TableLlama: Towards Generalist Large Language Models for Tables
Abstract
Semi-structured tables are ubiquitous. There has been a variety of tasks that aim to automatically interpret, augment, and query tables. Current methods often require pretraining on tables or special model architecture design, are restricted to specific table types, or have simplifying assumptions about tables and tasks. This paper makes the first step towards developing open-source large language models (LLMs) as generalists for a diversity of table-based tasks. Towards that end, we construct TableInstruct, a new dataset with a variety of realistic tables and tasks, for instruction tuning and evaluating LLMs. We further develop the first open-source generalist model for tables, TableLlama, by fine-tuning Llama 2 (7B) with LongLoRA to address the long context challenge. We experiment under both in-domain setting and out-of-domain setting. On 7 out of 8 in-domain tasks, TableLlama achieves comparable or better performance than the SOTA for each task, despite the latter often has task-specific[Huan: can we say ‘task-specific’ as it’d be better] design. On 6 out-of-domain datasets, it achieves 5-44 absolute point gains compared with the base model, showing that training on TableInstruct enhances the model’s generalizability. We open source our dataset and trained model to boost future work on developing open generalist models for tables.111Code, model and data are available at: https://osu-nlp-group.github.io/TableLlama/.
1 Introduction
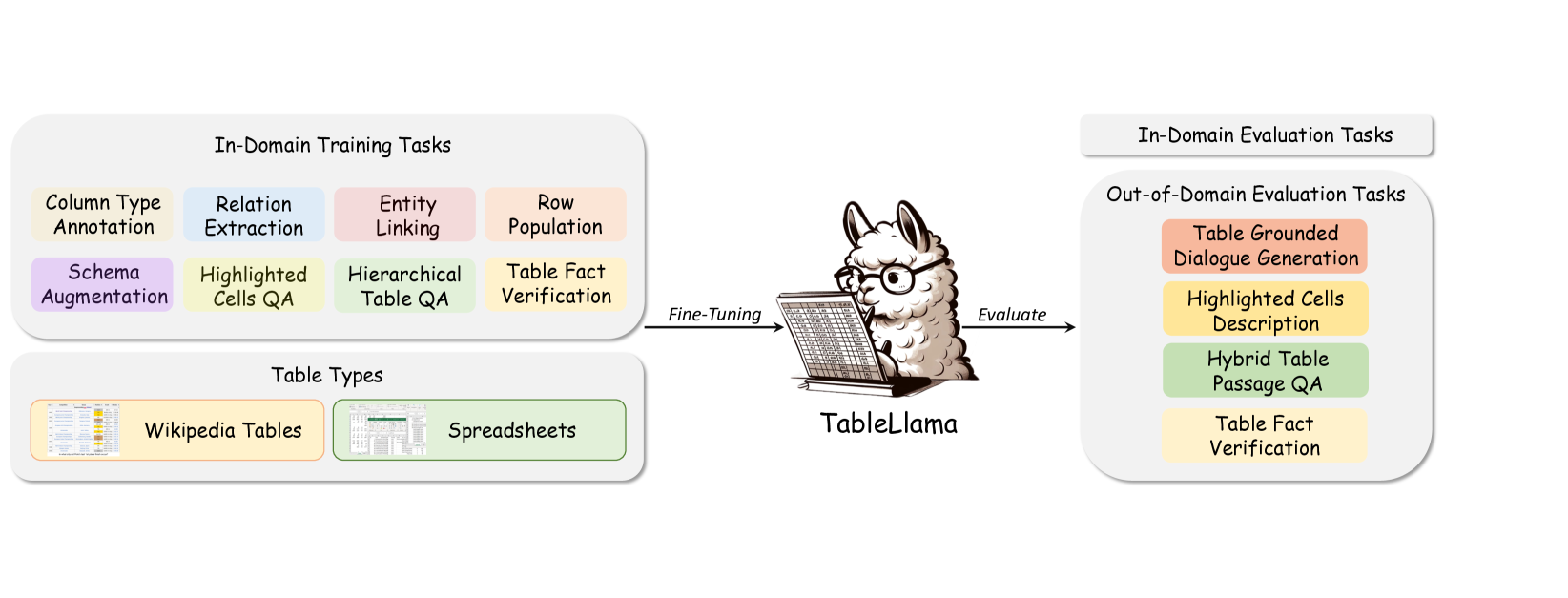
Semi-structured tables are prevalent data structures to store and present information in almost every domain, ranging from scientific research, business reports, and healthcare records to financial statements.[Huan: while it is fine to mention these domains, a question: tables in these domains usually have a lot of numbers, but in our datasets, we don’t specifically deal with numbers, right? or some tasks actually have a lot of numbers?]I feel it’s ok. We have one hierarchical qa task that contains a lot of numbers. A variety of table-based tasks have been proposed, such as entity linking (ritze2015matching), column type annotation (hulsebos2019sherlock), schema augmentation (zhang2017entitables), and table-based question answering (cheng-etal-2022-hitab; Nan2021FeTaQAFT; chen2020hybridqa), which have spurred significant research interest (deng2020turl; yin-etal-2020-tabert; wang2021tuta; iida-etal-2021-tabbie) in recent years.
