs
Intuitively, the performance of TabSyn appears to be highly dependent on the quality of the pre-trained VAE model. Therefore, we conduct further research to investigate how a less trained VAE model would impact the quality of synthetic data generated by TabSyn. To this end, we investigate the quality of synthetic data generated by TabSyn using the embeddings of the VAE obtained at different epochs as the latent space. Figure 9 plots the results of single-column density estimation and pair-wise column correlation estimation on the Adult and Default datasets, with intervals set at 400 epochs. We can observe that increasing the training epochs of the VAE does indeed improve the quality of TabSyn’s generated data. Additionally, even when the VAE is sub-optimal (e.g., training epochs around 2000), TabSyn’s performance is already very close to the optimal ones. Furthermore, even with a relatively low number of VAE training epochs (e.g., 800-1200), TabSyn’s performance approaches or even surpasses the most competitive baseline, TabDDPM. Based on this observation, we recommend thoroughly training the VAE to achieve superior data generation quality when resources are abundant. However, when resources are limited, reducing the VAE training duration still yields decent performance.
F.6 Privacy Protection: Distance to Closest Record (DCR)
To study if the synthetic data will cause privacy information leakage issues, we compute the DCRs of the synthetic data. Specifically, we follow the ’synthetic vs. holdout’ setting 101010https://www.clearbox.ai/blog/2022-06-07-synthetic-data-for-privacy-
preservation-part-2. We initially divide the dataset into two equal parts: the first part served as the training set for training our generative model, while the second part was designated as the holdout set, which is not used for training. After completing model training, we sample a synthetic set of the same size as the training set (and the holdout set).
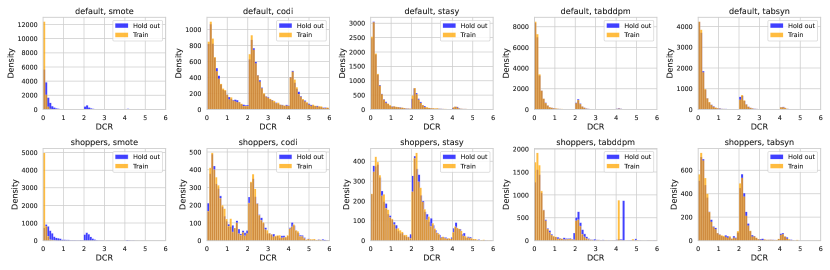
We then calculate the DCR scores for each sample in the synthetic set concerning both the training set and the holdout set. We can create histograms to visualize the distribution of DCR scores for the synthetic set in comparison to both the training and holdout sets. Intuitively, if there is a privacy issue (e.g. if the synthetic set is directly copied from the training set), then the DCR scores for the training set should be closer to 0 than those for the testing set. Conversely, if there is no privacy issue, the distributions of DCR scores of the training and holdout sets should largely overlap. In Figure 10, we plot the distributions of synthetic sets’ DCRs concerning the training set and holdout set on Default and Shoppers. We can observe that deep generative models such as CoDi, STaSy, TabDDPM, and TabSyn do not suffer from privacy issues, while the interpolation-based method SMOTE might not be able to protect privacy information.
Additionally, we calculate the probability that a synthetic sample is closer to the training set (rather than the holdout set). When this probability is close to 50% (i.e., 0.5), it indicates that the distribution of distances between synthetic and training instances is very similar (or at least not systematically smaller) than the distribution of distances between synthetic and holdout instances, which is a positive indicator in terms of privacy risk. Table 13 displays the results obtained by different models on Default and Shoppers datasets.
| Method | Default | Shoppers |
| SMOTE | % | % |
| STaSy | % | % |
| CoDi | % | % |
| TabDDPM | % | % |
| TabSyn | % | % |
Appendix G Details for Reproduction
In this section, we introduce the details of TabSyn, such as the data preprocessing, training, and hyperparameter details. We also present details of our reproduction for the baseline methods.
G.1 Details of implementing TabSyn
Data Preprocessing.
