Dissecting the Runtime Performance of the Training, Fine-tuning, and Inference of Large Language Models
††thanks: *Equal contribution.
††thanks: †Corresponding author.
Abstract
Large Language Models (LLMs) have seen great advance in both academia and industry, and their popularity results in numerous open-source frameworks and techniques in accelerating LLM pre-training, fine-tuning, and inference. Training and deploying LLMs are expensive as it requires considerable computing resources and memory, hence many efficient approaches have been developed for improving system pipelines as well as operators. However, the runtime performance can vary significantly across hardware and software stacks, which makes it difficult to choose the best configuration. In this work, we aim to benchmark the performance from both macro and micro perspectives. First, we benchmark the end-to-end performance of pre-training, fine-tuning, and serving LLMs in different sizes , i.e., 7, 13, and 70 billion parameters (7B, 13B, and 70B) on three 8-GPU platforms with and without individual optimization techniques, including ZeRO, quantization, recomputation, FlashAttention. Then, we dive deeper to provide a detailed runtime analysis of the sub-modules, including computing and communication operators in LLMs. For end users, our benchmark and findings help better understand different optimization techniques, training and inference frameworks, together with hardware platforms in choosing configurations for deploying LLMs. For researchers, our in-depth module-wise analyses discover potential opportunities for future work to further optimize the runtime performance of LLMs.
Index Terms:
Large Language Models, Performance Evaluation, BenchmarksI Introduction
In recent years, large language models (LLMs) have become very popular in AI applications [1, 2]. With an increased size, LLMs demonstrate much better generalization capabilities in various tasks [3, 4, 5]. However, the model size gets huge in recent work, for example, GPT-3 [6] has 175 billion parameters and PaLM [7] has 540 billion parameters. As a result, training and deploying LLMs is complex and expensive.
Specifically, the pipeline of LLMs (as shown in Figure 1) has three main stages, pre-training, fine-tuning, and serving, for deploying a LLM for a real-world application [8]. First, the model (e.g., Llama2) is pre-trained using self-supervised learning before it is applied to downstream tasks, which is the most time-consuming stage in the LLM pipeline. For example, pre-training a PaLM model requires around floating-point operations (FLOPs) and takes 64 days when executed on 6,144 Google TPUv4 chips [7]. Second, the pre-trained model is further fine-tuned on downstream tasks or instruction datasets111Instruction tuning with human feedback is also regarded as fine-tuning throughout this paper as its paradigm is almost identical with fine-tuning with downstream task datasets. to improve its performance in real-world applications [1], e.g., Llama2-Chat is fine-tuned with Llama2 using fine-turning and RLHF data. Third, after the model has been fine-tuned (e.g., Llama2-Chat), it is deployed as a web (or API) service that provides inference results for given input queries.
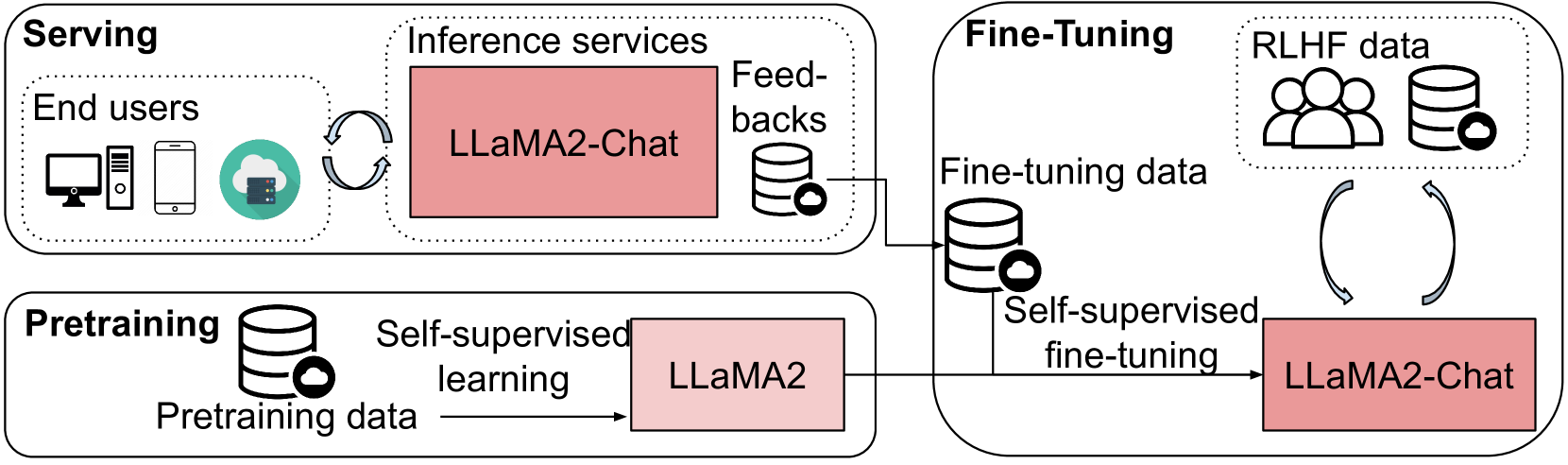
To reduce the computational costs in the pipeline of LLMs, dedicated frameworks have been proposed for efficient pre-training (e.g., DeepSpeed [10] and Megatron-LM [11]), fine-tuning (e.g., PEFT [12]), and inference (e.g., vLLM [13], LightLLM [14], and TGI [15]). Inside each framework, optimization techniques have been applied for memory and compute efficiency. Specifically, in pre-training, memory-efficient approaches (ZeRO [16], activation recomputation [17, 18, 19], and quantization [20]) are commonly adopted to enable GPUs that have limited memory to train large models. In fine-tuning, parameter-efficient fine-tuning (PEFT) methods such as LoRA [21, 22] have been used to fine-tune LLMs by tuning the parameters of adaptors instead of full parameters of the model so that GPUs with limited memory are able to fine-tune LLMs. In LLM serving, to maximally utilize the GPU resources in deployment, quantization [20] and kernel-level optimization [23] are performed on the trained model.
However, with various LLM frameworks and related optimization techniques running on different types of hardware (e.g., high-end GPUs such as Nvidia A800 and consumer-level GPUs, e.g., Nvidia Geforce RTX4090 and RTX3090), there are two under-explored problems that are crucial for end-users and researchers. First, what configurations are required for pre-training, fine-tuning, and deploying LLMs for particular applications to balance the efficiency and cost? For example, are 8x A800 80GB GPUs sufficient to pre-train a 7B model, how long will it take, and what kind of optimization techniques should be enabled to accelerate the training? Second, do existing state-of-the-art systems with highly optimized techniques fully utilize the GPU resources and where is the performance bottleneck? In particular, what is the peak utilization of compute and bandwidth resources on modern GPU servers under different configurations?
To address these questions, we benchmark the runtime and memory performance of existing systems in the LLM pipeline on various types of GPU servers. Specifically, we provide the following detailed benchmarks to understand the time and memory efficiency of different software and hardware systems. (1) On the framework-level, we choose DeepSpeed and Megatron-LM to study their training performance of Llama2 [9] with three scales (7B, 13B, and 70B) on three types of hardware (A800, RTX4090, and RTX3090 servers). (2) We study the impact on the memory and compute efficiency of integrating ZeRO, quantization, activation recomputation, and FlashAttention. (3) We evaluate popular PEFT frameworks including LoRA and QLoRA, to understand their fine-tuning efficiency. (4) We study the end-to-end inference performance using highly optimized inference libraries including vLLM, LightLLM, and TGI. (5) To understand the performance in-depth, we microbenchmark the key kernels that are the most time-consuming.
Through comprehensive benchmarks and analysis, we conclude the following important findings. (1) DeepSpeed achieves higher throughput than Megatron-LM in all configurations. (2) ZeRO saves great amount of memory without sacrificing training efficiency, or it may suffer from OOM when the number of GPUs is under 4. (3) Offloading further reduces memory usage but significantly slows down the training process. (4) Activation recomputation works well only when combined with other optimization techniques, otherwise it cannot reduce much memory consumption. (5) Quantization boosts the training speed, achieves the largest throughput on all hardware platforms, compared with other methods. However it may lead to convergence failure. (6) FlashAttentionn accelerates the training process on various hardware platforms, with a slightly higher peak memory consumption, which can be migrated with other memory-efficient methods. (7) The PEFT method has enabled various devices to train LLMs. (8) On the A800 platform, LightLLM exhibits superior throughput. In converse, on the 24G GPU platform, TGI demonstrates enhanced throughput, whereas the vLLM and LightLLM display comparable levels of throughput.
II Background and Preliminaries
II-A Decoder-only Transformer-based LLMs
The traditional transformer [24] consists of encoder and decoder architectures, and the decoder has been widely used for modern text-generation LLMs (e.g., GPT-3 [25], Llama [26], Llama2 [9], BLOOM [27], etc.). The decoder has the structure as shown in Figure 2. The input data is first encoded through the embedding layer, whose output are fed into multiple attention blocks. Each attention block consists of a multi-head attention and a feed-forward network which has several linear layers. Then, the output of multiple blocks are concatenated as the input for the next linear layer, called generation or classification head, followed by a softmax layer to calculate the probability for the next token.

II-B Pre-training Frameworks
DeepSpeed. DeepSpeed [10] is a cutting-edge deep learning (DL) optimization software suite developed for both large-scale training and inference. It adopts ZeRO [16, 28, 29], offloading, and DeepSpeed-Inference [30], and other techniques. The software is encapsulated in an open-source library, allowing seamless integration into training and inference. It has been widely adopted in the DL community and is a cornerstone of Microsoft’s AI at Scale initiative.
Megatron-LM. Megatron-LM [31, 11] addresses the challenge of efficiently training expensive transformer models. Megatron-LM is well optimized for supporting 3D-parallelism and activation recomputation [17]. It also introduces sequence parallelism to be combined with tensor parallelism, so it substantially reduces the need for activation recomputation. Since Megatron-LM is highly scalable, it has been a commonly used LLM training system.
II-C Fine-tuning Frameworks
A straight-forward way of fine-tuning LLM for downstream tasks is to fine-tune all parameters (i.e., Full-FT), but it is very memory-expensive and time-consuming. In real-world applications, parameter-efficient fine-tuning (PEFT) [12] approaches are more popular as they require much less memory resources to fine-tune a model than Full-FT. In PEFT, LoRA [21] (or QLoRA [22], the quantization version of LoRA) and Prompt Tuning [32] are two widely adopted methods.
LoRA. The low-rank adaptation (LoRA) method [21] is based on the observation that over-parameterized models often operate within a low intrinsic dimension. For a pre-trained weight matrix , its update is constrained using a low-rank decomposition: , where , , and the rank . During training, remains static without gradient updates, while and are trainable. The modified forward pass is represented as . Thus, LoRA approximates Full-FT by setting the LoRA rank to the pre-trained weight matrices to train the low-rank matrices and incurs little additional overhead during inference.
QLoRA. QLoRA [22] is a quantization version of LoRA. It converts pretrained models to a particular 4-bit data type (NormalFloat or NF4), thereby drastically reducing memory usage and improving compute efficiency while preserving data integrity during quantization.
Prompt Tuning. Prompt tuning [32] is a novel technique tailored for adapting frozen language models to specific downstream tasks. Specifically, prompt-tuning emphasizes the learning of “soft prompts” via backpropagation, allowing them to be fine-tuned using signals from labeled examples.
II-D Inference Frameworks
TGI. Text Generation Inference (TGI) [15] is a toolkit designed specifically for the deployment and serving of LLMs. Catering to a range of renowned open-source LLMs, including Llama series [26, 9], BLOOM [27]. It adopts tensor parallelism (or model parallelism [33]) for accelerated inference across multiple GPUs and employs token streaming via Server-Sent Events (SSE) [34]. Notably, TGI’s continuous batching optimizes the handling of incoming requests, maximizing throughput. The toolkit further refines inference with optimized transformer code, leveraging advanced techniques such as FlashAttention [23] and PagedAttention [13].
vLLM. The PagedAttention algorithm [13], inspired by virtual memory and paging mechanisms from operating systems, segments the dynamically changing key-value cache (KV cache) memory into smaller blocks, which can be placed in non-contiguous areas. This approach resolves issues such as fragmentation, paving the way for optimized memory utilization. Building upon the PagedAttention foundation, vLLM222https://github.com/vllm-project/vllm is a high-throughput LLM serving engine.
LightLLM. LightLLM [14] stands out as a cutting-edge, Python-based LLM inference and serving framework, distinguished by its lightweight architecture, scalability, and swift performance. LightLLM employs a tri-process asynchronous collaboration, scheme allowing tokenization, model inference, and detokenization occuring concurrently, thereby maximizing GPU utilization. Additionally, it introduces the ”Nopad” feature to adeptly manage requests with varying lengths and a dynamic batch scheduling mechanism to streamline request processing. LightLLM’s unique token-wise KV cache memory management, termed ”Token Attention”, significantly reduces memory usage during inference. Another feature is the Int8KV Cache, which effectively doubles the token capacity.
II-E Optimization Techniques
ZeRO. ZeRO serial techniques (i.e., ZoRO-1/2/3 [16], ZeRO-Offload [28], and ZeRO-Infinity [29]) optimize the memory efficiency in training LLMs. ZeRO-1 partitions the model’s optimizer states across GPUs, reducing memory used for these states. ZeRO-2 extends ZeRO-1 by adding partitioning of gradients across GPUs, further decreasing memory required for gradients. However, ZeRO-2 introduces extra Reduce collective communication primitives into the backward process. Based on ZeRO-1 and ZeRO-2, ZeRO-3 further adds model parameter partitioning and model parallelism for activations, maximizing memory savings and allowing for the training of even larger models with reduced communication overhead, but it requires extra Reduce-Scatter for partitioning model parameters. With ZeRO-Offload, the authors aim to make billion-scale model training more accessible, bridging the gap between computational demands and available resources.
Activation Offloading. Activation offloading [28] is a technique aimed at efficiently managing the substantial computational and GPU memory demands inherent in training and deploying LLMs. By selectively transferring the activations (intermediate neuron output) from GPU memory to CPU memory or disk storage during the forward pass of a neural network and subsequently reloading them during the backward pass for gradient computations, activation offloading facilitates memory and computational resource optimization. Furthermore, two primary methods, optimizer offloading and model parameter offloading, can be employed to significantly alleviate pressure on GPU memory. However, it introduces additional data transfer overhead.
Activation Recomputation. It involves the re-computation of intermediate activations during the backward pass of training, rather than retaining them from the forward pass so as to optimize memory usage. By eschewing the storage of activations for each layer of a model, it can significantly reduce memory consumption. However, this method introduces additional computational overhead. While the memory benefits are substantial, the recomputation process necessitates alterations to the conventional backpropagation algorithm, adding a layer of complexity to the training paradigm.
Quantization.Quantization is an important technique to represent the weights or activations using low-bit format to reduce both memory size and compute time. ZeroQuant [20] is one of the popular systems, which introduces a novel post-training quantization approach and develops a hardware-friendly quantization scheme for both weights and activations, a unique layer-by-layer knowledge distillation algorithm, and a highly optimized system backend for quantization. It has demonstrated the capability to reduce the precision for weights and activations to INT8 for models such as BERT and GPT-3 with minimal accuracy degradation.
FlashAttention. FlashAttention [23], is tailored to address the inherent challenges posed by transformers in processing extensive sequences. This algorithm is IO-aware in that it optimizes the interplay between GPU memory levels. It utilizes tiling to reduce memory reads/writes between the GPU’s High Bandwidth Memory (HBM) and on-chip Static Random-Access Memory (SRAM) to improve the attention efficiency.
