A General Theoretical Paradigm to Understand Learning from Human Preferences
Mohammad Gheshlaghi Azar Mark Rowland Bilal Piot
Daniel Guo Daniele Calandriello Michal Valko Rémi Munos
Google DeepMind
Abstract
The prevalent deployment of learning from human preferences through reinforcement learning (RLHF) relies on two important approximations: the first assumes that pairwise preferences can be substituted with pointwise rewards. The second assumes that a reward model trained on these pointwise rewards can generalize from collected data to out-of-distribution data sampled by the policy. Recently, Direct Preference Optimisation (DPO) has been proposed as an approach that bypasses the second approximation and learn directly a policy from collected data without the reward modelling stage. However, this method still heavily relies on the first approximation.
In this paper we try to gain a deeper theoretical understanding of these practical algorithms. In particular we derive a new general objective called PO for learning from human preferences that is expressed in terms of pairwise preferences and therefore bypasses both approximations. This new general objective allows us to perform an in-depth analysis of the behavior of RLHF and DPO (as special cases of PO) and to identify their potential pitfalls. We then consider another special case for PO by setting simply to Identity, for which we can derive an efficient optimisation procedure, prove performance guarantees and demonstrate its empirical superiority to DPO on some illustrative examples.
1 Introduction
Learning from human preferences (Christiano et al., 2017) is a paradigm adopted in the natural language processing literature to better align pretrained (Radford et al., 2018; Ramachandran et al., 2016) and instruction-tuned (Wei et al., 2022) generative language models to human desiderata. It consists in first collecting large amounts of data where each datum is composed of a context, pairs of continuations of the context, also called generations, and a pairwise human preference that indicates which generation is the best. Then, a policy generating good generations given a context is learnt from the collected data. We frame the problem of learning from human preferences as an offline contextual bandit problem (Lu et al., 2010). The goal of this bandit problem is that given a context to choose an action (playing the role of the generation) which is most preferred by a human rater under the constraint that the resulting bandit policy should be close to some known reference policy. The constraint of staying close to a known reference policy can be satisfied e.g., by using KL regularisation (Geist et al., 2019) and its role is to avoid model drift (Lazaridou et al., 2020; Lu et al., 2020).
A prominent approach to tackle the problem of learning from human preferences is through reinforcement learning from human feedback (RLHF, Ouyang et al., 2022; Stiennon et al., 2020) in which first a reward model is trained in the form of a classifier of preferred and dispreferred actions. Then the bandit policy is trained through RL to maximize this learned reward model while minimizing the distance with the reference policy. Recently RLHF has been used successfully in solving the problem of aligning generative language models with human preferences (Ouyang et al., 2022). Furthermore recent works such as direct preference optimisation (DPO, Rafailov et al., 2023) and (SLiC-HF, Zhao et al., 2023) have shown that it is possible to optimize the bandit policy directly from human preferences without learning a reward model. They also have shown that on a selection of standard language tasks they are competitive with the state of the art RLHF while they are simpler to implement and require less resources.
Despite this practical success, little is known regarding theoretical foundations of these practical methods. Notable exceptions, that consider specific special cases, are (Wang et al., 2023; Chen et al., 2022) and prior work on preference-based (Busa-Fekete et al., 2014, 2013) and dueling bandits and RL (Novoseller et al., 2020; Pacchiano et al., 2023). However, these theoretical works focus on providing theoretical guarantees in terms of regret bounds in the standard bandit setting and they do not deal with the practical setting of RLHF, DPO and SLiC-HF.
In this work, our focus is on bridging the gap between theory and practice by introducing a simple and general theoretical representation of the practical algorithms for learning from human preferences. In particular, we show that it is possible to characterise the objective functions of RLHF and DPO as special cases of a more general objective exclusively expressed in terms of pairwise preferences. We call this objective -preference optimisation (PO) objective, where is an arbitrary non-deceasing mapping. We then analyze this objective function in the special cases of RLHF and DPO and investigate its potential pitfalls. Our theoretical investigation of RLHF and DPO reveals that in principle they can be both vulnerable to overfitting. This is due to the fact that those methods rely on the strong assumption that pairwise preferences can be substituted with ELo-score (pointwise rewards) via a Bradley-Terry (BT) modelisation (Bradley and Terry, 1952). In particular, this assumption could be problematic when the (sampled) preferences are deterministic or nearly deterministic as it leads to over-fitting to the preference dataset at the expense of ignoring the KL-regularisation term (see Sec. 4.2). We then present a simple solution to avoid the problem of overfitting, namely by setting to identity in the PO. This method is called Identity-PO (IPO) and by construction bypasses the BT modelisation assumption for preferences (see Sec. 5). Finally, we propose a practical solution, via a sampled loss function (see Sec. 5.2), to optimize this simplified version of PO empirically and, we compare its performance with DPO on simple bandit examples, providing empirical support for our theoretical findings (see Sec. 5.3 and Sec. 5.4).
