USM-Lite: Quantization and Sparsity Aware Fine-tuning for Speech Recognition with Universal Speech Models
Abstract
End-to-end automatic speech recognition (ASR) models have seen revolutionary quality gains with the recent development of large-scale universal speech models (USM). However, deploying these massive USMs is extremely expensive due to the enormous memory usage and computational cost. Therefore, model compression is an important research topic to fit USM-based ASR under budget in real-world scenarios. In this study, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and : structured sparsity aware paradigm on the model weights, reducing the model complexity from parameter precision and matrix topology perspectives. We conducted extensive experiments with a 2-billion parameter USM on a large-scale voice search dataset to evaluate our proposed method. A series of ablation studies validate the effectiveness of up to int4 quantization and 2:4 sparsity. However, a single compression technique fails to recover the performance well under extreme setups including int2 quantization and 1:4 sparsity. By contrast, our proposed method can compress the model to have 9.4% of the size, at the cost of only 7.3% relative word error rate (WER) regressions. We also provided in-depth analyses on the results and discussions on the limitations and potential solutions, which would be valuable for future studies.
Index Terms— speech recognition, model quantization, model pruning, sparsity, universal speech model
1 Introduction
End-to-end Automatic speech recognition [1, 2, 3, 4, 5], a technique that transcribes audio to text, has been widely integrated into modern user-interactive AI services and devices (e.g., search by voice, voice assistant, etc.). Over the past few years, ASR models have seen quality and latency improvements under diverse test conditions [6, 7, 8, 9]. Meanwhile, end-to-end ASR has been shown to dramatically benefit from self-supervised learned (SSL) speech representations [10, 11, 12, 13] in both quality and production perspectives. Fine-tuning from these self-supervised speech models significantly improves ASR quality. More significantly, they provide a suitable initialization and reduce training cost for all the downstream tasks.
More recently, with the rapid emergence of high capacity hardware and the availability of large-scale datasets, SSL speech models see a trend of growing larger [14, 15, 16]. These models scale conventional SSL speech models up, to capture multi-domain and multi-lingual distributions. With such capability, they can serve as a universal foundation model for most of the speech processing tasks. However, the massive size of these models (several billions of parameters) makes them extremely expensive in deployment due to the need of the considerable amount of memory and computational units. Therefore, efficient fine-tuning and model compression algorithms have become unprecedentedly important research topics.
From prior studies, we have seen success on end-to-end ASR compression through sparse network pruning [17, 18, 19, 20, 21] and model quantization [22, 23, 24, 25] However, compressing these massive universal speech models can lead to new challenges on the top of regular end-to-end models. For example, USMs have much large model sizes, and therefore higher compression ratios are needed to reach the efficiency requirements for deployments. More importantly, most current compression methods have considerable quality regressions at high compression ratios (e.g., >75% sparsity, 2-bit quantization), which could lead to inferior user experiences when deployed to productions.
This motives us to investigate the effectiveness of compressing the model from different perspectives at the same time: quantization reduces the model complexity from the parameter precision, while sparsity focusing on the matrix topology. Accordingly, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and : structured sparsity [26] aware paradigm on model weights, where both techniques are hardware friendly and are supported by modern GPUs and TPUs. During forward-propagation, we first perform magnitude pruning on a weight matrix with : sparsity, and then, we perform per-channel quantization on the non-zero weights. At back-propagation time, we adopt straight through estimator (STE) [27] to bypass the quantization rounding functions.
We conducted extensive experiments on a large-scale voice search dataset with the 2-billion parameter CTC USM backbone from [15] to evaluate the proposed approach. With our proposed approach of 4-bit quantization and 2:4 sparsity aware training scheme, the model size can be reduced to 9.4% of the float32 size, at the cost of only 7.3% of relative WER regressions. Additionally, we systematically benchmark and analyze the effectiveness of quantization and sparsity through an ablation study, and we discuss the results with related studies. These benchmarks and discussions provide useful information for future research and productions.
2 Related Work
Self-supervised learning for ASR. Schneider et al. [10] presented the first exemplar study on SSL speech model, which directly learns speech representations from the raw waveform through a contrastive loss. Subsequent studies improves SSL speech models through advanced learning paradigms [11, 12, 13] as well as data and model size expansions [14, 15, 16]. Initializing from SSL pre-trained encoders has significantly improved state-of-the-art ASR performance, especially under a low-supervised-data setup.