Building models for tables is not new. However, none of them meets all the requirements for a generalist model listed above. Most existing methods for table-based tasks have at least one of the following limitations: (1) Require table pretraining (liu2022tapex; yin-etal-2020-tabert; deng2020turl; iida-etal-2021-tabbie) and/or special model architecture design for tables (deng2020turl; wang2021tuta; iida-etal-2021-tabbie), (2) only support limited, specific types of tables and tasks (Chen2020TabFact:; Nan2021FeTaQAFT), (3) make strong simplifying assumptions (See the “in-domain” part of Section 2.1) about tables and tasks (li2023tablegpt).
On the other hand, language models like T5 (raffel2020exploring) have been shown to excel in grounding language to structured knowledge (xie2022unifiedskg). In addition, instruction tuning (chung2022scaling; wang-etal-2022-super; mishra-etal-2022-cross) appears as an important technique that can guide LLMs to follow instructions to complete a variety of tasks.
[Huan: it’s too early to directly throw out this question.. in addtion to the above comment, you should also mention the recent trend showing the promise of using LLMs for multiple tasks via instruction tuning. therefore, you explore the following question. Currently there is too much a gap between your first sentence and this one.] Under this background, we seek to answer the following question: Can we build a generalist model to handle a variety of table-based tasks using LLMs and instruction tuning? Some exemplar tasks are shown in Figure 1.A generalist model for tables could ? make the tables more easily to be manipulated and annotated, thus can serve as a user-friendly tool to largely reduce manual labor ().[Huan: Are you trying to use the last sentence to motivate why building a generalist model vs fine-tuning a specific model for each task? if so, it’s not convincing at all. why is it better than the latter in terms of ”…more easily to be manipulated and annotated” and ”as a user-friendly tool to largely reduce manual labor”?] Such a generalist model shall meet the following desiderata: First, it should not only work well on diverse table-based tasks, but also generalize to unseen tasks. Since new table data and tasks can be constructed dynamically as new information arrives, it is hard to collect training data that covers all tasks and all tables, which requires a model to be inherently generalizable to tasks[Huan: in our OOD setting, it has two sub-settings, right? one is to test on new tasks, the other to test on old tasks but new datasets] and datasets it has never seen before. Second, it should work on real-world tables and realistic tasks, which can be large, intricate, and incomplete. The model should not make strong assumptions to only handle simplified synthetic tables and tasks, but must embrace practical challenges such as handling complex numerical reasoning on large hierarchical spreadsheets as well as a large number of candidates for classification and ranking tasks.
In pursuing this goal, we realize there lacks a comprehensive collection of realistic tables and tasks that can support the development and evaluation of generalist models. Therefore, we construct TableInstruct, by meticulously selecting representative table-based tasks from widely used datasets, unifying the format for all tasks and manually annotating instructions. TableInstruct shown in Table 1 offers the following unique features: (1) Diverse coverage of tables and tasks. TableInstruct boasts a collection of 14 datasets of 11 tasks in total, with both in-domain and out-of-domain evaluation settings. Our training data includes 8 tasks, which are curated from 1.24M tables containing 2.6M instances spanning from table interpretation, table augmentation[Huan: can you in table 1 mark what tasks are table interpretation and table augmentation? I don’t think people are very familiar with these two.], table-based QA, and table-based fact verification. We choose 8 datasets for these 8 tasks for in-domain evaluation and leave the other 6 datasets for 4 tasks for out-of-domain evaluation. The in-domain training tasks can enable the model to learn more fundamental table understanding abilities such as table interpretation and table augmentation, while we choose tasks that require more high-level reasoning abilities such as table QA and cell description to test the model’s generalization ability. This extensive range of tables and diverse tasks not only provide valuable resources for table modeling, but also foster a more comprehensive evaluation of generalist models. [Huan: should we talk a bit more about the InD and OOD setting? how many/what are InD and OOD? Is there any rationale for choosing some as InD while others as OOD?] (2) The use of real-world tables and realistic tasks. TableInstruct uses authentic real-world instead of overly simplified synthetic task data compared with existing work (li2023tablegpt). We incorporate a large number of Wikipedia tables and spreadsheets from statistical scientific reports, and collect[Huan: I still have the earlier question: did we ‘collect’? if not, then reprase this as ‘as well as tables with varied length…’] tables with varied length of contents, realistic and complex semantic types from Freebase (freebase) for column type annotation and relation extraction, and a large referent entity corpus with rich metadata from Wikidata (vrandevcic2014wikidata) for entity linking. In addition, we include complicated numerical reasoning tasks with hierarchical table structure and existing manually annotated [Huan: do you mean they ‘manually annotated’ or you did that?]table QA and fact verification tasks. By doing so, we aim to equip models with the capability to cope with realistic and complex table-based tasks.
