A Framework for Exploring Federated Community Detection
Abstract
Federated Learning is machine learning in the context of a network of clients whilst maintaining data residency and/or privacy constraints. Community detection is the unsupervised discovery of clusters of nodes within graph-structured data. The intersection of these two fields uncovers much opportunity, but also challenge. For example, it adds complexity due to missing connectivity information between privately held graphs. In this work, we explore the potential of federated community detection by conducting initial experiments across a range of existing datasets that showcase the gap in performance introduced by the distributed data. We demonstrate that isolated models would benefit from collaboration establishing a framework for investigating challenges within this domain. The intricacies of these research frontiers are discussed alongside proposed solutions to these issues.
Introduction
Data ownership can be distributed across institutions or individuals who may not be able to share it for technical or legal reasons to enable the use of centralised machine learning (Liu and Yu 2022; Tan et al. 2022). Federated learning over graphs is complex due to the variety of scenarios created by partitions of this structure (Zhang et al. 2021). GNNs are used extensively in previous literature for learning network representations (Chen et al. 2020; Hamilton, Ying, and Leskovec 2017; Scarselli et al. 2008; Kipf and Welling 2016) and there are many works studying the unsupervised use of these methods (Tsitsulin et al. 2020; Wang et al. 2019). Identifying clusters based on latent patterns in the dataset, rather than the “ground-truth” is useful for applications with missing or prohibited information access. This makes community detection a powerful tool for studying federated learning on graphs. Numerous surveys exist on federated learning methods (Ma et al. 2022; Yang et al. 2019) and graph federated learning (Yang et al. 2019; Liu and Yu 2022) but none on federated community detection.
Federated graph learning encompasses a diverse range of scenarios, each with important applications. For banks that want to collaborate for anti-fraud measures but can’t share client information (Suzumura et al. 2019) it is useful to study the setup where each client owns a sub-section of a global graph. Social media networks suffer from fake news propagating between the networks (Han, Karunasekera, and Leckie 2020; Liu et al. 2022) but data is split heterogeneous between clients as a comment on one platform is not the same as a retweet. Pharmaceutical companies own molecular copyright and don’t want to share (Manu et al. 2021) meaning that they are aware of the space graph structure but do not want to share important feature space information that is expensive to gather. Hospitals cannot share sensitive information but working together would improve patient care so studying a partition where there are missing connections between nodes is helpful here. This federated paradigm is also applicable to learning a personalised model where each client is a user of the same platform. It is desirable to learn a model specific to each user whilst also sharing global information insights which is pertinent in context of data privacy regulations such as the General Data Protection Regulation (GDPR) (Truong et al. 2021). Therefore, this paradigm also can extend to learning topology of clients to facilitate better communication between a network of clients.
We explore an initial scenario and method for unsupervised federated graph clustering which averages the weights of clients (McMahan et al. 2017) with a modularity based clustering objective (Tsitsulin et al. 2020). We test the method against clients that do not collaborate over three datasets and demonstrate that the federation leads to better performance than the isolated case but still lacks compared to the centralised alternative. This work creates a benchmark and framework on which other graph clustering objectives and federation approaches can be used. Solutions have been proposed that use GNNs for supervised federated graph learning solving various sub-problems that can be adapted for the unsupervised version of the problem such as: personalisation (Xie et al. 2021), non-identically distribution graphs (Caldarola et al. 2021), multi-task and multi-domain federation learning (Zhuang et al. 2021). Some unsupervised federated techniques that have already been applied to images include non-IID data (Zhang et al. 2020) and for unbalanced data (Servetnyk, Fung, and Han 2020).
We will discuss open challenges directly related to graph federated learning that become increasingly difficult without explicit labels such as malicious attack vulnerability and distributed communication protocols in combination with solutions to alleviate these.
A Methodology For Experimentation
Baseline Problem Statement
We consider the simplest version of federated graph learning which is that the problem is defined by having number of clients , which each own sub-graphs of a global graph. Each graph is represented by a set of nodes and a set of edges that depends on the set of nodes allocated to each client which also dictates the number of total edges but all own the same set of features. This allows us to represent the each clients graph as , where is the node feature matrix and the adjacency matrix is represented by . A node has a degree which is the number of nodes it is connected to . The degree vector is therefore given by . We seek to learn a function for each client to find cluster assignments for the clusters present in the data. In practise, each client finds their own cluster assignment, so the size of the matrix will depend on the number of nodes each client has, denoted by .
