Prompts have evil twins
Abstract
We discover that many natural-language prompts can be replaced by corresponding prompts that are unintelligible to humans but that provably elicit similar behavior in language models. We call these prompts “evil twins” because they are obfuscated and uninterpretable (evil), but at the same time mimic the functionality of the original natural-language prompts (twins). Remarkably, evil twins transfer between models. We find these prompts by solving a maximum-likelihood problem which has applications of independent interest.111Our code and data is available at https://github.com/rimon15/evil_twins.
Prompts have evil twins
Rimon Melamed GWU rmelamed@gwu.edu Lucas H. McCabe GWU and LMI lucasmccabe@gwu.edu Tanay Wakhare MIT twakhare@mit.edu
Yejin Kim GWU yejinjenny@gwu.edu H. Howie Huang GWU howie@gwu.edu Enric Boix-Adsera MIT eboix@mit.edu
1 Introduction
Large Language Models (LLMs) are rapidly improving across a wide range of tasks (OpenAI, 2023; Touvron et al., 2023a, b; Jiang et al., 2023; Bubeck et al., 2023). LLMs are typically instruction-tuned (Ouyang et al., 2022) to accept user queries as prompts, and these prompts have become the primary interface for interacting with these models. Nevertheless, many basic questions on how models parse prompts remain largely open. In this paper, we examine the question:
Do language model prompts have to be understandable by humans in order to elicit desired behavior?
This question has far-reaching relevance, both to engineering prompts in order to maximize performance, and for safety (e.g., uninterpretable prompts could be used to bypass safety filters and induce malicious behaviors in language models); see discussion in Section 2.
1.1 Our contributions
The main contribution of this paper is to build negative evidence towards the above question. We show that natural-language prompts can often be replaced by prompts that are unintelligible to humans, but that cause the model to behave functionally similarly to the original natural-language prompt. In more detail:

Functional similarity between prompts
First, we propose a quantitative measure of functional similarity between two prompts and , by viewing them as inducing distributions and over outputs when fed into a language model. The two prompts are functionally similar if these distributions are similar, which we measure through the Kullback-Leibler divergence (KL):
| (1) |
The KL divergence is an information-theoretic measure of the distance between two distributions, which is zero if and only if the two distributions are identical (Cover et al., 1991).
Finding prompts with similar functionality
Given a ground-truth prompt , we seek to find a functionally similar prompt . To do so, we draw a set of outputs from the model, and solve the maximum-likelihood problem where the objective is to find the prompt under which the example outputs are most likely to have been drawn.
| (2) |
This problem corresponds to optimizing an empirical approximation of the KL divergence between prompts and , and is derived in Section 4.
In solving (2), the central obstacle is that prompts are discrete strings of tokens. Therefore, (2) is a discrete optimization problem and typical continuous optimization methods such as gradient descent do not apply. Instead, to perform this optimization, we build on methods developed in the adversarial attacks literature (see (Zou et al., 2023) and related work in Section 2).
Investigations on optimized prompts
We explore several interesting properties of these optimized prompts.
-
•
Evil twins. In many cases, the optimized prompts that we find are similar in function to the original prompts (twins), but garbled and unintelligible to humans (evil). For this reason, we refer to them as evil twins. See Figure 1 for some examples.
-
•
Transferability. Remarkably, these “evil twin” prompts transfer between a variety of open-source and proprietary language models; see Section 6.
-
•
Robustness. We investigate the robustness of evil twin prompts to changes in their token-order and to replacements of their tokens. We find that whether evil twins are robust to randomly permuting their tokens depends on the LLM family. On the other hand, across LLM families, evil twins are more impacted by randomly replacing their tokens than ground truth prompts. This suggests that even the uncommon, non-English tokens in the optimized prompts play an important role in driving the model output; see Section 7.
-
•
Improving prompt intelligibility. We explore variants of the optimization problem (2) that encourage the optimized prompts to be more interpretable (adding a fluency penalty and restricting the vocabulary to common English tokens). However, we find that these modifications do not improve the KL divergence of the optimized prompts to the ground truth; see Section 8.
2 Related work
This paper fits into a quickly growing literature studying how language models parse prompts. Furthermore, the techniques used in this paper build off of a body of work on prompt optimization. We survey relevant work below.
How models parse prompts
There is rapidly mounting evidence that LLMs interpret natural-language prompts in counterintuitive ways. For instance, models struggle with prompts that are negated, such as prompts that ask to “Give an incorrect example” instead of to “Give a correct example” (Jang et al., 2023). Additionally, natural-language instructions in prompts in few-shot settings can often be replaced by irrelevant strings of text, with no drop in performance (Webson and Pavlick, 2022). Moreover, in few-shot settings the in-context examples’ labels can be replaced by random labels with little drop in performance (Min et al., 2022). These experiments indicate that LLMs follow instructions in prompts differently than humans do, which agrees in spirit with our finding of evil twin prompts.
There is also existing evidence that LLMs are able to parse some non-natural language prompts. Daras and Dimakis, 2022 finds that garbled text appearing in DALLE-2 images can be repurposed in prompts to the image generation model, and yields natural images. Millière, 2022 suggests that this may be an artifact of the model’s byte pair encoding, pointing out that the example prompt “Apoploe vesrreaitais”, which generates bird images, is reminiscent of the real Latin bird families Apodidae and Ploceidae. Furthermore, adversarial example prompts that jailbreak models sometimes contain uninterpretable suffixes (e.g., (Cherepanova and Zou, 2024; Zou et al., 2023; Liu et al., 2023)). Our results in this paper demonstrate that the phenomenon of language models parsing non-natural language prompts is more widespread than previously known, since many natural language prompts have non-natural language analogues. A full understanding of how models parse prompts will require contending with the existence of evil twin prompts.
Prompt optimization
The techniques in this work draw from the prompt optimization literature. This literature primarily includes optimization methods for hard prompts (which are text strings, i.e., sequences of tokens), and soft prompts (i.e., sequences of embedding vectors that are not constrained to correspond to a textual string). Hard prompts are more desirable because they are more easily inspected by humans, and can be inputted across different models.
Foundational work for soft prompt optimization includes prefix tuning (Li and Liang, 2021; Lester et al., 2021), which trains a soft prompt with gradient descent. This soft prompt is then prepended to a hard prompt for improved conditional generation on a range of tasks. We include experiments on soft prompts in Appendix D, but the focus of this paper is on hard prompts.
Hard prompt optimization operates in the model’s discrete token space, meaning that the optimization is not directly differentiable. Hard prompt optimization is most frequently described in the context of adversarial attacks or finding “jailbreaks” (prompts) that generate malicious output, or induce model misclassification. Several methods such as HotFlip (Ebrahimi et al., 2018), AutoPrompt (Shin et al., 2020), Greedy Coordinate Gradient (GCG) (Zou et al., 2023), and AutoDAN (Liu et al., 2023) have been developed to optimize over hard prompts. These methods work by starting with an arbitrary prompt and iteratively modifying tokens towards the goal of obtaining the adversarial attack behavior. In our work, we apply GCG (plus extra warm starts, pruning, and fluency penalties) to our optimization framework, demonstrating that it can be used in settings beyond adversarial attacks.
