In vivo learning-based control of microbial populations density
in bioreactors
Abstract
A key problem toward the use of microorganisms as bio-factories is reaching and maintaining cellular communities at a desired density and composition so that they can efficiently convert their biomass into useful compounds. Promising technological platforms for the real time, scalable control of cellular density are bioreactors. In this work, we developed a learning-based strategy to expand the toolbox of available control algorithms capable of regulating the density of a single bacterial population in bioreactors. Specifically, we used a sim-to-real paradigm, where a simple mathematical model, calibrated using a few data, was adopted to generate synthetic data for the training of the controller. The resulting policy was then exhaustively tested in vivo using a low-cost bioreactor known as Chi.Bio, assessing performance and robustness. In addition, we compared the performance with more traditional controllers (namely, a PI and an MPC), confirming that the learning-based controller exhibits similar performance in vivo. Our work showcases the viability of learning-based strategies for the control of cellular density in bioreactors, making a step forward toward their use for the control of the composition of microbial consortia.
keywords:
Control Applications, Learning-Based Control, In Vivo Validation, Sim-To-Real, Synthetic Biology*Corresponding authors
1 Introduction
Microorganisms, such as bacteria and yeast, have been used in industry as efficient, low-waste bio-factories able to convert nutrients into useful proteins or chemicals (Brenner et al.(2008)Brenner, You, and Arnold; Satyanarayana(2009); Su et al.(2020)Su, Liu, Fang, and Zhang; Jullesson et al.(2015)Jullesson, David, Pfleger, and Nielsen; Choi et al.(2018)Choi, Park, Lee, and Lee; Hug et al.(2020)Hug, Krug, and Müller). This is made possible by engineering de-novo synthetic circuits into cells or combining the natural bio-processing capabilities of different organisms. In this context, an important issue is how to employ cell resources to efficiently transform biomass into protein production while preventing the accumulation of toxic by-products (Mauri et al.(2020)Mauri, Gouzé, De Jong, and Cinquemani; Tian et al.(2020)Tian, Liu, Cao, Zhang, Li, Liu, Du, and Chen; Xu et al.(2018)Xu, Lybrand, Bennewitz, Tissier, Last, and Pichersky; Lv et al.(2019)Lv, Qian, Du, Chen, Zhou, and Xu). Using bioreactors, it is possible to reach and maintain a desired cell density in the growth environment, to create the optimal growth conditions for the bio-production of a given chemical. Figure 1 presents an example of automated control architecture applied to cell growth regulation. Specifically, by modulating the dilution with the introduction of new nutrients in the growth environment, it is possible to adjust in real time the density of the culture. To do so, an external controller can be designed to run on a computer and automatically regulate the density of the cells in bioreactors, by evaluating the error between the measure of the density inside the chamber and the desired density level to be achieved. Various strategies exist for regulating cell populations within a chamber, including those that manipulate dilution rates in chemostats (De Leenheer and Smith(2003)), while others leverage genetic interventions of the cell strains, and utilize different control inputs such as lights (Gutiérrez Mena et al.(2022)Gutiérrez Mena, Kumar, and Khammash) or various nutrients (Treloar et al.(2020)Treloar, Fedorec, Ingalls, and Barnes). From a control design perspective, existing approaches utilize traditional controllers like PIs (Kusuda et al.(2021)Kusuda, Shimizu, and Toya), non-linear piecewise smooth methods, or gain scheduling state feedback strategies (Fiore et al.(2021)Fiore, Della Rossa, Guarino, and di Bernardo). Some also harness computational capabilities to derive control laws incorporating constraints, either through mechanistic models (Bertaux et al.(2022)Bertaux, Sosa-Carrillo, Gross, Fraisse, Aditya, Furstenheim, and Batt; Aditya et al.(2021)Aditya, Bertaux, Batt, and Ruess; Zhu et al.(2000)Zhu, Zamamiri, Henson, and Hjortsø) or entirely through data-driven methods utilizing reinforcement learning (Treloar et al.(2020)Treloar, Fedorec, Ingalls, and Barnes).
Recent developments in quantitative systems and synthetic biology have led to the increased adoption of compact and cost-effective bioreactors, such as those explored by Bertaux et al.(2022)Bertaux, Sosa-Carrillo, Gross, Fraisse, Aditya, Furstenheim, and Batt; Steel et al.(2019)Steel, Habgood, Kelly, and Papachristodoulou; Wong et al.(2018)Wong, Mancuso, Kiriakov, Bashor, and Khalil. These bioreactors offer integrated control equipment and multiple sensors in a unified platform, enabling precise manipulation of environmental conditions for extended periods of time in microbial cultures, making them highly attractive for controlling microbial consortia. Among the different low-cost, open-source bioreactor platforms available for the rapid prototyping of novel microbial communities for bio-production, the Chi.Bio (Steel et al.(2019)Steel, Habgood, Kelly, and Papachristodoulou) offers the possibility to have a controlled, static environment in which culture parameters such as nutrient availability and temperature can be regulated, and includes the ability to frequently measure cellular density and bulk fluorescence, and the possibility of optogenetic actuation. This platform makes use of a PI controller for the real time control of the density of the cells in the culture vial. Although this controller is able to stabilize and maintain the density of a cellular population to a desired fixed value, the optimal tuning of the controller gains requires accurate knowledge of the controlled system.
