FedDiv: Collaborative Noise Filtering for Federated Learning with Noisy Labels
Abstract
Federated Learning with Noisy Labels (F-LNL) aims at seeking an optimal server model via collaborative distributed learning by aggregating multiple client models trained with local noisy or clean samples. On the basis of a federated learning framework, recent advances primarily adopt label noise filtering to separate clean samples from noisy ones on each client, thereby mitigating the negative impact of label noise. However, these prior methods do not learn noise filters by exploiting knowledge across all clients, leading to sub-optimal and inferior noise filtering performance and thus damaging training stability. In this paper, we present FedDiv to tackle the challenges of F-LNL. Specifically, we propose a global noise filter called Federated Noise Filter for effectively identifying samples with noisy labels on every client, thereby raising stability during local training sessions. Without sacrificing data privacy, this is achieved by modeling the global distribution of label noise across all clients. Then, in an effort to make the global model achieve higher performance, we introduce a Predictive Consistency based Sampler to identify more credible local data for local model training, thus preventing noise memorization and further boosting the training stability. Extensive experiments on CIFAR-10, CIFAR-100, and Clothing1M demonstrate that FedDiv achieves superior performance over state-of-the-art F-LNL methods under different label noise settings for both IID and non-IID data partitions. Source code is publicly available at https://github.com/lijichang/FLNL-FedDiv.
Introduction
Compared to traditional Centralized Learning (Li et al. 2019b, 2021, a; Wu et al. 2019b, a; Huang et al. 2023), Federated Learning (FL) is a novel paradigm facilitating collaborative learning across multiple clients without requiring centralized local data (McMahan et al. 2017). Recently, FL has shown significant real-world success in areas like healthcare (Nguyen et al. 2022), recommender systems (Yang et al. 2020), and smart cities (Zheng et al. 2022). However, these FL methods presume clean labels for all client’s private data, which is often not the case in reality due to data complexity and uncontrolled label annotation quality (Tanno et al. 2019; Kuznetsova et al. 2020). Especially with the blessing of privacy protection, it is impossible to ensure absolute label accuracy. Therefore, this work centers on Federated Learning with Noisy Labels (F-LNL). In F-LNL, a global neural network model is fine-tuned via distributed learning across multiple local clients with noisy samples. Like (Xu et al. 2022), we here also assume some local clients have noisy labels (namely noisy clients), while others have only clean labels (namely clean clients).
Besides the private data on local clients, F-LNL faces two primary challenges: data heterogeneity and noise heterogeneity (Kim et al. 2022; Yang et al. 2022b). Data heterogeneity refers to the statistically heterogeneous data distributions across different clients, while noise heterogeneity represents the varying noise distributions among clients. It has been demonstrated by (Xu et al. 2022; Kim et al. 2022) that these two challenges in F-LNL may lead to instability during local training sessions. Previous studies in F-LNL (Xu et al. 2022; Kim et al. 2022) have demonstrated that many FL approaches, such as (McMahan et al. 2017; Li et al. 2020), are now in use to adequately address the first challenge. These approaches primarily focus on achieving training stability with convergence guarantees by aligning the optimization objectives of local updates and global aggregation. However, they do not address label noise on individual clients. Therefore, to tackle noise heterogeneity, such F-LNL algorithms propose separating noisy data into clean and noisy samples, occasionally complemented by relabeling the noisy samples. This aims to mitigate the negative effects of noisy labels and prevent local model overfitting to such label noise, avoiding severe destabilization of the local training process.
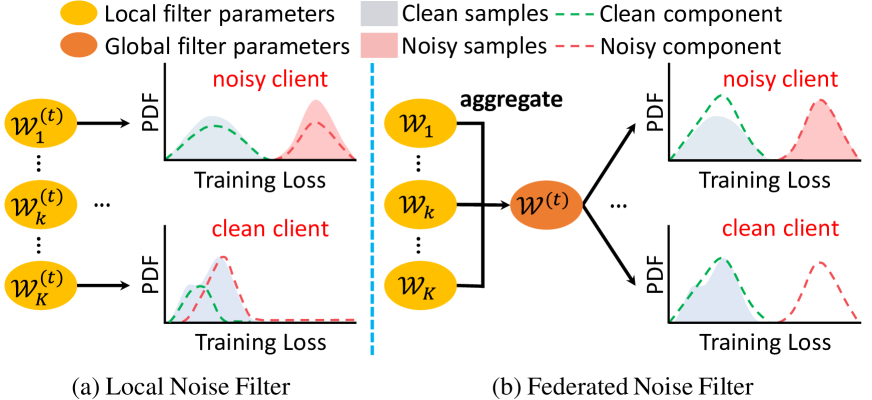
Some F-LNL methods (Kim et al. 2022; Xu et al. 2022) thus emphasize proposing local noise filtering, where each client develops its own noise filter to identify noisy labels. However, these noise filtering strategies omit the potential of learning prosperous knowledge from other clients to strengthen their capacities. Instead, they rely heavily on each client’s own private data for training, thus leading to sub-optimal and inferior performance. For example, as shown in Figure 1(a), limited training samples available on each client impede the accurate modeling of their local noise distributions, significantly restricting noise filtering capabilities. In addition, if noise filtering and relabeling are not handled properly, overfitting of noisy labels can inevitably occur, leading to noise memorization and thus degrading global performance upon model aggregation. Developing strategies to prevent noise memorization (Yang et al. 2022a) while enhancing training stability is critical, yet existing F-LNL algorithms have not succeeded in achieving this.
In this paper, we present a novel framework, FedDiv, to address the challenges of F-LNL. To perform label noise filtering per client, FedDiv consists of a global noise filter, called Federated Noise Filter (FNF), constructed by modeling the global distribution of noisy samples across all clients. Specifically, by fitting the loss function values of private data, the parameters of a local Gaussian Mixture Model (GMM) can be iteratively learned on each client to model its local noise distributions. These parameters are then aggregated on the server to construct a global GMM model that serves as a global noise filter, effectively classifying samples on each local client into clean or noisy. As depicted in Figure 1(b), by leveraging collaboratively learned knowledge across all clients, FedDiv demonstrates a robust capability to fit the local label noise distributions within individual clean or noisy clients. This ability enhances noise filtering performance per client, and thus reduces training instability during local training sessions, while preserving data privacy.
After label noise filtering, we remove noisy labels from the identified noisy samples on each client and relabel those samples exhibiting high prediction confidence using the pseudo-labels predicted by the global model. To further prevent local models from memorizing label noise and improve training stability, we introduce a Predictive Consistency based Sampler (PCS) for identifying credible local data for local model training. Specifically, we enforce the consistency of class labels predicted by both global and local models, and apply counterfactual reasoning (Holland 1986; Wang et al. 2022) to generate more reliable predictions for local samples.
In summary, the contributions of this paper are as follows.
-
•
We propose a novel one-stage framework, FedDiv, for addressing the task of Federated Learning with Noisy Labels (F-LNL). To enable stable training, FedDiv learns a global noise filter by distilling the complementary knowledge from all clients while performing label noise filtering locally on every client.
-
•
We introduce a Predictive Consistency based Sampler to perform labeled sample re-selection on every client, thereby preventing local models from memorizing label noise and further improving training stability.
-
•
Through extensive experiments conducted on CIFAR-10 (Krizhevsky 2009), CIFAR-100 (Krizhevsky 2009), and Clothing1M (Xiao et al. 2015) datasets, we demonstrate that FedDiv significantly outperforms state-of-the-art F-LNL methods under various label noise settings for both IID and non-IID data partitions.
Related Work
Centralized Learning with Noisy Labels (C-LNL). Diverging from conventional paradigms for centralized learning, e.g. (Li, Li, and Yu 2023a, b), which operates on training samples only with clean labels, several studies have demonstrated the effect of methods to address C-LNL in reducing model overfitting to noisy labels. For instance, JointOpt (Tanaka et al. 2018a) proposed a joint optimization framework to correct labels of noisy samples during training by alternating between updating model parameters and labels. As well, DivideMix (Li, Socher, and Hoi 2019) dynamically segregated training examples with label noise into clean and noisy subsets, incorporating auxiliary semi-supervised learning algorithms for further model training. Other strategies for handling C-LNL tasks include estimating the noise transition matrix (Cheng et al. 2022), reweighing the training data (Ren et al. 2018), designing robust loss functions (Englesson and Azizpour 2021), ensembling existing techniques (Li et al. 2022), and so on.
Given privacy constraints in decentralized applications, the server cannot directly access local samples of all clients to construct centralized noise filtering algorithms. Besides, a limited number of private data on local clients may also restrict the noise filtering capability. Hence, despite the success of existing C-LNL algorithms, they may no longer be feasible in federated settings (Xu et al. 2022).