The closest work to ours is PEZ (Wen et al., 2023), which proposes a method that takes input images and finds matching prompts in CLIP embedding space. This bears similarity to the maximum-likelihood problem in (2), but our setting differs significantly from PEZ in that our optimization problem does not rely on a multimodal model with a shared embedding space – all that we require is the ability to compute the log-likelihood of a document given a prompt. In particular, our formulation of prompt optimization means that our method is applicable even when the documents outputted by the model do not have the same meaning as the prompt (i.e., the twin prompt does not have to be close to the documents in some embedding space). This is the setting in all conversational language models, where the model’s responses are not paraphrases of the prompt.
3 Preliminaries
3.1 Autoregressive language models
In our work, we focus on transformers (Vaswani et al., 2017) with a decoder-only architecture, as the majority of recent language models have adopted this architecture. We define a transformer language model , with a vocabulary size of tokens, where each token maps to a dimensional embedding. The input to the model is a length- sequence represented as a matrix by stacking one-hot encodings of tokens.
Given a sequence , the model outputs logits for the token probabilities .
3.2 Probability of a document
Given the input sequence , the model induces a probability distribution over the input:
where is th row of , and for any vector , the softmax is a vector in given by .
Now, given an input sequence of a prompt concatenated with a document in the form
where and are the prompt and document respectively, the conditional probability of the document given the prompt is
| (3) |
4 Optimization problem
4.1 KL divergence between prompts
Given two prompts, , we use the KL divergence (1) to measure how the distributions over documents that the prompts induce differ. Since the KL divergence between distributions is defined as
our distance between prompts can be equivalently formulated as
Since we have access to the output log probabilities from the model, we can estimate the distance by drawing some number of documents and computing
| (4) |
As we increase , the estimator concentrates around its expectation , and we obtain a good-quality approximation. We select the KL divergence as the statistical distance for prompt optimization because (i) it bounds the total variation distance by Pinsker’s inequality (Pinsker, 1964), and, as we will now see, (ii) minimizing it naturally corresponds to maximum likelihood estimation, and (iii) it allows for efficient optimization.
4.2 Optimization problem
We seek a prompt that minimizes the empirical estimate of the KL divergence between and given in (4). However, (4) involves additive terms that depend on , which we cannot compute unless we know . Fortunately, these terms do not depend on , so in the optimization we can drop these terms and define the loss function
and the set of solutions remains unchanged
| (5) |
Here is the set of hard prompts where each row of is a one-hot indicator vector for a token.
Remark. As discussed in the introduction, the optimization problem that we solve corresponds to finding a maximum-likelihood estimator (MLE)
which is the prompt that maximizes the probability that the documents are drawn.
5 Comparison of optimization methods
We consider various methods to optimize (5).
-
•
Asking GPT-4. Since this optimization is equivalent to the maximum-likelihood problem, we benchmark our methods against the “optimization” ability of commercial LLMs. Namely, we provide GPT-4 with our training corpus, containing the documents which are used for optimization, and ask it to provide an example prompt that could have generated the corpus; see Appendix E for more details and the GPT-4 prompt template.
-
•
GCG with cold start. We optimize (5) with the Greedy Coordinate Gradient (GCG) algorithm (Zou et al., 2023), which computes per-token gradients for each position in the prompt, and iteratively flips tokens in order to minimize the loss. The full GCG algorithm is reproduced in Appendix A. In the cold start version, we initialize a prompt to some arbitrary tokens from the vocabulary.
-
•
GCG with warm start. We experiment with combining both of the above methods, by warm-starting the GCG algorithm using the suggested prompt from GPT-4.
-
•
GCG with warm start, fluency penalty, and vocabulary pruning. Since GCG (with both cold and warm starts) typically returns unintelligible prompts, we experiment with methods to get more interpretable prompts. These are presented and discussed in Section 8.
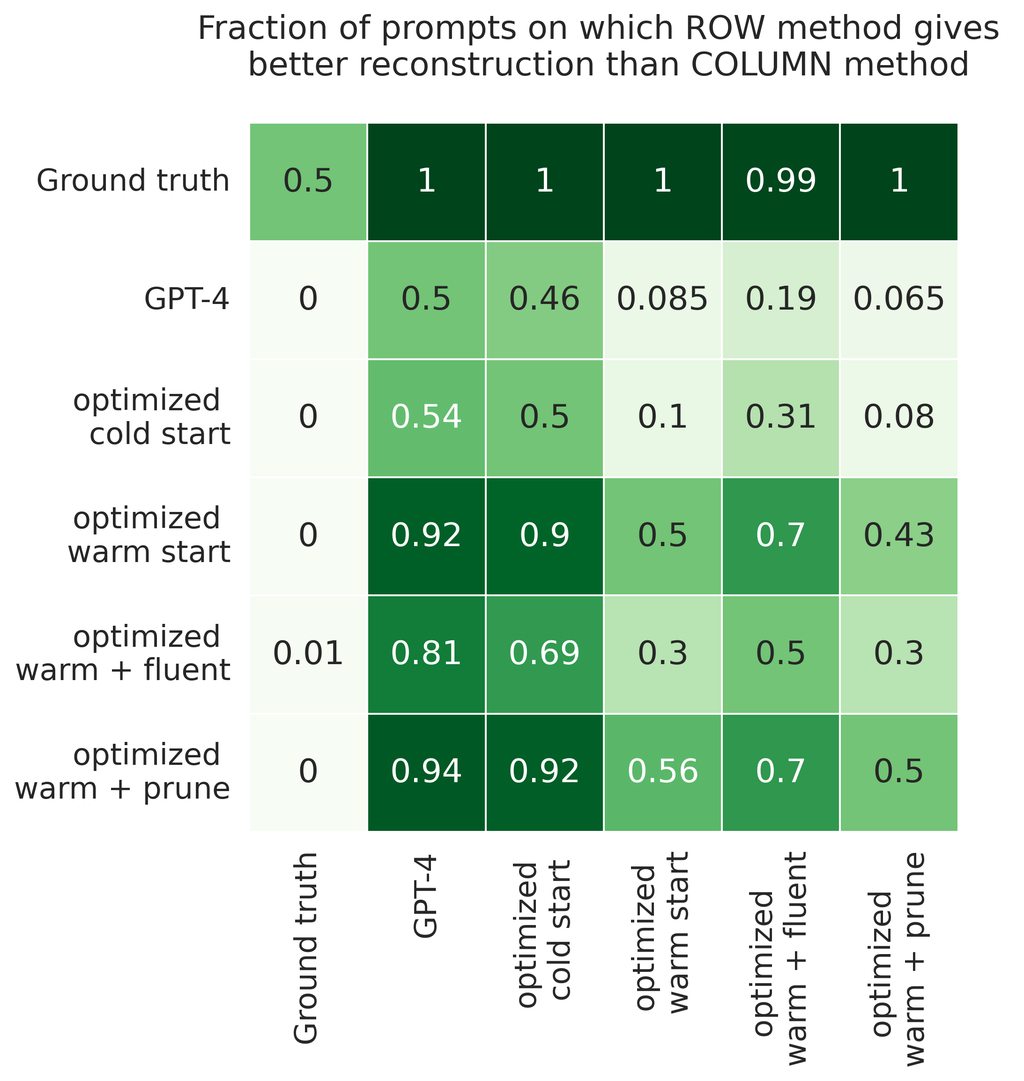
We compare these methods on 100 randomly sampled prompts from the Alpaca instruction tuning dataset (Taori et al., 2023), where Vicuna-7b-v1.5 is the instruction-tuned model. Additional experiments on various model families and datasets are presented in Appendix C. For each method and prompt, we compute the KL divergence of the optimized prompt with respect to the original prompt. We compare pairs of methods based on which one finds the closer prompt to the ground truth; see Figure 2. GPT-4 suggestions perform roughly on par with those from cold-start GCG. On the other hand, GCG with a warm start provides a strong improvement over both cold-start GCG and the GPT-4 prompt suggestions. Enforcing interpretability by adding a fluency penalty or pruning the vocabulary does not improve the optimized prompt (see Section 8). All results are reported in Figure 10.
