Rethinking Tabular Data Understanding with Large Language Models
Abstract
Large Language Models (LLMs) have shown to be capable of various tasks, yet their capability in interpreting and reasoning over tabular data remains an underexplored area. In this context, this study investigates from three core perspectives: the robustness of LLMs to structural perturbations in tables, the comparative analysis of textual and symbolic reasoning on tables, and the potential of boosting model performance through the aggregation of multiple reasoning pathways. We discover that structural variance of tables presenting the same content reveals a notable performance decline, particularly in symbolic reasoning tasks. This prompts the proposal of a method for table structure normalization. Moreover, textual reasoning slightly edges out symbolic reasoning, and a detailed error analysis reveals that each exhibits different strengths depending on the specific tasks. Notably, the aggregation of textual and symbolic reasoning pathways, bolstered by a mix self-consistency mechanism, resulted in achieving SOTA performance, with an accuracy of 73.6% on WikiTableQuestions, representing a substantial advancement over previous existing table processing paradigms of LLMs.
Rethinking Tabular Data Understanding with Large Language Models
Tianyang Liu UC San Diego til040@ucsd.edu Fei Wang USC fwang598@usc.edu Muhao Chen UC Davis muhchen@ucdavis.edu
1 Introduction
Large Language Models (LLMs; Brown et al. 2020; Chowdhery et al. 2022; Zhang et al. 2022; OpenAI 2022, 2023a, 2023c; Touvron et al. 2023a, b) have revolutionized the field of NLP, demonstrating an extraordinary ability to understand and reason over rich textual data Wei et al. (2023); Wang et al. (2023); Zhou et al. (2023); Kojima et al. (2023); Li