III Methodologies
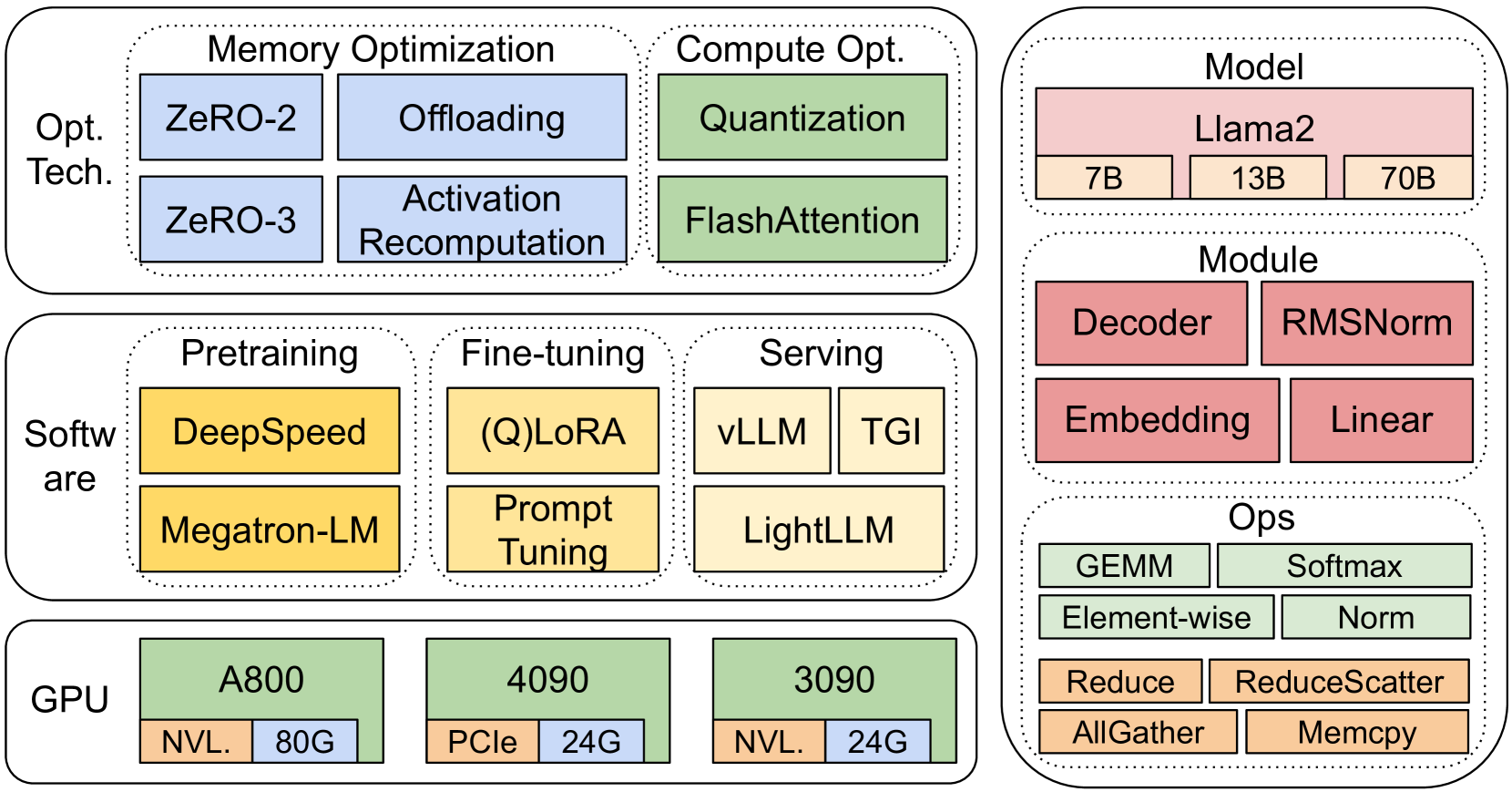
Our benchmarks use a top-down methodology that covers the end-to-end step time performance, module-level time performance, and operators time performance of Llama2 [9] on three 8-GPU hardware platforms as shown in Figure 3.
| Platform | A800 | RTX4090 | RTX3090 |
| GPU | A800-80G | RTX4090-24G | RTX3090-24G |
| @ 1.155GHz | @ 2.235GHz | @ 1.395GHz | |
| CPU | 2x AMD | 2x Intel(R) | 2x AMD |
| 7402 | Xeon(R) Gold 6230 | 7302 | |
| @ 2.80GHz | @ 2.10GHz | @ 3.00GHz | |
| Memory | 512GiB DDR4 | 512GB DDR4 | 128GB |
| Network | NVLink | PCIe4.0x16 | NVLink |
Hardware. In the aspect of hardware evaluation, we cover three 8-GPU platforms, of which the configurations are shown in Table I. In these platforms, we measure the time performance in pre-training, fine-tuning, and serving of LLMs using the different software (e.g., DeepSpeed and Megatron-LM).
Software. In the aspect of software evaluation, we compare DeepSpeed and Megatron-LM with end-to-end step time in pre-training and fine-tuning. To evaluate optimization techniques, we use DeepSpeed to enable these optimizations (i.e., ZeRO-2, ZeRO-3, offloading, activation recomputation, quantization, and FlashAttention) one by one to measure performance improvement and degradation in time and memory consumption. On LLM serving, there are three highly optimized systems, vLLM [13], LightLLM [14], and TGI [15]. We compare their performance (latency and throughput) on three testbeds. To understand the end-to-end performance in-depth, we provide microbenchmarks on the performance of model modules and operators that are fundamental components in pre-training, fine-tuning, and inference serving pipelines.
Datasets. In order to ensure the accuracy and reproducibility of the results, we calculated the average length of instruction, input and output of the commonly used dataset alpaca for LLM, i.e., 350 tokens per sample, and randomly generated strings to reach a sequence length of 350, in pre-training, fine-tuning and module-wise analysis. In inference serving, to comprehensively utilize the computational resources and evaluate the robustness and efficiency of the frameworks, all requests were dispatched in a burst pattern. The experimental dataset consists of 1000 synthetic sentences, each containing 512 input tokens, ensuring a consistent evaluation environment. We consistently maintained the “max generated tokens length” parameter across all experiments on the same GPU platform to guarantee uniformity and comparability of the results.
III-A Measuring End-to-end Performance
We measure the end-to-end performance by using the metrics of step time, throughput, and memory consumption in pre-training, fine-tuning, and serving three sizes of Llama2 models (Llama2-7B, Llama2-13B, and Llama2-70B) on three testbeds.
Pre-training (§IV). We first compare the performance (throughput, time, and memory) differences between DeepSpeed and Magetron-LM. Then, we use DeepSpeed to evaluate the impact of optimization techniques ZeRO-2, ZeRO-3, offloading, activation recomputation, quantization, and FlashAttention on both time and memory efficiency on our testbeds. To understand the root reasons resulting in the measured performance, we further measure the module and operators performance.
Fine-tuning (§V). We compare two popular fine-tuning techniques, LoRA and QLoRA with the baseline (full parameter tuning, or Full-FT) on three testbeds with the metrics of throughput and memory consumption.
Inference Serving (§VI). We evaluate three widely-recognized inference serving systems: vLLM [13], LightLLM [14], and TGI [15], using three testbeds, focusing on metrics such as latency, throughput, and memory consumption. Initially, we deployed the API servers for each of these frameworks. Subsequently, a benchmarking script was used, leveraging asyncio, to dispatch HTTP requests to the model server. As an acknowledged bug333RTX 40x0 NCCL Issue Comment exists for the RTX40X0 GPU series, to rectify this issue and ensure that the inference framework functions appropriately on the RTX4090, the configuration NCCL_P2P_DISABLE=1 was applied. However, this configuration might impact the final performance, putting RTX4090 at a disadvantage against other platforms.
III-B Measuring Module-wise Performance
An LLM typically consists of a series of modules (or layers). Taking the Llama2 model as an example. The top level class LlamaForCausalLM consists of one LlamaModel module with a linear layer for downstream tasks. Each module has its own sub-modules which may have unique computation and communication characteristics. Specifically, a LlamaModel is formed by an embedding layer and multiple decoder layers (LlamaDecoderLayer) [24], and the number of LlamaDecoderLayer is configurable. LlamaAttention is the self-attention layer [24] that consists of four linear layers for computing , , , and projections and one embedding layer (LlamaRotaryEmbedding). LlamaMLP consists of three linear layers whose sizes are configurable and one SiLU activation [35] layer (SiLUActivation). LlamaRMSNorm is the RMS normalization [36] layer. In summary, the key modules that form the Llama2 model are Embedding (naive Embedding and LlamaRotaryEmbedding), LlamaDecoderLayer, Linear, SiLUActivation, and LlamaRMSNorm.
In fine-tuning, different approaches introduce extra modules for updating model parameters or adapter parameters. Particularly, LoRA requires extra Linear layers, i.e., the low-rank adapters. QLoRA has a similar training paradigm to LoRA, but its computation uses low-bit representation, which results in low-precision Linear layers, such as 8-bit or 4-bit Linear layers.
IV Results on Pre-training
In this section, we first analyze the pre-training performance (iteration time or throughput and memory consumption) on different model sizes (7B, 13B, 70B) on three testbeds (§IV-A), followed by module-wise and ops-level micro-benchmarks (§VII). Unless otherwise specified, each metric (iteration time or throughput and memory consumption) is measured three times for each task and the average is reported.
IV-A End-to-End Performance
| Framework | BS | Throughput (Tokens/s) | Memory (GB) |
|---|---|---|---|
| Megatron | 1 | 10936 | 49.1 |
| 32 | 13977 | 55.6 | |
| DeepSpeed | 1 | 7488 | 66.76 |
| 4 | 19348 | 72.64 |
IV-A1 Megatron-LM vs. DeepSpeed
We first conduct an experiment to compare the performance between Megatron-LM and DeepSpeed, neither of which use any memory optimization techniques e.g., ZeRO, in pre-training Llama2-7B on the A800-80GB server. We use a sequence length of 350, and two sets of batch sizes (BS) for both Megatron-LM and DeepSpeed, from 1 to the maximum batch size. We report the training throughput (tokens per second, or tokens/s) and consumed GPU memory in GB as the benchmarks. The results are presented in Table II. The results show that Megatron-LM performs slightly faster than DeepSpeed when the batch size equals 1, however DeepSpeed leads the board in terms of training speed when they reach the maximum batch size. At the same batch size, DeepSpeed consumes more GPU memory, compared to the tensor parallel based Megatron-LM. Both systems take up a considerable amount of GPU memory even if the batch size is small, which causes out-of-memory (OOM) on the RTX4090 or RTX3090 GPU servers.
IV-A2 GPU Scaling Efficiency
We use DeepSpeed with quantization to study scaling efficiency (from 1 GPU to 8 GPUs) on different hardware platforms in training Llama2-7B (sequence length is 350, batch size is 2). The results are presented in Figure 4, where the slope indicates scaling efficiency. The figure shows that A800 has almost linear scaling, whereas RTX4090 and RTX3090 have slightly low scaling efficiency (90.8% and 85.9% respectively). RTX4090 achieves 4.9% higher scaling efficiency than RTX3090. In the RTX3090 platform, NVLink connection helps improve the scaling efficiency by 10% over without NVLink.
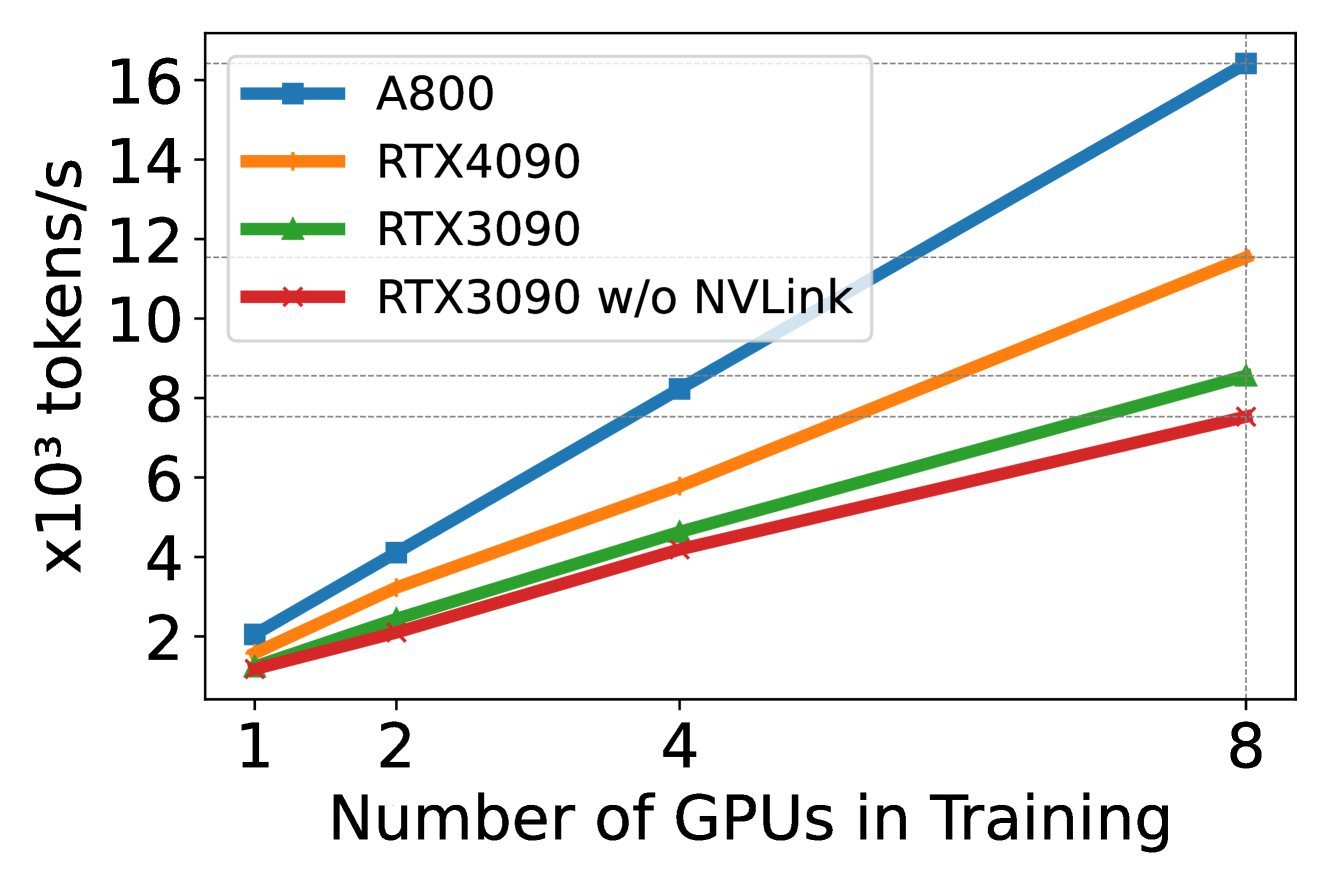
IV-A3 Hardware and Optimized Techniques
We use DeepSpeed to evaluate the training performance under different memory- and compute-efficient methods. We use a sequence length of 350, and batch size of 1 across all evaluations for a fair comparison, and load the model weight into bf16 by default for all experiments. For ZeRO-2 and ZeRO-3 with offloading, we offload the optimizer state and optimizer state + model weights to CPU RAM, respectively. For quantization, we use the configuration of 4 bits with double quantization as suggested in a prior study[22]. We also report the performance on RTX3090 when NVLink is disabled, i.e., all data are transmitted by PCIe buses. The results are presented in Table III.
| Model | Method | Hardware platform | |||||||
|---|---|---|---|---|---|---|---|---|---|
| A800 | RTX4090 | RTX3090 w/ NVLink | RTX3090 w/o NVLink | ||||||
| Tokens/s | M (GB) | Tokens/s | M (GB) | Tokens/s | M (GB) | Tokens/s | M (GB) | ||
| 7B | Naive | 66.7 | - | - | - | ||||
| Z2 | 37.8 | - | - | - | |||||
| Z2+O | 32.8 | 19.1 | 19 | 19 | |||||
| Z3 | 30.5 | 22.6 | 22.6 | 22.6 | |||||
| Z3+O | 10.4 | 10.4 | 10.4 | 10.4 | |||||
| Q | 9.8 | 10.1 | 9.8 | 9.8 | |||||
| R | 65.9 | - | - | - | |||||
| F | 66.7 | - | - | - | |||||
| R+Z2 | 38.1 | - | - | - | |||||
| R+Z2+O | 29.6 | 19 | 19 | 19 | |||||
| R+Z3 | 28.8 | 22.6 | 22.6 | 22.6 | |||||
| R+Z3+O | 6.4 | 6.4 | 6.4 | 6.4 | |||||
| R+Q | 6 | 6 | 6 | 6.0 | |||||
| R+F | 66.1 | - | - | - | |||||
| F+Z2 | 38.2 | - | - | - | |||||
| F+Z2+O | 32 | 18.1 | 18 | 18 | |||||
| F+Z3 | 29.2 | 21.6 | 21.4 | 21.4 | |||||
| F+Z3+O | 8.8 | 8.8 | 8.8 | 8.8 | |||||
| F+R+Z2 | 38.1 | - | - | - | |||||
| F+R+Z2+O | 29.6 | 17.7 | 17.7 | 17.7 | |||||
| F+R+Z3 | 27.4 | 21 | 21 | 21 | |||||
| F+R+Z3+O | 6.7 | 6.7 | 6.5 | 6.5 | |||||
| 13B | Z2 | 71.4 | - | - | - | ||||
| Z2+O | 57.9 | - | - | - | |||||
| Z3 | 48.9 | - | - | - | |||||
| Z3+O | 12.7 | 12.7 | 12.2 | 12.2 | |||||
| R+Z2 | 71.8 | - | - | - | |||||
| R+Z2+O | 53.1 | - | - | - | |||||
| R+Z3 | 48.9 | - | - | - | |||||
| R+Z3+O | 7.8 | 7.8 | 7.8 | 7.8 | |||||
| F+Z2 | 72.2 | - | - | - | |||||
| F+Z2+O | 56.8 | - | - | - | |||||
| F+Z3 | 52.2 | - | - | ||||||
| F+Z3+O | 11.5 | 11.5 | 11.3 | 11.3 | |||||
| F+R+Z2 | 71.7 | - | - | - | |||||
| F+R+Z2+O | 52.9 | - | - | - | |||||
| F+R+Z3 | 53.7 | - | - | - | |||||
| F+R+Z3+O | 7.9 | 7.9 | 7.9 | 7.9 | |||||
Hardware Impact. (1) The throughput of A800 exceeds 50 times that of RTX4090 and RTX3090 GPUs on all evaluated cases except quantization. In the case of using quantization, RTX GPUs can achieve half of the A800 performance. (2) RTX4090 is 50% better than RTX3090, and NVLink in RTX3090 helps improve the performance by around 10%. (3) Since A800 has 80GB memory, while RTX4090 and RTX3090 have only 24GB each, so some cases, e.g., Naive and ZeRO-2 cannot run on RTX4090 and RTX3090 GPUs. (4) With ZeRO (and offloading), a 8x 80GB (8x 24GB) GPU server can at most fit a 30B model for mixed half-precision training.