An alternative approach to overcome the need for an accurate, well-calibrated mathematical model is to leverage learning-based control methods to learn the policy by directly interacting with the system. As proposed by (Treloar et al.(2020)Treloar, Fedorec, Ingalls, and Barnes), a suitable control law can be learned within 24 hours using five parallel bioreactors. However, this approach was only validated in-silico and doesn’t consider the stochasticity and variability of the biological process, displaying the necessity for additional investigations into the feasibility of such approaches. Indeed, the learning process can be “sample inefficient”, requiring long times and a large number of experimental data to learn the policy, which could hinder its use in biology (see Buşoniu et al.(2018)Buşoniu, de Bruin, Tolić, Kober, and Palunko; Bertsekas(2005)). A possible solution to learn a control policy without the need for a large set of experimental data comes from the sim-to-real approach, where the control policy is learnt on simulated environments and subsequently exported to the real system (Rusu et al.(2017)Rusu, Večerík, Rothörl, Heess, Pascanu, and Hadsell; Tan et al.(2018)Tan, Zhang, Coumans, Iscen, Bai, Hafner, Bohez, and Vanhoucke; James et al.(2017)James, Davison, and Johns). This can be particularly challenging in applications to biological systems as they evolve and grow, and are characterized by cell-to-cell variability, uncertainties and other disturbances that are cumbersome to accurately capture in synthetic mathematical models. Hence, a key open problem is to understand if and how learning-based controllers trained using a sim-to-real approach can be effectively deployed in vivo to control bacterial populations.
In this work, we address this problem by developing a learning-based controller for the regulation of cellular density to a desired value in a bioreactor. In line with the sim-to-real approach, the control law is learnt by interacting with synthetically generated data. These data are generated from a simple model capturing the main features of the growth dynamics. Note that, even though partial knowledge of the system’s dynamics is needed, a coarse calibration of the parameters, obtained using a few open-loop experiments, is enough to generate the data required for the training of the control algorithm. We show via a set of exhaustive in vivo experiments that the sim-to-real gap can be filled and that the control performance learnt using a simple, inaccurate model can be transferred to real experiments carried out using a bioreactor. We benchmark our controller in terms of performance and robustness against the on-board PI controller in the Chi.Bio and a Model Predictive Controller that was developed for the sake of comparison taking advantage of the simple model used to generate synthetic data for the learning-based controller.
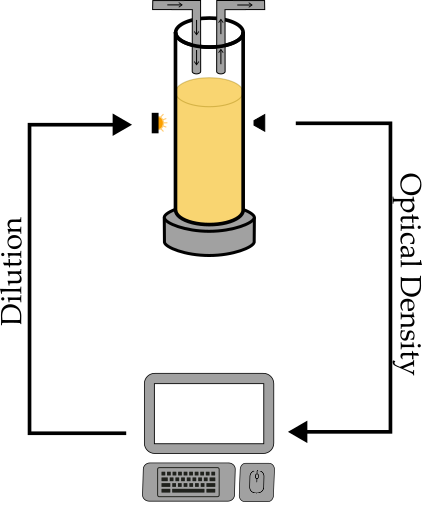
2 Control problem formulation
We consider the growth dynamics of a bacterial species inside a microbial culture chamber described as a continuous time dynamical system of the form:
| (1) |
where is the concentration of bacteria in the microbial culture chamber at time , with being the state space, is the initial concentration, is the control input or pump rate delivered as an exogenous injection of fresh growth media in the microbial chamber, with being the set of feasible inputs, is the vector field defining the system dynamics, and the output is the optical density (OD) measured by the platform, expressed in arbitrary units. For the sake of simplicity, we assume that is equal to 1, and therefore from now on we will equivalently refer to either bacterial concentration or optical density .
To take into account the technological constraints of common microbiology platforms, we consider the case where the control input can only be applied at fixed discrete time steps. Therefore, we design our control strategy starting from the following discrete time dynamical system:
| (2) |
where is the discrete time, and is a piecewise constant function defining the constant pump rate applied in the time interval to the system dynamics (1). Moreover, notice that when , that is when fresh media is pumped into the chamber, the experimental platform automatically expels some of the fluid from the chamber with a rate greater then the input rate, in order to avoid overflow of the media from the vessel. Considering the following assumptions:
-
•
A1. The concentration x is quantified through OD measures
-
•
A2. The measures are collected every minute
-
•
A3. The control input, i.e. the pump rate is limited to avoid overflow
the control goal is to regulate at steady state the bacterial concentration in the chamber to some desired value , which corresponds to the operating condition for which the cells are at exponential growth, where protein production is facilitated.
