Dual-Teacher De-biasing Distillation Framework for Multi-domain Fake News Detection
††thanks: Jiayang Li and Xuan Feng have contributed to this work equally.
††thanks: Tianlong Gu is the corresponding author.
††thanks: This work was supported by the National Natural Science Foundation of China (Grant No. U22A2099).
Abstract
Multi-domain fake news detection aims to identify whether various news from different domains is real or fake and has become urgent and important. However, existing methods are dedicated to improving the overall performance of fake news detection, ignoring the fact that unbalanced data leads to disparate treatment for different domains, i.e., the domain bias problem. To solve this problem, we propose the Dual-Teacher De-biasing Distillation framework (DTDBD) to mitigate bias across different domains. Following the knowledge distillation methods, DTDBD adopts a teacher-student structure, where pre-trained large teachers instruct a student model. In particular, the DTDBD consists of an unbiased teacher and a clean teacher that jointly guide the student model in mitigating domain bias and maintaining performance. For the unbiased teacher, we introduce an adversarial de-biasing distillation loss to instruct the student model in learning unbiased domain knowledge. For the clean teacher, we design domain knowledge distillation loss, which effectively incentivizes the student model to focus on representing domain features while maintaining performance. Moreover, we present a momentum-based dynamic adjustment algorithm to trade off the effects of two teachers. Extensive experiments on Chinese and English datasets show that the proposed method substantially outperforms the state-of-the-art baseline methods in terms of bias metrics while guaranteeing competitive performance 111Our codes are available at https://github.com/ningljy/DTDBD.
Index Terms:
Multi-domain Fake news Detection, Knowledge Distillation, Domain Adversarial TrainingI Introduction
With the popularity of social media platforms, multi-domain fake news detection has become urgent and important. The task aims to identify whether various news from different domains is real or fake [1, 2]. Despite the extraordinary achievements of extant methods in terms of average performance, they lack unbiased consideration of each domain [3]. Disparate treatment of fake news in different domains can lead to serious consequences [4, 5, 6, 7]. For example, misclassifying real disaster news as fake news potentially leads to delaying a user’s emergency response to the danger. Therefore, reducing bias is one of the most critical aspects of deploying multi-domain fake news detection models in real-world scenarios.
| Domain | Science | Military | Education | Disaster | Politics |
|---|---|---|---|---|---|
| %Fake | 39.4 | 64.7 | 50.5 | 76.1 | 64.0 |
| %News | 2.6 | 3.8 | 5.3 | 8.5 | 9.3 |
| Domain | Health | Finance | Ent. | Society | Average |
| %Fake | 51.5 | 27.4 | 30.5 | 55.1 | 51.0 |
| %News | 11.0 | 14.5 | 15.8 | 29.2 | 11.1 |
| Method | Single-domain | Multi-domain | Debiasing | Bias Type | Dataset |
|---|---|---|---|---|---|
| BiGRU[8] | Twitter, Weibo | ||||
| StyleLSTM[9] | StyleLSTM | ||||
| DualEmo[10] | RumourEval-19, Weibo-16, Weibo-20 | ||||
| EANN [11] | Twitter, Weibo | ||||
| Diachronic Bias Mitigation [12] | Diachronic | MultiFC, Horne17, Celebrity, Constraint | |||
| EDDFN[13] | PolitiFact, Gossipcop, CoAID | ||||
| MDFEND[1] | Weibo21 | ||||
| ENDEF[7] | Entity | Weibo, GossipCop | |||
| M3FEND[14] | Weibo21, Politifact, Gossipcop, COVID | ||||
| Our | Domain | Weibo21, Politifact, Gossipcop, COVID |
The amount of news in different domains differs greatly due to real-time events, social trends, public information needs, and other factors [15, 16]. The existing dataset also suffers from the following limitations owing to this property (taking Weibo21 [1] as an example, whose statistics are shown in Table I)): 1) the amount of fake news pieces is unbalanced across domains (e.g., Social news accounts for 29.2% of the total number of fake news pieces, while Science accounts for only 2.6%); 2) the rate of fake news pieces is practically unequal across domains (e.g., only 27.4% of Finance news and 30.5% of Entertainment news are fake. Yet, this percentage is up to 76.1% and 64.0% on Disaster news and Politics news); 3) models trained on unbalanced datasets may discriminate in predicting news from different domains. In addition, imbalanced datasets can lead to models learning spurious correlations between news labels and domain labels, which may affect generalization and incur serious domain bias problems. Thus, tackling the domain bias problem exposed by multi-domain fake news detection in a supervised setting requires more attention.
Existing single-domain fake news detection methods [17, 8, 18] are dedicated to improving detection performance while ignoring domain features of news. This leads them to be vulnerable in learning or even amplifying domain bias based on unbalanced datasets. In turn, most multi-domain fake news detection efforts [1, 14] incorporate domain knowledge to guide the representation of more comprehensive features. However, it is possible that models lacking unbiased designs may unintentionally establish spurious correlations between the domain and the authenticity of the news. In fact, a piece of news may be related to multiple domains but has limited relevance to others. As such, forcing models to learn invariant features of all domains will further deteriorate the domain bias. Nevertheless, although directly applying existing debiasing methods [11, 13] can mitigate bias to some extent, it will cause serious performance degradation. Hence, the trade-off between the de-biasing effectiveness and the prediction performance in multi-domain fake news detection tasks is an imperative problem to be solved.
In these regards, we propose the Dual-Teacher De-biasing Distillation framework (DTDBD), which mitigates domain bias arising from the unbalanced distribution of domains and categories in real-world datasets. Following the knowledge distillation methods, DTDBD adopts a teacher-student structure, where pre-trained large teachers instruct a student model. In particular, the DTDBD consists of an unbiased teacher and a clean teacher that jointly guide the student model. For the unbiased teacher, inspired by feature distillation [19], we design a novel optimization objective called adversarial de-biasing distillation that transfers unbiased distribution as knowledge. By treating the unbiased distribution as a soft label, we prevent the student model from being solely responsible for learning the intricacies of the unbiased distribution from the unbiased teacher model. For the clean teacher, we introduce a domain knowledge distillation loss to encourage the student model to flexibly focus on multiple relevant domains for each domain. Furthermore, we present a momentum-based dynamic adjustment algorithm, which dynamically adjusts the weights of the unbiased and the clean teachers. The trade-off between unbiased representation and news representation enables the DTDBD to mitigate bias while maintaining competitive performance.
To sum up, the contributions can be summarized in the followings:
-
•
We propose a novel Dual-Teacher De-biasing Distillation framework (DTDBD) to mitigate the domain bias in multi-domain fake news detection. It consists of an unbiased teacher and a clean teacher with distinct specialties to jointly guide the student model.
-
•
To reduce the domain bias of the student model, we design an adversarial de-biasing distillation for the unbiased teacher. This distillation method captures the correlation of samples in the intermediate layer and utilizes it as knowledge for de-biasing distillation.
-
•
Considering the trade-off between the impact of the two teachers, we introduce a momentum-based dynamic adjustment algorithm, which is determined by the change in the performance and bias metrics of the student model.
-
•
Extensive experimental results demonstrate the effectiveness of our method in simultaneously improving model performance and mitigating domain bias. Additionally, our method achieves state-of-the-art performance on Chinese datasets, highlighting its superiority in multi-domain fake news detection.
