A Variational Autoencoder for Neural Temporal Point Processes with Dynamic Latent Graphs
Abstract
Continuously-observed event occurrences, often exhibit self- and mutually-exciting effects, which can be well modeled using temporal point processes. Beyond that, these event dynamics may also change over time, with certain periodic trends. We propose a novel variational auto-encoder to capture such a mixture of temporal dynamics. More specifically, the whole time interval of the input sequence is partitioned into a set of sub-intervals. The event dynamics are assumed to be stationary within each sub-interval, but could be changing across those sub-intervals. In particular, we use a sequential latent variable model to learn a dependency graph between the observed dimensions, for each sub-interval. The model predicts the future event times, by using the learned dependency graph to remove the non-contributing influences of past events. By doing so, the proposed model demonstrates its higher accuracy in predicting inter-event times and event types for several real-world event sequences, compared with existing state of the art neural point processes.
Introduction
There has been growing interests in modeling and understanding temporal dynamics in event occurrences. For instance, modeling customer behaviors and interactions, is crucial for recommendation systems and online social media, to improve the resource allocation and customer experience (Farajtabar et al. 2014, 2016). These event occurrences usually demonstrate heterogeneous dynamics. On one aspect, individuals usually reciprocate in their interactions with each other (reciprocity). For example, if Alice sends an email to Bob, then Bob is more likely to send an email to Alice soon afterwards. On the other aspect, long event sequences often exhibit a certain amount of periodic trends. For instance, during working time, individuals are more likely to reciprocate in the email interactions with their colleagues, but such mutually exciting effects will become weaker during non-working time, as illustrated in Fig. 1.
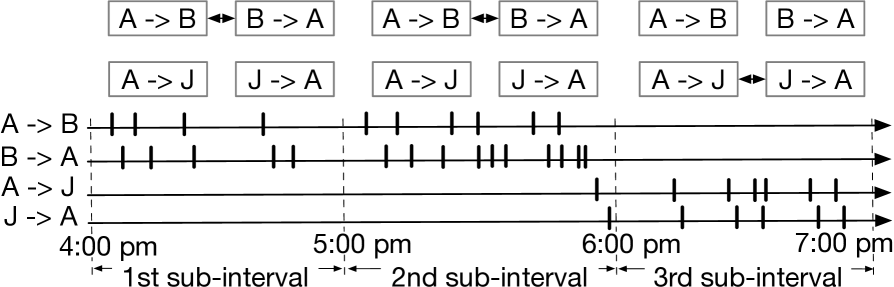
Temporal point processes (TPPs), such as Hawkes processes (HPs) (Hawkes 1971), are in particular well-fitted to capture the reciprocal and clustering effects in event dynamics. Nonetheless, the conventional HPs cannot adequately capture the latent state-transition dynamics. Recently, neural temporal point processes (neural TPPs) demonstrate a strong capability in capturing long-range dependencies in event sequences using neural networks (Du et al. 2016; Xiao et al. 2017, 2019; Omi, Ueda, and Aihara 2019), attention mechanisms (Zhang et al. 2020; Zuo et al. 2020) and neural density estimation (Shchur, Bilos, and Günnemann 2019). These neural TPPs often use all the past events to predict a future event’s occurring time, and thus cannot remove the disturbances of the non-contributing events. To mitigate this defect, some recent works (Zhang, Lipani, and Yilmaz 2021; Lin et al. 2021) formulate the neural temporal point processes by learning a static graph to explicitly capture dependencies among event types. They hence can improve the accuracy in predicting future event time, by removing the non-contributing influences of past events via the learned graph. Nonetheless, the dependencies between event types, may also change over time. Using a static graph, the neural TPPs will retrieve a dependency graph averaged over time. To fill the gap, some main contributions are made in this paper: (i) We propose to learn a dynamic graph between the event types of an input sequence, from a novel variational auto-encoder (VAE) perspective (Kingma and Welling 2014; Rezende, Mohamed, and Wierstra 2014). More specifically, we use regularly-spaced intervals to capture the different states, and assume stationary dynamics within each sub-interval. In particular, the dependencies between two event types, is captured using a latent variable, which allows to evolve over sub-intervals. We formulate the variational auto-encoder framework, by encoding a latent dynamic graph among event types, from observed sequences. The inter-event waiting times, are decoded using log-normal mixture distributions. Via the learned graph, the non-contributing influences of past events, can be effectively removed. (ii) The final experiments demonstrate the improved accuracy of the proposed method in predicting event time and types, compared against the existing closely-related methods. The interpretability of the dynamic graph estimated by the proposed method, is demonstrated with both New York Motor Vehicle Collision data.
Background
Multivariate Point Processes. Temporal point processes (TPPs) are concerned with modeling random event sequences in continuous time domain. Let denote a sequence of events, with being the timestamp and being the type of -th event. In addition, denotes the sequence of historical events occurring up to time . Multivariate Hawkes processes (MHPs) capture mutually-excitations among event types using the conditional intensity function specified by
| (1) |
where is the base rate of -th event type, captures the instantaneous boost to the intensity due to event ’s arrival, and determines the influence decay of that event over time. The stationary condition for MHPs requires .