TableInstruct requires models to accommodate long inputs[Huan: can you in Table 1 show the min/max/median of the context length?] (Table 1). We adopt LongLoRA (longlora) based on Llama 2 (7B) (touvron2023llama) as our backbone model, which has been shown efficient and effective to handle long contexts. We fine-tune it on TableInstruct and name our model TableLlama. We conducted extensive experiments and analysis [Huan: there is no analysis, right?] under both in-domain and out-of-domain settings. Our experiments show TableLlama has strong capabilities for various in-domain table understanding and augmentation tasks, and also achieves promising performance in generalizing to unseen tasks and datasets.

In summary, our main contributions are:
-
We construct TableInstruct, a large-scale instruction tuning dataset with diverse, realistic tasks based on real-world tables. We unify their format and manually annotate instructions to guarantee quality.
-
We develop TableLlama, an open-source LLM-based generalist model fine-tuned on TableInstruct. Experiments show that compared with the SOTA on each task that often has special pre-training or model architecture design for tables, TableLlama can achieve similar or even better performance on almost all of the in-domain tasks[Huan: it is confusing here. what do you mean by this: when using the same training data for tables]. For out-of-domain tasks, compared with the base model, TableLlama can achieve 5-44 absolute point gains on 6 datasets, and compared with GPT-4, TableLlama has less gap or even better zero-shot performance on 4 out of 6 datasets, which demonstrate that TableInstruct can substantially enhance model generalizability. [Huan: I think the last part isn’t very convincing; why comparing with pre-trained model? I think you can admit for OOD, there is still some gap with SoTAs, which is understandable, and then stress on the improvement over the pre-trained/un-fine-tuned model]
[Huan: In this paragraph, you should talk about your effort to unify the task format and prepare instructions (briefly), followed by what models you trained to do instruction tuning, as well as how you solved the long context issue.] [Huan: Give a summary of the results in this paragraph and maybe also talk about insights for future work.]
2 TableInstruct Benchmark
| Task Category | Task Name | Dataset | In- domain | #Train | #Test | Input Token Length | ||||||
| (Table/Sample) | (Table/Sample) | min | max | median | ||||||||
| Table Interpretation | Col Type Annot. | TURL (deng2020turl) | Yes | 397K/628K | 1K/2K | 106 | 8192 | 2613 | ||||
| Relation Extract. | Yes | 53K/63K | 1K/2K | 2602 | 8192 | 3219 | ||||||
| Entity Linking | Yes | 193K/1264K | 1K/2K | 299 | 8192 | 4667 | ||||||
| Table Augmentation | Schema Aug. | TURL (deng2020turl) | Yes | 288K/288K | 4K/4K | 160 | 1188 | 215 | ||||
| Row Pop. | Yes | 286K/286K | 0.3K/0.3K | 264 | 8192 | 1508 | ||||||
| Question Answering | Hierarchical Table QA | HiTab (cheng-etal-2022-hitab) | Yes | 3K/7K | 1K/1K | 206 | 5616 | 978 | ||||
| Highlighted Cells QA | FeTaQA (Nan2021FeTaQAFT) | Yes | 7K/7K | 2K/2K | 261 | 5923 | 740 | |||||
| Hybrid Table QA | HybridQA (chen2020hybridqa) | No | – | 3K/3K | 248 | 2497 | 675 | |||||
| Table QA | WikiSQL (wikisql) | No | – | 5K/16K | 198 | 2091 | 575 | |||||
| Table QA | WikiTQ (wikitq) | No | – | 0.4K/4K | 263 | 2688 | 709 | |||||
| Fact Verification | Fact Verification | TabFact (Chen2020TabFact:) | Yes | 16K/92K | 2K/12K | 253 | 4975 | 630 | ||||
| FEVEROUS (feverous) | No | – | 4K/7K | 247 | 8192 | 648 | ||||||
|
|
KVRET (kvret) | No | – | 0.3K/0.8K | 187 | 1103 | 527 | ||||
| Data-to-Text |
|
ToTTo (parikh-etal-2020-totto) | No | – | 7K/8K | 152 | 8192 | 246 | ||||
Unlike existing datasets predominantly designed for training task-specific table models, our objective is to bridge the gap between multiple complex task-specific models and one simple generalist model that can deal with all the table-based tasks without extra model-design efforts. To achieve this, our approach for constructing TableInstruct adheres to the following principles. First, instead of collecting multiple datasets from highly homogeneous tasks, we try to diversify the tasks and table types. We pick representative table-based tasks that necessitate different abilities of models, such as table interpretation, table augmentation, table QA and table fact verification from Wikipedia tables and spreadsheets in statistical scientific reports. Second, we select realistic tasks and construct high-quality instruction data in a unified fashion without simplifying assumptions (see “in-domain” part of 2.1)I think ”simplifying assumptions” this term occurs many times so far. We should clarify this concept at the first time. TableInstruct will support powerful modeling and realistic evaluation approaches, ensuring a valuable and practical dataset for research.
2.1 Data Collection
TableInstruct incorporates samples from 14 table-based datasets of 11 distinctive tasks (Table 1). We separate them and select 8 datasets of 8 tasks for training and in-domain evaluation. We leave the other 6 datasets of 4 tasks as held-out unseen datasets for out-of-domain evaluation.