II Related Work
II-A Multi-domain Fake news detection
Fake news detection aims to identify news pieces as real or fake [20]. Traditional methods [17, 8, 18] focus on a single domain of fake news detection. These methods can be broadly classified into content-based and social context-based fake news detection. Content-based information includes news text [21, 22], images [23, 24], styles [25, 9], and emotions [26, 10, 27]. Social context-based information depends on user profiles [28, 29], propagation networks [30, 31, 32], and crowd feedback [33, 34].
In real-world scenarios, fake news typically originates from multiple different domains, thus multi-domain fake news detection has received attention. Wang et al. [11] first recognized the impact of news event diversity on fake news detection. They introduced an event adversarial neural network (EANN) that learned event-invariant features. Silva et al. [13] proposed a framework with domain-specific and cross-domain knowledge to detect the authenticity of news from different domains. Nan et al. [1] collected a Chinese multi-domain fake news detection dataset Weibo21 from Sina Weibo, which includes nine domains: science, military, education, disasters, politics, health, finance, entertainment, and society. They developed a learnable domain gate to aggregate features extracted by multiple experts. Zhu et al. [14] further designed a Domain Memory Bank to discover potential domain labels of news for guiding the aggregated features of domain adapters. However, the above efforts merely focus on performance improvements and ignore the problem of biases that exist among domains. Only a few studies have paid attentions to the bias problem in fake news detection. Zhu et al. [7] employed causal diagrams to eliminate the entity bias between entities and news in the inference process. To mitigate diachronic bias, Murayama T et al. [12] substituted Wikidata for proper names, encompassing individuals and geographical locations. The functional comparison of fake news detection related works are shown in Table II.
| Model | Disaster | Politics | Finance | Ent. | ||||
|---|---|---|---|---|---|---|---|---|
| FNR | FPR | FNR | FPR | FNR | FPR | FNR | FPR | |
| EANN [11] | 0.0738 | 0.1756 | 0.0420 | 0.2115 | 0.1644 | 0.0938 | 0.1310 | 0.0735 |
| EDDFN [13] | 0.0656 | 0.2674 | 0.1261 | 0.1923 | 0.1918 | 0.0729 | 0.1429 | 0.0735 |
| MDFEND [1] | 0.0574 | 0.1471 | 0.0588 | 0.1713 | 0.1370 | 0.0573 | 0.1429 | 0.0441 |
| M3FEND[14] | 0.0410 | 0.2059 | 0.0420 | 0.2308 | 0.1370 | 0.0573 | 0.1429 | 0.0245 |
II-B Domain adversarial training
Domain adversarial training [35] aims to map data from the source domain and target domain with different distributions into the same feature space. Simultaneously, the method expects the distances of differently distributed data to be as close as possible in this space. Ganin et al. [36] introduced the domain adversarial neural network (DANN), which has been successfully applied to mitigate bias by utilizing domain adversarial training. Kashyap et al. [37] tailored a domain adversarial method to mitigate texture bias in machine learning models. Liu et al. [38] employed domain adversarial learning to address gender bias in neural dialogue generation. Chowdhury et al. [39] introduced “adversarial scrubbers”, an adversarial learning framework that intends to remove contextual representations and mitigate bias caused by demographic correlations. Choi et al. [40] integrated a domain adversarial module into an action recognition framework to alleviate scene bias arising from action scene co-occurrence.
II-C Fair knowledge distillation
Knowledge distillation [41] is a model compression method to achieve model lightweight and performance improvement by transferring knowledge from a complex model (teacher model) to a simple model (student model). Previous work has focused on how to transfer knowledge [41, 19, 42] and what kind of knowledge to transfer [43, 44] in order to improve the performance of the student model.
Recently, several studies have found that model compression can affect fairness, and there has been growing attention on the role of knowledge distillation in bias mitigation tasks [45, 6]. Chai et al. [46] adopted knowledge distillation to mitigate group bias without relying on demographic information. Liu et al. [47] proposed a novel generic knowledge distillation framework to address bias in recommender systems. In addition, knowledge distillation has been leveraged to handle bias in information retrieval [48] and face recognition [49, 50]. Thus, knowledge distillation is a promising way to mitigate domain bias.
III Preliminary
In this section, we initially present the fundamental notations and preliminary concepts employed in this paper. Subsequently, we proceed to formalize the problem of domain bias.
III-A Notations and Definitions
Definition 1 (Fake News Detection [15]). Given a news dataset , where is a set of news text and is a set of news label. Each news item is associated with binary labels , where indicates the news is real and indicates it is fake. Fake news detection aims to detect the authenticity of news by training a model to find the association between the news text and the label .
Definition 2 (Multi-domain Fake News Detection [1]). We represent a multi-domain news dataset as , where represent the news texts, denote the news label, and is the domain of the news. Each news is assigned a domain label and a news label . Multi-domain fake news detection is characterized by the use of domain labels for capturing the characteristics of news in the same domain to detect fake news.
Definition 3 (Domain Disparate Mistreatment [51]). Domain disparate mistreatment is a metric of domain bias. Given a fake news detection model and a sample , where is the news text, is the news domain, and is the news label. It is called unbiased if the rate of true positives or false positives of this classifier on any two different domains , is equal, i.e.,
| (1) |
| (2) |
Definition 4 (Knowledge Distillation [41]). Knowledge distillation aims to enable the student model to learn from the teacher model by minimizing the discrepancy between their logits. In this context, the teacher model is typically a complex and high-performing model, while the student model is a lightweight model. Given a pre-trained teacher model and an untrained student model , we denote the logits of the news data from the teacher model and the student model as (soft labels) and , respectively. It is essential to highlight that logits are response-based knowledge. Furthermore, in our method, we leverage feature-based distillation[19], where the intermediate layer outputs of the model serve as knowledge to be transferred.
III-B Problem Statement
Given a multi-domain news dataset , our objective is to train a fake news detection model, which treats news from different domains unbiasedly. In our problem setting, we adopt domain disparate mistreatment to measure the false negative rates (FNR) and false positive rates (FPR) of the model. Given the FNR and the FPR of a pre-trained model on two different domains , . The domain bias constraint can be expressed as:
| (3) |
| (4) |
IV Analysis of Domain bias
IV-A Domain bias in existing methods
A thorough analysis was conducted on four imbalanced domains using four advanced fake news detection models, revealing a noteworthy concern about the domain bias problem. Table III illustrates that the Disaster and Political domains display significantly elevated FPR compared to the average. This implies that the models have developed a tendency to label news from domains with a substantial prevalence of fake news as fake. On the contrary, the Financial and Entertainment domains, which consist of a greater proportion of real news, exhibit higher FNR. This indicates that the models are more inclined to classify news from these domains as real.
IV-B Challenges
To tackle the domain bias problem, we emphasize the following two key points:
IV-B1 Integration of domain knowledge
The inclusion of domain knowledge in the learning process is crucial for mitigating domain drift and enhancing learning performance. In this context, domain drift refers to the fact that fake news originating from different domains exhibits significant variations in vocabulary, emotional tone, and writing style [14]. However, it is essential to exercise caution when utilizing domain knowledge as a categorization factor, as it may inadvertently learn domain preferences, potentially impacting generalization and bringing the domain bias problem.
IV-B2 Consideration of fuzzy labels
The topics covered in real-world news are diverse, and a news item can often be relevant to multiple domains simultaneously [14]. Therefore, the domain labels of news should be ambiguous; in other words, the domain labels should reflect the degree of similarity of the news to each domain. Incorporating fuzzy labels aids in identifying potentially relevant news beyond the confines of a single domain. However, excessive emphasis on data with low relevance may impede the acquisition of cross-domain knowledge.