In contrast to MHPs, a mutually regressive point process (MRPP) (Apostolopoulou et al. 2019) is to capture both excitatory and inhibitory effects among event types. These parametric point processes capture a certain form of dependencies on the historical events by designing the conditional intensity functions accordingly.
Despite being simple and useful,
these parametric point processes either suffer from certain approximation errors caused by the model misspecifications in practice, or lack the ability to capture long-range dependencies.To address these limitations, some recent advancements (Du et al. 2016; Omi, Ueda, and Aihara 2019; Shchur, Bilos, and Günnemann 2019; Zhang et al. 2020; Zuo et al. 2020) combine temporal point processes and deep learning approaches to model complicated dependency structure behind event sequences. At a high level, these neural temporal point processes treat each event as a feature, and encode a sequence of events into an history embedding using various deep learning methods including recurrent neural nets (RNNs), gated recurrent units (GRUs), or long-short term memory (LSTM) nets.
Du et al. (2016) uses a recurrent neural net to extract history embedding from observed past events, and then use the history embedding to parameterize its conditional intensity function. The exponential form of this intensity, admits a closed-form integral , and thus leads to a tractable log-likelihood.
Mei and Eisner (2017) studied a more sophisticated conditional intensity function, while calculating the log-likelihood involves approximating the integral using Monte Carlo methods. Omi, Ueda, and Aihara (2019) proposes to model the cumulative conditional intensity function using neural nets, and hence allows to compute the log-likelihood exactly and efficiently. However, sampling using this approach is expensive, and the derived probability density function does not integrate to one. To remedy these issues, Shchur, Bilos, and Günnemann (2019) proposes to directly model the inter-event times using normalizing flows. The neural density estimation method (Shchur, Bilos, and Günnemann 2019) not only allows to perform sampling and likelihood computation analytically, but also shows competitive performance in various applications, compared with the other neural TPPs.
Variational Auto-Encoder.
We briefly introduce the definition of variational auto-encoder (VAE), and refer the readers to (Kingma and Welling 2014; Rezende, Mohamed, and Wierstra 2014) for more properties.
VAE is one of the most successful generative models, which allows to straightforwardly sample from the data distribution . It is in particular useful to model high-dimensional data distribution, for which sampling with Markov chain Monte Carlo is notoriously slow. More specifically, we aim at maximizing the data log-likelihood under the generative process specified by
where is the latent variable, and denotes the prior distribution, and the observation component is parameterized by .