Task category: Tasks in TableInstruct can be categorized into several groups: table interpretation, table augmentation, question answering, fact verification, dialogue generation, and data-to-text. Table interpretation aims to uncover the semantic attributes of the data contained in relational tables, and transform this information into machine understandable knowledge. Table augmentation is to expand the partial tables with additional data. Question answering aims to obtain the answer with tables and optional highlighted cells or passages as evidence. Fact verification is to discriminate whether the tables can support or refute the claims. Dialogue generation is to generate a response grounded on the table and dialogue history. Data-to-text is to generate a description based on the highlighted cells.We choose table interpretation, table augmentation, some representative question answering tasks and one dataset of fact verification as in-domain datasets for training the model. We hold out the rest of the datasets spanning from question answering, fact verification, dialogue generation to data-to-text as out-of-domain datasets. By choosing the tasks that require models to learn more fundamental table understanding abilities such as table interpretation and table augmentation for training, we hope the model can demonstrate generalization ability on out-of-domain datasets such as high-level table QA and table cell description tasks. [Huan: maybe here you briefly introduce the task category like what table interpretation in general does, and then introduce your rationale why some are used for in-domain evaluation and some are for ood.]
In-domain: The tasks for training the generalist table model include column type annotation, relation extraction, entity linking, row population, schema augmentation, hierarchical table QA, highlighted cells QA, and table fact verification.The tasks for training the generalist table model include column type annotation (deng2020turl), relation extraction (deng2020turl), entity linking (deng2020turl), row population (deng2020turl), schema augmentation (deng2020turl), hierarchical table QA (cheng-etal-2022-hitab), highlighted cells QA (Nan2021FeTaQAFT), and table fact verification (Chen2020TabFact:). These tasks require the model to understand the semantics of table columns, the relation between table column pairs, the semantics of table cells and require the model to gain reasoning ability to answer table-related questions and verify the facts. For the dataset of each task, we intentionally pick up those that enjoy realistic task complexity without simplifying assumptions. For example, for column type annotation and relation extraction, these two tasks are multi-choice classification tasks in essence. We use real-world column semantic types and relation types from Freebase (freebase), which contains hundreds of complex choices such as “government.politician.partygovernment.political_party_tenure.party” shown in Figure LABEL:fig:rel_extraction in Appendix LABEL:sec:prompt_format. For entity linking, the referent entities are from real-world Wikidata (vrandevcic2014wikidata), which contains hundreds of complex metadata, such as “¡2011-12 Melbourne Victory season [DESCRIPTION] Association football club 2011/12 season for Melbourne Victory [TYPE] SoccerClubSeason¿” as shown in Figure LABEL:fig:ent_link in Appendix LABEL:sec:prompt_format. For schema augmentation and row population, there are a huge number of candidates that LLMs need to rank. For hierarchical table QA, all the tables are engaged with intricate structures with multi-level column names and row names. In addition, it is intensive in numerical reasoning which requires LLMs to understand table structure, identify related cells and do calculations. By doing so, we hope to enable LLMs to become truly powerful generalist models that can handle sophisticated table tasks and TableInstruct can be a realistic benchmark to evaluate LLMs’ abilities compared with specially designed table models.
Out-of-domain: A powerful generalist table model is expected to not only demonstrate strong performance on in-domain tasks, but also generalize well to unseen tasks or unseen datasets of the same tasks. The underlying table understanding ability learned by the model should be able to transfer to unseen tasks or datasets. We choose tasks such as table QA and cell description that require the model’s high-level table understanding and reasoning ability as out-of-domain datasets. We involve HybridQA (chen2020hybridqa), KVRET (kvret), FEVEROUS (feverous), ToTTo (parikh-etal-2020-totto), WikiSQL (wikisql) and WikiTQ (wikitq) as 6 out-of-domain datasets to test our model’s generalization ability. HybridQA is a table and passages grounded question answering task. KVRET is a response generation task grounded on table and dialogue history. ToTTo is to generate text descriptions based on highlighted table cells. FEVEROUS is a table fact verification task. WikiSQL and WikiTQ are two table QA tasks[Huan: you don’t have such a description for each task in the previous paragraph. Maybe as said in the caption of Table 1” leave such a brief description in appendix.]. By evaluating our model on these datasets, we hope to demonstrate our model’s generalization ability. [Huan: provide the rationale why some are in-domain while others are OOD. polish the language you said on Teams]
2.2 Task Formulation and Challenges
[Huan: I think you should first talk about Section 3.2 (what these tasks are) and then talk about Section 3.1 (how to formulate them into a unified format). Do point readers to some examples, whether in the main content or in the appendix. Otherwise, it’s very boring to read.]
