Visual Grounding of Whole Radiology Reports for 3D CT Images
Abstract
Building a large-scale training dataset is an essential problem in the development of medical image recognition systems. Visual grounding techniques, which automatically associate objects in images with corresponding descriptions, can facilitate labeling of large number of images. However, visual grounding of radiology reports for CT images remains challenging, because so many kinds of anomalies are detectable via CT imaging, and resulting report descriptions are long and complex. In this paper, we present the first visual grounding framework designed for CT image and report pairs covering various body parts and diverse anomaly types. Our framework combines two components of 1) anatomical segmentation of images, and 2) report structuring. The anatomical segmentation provides multiple organ masks of given CT images, and helps the grounding model recognize detailed anatomies. The report structuring helps to accurately extract information regarding the presence, location, and type of each anomaly described in corresponding reports. Given the two additional image/report features, the grounding model can achieve better localization. In the verification process, we constructed a large-scale dataset with region-description correspondence annotations for 10,410 studies of 7,321 unique patients. We evaluated our framework using grounding accuracy, the percentage of correctly localized anomalies, as a metric and demonstrated that the combination of the anatomical segmentation and the report structuring improves the performance with a large margin over the baseline model (66.0% vs 77.8%). Comparison with the prior techniques also showed higher performance of our method.
Keywords:
Deep Learning Vision Language Visual Grounding Computed Tomography.1 Introduction
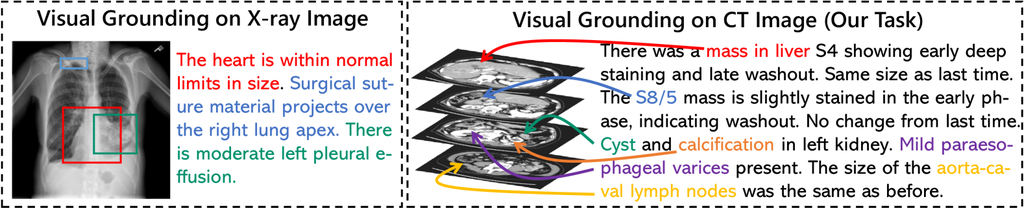
In recent years, a number of medical image recognition systems have been developed [6] to alleviate the increasing burden on radiologists [2, 22, 21]. In the development of such systems, the task of manually labeling images is a significant bottleneck. Auto-labeling, the process of automatically assigning labels to images using machine learning algorithms, has emerged as a promising solution to this problem. In cases where there are plenty of image and caption pairs, one potential approach to auto-labeling is visual grounding [12], which utilizes natural language descriptions to identify and localize objects in images.
With the recent advances in cross-modal technology based on deep learning, many frameworks for visual grounding has been proposed [11, 7]. Within the medical domain, several large scale datasets with radiology reports are available (e.g. OpenI [3], MIMIC-CXR [9]), and these produced researches on medical image visual grounding [25, 1]. However, to the best of our knowledge, prior studies have focused on 2D X-ray images [28] or videos [15], and there has been no research applying visual grounding to 3D computed tomography (CT) images so far. Visual grounding on CT images has the following difficulties: 1) Large number of anomaly types to detect: Existing researches on visual grounding using X-ray images handled only chest X-ray images. The number of anomaly types to detect is at most dozen or so (e.g. 13 findings [8]). In contrast, our research handles CT images including various parts of the human body. Consequently, the number of anomaly types to be detected is larger than one hundred. 2) Long and complex sentences: Radiology reports on X-ray images are often simple, noting only the presence or absence of anomalies. On the other hand, in CT examinations, the qualitative diagnosis of each anomaly is often performed. In cases, multiple anomalies are simultaneously described in a sentence. Therefore, the description tend to be long and complicated with multiple sentences (Fig. 1). Visual grounding for CT images requires the extraction of information about the location and type of each anomaly from these complex sentences.
In this work, we propose a novel visual grounding framework for 3D CT images and radiology reports. The main idea is to separate the task into three parts: 1) anatomical segmentation on images, 2) report structuring, and 3) localization of described anomalies. In the anatomical segmentation, multiple organs and tissues are extracted using the deep learning based segmentation model and provided as landmarks. The report structuring model, which is based on BERT [5], is also introduced to extract information of each anomaly from a complex report. Both of these features are fed into the grounding model (3) to extrapolate medical domain knowledge, thereby enabling accurate visual grounding.
Our contributions are as follows:
-
•
We show the first visual grounding results for 3D CT images that covers various body parts and anomalies.
-
•
We introduce a novel grounding architecture that can leverage report structuring results of presence/type/location of described anomalies.
-
•
We validate the efficacy of the proposed framework using a large-scale dataset with region-description correspondence annotations.