Under the VAE framework, the posterior distribution can be defined as where refer to a normal distribution, the mean and covariance are parameterized by neural networks with parameter .
To learn the model parameters, we maximize the evidence lower bound (ELBO) given by
where denotes the Kullback–Leibler (KL) divergence. The first term is to make the approximate posterior to produce latent variables that can reconstruct data as well as possible.
The second term is to match the approximate posterior of the latent variables to the prior distribution of the latent variables.
Using the reparameterization trick (Kingma and Welling 2014), we learn and by maximizing the ELBO using stochastic gradient descent aided by automatic differentiation.
Models
Given a sequence of events , we aim to capture the complicated dependence between event types, using a dynamic graph-structured neural point process.
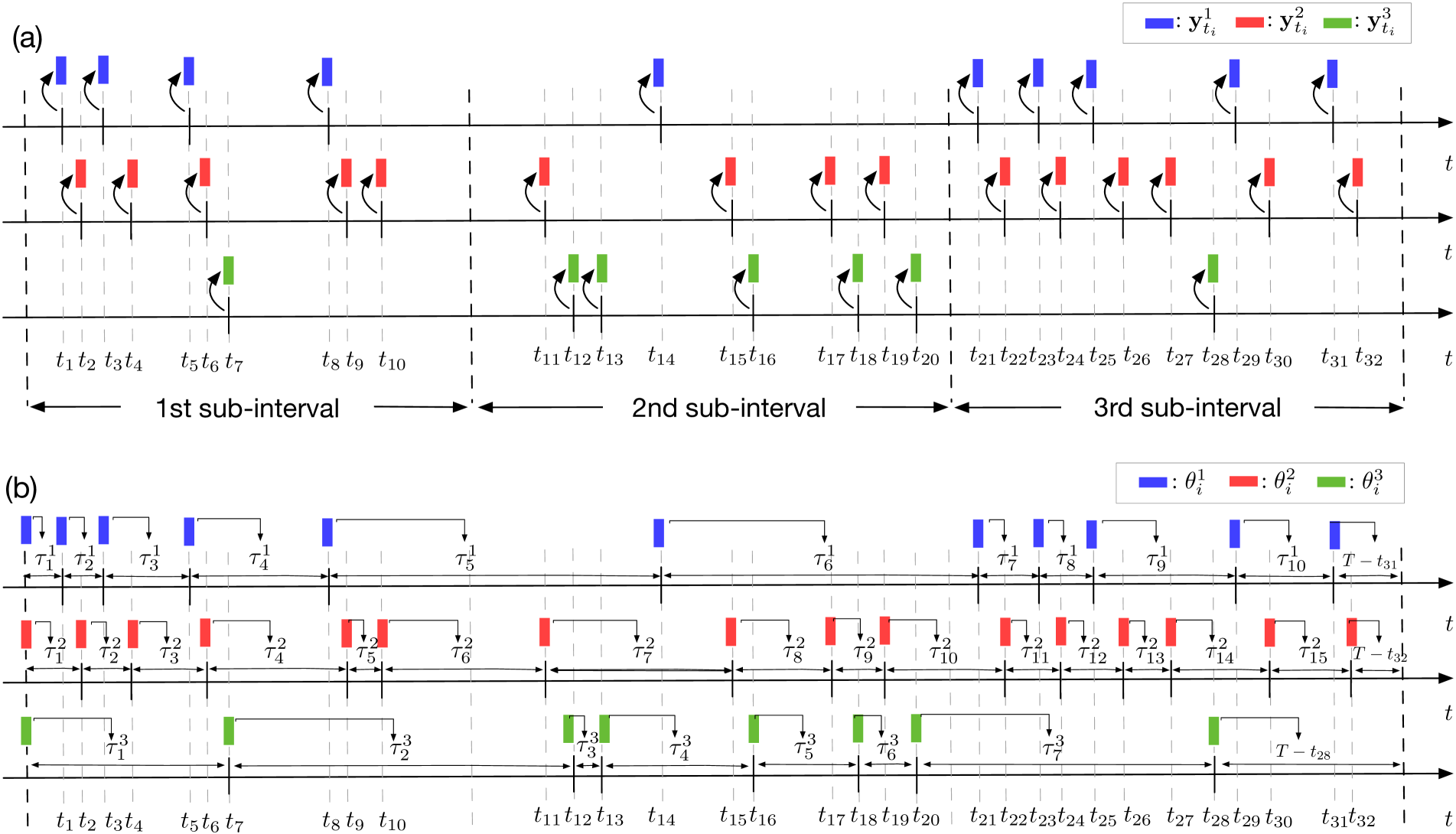
The whole time-interval of the sequence is partitioned into regularly-spaced sub-intervals with specified a priori, to approximately represent the different states.
We assume
the latent graph among the event types, is changing over states, but stationary within each sub-interval, as illustrated in Fig. 2(a). Specifically, let stand for the -th sub-interval with being the start point and being the end point. Let the latent variable capture the dependence of -th event type on -th event type within -th sub-interval. For ease of exposition, we denote the set of events occurring within the -th sub-interval by
. Note that we model the inter-event time for each event type using log-normal mixtures. Hence, we represent the event sequence of -th type by , where is -th event observed in the sequence of -th event type, denotes the corresponding inter-event time, and the total number of events .
Next we shall explain each component of the variational autoencoder in the following subsections.
Prior. We assume that the dependency graph among event types, evolves over sub-intervals. Hence, we use an autoregressive model to capture the the prior probabilities of the latent variables . More specifically, the prior distribution of depends on its previous state and the event sequence up to time (all the events in first sub-intervals):
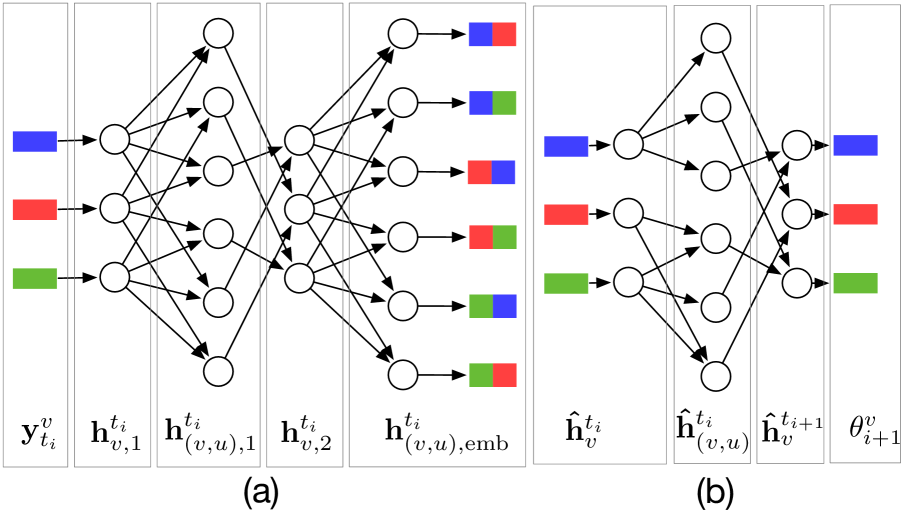
The prior component is specified as follows: for each event of -th type , where represents the auxiliary event mark if available, we embed and into a fixed-dimensional vector . Then, we pass the event embedding through a fully-connected graph neural network (GNN) to obtain the relation embedding between event types and :
where denotes a multilayer perceptron (MLP) for each layer of the GNN, and represent the node-wise and edge-wise hidden states of the -th intermediate layer, respectively. The final output of the GNN models the relation at time . The GNN architecture is illustrated in Fig. 3(a).