et al. (2023b). On top of LLMs’ existing capabilities for NLP, further bolstering their potential for decision-making by drawing from external knowledge sources remains an exciting research frontier Nakano et al. (2022); Mialon et al. (2023); Hao et al. (2023); Jiang et al. (2023b). Amongst such knowledge sources, tabular data serve as a ubiquitous kind due to their expressiveness for relations, properties and statistics, and their being easy to construct by human curators.
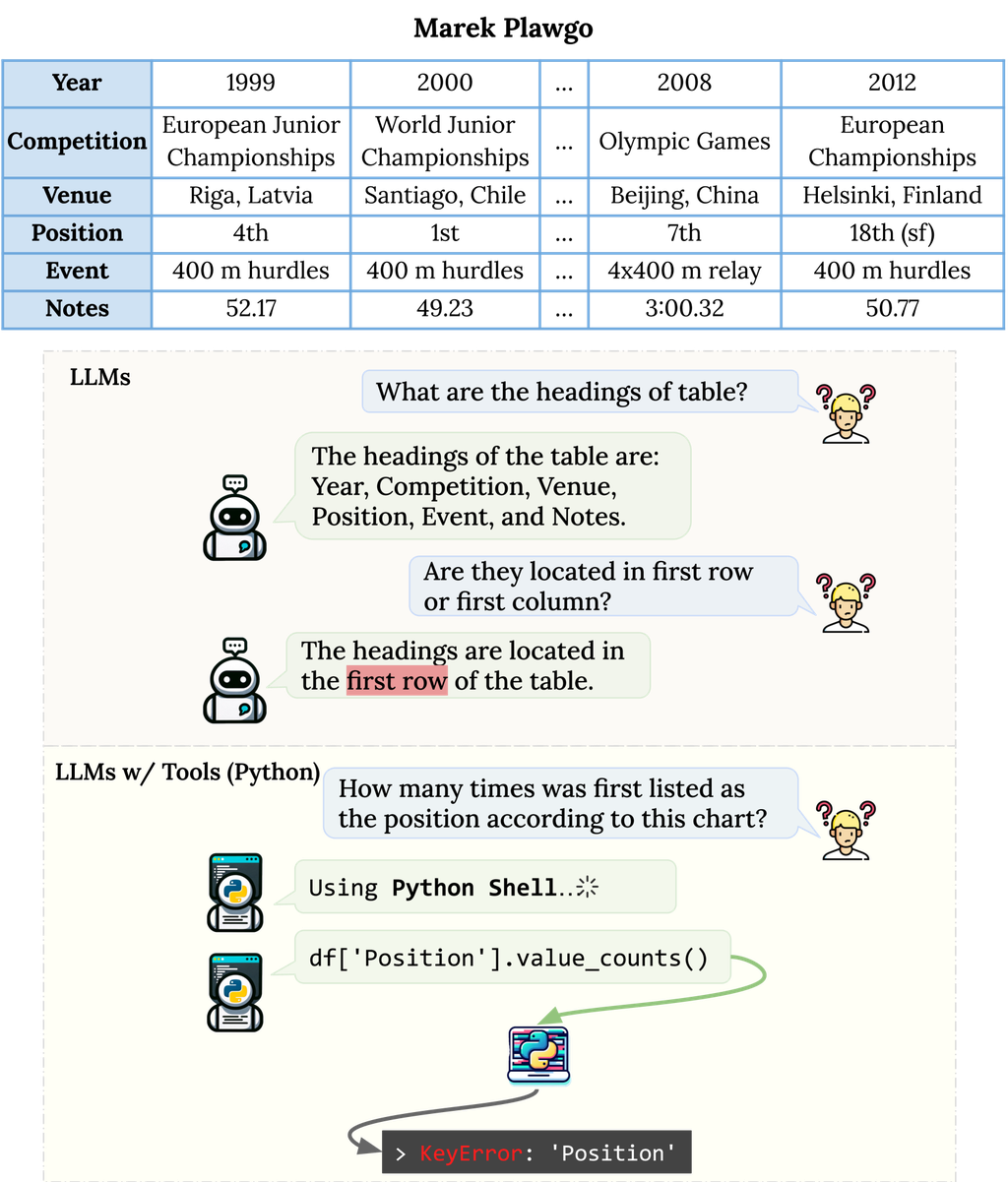
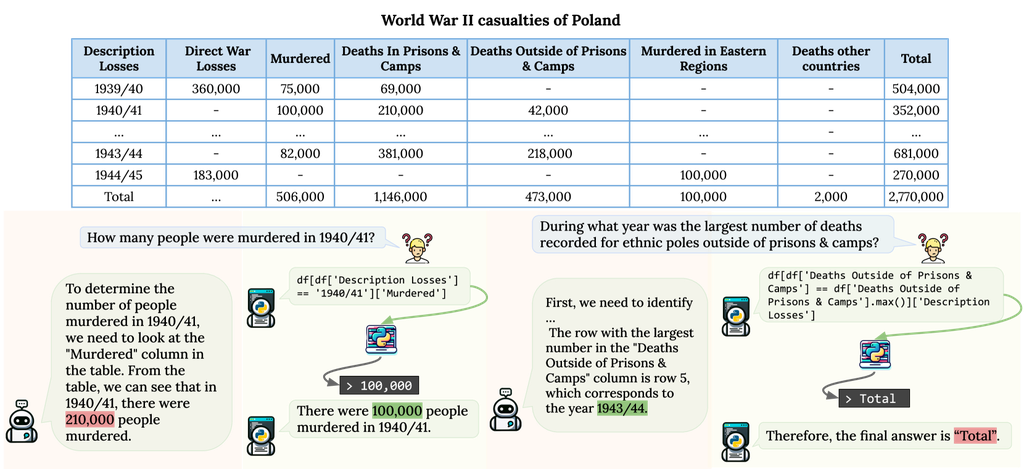
Like humans, LLMs can also benefit from reading tabular data accompanying text. However, as indicated in Figure 1, the structural nature of tables presents unique challenges to these models. Inherently designed to parse and process vast expanses of unstructured textual content, LLMs confront a paradigm shift when facing tabular data. Linearizing tables to suit the LLM paradigm can obscure the inherent structural and relational information, making tasks such as precise localization and complex statistical analyses. Additionally, the design variations in tables, whether ‘column tables’ with headers in the first row or ‘row tables’ with headers in the first column, further complicate the interpretation process. Beyond structural concerns, numerical reasoning and aggregation over tabular data present another layer of complexity. While LLMs excel at textual understanding, they occasionally stumble when confronted with tasks necessitating precise numerical computation within tables. Moreover, tables often present a dense amalgamation of textual or numerical data. The sheer volume and intricacy of this information can risk overshadowing crucial details, potentially impeding the LLM’s decision-making abilities Shi et al. (2023).