2.1 Stating the learning-based control problem
Following (De Lellis et al.(2022)De Lellis, Coraggio, Russo, Musolesi, and di Bernardo; De Lellis et al.(2023)De Lellis, Coraggio, Russo, Musolesi, and di Bernardo), the previous control goal can be reformulated as a learning-based control problem. Specifically, we want to learn the control policy to solve the following optimal control problem over a finite time horizon :
| (3a) | ||||
| s.t. | (3b) | |||
| (3c) | ||||
| (3d) |
where the objective function is a discounted cumulative reward defined as:
| (4) |
with being the reward received by the learning agent, a forgetting factor equal to , and being the final reward. In particular, the reward function is formulated as a distance-like function between the bacterial density in the chamber and a given reference setpoint as follows:
| (5) |
which steers the learning agent towards achieving and maintaining the bacterial density to the reference setpoint value .
3 Control design and validation
To solve the above learning problem and thus regulate the density of the bacterial population in a bioreactor, we designed a Deep Q-Learning algorithm leveraging the so-called sim-to-real approach. Specifically, as a test-bed species, we utilized the Escherichia coli (E. coli) strain designed by Gardner et al.(2000)Gardner, Cantor, and Collins embedding a plasmid that implements a genetic toggle-switch (i.e. a reversible bistable memory mechanism).
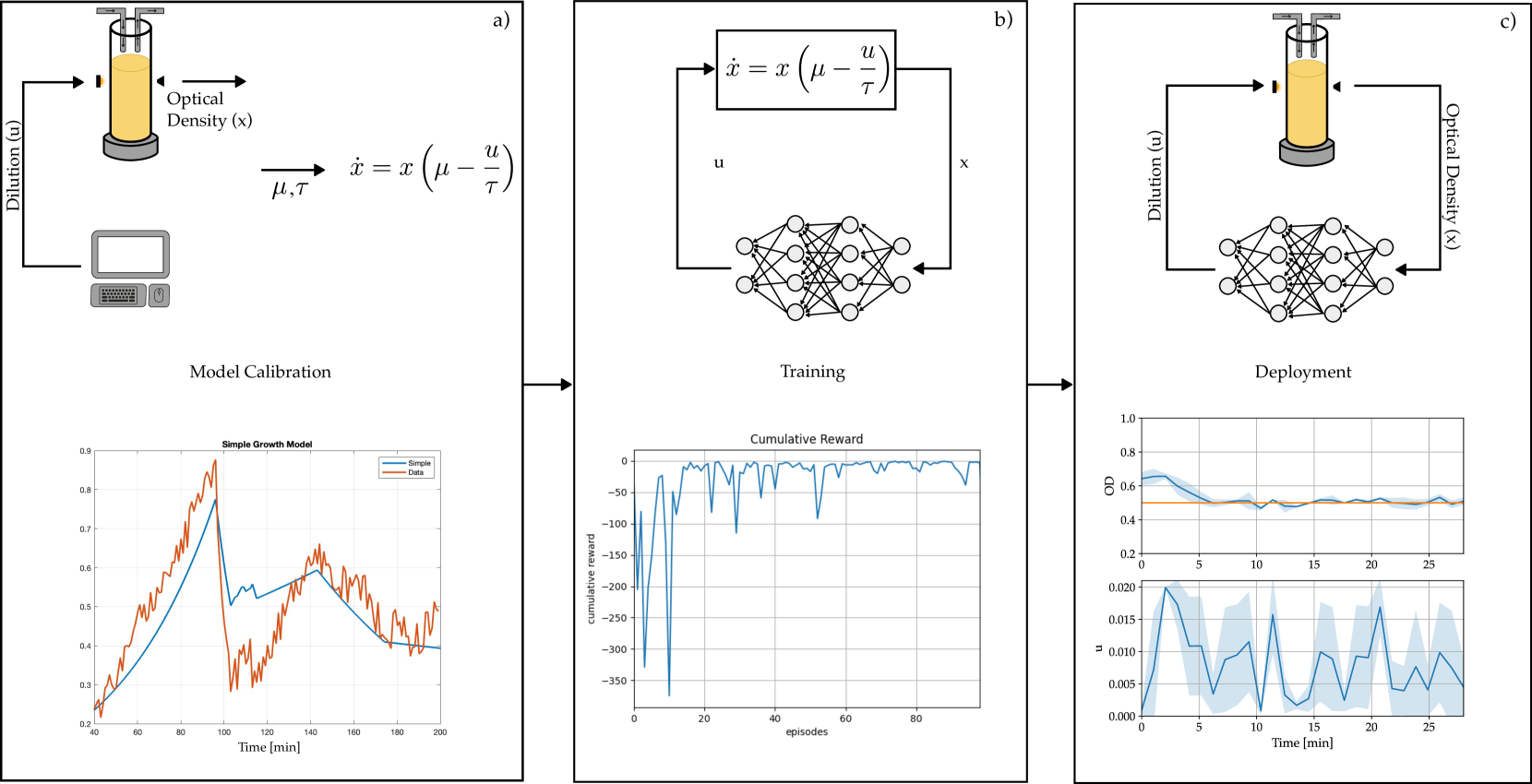
In this section, we illustrate the three-step pipeline we used to develop our control algorithm (Figure 2). Specifically, first, we chose and calibrated a dynamical model able to capture the growth dynamics of the microorganisms. Then, the mathematical model was used to generate synthetic data for the training of the neural network. Finally, the trained network was deployed in vivo to control the density of the population inside the bioreactor.
