Expressive Forecasting of 3D Whole-body Human Motions
Abstract
Human motion forecasting, with the goal of estimating future human behavior over a period of time, is a fundamental task in many real-world applications. However, existing works typically concentrate on predicting the major joints of the human body without considering the delicate movements of the human hands. In practical applications, hand gesture plays an important role in human communication with the real world, and expresses the primary intention of human beings. In this work, we are the first to formulate a whole-body human pose forecasting task, which jointly predicts the future body and hand activities. Correspondingly, we propose a novel Encoding-Alignment-Interaction (EAI) framework that aims to predict both coarse (body joints) and fine-grained (gestures) activities collaboratively, enabling expressive and cross-facilitated forecasting of 3D whole-body human motions. Specifically, our model involves two key constituents: cross-context alignment (XCA) and cross-context interaction (XCI). Considering the heterogeneous information within the whole-body, XCA aims to align the latent features of various human components, while XCI focuses on effectively capturing the context interaction among the human components. We conduct extensive experiments on a newly-introduced large-scale benchmark and achieve state-of-the-art performance. The code is public for research purposes at https://github.com/Dingpx/EAI.
Introduction
Predicting the evolution of human behavior/activity in the physical world over time is an essential aspect of machine intelligence (Tarvainen and Valpola 2017; Ruiz, Gall, and Moreno-Noguer 2018; Yuan and Kitani 2020). For instance, to make the seamless human-robot interaction (HRI), a robot is supposed to have some notion of how people will move or act in the near future, conditioned on a series of historically observed poses (Gui et al. 2018; Cui and Sun 2021; Zhang, Black, and Tang 2021; Mao et al. 2019; Cai et al. 2020; Dang et al. 2021; Ding and Yin 2021).
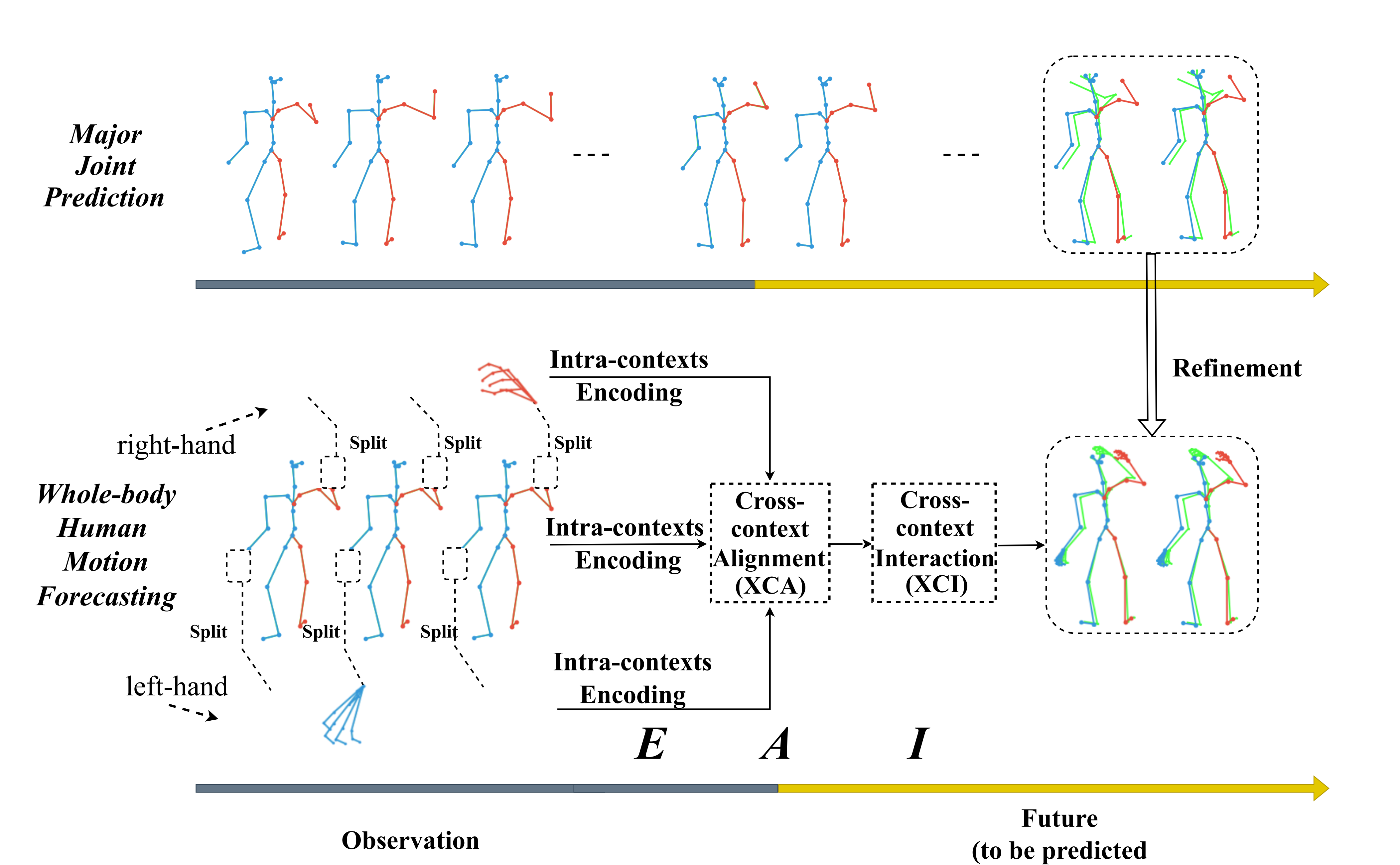
Over the past few years, this attractive topic has received considerable attention, emerging a large number of approaches, with deep learning techniques proving to be sought-after (Cai et al. 2021; Feng et al. 2021; Li et al. 2022; Petrovich, Black, and Varol 2021; Ruiz, Gall, and Moreno-Noguer 2018; Vaswani et al. 2017). Moreover, we note that existing works fall into the coarse-grained scope, i.e., forecasting major joint movements of the human body (Adeli et al. 2021; Cui and Sun 2021; Butepage et al. 2017; Ruiz, Gall, and Moreno-Noguer 2018; Zhong et al. 2022; Ma et al. 2022). However, in terms of realistic applications, it remains a significant limitation: the subtle activity (i.e., gestures) is not considered. The human hand is a vital bridge for interacting with the world, and meanwhile, for the HRI application, it typically includes a detailed command to the robot, embodying human behaviors with the major body (Zhang, Black, and Tang 2021; Diller, Funkhouser, and Dai 2022; Jin et al. 2020; Hidalgo et al. 2019; Taheri et al. 2020). From real applications of human pose forecasting, we, therefore, suggest that considering only major joints, while ignoring the subtle hand gestures, is not sufficient.