With the emergence of instruction fine-tuning techniques Wei et al. (2022); Chung et al. (2022) and the application of Reinforcement Learning from Human Feedback (RLHF) Stiennon et al. (2022); Gao et al. (2022); Christiano et al. (2017), LLMs have witnessed significant enhancements in their alignment capabilities, paving the way for transitioning from few-shot to zero-shot learning settings Kojima et al. (2023). In light of these advancements, this paper delves deep into the the challenges and intricacies of tabular understanding and reasoning by LLMs, exemplified in Figure 2. We organize our exploration around three pivotal research questions: (1) How well do LLMs perceive table structures and how can we ensure robustness against structural variations? (2) Comparing textual and symbolic reasoning for table data in LLMs, which prevails in effectiveness, and what advantages and challenges manifest in each strategy? (3) Will the aggregation of multiple reasoning pathways enhance the accuracy and reliability of tabular data interpretation by LLMs?
In pursuit of answering the aforementioned research questions, we conduct experiments on SOTA LLMs such as GPT-3.5 OpenAI (2023a). Our findings in Section 4 underscore that while LLMs are adept at semantically interpreting tables, their capability to resist structural variance (Section 4.1) and understand table structures (Section 4.2) is suboptimal. Motivated by these findings, we propose a table structure normalization method to enhance LLMs’ resilience against structural table variations in Section 4.3. Intriguingly, Section 5.1 reveals that textual reasoning surpasses symbolic reasoning in contexts with limited table content, defying conventional conceptions of symbolic reasoning’s dominance in other domains Mialon et al. (2023). Both textual and symbolic reasoning strategies encompass different advantages and challenges, which is detailed in Section 5.2. To harness the unique strengths of each, we implement mix self-consistency mechanism (Section 6) that remarkably attains SOTA performance on Table QA, exemplifying the synergistic potential when both reasoning strategies are aggregated.
2 Related Work
PLMs for Tabular Data Processing. Tabular reasoning presents unique challenges due to the fusion of free-form natural language questions with structured or semi-structured tabular data, for which PLMs jointly trained on tables and text are developed in the past few years, including TaBERT Yin et al. (2020), TaPas Herzig et al. (2020), TAPEX Liu et al. (2022), ReasTAP Zhao et al. (2022), and PASTA Gu et al. (2022). Despite these advancements, recent studies have identified generalization issues under table perturbations Zhao et al. (2023); Chang et al. (2023), raising concerns regarding the robustness of PLMs. Specific efforts like LETA Zhao et al. (2023) and LATTICE Wang et al. (2022) have investigated and mitigated the vulnerabilities related to structural perturbations of tabular data, like row/column shuffling and table transpose, through various techniques, including data augmentation and order-invariant graph attention. However, these approaches require whitebox access to the models, limiting their applicability to SOTA LLMs with only blackbox accessibility, a limitation directly addressed in this work.
Tabular Data Processing with LLMs. Recent advancements in LLMs, notably within few-shot learning, have demonstrated their potential for tabular reasoning. Chen (2023) leveraged the Chain-of-Thought (CoT) technique Wei et al. (2023) to illustrate LLMs’ effectiveness in this domain. Building upon CoT, Cheng et al. (2023a) and Ye et al. (2023) introduced frameworks that incorporate symbolic reasoning for improved comprehension, with Ye et al. emphasizing their ability to adeptly decompose both evidence and questions. The advent of aligned models, such as ChatGPT, has enabled zero-shot table reasoning. However, these models often lack sensitivity to table structures, struggling with structural perturbations. StructGPT Jiang et al. (2023a), while introducing a promising framework for LLMs to efficiently engage with structured data, has its effectiveness limited by not integrating symbolic reasoning, a critical aspect for enhancing the full capabilities of LLMs in tabular reasoning, which is the focal point of this study. Furthermore, while programming-based approaches can mitigate some challenges, they are limited in addressing free-form queries, creating a gap in the landscape. Innovations like AutoGPT Significant Gravitas (2023) have sought to address this, spawning the development of tabular agents like LangChain Chase (2022), SheetCopilot Li et al. (2023a), and DataCopilot Zhang et al. (2023). These agents offer solutions unattainable through conventional programming but still require rigorous evaluation in various scenarios. In our study, we delve into addressing these challenges for enhancing LLMs’ reasoning capabilities within structural perturbations, hence providing insights that facilitate improved accuracy in the current context.
3 Preliminaries
This section succinctly introduces the foundational aspects of our study over structurally perturbed tabular data. Section 3.1 formally defines the problem, delineating the critical notations and conceptual frameworks, and Section 3.2 explicates our experimental setup details, elucidating dataset choice, model utilization, and evaluation strategy.
