GPTuner: A Manual-Reading Database Tuning System via GPT-Guided Bayesian Optimization
Abstract.
Modern database management systems (DBMS) expose hundreds of configurable knobs to control system behaviours. Determining the appropriate values for these knobs to improve DBMS performance is a long-standing problem in the database community. As there is an increasing number of knobs to tune and each knob could be in continuous or categorical values, manual tuning becomes impractical. Recently, automatic tuning systems using machine learning methods have shown great potentials. However, existing approaches still incur significant tuning costs or only yields sub-optimal performance. This is because they either ignore the extensive domain knowledge available (e.g., DBMS manuals and forum discussions) and only rely on the runtime feedback of benchmark evaluations to guide the optimization, or they utilize the domain knowledge in a limited way. Hence, we propose GPTuner, a manual-reading database tuning system that leverages domain knowledge extensively and automatically to optimize search space and enhance the runtime feedback-based optimization process. Firstly, we develop a Large Language Model (LLM)-based pipeline to collect and refine heterogeneous knowledge, and propose a prompt ensemble algorithm to unify a structured view of the refined knowledge. Secondly, using the structured knowledge, we (1) design a workload-aware and training-free knob selection strategy, (2) develop a search space optimization technique considering the value range of each knob, and (3) propose a Coarse-to-Fine Bayesian Optimization Framework to explore the optimized space. Finally, we evaluate GPTuner under different benchmarks (TPC-C and TPC-H), metrics (throughput and latency) as well as DBMS (PostgreSQL and MySQL). Compared to the state-of-the-art approaches, GPTuner identifies better configurations in 16x less time on average. Moreover, GPTuner achieves up to 30% performance improvement (higher throughput or lower latency) over the best-performing alternative.
PVLDB Artifact Availability:
The source code, data, and/or other artifacts have been made available at %leave␣empty␣if␣no␣availability␣url␣should␣be␣sethttps://github.com/SolidLao/GPTuner.
1. Introduction
Modern Database Management Systems (DBMS) expose hundreds of configurable parameters (i.e., knobs) to control their runtime behaviours (pavlo2017self). The selection of appropriate values for these knobs is crucial to improve DBMS performance, constituting a long-standing challenge within the database community (10.14778/3450980.3450992). Given the high dimensionality of the configuration space (e.g., PostgreSQL v14.7 has 351 knobs), and the inherent heterogeneity of these knobs (due to their continuous and categorical domains), database administrators (DBAs) encounter substantial difficulties in identifying promising configurations tailored to specific query workloads. The magnitude of this challenge becomes even more pronounced in the cloud environment, where the underlying physical configurations can significantly vary among distinct DBMS instances (10.14778/3476311.3476411).
To reduce the manual tuning efforts of DBAs, state-of-the-art approaches automate the knob tuning via Machine Learning (ML) techniques, including Bayesian Optimization (10.14778/1687627.1687767; 10.1145/3035918.3064029; 10.1145/3448016.3457291; 10.14778/3457390.3457404; 10.1145/3514221.3526176; 10.1145/3318464.3380591) and Reinforcement Learning (10.1145/3299869.3300085; 10.14778/3352063.3352129; 10.1145/3514221.3517882; 10.1145/3514221.3517843). These ML-based tuning systems follow the main concept of “trial and error” to explore the configuration space iteratively, balancing between the exploration of unseen regions and the exploitation of known space.