We need to concatenate all the relation variable, , and transform them into the relation state of -th sub-interval, using a MLP:
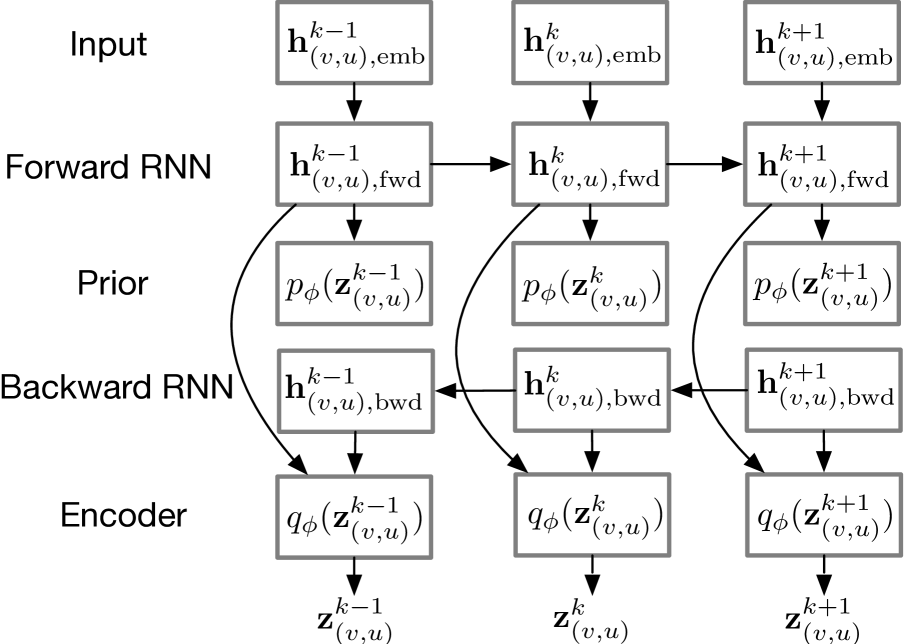
A forward recurrent neural network (RNN) is used to capture the dependence of an relation state on its current embedding , and its previous state :
Finally, we encode into the logits of the prior distribution for , using a MLP:
Fig. 4 shows the prior distribution built upon the foward RNN.
Encoder. The posterior distribution of the latent variables depends on both the past and future events:
Hence, the encoder is designed to approximate the distribution of the relation variables using the whole event sequence. To that end, a backward GNN is used to propagate the hidden states reversely:
Finally, we concatenate both the forward state and the backward state , and transform them into the logits of the approximate posterior, using a MLP:
Note that the prior and encoder share parameters, and thus the parameters of the two components are denoted by .
Decoder. The role of the decoder is to predict the inter-event times for each event type . In particular, we capture the latent dynamics behind these inter-event times using a graph recurrent neural network (GRNN) specified by
where determines how the -th event type influences the -th event type through the relation at time . The latent embedding itself evolves over time, using a gated recurrent unit (GRU).
Given the dynamic embeddings , we model the inter-event time using a log-normal mixture model (Shchur, Bilos, and Günnemann 2019),
where represent the mixture weights, the mean and the standard deviations of -th mixture component, respectively. In particular, the parameters of the distribution for each inter-event time is constructed as
where refer to the learnable parameters. We use softmax and exp transformations to impose the sum-to-one and positive constraints on the distribution parameters accordingly. Fig. 3(b) presents the GNN architecture used to construct the parameters of the log-normal mixtures in the decoder part. We assume the inter-event time is conditionally independent of the past events, given the model parameters. Hence, the distribution of the inter-event time under the decoder, factorizes as
The decoder part of the VAE framework is illustrated in Fig. 2 (b). Hence, we can naturally make the next event time prediction using
Training. We next explain how to learn the parameters of the VAE framework for dynamic graph-structured neural point processes. The event sequences are passed through the GNN in the encoder, to obtain the relation embedding for all the timestamps and each pair of two event types . We then concatenate all the relation embeddings, and transform them into a relation state for each sub-interval . The relational states are fed into the forward and backward RNNs to compute the prior distribution and posterior distribution . We then sample from the concrete reparameterizable approximation of the posterior distribution. The hidden states evolve through a GRNN, in which the messages can only pass through the non-zero edges hinted by . These hidden states are used to parameterize the log-normal mixture distribution for the inter-event times. To learn the model parameters, we calculate the evidence lower bound (ELBO) as
| (2) | |||
As we draw samples using an reparameterizable approximation, we can calculate gradients using backpropagation and optimize the ELBO. Hereafter, we denote the proposed model as variational autoencoder temporal point process (VAETPP).