Federated Learning with Noisy Labels. Numerous methods address challenges in federated scenarios with label noise. For instance, FedRN (Kim et al. 2022) detects clean samples in local clients using ensembled Gaussian Mixture Models (GMMs) trained to fit loss function values of local data assessed by multiple reliable neighboring client models. RoFL (Yang et al. 2022b) directly optimizes using small-loss instances of clients during local training to mitigate label noise effects. Meanwhile, FedCorr(Xu et al. 2022) first introduces a dimensionality-based noise filter to segregate clients into clean and noisy groups using local intrinsic dimensionalities (Ma et al. 2018), and trains local noise filters to separate clean examples from identified noisy clients based on per-sample training losses.
However, existing F-LNL algorithms concentrate on local noise filtering, utilizing each client’s private data but failing to exploit collective knowledge across clients. This limitation might compromise noise filtering efficacy, resulting in incomplete label noise removal and impacting the stability of local training sessions. Conversely, FedDiv proposes distilling knowledge from all clients for federated noise filtering, enhancing label noise identification in each client’s sample and improving FL model training amidst label noise.
Methodology
In this section, we introduce the proposed one-stage framework named FedDiv for federated learning with noisy labels. In detail, we first adopt the classic FL paradigm, namely FedAvg (McMahan et al. 2017), to train a neural network model. On the basis of this FL framework, we propose a global filter model called Federated Noise Filter (FNF) to perform label noise filtering and noisy sample relabeling on every client. Then, to improve the stability of local training, a Predictive Consistency based Sampler (PCS) is presented to conduct labeled sample re-selection, keeping client models from memorizing label noise.
Let us consider an FL scenario with one server and local clients denoted by . Each client has its own private data consisting of sample-label pairs , where is a training sample, and is a label index over classes. Here, we divide local clients into two groups: clean clients (with noise level where ), which only have samples with clean labels, and noisy clients (with ), whose private data might have label noise at various levels. Also, in this work, both IID and non-IID heterogeneous data partitions are considered.
| Method | Best Test Accuracy Standard Deviation | |||||
|---|---|---|---|---|---|---|
| =0.4 | =0.6 | =0.8 | ||||
| =0.0 | =0.5 | =0.0 | =0.5 | =0.0 | =0.5 | |
| FedAvg | 89.460.39 | 88.310.80 | 86.090.50 | 81.221.72 | 82.911.35 | 72.002.76 |
| RoFL | 88.250.33 | 87.200.26 | 87.770.83 | 83.401.20 | 87.080.65 | 74.133.90 |
| ARFL | 85.871.85 | 83.143.45 | 76.771.90 | 64.313.73 | 73.221.48 | 53.231.67 |
| JointOpt | 84.420.70 | 83.010.88 | 80.821.19 | 74.091.43 | 76.131.15 | 66.161.71 |
| DivideMix | 77.350.20 | 74.402.69 | 72.673.39 | 72.830.30 | 68.660.51 | 68.041.38 |
| FedCorr | 94.010.22 | 94.150.18 | 92.930.25 | 92.500.28 | 91.520.50 | 90.590.70 |
| FedDiv (Ours) | 94.420.29 | 94.300.19 | 93.670.22 | 93.410.21 | 92.980.60 | 91.440.25 |
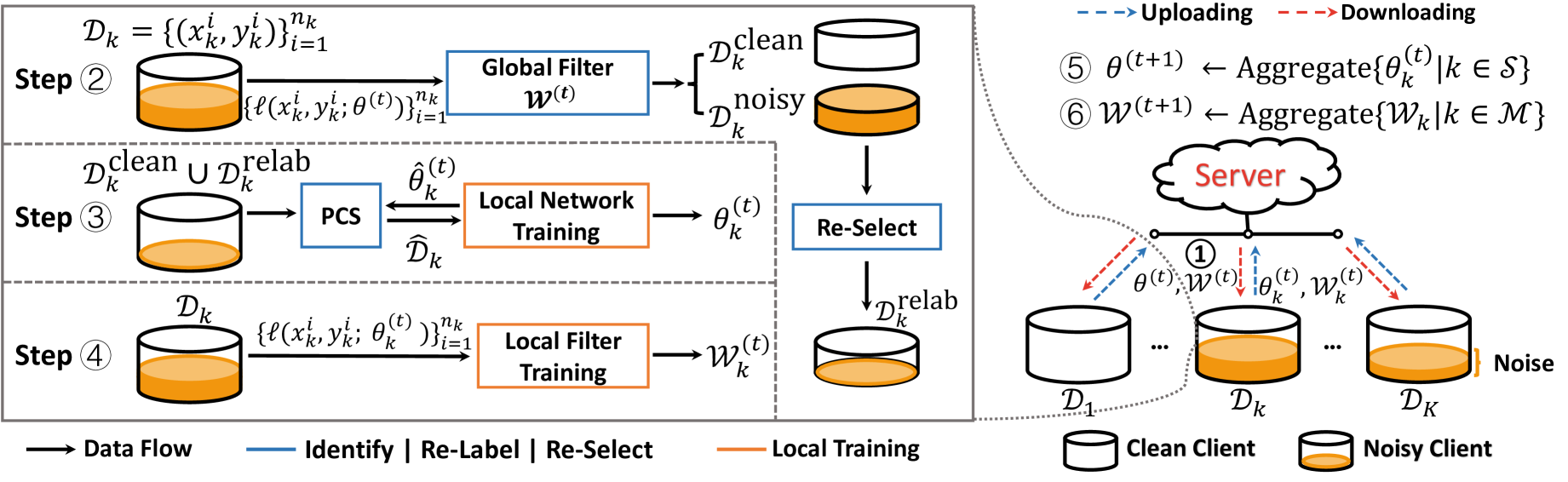
As shown in Figure 2, the training procedure of the -th communication round performs the following steps:
Step : The server broadcasts the parameters of the global neural network model and the federated noise filtering model to every client , where is a subset of clients randomly selected with a fixed fraction in this round.
Step : On every , is used to separate into noisy and clean samples, and those noisy samples with high prediction confidence are assigned pseudo-labels predicted by .
Step (Local model training): Every client trains its local neural network using a subset of the clean and relabeled noisy samples selected using PCS to obtain its updated local parameters . Here, we use to denote the parameters of the local model being optimized during this training session.
Step (Local filter training): Every client trains a local noise filter model with updated parameters by fitting the per-sample loss function values of its private data . Such loss function values are evaluated using the logits of training samples in predicted by .
Step : The server aggregates and then updates the global model as follows,
| (1) |
Step (Federated filter aggregation): The server collects to update existing server-cached local filter parameters , and then aggregates all local filters to obtain an updated federated noise filtering model .
This training procedure is repeated until the global model converges steadily or the pre-defined number of communication rounds is reached. Each communication round involves local training sessions (Step - ) on several randomly selected clients and the model aggregation phase (Step - ) on the server. The details of Step , Step , and Step are provided in “Federated Noise Filter”, while the detailed description of Step is given in “Predictive Consistency Based Sampler” and “Objectives for Local Model Training”.
Federated Noise Filter
Aiming at identifying label noise for the F-LNL task, we propose a Federated Noise Filter (FNF), which models the global distribution of clean and noisy samples across all clients. Motivated by (Zhu et al. 2022), this FNF model can be constructed via the federated EM algorithm. Specifically, we first conduct local filter training to obtain locally estimated GMM parameters. This goal is reached by iteratively executing the standard EM algorithm (Dempster, Laird, and Rubin 1977) per client to fit its local noise distribution. Then, we perform federated filter aggregation to aggregate local GMM parameters received from all clients to construct a federated noise filter.
Local filter training. In general, samples with label noise tend to possess higher loss function values during model training, making it feasible to use mixture models to separate noisy samples from clean ones using per-sample loss values of the training samples (Arazo et al. 2019a; Li, Socher, and Hoi 2019). Therefore, for the -th client in the -th communication round, a local GMM can be built to model the local distribution of clean and noisy samples by fitting the per-sample loss distribution,
| (2) |
where is the cross-entropy loss of a sample-label pair when the local model is used for prediction. Then, we denote the two-component GMM model by , where and are vectors with entries and denoting the mean and variance of the -th Gaussian component, respectively. Here, we set to represent the “clean” Gaussian component, i.e., the Gaussian component with a smaller mean (smaller loss), while denotes the “noisy” one.
We further define a discrete variable to represent whether a sample is clean or noisy. denotes the prior distribution of , i.e., , where should satisfy and for . Thus, is modeled as a Gaussian distribution . Then, the posterior , which represents the probability of a sample being clean () or noisy () given its loss value, can be computed as
| (3) |
Afterwards, for each client , leveraging its private data , updated local parameters , and the federated filter parameters received from the server, its optimal local filter parameters at current round are derived through the training of the local GMM models utilizing a standard EM algorithm (Dempster, Laird, and Rubin 1977). Noted that, originated from the server here is used to initialize for expediting convergence.
