A Survey of Graph Meets Large Language Model: Progress and Future Directions
Abstract
Graph plays a significant role in representing and analyzing complex relationships in real-world applications such as citation networks, social networks, and biological data. Recently, Large Language Models (LLMs), which have achieved tremendous success in various domains, have also been leveraged in graph-related tasks to surpass traditional Graph Neural Networks (GNNs) based methods and yield state-of-the-art performance. In this survey, we first present a comprehensive review and analysis of existing methods that integrate LLMs with graphs. First of all, we propose a new taxonomy, which organizes existing methods into three categories based on the role (i.e., enhancer, predictor, and alignment component) played by LLMs in graph-related tasks. Then we systematically survey the representative methods along the three categories of the taxonomy. Finally, we discuss the remaining limitations of existing studies and highlight promising avenues for future research. The relevant papers are summarized and will be consistently updated at: https://github.com/yhLeeee/Awesome-LLMs-in-Graph-tasks.
1 Introduction
Graph, or graph theory, serves as a fundamental part of numerous areas in the modern world, particularly in technology, science, and logistics (Ji et al., 2021). Graph data represents the structural characteristics between nodes, thus illuminating relationships within the graph’s components. Many real-world datasets, such as citation networks (Sen et al., 2008), social networks (Hamilton et al., 2017), and molecular (Wu et al., 2018), are intrinsically represented as graphs. To tackle graph-related tasks, Graph Neural Networks (GNNs) (Kipf and Welling, 2016; Velickovic et al., 2018) have emerged as one of the most popular choices for processing and analyzing graph data. The main objective of GNNs is to acquire expressive representations at the node, edge, or graph level for different kinds of downstream tasks through recursive message passing and aggregation mechanisms among nodes.
In recent years, significant advancements have been made in Large Language Models (LLMs) like Transformers (Vaswani et al., 2017), BERT (Kenton and Toutanova, 2019), GPT (Brown et al., 2020), and their variants. These LLMs can be easily applied to various downstream tasks with little adaptation, demonstrating remarkable performance across various natural language processing tasks, such as sentiment analysis, machine translation, and text classification (Zhao et al., 2023d). While their primary focus has been on text sequences, there is a growing interest in enhancing the multi-modal capabilities of LLMs to enable them to handle diverse data types, including graphs (Chai et al., 2023), images (Zhang et al., 2023b), and videos (Zhang et al., 2023a).
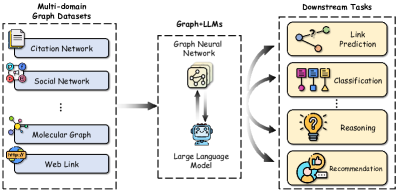
LLMs help graph-related tasks. With the help of LLMs, there has been a notable shift in the way we interact with graphs, particularly those containing nodes associated with text attributes. As shown in Figure 1, the integration of graphs and LLMs demonstrates success in various downstream tasks across a myriad of graph domains. Integrating LLMs with traditional GNNs can be mutually beneficial and enhance graph learning. While GNNs are proficient at capturing structural information, they primarily rely on semantically constrained embeddings as node features, limiting their ability to express the full complexities of the nodes. Incorporating LLMs, GNNs can be enhanced with stronger node features that effectively capture both structural and contextual aspects. On the other hand, LLMs excel at encoding text but often struggle to capture structural information present in graph data. Combining GNNs with LLMs can leverage the robust textual understanding of LLMs while harnessing GNNs’ ability to capture structural relationships, leading to more comprehensive and powerful graph learning. For example, TAPE (He et al., 2023) leverages semantic knowledge that is relevant to the nodes (i.e., papers) generated by LLMs to improve the quality of initial node embeddings in GNNs. In addition, InstructGLM (Ye et al., 2023) replaces the predictor from GNNs with LLMs, leveraging the expressive power of natural language through techniques such as flattening graphs and designing instruction prompts. MoleculeSTM (Liu et al., 2022) aligns GNNs and LLMs into the same vector space to introduce textual knowledge into graphs (i.e., molecules), thereby improving reasoning abilities.
0-1=
Graph Meets Large Language Model
It is evident that LLMs have a significant influence on graph-related tasks from different perspectives. To achieve a better systematic overview, as shown in Figure 2, we follow Chen et al. (2023a) to organize our first-level taxonomy, categorizing based on the role (i.e., enhancer, predictor, and alignment component) played by LLMs throughout the entire model pipeline. We further refine our taxonomy and introduce more granularity to the initial categories.
Motivations. Although LLMs have been increasingly applied in graph-related tasks, this rapidly expanding field still lacks a systematic review. Zhang et al. (2023d) conducts a forward-looking survey, presenting a perspective paper that discusses the challenges and opportunities associated with the integration of graphs and LLMs. Liu et al. (2023b) provide another related survey that summarizes existing graph foundation models and offers an overview of pre-training and adaptation strategies. However, both of them have limitations in terms of comprehensive coverage and the absence of a taxonomy specifically focused on how LLMs enhance graphs. In contrast, we concentrate on scenarios where both graph and text modalities coexist and propose a more fine-grained taxonomy to systematically review and summarize the current status of LLMs techniques for graph-related tasks.
Contributions. The contributions of this work can be summarized from the following three aspects. (1) A structured taxonomy. A broad overview of the field is presented with a structured taxonomy that categorizes existing works into four categories (Figure 2). (2) A comprehensive review. Based on the proposed taxonomy, the current research progress of LLMs for graph-related tasks is systematically delineated. (3) Some future directions. We discuss the remaining limitations of existing works and point out possible future directions.
2 Preliminary
In this section, we first introduce the basic concepts of two key areas related to this survey, i.e., GNNs and LLMs. Next, we give a brief introduction to the newly proposed taxonomy.
2.1 Graph Neural Networks
Definitions. Most existing GNNs follow the message-passing paradigm which contains message aggregation and feature update, such as GCN (Kipf and Welling, 2016) and GAT (Velickovic et al., 2018). They generate node representations by iteratively aggregating information of neighbors and updating them with non-linear functions. The forward process can be defined as:
where is the feature vector of node in the -th layer, and is a set of neighbor nodes of node . denotes the message passing function of aggregating neighbor information, denotes the update function with central node feature and neighbor node features as input. By stacking multiple layers, GNNs can aggregate messages from higher-order neighbors.
Graph pre-training and prompting. While GNNs have achieved some success in graph machine learning, they require expensive annotations and barely generalize to unseen data. To remedy these deficiencies, graph pre-training aims to extract some general knowledge for the graph models to easily deal with different tasks without significant annotation cost. The current mainstream graph pertaining methods can be divided into contrastive and generative approaches. For instance, GraphCL (You et al., 2020) and GCA (Zhu et al., 2021) follow a contrastive learning framework and maximize the agreement between two augmented views. Sun et al. (2023b) extend the contrastive idea to hypergraphs. GraphMAE (Hou et al., 2022), S2GAE (Tan et al., 2023a), and WGDN (Cheng et al., 2023) mask the component of the graph and attempt to reconstruct the original data. The typical learning scheme of “pre-training and fine-tuning” is based on the assumption that the pre-training task and downstream tasks share some common intrinsic task space. Instead, in the NLP area, researchers gradually focus on a new paradigm of “pre-training, prompting, and fine-tuning”, which aims to reformulate input data to fit the pretext. This idea has also been naturally applied to the graph learning area. GPPT (Sun et al., 2022) first pre-trains graph model by masked edge prediction, then modify the standalone node into a token pair and reformulate the downstream classification as edge prediction task. Additionally, All in One (Sun et al., 2023a) proposes a multi-task prompting framework, which unifies the format of graph prompts and language prompts.
2.2 Large Language Models
Definitions. While there is currently no clear definition for LLMs (Shayegani et al., 2023), here we provide a specific definition for LLMs mentioned in this survey. Two influential surveys on LLMs (Zhao et al., 2023d; Yang et al., 2023) distinguish between LLMs and pre-trained language models (PLMs) from the perspectives of model size and training approach. To be specific, LLMs are those huge language models (i.e., billion-level) that undergo pre-training on a significant amount of data, whereas PLMs refer to those early pre-trained models with moderate parameter sizes (i.e., million-level), which can be easily further fine-tuned on task-specific data to achieve better results to downstream tasks. Due to the relatively smaller parameter size of GNNs, incorporating GNNs and LLMs often does not require LLMs with large parameters. Hence, we follow Liu et al. (2023b) to extend the definition of LLMs in this survey to encompass both LLMs and PLMs as defined in previous surveys.