[Huan: this paragraph could be significantly polished. you could refer to Figure LABEL:fig:examplars b-d in the beginning of this paragraph when talking about the prompt format. and then stress on the challenges in our task formulation, e.g., number of candidates and context length.] The primary objective of TableInstruct is to design one generalist model for all table-based tasks. As Figure 2 (a)-(c) shows, each instance in our dataset maps three components: ¡instruction, table input, question¿ to an output. The instruction is manually designed to point out the task and give a detailed task description. We concatenate table metadata such as the Wikipedia page title, section title and table caption with the serialized table as table input. In the question, we put all the information the model needed to complete the task and prompt the model to generate an answer. For example, for the column type annotation task, as Figure 2 (a) shows, the column named “Player” needs to be annotated with its semantic types. In the format, the “instruction” gives the description of the task. The “input” contains the table-related information. Then we provide the entire candidate pool in the “question” and ask the model to choose one or multiple correct semantic types for this column.
Challenges. Since we select realistic tasks and tables, the table length can vary from several to thousands of rows. Besides, for some tasks that are essentially multi-choice classification or ranking, the entire candidate pool can be very large up to thousands. Furthermore, as the candidates are from real-world Freebase (freebase)and Wikidata(vrandevcic2014wikidata), each candidate is long, such as “¡2011-12 Melbourne Victory season [DESCRIPTION] Association football club 2011/12 season for Melbourne Victory [TYPE] SoccerClubSeason¿” is one candidate for entity linking. These characteristics can not only make it difficult for the model to learn, but also introduce the challenge of handling long contexts.
[Huan: maybe allocate one specific paragraph to talk about challenges of our task formulation. for example, move some stuff in the above paragraph and the first few sentences in the ‘model selection’ paraphraph in Section 3 to here.]
3 Experiments
[Huan: do we still want to put the results of models from earlier experiments where you use the tricks to deal with long contexts? If so, you should think about how to describe them in the main content without diving into too many details. I think you might just include Llama 2’s results there, i.e, there are llama 2 (with short pruned candiates using your tricks) vs Llama 2 (with long context using LongLoRa).]
We demonstrate the capability of completing table tasks on five LLMs: Alpaca, Llama-2, Llama-2-Chat, Vicuna-1.5, and Tulu. Alpaca is an instruction-tuned model that originates from Llama-1. Llama2 is a more powerful pretrained model, which has demonstrated better performance than Llama-1. Llama-2-Chat is a fine-tuned version of Llama-2 that is optimized for dialogue use cases. It’s trained by alignment techniques such as instruction tuning and RLHF. Vicuna-1.5 is the latest version by fine-tuning Llama 2 on user-shared conversations collected from ShareGPT. Tulu is a Llama model finetuned on a mixture of instruction datasets such as FLAN V2, CoT, Dolly, Open Assistant 1, GPT4-Alpaca, Code-Alpaca, and ShareGPT. These are LLaMA families with only the decoder architecture. Due to the computing resource limit, we only evaluate the performance of the 7B model for the LLaMA family and leave the larger size model performance for future work. We also largely reduce the training examples, which are 100 training examples and 1000 training examples for each task to demonstrate LLMs’ ability.
Evaluation Metrics. We follow existing work to use their metrics. For multi-label classification tasks (column type annotation and relation extraction), we use precision, recall and F1. For entity linking which there is only one ground truth and fact verification, we use accuracy. For ranking tasks (row population and schema augmentation), we use MAP (mean average precision). For free-form QA, we use scareBLEU, Rough-1, Rough-2, Rough-L and METEOR. For hierarchical table QA, we use execution accuracy.
Training and Inference Details. For the dynamic table segmentation, the reserved instruction length for free-form QA is 50; for entity linking is 500; for other datasets is 100. The offset for all tasks is 200. The reserved table metadata length for all tasks is 20. We train LLaMA-family models for 1 epoch when using the entire 968k training data. We train 3 epochs when using 100 and 1000 training examples. The candidate size in the instructions for column type annotation, relation extraction and entity linking is 10, The subset size for row population is 20. The max generation length for row population is 512; for free-form QA and schema augmentation is 128; for others is 64.