In the -th communication round, once we have performed local filter training on the clients in , we upload the local filter parameters to the server. Then, the server updates its cached local filter parameters corresponding to each client in as follows,
| (4) |
where is the server-cached version of the local noise filter on the -th client. Note that FedDiv only sends three numerical matrices (i.e., , , and ) from each client to the server, and they merely reflect each client’s local noise distributions instead of the raw input data, avoiding any risk of data privacy leakage.
| Method | Best Test Accuracy Standard Deviation | ||
|---|---|---|---|
| FedAvg | 78.882.34 | 75.982.92 | 67.754.38 |
| RoFL | 79.561.39 | 72.752.21 | 60.723.23 |
| ARFL | 60.193.33 | 55.863.30 | 45.782.84 |
| JointOpt | 72.191.59 | 66.921.89 | 58.082.18 |
| DivideMix | 65.700.35 | 61.680.56 | 56.671.73 |
| FedCorr | 90.520.89 | 88.031.08 | 81.573.68 |
| FedDiv (Ours) | 93.180.42 | 91.950.26 | 85.312.28 |
Federated filter aggregation. After parameter uploading, the federated filter model can be constructed by aggregating the local filter parameters corresponding to all the clients as follows,
| (5) |
where will be used to perform label noise filtering on the selected clients at the beginning of the -th communication round.
Label noise filtering. In the -th communication round, once the -th client has received the parameters of the global model and the federated filter model from the server, the probability of a sample from being clean can be estimated through its posterior probability for the “clean” component as follows,
| (6) |
Afterwards, we can divide the samples of into a clean subset and a noisy subset by thresholding their probabilities of being clean with the threshold as follows,
| (7) |
Noisy sample relabeling. We compute the noise level of the -th client as , while a client is considered a noisy one if ; and otherwise, a clean one. For an identified noisy client, we simply discard the given labels of noisy samples from to prevent the model from memorizing label noise in further local training. In an effort to leverage these unlabeled (noisy) samples, we relabel those samples with high prediction confidence (by setting a confidence threshold ) by assigning predicted labels from the global model as follows,
| (8) |
where is the pseudo-label for the sample predicted by the global model .
| Method | Best Test Accuracy Standard Deviation | ||
|---|---|---|---|
| =0.4 | =0.6 | =0.8 | |
| =0.5 | =0.5 | =0.5 | |
| FedAvg | 64.411.79 | 53.512.85 | 44.452.86 |
| RoFL | 59.422.69 | 46.243.59 | 36.653.36 |
| ARFL | 51.534.38 | 33.031.81 | 27.471.08 |
| JointOpt | 58.431.88 | 44.542.87 | 35.253.02 |
| DivideMix | 43.251.01 | 40.721.41 | 38.911.25 |
| FedCorr | 74.430.72 | 66.784.65 | 59.105.12 |
| FedDiv (Ours) | 74.860.91 | 72.371.12 | 65.492.20 |
Predictive Consistency Based Sampler
During the -th round on client , upon obtaining the clean subset and the relabeled subset , we integrate them into supervised local model training across local epochs. However, the complete elimination of label noise among clients during noise filtering and relabeling is unattainable. On the other hand, relabeling inevitably introduces new label noise, causing instability in local model training, which further negatively affects the performance of the global model during aggregation. To tackle this, we propose a Predictive Consistency based Sampler (PCS) to reselect labeled samples for local training. Specifically, we observe enforcing the consistency of class labels respectively predicted by global and local models is a good strategy to achieve this goal. As training proceeds, the robustness of the model against label noise would be significantly increased (See below.), thus easily improving predictions’ reliability of the samples having new label noise.
In addition, due to data heterogeneity in federated settings, especially for non-IID data partitions, local training samples owned by individual clients often belong to a smaller set of dominant classes. Thus, samples of dominant classes with newly introduced label noise would be better self-corrected during local model training, gradually leading to inconsistent predictions w.r.t those of the global model. However, such class-unbalanced local data would also contribute to the cause of the local model bias towards the dominant classes (Wei et al. 2021), which makes it more difficult for the local model to produce correct pseudo-labels for the samples that belong to minority classes. The proposed PCS strategy mitigates model bias to improve the reliability of class labels produced by local models. Here, we can de-bias the model predictions by improving causality via counterfactual reasoning (Holland 1986; Pearl 2009; Wang et al. 2022), and therefore, the de-biased logit of a sample from or is induced as follows,
| (9) |
where is the de-biased logit later used for generating the de-biased pseudo-label, i.e., , and is a de-bias factor. is the original logit for the sample produced by the local model , currently being optimized. represents the overall bias of the local model w.r.t all classes, which was previously updated according to Eq. (12) and cached on the -th client during the last local training session.
| Dataset | CIFAR-100 | Clothing1M |
|---|---|---|
| Noise level (, ) | (0.4, 0.0) | - |
| Method\(, ) | (0.7, 10) | - |
| FedAvg | 64.751.75 | 70.49 |
| RoFL | 59.314.14 | 70.39 |
| ARFL | 48.034.39 | 70.91 |
| JointOpt | 59.841.99 | 71.78 |
| DivideMix | 39.761.18 | 68.83 |
| FedCorr | 72.731.02 | 72.55 |
| FedDiv (Ours) | 74.470.34 | 72.960.43 |
Afterwards, PCS is used to re-select higher-quality and more reliable labeled training samples to perform local training as follows,
| (10) |
Similar to (Xu et al. 2022), we update the training dataset for further optimizing the local model as follows,
| (11) |
Once having the optimized from a local training session, we use it to update with momentum as follows,
| (12) |
where is a momentum coefficient. We save on the -th client to update existing client-cached .
Objectives for Local Model Training
To enhance the model’s robustness against label noise, we here use MixUp regularization (Zhang et al. 2018) for local model training, further undermining the instability of training. Specifically, two sample-label pairs and from are augmented using linear interpolation, and , where is a mixup ratio, is a scalar to control its distribution, and is a function to generate a one-hot vector for a given label. Hence, on the -th client in the -th communication round, the local model is trained with the cross-entropy loss applied to augmented samples in one mini-batch as follows,
| (13) |
With the high heterogeneity of the non-IID data partitions, there could be only a limited number of categories on each client, and extensive experiments have shown that such a data partition forces a local model to predict the same class label to minimize the training loss. As in (Tanaka et al. 2018b; Arazo et al. 2019b), regularizing the average prediction of a local model over every mini-batch using a uniform prior distribution is a viable solution to overcome the above problem, i.e.,
| (14) |
where denotes the prior probability of a class . is the -th element of the vector q, which refers to the predicted probability of the class averaged over augmented training samples in a mini-batch.
Finally, on the -th client in the -th communication round, the overall loss function for optimizing the local model is defined as follows,
| (15) |
where is a weighting factor balancing and . In the experiments, we set when the data partition is non-IID; and otherwise, .
Experiments
Experimental Setups
To be fair, we here adopt the consistent experimental setups with FedCorr (Xu et al. 2022) to assess the efficacy of our proposed approach FedDiv. Further details, e.g., data partitions and additional implementations and analysis, are provided in the supplementary document (abbr. Supp111https://github.com/lijichang/FLNL-FedDiv/blob/main/supp.pdf).
Datasets and data partitions. We validate FedDiv’s superiority on three classic benchmark datasets, including two synthetic datasets namely CIFAR-10 (Krizhevsky 2009) and CIFAR-100 (Krizhevsky 2009), and one real-world noisy dataset, i.e., Clothing1M (Xiao et al. 2015). Like (Xu et al. 2022), we take both IID and non-IID data partitions into account on CIFAR-10 and CIFAR-100, but only consider non-IID data partitions on Clothing1M. Under the IID data partitions, each client is randomly assigned the same number of samples with respect to each class. For non-IID data partitions, it is constructed using a Dirichlet distribution (Lin et al. 2020) with two pre-defined parameters, namely the fixed probability and the concentration parameter .
Label noise settings. Similar to (Xu et al. 2022), the noise level for the -th client can be defined as follows:
| (16) |
Here, signifies the probability of a client being noisy. For a noisy client with , the noise level is initially sampled at random from the uniform distribution , with being its lower bound. Subsequently, of local examples are randomly selected as noisy samples, with their ground-truth labels replaced by all possible class labels.
Baselines. We compare FedDiv with existing state-of-the-art (SOTA) F-LNL methods, including FedAvg (McMahan et al. 2017), RoFL (Yang et al. 2022b), ARFL (Yang et al. 2022b), JointOpt (Tanaka et al. 2018a), DivideMix (Li, Socher, and Hoi 2019), and FedCorr (Xu et al. 2022). Their experimental results reported in this paper are borrowed from (Xu et al. 2022).