While these tuning systems do possess the potential to reach well-performing knob configurations eventually, they still incur significant tuning costs (10.14778/3551793.3551844; 10.1145/3318464.3380591). For example, previous studies (10.1145/3514221.3517882; 10.1145/3448016.3457291; 10.14778/3538598.3538604) have revealed that state-of-the-art systems still require hundreds to thousands iterations to reach an ideal configuration, with each iteration taking several minutes or more to execute the target workload. Such high tuning costs stem from their inefficiency in handling two difficulties: (1) the large number of knobs that requires tuning and (2) the wide search space of possible values for each knob. For the first difficulty, most approaches either select a fixed subset of knobs (10.1145/3514221.3517882; 10.14778/3551793.3551844; 10.14778/3457390.3457404; 10.14778/1687627.1687767; 10.1145/3299869.3300085; 10.1145/3127479.3128605), sacrificing the flexibility to choose workload-relevant knobs, or execute workloads numerous times to identify the important knobs (10.14778/3538598.3538604; 10.1145/3035918.3064029; 10.5555/3488733.3488749), which is resource-intensive. Regarding the second difficulty, most approaches use the default value ranges provided by DBMS vendors (10.14778/1687627.1687767; 10.1145/3035918.3064029; 10.1145/3448016.3457291; 10.14778/3457390.3457404; 10.1145/3514221.3526176; 10.1145/3318464.3380591; 10.1145/3299869.3300085; 10.14778/3352063.3352129; 10.1145/3514221.3517882). However, since the default value ranges are excessively broad for flexibility, it complicates the optimization process and introduces the risk of system crashes (10.14778/3476311.3476411; 10.14778/3450980.3450992).
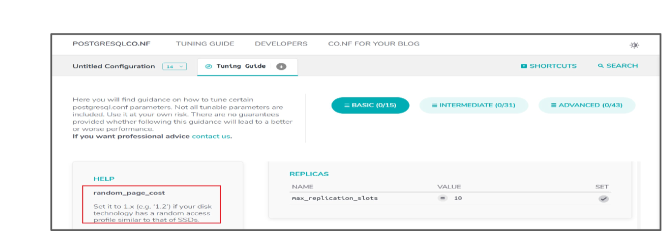
In contrast to ML-based tuning approaches that adjust the DBMS solely based on performance statistics, human DBAs often rely on domain knowledge for tuning (e.g., DBMS manuals and discussions from DBMS forums). Unlike performance statistics, external domain knowledge directly reveals tuning hints, including the important knobs and typical value ranges for each knob. First, there are discussions on which knobs significantly impact DBMS performance. For instance, in web forums like Hacker News, it is commonly mentioned that parallel knobs (e.g., “max_parallel_workers_per_gather”) are crucial for OLAP workloads, while I/O-related knobs (e.g., “max_wal_size”) are important for OLTP workloads (hackernews). Second, there are typical value ranges summarized for knobs. Table 1 provides two examples of extracting improved value ranges from natural language tuning guidance. For knob “shared_buffers”, instead of using the default value range [0.125 MB, 8192 GB], the improved value range can be [4 GB, 6.4 GB] since the guidance suggests setting the value between 25% and 40% of the RAM (on a machine with 16 GB of RAM). For knob “random_page_cost”, we can try out value range [1.0, 2.0] rather than [0, 1.79769 ] if the machine uses SSDs as disks. We can observe that these hints are highly valuable in reducing the search space of ML-based methods and thus expedite convergence and achieve better performance.
| 2 Knob | shared_buffers | random_page_cost |
|---|---|---|
| Default Range | ||
| Guidance | “shared_buffers” can be 25% of the RAM but no more than 40% …(PostgreSQL2023) | “random_page_cost” can be 1.x if disk has a speed similar to SSDs …(PostgreSQLCONF) |
| DBA | The machine has a 16 GB RAM. Thus we can set “shared_buffers” from 16 GB 25% = 4 GB to 16 GB 40% = 6.4 GB. | The machine uses SSDs as disks. Thus we can set “random_page_cost” to a value from 1.0 to 2.0. |
| Improved Range | [4 GB, 6.4 GB] | [1.0, 2.0] |
| 2 |
Therefore, to mitigate the high tuning costs of ML-based techniques, it is desirable to design a knob-tuning system leveraging domain knowledge to enhance the optimization process. However, this is non-trivial for the following challenges. C1. It is challenging to unify a structured view of the heterogeneous domain knowledge while balancing a trade-off between cost and quality. Domain knowledge typically comes in the form of DBMS manuals and discussions on the web forums. To leverage such knowledge in the ML-based techniques, we need to transfer it into a unified machine-readable format (i.e., structured data). However, preparing such a structured view involves a complex and lengthy workflow: data ingestion, data cleaning, data integration and data extraction (nargesian2019data), and existing approaches cannot meet our trade-off between cost and quality. They either demand domain specific training (shin2015incremental), which is more complicated in our scenario since it requires expert knowledge to annotate DBMS tuning knowledge, or they rely on strong assumptions that lack of flexibility (e.g., focusing on specific document format) (deng2022dom; lockard2019openceres; lockard2020zeroshotceres). C2. Even with the prepared structured knowledge, we lack a way to integrate the knowledge into the optimization process. The inherent design of optimization algorithms like Bayesian Optimization (snoek2012practical) and Reinforcement Learning (henderson2018deep) does not support the integration of external domain knowledge directly, necessitating extensive modifications to their standard workflows. For approaches that manually summarize static rules from domain knowledge, the resulting rules cannot capture the nuances of all workloads, and the updates of environments can make them out of date (10.5555/1287369.1287454; Kwan2002AutomaticCF). To address the challenges above, we propose GPTuner, a manual-reading database tuning system that leverages domain knowledge automatically and extensively to enhance the optimization process.
