Scalable AI Generative Content for Vehicular Network Semantic Communication
Abstract
Perceiving vehicles in a driver’s blind spot is vital for safe driving. The detection of potentially dangerous vehicles in these blind spots can benefit from vehicular network semantic communication technology. However, efficient semantic communication involves a trade-off between accuracy and delay, especially in bandwidth-limited situations. This paper unveils a scalable Artificial Intelligence Generated Content (AIGC) system that leverages an encoder-decoder architecture. This system converts images into textual representations and reconstructs them into quality-acceptable images, optimizing transmission for vehicular network semantic communication. Moreover, when bandwidth allows, auxiliary information is integrated. The encoder-decoder aims to maintain semantic equivalence with the original images across various tasks. Then the proposed approach employs reinforcement learning to enhance the reliability of the generated contents. Experimental results suggest that the proposed method surpasses the baseline in perceiving vehicles in blind spots and effectively compresses communication data. While this method is specifically designed for driving scenarios, this encoder-decoder architecture also holds potential for wide use across various semantic communication scenarios.
Index Terms— Vehicular Network Semantic Communication, Scalable Artificial Intelligence Generated Content, Encoder-Decoder, Reinforcement Learning
1 Introduction
Artificial Intelligence Generated Content (AIGC) [1, 2, 3, 4] leverages advanced machine learning and deep learning techniques, enabling computers to produce vast amounts of textual, graphical, auditory, and video content from minimal information. However, challenges persist in AIGC applications, including the generation of task-specific, contextually relevant content and assessment of output quality.
One practical application of AIGC is in vehicular network semantic communication. When driving at high speeds on highways, drivers typically focus their vision forward, leading to side blind spots. Assisting drivers in detecting movements in these blind spots, especially from swiftly approaching vehicles, is essential for safety. Vehicular network semantic communication technology can detect potentially hazardous vehicles in these blind spots. It achieves this by capturing, encoding, and transmitting real-time imagery of these vehicles, and then decoding and presenting this information as images to the driver. However, vehicular network semantic communication often grapples with bandwidth limitations, making effective image transmission a challenge.
To overcome this challenge, in this paper, we propose a scalable AIGC encoder-decoder architecture that extracts task-specific image semantics and transmits them in the form of text through the Internet of Vehicles [5]. During this process, reinforcement learning techniques [6, 7] enhance the textual representation of the semantic information. If bandwidth permits, image regions with significant semantics are also conveyed. The ultimate objective is to refine and evaluate the quality of the reconstructed image until it meets acceptance criteria. The key contributions of this paper include:
-
1.
We introduce a scalable AIGC encoder-decoder architecture that primarily transforms images into semantic textual information. Depending on bandwidth availability, it can additionally include relevant semantic image data. Our approach offers a twofold benefit: when bandwidth is constrained, it prioritizes transmitting semantic textual information, and when bandwidth is ample, it incorporates local image regions with significant semantics.
-
2.
We utilize reinforcement learning techniques to optimize encoding and decoding processes. By treating encoding and decoding as sequential decisions, we ensure the generated textual data retains ample semantic information, aiming to maximize the quality of the reconstructed image.
-
3.
We conduct experiments using a vehicle image dataset to validate the effectiveness of our proposed AIGC method. The results illustrate that our proposed method surpasses the baseline in both image quality and compression rate, suggesting its potential usefulness for real-world scenarios such as vehicular communication under varying bandwidth conditions.
2 Related Work
2.1 Image Compression and Transmission
Conventional image compression methods like JPEG [8] and PNG [9] are extensively used to decrease image size while maintaining acceptable quality. Recent advancements utilize deep learning architectures, like Recurrent Neural Networks (RNNs) [10] and autoencoders [11], to attain superior compression rates without compromising image fidelity.
2.2 Textual Descriptions from Visual Data
Transforming images into textual descriptions or prompts has gained traction in research, particularly since the rise of deep learning. Initial efforts centered on template-driven techniques [12], while more recent approaches utilize RNNs [13] and Transformers [14] to generate more natural and descriptive captions for images.