Related Work
Wasserman (1980); Huisman and Snijders (2003) proposed to capture the non-stationary network dynamics using continuous-time Markov chains. Graph-Structured Temporal Point Processes. Bhattacharjya, Subramanian, and Gao (2018) proposed a proximal graphical event model to infer the relationships among event types, and thus assumes that the occurrence of an event only depends on the occurring of its parents shortly before. Shang and Sun (2019) developed a geometric Hawkes process to capture correlations among multiple point processes using graph convolutional neural networks although the inferred graph is undirected. Zuo et al. (2020) developed a graph-structured transformer Hawkes process between multiple point processes. It assumes that each point process is associated with a vertex of a static graph, and model the dependency among those point processes by incorporating that graph into the attention module design. Zhang, Lipani, and Yilmaz (2021) formulated a graph-structured neural temporal point process (NTPP) by sampling a latent graph using a generator. The model parameters of the graph-structured NTPP and its associated graph, can be simultaneously optimized using an efficient bi-level programming. Lin et al. (2021) recently also developed a variational framework for graph-structured neural point processes by generating a latent graph using intra-type history embeddings. The latent graph is then used to govern the message passing between intra-type embedding to decode the type-wise conditional intensity function. Zhang and Yan (2021) proposed to learn a static conditional graph between event types, by incorporating prior knowledge. Additionally, Linderman and Adams (2014) proposed to learn the latent graph structure among events via a probabilistic model. Wu et al. (2020) tries to model event propagation using a graph-biased temporal point process, with a graph specified by the following relationships among individuals on social media. Pan et al. (2020) studied a variational auto-encoder framework for modeling event sequences but haven’t consider capturing latent graphs among dimensions. Dynamic Latent Graphs behind Time Series. Kipf et al. (2018) developed an variational autoencoder to learn a latent static graph among the entities that interact in a physical dynamical system. Following this success, Graber and Schwing (2020) used a sequential latent variable model to infer dynamic latent graphs among the entities from the discrete-time observations. Although Graber and Schwing (2020) and the proposed method both aim to learn dynamic graphs behind multivariate sequential observations, the main differences lie in that our input is asynchronous event sequences, for which we need to determine the regularly-spaced sub-intervals, and simultaneously learn a dynamic graph for each sub-interval. An interesting yet challenging direction, is to automatically infer the regularly-spaced time intervals and the dynamic graph structure, which we leave to future research.
Experiments
The proposed variational autoencoder temporal point process, is evaluated on the task of event time and type prediction. We used four real-world data to demonstrate the proposed method, compared with existing related methods. New York Motor Vehicle Collisions(NYMVC): This data contains a collection of vehicle collision events occurring at New York city since April, 2014. Each crash event records a motor vehicle collision occurring in district , at time . Specifically, during peak periods, a vehicle collision may give rise to a sequence of collisions in the same or nearby districts, in short time. Hence, it is well-fitted to model and predict the occurrences of these events using multivariate point processes. In addition, the influence relations among the districts may change over time as the aforementioned triggering effects become weaker during night time, compared to day time. We created each event sequence using the motor vehicle collision records between 8:00 and 23:00, and treated each three hours as a sub-interval. We considered the five districts, Manhattan, Brooklyn, Bronx, Queens and Staten Island as the event types.
| Methods | MathOF | AskUbuntu | SuperUser | NYMVC |
|---|---|---|---|---|
| Exponential | ||||
| RMTPP | ||||
| FullyNN | ||||
| LogNormMix | ||||
| THP | ||||
| VAETPP (static) | ||||
| VAETPP |
| Datasets | sequences | events | types |
|---|---|---|---|
| MathOF | |||
| AskUbuntu | |||
| SuperUser | |||
| NYMVC |
Stack Exchange Data: The three stack exchange data from different sources, are included in the experiments: MathOF, AskUbuntu, and SuperUser. The stack exchange data consists of various interactions among the participant. Each event means that at timestamp , user may post an answer or comment to ’s questions or comments. These interaction events among users usually exhibit a certain amount of clustering effects and periodic trends. For instance, some questions about popular technology, may quickly lead to a lot of answers or comments from the others who share similar interests. Additionally, these triggering effects demonstrate periodic trends: users are more inclined to response to technical topics during working days, than weekends/holidays. We consider the user who makes the action toward the other as the event type. Hence, we derived each sequence from events occurring within one week, and consider each day as a sub-interval. These datasets are detailed in Table 2.