Facing the challenge C1, we develop a Large Language Model (LLM)-based pipeline to collect and refine heterogeneous knowledge, and propose a prompt ensemble algorithm to unify a structured view of the refined knowledge. First, we prepare heterogeneous tuning knowledge from various resources (data ingestion). Second, we filter out noisy knowledge (data cleaning). Third, we summarize the multi-source knowledge by handling the possible conflict in a priority way (data integration). Fourth, we ensure the summarization result is factually consistent with source contents (data correction). Finally, we develop a prompt ensemble algorithm to construct a structured view of the knowledge (data extraction).
Regarding the challenge C2, we use the structured knowledge to (1) design a workload-aware and training-free knob selection strategy, (2) develop a search space optimization technique considering the value range of each knob, and (3) propose a novel knowledge-based optimization framework to explore the optimized space. Before the tuning process, we optimize the search space based on data dimensionality and the values in each dimension. For data dimensionality, we leverage the text analysis ability of LLM to simulate the knob selection process of DBAs, considering the characteristic of DBMS, workload, specific query and knob dependencies. For values in each dimension, we discard meaningless regions, highlight promising space and take special situations into consideration. Next, we develop a novel Coarse-to-Fine Bayesian Optimization Framework. At first, since it is non-trivial to reduce the size of search space while still retaining the potential for optimal results (feurer2019hyperparameter), we seek help from domain knowledge to carefully design two search spaces of different granularity. Next, the two spaces are explored sequentially by BO from coarse granularity to fine granularity, with a bootstrap technique to serve as a bridging mechanism. This framework balances between the efficiency of coarse-grained search and the thoroughness of fine-grained search.
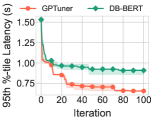
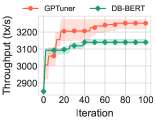
We are aware of only one work DB-BERT (10.1145/3514221.3517843) that utilizes a pre-trained language model to read manuals and uses the mined hints to guide a reinforcement learning algorithm. It exhibits rapid convergence as it benefits from the information gained via text analysis. However, it only yields sub-optimal performance since it utilizes the domain knowledge narrowly and suffers from the inadequate exploration of search space. GPTuner tackles these limitations and thus achieves faster convergence and better performance improvement. As shown in Figure 1, GPTuner significantly outperforms DB-BERT on two representative benchmarks (TPC-H and TPC-C) with different optimization objective (latency and throughput). It is important to note that GPTuner is a distinct approach compared to DB-BERT, and its efficacy does not stem from simply substituting the language model. We verify this by replacing the BERT model in DB-BERT with GPT-4 and compare it with GPTuner again. More details are provided in Section 2.3.
