Unified-IO 2:
Scaling Autoregressive Multimodal Models
with Vision, Language, Audio, and Action
Abstract
We present Unified-IO 2, the first autoregressive multimodal model that is capable of understanding and generating image, text, audio, and action. To unify different modalities, we tokenize inputs and outputs – images, text, audio, action, bounding boxes etc., into a shared semantic space and then process them with a single encoder-decoder transformer model. Since training with such diverse modalities is challenging, we propose various architectural improvements to stabilize model training. We train our model from scratch on a large multimodal pre-training corpus from diverse sources with a multimodal mixture of denoisers objective. To learn an expansive set of skills, such as following multimodal instructions, we construct and finetune on an ensemble of 120 datasets with prompts and augmentations. With a single unified model, Unified-IO 2 achieves state-of-the-art performance on the GRIT benchmark and strong results in more than 35 benchmarks, including image generation and understanding, natural language understanding, video and audio understanding, and robotic manipulation. We release all our models to the research community.
![[Uncaptioned image]](x1.png)
1 Introduction
As AI researchers, we seek to build intelligent agents that can perceive their environment, communicate with others, act in the world, and reason about their interactions. The world is multimodal, so our agents must partake in rich interactions that are multimodal in nature via vision, language, sound, action etc. Psychologists have argued that the redundancy of our sensory systems serves as supervisory mechanisms to improve each other [144, 48, 167]. This provides a natural motivation to create models with similar learning capabilities, supporting many different modalities that can supervise each other during training.
Building models that can parse and produce many modalities is a complex undertaking. Training Large Language Models (LLMs) with billions of parameters, despite only supporting a single modality, is extremely challenging across many fronts – from sourcing and processing massive datasets, ensuring data quality and managing biases, designing effective model architectures, maintaining stable training processes, and instruction tuning to enhance the model’s ability to follow and understand user instructions. These challenges are hugely amplified with the addition of each new modality.
In light of these difficulties, a line of recent works in building multimodal systems has leveraged pre-trained LLMs, with some augmenting with new modality encoders [5, 46, 119], some adding modality specific decoders [96, 14] and others leveraging the LLM’s capabilities to build modular frameworks [64, 166, 173]. Another line of works on training multimodal models from scratch has focused on generating text output [81, 143] with a few recent works supporting the understanding and generation of two modalities – text and images [125, 123]. Building generative models with a wider coverage of modalities, particularly when training from scratch, remains an open challenge.
In this work, we present Unified-IO 2, a large multimodal model (LMM) that can encode text, image, audio, video, and interleaved sequences and produce text, action, audio, image, and sparse or dense labels. It can output free-form multimodal responses and handle tasks unseen during training through instruction-following. Unified-IO 2 contains 7 billion parameters and is pre-trained from scratch on an extensive variety of multimodal data – 1 billion image-text pairs, 1 trillion text tokens, 180 million video clips, 130 million interleaved image & text, 3 million 3D assets, and 1 million agent trajectories. We further instruction-tune the model with a massive multimodal corpus by combining more than 120 datasets covering 220 tasks across vision, language, audio, and action.
Our pre-training and instruction tuning data, totaling over 600 terabytes, presents significant challenges for training due to its diversity and volume. To effectively facilitate self-supervised learning signals across multiple modalities, we develop a novel multimodal mixture of denoiser objective that combines denoising and generation across modalities. We also develop dynamic packing – an efficient implementation that provides a 4x increase in training throughput to deal with highly variable sequences. To overcome the stability and scalability issues in training, we propose to apply key architectural changes, including 2D rotary embeddings, QK normalization, and scaled cosine attention mechanisms on the perceiver resampler. For instruction tuning, we ensure every task has a clear prompt, either using existing ones or crafting new ones. We also include open-ended tasks and create synthetic tasks for less common modalities to enhance task and instruction variety.
We evaluate Unified-IO 2 on over 35 datasets across the various modalities it supports. Our single model sets the new state of the art on the GRIT [66] benchmark, which includes diverse tasks such as keypoint estimation and surface normal estimation. On vision & language tasks, it matches or outperforms the performance of many recently proposed VLMs that leverage pre-trained LLMs. On image generation, it outperforms the closest competitor [174] that leverages the pre-trained stable diffusion model [154], especially in terms of faithfulness as per the metrics defined in [76]. It also shows effectiveness in video, natural language, audio, and embodied AI tasks, showcasing versatility despite its broad capability range. Moreover, Unified-IO 2 can follow free-form instructions, including novel ones. Figure 1 offers a glimpse into how it handles various tasks. Further examples, along with the code and models, are accessible on our project website.
2 Related Work
Inspired by the success of language models as general-purpose text processing systems [122, 177, 20], there has been a recent wave of multimodal systems trying to achieve similar general-purpose capabilities with additional modalities. A common approach is to use a vision-encoder to build features for input images and then an adapter to map those features into embeddings that can be used as part of the input to an LLM. The network is then trained on paired image/language data to adapt the LLM to the visual features. These models can already perform some tasks zero-shot or with in-context examples [178, 109, 132], but generally a second stage of visual instruction tuning follows using instructions, visual inputs, and target text triples to increase zero-shot capabilities [119, 118, 218, 34, 205, 225, 25].
Building upon this design, many researchers have expanded the breadth of tasks these models can support. This includes creating models that can do OCR [220, 12], visual grounding [26, 189, 219, 143, 207, 12, 212], image-text-retrieval [97], additional languages [112], embodied AI tasks [17, 140, 135, 152] or leverage other expert systems [52]. Other efforts have added new input modalities. This includes video inputs [110, 126], audio [80] or both [216]. PandaGPT [170] and ImageBind-LLM [69] use the universal encoder ImageBind [56] to encode many kinds of input modalities, and ChatBridge [222] uses a similar universal encoder based on language. While these efforts are effective for understanding tasks, they do not allow complex multimodal generation and often exclude modalities long considered central to computer vision (e.g., ImageBind cannot support sparse annotation of images).
Fewer works have considered multimodal generation. Unified-IO [123], LaVIT [88], OFA [186], Emu [172] and CM3Leon [210] train models to generate tokens that a VQ-GAN [49, 179] can then decode into an image, while GILL [96], Kosmos-G [141] and SEED [53] generate features that a diffusion model can use, and JAM [4] fuses pre-trained language and image generation models. Unified-IO 2 also uses a VQ-GAN, but supports text, image, and audio generation.
Overall, this shows a strong trend towards expanding the number of supported tasks and modalities. Unified-IO 2 pushes this trend to its limit, including the capabilities of these prior works with few exceptions and the ability to generate outputs in more modalities. Recently, CoDi [174] also achieved similar any-to-any generation capabilities by using multiple independently trained diffusion models and aligning their embedding spaces. Unified-IO 2 has stronger language abilities and can perform well on many more tasks.
A notable feature of Unified-IO 2 is that the model is trained from scratch instead of being initialized with a pre-trained LLM. Prior works [186, 188, 192, 114] following this approach are typically not designed to produce complex generations like free-form text responses, images or sounds, or follow text instructions. Compared to recent general-purpose multimodals models [81, 143, 210], Unified-IO 2 has a significantly broader scope of tasks and outputs. Training from scratch means that the method can be reproduced without a costly preliminary stage of language model pre-training and is a more natural fit for how humans learn modalities simultaneously through their co-occurrences, not one at a time.
3 Approach
In this section, we discuss the unified task representation (3.1), the model architecture and techniques to stabilize training (3.2), the multimodal training objective (3.3) and the efficiency optimizations (3.4) used in Unified-IO 2.
3.1 Unified Task Representation
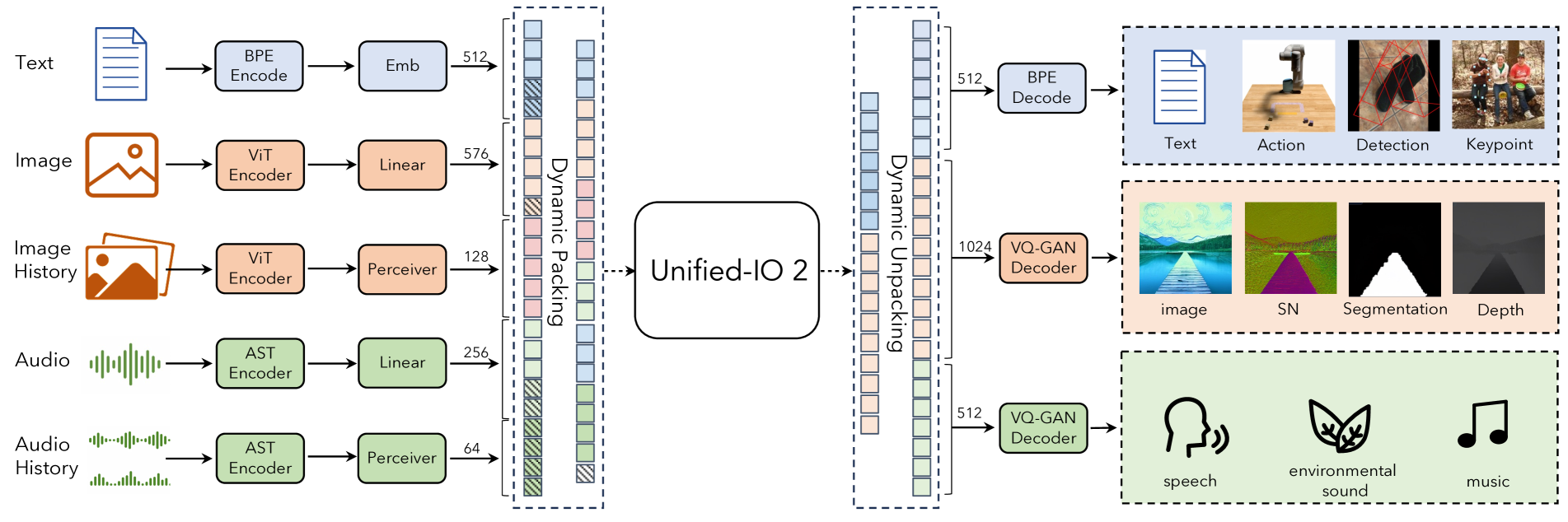
Unified-IO 2 processes all modalities with a single, unified encoder-decoder transformer [181]. This is achieved by encoding various inputs and outputs – images, text, audio, action, boxes etc., into sequences of tokens in a shared representation space. Our encoding procedure follows the design of Unified-IO [123], with several modifications to improve performance and new encoders and decoders for additional modalities. Figure 2 shows an overview of the model. Details about how modalities are encoded are given below.
Text, Sparse Structures, and Action. Text inputs and outputs are tokenized using the byte-pair encoding [161] from LLaMA [177], which we chose since it supports Unicode symbols and preserves whitespace. Sparse structures such as bounding boxes, keypoints, and camera poses are discretized and then encoded using 1000 special tokens added to the vocabulary [27, 123]. Points are encoded with a sequence of two such tokens (one for and one for ), boxes are encoded with a sequence of four tokens (upper left and lower right corners), and 3D cuboids are represented with 12 tokens that encode the projected center, virtual depth, log-normalized box dimension, and continuous allocentric rotation [16]. For embodied tasks, discrete robot actions [17] are generated as text commands (e.g., “move ahead” to command the robot to move forward in navigation). Special tokens are used to encode the robot’s state, such as its position and rotation. Details are in Appendix B.1.
Images and Dense Structures. Images are encoded with a pre-trained Vision Transformer (ViT) [84]. We concatenate the patch features from the second and second-to-last layers of the ViT to capture both low and high-level visual information. These features are passed through a linear layer to get embeddings that can be used as part of the input sequence for the transformer. To generate images, we use VQ-GAN [49] to convert images into discrete tokens. These tokens are added to the vocabulary and then used as the target output sequence in order to generate an image. For better image quality, we use a dense pre-trained VQ-GAN model with patch size that encodes a image into 1024 tokens with a codebook size of 16512.
Following [123], we represent per-pixel labels, which include depth, surface normals, and binary segmentation masks, as RGB images that can be generated or encoded with our image generation and encoding abilities. For segmentation, Unified-IO 2 is trained to predict a binary mask given a class and bounding box. An entire image can be segmented by first doing detection, and then querying the model for a segmentation mask for each detected bounding box and class. See Appendix B.1 for details.
Audio. Unified-IO 2 encodes up to 4.08 seconds of audio into a spectrogram (See Appendix B.1 and Table 8). The spectrogram is then encoded with a pre-trained Audio Spectrogram Transformer (AST) [57], and the input embeddings are built by concatenating the second and second-to-last layer features from the AST and applying a linear layer just as with the image ViT. To generate audio, we use a ViT-VQGAN [208] to convert the audio into discrete tokens. Since there is no public codebase, we implement and train our own ViT-VQGAN with patch size that encodes a spectrogram into 512 tokens with a codebook size of 8196.
Image and Audio History. We allow up to four additional images and audio segments to be given as input, which we refer to as the image or audio history. These elements are also encoded using the ViT or AST, but we then use a perceiver resampler [5], see Table 8 for hyperparameters, to further compress the features into a smaller number of tokens (32 for images and 16 for audio). This approach greatly reduces the sequence length and allows the model to inspect an image or audio segment in a high level of detail while using elements in the history for context. This history is used to encode previous video frames, previous audio segments, or reference images for tasks such as multi-view image reconstruction or image-conditioned image editing. Eight special tokens are added to the text vocabulary and used to reference the individual elements in these histories in the text input or output.

3.2 Architecture
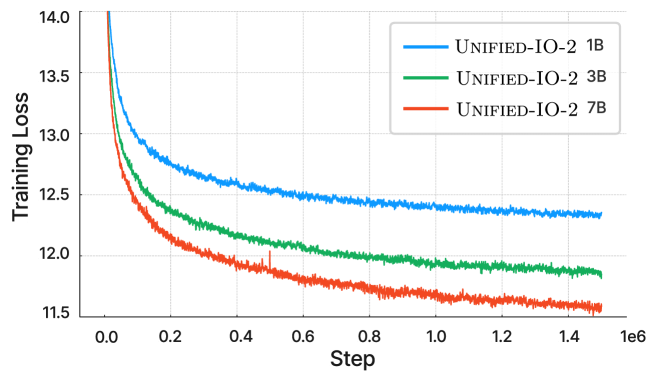
Unified-IO 2 uses a transformer encoder-decoder architecture. However, we observe that using a standard implementation following Unified-IO leads to increasingly unstable training as we integrate additional modalities. As shown in Figure 3 (a) and (b), training only on image generation (green curve) results in stable loss and gradient norm convergence. Introducing a combination of image and text tasks (orange curve) slightly increases the gradient norm compared to a single modality, but remains stable. However, the subsequent inclusion of the video modality (blue curve) leads to an unrestrained escalation in the gradient norm. When an XXL version of this model is trained on all modalities, as shown in Figure 3 (c) and (d), the loss explodes after 350k steps, and the next token prediction accuracy significantly drops at 400k steps. To address this, we include various architectural changes that significantly stabilize multimodal training.