Optimization Techniques. In pre-training Llama2-7B, ZeRO-2’s GPU memory consumption is about 57% of Naive’s, without sacrificing model performance and training efficiency. Meanwhile, ZeRO-3 performs slightly slower than ZeRO-2, with less memory consumption. However, ZeRO-3 outperforms ZeRO-2 when pre-training Llama2-13B. This difference is because sharding the full model state helps reduce communication further, especially when training larger models. Offloading significantly slows down the training process as it offloads some shards and computing to RAM and CPU, and reduce the GPU memory consumption. Quantization achieves the highest throughput on all hardware platforms, but may affect convergence. FlashAttention also accelerates training and can be used together with memory-efficient methods, such as ZeRO. Activation recomputation further reduces GPU memory usage but decreases throughput. Note that the activation memory is small when batch size = 1, and activation recomputation could save more memory with higher batch sizes. In Table III, when using ZeRO or offloading, memory consumption of the same method varies across platforms. Specifically, it takes more memory on A800 than on the other platforms. This difference is because memory are pinned on CPU in sharding and offloading, and the handles are dynamically loaded into GPU memory, based on available physical memory which is larger on A800 than the other platforms. This table also demonstrates that training Llama2-13B achieves half of the Llama2-7B training’s throughput. With such model performance between Llama2-7B and Llama2-13B, training a model with 13B parameters may be a better choice than a 7B model. We further leverage the computing power of different GPU servers, by maximizing the batch sizes of each method to get the maximum throughput. The result is presented in Table IV.
In this table, we find that when batch size is 16, FlashAttention with ZeRO-3 and offloading consumes even more GPU memory compared to FlashAttention with ZeRO3 (77.5GB vs. 73GB). When conducting this experiment, ZeRO-3 with offloading often yields an inbalanced device map, i.e, it takes more memory on GPU 0 than on other GPUs. We will address this problem in future studies. Overall, Table IV shows that enlarging the batch size easily boosts the training process, which also overlaps communication and GPU computing. Hence, a GPU server with high bandwidth and large GPU memory is more suitable for full parameter mix-precision pre-training than a consumer-level GPU server.
| Model | Method | Hardware platform | |||||||||||
| A800 | RTX4090 | RTX3090 w/ NVLink | RTX3090 w/o NVLink | ||||||||||
| Tokens/s | M (GB) | BS | Tokens/s | M (GB) | BS | Tokens/s | M (GB) | BS | Tokens/s | M (GB) | BS | ||
| 7B | Naive | 72.6 | 4 | - | - | - | |||||||
| Z2 | 58.0 | 8 | - | - | - | ||||||||
| Z2+O | 77.7 | 16 | 22.5 | 2 | 22.5 | 2 | 22.5 | 2 | |||||
| Z3 | 77.2 | 16 | 22.6 | 2 | 22.68 | 2 | 22.6 | 2 | |||||
| Z3+O | 74.9 | 16 | 20.5 | 4 | 20.5 | 4 | 20.5 | 4 | |||||
| Q | 49.8 | 8 | 22.7 | 4 | 22.7 | 4 | 22.7 | 4 | |||||
| R | 75.1 | 64 | - | - | - | ||||||||
| F | 76.4 | 8 | - | - | - | ||||||||
| R+Z2 | 45.9 | 64 | - | - | - | ||||||||
| R+Z2+O | 58.5 | 64 | 19.8 | 16 | 19.8 | 16 | 19.8 | 16 | |||||
| R+Z3 | 59.2 | 64 | 22.8 | 16 | 22.8 | 16 | 22.8 | 16 | |||||
| R+Z3+O | 52.8 | 64 | 22.5 | 64 | 17.5 | 32 | 17.5 | 32 | |||||
| R+Q | 56.8 | 64 | 20 | 32 | 18.9 | 16 | 18.9 | 16 | |||||
| R+F | 73.1 | 64 | - | - | - | ||||||||
| F+Z2 | 76.5 | 16 | - | - | - | ||||||||
| F+Z2+O | 70.3 | 16 | 18.1 | 1 | 18 | 1 | 18 | 1 | |||||
| F+Z3 | 73 | 16 | 21.6 | 1 | 21.4 | 1 | 21.4 | 1 | |||||
| F+Z3+O | 77.5 | 16 | 19.4 | 16 | 19.4 | 16 | 19.4 | 16 | |||||
| F+R+Z2 | 45.4 | 64 | - | - | - | ||||||||
| F+R+Z2+O | 61 | 64 | 17.7 | 1 | 17.7 | 1 | 17.7 | 1 | |||||
| F+R+Z3 | 56.7 | 64 | 21 | 1 | 21 | 1 | 21 | 1 | |||||
| F+R+Z3+O | 49.8 | 64 | 17.2 | 32 | 17.2 | 32 | 17.2 | 32 | |||||
| 13B | Z2 | 71.8 | 4 | - | - | - | |||||||
| Z2+O | 78.9 | 8 | - | - | - | ||||||||
| Z3 | 78.5 | 8 | - | - | - | ||||||||
| Z3+O | 66.7 | 8 | 18.8 | 2 | 18.8 | 2 | 18.8 | 2 | |||||
| R+Z2 | 75.7 | 64 | - | - | - | ||||||||
| R+Z2+O | 77.7 | 64 | - | - | - | ||||||||
| R+Z3 | 77.8 | 64 | - | - | - | ||||||||
| R+Z3+O | 63.6 | 64 | 22 | 16 | 22 | 16 | 22 | 16 | |||||
| F+Z2 | 75.7 | 4 | - | - | - | ||||||||
| F+Z2+O | 27.5 | 8 | - | - | - | ||||||||
| F+Z3 | 74.4 | 8 | - | - | - | ||||||||
| F+Z3+O | 74.9 | 16 | 22.6 | 4 | 22.6 | 4 | 22.6 | 4 | |||||
| F+R+Z2 | 71.8 | 64 | - | - | - | ||||||||
| F+R+Z2+O | 57.9 | 64 | - | - | - | ||||||||
| F+R+Z3 | 77.1 | 64 | - | - | - | ||||||||
| F+R+Z3+O | 34.9 | 64 | 23 | 32 | 23 | 32 | 23 | 32 | |||||
IV-B Module-wise Analysis
To gain an insight into pre-training performance, we conducted detailed module-wise profiling on the pre-training process. Specifically, we selected the Llama2-7B model on the A800 platform to ensure that all cases can run for performance analysis. The traces were generated using “torch.profiler”, and all performance numbers presented in this section are averaged over ten steps. The experimental setup aligns with that described in Section IV-A.
| Forward | Backward | Optimizer | ||
|---|---|---|---|---|
| Overall (ms) | 75.0 | 250.0 | 193.9 | |
| Breakdown in one step(%) | 14.3 | 47.5 | 36.9 | |
|
68.8 | 200.9 | 181.4 |
Given the memory capacity of the A800, we set the batch size to 2. The time consumed in the forward, backward, and optimizer phases in one pre-training step are detailed in Table V. Notably, about 37% of the time is dedicated to the optimizer, which deviates from expectations as the optimizer has only element-wise operations. We analyze this phenomenon in Section IV-C, with a focus on the impact of recomputation.
We conducted module-wise time analysis for both the forward and backward phases, and the results are presented in Table V.
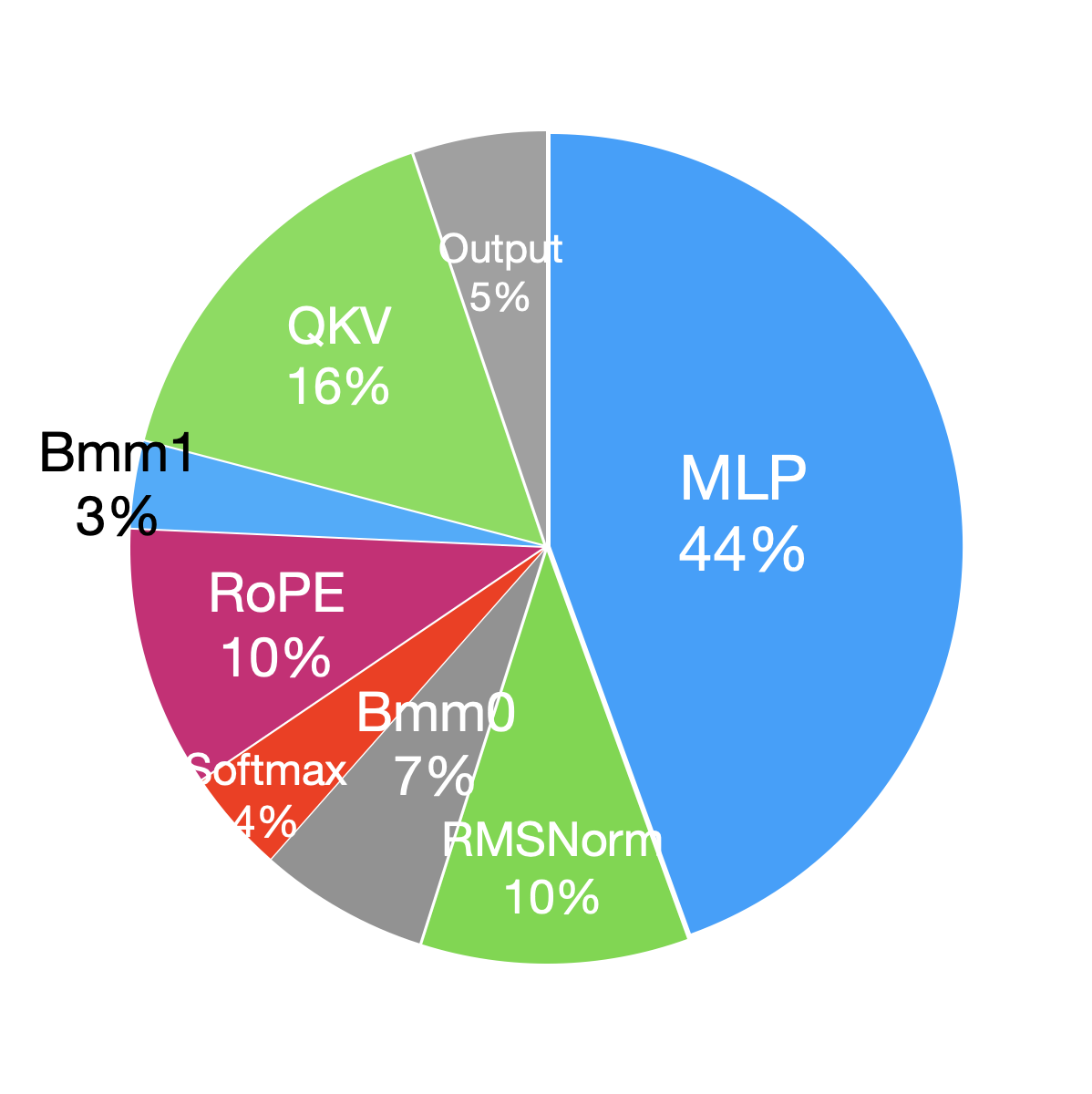
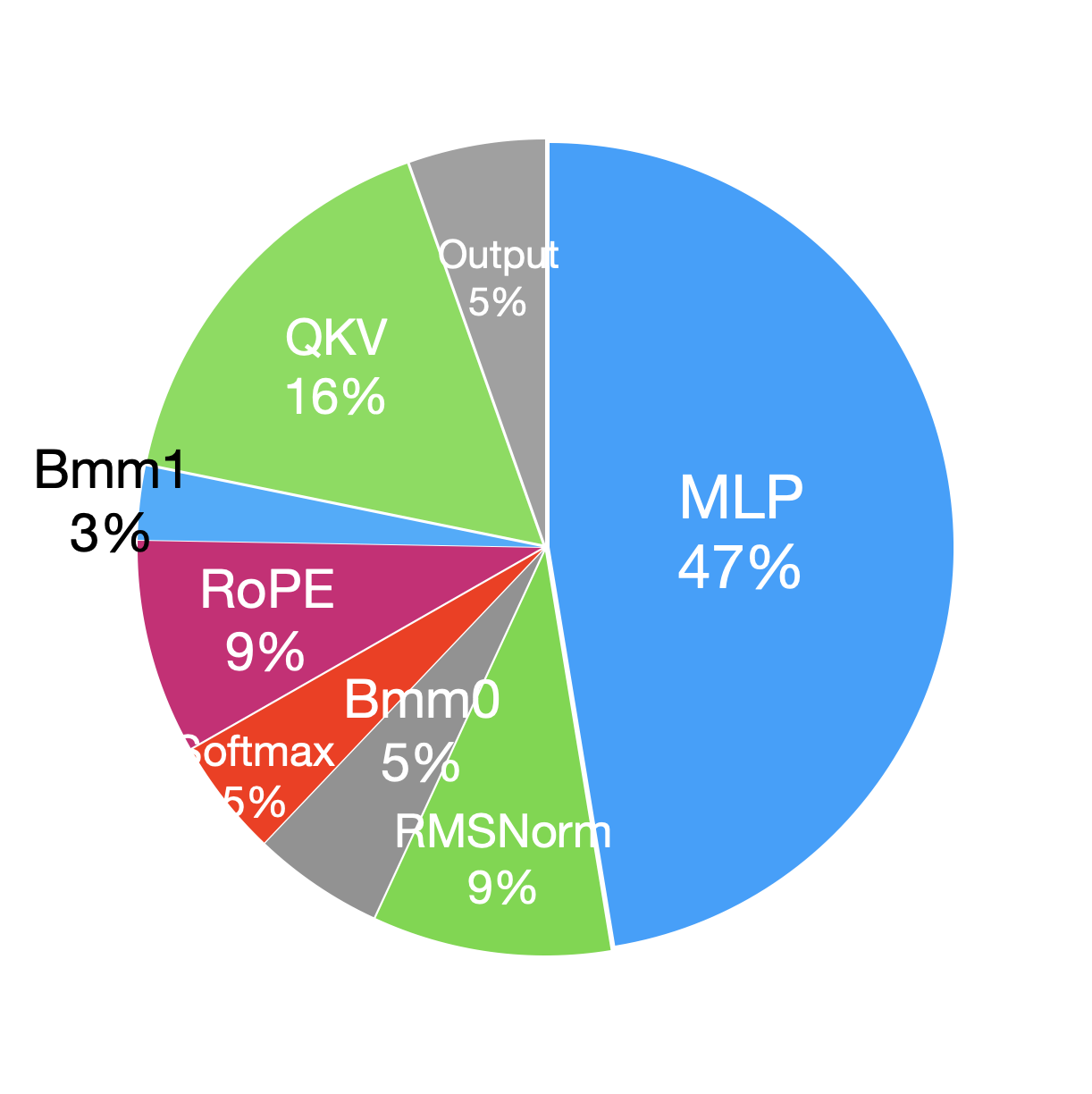
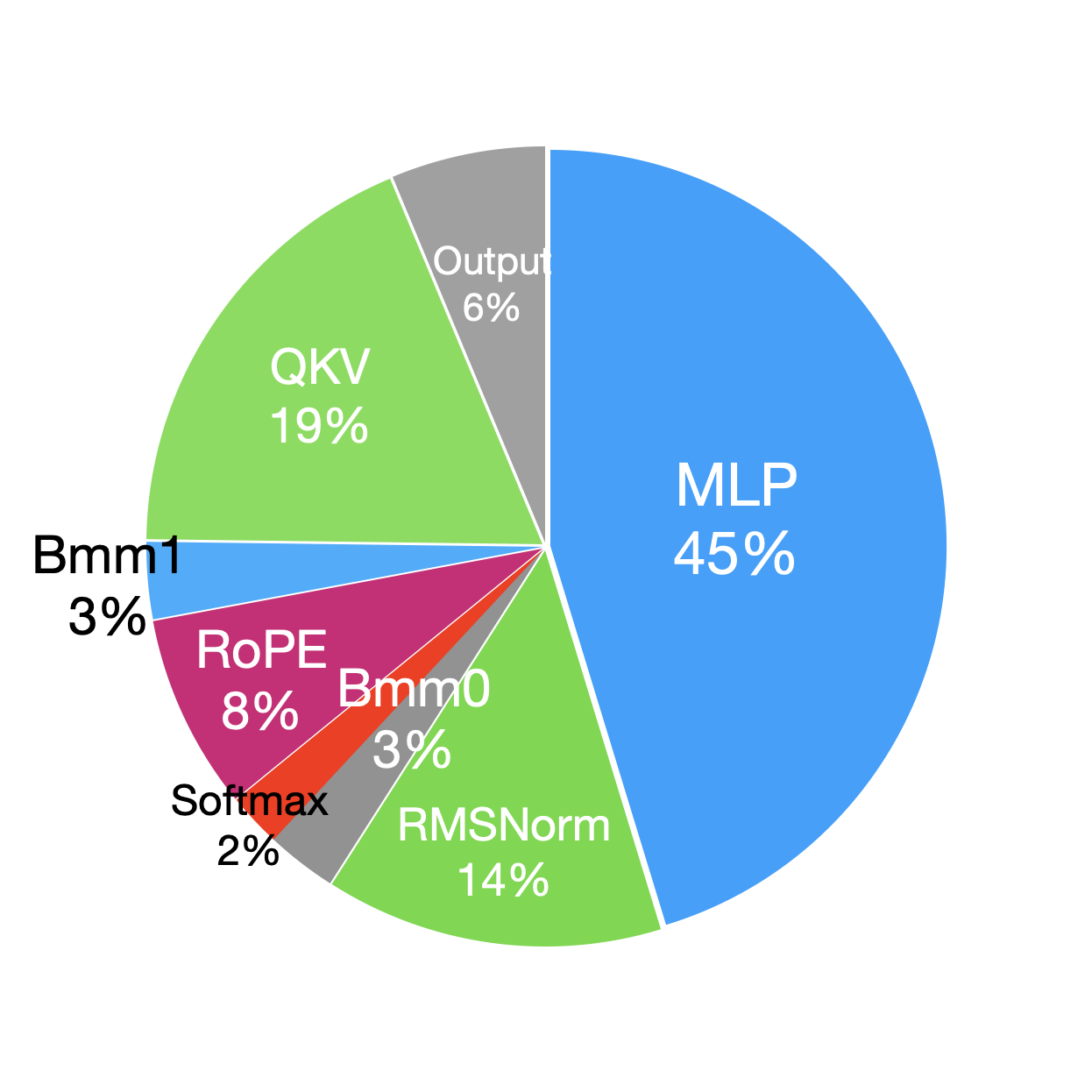
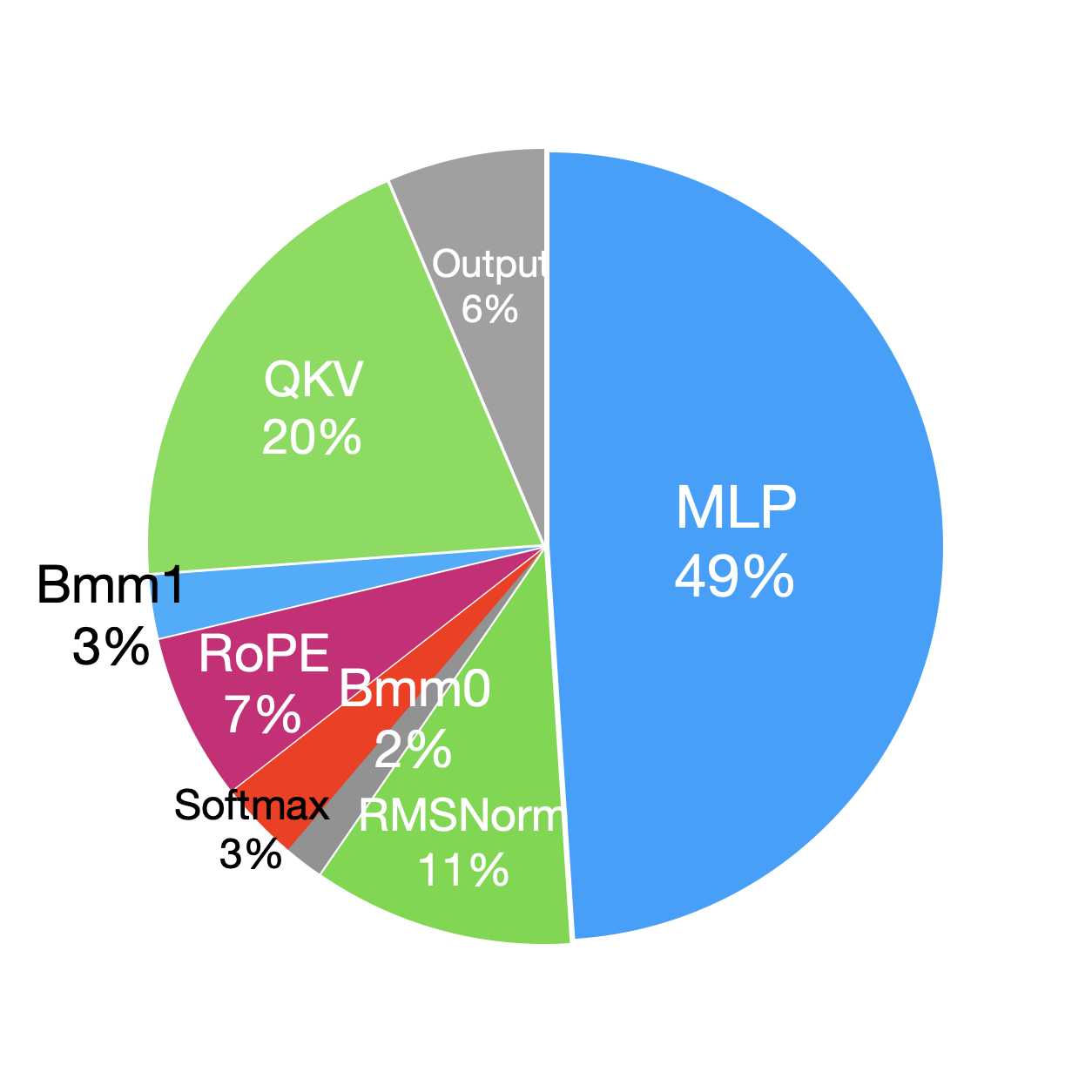
In Llama2, the decoder layer, built on a Transformer-decoder architecture, accounts for the majority of the computation time. Specifically, the multi-layer perceptron (MLP) and the query, key, and value (QKV) projections, which rely on general matrix multiplications (GEMM) operations, are the most time-consuming components. Additionally, the RMSNorm and RoPE modules take significant amounts of time due to the great number of element-wise operations. Compared to the forward phase, the backward phase incurs additional communication overhead for gradient synchronization across GPUs.
| Module | Time(ms) | Percentage(%) | Module | Time(ms) | Percentage(%) | ||
| Forward | Embedding | 0.032 | 0.04 | Backward | Embedding | 0.252 | 0.1 |
| QKV | 9.92 | 13.2 | QKV | 36.26 | 14.5 | ||
| RoPE | 6.66 | 8.9 | RoPE | 15.58 | 6.2 | ||
| Bmm0 | 4.32 | 5.8 | Bmm0 | 5.63 | 2.3 | ||
| Softmax | 2.62 | 3.5 | Softmax | 4.29 | 1.7 | ||
| Bmm1 | 2.21 | 2.9 | Bmm1 | 6.14 | 2.5 | ||
| Output | 3.39 | 4.5 | Output | 12.32 | 4.9 | ||
| MLP | 29.06 | 38.7 | MLP | 88.70 | 35.5 | ||
| RMSNorm | 6.91 | 9.2 | RMSNorm | 27.40 | 11.0 | ||
| Linear | 1.08 | 1.4 | Linear | 2.898 | 1.2 | ||
| - | - | - |
|
38.76 | 15.5 |
IV-C Impact of Recomputation and FlashAttention