4 Results and Analysis.
| Alpaca | Llama-2 | Vicuna-1.5 | Tulu | Llama-2-Chat | SOTA | ||||
| 100 | 1000 | full | full | ||||||
| Column Type Annotation | Precision | 24.30 | 67.75 (0.08%x) (71%) | 88.74 | 89.26 | 88.84 | 89.48 (5%x)(94%) | 95.15 | |
| Recall | 30.16 | 64.94 (0.08%x)(69%) | 87.40 (5%x) (92%) | 86.75 | 87.13 | 86.60 | 94.54 | ||
| F1 | 26.91 | 66.31(0.08%x)(71%) | 88.07 (5%x) (94%) | 87.99 | 87.98 | 88.02 | 93.94 | ||
| Relation Extraction | Precision | 32.28 | 59.39 (0.2%x)(63%) | 91.53 | 93.07 (40%x)(98%) | 92.43 | 92.45 | 94.57 | |
| Recall | 5.54 | 43.08 (0.2%x)(45%) | 73.19 (40%x) (77%) | 73.00 | 72.14 | 72.28 | 95.25 | ||
| F1 | 9.46 | 49.94 (0.2%x)(53%) | 81.34 | 81.83 (40%x) (86%) | 81.03 | 81.13 | 94.91 | ||
| Entity Linking | EM | 16.69 | 62.57 | 71.91 | 69.57 | 71.41 | 67.91 | – | |
| Relax EM? | 23.34 | 69.73 | 81.77 | 82.2 | 80.41 | 79.94 | – | ||
| Schema Augmentation | MAP | 42.06 | 48.84 (0.3%x)(63%) | 68.10 (10%x)(88%) | 67.74 | 67.39 | 67.89 | 77.55 | |
| Row Population | MAP | 18.55 | 24.79 | 25.99 | 29.09 | 53.78 | 45.32 | – | |
| Hierarchical Table QA | Exec Acc | 30.43 (68%) | 36.74 (14%x)(81%) | 34.47 | 39.58 (100%x)(88%) | 37.63 | 34.91 | 45.1 | |
| Free-form QA | sacreBLEU | 30.90 (92%) | 35.77 (14%x)(107%) | 36.62 | 36.79 | 36.66 | 36.93 (100%x) (110%) | 33.44 | |
| Rough-1 | 64.51 (99%) | 69.10 (14%x)(106%) | 71.11 | 71.13 | 71.32 (100%x)(109%) | 71.27 | 65.21 | ||
| Rough-2 | 41.51 (96%) | 45.87 (14%x)(106%) | 48.43 | 48.56 | 48.73 (100%x)(113%) | 48.61 | 43.09 | ||
| Rough-L | 53.22 (96%) | 57.16 (14%x)(103%) | 59.82 | 59.71 | 59.97 | 60.20 (100%x)(109%) | 55.31 | ||
| METEOR | 58.64 (114%) | 63.06 (14%x)(123%) | 63.55 | 63.77 | 63.84 (100%x)(125%) | 63.79 | 51.23 | ||
| Fact Verification | Accuracy | 50.00 | 51.58 (1%x)(61%) | 66.93 | 64.40 | 64.51 | 68.35 (20%x)(81%) | 84.2 | |
4.1 Overall Performance.
Table2 shows the five instruction-following LLMs’ performance on our benchmark. Compared the full training size performance among five LLMs, we find that: (1) There is not a best model across all the tasks. (2) The performances are pretty similar across different LMs for most tasks except for row population. As those LLMs are either no instruction tuned or instruction tuned on different datasets, we hypothesize that those different datasets help models gain different ability that related to our different tasks, so that in our case, different models are in favor more of different tasks. However, the similar performances indicate those learned ability doesn’t significantly matter for most tasks, since Llama-2 is only pretrained without any instruction tuning, but other LLMs’ performances are not significantly better than Llama-2. (3) With only no more than 1.4% training data, LLMs can achieve more than 60% SOTA performance on most tasks; with 5%-40% training data, LLMs can achieve more than 80% SOTA performance, some can even be better than SOTA.
4.2 Analysis of different tasks.
Column Type Annotation. We investigated different factors that affect LLMs’ performance on large category classification tasks. We investigate how the Pos and Neg ratio, instruction order, and adding other tasks affect the column annotation task. We do experiment on four settings: (1) Pos:Neg = 1:3, first instruction then table input (2) Pos:Neg = 1:10, first table input then instruction (3) Pos:Neg = 1:3, first instruction then table input (4) Pos:Neg = 1:3, unified model, first instruction then table input.
| Precision | Recall | F1 | |
|---|---|---|---|
| (1) | 81.60 | 85.08 | 83.30 |
| (2) | 88.49 | 87.55 | 88.02 |
| (3) | 81.17 | 92.58 | 86.50 |
| (4) | 81.36 | 92.14 | 86.41 |
Comparing (1) with (2), we can see the ratio of the positive class and the negative class matters: both precision and recall improve largely by increasing the negative class training examples. Comparing (1) with (3), we can see the order of the instruction and the table matters: the precision improves largely while precision is maintained. As (liu2023lost) finds that LLMs’ performance is always highest when the relevant information occurs at the beginning or the end of the input context, our observation may be because the candidates are at the end of the instruction and the model will pay more attention to the candidates so as to help models choose more correct candidates easily. Comparing (1) and (4), we can see merging other table tasks matters, which can increase the recall largely for the column type annotation task.
Entity Linking. We observe most of the errors come from the model choosing a very similar entity name while the description is not correct. Since the description is usually highly correlated with the Wikipedia page title, we hypothesize that the model doesn’t get enough attention on the title so choose the wrong entity. This indicates for the instruction design, giving some special hints to explicitly highlight the Wikipedia title may help the model make the correct choice.