3.1 Problem Definition
Question answering (QA) over tabular data, commonly known as the TableQA task, is an important challenge in NLP. In this study, we targets TableQA to explore and enhance the proficiency of LLMs, in reasoning over tabular data. Additionally, we probe the robustness and adaptability of these models by introducing structural perturbations to tables.
Let represent a table consisting of rows and columns, and represent its title/caption. Each cell in is denoted by , where and . are headers. Given a question pertaining to the table, our task is to identify an answer . This answer is generally a collection of values, denoted as , where .
Furthermore, to delve deeper into the structural comprehension of LLMs, we introduce structural perturbations, which include:111Column shuffling was not employed as the typical number of columns is limited and this shuffling had minimal impact on accuracy Zhao et al. (2023).
-
1.
Transposed Table (): A table obtained by converting rows to columns and vice-versa, maintaining the row and column order:
-
2.
Row Shuffled Table (): A table obtained by randomly shuffling the rows (excluding the headers) with a random permutation function , while keeping the order of columns unchanged:
-
3.
Row Shuffled and Transposed Table (): A table obtained by first randomly shuffling the rows (excluding headers) and then applying transposition:
Defining our research problem more formally: our primary objective is to investigate the function, , that can appropriately answer the posed question using the provided table. Specifically, this function will take three arguments: the table variant , its title , and the question . It will output an answer . The entire problem can be formally framed as:
3.2 Experimental Setup
This section details the experimental setup adopted in our study, including the datasets employed, model selection, evaluation metrics, reasoning methods, and other details.
Dataset. We used the WikiTableQuestions (WTQ; Pasupat and Liang 2015) dataset for our experiments. The test set comprises 421 tables. Each table provides up to two question-answer pairs; if a table has fewer than two, only one was chosen, totaling 837 unique data points. With our four table configurations (original and three perturbations), the overall evaluation data points amount to .
Models. We employ the GPT-3.5 OpenAI (2023a) series for our research. Given that tables usually have extensive data, depending on the prompt length, we dynamically use gpt-3.5-turbo-0613 and gpt-3.5-turbo-16k-0613, with a primary aim to optimize cost when querying the API.
Evaluation Metrics. Following prior works Jiang et al. (2022); Ni et al. (2023); Cheng et al. (2023b); Ye et al. (2023), we employ Exact Match Accuracy as the evaluation metric to validate predictions against ground truths, embedding instructions in prompts for consistent and parseable outputs.
Reasoning Methods. Our evaluation hinges on two distinct zero-shot reasoning approaches:
-
•
Direct Prompting (DP) is a textual reasoning method that prompts LLMs to answer questions in a zero-shot manner. Rather than directly providing the answer, LLMs are instructed to reason step-by-step before concluding. More details can be found in Section A.1,
-
•
Python Shell Agent (PyAgent) is a symbolic reasoning approach where the model dynamically interacts with a Python shell. Specifically, LLMs use the Python Shell as an external tool to execute commands, process data, and scrutinize results, particularly within a pandas dataframe, limited to a maximum of five iterative steps. Detailed prompt is presented in Section A.2.
Other Details. Depending on the scenario, we adjust the temperature setting. In cases not employing self-consistency, we set it to 0. For scenarios involving self-consistency, the temperature is set to 0.8. For further granularity, Appendix A offers an exhaustive list of the prompts implemented in our experiments. Importantly, it should be noted that all prompts are deployed in a zero-shot manner, without any demonstrations or examples.
4 LLM Robustness to Structural Perturbations
This section explores how LLMs interpret varied table structures in response to our first research question (Section 1). We probe the impact of three table perturbations on LLM performance (Section 4.1), uncover LLMs’ challenges and limitations for direct table transposition and recoganize tranposed tables (Section 4.2), and introduce a structure normalization strategy (Norm) to mitigate these issues (Section 4.3).
