ChipNeMo: Domain-Adapted LLMs for Chip Design
ChipNeMo: Domain-Adapted LLMs for Chip Design
Abstract
ChipNeMo aims to explore the applications of large language models (LLMs) for industrial chip design. Instead of directly deploying off-the-shelf commercial or open-source LLMs, we instead adopt the following domain adaptation techniques: domain-adaptive tokenization, domain-adaptive continued pretraining, model alignment with domain-specific instructions, and domain-adapted retrieval models. We evaluate these methods on three selected LLM applications for chip design: an engineering assistant chatbot, EDA script generation, and bug summarization and analysis. Our evaluations demonstrate that domain-adaptive pretraining of language models, can lead to superior performance in domain related downstream tasks compared to their base LLaMA2 counterparts, without degradations in generic capabilities. In particular, our largest model, ChipNeMo-70B, outperforms the highly capable GPT-4 on two of our use cases, namely engineering assistant chatbot and EDA scripts generation, while exhibiting competitive performance on bug summarization and analysis. These results underscore the potential of domain-specific customization for enhancing the effectiveness of large language models in specialized applications.
1 Introduction
Over the last few decades, Electronic Design Automation (EDA) algorithms and tools have provided huge gains in chip design productivity. Coupled with the exponential increases in transistor densities provided by Moore’s law, EDA has enabled the development of feature-rich complex SoC designs with billions of transistors. More recently, researchers have been exploring ways to apply AI to EDA algorithms and the chip design process to further improve chip design productivity (Khailany et al., 2020; Ren & Fojtik, 2021; Roy et al., 2021). However, many time-consuming chip design tasks that involve interfacing with natural languages or programming languages still have not been automated. The latest advancements in commercial (ChatGPT, Bard, etc.) and open-source (Vicuna (Chiang et al., 2023), LLaMA2 (Touvron et al., 2023), etc.) large language models (LLM) provide an unprecedented opportunity to help automate these language-related chip design tasks. Indeed, early academic research (Thakur et al., 2023; Blocklove et al., 2023; He et al., 2023) has explored applications of LLMs for generating Register Transfer Level (RTL) code that can perform simple tasks in small design modules as well as generating scripts for EDA tools.
We believe that LLMs have the potential to help chip design productivity by using generative AI to automate many language-related chip design tasks such as code generation, responses to engineering questions via a natural language interface, analysis and report generation, and bug triage. In this study, we focus on three specific LLM applications: an engineering assistant chatbot for GPU ASIC and Architecture design engineers, which understands internal hardware designs and is capable of explaining complex design topics; EDA scripts generation for two domain specific tools based on Python and Tcl for VLSI timing analysis tasks specified in English; bug summarization and analysis as part of an internal bug and issue tracking system.
Although general-purpose LLMs trained on vast amounts of internet data exhibit remarkable capabilities in generative AI tasks across diverse domains (as demonstrated in (Bubeck et al., 2023)), recent work such as BloombergGPT (Wu et al., 2023) and BioMedLLM (Venigalla et al., 2022) demonstrate that domain-specific LLM models can outperform a general purpose model on domain-specific tasks. In the hardware design domain, (Thakur et al., 2023; Liu et al., 2023) showed that open-source LLMs (CodeGen (Nijkamp et al., 2023)) fine-tuned on additional Verilog data can outperform state-of-art OpenAI GPT-3.5 models. Customizing LLMs in this manner also avoids security risks associated with sending proprietary chip design data to third party LLMs via APIs. However, it would be prohibitively expensive to train domain-specific models for every domain from scratch, since this often requires millions of GPU training hours. To cost-effectively train domain-specific models, we instead propose to combine the following techniques: Domain-Adaptive Pre-Training (DAPT) (Gururangan et al., 2020) of foundation models with domain-adapted tokenizers, model alignment using general and domain-specific instructions, and retrieval-augmented generation (RAG) (Lewis et al., 2021b) with a trained domain-adapted retrieval model.
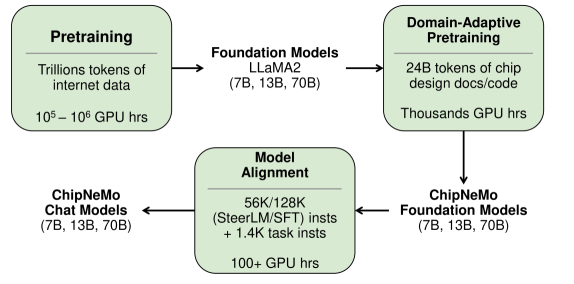
As shown in Figure 1, our approach is to start with a base foundational model and apply DAPT followed by model alignment. DAPT, also known as continued pretraining with in-domain data, has been shown to be effective in areas such as biomedical and computer science publications, news, and reviews. In our case, we construct our domain-specific pre-training dataset from a collection of proprietary hardware-related code (e.g. software, RTL, verification testbenches, etc.) and natural language datasets (e.g. hardware specifications, documentation, etc.). We clean up and preprocess the raw dataset, then continued-pretrain a foundation model with the domain-specific data. We call the resulting model a ChipNeMo foundation model. DAPT is done on a fraction of the tokens used in pre-training, and is much cheaper, only requiring roughly 1.5% of the pretraining compute.
LLM tokenizers convert text into sequences of tokens for training and inference. A domain-adapted tokenizer improves the tokenization efficiency by tailoring rules and patterns for domain-specific terms such as keywords commonly found in RTL. For DAPT, we cannot retrain a new domain-specific tokenizer from scratch, since it would make the foundation model invalid. Instead of restricting ChipNeMo to the pre-trained general-purpose tokenizer used by the foundation model, we instead adapt the pre-trained tokenizer to our chip design dataset, only adding new tokens for domain-specific terms.
ChipNeMo foundation models are completion models which require model alignment to adapt to tasks such as chat. We use largely publicly available general-purpose chat instruction datasets for multi-turn chat together with a small amount of domain-specific instruction datasets to perform alignment on the ChipNeMo foundation model, which produces the ChipNeMo chat model. We observe that alignment with a general purpose chat instruction dataset is adequate to align the ChipNeMo foundation models with queries in the chip design domain. We also added a small amount of task-specific instruction data, which further improves the alignment. We trained multiple ChipNeMo foundation and chat models based on variants of LLaMA2 models used as the base foundation model.
To improve performance on the engineering assistant chatbot application, we also leverage Retrieval Augmented Generation (RAG). RAG is an open-book approach for giving LLMs precise context for user queries. It retrieves relevant in-domain knowledge from its data store to augment the response generation given a user query. This method shows significant improvement in grounding the model to the context of a particular question. Crucially we observed significant improvements in retrieval hit rate when finetuning a pretrained retrieval model with domain data. This led to even further improvements in model quality.
Our results show that domain-adaptive pretraining was the primary technique driving enhanced performance in domain-specific tasks. We highlight the following contributions and findings for adapting LLMs to the chip design domain:
-
•
We demonstrate domain-adapted LLM effectiveness on three use-cases: an engineering assistant chatbot, EDA tool script generation, and bug summarization and analysis. We achieve a score of 6.0 on a 7 point Likert scale for engineering assistant chatbot based on expert evaluations, more than 70% correctness on the generation of simple EDA scripts, and expert evaluation ratings above 5 on a 7 point scale for summarizations and assignment identification tasks.
-
•
Domain-adapted ChipNeMo models dramatically outperforms all vanilla LLMs evaluated on both multiple-choice domain-specific AutoEval benchmarks and human evaluations for applications.
-
•
Using the SteerLM alignment method (Dong et al., 2023) over traditional SFT improves human evaluation scores for the engineering assistant chatbot by 0.62 points on a 7 point Likert scale.
-
•
SFT on an additional domain-specific instructions significantly improves the model’s proficiency at generating correct EDA tool scripts by .
-
•
Domain-adaptive tokenization reduce domain data token count by up to without hurting effectiveness on applications.
-
•
Fine-tuning our ChipNeMo retrieval model with domain-specific data improves the retriever hit rate by 30% over a pre-trained state-of-the-art retriever, in turn improving overall quality of RAG responses.
The paper is organized as follows. Section 2 outlines domain adaptation and training methods used including the adapted tokenizer, DAPT, model alignment, and RAG. Section 3 describes the experimental results including human evaluations for each application. Section 4 describes relevant LLM methods and other work targeting LLMs for chip design. Finally, detailed results along with additional model training details and examples of text generated by the application use-cases are illustrated in the Appendix.
2 ChipNeMo Domain Adaptation Methods
ChipNeMo implements multiple domain adaptation techniques to adapt LLMs to the chip design domain. These techniques include domain-adaptive tokenization for chip design data, domain adaptive pretraining with large corpus of domain data, model alignment to domain specific tasks, and retrieval-augmented generation with a fine-tuned retrieval model. We illustrate the details of each technique in this section.
2.1 Domain-Adaptive Tokenization
When adapting a pre-trained tokenizer, the main goals are to improve tokenization efficiency on domain-specific data, maintain language model performance on general datasets, and minimize the effort for retraining/fine-tuning. To achieve this, we developed the following approach:
-
1.
Train a tokenizer from scratch using domain-specific data.
-
2.
From the vocabulary of the new tokenizer, identifying tokens that are absent in the general-purpose tokenizer and are rarely found in general-purpose datasets.
-
3.
Expand the general-purpose tokenizer with the newly identified tokens at Step 2.
-
4.
Initialize model embeddings of the new tokens by utilizing the general-purpose tokenizer.
Specifically for Step 4, when a new token is encountered, it is first re-tokenized using the original pretrained general-purpose tokenizer. The LLM’s token embedding for the new token is determined by averaging the embeddings of the tokens generated by the general-purpose tokenizer (Koto et al., 2021). The LLM’s final output layer weights for the new tokens are initialized to zero.
Step 2 helps maintain the performance of the pre-trained LLM on general datasets by selectively introducing new tokens that are infrequently encountered in general-purpose datasets. Step 4 reduces the effort required for retraining or finetuning the LLM via initialization of the embeddings of new tokens guided by the general-purpose tokenizer.
2.2 Domain Adaptive Pretraining
In our study, we apply DAPT on pretrained foundation base models: LLaMA2 7B/13B/70B. Each DAPT model is initialized using the weights of their corresponding pretrained foundational base models. We name our domain-adapted models ChipNeMo. We employ tokenizer augmentation as depicted in Section 2.1 and initialize embedding weight accordingly (Koto et al., 2021). We conduct further pretraining on domain-specific data by employing the standard autoregressive language modeling objective. All model training procedures are conducted using the NVIDIA NeMo framework (Kuchaiev et al., 2019), incorporating techniques such as tensor parallelism (Shoeybi et al., 2019) and flash attention (Dao et al., 2022) for enhanced efficiency.
Our models undergo a consistent training regimen with similar configurations. A small learning rate of is employed, and training is facilitated using the Adam optimizer, without the use of learning rate schedulers. The global batch size is set at 256, and a context window of 4096 tokens is applied, resulting in an effective batch size of 1M tokens. The total number of training steps is set to 23,200, equating to roughly 1 epoch of the data blend.
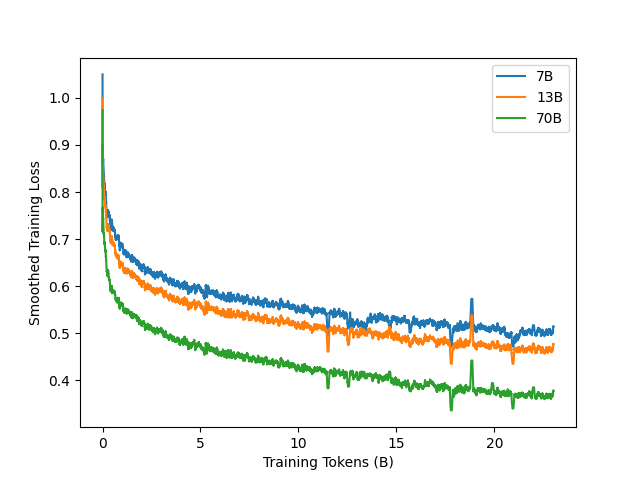
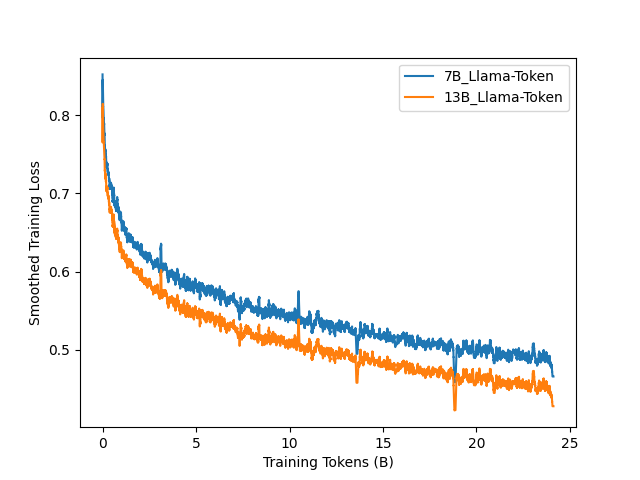
Figure 2 illustrates the training loss of ChipNeMo under the specified hyperparameters. We do observe spikes in the training loss. In contrast to the hypothesis in (Chowdhery et al., 2022), we postulate that in our scenario, these spikes can be attributed to “bad data” since these irregularities seem to consistently occur in similar training steps for the same model, even across different model sizes. We chose not to address this issue, as these anomalies did not appear to significantly impede subsequent training steps (with no noticeable degradation in validation loss), possibly due to our application of a low learning rate.