Evolution. LLMs can be divided into two categories based on non-autoregressive and autoregressive language modeling. Non-autoregressive LLMs typically concentrate on natural language understanding and employ a “masked language modeling” pre-training task, while autoregressive LLMs focus more on natural language generation, frequently leveraging the “next token prediction” objective as their foundational task. Classic encoder-only models such as BERT (Kenton and Toutanova, 2019), SciBERT (Beltagy et al., 2019), and RoBERTa (Liu et al., 2019) fall under the category of non-autoregressive LLMs. Recently, autoregressive LLMs have witnessed continuous development. Examples include Flan-T5 (Chung et al., 2022) and ChatGLM (Zeng et al., 2022), which are built upon the encoder-decoder structure, as well as GPT-3 (Brown et al., 2020), PaLM (Chowdhery et al., 2022), Galactica (Taylor et al., 2022), and LLaMA (Touvron et al., 2023), which are based on decoder-only architectures. Significantly, advancements in architectures and training methodologies of LLMs have given rise to emergent capabilities (Wei et al., 2022a), which is the ability to handle complex tasks in few-shot or zero-shot scenarios via some techniques such as in-context learning (Radford et al., 2021; Dong et al., 2022) and chain-of-thought (Wei et al., 2022b).
2.3 Proposed Taxonomy
We propose a taxonomy (as illustrated in Figure 2) that organizes representative techniques involving both graph and text modalities into three main categories: (1) LLM as Enhancer, where LLMs are used to enhance the classification performance of GNNs. (2) LLM as Predictor, where LLMs utilize the input graph structure information to make predictions. (3) GNN-LLM Alignment, where LLMs semantically enhance GNNs through alignment techniques. We note that in some models, due to the rarity of LLMs’ involvement, it becomes difficult to categorize them into these three main classes. Therefore, we separately organize them into the “Others” category and provide their specific roles in Figure 2. For example, LLM-GNN (Chen et al., 2023b) actively selects nodes for ChatGPT to annotate, thereby augmenting the GNN training by utilizing the LLM as an annotator. GPT4GNAS (Wang et al., 2023a) considers the LLM as an experienced controller in the task of graph neural architecture search. It utilizes GPT-4 (OpenAI, 2023) to explore the search space and generate novel GNN architectures. Furthermore, ENG (Yu et al., 2023) empowers the LLM as a sample generator to generate additional training samples with labels to provide sufficient supervision signals for GNNs.
In the following sections, we present a comprehensive survey along the three main categories of our taxonomy for incorporating LLMs into graph-related tasks, respectively.
3 LLM as Enhancer
GNNs have become powerful tools to analyze graph-structure data. However, the most mainstream benchmark datasets (e.g., Cora (Yang et al., 2016) and Ogbn-Arxiv (Hu et al., 2020)) adopt naive methods to encode text information in TAGs using shallow embeddings, such as bag-of-words, skip-gram (Mikolov et al., 2013), or TF-IDF (Salton and Buckley, 1988). This inevitably constrains the performance of GNNs on TAGs. LLM-as-enhancer approaches correspond to enhancing the quality of node embeddings with the help of powerful LLMs. The derived embeddings are attached to the graph structure to be utilized by any GNNs or directly inputted into downstream classifiers for various tasks. We naturally categorize these approaches into two branches: explanation-based and embedding-based, depending on whether they use LLMs to produce additional textual information.
3.1 Explanation-based Enhancement
To enrich the textual attributes, explanation-based enhancement approaches focus on utilizing the strong zero-shot capability of LLMs to capture higher-level information. As shown in Figure 3(a), generally they prompt LLMs to generate semantically enriched additional information, such as explanations, knowledge entities, and pseudo labels. The typical pipeline is as follows:
where is the original text attributes, is the designed textual prompts, is the additional textual output of LLMs, and denotes the enhanced initial node embedding of node with the dimension and embedding matrix, along with adjacency matrix to obtain node representations by GNNs, where is the dimension of representations. For instance, TAPE (He et al., 2023) is a pioneer work of explanation-based enhancement, which prompts LLMs to generate explanations and pseudo labels to augment textual attributes. After that, relatively small language models are fine-tuned on both original text data and explanations to encode text semantic information as initial node embeddings. Chen et al. (2023a) explore the potential competence of LLMs in graph learning. They first compare embedding-visible LLMs with shallow embedding methods and then propose KEA to enrich the text attributes. KEA prompts LLMs to generate a list of knowledge entities along with text descriptions and encodes them by fine-tuned PLMs and deep sentence embedding models. LLM4Mol (Qian et al., 2023) attempts to employ LLMs to assist in molecular property prediction. Specifically, it uses LLMs to generate semantically enriched explanations for the original SMILES and then fine-tunes a small-scale language model to conduct downstream tasks. LLMRec (Wei et al., 2023) aims to utilize LLMs to figure out data sparsity and data quality issues in the graph recommendation system. It reinforces user-item interaction edges and generates user/item side information by LLMs. Lastly, it employs a lightweight GNN (He et al., 2020) to encode the augmented recommendation network.
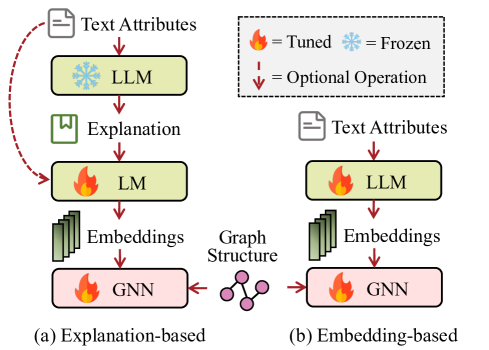
3.2 Embedding-based Enhancement
Refer to Figure 3(b), embedding-based enhancement approaches directly utilize LLMs to output text embeddings as initial node embeddings for GNN training:
This kind of approach requires the use of embedding-visible or open-source LLMs because it needs to access text embeddings straightaway and fine-tune LLMs with structural information. Many of the current advanced LLMs (e.g., GPT4 (OpenAI, 2023) and PaLM (Chowdhery et al., 2022)) are closed-source and only provide online services. Strict restrictions prevent researchers from accessing their parameters and output embeddings. This kind of approach mostly adopts a cascading form and utilizes structure information to assist the language model in pre-training or fine-tuning. Typically, GALM (Xie et al., 2023) pre-trains PLMs and GNN aggregator on a given large graph corpus to capture the information that can maximize utility towards massive applications and then fine-tunes the framework on a specific downstream application to further improve the performance.
Several works aim to generate node embeddings by incorporating structural information into the fine-tuning phase of LLMs. Representatively, GIANT (Chien et al., 2021) fine-tunes the language model by a novel self-supervised learning framework, which employs XR-Transformers to solve extreme multi-label classification over link prediction. SimTeG (Duan et al., 2023) and TouchUp-G (Zhu et al., 2023) follow a similar way, they both fine-tune PLMs through link-prediction-like methods to help them perceive structural information. The subtle difference between them is that TouchUp-G uses negative sampling during link prediction, while SimTeG employs parameter-efficient fine-tuning to accelerate the fine-tuning process. G-Prompt (Huang et al., 2023b) introduces a graph adapter at the end of PLMs to help extract graph-aware node features. Once trained, task-specific prompts are incorporated to produce interpretable node representations for various downstream tasks. WalkLM (Tan et al., 2023b) is an unsupervised generic graph representation learning method. The first step of it is to generate attributed random walks on the graph and compose roughly meaningful textual sequences by automated textualization program. The second step is to fine-tune an LLM using textual sequences and extract representations from LLM. METERN (Jin et al., 2023b) introduces relation prior tokens to capture the relation-specific signals and uses one language encoder to model the shared knowledge across relations. LEADING (Xue et al., 2023) effectively finetunes LLMs and transfers risk knowledge in LLM to downstream GNN model with less computation cost and memory overhead.
A recent work, OFA (Liu et al., 2023a), attempts to propose a general graph learning framework, which can utilize a single graph model to conduct adaptive downstream prediction. It describes all nodes and edges using human-readable texts and encodes them from different domains into the same space by LLMs. Subsequently, the framework is adaptive to perform different tasks by inserting task-specific prompting substructures into the input graph.
3.3 Discussions
LLM-as-enhancer approaches have demonstrated superior performance on TAG, being able to effectively capture both textual and structural information. Moreover, they also exhibit strong flexibility, as GNNs and LLMs are plug-and-play, allowing them to leverage the latest techniques to address the encountered issues. Another advantage of such methods (specifically explanation-based enhancement) is that they pave the way for using closed-source LLMs to assist graph-related tasks. However, despite some papers claiming strong scalability, in fact, LLM-as-enhancer approaches entail significant overhead when dealing with large-scale datasets. Taking explanation-based approaches as an example, they need to query LLMs’ APIs for times for a graph with nodes, which is indeed a substantial cost.