In our experiments, we compare GPTuner against DB-BERT as well as other state-of-the-art approaches that do not use text as input. We consider different benchmarks (TPC-C and TPC-H), metrics (throughput and latency), and DBMS (PostgreSQL and MySQL). Compared to the state-of-the-art approaches, GPTuner identifies better configurations in 16x less time on average. Moreover, GPTuner achieves up to 30% performance improvement (higher throughput or lower latency) over the best-performing alternative. In summary, we make the following contributions:
-
•
We propose GPTuner, a novel manual-reading database tuning system that leverages domain knowledge automatically and extensively to enhance the knob tuning process.
-
•
We develop a LLM-based pipeline to collect and refine domain knowledge, and propose a prompt ensemble algorithm to unify a structured view of the refined knowledge.
-
•
We design a workload-aware and training-free knob selection strategy, develop an optimization method for the value range of each knob, and propose a Coarse-to-Fine Bayesian Optimization framework to explore the optimized space.
-
•
We open-source the built structured domain knowledge for PostgreSQL and MySQL to enable the further study of broader database community.
-
•
We conduct extensive experiments to demonstrate the effectiveness of GPTuner, considering different benchmarks, metrics and DBMS. Compared with the state-of-the-art methods, GPTuner finds the best-performing knob configuration with significantly less tuning rounds.
2. Background and Related Work
2.1. Database Knob Tuning
DBMS expose tens to hundreds of configurable knobs to control their runtime behaviours (10.14778/3450980.3450992). The DBMS knob tuning problem is to select an appropriate value for each knob to optimize the DBMS performance (e.g., throughput or latency) on a certain workload (e.g., a workload is a set of SQL statements). Formally, given a set of configurable knobs along with their domains , the configuration space is defined as . We want to find a configuration to maximize DBMS performance :
| (1) |
Finding an optimal solution for this problem is challenging for two main reasons. Firstly, with hundreds of adjustable knobs, each potentially impacting performance, the complexity is immense. Secondly, the knobs themselves vary widely – some have continuous numerical values, while others are categorical, making the problem even more complicated since it is hard to model heterogeneous space. To address these challenges, three kinds of approaches are proposed: heuristic-based, Bayesian Optimization (BO)-based (snoek2012practical) and Reinforcement Learning (RL)-based (henderson2018deep).
• Heuristic-based. Heuristic-based methods can be classified into rule-based and search-based. Rule-based methods rely on manually created static rules to explore the space in a predefined way (10.5555/1287369.1287454; Kwan2002AutomaticCF). Search-based methods explore the space according to several heuristics (e.g., avoid to revisit explored regions and explore the nearby regions to improve the current optimum) (10.1145/3127479.3128605; 10.1145/2628071.2628092).
• BO-based. BO-based methods (10.14778/1687627.1687767; 10.1145/3035918.3064029; 10.1145/3448016.3457291; 10.14778/3457390.3457404; 10.1145/3514221.3526176; 10.1145/3318464.3380591) follow the generic BO framework to search for an optimal configuration: (1) fitting a probabilistic surrogate model to map the relation between knob configuration and DBMS performance, (2) selecting the next configuration that maximizes acquisition function.
• RL-based. RL-based methods explore configuration space with a trial-and-error strategy. The essence is to balance between exploring unexplored space and exploiting known regions, which is achieved by the interactions between an agent (e.g., neural network) and the target environment (e.g., DBMS) (10.1145/3299869.3300085; 10.14778/3352063.3352129; 10.1145/3514221.3517882).
Performance Comparison. An experimental evaluation is conducted to compare these approaches (10.14778/3538598.3538604). A BO-based method, Sequential Model-based Algorithm Configuration (SMAC) (lindauer-jmlr22a) yields the best performance because it uses Random Forest (RF) as the surrogate to leverage its efficiency in modeling the high-dimensional and heterogeneous configuration space. Since SMAC is evaluated as the best-performing optimizer, we view it as the current state-of-the-art that does not take text as input and aim to improve it further.