3.1 Modeling the microbial growth simulator
The production of synthetic data for the training of the model requires the choice and parametrization of a mathematical model capturing the main dynamical features of the growth of the bacteria. An established model for the description of exponential growth of bacteria in bioreactors (Monod(1949)) can be written as:
| (6) |
where is the density of the cellular population, is the growth rate of the population, is a scaling factor, and represents our control input (i.e. the dilution rate applied by modulating the speed of the pump carrying fresh media into the reactor). All the quantities in the above model are adimensional. Indeed, the measured optical density takes values between 0 and 1, which correspond to the absence and abundance of bacteria in the chamber, respectively, and are calibrated at the beginning of the experiments. To parametrize this model we carried out a single open-loop experiment growing the bacteria in the Chi.Bio at different values of the dilution rate changed randomly every 30 minutes. All the experiments, unless otherwise stated, were performed at 37 C in luria broth media supplemented with Kanamycin and Isopropyl -D-1-thiogalactopyranoside (IPTG).
The values of and were estimated from experimental data using a least square estimator in MATLAB and validated via open-loop experiments. In these experiments, cells were grown for 60 minutes. Subsequently, the cell culture was diluted using the maximum available dilution rate of until the optical density fell below 0.3. Finally, the dilution rate was randomly changed every 30 minutes. Figure 2 (bottom left panel) shows a comparison between the data generated by the model (in blue) and the real data recorded from the Chi.Bio (in red). Note that the model can effectively capture both the dynamics of the exponential growth of the population and the effects of dilution. However, as expected the prediction of the system trajectories is not very accurate, as demonstrated by the relatively high mean squared error between the estimated data and the recorded data (with a percentage mean square error (PMSE) equal to ). The question is now whether using such a simple model can be effective when generating synthetic data for the design of a learning-based controller to be used in vivo.
3.2 Training and deployment of the learning-based controller
We implement a DQN algorithm (Mnih et al.(2015)Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, et al.) in which a neural network approximates the optimal action-value function (see Watkins and Dayan(1992)). Specifically, the neural network is used to estimate the action based on the OD measure and the desired reference values of the OD, which are the neural network inputs. The training is performed by using synthetic data generated by the simplified mathematical model (6), whilst is randomly drawn with uniform distribution from the discrete set at each episode. The possible control actions, , are 17 discrete values taken uniformly in the interval of admissible pump rates. The neural network has two fully connected layers of 64 nodes each, activated by ReLU functions. The training was performed using Adam Optimizer with a learning rate of 0.001. We train the agent with 100 episodes in-silico by using the model (6). Each episode comprises 100 steps with each time step equal to 1 minute, which is the sampling time imposed by the constraints of the bioreactor. The synthetic OD measures, , are generated by integrating (6) with a smaller time step of , to simulate the continuous-time dynamics of the cells accurately. The results of the cumulative reward are shown in Figure 2.b.
Once a synthetically trained DQN had been obtained, we implemented the control strategy in real-time to regulate the OD inside a Chi.Bio. The bioreactor contained a culture of E. coli strain hosting a plasmid with a genetic toggle switch.
The time evolution of the OD in Figure 2.c demonstrate the controller’s effectiveness in successfully reaching and maintaining the desired set-point, set at 0.5. This was achieved with an average settling time of 10 minutes, indicating the controller’s ability to efficiently and rapidly stabilize the system.
Next, we test the performance of the proposed controller to change the desired OD and its robustness to variation of the temperature of the culture affecting the intrinsic growth rate of the cells.