2 Related Work
Visual Grounding
Visual grounding task involves learning the correspondences between descriptions in the text and image regions from a given training set of region-description pairs [12]. There are mainly two approaches: one-stage approach and two-stage approach. Most studies follow a two-stage approach [14, 17]. However, this approach usually employs a pre-trained object detector, and it leads to restrict the capability of categories and attributes in grounding. Accordingly, recent studies is shifting to employ the one-stage approach, in which visual grounding is performed by end-to-end training [27, 4, 10].
Vision-Language Tasks on Medical Image
The existence of public datasets with paired images and reports [3, 9, 26] has accelerated research on cross-modal tasks in the medical field [25, 16]. Inspired by the success of visual grounding, several studies of visual grounding for medical images and radiology reports have also been reported [28, 1, 23]. These studies utilized a large scale dataset and an attention-based language interpretation model such as BERT [5] to ground the descriptions in the report. However, these studies have focused on X-ray images, and to the best of our knowledge, there have been no studies on CT images, which cover the entire body and have a complex report.
3 Methods
We first formulate the problem. Next, we explain three key components of anatomical segmentation, report structuring, and anomaly localization in our framework. In our framework, multiple organ labels obtained as the output of anatomical segmentation encourage the grounding model to learn detailed anatomy, and report structuring allows the grounding model to accurately extract the features of the target anomaly from complex sentences.
3.1 Problem Formulation
Our research assumes that a dataset of image-report pairs with region-description correspondence annotations is provided for training. We show the overall framework in Fig. 2. We denote an image and a paired report as I and T respectively. Let be a label image in which multiple organs are extracted from . Each report contains descriptions of multiple (image) anomalies. We denote each anomalies as . Given an image I and corresponding organ label images encoded as and a description about an anomaly encoded as , the goal of our framework is to generate a segmentation map that represents the location of the anomaly .
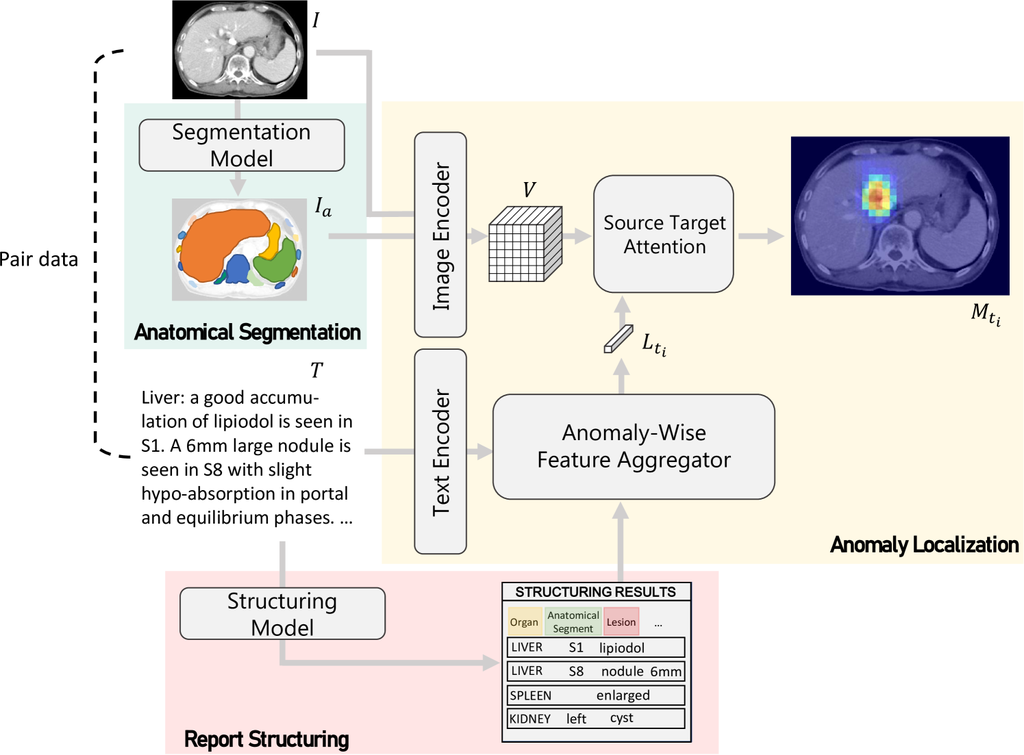
3.2 Anatomical Segmentation
The task of the anatomical segmentation is to extract relevant anatomies that can be clues for visual grounding. We use the commercial version of the 3D image analysis software (Synapse 3D V6.8, FUJIFILM corporation, Japan) to extract 32 organs and tissues (See Appendix Table. A1). In this software, anatomies are extracted using U-Net based architectures [13, 18]. The extracted anatomical label images are .