2.2. Language Models
The field of Natural Language Processing (NLP) has undergone a significant transformation with the advent of Large Language Models (LLMs). Starting with the introduction of attention and transformer architecture (wolf-etal-2020-transformers), numerous language models (LMs) have been developed, resulting in a substantial enhancement of language processing capabilities. Notably, BERT, which introduced the encoder-only transformer architecture, revolutionized downstream learning tasks by improving embeddings (devlin-etal-2019-bert). More recent additions to the GPT series, such as ChatGPT (luo2023chatgpt) and GPT-4 (openai2023gpt4), have demonstrated greater prowess across a wide range of tasks.
Moreover, the impact of these LLMs extends beyond the scope of NLP. The database community has experienced a surge in the adoption of LLMs to enhance various aspects of DBMS, including data profiling (zhang2023schema; trummer2021can; narayan2022foundation), code generation (trummer2023demonstrating; yu2019spider; cheng2023binding; scholak2021picard) and table-based question answering (ye2023large; zhang2023reactable; jiang2022omnitab). When using LLMs in practice, there are three typical design choices: (1) training a language model from scratch, (2) fine-tuning an existing language model, and (3) using a pre-trained language model without parameter modifications. The first two options require a relatively large amount of resources, including both hardware resources and training data. Given the impressive in-context learning capabilities demonstrated by GPT-4, we have chosen the third option and use GPT-4 as our default language model throughout the paper unless noted otherwise.
| Criterion | DB-BERT | GPTuner |
|---|---|---|
| Language Model | BERT | GPT-4 |
| Workload-Aware Knob Selection | no | yes |
| Fine-Tuning | yes | no |
| Filter Noise | no | yes |
| Space Type | Discrete | Heterogeneous |
| Optimization Algorithm | Reinforcement Learning | Coarse-to-Fine Bayesian |
| Considered Knowledge | Suggested Value | Suggested Value Bound Constraint Special Cases |
2.3. Enhancing DBMS Knob Tuning with LMs
With the vast corpus of tuning guidance available on the internet or provided by DBMS vendors, language models can be harnessed to “read the manual” and provide structured tuning hints to enhance the knob tuning approaches. As the state-of-the-art LM-enhanced tuning approach, DB-BERT (10.1145/3514221.3517843) models the tuning process as a series of “multiple choice question answering problem”, and uses Reinforcement Learning to fine-tune a pre-trained BERT model to answer these problems. While DB-BERT converges fast as it benefits from the text analysis, it only yields sub-optimal performance.
We summarize the main differences between GPTuner and DB-BERT in Table 2. Firstly, the knob selection of DB-BERT is not workload-aware since it only tune knobs mentioned in the input documents. GPTuner considers the tuning context (e.g., the characteristic of DBMS, workload, specific query and the knob dependencies) to select which knobs are worth tuning. Secondly, DB-BERT requires fine-tuning of BERT model in both offline training and online tuning stages, which requires a lot of resources. GPTuner adopts in-context learning ability of LLM without modifying the model parameters. Thirdly, DB-BERT relies on the input documents without filtering out noisy contents, while GPTuner tackles this by comparing the contents with the system view from DBMS (e.g., pg_settings from PostgreSQL). Fourth, DB-BERT only rely on the suggested values from documents to construct a discrete space and only explore this space. However, such limited utilization of domain knowledge and inadequate exploration of search space are the decisive factors leading to sub-optimal performance. GPTuner, on the other hand, leverages more information from domain knowledge (e.g., suggested value, bound constraint, and special cases), and explores the search space with a novel Knowledge-based Optimization Framework. Finally, we conduct experiments to evaluate the performance of both methods in Section LABEL:subsec:_performance-compare. Moreover, we investigate the effect the language model in Section LABEL:subsec:_differ-llm. Whether using the same advanced model (both GPT-4) or a less complex one (i.e., DB-BERT with GPT-4 and GPTuner with GPT-3.5), GPTuner consistently outperforms DB-BERT in both scenarios.