6 Evil twin prompts transfer between models
We test whether prompts optimized on one model work on other models from different families and of different sizes.
6.1 Transferability to open source and proprietary models
Although the optimized “evil twin” prompts are generally unintelligible to humans, we surprisingly find that they transfer to a number of open source and closed industrial LLMs. We use 100 optimized (from a GPT-4 warm start) prompts from Vicuna and run them through a variety of open source and closed models. We use GPT-4 as a judge to determine if the induced responses from the optimized prompt are faithful to the original prompt on a scale of 1 to 3.
| Model | Score = 1 | Score = 2 | Score = 3 (best) |
| Gemini Pro | 17 | 8 | 75 |
| GPT-3.5-turbo | 31 | 6 | 63 |
| GPT-4 | 31 | 7 | 62 |
| Claude 3 Haiku | 59 | 5 | 36 |
| Claude 3 Sonnet | 38 | 8 | 54 |
| mistral-medium | 16 | 30 | 54 |
| mistral-small | 21 | 12 | 67 |
| mistral-tiny | 24 | 22 | 53 |
| OpenHermes-2.5 | 5 | 24 | 71 |
| OpenHermes-13B | 28 | 19 | 53 |
| Llama2-7b-chat | 7 | 28 | 64 |
| Llama2-13b-chat | 8 | 27 | 64 |
| Vicuna-7B | 7 | 22 | 71 |
| Vicuna-13B | 8 | 27 | 64 |
Specifically, the prompt that we use for GPT-4 is:
Please judge if the following response answers the prompt. Use a scale of 3 rating, where: 1 means that the response does not answer the prompt at all, and is completely wrong; 2 means that the response gets the general idea of the prompt and answers it to some extent; and 3 means that the response faithfully answers the prompt.
6.2 Transferability between model sizes
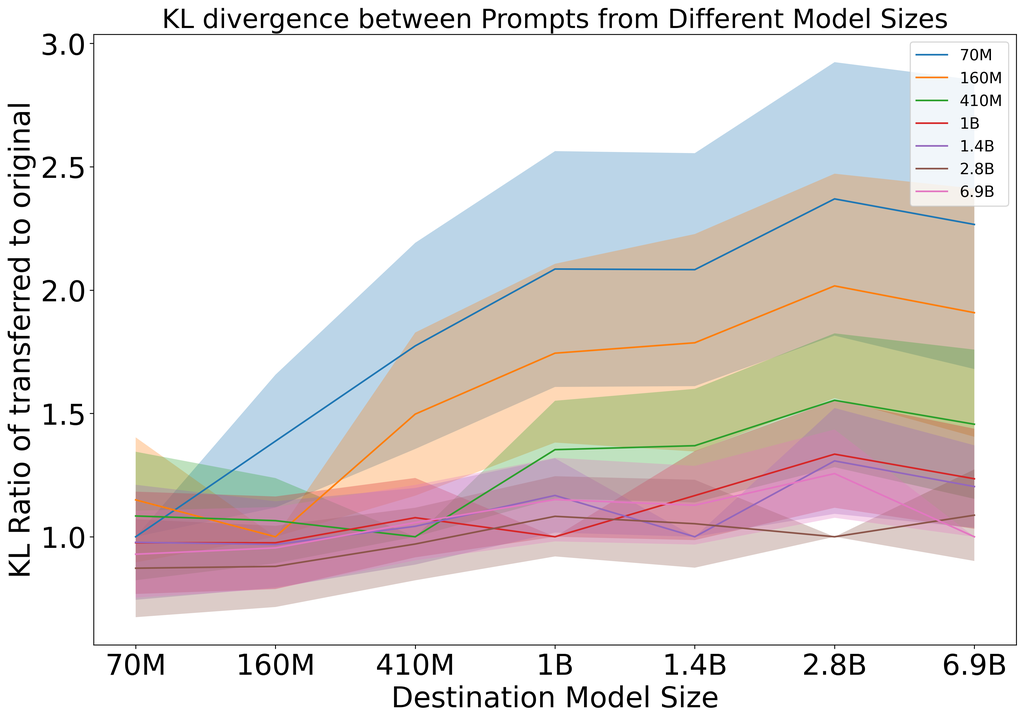
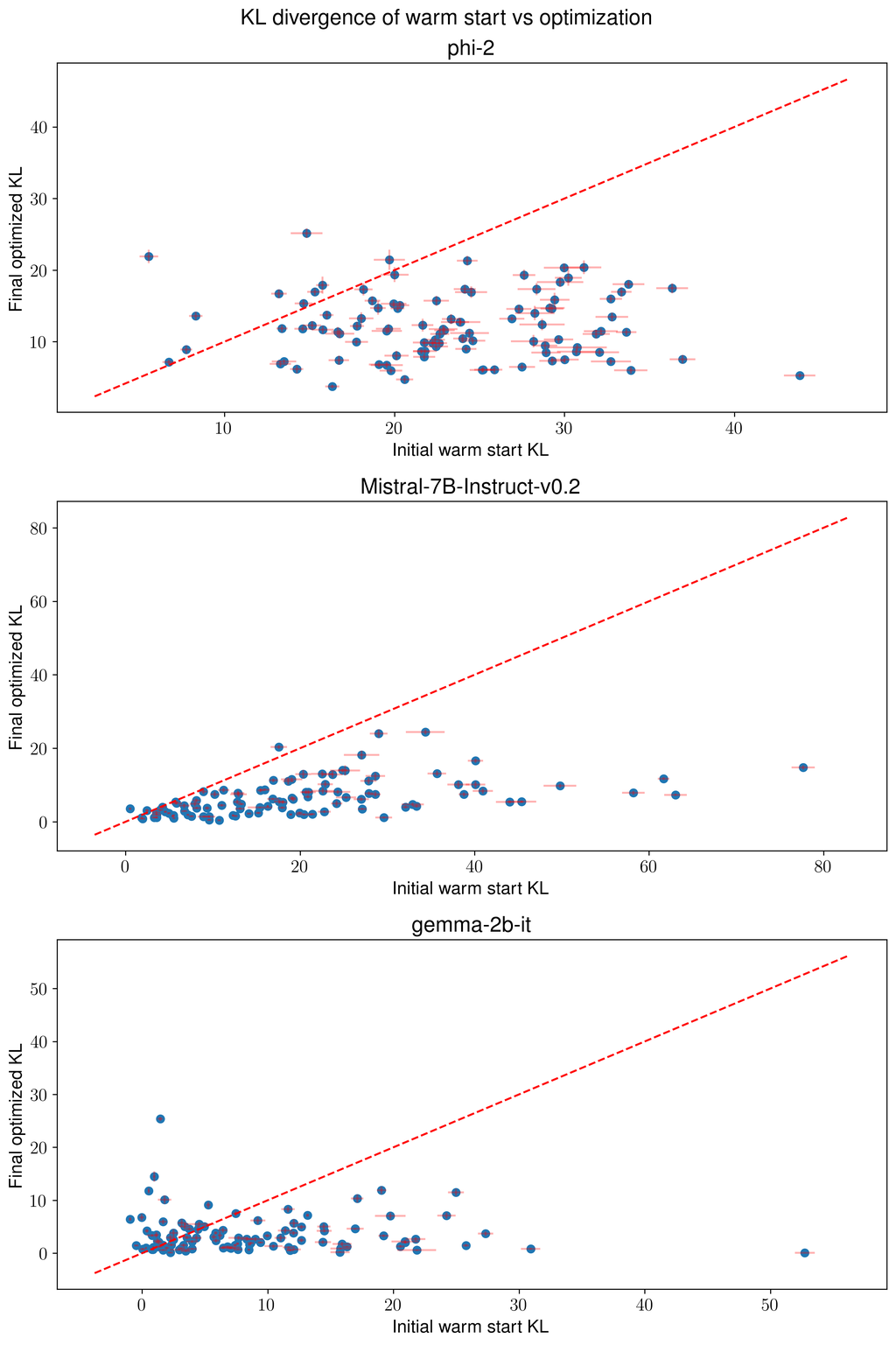
Next, we study the transferability of optimized prompts between different models within a model family while varying the size. The Pythia (Biderman et al., 2023) suite includes models ranging from 70M to 12B parameters. Each model is identical apart from the number of parameters, which makes it ideal for investigating how the distance between prompts changes with model size. Additionally, each model is trained with the same data seen in the same order. Our results are shown in Figure 3. We find that prompts optimized on smaller models have worse transferability to larger ones. However, prompts optimized on larger models transfer very well to smaller ones.
7 Robustness of optimized prompts
7.1 Token order sensitivity