2.3 Model Alignment
After DAPT, we perform model alignment. We specifically leverage two alignment techniques: supervised fine-tuning (SFT) and SteerLM (Dong et al., 2023). We adopt the identical hyperparameter training configuration as DAPT for all models, with the exception of using a reduced global batch size of 128. We employ an autoregressive optimization objective, implementing a strategy where losses associated with tokens originating from the system and user prompts are masked (Touvron et al., 2023). This approach ensures that during backpropagation, our focus is exclusively directed towards the optimization of answer tokens.
We combined our domain alignment dataset, consisting of approximately 1.4k samples, with larger general chat datasets. For SFT, we blended the domain instructional data with 128k commercial-viable chat data and then performed fine-tuning for a single epoch after random shuffling. We conducted experiments involving augmentation of the domain-specific SFT dataset for more than one epoch. However, it became apparent that the model rapidly exhibited signs of overfitting when presented with in-domain questions, often repeating irrelevant answers from the domain SFT dataset. For SteerLM, we closely followed the steps outlined in (Wang et al., 2023). We first trained an attribute model instantiated with LLaMA2-13B model on the HelpSteer and OASST datasets. We then used the attribute model to label all attributes for OASST data and our domain instructional data. Finally, we conducted attribute-conditioned fine-tuning and also masked the attribute labels and trained on ChipNeMo models for 2 epochs. We refer readers to Appendix A.4 for details on the alignment datasets and A.7 on implementations details.
We also experimented with DAPT directly on a chat aligned model, such as the LLaMA2-Chat model. We found that DAPT significantly degraded the model’s alignment, making the resulting model useless for downstream tasks.
2.4 Domain-Adapted Retrieval Model
It is well known that LLMs can generate inaccurate text, so-called hallucination (Ji et al., 2023). Although the phenomenon is not completely understood, we still must mitigate hallucinations since they are particularly problematic in an engineering assistant chatbot context, where accuracy is critical. Our proposal is to leverage the retrieval augmented generation (RAG) method. RAG tries to retrieve relevant passages from a database to be included in the prompt together with the question, which grounds the LLM to produce more accurate answers. We find that using a domain adapted language model for RAG significantly improves answer quality on our domain specific questions. Also, we find that fine-tuning an off-the-shelf unsupervised pre-trained dense retrieval model with a modest amount of domain specific training data significantly improves retrieval accuracy. Our domain-adapted RAG implementation diagram is illustrated on Figure 3.
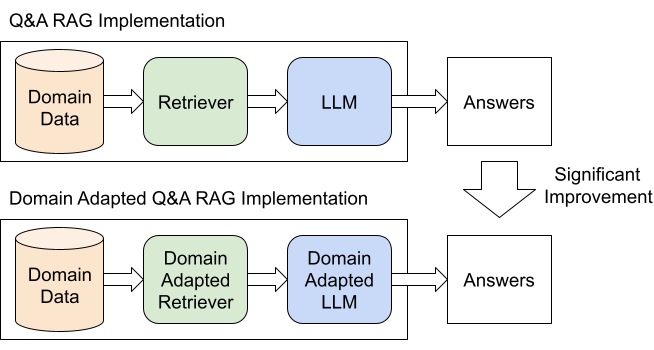
We created our domain adapted retrieval model by fine-tuning the e5_small_unsupervised model (Wang et al., 2022) with 3000 domain specific auto-generated samples using the Tevatron framework (Gao et al., 2022). We refer readers to the details on the sample generation and training process in Appendix A.8.
Even with the significant gains that come with fine-tuning a retrieval model, the fact remains that retrieval still struggles with queries that do not map directly to passages in the document corpus or require more context not present in the passage. Unfortunately, these queries are also more representative of queries that will be asked by engineers in real situations. Combining retrieval with a domain adapted language model is one way to address this issue.
3 Evaluations
We evaluate our training methodology and application performance in this section. We study our 7B, 13B, and 70B models in the training methodology evaluation, and only our ChipNeMo-70B model using SteerLM for model alignment in the application performance evaluation. For comparison, we also evaluate two baseline chat models: LLaMA2-70B-Chat and GPT-4. LLaMA2-70B-Chat is the publicly released LLaMA2-Chat model trained with RLHF and is considered to be the state-of-the-art open-source chat model, while GPT-4 is considered to be the state-of-the-art proprietary chat model.
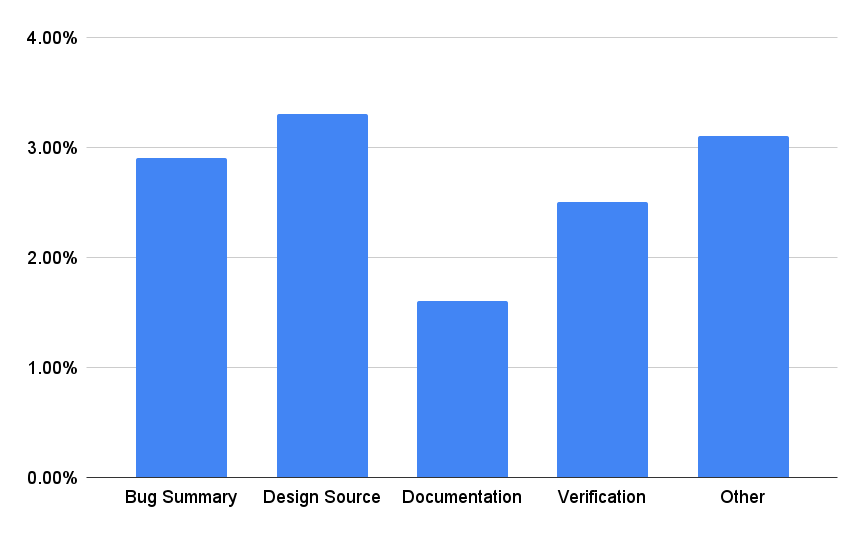
3.1 Domain-Adaptive Tokenization
We adapt the LLaMA2 tokenizer (containing 32K tokens) to chip design datasets using the previously outlined four-step process. Approximately 9K new tokens are added to the LLaMA2 tokenizer. The adapted tokenizers can improve tokenization efficiency by 1.6% to 3.3% across various chip design datasets as shown in Figure 4. We observe no obvious changes to tokenizer efficiency on public data. Importantly, we have not observed significant decline in the LLM’s accuracy on public benchmarks when using the domain-adapted tokenizers even prior to DAPT.
3.2 Domain Adaptive Pretraining
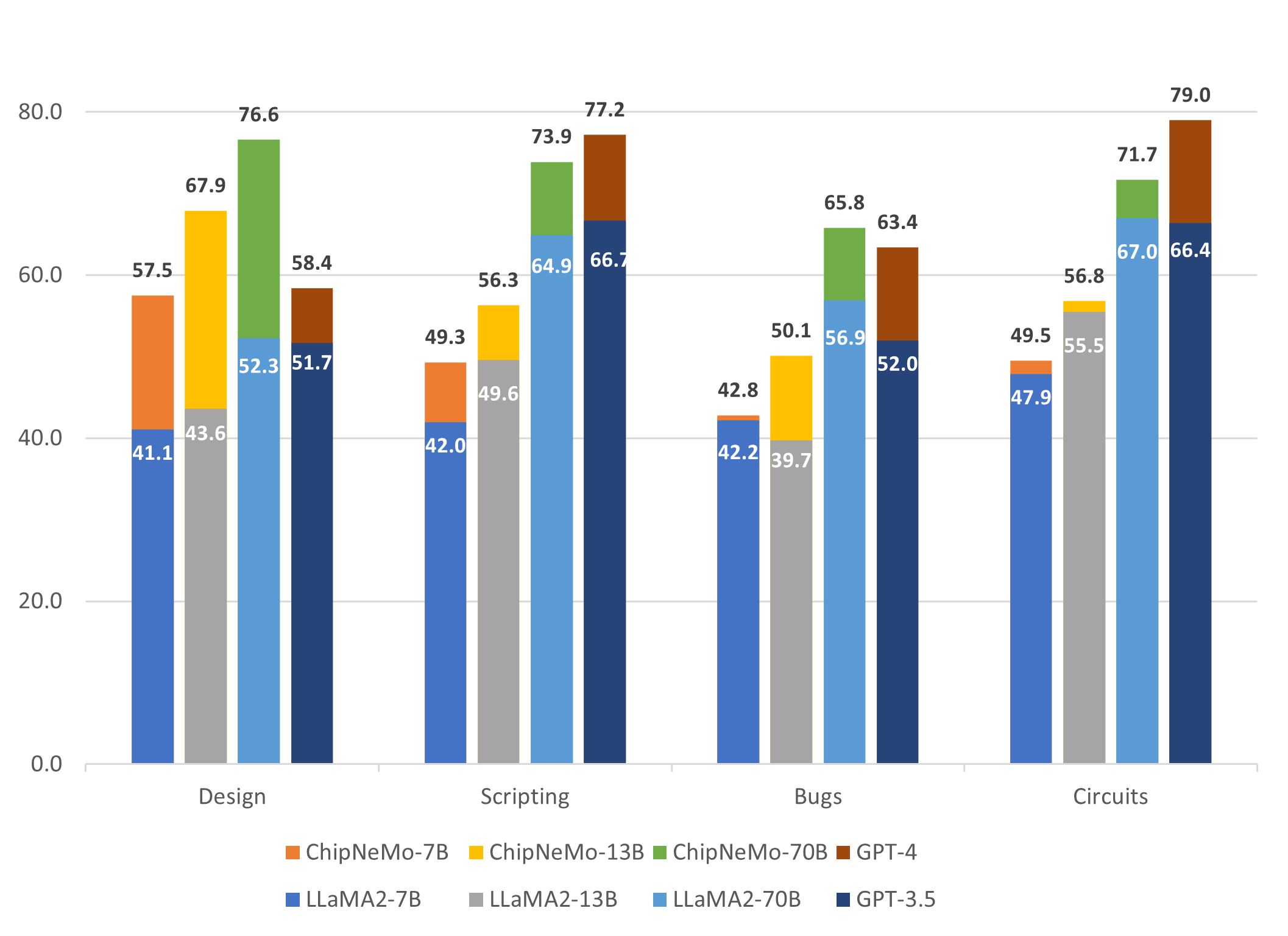
Figure 5 presents the outcomes for ChipNeMo models on the AutoEval benchmark for chip design domain (detailed in Appendix A.5). Results on open domain academic benchmark results are presented in Appendix A.6. Our research findings can be summarized as follows:
-
•
DAPT exerts a substantial positive impact on tasks within the domain itself. This effect is manifested in significant improvements in internal design knowledge as well as general circuit design knowledge.
-
•
DAPT models exhibit a slight degradation in performance on open-domain academic benchmarks.
-
•
The use of larger and more performant foundational models yields better zero-shot results on domain-specific tasks. Furthermore, the employment of superior base models results in enhanced domain models post-DAPT, leading to heightened performance on in-domain tasks.
-
•
Improvements attributed to DAPT with in-domain tasks exhibit a positive correlation with model size, with larger models demonstrating more pronounced enhancements in domain-specific task performance.
3.3 Training Ablation Studies
For our ablation studies, we conducted multiple rounds of domain adaptive pre-training. We provide brief summaries and refer to the Appendix A.6 for details.
The differences between training with the augmented tokenizer and the original tokenizer appeared to be negligible. We thus primarily attribute the accuracy degradation on open-domain academic benchmarks to domain data. Moreover, the removal of the public dataset only slightly regressed on most tasks including academic benchmarks.