Datasets
In these experiments the models are tested over three different datasets, Cora (McCallum et al. 2000), Citeseer (Giles, Bollacker, and Lawrence 1998) and PubMed (Sen et al. 2008) which are split via nodes to create the dataset partitions for each client. This allows a direct comparison to the typical GNN clustering algorithm which these are usually used to test which mimics the centralised alternative. Each graph is a publication citation network with features extracted from the words in the papers. We contextualise these graphs in terms of potential graph topologies as the partitioning scheme may result in non-isomorphic graph compared to the original. The average clustering coefficient is the average of all the local clustering coefficients calculated for each node, which is the proportion of all the connections that exist in a nodes neighbourhood, over all the links that could exist in that neighbourhood. Closeness centrality is defined as the reciprocal of the mean shortest path distance from all other nodes in the graph, so the average of this is a measure of how close the average node is to other nodes.
| Datasets | Cora | CiteSeer | PubMed |
|---|---|---|---|
| N Nodes | 2708 | 3327 | 19717 |
| N Features | 1433 | 3703 | 500 |
| N Edges | 10556 | 9104 | 88648 |
| Mean Closeness | |||
| Centrality | 0.137 | 0.047 | 0.160 |
| Average Clustering | |||
| Coefficient | 0.241 | 0.144 | 0.060 |
Unsupervised GNN Clustering Architecture
Here the clustering objective and forward pass of each GNN that is optimised by each client is described and for simplicity we omit the client superscript. In these experiments, the same model is used for each client as the federated part of the algorithm averages weights. There is potential to use different GNN models if the federation aggregation used an embedded space minimisation (Makhija et al. 2022).
The graph neural network (GNN) computes a function over every node’s neighbourhood . Computing the function over the features at layer gives the features at the next layer and the permutation-invariant aggregator operator that we use is . The first step in the GNN architecture used is to transform the adjacency matrix by adding self loops then normalising by the degree matrix so . The neighbourhood of a node as the node’s that it is connected to. The neighbourhood feature matrix for a node is the multi-set of all neighbourhood features , which includes the features of node . We use a single layer GNN so the hidden representation for a single node is given by , where ; is the bias for the node and the chosen activation function is SELU (Klambauer et al. 2017).
The forward pass is given by , where is a neural network and is the Softmax activation function, which is chosen as to find cluster assignments . The algorithm optimises modularity given by Equation (1), where the function if nodes and belong the same cluster and otherwise. Modularity measures the divergence between the intra-cluster edges from the expected one under a random graph with given degrees and for that connect nodes and with probability .
| (1) |
We use the optimisation procedure as formulated by Tsitsulin et al. (2020) which first relaxes the cluster assignment matrix to a one-hot assignment matrix so that it becomes . The optimal that maximises is the top-k eigenvectors of the modularity matrix . The modularity matrix can be reformulated as which allows us to decompose the computation as a sum of sparse matrix-matrix multiplication and rank-one degree normalization reduces the time complexity, so the computation becomes . A collapse regularisation term is used where is the Frobenius norm. Therefore, the loss function for the model is given by Equation (2), noting that and are respectively defined as the number of nodes and edges in the graph .
| (2) | |||
Federated Learning
The weight averaging algorithm from McMahan et al. (2017) is used to create the federated part of the algorithm, which averages all clients parameters at the server then distributes the result back to each client for local training. If the federation was acting over heterogeneous graphs then this would not be appropriate as the weights would correspond to different feature so the activation’s would not be in alignment. In these experiments, the contribution of each client to the average is weighted by the number of local data samples as the partitioning is node wise. The cycle is defined the global aggregation in Equation (3) after a preset number of local epochs where the parameters are updated at each round using , where is the learning rate. This is not be appropriate for all scenarios discussed as clients may experience different flows of data which will affect how much the parameters update between each communication round. In that scenario, techniques would need to be developed to moderate each clients contribution and the redistribution. However, here redistribution occurs for all clients after the global aggregation. The parameters are initialised from a Xavier uniform distribution and this term hereafter is used to refer to all weights in the forward pass including both the GNN , and the linear layer with all bias terms.
| (3) |
Experiment Details
In all experiments, the algorithm variations of the federation, centralised model and the isolated models that do not collaborate are subject to the following constraints. The experiments are designed so that in one, only one client may have access to each node, compared to the relaxing of this constraint. Each set of models are trained for the equivalent of five local epochs for every communication round and train for a total of 250 rounds. The cluster size regularisation parameter is set constant in the experiment and the number of clients is varied between two and fifteen.