Natural language is sensitive to token order, in that the meaning of a sequence can be affected by re-arrangement of its constituent tokens. Ishibashi et al., 2023 finds that prompts learned by AutoPrompt are more sensitive to token rearrangement than prompts written manually, as measured by performance on natural language inference tasks. We examine whether this is also true of our optimized prompts, invoking a KL-based assessment:
Definition 1.
Given prompts and , define to be random prompts formed by uniformly shuffling their tokens. We say that prompt is more token-order-sensitive than if
We wish to compare the token-order-sensitivity of optimized prompts to that of the natural-language ground truth prompts. We evaluate this using Algorithm 1, which calculates a token-order-sensitivity “win rate” between and , comparing how much the prompts change under random token reordering.
| Model | ||
| pythia-70m | (, ) | (, ) |
| pythia-160m | (, ) | (, ) |
| pythia-410m | (, ) | (, ) |
| pythia-1b | (, ) | (, ) |
| pythia-1.4b | (, ) | (, ) |
| pythia-2.8b | (, ) | (, ) |
| pythia-6.9b | (, ) | (, ) |
| vicuna-7b (cold) | (, ) | (, ) |
| vicuna-7b (warm) | (, ) | (, ) |
| gemma-2b-it (cold) | (, ) | (, ) |
| gemma-2b-it (warm) | (, ) | (, ) |
| mistral-7b-ins (warm) | (, ) | (, ) |
| phi-2 (warm) | (, ) | (, ) |
We find that token order sensitivity appears to be dependent on the model family; see Table 2. For Pythia, Phi-2 and Gemma, the optimized prompts are significantly less order sensitive than the ground truth prompts. For Mistral, the optimized prompts are somewhat more order sensitive. And for Vicuna, there is no significant difference between optimized and ground truth prompts.
7.2 Token replacement sensitivity
Based on visual inspection of the evil twin prompts in Figures 1 and 10, one can hypothesize that these consist of some tokens that are highly-related to the ground truth prompts and that drive the model’s output, as well as some tokens that appear unrelated and can be safely ignored or replaced.
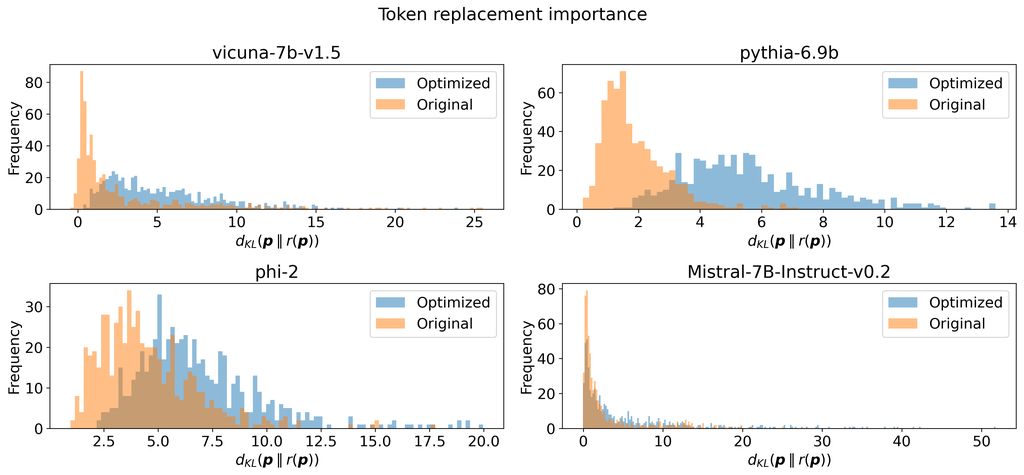
We test this hypothesis quantitatively, checking whether there are a few tokens in the optimized prompts that have an outsized effect on the prompt’s functionality. We compute for each optimized prompt , where is a function that replaces the token of a sequence with [UNK]. We do the same for the ground truth prompts . Figure 4 plots histograms of these KL divergences over all prompts and token positions .