4 LLM as Predictor
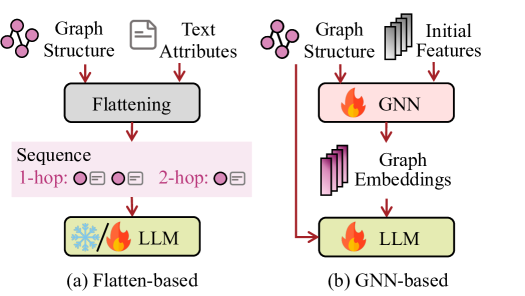
The core idea behind this category is to utilize LLMs to make predictions for a wide range of graph-related tasks, such as classifications and reasonings, within a unified generative paradigm. However, applying LLMs to graph modalities presents unique challenges, primarily because graph data often lacks straightforward transformation into sequential text, as different graphs define structures and features in different ways. In this section, we classify the models broadly into flatten-based and GNN-based predictions, depending on whether they employ GNNs to extract structural features for LLMs.
4.1 Flatten-based Prediction
The majority of the existing attempts that utilize LLMs as predictors employ the strategy of flattening the graph into textual descriptions, which facilitates direct processing of graph data by LLMs through text sequences. As shown in Figure 4(a), flatten-based prediction typically involves two steps: (1) utilizing a flatten function to transform a graph structure into a sequence of nodes or tokens , and (2) a parsing function is then applied to retrieve the predicted label from the output generated by LLMs, as illustrated below:
where , , , and denotes the set of nodes, edges, node text attributes, and edge text attributes, respectively. indicates the instruction prompt for the current graph task and is the predicted label.
The parsing strategies of models are generally standardized. For example, given that the output of LLMs often involves their reasoning and logic processes, particularly in the chain-of-thought (CoT) scenario, several works (Fatemi et al., 2023; Zhao et al., 2023c; Chen et al., 2023a; Guo et al., 2023; Liu and Wu, 2023; Wang et al., 2023b) utilize regular expressions to extract the predicted label from the output. Some models (Chen et al., 2023a; Fatemi et al., 2023; Wang et al., 2023b; Chai et al., 2023; Huang et al., 2023a) further set the decoding temperature of the LLM to , in order to reduce the variance of LLM’s predictions and obtain more reliable results. Another direction is to formulate graph tasks as multi-choice QA problems (Robinson and Wingate, 2022) where LLMs are instructed to select the correct answer among provided choices. For instance, some works (Huang et al., 2023a; Hu et al., 2023; Shi et al., 2023) constrain LLM’s output format via giving choices and appending instructions in prompts in zero-shot setting, such as “Do not give any reasoning or logic for your answer”. In addition, some methods, such as GIMLET (Zhao et al., 2023a) and InstructGLM (Ye et al., 2023), fine-tune LLMs to directly output predicted labels, empowering them to provide accurate predictions without the need for additional parsing steps.
Compared to parsing strategies, flattening strategies can exhibit significant variation. In the following, we organize the methods for flattening based on whether the parameters of LLMs are updated.
4.1.1 LLM Frozen
GPT4Graph (Guo et al., 2023) utilizes graph description languages such as GML (Himsolt, 1997) and GraphML (Brandes et al., 2013) to represent graphs. These languages provide standardized syntax and semantics for representing the nodes and edges within a graph. Inspired by linguistic syntax trees (Chiswell and Hodges, 2007), GraphText (Zhao et al., 2023c) leverages graph-syntax trees to convert a graph structure to a sequence of nodes, which is then fed to LLMs for training-free graph reasoning. Furthermore, ReLM (Shi et al., 2023) uses simplified molecular input line entry system (SMILES) strings to provide one-dimensional linearizations of molecular graph structures. Graph data can be also represented through methods like adjacency matrices and adjacency lists. Several methods (Wang et al., 2023b; Fatemi et al., 2023; Liu and Wu, 2023; Zhang et al., 2023c) directly employ numerically organized node and edge lists to depict the graph data in plain text. GraphTMI (Das et al., 2023) further explores different modalities such as motif and image to integrate graph data with LLMs.
Instead, the use of natural narration to express graph structures is also making steady progress. Chen et al. (2023a) and Hu et al. (2023) both integrate the structural information of citation networks into the prompts, which is achieved by explicitly representing the edge relationship through the word “cite” and representing the nodes using paper indexes or titles. Huang et al. (2023a), on the other hand, does not use the word “cite” to represent edges but instead describes the relationships via enumerating randomly selected -hop neighbors of the current node. In addition, GPT4Graph (Guo et al., 2023) and Chen et al. (2023a) imitate the aggregation behavior of GNNs and summarize the current neighbor’s attributes as additional inputs, aiming to provide more structural information. It is worth noting that Fatemi et al. (2023) investigates various methodologies to represent nodes and edges, examining a total of 11 strategies. For example, they use indexes or alphabet letters to denote nodes and apply arrows or parentheses to signify edges.
4.1.2 LLM Tuning
GIMLET (Zhao et al., 2023a) adopts distance-based position embedding to extend the capability of LLMs to perceive graph structures. When performing positional encoding of the graph, GIMLET defines the relative position of two nodes as the shortest distance between them in the graph, which has been widely utilized in the literature of graph transformers (Ying et al., 2021). Similar to Huang et al. (2023a), InstructGLM (Ye et al., 2023) designs a series of scalable prompts based on the maximum hop level. These prompts allow a central paper node to establish direct associations with its neighbors up to any desired hop level by utilizing the described connectivity relationships expressed in natural language.
4.2 GNN-based Prediction
GNNs have demonstrated impressive capabilities in understanding graph structures through recursive information exchange and aggregation among nodes. As illustrated in Figure 4(b), in contrast to flatten-based prediction, which converts graph data into textual descriptions as inputs to LLMs, GNN-based prediction leverages the advantages of GNNs to incorporate inherent structural characteristics and dependencies present in graph data with LLMs, allowing LLMs to be structure-aware as follows:
where denotes the node embedding matrix, is the adjacency matrix, and denotes the structure-aware embeddings associated with the graph. GNN-based prediction also relies on a parser to extract the output from LLMs. However, integrating GNN representations into LLMs often requires tuning, making it easier to standardize the prediction format of LLMs by providing desirable outputs during training.
Various strategies have been proposed to fuse the structural patterns learned by GNNs and the contextual information captured by LLMs. For instance, GIT-Mol (Liu et al., 2023c) and MolCA (Liu et al., 2023d) both implement BLIP-2’s Q-Former (Li et al., 2023a) as the cross-modal projector to map the graph encoder’s output to the LLM’s input text space. Multiple objectives with different attention masking strategies are employed for effective graph-text interactions. GraphLLM (Chai et al., 2023) derives the graph-enhanced prefix by applying a linear projection to the graph representation during prefix tuning, allowing the LLM to synergize with the graph transformer to incorporate structural information crucial to graph reasoning. Additionally, both GraphGPT (Tang et al., 2023) and InstructMol (Cao et al., 2023) employ a simple linear layer as the lightweight alignment projector to map the encoded graph representation to some graph tokens, while the LLM excels at aligning these tokens with diverse text information. DGTL (Qin et al., 2023) injects the disentangled graph embeddings directly into each layer of the LLM, highlighting different aspects of the graph’s topology and semantics.
4.3 Discussions
Utilizing LLMs directly as predictors shows superiority in processing textual attributes of graphs, especially achieving remarkable zero-shot performance compared with traditional GNNs. The ultimate goal is to develop and refine methods for encoding graph-structured information into a format that LLMs can comprehend and manipulate effectively and efficiently. Flatten-based prediction may have an advantage in terms of effectiveness, while GNN-based prediction tends to be more efficient. In flatten-based prediction, the input length limitation of LLMs restricts each node’s access to only its neighbors within a few hops, making it challenging to capture long-range dependencies. Additionally, without the involvement of GNNs, inherent issues of GNNs such as heterophily cannot be addressed. On the other hand, for GNN-based prediction, training an additional GNN module and inserting it into LLMs for joint training is challenging due to the problem of vanishing gradients in the early layers of deep transformers (Zhao et al., 2023a; Qin et al., 2023).