To fully investigate this issue, we propose a novel paradigm: whole-body human motion forecasting, that is, conjointly predicting future activities of all joints within the body and hands, as shown in Figure 1. In contrast to the conventional task, it presents significant challenges in the following aspects: 1) There are distinct motion patterns in major body and gesture (amplitude of movement, skeletal freedom), and hence it is sub-optimal to treat them equally; 2) A human activity usually involves collaboration/interactivity of different parts within the whole-body; For instance, the clapping-hand embodies the interaction of both hands; and for drinking, it is dominated by the semantic association of the hands and mouth. 3) Due to the heterogeneous scales and characteristics, it is not feasible to directly model such cross-grained interaction as existing multi-person interactive forecasting methods do (Guo et al. 2022).
In this work, we propose a novel Encoding-Alignment-Interaction (EAI) framework to address these challenging issues. Specifically, to avoid negative mutual-interference, we first extract their separate internal spatio-temporal correlations from the body and gesture’s heterogeneous motion properties. We observe that, the interaction/collaboration of various elements within the whole-body is critical for performing a specific activity. However, such interaction is incompatible with the existing multi-person interaction (Guo et al. 2022), because person-to-person information is scale-uniform, whereas intra-body context is heterogeneous, e.g., coarse-to-fine-grained (body-to-gesture), or vice versa. Therefore, we propose to exploit the cross-context alignment (XCA) to effectively align and smooth the latent features of different parts, thus eliminating their heterogeneity. Finally, with the aligned features, we further introduce cross-context interaction (XCI), a variant of cross-attention (Hao et al. 2017), that is able to capture the pairwise interactivity between various human parts within the whole-body. We note that, the proposed EAI is a generic framework capable of simutaneously consider the interactivity of different parts within the whole-body as well as the heterogeneous properties, resulting in the higher-quality whole-body prediction.
Our contributions are as follows: (1) To the best of our knowledge, this work is the first to predict the future actions of major joints and human gestures simultaneously. (2) We propose a Encoding-Alignment-Interaction (EAI) approach, equipped with the XCA and XCI, which is capable of extracting the heterogeneous interaction within the whole body. (3) Extensive experiments show that our model achieves superior performance for both short- and long-term prediction compared to the competitors.
Related Work
Human Motion Forecasting. RNNs are the widely-used architectures for time-series data modeling and human pose prediction (Butepage et al. 2017; Bütepage, Kjellström, and Kragic 2018; Honda, Kawakami, and Naemura 2020; Corona et al. 2020). Despite encouraging progress, they typically suffer from error accumulation and tend to converge to a static pose. Feed-forward networks, such as convolutional neural networks (CNNs) (Liu et al. 2020; Ding and Yin 2022) and graph neural networks (GNNs)(Mao et al. 2019; Mao, Liu, and Salzmann 2020; Li et al. 2021, 2022), are proposed as an alternative solution to alleviate the drawbacks of recurrent models. (Mao et al. 2019) presents the learnable adjacent matrix to model spatial dependencies among human body joints. This approach is later extended with self-attention on an entire piece of historical information (Mao, Liu, and Salzmann 2020) or a selection of them (Li et al. 2021). Despite the promising performance, the existing approaches all fall into the scope of predicting the motions of major human joints, without co-analyzing the hand gestures (Pavlakos et al. 2019; Cui and Sun 2021). From the realistic application, we note that subtle hand movements are indispensable for the expressive human behavior and intention. Our work first notices this challenging issue, i.e., how to predict the expressive whole-body human motion (unifying the gesture and major human joints), and aims to solve it.
Contextual Interaction. Contextual Interaction have proven to be effective in the human-to-human interactions (Guo et al. 2022; Wang et al. 2021; Rong, Shiratori, and Joo 2021). Specifically, (Wang et al. 2021) models the context of individual motion and social interactions through a Multi-Range Transformers structure. (Guo et al. 2022) explores the multi-person contextual interactions via a designed cross-interaction module. However, the interaction/collaboration of various components within the whole-body is incompatible with the above method because human-to-human information is scale-uniform, whereas the intra-body context is heterogeneous. Therefore, in our proposed EAI, we introduce the alignment of heterogeneous features across human components to extract subsequent whole-body internal interactivity more effectively.
Proposed Method
Problem Setup. Previous works typically consider the forecasting of the major human joints. Given history human poses , informally, its objective can be defined as learning a mapping to estimate the future poses Y, where X is the observed major joints, is the corresponding future ones over frames. This work extends the above standard setup to united whole-body human motion forecasting, including major body, left and right hand, denoted by , , variables for the sake of simplicity. Analogously, we define the novel task as learning a united mapping :
|
|
(1) |
where () is the past (future) skeletal sequence of major body. is the number of 3D joint coordinates in a single frame and is the number of major body joints. Also, and are the past and future motion of the left (right) hands.
Intra-context Encoding
Due to the distinct motion patterns of major body and gestures, we should consider the different body parts individually. Notably, we extract the intra-context of 3D skeletal sequences comprising of left hand, head, and right hand positions, denoted as , in feature space. This is because the spatio-temporal correlations in feature space are more expressive than the correlations in the original motion space. Next, we illustrate the details of the encoding process by taking the major body as a specific example.
In the temporal domain, Discrete Cosine Transform (DCT) is exploited to capture the temporal smoothness by transforming the observed sequence into trajectory space. Given the past motion , we compute the DCT coefficients of this sequence as:
|
|
(2) |
where is a variant of by replicating the last observed pose times following (Mao et al. 2019); is the predefined DCT matrix and each row of C is the DCT coefficients for a trajectory.
In the spatial domain, we exploit GCNs (Mao et al. 2019; Cui and Sun 2021) to denote the skeleton as a fully-connected graph, depicted as an adjacency matrix . Formally, we define as the input feature of -th layer in GCNs, and as the weight matrix. Then the output feature is derived as:
|
|
(3) |
where is the input feature and at the first layer; The number of hidden layers are set to ; is an activation function. The final output features of last layer are , w.r.t .
Following the above formalism, we also attain the intra-context of the left (right) hands, forming the whole-body intra-context . We note that, although in the standard anatomy the wrist is considered to come from the major body, due to the physical connection with hands, we also include it in the hands feature extraction. Accordingly, the feature dimension of the hands is slightly changed as and .