3.3 In vivo performance and robustness assessment
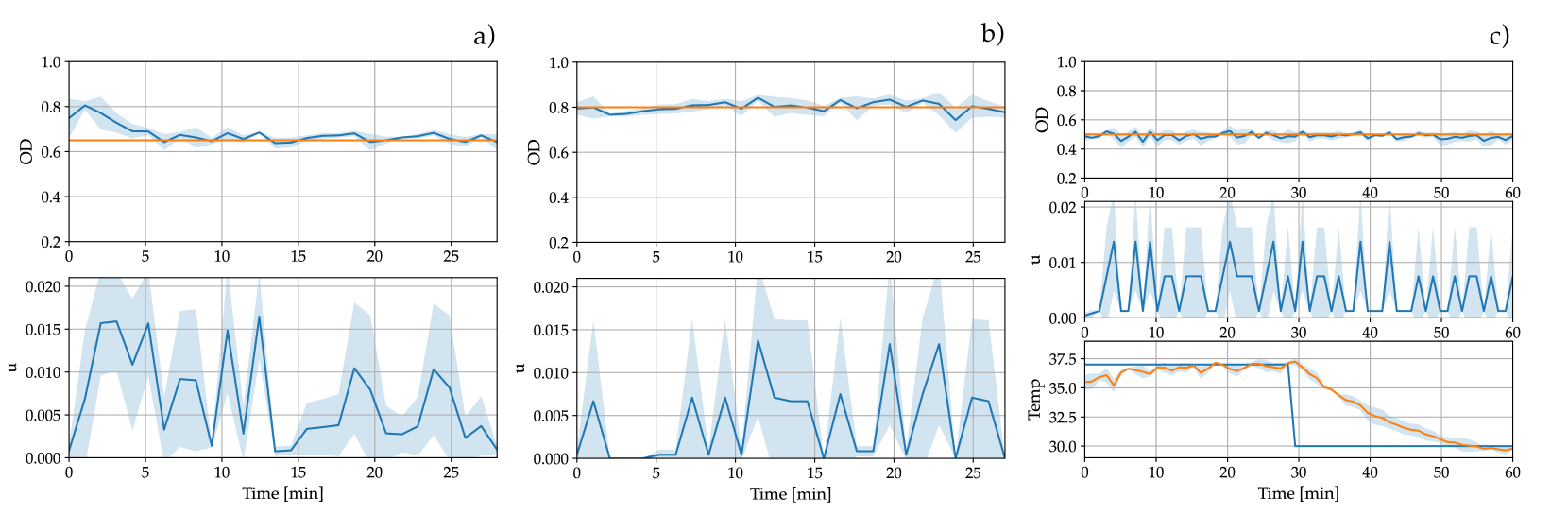
We tested the performance of the sim-to-real DQN controller conducting several experiments with the Chi.Bio. After a recovery phase, in which the cells were left to grow with abundant nutrients, we diluted the sample to a target OD value of 0.8. We kept this reference OD value for 30 minutes. After that, we switched to a target value of 0.65 and after 30 minutes we switched it to 0.5 for another 30 minutes. The experiments were replicated three times, for each desired value of OD of 0.8, 0.65, and 0.5. The average of the controlled OD together with the standard deviations for each experimental scenario are shown in Figure 3a-b.
Moreover, we assessed the robustness of the DQN controller to temperature variation, which directly affects the growth rate of the cells. Indeed, with respect to the nominal condition of 37°C, we experimentally observed a decrease of of the growth rate when the temperature was changed to 30°C. The test was conducted by starting the experiments at 37°C, regulating the OD to a target value of 0.5 for 30 min. After that, we switched the temperature of the Chi.Bio to 30°C. The results of this experiment are reported in Figure 3.c. It can be noticed that the controller successfully maintains the OD to the desired value despite the perturbation in the intrinsic growth rate of the cell due to the change of the temperature capturing its robustness.
4 Control benchmarks and comparison
In what follows, we compare the proposed learning-based controller to other controller types often used in synthetic biology applications for the regulation of biochemical processes, namely the Proportional Integral (PI) controller and the Model Predictive Controller (MPC). The PI controller considered here is already embedded in the Chi.Bio (Steel et al.(2019)Steel, Habgood, Kelly, and Papachristodoulou), while the MPC has been specifically designed here for the sake of comparison. Based on the error between the desired OD value and the measured OD, the PI controller evaluates a proportional action and two integral actions: one classical action to reject steady-state error, and another one to compensate for the effect of faulty gaskets in the pumps. The MPC evaluates what value of the control input must be applied to the system by solving an optimization problem at each control cycle. Specifically, at each time step, it solves an optimization problem on a finite prediction horizon of length searching for the policy that minimizes the cost function:
| (7) |
where the cost term is defined as:
| (8) |
so as to penalize also the violation of the constraints on the actuators; the final cost being defined as . The algorithm employs model (6) to run the optimization problem, which is solved by means of a particle swarm optimizer (Bonyadi and Michalewicz(2017)). The control input obtained as a solution to this optimization problem is then applied to the real system in the next time interval of 1 min (i.e. the control horizon ).