2.3 Text-to-Image Synthesis
The reverse challenge of transforming textual descriptions back into images has also attracted considerable interest. Generative Adversarial Networks (GANs) [1] have been at the forefront of this research, with models like DALL·E [2] demonstrating the capability to generate high-quality images from textual prompts. Integrating supplementary cues or context to direct the synthesis process has been explored, bolstering the accuracy and relevance of the produced images [15].
2.4 Reinforcement Learning in Image Processing
The application of reinforcement learning in image processing tasks, such as optimization and enhancement, is a relatively new avenue. Works like [16] have shown the potential of RL-based methods in achieving superior results compared to traditional techniques, especially in scenarios where the objective is not explicitly defined.
3 Methodology
The proposed scalable AIGC system represents a paradigm shift in how we approach data transmission and semantic communication, especially in bandwidth-constrained environments. The scalable AIGC system dynamically adapts to bandwidth availability, prioritizing the transmission of essential information. This adaptability stems from sophisticated encoding and reinforcement learning optimization, enabling the scalable AIGC system to decide what and how to transmit.
The motivation of the scalable AIGC system is that transmitting high-resolution images isn’t always practical or necessary. Often, a succinct textual representation capturing the image’s essence is adequate. By transforming images into communication data, the scalable AIGC system ensures efficient transmission while retaining the data’s semantic value.
The core of the proposed scalable AIGC system is to convert image data into a task-specific and more compact communication data format. Once transmitted, this data is optimized using reinforcement learning before being decoded into an image. The reinforcement learning method can force the communication data to be more related to the specific task. There are three main phases in our proposed method:
-
•
Information Encoding. The initial phase involves encoding the image into a textual representation. This process, which we term as “information encoding”, leverages an encoder that distills the essential features of an image into a concise textual format suitable for transmission.
-
•
Reinforcement Learning-based Optimization. Before decoding, the communication data is passed through a reinforcement learning module. This module identifies and adjusts the textual information, ensuring that the decoded image aligns well with the intended context and requirements. Specifically, using the actor-critic method, the model discerns detrimental textual details and recognizes phrases that can enhance the final image representation.
-
•
Information Decoding. The optimized communication data is then fed into a decoder, translating the textual information back into its visual form, resulting in an image that is both bandwidth-efficient and contextually relevant.
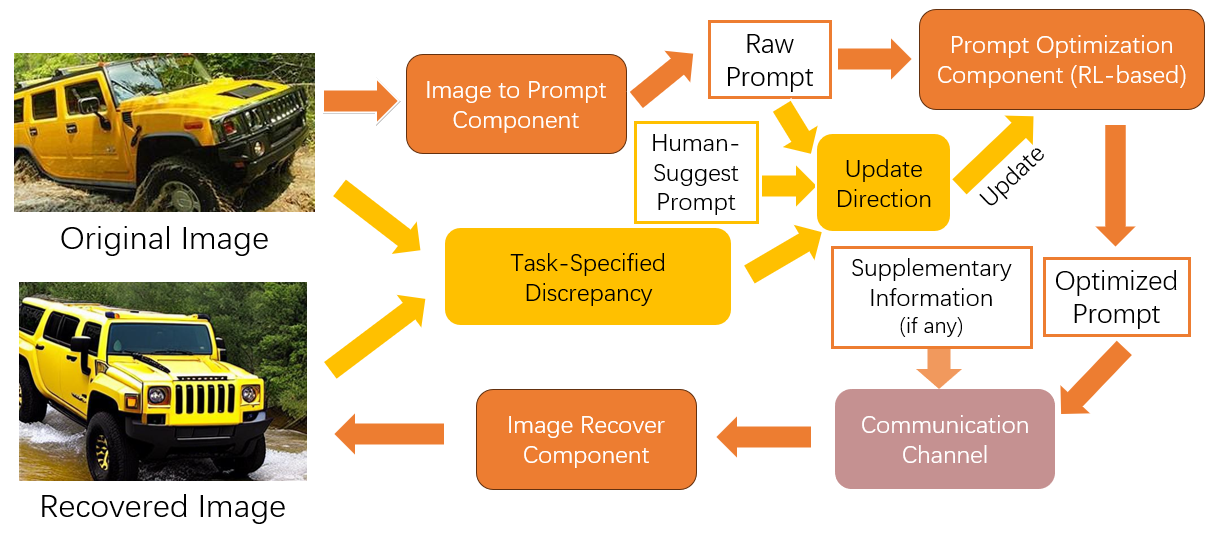
As illustrated in Figure 1, the scalable AIGC system encompasses three distinct components: the Image to Prompt Component, the Prompt Optimization Component, and the Image Recover Component. These components correspond respectively to the three stages previously described. In the subsequent sections, we will delve into a detailed discussion of these components respectively.