2D Rotary Embedding. Instead of relative positional embedding [147], we apply rotary positional embeddings (RoPE) [169] at each transformer layer. For non-text modalities, we extend RoPE to two-dimensional positions: For any 2D indexes , we split each of the query and key embeddings of the transformer attention heads in half and apply separate rotary embeddings constructed by each of the two coordinates to the halves, see Appendix B.2.
QK Normalization. We observe extremely large values in the multi-head attention logits when including image and audio modalities, which leads to attention weights becoming either 0 or 1 and contributes to training instability. To solve this, following [38], we apply LayerNorm [10] to the queries and keys before the dot-product attention computation.
Scaled Cosine Attention. We use perceiver resampler [86] to compress each image frame and audio segment into a fixed number of tokens. We found that even with QK normalization, the attention logits in the perceiver can grow to extreme values. Therefore, we apply more strict normalization in the perceiver by using scaled cosine attention [121], which significantly stabilizes training.
To avoid numerical instabilities, we also enable float32 attention logits. Jointly updating the pre-trained ViT and AST can also cause instabilities. Thus, we freeze the ViT and AST during pretraining and finetune them at the end of instruction tuning. Figure 4 shows that the pre-training loss for our model is stable despite the heterogeneity of input and output modalities.
3.3 Training Objective
A strong multimodal model has to be exposed to solving diverse sets of problems during pre-training. UL2 [175] proposed the Mixture of Denoisers (MoD), a unified perspective to train LLMs, which combines the span corruption [147] and causal language modeling [19] objectives. Motivated by this, we propose a generalized and unified perspective for multimodal pre-training.
Multimodal Mixture of Denoisers. MoD uses three paradigms: [R] – standard span corruption, [S] – causal language modeling, and [X] – extreme span corruption. For text targets, we follow the UL2 paradigms. For image and audio targets, we define two analogous paradigms: [R] – masked denoising where we randomly mask % of the input image or audio patch features and task the model to re-construct it and [S] – where we ask the model to generate the target modality conditioned only on other input modalities. During training, we prefix the input text with a modality token ([Text], [Image], or [Audio]) and a paradigm token ([R], [S], or [X]) to indicate the task.
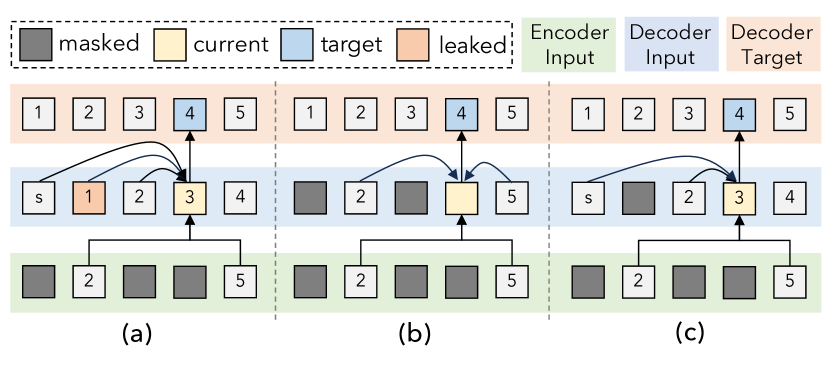
Autoregressive with Dynamic Masking. One problem with image and audio masked denoising in an autoregressive manner is an information leak on the decoder side; see Figure 5 (a). The current decoder’s input token (3) is conditioned on enocoder’s information (2, 5) and all previous tokens (s 2) to predict target (4). As a result, the predicted token will be conditioned on 1 even though it was masked in the encoder since it appears in the decoder, which will simplify the task and harm representation learning. Simply masking the token in the decoder, as shown in Figure 5 (b), avoids this information leakage but causes the generation and de-noising tasks to interfere with one another. For example, we found that joint training with generation (50% MAE and 50% causal modeling) significantly reduced image generation performance. Our solution is to mask the token in the decoder except when predicting that token, as shown in Figure 5 (c), which does not interfere with causal prediction whilst mostly eliminating data leakage. For image and audio generation, we also use row, column, and conv-shaped masked sparse attention [148] in the decoder.
3.4 Efficient Implementation
Training on heavily multimodal data results in highly variable sequence lengths for the transformer’s inputs and outputs, both because modalities are often missing for individual examples and because the number of tokens used to encode particular modalities can vary from just a few tokens (for a sentence) to 1024 tokens (for an output image). To handle this efficiently, we use packing, a process where the tokens of multiple examples are packed into a single sequence, and the attentions are masked to prevent the transformer from cross-attending between examples.
Typically, packing is done during pre-processing, but it is challenging in our setup since our encoders and decoder do not always support it. Instead, we do packing right before and after the transformer encoder-decoder stage, which allows the modality encoders/decoder to run on the unpacked data. During training, we use a heuristic algorithm to re-arrange data being streamed to the model so that long examples are matched with short examples they can be packed with. Packing optimization was also explored in [100], but not in the streaming setup. Dynamic packing leads to an almost 4x increase in training throughput (Details in Appendix B.3).
| Model | model dims | mlp dims | encoder lyr | decoder lyr | heads | Params |
|---|---|---|---|---|---|---|
| UIO-2 | 1024 | 2816 | 24 | 24 | 16 | 1.1B |
| UIO-2 | 2048 | 5120 | 24 | 24 | 16 | 3.2B |
| UIO-2 | 3072 | 8192 | 24 | 24 | 24 | 6.8B |
3.5 Optimizer
We use Adafactor [164] as our optimizer with a linear warm-up for the first 5,000 steps and a learning rate decay of . We train with and , where is the step number. We use global norm gradient clipping with a threshold of 1.0 and find that this is crucial to stabilized training. Table 1 gives the details of our different models. For all models, we train M steps – M for pre-training and 1.5M for instruction tuning, respectively. More details in Appendix B.4.
4 Multimodal Data
One critical difference between Unified-IO 2 and prior work is that we train the model with a diverse set of multimodal data from scratch. This requires curating high-quality, open-source multimodal data for both pre-training (4.1) and instruction tuning (4.2).
4.1 Pre-training Data
Our pre-training data comes from various sources and covers many modalities. We provide a high-level overview and details in Appendix C.
NLP [33%]. We use the publicly available datasets that were employed to train MPT-7B [176]. This dataset emphasizes English natural language text but also contains code and markdown. It includes text from the RedPajama dataset [32], C4 [68], Wikipedia, and stack overflow. We follow the proportion suggested by [176] and remove multi-lingual and scientific data.
Image & Text [40%]. Text and image paired data comes from LAION-400M [159], CC3M [163], CC12M [23], and RedCaps [42]. To help train the image-history modality, we also use the interleaved image/text data from OBELICS [104]. We use the last image as the image input and the remaining images as the image history. Special tokens are used to mark where those images occur in the text.
Video & Audio [25%]. Video provides strong self-supervisory signals with high correlations between audio and visual channels. We sample audio and video data from various public datasets including YT-Temporal-1B [215], ACAV100M [105], AudioSet [54], WebVid-10M [13], HD-VILA-10M [200] and Ego4D [60].
3D & Embodiment [1%]. For self-supervised 3D and embodiment pre-training, we use CroCo [194] for cross-view generation and denoising; Objaverse [40] for view synthesis; and random trajectories in ProcTHOR [39] and Habitat [157] for the next action and frame predictions.
Augmentation [1%]. While there is a lot of unsupervised data on the web for images, text, video, and audio, options are much more limited for dense and sparse annotations. We propose to solve this through large-scale data augmentation. We consider two types of data augmentation: 1. Automatically generated segmentation data from SAM [94] to train the model to segment an object given a point or bounding box. 2. Synthetic patch-detection data which tasks the model to list the bounding boxes of synthetically added shapes in an image. We additionally train the model to output the total number of patches in the image to pre-train its counting abilities.
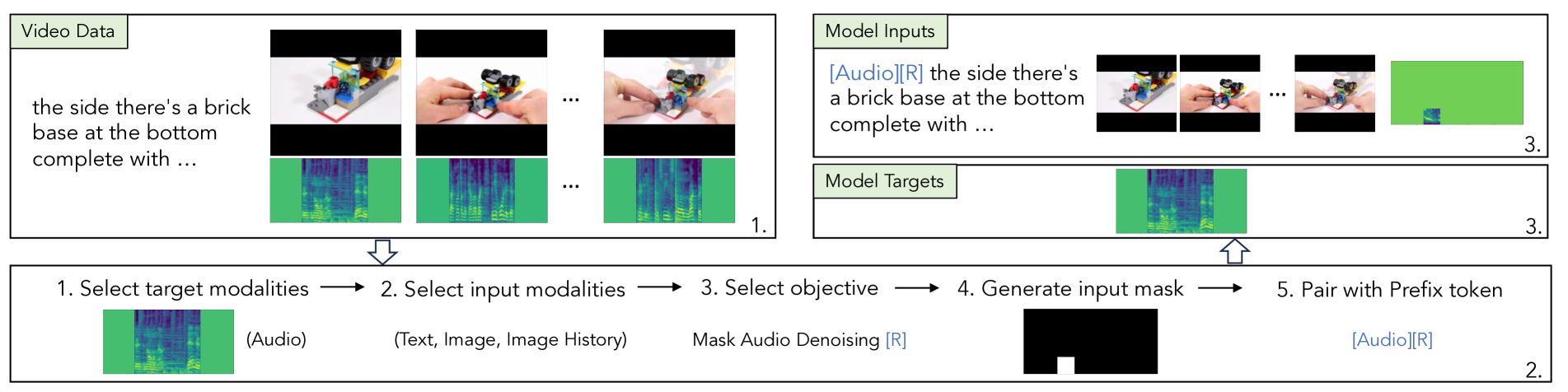
Training Sample Construction. During pre-training, most of our data contains various modalities without a supervised target. In these cases, we randomly pick one of the modalities present to be the target output. Then, we either remove that modality from the example or replace it with a corrupted version. Other modalities that might be present in the example are randomly kept or masked to force the model to make predictions using whatever information is left. Figure 7 shows an example when using a video that contains a sequence of image frames, the corresponding audio, and a text transcript. The pre-training sample is constructed by following the procedure: 1. select the target modality; 2. select which other input modalities to keep; 3. select the objective; 4. generate the random input mask depending on the task of denoising or generation; 5. add a prefix token indicating the task.

4.2 Instruction Tuning Data
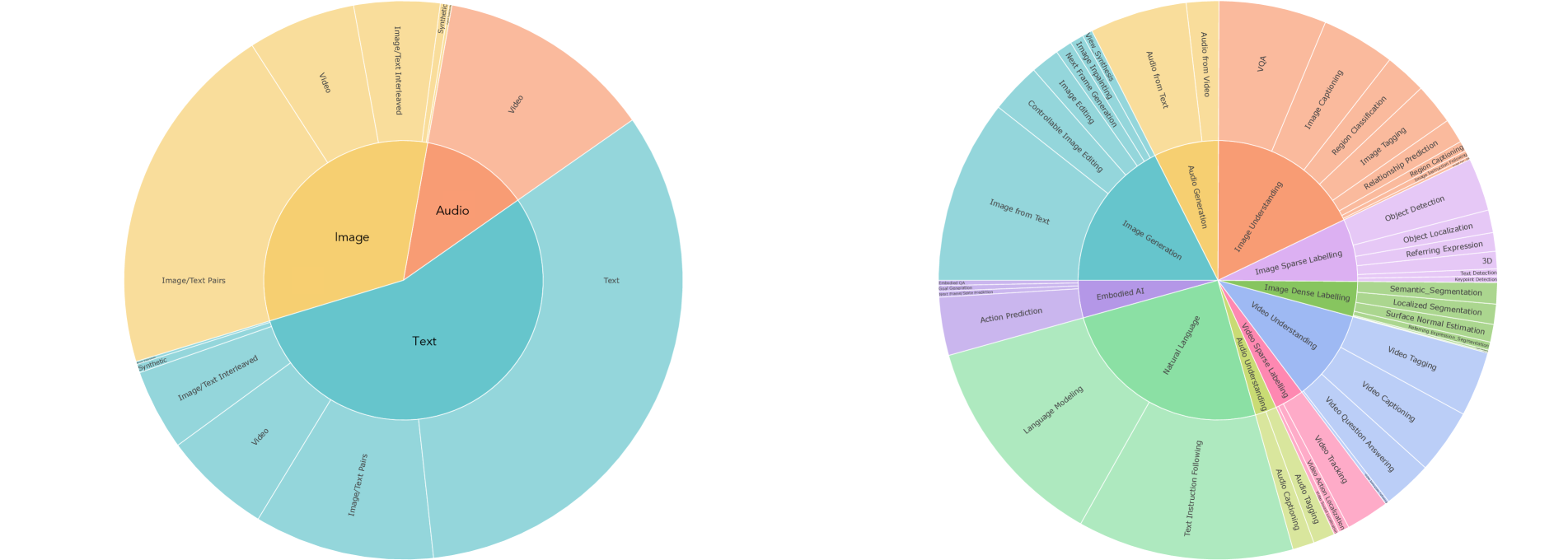
Multimodal instruction tuning is the key process to equip the model with diverse skills and capabilities across various modalities and even adapt to new and unique instructions. We construct the multimodal instruction tuning dataset by combining a wide range of supervised datasets and tasks. We ensure every task has a clear prompt, either using existing ones or writing new ones. We also include open-ended tasks and create synthetic tasks for less common modalities to enhance task and instruction variety. Our mixture includes 220 tasks drawn from over 120 external datasets. We provide a high-level overview and examples here and leave details in Appendix D.
Natural Language [25.0%]. For natural language, we use the mixture from FlanV2 [122] and various other instruction following datasets [33, 142]. In addition, we continue pre-training on our unsupervised NLP mixture to help prevent the model from forgetting information learned from pre-training during the extensive instruction tuning stage.
Image Generation [17.6%]. For text-to-image generation, we use the same image & text pairs we used during pre-training. We also include data from [103, 115, 102] that provide better caption quality. We additionally train the model to generate images through view synthesis [194, 40], image editing [18, 217], segmentation-based image generation [123] and inpainting [123].
Audio Generation [7.5%]. This includes text-to-audio datasets with audio in the wild [93, 47, 131], music [2], and human speech [85]. We also add pre-training data with the task of predicting the next audio clip in a video. More specifically, we divide the audio into segments and then generate one of them given both the text and previous segments as input.
Image Understanding [17.8%]. We include various data sources from visual question answering [6], image tagging [41], region classification [102], and datasets with open-ended chat-like responses [119, 220]. We also include the multimodal instruction tuning datasets MIT [112] and MIMIC-IT [107].
Video Understanding [10.6%]. We include data sources from video captioning [190, 199], video tagging [168, 111, 35], and video question answering [198, 196]. We also use examples from MIT [112] and MIMIC-IT [107] for video instruction following.
Audio Understanding [10.6%]. We include data sources from audio tagging [54, 24], and audio captioning [93, 47]. We also include data from video action classification [7] with audio in the dataset.
Image Sparse Labelling [7.25%]. These tasks require outputting sparse coordinates based on an input image. We mainly consider object detection [115], referring expression [91], 3D detection [16], camera pose prediction [40], text detection [183] and human keypoints [115].