In light of the heterogeneity and interactivity across part-specific representations, we therefore propose cross-context alignment (XCA) and cross-context interaction (XCI) to effectively capture the cooperation within the whole-body in the following sections.
Cross-context Alignment (XCA)
In contrast to personperson interactivity (Guo et al. 2022) task, the intra-body context of different body component is scale-inconsistent due to the distinctive motion patterns. The intra-body context is heterogeneous, coarse-to-fine-grained (body-to-gesture), or vice versa, in contrast to the current multi-person interaction where person-to-person information is scale-uniform. In other words, these differences in motion patterns need to be alleviated because they may enormously disturb the overall motion perception.
Intuitively, the heterogeneous context within the whole-body mainly originated from the amplitude of movement, scale, and skeletal freedom of different parts, typically reflecting the discrepancy of feature distribution (Li et al. 2018). To address this issue, we introduce cross-neutralization among the body components combined with discrepancy constraints to effectively align the latent features of different parts. Specifically, we neutralize the distribution discrepancy among different features via a learnable factor that can be automatically adjusted according to the MMD constraint. This reorganizes the original features into new features with a closer distribution. Such a strategy is able to alleviate the incompatibility of different body components while being more conducive to extracting the interaction. We take the alignment process of the major body and left hand as an example.
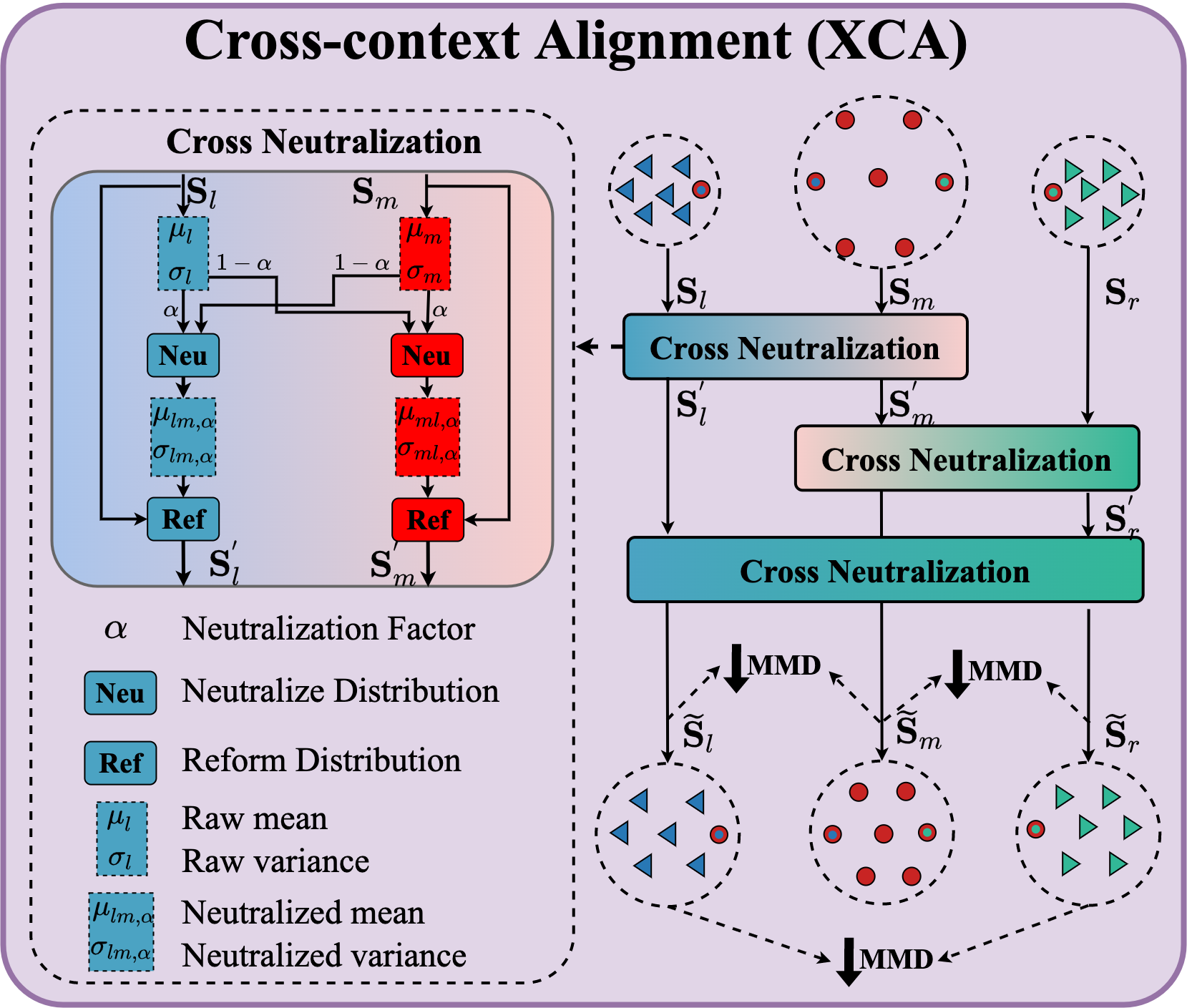
Cross Neutralization (CN). Given the intra-context , , we introduce a learnable factor to constitute the fused distribution to neutralize the distributions discrepancy between and . Formally, the is defined as:
| (4) | ||||
where and are the mean and variance of intra-context features ; and can be obtained similarly; and is the operation to calculate mean and variance along the joint dimension; ; () are the mean and variance vector of fused features distribution; (), () are the row vector of intra-context features () and fused features (); is a factor to avoid numerical issues. To further part-to-part alignment, we extend to the circular version:
| (5) | ||||
where , , and are the intermediate (output) features of the circular ; and are the factors similar to , which are updated in the training phase.
Discrepancy Constraint. We apply maximum mean discrepancy (MMD) to alleviate the part-to-part discrepancy.
| (6) |
where is the average operation along the spatial dimension, and /. and can be obtained similarly.
With the cross neutralization and discrepancy constraint, where the distribution discrepancy of intra-context features is reduced, our proposed cross-context alignment (XCA) could alleviate the heterogeneity of different intra-context. Next, we present cross-context interaction (XCI) to explore the interactions within the whole body that provides the vital cues to perceive future human intention.