3.1 Information Encoding and Decoding
3.1.1 Information Encoding
The process of information encoding in our system leverages the capabilities of large language models. Given an image, the primary objective of this phase is to generate a concise and descriptive textual prompt that encapsulates the essential features and details of the image. This is achieved by feeding the image into our encoder, which has been trained on a vast dataset of image-text pairs. The underlying principle is to harness the power of state-of-the-art language models to distill the rich visual information of an image into a compact textual representation. This representation, termed as the “prompt”, serves as a bridge between the visual and textual domains, ensuring that the core semantics of the image are preserved in a bandwidth-efficient manner.
3.1.2 Information Decoding
The decoding phase is tasked with the conversion of the generated textual prompt back into a visual representation. This is not a straightforward translation, as the challenge lies in regenerating an image that is both contextually relevant and closely resembles the original image. Our decoder employs advanced text-to-image synthesis techniques to achieve this.
Furthermore, to enhance the accuracy and fidelity of the regenerated image, our system allows the integration of image hints. These hints provide additional context and guidance to the decoder, ensuring that the output image aligns well with the original context. For instance, if the original image was of a sunset over a mountain range, the hint might emphasize the color palette or the silhouette of the mountains. By incorporating these hints, our decoder can produce images that are not only semantically aligned with the textual prompt but also visually congruent with the original image.
In essence, our encoding and decoding methodologies ensures a seamless transition between the visual and textual domains, paving the way for efficient and semantically rich communication in bandwidth-constrained scenarios.
3.2 Reinforcement Learning-based Optimization
The process of compressing the rich details of an image into a textual representation, termed as “information encoding”, may not always capture the nuances vital for specific tasks and application scenarios. For instance, when encoding the details of surrounding vehicles, users are primarily concerned with specific aspects such as the direction from which the vehicle is approaching, the orientation of its front, and its type (be it a large truck, a sedan, or a small three-wheeled electric vehicle).
To bridge this gap between model-generated content and user-centric requirements, we propose a reinforcement learning-based approach to enhance the expressive capability of the encoded textual information. The objective is to seamlessly integrate details that are highly pertinent to driving contexts into the generated text, thereby elevating the model’s performance.
The primary objective of employing the reinforcement learning method in our context is twofold:
-
1.
Identification of Detrimental Information. Recognize and pinpoint textual elements within the encoded communication data that might be counterproductive or irrelevant to the overarching task.
-
2.
Infusion of Beneficial Phrases. Detect and suggest phrases or details that can significantly enhance the model’s output in terms of contextual relevance and accuracy.
By achieving these objectives, the model aims to eliminate detrimental textual details and incorporate beneficial information, ensuring that the decoded visual representation is both contextually rich and aligned with user preferences.
We use the actor-critic framework. The state is defined as the current textual representation. The initial state is the communication data generated from the input image. The possible action is one of addition, deletion and modification. The three kinds of actions can introduce a new phrase or detail into the communication data, remove a specific phrase or detail from the communication data, and alter an existing phrase or detail within the communication data, respectively. The reward is a measure of the quality of the adjusted communication data in terms of its ability to be decoded into a contextually relevant image. Where the quality can be a function of various factors like contextual relevance, clarity, and alignment with user preferences.
There is an actor and a critic in the framework. The actor defines a policy which gives the probability of taking action in state . It’s represented as:
The critic evaluates the expected return or value of taking an action in a particular state. It’s given by:
The advantage function measures the relative value of taking a particular action over the average action in that state:
where is the discount factor.