In our exploration, we experimented with employing a larger learning rate, as in CodeLLaMA (Rozière et al., 2023). We observed large spikes in training loss at the initial training steps. Although this approach eventually led to improved training and validation loss, we noted substantial degradations across all domain-specific and academic benchmarks, except on coding. We hypothesize that a smaller learning rate played a dual role, facilitating the distillation of domain knowledge through DAPT while maintaining a balance that did not veer too far from the base model, thus preserving general natural language capabilities.
We also explored the application of Parameter Efficient Fine-Tuning (PEFT) in the context of Domain-Adaptive Pre-training (DAPT). In this pursuit, we conducted two experiments involving the incorporation of LoRA adapters (Hu et al., 2021), introducing additional parameters of 26.4 million (small) and 211.2 million (large) respectively. In both instances, our findings revealed a significant accuracy gap on in-domain tasks when compared to the full-parameter DAPT approach. Furthermore, when contrasting the outcomes between small and large PEFT models, we observed a marginal enhancement on in-domain task accuracy, with large adapter exhibiting a slight improvement.
3.4 Training Cost
All models have undergone training using 128 A100 GPUs. We estimate the costs associated with domain adaptive pretraining for ChipNeMo as illustrated in Table 1. It is worth noting that DAPT accounts for less than 1.5% of the overall cost of pretraining a foundational model from scratch.
| Model Size | Pretraining | DAPT | SFT |
| 7B | 184,320 | 2,620 | 90 |
| 13B | 368,640 | 4,940 | 160 |
| 70B | 1,720,320 | 20,500 | 840 |
3.5 RAG and Engineering Assistant Chatbot
We created a benchmark to evaluate the performance of design chat assistance, which uses the RAG method. This benchmark includes 88 questions in three categories: architecture/design/verification specifications (Specs), testbench regression documentation (Testbench), and build infrastructure documentation (Build). For each question, we specify the golden answer as well as the paragraphs in the design document that contains the relevant knowledge for the answer. These questions are created by designers manually based on a set of design documents as the data store for retrieval. It includes about 1.8K documents, which were segmented into 67K passages, each about 512 characters.
First, we compare our domain adapted retrieval model with Sentence Transformer (Reimers & Gurevych, 2019) and e5_small_unsupervised (Wang et al., 2022) on each category. Each model fetches its top 8 passages from the data store.
As shown in Figure 6, our domain-adapted model performed 2x better than the original e5_small_unsupervised model and 30% better than sentence transformer.
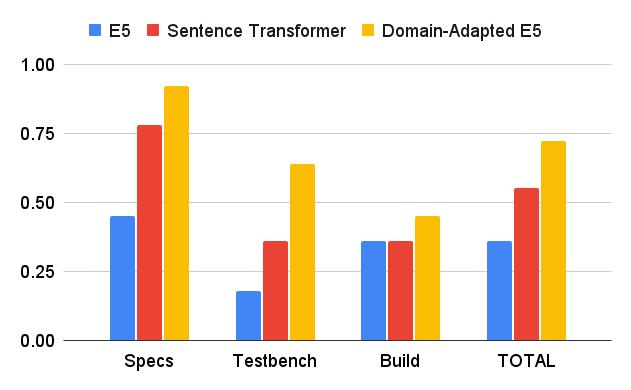
The queries in the Specs category are derived directly from passages in the documents, so their answers are often nicely contained in a concise passage and clearly address the query. On the other hand, the queries of the Testbench and Build categories are not directly derived from passages, so their answers were often not as apparent in the fetched passages and required more context (see Appendix A.8 for detailed examples). This significantly contributes to the difference in retrieval quality between the categories.
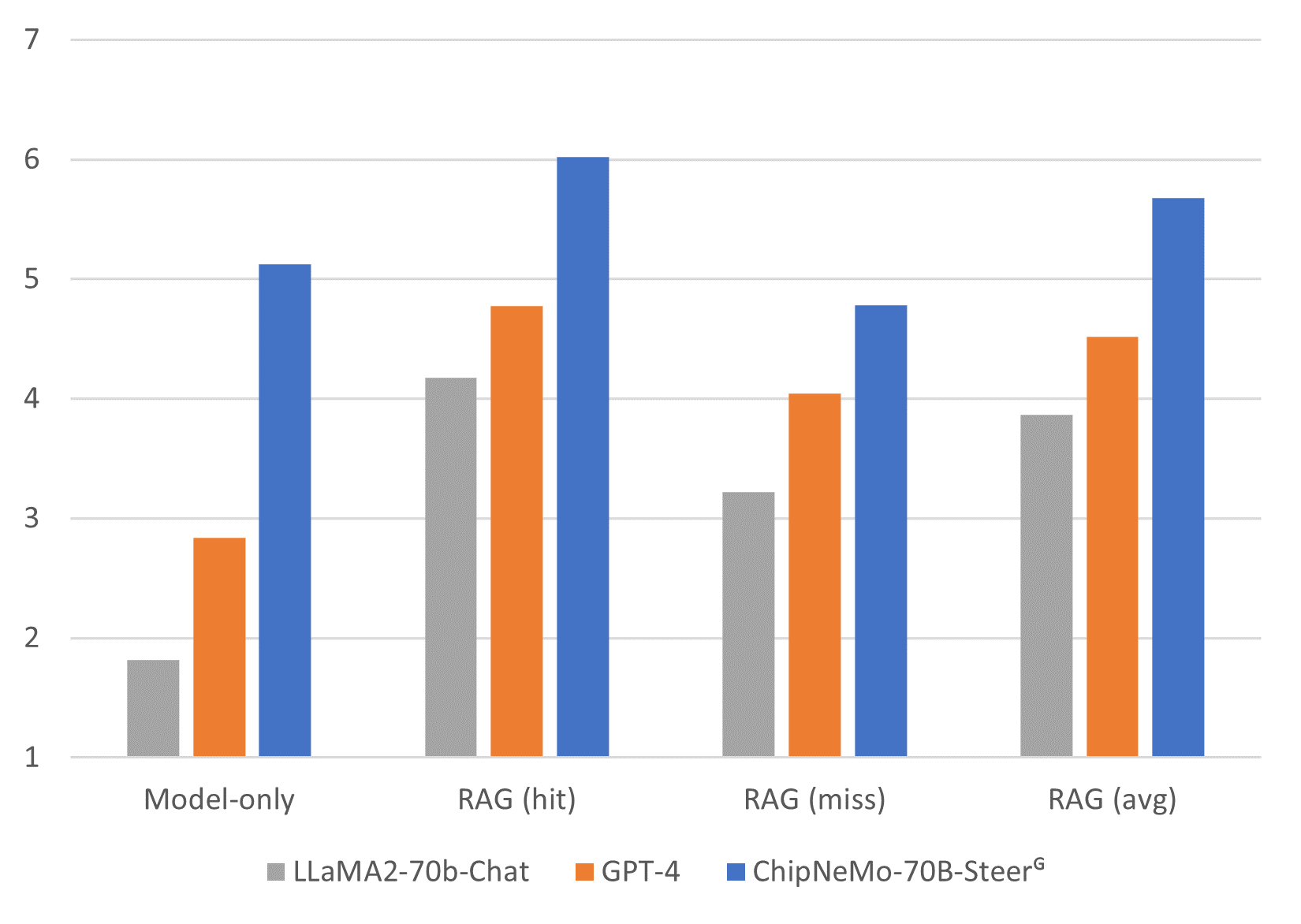
We conducted evaluation of multiple ChipNeMo models and LLaMA2 models with and without RAG. The results were then scored by human evaluators on a 7 point Likert scale and shown in Figure 7. We highlight the following:
-
•
ChipNeMo-70B-Steer outperforms GPT-4 in all categories, including both RAG misses and hits.
-
•
ChipNeMo-70B-Steer outperforms similar sized LLaMA2-70b-Chat in model-only and RAG evaluations by 3.31 and 1.81, respectively.
Our results indicate that RAG significantly boosts human scores. RAG improves ChipNeMo-70B-Steer, GPT-4, and LLaMA2-70b-Chat by 0.56, 1.68, and 2.05, respectively. Even when RAG misses, scores are generally higher than without using retrieval. The inclusion of relevant in-domain context still led to improved performance, as retrieval is not a strictly binary outcome. Furthermore, while ChipNeMo-70B-SFT outperforms GPT4 by a large margin through traditional supervised fine-tuning, applying SteerLM methods (Wang et al., 2023) leads to further elevated chatbot ratings. We refer readers to the complete evaluation results in Appendix 17.
3.6 EDA Script Generation
In order to evaluate our model on the EDA script generation task, we created two different types of benchmarks. The first is a set of “Easy” and “Medium” difficulty tasks (1-4 line solutions) that can be evaluated without human intervention by comparing with a golden response or comparing the generated output after code execution. The second set of tasks “Hard” come from real use case scenarios that our engineers chose. These tasks are much harder requiring multiple API calls and understanding relationship between different VLSI objects. Because these are hard to evaluate in an automated way (with current model performance), we had human engineers judge the correctness between 0-10. We evaluate the model on two tools, one is a fully in-house Python based tool and the other is a Tcl based EDA tool with limited public data. The size of these benchmarks are described in Table 2. Work is ongoing to both increase the size and scope for these benchmarks to allow us to further assess and improve these models.
| Evaluation Benchmark Name | Size |
| Python Tool - Automatic (Easy) | 146 |
| Python Tool - Automatic (Medium) | 28 |
| Python Tool - Human (Hard) | 25 |
| Tcl Tool - Automatic (Easy) | 708 |
| Tcl Tool - Automatic (Medium) | 27 |
| Tcl Tool - Human (Hard) | 25 |
The comparative performance of our models on these evaluations are shown in Figures 8 and 9. Figure 8 shows the results on automated “easy” and “medium” benchmarks where we check for fully accurate code. For “Hard” benchmarks in Figure 9 we check for partial correctness of the code, which is evaluated by a human user on a 0-10 scale. ChipNeMo-70B-Steer performs significantly better than off-the-shelf GPT-4 and LLaMA2-70B-Chat model.
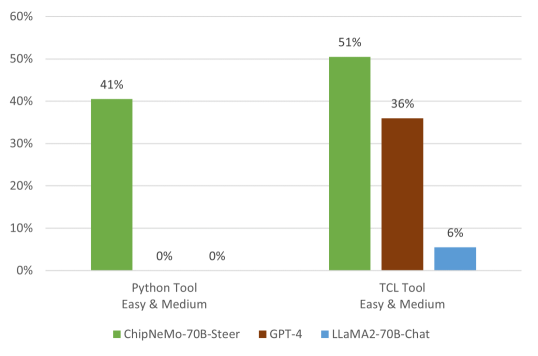
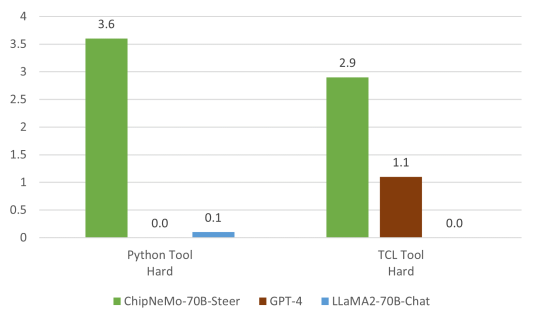
As seen in Figure 8, models like GPT-4 and LLaMA2-70B-Chat have close to zero accuracy for the Python tool where the domain knowledge related to APIs of the tool are necessary. This shows the importance of DAPT. Without DAPT, the model had little to no understanding of the underlying APIs and performed poorly on both automatic and human evaluated benchmarks. Our aligned model further improved the results of DAPT because our domain instructional data helps guide the model to present the final script in the most useful manner. An ablation study on inclusion of domain instructional data for model alignment and the application of retrieval is provided in Appendix A.9.
Our non-domain models performed better on our Tcl tool than the Python tool, but the trend for our domain trained model was the opposite. We suspect this was due to the proprietary nature of our Python tool. It was difficult for general LLMs to perform well on our Python tool benchmark without knowledge of the APIs. Since ChipNeMo is trained with domain data, the inherent python coding ability of the base model allows ChipNeMo-70B-Steer to perform better. This again highlights the importance of DAPT for low-volume or proprietary programming languages.