Image Dense Labelling [4.06%]. We do several image labeling tasks, including surface normal estimation [78, 204], depth estimation [138], and optical flow [44, 21]. We also train our models on various segmentation tasks, including semantic segmentation, localization segmentation, and referring expression segmentation.
Video Sparse Labelling [3.42%]. We do video detection [151], single object tracking [50, 79] and video action localization [61].
Embodied AI [4.33%]. For VIMA-Bench [87], we use the image input as the initial observation of the environment and the image history for the images or videos in the prompt. We add large-scale manipulation datasets [127, 184, 63] with continuous control in both simulated and real-world environments. We also train on the PointNav task from Habitat Gibson scenes.
The distribution of the instruction tuning data is in Figure 6. Overall, our instruction tuning mixture is composed of 60% prompting data, meaning supervised datasets combined with prompts. To avoid catastrophic forgetting, 30% of the data is carried over from pre-training. Additionally, 6% is task augmentation data we build by constructing novel tasks using existing data sources, which enhances existing tasks and increases task diversity. The remaining 4% consists of free-form text to enable chat-like responses.
5 Experiments
In this section, we evaluate our pre-trained and instruction-tuned models on a broad range of tasks that require parsing and producing all modalities: images, video, audio, text, and actions. We do not perform task-specific finetuning in any experiments. Details about experimental setups, additional result details, results on natural language tasks, and additional studies for Unified-IO 2’s instruction capabilities are in Appendix E.
5.1 Pre-training Evaluation
We demonstrate the effectiveness of our pre-training by evaluating Unified-IO 2 on commonsense natural language inference (HellaSwag [214]), text-to-image generation (TIFA [76]) and text-to-audio generation (AudioCaps [93]). We also assess spatial and temporal understanding on SEED-Bench [106], a benchmark for comprehensively evaluating perception and reasoning on image and video modalities. Table 2 shows that Unified-IO 2 achieves comparable or even better performance on both generation and comprehension tasks compared to the task-specific specialist [154] or the universal multimodal model [9].
Despite extensive multitasking, the results on HellaSwag suggest that Unified-IO 2 has language modeling capabilities between typical 3B and 7B language models. This may be due to that the model sees far fewer tokens compared to language-based LLMs – approximately 250 billion tokens in total. Qualitative results of pre-training are in Appendix E.1.
| Method | HellaSwag | TIFA | SEED-S | SEED-T | AudioCaps |
|---|---|---|---|---|---|
| LLaMA-7B [177] | 76.1 | - | - | - | - |
| OpenLLaMa-3Bv2 [55] | 52.1 | - | - | - | - |
| SD v1.5 [154] | - | 78.4 | - | - | - |
| OpenFlamingo-7B [9] | - | - | 34.5 | 33.1 | - |
| UIO-2 | 38.3 | 70.2 | 37.2 | 32.2 | 3.08 |
| UIO-2 | 47.6 | 77.2 | 40.9 | 34.0 | 3.10 |
| UIO-2 | 54.3 | 78.7 | 40.7 | 35.0 | 3.02 |
| Method | Cat. | Loc. | Vqa | Ref. | Seg. | KP | Norm. | All | |
|---|---|---|---|---|---|---|---|---|---|
| Ablation | UIO-2 | 70.1 | 66.1 | 67.6 | 66.6 | 53.8 | 56.8 | 44.5 | 60.8 |
| UIO-2 | 74.2 | 69.1 | 69.0 | 71.9 | 57.3 | 68.2 | 46.7 | 65.2 | |
| UIO-2 | 74.9 | 70.3 | 71.3 | 75.5 | 58.2 | 72.8 | 45.2 | 66.9 | |
| Test | GPV-2 [89] | 55.1 | 53.6 | 63.2 | 52.1 | - | - | - | - |
| UIO [123] | 60.8 | 67.1 | 74.5 | 78.9 | 56.5 | 67.7 | 44.3 | 64.3 | |
| UIO-2 | 75.2 | 70.2 | 71.1 | 75.5 | 58.8 | 73.2 | 44.7 | 67.0 |
5.2 GRIT Results
We evaluate on the General Robust Image Task (GRIT) Benchmark [66], which includes seven tasks: categorization, localization, VQA, referring expression, instance segmentation, keypoint, and surface normal estimation. Completing all 7 tasks requires understanding image, text, and sparse inputs and generating text, sparse, and dense outputs. Although this is a subset of the modalities Unified-IO 2 supports, we evaluate on GRIT because it provides a standardized and comprehensive benchmark on this set of capabilities. See Appendix E.3 for additional inference details on GRIT.
Results are shown in Table 3. Overall, Unified-IO 2 is state-of-the-art on GRIT, surpassing the previous best model, Unified-IO, by 2.7 points. On individual tasks, we can observe gains in localization (3 points), categorization (14 points), segmentation (2 points), and keypoint (5 points). On VQA, our GRIT evaluations show Unified-IO 2 is better on same-source (84.6 vs. 81.2) questions, suggesting the gap is due to reduced performance on the new-source questions that were constructed from Visual Genome; see Appendix E.3 for additional discussion. Despite being slightly behind Unified-IO, Unified-IO 2 still obtains strong referring expression scores that compare favorably to prior work on generalist multimodal models, see Table 5. Surpassing Unified-IO while also supporting much higher quality image and text generation, along with many more tasks and modalities, illustrates the impressive multi-tasking capabilities of our model. Unified-IO 2 even maintains better overall performance with the 3-billion parameter model (65.2 vs. 64.5), which is roughly equal in size to Unified-IO. Ablation results show average performance, and all individual tasks improve with model size, showing that Unified-IO 2 benefits from scale.
5.3 Generation Results
| Method | Image | Audio | Action | |||
|---|---|---|---|---|---|---|
| FID | TIFA | FAD | IS | KL | Succ. | |
| minDALL-E [37] | - | 79.4 | - | - | - | - |
| SD-1.5 [154] | - | 78.4 | - | - | - | - |
| AudioLDM-L [117] | - | - | 1.96 | 8.13 | 1.59 | - |
| AudioGen [101] | - | - | 3.13 | - | 2.09 | - |
| DiffSound [203] | - | - | 7.75 | 4.01 | 2.52 | - |
| VIMA [87] | - | - | - | - | - | 72.6 |
| VIMA-IMG [87] | - | - | - | - | - | 42.5 |
| CoDi [174] | 11.26 | 71.6 | 1.80 | 8.77 | 1.40 | - |
| Emu [172] | 11.66 | 65.5 | - | - | - | - |
| UIO-2 | 16.68 | 74.3 | 2.82 | 5.37 | 1.93 | 50.2 |
| UIO-2 | 14.11 | 80.0 | 2.59 | 5.11 | 1.74 | 54.2 |
| UIO-2 | 13.39 | 81.3 | 2.64 | 5.89 | 1.80 | 56.3 |
| Method | VQA | OKVQA | SQA | SQA | Tally-QA | RefCOCO | RefCOCO+ | RefCOCO-g | COCO-Cap. | POPE | SEED | MMB |
| InstructBLIP (8.2B) | - | - | - | 79.5 | 68.2 | - | - | - | 102.2 | - | 53.4 | 36 |
| Shikra (7.2B) | 77.4 | 47.2 | - | - | - | 87.0 | 81.6 | 82.3 | 117.5 | 84.7 | - | 58.8 |
| Ferret (7.2B) | - | - | - | - | - | 87.5 | 80.8 | 83.9 | - | 85.8 | - | - |
| Qwen-VL (9.6B) | 78.8 | 58.6 | - | 67.1 | - | 89.4 | 83.1 | 85.6 | 131.9 | - | 38.2 | |
| mPLUG-Owl2 (8.2B) | 79.4 | 57.7 | - | 68.7 | - | - | - | - | 137.3 | 86.2 | 57.8 | 64.5 |
| LLaVa-1.5 (7.2B) | 78.5 | - | - | 66.8 | - | - | - | - | - | 85.9 | 58.6 | 64.3 |
| LLaVa-1.5 (13B) | 80.0 | - | - | 71.6 | 72.4 | - | - | - | - | 85.9 | 61.6 | 67.7 |
| Single Task SoTA | 86.0 [29] | 66.8 [77] | 90.9 [119] | 90.7 [34] | 82.4 [77] | 92.64 [202] | 88.77 [187] | 89.22 [187] | 149.1 [29] | - | - | - |
| UIO-2 (1.1B) | 75.3 | 50.2 | 81.6 | 78.6 | 69.1 | 84.1 | 71.7 | 79.0 | 128.2 | 77.8 | 51.1 | 62.1 |
| UIO-2 (3.2B) | 78.1 | 53.7 | 88.8 | 87.4 | 72.2 | 88.2 | 79.8 | 84.0 | 130.3 | 87.2 | 60.2 | 68.1 |
| UIO-2 (6.8B) | 79.4 | 55.5 | 88.7 | 86.2 | 75.9 | 90.7 | 83.1 | 86.6 | 125.4 | 87.7 | 61.8 | 71.5 |
Table 4 shows results on tasks that require generating image, audio, and action outputs. We evaluate using TIFA [76], which measures faithfulness to the prompt using VQA models and has been shown to correlate well with human judgments, and FID [73] on MS COCO [115]. On TIFA, we find that Unified-IO 2 scores close to minDALL-E [37], and about 10 points ahead of other generalist models such as CoDi [174] and Emu [172]. We attribute this strong image generation ability to extensive pre-training and the use of a fine-grained VQ-GAN. We include examples of our generation results from the TIFA benchmark in the Appendix E.5. Unified-IO 2’s FID scores are slightly higher than the compared models, although we note that qualitatively the generated images are still very smooth and detailed.
For text-to-audio generation, we evaluate on the AudioCaps [93] test set. AudioCaps consists of 10-second audio clips, while our model can generate 4.08-second audio at a time, so we cannot do a direct evaluation on this benchmark. Instead, we generate an audio segment based on the text description and previous audio segments as additional input; see Appendix E.6 for more details. While this is not a directly comparable setup to related work, it still gives a reasonable quantitative measure of our audio generation abilities. Unified-IO 2 scores higher then specialist models except the recent latent diffusion model [117], which shows it’s competitive audio generation ability.
For action, we evaluate using VIMA-Bench [87], a robot manipulation benchmark containing 17 tasks with text-image interleaved prompts. Since VIMA’s action space is action primitives, Unified-IO 2 directly predicts all actions at once given the initial observation and multimodal prompt. We report the average success rate for 4-level evaluation protocol [87] and compare with the original casual VIMA policy with object-centric inputs, as well as VIMA-IMG, a Gato [152]-like policy with image inputs like ours.
5.4 Vision Language Results
We evaluate vision language performance and compare it against other vision/language generalist models, i.e., models that are also designed to perform many tasks and can follow instructions. Results on a collection of 12 vision/language benchmarks are shown in Table 5. SoTA results from specialist models are shown for reference.
Unified-IO 2 achieves strong results on VQA, only passed by the much larger 13B LLaVa model [118] on VQA v2 [59], and ahead of all other generalist models on ScienceQA [124] and TallyQA [1]. OK-VQA [130] is the exception. We hypothesize that because it requires external knowledge, extensive language pre-training is important for this task, and therefore our reduced performance is since Unified-IO 2 was not pre-trained as extensively on text as the dedicated language models used by Qwen-VL [12] and mPLUG-Owl2 [206].
| Video | Audio | |||||||||
| Method |
Kinetics-400 [90] |
VATEXCaption [190] |
MSR-VTT [199] |
MSRVTT-QA [198] |
MSVD-QA [198] |
STAR [196] |
SEED-T [106] |
VGG-Sound [24] |
AudioCaps [93] |
Kinetics-Sounds [7] |
| MBT [137] | - | - | - | - | - | - | - | 52.3 | - | 85.0 |
| CoDi [174] | - | - | 74.4 | - | - | - | - | - | 78.9 | - |
| ImageBind [69] | 50.0 | - | - | - | - | - | - | 27.8 | - | - |
| BLIP-2 [109] | - | - | - | 9.2 | 18.3 | - | 36.7 | - | - | - |
| InstructBLIP [34] | - | - | - | 22.1 | 41.8 | - | 38.3 | - | - | - |
| Emu [172] | - | - | - | 24.1 | 39.8 | - | - | - | - | - |
| Flamingo-9B [5] | - | 57.4 | - | 29.4 | 47.2 | 41.2 | - | - | ||
| Flamingo-80B [5] | - | 84.2 | - | 47.4 | - | - | - | - | - | - |
| UIO-2 | 68.5 | 37.1 | 44.0 | 39.6 | 48.2 | 51.0 | 37.5 | 37.8 | 45.7 | 86.1 |
| UIO-2 | 71.4 | 41.6 | 47.1 | 39.3 | 50.4 | 52.0 | 45.6 | 44.2 | 45.7 | 88.0 |
| UIO-2 | 73.8 | 45.6 | 48.8 | 41.5 | 52.1 | 52.2 | 46.8 | 47.7 | 48.9 | 89.3 |
On referring expression, Unified-IO 2 is ahead of Shikra [26] and Ferret [207] and matches the scores achieved by Qwen-VL. On captioning, Unified-IO 2 also achieves a strong CIDEr score [182] of 130.3, ahead of Shikra and InstructBLIP [34] but behind Qwen-VL and mPLUG-Owl2.
Finally, we evaluate using three recently proposed evaluation-only benchmarks. MMB (MMBench [120]) tests multiple facets of vision language understanding with multiple choice questions, while SEED-Bench additionally tests video understanding. We show a detailed breakdown of our score in the Appendix E.4. Regarding the overall score, Unified-IO 2 has the strongest score of any 7B model on the SEED-Bench leaderboard111as of 11/17/23, and scores the highest on MMB by 3.8 points. Notably, it excels LLaVa-1.5 13B model in both benchmarks. Unified-IO 2 also reaches 87.7 on the POPE object hallucination benchmark [113], showing that it is not very prone to object hallucination.
Overall, Unified-IO 2 can match or surpass other vision & language generalist models on these benchmarks despite encompassing many more modalities and supporting high-quality image and audio generation. This shows that its wide breadth of capabilities does not come at the expense of vision/language performance.
5.5 Video, Audio and other Results
| AP3D | AP3D@15 | AP3D@25 | AP3D@50 | |
|---|---|---|---|---|
| Cube-RCNN [16] | 50.8 | 65.7 | 54.0 | 22.5 |
| UIO-2 | 42.9 | 54.4 | 45.7 | 21.7 |
| UIO-2 | 43.3 | 54.4 | 46.8 | 21.8 |
| UIO-2 | 42.4 | 54.0 | 45.6 | 20.9 |
Unified-IO 2 shows reasonable performance on audio and video classification and captioning, as well as video question answering, as shown in Table 6. Notably, Unified-IO 2 outperforms BLIP-2 [109] and InstructBLIP [34] on Seed-Bench Temporal [106] by 8.5 points. Unified-IO 2 also achieves better performance on Kinetics-Sounds [7] than MBT [137], which is trained solely on that dataset.