2 Notations
In the remaining, we build on the notations of DPO (Rafailov et al., 2023). Given a context , where is the finite space of contexts, we assume a finite action space . A policy associates to each context a discrete probability distribution where is the set of discrete distributions over . We denote the behavior policy. From a given context , let be two actions generated independently by the reference policy. These are then presented to human raters who express preferences for one of the generations, denoted as where and denote the preferred and dispreferred actions amongst respectively. We then write true human preference the probability of being preferred to knowing the context . The probability comes from the randomness of the choice of the human we ask for their preference. So , where the expectation is over humans . We also introduce the expected preference of a generation over a distribution knowing , noted , via the following equation:
For any two policy and a context distribution we denote the total preference of policy to as
In practice, we do not observe directly, but samples from a Bernoulli distribution with mean (i.e., is with probability and , where is the dataset size. In addition, for a general finite set , a discrete probability distribution and a real function , we note the expectation of under as . For a finite dataset , with for each , and a real function , we denote the empirical expectation of under as .
3 Background
3.1 Reinforcement Learning from Human Feedback (RLHF)
The standard RLHF paradigm (Christiano et al., 2017; Stiennon et al., 2020) consists of two main stages: (i) learning the reward model; (ii) policy optimisation using the learned reward. Here we provide a recap of these stages.
3.1.1 Learning the Reward Model
Learning a reward model consists in training a binary classifier to discriminate between the preferred and dis-preferred actions using a logistic regression loss. For the classifier, a popular choice is Bradley-Terry model: for a given context and action , we denote the pointwise reward, which can also be interpreted as an Elo score, of given by . The Bradley-Terry model represents the preference function (classifier) as a sigmoid of the difference of rewards:
| (1) |
where denotes the sigmoid function and plays the role of normalisation. Given the dataset one can learn the reward function by optimizing the following logistic regression loss
| (2) |
Assuming that conforms to the Bradley-Terry model, one can show that as the size of the dataset grows, becomes a more and more accurate estimate of true and in the limit converges to .
3.1.2 Policy Optimisation with the Learned Reward
Using the reward (Elo-score) the RLHF objective is simply to optimize for the policy that maximizes the expected reward while minimizing the distance between and some reference policy through the following KL-regularized objective function:
| (3) |
in which the context is drawn from and the action is drawn from . The divergence is defined as follows:
where:
The objective in Equation (3) is essentially optimized by PPO (Schulman et al., 2017) or similar approaches.
The combination of RLHF +PPO has been used with great success in practice (e.g., InsturctGPT and GPT-4 Ouyang et al., 2022; OpenAI, 2023).
3.2 Direct Preference Optimisation
An alternative approach to the RL paradigm described above is direct preference optimisation (DPO; Rafailov et al., 2023), which avoids the training of a reward model altogether. The loss that DPO optimises, given an empirical dataset , as a function of , is given by
| (4) |
In its population form, the loss takes on the form
| (5) |
Rafailov et al. (2023) show that when (i) the Bradley-Terry model in Equation (1) perfectly fits the preference data and (ii) the optimal reward function is obtained from the loss in Equation (2), then the global optimisers of the RLHF objective in Equation (3) and the DPO objective in Equation (3.2) perfectly coincide. In fact, this correspondence is true more generally; see Proposition 4 in Appendix B.
4 A General Objective for Preference Optimisation
A central conceptual contribution of the paper is to propose a general objective for RLHF, based on maximizing a non-linear function of preferences. To this end, we consider a general non-decreasing function , a reference policy , and a real positive regularisation parameter , and define the -preference optimisation objective (PO) as
| (6) |
This objective balances the maximisation of a potentially non-linear function of preference probabilities with the KL regularisation term which encourages policies to be close to the reference . This is motivated by the form of Equation (3), and we will see in the next subsection that it strictly generalises both RLHF and DPO, when the BT model holds.
4.1 A Deeper Analysis of DPO and RLHF
In the remaining, we omit the dependency on for the ease of notations. This is without losing generality and all the following results are true for all .
We first connect DPO and RLHF with the -preference objective in Equation (6), under the special choice of . More precisely, the following proposition establishes this connection.
Proposition 1.
Proof.