3.7 Bug Summarization and Analysis
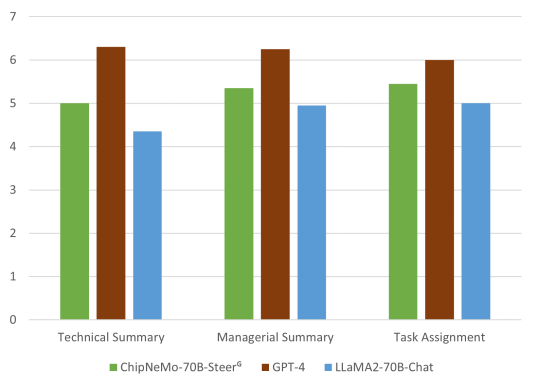
To evaluate our models on bug summarization and analysis we have a hold out set of 30 bugs which are ideal candidates for summarization. This includes having a long comment history or other data which makes the bugs hard for a human to quickly summarize. As described in Appendix A.10.3 the long length of each individual bug requires the LLM to perform hierarchical summarization.
We study three separate sub-tasks: summarization focused on technical details, summarization focused on managerial details, and a post-summarization recommendation of task assignnment. Participants are tasked with rating the model’s performance on a 7-point Likert scale for each of these three assignments. The results can be found in Figure 10. Although the GPT-4 model excels in all three tasks, outperforming both our ChipNeMo-70B-Steer model and the LLaMA2-70B-Chat model, ChipNeMo-70B-Steer does exhibit enhancements compared to the off-the-shelf LLaMA model of equivalent size. We attribute the comparatively lower improvements in summarization tasks resulting from our domain-adaptation to the limited necessity for domain-specific knowledge in summarization compared to other use-cases.
4 Related Works
Many domains have a significant amount of proprietary data which can be used to train a domain-specific LLM. One approach is to train a domain specific foundation model from scratch, e.g., BloombergGPT(Wu et al., 2023) for finance, BioMedLLM(Venigalla et al., 2022) for biomed, and Galactica(Taylor et al., 2022) for science. These models were usually trained on more than 100B tokens of raw domain data. The second approach is domain-adaptive pretraining (DAPT) (Gururangan et al., 2020) which continues to train a pretrained foundation model on additional raw domain data. It shows slight performance boost on domain-specific tasks in domains such as biomedical, computer science publications, news, and reviews. In one example, (Lewkowycz et al., 2022) continued-pretrained a foundation model on technical content datasets and achieved state-of-the-art performance on many quantitative reasoning tasks.
Retrieval Augmented Generation (RAG) helps ground the LLM to generate accurate information and to extract up-to-date information to improve knowledge-intensive NLP tasks (Lewis et al., 2021a). It is observed that smaller models with RAG can outperform larger models without RAG (Borgeaud et al., 2022). Retrieval methods include sparse retrieval methods such as TF-IDF or BM25(Robertson & Zaragoza, 2009), which analyze word statistic information and find matching documents with a high dimensional sparse vector. Dense retrieval methods such as (Karpukhin et al., 2020; Izacard et al., 2022a) find matching documents on an embedding space generated by a retrieval model pretrained on a large corpus with or without fine-tuning on a retrieval dataset. The retrieval model can be trained standalone (Karpukhin et al., 2020; Izacard et al., 2022a; Shi et al., 2023) or jointly with language models (Izacard et al., 2022b; Borgeaud et al., 2022). In addition, it has been shown that off-the-shelf general purpose retrievers can improve a baseline language model significantly without further fine-tuning (Ram et al., 2023). RAG is also proposed to perform code generation tasks (Zhou et al., 2023) by retrieving from coding documents.
Foundation models are completion models, which have limited chat and instruction following capabilities. Therefore, a model alignment process is applied to the foundation models to train a corresponding chat model. Instruction fine-tuning (Wei et al., 2022) and reinforcement learning from human feedback (RLHF) (Ouyang et al., 2022) are two common model alignment techniques. Instruction fine-tuning further trains a foundation model using instructions datasets. RLHF leverages human feedback to label a dataset to train a reward model and applies reinforcement learning to further improve models given the trained reward model. RLHF is usually more complex and resource hungry than instruction fine-tuning. Therefore, recent studies also propose to reduce this overhead with simpler methods such as DPO (Rafailov et al., 2023) and SteerLM (Dong et al., 2023).
Researchers have started to apply LLM to chip design problems. Early works such as Dave (Pearce et al., 2020) first explored the possibility of generating Verilog from English with a language model (GPT-2). Following that work, (Thakur et al., 2023) showed that fine-tuned open-source LLMs (CodeGen) on Verilog datasets collected from GitHub and Verilog textbooks outperformed state-of-the-art OpenAI models such as code-davinci-002 on 17 Verilog questions. (Liu et al., 2023) proposed a benchmark with more than 150 problems and demonstrated that the Verilog code generation capability of pretrained language models could be improved with supervised fine-tuning by bootstrapping with LLM generated synthetic problem-code pairs. Chip-Chat (Blocklove et al., 2023) experimented with conversational flows to design and verify a 8-bit accumulator-based microprocessor with GPT-4 and GPT-3.5. Their findings showed that although GPT-4 produced relatively high-quality codes, it still does not perform well enough at understanding and fixing the errors. ChipEDA (He et al., 2023) proposed to use LLMs to generate EDA tools scripts. It also demonstrated that fine-tuned LLaMA2 70B model outperforms GPT-4 model on this task.
5 Conclusions
We explored domain-adapted approaches to improve LLM performance for industrial chip design tasks. Our results show that domain-adaptive pretrained models, such as the 7B, 13B, and 70B variants of ChipNeMo, achieve similar or better results than their base LLaMA2 models with only 1.5% additional pretraining compute cost. Our largest trained model, ChipNeMo-70B, also surpasses the much more powerful GPT-4 on two of our use cases, engineering assistant chatbot and EDA scripts generation, while showing competitive performance on bug summarization and analysis. Our future work will focus on further improving ChipNeMo models and methods for production use.
References
- Blocklove et al. (2023) Blocklove, J., Garg, S., Karri, R., and Pearce, H. Chip-chat: Challenges and opportunities in conversational hardware design, 2023.
- Borgeaud et al. (2022) Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., Millican, K., van den Driessche, G., Lespiau, J.-B., Damoc, B., Clark, A., de Las Casas, D., Guy, A., Menick, J., Ring, R., Hennigan, T., Huang, S., Maggiore, L., Jones, C., Cassirer, A., Brock, A., Paganini, M., Irving, G., Vinyals, O., Osindero, S., Simonyan, K., Rae, J. W., Elsen, E., and Sifre, L. Improving language models by retrieving from trillions of tokens, 2022.
- Bubeck et al. (2023) Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., Nori, H., Palangi, H., Ribeiro, M. T., and Zhang, Y. Sparks of artificial general intelligence: Early experiments with gpt-4, 2023.
- Chen et al. (2021) Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H. P., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F. P., Cummings, D., Plappert, M., Chantzis, F., Barnes, E., Herbert-Voss, A., Guss, W. H., Nichol, A., Paino, A., Tezak, N., Tang, J., Babuschkin, I., Balaji, S., Jain, S., Saunders, W., Hesse, C., Carr, A. N., Leike, J., Achiam, J., Misra, V., Morikawa, E., Radford, A., Knight, M., Brundage, M., Murati, M., Mayer, K., Welinder, P., McGrew, B., Amodei, D., McCandlish, S., Sutskever, I., and Zaremba, W. Evaluating large language models trained on code, 2021.
- Chiang et al. (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J. E., Stoica, I., and Xing, E. P. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Chowdhery et al. (2022) Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prabhakaran, V., Reif, E., Du, N., Hutchinson, B., Pope, R., Bradbury, J., Austin, J., Isard, M., Gur-Ari, G., Yin, P., Duke, T., Levskaya, A., Ghemawat, S., Dev, S., Michalewski, H., Garcia, X., Misra, V., Robinson, K., Fedus, L., Zhou, D., Ippolito, D., Luan, D., Lim, H., Zoph, B., Spiridonov, A., Sepassi, R., Dohan, D., Agrawal, S., Omernick, M., Dai, A. M., Pillai, T. S., Pellat, M., Lewkowycz, A., Moreira, E., Child, R., Polozov, O., Lee, K., Zhou, Z., Wang, X., Saeta, B., Diaz, M., Firat, O., Catasta, M., Wei, J., Meier-Hellstern, K., Eck, D., Dean, J., Petrov, S., and Fiedel, N. Palm: Scaling language modeling with pathways, 2022.
- Clark et al. (2018) Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018.
- Dao et al. (2022) Dao, T., Fu, D. Y., Ermon, S., Rudra, A., and Ré, C. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. In Advances in Neural Information Processing Systems, 2022.
- Dong et al. (2023) Dong, Y., Wang, Z., Sreedhar, M. N., Wu, X., and Kuchaiev, O. Steerlm: Attribute conditioned sft as an (user-steerable) alternative to rlhf, 2023.
- Gao et al. (2020) Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., Presser, S., and Leahy, C. The pile: An 800gb dataset of diverse text for language modeling, 2020.
- Gao et al. (2022) Gao, L., Ma, X., Lin, J., and Callan, J. Tevatron: An efficient and flexible toolkit for dense retrieval, 2022.
- Gao et al. (2024) Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Guo, Q., Wang, M., and Wang, H. Retrieval-augmented generation for large language models: A survey, 2024.
- Gururangan et al. (2020) Gururangan, S., Marasović, A., Swayamdipta, S., Lo, K., Beltagy, I., Downey, D., and Smith, N. A. Don’t stop pretraining: Adapt language models to domains and tasks, 2020.
- He et al. (2023) He, Z., Wu, H., Zhang, X., Yao, X., Zheng, S., Zheng, H., and Yu, B. Chateda: A large language model powered autonomous agent for eda, 2023.
- Hendrycks et al. (2021) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding, 2021.
- Hu et al. (2021) Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., and Chen, W. Lora: Low-rank adaptation of large language models. CoRR, abs/2106.09685, 2021. URL https://arxiv.org/abs/2106.09685.
- Izacard et al. (2022a) Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., and Grave, E. Unsupervised dense information retrieval with contrastive learning, 2022a.
- Izacard et al. (2022b) Izacard, G., Lewis, P., Lomeli, M., Hosseini, L., Petroni, F., Schick, T., Dwivedi-Yu, J., Joulin, A., Riedel, S., and Grave, E. Atlas: Few-shot learning with retrieval augmented language models, 2022b.
- Ji et al. (2023) Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y. J., Madotto, A., and Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv., 55(12), mar 2023. ISSN 0360-0300. doi: 10.1145/3571730. URL https://doi.org/10.1145/3571730.
- Karpukhin et al. (2020) Karpukhin, V., Oğuz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and tau Yih, W. Dense passage retrieval for open-domain question answering, 2020.
- Khailany et al. (2020) Khailany, B., Ren, H., Dai, S., Godil, S., Keller, B., Kirby, R., Klinefelter, A., Venkatesan, R., Zhang, Y., Catanzaro, B., and Dally, W. J. Accelerating chip design with machine learning. IEEE Micro, 40(6):23–32, 2020. doi: 10.1109/MM.2020.3026231.
- Kocetkov et al. (2022) Kocetkov, D., Li, R., Allal, L. B., Li, J., Mou, C., Ferrandis, C. M., Jernite, Y., Mitchell, M., Hughes, S., Wolf, T., Bahdanau, D., von Werra, L., and de Vries, H. The stack: 3 tb of permissively licensed source code, 2022.
- Koto et al. (2021) Koto, F., Lau, J. H., and Baldwin, T. IndoBERTweet: A pretrained language model for Indonesian Twitter with effective domain-specific vocabulary initialization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 10660–10668, November 2021.
- Kuchaiev et al. (2019) Kuchaiev, O., Li, J., Nguyen, H., Hrinchuk, O., Leary, R., Ginsburg, B., Kriman, S., Beliaev, S., Lavrukhin, V., Cook, J., Castonguay, P., Popova, M., Huang, J., and Cohen, J. M. Nemo: a toolkit for building ai applications using neural modules, 2019.
- Köpf et al. (2023) Köpf, A., Kilcher, Y., von Rütte, D., Anagnostidis, S., Tam, Z.-R., Stevens, K., Barhoum, A., Duc, N. M., Stanley, O., Nagyfi, R., ES, S., Suri, S., Glushkov, D., Dantuluri, A., Maguire, A., Schuhmann, C., Nguyen, H., and Mattick, A. Openassistant conversations – democratizing large language model alignment, 2023.
- Lai et al. (2017) Lai, G., Xie, Q., Liu, H., Yang, Y., and Hovy, E. Race: Large-scale reading comprehension dataset from examinations, 2017.
- Lewis et al. (2021a) Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., tau Yih, W., Rocktäschel, T., Riedel, S., and Kiela, D. Retrieval-augmented generation for knowledge-intensive nlp tasks, 2021a.