Real-world tabular data often contain missing values, and each column’s data may have distinct scales. Therefore, we need to preprocess the data. Following TabDDPM (Kotelnikov et al., 2023), missing cells are filled with the column’s average for numerical columns. For categorical columns, missing cells are treated as one additional category. Then, each numerical/categorical column is transformed using the QuantileTransformer111111https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.QuantileTransformer.html/OneHotEncoder121212https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html from scikit-learn, respectively.
Hyperparameter settings.
TabSyn uses the same set of parameters for different datasets. (except for Shoppers). The detailed architectures of the VAE and Diffusion model of TabSyn have been presented in Appendix D.1 and Appendix D.2, respectively. Below is the detailed hyperparameter setting.
Hyperparameters of VAE:
-
•
Token dimension ,
-
•
Number of Layers of VAEs’ encoder/decoder: ,
-
•
Hidden dimension of Transformer’s FFN: ,
-
•
( for Shoppers),
-
•
,
-
•
.
Hyperparameters of Diffusion:
-
•
MLP’s hidden dimension .
Unlike the cumbersome hyperparameter search process in some current methods (Kotelnikov et al., 2023; Kim et al., 2023; Lee et al., 2023) to obtain the optimal hyperparameters, TabSyn consistently generates high-quality data without the need for meticulous hyperparameter tuning.
G.2 Details of implementing baselines
Since different methods have adopted distinct neural network architectures, it is inappropriate to compare the performance of different methods using identical networks. For fair comparison, we adjust the hidden dimensions of different methods, ensuring that the numbers of trainable parameters are close (around million). Note that enlarging the model size does lead to better performance for the baseline methods. Under these conditions, we reproduced the baseline methods based on the official codes, and our reproduced codes are provided in the supplementary. Below are the detailed implementations of the baselines.
CTGAN and TVAE (Xu et al., 2019): For CTGAN, we follow the implementations in the official codes131313https://github.com/sdv-dev/CTGAN, where the hyperparameters are well-given. Since the default discriminator/generator MLPs are small, we enlarge them to be the same size as TabSyn for fair comparison. The interface for TVAE is not provided, so we simply use the default hyperparameters defined in the TVAE module. The sizes of TVAE’s encoder/decoder are enlarged as well.
GOGGLE (Liu et al., 2023b): We follow the official implementations141414https://github.com/vanderschaarlab/GOGGLE. In GOGGLE’s official implementation, each node is a column, and the node feature is the -dimensional numerical value of this column. However, GOGGLE did not illustrate and failed to explain how to handle categorical columns 151515https://github.com/tennisonliu/GOGGLE/issues/2. To extend GOGGLE to mixed-type tabular data, we first transform each categorical column into its -dimensional one-hot encoding. Then, each single dimension of binary values becomes the graph node. Consequently, for a mixed-type tabular data of numerical columns and categorical columns and the -th categorical column of categories, GOGGLE’s graph has nodes.
GReaT: We follow the official implementations161616https://github.com/kathrinse/be_great/tree/main. During our reproduction, we found that the training of GReaT is memory and time-consuming (because it is fine-tuning a large language model). Typically, the batch size is limited to on the Adult dataset, and training for epochs takes over hours. In addition, since GReaT is textual-based, the generated content is not guaranteed to follow the format of the given table. Therefore, additional post-processing has to be applied.
STaSy (Kim et al., 2023): In STaSy, the categorical columns are encoded with one-hot encoding and then are put into the continuous diffusion model together with the numerical columns. We follow the default hyperparameters given by the official codes171717https://github.com/JayoungKim408/STaSy/tree/main except for the denoising function’s size, which is enlarged for a fair comparison.
CoDi (Lee et al., 2023): We follow the default hyperparameters given by the official codes181818https://github.com/ChaejeongLee/CoDi/tree/main. Similarly, the denoising U-Nets used by CoDi are also enlarged to ensure similar model parameters.
TabDDPM (Kotelnikov et al., 2023): The official code of TabDDPM191919https://github.com/yandex-research/tab-ddpm is for conditional generation tasks, where the non-target columns are generated conditioned on the target column(s). We slightly modify the code to be applied to unconditional generation.