Note that under the assumption that the Bradley-Terry model holds, we have
This is equal to the reward in Equation (3), up to an additive constant, and so it therefore follows that the optimal policy for Equation (6) and for optimizing the objective in Equation (3) are identical. Further, as shown by Rafailov et al. (2023), the optimal policy for the DPO objective in Equation (3.2) and the objective in Equation (3) are identical, which gives the statement of the proposition. ∎
Applying this proposition to the objective function of Equation (6), for which there exists an analytical solution, reveals that under the BT assumption the closed-form solution to DPO and RLHF can be written as
| (7) |
The derivations leading to Equation 7 is a well known result and is provided in App. A.1 for completeness.
4.2 Weak Regularisation and Overfitting
It is worth taking a step back, and asking what kinds of policies the above objective leads us to discover. This highly non-linear transformation of the preference probabilities means that small increases in preference probabilities already close to 1 are just as incentivized as larger increases in preference probabilities around , which may be undesirable. The maximisation of logit-preferences, or Elo score in game-theoretic terminology, can also have counter-intuitive effects, even in transitive settings (Bertrand et al., 2023).
Consider the simple example where we have two actions and such that , i.e., is always preferred to . Then the Bradley-Terry model would require that to satisfy (1). If we plug this into the optimal policy (7) then we would get that (i.e., ) irrespective of what constant is used for the KL-regularisation. Thus the strength of the KL-regularisation becomes weaker and weaker the more deterministic the preferences.
The weakness of the KL-regularisation becomes even more pronounced in the finite data regime, where we only have access to a sample estimate of the preference . Even if the true preference is, e.g., , empirically it can be very possible when we only have a few data points to estimate , in which case the empirical optimal policy would make for any . This means that overfitting can be a substantial empirical issue, especially when the context and action spaces are extremely large as it is for large language models.
Why may standard RLHF be more robust to this problem in practice? While a purported advantage of DPO is that it avoids the need to fit a reward function, we observe that in practice when empirical preference probabilities are in the set , the reward function ends up being underfit. The optimal rewards in the presence of preference probabilities are infinite, but these values are avoided, and indeed regularisation of the reward function has been observed to be an important aspect of RLHF training in practice (Christiano et al., 2017). This underfitting of the reward function is thus crucial in obtaining a final policy that is sufficiently regularised towards the reference policy , and DPO, in avoiding the training of the reward function, loses the regularisation of the policy that the underfitted reward function affords.
While standard empirical practices such as early-stopping can still be used as an additional form of regularisation to curtail this kind of overfitting, in the next section, we will introduce a modification of the PO objective such that the optimal empirical policy can be close to even when preferences are deterministic.
5 IPO: PO with identity mapping
We have observed in the previous section that DPO is prone to overfitting, and this stems from a combination of the unboundedness of , together with not training an explicit reward function. Not training a reward function directly is a clear advantage of DPO, but we would like to avoid the problems of overfitting as well.
This analysis of DPO motivates choices of which are bounded, ensuring that the KL regularisation in Equation 6 remains effective even in the regime of -valued preferences, as it is often the case when working with empirical datasets. A particularly natural form of objective to consider is given by taking to be the identity mapping in Equation (6), leading to direct regularized optimisation of total preferences:
| (8) |
The standard approach to optimize the objective function of Equation (8) is through RLHF with the choice of reward . However both using RL and estimating the reward model can be costly. Inspired by DPO one would like to devise an empirical solution for the optimisation problem of Equation (8) which can directly learn from the preference dataset. Thus it would be able to avoid RL and reward modeling altogether.
5.1 Derivations and Computationally Efficient Algorithm
As with DPO, it will be beneficial to re-express Equation (8) as an offline learning objective. To derive such an expression, we begin by following the derivation of Rafailov et al. (2023), manipulating the analytic expression for the optimal policy into a system of root-finding problems. As in the previous section, we drop dependence on the context from our notation, as all arguments can be applied on a per-context basis.
Root-finding problems. Let . Then we have
| (9) |
For any , we therefore have
| (10) |
By letting
and rearranging Equation (10), we obtain
| (11) |
The core idea now is to consider a policy , define
and aim to solve the equations:
| (12) |
Loss for IPO. We now depart from the approach to the analysis employed by Rafailov et al. (2023), to obtain a novel offline formulation of Equation (6), in the specific case of as the identity function. In this case, Equation (12) reduces to
We begin by re-expressing these root-finding problems as a single optimisation problem :
| (13) |
One can easily show that for the choice of we have . Thus is a global minimizer of . The following theorem establishes the uniqueness of this solution.
Theorem 2 (Uniqueness of Global/Local Optima).
Assume that and define to be the set of policies such that . Then has a unique local/global minimum in , which is .