All models are optimised with the Adam optimiser (Kingma and Ba 2014) using a learning rate of , with no weight decay. The GNN functions that underpin each model reduce the dimensionality of features to . The training/validation/testing splits are created by partitioning the adjacency matrix into the proportions . All graphs considered are undirected which is maintained in the splits. Macro-F1 is used to assess performance to ensure that the evaluation is biased by label distribution. The best weight parameters over training are taken at the point of highest F1 validation score and performance is determined by the test set. All experiments are evaluated over three seeds and the average performance is reported. All experiments are performed on a single 2080 Ti GPU (12GB) with 96GB of RAM, and a 16core Xeon CPU. The Randomness Coefficient is used to assess the reliability of the results, where a lower value indicates higher consistency across random seeds over the experiment (Leeney and McConville 2023).
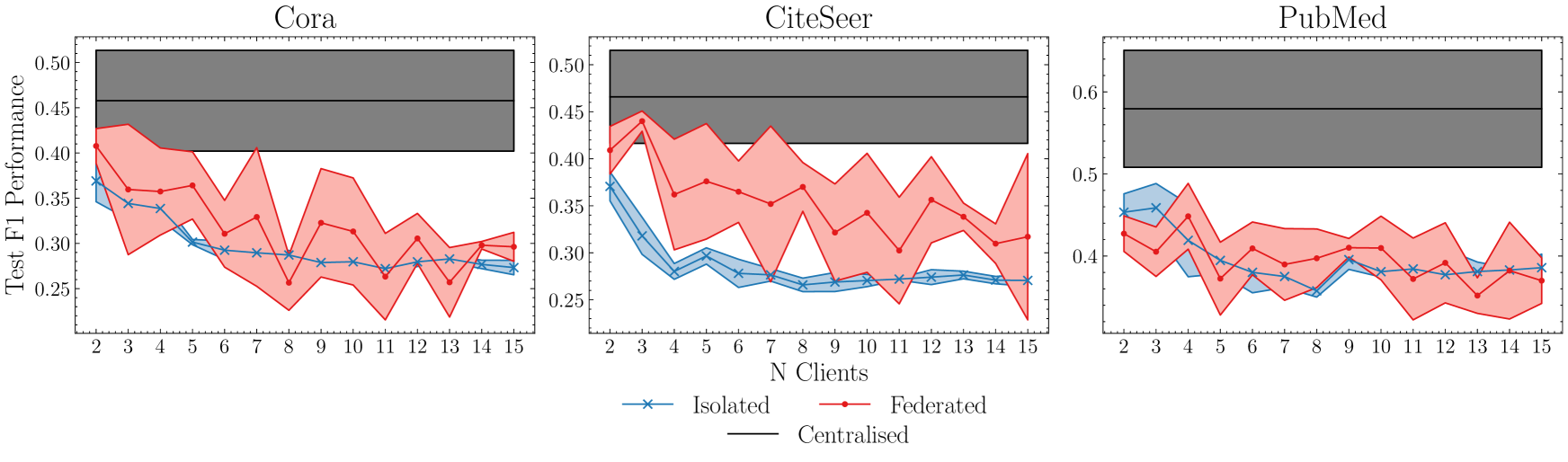
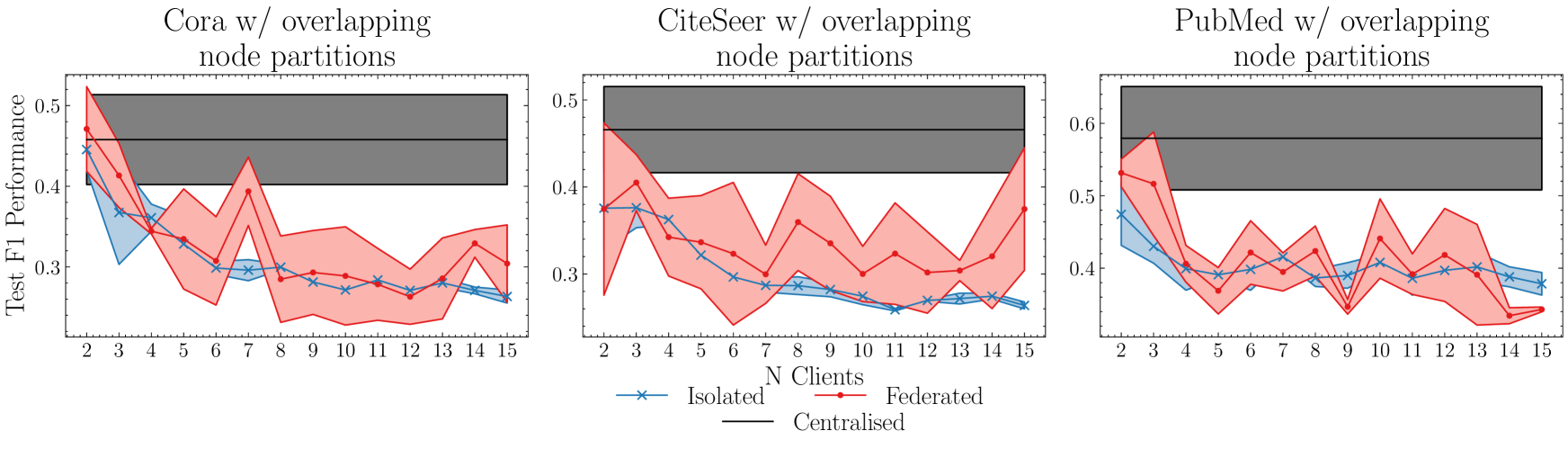
Discussion
Experiments
The centralised model performs better than any other number of clients. The lighter region of colour in Figure 1 shows performance variation due to random seed. In general, the federation performs better than the isolated models and performance degrades as number of clients is increased. In contrast, in Figure 2, performance has increased for both the federation of clients and those that are isolated, so that for two clients performance is almost on par with the centralised model. In addition, the difference between the two client models is less than the previous experiment, which shows that the lost connectivity between clients’ private nodes affects learning. Whilst still behind the centralised model that accesses all data, the potential of federated graph learning has been demonstrated at to be better than not collaborating for unsupervised clustering. A low randomness coefficient for both experiments means that these experiments are consistent across randomness and can therefore be trusted.