3. Motivation
ML-based methods still incur significant tuning costs. State-of-the-art ML-based tuning methods require hundreds to thousands of iterations to converge to a good DBMS knob configuration. Such high tuning expenses stem from the inefficiency of runtime feedback-based optimization algorithms. Specifically, the feedback information is limited (i.e., a few benchmark runs cannot provide a complete picture of the DBMS performance under all conditions) and unstable (i.e., DBMS performance is not guaranteed to improve after each step of knob tuning). Given such weak feedback, it takes a substantial number of observations for ML models to have sufficient confidence in predictions, especially when the space is complex.
Extensive domain knowledge helps, but not well-exploited. Since the early 2000s, when tuning systems take knob settings into consideration, extensive tuning knowledge has continually accumulated in the form of natural language and such knowledge does help in optimizing the search space. As shown in Figure 2 (left part), by analyzing the tuning knowledge, we can identify which knobs are worth tuning and gain insights of the typical value settings for knobs (e.g., suggested value to try, range constraint and special value). However, such wisdom seems exclusive to DBA and is not leveraged to mitigate the expensive tuning costs of ML-based approaches. There are approaches that utilize the static rules summarized by DBA to complete knob tuning. Unfortunately, these rules cannot capture the nuances of all workloads, and the updates of environments can make these static rules out of date. Thus we call for a more advanced approach to utilize the knowledge.
LLM is a notable step forward, but not adequate yet. While it is widely acknowledged that domain knowledge is useful, such wisdom is considered inaccessible to machines due to the barriers in natural language understanding. Recently, the advent of Large Language Model (LLM) makes it possible to leverage such knowledge since we can utilize LLM to transfer the knowledge into a unified machine-readable format (e.g., structured data like JSON and relational table). However, this process is still challenging for two main reasons. First, since domain knowledge typically comes in the form of DBMS documents and discussions from DBMS forums, it involves a complex and lengthy workflow to process such heterogeneous and noisy knowledge: data ingestion, data cleaning, data integration and data extraction. Second, the brittle nature of LLM (i.e. small modifications to the prompt can cause large variations in the model outputs) and the hallucination problem of LLM (i.e., LLM generates answers that seem correct but are factually false) make this challenge even more pronounced. For instance, as shown in Figure 2 (middle part), LLM can generate contents that are defective and even wrong. Thus, a reliable and effective approach to harness the power of LLM is both non-trivial and essential.
Even if structured knowledge is developed, its integration into the optimization process is deficient. To the best of our knowledge, no DBMS tuning framework accounts for structured knowledge. Existing optimization algorithms like BO and RL do not support the integration of external knowledge directly, necessitating extensive modification to their standard workflows. Without modification, the only information that can be used is the range constraint (i.e., lower and upper bounds) recommended by manuals. However, there is much more useful information available (e.g., suggested value and special value). We present some simple ideas to utilize these values in Figure 2 (right part). Unfortunately, it is predictable that such naive ideas cannot serve as an effective solution, especially in the context of DBMS knob tuning where the problem is proven to be NP-hard (10.1145/1005686.1005739). Therefore, the current situation calls for an innovative optimization framework that inherently supports the effective utilization of the structured domain knowledge.
4. Overview of GPTuner
Workflow. GPTuner is a manual-reading database tuning system to suggest satisfactory knob configurations with reduced tuning costs. Figure 3 presents the tuning workflow that involves seven steps. ❶ User provides the DBMS to be tuned (e.g., PostgreSQL or MySQL), the target workload, and the optimization objective (e.g., latency or throughput). ❷ GPTuner collects and refines the heterogeneous knowledge from different sources (e.g., GPT-4, DBMS manuals and web forums) to construct Tuning Lake, a collection of DBMS tuning knowledge. ❸ GPTuner unifies the refined tuning knowledge from Tuning Lake into a structured view accessible to machines (e.g., JSON). ❹ GPTuner reduces the search space dimensionality by selecting important knobs to tune (i.e., fewer knobs to tune means fewer dimensions). ❺ GPTuner optimizes the search space in terms of the value range for each knob based on structured knowledge. ❻ GPTuner explores the optimized space via a novel Coarse-to-Fine Bayesian Optimization framework, and finally ❼ identifies satisfactory knob configurations within resource limits (e.g., the maximum optimization time or iterations specified by users).