- Lewis et al. (2021b) Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., tau Yih, W., Rocktäschel, T., Riedel, S., and Kiela, D. Retrieval-augmented generation for knowledge-intensive nlp tasks, 2021b.
- Lewkowycz et al. (2022) Lewkowycz, A., Andreassen, A., Dohan, D., Dyer, E., Michalewski, H., Ramasesh, V., Slone, A., Anil, C., Schlag, I., Gutman-Solo, T., Wu, Y., Neyshabur, B., Gur-Ari, G., and Misra, V. Solving quantitative reasoning problems with language models, 2022.
- Liu et al. (2023) Liu, M., Pinckney, N., Khailany, B., and Ren, H. VerilogEval: evaluating large language models for verilog code generation. In 2023 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2023.
- Nijkamp et al. (2023) Nijkamp, E., Pang, B., Hayashi, H., Tu, L., Wang, H., Zhou, Y., Savarese, S., and Xiong, C. Codegen: An open large language model for code with multi-turn program synthesis. ICLR, 2023.
- OpenAI et al. (2023) OpenAI, :, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., Bello, I., Berdine, J., Bernadett-Shapiro, G., Berner, C., Bogdonoff, L., Boiko, O., Boyd, M., Brakman, A.-L., Brockman, G., Brooks, T., Brundage, M., Button, K., Cai, T., Campbell, R., Cann, A., Carey, B., Carlson, C., Carmichael, R., Chan, B., Chang, C., Chantzis, F., Chen, D., Chen, S., Chen, R., Chen, J., Chen, M., Chess, B., Cho, C., Chu, C., Chung, H. W., Cummings, D., Currier, J., Dai, Y., Decareaux, C., Degry, T., Deutsch, N., Deville, D., Dhar, A., Dohan, D., Dowling, S., Dunning, S., Ecoffet, A., Eleti, A., Eloundou, T., Farhi, D., Fedus, L., Felix, N., Fishman, S. P., Forte, J., Fulford, I., Gao, L., Georges, E., Gibson, C., Goel, V., Gogineni, T., Goh, G., Gontijo-Lopes, R., Gordon, J., Grafstein, M., Gray, S., Greene, R., Gross, J., Gu, S. S., Guo, Y., Hallacy, C., Han, J., Harris, J., He, Y., Heaton, M., Heidecke, J., Hesse, C., Hickey, A., Hickey, W., Hoeschele, P., Houghton, B., Hsu, K., Hu, S., Hu, X., Huizinga, J., Jain, S., Jain, S., Jang, J., Jiang, A., Jiang, R., Jin, H., Jin, D., Jomoto, S., Jonn, B., Jun, H., Kaftan, T., Łukasz Kaiser, Kamali, A., Kanitscheider, I., Keskar, N. S., Khan, T., Kilpatrick, L., Kim, J. W., Kim, C., Kim, Y., Kirchner, H., Kiros, J., Knight, M., Kokotajlo, D., Łukasz Kondraciuk, Kondrich, A., Konstantinidis, A., Kosic, K., Krueger, G., Kuo, V., Lampe, M., Lan, I., Lee, T., Leike, J., Leung, J., Levy, D., Li, C. M., Lim, R., Lin, M., Lin, S., Litwin, M., Lopez, T., Lowe, R., Lue, P., Makanju, A., Malfacini, K., Manning, S., Markov, T., Markovski, Y., Martin, B., Mayer, K., Mayne, A., McGrew, B., McKinney, S. M., McLeavey, C., McMillan, P., McNeil, J., Medina, D., Mehta, A., Menick, J., Metz, L., Mishchenko, A., Mishkin, P., Monaco, V., Morikawa, E., Mossing, D., Mu, T., Murati, M., Murk, O., Mély, D., Nair, A., Nakano, R., Nayak, R., Neelakantan, A., Ngo, R., Noh, H., Ouyang, L., O’Keefe, C., Pachocki, J., Paino, A., Palermo, J., Pantuliano, A., Parascandolo, G., Parish, J., Parparita, E., Passos, A., Pavlov, M., Peng, A., Perelman, A., de Avila Belbute Peres, F., Petrov, M., de Oliveira Pinto, H. P., Michael, Pokorny, Pokrass, M., Pong, V., Powell, T., Power, A., Power, B., Proehl, E., Puri, R., Radford, A., Rae, J., Ramesh, A., Raymond, C., Real, F., Rimbach, K., Ross, C., Rotsted, B., Roussez, H., Ryder, N., Saltarelli, M., Sanders, T., Santurkar, S., Sastry, G., Schmidt, H., Schnurr, D., Schulman, J., Selsam, D., Sheppard, K., Sherbakov, T., Shieh, J., Shoker, S., Shyam, P., Sidor, S., Sigler, E., Simens, M., Sitkin, J., Slama, K., Sohl, I., Sokolowsky, B., Song, Y., Staudacher, N., Such, F. P., Summers, N., Sutskever, I., Tang, J., Tezak, N., Thompson, M., Tillet, P., Tootoonchian, A., Tseng, E., Tuggle, P., Turley, N., Tworek, J., Uribe, J. F. C., Vallone, A., Vijayvergiya, A., Voss, C., Wainwright, C., Wang, J. J., Wang, A., Wang, B., Ward, J., Wei, J., Weinmann, C., Welihinda, A., Welinder, P., Weng, J., Weng, L., Wiethoff, M., Willner, D., Winter, C., Wolrich, S., Wong, H., Workman, L., Wu, S., Wu, J., Wu, M., Xiao, K., Xu, T., Yoo, S., Yu, K., Yuan, Q., Zaremba, W., Zellers, R., Zhang, C., Zhang, M., Zhao, S., Zheng, T., Zhuang, J., Zhuk, W., and Zoph, B. Gpt-4 technical report, 2023.
- Ouyang et al. (2022) Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., and Lowe, R. Training language models to follow instructions with human feedback, 2022.
- Pearce et al. (2020) Pearce, H., Tan, B., and Karri, R. Dave: Deriving automatically verilog from english. In Proceedings of the 2020 ACM/IEEE Workshop on Machine Learning for CAD, MLCAD ’20, pp. 27–32, New York, NY, USA, 2020. Association for Computing Machinery. ISBN 9781450375191. doi: 10.1145/3380446.3430634. URL https://doi.org/10.1145/3380446.3430634.
- Rafailov et al. (2023) Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., and Finn, C. Direct preference optimization: Your language model is secretly a reward model, 2023.
- Ram et al. (2023) Ram, O., Levine, Y., Dalmedigos, I., Muhlgay, D., Shashua, A., Leyton-Brown, K., and Shoham, Y. In-context retrieval-augmented language models, 2023.
- Reimers & Gurevych (2019) Reimers, N. and Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019. URL http://arxiv.org/abs/1908.10084.
- Ren & Fojtik (2021) Ren, H. and Fojtik, M. Invited- nvcell: Standard cell layout in advanced technology nodes with reinforcement learning. In 2021 58th ACM/IEEE Design Automation Conference (DAC), 2021.
- Richardson (2007) Richardson, L. Beautiful soup documentation. April, 2007.
- Robertson & Zaragoza (2009) Robertson, S. and Zaragoza, H. The probabilistic relevance framework: Bm25 and beyond. Found. Trends Inf. Retr., 3(4):333–389, apr 2009. ISSN 1554-0669. doi: 10.1561/1500000019. URL https://doi.org/10.1561/1500000019.
- Roy et al. (2021) Roy, R., Raiman, J., Kant, N., Elkin, I., Kirby, R., Siu, M., Oberman, S., Godil, S., and Catanzaro, B. PrefixRL: Optimization of parallel prefix circuits using deep reinforcement learning. In 2021 58th ACM/IEEE Design Automation Conference (DAC), 2021.
- Rozière et al. (2023) Rozière, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X. E., Adi, Y., Liu, J., Remez, T., Rapin, J., Kozhevnikov, A., Evtimov, I., Bitton, J., Bhatt, M., Ferrer, C. C., Grattafiori, A., Xiong, W., Défossez, A., Copet, J., Azhar, F., Touvron, H., Martin, L., Usunier, N., Scialom, T., and Synnaeve, G. Code llama: Open foundation models for code, 2023.
- Sakaguchi et al. (2019) Sakaguchi, K., Bras, R. L., Bhagavatula, C., and Choi, Y. Winogrande: An adversarial winograd schema challenge at scale. arXiv preprint arXiv:1907.10641, 2019.
- Sanh et al. (2022) Sanh, V., Webson, A., Raffel, C., Bach, S. H., Sutawika, L., Alyafeai, Z., Chaffin, A., Stiegler, A., Scao, T. L., Raja, A., Dey, M., Bari, M. S., Xu, C., Thakker, U., Sharma, S. S., Szczechla, E., Kim, T., Chhablani, G., Nayak, N., Datta, D., Chang, J., Jiang, M. T.-J., Wang, H., Manica, M., Shen, S., Yong, Z. X., Pandey, H., Bawden, R., Wang, T., Neeraj, T., Rozen, J., Sharma, A., Santilli, A., Fevry, T., Fries, J. A., Teehan, R., Bers, T., Biderman, S., Gao, L., Wolf, T., and Rush, A. M. Multitask prompted training enables zero-shot task generalization, 2022.
- Shi et al. (2023) Shi, W., Min, S., Yasunaga, M., Seo, M., James, R., Lewis, M., Zettlemoyer, L., and tau Yih, W. Replug: Retrieval-augmented black-box language models, 2023.
- Shoeybi et al. (2019) Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., and Catanzaro, B. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019.
- Taylor et al. (2022) Taylor, R., Kardas, M., Cucurull, G., Scialom, T., Hartshorn, A., Saravia, E., Poulton, A., Kerkez, V., and Stojnic, R. Galactica: A large language model for science, 2022.
- Thakur et al. (2023) Thakur, S., Ahmad, B., Fan, Z., Pearce, H., Tan, B., Karri, R., Dolan-Gavitt, B., and Garg, S. Benchmarking large language models for automated verilog rtl code generation. In 2023 Design, Automation & Test in Europe Conference & Exhibition (DATE), pp. 1–6, 2023. doi: 10.23919/DATE56975.2023.10137086.
- Touvron et al. (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V., Khabsa, M., Kloumann, I., Korenev, A., Koura, P. S., Lachaux, M.-A., Lavril, T., Lee, J., Liskovich, D., Lu, Y., Mao, Y., Martinet, X., Mihaylov, T., Mishra, P., Molybog, I., Nie, Y., Poulton, A., Reizenstein, J., Rungta, R., Saladi, K., Schelten, A., Silva, R., Smith, E. M., Subramanian, R., Tan, X. E., Tang, B., Taylor, R., Williams, A., Kuan, J. X., Xu, P., Yan, Z., Zarov, I., Zhang, Y., Fan, A., Kambadur, M., Narang, S., Rodriguez, A., Stojnic, R., Edunov, S., and Scialom, T. Llama 2: Open foundation and fine-tuned chat models, 2023.
- Venigalla et al. (2022) Venigalla, A., Frankle, J., and Carbin, M. BioMedLM: a domain-specific large language model for biomedical text, 2022. URL https://www.mosaicml.com/blog/introducing-pubmed-gpt.
- Wang et al. (2022) Wang, L., Yang, N., Huang, X., Jiao, B., Yang, L., Jiang, D., Majumder, R., and Wei, F. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022.
- Wang et al. (2023) Wang, Z., Dong, Y., Zeng, J., Adams, V., Sreedhar, M. N., Egert, D., Delalleau, O., Scowcroft, J. P., Kant, N., Swope, A., and Kuchaiev, O. Helpsteer: Multi-attribute helpfulness dataset for steerlm, 2023.
- Wei et al. (2022) Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., and Le, Q. V. Finetuned language models are zero-shot learners, 2022.
- Wu et al. (2023) Wu, S., Irsoy, O., Lu, S., Dabravolski, V., Dredze, M., Gehrmann, S., Kambadur, P., Rosenberg, D., and Mann, G. Bloomberggpt: A large language model for finance, 2023.
- Zellers et al. (2019) Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., and Choi, Y. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019.
- Zhou et al. (2023) Zhou, S., Alon, U., Xu, F. F., Wang, Z., Jiang, Z., and Neubig, G. Docprompting: Generating code by retrieving the docs, 2023.
Appendix A Appendix
A.1 Contributions
Mingjie Liu conducted DAPT and model alignment.
Teodor-Dumitru Ene, Robert Kirby developed inference and application evaluation infrastructure.
Chris Cheng developed RAG framework.
Nathaniel Pinckney collected and prepared data sets for training.
Rongjian Liang developed custom tokenizers.
Walker Turner, Charley Lind, George Kokai developed a general circuit design knowledge benchmark.