5 GNN-LLM Alignment
Aligning the embedding spaces of GNNs and LLMs is an effective way to integrate the graph modality with the text modality. GNN-LLM alignment ensures that each encoder’s unique functionalities are preserved while coordinating their embedding spaces at a specific stage. In this section, we summarize the techniques for aligning GNNs and LLMs, which can be classified as symmetric or asymmetric, depending on whether equal emphasis is placed on both GNNs and LLMs or if one modality is prioritized over the other.
5.1 Symmetric
Symmetric alignment refers to the equal treatment of the graph and text modalities during the alignment process. These approaches ensure that the encoders of both modalities achieve comparable performance in their respective applications.
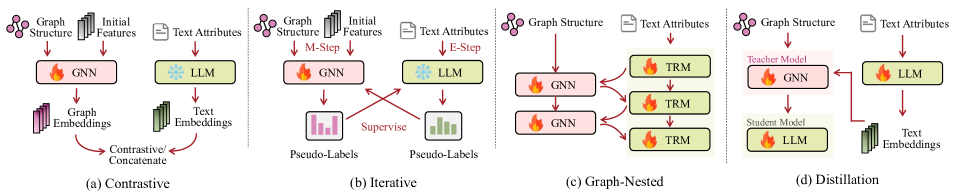
A typical symmetric alignment architecture, illustrated in Figure 5(a), adopts a two-tower style, employing separate encoders to individually encode the graph and text. Notice that during the alignment process, both modalities interact only once. Some methods, like SAFER (Chandra et al., 2020), utilize simple concatenation on these separate embeddings. However, this approach falls short in achieving a seamless fusion of structural and textual information, resulting in a loosely coupled integration of the two modalities. Consequently, the majority of two-tower style models utilize contrastive learning techniques to facilitate alignment, akin to CLIP (Radford et al., 2021) for aligning visual and language modalities. In general, the methods encompass two steps. The first step is feature extraction, where graph representations and text representations are obtained. The second step involves the use of a contrastive learning process with a modified InfoNCE loss (Oord et al., 2018) depicted with the following equation:
where represents the representation of a specific graph, while denotes the representation of the corresponding text of the graph. denotes the score function that assigns high values to the positive pair, and low values to negative pairs. is a temperature parameter and denotes the number of graphs in the training dataset. Parameters of both encoders are updated via backpropagation based on the contrastive loss.
| Model | GNN | LLM | Predictor | Fine-tuning | Prompting | Domain | Task | Code | |
| LLM as Enhancer | GIANT (Chien et al., 2021) | SAGE, RevGAT, etc. | BERT | GNN | ✗ | ✗ | Citation, Co-purchase | Node | Link |
| GALM (Xie et al., 2023) | RGCN, RGAT | BERT | GNN | ✓ | ✗ | E-Commerce, Recommendation | Node, Link | - | |
| TAPE (He et al., 2023) | RevGAT | ChatGPT | GNN | ✗ | ✓ | Citation | Node | Link | |
| Chen et al. (Chen et al., 2023a) | GCN, GAT | ChatGPT | GNN | ✗ | ✓ | Citation, Co-purchase | Node | - | |
| LLM4Mol (Qian et al., 2023) | - | ChatGPT | LM | ✗ | ✗ | Molecular | Graph | Link | |
| SimTeG (Duan et al., 2023) | SAGE, RevGAT, SEAL | allMiniLM-L6-v2, etc. | GNN | ✓♡ | ✗ | Citation, Co-purchase | Node, Link | Link | |
| G-Prompt (Huang et al., 2023b) | SAGE, RevGAT | RoBERTa-Large | GNN | ✓ | ✓ | Citation, Social | Node | - | |
| TouchUp-G (Zhu et al., 2023) | SAGE, MB-GCN, etc. | BERT | GNN | ✓ | ✗ | Citation, Co-purchase, Recommendation | Node, Link | - | |
| OFA (Liu et al., 2023a) | R-GCN | Sentence-BERT | GNN | ✗ | ✓ | Citation, Web link, Knowledge, Molecular | Node, Link, Graph | Link | |
| LLMRec (Wei et al., 2023) | LightGCN | ChatGPT | GNN | ✗ | ✓ | Recommendation | Recommendation | Link | |
| WalkLM (Tan et al., 2023b) | - | DistilRoBERTa | MLP | ✓ | ✗ | Knowledge | Node, Link | Link | |
| METERN (Jin et al., 2023b) | - | BERT | LM | ✓ | ✗ | Citation, E-Commerce | Node | - | |
| LEADING (Xue et al., 2023) | GCN, GAT | BERT | GNN | ✓ | ✗ | Citation | Node | - | |
| LLM as Predictor | NLGraph (Wang et al., 2023b) | - | Text-davinci-003 | LLM | ✗ | ✓ | - | Reasoning | Link |
| GPT4Graph (Guo et al., 2023) | - | Text-davinci-003 | LLM | ✗ | ✓ | - | Reasoning, Node, Graph | Link | |
| GIMLET (Zhao et al., 2023a) | - | T5 | LLM | ✓/✗ | ✓ | Molecular | Graph | Link | |
| Chen et al. (Chen et al., 2023a) | - | ChatGPT | LLM | ✗ | ✓ | Citation | Node | Link | |
| GIT-Mol (Liu et al., 2023c) | GIN | MolT5 | LLM | ✓♡ | ✓ | Molecular | Graph, Captioning | - | |
| InstructGLM (Ye et al., 2023) | - | FLAN-T5/LLaMA-v1 | LLM | ✓♡ | ✓ | Citation | Node | Link | |
| Liu et al. (Liu and Wu, 2023) | - | GPT-4, etc. | LLM | ✗ | ✓ | - | Reasoning | Link | |
| Huang et al. (Huang et al., 2023a) | - | ChatGPT | LLM | ✗ | ✓ | Citation, Co-purchase | Node | Link | |
| GraphText (Zhao et al., 2023c) | - | ChatGPT/GPT-4 | LLM | ✗ | ✓ | Citation, Web link | Node | - | |
| Fatemi et al. (Fatemi et al., 2023) | - | PaLM/PaLM 2 | LLM | ✗ | ✓ | - | Reasoning | - | |
| GraphLLM (Chai et al., 2023) | Graph Transformer | LLaMA-v2 | LLM | ✓♡ | ✓ | - | Reasoning | Link | |
| Hu et al. (Hu et al., 2023) | - | ChatGPT/GPT-4 | LLM | ✗ | ✓ | Citation, Knowledge, Social | Node, Link, Graph | - | |
| MolCA (Liu et al., 2023d) | GINE | Galactica/MolT5 | LLM | ✓♡ | ✓ | Molecular | Graph, Retrieval, Captioning | Link | |
| GraphGPT (Tang et al., 2023) | Graph Transformer | Vicuna | LLM | ✓♡ | ✓ | Citation | Node | Link | |
| ReLM (Shi et al., 2023) | TAG, GCN | Vicuna/ChatGPT | LLM | ✗ | ✓ | Molecular | Reaction Prediction | Link | |
| LLM4DyG (Zhang et al., 2023c) | - | Vicuna/LLaMA-v2/ChatGPT | LLM | ✗ | ✓ | - | Reasoning | - | |
| DGTL (Qin et al., 2023) | Disentangled GNN | LLaMA-v2 | LLM | ✓ | ✓ | Citation, E-Commerce | Node | - | |
| GraphTMI (Das et al., 2023) | - | GPT-4/GPT-4V | LLM | ✗ | ✓ | Citation | Node | - | |
| InstructMol (Cao et al., 2023) | GIN | Vicuna | LLM | ✓♡ | ✓ | Molecular | Graph, Captioning | Link | |
| GNN-LLM Alignment | SAFER(Chandra et al., 2020) | GCN, GAT, etc. | RoBERTa | Linear | ✓ | ✗ | News | Node | Link |
| GraphFormers (Yang et al., 2021) | Graph Transformer | UniLM | LLM | ✓ | ✗ | Citation, E-Commerce, Knowledge | Link | Link | |
| Text2Mol(Edwards et al., 2021) | GCN | SciBERT | GNN/LLM | ✓ | ✗ | Molecular | Retrieval | Link | |
| MoMu (Su et al., 2022) | GIN | BERT | GNN/LLM | ✓ | ✗ | Molecular | Graph, Retrieval | Link | |
| MoleculeSTM (Liu et al., 2022) | GIN | BERT | GNN/LLM | ✓ | ✗ | Molecular | Graph, Retrieval | Link | |
| GLEM (Zhao et al., 2022) | SAGE, RevGAT, etc. | DeBERTa | GNN/LLM | ✓ | ✗ | Citation, Co-purchase | Node | Link | |
| GRAD (Mavromatis et al., 2023) | SAGE | SciBERT/DistilBERT | LLM | ✓ | ✗ | Citation, Co-purchase | Node | Link | |
| G2P2 (Wen and Fang, 2023) | GCN | Transformer | GNN/LLM | ✓ | ✓ | Citation, Recommendation | Node | Link | |
| Patton (Jin et al., 2023a) | Graph Transformer | BERT/SciBERT | Linear/LLM | ✓ | ✗ | Citation, E-Commerce | Node, Link, Retrieval, Reranking | Link | |
| ConGraT (Brannon et al., 2023) | GAT | all-mpnet-base-v2/DistilGPT2 | GNN/LLM | ✓ | ✗ | Citation, Knowledge, Social | Node, Link | Link | |
| THLM (Zou et al., 2023) | R-HGNN | BERT | LLM | ✓ | ✗ | Academic, Recommendation, Patent | Node, Link | Link | |
| GRENADE (Li et al., 2023b) | SAGE, RevGAT-KD, etc. | BERT | GNN/MLP | ✓ | ✗ | Citation, Co-purchase | Node, Link | Link | |
| RLMRec (Ren et al., 2023) | GCCF, LightGCN, etc. | ChatGPT, text-embedding-ada-002 | GNN/LLM | ✓ | ✗ | Recommendation | Node | Link | |
| Others | LLM-GNN (Chen et al., 2023b) | GCN, SAGE | ChatGPT | GNN | ✗ | ✓ | Citation, Co-purchase | Node | Link |
| GPT4GNAS (Wang et al., 2023a) | GCN, GIN, etc. | GPT-4 | GNN | ✗ | ✓ | Citation | Node | - | |
| ENG (Yu et al., 2023) | GCN, GAT | ChatGPT | GNN | ✗ | ✓ | Citation | Node | - |
Text2Mol (Edwards et al., 2021) proposes a cross-modal attention mechanism to achieve early fusion of graph and textual embeddings. Implemented through a transformer decoder, Text2Mol uses the LLM’s output as a source sequence and the GNN’s output as a target sequence. This setup allows the attention mechanism to learn multimodal association rules. The decoder’s output is then utilized for contrastive learning, paired with the processed outputs from the GNN.