3.3 Report Structuring
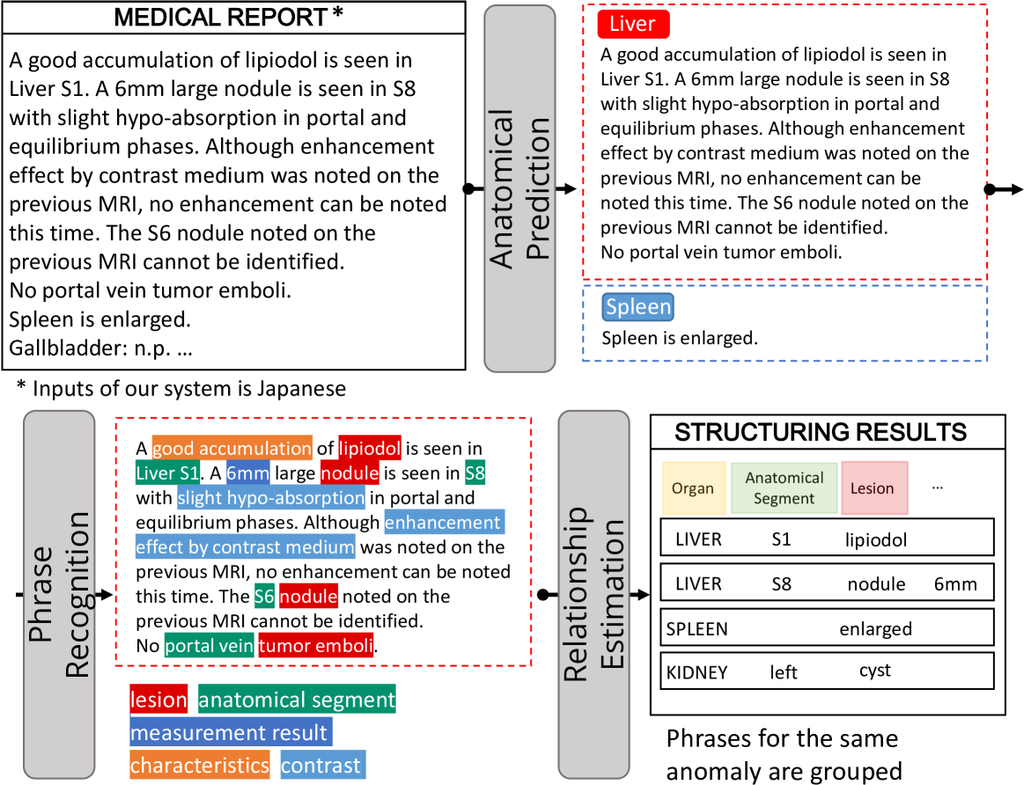
The tasks of the report structuring are as follows: 1) anatomical prediction, 2) phrase recognition, and 3) relationship estimation between phrases (See Appendix Fig. A1). The anatomical prediction is a sentence-wise prediction to determine which organ or body part is mentioned in each sentence. The organs and body parts to be recognized are shown in Appendix Table. A2. The sentences belonging to the same class are concatenated, then the phrase recognition and the relationship estimation are performed for each class.
The phrase recognition module extracts phrases and classifies each of them into 9 classes (See Appendix Table. A2). Subsequently, the relationship estimation module determines whether there is a relationship between anomaly phrases (e.g. ’nodule’, ’fracture’) and other phrases (e.g. ’6mm’, ’Liver S6’), resulting in the grouping of phrases related to the same anomaly. If multiple anatomical phrases are grouped in the same group, they are split into separate groups on a rule basis (e.g. [‘right S1’, ‘left S6’, ‘nodule’] -> [‘right S1’, ‘nodule’], [‘left S6’, ‘nodule’]). More details of implementation and training methods are reported in Nakano et al. [20] and Tagawa et al [24].