Techniques to accelerate pre-training can be roughly divided into two categories: saving memory to increase batch size and accelerating compute kernels. As shown in Table 5, the GPU is idle 5-10% of time in forward, backward, and optimizer phases. We believe this idle time is due to the small batch size. We test the maximum batch size that can be used with all available techniques and find that recomputation can increase the batch size from 2 to 32 at its largest. We therefore select recomputation for increasing batch size and flashattention for accelerating compute kernel analysis.
Recomputation. As the batch size increases, the time for forward and backward phases increases significantly, with little GPU idle time (Table VII). The optimizer updates the model parameters based on optimizer states, hence this process will have a lot of element-wise operations, and the time consumption will remain unchanged in spite of the increase of batch size. In contrast, there are many batch operations in forward and backward phases, which will increase the time consumption with the increase of batch size. Therefore, when the batch size is relatively small, the percentage of time taken by the optimizer will be relatively large; when using the recomputation technique to pre-train with a large batch size, the percentage of time taken by the optimizer will be very small.
To further explore the impact of larger batch sizes on pre-training performance, we compare the percentage of time taken by decoder layer modules in the forward and backward (removing the recomputation part in backward) phases with and without using recomputation (i.e. comparison between batch size = 32 and batch size = 2). Because the recomputation part in the backward phase essentially reruns the forward phase, we analyze the forward and backward phases separately during profiling. Figure 5 shows that when the batch size increases from 2 to 32, the time breakdowns of modules in both the forward and backward phases do not change much. This is because, element-wise operations are memory-bound and their running time roughly scales linearly with batch size. In comparison, GEMM operations in the decoder layer are compute-bound, changing batch size often affects only one of M, N, or K, so the running time also grows linearly with batch size.
| Forward | Backward# | Optimizer | ||
|---|---|---|---|---|
| Overall (ms) | 900.8 | 2651.8 | 187.7 | |
| Percentage(%) | 24.0 | 70.8 | 5.1 | |
|
895.0 | 2614.4 | 180.0 |
FlashAttention fuses the operations of , softmax, PV(P=softmax()) and a few element-wise operations into one kernel, using more accesses to the low-latency high-bandwidth GPU SRAM and reducing accesses to the high-latency low-bandwidth GPU DRAM. Table VIII shows that this technique can accelerate attention module by 34.9% and 24.7% respectively.
| Forward | backward | |
|---|---|---|
| Naive(ms) | 1.06 | 2.75 |
| FlashAttention(ms) | 0.69 | 2.07 |
| Improvement(%) | 34.9 | 24.7 |
V Results on Fine-tuning
In fine-tuning, our primary focus is on parameter-efficient fine-tuning methods (PEFT methods), as full parameter training has already been discussed in Section IV-A. We report on the fine-tuning performance of LoRA and QLoRA across various model sizes and hardware settings. We use a sequence length of 350, a batch size of 1, and a LoRA rank of 64, loading the model weight into bf16 by default. For QLoRA, we adopt a 4-bit configuration with double quantization[22]. We also combine LoRA and QLoRA with other techniques, maintaining the same configurations as in Section IV-A. The fine-tuning results for Llama2-7B are presented in Table IX.
Table IX reveals that the performance trend in fine-tuning Llama2-13B using LoRA and QLoRA is consistent with that of Llama2-7B. Specifically, LoRA achieves approximately higher throughput than QLoRA in all evaluations, primarily due to the overhead associated with quantization and de-quantization operations. However, QLoRA’s memory consumption is half that of LoRA’s. FlashAttention and ZeRO-2, when combined with LoRA in fine-tuning, achieve 20% and 10% more throughput, respectively, than LoRA alone on all hardware platforms. In contrast, ZeRO-3 or offloading shows poor performance in LoRA fine-tuning, as LoRA updates only a small group of parameters, namely the low-rank adapters. Since the optimizer state is limited to handling LoRA parameter updates, which are not compute-bound, offloading or sharding such a small fraction of states introduces more communication overhead compared to computing time, and it does not significantly reduce memory usage.
The throughput for fine-tuning Llama2-13B shows a decrease of about 30% compared to that of Llama2-7B. However, when all optimization techniques are combined, even RTX4090 and RTX3090 can fine-tune Llama2-70B, achieving a total throughput of around 200 tokens per second.
| Model | Method | Hardware platform | |||||||
|---|---|---|---|---|---|---|---|---|---|
| A800 | RTX4090 | RTX3090 w/ NVLink | RTX3090 w/o NVLink | ||||||
| Tokens/s | M (GB) | Tokens/s | M (GB) | Tokens/s | M (GB) | Tokens/s | M (GB) | ||
| 7B | L | 22.7 | 20.5 | 20.5 | 20.5 | ||||
| QL | 13.7 | 14 | 14 | 14 | |||||
| L+R | 21.9 | 20.1 | 20.1 | 20.1 | |||||
| QL+R | 11 | 11.9 | 11.9 | 11.9 | |||||
| L+F | 20.5 | 18.9 | 18.9 | 18.9 | |||||
| QL+F | 9.5 | 10.5 | 10.5 | 10.5 | |||||
| L+Z2 | 19.1 | 19 | 19 | 19 | |||||
| L+Z2+O | 18.8 | 18.7 | 18.7 | 18.7 | |||||
| L+Z3 | 13.3 | 13.3 | 13.3 | 13.3 | |||||
| L+Z3+O | 11.2 | 11.4 | 11.4 | 11.4 | |||||
| QL+Z2 | 10.6 | 10.5 | 10.5 | 10.5 | |||||
| QL+Z2+O | 10.3 | 10.3 | 10.3 | 10.3 | |||||
| L+F+R | 22.2 | 18.9 | 18.9 | 18.9 | |||||
| QL+F+R | 8.5 | 10.1 | 10.1 | 10.1 | |||||
| L+F+R+Z2 | 15.6 | 15.5 | 15.5 | 15.5 | |||||
| L+F+R+Z2+O | 15.3 | 15.2 | 15.2 | 15.2 | |||||
| L+F+R+Z3 | 8.5 | 9.3 | 9.3 | 9.3 | |||||
| L+F+R+Z3+O | 7 | 7.7 | 7.7 | 7.7 | |||||
| 13B | L | 40.3 | - | - | - | ||||
| QL | 21.7 | 21.7 | 21.7 | 21.7 | |||||
| L+R | 36.5 | - | - | - | |||||
| QL+R | 15.5 | 18.5 | 18.5 | 18.5 | |||||
| L+F | 41.4 | - | - | - | |||||
| QL+F | 15.7 | 16.8 | 16.8 | 16.8 | |||||
| L+Z2 | 33.8 | - | - | - | |||||
| L+Z2+O | 33.5 | - | - | - | |||||
| L+Z3 | 18.1 | 17.9 | 17.9 | 17.9 | |||||
| L+Z3+O | 14.1 | 14.2 | 14.2 | 14.2 | |||||
| QL+Z2 | 16.7 | 16.8 | 16.8 | 16.8 | |||||
| QL+Z2+O | 16.3 | 16.4 | 16.4 | 16.4 | |||||
| L+F+R | 40.3 | - | - | - | |||||
| QL+F+R | 13.9 | 16.8 | 16.8 | 16.8 | |||||
| L+F+R+Z2 | 28.1 | - | - | - | |||||
| L+F+R+Z2+O | 27.8 | - | - | - | |||||
| L+F+R+Z3 | 10.8 | 11.9 | 11.9 | 11.9 | |||||
| L+F+R+Z3+O | 8.7 | 8.8 | 8.8 | 8.8 | |||||
| 70B | QL+F+R | 59.8 | - | - | - | ||||
| L+F+R+Z3 | 29.4 | - | - | - | |||||
| L+F+R+Z3+O | 13.2 | 13.2 | 13.2 | 13.2 | |||||
| QL+R | 63.6 | - | - | - | |||||
| QL+F | 61.2 | - | - | - | |||||
VI Results on Inference
VI-A End-to-end Performance
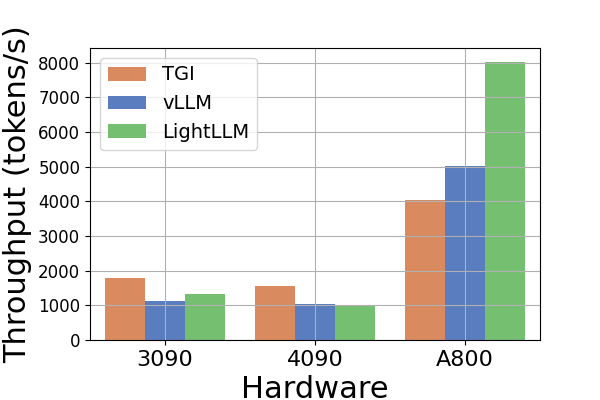
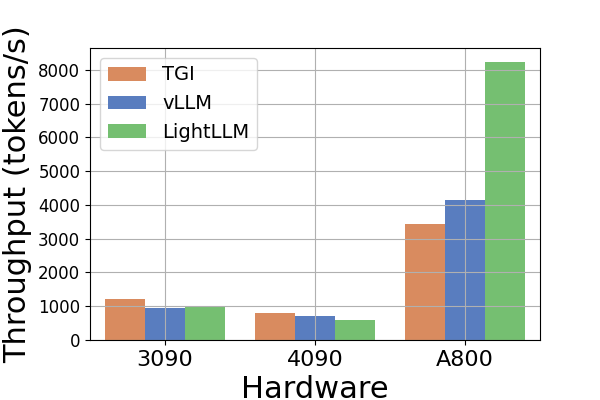
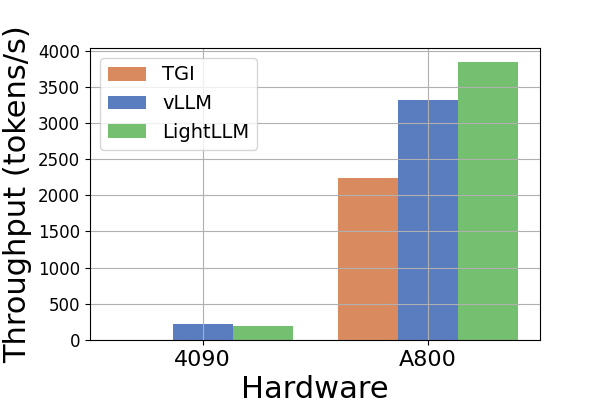
Throughput. A comparative analysis of throughput across various hardware platforms and inference frameworks is presented in Figure 6. As the Llama2-70B model induces an OOM error with the TGI framework on RTX3090 and RTX4090, related data inference to Llama2-70B is omitted in Figure 6. The TGI framework demonstrates superior throughput, particularly on GPUs with 24GB memory, such as RTX3090 and RTX4090. In comparison, LightLLM significantly outperforms TGI and vLLM on the A800 GPU platform by nearly doubling the throughput. These experiments reveal that the TGI inference framework yields superior performance on 24GB GPU platforms, whereas the LightLLM inference framework exhibits the highest throughput on the A800 80GB GPU platform. This finding shows that LightLLM is specifically optimized for high-performance GPUs such as the A800/A100 series.