Open Challenges
Diverse Models
Figure 1 highlights that the centralised model performs better than both the Legion and the clients that do not collaborate. This establishes the framework for federated community detection, however, only one federated GNN model is considered. A comprehensive study should consider a diverse range of GNN models. The dataset partitioning means that the local GNN cannot extract information from high-order neighbours due to the lost connectivity hence the drop in performance compared to the centralised model. Additionally, it may not be practical to share details of the model and hence share via weight aggregation. Using a loss function to minimise distance in the embedded space similar to Makhija et al. (2022) may be the solution to this.
Non-IID Data
The isolated models performance is proportional to the edges lost in the dataset partitioning scheme and the increase in the number of clients. A biased partition of the data, where each client owns the majority of nodes in one cluster, would increase the drop in performance compared to the centralised model (Ma et al. 2022). An extension of this work that may be suitable for this scenario is to scale the weight averaging in proportion to the similarity function based on cluster size distributions. Alternatively, it may be pertinent to share cluster centers and modulate weight averaging by computing the average distances between clients cluster centers.
Heterogeneous Partitions
The constraint of all clients learning on the same graph is used in this work to demonstrate the potential of unsupervised federated graph learning, however there are many applications that deal with complex graphs. MuMin (Nielsen and McConville 2022) is a multi-modal graph dataset for research and development of misinformation detection which is traditionally unsupervised task due to the unknown origin behind real world fake news. A federation that learns what feature information is relevant globally by feature alignment similar to Zhuang et al. (2021) is likely to be useful for aggregating between these different modalities.