3.4 Anomaly Localization
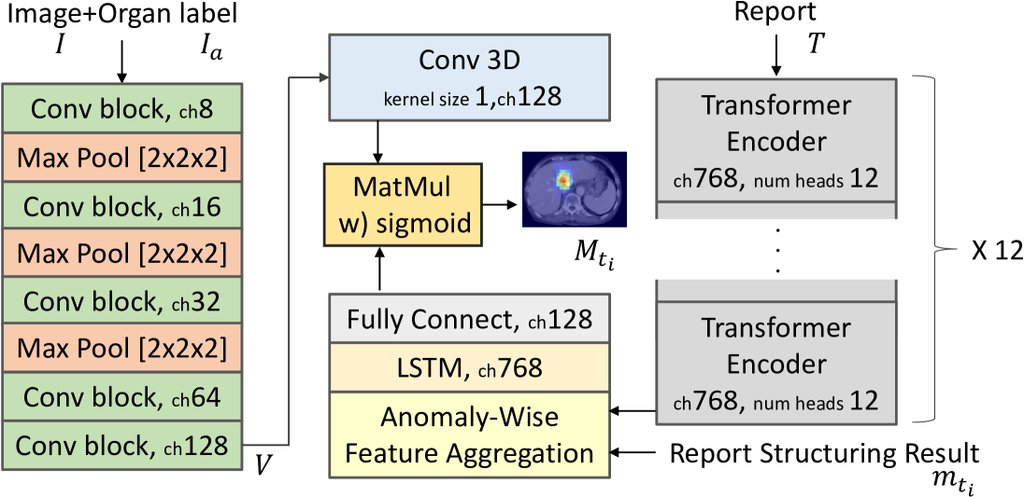
The task of the anomaly localization is to output a localization map of the anomaly mentioned in the input report . The CT image and the organ label image are concatenated along the channel dimension and encoded by a convolutional backbone to generate a visual embedding . The sentences in the report are encoded by BERT [5] to generate embeddings for each character. Let be the set of character embeddings where is the number of characters. Our framework next adopt the Anomaly-Wise Feature Aggregator (AFA). For each anomaly , AFA generates a representative embedding by aggregating the embeddings of related phrases based on report structuring results. The final grounding result is obtained by the following Source-Target Attention.
| (1) |
where , are trainable variables.
The overall architecture of this module is illustrated in Appendix Fig. A2.
3.4.1 Anomaly-Wise Feature Aggregator
The results of the report structuring are defined as follows:
| (2) |
| (3) |
where is the class index labeled by the phrase recognition module (Let be the number of classes). In this module, aggregate character-wise embeddings based on the following formula.
| (4) |
| (5) |
where and are trainable embeddings for each organ and each class label respectively. stands for concatenation operation. In this way, embeddings of characters related to the anomaly are aggregated and concatenated. Subsequently, representative embeddings of the anomaly are generated by an LSTM layer. In the task of visual grounding focused on 3D CT images, the size of the dataset that can be created is relatively small. Considering this limitation, we use an LSTM layer with strong inductive bias to achieve high generalization performance.
4 Dataset and Implementation Details
4.1 Clinical Data
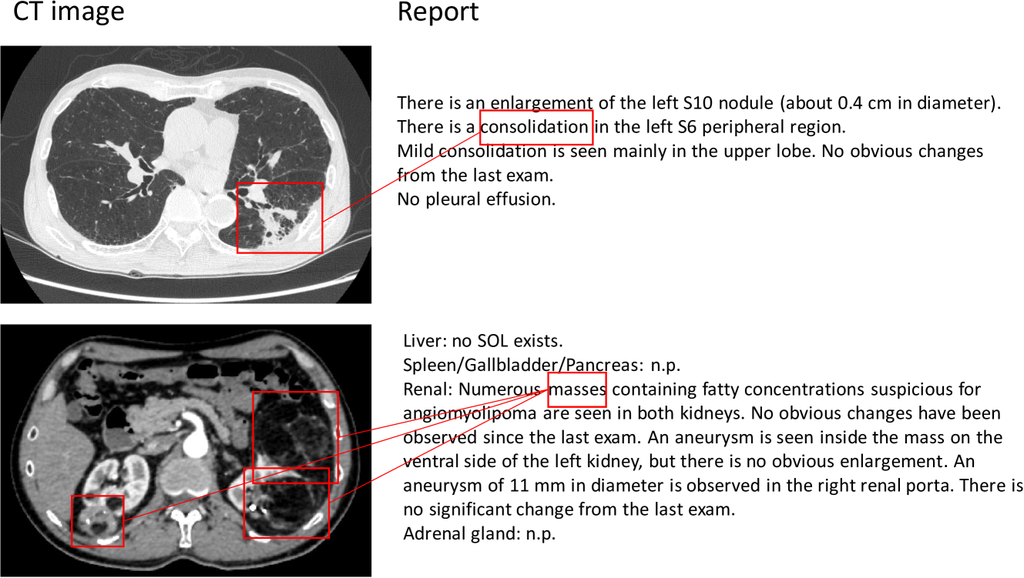
We retrospectively collected 10,410 CT studies (11,163 volumes/7,321 unique patients) and 671,691 radiology reports from one university hospital in Japan. We assigned a bounding box to each anomaly described in the reports as shown in Appendix Fig. A3. The total category number is about 130 in combination of anatomical regions and anomaly types (The details are in Fig. 4) For each anomaly, a correspondence annotation was made with anomaly phrases in the report. The total number of annotated regions is 17,536 (head: 713 regions, neck: 285 regions, chest: 8,598 regions, and abdomen: 7,940 regions). We divide the data into 9,163/1,000/1,000 volumes as a training/validation/test split.