Initially, our objective was to eliminate spurious correlations between domains and news veracity. Nevertheless, we discovered that news from different domains can exhibit high correlations. Eliminating this correlation weakens the connection between news text and its veracity. Consequently, we adopt a dual-teacher knowledge distillation framework. This framework not only eliminates spurious correlations between domains and news veracity but also preserves correlations between news content and its truthfulness. By employing knowledge distillation, we ensure that the learned associations are more accurate and aligned with the actual truthfulness of the news.
V Framework
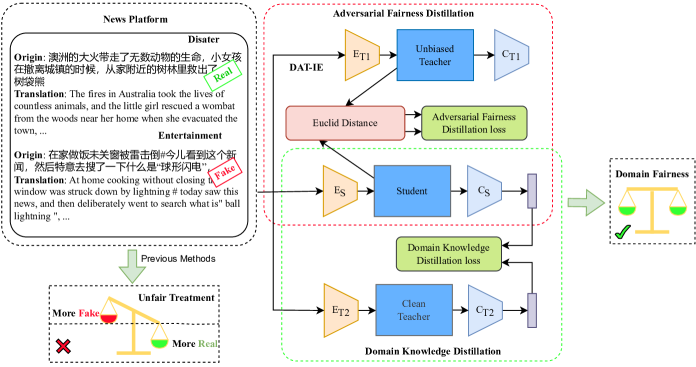
In this section, we present a detailed explanation of the proposed DTDBD framework, which consists of adversarial de-biasing distillation and domain knowledge distillation. Additionally, we introduce a momentum-based dynamic adjustment algorithm utilized to adaptively adjust the weights of these two distillation methods. The overall framework of DTDBD is shown in Figure 1.
V-A The DTDBD Framework
To reduce domain bias while mitigating performance degradation in the context of multi-domain fake news detection, we propose a novel de-biasing framework called Dual-Teacher De-biasing Distillation (DTDBD). Unlike previous multi-teacher distillation methods [52, 53], our method simultaneously focuses on two distinct metrics: bias and performance.
While some prior work has utilized adversarial knowledge distillation [54, 55] to enhance the robustness of the student model by introducing adversarial examples for transferring knowledge from teacher models, robustness primarily remains a performance metric in anomalous situations. In contrast, DTDBD integrates two key distillation approaches: adversarial de-biasing distillation and domain knowledge distillation, leveraging an unbiased teacher and a clean teacher to guide the student model, respectively. It is worth noting that the weights of the unbiased and clean teachers are frozen during the distillation process.
The adversarial de-biasing distillation is designed to mitigate domain bias by using the unbiased teacher to transfer the knowledge related to unbiased distributions to the student model. On the other hand, the domain knowledge distillation leverages the clean teacher to transfer domain-specific knowledge to the student model, enabling it to effectively handle the nuances and characteristics of different domains.
By combining these two distillation approaches, DTDBD provides a comprehensive framework that guarantees performance while addressing domain bias in multi-domain fake news detection, resulting in a more balanced and effective framework. First, we select a fine-tuned multi-domain fake news detection model with a domain knowledge learning module as a clean teacher and train an unbiased teacher model. Second, the adversarial de-biasing distillation loss and the domain knowledge distillation loss of the student model are computed under the guidance of the unbiased teacher and the clean teacher, respectively. Finally, a momentum-based dynamic adjustment algorithm assigns weights to these two losses and subsequently updates the student model.
V-B Adversarial de-biasing distillation
While enforcing the model to learn invariant features can mitigate bias to some extent, it can have a serious impact on performance. Therefore, we design the adversarial de-biasing distillation to reduce domain bias by transferring unbiased distribution as knowledge to the student model. Considering that bias is reflected in the relative relationship among samples, we use the correlation between the intermediate features as unbiased distribution knowledge, and adopt Euclidean distance to measure the correlation of two samples. Given a set of intermediate features , which is obtained by a feature extractor, the correlation matrix M can be expressed as:
| (5) |
Then we perform adversarial de-biasing distillation in the intermediate layer, which enables the student model to learn correlations between samples mastered by the unbiased teacher. Adversarial de-biasing distillation can be formulated as:
| (6) |
where KL is Kullback-Leibler divergence loss, is a temperature hyperparameter used in knowledge distillation. and follow from unbiased teacher and student , which represents student network with parameters and unbiased teacher network with parameters .
For the design of the unbiased teacher, due to the large gap between the encoders of the different models and the difficulty of transferring the learned knowledge of unbiased distribution to each other, we set the structure of the unbiased teacher to be the same as that of the student model. Domain adversarial training was applied to get an unbiased teacher. Specifically, encoder , domain classifier , and label classifier can be described as the following optimization process:
| (7) |
| (8) |
| (9) |
However, we find that on multi-domain fake news detection tasks, this approach causes the model to learn a shortcut, i.e., to learn only the common features of the domains most relevant to its own domain, while ignoring other relevant domains.
To solve this problem, we propose the domain adversarial training - information entropy (DAT-IE) loss, which encourages the model to focus on more relevant domains by adding information entropy loss to domain adversarial training. Information entropy can express the degree of uncertainty of a vector, which is the same as our goal in domain adversarial. Despite this may lead to the model failing to differentiate between domains instead of misclassification, Information entropy loss can be defined as:
| (10) |
At this point, the DAT-IE loss can be expressed as:
| (11) |
where denotes loss of cross entropy. In this paper, we set to extend the range of attention to invariant features.
V-C Domain knowledge distillation
Previous work in multi-domain fake news detection [14, 56] has demonstrated that fuzzy domain labels facilitate the accuracy of fake news detection. Moreover, we find that some news pieces from different domains may exhibit more similarities than those within the same domain.
Therefore, we design the domain knowledge distillation to encourage models to learn transferable unbiased domain knowledge which guarantees performance in bias mitigation. In domain knowledge distillation, we use a state-of-the-art fine-tuned multi-domain fake news detection model M3FEND [14] as a teacher for this part since it learns effectively shared domain knowledge by building domain knowledge learning modules. The loss of domain knowledge distillation process can be represented as:
| (12) |
where and denote the classifiers of the clean teacher and the student respectively. and are intermediate features of clean teacher and student, respectively.
V-D Momentum-based dynamic adjustment algorithm
In order to trade off the impact of the unbiased teacher and the clean teacher on the student model and prevent a single teacher from overplaying their role, we introduce a momentum-based dynamic adjustment algorithm. DTDBD uses the weighting of adversarial de-biasing distillation loss, domain knowledge distillation loss, and classification loss as the overall loss, which can be expressed as follows:
| (13) |
where , , denote the weights of adversarial de-biasing distillation loss, domain knowledge distillation loss, and student classification loss, respectively. We calculate the change in performance and in bias metrics since the second epoch. The update process of and can be formulated as follows:
| (14) |
| (15) |
where is a momentum coefficient.
We detail the DTDBD framework in Algorithm 1.
| Domain | Science | Military | Education | Disaster | Politics |
|---|---|---|---|---|---|
| Fake | 93 | 222 | 248 | 591 | 546 |
| Real | 143 | 121 | 243 | 185 | 306 |
| Total | 236 | 343 | 491 | 776 | 852 |
| Domain | Health | Finance | Ent. | Society | All |
| Fake | 515 | 362 | 440 | 1,471 | 4,488 |
| Real | 485 | 959 | 1,000 | 1,198 | 4,640 |
| Total | 1,000 | 1,321 | 1,440 | 2,669 | 9,128 |
| Domain | Gossipcop | Politifact | COVID | All |
|---|---|---|---|---|
| Fake | 5,067 | 379 | 1,317 | 6,763 |
| Real | 16,804 | 447 | 4,750 | 22,001 |
| Total | 21,871 | 826 | 6,067 | 28,764 |
VI Experiments
VI-A Experimental Settings
VI-A1 Datasets
We evaluate our DTDBD on Chinese dataset Weibo21[1] and English datasets including FakeNewsNet [57] and COVID [58]. The statistics of Chinese and English datasets are shown in Table IV and V.