4.1 Comparison
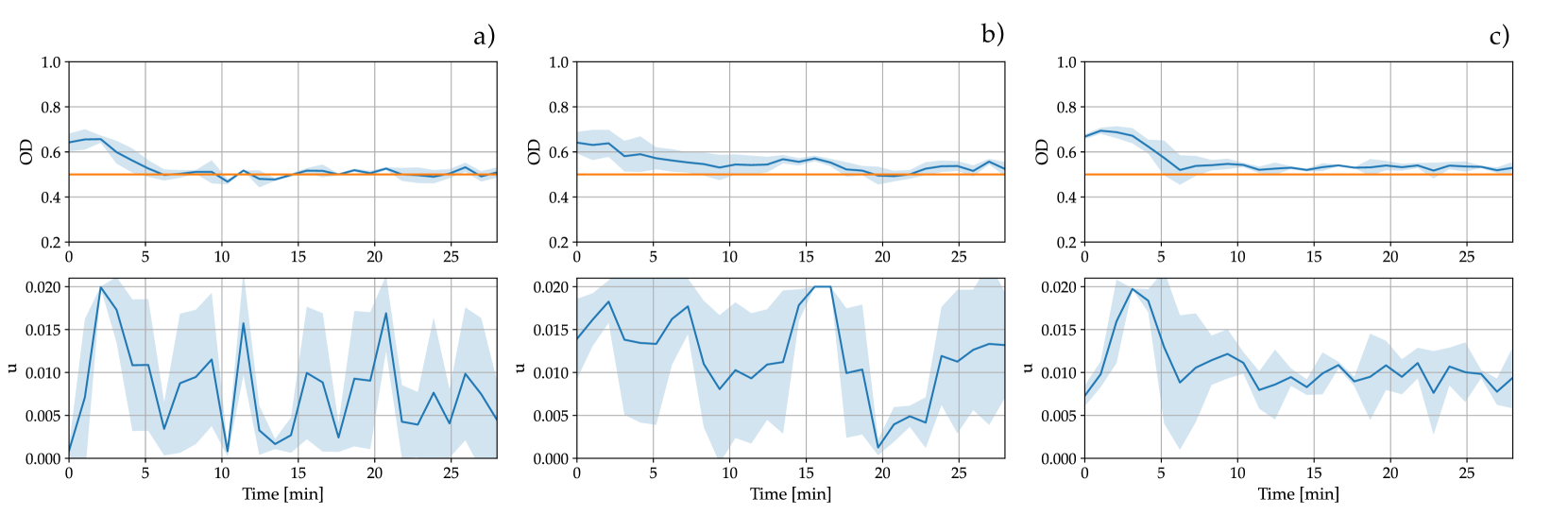
To assess quantitatively the performance of the control algorithms we used two integral metrics, namely the Integral Squared Error (ISE) and the Integral Time Absolute Error (ITAE), that provide a quantitative measure of the transient and static performance, respectively. More precisely, the ISE and ITAE are defined as (Fiore et al.(2016)Fiore, Perrino, di Bernardo, and di Bernardo; Guarino et al.(2020)Guarino, Fiore, Salzano, and di Bernardo):
| (9) |
where is the desired density and is the control horizon. The outcome of the experiments shown in Figure 4 confirms the ability of all the controllers to regulate the density of the population of interest. Furthermore, Table 1 shows the controller’s performances, comparing the learning-based control strategy with the PI and the MPC, confirming the viability of a sim-to-real paradigm in a biological setting. Note that all the controllers have comparable performances with the DQN offering comparable performance and robustness to those of the MPC (see Table 1) despite the use of a sim-to-real approach based on an uncertain, simple model of the bacterial growth dynamics.
| DQN | PI | MPC | |
| Reference 0.8 | |||
| ISE | |||
| ITAE | |||
| Reference 0.65 | |||
| ISE | |||
| ITAE | |||
| Reference 0.5 | |||
| ISE | |||
| ITAE | |||
| DQN | PI | MPC | |
| Temperature 37°C | |||
| ISE | |||
| ITAE | |||
| Temperature 30°C | |||
| ISE | |||
| ITAE | |||
5 Discussion
We regulate the growth of an E. coli population in a small turbidostat by using a machine learning-based external control approach to regulate OD measures. To address the data efficiency issue that could render the algorithm impractical for synthetic biology applications, we adopted and experimentally validated the use of a sim-to-real paradigm. In particular, the policy is initially acquired through training with a mathematical model of cell growth. This model was parametrized using a limited number of experiments, allowing us to address the substantial data requirement needed during the training phase. Subsequently, we validated it through in vivo experimental testing. Our experiments confirm the feasibility of this approach, demonstrating that it is possible to close the gap between simulations and experiments with a learning-based controller that can effectively regulate population density in a compact bioreactor like the Chi.Bio during in vivo experiments. Starting from the results presented here, future work will be focused on the development of a learning-based controller leveraging the difference in growth rates of two different cell populations to regulate their relative densities inside a bioreactor, a much harder problem to solve with the more traditional approaches.
We express our sincere gratitude to the TIGEM Institute and Scuola Superiore Meridionale for their support and resources, which contributed to the successful completion of this scientific paper.
References
- [Aditya et al.(2021)Aditya, Bertaux, Batt, and Ruess] Chetan Aditya, François Bertaux, Gregory Batt, and Jakob Ruess. A light tunable differentiation system for the creation and control of consortia in yeast. Nature Communications, 12(1):5829, 2021.
- [Bertaux et al.(2022)Bertaux, Sosa-Carrillo, Gross, Fraisse, Aditya, Furstenheim, and Batt] François Bertaux, Sebastián Sosa-Carrillo, Viktoriia Gross, Achille Fraisse, Chetan Aditya, Mariela Furstenheim, and Gregory Batt. Enhancing bioreactor arrays for automated measurements and reactive control with reacsight. Nature Communications, 13(1):3363, 2022.