The actor is updated using the policy gradient method:
The critic is updated based on the mean squared error between its predicted value and the actual return:
4 Experiment
In the experiment, we utilize the Stanford Cars dataset for our experiments. This dataset comprises 196 classes of cars, totaling 16,185 images. The categorization is typically based on the Make, Model, and Year of the cars. Each image has dimensions of 360×240.
We consider a method that immediately translates an image to text and then back to an image as our baseline. We compare the performance of the scalable AIGC system against this baseline. The experiments are conducted using i9-10920X CPU and GeForce RTX 2080 Ti. The evaluation is based on the Recall@k metric on the reconstructed images. This metric evaluates the accuracy of the top-k predictions for the classification task on the test set, making it suitable for assessing the performance of our image reconstruction.
We report results using a subset of the Stanford Cars dataset: 200 images for training and 50 images for testing.

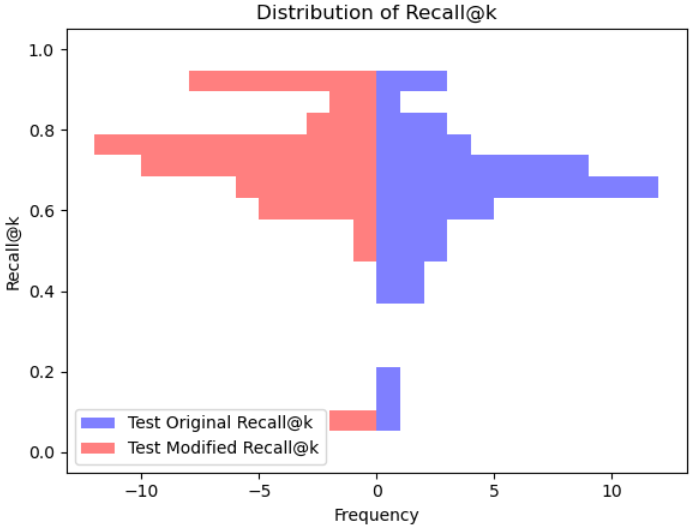
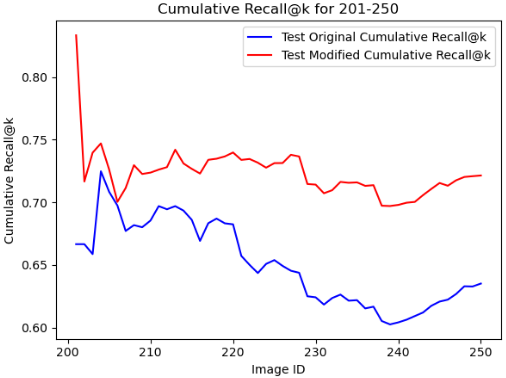
Performance Distribution: Figure 4 shows the distribution of the Recall@k metric for both our method (the scalable AIGC system, denoted as “Modified”) and the baseline (denoted as “Original”) on the same test set. Figure 4 shows the comparision between the cumulative Recall@k metrics of the proposed method and the baseline. From the presented figures, the proposed scalable AIGC system demonstrates some advantages over the baselines, suggesting good performance on specific tasks.
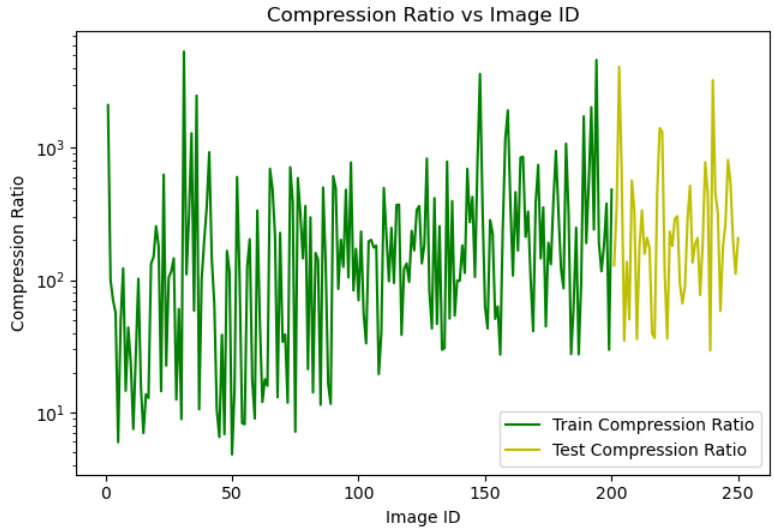
Compression Rate: Figure 4 highlights the compression rate achieved by our method. Given that the proposed scalable AIGC system transmits adjusted textual information rather than the original image, it realizes substantial compression. This particularly advantageous in bandwidth-constrained situations, ensuring swift information transfer without compromising the semantic integrity of the reconstructed image. Therefore, the scalable AIGC system is a promising approach for bandwidth-constrained communication scenarios. Figure 5 shows an example of the recovered image derived solely from text representations via the proposed system and the corresponding original image. As evident from the figure, the images retain visual semantic consistency before and after processing.