ASR model compression through quantization and sparsity. A standard design approach to fit the ASR model under budget is to apply model quantization or network pruning to large models. Recent quantization studies [22, 23, 24, 25] have shown that it is possible to quantize the ASR models to 4-bit and even 2-bit with only marginal performance loss. Similarly, in terms of network pruning, both unstructured and structured sparsity [17, 18, 19, 20, 21] patterns have seen reasonable performance at high sparsity level, through various algorithms based on iterative magnitude pruning.
Relation to prior work. There are several previous studies that investigate SSL speech model compression [28, 20, 29, 30] through sparsity, knowledge distillation, attention re-use, or their combinations. Our proposed study differs from them in several aspects. First, we explore the combination of sparsity and quantization for compression, which has not been investigated in previous studies. The native operations in quantization provides significant speed up during both training and inference time compared to prior studies. More importantly, all of these prior studies show considerable quality drop at high compression ratio. By contrast, our model has only 7.3% relative WER regression at 9.4% of the original model size. In addition, we focus on model compression during the ASR fine-tuning stage of SSL models, instead of pre-training. The dense model and compressed model usually have very different distributions at convergence. When initializing from the near-optimal pre-trained weights of the dense model, we need to adapt the distribution to be optimal to the compressed model within limited training steps, which makes it a more challenging task. Lastly, the backbone size (2B vs. 10-100M parameters) and data size (1M hours vs. 1,000 hours) are much larger than previous studies.
3 Method
3.1 USM Backbone Architecture
We use the state-of-the-art USM-CTC [15] backbone with 2B parameters in this study. The encoder is comprised of 32 Conformer layers [31], with a dimensionality of 1536. We use relative attention [32] in the self-attention layer, with 16 attention heads. The kernel size of the depthwise convolution is set to 5. The model is pre-trained with BEST-RQ [13] on over 12 million hours of speech data in over 500 languages collected from YouTube. BEST-RQ runs in the BERT training fashion, which takes the audio as the input and predicts the masked speech representations. In addition, the left and right attention context per layer is set to 128 frames.
Given a pre-trained USM, we extract the encoder and pair it with a randomly initialized softmax layer corresponding to the word piece model (WPM). Following this, the model is fine-tuned with the vanilla connectionist temporal classification (CTC) [33] loss. Although RNN-T [3] or LAS [34] may lead to improved WER due to the additional language modeling capability, these models runs in an auto-regressive manner during inference, which is hard to parallelize during inference and has a much higher latency with such a massive encoder. By contrast, CTC based model has an encoder only architecture without any auto-regressive dependency that can be easily parallelized, and it is therefore more efficient for large-scale models.
3.2 Native Quantization Aware Training (QAT)
Suppose we have a single linear layer matrix multiplication , where , and are the input, output, and weight, respectively. Running a matrix multiplication with per-channel weight quantization can be represented as:
| (1) |
where the operation does:
| (2) |
denotes the scale of the -th channel, and is the -th column of . The scale is computed by dividing the maximum value of with the maximum value of the integer range. For int8 and int4 quantization, we use the simplest symmetric quantization introduced in [24] (e.g., [-127, 127] for int8 and [-7, 7] for int4). However, when the precision reduces to 2-bit, symmetric quantization under-utilizes the quantization buckets (i.e., only three values are used). Therefore, following [25], we adopt asymmetric quantization for int2 models, along with sub-channel quantization, which splits a channel into several groups with dedicated scales for each group.
During the forward propagation of quantization aware training, we apply eq.(1) to all the fully-connected layers of the model, and use STE to bypass the rounding function that is not derivative at back propagation (zero derivative almost everywhere). More importantly, we cast the quantized weight from eq.(2) to the native integer type. Compared to commonly used “fake" quantization [35] that uses float operations during training and integer operations during inference, this avoids the numerical difference caused by the operation mismatch between training and inference.