MoMu (Su et al., 2022), MoleculeSTM (Liu et al., 2022), ConGraT (Brannon et al., 2023), and RLMRec (Ren et al., 2023) share a similar framework, which adopts paired graph embeddings and text embeddings to implement contrastive learning, but there are still differences in detail. Both MoMu and MoleculeSTM gather molecules from PubChem (Wang et al., 2009). The former retrieves related texts from published scientific papers, while the latter utilizes the corresponding descriptions of the molecules. ConGraT expands this architecture beyond the molecular domain. It has validated this graph-text paired contrastive learning method on social, knowledge, and citation networks. RLMRec proposes to align the semantic space of LLMs with the representation space of collaborative relational signals (which indicate user-item interactions) in recommendation systems through a contrastive modeling.
Several studies such as G2P2 (Wen and Fang, 2023) and GRENADE (Li et al., 2023b) have further advanced the use of contrastive learning. Specifically, G2P2 enhances the granularity of contrastive learning and introduces prompts during the fine-tuning stage. It employs contrastive learning at three levels during the pre-training stage: node-text, text-text summary, and node-node summary, thereby strengthening the alignment between text and graph representations. Prompts are utilized in downstream tasks, demonstrating strong performance in few-shot and zero-shot text classification and node classification tasks. On the other hand, GRENADE is optimized by integrating graph-centric contrastive learning with dual-level graph-centric knowledge alignment, which includes both node-level and neighborhood-level alignment.
Contrary to previous methods, the iterative alignment approach, depicted in Figure 5(b), treats both modalities equally but distinguishes itself in the training process by allowing for iterative interaction between the modalities. For example, GLEM (Zhao et al., 2022) employs the Expectation-Maximization (EM) framework, where one encoder iteratively generates pseudo-labels for the other encoder, allowing them to align their representation spaces.
5.2 Asymmetric
While symmetric alignment aims to give equal emphasis to both modalities, asymmetric alignment focuses on allowing one modality to assist or enhance the other. In current studies, the predominant approach involves leveraging the capabilities of GNNs to process structural information to reinforce LLMs. These studies can be categorized into two types: graph-nested transformer and graph-aware distillation.
The graph-nested transformer, as exemplified by Graphformer (Yang et al., 2021) in Figure 5(c), demonstrates asymmetric alignment through the integration of GNNs into each transformer layer. Within each layer of the LLM, the node embedding is obtained from the first token-level embedding, which corresponds to the [CLS] token. The process involves gathering embeddings from all relevant nodes and applying them to a graph transformer. The output is then concatenated with the input embeddings and passed on to the next layer of the LLM. Patton (Jin et al., 2023a) extends GraphFormer by proposing two pre-training strategies, i.e., network-contextualized masked language modeling and masked node prediction, specifically for text-rich graphs. Its strong performance is shown in various downstream tasks, including classification, retrieval, reranking, and link prediction.
Additionally, GRAD (Mavromatis et al., 2023) employs graph-aware distillation for aligning two modalities, depicted in Figure 5(d). It utilizes a GNN as a teacher model to generate soft labels for an LLM, facilitating the transfer of aggregated information. Moreover, since the LLMs share parameters, the GNN can benefit from improved textual encodings after the updates to the LLMs’ parameters. Through iterative updates, a graph-aware LLM is developed, resulting in enhanced scalability in inference due to the absence of the GNN. Similar to GRAD, THLM (Zou et al., 2023) employs a heterogeneous GNN to enhance LLMs with multi-order topology learning capabilities. It involves pretraining a LLM alongside an auxiliary GNN through two distinct strategies. The first strategy focuses on predicting whether a node is part of the context graph of a target node. The second strategy utilizes a Masked Language Modeling task, which aids in developing a robust language comprehension by the LLM. After the pretraining process, the auxiliary GNN is discarded and the LLM is fine-tuned for downstream tasks.
5.3 Discussions
To align GNNs and LLMs, symmetric alignments treat each modality equally, with the objective of enhancing GNNs and LLMs simultaneously. This leads to encoders that can effectively handle tasks involving both modalities, leveraging their individual encoding strengths to improve modality-specific representations. In addition, asymmetric methods enhance LLMs by inserting graph encoders into transformers or directly using GNNs as teachers. However, alignment techniques face challenges when dealing with data scarcity. In particular, only a few graph datasets (i.e., molecular datasets) contain native graph-text pairs, limiting the applicability of these methods.
6 Future Directions
Table 1 summarizes the models that leverage LLMs to assist graph-related tasks according to the proposed taxonomy. Based on the above review and analysis, we believe that there is still much space for further enhancement in this field. In this section, we discuss the remaining limitations of leveraging LLM’s ability to comprehend graph data and list some directions for further exploration in subsequent research.
Dealing with non-TAG. Utilizing LLMs to assist learning on text-attributed graphs has already demonstrated excellent performance. However, graph-structured data is ubiquitous in real-world scenarios, and a great deal of it lacks rich textual information. For example, in a traffic network (e.g., PeMS03 (Song et al., 2020)), each node represents an operational sensor, while in a superpixel graph (e.g., PascalVOC-SP (Dwivedi et al., 2022)), each node represents a superpixel. These datasets do not have attached text attributes on each node, and it is also challenging to describe the semantic meaning of each node using human-understandable language. Although OFA (Liu et al., 2023a) proposes to describe all nodes and edges using human-understandable texts and embed the texts into the same space by LLMs, it may not be applicable to all domains (e.g., superpixel graph), and its performance may be suboptimal in certain domains and datasets. Exploring how to leverage the powerful generalization capabilities of LLMs to help in constructing graph foundation models is a valuable research direction.
Dealing with data leakage. Data leakage in LLMs has become a focal point of discussion (Aiyappa et al., 2023). Given that LLMs undergo pre-training on extensive text corpora, it’s likely that LLMs may have seen and memorized at least part of the test data of the common benchmark datasets, especially for citation networks. This undermines the reliability of current studies that rely on earlier benchmark datasets. In addition, Chen et al. (2023a) proves that specific prompts could potentially enhance the “activation” of LLMs’ corresponding memory, thereby influencing the evaluation. Both Huang et al. (2023a) and He et al. (2023) have tried to avoid the data leakage issue by collecting a new citation dataset, ensuring that the test papers are sampled from time periods post the data cut-off of ChatGPT. However, they still remain limited to the citation domain and the impact of graph structures in their datasets is not significant. Hence, it’s crucial to reconsider the methods employed to accurately evaluate the performance of LLMs on graph-related tasks. A fair, systematic, and comprehensive benchmark is also needed.