- [Bertsekas(2005)] Dimitri P. Bertsekas. Dynamic Programming and Optimal Control, volume I. Athena Scientific, Belmont, MA, USA, 3rd edition, 2005.
- [Bonyadi and Michalewicz(2017)] Mohammad Reza Bonyadi and Zbigniew Michalewicz. Particle swarm optimization for single objective continuous space problems: a review. Evolutionary Computation, 25(1):1–54, 2017.
- [Brenner et al.(2008)Brenner, You, and Arnold] Katie Brenner, Lingchong You, and Frances H Arnold. Engineering microbial consortia: a new frontier in synthetic biology. Trends in Biotechnology, 26(9):483–489, 2008.
- [Buşoniu et al.(2018)Buşoniu, de Bruin, Tolić, Kober, and Palunko] Lucian Buşoniu, Tim de Bruin, Domagoj Tolić, Jens Kober, and Ivana Palunko. Reinforcement learning for control: Performance, stability, and deep approximators. Annual Reviews in Control, 46:8–28, 2018.
- [Choi et al.(2018)Choi, Park, Lee, and Lee] Yoojin Choi, Tae Jung Park, Doh C Lee, and Sang Yup Lee. Recombinant escherichia coli as a biofactory for various single-and multi-element nanomaterials. Proceedings of the National Academy of Sciences, 115(23):5944–5949, 2018.
- [De Leenheer and Smith(2003)] Patrick De Leenheer and Hal Smith. Feedback control for chemostat models. Journal of Mathematical Biology, 46(1):48–70, 2003.
- [De Lellis et al.(2022)De Lellis, Coraggio, Russo, Musolesi, and di Bernardo] Francesco De Lellis, Marco Coraggio, Giovanni Russo, Mirco Musolesi, and Mario di Bernardo. Control-tutored reinforcement learning: Towards the integration of data-driven and model-based control. In Proceedings of the 4th Annual Learning for Dynamics and Control Conference (L4DC 2022), volume 168 of Proceedings of Machine Learning Research, pages 1048–1059. PMLR, 2022.
- [De Lellis et al.(2023)De Lellis, Coraggio, Russo, Musolesi, and di Bernardo] Francesco De Lellis, Marco Coraggio, Giovanni Russo, Mirco Musolesi, and Mario di Bernardo. CT-DQN: Control-tutored deep reinforcement learning. In Proceedings of the 5th Annual Learning for Dynamics and Control Conference (L4DC 2023), volume 211 of Proceedings of Machine Learning Research, pages 941–953. PMLR, 2023.
- [Fiore et al.(2021)Fiore, Della Rossa, Guarino, and di Bernardo] Davide Fiore, Fabio Della Rossa, Agostino Guarino, and Mario di Bernardo. Feedback ratiometric control of two microbial populations in a single chemostat. IEEE Control Systems Letters, 6:800–805, 2021.
- [Fiore et al.(2016)Fiore, Perrino, di Bernardo, and di Bernardo] Gianfranco Fiore, Giansimone Perrino, Mario di Bernardo, and Diego di Bernardo. In vivo real-time control of gene expression: a comparative analysis of feedback control strategies in yeast. ACS Synthetic Biology, 5(2):154–162, 2016.
- [Gardner et al.(2000)Gardner, Cantor, and Collins] Timothy S Gardner, Charles R Cantor, and James J Collins. Construction of a genetic toggle switch in Escherichia coli. Nature, 403(6767):339–342, 2000.
- [Guarino et al.(2020)Guarino, Fiore, Salzano, and di Bernardo] Agostino Guarino, Davide Fiore, Davide Salzano, and Mario di Bernardo. Balancing cell populations endowed with a synthetic toggle switch via adaptive pulsatile feedback control. ACS Synthetic Biology, 9(4):793–803, 2020.
- [Gutiérrez Mena et al.(2022)Gutiérrez Mena, Kumar, and Khammash] Joaquín Gutiérrez Mena, Sant Kumar, and Mustafa Khammash. Dynamic cybergenetic control of bacterial co-culture composition via optogenetic feedback. Nature Communications, 13(1):4808, 2022.
- [Hug et al.(2020)Hug, Krug, and Müller] Joachim J Hug, Daniel Krug, and Rolf Müller. Bacteria as genetically programmable producers of bioactive natural products. Nature Reviews Chemistry, 4(4):172–193, 2020.
- [James et al.(2017)James, Davison, and Johns] Stephen James, Andrew J Davison, and Edward Johns. Transferring end-to-end visuomotor control from simulation to real world for a multi-stage task. In Proceedings of the 1st Annual Conference on Robot Learning, volume 78 of Proceedings of Machine Learning Research, pages 334–343. PMLR, 2017.
- [Jullesson et al.(2015)Jullesson, David, Pfleger, and Nielsen] David Jullesson, Florian David, Brian Pfleger, and Jens Nielsen. Impact of synthetic biology and metabolic engineering on industrial production of fine chemicals. Biotechnology Advances, 33(7):1395–1402, 2015.