4.1 Impacts of Table Perturbations on LLMs
| Perturbation | DP | PyAgent |
| Original | 59.50 | 55.91 |
| +Shuffle | 52.21 -12.25% | 47.91 -14.31% |
| +Transpose | 51.14 -14.05% | 12.45 -77.73% |
| +Transpose&Shuffle | 37.51 -36.96% | 8.96 -83.97% |
In Section 3.1, we present three types of structural table perturbations: transposition (), row-shuffling (), and their combination (). As demonstrated in Table 1, both reasoning methods, DP and PyAgent, exhibit significant performance declines, with more pronounced when transposition is applied. DP consistently outperforms PyAgent largely across perturbations, indicating that textual reasoning tends to be more resilient to these structural changes. This resilience can be attributed to LLMs’ ability to grasp semantic connections and meanings irrespective of structural shifts. In contrast, symbolic reasoning, exemplified by PyAgent, is heavily reliant on table structure, making it more vulnerable, especially to transposition.
| LLMs As | Task Description | Accuracy |
| Transposer | 53.68 | |
| 51.07 | ||
| Detector | 93.35 | |
| 32.54 | ||
| Determinator | 97.39 | |
| 94.77 |
4.2 Limitations of Table Transposition with LLMs
To better understand LLMs’ capabilities with regards to table structures, we investigate their ability on detecting tables in need of transposition and performing table transposition.
LLMs as Transposition Detectors. Given a table , the goal is to detect whether a table should be transposed for better comprehension by LLMs. This is formulated as a binary classification task:
Where 0 denotes ‘no need of transposition’ and 1 indicates ‘transposition needed’. Table 2 shows the results using the prompt in Section A.4. GPT-3.5 correctly classified 93.35% of original tables as not requiring transposition. However, its accuracy dramatically decreased to 32.54% on transposed tables . Our observations highlight that LLMs suffer from structural bias in the interpretation of table orientations, predominantly leading to recommendations against transposition.
LLMs as Table Transposers. The objective is to switch between original and transposed table formats. Specifically, the goal is to directly yield given , and vice versa. Formally, the task is:
We observed that GPT-3.5’s proficiency in this task is limited, with an accuracy of 53.68% transposing row tables and 51.07% for the inverse operation, suggesting that LLMs can not transpose tables precisely. For a detailed error case study and further analysis, refer to the Appendix B.
4.3 Table Structure Normalization
In addressing structural variations in tables, our goal is to ensure consistent interpretation and utility across diverse table structures. To normalize various table structures into well-ordered row-tables prior to downstream tasks, we introduce Norm, which is a two-stage normalization strategy: the first stage detects column-tables and transposing them into row-tables, while the second stage sorts the row-tables for enhanced comprehensibility. Through this approach, Norm accommodates for structural perturbations without compromising the understanding of the standardized row-tables.
Content-Aware Transposition Determination In the straightforward methods mentioned in Section 4.2, LLMs are affected by the loss of structure information of the table. Our approach aims to reduce this structural dependence by introducing a content-aware determination process, which leverages the semantic reasoning capabilities of LLMs, instead of perceiving the table’s structure. Specifically, we analyze the inherent content within the first row () and the first column () of a given table () to decide which is more semantically fitting to serve as the table’s heading. This content-aware approach can be mathematically modeled as:
Here, a selection of the first row suggests that the current table structure is preferred, whereas opting for the first column signifies a need for transposition. The prompt detailing this method is provided in Section A.5. Results in Table 2 highlight capability of GPT-3.5 in discerning table headings semantically, with accuracies of 97.39% and 94.77% respectively for original table and tranposed table.
| Method | ||||
| DP | 59.50 | 52.21 | 51.14 | 37.51 |
| +Norm | 58.66 | 58.66 | 58.30 | 57.71 |
| -1.41% | +12.35% | +14.00% | +53.85% | |
| PyAgent | 55.91 | 47.91 | 12.43 | 8.96 |
| +Norm | 56.87 | 57.11 | 55.44 | 55.08 |
| +1.72% | +19.20% | +346.02% | +514.73% |
Row Reordering. Upon transposition, our next objective is to ensure the logical coherence of the table data through reordering the rows. We instruct LLMs to suggest improved reordering strategies using the prompts as detailed in Section A.6. Due to the subjective nature involved in identifying the most suitable order of a tabular data, and given that there are no widely recognized standards for this process, the effectiveness of the proposed sorting strategy will be evaluated based its downstream impact on the results of table QA task. We notice that when the entire well-ordered table is exposed, GPT-3.5 occasionally suggests alternative sorting strategies, leading to unnecessary complexity. To counteract this tendency and ensure a better sorting proposal, we strategically present the model with only the first three and the last three rows of the table. This selective exposure typically allows the model to discern logical ordering patterns without being influenced by existing table configurations.