Proof.
By assumption, , and by definition as is an expectation of squared terms. Further, from Equation (11), it follows immediately that , and so we deduce that is a global optimum for . We now show that there are no other local/global minima for in .
We write . We parametrise the set via vectors of logits , setting for , and otherwise. Let us write for the objective as a function of the logits .
| (14) | ||||
The objective is quadratic as a function of the logits . Further, by expanding the quadratic above, we see that the loss can be expressed as a sum of squares
| (15) |
plus linear and constant terms. This is therefore a positive-semidefinite quadratic, and hence is convex. We thus deduce that all local minimisers of the loss are global minimisers as well (Boyd and Vandenberghe, 2004, Chap. 4). We now notice since is a surjective continuous mapping from to one can easily show from the definition of local minimum that every local minimiser of corresponds to a set of local minimisers of . Thus all local minimums of are also global minimums as well.
Finally, the only direction in which the quadratic in Equation (15) does not increase away from 0 is when all bracketed terms remain 0; that is, in the direction . Thus, is strictly convex, except in the direction . (Boyd and Vandenberghe, 2004, Chap. 3). However, modifying logits in the direction does not modify the resulting policy , since, for ,
The strict convexity combined with the fact that is a global minima proves that is the unique global/local minima in (Boyd and Vandenberghe, 2004, Chap. 4). ∎
5.2 Sampled Loss for IPO
In order to obtain the sampled loss for IPO we need to show that we can build an unbiased estimate of the right-hand side of the equation (13). To this end, we consider the Population IPO Loss:
| (16) |
where is drawn from a Bernoulli distribution with mean , i.e., is if is preferred to (which happens with probability ), and from the preference dataset, and consulting the recorded preference to obtain a sample from . The following proposition justifies the switch from Equation (13) to Equation (16), by demonstrating their equality.
Proposition 3.
Proof.
This equivalence is not completely trivial, since in general the conditional expectation
is not equal to the corresponding quantity appearing in Equation (13), namely
We instead need to exploit some symmetry between the distributions of and , and use the fact that decomposes as an additive function of and . To show this equality of losses, it is enough to focus on the “cross-terms” obtained when expanding the quadratics in Equations (13) and (16); that is, to show
Now, starting with the right-hand side, and using the shorthand , , , and similarly for , we have
where we have used iid-ness of and , and . Turning to the left-hand side, we have
where we use the fact that and . This demonstrates equality of the losses, as required. ∎
We now discuss how to approximate the loss in Equation (16) with an empirical dataset. As in our earlier discussion, the empirical dataset takes the form . Note that each datapoint contributes two terms to an empirical approximation of Equation (16), with , and also . This symmetry is important to exploit, and leads to a reduction in the variance of the loss. The overall empirical loss is therefore given by
| , |
which up to a constant equals:
| (17) |
This simplified form of the loss provides some valuable insights on the way in which IPO optimizes the policy : (i) IPO learns from preferences dataset simply by increasing the log-likelihood ratio by a constant . So the weaker the regularisation becomes, the higher would be the log-likelihood ratio of to . (ii) IPO, unlike DPO, always regularizes its solution towards by controlling the distance between the log-likelihood ratios and , thus avoiding the over-fitting to the preference dataset.
5.3 Illustrative Examples
To illustrate the qualitative difference between our algorithm and DPO we will consider a few simple cases. For simplicity we assume there is no context , i.e., we are in the bandit setting.
5.3.1 Asymptotic Setting
We first consider the simple case where we have 2 actions only, and , and a deterministic preference between them: . Suppose we start with a uniform and . We know from Section 4.2 that DPO will converge to the deterministic policy , regardless of the value of . Thus even when the regularisation coefficient is very large, this is very different from the uniform .
Now, let us derive the optimal policy for IPO. We have and . Plugging this into equation (9) with we get that , and , where is the sigmoid function. Hence we see that if we have large regularisation as , then converges to the uniform policy , and on the flip side as , then and , which is the deterministic optimal policy. The regularisation parameter can now actually be used to control how close to we are.
5.4 Sampled Preferences
So far we relied on the closed-form optimal policy from Eq. (9) to study DPO and IPO’s stability, but this equation is not applicable to more complex settings where we only have access to sampled preference instead of . We can still however find accurate approximations of the optimal policy by choosing a parametrisation and optimize with an empirical loss over a dataset and iterative gradient-based updates. We will use this approach to show two non-asymptotic examples where DPO over-fits the dataset of preferences and ignore : when one action wins against all others DPO pushes to 1 regardless of , and conversely when one action never wins against the others DPO pushes to 0 again regardless of . In the same scenarios, IPO does not converge to these degenerate solutions but instead remains close to based on the strength of the regularisation .