Surprisingly, this experiment contradicts the hypothesis. Figure 4 shows that the effect of replacing a token in the optimized prompts with the “unknown” token, [UNK], is generally greater than the effect of replacing a token with [UNK] in the ground truth prompts. Thus, optimized prompts are more dependent on all of their tokens being present in a way that natural prompts are not, even though many of these tokens may appear garbled and uninterpretable. This effect is especially significant in the Pythia, Vicuna, and Phi-2 models, since very few tokens in the optimized prompts yield zero KL divergence change when they are replaced by [UNK].
8 Optimizing for more intelligible prompts
The prompts generated by our optimization are often unintelligible, and it may be desirable to recover a prompt that is more interpretable by humans. In this section, we explore two adjustments to our optimization procedure that aim to improve intelligibility: (1) fluency penalty, and (2) limiting the optimized prompt’s vocabulary to common English tokens. We find that these variants do not improve the KL divergence of the optimized prompt to the original.
8.1 Fluency penalty
Inspired by prior work (Guo et al., 2021; Mehrabi et al., 2022; Shi et al., 2022; Wen et al., 2023) on adding additional terms such as perplexity, BERTscore (Zhang* et al., 2020) and a fluency penalty to the loss in order to improve downstream performance, we follow (Shi et al., 2022) and add a term to the hard prompt loss function in order to penalize the log-likelihood of the prompt (fluency penalty). Our hard prompt loss function then becomes
where is a parameter controlling the importance of recovering a natural prompt. Larger biases the optimization towards more natural prompts that may not necessarily fit the documents as well. We find that adding the fluency penalty decreases the similarity between the optimized and ground truth prompt; see Figure 2. However, the prompts generated with a fluency penalty contain fewer strange tokens, and have higher fluency; see Figure 10 for the full results. An analysis of tuning the fluency hyperparameter is provided in Appendix B.
8.2 Vocabulary pruning
We explore limiting the tokens chosen for GCG in order to improve reconstruction and fluency. Since all of our testing is carried out on English prompts and documents, we focus on English sub-words in the tokenizer only. In order to achieve this, we run the Llama tokenizer on an English corpus obtained from spaCy (Honnibal and Montani, 2017), and mask out all tokens that do not appear in the corpus. The Llama tokenizer contains 32,000 tokens, and our pruning procedure results in about 15,000 tokens being removed.
9 Discussion and future work
Our work takes a new perspective on prompt optimization by inquiring whether we can optimize prompts to be functionally equivalent to a certain ground-truth prompt. Functional similarity is quantified via the KL divergence between the ground truth prompt distribution and the optimized prompt’s distribution. This yields a maximum-likelihood problem (2), whose solution uncovers “evil twin” prompts. Beyond our explorations of the transferability between models and robustness to perturbations of evil twin prompts, there are several open directions for future work. These directions include applications of the maximum-likelihood problem (2) that are of independent interest.
-
•
Prompt compression. By adding a length penalty to the optimized prompt in (2), our framework can be used to generate shorter prompts that mimic an original, longer prompt, which can then be used for pay-by-token API services in order to reduce inference time, context length usage, and total costs.
-
•
Conditional generation. The maximum-likelihood problem (2) can be extended to prompts that allow for conditional generation. An example of where this may be useful is in style/content transfer: given a set of user emails in the form (topic, email), a user could optimize a prompt such that the concatenated input string [prompt; topic] would be likely to generate the corresponding emails, and could write new e-mails on new topics in the user’s style as defined by the user’s corpus of previous e-mails.
-
•
Corpus compression. One could apply our framework (2) to help compress corpora of documents. Given documents drawn from a distribution, one would find an optimized prompt that would configure the model to be better at predicting documents from that distribution. This could yield improved performance if the model were used as a compression algorithm via arithmetic encoding as in (Delétang et al., 2023).
Limitations
The evil twins that we find are discovered using the GCG algorithm (Zou et al., 2023) plus additional warm-starting, token pruning, and fluency penalties. However, GCG may not result in a stable optimization in all cases. This can be seen in Appendix E, where for some examples the optimization fails to find prompts with low KL divergence to the original prompt. Thus, in the future it makes sense to explore alternative optimization algorithms, such as algorithms that may edit not just one token at a time, but may also make multi-token insertions and deletions, as well as vary the number of tokens during the optimization. Also, additional future work is required to adapt our framework for the applications of independent interest, because GCG may take many iterations to converge, which may introduce a significant runtime overhead.
Our approach for finding evil twins relies on having full access to the model’s gradients, which is not the case for many closed-source models such as GPT-4. Nevertheless, the transferability of evil twins between models allows us to find them on open-source models and apply them to closed-source models.
Potential risks
It is possible for a malicious user to use our framework to construct a prompt that generates a corpus of toxic or harmful documents, while not appearing malicious at surface level. However, there are many ways to mitigate the risks, such as perplexity filters and prompt paraphrasing (Jain et al., 2023).
Acknowledgements
This research was developed in part with funding from NSF under grant 2127207. EB was funded by NSF grant 1745302.
References
- Bailey et al. (2023) Luke Bailey, Gustaf Ahdritz, Anat Kleiman, Siddharth Swaroop, Finale Doshi-Velez, and Weiwei Pan. 2023. Soft prompting might be a bug, not a feature. In ICML 2023 Workshop on Deployment Challenges for Generative AI.
- Biderman et al. (2023) Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. 2023. Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR.
- Bubeck et al. (2023) Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. 2023. Sparks of Artificial General Intelligence: Early experiments with GPT-4. arXiv preprint arXiv:2303.12712.
- Cherepanova and Zou (2024) Valeriia Cherepanova and James Zou. 2024. Talking nonsense: Probing large language models’ understanding of adversarial gibberish inputs. In ICML 2024 Next Generation of AI Safety Workshop.
- Clopper and Pearson (1934) Charles J Clopper and Egon S Pearson. 1934. The Use of Confidence or Fiducial Limits Illustrated in the Case of the Binomial. Biometrika, 26(4):404–413.
- Cover et al. (1991) Thomas M Cover, Joy A Thomas, et al. 1991. Entropy, relative entropy and mutual information. Elements of information theory, 2(1):12–13.
- Daras and Dimakis (2022) Giannis Daras and Alex Dimakis. 2022. Discovering the Hidden Vocabulary of DALLE-2. In NeurIPS 2022 Workshop on Score-Based Methods.