Cross-context Interaction (XCI)
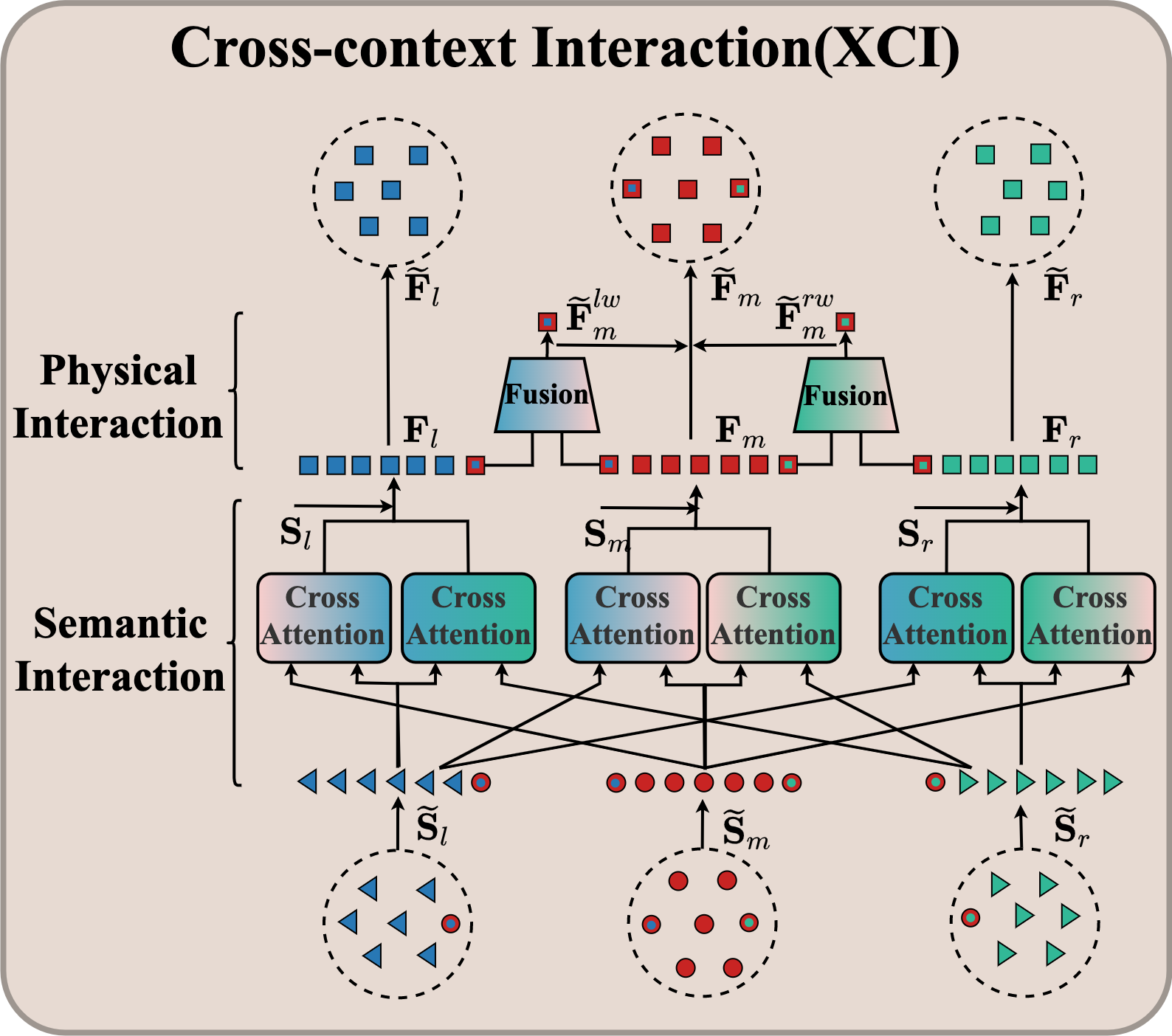
In contrast to the personperson external interaction (Guo et al. 2022), the bodyhands/handshands involves the internal interaction across different parts within the whole body. To be precise, it includes both semantic interaction (driven by the collaboration of different parts to perform a specific action) and physical interaction (inherent in the chain link via the bodyhands wrist). Thus, we present a variant of cross-attention (Hao et al. 2017) to capture the semantic and physical interactivity of various human parts.
Semantic Interaction. The relevance of the three body parts is mainly derived from the mutual semantic interaction within the integrated action. For example, for the action of eating, fingers and head joints have strong correlations. Therefore, we aim to model the semantic dependency across components via cross-attention mechanism (Hao et al. 2017). We take the cross-context semantic interaction between the major body and left hand as an example. The whole process is described as:
| (7) | ||||
where () is the input (output) features; The input feature of the first layer is and the output features of the last layer ; , and are the projection matrix with the size of ; , , and are the query, key and value features respectively; is the attention map calculated by the . is composed of multi-layer perceptrons (MLPs).
For the major body, the semantic relevance with the left hand could be leveraged to fuse the semantic interaction context into itself progressively. Similarly, we can also obtain the cross-context semantic interaction of the right hand for major body . Combing the above semantic-related features with the ego features, we can obtain the expressive features :
| (8) |
where is the concatenate operation along the feature dimension. We also attain the features , for left and right hand.
Physical Interaction. As the bridge between the body and hands, the wrist offers direct chain correlation between these two components. Therefore, we apply the ‘divide-and-fusion’ strategy. That is to say, we first replicate the wrist joint to involve it, as illustrated in section Intra-context Encoding for body and hand independently, and then perform dynamic feature fusion to form the final wrist features. In this way, the physical connection between body parts could be better modeled. Specifically, we identify the feature of the wrist in major body, left hand as the complementary pair. It is fed into MLPs to measure the mutual confidence, which are used as a weight to fuse paired features for more informed inference:
| (9) | |||
| (10) |
where (or ) is the features of the wrist in the left hand (or major body); and is the importance weight. is the fused wrist features. is a learnable temperature coefficient, jointly trained with all network parameters. Similarly, we obtain the fused wrist features for major body, right hand.