Implementations. We set and to 950, 900 and 100, and 0.1, 0.1 and 0.02 on CIFAR-10, CIFAR-100 and Clothing1M, respectively, while we also set the confidence threshold for relabeling on all datasets. Note that, to enable faster convergence, we warm up local neural network models of each client for iterations (not training rounds; see (Xu et al. 2022)) using MixUp regularization (Zhang et al. 2018). Additionally, to be fair, most of our implementation details involving both local training and model aggregation are consistent with FedCorr (Xu et al. 2022) for each dataset under all federated settings and all label noise settings.
Model variants. We build the variants of FedDiv to evaluate the effect of the proposed noise filter as follows.
-
•
FedDiv(Degraded): Following (Zhu et al. 2022), we here degrade the proposed federated noise filter by constructing the global noise filter using only the local filter parameters received in the current round instead of those from all clients.
-
•
FedDiv(Local filter): A local noise filter is trained for each client using its own private data to identify noisy labels within individual clients.
Comparisons with State-of-the-Arts
Tables 1-4 summarize classification performance of FedDiv against state-of-the-art (SOTA) F-LNL methods on CIFAR-10, CIFAR-100, and Clothing1M across various noise settings for both IID and non-IID data partitions. Comparison results, based on mean accuracy and standard deviation over five trials, demonstrate FedDiv’s significant superiority over existing F-LNL algorithms, especially in challenging cases. For instance, in IID data partitions, Table 3 illustrates FedDiv outperforming FedCorr on CIFAR-100 by 6.39% in the toughest noise setting with . Similarly, for non-IID partitions in Table 2, FedDiv consistently surpasses FedCorr by 3.74% in the most challenging setting on CIFAR-10. Additionally, in Table 4, FedDiv exhibits a 0.41% improvement over FedCorr on Clothing1M, indicating its efficacy in real-world label noise distributions.
| Dataset | CIFAR-10 | CIFAR-100 |
|---|---|---|
| Noise level (, ) | (0.6, 0.5) | (0.4,0.0) |
| Method\(, ) | (0.3, 10) | (0.7, 10) |
| FedDiv (Ours) | 85.312.28 | 74.470.34 |
| FedDiv (Degraded) | 83.222.61 | 73.060.93 |
| FedDiv (Local filter) | 81.343.65 | 71.370.76 |
| FedDiv w/o Relab. & w/o PCS | 82.173.06 | 73.091.89 |
| FedDiv w/o PCS | 82.832.59 | 73.660.96 |
| FedDiv w/o | 83.603.65 | 72.431.29 |
Ablation Analysis
To underscore the efficacy of FedDiv, we perform an ablation study to demonstrate the effect of each component.
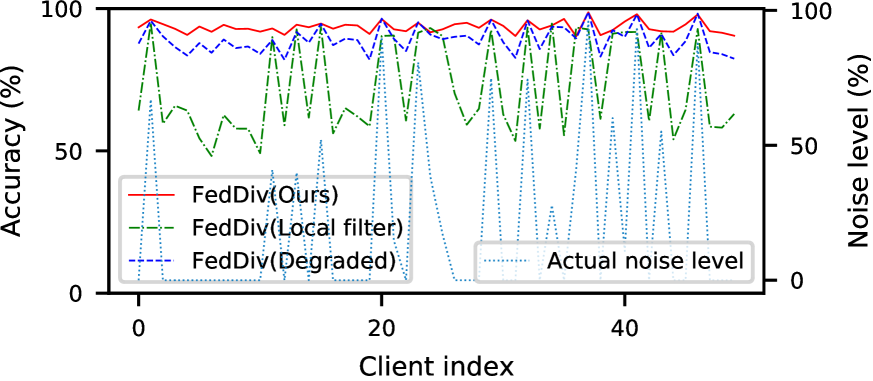
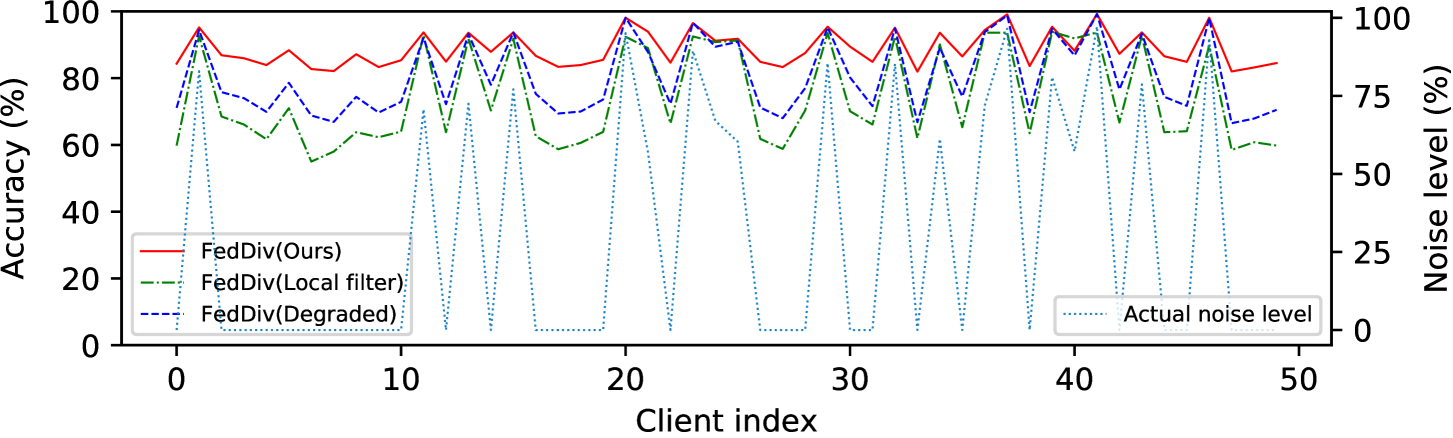
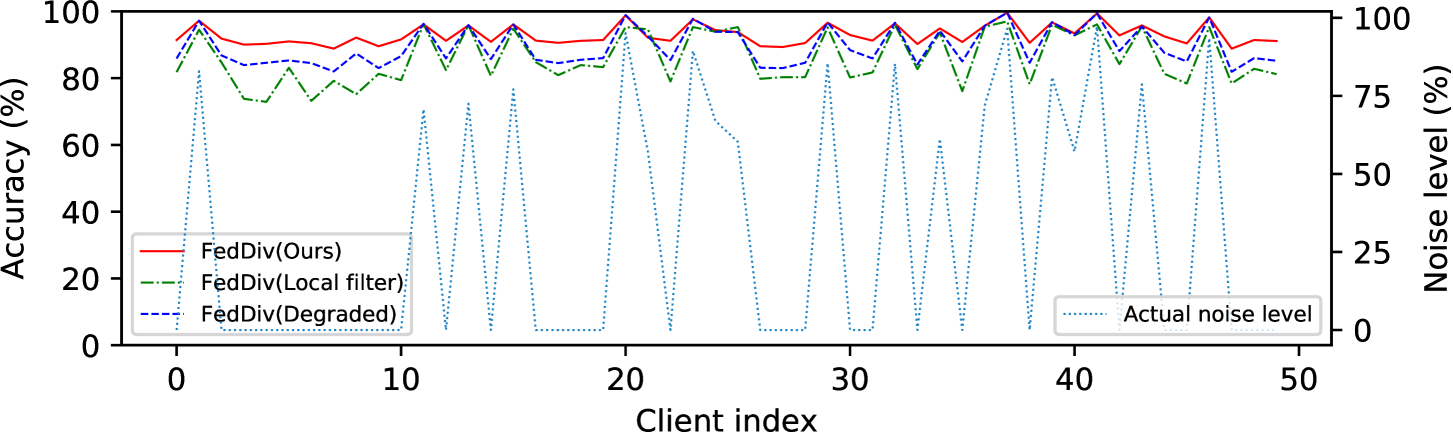
Evaluation of federated noise filtering. To affirm the superiority of the proposed scheme for label noise filtering, we first compare FedDiv with our model variants FedDiv(Local filter) and FedDiv(Degraded). As per Figure 3 and Table 5, the proposed noise filter exhibits a superior capacity of identifying label noise on both clean and noisy clients, leading to considerably improved classification performance in comparison to its two variants.
Evaluation of relabeling and re-selection. To assess the efficacy of the proposed strategies for noisy sample relabeling and labeled sample re-selection, we systematically remove their respective components from the FedDiv framework. The results depicted in Table 5 demonstrate a substantial decrease in accuracy across various noise settings for both types of data partitions. This indicates the importance of each individual component.
Conclusions
In this paper, we have presented FedDiv to handle the task of Federated Learning with Noisy Labels (F-LNL). It can effectively respond to the challenges in F-LNL tasks involving both data heterogeneity and noise heterogeneity while taking privacy concerns into account. On the basis of an FL framework, we first propose Federated Noise Filtering to separate clean samples from noisy ones on each client, thereby diminishing the instability during training. Then we perform relabeling to assign pseudo-labels to noisy samples with high predicted confidence. In addition, we introduce a Predictive Consistency based Sampler to identify credible local data for local model training, thus avoiding label noise memorization and further improving training stability. Experiments as well as comprehensive ablation analysis have revealed FedDiv’s superiority in handling F-LNL tasks.