4.2 Implementation Details
We use a VGG-like network as Image Encoder, with 15 3D-convolutional layers and 3 max pooling layers. For training, the voxel spacings in all three dimensions are normalized to 1.0 mm. CT values are linearly normalized to obtain a value of [0–1]. The anatomy label image, in which only one label is assigned to each voxel, is also normalized to the value [0–1], and the CT image and the label image are concatenated along the channel dimension. As our Text Encoder, we use a BERT with 12 transformer encoder layers, each with hidden dimension of 768 and 12 heads in the multi-head attention. At first, we pre-train the BERT using 6.7M sentences extracted from the reports in a Masked Language Model task. Then we train the whole architecture jointly using dice loss [19] with the first 8 transformer encoder layers of the BERT frozen. Further information about implementation are shown in Appendix Table. A3.
5 Experiments
We did two kinds of experiments for comparison and ablation studies. The comparison study was made against TransVG [4] and MDETR [10] that are one-stage visual grounding approaches and established state-of-the-art performances on photos and captions. To adapt TransVG and MDETR for the 3D modality, the backbone was changed to a VGG-like network with 3D convolution layers, the same as the proposed method. We refer one of the proposed method without anatomical segmentation and report structuring as the baseline model.
5.1 Evaluation Metrics
We report segmentation performance using Dice score, mean intersection over union (mIoU), and the grounding accuracy. The output masks are thresholded to compute mIoU and grounding accuracy score. The mIoU is defined as an average IoU over the thresholds [0.1, 0.2, 0.3, 0.4, 0.5]. The grounding accuracy is defined as the percentage of anomalies for which the IoU exceeds 0.1 under the threshold 0.1.
5.2 Results
The experimental results of the two studies are shown in Table. 1. Both of MDETR and TransVG failed to achieve stable grounding in this task. A main difference between these models and our baseline model is using a source-target attention layer instead of the transformer. It is known that a transformer-based algorithm with many parameters and no strong inductive bias is difficult to generalize with such a relatively limited number of training data. For this reason, the baseline model achieved a much higher accuracy than the comparison methods.