We show the single-object 3D detection results in Table 7. Our model shows decent results, similar to Cube-RCNN [16], on the Objectron benchmark [3]. However, its performance drops significantly in multi-object 3D detection tasks, like those on nuScenes [22] and Hypersim [153]. This could be because only 1.0% of our training data focuses on 3D detection. A potential solution might be to combine 2D and 3D detection techniques.
In COCO object detection, excluding the ‘stuff’ categories, our model reached an average precision (AP) of 47.2, with AP50 at 57.7 and AP75 at 50.0. However, it has difficulties with images containing many objects. Previous research, like Pix2Seq [27], suggests that autoregressive models face similar challenges, which can be improved with extensive data augmentation. Our model’s data augmentation on object detection is comparatively more limited.
Our model shows weak performance in depth estimation, with an RMSE of 0.623 on NYUv2 depth dataset [138]. However, fine-tuning specifically for this task improved the RMSE to 0.423. In our experiment, we simply normalize the depth map with the max depth value in each dataset. Due to the incompatibility of dense ground-truth depth across different datasets [150], our model failed to capture the exact scale in the current prompt, which could potentially be solved by using better normalization and metric evaluation.
Appendix E shows qualitative visualizations of other tasks, such as single object tracking, future state prediction of robotic manipulation, and image-based 3D view synthesis, etc. missing
6 Limitation
-
•
Due to memory constraints, we use the base versions of the ViT and AST models for image and audio features throughout the project. Using a larger version of these image and audio encoders could substantially improve performance.
-
•
While our image generation is more faithful compared to SD-based methods, its quality doesn’t match that of the stable diffusion model. Additionally, our audio generation is capped at approximately 4 seconds, which restricts the practical application of the audio outputs.
-
•
Limited computational resources constrained our exploration of the model’s hyperparameters. It’s likely that using a significantly larger batch size could enhance the model’s performance.
-
•
Our model is much less reliable for modalities like depth, video or when requiring more niche abilities like 3D object detection, etc. This is probably due to the limited variety of tasks we have in these areas.
-
•
Improving the quality of our data could enhance the model’s performance. However, despite considerable efforts, our human-written prompts still fall short in diversity. We notice a notable decrease in the model’s performance when dealing with new instruction tasks, as opposed to those it was trained on.
7 Conclusion
We introduced Unified-IO 2, the first autoregressive multimodal model that is capable of understanding and generating image, text, audio, and action. This model was trained from scratch on a wide range of multimodal data and further refined with instruction tuning on a massive multimodal corpus. We developed various architectural changes to stabilize the multimodal training and proposed a multimodal mixture of denoiser objective to effectively utilize the multimodal signals. Our model achieves promising results across a wide range of tasks. We show that going from LLMs to LMMs enables new capabilities and opportunities. In the future, we would like to extend Unified-IO 2 from the encoder-decoder model to a decoder-only model. Additionally, we plan to expand the model’s size, enhance the data quality, and refine the overall model design.
Acknowledgement We thank Klemen Kotar for helping gather Embodied AI pre-training data, Jonathan Frankle from MosaicML for suggesting the mixture of NLP pre-training data, Jack Hessel for interleaved image & text dataset and Micheal Schmitz for helping support the compute infrastructure. We also thank Tanmay Gupta for helpful discussions, as well as Hamish Ivison, and Ananya Harsh Jha for their insightful discussions about model design. We additionally thank Oscar Michel, Yushi Hu and Yanbei Chen for their help editing the paper, and Matt Deitke for help setting up the webpage. Savya Khosla and Derek Hoiem were supported in part by ONR award N00014-23-1-2383. This research was made possible with cloud TPUs from Google’s TPU Research Cloud (TRC).
References
- Acharya et al. [2019] Manoj Acharya, Kushal Kafle, and Christopher Kanan. TallyQA: Answering Complex Counting Questions. In AAAI, 2019.
- Agostinelli et al. [2023] Andrea Agostinelli, Timo I Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, et al. MusicLM: Generating Music From Text. arXiv preprint arXiv:2301.11325, 2023.
- Ahmadyan et al. [2021] Adel Ahmadyan, Liangkai Zhang, Artsiom Ablavatski, Jianing Wei, and Matthias Grundmann. Objectron: A Large Scale Dataset of Object-Centric Videos in the Wild with Pose Annotations. In CVPR, 2021.
- Aiello et al. [2023] Emanuele Aiello, Lili Yu, Yixin Nie, Armen Aghajanyan, and Barlas Oguz. Jointly Training Large Autoregressive Multimodal Models. arXiv preprint arXiv:2309.15564, 2023.
- Alayrac et al. [2022] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a Visual Language Model for Few-Shot Learning. In NeurIPS, 2022.
- Antol et al. [2015] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. VQA: Visual Question Answering. In ICCV, 2015.
- Arandjelovic and Zisserman [2017] Relja Arandjelovic and Andrew Zisserman. Look, Listen and Learn. In ICCV, 2017.
- Austin et al. [2021] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program Synthesis with Large Language Models. arXiv preprint arXiv:2108.07732, 2021.
- Awadalla et al. [2023] Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, et al. OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models. arXiv preprint arXiv:2308.01390, 2023.
- Ba et al. [2016] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer Normalization. In NeurIPS Deep Learning Symposium, 2016.
- Bae et al. [2021] Gwangbin Bae, Ignas Budvytis, and Roberto Cipolla. Estimating and Exploiting the Aleatoric Uncertainty in Surface Normal Estimation. In ICCV, 2021.
- Bai et al. [2023] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. arXiv preprint arXiv:2308.12966, 2023.
- Bain et al. [2021] Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval. In ICCV, 2021.
- Borsos et al. [2023] Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, et al. AudioLM: A Language Modeling Approach to Audio Generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:2523–2533, 2023.
- Bradbury et al. [2018] James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. Jax: composable transformations of python+numpy programs, 2018.
- Brazil et al. [2023] Garrick Brazil, Abhinav Kumar, Julian Straub, Nikhila Ravi, Justin Johnson, and Georgia Gkioxari. Omni3D: A Large Benchmark and Model for 3D Object Detection in the Wild. In CVPR, 2023.
- Brohan et al. [2023] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. In CoRL, 2023.
- Brooks et al. [2023] Tim Brooks, Aleksander Holynski, and Alexei A Efros. InstructPix2Pix: Learning to Follow Image Editing Instructions. In CVPR, 2023.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language Models are Few-Shot Learners. In NeurIPS, 2020.
- Bubeck et al. [2023] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of Artificial General Intelligence: Early experiments with GPT-4. arXiv preprint arXiv:2303.12712, 2023.
- Butler et al. [2012] Daniel J Butler, Jonas Wulff, Garrett B Stanley, and Michael J Black. A Naturalistic Open Source Movie for Optical Flow Evaluation. In ECCV, 2012.
- Caesar et al. [2020] Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A multimodal dataset for autonomous driving. In CVPR, 2020.
- Changpinyo et al. [2021] Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts. In CVPR, 2021.
- Chen et al. [2020] Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. VGGSound: A Large-Scale Audio-Visual Dataset. In ICASSP, 2020.
- Chen et al. [2023a] Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, and Mohamed Elhoseiny. MiniGPT-v2: Large Language Model As a Unified Interface for Vision-Language Multi-task Learning. arXiv preprint arXiv:2310.09478, 2023a.
- Chen et al. [2023b] Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic. arXiv preprint arXiv:2306.15195, 2023b.
- Chen et al. [2022] Ting Chen, Saurabh Saxena, Lala Li, David J Fleet, and Geoffrey Hinton. Pix2seq: A Language Modeling Framework for Object Detection. In ICLR, 2022.
- Chen et al. [2015] Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO Captions: Data Collection and Evaluation Server. arXiv preprint arXiv:1504.00325, 2015.
- Chen et al. [2023c] Xi Chen, Josip Djolonga, Piotr Padlewski, Basil Mustafa, Soravit Changpinyo, Jialin Wu, Carlos Riquelme Ruiz, Sebastian Goodman, Xiao Wang, Yi Tay, et al. PaLI-X: On Scaling up a Multilingual Vision and Language Model. arXiv preprint arXiv:2305.18565, 2023c.
- Clark et al. [2019] Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions. In NAACL-HLT, 2019.
- Clark et al. [2018] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge. arXiv preprint arXiv:1803.05457, 2018.
- Computer [2023] Together Computer. RedPajama: an Open Dataset for Training Large Language Models. https://github.com/togethercomputer/RedPajama-Data, 2023.
- Conover et al. [2023] Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. Free Dolly: Introducing the World’s First Truly Open Instruction-Tuned LLM. https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm, 2023.
- Dai et al. [2023] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. In NeurIPS, 2023.
- Damen et al. [2022] Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Jian Ma, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Rescaling Egocentric Vision: Collection, Pipeline and Challenges for EPIC-KITCHENS-100. International Journal of Computer Vision, 130:33–55, 2022.
- Das et al. [2017] Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, José MF Moura, Devi Parikh, and Dhruv Batra. Visual Dialog. In CVPR, 2017.
- Dayma et al. [2021] Boris Dayma, Suraj Patil, Pedro Cuenca, Khalid Saifullah, Tanishq Abraham, Phúc Lê Khac, Luke Melas, and Ritobrata Ghosh. DALL·E Mini, 2021.
- Dehghani et al. [2023] Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, et al. Scaling Vision Transformers to 22 Billion Parameters. In ICML, 2023.
- Deitke et al. [2022] Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Kiana Ehsani, Jordi Salvador, Winson Han, Eric Kolve, Aniruddha Kembhavi, and Roozbeh Mottaghi. ProcTHOR: Large-Scale Embodied AI Using Procedural Generation. In NeurIPS, 2022.
- Deitke et al. [2023] Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A Universe of Annotated 3D Objects. In CVPR, 2023.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR, 2009.
- Desai et al. [2021] Karan Desai, Gaurav Kaul, Zubin Aysola, and Justin Johnson. RedCaps: Web-curated image-text data created by the people, for the people. In NeurIPS Datasets and Benchmarks Track, 2021.
- Ding et al. [2021] Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, et al. CogView: Mastering Text-to-Image Generation via Transformers. In NeurIPS, 2021.
- Dosovitskiy et al. [2015] Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Hausser, Caner Hazirbas, Vladimir Golkov, Patrick Van Der Smagt, Daniel Cremers, and Thomas Brox. FlowNet: Learning Optical Flow with Convolutional Networks. In ICCV, 2015.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In ICLR, 2021.
- Driess et al. [2023] Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. PaLM-E: An Embodied Multimodal Language Model. In ICML, 2023.
- Drossos et al. [2020] Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. Clotho: An Audio Captioning Dataset. In ICASSP, 2020.
- Edelman [1993] Gerald M Edelman. Neural Darwinism: Selection and reentrant signaling in higher brain function. Neuron, 10(2):115–125, 1993.
- Esser et al. [2021] Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming Transformers for High-Resolution Image Synthesis. In CVPR, 2021.
- Fan et al. [2021] Heng Fan, Hexin Bai, Liting Lin, Fan Yang, Peng Chu, Ge Deng, Sijia Yu, Harshit, Mingzhen Huang, Juehuan Liu, et al. LaSOT: A High-quality Large-scale Single Object Tracking Benchmark. International Journal of Computer Vision, 129:439–461, 2021.
- Gao et al. [2021] Leo Gao, Jonathan Tow, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Kyle McDonell, Niklas Muennighoff, Jason Phang, Laria Reynolds, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot language model evaluation, 2021.
- Gao et al. [2023] Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, et al. LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model. arXiv preprint arXiv:2304.15010, 2023.
- Ge et al. [2023] Yuying Ge, Yixiao Ge, Ziyun Zeng, Xintao Wang, and Ying Shan. Planting a SEED of Vision in Large Language Model. arXiv preprint arXiv:2307.08041, 2023.
- Gemmeke et al. [2017] Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. Audio Set: An Ontology and Human-Labeled Dataset for Audio Events. In ICASSP, 2017.
- Geng and Liu [2023] Xinyang Geng and Hao Liu. OpenLLaMA: An Open Reproduction of LLaMA. https://github.com/openlm-research/open_llama, 2023.
- Girdhar et al. [2023] Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. ImageBind: One Embedding Space To Bind Them All. In CVPR, 2023.
- Gong et al. [2021] Yuan Gong, Yu-An Chung, and James Glass. AST: Audio Spectrogram Transformer. In Interspeech, 2021.
- Goyal et al. [2017a] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The” something something” video database for learning and evaluating visual common sense. In ICCV, 2017a.
- Goyal et al. [2017b] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. In CVPR, 2017b.
- Grauman et al. [2022] Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4D: Around the World in 3,000 Hours of Egocentric Video. In CVPR, 2022.
- Gu et al. [2018] Chunhui Gu, Chen Sun, David A Ross, Carl Vondrick, Caroline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, et al. AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions. In CVPR, 2018.
- Gupta et al. [2019a] Agrim Gupta, Piotr Dollar, and Ross Girshick. LVIS: A Dataset for Large Vocabulary Instance Segmentation. In CVPR, 2019a.
- Gupta et al. [2019b] Abhishek Gupta, Vikash Kumar, Corey Lynch, Sergey Levine, and Karol Hausman. Relay Policy Learning: Solving Long-Horizon Tasks via Imitation and Reinforcement Learning. In CoRL, 2019b.
- Gupta and Kembhavi [2023] Tanmay Gupta and Aniruddha Kembhavi. Visual Programming: Compositional visual reasoning without training. In CVPR, 2023.
- Gupta et al. [2022a] Tanmay Gupta, Amita Kamath, Aniruddha Kembhavi, and Derek Hoiem. Towards General Purpose Vision Systems: An End-to-End Task-Agnostic Vision-Language Architecture. In CVPR, 2022a.
- Gupta et al. [2022b] Tanmay Gupta, Ryan Marten, Aniruddha Kembhavi, and Derek Hoiem. GRIT: General Robust Image Task Benchmark. arXiv preprint arXiv:2204.13653, 2022b.
- Gurari et al. [2018] Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. VizWiz Grand Challenge: Answering Visual Questions from Blind People. In CVPR, 2018.
- Habernal et al. [2016] Ivan Habernal, Omnia Zayed, and Iryna Gurevych. C4Corpus: Multilingual Web-size Corpus with Free License. In LREC, 2016.
- Han et al. [2023] Jiaming Han, Renrui Zhang, Wenqi Shao, Peng Gao, Peng Xu, Han Xiao, Kaipeng Zhang, Chris Liu, Song Wen, Ziyu Guo, et al. ImageBind-LLM: Multi-modality Instruction Tuning. arXiv preprint arXiv:2309.03905, 2023.
- He et al. [2017] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask R-CNN. In ICCV, 2017.
- He et al. [2022] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked Autoencoders Are Scalable Vision Learners. In CVPR, 2022.
- Hendrycks et al. [2021] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring Massive Multitask Language Understanding. In ICLR, 2021.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In NeurIPS, 2017.
- Ho and Salimans [2021] Jonathan Ho and Tim Salimans. Classifier-Free Diffusion Guidance. In NeurIPS Workshop on Deep Generative Models and Downstream Applications, 2021.
- Holtzman et al. [2020] Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The Curious Case of Neural Text Degeneration. In ICLR, 2020.