| Body Parts | Major body | Left Hands | Right Hands | Left Hands (AW) | Right Hands (AW) | Whole Body | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Time (sec) | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | |
| LTD (D) | 8.7 | 18.9 | 48.7 | 19.7 | 57.0 | 181.5 | 33.3 | 77.5 | 195.6 | 9.1 | 18.3 | 41.4 | 17.2 | 28.3 | 53.1 | 18.3 | 45.6 | 126.1 | |
| DMGNN (D) | 11.2 | 23.1 | 53.5 | 24.8 | 62.0 | 190.1 | 38.1 | 83.0 | 205.7 | 10.0 | 21.7 | 44.4 | 21.6 | 32.6 | 60.5 | 23.0 | 55.7 | 131.4 | |
| PGBIG (D) | 10.4 | 21.7 | 52.8 | 22.8 | 61.5 | 186.7 | 37.6 | 82.4 | 203.9 | 10.5 | 22.2 | 43.5 | 21.5 | 31.1 | 58.7 | 22.6 | 53.6 | 129.6 | |
| Divided | SPGSN (D) | 9.3 | 21.0 | 52.6 | 25.3 | 61.1 | 164.2 | 37.2 | 81.5 | 202.8 | 9.3 | 18.5 | 41.6 | 16.1 | 28.8 | 56.9 | 21.2 | 48.4 | 124.0 |
| LTD (U) | 9.1 | 19.9 | 50.2 | 19.9 | 50.5 | 162.5 | 32.3 | 74.6 | 195.5 | 8.9 | 17.1 | 42.5 | 16.7 | 29.3 | 58.3 | 18.4 | 43.1 | 120.4 | |
| DMGNN (U) | 13.7 | 26.4 | 56.9 | 22.4 | 57.3 | 172.0 | 36.3 | 78.9 | 203.7 | 9.7 | 20.3 | 46.4 | 19.0 | 33.2 | 64.1 | 22.7 | 50.0 | 128.2 | |
| PGBIG (U) | 13.2 | 24.9 | 54.2 | 23.0 | 56.4 | 165.7 | 35.0 | 77.2 | 199.4 | 10.2 | 19.5 | 45.7 | 19.1 | 32.5 | 62.0 | 22.2 | 48.1 | 125.8 | |
| SPGSN (U) | 12.7 | 24.5 | 53.4 | 21.6 | 55.5 | 161.6 | 34.3 | 75.5 | 190.8 | 9.6 | 18.2 | 42.3 | 18.5 | 31.0 | 58.2 | 21.0 | 46.9 | 120.3 | |
| United | EAI (Ours) | 8.3 | 18.7 | 46.8 | 17.7 | 49.2 | 136.4 | 29.8 | 69.0 | 169.0 | 8.6 | 17.3 | 38.8 | 16.2 | 27.8 | 51.6 | 16.7 | 40.7 | 104.6 |
Then, the final expressive features are further reorganized as follows: (1) Removing the left (right) wrist features / from the /, the final features of left/right hand changes to (); (2) As to the body, after physical wrist refinement, the dimension of the feature is unchanged, but with / updated by / to generate the final features ; (3) The resulting features are then followed by a predictor composed of a MLP and IDCT to regress the final features into predicted sequence , where , , and .
Training Loss: Prediction Loss is defined to to measure the accuracy of the predicted 3D coordinates, we calculate the mean per joint position error:
|
|
(11) |
where denotes the predicted -th joint position in frame , the corresponding ground truth (GT). the number of joints in the left hand skeleton. Similarly, we can also achieve and for right hand and body, forming the prediction loss of whole body .
Additionally, to further consider the hand semantics, we preprocess the gestures to be aligned with its wrist:
|
|
(12) |
where denotes the predicted -th joint position aligned with the left wrist, is the corresponding GT. Then, we can obtain the fine-grained prediction loss of two hands .
Since bone length is fixed for a human skeleton, we introduce the bone length loss:
|
|
(13) |
where denotes the length of -th bone, and the GT. the bone length loss of whole body.
To alleviate the features heterogeneity of different body components, we utilize the minimum distribution discrepancy error, proposed in section Cross-context Alignment (XCA), as the alignment Loss
| (14) |
Final Loss, is the weighted sum of the above losses:
| (15) |
where , , are the trade-off parameters.
Experiments
| Action | A1 pass | A2 eat | A3 drink | A4 lift | A5 on | A6 squeeze | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Time (sec) | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | 0.2 | 0.4 | 1.0 | |
| LTD (U) | 10.2 | 20.8 | 42.4 | 12.1 | 28.0 | 71.7 | 12.2 | 23.4 | 40.1 | 7.9 | 20.3 | 54.9 | 9.8 | 17.8 | 36.4 | 5.6 | 12.7 | 26.6 | |
| DMGNN (U) | 11.7 | 26.4 | 40.7 | 17.9 | 37.6 | 88.4 | 14.5 | 32.1 | 58.0 | 12.1 | 26.3 | 61.5 | 12.2 | 22.0 | 42.5 | 23.1 | 48.1 | 75.4 | |
| PGBIG (U) | 12.0 | 26.9 | 38.9 | 17.5 | 36.5 | 83.2 | 15.7 | 30.2 | 53.2 | 11.4 | 24.3 | 62.4 | 13.0 | 20.7 | 41.2 | 21.5 | 46.2 | 72.4 | |
| SPGSN (U) | 13.1 | 25.8 | 35.1 | 18.4 | 34.8 | 82.0 | 15.6 | 28.9 | 48.6 | 10.6 | 22.6 | 51.6 | 12.4 | 21.7 | 39.3 | 7.9 | 13.8 | 27.9 | |
| Major body | EAI (Ours) | 9.0 | 19.7 | 31.6 | 10.5 | 26.4 | 72.5 | 10.2 | 19.1 | 30.8 | 6.5 | 16.4 | 44.4 | 7.9 | 15.6 | 31.3 | 5.4 | 12.2 | 24.4 |
| LTD (U) | 24.4 | 52.2 | 211.2 | 21.7 | 52.5 | 187.5 | 51.8 | 123.4 | 185.8 | 21.0 | 66.3 | 163.8 | 12.1 | 34.1 | 50.1 | 18.1 | 35.6 | 54.6 | |
| DMGNN (U) | 36.7 | 68.9 | 196.6 | 38.6 | 87.5 | 234.4 | 56.2 | 128.8 | 265.4 | 22.2 | 68.7 | 181.2 | 15.3 | 44.3 | 54.2 | 24.1 | 49.3 | 73.1 | |
| PGBIG(U) | 33.5 | 66.3 | 186.2 | 36.9 | 88.2 | 225.6 | 56.7 | 126.4 | 264.6 | 23.1 | 66.9 | 178.4 | 15.0 | 43.2 | 50.1 | 23.0 | 45.6 | 72.4 | |
| SPGSN (U) | 30.9 | 71.1 | 165.1 | 36.5 | 94.6 | 263.6 | 51.4 | 119.8 | 242.7 | 20.3 | 65.2 | 175.5 | 14.9 | 41.1 | 53.7 | 22.9 | 47.3 | 70.3 | |
| Left hands | EAI (Ours) | 25.4 | 52.6 | 145.1 | 17.8 | 49.0 | 148.7 | 42.5 | 107.7 | 144.4 | 14.3 | 48.4 | 129.7 | 9.6 | 28.5 | 45.8 | 10.8 | 32.9 | 42.2 |
| LTD (U) | 37.0 | 82.1 | 136.1 | 35.3 | 79.3 | 204.3 | 22.9 | 82.2 | 167.2 | 25.5 | 81.5 | 229.1 | 45.1 | 97.0 | 187.2 | 25.1 | 47.8 | 93.7 | |
| DMGNN (U) | 39.2 | 80.5 | 129.5 | 37.5 | 78.3 | 215.0 | 23.5 | 85.8 | 221.4 | 27.3 | 83.4 | 231.0 | 47.3 | 105.6 | 230.2 | 26.4 | 54.2 | 103.7 | |
| PGBIG (U) | 36.8 | 78.3 | 124.6 | 34.2 | 76.4 | 212.5 | 24.0 | 87.6 | 210.5 | 26.1 | 82.5 | 233.7 | 47.2 | 103.4 | 221.9 | 25.7 | 54.0 | 102.5 | |
| SPGSN (U) | 33.7 | 73.0 | 108.7 | 31.8 | 59.5 | 207.6 | 22.5 | 92.0 | 249.4 | 21.3 | 76.4 | 215.6 | 42.4 | 101.4 | 173.5 | 24.7 | 52.6 | 98.7 | |
| Right hands | EAI (Ours) | 21.7 | 50.3 | 69.6 | 31.8 | 70.2 | 180.3 | 15.2 | 60.8 | 111.0 | 17.6 | 51.0 | 136.9 | 35.1 | 79.5 | 146.2 | 23.1 | 46.1 | 86.6 |