Table QA and Fact Verification. In our experiments (Figure4, we found that after unifying
| Train | Hitab | Unified | ||
|---|---|---|---|---|
| Eval | Hitab | Exec Acc | 58.71 | 34.47 |
| FeTaQA | sacreBLEU | 23.47 | 36.62 | |
| Rough-1 | 19.70 | 71.11 | ||
| Rough-1 | 9.23 | 48.43 | ||
| Rough-L | 18.14 | 59.82 | ||
| METEOR | 8.84 | 63.55 | ||
| TabFact | Accuracy | 15.42 | 66.93 | |
different tasks to get one unified model, the performance drops significantly for hierarchical table QA (Hitab) task compared with only instruction tune the single task. As (Gudibande et al., 2023) proposed that instruction tuning mainly improves on tasks that are heavily supported in its training dataset, we hypothesize that the performance drop is due to the very smaller training size for hierarchical table QA task, if compared with other tasks when training a unified model. In addition, we also show the performance on task transfer among Hitab, FeTaQA and TabFact. We can see if the model is only instruction tuned on Hitab, then the model performance for FeTaQA and TabFact will have a large gap compared with the unified model, which also demonstrates the necessity of constructing table-specific data from different tasks and training the generalist models for tables.
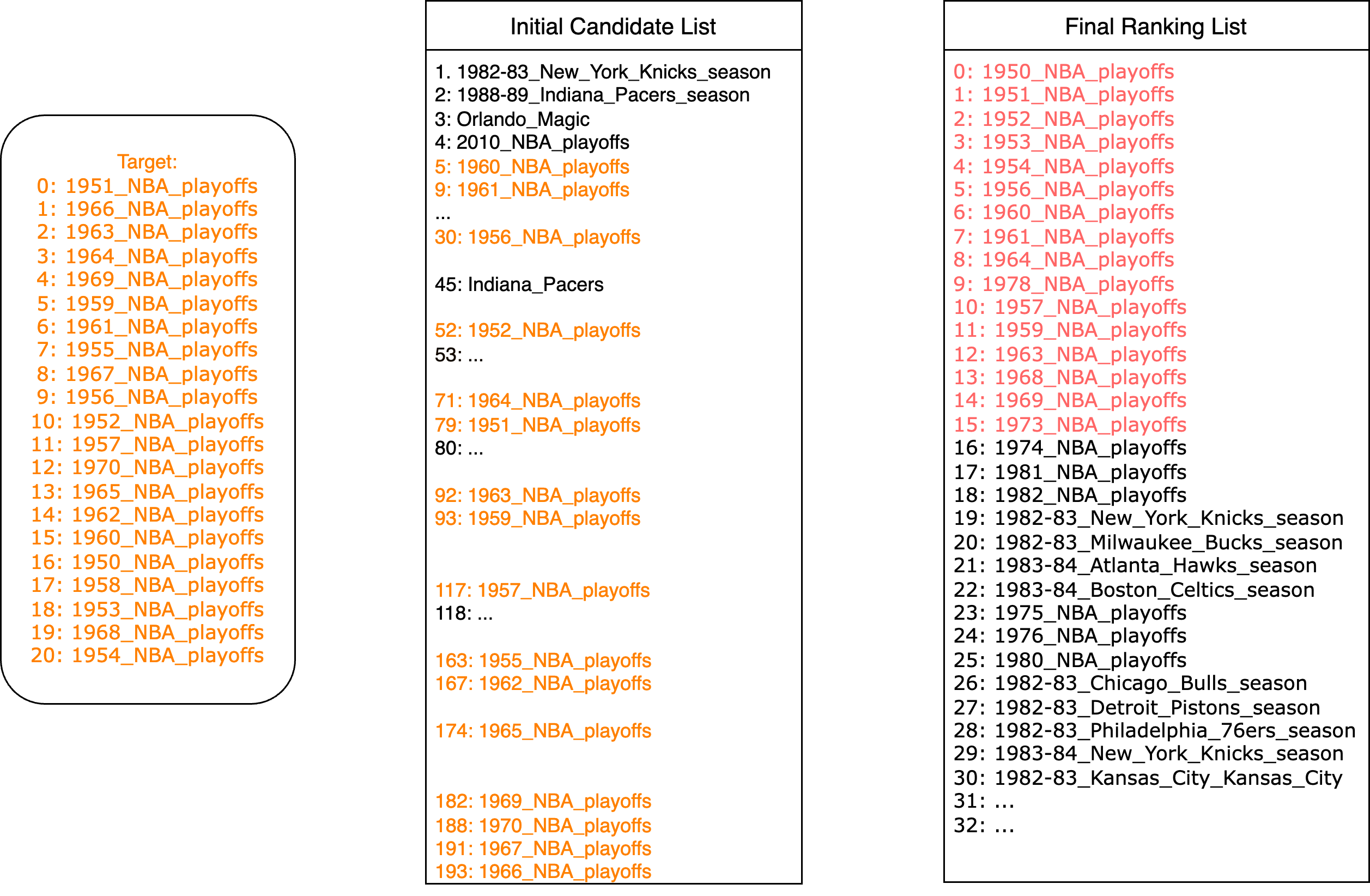
Row Population. Figure3 shows an case study for row population task. The left subfigrue shows the initial candidate list which is waiting to be ranked. The orange candidates are target candidates, but currently they scattered in the different places of the entire candidate list. The entire candidate size is around 200. The right subfigure shows the ranked list after applying our tree-rank algorithm. We can see the target candidates are ranked top in the list, which demonstrates the effectiveness of our designed algorithm.