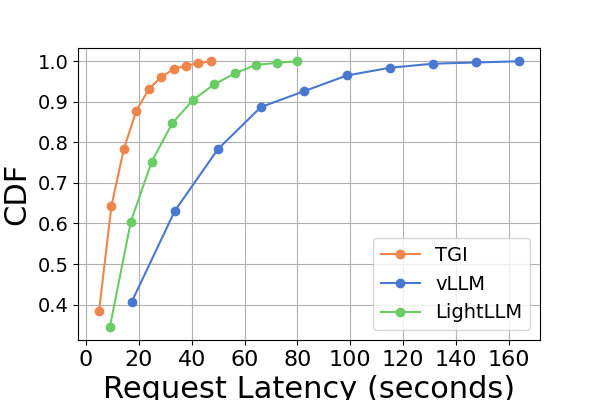
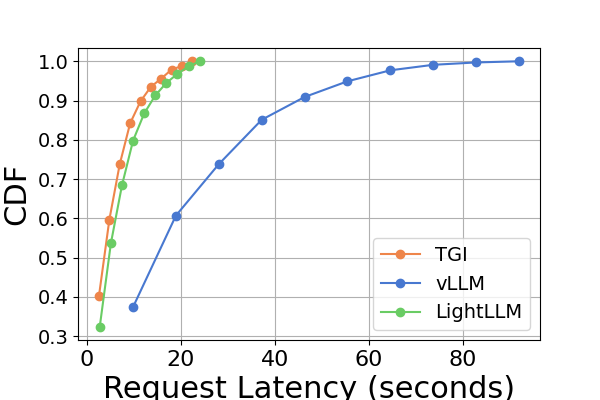
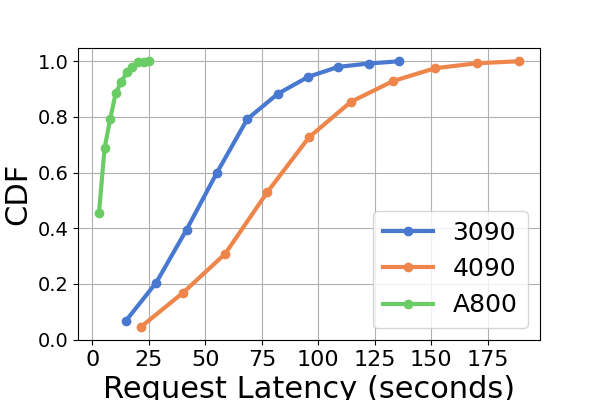
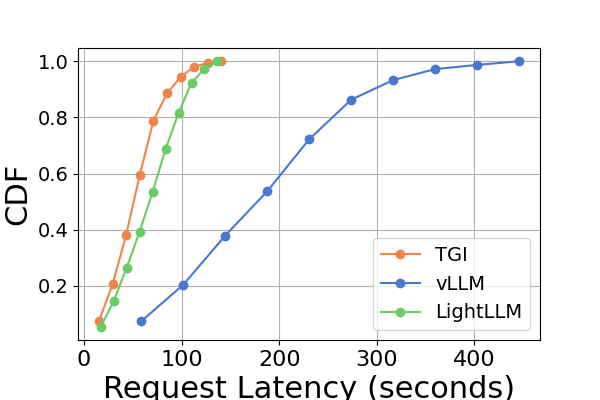
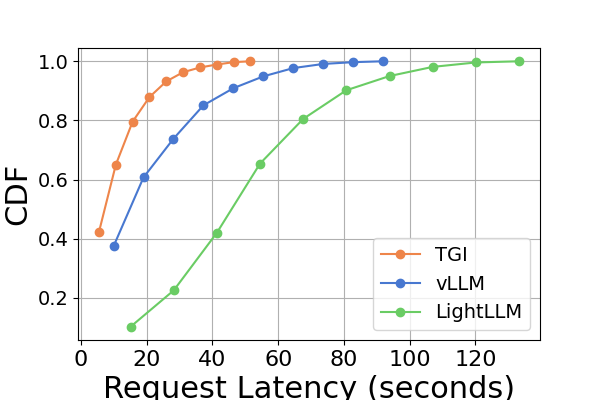
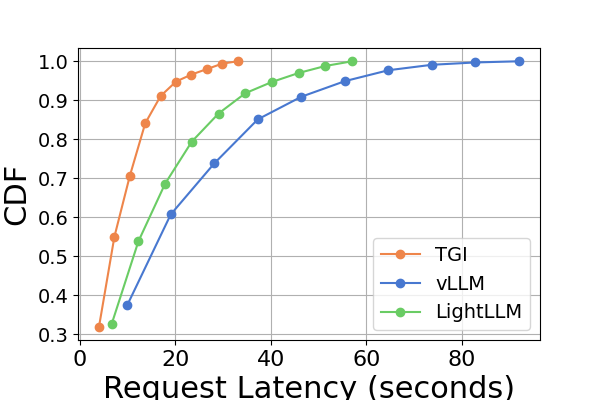
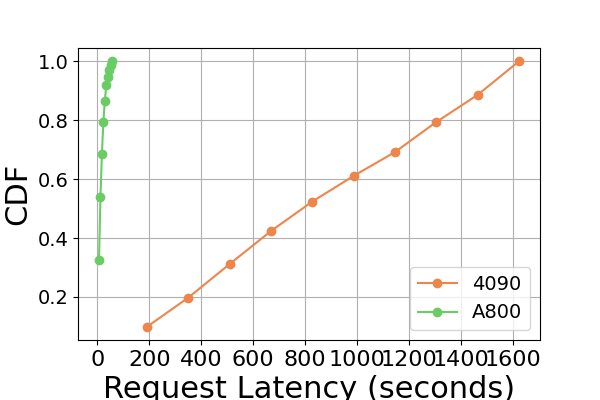
Latency. A comparative analysis of latency across various hardware platforms and inference frameworks is presented in Figure 7 and Figure 8 and Figure 9 and Figure 10. We use the Cumulative Distribution Function (CDF) to plot the latency across different inference frameworks. The CDF represents the probability that a variable takes on a value less than or equal to a particular point in the sample space. For example, in Figure 7 illustrates that LightLLM takes approximately 20 seconds to respond to 60% of the requests, and requires around 80 seconds to respond to 100% of the requests.
In Figure 7, we compare the latency of three inference frameworks specifically on the same GPU platform. The performance on RTX3090 and A800 platforms exhibits similar trends, with TGI showing the lowest latency, followed by LightLLM, and vLLM having the highest latency. Additional experiments are presented in Figure 9.
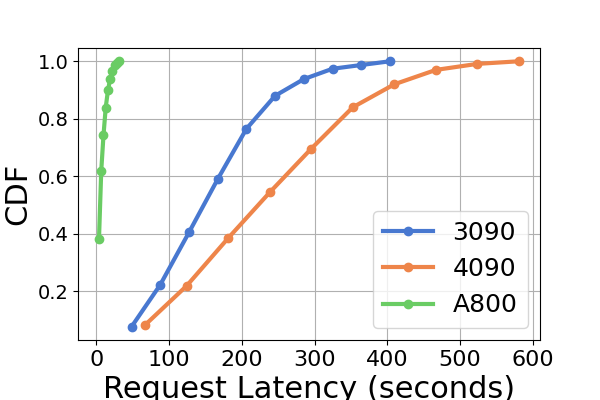
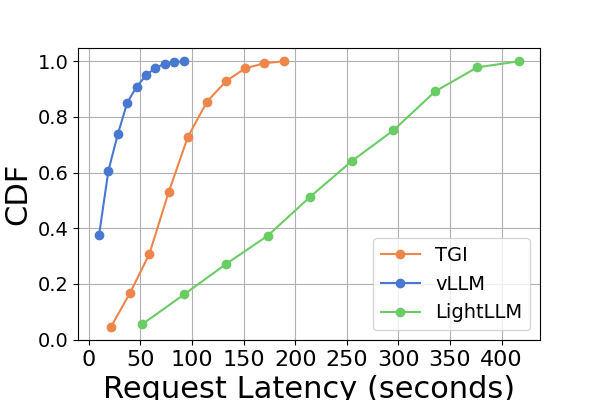
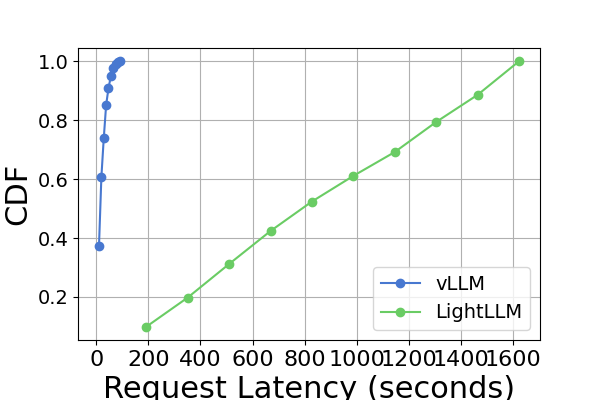
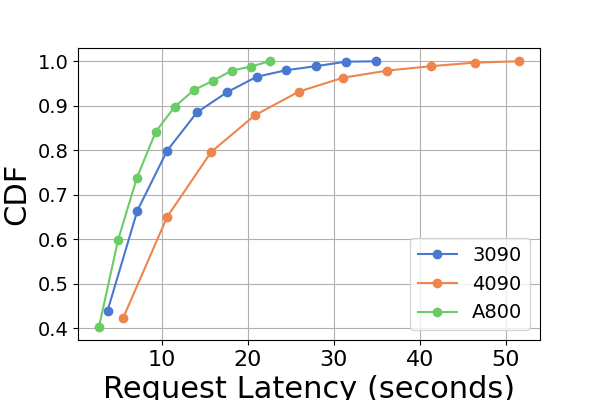
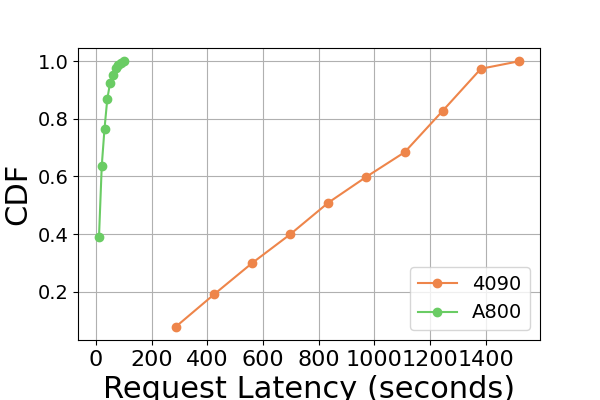
Figure 9 is an extension to Figure 7, containing additional latency experiments on the same GPU platform for the inference benchmark. The performance results on the RTX4090 platform are different from the other two platforms. This discrepancy might be due to the NCCL_P2P_DISABLE=1 setting. On the RTX4090 platform, LightLLM shows the highest latency, and TGI has the lowest latency for the Llama2-7B model. Another distinct finding from the latency experiment is that on the consumer-level GPU platforms the total inference time increases as the model’s parameter size grows. Specifically on the RTX4090 platform, the inference time difference between Llama2-7B and Llama2-70B can reach up to 13 times, from 120 seconds to 1600 seconds. However, this phenomenon is not observed on the A800 GPU platform, where the inference time for larger models remains within a narrow range. This indicates that for currently popular LLM sizes, the A800 platform can handle inference without any latency implications, and that the 70B model has not reached the performance limit of the A800 platform for inference.
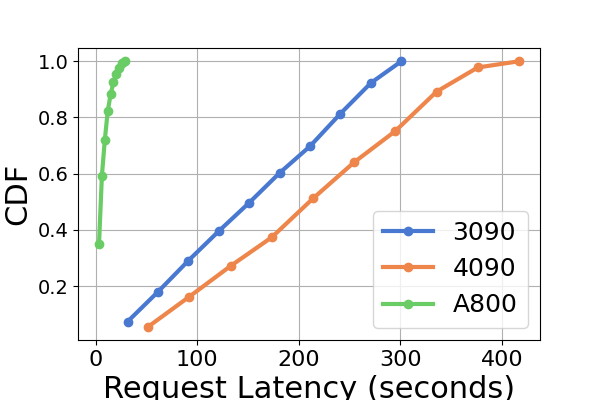
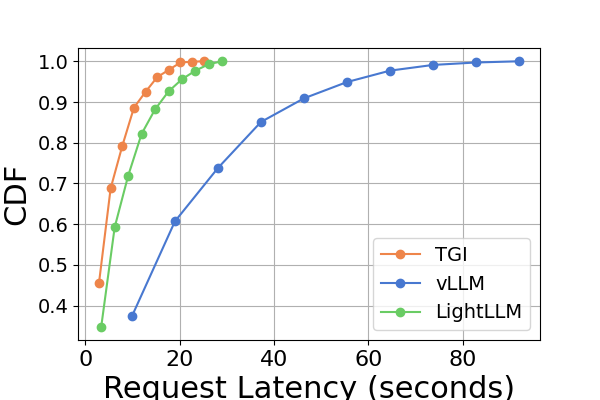
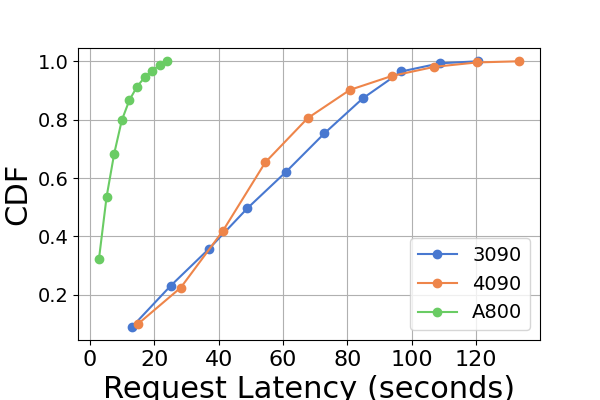
In Figure 8 we compare the latency of each inference framework across different GPU platforms. A800 consistently exhibits the lowest latency in almost all experiments. Furthermore, the RTX3090 GPU platform demonstrates a lower latency than the RTX4090 in the majority of experiments, a situation that might also result from the NCCL_P2P_DISABLE=1 setting. These experiments suggest that if one aims for an inference service with the least latency, the A800 GPU platform is the best choice, offering significant performance advantages across various model and inference framework combinations. Additional experiments are presented in Figure 10.
Figure 10 is an extension to Figure 8, containing additional latency experiments on the same inference framework for the inference benchmark.
In summary, the A800 platform significantly outperforms the other two consumer-level platforms in both throughput and latency. Among the two consumer-level platforms, the RTX3090 has a slight advantage over the RTX4090. When operating on a consumer-level platform, the three inference frameworks do not show a substantial difference in terms of throughput. In contrast, the TGI framework consistently outperforms the others in latency. On the A800 GPU platform, LightLLM is the top performer on throughput, and its latency is also remarkably close to the TGI framework.
| (a) TGI |
| (b) vLLM |
| (c) LightLLM |
| (a) Llama2-7B with |
| TGI |

| (b) Llama2-7B with |
| vLLM |
| (c) Llama2-70B with |
| vLLM |
| (d) Llama2-7B with |
| LightLLM |
| (e) Llama2-70B with |
| LightLLM |
VI-B Module-wise Analysis
In this subsection, we discuss the module-wise time cost using LightLLM as an example. To simulate a scenario with a large number of users accessing the service, we set the batch size to 1024, the output length to 64, and the prompt length to 512 on the A800 GPU server. The results are presented in Table X and Table XI. We observe that the GPU experiences a bottleneck, evident in the ’Other’ row of Table X, which accounts for 7.55% of the total time. This suggests that fusing GPU kernels could potentially reduce the overall duration of this bottleneck.
| Task | Time(ms) | Percentage(%) | ||||
| Forward | Comp. | Element-Wise | 36 | 1.69 | 70.44 | 3.3 |
| RoPE | 0.19 | 0.37 | ||||
| Triton | 23.05 | 45.1 | ||||
| GeMM | 9.4 | 18.4 | ||||
| RMSNorm | 1.18 | 2.31 | ||||
| Other | 0.49 | 0.96 | ||||
| Comm. | AllReduce | 11.3 | 10.74 | 22.11 | 21.01 | |
| AllGather | 0.46 | 0.9 | ||||
| Other | 0.1 | 0.2 | ||||
| Other | 3.81 | 7.55 | ||||
| Timeline | Time(ms) | Percentage(%) | |||
| Before Transformer | 1.66 | 3.25 | |||
| Transformer | 32 x Attention | 47.60 | 35.13 | 93.13 | 68.73 |
| 32 x FFN | 12.47 | 24.4 | |||
| After Transformer | 1.85 | 3.62 | |||
VII Microbenchmarks
In order to get a deeper understanding on the experimental results, we conducted a microbenchmark analysis covering both computations and communications.