Table 3 underscores the efficacy of Norm when applied prior to the two reasoning methods – DP and PyAgent. Demonstrably, Norm robustly mitigates structural perturbations, optimizing table comprehensibility for LLMs. The results illustrate that applying Norm does not detrimentally affect the original results (), and it effectively refines perturbated data, aligning the outcomes closely with the original results, and in some instances, even showing slight improvement. This suggests that Norm as a preprocessing step for preparing tabular data can enhance robust analysis by LLMs.
In addressing our initial research question, the analysis indicates that LLMs’ performance is sensitive to table structural variations, with significant struggles observed in accurately interpreting the same tabular content under transposition and shuffling. While textual reasoning demonstrates some resilience to structural variations, symbolic reasoning is significantly impacted, particularly with transposed tables. The Norm strategy effectively navigates these challenges by eliminating dependency on table structures, providing consistent interpretation across diverse table structures without compromising the integrity or meaning of the original content.
5 Comparing Textual and Symbolic Reasoning
In this section, we delve into the comparison of textual and symbolic reasoning methods in LLMs for tabular data understanding (Section 5.1), further conducting a detailed error analysis (Section 5.2) to address the second research question (Section 1). We evaluate the performance of each reasoning strategy using GPT-3.5, shedding light on their strengths and challenges. In Section 4.3, we explored Norm to mitigate structural perturbations, enhancing generalized LLM performance and successfully restoring perturbed tables to accuracy levels similar to their original states. Therefore, subsequent analyses will exclusively consider the original tables ().
5.1 Results
| Method | Accuracy (%) |
| Few-shot Prompting Methods | |
| Binder Cheng et al. (2023b) | 63.61 |
| Binder Cheng et al. (2023b) | 55.07 |
| DATER w/o SC Ye et al. (2023) | 61.75 |
| DATER w/ SC Ye et al. (2023) | 68.99 |
| Zero-shot Prompting Methods | |
| StructGPT Jiang et al. (2023a) | 51.77 |
| Norm+DP | 58.66 |
| Norm+PyAgent | 56.87 |
| Norm+PyAgent-Omitted | 52.45 |
| Norm+DP&PyAgent w/ Eval | 64.22 |
| DP w/ SC | 66.39 |
| +Norm | 64.10 |
| +Norm w/o Resort | 66.99 |
| PyAgent w/ SC | 61.39 |
| +Norm | 63.77 |
| +Norm w/o Resort | 62.84 |
| DP&PyAgent w/ Mix-SC | 73.06 |
| +Norm | 72.40 |
| +Norm w/o Resort | 73.65 |
| Error Types | DP | PyAgent | Description | Case Study |
| Table Misinterpretation | 42% | - |
LLMs incorrectly interpret the content in tables. |
|
| Coding Errors | - | 38% |
LLMs produce inaccurate code, typically due to issues with minor details. |
|
| Misalignment Issue | 24% | 28% |
Outputs are conceptually correct but the answers do not align with the instructions. |
|
| Logical Inconsistency | 20% | 10% |
LLMs exhibit failures in reasoning, leading to contradictions or inconsistencies. |
|
| Execution Issue | - | 12% |
Issues emerge related to the execution of Python code. |
|
| Resorting Issue | 10% | 8% |
The resorting stage in Norm changes the answers of some sequence-dependent questions. |
Footnote 3 showcases the performance of GPT-3.5 when employed for both direct textual reasoning using DP and interactive symbolic reasoning using PyAgent. By instructing the model with the CoT Wei et al. (2023) reasoning strategy to think step by step, and then give the final answer, as detailed in Section A.1, we can achieve an accuracy of 58.66%. This surpasses the StructGPT’s Iterative Reading-then-Reasoning method, which concentrates reasoning tasks by continually collecting relevant evidence. For tables with limited tokens, symbolic reasoning via PyAgent offers an accuracy of 56.87%, which is slightly behind the accuracy by DP in a single attempt. A distinct advantage of symbolic reasoning is its ability to only present parts of the table in the prompt. As our experiments revealed, after excluding the central rows and showcasing only the initial and final three rows, we manage to maintain an accuracy of 52.45% with a 4.42% drop compared to the full-table PyAgent results. This makes it possible to deal with larger tables with numerous rows using LLMs with limited context window. In the following sections, we will present a comprehensive analysis of the discrepancies and errors observed across these methods.