Components. GPTuner consists of three components: Knowledge Handler, Knowledge-Based Search Space Optimizer and Knowledge-Based Configuration Recommender and they work as follows:
Knowledge Handler. Knowledge Handler uses a DBMS tuning knowledge-oriented data pipeline to unify a structured view of the heterogeneous domain knowledge. At first, we propose a LLM-based pipeline to balance between cost and quality in Section 5.1. Next, we propose a LLM-based Prompt Ensemble Algorithm to transfer the refined knowledge into a structured format such that it can be utilized by machines in Section LABEL:subsec:_knowledge-transform.
Knowledge-Based Search Space Optimizer. The optimizer optimizes the search space from two aspects. Firstly, it reduces the size of the search space in terms of dimensionality. Specifically, we propose a workload-aware and training-free approach to select important knobs in Section LABEL:subsec:_knob-select. Secondly, we optimize the search space by focusing on the value range of each knob. We propose Region Discard, Tiny Feasible Space and Virtual Knob Extension methods to discard meaningless regions, highlight promising space and handle special situations, respectively (Section LABEL:subsec:_space-reduction).
Knowledge-Based Configuration Recommender. The recommender uses a novel Coarse-to-Fine BO Framework to compute optimal configurations. In the first stage, BO only explores a discrete subspace of the whole heterogeneous space. This subspace is small in size but promising to contain good configurations since we generate it based on the reliable domain knowledge. In the next stage, in order to avoid the overlooking problem of coarse-grained search (i.e., it is inevitable to lose some useful configurations for any space reduction technique), BO explores the heterogeneous space thoroughly with the optimizations in Section LABEL:sec:_space-explorer. After the two stages, the recommender outputs the best-performing knob configurations found within the budget limits specified by users.
5. Knowledge Handler
5.1. Knowledge Preparation
In this section, we discuss how Knowledge Handler completes Knowledge Preparation task. As outlined in Algorithm 1, this task is to collect tuning knowledge from various resources (data ingestion, Line 1-3), filter out noisy contents (data cleaning, Line 4), summarize the legal parts (data integration, Line 5-6) and make sure the summarization is factual consistent with source contents (data correction, Line 7-10). The output is a Tuning Lake defined as follows:
Definition 1 (Tuning Lake).
Tuning Lake is a set of texts, where is the number of configurable knobs and is the natural language tuning knowledge for -th knob. For example, “set shared_buffers to 25% of the RAM” (denoted as ) is the tuning knowledge for knob “shared_buffers” (the -th knob).
Step 1: Extracting knowledge from LLM. Except for the common tuning knowledge sources (e.g., manuals and web contents), we propose utilizing LLM as a knowledge source as well. Since GPT is trained on a vast corpus related to database (ameryahia2023large), GPT itself is an informative manual and allows us to retrieve the knowledge through prompt. In practice, we surprisingly find that GPT can give reasonable suggestions that are not included in the manuals. Such suggestions come from web contents summarized by DBAs and were used as training data for GPT. Since it is impossible to provide all web contents to any system and GPT already knows much of it, it is reasonable to use GPT as a complementary source of knowledge. In case that GPT gives nonsense suggestions, we utilize LLM to handle such abnormal situation in the next step.

Example 0.
Figure 4 depicts the process of extracting knowledge from GPT for knob “effective_io_concurrency”. While the manual provides no useful suggestions, GPT recommends value 200 for SSDs and 2 for HDDs, which is available from a blog (metis).
Step 2: Filtering noisy knowledge. The tuning knowledge comes from various sources and its quality cannot be guaranteed. Thus we filter out noisy knowledge by modeling this process as a “binary classification problem” and utilize LLM to solve it. We provide LLM with the candidate tuning knowledge for a knob and an official system view for this knob (e.g., pg_settings from PostgreSQL and information_schema from MySQL). Moreover, we give a few examples in the prompt to utilize the in-context learning ability of LLM (dai-etal-2023-gpt). LLM evaluates whether the tuning knowledge conflicts with the system view and we discard any knowledge that does conflict.