Datasets: To our knowledge, previous widely-used datasets, e.g., H3.6M (Ionescu et al. 2013), 3DPW (von Marcard et al. 2018), only record the major body motions (without human hands). To be compatible with our proposed novel task, here we select the GRAB (Taheri et al. 2020). It is a recently released dataset with over 1.6 million frames of 10 different actors performing a total of 29 actions.
It is captured using high-precision motion capture techniques. GRAB provides SMPL-X (Pavlakos et al. 2019) parameters from which we extract 25 joints (3D position) defined as the body (), and each hand is represented as 15-joints ().
Baselines: We note that for 3D whole-body human motions forecasting, there are no direct methods for comparisons. Therefore, to comprehensively investigate the proposed EAI, we select 4 SOTA approaches of standard major-joint prediction as our baselines, including LTD (Mao et al. 2019), DMGNN (Li et al. 2020), PGBIG (Ma et al. 2022), SPGSN (Li et al. 2022). Notably, all baselines are based on GCNs to consider the -joint human skeleton ( or ). To a fair comparison, we retrain the baselines under the following training setups.
We apply two training strategies to investigate this new task. (1) For the divided (D) training, we separately train the baselines for each human components. This independent strategy lacks the interaction of components and thus can be used to illustrate the effectiveness of XCI. (2) For the united (D) training, we extend the node number of GCNs to 55 (, ), as in our experimental setup. This strategy implicitly contains the cross-context interaction via a whole-body graph but does not consider the heterogeneity of different body parts. Therefore, it is used to demonstrate the effectiveness of XCA.
Training details: We employ AdamW (Loshchilov and Hutter 2017) optimizer with an initial learning rate of 0.001 and batch size of 64 to train our model (50 epochs). The learning rate is decayed by 0.96 for every two epochs. The trade-off parameters are set as . More details are set in the supplementary materials.
Metrics: For the whole-body motion, we use the mean per joint position error (MPJPE) (Mao et al. 2019; Mao, Liu, and Salzmann 2020; Li et al. 2020; Ma et al. 2022) to measure the 3D prediction accuracy of overall movement. Besides, since there are no baselines for hand prediction, we extend the baseline of major body motion prediction (Mao et al. 2019; Mao, Liu, and Salzmann 2020; Li et al. 2020; Ma et al. 2022) into hand prediction and also leverage MPJPE to measure the prediction accuracy. However, the MPJPE of hands is affected by wrist movement severely, which is not able to show subtle hand activities and semantic information. Therefore, we also report the MPJPE-AW after alignment(Martinez et al. 2017) with the wrist.
Comparison with the SOTA methods
Baselines (U) v.s. Baselines (D). Table 1 shows the average prediction error of all actions between our method and the above four baselines. The baselines are trained with two strategies: divided and united, as illustrated in section 2. Notably, because the MPJPE of hands is severely affected by wrist movement, we also show the MPJPE-AW on the prediction of delicate hand movement. Compared with the divided strategy, the predicted results for the body are worse when training unitedly. And the hands’ results show opposite trends on the two metrics. The above result reveals that: (1) The interaction is indeed meaningful to improve prediction accuracy (MPJPE of hands is lower). (2) However, the implicit modeling of interaction within a whole-body graph may bring negative mutual interference (MPJPE of body and MPJPE-AW of hands are higher) because major body and gestures have heterogeneous motion patterns.
EAI v.s. Baselines (UD). Our proposed EAI addresses the above two limitations of existing methods. (1) As to the united strategy, EAI is superior to all baselines by a large margin. It verifies the effectiveness of cross-context alignment (XCA), which considers the motion heterogeneity of different body parts. (2) Compared with the baseline results using the divided strategy, our method is better, which demonstrates that cross-context interaction (XCI) across body components is vital. Both rough (major joints) and delicate (gestures) properties are cross-facilitated to achieve a higher-fidelity prediction via the EAI framework.
Compatibility. Table 2 shows more detailed results on common action with the evaluation metrics MPJPE. The error obtained by our method is smaller than others in most cases. The activity with both fine-grained (drink eat) and coarse-grained (lift pass) motion patterns achieve more improvements than the baseline approaches, which evidences the compatibility of our proposed EAI. Moreover, the enhanced performance on all body parts also verifies the necessity of considering both the heterogeneity and interactivity across different body parts. Results of the other actions can be found in the supplementary material.
Visualization. In Figure 5, we show the whole-body qualitative results of the ’play’ action via the skeletal form. As highlighted by the purple dashed ellipse, the absolute prediction of upper limbs and hands is much closer to ground truth (denoted by solid green lines). It demonstrates that expressive context information extracted from EAI leads to the overall refinement of coarse-fined motion. Besides, the other two dashed ellipses show fine-grained gestures by aligning the hand sequence with the wrist. We observe that EAI still outperforms other baselines in the relative results, which illustrates that the delicate semantic information of gestures could be better considered. The results of fine-grained and coarse-grained motion are enhanced, verifying the significance of co-analyzing different body components for the novel whole-body pose forecasting task.