-
•
Chinese Dataset. Weibo21 [1] is a Chinese multi-domain fake news detection dataset designed to evaluate the average performance of fake news detection models across various domains. It consists of the news collected from Sina Weibo and is categorized into nine domains, including science, military, education, disaster, politics, health, finance, entertainment, and society.
-
•
English Dataset. Following [14, 3], the English dataset we use is a merger of FakeNewsNet [57] and COVID [58], including three domains: gossipcop, politics, and COVID.
VI-A2 Baseline Models
In our study, we employed a state-of-the-art multi-domain fake news detection method [14] and adopted the same baselines as used in that work. Our baseline models encompass the following 11 approaches:
| Methods | Science | Military | Education | Disaster | Politics | Health | Finance | Ent. | Society | Overall | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | FNED | FPED | Total | ||||||||||
| BiGRU[8] | 0.7479 | 0.9129 | 0.8182 | 0.8574 | 0.8694 | 0.8850 | 0.8582 | 0.8671 | 0.8602 | 0.8754 | 0.6361 | 0.3538 | 0.9899 |
| TextCNN[59] | 0.7890 | 0.9270 | 0.9091 | 0.8765 | 0.8680 | 0.9250 | 0.8935 | 0.8404 | 0.8801 | 0.8934 | 0.5730 | 0.4535 | 1.0265 |
| BERT | 0.7566 | 0.9129 | 0.8887 | 0.8895 | 0.8728 | 0.9200 | 0.8823 | 0.9076 | 0.8901 | 0.9032 | 0.6241 | 0.4160 | 1.0401 |
| RoBERTa[60] | 0.7166 | 0.9417 | 0.8382 | 0.8684 | 0.8806 | 0.9100 | 0.8000 | 0.8750 | 0.8754 | 0.8884 | 0.8287 | 0.4108 | 1.2395 |
| StyleLSTM[9] | 0.8196 | 0.9273 | 0.8582 | 0.8790 | 0.8697 | 0.9250 | 0.8932 | 0.9121 | 0.8881 | 0.9049 | 0.5616 | 0.5464 | 1.1080 |
| DualEmo[10] | 0.8271 | 0.9419 | 0.8384 | 0.8821 | 0.8665 | 0.9050 | 0.8889 | 0.9133 | 0.8992 | 0.9027 | 0.5429 | 0.4261 | 0.9690 |
| EANN[11] | 0.8487 | 0.9419 | 0.8485 | 0.8760 | 0.8525 | 0.9300 | 0.8833 | 0.8967 | 0.8963 | 0.9021 | 0.4438 | 0.3410 | 0.7848 |
| EANN_NoDAT | 0.8196 | 0.9417 | 0.9089 | 0.8684 | 0.8934 | 0.9350 | 0.9012 | 0.9069 | 0.9033 | 0.9132 | 0.5696 | 0.3964 | 0.9660 |
| MMoE[61] | 0.8594 | 0.9275 | 0.8888 | 0.8496 | 0.8618 | 0.9299 | 0.8417 | 0.8840 | 0.8739 | 0.8911 | 0.4728 | 0.3982 | 0.8710 |
| MoSE | 0.8125 | 0.8384 | 0.8586 | 0.8014 | 0.8240 | 0.9050 | 0.8573 | 0.9108 | 0.8676 | 0.8825 | 0.5093 | 0.8786 | 1.3879 |
| EDDFN[13] | 0.8271 | 0.9273 | 0.8574 | 0.8765 | 0.8244 | 0.9374 | 0.8573 | 0.8802 | 0.8749 | 0.8912 | 0.5790 | 0.5597 | 1.1387 |
| EDDFN_NoDAT | 0.8021 | 0.9270 | 0.9088 | 0.8694 | 0.8525 | 0.9247 | 0.8414 | 0.8810 | 0.8624 | 0.8916 | 0.5507 | 0.4530 | 1.0037 |
| MDFEND[1] | 0.8487 | 0.9417 | 0.8917 | 0.8872 | 0.8597 | 0.9400 | 0.9020 | 0.9121 | 0.8903 | 0.9120 | 0.5795 | 0.5250 | 1.1045 |
| M3FEND[14] | 0.8196 | 0.9417 | 0.8787 | 0.8684 | 0.8856 | 0.9450 | 0.9016 | 0.9318 | 0.9131 | 0.9207 | 0.5867 | 0.5099 | 1.0966 |
| Our(MD) | 0.9030 | 0.9419 | 0.8987 | 0.9060 | 0.9152 | 0.9450 | 0.8893 | 0.9023 | 0.9131 | 0.9213 | 0.4345 | 0.3155 | 0.7500 |
| Our(M3) | 0.9259 | 0.9546 | 0.9292 | 0.8955 | 0.9087 | 0.9500 | 0.9074 | 0.9293 | 0.9234 | 0.9290 | 0.3446 | 0.4038 | 0.7484 |
-
•
Roberta [60]. This is a pre-trained model that employs dynamic masking language modeling techniques. We used it as an encoder with frozen parameters to preserve learned representations. The model incorporates a Multilayer Perceptron (MLP) for classification.
-
•
BiGRU [8]. It is a text encoder based on a common recurrent neural network (RNN) architecture. In our implementation, we utilized a one-layer BiGRU with a hidden layer size of 300.
-
•
TextCNN [59]. Specifically designed for processing and analyzing text data, TextCNN employs a convolutional neural network architecture. We utilized five convolutional kernels with different kernel steps of 1, 2, 3, 5, and 10, each with 64 channels.
-
•
StyleLSTM [9]. This model utilizes a bidirectional LSTM as an encoder. The encoded features are then fed into the MLP along with style features to obtain prediction results.
-
•
DualEmo [10]. It employs BiGRU as an encoder, and sentiment features are input to the MLP along with the text features. The encoder settings are similar to the BiGRU method.
-
•
MMoE [61]. This model adopts MLP as an expert network and combines representations from multiple experts using a gating mechanism.
-
•
MoSE. Similar to MMoE, MoSE replaces the MLP with an LSTM as an expert network.
-
•
EANN [11]. It consists of a feature extractor, a fake news classifier, and an event discriminator. Its objective is to identify and remove event-specific features while retaining shared features among different events. We utilized the setup described in [14].
-
•
EDDFN [13]. This framework aims to retain domain-specific and cross-domain knowledge in news data for detecting fake news across different domains. We followed the setup described in [1].
-
•
MDFEND [1]. It is a multi-domain detection model that employs learnable domain gates to aggregate expert networks. TextCNN serves as an expert network, and the setup of each expert network is similar to the baseline TextCNN approach.