Siddhanth Dhodhi, Ismet Bayraktaroglu, Himyanshu Anand, Eric Hill designed engineering assistant chatbot, provided domain instruction datasets, evaluation benchmarks, and conducted evaluation.
Parikshit Deshpande, Zhengjiang Shao, Kaizhe Xu, Jiashang Hu, Laura Dang, Xiaowei Li, Hao Liu, Ambar Sarkar developed engineering assistant chatbot application.
Sreedhar Pratty, Kishor Kunal, Ghasem Pasandi, Varun Tej, Sumit Jain, Sujeet Omar, Pratik P Suthar, Hanfei Sun developed EDA scripts generation application, provided domain instruction datasets and evaluation benchmarks.
Bonita Bhaskaran, Arjun Chaudhuri, Sanmitra Banerjee, Ghasem Pasandi developed bug summarization and analysis application, provided domain instruction datasets and evaluation benchmarks.
Brucek Khailany, Stuart Oberman, Sharon Clay, Sameer Halepete, Jonathan Raiman, Bryan Catanzaro, Jonah Alben, Bill Dally advised from AI research and hardware engineering perspectives.
Haoxing Ren designed and led the research.
A.2 Data Collection Process
Collection was implemented with a set of shell and Python scripts, designed to identify relevant design data and documentation, convert them to plain text if applicable, filter them using basic quality metrics, compute a checksum for precise file deduplication, and compress them for storage. The collection flow did not use off-the-shelf LLM-specific scraping and collection scripts, as we aimed to minimize space requirements through in-situ data collection of internal data sources (both networked file systems and internal web applications). For file system-based collection, data was kept in-place while being filtered for quality, instead of storing additional sets of raw data locally.
The design and verification data collection encompassed a variety of source files, including Verilog and VHDL (RTL and netlists), C++, Spice, Tcl, various scripting languages, and build-related configuration files. Data from internal web services were gathered through both REST API calls and conventional crawling, with HTML formatting being removed using the open-source BeautifulSoup(Richardson, 2007) Python library in both instances to minimize inadvertent removal of coding examples, at the cost of introducing more boiler plate navigation bars and other HTML page elements. Our data collection flow supported conventional documentation formats, including .docx, .pptx, and .pdf, using readily available Python conversion libraries and open-source tools.
As most internal data is believe to be of high quality, minimal filtering was applied: line count filtering was used to ensure that exceedingly large or small files were excluded, and files were sorted into broad categories of manually written versus tool-generated.
A.3 Training Data
During Domain-Adaptive Pre-Training (DAPT), we assemble a dataset from a combination of proprietary chip design specific data sources and publicly available datasets.
Chip Design Datasets: Our internal dataset consists of a diverse range of text sources pertinent to chip design, spanning design, verification, infrastructure, and internal documentation. Table 3 provides a breakdown of the data collected after filtering, and the corresponding number of tokens using the LLaMA2 tokenizer. We construct the dataset by gathering all relevant internal data, then filtering by file type, based on filename extensions and distinguishing between machine-generated and human-written content. Although we evaluated on three specific use cases, we did not specifically limit the dataset to sources known to be relevant to these use cases since we believed that incorporating additional domain knowledge would improve performance. After collection, cleaning, and filtering, the internal data training corpus has 23.1 billion tokens. Further details of the data collection process are covered in Appendix A.2.
| Data Source Type | Data | Data | Training | Training |
| Percentage (%) | Tokens (B) | Percentage (%) | Tokens (B) | |
| Bug Summary | 9.5% | 2.4 | 10.0% | 2.4 |
| Design Source | 47.0% | 11.9 | 24.5% | 5.9 |
| Documentation | 17.8% | 4.5 | 34.0% | 8.2 |
| Verification | 9.1% | 2.3 | 10.4% | 2.5 |
| Other | 7.9% | 2.0 | 12.0% | 2.9 |
| Wikipedia | 5.9% | 1.5 | 6.2% | 1.5 |
| Github | 2.8% | 0.7 | 3.0% | 0.7 |
| Total | 100.0% | 25.3 | 100.0% | 24.1 |
Public Datasets: We augment the chip design specific data with a sample of publicly available data from various sources, a common practice in the development of foundational large language models. Our approach was to reuse public training data from other language models, with the stipulation that it must be publicly accessible and compatible with open sourcing. These datasets exhibit a high degree of correlation with the pretraining data used in LLaMA2 (Touvron et al., 2023), with the intention of preserving general knowledge and natural language capabilities during DAPT. The public datasets used by ChipNeMo can be categorized into two groups, natural language and code. For the natural language component, we draw from Wikipedia data (Gao et al., 2020), as it is widely regarded for its high data quality. For code, we leverage GitHub data (Kocetkov et al., 2022), focusing on programming languages also present in our internal data chip design dataset such as C++, Python, and Verilog. To ensure that the overall dataset is representative of pre-training distributions, we perform a sub-sampling operation that results in approximately 9.2% of the total training tokens being sampled from these public datasets, with a balanced representation of natural language and code.
Data Blend: A significant proportion of the domain data we gathered is comprised of unannotated code from diverse origins. In an effort to enhance the model’s comprehension of domain-specific knowledge, we conducted downsampling of code data while concurrently upsampling natural language data, specifically design documentation, over a span of 2 to 4 training epochs. We also increased the representation of data that we deemed more pertinent to downstream applications, such as human-written EDA tool scripts. Furthermore, we incorporated publicly available domain data for 1 epoch. Details of the token distribution for training are shown in Table 3.
A.4 Alignment Data
During Supervised Fine-Tuning (SFT), we employ a general chat SFT instruction dataset that is accessible for commercial use. The dataset is comprised largely of publicly available instruction following datasets including OASST (Köpf et al., 2023), FLAN (Wei et al., 2022), P3 (Sanh et al., 2022) and a small amount of a broad domain proprietary dataset comprising various topics such as brainstorming, open-ended question answering, rewriting, summarization etc. It’s important to note that the SFT instruction data we discuss here is focused on general natural language tasks and does not contain any information or tasks related to the downstream use cases in chip design. In total, this dataset comprises 128,000 training samples.
For SteerLM (Dong et al., 2023) we closely follow the implementations in (Wang et al., 2023). The attribute training data only contains public available data from HelpSteer (Wang et al., 2023) and OASST (Köpf et al., 2023). For the models attribute-conditioned finetuning,we only used the OASST data comprised of 56,000 training samples.
Additionally, we meticulously assembled a domain-specific instruction dataset for aligning the model to downstream use cases. These examples have been meticulously crafted by subject matter experts and are formatted as single-turn questions and answers. Table 4 depicts the quantity of our domain-specific instruction dataset. It’s worth noting that the total number of training samples in the domain-specific instruction dataset is quite small when compared to the extensive amount of generative chat instruction data.
| Domain Source | Number of Samples |
| Design Knowledge | 302 |
| EDA Script Generation | 480 |
| Bug summarization and analysis | 648 |
| Total | 1430 |
A.5 Domain Evaluation Benchmarks
In order to quickly and quantitatively assess the accuracy of various models, we established evaluation criteria structured as multiple-choice question-and-answer formats for each use case, designed to closely align with established benchmarks, such as MMLU (Hendrycks et al., 2021). In the process of formulating these multiple-choice questions, collaboration with domain experts was pivotal. The goal was to ensure that each question included at least one complex answer choice, thereby posing a challenge to individuals with limited domain expertise. Careful attention was also given to prevent any inadvertent contamination of the questions with data from our domain-specific alignment data. In addition to the per-use-case benchmarks, an additional benchmark was created for general circuit design knowledge, covering both analog and digital design topics. The number of multiple-choice questions for evaluation benchmark are shown in Table 5.
| Domain Source | Number of Questions |
| Design Knowledge (Design) | 94 |
| EDA Script Generation (Scripting) | 74 |
| Bug Summarization and Analysis (Bugs) | 70 |
| Open Domain Circuit Design (Circuits) | 227 |
When we report results on the above benchmarks, we take average results obtained from five distinct runs to mitigate the effects of variance and noise in the testing process. Each iteration employs a set of 5-shot examples, with variations introduced across each individual runs.
In addition to these domain-specific evaluation benchmarks, we also include commonly-used publicly available LLM academic benchmarks. Furthermore, we measure the model’s code generation capabilities, by evaluating HumanEval (Chen et al., 2021) for Python and VerilogEval (Liu et al., 2023) for Verilog.
A.6 Domain Adaptive Pretraining (DAPT)
In this section we present detailed results on our domain adaptive pretrained models. We also detail our ablation experiments on domain adaptive pretraining.
DAPT Hyperparameters: Details presented in Table 6.
| Hyperparameters | Value |
| Context Window | 4096 |
| Global Batch Size | 256 (128) |
| Optimizer | distributed_fused_adam |
| Weight Decay | 0.01 |
| Betas | 0.9, 0.95 (0.9, 0.98) |
| Learning Rate | |
| Scheduler | None |
Auto Eval Results: We present detailed results on auto evaluation benchmarks in Table 7 and Table 8. For simplicity, in the remainders of the section we present aggregated benchmark results for ablation studies:
-
•
Chip: We report average results on in-domain Design, Scripting, Bugs, and Circuits benchmarks from Table 5 (5-shot).
-
•
MMLU: We report the overall results on MMLU (5-shot) (Hendrycks et al., 2021) a popular aggregated benchmark on a wide variety of subjects.
-
•
Reasoning: We report average results on popular public benchmarks on common sense reasoning (0-shot), including Winogrande (Sakaguchi et al., 2019), hellaswag (Zellers et al., 2019), ARC-easy (Clark et al., 2018), and RACE-High (Lai et al., 2017).
-
•
Code: We report average pass-rate of coding benchmarks with greedy decoding, including HumanEval (Chen et al., 2021), VerilogEval-Machine (Liu et al., 2023), and VerilogEval-Human (Liu et al., 2023).
|
Model |
Design |
Scripting |
Bugs |
Circuits |
MMLU |
Winogrande |
hellaswag |
ARC-e |
RACE-H |
|
LLaMA2-7B |
41.1 |
42.0 |
42.2 |
47.9 |
45.7 |
68.9 |
75.6 |
73.5 |
46.2 |
|
ChipNeMo-7B |
57.5 |
49.3 |
42.8 |
49.5 |
44.6 |
67.4 |
76.3 |
73.7 |
46.2 |
|
LLaMA2-13B |
43.6 |
49.6 |
39.7 |
55.5 |
55.4 |
72.1 |
79.3 |
76.3 |
46.7 |
|
ChipNeMo-13B |
67.9 |
56.3 |
50.1 |
56.8 |
53.4 |
71.1 |
80.3 |
76.7 |
46.1 |
|
LLaMA2-70B |
52.3 |
64.9 |
56.9 |
67.0 |
68.6 |
77.6 |
83.6 |
79.6 |
48.9 |
|
ChipNeMo-70B |
76.6 |
73.9 |
65.8 |
71.7 |
69.4 |
78.0 |
85.1 |
80.9 |
48.9 |
|
GPT-3.5 |
51.7 |
66.7 |
52.0 |
66.5 |
- |
||||
|
GPT-4 |
58.4 |
77.4 |
63.4 |
79.0 |
- |
| Model | HumanEval |
VerilogEval-Human |
VerilogEval-Machine |
|
LLaMA2-7B |
14.0 |
3.8 |
24.5 |
|
ChipNeMo-7B |
12.2 |
8.3 |
28.7 |
|
LLaMA2-13B |
17.1 |
9.0 |
30.8 |
|
ChipNeMo-13B |
17.7 |
22.4 |
43.4 |
|
LLaMA2-70B |
28.0 |
30.8 |
51.0 |
|
ChipNeMo-70B |
30.5 |
27.6 |
53.8 |
|
GPT-3.5 |
|||
|
GPT-4 |
Domain-Adaptive Tokenization: We experimented with DAPT using the original LLaMA2 tokenizer and the domain-adapted tokenizer as described in Section 2.1. Figure 11 depicts smoothed training loss for ChipNeMo with the original unmodified tokenizer. When compared with Figure 2, we observe that the domain-adapted tokenizer has larger training loss upon initialization, due to added tokens never being observed during foundation model pretraining. Similar training loss is achieved for DAPT with 1 epoch.