| Method | Anatomical | Report | Dice | mIoU | Accuracy |
|---|---|---|---|---|---|
| Seg. | Struct. | ||||
| MDETR [10] |
- |
- |
N/A |
- |
- |
| TransVG [4] |
- |
- |
N/A |
8.5 |
21.8 |
| Baseline |
✗ |
✗ |
27.4 |
15.6 |
66.0 |
| Proposed |
✓ |
✗ |
28.1 |
16.6 |
67.9 |
|
✗ |
✓ |
33.0 |
20.3 |
75.9 |
|
|
✓ |
✓ |
34.5 | 21.5 | 77.8 |
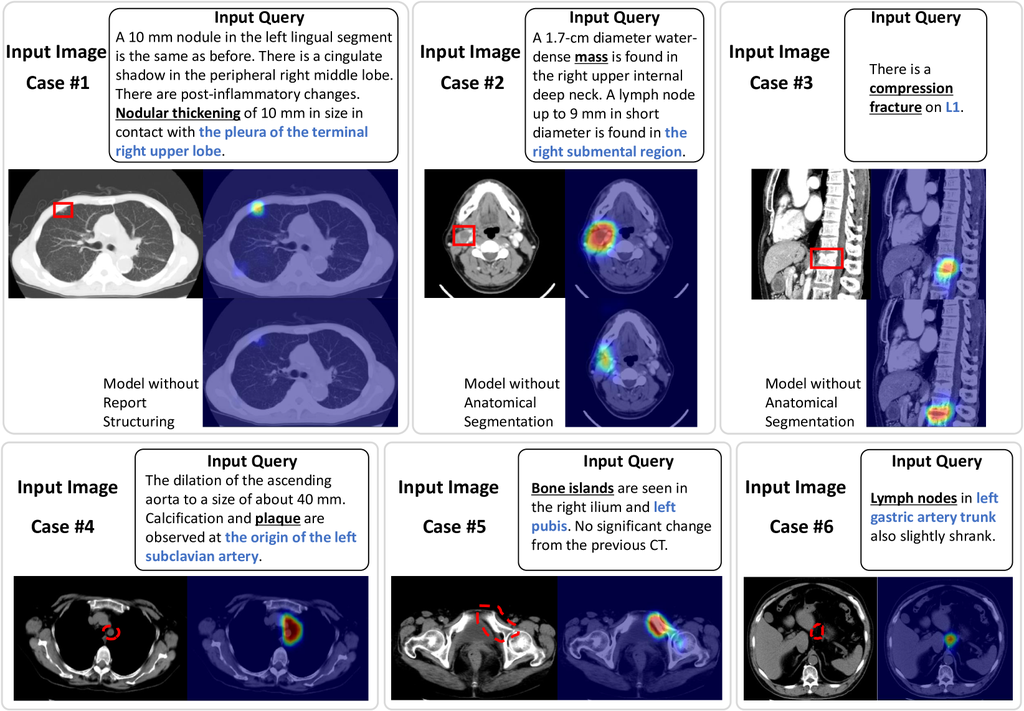
The ablation study showed that the anatomical segmentation and the report structuring can improve the performance. In Fig. 3 (upper row), we demonstrate several cases that facilitate an intuitive understanding of each effect. Longer reports often mention more than one anomaly, making it difficult to recognize the grounding target and cause localization errors. The proposed method can explicitly indicate phrases such as the location and size of the target anomaly, reducing the risk of failure. Fig. 3 (lower row) shows examples of grounding results when a query that is not related to the image is inputted. In this case, the grounding results were less consistent with the anatomical phrases. The results suggest that the model performs grounding with an emphasis on anatomical information against the backdrop of abundant anatomical knowledge.
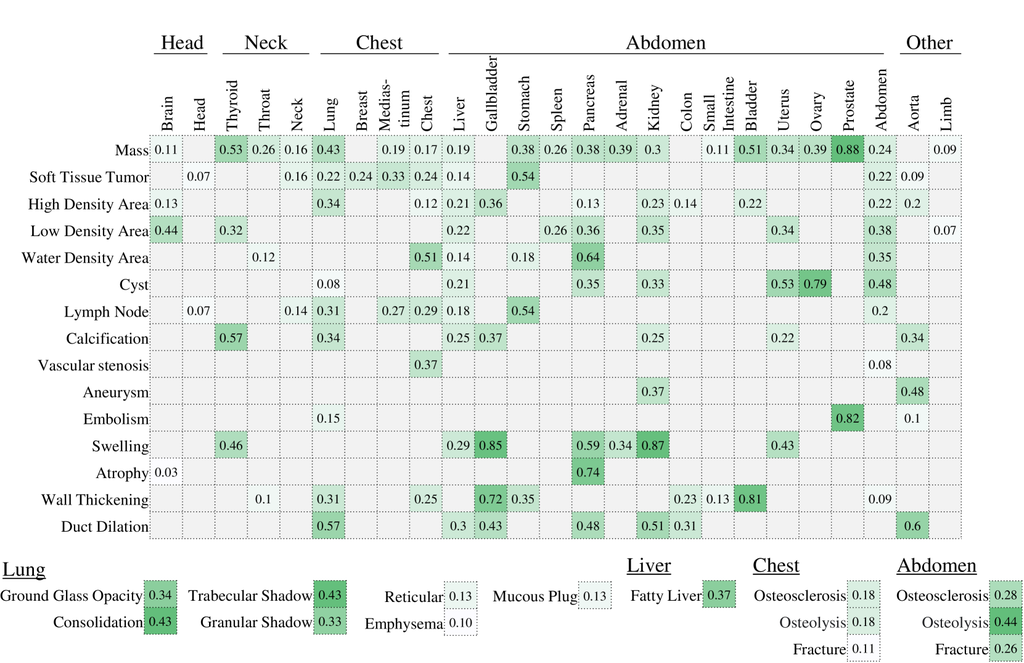
The grounding performance for each combination of organ and anomaly type is shown in Fig. 4. The performance is relatively high for organ shape abnormalities (e.g. swelling, duct dilation) and high-frequency anomalies in small organs (e.g. thyroid/prostate mass). For these anomaly types, our model is considered to be available for automatic training data generation. On the other hand, the performance tends to be low for rare anomalies (e.g. mass in small intestine) and anomalies in large body part (e.g. limb). Improving grounding performance for these targets will be an important future work.
6 Conclusion
In this paper, we proposed the first visual grounding framework for 3D CT images and reports. To deal with various type of anomalies throughout the body and complex reports, we introduced a new approach using anatomical recognition results and report structuring results. The experiments showed the effectiveness of our approach and achieved higher performance compared to prior techniques. However, in clinical practice, radiologists write reports from comparing multiple images such as time-series images, or multi-phase scans. Realizing such sophisticated diagnose process by a visual grounding model will be a future research.