5 Related Work
Table Representation Learning. Given the vast amount of knowledge stored in tables, various table-based tasks have been proposed pujara2021tables, such as column type annotation (hulsebos2019sherlock), row population (zhang2017entitables), table QA sun2016table; wikitq; cheng-etal-2022-hitab; Nan2021FeTaQAFT, etc. In order to handle the semi-structured tables, existing work puts their efforts into designing special model architectures, [Huan: for the work you are going to mention, if they have a model name, mention it, as it could make people easily recall the work.] such as TURL with structure-aware attention (deng2020turl), TUTA with tree-based attention (wang2021tuta) and TaBERT with vertical self-attention mechanism (yin-etal-2020-tabert); or designing special encodings such as cell text encoding (yin-etal-2020-tabert; eisenschlos2021mate; wang2021tuta), table position encoding (herzig-etal-2020-tapas; wang2021tuta), and numerical encoding (wang2021tuta) to better encode the table structure and infuse more information to the neural architecture. In addition, some work focuses on table pretraining (liu2022tapex; yin-etal-2020-tabert; deng2020turl; iida-etal-2021-tabbie) to encode knowledge in large-scale tables. However, although such existing works have shown promising progress, they are still data-specific and downstream task-specific, which requires special design tailored for tables and table-based tasks.
Our work proposes TableInstruct to unify different table-based tasks and develops a one-for-all LLM TableLlama to reduce those extra efforts during modeling, and evaluate its table understanding and generalization ability under both in-domain and out-of-domain settings. This high-level insight is similar to UnifiedSKG (xie2022unifiedskg), which unifies a diverse set of structured knowledge grounding tasks into a text-to-text format. and enhance T5 model’s performance via multi-task fine-tuning. However, UnifiedSKG deals with different knowledge sources such as databases, knowledge graphs and web tables and does not explore instruction tuning, while we focus on a wide range of realistic tasks based on real-world tables via instruction tuning. In addition, a concurrent work (li2023tablegpt) synthesizes diverse table-related tasks and finetunes close-source LLMs such as GPT-3.5 via instruction tuning. [Huan: rephrase? what do you mean? unify diverse table-based tasks on closed-source LLMs such as ChatGPT,] Compared to theirs, we collect more realistic and complex task data such as HiTab as well as classification and ranking tasks with candidates from Freebase and Wikidata and develop open-source LLMs for table-based tasks. We believe both our constructed high-quality table instruction tuning dataset and the trained model can be valuable resources for facilitating this line of research.
Instruction Tuning. Instruction tuning that trains LLMs using instruction, output pairs in a supervised fashion is a crucial technique to enhance the capabilities and controllability of LLMs (chung2022scaling; wang-etal-2022-super; mishra-etal-2022-cross). The instructions serve to constrain the model’s outputs to align with the desired response characteristics or domain knowledge and can help LLMs rapidly adapt to a specific domain without extensive retraining or architecture designs (zhang2023instruction). Therefore, different instruction tuning datasets have been proposed to guide LLMs’ behaviors (wang-etal-2022-super; honovich2022unnatural; longpre2023flan; xu2023wizardlm; yue2024mammoth). Those datasets are collected either from formatting existing natural language processing tasks by templates (longpre2023flan) or prompting ChatGPT (xu2023wizardlm) and GPT-4 (gpt4llm) to generate instructions. Different instruction tuning models such as InstructGPT (instructgpt), Vicuna (vicuna) and Claude222https://www.anthropic.com/index/introducing-claude[Huan: can you use another way to cite Claude? it’s weird to have the first footnote towards the end of the paper. If you cannot find a paper, just create a bibtex for this url.] emerge and demonstrate boosted performance compared with the pre-trained models. In addition, instruction tuning has been applied to different modalities such as images, videos and audio (li2023blip2) and has shown promising results. This signals that instruction tuning can be a promising technique to enable large pre-trained models to handle various tasks. However, how to utilize instruction tuning to guide LLMs to complete tables-based tasks is still under-explored. Our work fills this gap by constructing a high-quality table instruction tuning dataset: TableInstruct, which covers large-scale diverse and realistic tables and tasks to enable both modeling and evaluation. We also release TableLlama, an open-source LLM-based generalist model fine-tuned on TableInstruct to promote this avenue of research.
6 Conclusion
This paper makes the first step towards developing open-source large generalist models for a diversity of table-based tasks. Towards that end, we construct TableInstruct and develop the first open-source generalist model for tables, TableLlama., a comprehensive dataset for instructing tuning and evaluating LLMs for tables and develop the first open-source generalist model for tables, TableLlama, by fine-tuning Llama 2 (7B) with LongLoRA to address the context length challenge. We evaluate both in-domain and out-of-domain settings and the experiments show that TableLlama has gained strong table understanding ability and generalization ability. On 7 out of 8 in-domain tasks, our generalist model TableLlama achieves comparable or better performance than the existing SOTA method for each task, despite the latter often has table-specific model design or pre-training. On 6 out-of-domain datasets, it achieves 6-48 absolute point gains compared with the base model, showing that training on our TableInstruct enhances generalizability.