Improving transferability. Transferability has always been a challenging problem in the graph domain (Jiang et al., 2022). The transferability of learned knowledge from one dataset to another, or from one domain to another, is not straightforward due to the unique characteristics and structures of individual graphs. Graphs can vary significantly in terms of size, connectivity, node types, edge types, and overall topology, making it difficult to directly transfer knowledge between them. While LLMs have demonstrated promising zero/few-shot abilities in language tasks due to their extensive pre-training on vast amounts of corpora, the exploration of utilizing the knowledge embedded within LLMs to enhance the transferability of graph-related tasks has been relatively limited. OFA (Liu et al., 2023a) attempts a unified way to perform cross-domain on graphs by describing all nodes and edges as human-readable texts and embedding the texts from different domains into the same embedding space with a single LLM. The topic of improving transferability is still worth investigating.
Improving explainability. Explainability, also known as interpretability, denotes the ability to explain or present the behavior of models in human-understandable terms (Zhao et al., 2023b). LLMs exhibit improved explainability compared to GNNs when handling graph-related tasks, primarily due to the reasoning and explaining ability of LLMs to produce user-friendly explanations for graph reasoning, including generating additional explanations as enhancers discussed in Section 3 and offering reasoning processes as predictors discussed in Section 4. Several studies have examined explaining techniques within the prompting paradigm, such as in-context learning (Radford et al., 2021) and chain-of-thought (Wei et al., 2022b), which involve feeding a sequence of demonstrations and prompts to the LLM to steer its generation in a particular direction and have it explain its reasoning. Further explorations should be conducted to enhance explainability.
Improving efficiency. While LLMs have demonstrated their effectiveness in learning on graphs, they may face inefficiencies in terms of time and space, particularly compared to dedicated graph learning models such as GNNs that inherently process graph structures. This is especially obvious when LLMs rely on sequential graph descriptions for predictions discussed in Section 4. For example, while accessing LLMs through APIs (i.e., ChatGPT and GPT-4), the billing model incurs high costs for processing large-scale graphs. Additionally, both training and inference for locally deployed open-source LLMs require significant time consumption and substantial hardware resources. Existing studies (Duan et al., 2023; Liu et al., 2023c; Ye et al., 2023; Chai et al., 2023; Liu et al., 2023d; Tang et al., 2023) have tried to enable LLMs’ efficient adaption via adopting parameter-efficient fine-tuning strategies, such as LoRA (Hu et al., 2021) and prefix tuning (Li and Liang, 2021). We believe that more efficient methods may unlock more power of applying LLMs on graph-related tasks with limited computational resources.
Analysis and improvement of expressive ability. Despite the recent achievements of LLMs in graph-related tasks, their theoretical expressive power remains largely unexplored. It is widely acknowledged that standard message-passing neural networks are as expressive as the 1-Weisfeiler-Lehman (WL) test, meaning that they fail to distinguish non-isomorphic graphs under 1-hop aggregation (Xu et al., 2018). Therefore, two fundamental questions arise: How effectively do LLMs understand graph structures? Can their expressive ability surpass those of GNNs or the WL-test? Besides, permutation equivariance is an intriguing property of typical GNNs, which is significant in geometric graph learning (Han et al., 2022). Exploring how to endow LLMs with this property is also an interesting direction.
LLMs as agent. In the current integration of graphs with LLMs, LLMs often play the role of enhancers, predictors, and alignment components. However, in more complex scenarios, such applications may not fully unlock the potential of LLMs. Recent research has explored new roles for LLMs as agents, such as generative agents (Park et al., 2023) and domain-specific agents (Bran et al., 2023). In an LLM-powered agent system, LLMs function as the agent’s brain, supported by essential components like planning, memory, and tool using (Weng, 2023). In complex graph-related scenarios, such as recommendation systems and knowledge discovery, treating LLMs as agents to first decompose tasks into multiple subtasks, and then identifying the most suitable tools (e.g., GNNs) for each subtask may potentially yield enhanced performance. Furthermore, employing LLMs as agents holds promise for constructing a powerful and highly generalizable solver for graph-related tasks.
7 Conclusion
The application of LLMs to graph-related tasks has emerged as a prominent area of research in recent years. In this survey, we aim to provide an in-depth overview of existing strategies for adapting LLMs to graphs. Firstly, we introduce a novel taxonomy that categorizes techniques involving both graph and text modalities into three categories based on the different roles played by LLMs, i.e., enhancer, predictor, and alignment component. Secondly, we systematically review the representative studies according to the taxonomy. Finally, we discuss some limitations and highlight several future research directions. Through this comprehensive review, we aspire to shed light on the advancements and challenges in the field of graph learning with LLMs, thereby encouraging further enhancements in this domain.
References
- Aiyappa et al. [2023] Rachith Aiyappa, Jisun An, Haewoon Kwak, and Yong-Yeol Ahn. Can we trust the evaluation on chatgpt? arXiv preprint arXiv:2303.12767, 2023.
- Beltagy et al. [2019] Iz Beltagy, Kyle Lo, and Arman Cohan. Scibert: A pretrained language model for scientific text. arXiv preprint arXiv:1903.10676, 2019.
- Bran et al. [2023] Andres M Bran, Sam Cox, Andrew D White, and Philippe Schwaller. Chemcrow: Augmenting large-language models with chemistry tools. arXiv preprint arXiv:2304.05376, 2023.
- Brandes et al. [2013] Ulrik Brandes, Markus Eiglsperger, Jürgen Lerner, and Christian Pich. Graph markup language (graphml). 2013.
- Brannon et al. [2023] William Brannon, Suyash Fulay, Hang Jiang, Wonjune Kang, Brandon Roy, Jad Kabbara, and Deb Roy. Congrat: Self-supervised contrastive pretraining for joint graph and text embeddings. arXiv preprint arXiv:2305.14321, 2023.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. NeurIPS, 33:1877–1901, 2020.
- Cao et al. [2023] He Cao, Zijing Liu, Xingyu Lu, Yuan Yao, and Yu Li. Instructmol: Multi-modal integration for building a versatile and reliable molecular assistant in drug discovery. arXiv preprint arXiv:2311.16208, 2023.
- Chai et al. [2023] Ziwei Chai, Tianjie Zhang, Liang Wu, Kaiqiao Han, Xiaohai Hu, Xuanwen Huang, and Yang Yang. Graphllm: Boosting graph reasoning ability of large language model. arXiv preprint arXiv:2310.05845, 2023.
- Chandra et al. [2020] Shantanu Chandra, Pushkar Mishra, Helen Yannakoudakis, Madhav Nimishakavi, Marzieh Saeidi, and Ekaterina Shutova. Graph-based modeling of online communities for fake news detection. arXiv preprint arXiv:2008.06274, 2020.
- Chen et al. [2023a] Zhikai Chen, Haitao Mao, Hang Li, Wei Jin, Hongzhi Wen, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Wenqi Fan, Hui Liu, et al. Exploring the potential of large language models (llms) in learning on graphs. arXiv preprint arXiv:2307.03393, 2023.
- Chen et al. [2023b] Zhikai Chen, Haitao Mao, Hongzhi Wen, Haoyu Han, Wei Jin, Haiyang Zhang, Hui Liu, and Jiliang Tang. Label-free node classification on graphs with large language models (llms). arXiv preprint arXiv:2310.04668, 2023.
- Cheng et al. [2023] Jiashun Cheng, Man Li, Jia Li, and Fugee Tsung. Wiener graph deconvolutional network improves graph self-supervised learning. In AAAI, pages 7131–7139, 2023.
- Chien et al. [2021] Eli Chien, Wei-Cheng Chang, Cho-Jui Hsieh, Hsiang-Fu Yu, Jiong Zhang, Olgica Milenkovic, and Inderjit S Dhillon. Node feature extraction by self-supervised multi-scale neighborhood prediction. arXiv preprint arXiv:2111.00064, 2021.
- Chiswell and Hodges [2007] Ian Chiswell and Wilfrid Hodges. Mathematical logic. OUP Oxford, 2007.
- Chowdhery et al. [2022] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Chung et al. [2022] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- Das et al. [2023] Debarati Das, Ishaan Gupta, Jaideep Srivastava, and Dongyeop Kang. Which modality should i use–text, motif, or image?: Understanding graphs with large language models. arXiv preprint arXiv:2311.09862, 2023.
- Dong et al. [2022] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. A survey for in-context learning. arXiv preprint arXiv:2301.00234, 2022.