-
•
M3FEND [14]. It is a state-of-the-art multi-domain fake news detection model that uses domain adapters to aggregate semantics, sentiment, and style to obtain a comprehensive news representation while using a domain memory bank to generate latent domain labels for the sample.
| Method | Gossipcop | Politics | COVID | Overall | |||
|---|---|---|---|---|---|---|---|
| F1 | FNED | FPED | Total | ||||
| BiGRU[8] | 0.7774 | 0.7726 | 0.9016 | 0.8048 | 0.2125 | 0.1317 | 0.3442 |
| TextCNN[59] | 0.7953 | 0.7145 | 0.8851 | 0.8114 | 0.1619 | 0.1173 | 0.2792 |
| RoBERTa[60] | 0.7998 | 0.8033 | 0.9131 | 0.8258 | 0.2918 | 0.2315 | 0.5233 |
| StyleLSTM[9] | 0.7983 | 0.8123 | 0.9264 | 0.8268 | 0.2031 | 0.0767 | 0.2798 |
| DualEmo[10] | 0.7941 | 0.8204 | 0.9007 | 0.8194 | 0.2480 | 0.1282 | 0.3762 |
| EANN[11] | 0.7934 | 0.7731 | 0.8749 | 0.8019 | 0.1196 | 0.1475 | 0.2671 |
| EANN_NoDAT | 0.7857 | 0.7386 | 0.8734 | 0.8062 | 0.3381 | 0.1304 | 0.4685 |
| MMoE[61] | 0.8047 | 0.8486 | 0.9453 | 0.8380 | 0.3079 | 0.0750 | 0.3829 |
| MoSE | 0.7982 | 0.8553 | 0.9380 | 0.8324 | 0.3723 | 0.1156 | 0.4879 |
| EDDFN[13] | 0.7862 | 0.8605 | 0.9307 | 0.8217 | 0.3495 | 0.0754 | 0.4249 |
| EDDFN_NoDAT | 0.7986 | 0.8451 | 0.9423 | 0.8343 | 0.4156 | 0.0859 | 0.5015 |
| MDFEND[1] | 0.8080 | 0.8473 | 0.9331 | 0.8433 | 0.4376 | 0.1076 | 0.5452 |
| M3FEND [14] | 0.8237 | 0.8478 | 0.9392 | 0.8454 | 0.4397 | 0.1472 | 0.5869 |
| Our(MD) | 0.8025 | 0.8005 | 0.9259 | 0.8294 | 0.1779 | 0.0830 | 0.2609 |
| Our(M3) | 0.8073 | 0.8291 | 0.9332 | 0.8359 | 0.2021 | 0.0677 | 0.2698 |
In addition, we evaluated the versions of EANN and EDDFN that do not contain the domain countermeasure module, which are denoted as EANN_NoDAT and EDDFN_NoDAT.
It is important to highlight that among these baseline models, only EANN, EDDFN, MDFEND, and M3FEND incorporate the domain labels as part of their input.
VI-A3 Evaluation Metrics
Consistent with many previous studies [62, 63, 64, 65], we utilize false positive equality differences (FPED) and false negative equality differences (FNED) [66] to measure bias, along with F1 scores to assess performance. FPED quantifies the absolute difference between the overall FNR and the FPR for each domain, while FNED performs a similar calculation for false negatives, as shown in (16) and (17). We use Total to denote the sum of FNED and FPED.
| (16) |
| (17) |
VI-A4 Teacher and Student Networks
For the adversarial de-biasing distillation, we employ a network with the same architecture as the student model for domain adversarial training. This allows us to obtain an unbiased teacher model that facilitates the migration of the knowledge of unbiased distribution. In the domain knowledge distillation stage, we select two state-of-the-art multi-domain fake news detection methods, namely MDFEND [1] and M3FEND [14], as the clean teacher models due to their effectiveness in capturing domain knowledge. It is worth noting that MDFEND and M3FEND have 8.14M and 11.36M trainable parameters, respectively. To ensure comparability, we design a student network called TextCNN-S, which utilizes commonly used network structures and had 7.71M trainable parameters. TextCNN-S incorporate BERT with the activation of layer 11 and employ five convolutional kernels with 64 channels, each with different kernel steps of 1, 2, 3, and 5 as the encoder. MLP was used for classification purposes.
VI-A5 Training Setup
Our framework is implemented by PyTorch and trained on an NVIDIA GeForce RTX 3090. In accordance with the experimental setup outlined in [14], we measure the bias metrics of the baseline models and implement our approach. All baseline models were trained following the settings in the original paper and [14]. For the teacher-student distillation framework proposed in this paper, we freeze the weights of both teachers during the distillation process. In addition, all the experiments were conducted on all domains. Our student model, TextCNN-U, uses a learning rate of 0.001 during domain adversarial training. In the case of our DTDBD framework, we set the initial learning rate to 0.0001, and the weights of the two teachers were dynamically adjusted using (14) and (15).
VI-B Performance Comparison
In this section, we evaluate the effectiveness of DTDBD on both Chinese and English multi-domain fake news detection datasets. The evaluation results are presented in Tables VI and VII, which show the F1 scores for each domain and overall metrics including F1, FPED, and FNED. The best-performing results are highlighted in bold, while the second-best results are underlined.
| Model | TextCNN-S | BiGRU-S | ||||||
|---|---|---|---|---|---|---|---|---|
| F1 | FNED | FPED | Total | F1 | FNED | FPED | Total | |
| Student | 0.9136 | 0.7161 | 0.4059 | 1.1220 | 0.8999 | 0.6503 | 0.4577 | 1.1080 |
| Student+DAT-IE | 0.8967 | 0.3409 | 0.3347 | 0.6756 | 0.8743 | 0.4735 | 0.3229 | 0.7964 |
| Teacher(M3) | 0.9207 | 0.5867 | 0.5099 | 1.0996 | 0.9207 | 0.5867 | 0.5099 | 1.0996 |
| Student+DND | 0.9185 | 0.6721 | 0.4271 | 1.0992 | 0.9127 | 0.5272 | 0.4418 | 0.9690 |
| Student+ADD | 0.9109 | 0.4741 | 0.3053 | 0.7794 | 0.8980 | 0.5294 | 0.3391 | 0.8685 |
| w/o DAA | 0.9213 | 0.4908 | 0.4597 | 0.9505 | 0.9131 | 0.4361 | 0.4253 | 0.8614 |
| Our(M3) | 0.9290 | 0.3446 | 0.4038 | 0.7484 | 0.9142 | 0.4138 | 0.3491 | 0.7629 |
VI-B1 Domain unfairness measurement
By analyzing the results of the baseline methods, we observe that most single-domain and multi-domain fake news detection methods exhibit high FPED and FNED values. This indicates that these methods tend to learn domain bias from unbalanced datasets. We also find that EANN achieves the best debiasing results among the baseline models, suggesting that enforcing the model to learn cross-domain features is beneficial in mitigating domain bias. However, the performance of EANN is significantly lower than that of EANN_NODAT, which validates the effectiveness of domain adversarial training. The reason behind this discrepancy is that the adversarial structure ignores scenarios where a news item may be related to multiple domains with varying degrees of relevance. Notably, EDDFN_NODAT demonstrates a significant performance improvement compared to EDDFN on the English dataset, but the change is less pronounced on the Chinese dataset. This may be attributed to the fact that EDDFN incorporates an intra-domain knowledge learning module, which reduces the influence of the domain adversarial module in learning cross-domain features. Furthermore, since the English dataset only consists of three domains with substantial content gaps between them, the intra-domain knowledge learning module does not have a noticeable impact.
| Model | TextCNN-S | BiGRU-S | ||||||
|---|---|---|---|---|---|---|---|---|
| F1 | FNED | FPED | Total | F1 | FNED | FPED | Total | |
| Student | 0.9136 | 0.7161 | 0.4059 | 1.1220 | 0.8999 | 0.6503 | 0.4577 | 1.1080 |
| Student+DAT | 0.8856 | 0.3719 | 0.3807 | 0.7526 | 0.8599 | 0.4836 | 0.3290 | 0.8126 |
| Student+DAT-IE | 0.8967 | 0.3409 | 0.3347 | 0.6756 | 0.8743 | 0.4735 | 0.3229 | 0.7964 |
VI-B2 Results for DTDBD
Regarding our proposed method, TextCNN-U trained with DTDBD achieves state-of-the-art debiasing results while also attaining state-of-the-art performance on the Chinese datasets. This demonstrates that DTDBD is an effective approach that not only reduces domain bias but also mitigates the performance degradation problem. The main reason behind this success lies in the dual-teacher distillation structure employed by DTDBD, which transfers both the knowledge of unbiased distribution and domain knowledge to the student model. However, on the English dataset, the performance of our method is slightly lower than that of MDFEND and M3FEND, but there is a significant improvement in domain bias mitigating. This discrepancy can be attributed to the fact that the English dataset comprises only three domains with substantial differences in news content, making it challenging to learn important cross-domain knowledge.