| Methods | MathOF | AskUbuntu | SuperUser | NYMVC |
|---|---|---|---|---|
| RMTPP | ||||
| LogNormMix | ||||
| THP | ||||
| VAETPP(static) | ||||
| VAETPP |
| Methods | MathOF | AskUbuntu | SuperUser | NYMVC |
|---|---|---|---|---|
| RMTPP | ||||
| LogNormMix | ||||
| THP | ||||
| VAETPP(static) | ||||
| VAETPP |
Experimental Setup. We compared the ability of the models in predicting the inter-event times using the historical events , for each event type , as illustrated in Fig. 2(b). Each real-world data is split into multiple event sequences. For each real-world data, we choose the of the sequences for training, for validation, and for testing. For training, we maximize the ELBO in Eq. 2 for the proposed model, and the expected log-likelihood for the other models. With the learned parameters, we measure the predictive performance of each model, using its obtained negative log-likelihood (NLL) on the validation set. Hence, the model configuration that achieves best predictive performance, can be chose using the validation set. Finally, the NLL loss on the test set, are used to compare the ability of the models in predicting inter-event times. We report the results averaged over ten random training/validation/testing splits. For the developed VAETPP, the dimension of the input embedding is . For the fully-connected GNN of the encoder, , and are two-layer MLPs with 64 units for each layer and Exponential Linear Unit (ELU) activations. We use to transform the concatenated hidden states within each sub-interval into one hidden state, and thus parameterize using a one-layer MLP with 64 hidden units and ReLU activations. Both the forward RNN and backward RNN have 64 hidden units. We parameterize and by a one-layer MLP with 64 hidden units and Rectified Linear Unit (ReLU) activations. We set the number of edge types of the dynamic graph among event types to be two, and specify the first edge type to indicate no dependency. For the decoder part, we parameterize using a separate two-layer MLP with 64 hidden/output units, for each of the two edge types. The GRU has 64 hidden units. We chose the number of mixing components used in the log-normal mixture distribution for the VAETPP, using the validation data. In the experiments, we used mixing components in the experiments. We also consider restricting the VAETPP with a static latent graph, and denote it as VAETPP (static), to validate the importance of learning dynamic graphs in capturing period trends in event sequences. We compared the proposed method against the following baselines: Exponential. The conditional intensity function of the constant intensity model (Upadhyay, De, and Gomez-Rodrizuez 2018) is defined as , in which denotes the event history embedding learned by a RNN, and refer to the model parameters. The probability density function (PDF) of the constant intensity model is an exponential distribution, as given by , where . Recurrent Marked Temporal Point Processes(RMTPP) (Du et al. 2016). The method encodes past events into historical embeddings using a RNN, and models exponential-distributed conditional intensity. Fully Neural Networks (FullyNN) (Omi, Ueda, and Aihara 2019). It captures the cumulative distributions of inter-event times using a neural network. Log Normal Mixture (LogNormMix) (Shchur, Bilos, and Günnemann 2019). The method encodes the event history into embedding vectors with a RNN, and decodes the inter-waiting time with a log-normal mixture distribution. Transformer Hawkes Process (THP) (Zuo et al. 2020). It leverages the self-attention mechanism to capture long-term dependencies in observed event sequences.
Negative Log-likelihood Comparison. Table 1 compares the negative log-likelihood loss of all the methods in modeling inter-event times. As expected, the LogNormMix admits more flexibility compared with simple model using unimodal distributions (Gompertz/RMTPP, Exponential), and thus shows improved performance by large margins. Transformer Hawkes process (THP) can effectively learn long-range dependencies among events, and thus achieves lower NLL loss. The proposed VAETPP not only can capture the complicated inter-event time distribution using a log-normal mixture decoder. It can also improve the inter-event time prediction in further by effectively removing the non-contributing effects of irrelevant past events, via the dynamic dependency graph. Hence, the proposed VAETPP achieves the best NLL loss values consistently on all the datasets.
Event Prediction Comparison. We also consider the tasks of event time and type prediction in the experiments. In particular, following (Zuo et al. 2020), we make the next event time prediction using a linear predictor as where is the history embedding updated by the VAETPP after observing of -th event of -th type, and denotes the event time predictor’s parameter. The next event type prediction is
where denotes the event type predictor’s parameter, and refers to the -th entry of . The loss functions for event time and type prediction are defined as
respectively, where is the one-hot encoding for
the type of -th event.
To learn the parameters of the event time and type predictor, we consider minimizing a composite loss function as
where is the evidence lower bound derived in Eq.2.
We used the training data to learn the model parameters, and choose the best configuration according to the predictive performance on the validation set. Finally, we evaluated model performance on the test set. Specifically, we predicted each held-out event given its history. We evaluated event type prediction by accuracy and event time prediction by Root Mean Square Error (RMSE). Tab. 3 and 4 shows the results for event time and type prediction, respectively. Our VAETPP outperforms the baselines in predicting event time and types on all the data.