- Hu et al. [2023a] Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A. Smith. TIFA: Accurate and Interpretable Text-to-Image Faithfulness Evaluation with Question Answering. In ICCV, 2023a.
- Hu et al. [2023b] Yushi Hu, Otilia Stretcu, Chun-Ta Lu, Krishnamurthy Viswanathan, Kenji Hata, Enming Luo, Ranjay Krishna, and Ariel Fuxman. Visual Program Distillation: Distilling Tools and Programmatic Reasoning into Vision-Language Models. arXiv preprint arXiv:2312.03052, 2023b.
- Huang et al. [2019a] Jingwei Huang, Yichao Zhou, Thomas Funkhouser, and Leonidas J Guibas. FrameNet: Learning Local Canonical Frames of 3D Surfaces from a Single RGB Image. In ICCV, 2019a.
- Huang et al. [2019b] Lianghua Huang, Xin Zhao, and Kaiqi Huang. GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(5):1562–1577, 2019b.
- Huang et al. [2023a] Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, et al. AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head. arXiv preprint arXiv:2304.12995, 2023a.
- Huang et al. [2023b] Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Qiang Liu, et al. Language Is Not All You Need: Aligning Perception with Language Models. In NeurIPS, 2023b.
- Huang et al. [2016] Ting-Hao Huang, Francis Ferraro, Nasrin Mostafazadeh, Ishan Misra, Aishwarya Agrawal, Jacob Devlin, Ross Girshick, Xiaodong He, Pushmeet Kohli, Dhruv Batra, et al. Visual Storytelling. In NAACL-HLT, 2016.
- Hudson and Manning [2019] Drew A Hudson and Christopher D Manning. GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering. In CVPR, 2019.
- Ilharco et al. [2021] Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. OpenCLIP, 2021.
- Ito and Johnson [2017] Keith Ito and Linda Johnson. The LJ Speech Dataset. https://keithito.com/LJ-Speech-Dataset/, 2017.
- Jaegle et al. [2022] Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver IO: A General Architecture for Structured Inputs & Outputs. In ICLR, 2022.
- Jiang et al. [2023] Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, and Linxi Fan. VIMA: General Robot Manipulation with Multimodal Prompts. In ICML, 2023.
- Jin et al. [2023] Yang Jin, Kun Xu, Liwei Chen, Chao Liao, Jianchao Tan, Bin Chen, Chenyi Lei, An Liu, Chengru Song, Xiaoqiang Lei, et al. Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization. arXiv preprint arXiv:2309.04669, 2023.
- Kamath et al. [2022] Amita Kamath, Christopher Clark, Tanmay Gupta, Eric Kolve, Derek Hoiem, and Aniruddha Kembhavi. Webly Supervised Concept Expansion for General Purpose Vision Models. In ECCV, 2022.
- Kay et al. [2017] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The Kinetics Human Action Video Dataset. arXiv preprint arXiv:1705.06950, 2017.
- Kazemzadeh et al. [2014] Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. ReferItGame: Referring to Objects in Photographs of Natural Scenes. In EMNLP, 2014.
- Kilgour et al. [2019] Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. Fréchet Audio Distance: A Reference-Free Metric for Evaluating Music Enhancement Algorithms. In Interspeech, 2019.
- Kim et al. [2019] Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. AudioCaps: Generating Captions for Audios in The Wild. In NAACL-HLT, 2019.
- Kirillov et al. [2023] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment Anything. In ICCV, 2023.
- Kocetkov et al. [2023] Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, Dzmitry Bahdanau, Leandro von Werra, and Harm de Vries. The Stack: 3 TB of permissively licensed source code. Transactions on Machine Learning Research, 2023.
- Koh et al. [2023a] Jing Yu Koh, Daniel Fried, and Ruslan Salakhutdinov. Generating Images with Multimodal Language Models. In NeurIPS, 2023a.
- Koh et al. [2023b] Jing Yu Koh, Ruslan Salakhutdinov, and Daniel Fried. Grounding Language Models to Images for Multimodal Inputs and Outputs. In ICML, 2023b.
- Kong et al. [2020] Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. In NeurIPS, 2020.
- Köpf et al. [2023] Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, et al. OpenAssistant Conversations – Democratizing Large Language Model Alignment. In NeurIPS Datasets and Benchmarks Track, 2023.
- Krell et al. [2021] Mario Michael Krell, Matej Kosec, Sergio P Perez, and Andrew Fitzgibbon. Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance. arXiv preprint arXiv:2107.02027, 2021.
- Kreuk et al. [2023] Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre Défossez, Jade Copet, Devi Parikh, Yaniv Taigman, and Yossi Adi. AudioGen: Textually Guided Audio Generation. In ICLR, 2023.
- Krishna et al. [2017] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Fei-Fei Li. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. International Journal of Computer Vision, 2017.
- Kuznetsova et al. [2020] Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, Tom Duerig, and Vittorio Ferrari. The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. International Journal of Computer Vision, 128(7):1956–1981, 2020.
- Laurençon et al. [2023] Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M Rush, Douwe Kiela, et al. OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents. In NeurIPS Datasets and Benchmarks Track, 2023.
- Lee et al. [2021] Sangho Lee, Jiwan Chung, Youngjae Yu, Gunhee Kim, Thomas Breuel, Gal Chechik, and Yale Song. ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning. In ICCV, 2021.
- Li et al. [2023a] Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension. arXiv preprint arXiv:2307.16125, 2023a.
- Li et al. [2023b] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Jingkang Yang, Chunyuan Li, and Ziwei Liu. MIMIC-IT: Multi-Modal In-Context Instruction Tuning. arXiv preprint arXiv:2306.05425, 2023b.
- Li et al. [2023c] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: A Multi-Modal Model with In-Context Instruction Tuning. arXiv preprint arXiv:2305.03726, 2023c.
- Li et al. [2023d] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. In ICML, 2023d.
- Li et al. [2023e] Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wen Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. VideoChat: Chat-Centric Video Understanding. arXiv preprint arXiv:2305.06355, 2023e.
- Li et al. [2023f] Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Limin Wang, and Yu Qiao. UniFormerV2: Unlocking the Potential of Image ViTs for Video Understanding. In ICCV, 2023f.
- Li et al. [2023g] Lei Li, Yuwei Yin, Shicheng Li, Liang Chen, Peiyi Wang, Shuhuai Ren, Mukai Li, Yazheng Yang, Jingjing Xu, Xu Sun, et al. MIT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning. arXiv preprint arXiv:2306.04387, 2023g.
- Li et al. [2023h] Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji rong Wen. Evaluating Object Hallucination in Large Vision-Language Models. In EMNLP, 2023h.
- Liang et al. [2023] Paul Pu Liang, Yiwei Lyu, Xiang Fan, Jeffrey Tsaw, Yudong Liu, Shentong Mo, Dani Yogatama, Louis-Philippe Morency, and Russ Salakhutdinov. High-Modality Multimodal Transformer: Quantifying Modality & Interaction Heterogeneity for High-Modality Representation Learning. TMLR, 2023.
- Lin et al. [2014] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO: Common Objects in Context. In ECCV, 2014.
- Liu et al. [2023a] Fangyu Liu, Guy Emerson, and Nigel Collier. Visual Spatial Reasoning. Transactions of the Association for Computational Linguistics, 11:635–651, 2023a.
- Liu et al. [2023b] Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. AudioLDM: Text-to-Audio Generation with Latent Diffusion Models. In ICML, 2023b.
- Liu et al. [2023c] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved Baselines with Visual Instruction Tuning. arXiv preprint arXiv:2310.03744, 2023c.
- Liu et al. [2023d] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual Instruction Tuning. In NeurIPS, 2023d.
- Liu et al. [2023e] Yuanzhan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. MMBench: Is Your Multi-modal Model an All-around Player? arXiv preprint arXiv:2307.06281, 2023e.
- Liu et al. [2022] Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, et al. Swin Transformer V2: Scaling Up Capacity and Resolution. In CVPR, 2022.
- Longpre et al. [2023] Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, and Adam Roberts. The Flan Collection: Designing Data and Methods for Effective Instruction Tuning. In ICML, 2023.
- Lu et al. [2023a] Jiasen Lu, Christopher Clark, Rowan Zellers, Roozbeh Mottaghi, and Aniruddha Kembhavi. Unified-IO: A Unified Model for Vision, Language, and Multi-Modal Tasks. In ICLR, 2023a.
- Lu et al. [2022] Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering. In NeurIPS, 2022.
- Lu et al. [2023b] Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, and Jianfeng Gao. Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models. In NeurIPS, 2023b.
- Luo et al. [2023] Ruipu Luo, Ziwang Zhao, Min Yang, Junwei Dong, Ming-Hui Qiu, Pengcheng Lu, Tao Wang, and Zhongyu Wei. Valley: Video Assistant with Large Language model Enhanced abilitY. arXiv preprint arXiv:2306.07207, 2023.
- Lynch et al. [2023] Corey Lynch, Ayzaan Wahid, Jonathan Tompson, Tianli Ding, James Betker, Robert Baruch, Travis Armstrong, and Pete Florence. Interactive Language: Talking to Robots in Real Time. IEEE Robotics and Automation Letters, 2023.
- Maaz et al. [2023] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. arXiv preprint arXiv:2306.05424, 2023.
- Mao et al. [2016] Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan Yuille, and Kevin Murphy. Generation and Comprehension of Unambiguous Object Descriptions. In CVPR, 2016.
- Marino et al. [2019] Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge. In CVPR, 2019.
- Martin Morato and Mesaros [2021] Irene Martin Morato and Annamaria Mesaros. Diversity and Bias in Audio Captioning Datasets. In DCASE, 2021.
- Merullo et al. [2023] Jack Merullo, Louis Castricato, Carsten Eickhoff, and Ellie Pavlick. Linearly Mapping from Image to Text Space. In ICLR, 2023.
- Mishra et al. [2019] Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. OCR-VQA: Visual Question Answering by Reading Text in Images. In ICDAR, 2019.
- Mishra et al. [2023] Utkarsh Mishra, Shangjie Xue, Yongxin Chen, and Danfei Xu. Generative Skill Chaining: Long-Horizon Skill Planning with Diffusion Models. In CoRL, 2023.
- Mu et al. [2023] Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, and Ping Luo. EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought. In NeurIPS, 2023.
- Nagaraja et al. [2016] Varun K Nagaraja, Vlad I Morariu, and Larry S Davis. Modeling Context Between Objects for Referring Expression Understanding. In ECCV, 2016.
- Nagrani et al. [2021] Arsha Nagrani, Shan Yang, Anurag Arnab, Aren Jansen, Cordelia Schmid, and Chen Sun. Attention Bottlenecks for Multimodal Fusion. In NeurIPS, 2021.
- Nathan Silberman and Fergus [2012] Pushmeet Kohli Nathan Silberman, Derek Hoiem and Rob Fergus. Indoor Segmentation and Support Inference from RGBD Images. In ECCV, 2012.
- Oquab et al. [2023] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning Robust Visual Features without Supervision. arXiv preprint arXiv:2304.07193, 2023.
- Padalkar et al. [2023] Abhishek Padalkar, Acorn Pooley, Ajinkya Jain, Alex Bewley, Alex Herzog, Alex Irpan, Alexander Khazatsky, Anant Rai, Anikait Singh, Anthony Brohan, et al. Open X-Embodiment: Robotic Learning Datasets and RT-X Models. In CoRL Workshop TGR, 2023.
- Pan et al. [2023] Xichen Pan, Li Dong, Shaohan Huang, Zhiliang Peng, Wenhu Chen, and Furu Wei. Kosmos-G: Generating Images in Context with Multimodal Large Language Models. arXiv preprint arXiv:2310.02992, 2023.
- Peng et al. [2023a] Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction Tuning with GPT-4. arXiv preprint arXiv:2304.03277, 2023a.
- Peng et al. [2023b] Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding Multimodal Large Language Models to the World. arXiv preprint arXiv:2306.14824, 2023b.
- Piaget et al. [1952] Jean Piaget, Margaret Cook, et al. The Origins of Intelligence in Children. International Universities Press New York, 1952.
- Qin et al. [2023] Can Qin, Shu Zhang, Ning Yu, Yihao Feng, Xinyi Yang, Yingbo Zhou, Huan Wang, Juan Carlos Niebles, Caiming Xiong, Silvio Savarese, et al. UniControl: A Unified Diffusion Model for Controllable Visual Generation In the Wild. In NeurIPS, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning Transferable Visual Models From Natural Language Supervision. In ICML, 2021.
- Raffel et al. [2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. JMLR, 21(140):1–67, 2020.
- Ramesh et al. [2021] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-Shot Text-to-Image Generation. In ICML, 2021.
- Ramrakhya et al. [2022] Ram Ramrakhya, Eric Undersander, Dhruv Batra, and Abhishek Das. Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale. In CVPR, 2022.
- Ranftl et al. [2020] René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(3):1623–1637, 2020.
- Real et al. [2017] Esteban Real, Jonathon Shlens, Stefano Mazzocchi, Xin Pan, and Vincent Vanhoucke. YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video. In CVPR, 2017.
- Reed et al. [2022] Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, et al. A Generalist Agent. Transactions on Machine Learning Research, 2022.
- Roberts et al. [2021] Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding. In ICCV, 2021.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-Resolution Image Synthesis With Latent Diffusion Models. In CVPR, 2022.
- Salimans et al. [2016] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved Techniques for Training GANs. In NeurIPS, 2016.
- Sanh et al. [2022] Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al. Multitask Prompted Training Enables Zero-Shot Task Generalization. In ICLR, 2022.
- Savva et al. [2019] Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A Platform for Embodied AI Research. In ICCV, 2019.
- Schuhmann [2022] Christoph Schuhmann. LAION-AESTHETICS. https://laion.ai/blog/laion-aesthetics/, 2022.
- Schuhmann et al. [2021] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs. In NeurIPS Data-Centric AI Workshop, 2021.
- Schwenk et al. [2022] Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. A-OKVQA: A Benchmark for Visual Question Answering using World Knowledge. In ECCV, 2022.
- Sennrich et al. [2016] Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural Machine Translation of Rare Words with Subword Units. In ACL, 2016.
- Sermanet et al. [2023] Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, Debidatta Dwibedi, Keerthana Gopalakrishnan, Christine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J Joshi, et al. RoboVQA: Multimodal Long-Horizon Reasoning for Robotics. arXiv preprint arXiv:2311.00899, 2023.
- Sharma et al. [2018] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning. In ACL, 2018.
- Shazeer and Stern [2018] Noam Shazeer and Mitchell Stern. Adafactor: Adaptive Learning Rates with Sublinear Memory Cost. In ICML, 2018.
- Singh et al. [2019] Amanpreet Singh, Vivek Natarjan, Meet Shah, Yu Jiang, Xinlei Chen, Devi Parikh, and Marcus Rohrbach. Towards VQA Models That Can Read. In CVPR, 2019.
- Singh et al. [2023] Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. ProgPrompt: Generating Situated Robot Task Plans using Large Language Models. ICRA, 2023.
- Smith and Gasser [2005] Linda Smith and Michael Gasser. The Development of Embodied Cognition: Six Lessons from Babies. Artificial life, 11(1-2):13–29, 2005.