VII-A GEMM Analysis
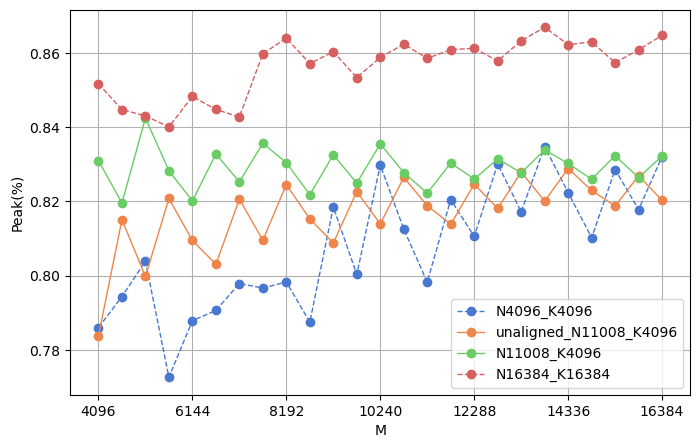
In Section IV-B, we observe that the time consumption for modules containing GEMM operations is relatively high. We calculate the time breakdown of GEMM operations in the forward and backward phases using both the naive method and recomputation. Table XIII shows that the GEMM kernel accounts for over 60% of the time in both phases, highlighting the critical nature of GEMM performance for LLMs. To better understand GEMM performance, we analyze the first GEMM in the MLP module (Table XII). We choose this GEMM operation because MLP is the most time-consuming module, containing three GEMMs of similar sizes. The main reason for the lower peak values with the naive method compared to recomputation is the small matrix size, which fails to fully utilize the hardware. After increasing the size by 32 times using recomputation, the peak performance is still lower than the ideal value of 90%. We test different matrix sizes on our experimental platform (A800), and the results are shown in Figure 11. In these GEMM operations, the batch size affects . Since we gradually increase under constant and values, there are two scenarios for choosing . For N4096_K4096, N11008_K4096 (shapes determined by the Llama2-7B model), and N16384_K16384, is increased from 4096 to 16384 in steps of 512, ensuring the size is a multiple of the TensorCore compute scale. These three curves demonstrate that blindly increasing the batch size does not always yield improved peak performance. Once the batch size is sufficiently large, further improvements in GEMM peak can be achieved by increasing and . For the unaligned_N11008_K4096 case, our starts from 4096+13 (the magic number 13 is an odd number chosen to not significantly affect the size of ) and increases to 16384+13 in steps of 512. We analyze the performance differences between as integer multiples of the TensorCore compute scale and non-integer multiples. The results clearly show that when is an integer multiple of the TensorCore compute scale, the peak performance is higher than for non-integer multiples.
| Naive | Recomputation | |
|---|---|---|
| Shape(,,) | 666,11008,4096 | 10624,11008,4096 |
| Time(ms) | 0.289 | 3.870 |
| Peak(%) | 66.6 | 79.4 |
| Forward | Backward | |
|---|---|---|
| Naive | 66.4% | 62.5% |
| Recomputation | 66.1% | 69.0% |
VII-B Memory Copy
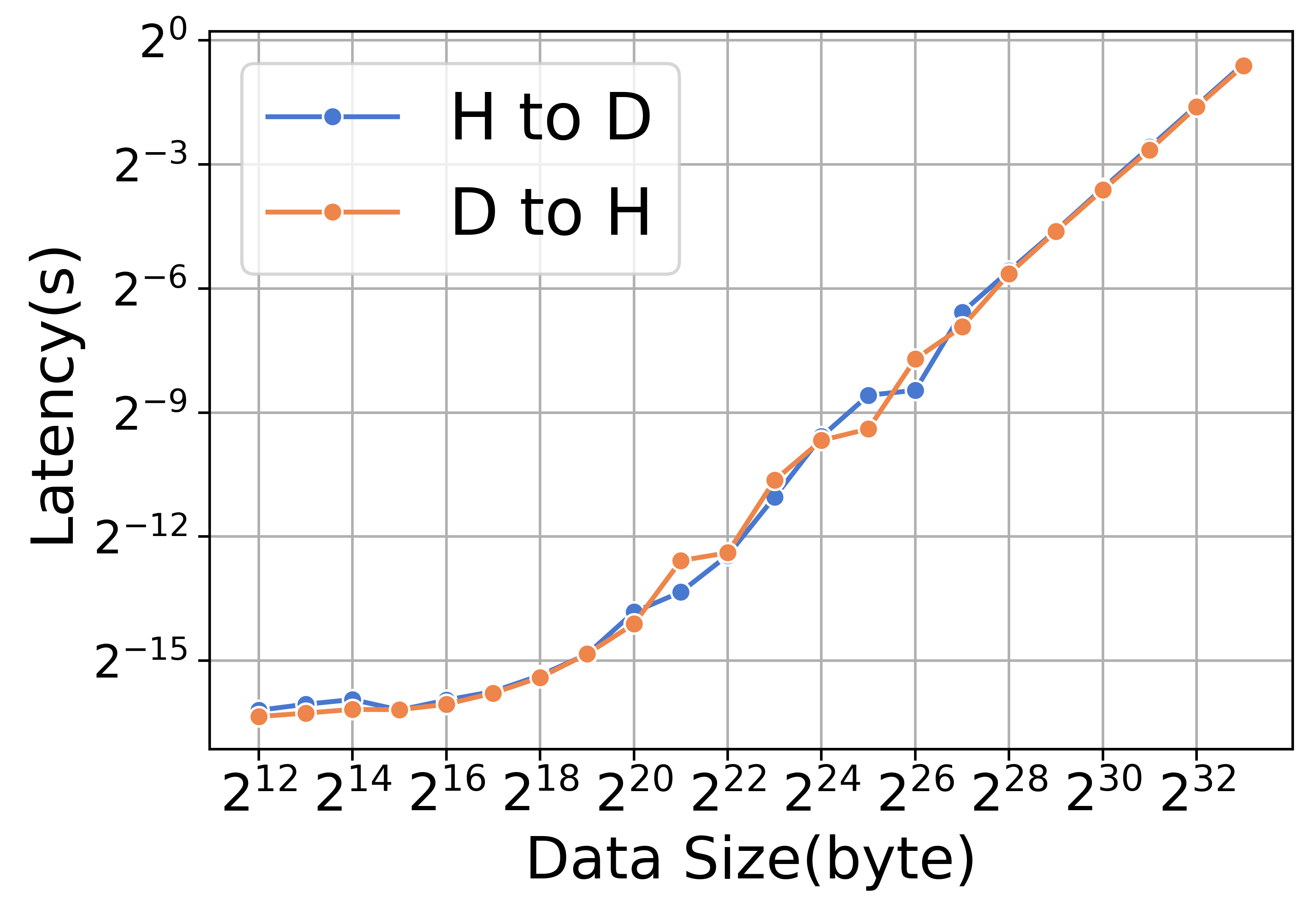
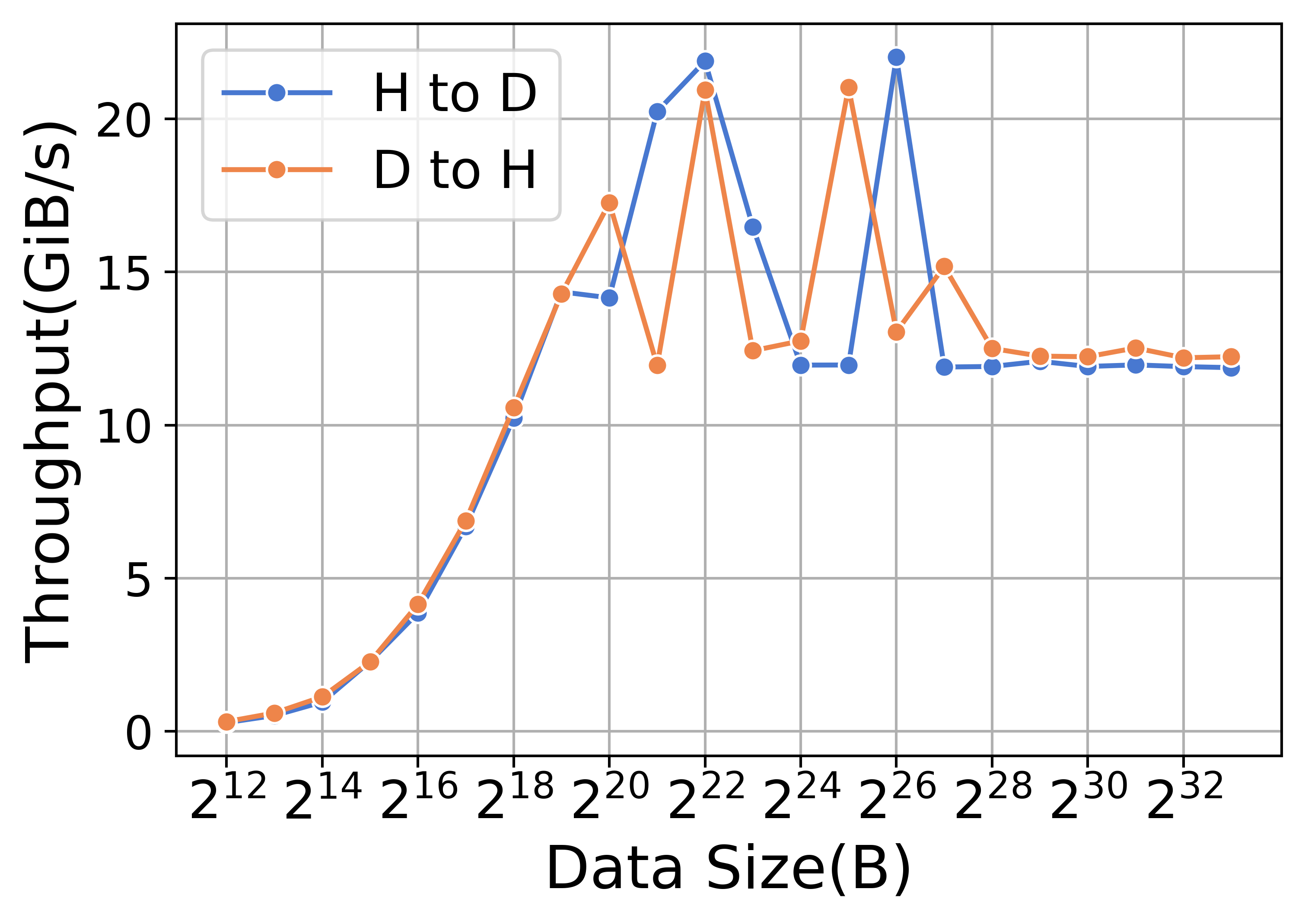
Offloading and uploading operations are implemented using memory copy kernels. Table XIV summarizes the absolute time cost and the percentage of memory copy in each iteration on the A800 platform. As indicated in Table XIV, ZeRO-3 incurs greater uploading and offloading times compared to ZeRO-2. However, the impact of memory copy in this context is relatively minor. Figure 12 demonstrates the performance of upload operations (denoted H to D) and offload operations (denoted D to H) in terms of kernels. This figure reveals that the throughput and latency for both uploading and offloading operations are similar. For smaller data sizes, the startup time tends to be dominant, while for larger data sizes, bandwidth becomes increasingly crucial.
| Method | Model | Time(s/iteration) | Percentage(%) |
|---|---|---|---|
| ZeRO-2 | Llama2-7B | 0.596 | 4.9% |
| Llama2-13B | 1.160 | 7.3% | |
| ZeRO-3 | Llama2-7B | 0.638 | 4.0% |
| Llama2-13B | 1.560 | 6.7% |
VII-C Collective Communication
We first emphasize the high communication speed provided by NVLink. When conducting AllGather operations at various data scales, it is observed that the RTX3090 equipped with NVLink significantly outperforms its counterpart without NVLink, as illustrated in Figure 13.
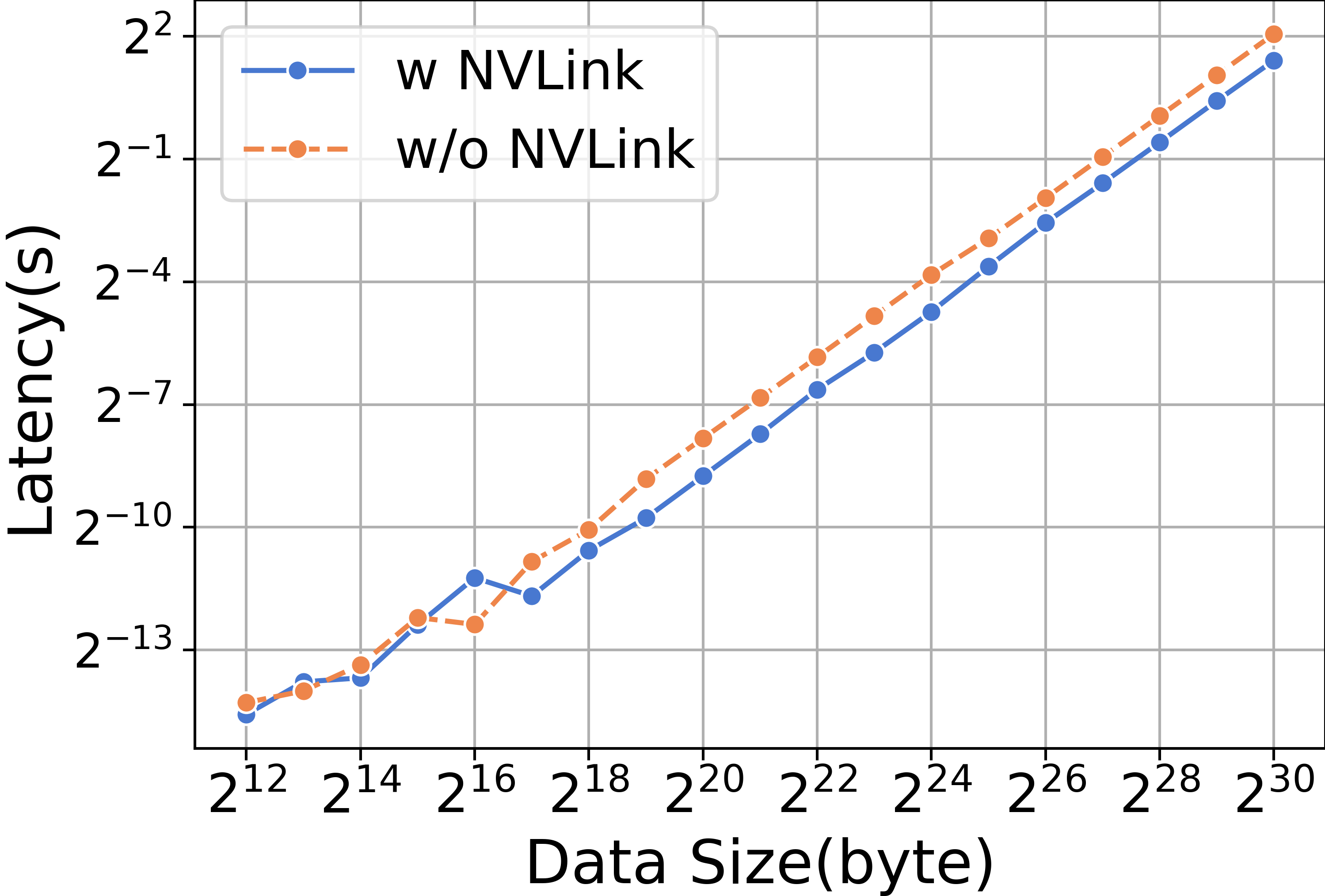
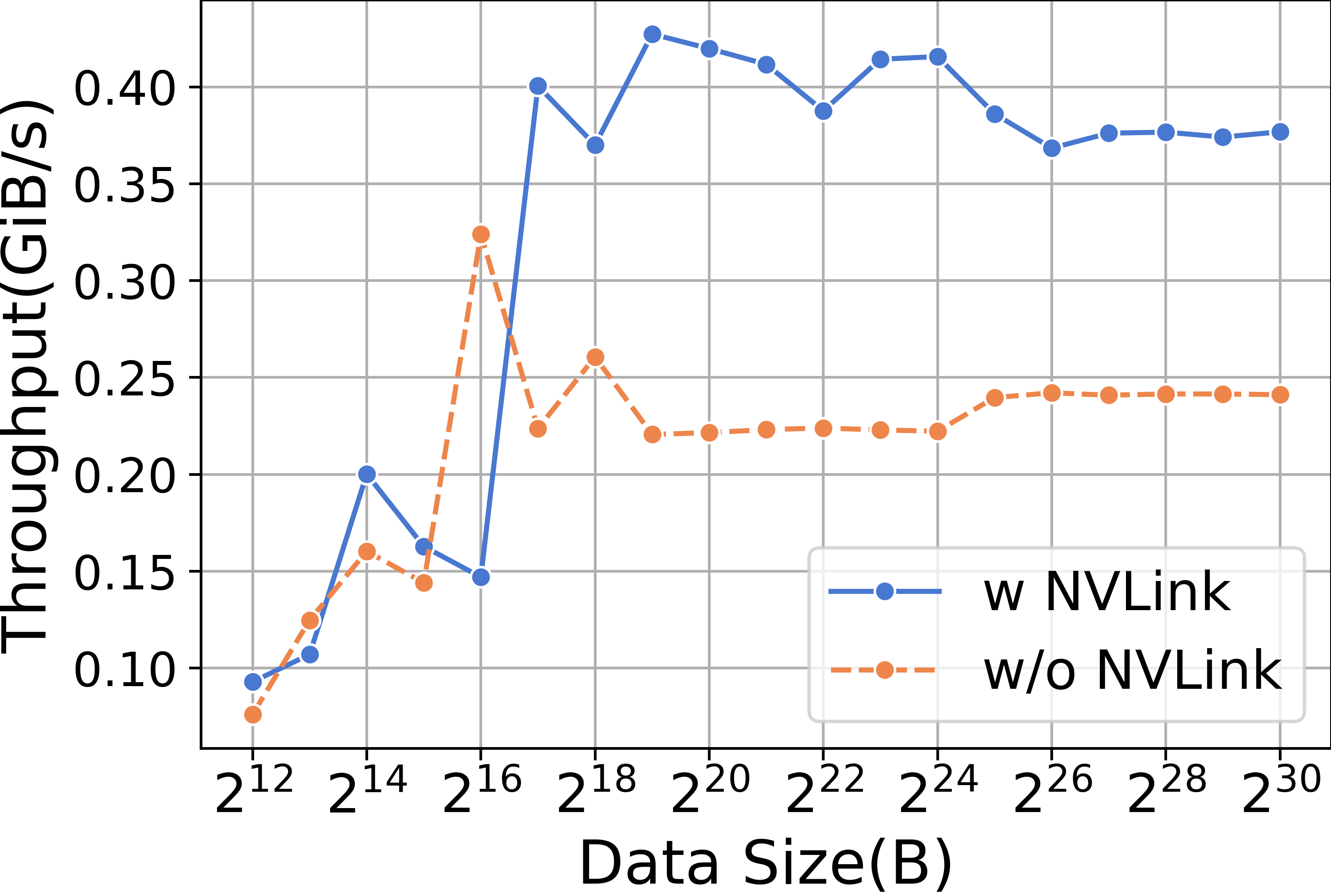
Different training paradigms involve various collective communication operations. In data parallel paradigms, AllReduce is used during the backward phase to synchronize weights, as illustrated in Table XV.