- Delétang et al. (2023) Grégoire Delétang, Anian Ruoss, Paul-Ambroise Duquenne, Elliot Catt, Tim Genewein, Christopher Mattern, Jordi Grau-Moya, Li Kevin Wenliang, Matthew Aitchison, Laurent Orseau, et al. 2023. Language Modeling Is Compression. arXiv preprint arXiv:2309.10668.
- Ebrahimi et al. (2018) Javid Ebrahimi, Anyi Rao, Daniel Lowd, and Dejing Dou. 2018. HotFlip: White-box adversarial examples for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 31–36, Melbourne, Australia. Association for Computational Linguistics.
- Google (2024) Google. 2024. Gemma: Open models based on gemini research and technology.
- Guo et al. (2021) Chuan Guo, Alexandre Sablayrolles, Hervé Jégou, and Douwe Kiela. 2021. Gradient-based adversarial attacks against text transformers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5747–5757, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Honnibal and Montani (2017) Matthew Honnibal and Ines Montani. 2017. spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing. To appear.
- Ishibashi et al. (2023) Yoichi Ishibashi, Danushka Bollegala, Katsuhito Sudoh, and Satoshi Nakamura. 2023. Evaluating the robustness of discrete prompts. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2373–2384, Dubrovnik, Croatia. Association for Computational Linguistics.
- Jain et al. (2023) Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping-yeh Chiang, Micah Goldblum, Aniruddha Saha, Jonas Geiping, and Tom Goldstein. 2023. Baseline defenses for adversarial attacks against aligned language models. arXiv preprint arXiv:2309.00614.
- Jang et al. (2023) Joel Jang, Seonghyeon Ye, and Minjoon Seo. 2023. Can large language models truly understand prompts? a case study with negated prompts. In Transfer Learning for Natural Language Processing Workshop, pages 52–62. PMLR.
- Jiang et al. (2023) Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7b.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, Online. Association for Computational Linguistics.
- Liu et al. (2023) Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2023. AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models.
- Mehrabi et al. (2022) Ninareh Mehrabi, Ahmad Beirami, Fred Morstatter, and Aram Galstyan. 2022. Robust conversational agents against imperceptible toxicity triggers. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2831–2847, Seattle, United States. Association for Computational Linguistics.
- Millière (2022) Raphaël Millière. 2022. Adversarial attacks on image generation with made-up words. arXiv preprint arXiv:2208.04135.
- Min et al. (2022) Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. Rethinking the role of demonstrations: What makes in-context learning work? arXiv preprint arXiv:2202.12837.
- OpenAI (2023) OpenAI. 2023. GPT-4 technical report. arXiv, pages 2303–08774.
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback.
- Pinsker (1964) Mark S. Pinsker. 1964. Information and Information Stability of Random Variables and Processes. Holden-Day, San Francisco.
- Shi et al. (2022) Weijia Shi, Xiaochuang Han, Hila Gonen, Ari Holtzman, Yulia Tsvetkov, and Luke Zettlemoyer. 2022. Toward Human Readable Prompt Tuning: Kubrick’s The Shining is a good movie, and a good prompt too? arXiv preprint arXiv:2212.10539.
- Shin et al. (2020) Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. 2020. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4222–4235, Online. Association for Computational Linguistics.
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_alpaca.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All You Need. In Advances in Neural Information Processing Systems.
- Webson and Pavlick (2022) Albert Webson and Ellie Pavlick. 2022. Do prompt-based models really understand the meaning of their prompts? In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2300–2344, Seattle, United States. Association for Computational Linguistics.
- Wen et al. (2023) Yuxin Wen, Neel Jain, John Kirchenbauer, Micah Goldblum, Jonas Geiping, and Tom Goldstein. 2023. Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery. In Thirty-seventh Conference on Neural Information Processing Systems.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. HellaSwag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy. Association for Computational Linguistics.
- Zhang* et al. (2020) Tianyi Zhang*, Varsha Kishore*, Felix Wu*, Kilian Q. Weinberger, and Yoav Artzi. 2020. BERTScore: Evaluating Text Generation with BERT. In International Conference on Learning Representations.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. arXiv preprint arXiv:2306.05685.
- Zou et al. (2023) Andy Zou, Zifan Wang, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043.
Appendix A Greedy Coordinate Gradient algorithm
Our paper builds on the Greedy Coordinate Gradient (GCG) algorithm from (Zou et al., 2023) for prompt optimization given in Algorithm 2, by incorporating warm starts and experimenting with vocabulary pruning. GCG falls in a line of discrete optimization algorithms that iteratively construct prompts using token flips, combined with various heuristics for which tokens to flip and in what order.
Early work, such as HotFlip (Ebrahimi et al., 2018), picks a token and approximates the top-1 token in the vocabulary which decreases the loss most when flipped to. This is able to induce incorrect classification for sentiment analysis.
Building on this, AutoPrompt appends a small number of randomly initialized "trigger" tokens to the original prompt. The tokens in this "trigger" are subsequently masked and optimized via masked language modeling, where the objective is to minimize the loss of the input sequence by by selecting some top- tokens with highest gradient for each trigger (Shin et al., 2020).
GCG utilizes a similar approach to AutoPrompt; given a suffix of tokens to the task prompt, they optimize this suffix by a computing the top- tokens with largest negative gradients for every position in the suffix, then uniformly sample a single token as a candidate replacement for each position in the suffix. Finally, for each candidate suffix, they compute the loss by running a forward pass, and select the candidate suffix with lowest loss as the final new suffix. Using their optimized suffixes, they are able to generate prompts which induce malicious output from open source LLMs such as Llama, as well as large commercial models such as ChatGPT and GPT-4. The full algorithm details for GCG are shown in Algorithm 2.