References
- [1] Bhalodia, R., Hatamizadeh, A., Tam, L., Xu, Z., Wang, X., Turkbey, E., Xu, D.: Improving Pneumonia Localization via Cross-Attention on Medical Images and Reports. In: Proceedings of Medical Image Computing and Computer Assisted Intervention. pp. 571–581. Springer (2021)
- [2] Dall, T.: The Complexities of Physician Supply and Demand: Projections from 2016 to 2030. IHS Markit Limited (2018)
- [3] Demner-Fushman, D., Kohli, M.D., Rosenman, M.B., Shooshan, S.E., Rodriguez, L., Antani, S., Thoma, G.R., McDonald, C.J.: Preparing a collection of radiology examinations for distribution and retrieval. Journal of the American Medical Informatics Association 23(2), 304–310 (2016)
- [4] Deng, J., Yang, Z., Chen, T., Zhou, W., Li, H.: TransVG: End-to-End Visual Grounding with Transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1769–1779 (2021)
- [5] Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In: Proceedings of NAACL-HLT. pp. 4171–4186 (2019)
- [6] Ebrahimian, S., Kalra, M.K., Agarwal, S., Bizzo, B.C., Elkholy, M., Wald, C., Allen, B., Dreyer, K.J.: FDA-regulated AI algorithms: Trends, Strengths, and Gaps of Validation Studies. Academic Radiology 29(4), 559–566 (2022)
- [7] Hu, R., Rohrbach, M., Darrell, T.: Segmentation from Natural Language Expressions. In: Proceedings of the European Conference on Computer Vision. pp. 108–124. Springer (2016)
- [8] Irvin, J., Rajpurkar, P., Ko, M., Yu, Y., Ciurea-Ilcus, S., Chute, C., Marklund, H., Haghgoo, B., Ball, R., Shpanskaya, K., et al.: CheXpert: A Large Chest Radiograph Dataset with Uncertainty Labels and Expert Comparison. In: Proceedings of the AAAI conference on artificial intelligence. vol. 33, pp. 590–597 (2019)
- [9] Johnson, A.E., Pollard, T.J., Berkowitz, S.J., Greenbaum, N.R., Lungren, M.P., Deng, C.y., Mark, R.G., Horng, S.: MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data 6(1), 317 (2019)
- [10] Kamath, A., Singh, M., LeCun, Y., Synnaeve, G., Misra, I., Carion, N.: MDETR-Modulated Detection for End-to-End Multi-Modal Understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1780–1790 (2021)
- [11] Karpathy, A., Fei-Fei, L.: Deep Visual-Semantic Alignments for Generating Image Descriptions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 3128–3137 (2015)
- [12] Karpathy, A., Joulin, A., Fei-Fei, L.F.: Deep Fragment Embeddings for Bidirectional Image Sentence Mapping. In: Proceedings of Advances in Neural Information Processing System. pp. 1889–1897 (2014)
- [13] Keshwani, D., Kitamura, Y., Li, Y.: Computation of Total Kidney Volume from CT Images in Autosomal Dominant Polycystic Kidney Disease Using Multi-task 3D Convolutional Neural Networks. In: Proceedings of Medical Image Computing and Computer Assisted Intervention. pp. 380–388. Springer (2018)
- [14] Lee, K.H., Chen, X., Hua, G., Hu, H., He, X.: Stacked Cross Attention for Image-Text Matching. In: Proceedings of the European Conference on Computer Vision. pp. 201–216 (2018)
- [15] Li, B., Weng, Y., Sun, B., Li, S.: Towards Visual-Prompt Temporal Answering Grounding in Medical Instructional Video. arXiv preprint arXiv:2203.06667 (2022)
- [16] Li, Y., Wang, H., Luo, Y.: A Comparison of Pre-Trained Vision-and-Language Models for Multimodal Representation Learning across Medical Images and Reports. In: Proceedings of the IEEE international conference on bioinformatics and biomedicine. pp. 1999–2004. IEEE (2020)
- [17] Lu, J., Batra, D., Parikh, D., Lee, S.: ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. Advances in neural information processing systems 32, 13–23 (2019)
- [18] Masuzawa, N., Kitamura, Y., Nakamura, K., Iizuka, S., Simo-Serra, E.: Automatic Segmentation, Localization, and Identification of Vertebrae in 3D CT Images Using Cascaded Convolutional Neural Networks. In: Proceedings of Medical Image Computing and Computer Assisted Intervention. pp. 681–690. Springer (2020)
- [19] Milletari, F., Navab, N., Ahmadi, S.A.: V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In: Proceedings of the international conference on 3D vision. pp. 565–571. IEEE (2016)