- [Kusuda et al.(2021)Kusuda, Shimizu, and Toya] Minori Kusuda, Hiroshi Shimizu, and Yoshihiro Toya. Reactor control system in bacterial co-culture based on fluorescent proteins using an arduino-based home-made device. Biotechnology Journal, 16(12):2100169, 2021.
- [Lv et al.(2019)Lv, Qian, Du, Chen, Zhou, and Xu] Yongkun Lv, Shuai Qian, Guocheng Du, Jian Chen, Jingwen Zhou, and Peng Xu. Coupling feedback genetic circuits with growth phenotype for dynamic population control and intelligent bioproduction. Metabolic Engineering, 54:109–116, 2019.
- [Mauri et al.(2020)Mauri, Gouzé, De Jong, and Cinquemani] Marco Mauri, Jean-Luc Gouzé, Hidde De Jong, and Eugenio Cinquemani. Enhanced production of heterologous proteins by a synthetic microbial community: Conditions and trade-offs. PLOS Computational Biology, 16(4):e1007795, 2020.
- [Mnih et al.(2015)Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, et al.] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. nature, 518(7540):529–533, 2015.
- [Monod(1949)] Jacques Monod. The growth of bacterial cultures. Annual review of microbiology, 3(1):371–394, 1949.
- [Rusu et al.(2017)Rusu, Večerík, Rothörl, Heess, Pascanu, and Hadsell] Andrei A. Rusu, Matej Večerík, Thomas Rothörl, Nicolas Heess, Razvan Pascanu, and Raia Hadsell. Sim-to-real robot learning from pixels with progressive nets. In Proceedings of the 1st Annual Conference on Robot Learning, volume 78 of Proceedings of Machine Learning Research, pages 262–270. PMLR, 2017.
- [Satyanarayana(2009)] Tulasi Satyanarayana. Yeast biotechnology: diversity and applications. Springer, 2009.
- [Steel et al.(2019)Steel, Habgood, Kelly, and Papachristodoulou] Harrison Steel, Robert Habgood, Ciarán Kelly, and Antonis Papachristodoulou. Chi. Bio: An open-source automated experimental platform for biological science research. BioRxiv, page 796516, 2019.
- [Su et al.(2020)Su, Liu, Fang, and Zhang] Yuan Su, Chuan Liu, Huan Fang, and Dawei Zhang. Bacillus subtilis: a universal cell factory for industry, agriculture, biomaterials and medicine. Microbial cell factories, 19(1):1–12, 2020.
- [Tan et al.(2018)Tan, Zhang, Coumans, Iscen, Bai, Hafner, Bohez, and Vanhoucke] Jie Tan, Tingnan Zhang, Erwin Coumans, Atil Iscen, Yunfei Bai, Danijar Hafner, Steven Bohez, and Vincent Vanhoucke. Sim-to-real: Learning agile locomotion for quadruped robots. arXiv preprint arXiv:1804.10332, 2018.
- [Tian et al.(2020)Tian, Liu, Cao, Zhang, Li, Liu, Du, and Chen] Rongzhen Tian, Yanfeng Liu, Yanting Cao, Zhongjie Zhang, Jianghua Li, Long Liu, Guocheng Du, and Jian Chen. Titrating bacterial growth and chemical biosynthesis for efficient n-acetylglucosamine and n-acetylneuraminic acid bioproduction. Nature Communications, 11(1):5078, 2020.
- [Treloar et al.(2020)Treloar, Fedorec, Ingalls, and Barnes] Neythen J Treloar, Alex JH Fedorec, Brian Ingalls, and Chris P Barnes. Deep reinforcement learning for the control of microbial co-cultures in bioreactors. PLoS Computational Biology, 16(4):e1007783, 2020.
- [Watkins and Dayan(1992)] Christopher JCH Watkins and Peter Dayan. Q-learning. Machine Learning, 8(3):279–292, 1992.
- [Wong et al.(2018)Wong, Mancuso, Kiriakov, Bashor, and Khalil] Brandon G Wong, Christopher P Mancuso, Szilvia Kiriakov, Caleb J Bashor, and Ahmad S Khalil. Precise, automated control of conditions for high-throughput growth of yeast and bacteria with evolver. Nature Biotechnology, 36(7):614–623, 2018.
- [Xu et al.(2018)Xu, Lybrand, Bennewitz, Tissier, Last, and Pichersky] Haiyang Xu, Daniel Lybrand, Stefan Bennewitz, Alain Tissier, Robert L Last, and Eran Pichersky. Production of trans-chrysanthemic acid, the monoterpene acid moiety of natural pyrethrin insecticides, in tomato fruit. Metabolic Engineering, 47:271–278, 2018.
- [Zhu et al.(2000)Zhu, Zamamiri, Henson, and Hjortsø] Guang-Yan Zhu, Abdelqader Zamamiri, Michael A Henson, and Martin A Hjortsø. Model predictive control of continuous yeast bioreactors using cell population balance models. Chemical Engineering Science, 55(24):6155–6167, 2000.