3.3 Magnitude based Pruning with : Sparsity
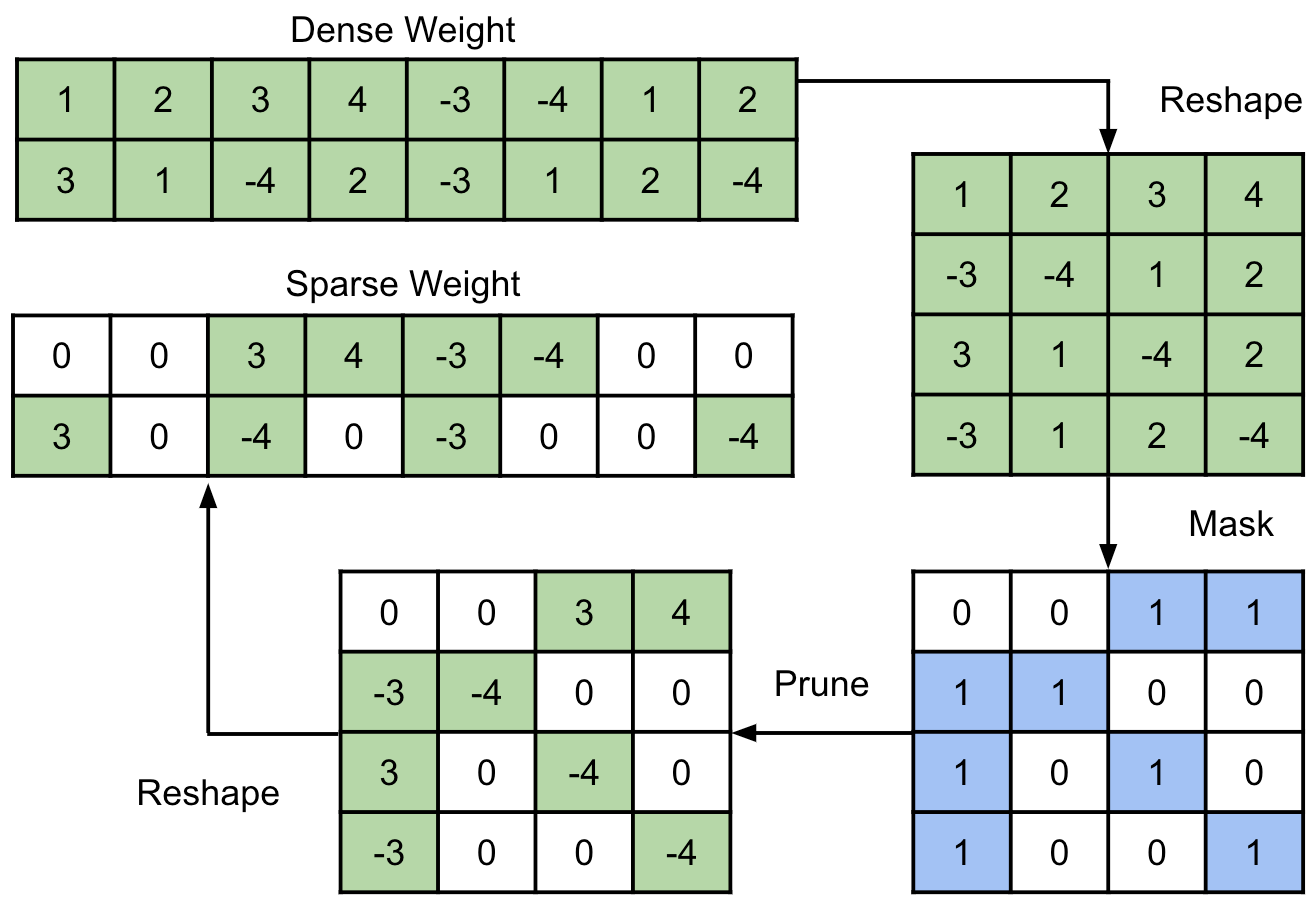
: sparsity has a pattern of: for each group of consecutive weights, there are at most non-zero values. In this work, we focus on the commonly used case of , but it can be easily extended to patterns with arbitrary . As shown in Figure 1, at a pruning step, we first reshape the dense weight matrix to be , where is the number of groups. Then, we identify the -th largest magnitude weight for each group, and generate the binary mask by:
| (3) |
The reshaped weight is pruned by the mask as:
| (4) |
where denotes the element-wise product. Finally we reshape the pruned sparse weight back to the original shape.