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China (NO. 62322608), in part by the Shenzhen Science and Technology Program (NO. JCYJ20220530141211024), in part by the Open Project Program of the Key Laboratory of Artificial Intelligence for Perception and Understanding, Liaoning Province (AIPU, No. 20230003), in part by Hong Kong Research Grants Council under Collaborative Research Fund (Project No. HKU C7004-22G).
References
- Arazo et al. (2019a) Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.; and McGuinness, K. 2019a. Unsupervised label noise modeling and loss correction. In International conference on machine learning, 312–321. PMLR.
- Arazo et al. (2019b) Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.; and McGuinness, K. 2019b. Unsupervised label noise modeling and loss correction. In International conference on machine learning, 312–321. PMLR.
- Cheng et al. (2022) Cheng, D.; Liu, T.; Ning, Y.; Wang, N.; Han, B.; Niu, G.; Gao, X.; and Sugiyama, M. 2022. Instance-Dependent Label-Noise Learning with Manifold-Regularized Transition Matrix Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16630–16639.
- Dempster, Laird, and Rubin (1977) Dempster, A. P.; Laird, N. M.; and Rubin, D. B. 1977. Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B (Methodological), 39(1): 1–22.
- Englesson and Azizpour (2021) Englesson, E.; and Azizpour, H. 2021. Generalized jensen-shannon divergence loss for learning with noisy labels. Advances in Neural Information Processing Systems, 34: 30284–30297.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
- Holland (1986) Holland, P. W. 1986. Statistics and causal inference. Journal of the American statistical Association, 81(396): 945–960.
- Huang et al. (2023) Huang, D.; Li, J.; Chen, W.; Huang, J.; Chai, Z.; and Li, G. 2023. Divide and Adapt: Active Domain Adaptation via Customized Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7651–7660.
- Kim et al. (2022) Kim, S.; Shin, W.; Jang, S.; Song, H.; and Yun, S.-Y. 2022. FedRN: Exploiting k-Reliable Neighbors Towards Robust Federated Learning. arXiv preprint arXiv:2205.01310.
- Krizhevsky (2009) Krizhevsky, A. 2009. Learning Multiple Layers of Features from Tiny Images. Master’s thesis, University of Tront.
- Kuznetsova et al. (2020) Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. 2020. The open images dataset v4. International Journal of Computer Vision, 128(7): 1956–1981.
- Li et al. (2022) Li, J.; Li, G.; Liu, F.; and Yu, Y. 2022. Neighborhood Collective Estimation for Noisy Label Identification and Correction. In European Conference on Computer Vision. Springer.
- Li et al. (2021) Li, J.; Li, G.; Shi, Y.; and Yu, Y. 2021. Cross-Domain Adaptive Clustering for Semi-Supervised Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2505–2514.
- Li, Li, and Yu (2023a) Li, J.; Li, G.; and Yu, Y. 2023a. Adaptive Betweenness Clustering for Semi-Supervised Domain Adaptation. IEEE Transactions on Image Processing.
- Li, Li, and Yu (2023b) Li, J.; Li, G.; and Yu, Y. 2023b. Inter-Domain Mixup for Semi-Supervised Domain Adaptation. Pattern Recognition.
- Li, Socher, and Hoi (2019) Li, J.; Socher, R.; and Hoi, S. C. 2019. DivideMix: Learning with Noisy Labels as Semi-supervised Learning. In International Conference on Learning Representations.
- Li et al. (2019a) Li, J.; Wu, S.; Liu, C.; Yu, Z.; and Wong, H.-S. 2019a. Semi-supervised deep coupled ensemble learning with classification landmark exploration. IEEE Transactions on Image Processing, 29: 538–550.
- Li et al. (2019b) Li, L.; Wang, J.; Li, J.; Ma, Q.; and Wei, J. 2019b. Relation classification via keyword-attentive sentence mechanism and synthetic stimulation loss. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(9): 1392–1404.
- Li et al. (2020) Li, T.; Sahu, A. K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; and Smith, V. 2020. Federated optimization in heterogeneous networks. Proceedings of Machine Learning and Systems, 2: 429–450.
- Lin et al. (2020) Lin, T.; Kong, L.; Stich, S. U.; and Jaggi, M. 2020. Ensemble distillation for robust model fusion in federated learning. Advances in Neural Information Processing Systems, 33: 2351–2363.
- Ma et al. (2018) Ma, X.; Wang, Y.; Houle, M. E.; Zhou, S.; Erfani, S.; Xia, S.; Wijewickrema, S.; and Bailey, J. 2018. Dimensionality-driven learning with noisy labels. In International Conference on Machine Learning, 3355–3364. PMLR.
- McMahan et al. (2017) McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; and y Arcas, B. A. 2017. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, 1273–1282. PMLR.
- Nguyen et al. (2022) Nguyen, D. C.; Pham, Q.-V.; Pathirana, P. N.; Ding, M.; Seneviratne, A.; Lin, Z.; Dobre, O.; and Hwang, W.-J. 2022. Federated learning for smart healthcare: A survey. ACM Computing Surveys (CSUR), 55(3): 1–37.
- Pearl (2009) Pearl, J. 2009. Causal inference in statistics: An overview. Statistics surveys, 3: 96–146.
- Ren et al. (2018) Ren, M.; Zeng, W.; Yang, B.; and Urtasun, R. 2018. Learning to reweight examples for robust deep learning. In International conference on machine learning, 4334–4343. PMLR.
- Tanaka et al. (2018a) Tanaka, D.; Ikami, D.; Yamasaki, T.; and Aizawa, K. 2018a. Joint optimization framework for learning with noisy labels. In Proceedings of the IEEE conference on computer vision and pattern recognition, 5552–5560.
- Tanaka et al. (2018b) Tanaka, D.; Ikami, D.; Yamasaki, T.; and Aizawa, K. 2018b. Joint optimization framework for learning with noisy labels. In Proceedings of the IEEE conference on computer vision and pattern recognition, 5552–5560.
- Tanno et al. (2019) Tanno, R.; Saeedi, A.; Sankaranarayanan, S.; Alexander, D. C.; and Silberman, N. 2019. Learning from noisy labels by regularized estimation of annotator confusion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11244–11253.
- Wang et al. (2022) Wang, X.; Wu, Z.; Lian, L.; and Yu, S. X. 2022. Debiased Learning from Naturally Imbalanced Pseudo-Labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14647–14657.
- Wei et al. (2021) Wei, C.; Sohn, K.; Mellina, C.; Yuille, A.; and Yang, F. 2021. Crest: A class-rebalancing self-training framework for imbalanced semi-supervised learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10857–10866.
- Wu et al. (2019a) Wu, S.; Deng, G.; Li, J.; Li, R.; Yu, Z.; and Wong, H.-S. 2019a. Enhancing TripleGAN for semi-supervised conditional instance synthesis and classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10091–10100.
- Wu et al. (2019b) Wu, S.; Li, J.; Liu, C.; Yu, Z.; and Wong, H.-S. 2019b. Mutual learning of complementary networks via residual correction for improving semi-supervised classification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 6500–6509.
- Xiao et al. (2015) Xiao, T.; Xia, T.; Yang, Y.; Huang, C.; and Wang, X. 2015. Learning from massive noisy labeled data for image classification. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2691–2699.
- Xu et al. (2022) Xu, J.; Chen, Z.; Quek, T. Q.; and Chong, K. F. E. 2022. FedCorr: Multi-Stage Federated Learning for Label Noise Correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10184–10193.
- Yang et al. (2022a) Yang, E.; Yao, D.; Liu, T.; and Deng, C. 2022a. Mutual Quantization for Cross-Modal Search With Noisy Labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7551–7560.
- Yang et al. (2020) Yang, L.; Tan, B.; Zheng, V. W.; Chen, K.; and Yang, Q. 2020. Federated recommendation systems. In Federated Learning, 225–239. Springer.
- Yang et al. (2022b) Yang, S.; Park, H.; Byun, J.; and Kim, C. 2022b. Robust federated learning with noisy labels. IEEE Intelligent Systems, 37(2): 35–43.
- Zhang et al. (2018) Zhang, H.; Cisse, M.; Dauphin, Y. N.; and Lopez-Paz, D. 2018. mixup: Beyond Empirical Risk Minimization. In International Conference on Learning Representations.
- Zheng et al. (2022) Zheng, Z.; Zhou, Y.; Sun, Y.; Wang, Z.; Liu, B.; and Li, K. 2022. Applications of federated learning in smart cities: recent advances, taxonomy, and open challenges. Connection Science, 34(1): 1–28.
- Zhu et al. (2022) Zhu, C.; Xu, Z.; Chen, M.; Konečný, J.; Hard, A.; and Goldstein, T. 2022. Diurnal or Nocturnal? Federated Learning of Multi-branch Networks from Periodically Shifting Distributions. In International Conference on Learning Representations.