Malicious Attack Vulnerability
In these experiments it is assumed that all parties are acting honestly and aren’t training on bad data to intentionally worsen the average of the federation. If it is not possible to verify the integrity of all clients then it will be important for solutions to be developed in awareness of this. A solution to this might be to generate random graphs to send to each participant, rank each client ability to cluster then scale the weight averaging in proportion to the trustworthiness score given by the W randomness coefficient.
Efficient Communication
Communication and memory consumption can be a key bottleneck when applying federated learning algorithms in practice (Liu and Yu 2022). This scheme for aggregating the weights of clients means that the entire network needs to be communicated to a server which comes with a significant memory overhead. Efficient communication protocols will be needed for real world implementations, which could be achieved by learning a sparse mask for minimising overhead similar to ideas proposed by Baek et al. (2022). An alternative may be to learn the topology of clients with a GNN which would allow clients to share over networks that aren’t fully connected.
Final Remarks
In this work, we propose a framework that combines federated graph learning with community detection and validate the feasibility of it, whilst demonstrating that lost connectivity with privately held data is significant. This framework extends to a diverse range of federations that are encompassed by different graph partitions, with each relevant to a practical application. Many open challenges in this paradigm that are revealed by the initial set of experiments performed herein and we discuss potential solutions to these.
References
- Baek et al. (2022) Baek, J.; Jeong, W.; Jin, J.; Yoon, J.; and Hwang, S. J. 2022. Personalized Subgraph Federated Learning. arXiv preprint arXiv:2206.10206.
- Caldarola et al. (2021) Caldarola, D.; Mancini, M.; Galasso, F.; Ciccone, M.; Rodolà, E.; and Caputo, B. 2021. Cluster-driven graph federated learning over multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2749–2758.
- Chen et al. (2020) Chen, F.; Wang, Y.-C.; Wang, B.; and Kuo, C.-C. J. 2020. Graph representation learning: a survey. APSIPA Transactions on Signal and Information Processing, 9: e15.
- Giles, Bollacker, and Lawrence (1998) Giles, C. L.; Bollacker, K. D.; and Lawrence, S. 1998. CiteSeer: An automatic citation indexing system. In Proceedings of the third ACM conference on Digital libraries, 89–98.
- Hamilton, Ying, and Leskovec (2017) Hamilton, W. L.; Ying, R.; and Leskovec, J. 2017. Representation learning on graphs: Methods and applications. arXiv preprint arXiv:1709.05584.
- Han, Karunasekera, and Leckie (2020) Han, Y.; Karunasekera, S.; and Leckie, C. 2020. Graph neural networks with continual learning for fake news detection from social media. arXiv preprint arXiv:2007.03316.
- Kingma and Ba (2014) Kingma, D. P.; and Ba, J. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Kipf and Welling (2016) Kipf, T. N.; and Welling, M. 2016. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907.
- Klambauer et al. (2017) Klambauer, G.; Unterthiner, T.; Mayr, A.; and Hochreiter, S. 2017. Self-normalizing neural networks. Advances in neural information processing systems, 30.
- Leeney and McConville (2023) Leeney, W.; and McConville, R. 2023. Uncertainty in GNN Learning Evaluations: The Importance of a Consistent Benchmark for Community Detection. Forthcoming.
- Liu and Yu (2022) Liu, R.; and Yu, H. 2022. Federated Graph Neural Networks: Overview, Techniques and Challenges. arXiv preprint arXiv:2202.07256.
- Liu et al. (2022) Liu, Z.; Yang, L.; Fan, Z.; Peng, H.; and Yu, P. S. 2022. Federated social recommendation with graph neural network. ACM Transactions on Intelligent Systems and Technology (TIST), 13(4): 1–24.
- Ma et al. (2022) Ma, X.; Zhu, J.; Lin, Z.; Chen, S.; and Qin, Y. 2022. A state-of-the-art survey on solving non-IID data in Federated Learning. Future Generation Computer Systems, 135: 244–258.