- Soomro et al. [2012] Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. arXiv preprint arXiv:1212.0402, 2012.
- Su et al. [2023a] Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced Transformer with Rotary Position Embedding. Neurocomputing, 2023a.
- Su et al. [2023b] Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. PandaGPT: One Model To Instruction-Follow Them All. arXiv preprint arXiv:2305.16355, 2023b.
- Suhr et al. [2019] Alane Suhr, Stephanie Zhou, Ally Zhang, Iris Zhang, Huajun Bai, and Yoav Artzi. A Corpus for Reasoning About Natural Language Grounded in Photographs. In ACL, 2019.
- Sun et al. [2023] Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative Pretraining in Multimodality. arXiv preprint arXiv:2307.05222, 2023.
- Surís et al. [2023] Dídac Surís, Sachit Menon, and Carl Vondrick. ViperGPT: Visual Inference via Python Execution for Reasoning. In ICCV, 2023.
- Tang et al. [2023] Zineng Tang, Ziyi Yang, Chenguang Zhu, Michael Zeng, and Mohit Bansal. Any-to-Any Generation via Composable Diffusion. In NeurIPS, 2023.
- Tay et al. [2023] Yi Tay, Mostafa Dehghani, Vinh Q Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Dara Bahri, Tal Schuster, Steven Zheng, et al. UL2: Unifying Language Learning Paradigms. In ICLR, 2023.
- Team [2023] MosaicML NLP Team. Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs, 2023. Accessed: 2023-05-05.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and Efficient Foundation Language Models. arXiv preprint arXiv:2302.13971, 2023.
- Tsimpoukelli et al. [2021] Maria Tsimpoukelli, Jacob Menick, Serkan Cabi, S. M. Ali Eslami, Oriol Vinyals, Felix Hill, and Zacharias Janssen. Multimodal Few-Shot Learning with Frozen Language Models. In NeurIPS, 2021.
- Van Den Oord et al. [2017] Aaron Van Den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural Discrete Representation Learning. In NeurIPS, 2017.
- Van Horn et al. [2018] Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The iNaturalist Species Classification and Detection Dataset. In CVPR, 2018.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention Is All You Need. In NeurIPS, 2017.
- Vedantam et al. [2015] Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. CIDEr: Consensus-based Image Description Evaluation. In CVPR, 2015.
- Veit et al. [2016] Andreas Veit, Tomas Matera, Lukas Neumann, Jiri Matas, and Serge Belongie. COCO-Text: Dataset and Benchmark for Text Detection and Recognition in Natural Images. arXiv preprint arXiv:1601.07140, 2016.
- Walke et al. [2023] Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, et al. BridgeData V2: A Dataset for Robot Learning at Scale. In CoRL, 2023.
- Wang et al. [2019a] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal Segment Networks for Action Recognition in Videos. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(11):2740–2755, 2019a.
- Wang et al. [2022a] Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework. In ICML, 2022a.
- Wang et al. [2023a] Peng Wang, Shijie Wang, Junyang Lin, Shuai Bai, Xiaohuan Zhou, Jingren Zhou, Xinggang Wang, and Chang Zhou. ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities. arXiv preprint arXiv:2305.11172, 2023a.
- Wang et al. [2023b] Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, and Furu Wei. Image as a Foreign Language: BEiT Pretraining for Vision and Vision-Language Tasks. In CVPR, 2023b.
- Wang et al. [2023c] Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, et al. VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks. In NeurIPS, 2023c.
- Wang et al. [2019b] Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. VATEX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language Research. In ICCV, 2019b.
- Wang et al. [2022b] Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap, et al. Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks. In EMNLP, 2022b.
- Wang et al. [2022c] Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, and Yuan Cao. SimVLM: Simple Visual Language Model Pretraining with Weak Supervision. In ICLR, 2022c.
- Wei et al. [2022] Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned Language Models are Zero-Shot Learners. In ICLR, 2022.
- Weinzaepfel et al. [2022] Philippe Weinzaepfel, Vincent Leroy, Thomas Lucas, Romain Brégier, Yohann Cabon, Vaibhav Arora, Leonid Antsfeld, Boris Chidlovskii, Gabriela Csurka, and Jérôme Revaud. CroCo: Self-Supervised Pre-training for 3D Vision Tasks by Cross-View Completion. In NeurIPS, 2022.
- Welinder et al. [2010] Peter Welinder, Steve Branson, Takeshi Mita, Catherine Wah, Florian Schroff, Serge Belongie, and Pietro Perona. Caltech-UCSD Birds 200. Technical Report CNS-TR-2010-001, California Institute of Technology, 2010.
- Wu et al. [2021] Bo Wu, Shoubin Yu, Zhenfang Chen, Joshua B Tenenbaum, and Chuang Gan. STAR: A Benchmark for Situated Reasoning in Real-World Videos. In NeurIPS Datasets and Benchmarks Track, 2021.
- Xiao et al. [2010] Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. SUN Database: Large-scale Scene Recognition from Abbey to Zoo. In CVPR, 2010.
- Xu et al. [2017] Dejing Xu, Zhou Zhao, Jun Xiao, Fei Wu, Hanwang Zhang, Xiangnan He, and Yueting Zhuang. Video Question Answering via Gradually Refined Attention over Appearance and Motion. In ACM MM, 2017.
- Xu et al. [2016] Jun Xu, Tao Mei, Ting Yao, and Yong Rui. MSR-VTT: A Large Video Description Dataset for Bridging Video and Language. In CVPR, 2016.
- Xue et al. [2022] Hongwei Xue, Tiankai Hang, Yanhong Zeng, Yuchong Sun, Bei Liu, Huan Yang, Jianlong Fu, and Baining Guo. Advancing High-Resolution Video-Language Representation with Large-Scale Video Transcriptions. In CVPR, 2022.
- Xue et al. [2021] Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In NAACL-HLT, 2021.
- Yan et al. [2023] Bin Yan, Yi Jiang, Jiannan Wu, Dong Wang, Zehuan Yuan, Ping Luo, and Huchuan Lu. Universal Instance Perception as Object Discovery and Retrieval. In CVPR, 2023.
- Yang et al. [2023] Dongchao Yang, Jianwei Yu, Helin Wang, Wen Wang, Chao Weng, Yuexian Zou, and Dong Yu. Diffsound: Discrete Diffusion Model for Text-to-sound Generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:1720–1733, 2023.
- Yao et al. [2020] Yao Yao, Zixin Luo, Shiwei Li, Jingyang Zhang, Yufan Ren, Lei Zhou, Tian Fang, and Long Quan. BlendedMVS: A Large-scale Dataset for Generalized Multi-view Stereo Networks. In CVPR, 2020.
- Ye et al. [2023a] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality. arXiv preprint arXiv:2304.14178, 2023a.
- Ye et al. [2023b] Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Haowei Liu, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration. arXiv preprint arXiv:2311.04257, 2023b.
- You et al. [2023] Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and Ground Anything Anywhere at Any Granularity. arXiv preprint arXiv:2310.07704, 2023.
- Yu et al. [2022] Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, and Yonghui Wu. Vector-quantized Image Modeling with Improved VQGAN. In ICLR, 2022.
- Yu et al. [2016] Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling Context in Referring Expressions. In ECCV, 2016.
- Yu et al. [2023] Lili Yu, Bowen Shi, Ramakanth Pasunuru, Benjamin Muller, Olga Golovneva, Tianlu Wang, Arun Babu, Binh Tang, Brian Karrer, Shelly Sheynin, et al. Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning. arXiv preprint arXiv:2309.02591, 2023.
- Zamir et al. [2018] Amir R Zamir, Alexander Sax, William Shen, Leonidas J Guibas, Jitendra Malik, and Silvio Savarese. Taskonomy: Disentangling Task Transfer Learning. In CVPR, 2018.
- Zang et al. [2023] Yuhang Zang, Wei Li, Jun Han, Kaiyang Zhou, and Chen Change Loy. Contextual Object Detection with Multimodal Large Language Models. arXiv preprint arXiv:2305.18279, 2023.
- Zellers et al. [2019a] Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. From Recognition to Cognition: Visual Commonsense Reasoning. In CVPR, 2019a.
- Zellers et al. [2019b] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a Machine Really Finish Your Sentence? In ACL, 2019b.
- Zellers et al. [2022] Rowan Zellers, Jiasen Lu, Ximing Lu, Youngjae Yu, Yanpeng Zhao, Mohammadreza Salehi, Aditya Kusupati, Jack Hessel, Ali Farhadi, and Yejin Choi. MERLOT Reserve: Neural Script Knowledge through Vision and Language and Sound. In CVPR, 2022.
- Zhang et al. [2023a] Hang Zhang, Xin Li, and Lidong Bing. Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding. arXiv preprint arXiv:2306.02858, 2023a.
- Zhang et al. [2023b] Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing. In NeurIPS Datasets and Benchmarks Track, 2023b.
- Zhang et al. [2023c] Renrui Zhang, Jiaming Han, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Peng Gao, and Yu Qiao. LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention. arXiv preprint arXiv:2303.16199, 2023c.
- Zhang et al. [2023d] Shilong Zhang, Peize Sun, Shoufa Chen, Min Xiao, Wenqi Shao, Wenwei Zhang, Kai Chen, and Ping Luo. GPT4RoI: Instruction Tuning Large Language Model on Region-of-Interest. arXiv preprint arXiv:2307.03601, 2023d.
- Zhang et al. [2023e] Yanzhe Zhang, Ruiyi Zhang, Jiuxiang Gu, Yufan Zhou, Nedim Lipka, Diyi Yang, and Tong Sun. LLaVAR: Enhanced Visual Instruction Tuning for Text-Rich Image Understanding. arXiv preprint arXiv:2306.17107, 2023e.
- Zhao et al. [2022] Minyi Zhao, Bingjia Li, Jie Wang, Wanqing Li, Wenjing Zhou, Lan Zhang, Shijie Xuyang, Zhihang Yu, Xinkun Yu, Guangze Li, et al. Towards Video Text Visual Question Answering: Benchmark and Baseline. In NeurIPS Datasets and Benchmarks Track, 2022.
- Zhao et al. [2023] Zijia Zhao, Longteng Guo, Tongtian Yue, Sihan Chen, Shuai Shao, Xinxin Zhu, Zehuan Yuan, and Jing Liu. ChatBridge: Bridging Modalities with Large Language Model as a Language Catalyst. arXiv preprint arXiv:2305.16103, 2023.
- Zheng et al. [2022] Chuanxia Zheng, Tung-Long Vuong, Jianfei Cai, and Dinh Phung. MoVQ: Modulating Quantized Vectors for High-Fidelity Image Generation. In NeurIPS, 2022.
- Zhou et al. [2017] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 Million Image Database for Scene Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(6):1452–1464, 2017.
- Zhu et al. [2023] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. arXiv preprint arXiv:2304.10592, 2023.
- Zhu et al. [2019] Minfeng Zhu, Pingbo Pan, Wei Chen, and Yi Yang. DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-to-Image Synthesis. In CVPR, 2019.
The appendix includes the following sections:
Appendix A Contributions
Jiasen Lu, Christopher Clark, Sangho Lee, and Zichen Zhang collectively contributed to dataset construction, prompt development, and conducted numerous exploratory experiments for this project.
Jiasen Lu led and designed the main idea and scope of the project. Developed the majority of the model pipeline – image and audio tokenizer, main architecture, model stabilization, and training objective. Led and designed the pre-training and instruction tuning data pipelines. Conducted experiments with various model and data hyperparameters, oversaw the model training process, and wrote the paper. Coordinate with the whole team.
Christopher Clark co-led and designed the infrastructure, instruction tuning, and evaluation. Developed the dynamic packing system, modality processing pipeline, and classifier-free guidance for image and audio inference. Added the NLP and many V&L datasets, added many synthetic tasks, and built prompts for instruction-tuning tasks. Ran the evaluation in § 5.1 (NLP), 5.2, and 6 (detection, depth) and wrote the paper.
Sangho Lee core contribution to the pre-training data pipeline. Added all large-scale multimodal pretraining datasets, and video and audio instruction tuning datasets. Developed sample construction pipeline for pre-training. Helped with the model implementation – position encoding, perceiver resamplers, and model stabilization. Ran the evaluation in § 5.1 (audio), 5.3 (audio and image FID), 6 (video and audio understanding) and wrote parts of the paper.
Zichen Zhang core contribution to the instruction tuning data pipeline. Added many V&L, embodiment, video, audio, data augmentation, and all instruction tuning datasets. Built prompts for instruction tuning. Investigated the model architectures and training pipelines and stabilized the training. Ran the experiments in § 5.1 (image TIFA, SeedBench), 5.3 (image TIFA, action), 5.4, wrote parts of the paper, developed the model demo and project page.
Savya Khosla added 3D object detection, optical flow, and multi-point tracking datasets, ran the evaluation of 3D detection, and initiated the demo.
Ryan Marten added part of video and tracking datasets.
Derek Hoiem advised on the research direction.
Aniruddha Kembhavi advised on the research direction and evaluation, helped manage compute resources and wrote the paper.
Appendix B Model Implementation Details
In this section, we present the implementation details of our model.
B.1 Detailed of Unified Task Representation
First, we provide details about how different modalities are represented in our model.
Text representation. The Byte Pair Encoding (BPE) vocabulary size is 32000. Similar to [147], we add 200 additional special tokens to indicated masked spans when de-noising. We further add 10 special tokens that can be used to reference the image, audio, and history input in the text. Two special tokens are to indicate the and , and 8 special tokens represent individual elements in the image and audio history inputs, both of which have a maximum of 4 frames. We use a maximum of 512 input and output tokens.
Sparse structures representation. We use an additional 1000 special tokens to represent all continuous values, such as points, boxes, camera transformation, and 3D cuboids. Points are represented with coordinates and boxes with coordinates with values normalized by the image size. Camera transformations are represented as polar angle , azimuth angle , and distance . 1000 special tokens to represent discretized angle from to . Following [16], 3D cuboids are represented with 12 parameters including projected center , virtual depth , log-normalized box dimension , and continuous allocentric rotation .
-
•
represent the projected 3D center on the image plane relative to the 2D RoI
-
•
is the object’s center depth in meters.
-
•
are the log-normalized physical box dimensions in meters.
-
•
is the continuous 6D allocentric rotation.
For 3D cuboid detection, we use prompts to indicate the target format, such as “Locate all objects in 3D using projected 3D center, virtual depth, log-normalized box size, and rotation in the image.”