Ablation Studies
We conduct ablation studies on model architecture for deeper analysis. More discussions are in the supplementary materials. We run experiments under the condition of separately removing the XCA and XCI, as well as the following sub-modules: (a) cross neutralization (CN), (b) discrepancy constraint (DC) in XCA; (c) semantic interaction (SI), (d) physical interaction (PI) in XCI.
Table 3 reports the detailed results. The full model contains both XCA and XCI, and the average prediction error is 61.9mm. (1) Without the CN and DC, the prediction error is 66.6mm, which is a noticeable performance drop, demonstrating the necessity to alleviate distribution discrepancy. Removing CN/DC, the average error increases by 2.5/1.4mm. It shows the CN is more critical in XCA; (2) Excluding the entire XCI, the prediction error drastically increases from 61.9mm to 68.7mm. This gap is larger than the case without the whole XCA, indicating that the interaction extraction is more vital than heterogeneity reduction relatively. Remarkably, the prediction error of XCI (w/o SI) / XCI (w/o PI) increased by 5.6/2.6mm. It reveals that the semantic relevance of body components is more valuable to perceive motion properties.
| CN | DC | PI | SI | 0.2s | 0.4s | 1.0s | Avg. | |
| ✓ | ✓ | ✓ | 16.7 | 40.7 | 90.4 | 64.4 | ||
| ✓ | ✓ | ✓ | 17.0 | 41.3 | 87.9 | 63.3 | ||
| XCA | ✓ | ✓ | 17.0 | 42.8 | 93.7 | 66.6 | ||
| ✓ | ✓ | ✓ | 16.7 | 41.1 | 89.8 | 64.5 | ||
| ✓ | ✓ | ✓ | 17.0 | 42.5 | 94.2 | 67.5 | ||
| XCI | ✓ | ✓ | 17.8 | 43.2 | 95.0 | 68.7 | ||
| Full model | ✓ | ✓ | ✓ | ✓ | 16.7 | 40.7 | 85.8 | 61.9 |
Conclusion
In this work, we introduce a new task: expressive forecasting of 3D whole-body human motions. To tackle this challenge, we propose a novel Encoding-Alignment-Interaction (EAI) framework that takes into account the heterogeneous information within the whole body and the collaboration among various human components. Our approach jointly considers the heterogeneous information within the whole body and the interaction/collaboration among various human components. Compared with conventional predictive algorithms, EAI could cross-facilitate both coarse- (body) and fine-grained (gestures) properties. Extensive experiments demonstrate that the proposed approach achieve the superior performance and surpasses the state-of-the-art methods by a large margin. Considering the downstream application of whole-body forecasting, we conclude that the proposed model is of practical importance; however, there are areas that need further exploration in the future. For instance, incorporating interactions with objects could provide vital cues to improve the accuracy of motion anticipation.
Acknowledgments
This work was supported by the National Science and Technology Innovation 2030 - Major Project (Grant No. 2022ZD0208800), and NSFC General Program (Grant No. 62176215). This work was supported in part by the National Natural Science Foundation of China (62306141), in part by the Jiangsu Funding Program for Excellent Postdoctoral Talent (2022ZB269), in part by the Natural Science Foundation of Jiangsu Province (BK20220939), and in part by the China Postdoctoral Science Foundation (2022M721629).
References
- Adeli et al. (2021) Adeli, V.; Ehsanpour, M.; Reid, I.; Niebles, J. C.; Savarese, S.; Adeli, E.; and Rezatofighi, H. 2021. TRiPOD: Human Trajectory and Pose Dynamics Forecasting in the Wild. In IEEE/CVF International Conference on Computer Vision, 13390–13400.
- Butepage et al. (2017) Butepage, J.; Black, M. J.; Kragic, D.; and Kjellstrom, H. 2017. Deep representation learning for human motion prediction and classification. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6158–6166.
- Bütepage, Kjellström, and Kragic (2018) Bütepage, J.; Kjellström, H.; and Kragic, D. 2018. Anticipating many futures: Online human motion prediction and generation for human-robot interaction. In 2018 IEEE/CVF International Conference on Robotics and Automation (ICRA), 4563–4570.
- Cai et al. (2020) Cai, Y.; Huang, L.; Wang, Y.; Cham, T.-J.; Cai, J.; Yuan, J.; Liu, J.; Yang, X.; Zhu, Y.; Shen, X.; et al. 2020. Learning progressive joint propagation for human motion prediction. In European Conference on Computer Vision, 226–242.
- Cai et al. (2021) Cai, Y.; Wang, Y.; Zhu, Y.; Cham, T.-J.; Cai, J.; Yuan, J.; Liu, J.; Zheng, C.; Yan, S.; Ding, H.; et al. 2021. A Unified 3D Human Motion Synthesis Model via Conditional Variational Auto-Encoder. In IEEE/CVF International Conference on Computer Vision, 11645–11655.
- Corona et al. (2020) Corona, E.; Pumarola, A.; Alenya, G.; and Moreno-Noguer, F. 2020. Context-aware human motion prediction. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6992–7001.
- Cui and Sun (2021) Cui, Q.; and Sun, H. 2021. Towards Accurate 3D Human Motion Prediction From Incomplete Observations. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4801–4810.
- Dang et al. (2021) Dang, L.; Nie, Y.; Long, C.; Zhang, Q.; and Li, G. 2021. MSR-GCN: Multi-Scale Residual Graph Convolution Networks for Human Motion Prediction. In IEEE/CVF International Conference on Computer Vision, 11467–11476.
- Diller, Funkhouser, and Dai (2022) Diller, C.; Funkhouser, T.; and Dai, A. 2022. Forecasting characteristic 3D poses of human actions. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 15914–15923.
- Ding and Yin (2021) Ding, P.; and Yin, J. 2021. Uncertainty-aware Human Motion Prediction. arXiv preprint arXiv:2107.03575.
- Ding and Yin (2022) Ding, P.; and Yin, J. 2022. Towards more realistic human motion prediction with attention to motion coordination. IEEE Transactions on Circuits and Systems for Video Technology, 32(9): 5846–5858.
- Feng et al. (2021) Feng, Y.; Choutas, V.; Bolkart, T.; Tzionas, D.; and Black, M. J. 2021. Collaborative regression of expressive bodies using moderation. In 2021 International Conference on 3D Vision (3DV), 792–804.