Supplementary Material (abbr. Supp)
In this supplementary material, we detail additional experimental setups encompassing data partitions, implementation specifics, and the baseline F-LNL methods. Furthermore, we provide further analysis of our proposed method, FedDiv. For a comprehensive understanding, we summarize the key notations of F-LNL and FedDiv in Table 6. Additionally, detailed training procedures of FedDiv and the specifics of local filter training are outlined in Algorithm 1 and Algorithm 2, respectively. To further enhance clarity, we present hyper-parameter summaries for each dataset in Table 7. Consistency in hyper-parameter settings is maintained across different label noise settings for both IID and non-IID data partitions on each dataset. It’s worth noting that all experiments are conducted on the widely-used PyTorch platform222https://pytorch.org/ and executed on an NVIDIA GeForce GTX 2080Ti GPU with 12GB memory.
| Symbol | Definition |
|---|---|
|
Current communication round |
|
|
Collection of all clients |
|
|
Collection of clients randomly selected at current round |
|
|
Current index for the client selected from or |
|
|
Given local samples for client |
|
|
Clean samples separated from |
|
|
Noisy samples separated from |
|
|
Relabeled samples produced from |
|
|
More reliable labeled samples re-selected by PCS |
|
|
Training data for further optimization of the local model |
|
|
Actual noise level for client |
|
|
Estimated noise level for client |
|
|
Global network model at round |
|
|
Local network model being optimized during local training for client at round |
|
|
Local network model for client at round |
|
|
Global filter parameters for client at round |
|
|
Server-cached local filter parameters for client |
|
|
Local filter parameters for client obtained at round |
|
|
Overall bias of the local model for client w.r.t all classes |
| Hyper-parameter | CIFAR-10 | CIFAR-100 | Clothing1M |
|---|---|---|---|
| # of clients () | 100 | 50 | 500 |
| # of classes () | 10 | 100 | 14 |
| # of samples | 50,000 | 50,000 | 1,000,000 |
| Architecture | ResNet-18 | ResNet-34 | Pre-trained ResNet-50 |
| Mini-batch size | 10 | 10 | 16 |
| Learning rate | 0.03 | 0.01 | 0.001 |
| 5 | 10 | 2 | |
| 500 | 450 | 50 | |
| 450 | 450 | 50 | |
| 950 | 900 | 100 | |
| 5 | 5 | 5 | |
| 0.1 | 0.1 | 0.02 |
Input: ; ; ; ; ; Initialized ; Initialized ; Initialized ; Initialized
Output: Global network model
Input: ; ;
Output: Optimal local filter parameters
Additional Experimental Setups
Non-IID data partitions. We employ Dirichlet distribution (Lin et al. 2020) with the fixed probability and the concentration parameter to construct non-IID data partitions. Specifically, we begin by introducing an indicator matrix , and each entry determines whether the -th client has samples from the -th class. For every entry, we assign a 1 or 0 sampled from the Bernoulli distribution with a fixed probability . For the row of the matrix that corresponds to the -th class, we sample a probability vector from the Dirichlet distribution with a concentration parameter , where . Then, we assign the -th client a proportion of the samples that belong to the -th category, where denotes the client index with , and .
Additional Implementation Details. Similar to FedCorr (Xu et al. 2022), we select ResNet-18 (He et al. 2016), ResNet-34 (He et al. 2016) and Pre-trained ResNet-50 (He et al. 2016) as the network backbones for CIFAR-10, CIFAR-100 and Clothing1M, respectively. During the local model training sessions, we train each local client model over local training epochs per communication round, using an SGD optimizer with a momentum of 0.5 and a mini-batch size of 10, 10, and 16 for CIFAR-10, CIFAR-100, and Clothing1M, respectively. For each optimizer, we set the learning rate as 0.03, 0.01, and 0.001 on CIFAR-10, CIFAR-100, and Clothing1M, respectively. In addition, during data pre-processing, the training samples are first normalized and then augmented by hiring random horizontal flipping and random cropping with padding of 4. For most thresholds conducted on the experiments, we set them to default as in FedCorr (Xu et al. 2022), e.g. in Eq. (11), the probability of a sample being clean/noisy in Eq. (7), in Eq. (9), etc. Additionally, we determine in Eq. (8) using a small validation set, where meets the peak of validation accuracies.
How to set , and . In this work, we streamlined the multi-stage F-LNL process proposed in FedCorr (Xu et al. 2022) into a one-stage process, avoiding the complexity of executing multiple intricate steps across different stages as in FedCorr. However, for fair comparisons, we maintained an equivalent number of communication rounds as in FedCorr. This totals , encompassing federated pre-processing from FedCorr’s training iterations, and , covering both federated fine-tuning and usual training stages involving FedCorr. Notably, within , we solely utilize MixUp regularization (Zhang et al. 2018) to warm up the local neural network models for faster convergence.
Below, we will begin by introducing the multi-stage F-LNL pipeline proposed by FedCorr, followed by an analysis of fraction scheduling and the construction of the training rounds of FedDiv.
-
•
FedCorr. FedCorr comprises three FL stages: federated pre-processing, federated fine-tuning, and federated usual training. During the pre-processing stage, the FL model is initially pre-trained on all clients for iterations (not training round) to guarantee initial convergence of model training. At the same time, FedCorr evaluates the quality of each client’s dataset and identifies and relabels noisy samples. After this stage, a dimensionality-based filter (Ma et al. 2018) is proposed to classify clients into clean and noisy ones. In the federated fine-tuning stage, FedCorr only fine-tunes the global model on relatively clean clients for rounds. At the end of this stage, FedCorr re-evaluates and relabels the remaining noisy clients. Finally, in the federated usual training stage, the global model is trained over rounds using FedAvg (McMahan et al. 2017) on all the clients, incorporating the labels corrected in the previous two training stages.
-
•
Fraction scheduling and communication rounds of FedDiv. During FL training, a fixed fraction of clients will be selected at random to participate in local model training at the beginning of each round. Here, we set a fraction parameter to control the fraction scheduling, which is the same as the fine-tuning and usual training stages in FedCorr. However, during the pre-processing stage of FedCorr, every client must participate in local training exactly once in each iteration. Hence, any one client may be randomly sampled from all the clients with a probability of to participate in local model training, without replacement. As three stages of FedCorr have been merged into one in FedDiv, to ensure fairness in training, we convert the training iterations of the pre-processing stage into the training rounds we used, which gives us the corresponding training rounds . Therefore, in our work, the total number of communication rounds in the entire training process is , where .
Additional Analysis
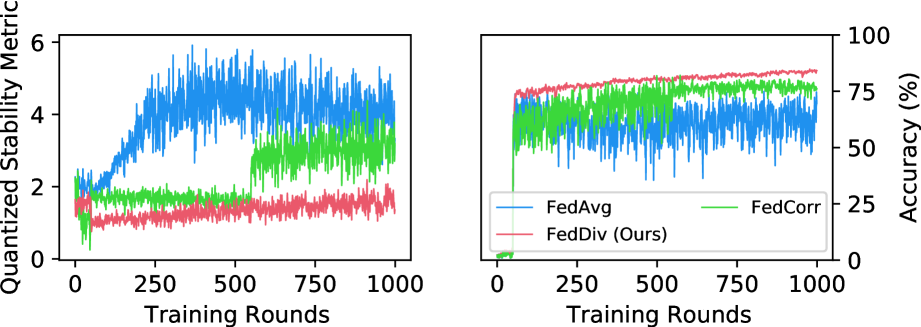
Quantized training stability. To better grasp the motivation behind this approach, we propose using “Quantized training stability” to quantify the impact of data heterogeneity and noise heterogeneity (Kim et al. 2022; Yang et al. 2022b) on the training instability experienced during local training sessions. Technically, quantized training stability can be measured by the average proximal regularization metric between local and global model weights, denoted as and respectively, at round . This is calculated by . As depicted in Figure 4, this instability results in notable discrepancies in weight divergence between local and global models, potentially hindering the performance enhancement of the aggregated model if left unaddressed. Additionally, considering the efficacy of different noise filtering strategies, our proposed federated noise filtering demonstrates superior performance in label noise identification per client, leading to decreased training instability during local training sessions and thus achieving higher classification performance of the aggregated model.