Additionally, we find that M3FEND is more effective in imparting domain knowledge compared to MDFEND. While both methods employ a soft sharing mechanism to learn cross-domain knowledge, M3FEND constructs a memory matrix for each domain, allowing for a richer representation of domain information by calculating the similarity of news samples to the memory matrix to obtain the domain label distribution.
VI-C Ablation Study
VI-C1 Importance of different components
To gain a deeper understanding of the teaching characteristics of the two teachers in our DTDBD, the role of information entropy loss, and the effects of momentum-based dynamic adjustment algorithm, we conduct a series of ablation studies. We employ the TextCNN-U model as the student model. Student+DND and Student+ADD indicate training the student model using domain knowledge distillation and adversarial de-biasing distillation, respectively. Student+DTDBD represents our DTDBD method. DAA denotes the momentum-based dynamic adjustment algorithm. Additionally, we introduce a BiGRU-S model to demonstrate the effectiveness of each distillation module, which utilizes a frozen BERT and a one-layer BiGRU with a hidden size of 300 for feature extraction, followed by an MLP for classification.
VI-C2 Effectiveness of adversarial de-biasing distillation
As demonstrated in Table VIII, adversarial de-biasing distillation significantly mitigates the domain bias of the model, indicating the effectiveness of using unbiased distribution as knowledge. Furthermore, we find that compared to domain adversarial training, adversarial de-biasing distillation mitigates the problem of performance degradation while bias mitigation is improved. This aligns with our objective of not excessively forcing the model to focus on learning invariant features but rather learning them in domains with a high degree of relevance whenever possible.
VI-C3 Effectiveness of domain knowledge distillation
As shown in Table VIII, we discover that domain knowledge distillation can improve the performance of the student model. The reason is that the clean teacher transfers effective domain knowledge to the students, which is not available in the student model. We also see that domain knowledge distillation slightly reduces the domain bias of the model, suggesting that the knowledge distillation method itself can limit the learning of redundant knowledge.

VI-C4 Effectiveness of momentum-based dynamic adjustment algorithm
As shown in Table VIII, we observe that enhancements in both performance and fairness can occur even in the absence of the momentum-based dynamic adjustment algorithm, underscoring the significance of addressing fairness distillation and domain knowledge distillation. Nevertheless, it is worth noting that the improvements in fairness tend to be relatively modest while achieving further performance enhancements poses greater challenges. This can be attributed to the absence of an adversarial module in both the student model and the clean teacher model. Consequently, the student model tends to predominantly acquire knowledge from the clean teacher, somewhat neglecting the contributions of the unbiased teacher. This results in an insufficient acquisition of fairness-related knowledge during the learning process, ultimately limiting the potential for further performance improvement.
VI-C5 Effectiveness of information entropy loss
We evaluate the impact of information entropy loss on two student models. Student+DAT indicates the use of traditional domain adversarial training, while Student+DAT-IE refers to our modified domain adversarial training incorporating information entropy loss. As shown in Table IX, we observe that DAT-IE helps further mitigate the domain bias and improve performance compared to the DAT approach. This is because the DAT approach allows the model to learn a shortcut by focusing only on the most relevant domains, ignoring the extraction of shared knowledge from other domains. On the contrary, the information entropy loss encourages the model to prioritize features common across all domains, highlighting the importance of shared features in reducing domain bias.
VI-D Visualization of DTDBD
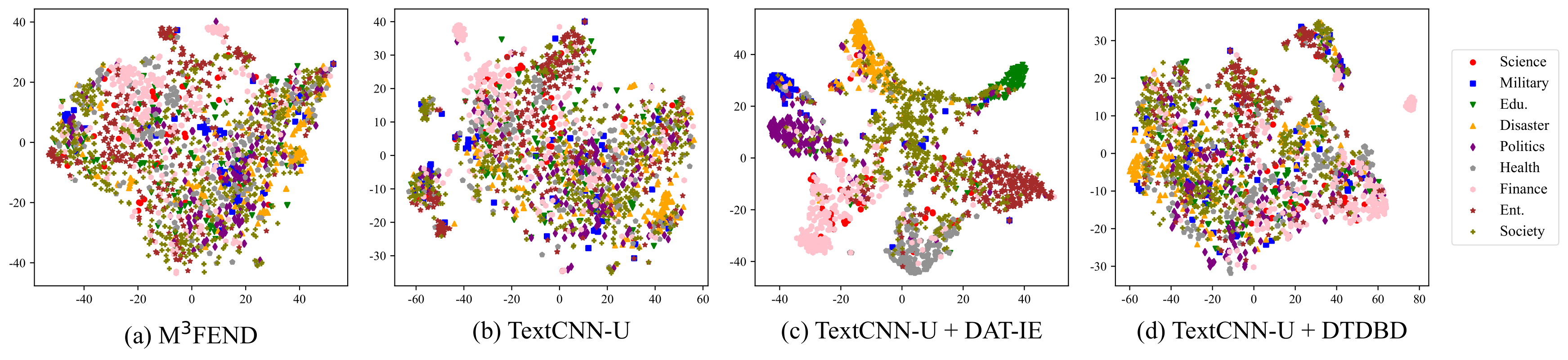
To visually illustrate the effectiveness of our method in learning cross-domain features, we employ dimensionality reduction using t-SNE to project the intermediate features of the test data into a 2-dimensional space, as shown in Figure 2. It is important to maintain a nuanced perspective on the sample distribution, considering the correlation between news from different domains.
We observe that in the M3FEND and TextCNN-U models, there are multiple areas containing samples from only one or a few domains. This suggests that these models may learn redundant domain-specific knowledge or focus primarily on shared features from a limited number of domains.
In the TextCNN-U+DAT-IE model, the aforementioned situation is more pronounced. This can be attributed to the incorporation of a DAT-IE loss in the news classification training, which compels the model to concentrate on the most relevant domains. Consequently, the model exhibits a higher degree of separation between domains in the feature space.
In comparison, the TextCNN-U model trained using our DTDBD method exhibits more diverse patterns in domain representations. In 2(d), most regions contain samples from multiple domains, demonstrating that DTDBD effectively mitigates the phenomenon of domain spurious correlation. Importantly, DTDBD not only avoids equal focus on each domain but also exhibits the ability to precisely prioritize domains with high relevance. These visual representations provide insights into how our method enables the model to learn shared features across domains while accurately capturing the relevance of individual domains.
VI-E Case Study
The case studies of the three news pieces are shown in Figure 3. From Case 1, it can be seen that when traditional fake news detectors encounter domains where fake news predominates (e.g., entertainment and finance), they are more likely to misclassify this news as fake news. Conversely, in domains where real content is abundant, such as disasters and politics, previous methods suffer from identical domain bias (as shown in Case 2). In contrast, our DTDBD framework effectively mitigates the influence of domain information on model decisions by utilizing domain knowledge distillation and adversarial de-biasing distillation.