We investigate both one-shot and few-shot pruning in training. One-shot pruning only update the mask once at the beginning of the USM fine-tuning stage, and then we freeze the mask and tune the weights only. Few-shot pruning updates the mask for times at the beginning, and similarly, the mask is frozen afterwards. We do not enable STE proposed in [26] in few-shot pruning, and only the unpruned weights are updated at each iteration.
3.4 Joint optimization with Quantization and Sparsity
Empirically, simply applying quantization or sparsity alone with high compression ratio introduces inevitable regressions (e.g., see results for 2-bit quantization and 1:4 sparsity in Section 5.1 and 5.2). To maximally reduce the model size while retaining the WER, we propose to compress the model from the aspects of parameter precision and matrix topology jointly, with a combination of quantization and sparsity. Our proposed approach is in a prune-and-quantize fashion, which makes it more convenient during implementation. As described in Section 3.3, the pruned weights are set to zero, which directly maps to the zero-point of symmetric quantization and has no effect on calculating the scale. The overall training process is shown in Algorithm 1.
4 Experimental setup
4.1 Datasets
We evaluate the proposed techniques on a large-scale voice search task. The pre-training dataset is described in Section 3.1. During fine-tuning, we train the model with an in-house dataset of 1.2-million-hour United States English audio-text pairs from voice search. All data are anonymized, and our data handling abides by Google AI Principles [36]. A small portion of the dataset is hand-transcribed, and the rest is pseudo-transcribed with a 600-million-parameter teacher model [37]. In evaluations, we report the WER on 8,884 anonymized and hand-transcribed utterances representing the voice search traffic.
4.2 Implementation details
In addition to the USM backbone architecture introduced in Section 3.1, the network takes an input sequence of 128-dimensional log Mel-filterbank energies, extracted from a 32ms window and 10ms shifts. The input features are down-sampled by 4 times through two 2-D convolution layers, and projected to 1,536 dimensions through a fully-connected layer, before feeding to the encoder. Each convolution layer has a kernels, strides, and 128, 32 channels, respectively.
The proposed method is implemented in Pax111https://github.com/google/paxml with the layer library Praxis222https://github.com/google/praxis. We open-sourced our implementations of quantization and sparsity here.. We do not quantize and sparsify convolution layers and the final softmax layers, as their parameter counts are much lower. The models are trained on Tensor Processing Unit (TPU) v3-128 [38] with an Adam optimize of transformer learning rate schedule [39]. The input feature and encoder modules have a base learning rate multiplier of 0.5, and the softmax layer has that of 2.0. The warm up steps are set to 5,000 and 1,500 for these modules respectively. All models are trained with 200,000 steps with a batch size of 2,048. During evaluations, we do not include any additional language models for rescoring to better benchmark the effectiveness of the compression techniques.
5 Experiments
| Exp | Model | Voice Search | Model Size |
|---|---|---|---|
| WER | Ratio | ||
| B0 | float32 dense 2B CTC USM | 4.1 | - |
| E0 | int8 PTQ | 4.2 | 25.0% |
| E1 | int8 QAT | 4.2 | 25.0% |
| E2 | int4 PTQ | 86.7 | 12.5% |
| E3 | int4 QAT | 4.3 | 12.5% |
| E4 | int2 QAT | 99.9 | 6.3% |
| E5 | int2 QAT + 16 sub-channel | 45.2 | 7.3% |
| E6 | int2 QAT + 32 sub-channel | 32.0 | 8.3% |
| E7 | int2 QAT + 64 sub-channel | 12.3 | 10.4% |
We conduct three sets of experiments to evaluate our proposed approach: 1) Ablation studies on quantization; 2) Ablation studies on sparsity; 3) Overall performance of the proposed combinations. Through the ablation studies on quantization and sparsity, we aim to examine and characterize the effectiveness of the two techniques on fine-tuning the USM model. In the evaluation of our proposed combinations, we compare to several dense/compression baselines and show the state-of-the-art quality and size reduction obtained from the proposed approach. Note that the sizes of the quantized/sparsified models are estimated without considering additional offset required by hardware, so the actual model size will be slightly larger.