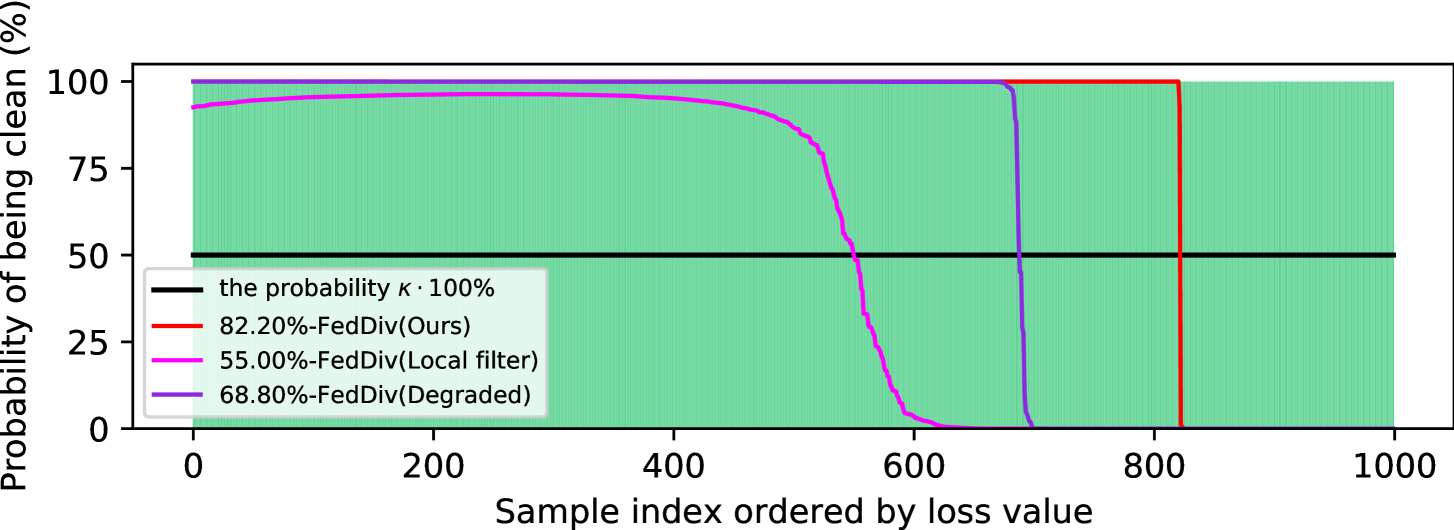
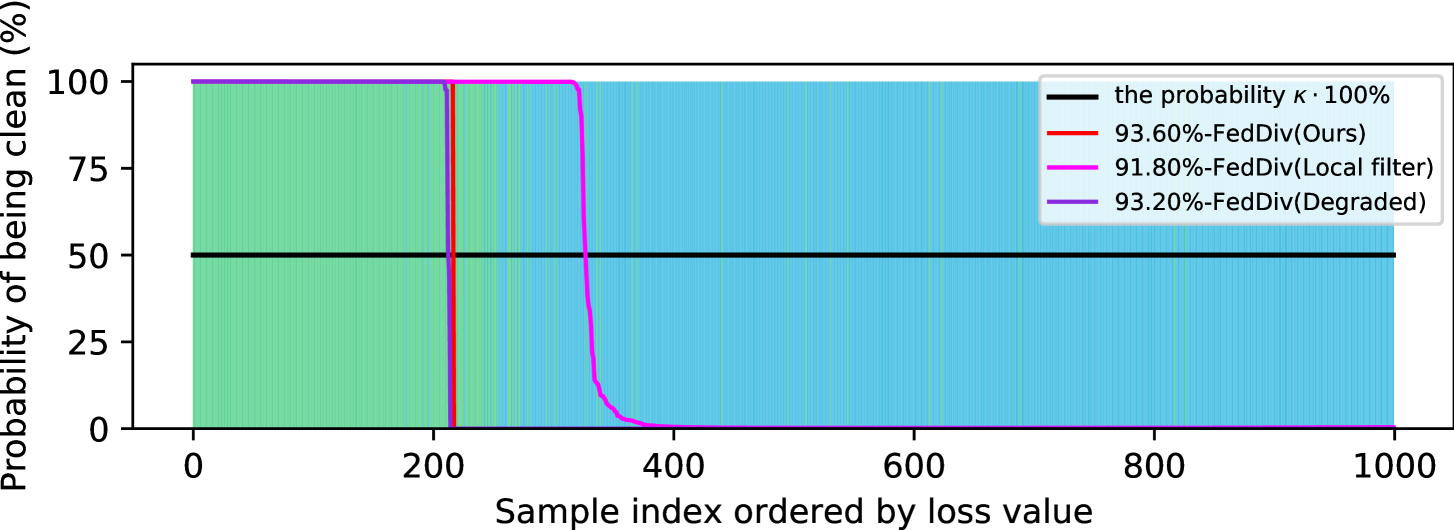
Further evaluation of federated noise filtering. To further verify the capability of our proposed label noise filtering strategy, we again compare FedDiv with FedDiv(Local filter) and FedDiv(Degraded) in Figure 5 and Figure 6. Both experiments are conducted on CIFAR-100 with the noise setting for the IID data partition. Specifically, Figure 5 shows the accuracy of label noise filtering over all 50 clients at different communication rounds, while Figure 6 provides two examples to illustrate the noise filtering performance of different noise filters on clean and noisy clients.
As depicted in both Figure 5 and Figure 6, the proposed strategy consistently produces stronger label noise filtering capabilities on the vast majority of clients than the alternative solutions. Additionally, Figure 5 also shows that all these three noise filtering schemes significantly improve the label noise identification performance as model training proceeds, especially on clean clients—possibly because the network model offers greater classification performance—but ours continues to perform the best. These results once again highlight the feasibility of our proposed noise filtering strategy.
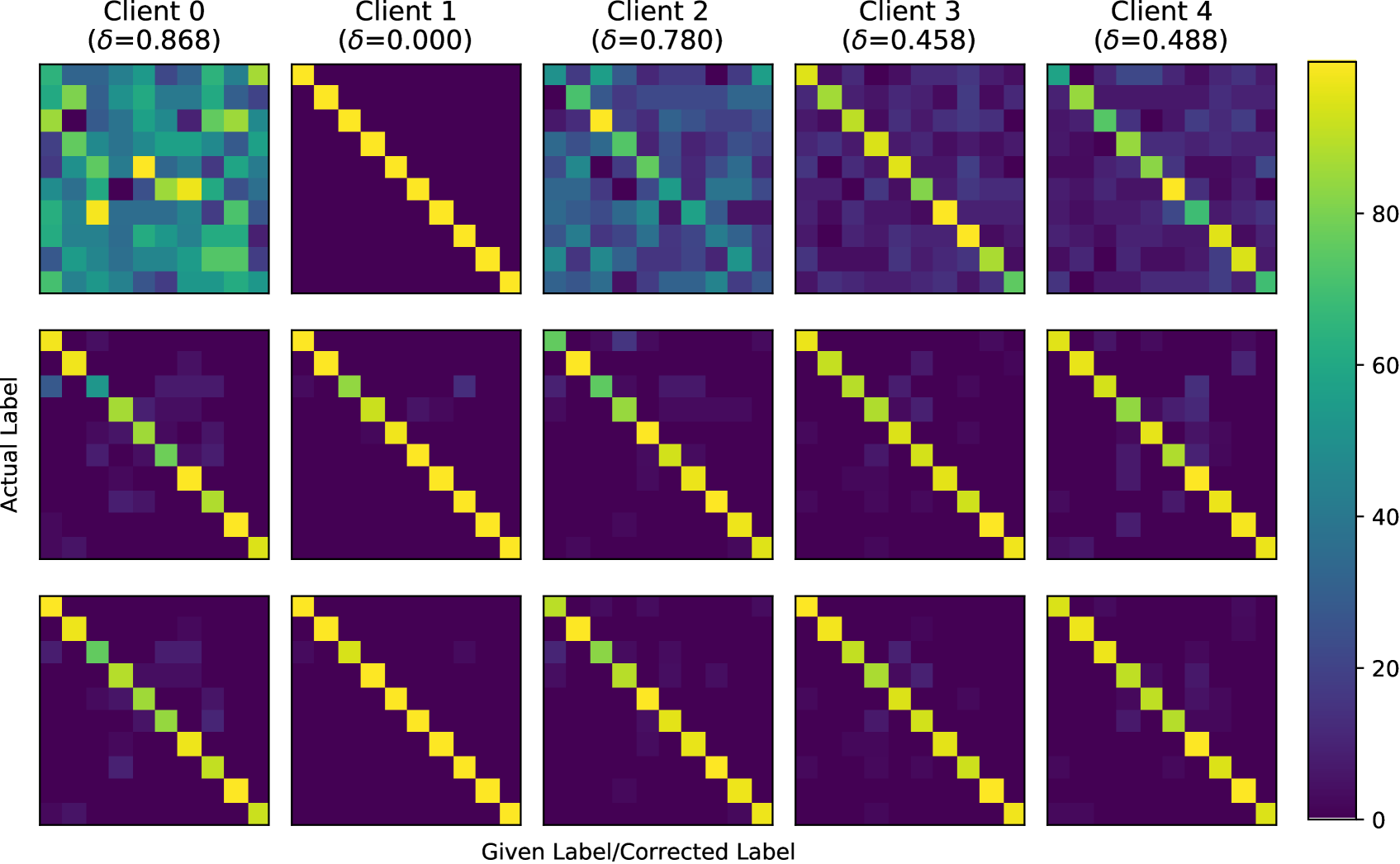
Further evaluation of filtering, relabeling and re-selection. To emphasize each FedDiv thread’s effectiveness in label noise filtering, noisy sample relabeling, and labeled sample re-selection, we compare confusion matrices before processing, after label noise filtering and noisy sample relabeling (Thread 1), and after labeled sample re-selection (Thread 2) in Figure 7. Figure 7 displays heat maps of these three confusion matrices on five representative clients. On clean or noisy clients with varying noise levels, each thread gradually eliminates label noise, confirming the performance of each FedDiv component.