For both scenarios we consider a discrete space with 3 actions, and select a dataset of pairs . Given , we leverage the empirical losses from Eq. 3.2 and Eq. 13 to find DPO’s and IPO’s optimal policy. We encode policies as using a vector , and optimize them for steps using Adam (Kingma and Ba, 2014) with learning rate and mini-batch size . Mini-batches are constructed using uniform sampling with replacement from . Both policies and losses are implemented using the flax python framework (Bradbury et al., 2018; Heek et al., 2023), and the Adam implementation is from optax (Babuschkin et al., 2020). For each set of hyper-parameters we repeat the experiment 10 times with different seeds, and report mean and 95% confidence intervals. All experiments are executed on a modern cloud virtual machine with 4 cores and 32GB of ram.
IPO Avoids Greedy Policies
For the first example we sample each unique action pair once to collect a dataset containing 3 observed preferences. Due to symmetries of pairwise preferences sampling only 3 preferences can results in only two outcomes (up to permutations of the actions):
where we focus on , which represent a total ordering, rather than , which represent a cycle. The outcome of the experiment is reported in Fig. 1 in which, we report the learning curves for varying values of . We observe that DPO always converges to the deterministic policy for all values of . In other word DPO completely ignores the reference policy, no matter how strong is the regularisation term, and converges to the action which is preferred in the dataset. On the other hand, IPO prevent the policy from becoming greedy when the regularisation is strong.
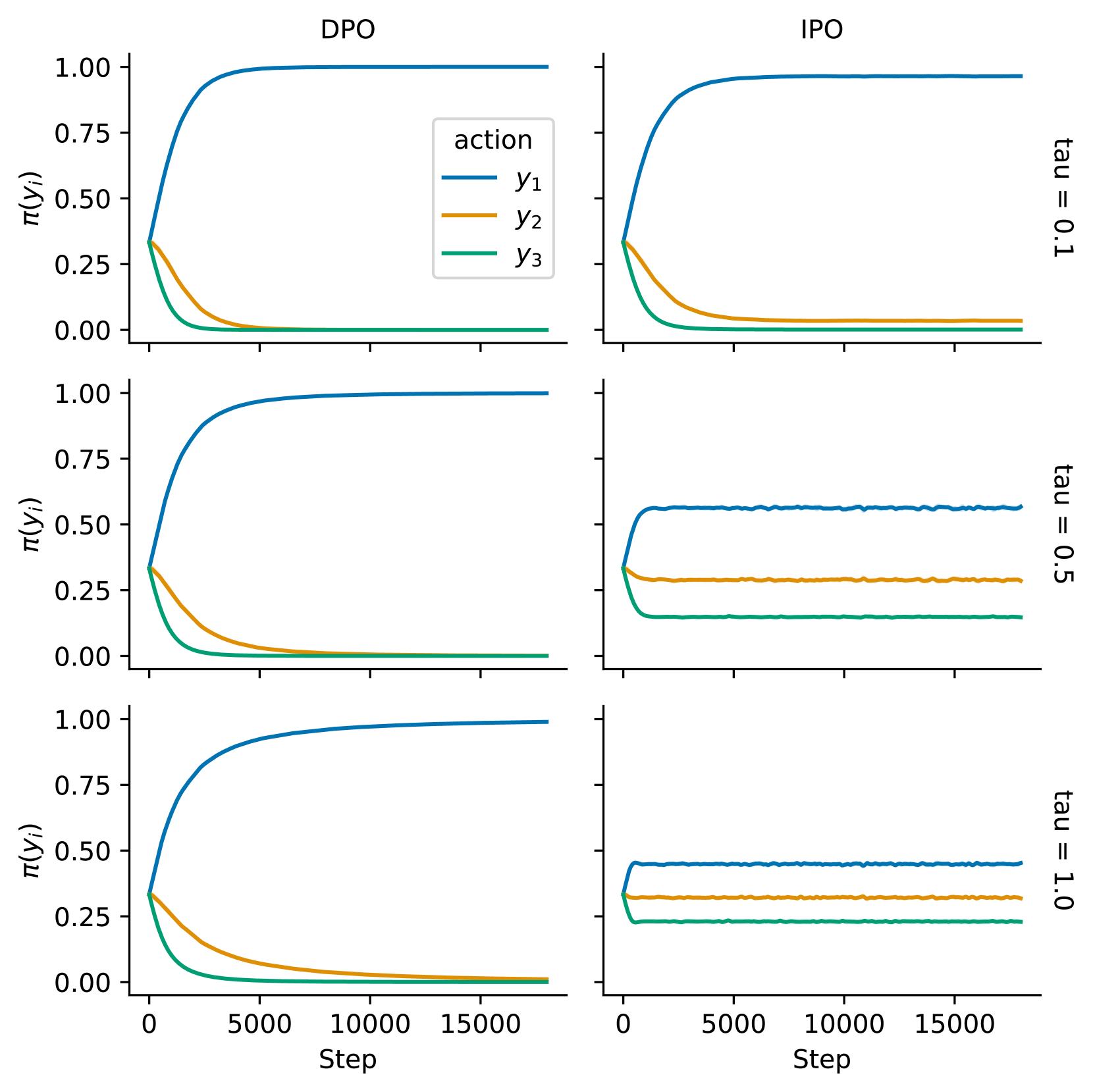
IPO Does not Exclude Actions
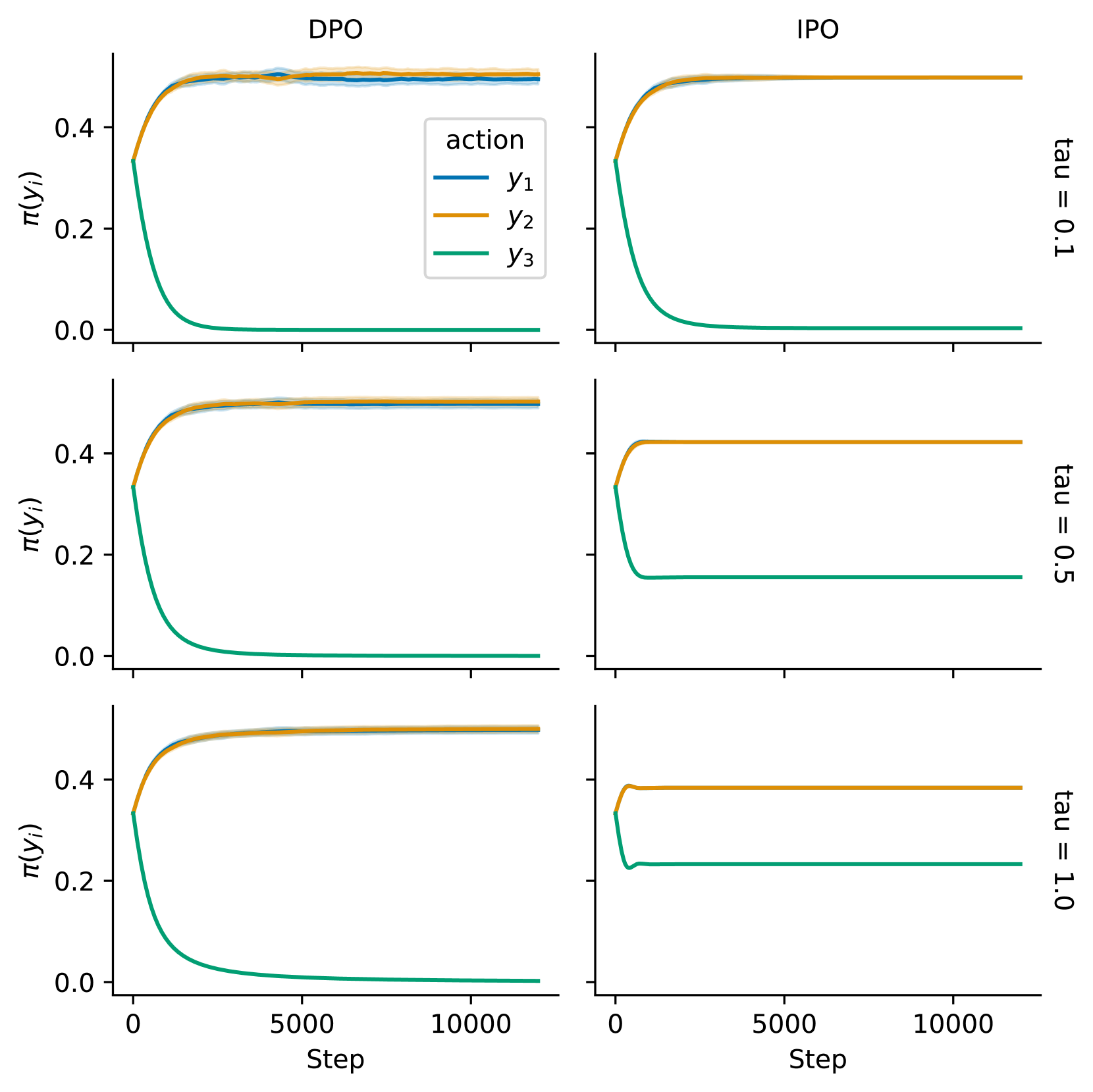
In the first example DPO converges to a deterministic policy because one action strictly dominates all others and the loss continues to push up its likelihood until it saturates. The opposite effect happens for the logical opposite condition, i.e., when one action does not have at least a victory in the dataset DPO will sets its probability to 0 regardless of . While this is less disruptive than the first example (a single probability is perturbed whereas previously the whole policy was warped by an over-achieving action) it is also much more common in real-world data. In particular, whenever the action space is large but the dataset small, some actions will necessarily be sampled rarely or only once, making it likely to never observe a victory. Especially because we do not have data on their performance should stick close to for safety, but DPO’s objective does not promote this.