5.1 Ablation Studies on Quantization
Table 1 shows the results of the ablation studies on quantization with int8, int4, and int2. Experiment B0 has the performance of the float32 dense 2B-parameter CTC USM, which serves as an upper-bound for both ablation studies. Besides QAT, we also explore the performance of post-training quantization (PTQ) with int8 and int4. As shown from the results, int8 PTQ (E0) and QAT (E1) can both retain the float32 model’s WER. With int4 precision, PTQ (E2) leads to much more significantly regressions, while QAT (E3) only having marginal WER regressions to the float32 model (4.3 vs. 4.1). When it comes to int2, the extreme quantization setup, vanilla asymmetric quantization does not result in a reasonable WER. With the increasing number of sub-channels, the WER can be gradually improved down to 12.3 at 64 sub-channels (E7). However, sub-channel scales introduce extra parameters (i.e., a float32 parameter per sub-channel), which are equivalent to 1%, 2%, and 4.1% of the original model size on 16, 32, and 64 sub-channel models, respectively. These observations mostly correspond to the conclusions from [24, 25].
5.2 Ablation Studies on Sparsity
Similarly, we show the ablation study results on sparsity in Table 2. Specifically, we investigate 2:4 and 1:4 structured sparsity patterns along with one-shot and few(1k)-shot pruning schedules. Sparse models need extra 1-bit (i.e., binary) parameters to store masks, which counts to 3.1% of the original model size. As shown from the table, one-shot (E8) and 1k-shot (E9) pruning with 2:4 sparsity have marginal regressions compared to the dense models, with 53.1% of the original model size. When pruning the model more aggressively with 1:4 sparsity, neither of the two models can retain the dense WER, and at the same time, 1k-shot (E11) pruning achieves a superior WER than one-shot (E10). A possible explanation could be that 1:4 sparsity is more sensitive to the mask, as it is a much hard task than 2:4 sparsity, and therefore, few-shot update can identify a more effective mask in this case.
| Exp | Model | Voice Search | Model Size |
|---|---|---|---|
| WER | Ratio | ||
| B0 | float32 dense 2B CTC USM | 4.1 | - |
| E8 | 2:4 sparsity one-shot | 4.4 | 53.1% |
| E9 | 2:4 sparsity 1k-shot | 4.3 | 53.1% |
| E10 | 1:4 sparsity one-shot | 11.7 | 28.1% |
| E11 | 1:4 sparsity 1k-shot | 10.6 | 28.1% |
5.3 Overall Performance of Combining Quantization with Sparsity.
According to the ablation studies from Section 5.1 and 5.2, we observe that either quantization or sparsity alone fails to have a reasonable WER at the extreme compression ratio. This motives us to investigate combining the two techniques through our proposed training scheme. Additionally, we train the float32 dense USM baselines with 1B (B1), 600M (B2), and 300M (B3) parameters for reference. Table 3 shows the results of this experiment. Our two proposed systems with int4 quantization and 2:4 sparsity achieves 4.4 (E12) and 4.5 (E13) WER, respectively. Compared to baseline B0, the model size has been reduced by over 10 times (9.4% of B0), with only 7.3% relative WER regression (4.4 vs. 4.1). Compared to the float32 dense baselines (B1 to B3), the WER of E12 is even better than the model with 1B parameters, but it only has about one fifth of the size of the 1B model. Finally, when comparing to the quantization (E7) or sparsity (E11) models at extreme compression rates, our proposed method significantly reduces the WERs of both models to be much closer to the dense model B0, while enjoying even smaller model size (9.4% vs. 10.4%). Regarding the comparisons between one-shot and few-shot pruning, we do not find significant WER difference with 2:4 sparsity, which is similar to our observations in 5.2. In summary, these results corroborate with our claim that compressing the model jointly from the parameter precision and the matrix topology aspects are more effective than an individual technique.