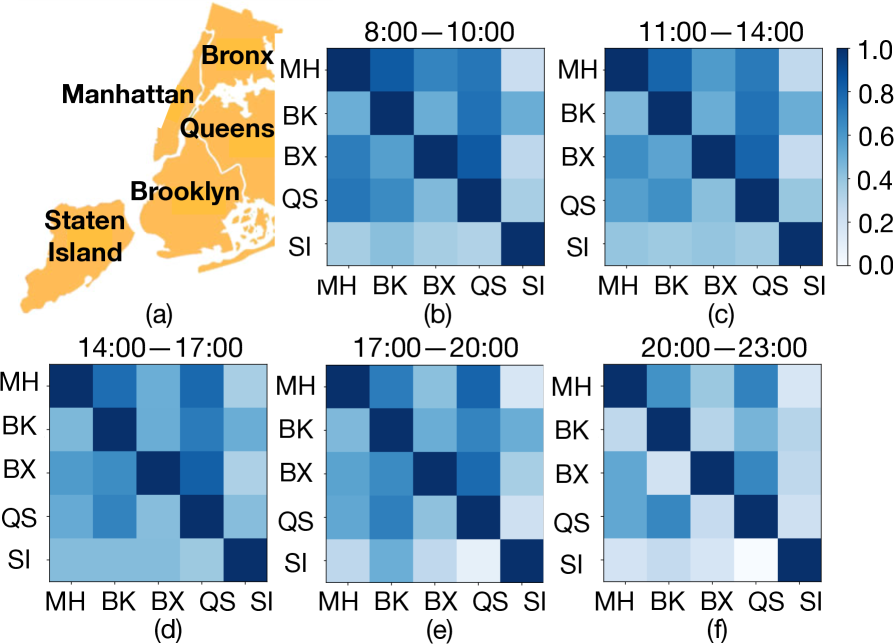
Model Interpretability. Fig. 5(a) shows the relative location of the five boroughs of New York city: Manhattan, Brooklyn, Bronx, Queens, Staten Island. The latent dynamic graphs for the five time-intervals, are plotted in Fig. 5(b-f). From the results, we find that the influences between Manhattan, Brooklyn, Bronx and Queens, are much stronger, compared with influences between these four areas and Staten Island. These influences between all the areas, gradually become weaker during night time, compared against day time. The results not only show the high model interpretability, but also explains why VAETPP obtains better prediction accuracy by effectively removing non-contributing historical events’ influences via its estimated graphs.
Conclusion
We have presented a novel variational auto-encoder for modeling asynchronous event sequences. To capture the periodic trends behind long sequences, we use regularly-spaced intervals to capture the different states behind the sequences, and assume stationary dynamics within each sub-interval. The dependency structure between event types, is captured using latent variables, which allow to be evolving over time, to capture the time-varying graphs. Hence, the proposed model can effectively remove the influences from the irrelevant past event types, and achieves better accuracy in predicting inter-event times and types, compared with other neural point processes. We plan to generalize the work to capture non-stationary network dynamics (Yang and Koeppl 2018b, a, 2020; Yang and Zha 2023) in the future research.
Acknowledgments
The work is partially funded by Shenzhen Science and Technology Program (JCYJ20210324120011032) and Shenzhen Institute of Artificial Intelligence and Robotics for Society.
References
- Apostolopoulou et al. (2019) Apostolopoulou, I.; Linderman, S.; Miller, K.; and Dubrawski, A. 2019. Mutually Regressive Point Processes. In Advances in Neural Information Processing Systems (NeurIPS), 1–12.
- Bhattacharjya, Subramanian, and Gao (2018) Bhattacharjya, D.; Subramanian, D.; and Gao, T. 2018. Proximal Graphical Event Models. In Advances in Neural Information Processing Systems (NeurIPS), 1–10.
- Du et al. (2016) Du, N.; Dai, H.; Trivedi, R. S.; Upadhyay, U.; Gomez-Rodriguez, M.; and Song, L. 2016. Recurrent Marked Temporal Point Processes: Embedding Event History to Vector. In SIGKDD, 1555–1564. New York, NY, USA.
- Farajtabar et al. (2014) Farajtabar, M.; Du, N.; Gomez-Rodriguez, M.; Valera, I.; Zha, H.; and Song, L. 2014. Shaping Social Activity by Incentivizing Users. In Advances in Neural Information Processing Systems (NeurIPS), 2474–2482.
- Farajtabar et al. (2016) Farajtabar, M.; Ye, X.; Harati, S.; Song, L.; and Zha, H. 2016. Multistage Campaigning in Social Networks. In Advances in Neural Information Processing Systems (NeurIPS), 2–9.
- Graber and Schwing (2020) Graber, C.; and Schwing, A. G. 2020. Dynamic Neural Relational Inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 8513–8522.
- Hawkes (1971) Hawkes, A. G. 1971. Spectra of some self-exciting and mutually exciting point processes. Biometrika, 58(1): 83–90.
- Huisman and Snijders (2003) Huisman, M.; and Snijders, T. 2003. Statistical analysis of longitudinal network data with changing composition. Sociological Methods & Research, 32(2): 253–287.
- Kingma and Welling (2014) Kingma, D. P.; and Welling, M. 2014. Auto-Encoding Variational Bayes. In Proceedings of the International Conference on Learning Representations (ICLR), 1–14.
- Kipf et al. (2018) Kipf, T.; Fetaya, E.; Wang, K.-C.; Welling, M.; and Zemel, R. 2018. Neural Relational Inference for Interacting Systems. In Proceedings of the International Conference on Machine Learning (ICML), 2688–2697.