When conducting experiments with ReduceScatter and varying data sizes, it is observed that the RTX3090 with NVLink significantly outperforms its counterpart without NVLink, as demonstrated in Figure 14.
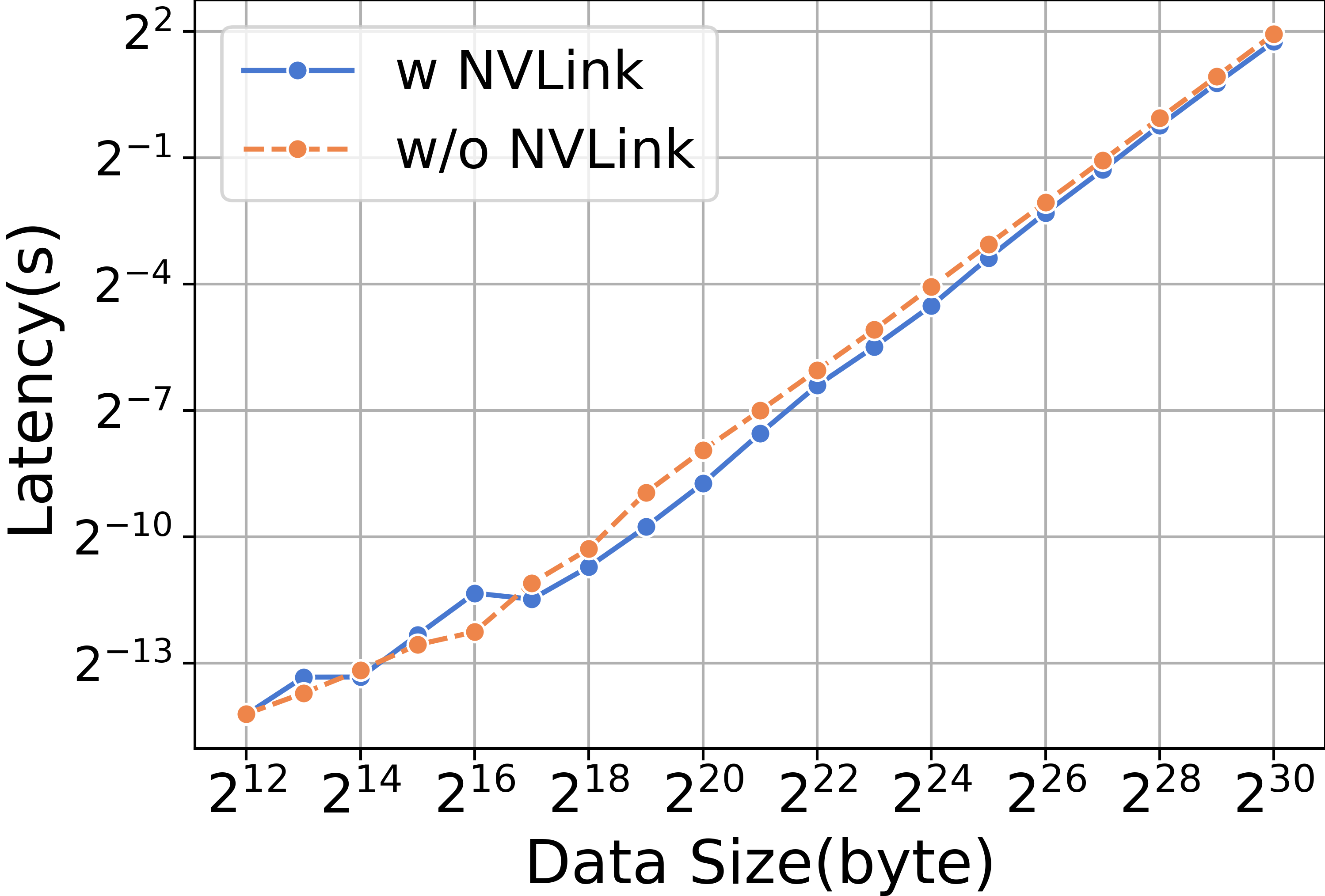
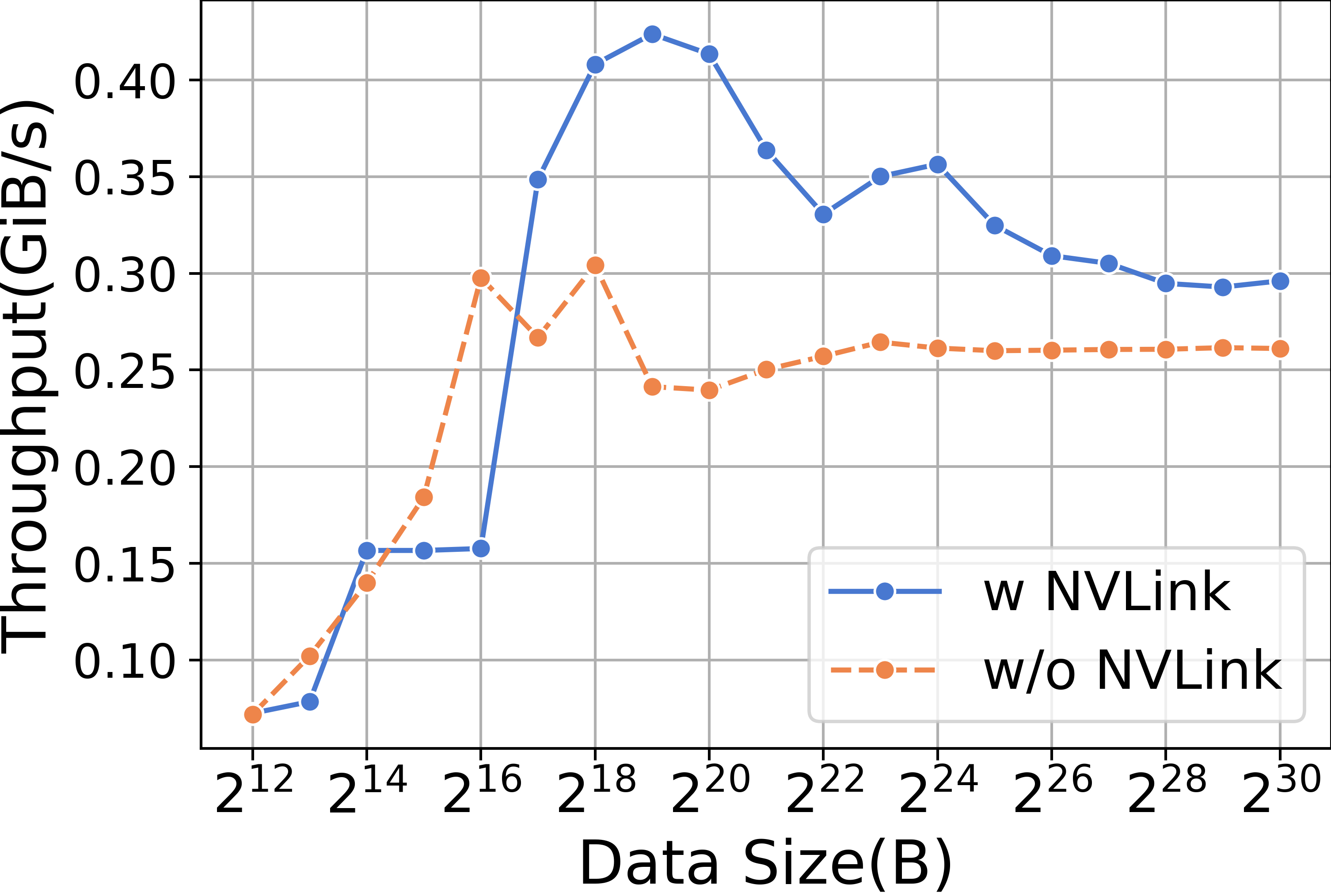
| Llama2-7B | Time(s/iteration) | Percentage(%) |
|---|---|---|
| Naive | 0.24 | 45.00 |
| F | 0.23 | 44.97 |
| R | 0.86 | 25.31 |
| R+F | 0.69 | 20.41 |
ZeRO-2 requires the use of Reduce collective communication primitives in the backward phase. Figure 15 displays the performance of Reduce kernels. Similar to memory copying, the small data size of the Reduce kernel results in the dominance of startup time, whereas the performance with large data sizes is dependent on bandwidth. In contrast, ZeRO-3 employs ReduceScatter instead of Reduce for collective communication in the backward phase. Figure 15 illustrates the performance of the ReduceScatter kernels. Both ZeRO-2 and ZeRO-3 utilize AllGather for updating parameters, and Figure 15 also presents the performance of AllGather kernels.
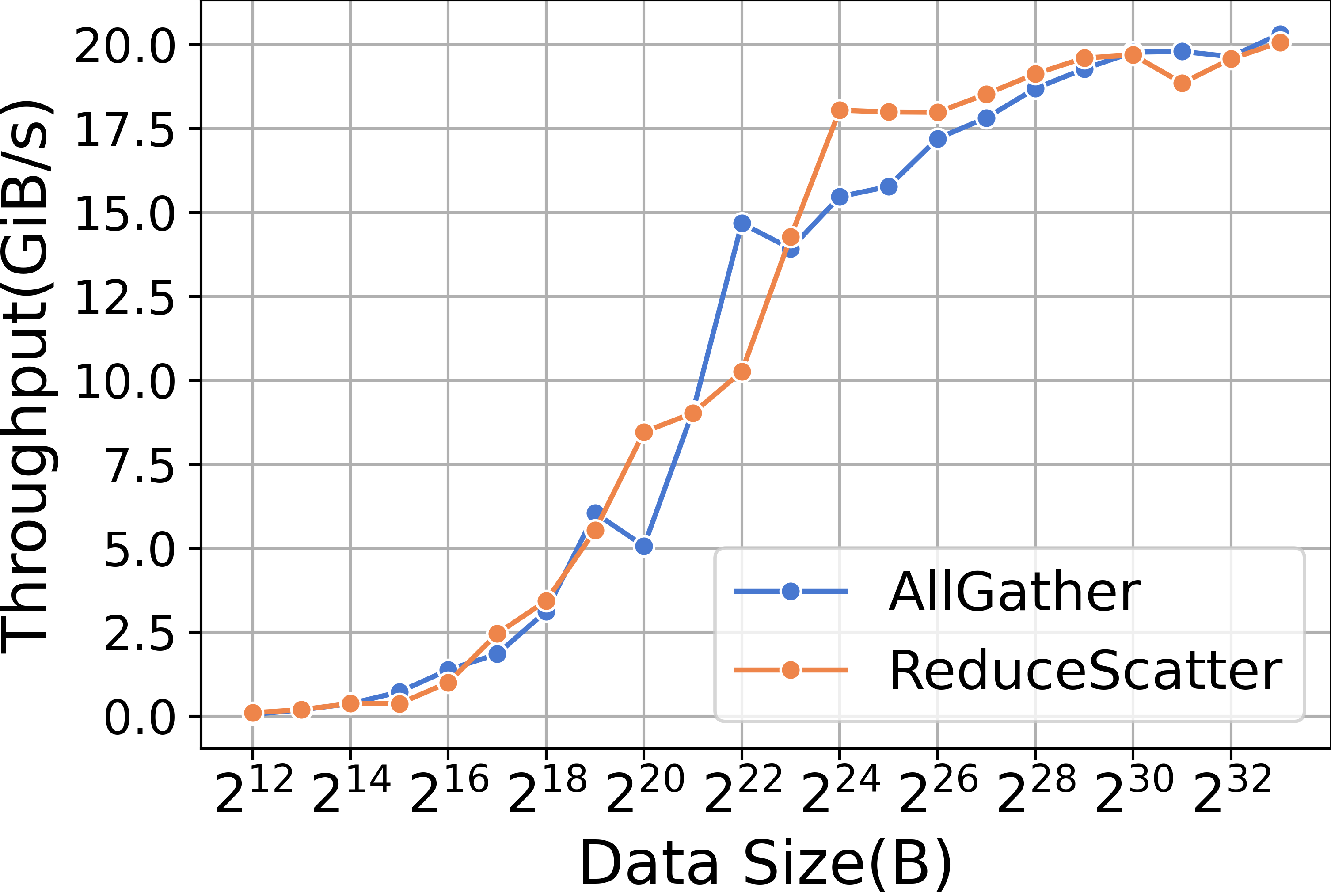
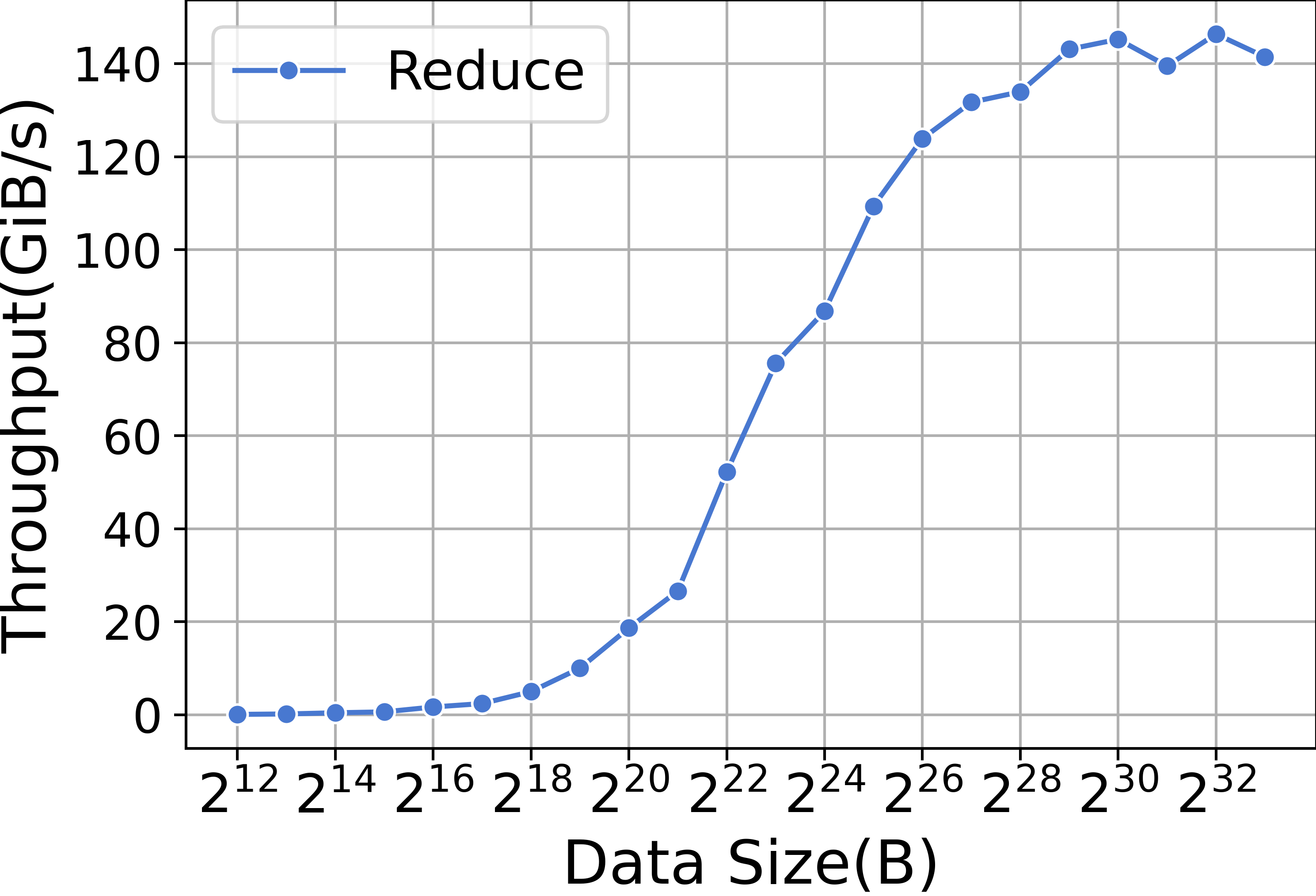
| Method | Model | Time(s/iteration) | Percentage(%) |
|---|---|---|---|
| ZeRO-2 | Llama2-7B | 4.254 | 41.8% |
| Llama2-13B | 3.779 | 27.4% | |
| ZeRO-3 | Llama2-7B | 4.576 | 28.1% |
| Llama2-13B | 2.791 | 11.9% |
VIII Related Works
Extensive studies have benchmarked model performance in terms of generalization capability and accuracy in downstream tasks[37, 8, 38, 39, 2]. However, few studies focus on evaluating and analyzing time to study hardware[40, 41] and software[42, 43] efficiency, and even fewer address these aspects in training, fine-tuning, and serving LLMs. AIPerf[44] implement the algorithms in a highly parallel and flexible way, and evaluate their performance on various systems. MLPerf[45] is another cutting-edge benchmark for comparing the time performance of deep learning (which includes LLMs) in training and inference, without limitations on hardware platforms. In the pre-LLM era, benchmarks were proposed to compare software and hardware performance across various models, including CNNs, LSTMs, and Transformers [46, 47, 48, 49, 50, 51, 52]. Xu et al.[53] provided a survey comparing model compression techniques, which are particularly useful in model fine-tuning and inference. Cao et al.[54] also provided an overview of efficient LLMs, focusing on algorithmic aspects such as ELECTRA [55], Prompt Tuning, etc. Liang et al., [56] proposed HELM, a comprehensive performance evaluation, for comparing both model generalization capability and time efficiency. However, their results on time efficiency focus on inference using a specific hardware platform with given software. Specifically in inference, LLMPerf[57] benchmarks the throughput performance of various LLMs.