| Exp | Model | Voice Search | Model Size |
| WER | Ratio | ||
| B0 | float32 dense 2B CTC USM | 4.1 | - |
| B1 | float32 dense 1B CTC USM | 4.5 | 50.2% |
| B2 | float32 dense 600M CTC USM | 4.7 | 33.5% |
| B3 | float32 dense 300M CTC USM | 5.0 | 18.9% |
| E7 | int2 QAT + 64 sub-channel | 12.3 | 10.4% |
| E11 | 1:4 sparsity 1k-shot | 10.6 | 28.1% |
| E12 | int4 QAT + 2:4 sparsity one-shot | 4.4 | 9.4% |
| E13 | int4 QAT + 2:4 sparsity 1k-shot | 4.5 | 9.4% |
5.4 Limitations and Discussions
Although we obtain very encouraging results from the aforementioned experiments, we observe several limitations of this work, which we would like to discuss here and further explore in future work. First, we notice that there are more regressions on int4 PTQ and int2 QAT in this work. One potential reasons could be that we do not enable global variational noise (VN) [40] during fine-tuning in this work, as it is not systematically investigated for USM fine-tuning yet. By contrast, [25] has it enabled, which has been shown to improve low-bit quantization performance [41]. Second, we have not enable STE during model pruning, which can possibly improve the performance of models with sparsity. In future work, we will examine the two approaches along with other techniques that have been shown to effective regarding quantization (e.g., learnable scale, outlier clipping [42], etc.) and : sparsity (e.g., SR-STE [26]), to seek for better quantized and sparse models. With advanced quantization and sparsity models, we will investigate more aggressive combinations such as int2 plus 2:4 to push the model size to the edge.
6 Conclusions
USM has significantly improved the quality and simplified the productionization of ASR along with other downstream tasks. In this paper, we for the first time proposed a joint quantization and sparsity aware paradigm for USM-based ASR fine-tuning. Through extensive experiments and ablation studies on large-scale datasets, we first benchmarked low-bit quantization and : structured sparsity on USM fine-tuning, validating the effectiveness of int4 QAT and 2:4 sparsity. More importantly, results suggest that our proposed combination of quantization and sparsity can further reduces the models size to 9.4% of the original model at the cost of marginal performance regressions. We also provided systematical analyses of our results on each of the compression technique and a discussion on the limitation and potential solutions for future investigations.
7 Acknowledgements
We would like to thanks Jeremiah Willcock, Emmanuel Guzman, Xingyu Cai, Wonpyo Park, Peiran Li, and Suvinay Subramanian for the discussions and help in this work.
References
- [1] D. Wang, X. Wang, and S. Lv, “An overview of end-to-end automatic speech recognition,” Symmetry, 2019.
- [2] A. Hannun, C. Case, J. Casper, et al., “Deep speech: Scaling up end-to-end speech recognition,” arXiv:1412.5567, 2014.
- [3] A. Graves, “Sequence transduction with recurrent neural networks,” arXiv:1211.3711, 2012.
- [4] J. Chorowski, D. Bahdanau, et al., “Attention-based models for speech recognition,” in ICONIP, 2015.
- [5] L. Dong, S. Xu, and B. Xu, “Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition,” in ICASSP, 2018.
- [6] J. Li, Y. Wu, Y. Gaur, et al., “On the Comparison of Popular End-to-End Models for Large Scale Speech Recognition,” in Interspeech, 2020.
- [7] Y. He, T. N. Sainath, R. Prabhavalkar, et al., “Streaming end-to-end speech recognition for mobile devices,” in ICASSP, 2019.
- [8] C.-C. Chiu, T. N. Sainath, et al., “State-of-the-art Speech Recognition With Sequence-to-Sequence Models,” in ICASSP, 2018.
- [9] S. Kim, T. Hori, and S. Watanabe, “Joint CTC-attention based end-to-end speech recognition using multi-task learning,” in ICASSP, 2017.
- [10] S. Schneider, A. Baevski, R. Collobert, and M. Auli, “wav2vec: Unsupervised pre-training for speech recognition,” arXiv:1904.05862, 2019.
- [11] A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” NeurIPS, 2020.
- [12] W.-N. Hsu, B. Bolte, Y.-H. H. Tsai, et al., “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM TASLP, 2021.
- [13] C.-C. Chiu, J. Qin, Y. Zhang, J. Yu, and Y. Wu, “Self-supervised learning with random-projection quantizer for speech recognition,” in ICML, 2022.
- [14] A. Radford, J. W. Kim, T. Xu, et al., “Robust speech recognition via large-scale weak supervision,” in ICML, 2023.
- [15] Y. Zhang, W. Han, J. Qin, et al., “Google usm: Scaling automatic speech recognition beyond 100 languages,” arXiv:2303.01037, 2023.