Furthermore, it can be seen from Cases 1, 2, and 3 that the dual-teacher framework DTDBD can predict news labels more accurately and with higher prediction confidence. This reflects the role of the clean teacher in the model performance. On the other hand, it also indicates the effectiveness of the momentum-based dynamic adjustment algorithm for the trade-off between debiasing and detection performance.
VII Conclusion
In this paper, we propose the Dual-Teacher De-biasing Distillation framework (DTDBD), which mitigates domain bias arising from the unbalanced distribution of real-world datasets. DTDBD consists of an unbiased teacher and a clean teacher that jointly guide the student model in reducing domain bias and mitigating the performance degradation problem. For the unbiased teacher, we design an adversarial de-biasing distillation loss that incorporates unbiased distribution as a form of knowledge. For the clean teacher, we introduce a domain knowledge distillation loss to incentivize the student model to focus on learning the knowledge across correlated domains. Furthermore, we present a momentum-based dynamic adjustment algorithm to balance the effects of two teachers on the student model. We conduct extensive experiments on English and Chinese multi-domain fake news datasets to evaluate the effectiveness of DTDBD. The results demonstrate that DTDBD effectively mitigates domain bias, improves performance, and achieves state-of-the-art performance on Chinese datasets.
References
- [1] Q. Nan, J. Cao, Y. Zhu, Y. Wang, and J. Li, “Mdfend: Multi-domain fake news detection,” in Proceedings of the 30th ACM International Conference on Information & Knowledge Management, 2021, pp. 3343–3347.
- [2] J. Zhang, B. Dong, and S. Y. Philip, “Fakedetector: Effective fake news detection with deep diffusive neural network,” in 2020 IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 2020, pp. 1826–1829.
- [3] Q. Nan, D. Wang, Y. Zhu, Q. Sheng, Y. Shi, J. Cao, and J. Li, “Improving fake news detection of influential domain via domain-and instance-level transfer,” in Proceedings of the 29th International Conference on Computational Linguistics, 2022, pp. 2834–2848.
- [4] Y. Wang, F. Fabbri, and M. Mathioudakis, “Streaming algorithms for diversity maximization with fairness constraints,” in 2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2022, pp. 41–53.
- [5] T.-D. Truong, N. Le, B. Raj, J. Cothren, and K. Luu, “Fredom: Fairness domain adaptation approach to semantic scene understanding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 988–19 997.
- [6] G. Xu and Q. Hu, “Can model compression improve nlp fairness,” arXiv preprint arXiv:2201.08542, 2022.
- [7] Y. Zhu, Q. Sheng, J. Cao, S. Li, D. Wang, and F. Zhuang, “Generalizing to the future: Mitigating entity bias in fake news detection,” in Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2022, pp. 2120–2125.
- [8] J. MA, W. GAO, P. MITRA, S. KWON, B. J. JANSEN, K.-F. WONG, and M. CHA, “Detecting rumors from microblogs with recurrent neural networks.(2016),” in Proceedings of the 25th International Joint Conference on Artificial Intelligence (IJCAI 2016), pp. 3818–3824.
- [9] P. Przybyla, “Capturing the style of fake news,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 01, 2020, pp. 490–497.
- [10] X. Zhang, J. Cao, X. Li, Q. Sheng, L. Zhong, and K. Shu, “Mining dual emotion for fake news detection,” in Proceedings of the Web Conference 2021, 2021, pp. 3465–3476.
- [11] Y. Wang, F. Ma, Z. Jin, Y. Yuan, G. Xun, K. Jha, L. Su, and J. Gao, “Eann: Event adversarial neural networks for multi-modal fake news detection,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018, pp. 849–857.
- [12] T. Murayama, S. Wakamiya, and E. Aramaki, “Mitigation of diachronic bias in fake news detection dataset,” in Proceedings of the Seventh Workshop on Noisy User-generated Text (W-NUT 2021), 2021, pp. 182–188.
- [13] A. Silva, L. Luo, S. Karunasekera, and C. Leckie, “Embracing domain differences in fake news: Cross-domain fake news detection using multi-modal data,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 1, 2021, pp. 557–565.
- [14] Y. Zhu, Q. Sheng, J. Cao, Q. Nan, K. Shu, M. Wu, J. Wang, and F. Zhuang, “Memory-guided multi-view multi-domain fake news detection,” IEEE Transactions on Knowledge and Data Engineering, pp. 7178–7191, 2022.
- [15] K. Shu, A. Sliva, S. Wang, J. Tang, and H. Liu, “Fake news detection on social media: A data mining perspective,” ACM SIGKDD Explorations Newsletter, vol. 19, no. 1, pp. 22–36, 2017.
- [16] S. Shetiya, I. P. Swift, A. Asudeh, and G. Das, “Fairness-aware range queries for selecting unbiased data,” in 2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2022, pp. 1423–1436.
- [17] N. Ruchansky, S. Seo, and Y. Liu, “Csi: A hybrid deep model for fake news detection,” in Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, 2017, pp. 797–806.
- [18] S. Kwon, M. Cha, K. Jung, W. Chen, and Y. Wang, “Prominent features of rumor propagation in online social media,” in 2013 IEEE 13th International Conference on Data Mining. IEEE, 2013, pp. 1103–1108.
- [19] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio, “Fitnets: Hints for thin deep nets,” arXiv preprint arXiv:1412.6550, 2014.
- [20] X. Zhou, R. Zafarani, K. Shu, and H. Liu, “Fake news: Fundamental theories, detection strategies and challenges,” in Proceedings of the twelfth ACM International Conference on Web Search and Data Mining, 2019, pp. 836–837.
- [21] Q. Sheng, J. Cao, X. Zhang, R. Li, D. Wang, and Y. Zhu, “Zoom out and observe: News environment perception for fake news detection,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 4543–4556.
- [22] J. Ma, W. Gao, and K.-F. Wong, “Detect rumors on twitter by promoting information campaigns with generative adversarial learning,” in The World Wide Web Conference, 2019, pp. 3049–3055.
- [23] Y. Wang, F. Ma, H. Wang, K. Jha, and J. Gao, “Multimodal emergent fake news detection via meta neural process networks,” in Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 3708–3716.
- [24] D. Khattar, J. S. Goud, M. Gupta, and V. Varma, “Mvae: Multimodal variational autoencoder for fake news detection,” in The World Wide Web Conference, 2019, pp. 2915–2921.
- [25] C. Castillo, M. Mendoza, and B. Poblete, “Information credibility on twitter,” in Proceedings of the 20th International Conference on World Wide Web, 2011, pp. 675–684.
- [26] A. Giachanou, P. Rosso, and F. Crestani, “Leveraging emotional signals for credibility detection,” in Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2019, pp. 877–880.
- [27] A. Choudhry, I. Khatri, A. Chakraborty, D. Vishwakarma, and M. Prasad, “Emotion-guided cross-domain fake news detection using adversarial domain adaptation,” in Proceedings of the 19th International Conference on Natural Language Processing (ICON), 2022, pp. 75–79.
- [28] Y. Dou, K. Shu, C. Xia, P. S. Yu, and L. Sun, “User preference-aware fake news detection,” in Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2021, pp. 2051–2055.
- [29] K. Shu, S. Wang, and H. Liu, “Understanding user profiles on social media for fake news detection,” in 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR). IEEE, 2018, pp. 430–435.