- Duan et al. [2023] Keyu Duan, Qian Liu, Tat-Seng Chua, Shuicheng Yan, Wei Tsang Ooi, Qizhe Xie, and Junxian He. Simteg: A frustratingly simple approach improves textual graph learning. arXiv preprint arXiv:2308.02565, 2023.
- Dwivedi et al. [2022] Vijay Prakash Dwivedi, Ladislav Rampášek, Michael Galkin, Ali Parviz, Guy Wolf, Anh Tuan Luu, and Dominique Beaini. Long range graph benchmark. NeurIPS, 35:22326–22340, 2022.
- Edwards et al. [2021] Carl Edwards, ChengXiang Zhai, and Heng Ji. Text2mol: Cross-modal molecule retrieval with natural language queries. In EMNLP, pages 595–607, 2021.
- Fatemi et al. [2023] Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. Talk like a graph: Encoding graphs for large language models. arXiv preprint arXiv:2310.04560, 2023.
- Guo et al. [2023] Jiayan Guo, Lun Du, and Hengyu Liu. Gpt4graph: Can large language models understand graph structured data? an empirical evaluation and benchmarking. arXiv preprint arXiv:2305.15066, 2023.
- Hamilton et al. [2017] Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. NeurIPS, 30, 2017.
- Han et al. [2022] Jiaqi Han, Yu Rong, Tingyang Xu, and Wenbing Huang. Geometrically equivariant graph neural networks: A survey. arXiv preprint arXiv:2202.07230, 2022.
- He et al. [2020] Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. Lightgcn: Simplifying and powering graph convolution network for recommendation. In SIGIR, pages 639–648, 2020.
- He et al. [2023] Xiaoxin He, Xavier Bresson, Thomas Laurent, and Bryan Hooi. Explanations as features: Llm-based features for text-attributed graphs. arXiv preprint arXiv:2305.19523, 2023.
- Himsolt [1997] Michael Himsolt. Gml: Graph modelling language. University of Passau, 1997.
- Hou et al. [2022] Zhenyu Hou, Xiao Liu, Yukuo Cen, Yuxiao Dong, Hongxia Yang, Chunjie Wang, and Jie Tang. Graphmae: Self-supervised masked graph autoencoders. In SIGKDD, pages 594–604, 2022.
- Hu et al. [2020] Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. NeurIPS, 33:22118–22133, 2020.
- Hu et al. [2021] Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. In ICLR, 2021.
- Hu et al. [2023] Yuntong Hu, Zheng Zhang, and Liang Zhao. Beyond text: A deep dive into large language models’ ability on understanding graph data. arXiv preprint arXiv:2310.04944, 2023.
- Huang et al. [2023a] Jin Huang, Xingjian Zhang, Qiaozhu Mei, and Jiaqi Ma. Can llms effectively leverage graph structural information: when and why. arXiv preprint arXiv:2309.16595, 2023.
- Huang et al. [2023b] Xuanwen Huang, Kaiqiao Han, Dezheng Bao, Quanjin Tao, Zhisheng Zhang, Yang Yang, and Qi Zhu. Prompt-based node feature extractor for few-shot learning on text-attributed graphs. arXiv preprint arXiv:2309.02848, 2023.
- Ji et al. [2021] Shaoxiong Ji, Shirui Pan, Erik Cambria, Pekka Marttinen, and S Yu Philip. A survey on knowledge graphs: Representation, acquisition, and applications. TNNLS, 33(2):494–514, 2021.
- Jiang et al. [2022] Junguang Jiang, Yang Shu, Jianmin Wang, and Mingsheng Long. Transferability in deep learning: A survey. arXiv preprint arXiv:2201.05867, 2022.
- Jin et al. [2023a] Bowen Jin, Wentao Zhang, Yu Zhang, Yu Meng, Xinyang Zhang, Qi Zhu, and Jiawei Han. Patton: Language model pretraining on text-rich networks. arXiv preprint arXiv:2305.12268, 2023.
- Jin et al. [2023b] Bowen Jin, Wentao Zhang, Yu Zhang, Yu Meng, Han Zhao, and Jiawei Han. Learning multiplex embeddings on text-rich networks with one text encoder. arXiv preprint arXiv:2310.06684, 2023.
- Kenton and Toutanova [2019] Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT, pages 4171–4186, 2019.
- Kipf and Welling [2016] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In ICLR, 2016.
- Li and Liang [2021] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. In ACL, pages 4582–4597, 2021.
- Li et al. [2023a] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- Li et al. [2023b] Yichuan Li, Kaize Ding, and Kyumin Lee. Grenade: Graph-centric language model for self-supervised representation learning on text-attributed graphs. arXiv preprint arXiv:2310.15109, 2023.
- Liu and Wu [2023] Chang Liu and Bo Wu. Evaluating large language models on graphs: Performance insights and comparative analysis. arXiv preprint arXiv:2308.11224, 2023.
- Liu et al. [2019] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- Liu et al. [2022] Shengchao Liu, Weili Nie, Chengpeng Wang, Jiarui Lu, Zhuoran Qiao, Ling Liu, Jian Tang, Chaowei Xiao, and Anima Anandkumar. Multi-modal molecule structure-text model for text-based retrieval and editing. arXiv preprint arXiv:2212.10789, 2022.
- Liu et al. [2023a] Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, and Muhan Zhang. One for all: Towards training one graph model for all classification tasks. arXiv preprint arXiv:2310.00149, 2023.
- Liu et al. [2023b] Jiawei Liu, Cheng Yang, Zhiyuan Lu, Junze Chen, Yibo Li, Mengmei Zhang, Ting Bai, Yuan Fang, Lichao Sun, Philip S Yu, et al. Towards graph foundation models: A survey and beyond. arXiv preprint arXiv:2310.11829, 2023.
- Liu et al. [2023c] Pengfei Liu, Yiming Ren, and Zhixiang Ren. Git-mol: A multi-modal large language model for molecular science with graph, image, and text. arXiv preprint arXiv:2308.06911, 2023.
- Liu et al. [2023d] Zhiyuan Liu, Sihang Li, Yanchen Luo, Hao Fei, Yixin Cao, Kenji Kawaguchi, Xiang Wang, and Tat-Seng Chua. Molca: Molecular graph-language modeling with cross-modal projector and uni-modal adapter. arXiv preprint arXiv:2310.12798, 2023.
- Mavromatis et al. [2023] Costas Mavromatis, Vassilis N Ioannidis, Shen Wang, Da Zheng, Soji Adeshina, Jun Ma, Han Zhao, Christos Faloutsos, and George Karypis. Train your own gnn teacher: Graph-aware distillation on textual graphs. arXiv preprint arXiv:2304.10668, 2023.
- Mikolov et al. [2013] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. NeurIPS, 26, 2013.
- Oord et al. [2018] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- OpenAI [2023] OpenAI. Gpt-4 technical report, 2023.
- Park et al. [2023] Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. arXiv preprint arXiv:2304.03442, 2023.
- Qian et al. [2023] Chen Qian, Huayi Tang, Zhirui Yang, Hong Liang, and Yong Liu. Can large language models empower molecular property prediction? arXiv preprint arXiv:2307.07443, 2023.
- Qin et al. [2023] Yijian Qin, Xin Wang, Ziwei Zhang, and Wenwu Zhu. Disentangled representation learning with large language models for text-attributed graphs. arXiv preprint arXiv:2310.18152, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICLR, pages 8748–8763, 2021.
- Ren et al. [2023] Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. Representation learning with large language models for recommendation. arXiv preprint arXiv:2310.15950, 2023.
- Robinson and Wingate [2022] Joshua Robinson and David Wingate. Leveraging large language models for multiple choice question answering. In ICLR, 2022.
- Salton and Buckley [1988] Gerard Salton and Christopher Buckley. Term-weighting approaches in automatic text retrieval. IPM, 24(5):513–523, 1988.
- Sen et al. [2008] Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data. AI magazine, 29(3):93–93, 2008.
- Shayegani et al. [2023] Erfan Shayegani, Md Abdullah Al Mamun, Yu Fu, Pedram Zaree, Yue Dong, and Nael Abu-Ghazaleh. Survey of vulnerabilities in large language models revealed by adversarial attacks. arXiv preprint arXiv:2310.10844, 2023.
- Shi et al. [2023] Yaorui Shi, An Zhang, Enzhi Zhang, Zhiyuan Liu, and Xiang Wang. Relm: Leveraging language models for enhanced chemical reaction prediction. arXiv preprint arXiv:2310.13590, 2023.