- [16] V. Pratap, A. Tjandra, B. Shi, et al., “Scaling speech technology to 1,000+ languages,” arXiv:2305.13516, 2023.
- [17] R. Takeda et al., “Node pruning based on entropy of weights and node activity for small-footprint acoustic model based on deep neural networks.,” in Interspeech, 2017.
- [18] Y. Shangguan, J. Li, Q. Liang, et al., “Optimizing speech recognition for the edge,” arXiv:1909.12408, 2019.
- [19] D. Gao, X. He, Z. Zhou, and otherss, “Rethinking pruning for accelerating deep inference at the edge,” in SIGKDD, 2020.
- [20] C.-I. J. Lai, Y. Zhang, A. H. Liu, et al., “Parp: Prune, adjust and re-prune for self-supervised speech recognition,” NeurIPS, 2021.
- [21] S. Ding, T. Chen, and Z. Wang, “Audio lottery: Speech recognition made ultra-lightweight, noise-robust, and transferable,” in ICLR, 2021.
- [22] A. Fasoli, C.-Y. Chen, et al., “4-bit quantization of lstm-based speech recognition models,” arXiv:2108.12074, 2021.
- [23] A. Bie, B. Venkitesh, J. Monteiro, et al., “A simplified fully quantized transformer for end-to-end speech recognition,” arXiv:1911.03604, 2019.
- [24] S. Ding, P. Meadowlark, Y. He, et al., “4-bit conformer with native quantization aware training for speech recognition,” arXiv:2203.15952, 2022.
- [25] O. Rybakov, P. Meadowlark, S. Ding, et al., “2-bit conformer quantization for automatic speech recognition,” arXiv:2305.16619, 2023.
- [26] A. Zhou, Y. Ma, J. Zhu, et al., “Learning n: m fine-grained structured sparse neural networks from scratch,” arXiv:2102.04010, 2021.
- [27] Y. Bengio, N. Léonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,” arXiv:1308.3432, 2013.
- [28] Y. Peng, Y. Sudo, S. Muhammad, and S. Watanabe, “Dphubert: Joint distillation and pruning of self-supervised speech models,” arXiv:2305.17651, 2023.
- [29] Y. Lee, K. Jang, J. Goo, et al., “Fithubert: Going thinner and deeper for knowledge distillation of speech self-supervised learning,” arXiv:2207.00555, 2022.
- [30] K. Jang, S. Kim, S.-Y. Yun, and H. Kim, “Recycle-and-distill: Universal compression strategy for transformer-based speech ssl models with attention map reusing and masking distillation,” arXiv:2305.11685, 2023.
- [31] A. Gulati, J. Qin, C.-C. Chiu, et al., “Conformer: Convolution-augmented transformer for speech recognition,” Interspeech, pp. 5036–5040, 2020.
- [32] Z. Dai, Z. Yang, Y. Yang, et al., “Transformer-xl: Attentive language models beyond a fixed-length context,” arXiv:1901.02860, 2019.
- [33] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in ICML, 2006.
- [34] W. Chan, N. Jaitly, Q. Le, and O. Vinyals, “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,” in ICASSP, 2016.
- [35] B. Jacob, S. Kligys, B. Chen, et al., “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” in CVPR, 2018.
- [36] Google, “Artificial Intelligence at Google: Our Principles,” .
- [37] D. Hwang, K. C. Sim, Z. Huo, and T. Strohman, “Pseudo label is better than human label,” in Interspeech, 2022.
- [38] “https://cloud.google.com/tpu/docs/supported-tpu-configurations,” .
- [39] A. Vaswani, N. Shazeer, N. Parmar, et al., “Attention is all you need,” NeurIPS, 2017.
- [40] A. Graves, “Practical variational inference for neural networks,” NeurIPS, 2011.
- [41] D. Qiu, D. Rim, S. Ding, O. Rybakov, and Y. He, “Rand: Robustness aware norm decay for quantized seq2seq models,” arXiv:2305.15536, 2023.
- [42] S. K. Esser, J. L. McKinstry, D. Bablani, R. Appuswamy, and D. S. Modha, “Learned step size quantization,” arXiv:1902.08153, 2019.