5 Conclusion
In this paper, we present a scalable AI generative content system—a approach to efficient semantic communication in bandwidth-limited settings. Utilizing encoder-decoder architecture and reinforcement learning, our method encodes the image into a leaner way for transmission and reconstruction at the decoder side. Experimental tests on a vehicle image dataset confirm that our framework compresses raw images into task-specific textual representations. It then produces high-quality images from these textual cues, as evidenced by the cumulative Recall@k metric. These outcomes illustrate the efficacy and promise of our scalable system, which we believe holds versatility for application in various fields.
References
- [1] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems, Montreal, Quebec, Canada, December 2014, pp. 2672–2680.
- [2] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” in Proceedings of the 38th International Conference on Machine Learning (ICML), Virtual Event, vol. 139, July 2021, pp. 8821–8831.
- [3] M. Xu, H. Du, D. Niyato, J. Kang, Z. Xiong, X. Shen, Z. Han, and H. V. Poor, “Unleashing the power of edge-cloud generative AI in mobile networks: A survey of AIGC services,” to appear IEEE Communications Surveys & Tutorials.
- [4] M. Xu, D. Niyato, J. Chen, H. Zhang, J. Kang, Z. Xiong, S. Mao, and Z. Han, “Generative AI-empowered simulation for autonomous driving in vehicular mixed reality metaverses,” to appear IEEE Journal on Selected Topics on Signal Processing.
- [5] B. Ji, X. Zhang, S. Mumtaz, C. Han, C. Li, H. Wen, and D. Wang, “Survey on the internet of vehicles: Network architectures and applications,” IEEE Communications Standards Magazine, vol. 4, no. 1, pp. 34–41, March 2020.
- [6] H. van Hasselt, “Double q-learning,” in Advances in Neural Information Processing Systems 23: 24th Annual Conference on Neural Information Processing Systems, Vancouver, British Columbia, Canada, December 2010, pp. 2613–2621.
- [7] H. van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning,” in Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, Arizona, February 2016, pp. 2094–2100.
- [8] G. K. Wallace, “The JPEG still picture compression standard,” Commun. ACM, vol. 34, no. 4, pp. 30–44, April 1991.
- [9] T. Boutell, “PNG (portable network graphics) specification version 1.0,” RFC, vol. 2083, no. 1, pp. 1–102, March 1997.
- [10] G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, and R. Sukthankar, “Variable rate image compression with recurrent neural networks,” in 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, May 2016.
- [11] L. Theis, W. Shi, A. Cunningham, and F. Huszár, “Lossy image compression with compressive autoencoders,” in 5th International Conference on Learning Representations (ICLR), Toulon, France, April 2017.
- [12] A. Farhadi, S. M. M. Hejrati, M. A. Sadeghi, P. Young, C. Rashtchian, J. Hockenmaier, and D. A. Forsyth, “Every picture tells a story: Generating sentences from images,” in 11th European Conference on Computer Vision (ECCV), Heraklion, Crete, Greece, vol. 6314, September 2010, pp. 15–29.
- [13] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, June 2015, pp. 3156–3164.
- [14] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, December 2017, pp. 5998–6008.
- [15] H. Zhang, T. Xu, and H. Li, “Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks,” in IEEE International Conference on Computer Vision (ICCV), Venice, Italy, October 2017, pp. 5908–5916.
- [16] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. A. Riedmiller, A. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,” Nat., vol. 518, no. 7540, pp. 529–533, February 2015.