- [30] Y. Liu and Y.-F. Wu, “Early detection of fake news on social media through propagation path classification with recurrent and convolutional networks,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32, no. 1, 2018, pp. 354–361.
- [31] V.-H. Nguyen, K. Sugiyama, P. Nakov, and M.-Y. Kan, “Fang: Leveraging social context for fake news detection using graph representation,” in Proceedings of the 29th ACM International Conference on Information & Knowledge Management, 2020, pp. 1165–1174.
- [32] A. Silva, Y. Han, L. Luo, S. Karunasekera, and C. Leckie, “Propagation2vec: Embedding partial propagation networks for explainable fake news early detection,” Information Processing & Management, vol. 58, no. 5, p. 102618, 2021.
- [33] K. Shu, L. Cui, S. Wang, D. Lee, and H. Liu, “defend: Explainable fake news detection,” in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019, pp. 395–405.
- [34] J. Ma, W. Gao, and K.-F. Wong, “Detect rumor and stance jointly by neural multi-task learning,” in Companion Proceedings of the Web Conference 2018, 2018, pp. 585–593.
- [35] C. Rong, J. Feng, and J. Ding, “Goddag: Generating origin-destination flow for new cities via domain adversarial training,” IEEE Transactions on Knowledge and Data Engineering, pp. 10 048–10 057, 2023.
- [36] Y. Ganin and V. Lempitsky, “Unsupervised domain adaptation by backpropagation,” in International Conference on Machine Learning. PMLR, 2015, pp. 1180–1189.
- [37] D. Kashyap, S. K. Aithal, C. Rakshith, and N. Subramanyam, “Towards domain adversarial methods to mitigate texture bias,” in ICML 2022: Workshop on Spurious Correlations, Invariance and Stability, 2022, pp. 1–8.
- [38] H. Liu, W. Wang, Y. Wang, H. Liu, Z. Liu, and J. Tang, “Mitigating gender bias for neural dialogue generation with adversarial learning,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 893–903.
- [39] S. B. R. Chowdhury, S. Ghosh, Y. Li, J. Oliva, S. Srivastava, and S. Chaturvedi, “Adversarial scrubbing of demographic information for text classification,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 550–562.
- [40] J. Choi, C. Gao, J. C. Messou, and J.-B. Huang, “Why can’t i dance in the mall? learning to mitigate scene bias in action recognition,” Advances in Neural Information Processing Systems, vol. 32, pp. 1–13, 2019.
- [41] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015.
- [42] W. Park, D. Kim, Y. Lu, and M. Cho, “Relational knowledge distillation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 3967–3976.
- [43] M. Ji, B. Heo, and S. Park, “Show, attend and distill: Knowledge distillation via attention-based feature matching,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 9, 2021, pp. 7945–7952.
- [44] S. Du, S. You, X. Li, J. Wu, F. Wang, C. Qian, and C. Zhang, “Agree to disagree: Adaptive ensemble knowledge distillation in gradient space,” Advances in Neural Information Processing Systems, vol. 33, pp. 12 345–12 355, 2020.
- [45] J. Ahn, H. Lee, J. Kim, and A. Oh, “Why knowledge distillation amplifies gender bias and how to mitigate from the perspective of distilbert,” in Proceedings of the 4th Workshop on Gender Bias in Natural Language Processing (GeBNLP), 2022, pp. 266–272.
- [46] J. Chai, T. Jang, and X. Wang, “Fairness without demographics through knowledge distillation,” Advances in Neural Information Processing Systems, vol. 35, pp. 19 152–19 164, 2022.
- [47] D. Liu, P. Cheng, Z. Lin, J. Luo, Z. Dong, X. He, W. Pan, and Z. Ming, “Kdcrec: Knowledge distillation for counterfactual recommendation via uniform data,” IEEE Transactions on Knowledge and Data Engineering, pp. 8143–8156, 2022.
- [48] Z. Zhu, S. Si, J. Wang, Y. Yang, and J. Xiao, “Debias the black-box: A fair ranking framework via knowledge distillation,” in International Conference on Web Information Systems Engineering. Springer, 2022, pp. 395–405.
- [49] P. Dhar, J. Gleason, A. Roy, C. D. Castillo, P. J. Phillips, and R. Chellappa, “Distill and de-bias: Mitigating bias in face verification using knowledge distillation,” arXiv preprint arXiv:2112.09786, 2021.
- [50] S. Jung, D. Lee, T. Park, and T. Moon, “Fair feature distillation for visual recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 12 115–12 124.
- [51] E. Purificato, L. Boratto, and E. W. De Luca, “Do graph neural networks build fair user models? assessing disparate impact and mistreatment in behavioural user profiling,” in Proceedings of the 31st ACM International Conference on Information & Knowledge Management, 2022, pp. 4399–4403.
- [52] T. Furlanello, Z. Lipton, M. Tschannen, L. Itti, and A. Anandkumar, “Born again neural networks,” in International Conference on Machine Learning. PMLR, 2018, pp. 1607–1616.
- [53] F. Yuan, L. Shou, J. Pei, W. Lin, M. Gong, Y. Fu, and D. Jiang, “Reinforced multi-teacher selection for knowledge distillation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 16, 2021, pp. 14 284–14 291.
- [54] S. Zhao, J. Yu, Z. Sun, B. Zhang, and X. Wei, “Enhanced accuracy and robustness via multi-teacher adversarial distillation,” in European Conference on Computer Vision. Springer, 2022, pp. 585–602.
- [55] P. Micaelli and A. J. Storkey, “Zero-shot knowledge transfer via adversarial belief matching,” Advances in Neural Information Processing Systems, vol. 32, pp. 9551–9561, 2019.
- [56] C. Liang, Y. Zhang, X. Li, J. Zhang, and Y. Yu, “Fudfend: fuzzy-domain for multi-domain fake news detection,” in CCF International Conference on Natural Language Processing and Chinese Computing. Springer, 2022, pp. 45–57.
- [57] K. Shu, D. Mahudeswaran, S. Wang, D. Lee, and H. Liu, “Fakenewsnet: A data repository with news content, social context, and spatiotemporal information for studying fake news on social media,” Big Data, vol. 8, no. 3, pp. 171–188, 2020.
- [58] Y. Li, B. Jiang, K. Shu, and H. Liu, “Mm-covid: A multilingual and multimodal data repository for combating covid-19 disinformation,” arXiv preprint arXiv:2011.04088, 2020.
- [59] Y. Kim, “Convolutional neural networks for sentence classification,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014, pp. 1746–1751.
- [60] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019.
- [61] J. Ma, Z. Zhao, X. Yi, J. Chen, L. Hong, and E. H. Chi, “Modeling task relationships in multi-task learning with multi-gate mixture-of-experts,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018, pp. 1930–1939.
- [62] H. Liu, W. Jin, H. Karimi, Z. Liu, and J. Tang, “The authors matter: Understanding and mitigating implicit bias in deep text classification,” in Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 2021, pp. 74–85.
- [63] J. H. Park, J. Shin, and P. Fung, “Reducing gender bias in abusive language detection,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 2799–2804.
- [64] P. Lertvittayakumjorn, L. Specia, and F. Toni, “Find: Human-in-the-loop debugging deep text classifiers,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 332–348.
- [65] F. Liu and B. Avci, “Incorporating priors with feature attribution on text classification,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 6274–6283.
- [66] L. Dixon, J. Li, J. Sorensen, N. Thain, and L. Vasserman, “Measuring and mitigating unintended bias in text classification,” in Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, 2018, pp. 67–73.