Table 9 presents aggregated auto evaluation benchmark results. We note that careful tokenizer adaptations and weight initialization only slightly impacts model performance on general academic benchmarks. DAPT significantly improved domain benchmarks with any tokenizer, including Verilog coding (no major difference in HumanEval). We conclude that domain-adapting the tokenizer comes with the benefit of improved tokenization and training efficiency with no degradation on the models general language and domain capabilities.
|
Model |
Tokenizer |
DAPT |
Chip |
MMLU |
Reason |
Code |
|
7B |
Ori. |
No |
43.4 |
45.7 |
66.1 |
14.1 |
|
7B |
Dpt. |
No |
42.7 |
44.6 |
65.9 |
13.9 |
|
7B |
Ori. |
Yes |
51.2 |
44.8 |
65.7 |
17.6 |
|
7B |
Dpt. |
Yes |
49.8 |
44.6 |
65.8 |
16.4 |
|
13B |
Ori. |
No |
47.1 |
55.4 |
68.6 |
18.9 |
|
13B |
Dpt. |
No |
46.0 |
55.1 |
68.6 |
18.4 |
|
13B |
Ori. |
Yes |
57.7 |
54.0 |
68.4 |
27.2 |
|
13B |
Dpt. |
Yes |
57.8 |
53.4 |
68.5 |
27.8 |
Public Datasets Mix-in: As introduced in Section A.3 we included public data in DAPT, sampled from commonly-used public datasets for foundation model pre-training. We primarily hoped that mixing in public data such as Wikipedia in DAPT could help “correct” disturbances brought by domain-adapted tokenizer and improve general natural language capabilities of models. We conducted another round of DAPT with domain-adapted tokenizer using only the domain data, training for the same number of steps equating to roughly 1.1 epoch of the data. We found that public data mix-in slightly improves results. We present detailed results in Table 10.
|
Public |
Chip |
MMLU |
Reason |
Code |
|
No |
56.9 |
53.0 |
67.5 |
24.1 |
|
Yes |
57.8 |
53.4 |
68.5 |
27.8 |
Learning Rate: We experimented with employing a larger learning rate, inspired by the approach used in CodeLLaMA (Rozière et al., 2023). We use similar training hyperparameters as in Table 11. We use a cosine schedule with 200 warm-up steps, and set the final learning rate to be 1/30th of the peak learning rate of . We use the same batch size and number of training steps as DAPT.
| Hyperparameters | Value |
| Context Window | 4096 |
| Global Batch Size | 256 |
| Optimizer | distributed_fused_adam |
| Weight Decay | 0.01 |
| Betas | 0.9, 0.95 |
| Learning Rate (lr) | |
| Scheduler | CosineAnnealing |
| Warmup Steps | 200 |
| min_lr |
Figure 12 shows the training loss for ChipNeMo-7B with augmented tokenizers including public dataset mix-in. We observed large spikes in training loss at the initial training steps with the final training loss for 7B models to even be better than 13B original DAPT hyperparameters. However, we note substantial degradation across natural language benchmarks as shown in Table 12, including in-domain chip design. Coding capabilities improved as consistent with the findings of (Rozière et al., 2023).
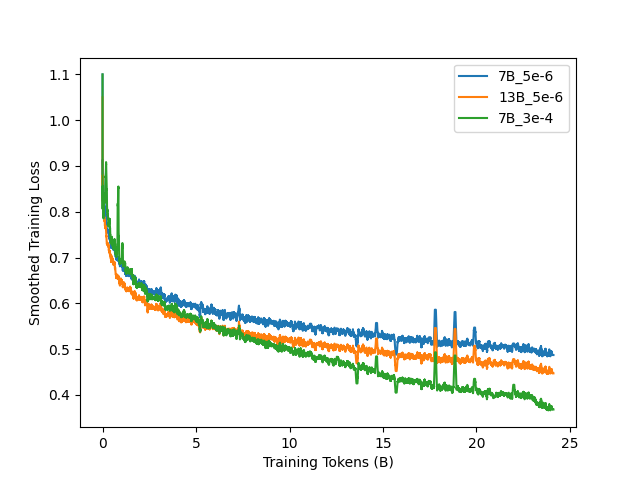
|
Learning Rate |
Chip |
MMLU |
Reason |
Code |
|
49.8 |
44.6 |
65.8 |
16.4 |
|
|
25.5 |
26.6 |
49.8 |
18.1 |
We highlight that our case differs from that in (Rozière et al., 2023). Although we also conduct “continued pretraining” initializing from pretrained checkpoints, we preferably want the model to maintain high degrees of performance on general capabilities, while distilling domain dataset information and knowledge (unseen in model pretraining) into model weights. In contrast, (Rozière et al., 2023) use publicly available code data that predominantly lacks natural language elements, emphasizing their primary focus on coding-related tasks. We hypothesize that a smaller learning rate played a dual role for domain adaptation, facilitating the distillation of domain knowledge through DAPT while maintaining a balance that did not veer too far from the base model, thus preserving general natural language capabilities while significantly improving performance on in-domain tasks.
Parameter Efficient Fine-Tuning (PEFT): Parameter efficient fine-tuning freezes the pre-trained model weights and injects trainable parameters in smaller adapter models for efficient fine-tuning of downstream tasks. We explore the use of PEFT in DAPT using Low-Rank Adaptation (LoRA) (Hu et al., 2021). Since our transformer layer implementation fuses KQV into a single projection, we add LoRA adapters for a single Low-Rank projection for each self attention layer in combined fashion. We experiment on LLaMA2-13B models with the original LLaMA2 tokenizer, using the same DAPT training setups in Table 6. We ran two experiments, introducing additional trainable parameters of 26.4 million (small) and 211.2 million (large) respectively.
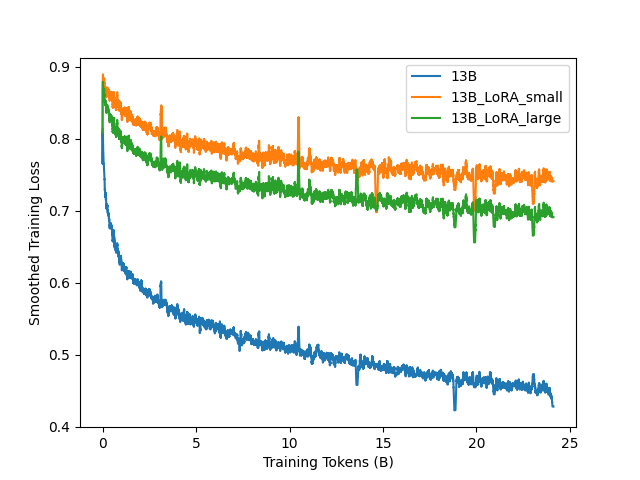
Figure 13 shows the training loss curves of LoRA models and compares with full parameter training. For both LoRA models, the loss quickly converges and stops decreasing beyond a certain point. Table 13 reports the evaluation results on LoRA models. Both LoRA models significantly underperforms full parameter training on in-domain chip design tasks. LoRA models improve in chip design tasks compared to their non-DAPT counterparts, with the larger model exhibiting slightly better (but non significant) results.
|
Parameters |
Chip |
MMLU |
Reason |
Code |
|
None |
47.1 |
55.4 |
68.6 |
18.9 |
|
26.4M |
49.0 |
55.0 |
68.2 |
13.0 |
|
211.2M |
49.6 |
54.2 |
68.6 |
15.3 |
|
13B |
57.7 |
54.0 |
68.4 |
27.2 |
A.7 Model Alignment
For standard supervised-finetuning (SFT) we used the following structured template:
For SteerLM we follow the steps in (Wang et al., 2023) and apply attribute labeling to our domain data:
-
1.
We trained a ”general” attribute scoring model. We only used HelpSteer and OASST attribute labeled data without any domain data with weights initialized from LLaMA2-13B.
-
2.
We scored domain data (1.4k samples) with the attribute scoring model in Step 1.
-
3.
We mixed OASST data (56k samples) with domain data (1.4k samples) for 2 epochs.
-
4.
We conduct attribute-conditioned fine-tuning on ChipNeMo models.
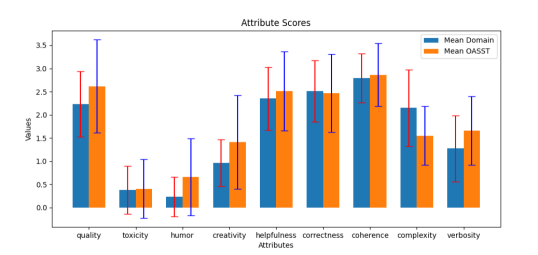
Figure 14 depicts the attribute scores (and their standard deviation) labeled by the general attribute scoring model. The attribute scoring model could generalize well to unseen domain data on attributes such as toxicity, humor, creativity, verbosity, but had slightly lower scores for domain data on metrics such as quality, helpfulness, correctness. This leaves room of improvement for the attribute scoring model on domain data, which could be improved by possibly initializing the attribute models from ChipNeMo (as respect to LLaMA2) and adding attribute labeled domain data. For our experiments we used the attribute labels as-is.
Additionally, we conducted an additional alignment using solely the general chat dataset, excluding any domain-specific alignment data. For clarity, we designate all our ChipNeMo models as follows:
-
•
ChipNeMo-SFT: Models fine-tuned with general chat data exclusively using standard SFT.
-
•
ChipNeMo-SFT: Models fine-tuned with both domain and general chat data using standard SFT;
-
•
ChipNeMo-Steer: Models fine-tuned with general chat data exclusively using SteerLM.
-
•
ChipNeMo-Steer: Models fine-tuned with both domain and general chat data using SteerLM;
A.8 Domain-Adaptive Retrieval Model
Manually generating training samples is very effort intensive, so we elected to implement a process to generate them automatically. Since we are using contrastive learning to fine-tune our model, each sample requires a set of both positive passages and negative passages, particularly hard negatives to maximize the accuracy.
A.8.1 Dataset Sampling Procedure
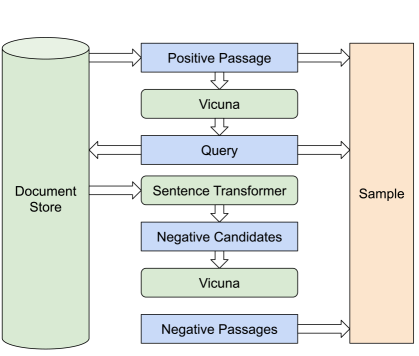
Figure 15 describes the steps taken to generate a sample:
-
1.
Randomly select a passage from the document corpus
-
2.
Use a language model (Vicuna) to generate a valid query from the passage
-
3.
Use a pre-existing retrieval model (sentence transformer) to fetch the top-N passages from the document corpus for the query where each passage is a potential hard-negative
-
4.
It is possible that some of the fetched passages are actually positive, so use the same language model to filter out the positive passages
-
5.
If there are not enough negative passages after this filtering process, supplement with random passages from the corpus
For our initial research we used Vicuna (Chiang et al., 2023) and Sentence Transformer (Reimers & Gurevych, 2019); however, they can easily be replaced with LLaMA2 (Touvron et al., 2023) and BM25 (Robertson & Zaragoza, 2009) respectively to produce a retrieval model that is commercially viable.
A.8.2 Hit Quality Comparison
Not all hits are created equal. The passage in the Spec example below clearly and completely answers its query. The passage in the Build example contains the answer; however, more context is required to answer the query.
Spec Example: Hit passage clearly answers the query.
Build Example: Additional information is required to fully answer the query. Such as: What is a DL? How do we know Arch-Build-Hotseat-XXX is a DL?
A.9 Additional Evaluation Results and Discussions
Table 14 shows the evaluation data for all models on the engineering assistant chatbot application. It should be noted that adding domain-specific instructional data to our SFT training led to only marginal improvement on the engineering assistant task. However, including this data in our SteerLM training degraded the quality of our model’s responses. We believe this is due to insufficient adaptation of our data to the SteerLM labeling system. Future work will see closer compatibility between general-purpose and domain-specific instructional data labeling, from which we expect to see improvements in the behavior of the model as a chatbot.
The evaluation results for all models on the EDA script generation task are presented in Table 15. In addition to the comparison with off-the-shelf models discussed in the main section of the paper 3.6, an ablation study was conducted to assess the significance of SteerLM training against ChipNeMo-70B-SFT and ChipNeMo-70B-Steer models. The observations suggest that SteerLM training helps on the “hard” benchmark, thus showcasing its effectiveness in generating relevant results for real world use cases.
Figure 16 and Figure 17 depict the comparison among LLaMA2-70B-Steer, ChipNeMo-70B-Steer model, and ChipNeMo-70B-Steer models. The results reveal a significant enhancement achieved solely through DAPT training, emphasizing the crucial role of domain knowledge. Moreover, a substantial improvement is observed when contrasting the chat model’s performance with and without domain instructional data. This emphasizes that the model’s capacity to produce accurate answers can be enhanced through improved alignment with domain instructional data. These results show the importance of both DAPT and model alignment for domain specific applications.