In the final example the dataset consists of two observed preferences and leave the pair completely unobserved. We compute solutions using Adam once again, and report the results in Fig. 2 for varying values of . We observe again here that DPO ignores the prior completely, no matter how strong we regularize the objective, whereas IPO gradually decreases the probability of unobserved action with .
6 Conclusion and Future Work
We presented a unified objective, called PO, for learning from preferences. It unifies RLHF and DPO methods. In addition, we introduced a particular case of PO, called IPO, that allows to learn directly from preferences without a reward modelling stage and without relying on the Bradley-Terry modelisation assumption that assumes that pairwise preferences can be substituted with pointwise rewards. This is important because it allows to avoid the overfitting problem. This theoretical contribution is only useful in practice if an empirical sampled loss function can be derived. This is what we have done in Sec 5 where we show that IPO can be formulated as a root-finding problem from which an empirical sampled loss function can be derived. The IPO loss function is simple, easy to implement and theoretically justified. Finally, in Sec. 5.3 and Sec. 5.4, we provide illustrative examples where we highlight the instabilities of DPO when the preferences are fully-known as well as when they are sampled. Those minimal experiments are sufficient to prove that IPO is better suited to learn from sampled preferences than DPO. Future works should scale those experiments to more complex settings such as training language models on human preferences data.
References
- Babuschkin et al. (2020) Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupatiraju, Jake Bruce, Peter Buchlovsky, David Budden, Trevor Cai, Aidan Clark, Ivo Danihelka, et al. The DeepMind JAX ecosystem, 2020, 2020. URL http://github.com/deepmind.
- Bertrand et al. (2023) Quentin Bertrand, Wojciech Marian Czarnecki, and Gauthier Gidel. On the limitations of the Elo: Real-world games are transitive, not additive. In Proceedings of the International Conference on Artificial Intelligence and Statistics, 2023.
- Boyd and Vandenberghe (2004) Stephen P. Boyd and Lieven Vandenberghe. Convex optimization. Cambridge University Press, 2004.
- Bradbury et al. (2018) James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URL http://github.com/google/jax.
- Bradley and Terry (1952) Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. The method of paired comparisons. Biometrika, 39(3/4):324–345, 1952.
- Busa-Fekete et al. (2014) Róbert Busa-Fekete, Balázs Szörényi, Paul Weng, Weiwei Cheng, and Eyke Hüllermeier. Preference-based reinforcement learning: Evolutionary direct policy search using a preference-based racing algorithm. Machine Learning, (3):327–351, 2014.
- Busa-Fekete et al. (2013) Róbert Busa-Fekete, Balázs Szörenyi, Paul Weng, Weiwei Cheng, and Eyke Hüllermeier. Preference-based evolutionary direct policy search. In Autonomous Learning Workshop @ ICRA, 2013.
- Chen et al. (2022) Xiaoyu Chen, Han Zhong, Zhuoran Yang, Zhaoran Wang, and Liwei Wang. Human-in-the-loop: Provably efficient preference-based reinforcement learning with general function approximation. In Proceedings of the International Conference on Machine Learning, 2022.
- Christiano et al. (2017) Paul F. Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems, 2017.
- Geist et al. (2019) Matthieu Geist, Bruno Scherrer, and Olivier Pietquin. A theory of regularized Markov decision processes. In Proceedings of the International Conference on Machine Learning, 2019.
- Heek et al. (2023) Jonathan Heek, Anselm Levskaya, Avital Oliver, Marvin Ritter, Bertrand Rondepierre, Andreas Steiner, and Marc van Zee. Flax: A neural network library and ecosystem for JAX, 2023. URL http://github.com/google/flax.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, 2014.
- Lazaridou et al. (2020) Angeliki Lazaridou, Anna Potapenko, and Olivier Tieleman. Multi-agent communication meets natural language: Synergies between functional and structural language learning. In Proceedings of the Annual Meeting of Association for Computational Linguistics, 2020.