- [20] Nakano, N., Tagawa, Y., Ozaki, R., Taniguchi, T., Ohkuma, T., Suzuki, Y., Kido, S., Tomiyama, N.: Pre-training methods for creating a language model with embedded knowledge of radiology reports. In: Proceedings of the annual meeting of the Association for Natural Language Processing (2022)
- [21] Nishie, A., Kakihara, D., Nojo, T., Nakamura, K., Kuribayashi, S., Kadoya, M., Ohtomo, K., Sugimura, K., Honda, H.: Current radiologist workload and the shortages in japan: how many full-time radiologists are required? Japanese journal of radiology 33, 266–272 (2015)
- [22] Rimmer, A.: Radiologist shortage leaves patient care at risk, warns royal college. BMJ: British Medical Journal (Online) 359 (2017)
- [23] Seibold, C., Reiß, S., Sarfraz, S., Fink, M.A., Mayer, V., Sellner, J., Kim, M.S., Maier-Hein, K.H., Kleesiek, J., Stiefelhagen, R.: Detailed Annotations of Chest X-Rays via CT Projection for Report Understanding. arXiv preprint arXiv:2210.03416 (2022)
- [24] Tagawa, Y., Nakano, N., Ozaki, R., Taniguchi, T., Ohkuma, T., Suzuki, Y., Kido, S., Tomiyama, N.: Performance improvement of named entity recognition on noisy data using teacher-student training. In: Proceedings of the annual meeting of the Association for Natural Language Processing (2022)
- [25] Wang, X., Peng, Y., Lu, L., Lu, Z., Summers, R.M.: TieNet: Text-Image Embedding Network for Common Thorax Disease Classification and Reporting in Chest X-rays. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 9049–9058 (2018)
- [26] Yan, K., Wang, X., Lu, L., Summers, R.M.: DeepLesion: automated mining of large-scale lesion annotations and universal lesion detection with deep learning. Journal of medical imaging 5(3), 036501–036501 (2018)
- [27] Yang, Z., Gong, B., Wang, L., Huang, W., Yu, D., Luo, J.: A Fast and Accurate One-Stage Approach to Visual Grounding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4683–4693 (2019)
- [28] You, D., Liu, F., Ge, S., Xie, X., Zhang, J., Wu, X.: AlignTransformer: Hierarchical Alignment of Visual Regions and Disease Tags for Medical Report Generation. In: Proceedings of Medical Image Computing and Computer Assisted Intervention. pp. 72–82. Springer (2021)
| Brain | Lung | Liver | Aorta |
| - Cerebraspinal Fluid | - Left Upper Lobe | Gallbladder | Bone |
| - Left Lateral Ventricle | - Left Lower Lobe | Stomach | - Cervical Vertebra |
| - Right Lateral Ventricle | - Right Upper Lobe | Duodenum | - Thoracic Vertebra |
| - Third Ventricle | - Right Middle Lobe | Spleen | - Lumber Vertebra |
| - Fourth Ventricle | - Right Lower Lobe | Pancreas | - Left Rib |
| - Brainstem | Heart | Kidney | - Right Rib |
| - Left Cerebellum | - Left Kidney | ||
| - Right Cerebellum | - Right Kidney | ||
| - Left Cerebrum | Prostate | ||
| - Right Cerebrum | Bladder |
| Anatomical Prediction |
Phrase Classification |
||
|---|---|---|---|
|
Head |
Breast |
Small Intestine |
Anatomical Segment |
|
Brain |
Pleural Cavity |
Colon |
Lesion |
|
Ear |
Chest |
Prostate |
Shape Abnormality |
|
Nose |
Liver |
Uterus |
Diagnosis |
|
Neck |
Stomach |
Bladder |
Characteristics |
|
Oropharynx |
Gallbladder |
Ovary |
Contrast Information |
|
Thyroid |
Adrenal |
Abdomen |
Quantity |
|
Lung |
Spleen |
Abdominal Cavity |
Measurement Result |
|
Heart |
Pancreas |
Limb |
Temporal Change |
|
Mediastinum |
Kidney |
Aorta |
|
| Value | |
|---|---|
| Optimizer |
Adam |
| Initial Learning Rate | |
| Learning Rate Schedule |
Linearly increased to within the first 5,000 steps, and then multiplied by 0.1 every 30,000 steps |
| Batch Size |
10 |
| Normalization Method |
Batch Renormalization |
| Data Augmentation for Image |
Random Crop, Random Rotation, Random Scaling, Sharpness change, Smoothing, and Gaussian noise addition |
| Data Augmentation for Text |
Random deletion, Random insertion, and Random crop |
| Machine Learning Library |
Tensorflow 2.3 |
| GPU |
NVIDIA Tesla V100 2 |