To the best of our knowledge, this is the first study to analyze runtime performance across all three key stages (pre-training, fine-tuning, and serving) of LLMs on various hardware platforms.
IX Conclusion
In this work, we have benchmarked the runtime performance of pre-training, fine-tuning, and serving LLMs on three 8-GPU hardware platforms: Nvidia A800-80G, RTX4090, and RTX3090. Based on the benchmark results, we analyzed the key modules and operators that are major contributors to the overall time. The experimental results and analyses provide more information for end-users in choosing configurations in terms of hardware, software, and optimization techniques for pre-training, fine-tuning, and serving LLMs. Additionally, an in-depth understanding of performance offers further opportunities for system optimization.
Acknowledgement
We would like to thank Mr. Yongke Zhao for the valuable feedback. This work was partially supported by National Natural Science Foundation of China under Grant No. 62272122, a Hong Kong RIF grant under Grant No. R6021-20, and Hong Kong CRF grants under Grant No. C2004-21GF and C7004-22GF. We also thank the HPC-AI-Integrated Intelligent Computing center of HKUST(GZ) for providing some of the hardware platforms in this project.
Revision history
Wed, 29 Nov 2023
- •
-
•
We updated the detailed introduction to benchmark settings, including the datasets, sequence length, etc., in Sec. III.
References
- [1] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training language models to follow instructions with human feedback,” Advances in Neural Information Processing Systems, vol. 35, pp. 27 730–27 744, 2022.
- [2] Y. Chang, X. Wang, J. Wang, Y. Wu, K. Zhu, H. Chen, L. Yang, X. Yi, C. Wang, Y. Wang et al., “A survey on evaluation of large language models,” arXiv preprint arXiv:2307.03109, 2023.
- [3] J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” arXiv preprint arXiv:2001.08361, 2020.
- [4] J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. d. L. Casas, L. A. Hendricks, J. Welbl, A. Clark et al., “Training compute-optimal large language models,” arXiv preprint arXiv:2203.15556, 2022.
- [5] OpenAI, “GPT-4 technical report,” 2023.
- [6] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020.
- [7] A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann et al., “PaLM: Scaling language modeling with pathways,” in Proceedings of Machine Learning and Systems 2022, 2022.
- [8] J. Kaddour, J. Harris, M. Mozes, H. Bradley, R. Raileanu, and R. McHardy, “Challenges and applications of large language models,” arXiv preprint arXiv:2307.10169, 2023.
- [9] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv preprint arXiv:2307.09288, 2023.
- [10] J. Rasley, S. Rajbhandari, O. Ruwase, and Y. He, “DeepSpeed: System optimizations enable training deep learning models with over 100 billion parameters,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020, pp. 3505–3506.
- [11] D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro et al., “Efficient large-scale language model training on gpu clusters using megatron-lm,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021, pp. 1–15.
- [12] S. Mangrulkar, S. Gugger, L. Debut, Y. Belkada, S. Paul, and B. Bossan, “PEFT: State-of-the-art parameter-efficient fine-tuning methods,” https://github.com/huggingface/peft, 2022.
- [13] W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” in Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023.
- [14] GitHub, “LightLLM: A python-based large language model inference and serving framework,” https://github.com/ModelTC/lightllm, 2023.
- [15] HuggingFace, “Text generation inference,” https://github.com/huggingface/text-generation-inference, 2023.
- [16] S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He, “ZeRO: Memory optimizations toward training trillion parameter models,” in SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020, pp. 1–16.
- [17] V. A. Korthikanti, J. Casper, S. Lym, L. McAfee, M. Andersch, M. Shoeybi, and B. Catanzaro, “Reducing activation recomputation in large transformer models,” Proceedings of Machine Learning and Systems, vol. 5, 2023.
- [18] P. Jain, A. Jain, A. Nrusimha, A. Gholami, P. Abbeel, K. Keutzer, I. Stoica, and J. E. Gonzalez, “Checkmate: Breaking the memory wall with optimal tensor rematerialization,” arXiv preprint arXiv:1910.02653, 2020.
- [19] S. Smith, M. Patwary, B. Norick, P. LeGresley, S. Rajbhandari, J. Casper, Z. Liu, S. Prabhumoye, G. Zerveas, V. Korthikanti, E. Zhang, R. Child, R. Y. Aminabadi, J. Bernauer, X. Song, M. Shoeybi, Y. He, M. Houston, S. Tiwary, and B. Catanzaro, “Using DeepSpeed and Megatron to train Megatron-turing NLG 530B, a large-scale generative language model,” arXiv preprint arXiv:2201.11990, 2022.
- [20] Z. Yao, R. Yazdani Aminabadi, M. Zhang, X. Wu, C. Li, and Y. He, “Zeroquant: Efficient and affordable post-training quantization for large-scale transformers,” Advances in Neural Information Processing Systems, vol. 35, pp. 27 168–27 183, 2022.
- [21] E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” in International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=nZeVKeeFYf9
- [22] T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “QLoRA: Efficient finetuning of quantized LLMs,” arXiv preprint arXiv:2305.14314, 2023.
- [23] T. Dao, D. Fu, S. Ermon, A. Rudra, and C. Ré, “Flashattention: Fast and memory-efficient exact attention with io-awareness,” Advances in Neural Information Processing Systems, vol. 35, pp. 16 344–16 359, 2022.
- [24] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in Neural Information Processing Systems, vol. 30, 2017.
- [25] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are Few-Shot learners,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 1877–1901. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
- [26] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023.
- [27] T. L. Scao, A. Fan, C. Akiki, E. Pavlick, S. Ilić, D. Hesslow, R. Castagné, A. S. Luccioni, F. Yvon, M. Gallé et al., “Bloom: A 176b-parameter open-access multilingual language model,” arXiv preprint arXiv:2211.05100, 2022.
- [28] J. Ren, S. Rajbhandari, R. Y. Aminabadi, O. Ruwase, S. Yang, M. Zhang, D. Li, and Y. He, “ZeRO-Offload: Democratizing Billion-Scale model training,” in 2021 USENIX Annual Technical Conference (USENIX ATC 21), 2021, pp. 551–564.
- [29] S. Rajbhandari, O. Ruwase, J. Rasley, S. Smith, and Y. He, “Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021, pp. 1–14.
- [30] R. Y. Aminabadi, S. Rajbhandari, A. A. Awan, C. Li, D. Li, E. Zheng, O. Ruwase, S. Smith, M. Zhang, J. Rasley et al., “DeepSpeed-inference: enabling efficient inference of transformer models at unprecedented scale,” in SC22: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2022, pp. 1–15.
- [31] M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-LM: Training multi-billion parameter language models using model parallelism,” arXiv preprint arXiv:1909.08053, 2019.
- [32] B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 3045–3059.
- [33] J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, M. Mao, M. Ranzato, A. Senior, P. Tucker, K. Yang et al., “Large scale distributed deep networks,” Advances in Neural Information Processing Systems, vol. 25, 2012.
- [34] S. Vinoski, “Server-sent events with yaws,” IEEE internet computing, vol. 16, no. 5, pp. 98–102, 2012.
- [35] S. Elfwing, E. Uchibe, and K. Doya, “Sigmoid-weighted linear units for neural network function approximation in reinforcement learning,” Neural Networks, vol. 107, pp. 3–11, 2018.
- [36] B. Zhang and R. Sennrich, “Root mean square layer normalization,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [37] W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong et al., “A survey of large language models,” arXiv preprint arXiv:2303.18223, 2023.
- [38] C. Fu, P. Chen, Y. Shen, Y. Qin, M. Zhang, X. Lin, Z. Qiu, W. Lin, J. Yang, X. Zheng et al., “MME: A comprehensive evaluation benchmark for multimodal large language models,” arXiv preprint arXiv:2306.13394, 2023.
- [39] K. Valmeekam, S. Sreedharan, M. Marquez, A. Olmo, and S. Kambhampati, “On the planning abilities of large language models (a critical investigation with a proposed benchmark),” arXiv preprint arXiv:2302.06706, 2023.
- [40] Y. Wang, Q. Wang, S. Shi, X. He, Z. Tang, K. Zhao, and X. Chu, “Benchmarking the performance and energy efficiency of AI accelerators for AI training,” in 2020 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), 2020, pp. 744–751.
- [41] D. Yan, W. Wang, and X. Chu, “Demystifying tensor cores to optimize half-precision matrix multiply,” in 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2020, pp. 634–643.
- [42] P. Xu, S. Shi, and X. Chu, “Performance evaluation of deep learning tools in docker containers,” in 2017 3rd International Conference on Big Data Computing and Communications (BIGCOM). IEEE, 2017, pp. 395–403.
- [43] S. Shi, Z. Tang, X. Chu, C. Liu, W. Wang, and B. Li, “A Quantitative Survey of Communication Optimizations in Distributed Deep Learning,” IEEE Network, vol. 35, no. 3, pp. 230–237, 2021.
- [44] Z. Ren, Y. Liu, T. Shi, L. Xie, Y. Zhou, J. Zhai, Y. Zhang, Y. Zhang, and W. Chen, “AIPerf: Automated machine learning as an AI-HPC benchmark,” 2021.
- [45] V. J. Reddi, C. Cheng, D. Kanter, P. Mattson, G. Schmuelling, C.-J. Wu, B. Anderson, M. Breughe, M. Charlebois, W. Chou, R. Chukka, C. Coleman, S. Davis, P. Deng, G. Diamos, J. Duke, D. Fick, J. S. Gardner, I. Hubara, S. Idgunji, T. B. Jablin, J. Jiao, T. S. John, P. Kanwar, D. Lee, J. Liao, A. Lokhmotov, F. Massa, P. Meng, P. Micikevicius, C. Osborne, G. Pekhimenko, A. T. R. Rajan, D. Sequeira, A. Sirasao, F. Sun, H. Tang, M. Thomson, F. Wei, E. Wu, L. Xu, K. Yamada, B. Yu, G. Yuan, A. Zhong, P. Zhang, and Y. Zhou, “MLPerf Inference Benchmark,” 2019.
- [46] S. Shi, Q. Wang, P. Xu, and X. Chu, “Benchmarking state-of-the-art deep learning software tools,” in 2016 7th International Conference on Cloud Computing and Big Data (CCBD). IEEE, 2016, pp. 99–104.
- [47] S. Shi, Q. Wang, and X. Chu, “Performance modeling and evaluation of distributed deep learning frameworks on GPUs,” in 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech). IEEE, 2018, pp. 949–957.
- [48] S. Li, R. J. Walls, and T. Guo, “Characterizing and modeling distributed training with transient cloud GPU servers,” in 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS). IEEE, 2020, pp. 943–953.
- [49] Z. Tang, S. Shi, X. Chu, W. Wang, and B. Li, “Communication-efficient distributed deep learning: A comprehensive survey,” arXiv preprint arXiv:2003.06307, 2020.
- [50] M. Jansen, V. Codreanu, and A.-L. Varbanescu, “DDLBench: towards a scalable benchmarking infrastructure for distributed deep learning,” in 2020 IEEE/ACM Fourth Workshop on Deep Learning on Supercomputers (DLS). IEEE, 2020, pp. 31–39.
- [51] G. Liang and I. Alsmadi, “Benchmark assessment for deepspeed optimization library,” arXiv preprint arXiv:2202.12831, 2022.
- [52] Z. Lu, C. Du, Y. Jiang, X. Xie, T. Li, and F. Yang, “Quantitative evaluation of deep learning frameworks in heterogeneous computing environment,” CCF Transactions on High Performance Computing, pp. 1–18, 2023.
- [53] C. Xu and J. McAuley, “A survey on model compression and acceleration for pretrained language models,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 9, 2023, pp. 10 566–10 575.
- [54] Y. Cao, S. Li, Y. Liu, Z. Yan, Y. Dai, P. S. Yu, and L. Sun, “A comprehensive survey of AI-generated content (AIGC): A history of generative AI from GAN to ChatGPT,” arXiv preprint arXiv:2303.04226, 2023.
- [55] K. Clark, M.-T. Luong, Q. V. Le, and C. D. Manning, “ELECTRA: Pre-training text encoders as discriminators rather than generators,” in International Conference on Learning Representations, 2020. [Online]. Available: https://openreview.net/forum?id=r1xMH1BtvB
- [56] P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y. Zhang, D. Narayanan, Y. Wu, A. Kumar, B. Newman, B. Yuan, B. Yan, C. Zhang, C. A. Cosgrove, C. D. Manning, C. Re, D. Acosta-Navas, D. A. Hudson, E. Zelikman, E. Durmus, F. Ladhak, F. Rong, H. Ren, H. Yao, J. WANG, K. Santhanam, L. Orr, L. Zheng, M. Yuksekgonul, M. Suzgun, N. Kim, N. Guha, N. S. Chatterji, O. Khattab, P. Henderson, Q. Huang, R. A. Chi, S. M. Xie, S. Santurkar, S. Ganguli, T. Hashimoto, T. Icard, T. Zhang, V. Chaudhary, W. Wang, X. Li, Y. Mai, Y. Zhang, and Y. Koreeda, “Holistic evaluation of language models,” Transactions on Machine Learning Research, 2023, featured Certification, Expert Certification. [Online]. Available: https://openreview.net/forum?id=iO4LZibEqW
- [57] ray project, “llmperf,” 2023, https://github.com/ray-project/llmperf.