- Song et al. [2020] Chao Song, Youfang Lin, Shengnan Guo, and Huaiyu Wan. Spatial-temporal synchronous graph convolutional networks: A new framework for spatial-temporal network data forecasting. In AAAI, pages 914–921, 2020.
- Su et al. [2022] Bing Su, Dazhao Du, Zhao Yang, Yujie Zhou, Jiangmeng Li, Anyi Rao, Hao Sun, Zhiwu Lu, and Ji-Rong Wen. A molecular multimodal foundation model associating molecule graphs with natural language. arXiv preprint arXiv:2209.05481, 2022.
- Sun et al. [2022] Mingchen Sun, Kaixiong Zhou, Xin He, Ying Wang, and Xin Wang. Gppt: Graph pre-training and prompt tuning to generalize graph neural networks. In SIGKDD, pages 1717–1727, 2022.
- Sun et al. [2023a] Xiangguo Sun, Hong Cheng, Jia Li, Bo Liu, and Jihong Guan. All in one: Multi-task prompting for graph neural networks. In SIGKDD, page 2120–2131, 2023.
- Sun et al. [2023b] Xiangguo Sun, Hong Cheng, Bo Liu, Jia Li, Hongyang Chen, Guandong Xu, and Hongzhi Yin. Self-supervised hypergraph representation learning for sociological analysis. TKDE, 2023.
- Tan et al. [2023a] Qiaoyu Tan, Ninghao Liu, Xiao Huang, Soo-Hyun Choi, Li Li, Rui Chen, and Xia Hu. S2gae: Self-supervised graph autoencoders are generalizable learners with graph masking. In WSDM, pages 787–795, 2023.
- Tan et al. [2023b] Yanchao Tan, Zihao Zhou, Hang Lv, Weiming Liu, and Carl Yang. Walklm: A uniform language model fine-tuning framework for attributed graph embedding. In NeurIPS, 2023.
- Tang et al. [2023] Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. Graphgpt: Graph instruction tuning for large language models. arXiv preprint arXiv:2310.13023, 2023.
- Taylor et al. [2022] Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. Galactica: A large language model for science. arXiv preprint arXiv:2211.09085, 2022.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. NeurIPS, 30, 2017.
- Velickovic et al. [2018] Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. stat, 1050:4, 2018.
- Wang et al. [2009] Yanli Wang, Jewen Xiao, Tugba O Suzek, Jian Zhang, Jiyao Wang, and Stephen H Bryant. Pubchem: a public information system for analyzing bioactivities of small molecules. Nucleic acids research, 37(suppl_2):W623–W633, 2009.
- Wang et al. [2023a] Haishuai Wang, Yang Gao, Xin Zheng, Peng Zhang, Hongyang Chen, and Jiajun Bu. Graph neural architecture search with gpt-4. arXiv preprint arXiv:2310.01436, 2023.
- Wang et al. [2023b] Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. Can language models solve graph problems in natural language? arXiv preprint arXiv:2305.10037, 2023.
- Wei et al. [2022a] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. TMLR, 2022.
- Wei et al. [2022b] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. NeurIPS, 35:24824–24837, 2022.
- Wei et al. [2023] Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. Llmrec: Large language models with graph augmentation for recommendation. arXiv preprint arXiv:2311.00423, 2023.
- Wen and Fang [2023] Zhihao Wen and Yuan Fang. Prompt tuning on graph-augmented low-resource text classification. arXiv preprint arXiv:2307.10230, 2023.
- Weng [2023] Lilian Weng. Llm-powered autonomous agents. lilianweng.github.io, Jun 2023.
- Wu et al. [2018] Zhenqin Wu, Bharath Ramsundar, Evan N Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S Pappu, Karl Leswing, and Vijay Pande. Moleculenet: a benchmark for molecular machine learning. Chemical science, 9(2):513–530, 2018.
- Xie et al. [2023] Han Xie, Da Zheng, Jun Ma, Houyu Zhang, Vassilis N Ioannidis, Xiang Song, Qing Ping, Sheng Wang, Carl Yang, Yi Xu, et al. Graph-aware language model pre-training on a large graph corpus can help multiple graph applications. arXiv preprint arXiv:2306.02592, 2023.
- Xu et al. [2018] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? arXiv preprint arXiv:1810.00826, 2018.
- Xue et al. [2023] Rui Xue, Xipeng Shen, Ruozhou Yu, and Xiaorui Liu. Efficient large language models fine-tuning on graphs. arXiv preprint arXiv:2312.04737, 2023.
- Yang et al. [2016] Zhilin Yang, William Cohen, and Ruslan Salakhudinov. Revisiting semi-supervised learning with graph embeddings. In ICLR, pages 40–48, 2016.
- Yang et al. [2021] Junhan Yang, Zheng Liu, Shitao Xiao, Chaozhuo Li, Defu Lian, Sanjay Agrawal, Amit Singh, Guangzhong Sun, and Xing Xie. Graphformers: Gnn-nested transformers for representation learning on textual graph. NeurIPS, 34:28798–28810, 2021.
- Yang et al. [2023] Jingfeng Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Bing Yin, and Xia Hu. Harnessing the power of llms in practice: A survey on chatgpt and beyond. arXiv preprint arXiv:2304.13712, 2023.
- Ye et al. [2023] Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. Natural language is all a graph needs. arXiv preprint arXiv:2308.07134, 2023.
- Ying et al. [2021] Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. Do transformers really perform badly for graph representation? NeurIPS, pages 28877–28888, 2021.
- You et al. [2020] Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. Graph contrastive learning with augmentations. NeurIPS, pages 5812–5823, 2020.
- Yu et al. [2023] Jianxiang Yu, Yuxiang Ren, Chenghua Gong, Jiaqi Tan, Xiang Li, and Xuecang Zhang. Empower text-attributed graphs learning with large language models (llms). arXiv preprint arXiv:2310.09872, 2023.
- Zeng et al. [2022] Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, et al. Glm-130b: An open bilingual pre-trained model. arXiv preprint arXiv:2210.02414, 2022.
- Zhang et al. [2023a] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023.
- Zhang et al. [2023b] Renrui Zhang, Jiaming Han, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Peng Gao, and Yu Qiao. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023.
- Zhang et al. [2023c] Zeyang Zhang, Xin Wang, Ziwei Zhang, Haoyang Li, Yijian Qin, Simin Wu, and Wenwu Zhu. Llm4dyg: Can large language models solve problems on dynamic graphs? arXiv preprint arXiv:2310.17110, 2023.
- Zhang et al. [2023d] Ziwei Zhang, Haoyang Li, Zeyang Zhang, Yijian Qin, Xin Wang, and Wenwu Zhu. Large graph models: A perspective. arXiv preprint arXiv:2308.14522, 2023.
- Zhao et al. [2022] Jianan Zhao, Meng Qu, Chaozhuo Li, Hao Yan, Qian Liu, Rui Li, Xing Xie, and Jian Tang. Learning on large-scale text-attributed graphs via variational inference. arXiv preprint arXiv:2210.14709, 2022.
- Zhao et al. [2023a] Haiteng Zhao, Shengchao Liu, Chang Ma, Hannan Xu, Jie Fu, Zhi-Hong Deng, Lingpeng Kong, and Qi Liu. Gimlet: A unified graph-text model for instruction-based molecule zero-shot learning. arXiv preprint arXiv:2306.13089, 2023.
- Zhao et al. [2023b] Haiyan Zhao, Hanjie Chen, Fan Yang, Ninghao Liu, Huiqi Deng, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, and Mengnan Du. Explainability for large language models: A survey. arXiv preprint arXiv:2309.01029, 2023.
- Zhao et al. [2023c] Jianan Zhao, Le Zhuo, Yikang Shen, Meng Qu, Kai Liu, Michael Bronstein, Zhaocheng Zhu, and Jian Tang. Graphtext: Graph reasoning in text space. arXiv preprint arXiv:2310.01089, 2023.
- Zhao et al. [2023d] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
- Zhu et al. [2021] Yanqiao Zhu, Yichen Xu, Feng Yu, Qiang Liu, Shu Wu, and Liang Wang. Graph contrastive learning with adaptive augmentation. In WWW, pages 2069–2080, 2021.
- Zhu et al. [2023] Jing Zhu, Xiang Song, Vassilis N Ioannidis, Danai Koutra, and Christos Faloutsos. Touchup-g: Improving feature representation through graph-centric finetuning. arXiv preprint arXiv:2309.13885, 2023.
- Zou et al. [2023] Tao Zou, Le Yu, Yifei Huang, Leilei Sun, and Bowen Du. Pretraining language models with text-attributed heterogeneous graphs. arXiv preprint arXiv:2310.12580, 2023.