- Gui et al. (2018) Gui, L.-Y.; Wang, Y.-X.; Liang, X.; and Moura, J. M. 2018. Adversarial geometry-aware human motion prediction. In European Conference on Computer Vision, 786–803.
- Guo et al. (2022) Guo, W.; Bie, X.; Alameda-Pineda, X.; and Moreno-Noguer, F. 2022. Multi-Person Extreme Motion Prediction. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13053–13064.
- Hao et al. (2017) Hao, Y.; Zhang, Y.; Liu, K.; He, S.; Liu, Z.; Wu, H.; and Zhao, J. 2017. An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 221–231.
- Hidalgo et al. (2019) Hidalgo, G.; Raaj, Y.; Idrees, H.; Xiang, D.; Joo, H.; Simon, T.; and Sheikh, Y. 2019. Single-network whole-body pose estimation. In IEEE/CVF International Conference on Computer Vision, 6982–6991.
- Honda, Kawakami, and Naemura (2020) Honda, Y.; Kawakami, R.; and Naemura, T. 2020. RNN-based Motion Prediction in Competitive Fencing Considering Interaction between Players. In BMVC.
- Ionescu et al. (2013) Ionescu, C.; Papava, D.; Olaru, V.; and Sminchisescu, C. 2013. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE transactions on pattern analysis and machine intelligence, 36(7): 1325–1339.
- Jin et al. (2020) Jin, S.; Xu, L.; Xu, J.; Wang, C.; Liu, W.; Qian, C.; Ouyang, W.; and Luo, P. 2020. Whole-body human pose estimation in the wild. In European Conference on Computer Vision, 196–214.
- Li et al. (2021) Li, J.; Yang, F.; Ma, H.; Malla, S.; Tomizuka, M.; and Choi, C. 2021. RAIN: Reinforced Hybrid Attention Inference Network for Motion Forecasting. In IEEE/CVF International Conference on Computer Vision.
- Li et al. (2022) Li, M.; Chen, S.; Zhang, Z.; Xie, L.; Tian, Q.; and Zhang, Y. 2022. Skeleton-Parted Graph Scattering Networks for 3D Human Motion Prediction. In European Conference on Computer Vision.
- Li et al. (2020) Li, M.; Chen, S.; Zhao, Y.; Zhang, Y.; Wang, Y.; and Tian, Q. 2020. Dynamic multiscale graph neural networks for 3d skeleton based human motion prediction. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 214–223.
- Li et al. (2018) Li, R.; Wang, S.; Zhu, F.; and Huang, J. 2018. Adaptive graph convolutional neural networks. In AAAI Conference on Artificial Intelligence, 1.
- Liu et al. (2020) Liu, X.; Yin, J.; Liu, J.; Ding, P.; Liu, J.; and Liu, H. 2020. Trajectorycnn: a new spatio-temporal feature learning network for human motion prediction. IEEE Transactions on Circuits and Systems for Video Technology, 31(6): 2133–2146.
- Loshchilov and Hutter (2017) Loshchilov, I.; and Hutter, F. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Ma et al. (2022) Ma, T.; Nie, Y.; Long, C.; Zhang, Q.; and Li, G. 2022. Progressively Generating Better Initial Guesses Towards Next Stages for High-Quality Human Motion Prediction. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6437–6446.
- Mao, Liu, and Salzmann (2020) Mao, W.; Liu, M.; and Salzmann, M. 2020. History repeats itself: Human motion prediction via motion attention. In European Conference on Computer Vision, 474–489.
- Mao et al. (2019) Mao, W.; Liu, M.; Salzmann, M.; and Li, H. 2019. Learning trajectory dependencies for human motion prediction. In International Conference on Computer Vision, 9489–9497.
- Martinez et al. (2017) Martinez, J.; Hossain, R.; Romero, J.; and Little, J. J. 2017. A simple yet effective baseline for 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2640–2649.
- Pavlakos et al. (2019) Pavlakos, G.; Choutas, V.; Ghorbani, N.; Bolkart, T.; Osman, A. A.; Tzionas, D.; and Black, M. J. 2019. Expressive body capture: 3d hands, face, and body from a single image. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10975–10985.
- Petrovich, Black, and Varol (2021) Petrovich, M.; Black, M. J.; and Varol, G. 2021. Action-Conditioned 3D Human Motion Synthesis With Transformer VAE. In IEEE/CVF International Conference on Computer Vision, 10985–10995.
- Rong, Shiratori, and Joo (2021) Rong, Y.; Shiratori, T.; and Joo, H. 2021. Frankmocap: A monocular 3d whole-body pose estimation system via regression and integration. In IEEE/CVF International Conference on Computer Vision, 1749–1759.
- Ruiz, Gall, and Moreno-Noguer (2018) Ruiz, A. H.; Gall, J.; and Moreno-Noguer, F. 2018. Human Motion Prediction via Spatio-Temporal Inpainting. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7134–7143.
- Taheri et al. (2020) Taheri, O.; Ghorbani, N.; Black, M. J.; and Tzionas, D. 2020. GRAB: A dataset of whole-body human grasping of objects. In European Conference on Computer Vision, 581–600.
- Tarvainen and Valpola (2017) Tarvainen, A.; and Valpola, H. 2017. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Advances in Neural Information Processing Systems, 30.
- Vaswani et al. (2017) Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, L.; and Polosukhin, I. 2017. Attention is All you Need. In Advances in Neural Information Processing Systems.
- von Marcard et al. (2018) von Marcard, T.; Henschel, R.; Black, M.; Rosenhahn, B.; and Pons-Moll, G. 2018. Recovering Accurate 3D Human Pose in The Wild Using IMUs and a Moving Camera. In European Conference on Computer Vision.
- Wang et al. (2021) Wang, J.; Xu, H.; Narasimhan, M.; and Wang, X. 2021. Multi-Person 3D Motion Prediction with Multi-Range Transformers. Advances in Neural Information Processing Systems, 34: 6036–6049.
- Yuan and Kitani (2020) Yuan, Y.; and Kitani, K. 2020. Dlow: Diversifying Latent Flows for Diverse Human Motion Prediction. In European Conference on Computer Vision, 346–364.
- Zhang, Black, and Tang (2021) Zhang, Y.; Black, M. J.; and Tang, S. 2021. We Are More Than Our Joints: Predicting How 3D Bodies Move. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3372–3382.
- Zhong et al. (2022) Zhong, C.; Hu, L.; Zhang, Z.; Ye, Y.; and Xia, S. 2022. Spatio-Temporal Gating-Adjacency GCN for Human Motion Prediction. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6447–6456.