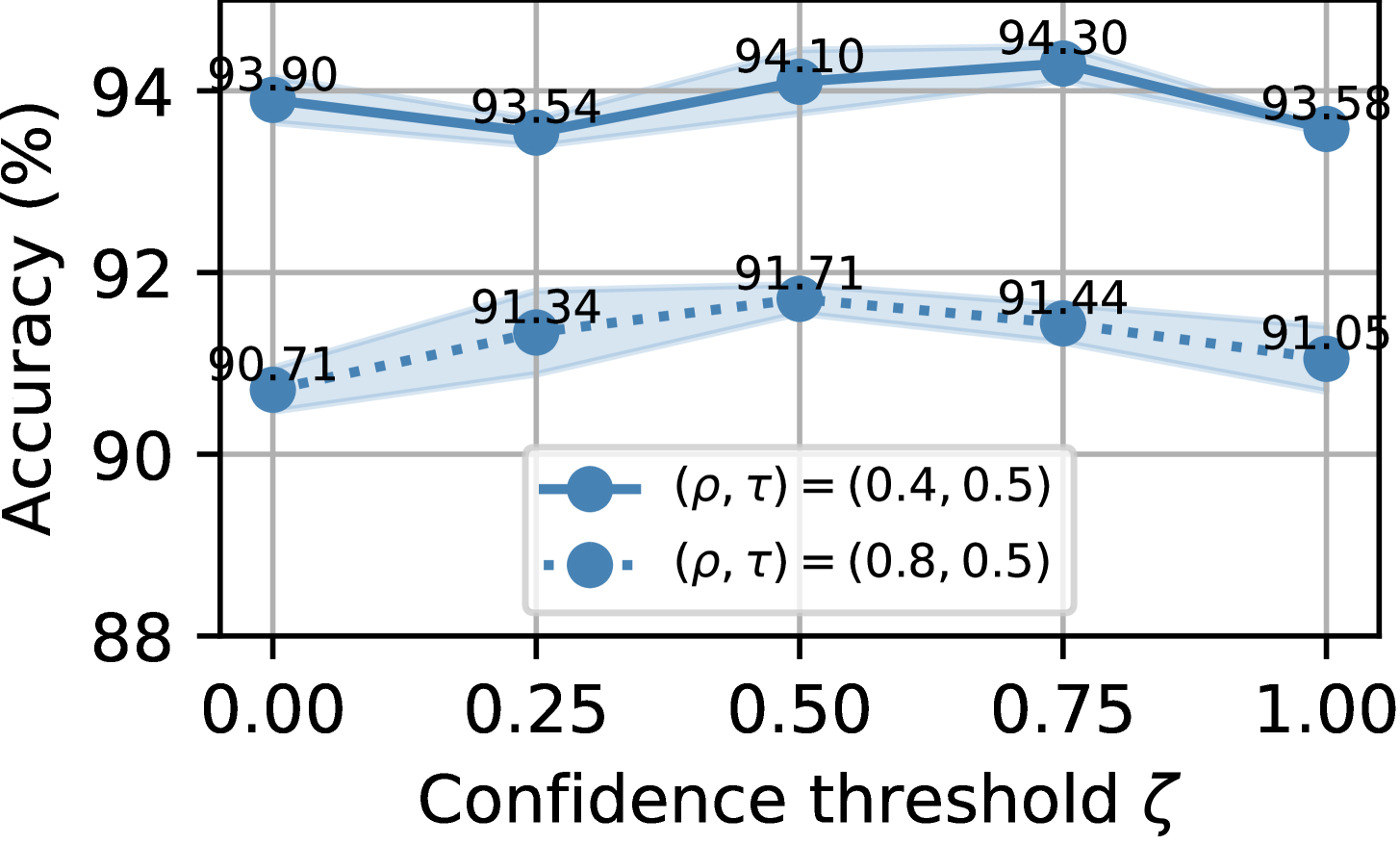
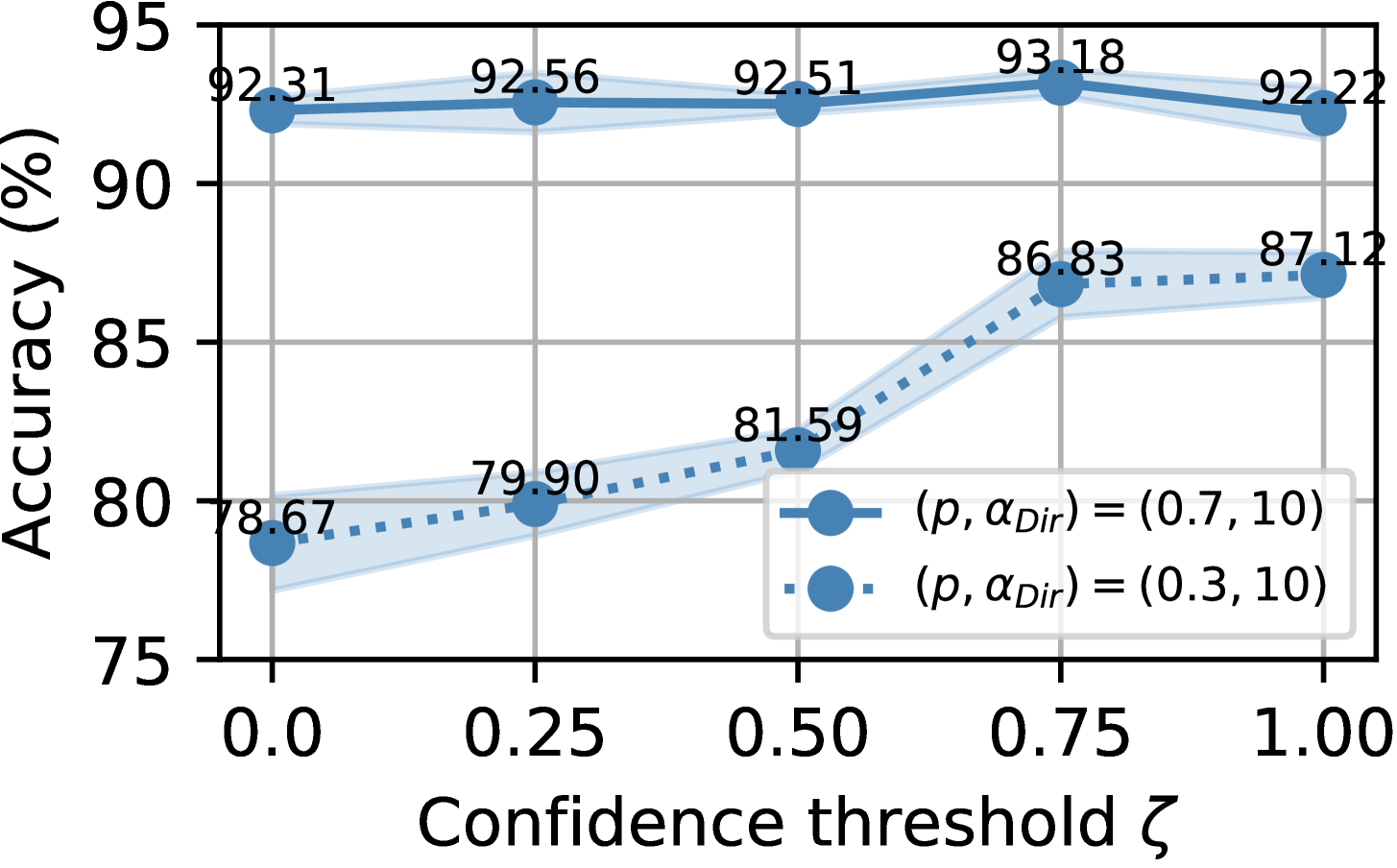
Hyper-parameter sensitivity. We analyze hyper-parameter sensitivity to the confidence threshold . As shown in Figure 8, the proposed approach consistently achieves higher classification performance when is set to 0.75. Therefore, is an excellent choice for setting the confidence threshold for noisy sample relabeling when training the FL model on CIFAR-10 and CIFAR-100 under different label noise settings for both IID and non-IID data partitions.
| Given |
 |
| Thread 1 | |
| Thread 2 |