- Lu et al. (2010) Tyler Lu, Dávid Pál, and Martin Pál. Contextual multi-armed bandits. In Proceedings of the International Conference on Artificial Intelligence and Statistics, 2010.
- Lu et al. (2020) Yuchen Lu, Soumye Singhal, Florian Strub, Aaron Courville, and Olivier Pietquin. Countering language drift with seeded iterated learning. In Proceedings of the International Conference on Machine Learning, 2020.
- Novoseller et al. (2020) Ellen Novoseller, Yibing Wei, Yanan Sui, Yisong Yue, and Joel Burdick. Dueling posterior sampling for preference-based reinforcement learning. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, 2020.
- OpenAI (2023) OpenAI. Gpt-4 technical report, 2023.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller amd Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, 2022.
- Pacchiano et al. (2023) Aldo Pacchiano, Aadirupa Saha, and Jonathan Lee. Dueling RL: Reinforcement learning with trajectory preferences. arXiv, 2023.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
- Rafailov et al. (2023) Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv, 2023.
- Ramachandran et al. (2016) Prajit Ramachandran, Peter J. Liu, and Quoc V. Le. Unsupervised pretraining for sequence to sequence learning. In Proceedings of the Conference on Empirical Methods in Natural Language Processings, 2016.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv, 2017.
- Stiennon et al. (2020) Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F. Christiano. Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 2020.
- Wang et al. (2023) Yuanhao Wang, Qinghua Liu, and Chi Jin. Is RLHF more difficult than standard RL? arXiv, 2023.
- Wei et al. (2022) Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. Finetuned language models are zero-shot learners. In Proceedings of the International Conference on Learning Representations, 2022.
- Zhao et al. (2023) Yao Zhao, Rishabh Joshi, Tianqi Liu, Misha Khalman, Mohammad Saleh, and Peter J Liu. SLiC-HF: Sequence likelihood calibration with human feedback. arXiv, 2023.
APPENDICES
Appendix A Proofs
A.1 Existence and uniqueness of the regularized argmaximum
For completeness, we briefly recall the proof of existence and uniqueness of the argmaximum of the following regularized criterion that can also be found in the work of Rafailov et al. (2023):
where is a finite set, a function mapping elements of to real numbers, a strictly positive real number, and are discrete probability distributions over . In particular, we recall that a discrete probability distribution can be identified as a positive real function verifying:
Now, if we define the softmax probability as:
then, under the previous definitions, we have the following result:
Proof.
By definition of the KL, we now that and as:
where is a constant (does not depend on ) and a positive multiplicative term, then and share the same argmaximum. This concludes the proof. ∎
A.2 Non uniqueness when :
Notice that if we search for solution where the support of is strictly larger than that of then there could be multiple solutions. Let us illustrate this case with a simple example. There is only one state and 3 actions The reference policy is uniform over and the policy assigns a probability to both and and .
Thus the loss is . We deduce that any policy such that is a global minimum of .
In particular there are an infinity of solutions different from the optimal solution . The problem comes from the fact that when the support of does not cover the whole action space there are not enough constraints to uniquely characterize . Assuming that the supports of and coincide enables us to recover uniqueness of the solution, as proven in Theorem 2.
Appendix B Additional results
In this section, we show the equivalence of DPO and RLHF, regardless of whether the preference model corresponds to a Bradley-Terry model. Note that the assumption of the existence of a minimizer is to exclude cases where the loss is minimized by taking the rewards of certain actions to .
Proposition 4.
Consider a preference model such that there exists a minimizer to the Bradley-Terry loss
Then, the optimal policy for the DPO objective in Equation (3.2) and for the RLHF objective in Equation (3) with reward model given as the minimizer to the Bradley-Terry loss above are identical, regardless of whether or not corresponds to a Bradley-Terry preference model.
Proof.
Recall that the optimal policy for a given reward function for the objective in Equation (3) is given by . It therefore follows that
In words, the value of the Bradley-Terry reward objective for is the value of the DPO objective for . We recall also that the map is surjective.
Now, suppose is optimal for the Bradley-Terry reward objective, meaning that is optimal for the RLHF objective. If is not optimal for the DPO objective, then there exists another policy that obtains a strictly lower value for the DPO loss. But then there exists a reward function such that , such as , and this therefore obtains a lower Bradley-Terry loss than , a contradiction.
Similarly, if is optimal for the DPO objective, the corresponding reward function must be optimal for the Bradley-Terry reward loss. The corresponding optimizer for the RLHF objective is then given by , as required. ∎