Action representation. For embodied navigation tasks, the discrete action space is directly represented as texts, e.g. “forward”, “left”, “right”, “stop”. For object manipulation tasks, the action is represented differently based on the robots. Overall, the positional change (e.g. ), rotational change (e.g. ), and gripper open or close are discretized using the same 1000 special tokens, and we use the text prompt to indicate the input and target format. For tasks that require multi-step planning (e.g. VIMA [87]), the actions are represented as human-readable texts with the indication of steps, skills used (e.g. pick, place, or push), and discretized positional and rotational parameters. Figure D.10 provides a detailed illustration of the robot tasks.
| Audio Input |
Sample rate |
16000 Hz |
|
FFT hop length |
256 samples | |
|
FFT window size |
1024 | |
|
Mel bins |
128 | |
|
Subsegment length |
256 hops, (4.08 sec) | |
|
Mel Spectrogram size |
128 mels 256 hops | |
|
fmin |
0 | |
|
fmax |
8000 | |
|
AST patch size |
16 | |
|
token size |
8 16 | |
|
Pretrain sub-sample |
64 | |
|
Final size |
64 or 128 tokens | |
| Image Input |
ViT patch size |
16 |
|
Pretraining size |
384 384 | |
|
Token size |
24 24 | |
|
Pretrain sub-sample |
288 | |
|
Final size |
288 or 576 tokens | |
| Text |
Seq length |
512 |
|
Final size |
512 tokens | |
| Image History |
ViT patch size |
16 |
|
Pretraining size |
256 256 | |
|
Token size |
16 16 | |
|
Pretrain sub-sample |
128 | |
|
Max num segments |
4 | |
|
Latent size |
32 | |
|
Final size |
32, 64, 96, 128 tokens | |
| Audio History |
AST patch size |
16 |
|
Pretraining size |
128 256 | |
|
Token size |
8 16 | |
|
Pretrain sub-sample |
64 | |
|
Max num segments |
4 | |
|
Latent size |
16 | |
|
Final size |
16, 32, 48, 64 tokens |
Images representation. Images are encoded with a pre-trained ViT [45]. We use the ViT-B checkpoint trained on LAION 2B dataset222https://github.com/mlfoundations/open_clip. For image inputs, we use a maximum length of 576 tokens (i.e. patch encoding from a image). We concatenate features from the second and second-last layers of the ViT to capture both low and high-level visual information. To generate the image, we encode these images as discrete tokens [49]. Different from Unified-IO [123], which uses the VQ-GAN trained on ImageNet [41] to convert resolution image into tokens, we use the VQ-GAN trained on the Open Images dataset [103] with a compression ratio of 8 and a vocabulary size of 16384333https://github.com/CompVis/taming-transformers. This converts resolution image into tokens. We also compare the VQ-GAN tokenizer with the ViT-VQGAN [208] and MoVQ [223]. We empirically find VQ-GAN leads to best generation results.
Dense structures representation. To handle this modality, we convert per-pixel labels into RGB images. For depth, we construct a grayscale image by normalizing the depth map. For surface normal estimation, we convert the orientations into values. For segmentation, we train Unified-IO 2 to predict a single black-and-white mask for a particular object specified by a class and a bounding box. Instance segmentation (as done in GRIT [66]) can then be performed by first performing localization for the target class and then performing segmentation for each detected box. Unified-IO instead trains the model to produce an image with a randomly selected color for each instance. We found this makes post-processing difficult since output images sometimes do not exactly follow the color scheme, and the model could struggle with images with many different instances.
Audio representation. This modality encodes a 4.08-second segment of audio. We take the waveform sampled at 16000 Hz and convert it to a log-mel-scaled spectrogram. We compute the spectrogram for an entire audio segment (4.08 seconds) simultaneously. Each window involves 1024 samples and 256 samples ‘hops’ between windows. The resulting spectrogram has a size of 128 mel bins with 256 windows. We chose these hyperparameters largely around efficiency. We then encode this with a pre-trained AST [57] with the patch size of , hence a total of 128 tokens.
To generate audio, we use ViT-VQGAN [208] to convert the spectrograms into discrete tokens. Since the authors of [208] did not release the source code or any pre-trained models, we implement and train our own version of ViT-VQGAN with patch size that encodes a spectrogram into 512 tokens with a codebook size of 8196. The model is trained with the audio on AudioSet [54], ACAV100M [105], and YT-Temporal-1B [215] datasets. After getting the log-mel-scaled spectrograms, we use HiFi-GAN444https://github.com/jik876/hifi-gan [98] vocoder to decode the spectrograms back to waveforms. We train the HiFi-GAN using the same parameters shown in Table 8. We trained the model on a mixture of AudioSet and LJSpeech [85] to cover natural sound and human voice.
History representation. Images and audio inputs in this history are first encoded in the same way as image and audio inputs. We then use a perceiver resampler [5] to further compress the image and audio features and produce a fixed number of visual outputs (32) and audio outputs (16) to reduce the total sequence length of the model. As shown in Table 8, we consider a maximum of 4 images and audio segments. In our experiments, we test with two different variants of perceiver implementations: 1) a small group of latent embeddings query each frame/segment individually [5, 9], 2) a large group of latent embeddings query all history at once. While the second implementation can finely represent the referenced image and audio, the first can preserve better temporal information. Thus, our final implementation uses the first one.
B.2 2D Rotary Embedding
We use a rotary position encoding to model the relative location of input sequences [169]. We chose this primarily because we did not want to use absolute (additive) position embeddings, which would have to be added to the inputs of each encoder, and also wanted to be consistent with the LLaMA [177] position encoding.
The rotary encoding uses no parameters and instead uses a kernel trick to allow the model to recover relative distances between key and query elements in a transformer’s attention head. For text, we apply rotary encoding at each layer of the network. For other modalities, we extend RoPE to two-dimensional cases by splitting each of the query and key embeddings of transformer attention heads in half and apply separate rotary embeddings constructed by each of the two coordinates to the halves.
We treat each token (image, audio, image history, and audio history) as having a 2-dimensional position corresponding to 1) coordinates in the image or audio spectrogram, 2) where and represent the indices of frame and perceiver latent vector in the image or audio history, respectively. Different from [215], which uses a 4-dimensional position to represent all the inputs, we use a combination of learnable segment (modality) embeddings and rotary encoding.
|
L |
XL |
XXL |
||
| Transformer |
Params |
1.1B |
3.2B |
6.8B |
|
Vocab size |
33280 | |||
|
Image vocab size |
16512 | |||
|
Audio vocab size |
8320 | |||
|
Model dims |
1024 |
2048 |
3072 |
|
|
MLP dims |
2816 |
5120 |
8192 |
|
|
encoder layer |
24 | |||
|
decoder layer |
24 | |||
|
Heads |
16 |
16 |
24 |
|
|
MLP activations |
silu, linear | |||
|
Logits_via_embedding |
True | |||
|
Dropout |
0 | |||
| Image Resampler |
Latents size |
32 | ||
|
Model dims |
768 |
1024 |
1024 |
|
|
Heads |
12 |
16 |
16 |
|
|
Head Dims |
64 | |||
|
Number layer |
2 | |||
|
MLP Dims |
2048 |
4096 |
4096 |
|
|
MLP activations |
gelu | |||
| Audio Resampler |
Latents size |
16 | ||
|
Model dims |
768 |
1024 |
1024 |
|
|
Heads |
12 |
16 |
16 |
|
|
Head Dims |
64 | |||
|
Number layer |
2 | |||
|
MLP Dims |
2048 |
4096 |
4096 |
|
|
MLP activations |
gelu | |||
| ViT |
Patch size |
16 | ||
|
Model dims |
768 | |||
|
Heads |
12 | |||
|
Head Dims |
64 | |||
|
Number layer |
11 | |||
|
MLP Dims |
3072 | |||
|
MLP activations |
gelu | |||
| AST |
Patch size |
16 | ||
|
Model dims |
768 | |||
|
Heads |
12 | |||
|
Head Dims |
64 | |||
|
Number layer |
11 | |||
|
MLP Dims |
2048 | |||
|
MLP activations |
gelu | |||
B.3 Dynamic Packing
Here, we describe the dynamic packing algorithm in more detail. As is standard practice, when batching together inputs, we pad input tensors to a maximum length and use attention masked to prevent the transformer from attending to padding elements. This, however, is highly inefficient in our multi-modal setting because many modalities are not present in most examples, which results in a huge amount of padding. For example, if one example in the batch has an image output, every other example must be padded with 1024 target image tokens, even if their output is in a different modality.
One solution is to arrange batches so that each batch contains examples with similar numbers of tokens in each modality. This is, however, complicated to do in practice since (1) our data does not fit in RAM, so we cannot easily sort and group data this way, especially if needing to match tokens across five input and three output modalities and (2) our coding framework, JAX [15], does not support variable length tensors when constructing the execution graph which makes handling variable lengths between batches extremely difficult.
Instead, we use packing, a process where the tokens of multiple examples are packed into a single sequence, and the attentions are masked to prevent the transformer from cross-attending between examples. Packing is often done as a pre-processing step when handling text, but this does not work in our setup since some parts of our network cannot operate on packed data (e.g., the VAE or image ViT). Instead, we start with an unpacked batch of examples, run these components first, and then dynamically pack the resulting tokens in a backdrop-compatible way before running the transformer. To run efficiently on TPUs we pack examples using matrix multiplication with carefully constructed one-hot matrices.
To account for all modalities, the maximum sequence length our transformer needs to take as input is 1152, and the maximum target length is 2048. When packing, we can generally pack two examples into an input sequence of 864 and a target sequence of 1280, which gives a roughly 4x speed up due to reduced sequence length and the ability to process two examples simultaneously. When streaming data, packing cannot be done reliably. For example, if two consecutive examples have an image output, they cannot be packed since they will total over 1280 output tokens. To handle this, we use a heuristic algorithm to re-arrange data as it is being streamed. The algorithm keeps a small pool of examples in memory. Given a new example, it pairs it with the largest example in the pool it can be packed with and outputs both as a pair. If no such example exists, it adds the example to the pool. If the pool reaches a maximum size of 10, the largest example is emitted and processed without being packed with another example. We find this occurs less than 0.1% of the time during training.
B.4 Full Model Details
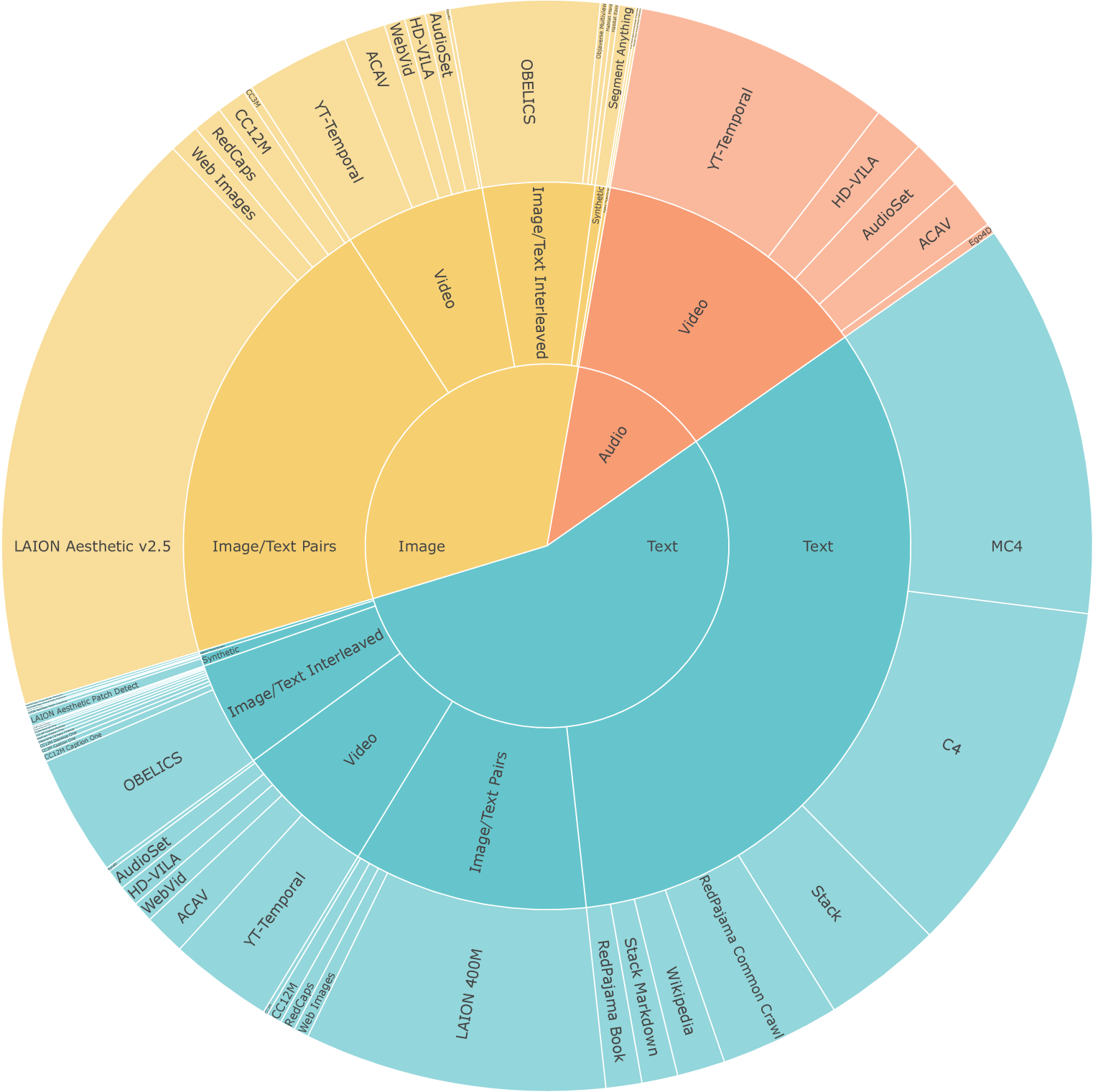
In Table 9, we present the full hyperparameters of our model. During pre-training, we train the UIO-2, UIO-2, and UIO-2 with a batch size of 512 due to memory limit. We sub-sample 50% of the image, audio, and history inputs patches. The total packing length is 864 for the encoder and 1280 for the decoder. During instruction tuning, we train all of our models with a batch size 256 due to computing constraints. We sub-sample 87.5% of the image, audio, and history input patches. The total packing length is 1024 for pretraining and 1280 for instruction tuning. 8-way in-layer parallelism and 64-way data parallelism were used to scale up to the 7B model training.
We train for 1.5 million steps with an effective batch size of 512. This results in training on approximately 1 trillion tokens. During pre-training, we keep at most 50% of the image patches in the image history or image encoder, as is common practice with MAE pre-training [71]. We use up to four images/segments in image/audio history.