- Makhija et al. (2022) Makhija, D.; Han, X.; Ho, N.; and Ghosh, J. 2022. Architecture agnostic federated learning for neural networks. In International Conference on Machine Learning, 14860–14870. PMLR.
- Manu et al. (2021) Manu, D.; Sheng, Y.; Yang, J.; Deng, J.; Geng, T.; Li, A.; Ding, C.; Jiang, W.; and Yang, L. 2021. FL-DISCO: Federated Generative Adversarial Network for Graph-based Molecule Drug Discovery: Special Session Paper. In 2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), 1–7. IEEE.
- McCallum et al. (2000) McCallum, A. K.; Nigam, K.; Rennie, J.; and Seymore, K. 2000. Automating the construction of internet portals with machine learning. Information Retrieval, 3(2): 127–163.
- McMahan et al. (2017) McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; and y Arcas, B. A. 2017. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, 1273–1282. PMLR.
- Nielsen and McConville (2022) Nielsen, D. S.; and McConville, R. 2022. Mumin: A large-scale multilingual multimodal fact-checked misinformation social network dataset. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, 3141–3153.
- Scarselli et al. (2008) Scarselli, F.; Gori, M.; Tsoi, A. C.; Hagenbuchner, M.; and Monfardini, G. 2008. The graph neural network model. IEEE transactions on neural networks, 20(1): 61–80.
- Sen et al. (2008) Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Galligher, B.; and Eliassi-Rad, T. 2008. Collective classification in network data. AI magazine, 29(3): 93–93.
- Servetnyk, Fung, and Han (2020) Servetnyk, M.; Fung, C. C.; and Han, Z. 2020. Unsupervised federated learning for unbalanced data. In GLOBECOM 2020-2020 IEEE Global Communications Conference, 1–6. IEEE.
- Suzumura et al. (2019) Suzumura, T.; Zhou, Y.; Baracaldo, N.; Ye, G.; Houck, K.; Kawahara, R.; Anwar, A.; Stavarache, L. L.; Watanabe, Y.; Loyola, P.; et al. 2019. Towards federated graph learning for collaborative financial crimes detection. arXiv preprint arXiv:1909.12946.
- Tan et al. (2022) Tan, A. Z.; Yu, H.; Cui, L.; and Yang, Q. 2022. Towards personalized federated learning. IEEE Transactions on Neural Networks and Learning Systems.
- Truong et al. (2021) Truong, N.; Sun, K.; Wang, S.; Guitton, F.; and Guo, Y. 2021. Privacy preservation in federated learning: An insightful survey from the GDPR perspective. Computers & Security, 110: 102402.
- Tsitsulin et al. (2020) Tsitsulin, A.; Palowitch, J.; Perozzi, B.; and Müller, E. 2020. Graph clustering with graph neural networks. arXiv preprint arXiv:2006.16904.
- Wang et al. (2019) Wang, C.; Pan, S.; Hu, R.; Long, G.; Jiang, J.; and Zhang, C. 2019. Attributed graph clustering: A deep attentional embedding approach. arXiv preprint arXiv:1906.06532.
- Xie et al. (2021) Xie, H.; Ma, J.; Xiong, L.; and Yang, C. 2021. Federated graph classification over non-iid graphs. Advances in Neural Information Processing Systems, 34: 18839–18852.
- Yang et al. (2019) Yang, Q.; Liu, Y.; Chen, T.; and Tong, Y. 2019. Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST), 10(2): 1–19.
- Zhang et al. (2020) Zhang, F.; Kuang, K.; You, Z.; Shen, T.; Xiao, J.; Zhang, Y.; Wu, C.; Zhuang, Y.; and Li, X. 2020. Federated unsupervised representation learning. arXiv preprint arXiv:2010.08982.
- Zhang et al. (2021) Zhang, H.; Shen, T.; Wu, F.; Yin, M.; Yang, H.; and Wu, C. 2021. Federated Graph Learning–A Position Paper. arXiv preprint arXiv:2105.11099.
- Zhuang et al. (2021) Zhuang, W.; Gan, X.; Wen, Y.; Zhang, X.; Zhang, S.; and Yi, S. 2021. Towards unsupervised domain adaptation for deep face recognition under privacy constraints via federated learning. arXiv preprint arXiv:2105.07606.