Appendix B Fluency hyperparameter analysis
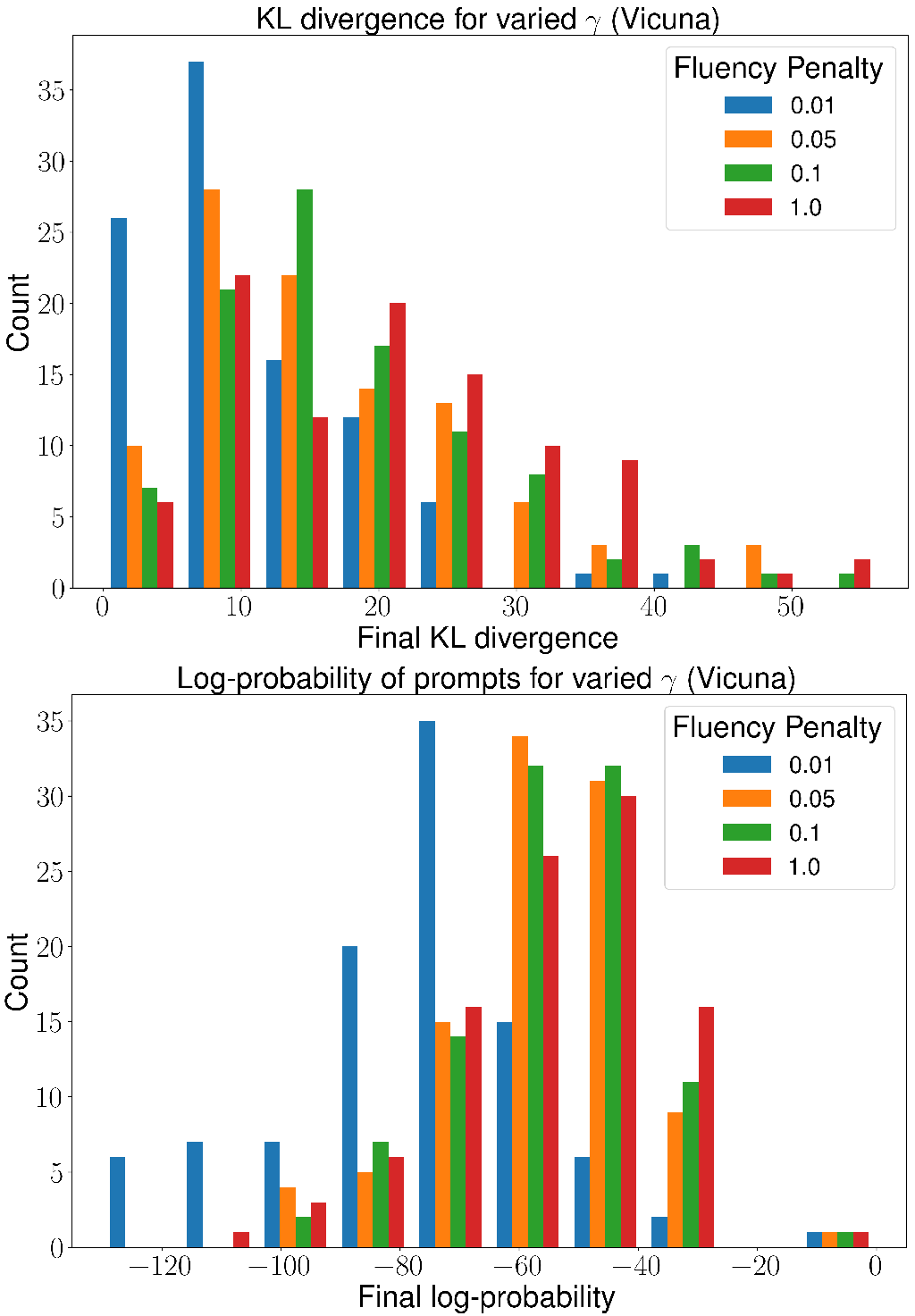
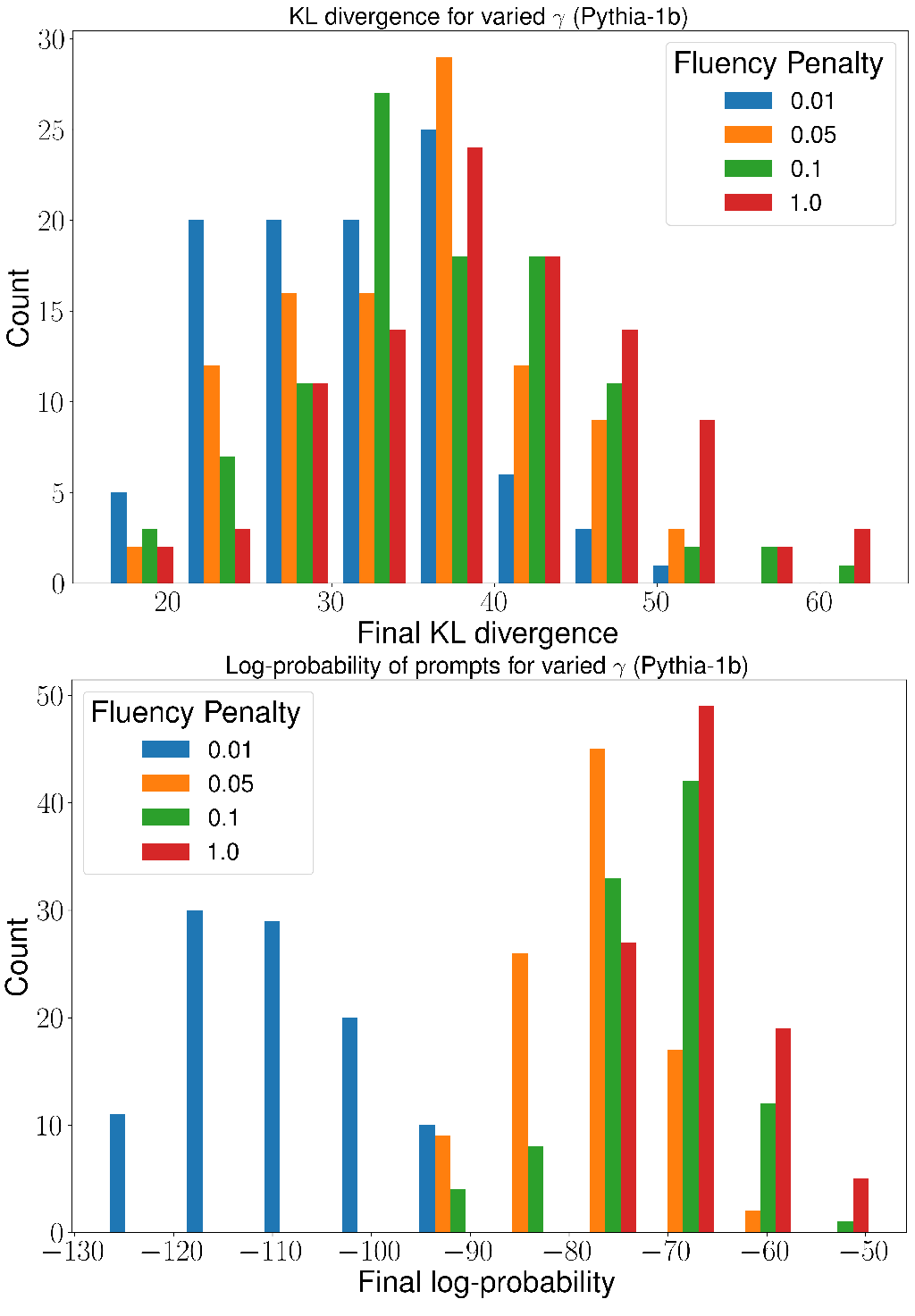
We explore the effects of varying the strength of the fluency penalty by selecting and running hard prompt optimization for 50 epochs on Vicuna-7b with a GPT-4 warm start; see Figure 5. We also run hard prompt optimization on Pythia-1b for 50 epochs from a cold start; see Figure 6.
These figures show a perhaps surprising trade-off between the readability of the prompt (as measured by the final log probability), and how well it reconstructs the original prompt. For our optimizations in Figure 2, we select , and this value does degrade the optimization performance in terms of KL divergence to the ground truth.