The impact of RAG for generating EDA scripts was also studied. The retrieved data consisted of specific APIs related to the questions along with a description of the API. This helped in improving the accuracy of “easy” and “medium” difficulty benchmark which depend heavily on the API knowledge. On the “hard” benchmark, a degradation in the accuracy is noticed as compared to non-RAG model. This showcases the difficulty of coupling existing retrieval techniques with non-natural language tasks such as code generation. While a wide variety of retrieval techniques have been proven to work for natural language tasks, there are comparatively fewer publications focused on retrieval-augment code generation (Gao et al., 2024). This emphasizes the importance of DAPT, especially in data regimes where there are insufficient quality examples and explanations to readily apply retrieval.
The evaluation results for the bug summarization and analysis task are presented in Table 16. Minor improvements are observed with DAPT, evident when comparing the non-DAPT LLaMA2-70B-Steer model to its DAPT counterpart, ChipNeMo-70B-Steer. When comparing SteerLM to traditional SFT training, a slight enhancement in summarization task performance is noted, while no significant difference is observed in task assignment.
Additionally, we investigated GPT-4 models in two versions. In the first approach, we utilized the conventional evaluation procedure employed for our other models, assuming limitations based on a comparable context window size. This procedure included breaking down substantial bugs into smaller segments and employing hierarchical summarization, as previously described. In the second approach, we successfully fitted each of our test bugs entirely within the 32k context size of GPT-4. The results of this ablation study suggest that our hierarchical summarization has minimal impact on response quality.
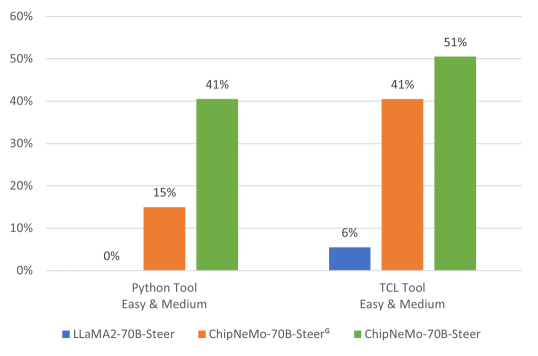
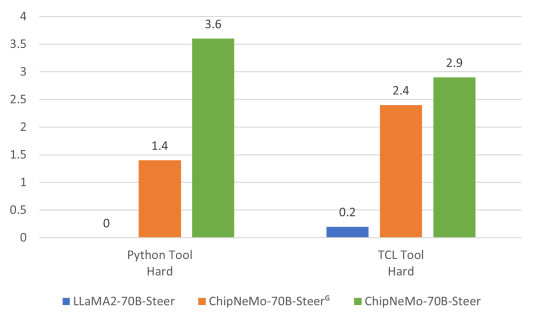
|
Model |
RAG | Hit | Miss | Avg. |
|
GPT-4 |
No | - | - | 2.84 |
|
LLaMA2-70B-Chat |
No | - | - | 1.81 |
|
LLaMA2-70B-Steer |
No | - | - | 1.99 |
|
ChipNeMo-70B-Steer |
No | - | - | 5.12 |
|
ChipNeMo-70B-Steer |
No | - | - | 4.80 |
|
ChipNeMo-70B-SFT |
No | - | - | 4.68 |
|
ChipNeMo-70B-SFT |
No | - | - | 4.89 |
|
GPT-4 |
Yes | 4.77 | 4.04 | 4.52 |
|
LLaMA2-70B-Chat |
Yes | 4.18 | 3.22 | 3.86 |
|
LLaMA2-70B-Steer |
Yes | 3.68 | 3.00 | 3.46 |
|
ChipNeMo-70B-Steer |
Yes | 6.02 | 4.78 | 5.68 |
|
ChipNeMo-70B-Steer |
Yes | 5.58 | 4.39 | 5.26 |
|
ChipNeMo-70B-SFT |
Yes | 5.18 | 4.79 | 5.06 |
|
ChipNeMo-70B-SFT |
Yes | 5.39 | 4.17 | 5.06 |
| Tool1 (Python) | Tool2 (Tcl) | |||||
| Model | Easy | Medium | Hard | Easy | Medium | Hard |
| (Automatic) | (Automatic) | (Human) | (Automatic) | (Automatic) | (Human) | |
| GPT-4 | 0% | 0% | 0.0 | 20% | 52% | 1.1 |
| LLaMA2-70B-Chat | 0% | 0% | 0.1 | 7% | 4% | 0.0 |
| LLaMA2-70B-Steer | 0% | 0% | 0 | 0% | 11% | 0.2 |
| ChipNeMo-70B-Steer | 19% | 11% | 1.4 | 29% | 52% | 2.4 |
| ChipNeMo-70B-SFT | 61% | 29% | 3.4 | 27% | 74% | 1.9 |
| ChipNeMo-70B-Steer | 49% | 32% | 3.6 | 45% | 56% | 2.9 |
| ChipNeMo-70B-Steer (w/RAG) | 77% | 36% | 2.3 | 84% | 85% | 0.8 |
| Model | Technical Summary | Managerial Summary | Task Assignment |
| GPT-4 | 6.30 | 6.25 | 6.00 |
| GPT-4 (32k, No Chunks) | 6.14 | 6.45 | 5.78 |
| LLaMA2-70B-Chat | 4.35 | 4.95 | 5.00 |
| LLaMA2-70B-Steer | 4.95 | 5.35 | 4.73 |
| ChipNeMo-70B-Steer | 5.00 | 5.35 | 5.45 |
| ChipNeMo-70B-Steer | 5.05 | 5.25 | 4.27 |
| ChipNeMo-70B-SFT | 4.50 | 5.15 | 5.45 |
A.10 Chip Design Applications
We conducted a survey of potential LLM applications within our design teams and categorized them into four buckets: code generation, question & answer, analysis and reporting, and triage. Code generation refers to LLM generating design code, testbenches, assertions, internal tools scripts, etc.; Q & A refers to an LLM answering questions about designs, tools, infrastructures, etc.; Analysis and reporting refers to an LLM analyzing data and providing reports; triage refers to an LLM helping debug design or tool problems given logs and reports. We selected one key application from each category to study in this work, except for the triage category which we leave for further research. The motivation and technical details of each application are given below.
A.10.1 Engineering Assistant Chatbot
This application aims to help design engineers with answers to their architecture, design, verification, and build questions, which could significantly improve their overall productivity without impacting the productivity of others. It is observed that design engineers often enjoy brainstorming, designing hardware, and writing code, but can be slowed down waiting for answers on design knowledge they lack. Design productivity can also be enhanced by avoiding having engineers write code based on mistaken assumptions or debugging code that they are unfamiliar with. Internal studies have shown that up to 60% of a typical chip designer’s time is spent in debug or checklist related tasks across a range of topics including design specifications, testbench construction, architecture definition, and tools or infrastructure. Experts on these issues are often spread around the globe in a multinational company, such that it is not always convenient to find immediate help. Therefore, an engineering assistant chatbot based on knowledge extracted from internal design documents, code, any recorded data about designs and technical communications such as emails and corporate instant communications, etc. could help significantly improve design productivity. We implemented this application with the domain-adapted RAG method mentioned in Section 2.4.
A.10.2 EDA Script Generation
Another common task in an industrial chip design flow is writing EDA scripts to accomplish a variety of tasks such as design implementation, introspection and transformation. These scripts often leverage both tool-specific and custom internal script libraries. Learning these libraries, navigating tool documentation, and writing and debugging these scripts, can take up a significant amount of engineering time.
LLMs have proven adept at small scale code generation on a wide array of tasks (Rozière et al., 2023) and therefore customizing these models to accelerate engineer productivity in this domain specific task is a natural fit. In this work we focus on generating two different types of scripts from natural language task descriptions. The first are scripts which leverage an internal python library for design editing and analysis. The second are Tcl scripts that use the command interface provided by a leading industrial static timing analysis tool.
In order to build our domain-specific fine-tuning dataset for this task, production scripts for both tools were collected from design experts. We observed that our DAPT models can generate reasonable inline comments for the code. This enabled us to use these models to improve the quality of collected scripts by generating additional inline comments. Human experts later verified and corrected these comments and created an associated prompt. These prompts and code pairs make up the data used for model alignment as discussed in A.4.
To provide and collect feedback in the most meaningful way, we spent significant effort building the flow shown in Fig. 18 where engineers can both query the model and run generated code through the same interface. This allows us to be confident in the correctness of generated code as well as provide accurate feedback by allowing engineers to see how many corrections they might need to get a functioning script. We support this integration by establishing interactive connections to tool servers.
Additionally, we provide a user feedback form, allowing us to compare different models and glean valuable insights from user feedback. This valuable information can aid us in further refining our models.
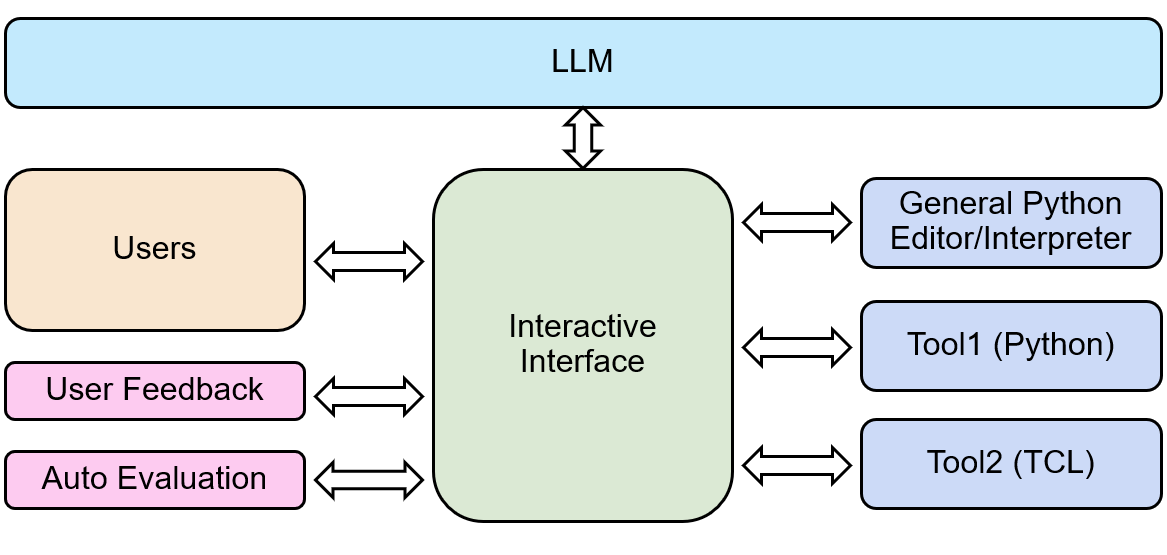
A.10.3 Bug Summarization and Analysis
Tracking the reporting, triage, debug and resolution of various features and bugs across stages of the production flow is a time-consuming process. Engineering managers spend a lot of time reviewing internal issue tracking databases to build understanding of the state of the project and help speed their execution. Therefore, a tool that is able to look at all supporting information and quickly summarize both technical and managerial data as well as suggest next steps would boost team productivity. We focus on using LLMs to generate three different outputs - one focused on technical details, one on managerial details and one recommending task assignment.
To study these tasks we used an internal bug database. This database is used for bug reporting, tracking and resolution as well as general task and feature tracking across the company. We expect ChipNeMo models to perform well on this task as a large amount of bug data was included in the DAPT dataset. Additionally, we built a domain-specific SFT dataset for this task that includes examples of the bug summarizing and task assignment tasks.
Often, bug descriptions contain large snippets of log files or code dumps along with long comment histories. In such cases, the bug text is too large for our LLM context windows. To work around this, we implemented two solutions. First, we found and replaced long path names with shorter aliases to allow the model to associate paths that occur in multiple places in the bug without needing to process the entire string. Second, we split the summarization task into an incremental task where the model is tasked with accumulating data across multiple summary and bug data chunks. We use a hierarchical approach where the bug is first separated into chunks that fit into the context window. Those chunks are then summarized and the summaries are accumulated then separated into chunks. This process is repeated until the entire set of summaries fits into a single context window and a single summary is generated. We use this same approach independent of the LLM used for summarization.
A.11 Examples
A.11.1 Engineering Assistant Chatbot
A.11.2 EDA Script Generation
Some function names and commands are obfuscated.
A.11.3 Bug Summary and Analysis
Usernames, chip names and paths are obfuscated.