- Lin et al. (2021) Lin, H.; Tan, C.; Wu, L.; Gao, Z.; and Li, S. Z. 2021. An Empirical Study: Extensive Deep Temporal Point Process. CoRR.
- Linderman and Adams (2014) Linderman, S. W.; and Adams, R. P. 2014. Discovering Latent Network Structure in Point Process Data. In Proceedings of the International Conference on Machine Learning (ICML), 1413–1421. Bejing, China.
- Mei and Eisner (2017) Mei, H.; and Eisner, J. 2017. The Neural Hawkes Process: A Neurally Self-Modulating Multivariate Point Process. In Advances in Neural Information Processing Systems (NeurIPS), 6757–6767.
- Omi, Ueda, and Aihara (2019) Omi, T.; Ueda, N.; and Aihara, K. 2019. Fully Neural Network based Model for General Temporal Point Processes. In Advances in Neural Information Processing Systems (NeurIPS), 1–11.
- Pan et al. (2020) Pan, Z.; Huang, Z.; Lian, D.; and Chen, E. 2020. A Variational Point Process Model for Social Event Sequences. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 173–180.
- Rezende, Mohamed, and Wierstra (2014) Rezende, D. J.; Mohamed, S.; and Wierstra, D. 2014. Stochastic Backpropagation and Approximate Inference in Deep Generative Models. In Proceedings of the International Conference on Machine Learning (ICML), 1278–1286. Bejing, China.
- Shang and Sun (2019) Shang, J.; and Sun, M. 2019. Geometric Hawkes Processes with Graph Convolutional Recurrent Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 4878–4885.
- Shchur, Bilos, and Günnemann (2019) Shchur, O.; Bilos, M.; and Günnemann, S. 2019. Intensity-Free Learning of Temporal Point Processes. In Proceedings of the International Conference on Learning Representations (ICLR), 1–21.
- Upadhyay, De, and Gomez-Rodrizuez (2018) Upadhyay, U.; De, A.; and Gomez-Rodrizuez, M. 2018. Deep Reinforcement Learning of Marked Temporal Point Processes. In Advances in Neural Information Processing Systems (NeurIPS), 3172–3182.
- Wasserman (1980) Wasserman, S. 1980. Analyzing Social Networks as Stochastic Processes. Journal of the American Statistical Association, 75(370): 280–294.
- Wu et al. (2020) Wu, W.; Liu, H.; Zhang, X.; Liu, Y.; and Zha, H. 2020. Modeling Event Propagation via Graph Biased Temporal Point Process. IEEE Transactions on Neural Networks and Learning Systems, 1–11.
- Xiao et al. (2017) Xiao, S.; Farajtabar, M.; Ye, X.; Yan, J.; Yang, X.; Song, L.; and Zha, H. 2017. Wasserstein Learning of Deep Generative Point Process Models. In Advances in Neural Information Processing Systems (NeurIPS).
- Xiao et al. (2019) Xiao, S.; Yan, J.; Farajtabar, M.; Song, L.; Yang, X.; and Zha, H. 2019. Learning Time Series Associated Event Sequences With Recurrent Point Process Networks. IEEE Transactions on Neural Networks and Learning Systems, 30(10): 3124–3136.
- Yang and Koeppl (2018a) Yang, S.; and Koeppl, H. 2018a. Dependent Relational Gamma Process Models for Longitudinal Networks. In Proceedings of the International Conference on Machine Learning (ICML), 5551–5560.
- Yang and Koeppl (2018b) Yang, S.; and Koeppl, H. 2018b. A Poisson Gamma Probabilistic Model for Latent Node-Group Memberships in Dynamic Networks. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 4366–4373.
- Yang and Koeppl (2020) Yang, S.; and Koeppl, H. 2020. The Hawkes Edge Partition Model for Continuous-time Event-based Temporal Networks. In Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI), 460–469.
- Yang and Zha (2023) Yang, S.; and Zha, H. 2023. Estimating Latent Population Flows from Aggregated Data via Inversing Multi-Marginal Optimal Transport. In Proceedings of the 2023 SIAM International Conference on Data Mining (SDM), 181–189.
- Zhang et al. (2020) Zhang, Q.; Lipani, A.; Kirnap, O.; and Yilmaz, E. 2020. Self-Attentive Hawkes Process. In Proceedings of the International Conference on Machine Learning (ICML), 11183–11193.
- Zhang, Lipani, and Yilmaz (2021) Zhang, Q.; Lipani, A.; and Yilmaz, E. 2021. Learning Neural Point Processes with Latent Graphs. In Proceedings of the international conference on World Wide Web (WWW), 1495–1505. New York, NY, USA.
- Zhang and Yan (2021) Zhang, Y.; and Yan, J. 2021. Neural Relation Inference for Multi-dimensional Temporal Point Processes via Message Passing Graph. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 3406–3412.
- Zuo et al. (2020) Zuo, S.; Jiang, H.; Li, Z.; Zhao, T.; and Zha, H. 2020. Transformer Hawkes Process. In Proceedings of the International Conference on Machine Learning (ICML), 11692–11702.