Appendix C Additional experiments with varied model families and datasets
We run additional experiments on Microsoft’s Phi-2 (2.7 billion parameters), Mistral’s Mistral-7B-Instruct-v0.2 (7 billion parameters), and Google’s Gemma (2 billion parameters) (Google, 2024). We use the popular prompt dataset OpenHermes-2.5, which contains a diverse variety of prompts for various tasks such as coding, Q&A, and many others. We filter for a subset of prompts that are related to writing code.
For all models, we run hard prompt optimization for 100 epochs, starting from a GPT-4 warm start. We find that we achieve similar results as we did with other model families; see Figure 7.
Appendix D Soft prompt results
Each token in the vocabulary maps to a dimensional embedding. We denote the embedding layer by , meaning that the model is in the form , where is the rest of the transformer model except the embedding layer.
Recall that soft prompts are sequences of vectors that lie in where is the dimensionality of the embedding space, rather than sequences of tokens. Specifically, we can represent the soft prompt as a matrix , which is fed into the LLM instead of the prompt’s embeddings, and similarly to (3) induces a distribution over documents . In a slight abuse of notation:
Thus, we can use the MLE formulation as defined in (5) with loss function
The vectors in soft prompts do not have to correspond to embeddings of tokens, which makes the optimization problem (5) continuous. This means that we can optimize the prompt by running gradient descent (GD), where we initialize with random embedding vectors on each row, and is a step size
| (GD on prompt embeddings) |
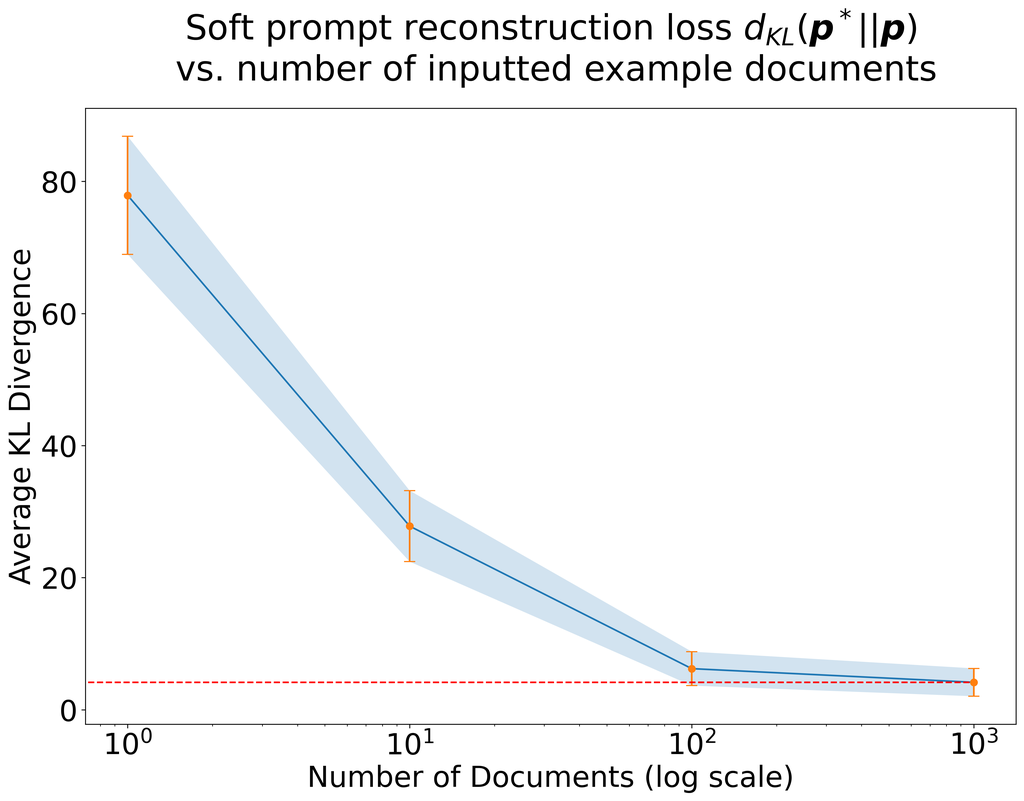
In Figure 8, we plot the results of soft-prompt reconstruction with varying numbers of documents. As the number of documents increases, the recovered soft prompt converges in KL divergence to the ground truth.
 |
Anagously to our hard prompt results, Bailey et al., 2023 study how soft prompts behave, and find that they are out of distribution when compared to the vocabulary token embeddings.
Appendix E Full prompt optimization results
We now report the full results for our experiments optimizing 100 randomly-sampled prompts from the Alpaca instruction tuning dataset (Taori et al., 2023), using Vicuna-7b-v1.5 as the LLM (Zheng et al., 2023).
In Figure 10 we report a complete table containing each of the 100 ground truth prompts, each of the optimized prompts found by the different methods, and each of the approximate KL divergences of the optimized prompts (lower is better). The methods are:
-
•
optimized cold start is the result of optimization from a random initialization.
-
•
optimized warm start is the result of optimization from a warm initialization based on GPT-4. We uniformly sample a warm start from 5 suggested GPT-4 prompts.
-
•
GPT-4 warm is the GPT-4 suggested prompt used to initialize the optimized warm start.
-
•
optimized warm + fluency is the result of optimization with a warm start and a fluency penalty. Notice that it generally contains fewer special characters and is somewhat more fluent than the method without this penalty.
-
•
GPT-4 warm + fluency is the GPT-4 suggested prompt to initialize optimized warm + fluency.
-
•
optimized warm + prune is the result of optimization with a warm start and vocabulary pruning to the most common tokens in English text. Notice that these optimized prompts do not contain special unicode characters.
-
•
GPT-4 warm + prune is the GPT-4 suggested prompt to initialize optimized warm + prune.
Note: in our examples we have omitted the instruction model’s prompt template, but this is actually present when we optimize (although it is not optimized).
The template we use for prompting GPT-4 is: Please generate 5 different prompts that could have created the following documents, and please make sure to generate the responses as JSON only and keep the prompts brief:
{document go here}
Here is an example for a set of documents about cooking steak:
{
"prompts":
[
"What is a good recipe for steak?",
"Give me a steak dinner recipe.",
"Tell me how to cook steak",
"What’s a good way to make a steak?",
"What is the best recipe for fast steak?",
]
}
Simply provide JSON in the following above format. Do not provide any additional text that deviates from the format specified in the example.
| Average KL | |||||||
| Size | 70M | 160M | 410M | 1B | 1.4B | 2.8B | 6.9B |
| 70M | |||||||
| 160M | |||||||
| 410M | |||||||
| 1B | |||||||
| 1.4B | |||||||
| 2.8B | |||||||
| 6.9B | |||||||
See pages 1-13 of img/table.pdf