Appendix C Pre-Training Details
| Size | Rate | Text | Sparse | Dense | Image | Audio | ImageH | AudioH | Text | Sparse | Dense | Image | Audio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Text | 6.6b | 33.0 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| MC4 [201] | 5.0b | 11.7 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| C4 [68] | 266m | 10.6 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Stack [95] | 147m | 3.55 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| RedPajama CC [32] | 1.2b | 3.55 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Wikipedia | 6.8m | 1.42 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| RedPajama Book [32] | 13m | 1.06 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Stack-Markdown [95] | 34m | 1.06 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Image/Text | 970m | 31.3 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | ✓ | - |
| LAION Aesthetics v2.5 [158] | 491m | 17.7 | ✓ | - | - | ✓ | - | - | - | - | - | - | ✓ | - |
| LAION-400M [159] | 346m | 8.95 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | - | - |
| CC12M [23] | 11m | 1.48 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | ✓ | - |
| RedCaps [42] | 12m | 1.39 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | ✓ | - |
| Web Images | 107m | 1.33 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | ✓ | - |
| CC3M [163] | 3.0m | 0.49 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | ✓ | - |
| Video | 181m | 25.0 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | ✓ |
| YT-Temporal [215] | 146m | 13.7 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | ✓ |
| ACAV [105] | 17m | 3.98 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | ✓ |
| HD-VILA [200] | 7.1m | 2.75 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | ✓ |
| AudioSet [54] | 1.7m | 2.75 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | ✓ |
| WebVid [13] | 9.2m | 1.23 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | - |
| Ego4D [60] | 0.7m | 0.55 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ | ✓ |
| Interleaved Image/Text | 157m | 8.70 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| OBELICS [104] | 131m | 8.00 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| CC12M Interleaved | 11m | 0.35 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | - | - |
| CC3M Interleaved | 3.0m | 0.21 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | - | - |
| RedCaps Interleaved | 12m | 0.14 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | - | - |
| Multi-View | 3.4m | 0.67 | ✓ | - | - | ✓ | - | ✓ | - | - | ✓ | - | ✓ | - |
| CroCo Habitat [194, 157] | 2.6m | 0.33 | ✓ | - | - | ✓ | - | ✓ | - | - | - | - | ✓ | - |
| Objaverse [40] | 0.8m | 0.33 | ✓ | - | - | ✓ | - | ✓ | - | - | ✓ | - | ✓ | - |
| Agent Trajectories | 1.3m | 0.33 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| ProcTHOR [39] | 0.7m | 0.17 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| Habitat [157] | 0.6m | 0.17 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| Synthetic | 504m | 1.00 | ✓ | ✓ | - | ✓ | - | - | - | - | ✓ | ✓ | - | - |
| Segment Anything [94] | 1.1m | 0.50 | ✓ | ✓ | - | ✓ | - | - | - | - | - | ✓ | - | - |
| Laion Aesthetics Patches | 491m | 0.45 | ✓ | - | - | ✓ | - | - | - | - | ✓ | - | - | - |
| RedCaps Patches | 12m | 0.05 | ✓ | - | - | ✓ | - | - | - | - | ✓ | - | - | - |
| All | 8.5b | 100 | ✓ | ✓ | - | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
In this section, we provide additional details about the data Unified-IO 2 is pre-trained on. The datasets we use for pre-training are listed in Table 10. Unless otherwise specified, we use the pre-training objective described in Section 3.3, where one of the present modalities is randomly selected as the target. We sample data to ensure all the output modalities are well represented and to balance how often our various corpora are used based on their size. The distribution is shown in Figure 9.
C.1 Data Sources
Text. Our data follows the mixture used by MPT-7B [176].
Image & Text. Image & text paired data comes from various unsupervised corpora, shown in Table 10. For LAION data, we only generate images from image/text pairs from LAION aesthetic, which contains higher quality images, while we generate text for image/text pairs from LAION 400M. We also only keep images from LAION if they are marked as being unlikely to be NSFW in the LAION metadata. Web images is a dataset of images we download and focuses on icons and stylized images.
Video. We gather a total of 180M short videos from various sources. During training, we pick a random sequence of up to five frames from the video. The first four will be encoded with an image/audio history encoder, while the fifth frame will be encoded with the image/audio encoder. The text matching these frames is encoded with a text encoder along with marker tokens to show where each frame occurred as stated in B.1, or, if the dataset only includes a single caption that is not aligned with individual frames, the entire caption is encoded instead. The text, audio, or image modality can be selected as the target modality. As usual, other modalities are randomly masked, and the target modality is randomly masked or injected with noise in the input. Note we have sub-sampled data from many of these corpora to keep the dataset size more manageable, and sometimes due to broken video links.
Interleaved Image & Text. We primarily use OBELICS [104], which contains paragraphs and images interleaved together. For each document, we randomly select an image or a paragraph as the target and use up to the previous four (if the target is an image) or five (if the target is a paragraph) images as context. The last image is encoded with the image encoder, and the remaining images are encoded in the image history. The text matching those images is concatenated and interjected with marker tokens to indicate where the images in the image history or image input occur. We either do de-noising, where a noisy version of the target is included in the input, or generation, where the target is not part of the input, although we always include both the text and image input modalities.
In addition, we construct interleaved data by interleaving multiple images and captions from several image/text pair corpora. The images are encoded as the image input and/or the image history, and matching text is constructed by specifying the caption for one, or all, of these images using special tokens to mark which image each caption refers to. For this task, we only target the text modality, and train the model to either (1) de-noise the caption of a single image, (2) generate a caption for a single image that is specified in an input prompt using a marker token or (3) generate a sequence of marker tokens and captions that describe each input image. This task aims to ensure the model learns the semantics of the images in the history and understands the marker tokens.
Multi-View. We train on the cross-view completion task from CroCo [194], where the model must complete a heavily noised image using an image of the same scene, but from a slightly different angle, as context. The noised input is encoded as an image and the second image is encoded through the image history encoder. In addition, we generate data using Objaverse [40] objects by capturing multiple views of the object in 3D, and either specify the camera coordinates in the input text and train the model to generate a new image matching new camera coordinates, or train the model to predict how the camera has moved between different images. We further augment the view synthesis task by providing in-context examples. For example, by giving one or more examples of the views and transformations in the image history, the model predicts the new view from the new camera transformation specified by the prompt. Both tasks aim to improve the model’s 3D understanding during pre-training.
Agent Trajectory. We use scripted shortest path trajectories in ProcTHOR [39] and human-collected demonstrations in Habitat [149, 157]. While the original datasets are for object navigation with relatively long episode lengths, we only subsample from the last few frames for image history and image input such that mostly the target object is within the observation. The task is randomly selected from 1) generating the next visual observation frame as the target image, 2) predicting the next positional observation coordinates as the text target, and 3) predicting the next action as the text target. 1) requires inferring from the image and image history input and the last action specified in the text input, 2) further requires the location information, and 3) is based on the target object name and visual observations for the next action prediction.
Synthetic. We add two synthetic tasks. First, we use the automatically annotated data from Segment Anything [94]. We give the model either a set of points or a bounding box as input and train it to generate a segmentation mask as output. Second, we add artificial patches of various shapes and colors to images from other unsupervised datasets and train the model to output their locations in order to train the model to generate sparse coordinates as output. We additionally train the model to output the total number of patches on the image to pre-train its counting abilities.
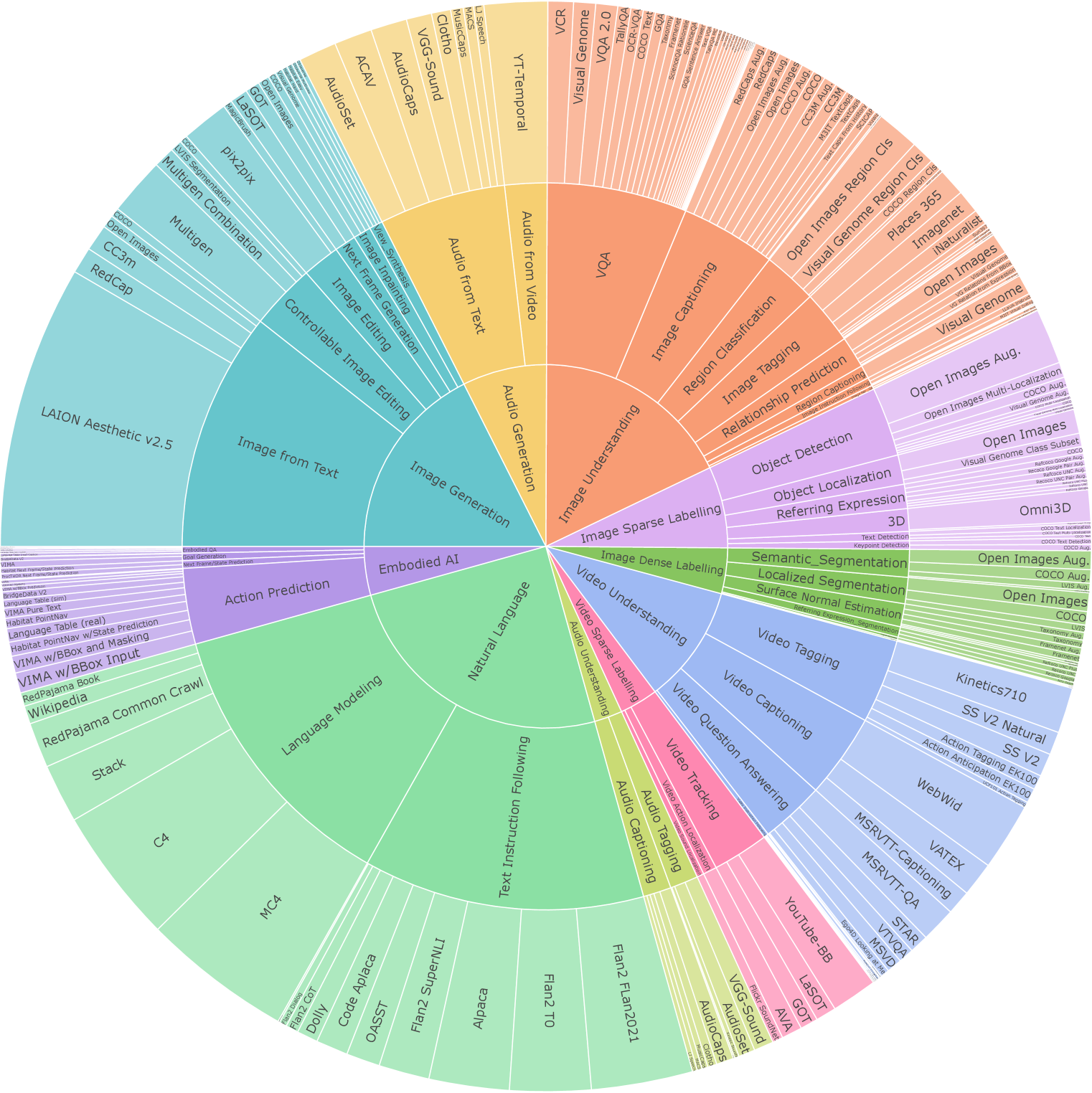
Appendix D Instruction Tuning Details
| Size | Rate | Datasets | Text | Sparse | Dense | Image | Audio | ImageH | AudioH | Text | Sparse | Dense | Image | Audio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Image Generation | 506m | 17.6 | 21 | ✓ | ✓ | ✓ | ✓ | - | ✓ | ✓ | ✓ | - | - | ✓ | - |
| Image from Text | 497m | 10.6 | 5 | ✓ | - | - | - | - | - | - | - | - | - | ✓ | - |
| Controllable Image Editing | 3.0m | 2.92 | 4 | ✓ | - | ✓ | ✓ | - | ✓ | - | - | - | - | ✓ | - |
| Image Editing | 1.1m | 1.66 | 3 | ✓ | - | - | ✓ | - | - | - | - | - | - | ✓ | - |
| Next Frame Generation | 24k | 0.96 | 2 | ✓ | ✓ | - | - | - | ✓ | ✓ | - | - | - | ✓ | - |
| Image Inpainting | 1.0m | 0.79 | 3 | ✓ | ✓ | - | ✓ | - | - | - | - | - | - | ✓ | - |
| View Synthesis | 4.2m | 0.60 | 4 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| Audio Generation | 164m | 7.50 | 9 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | - | - | - | - | ✓ |
| Audio from Text | 19m | 5.62 | 8 | ✓ | - | - | - | - | - | ✓ | - | - | - | - | ✓ |
| Audio from Video | 145m | 1.88 | 1 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | - | - | - | - | ✓ |
| Image Understanding | 53m | 17.8 | 73 | ✓ | ✓ | - | ✓ | - | ✓ | - | ✓ | - | - | - | - |
| VQA | 5.8m | 6.23 | 31 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Image Captioning | 32m | 4.25 | 14 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Region Classification | 6.1m | 2.41 | 4 | ✓ | ✓ | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Image Tagging | 3.8m | 2.38 | 8 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Relationship Prediction | 0.8m | 1.41 | 6 | ✓ | ✓ | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Region Captioning | 3.5m | 0.60 | 1 | ✓ | ✓ | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Image Instruction Following | 0.4m | 0.37 | 6 | ✓ | - | - | ✓ | - | - | - | ✓ | - | - | - | - |
| Image Pair QA | 0.1m | 0.17 | 3 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | - | - |
| Image Sparse Labelling | 13m | 7.25 | 26 | ✓ | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - | ✓ | - |
| Object Detection | 5.3m | 3.08 | 9 | ✓ | - | - | ✓ | - | - | - | - | ✓ | - | - | - |
| Object Localization | 6.0m | 1.31 | 3 | ✓ | - | - | ✓ | - | - | - | - | ✓ | - | - | - |
| Referring Expression | 0.2m | 1.08 | 7 | ✓ | - | - | ✓ | - | - | - | - | ✓ | - | - | - |
| 3D | 1.0m | 1.00 | 2 | ✓ | - | - | ✓ | - | ✓ | - | - | ✓ | - | ✓ | - |
| Text Detection | 37k | 0.41 | 3 | ✓ | - | - | ✓ | - | - | - | - | ✓ | - | - | - |
| Keypoint Detection | 0.3m | 0.38 | 2 | ✓ | ✓ | - | ✓ | - | - | - | - | ✓ | - | - | - |
| Image Dense Labelling | 6.9m | 4.06 | 19 | ✓ | ✓ | - | ✓ | - | ✓ | - | - | - | ✓ | - | - |
| Semantic Segmentation | 2.4m | 1.23 | 4 | ✓ | - | - | ✓ | - | - | - | - | - | ✓ | - | - |
| Localized Segmentation | 3.2m | 1.17 | 3 | ✓ | ✓ | - | ✓ | - | - | - | - | - | ✓ | - | - |
| Surface Normal Estimation | 1.1m | 1.03 | 6 | ✓ | - | - | ✓ | - | - | - | - | - | ✓ | - | - |
| Referring Expression Segmentation | 0.1m | 0.47 | 3 | ✓ | - | - | ✓ | - | - | - | - | - | ✓ | - | - |
| Depth Estimation | 47k | 0.11 | 1 | ✓ | - | - | ✓ | - | - | - | - | - | ✓ | - | - |
| Optical Flow | 24k | 0.06 | 2 | ✓ | - | - | ✓ | - | ✓ | - | - | - | ✓ | - | - |
| Video Understanding | 13m | 10.6 | 24 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | - | - |
| Video Captioning | 9.1m | 3.75 | 3 | ✓ | - | - | ✓ | - | ✓ | ✓ | ✓ | - | - | - | - |
| Video Tagging | 1.1m | 3.75 | 6 | ✓ | - | - | ✓ | - | ✓ | ✓ | ✓ | - | - | - | - |
| Video Question Answering | 2.5m | 2.84 | 9 | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | - | - |
| Video Instruction Following | 0.2m | 0.21 | 6 | ✓ | - | - | ✓ | - | ✓ | ✓ | ✓ | - | - | - | - |
| Video Sparse Labelling | 0.4m | 3.42 | 5 | ✓ | ✓ | - | ✓ | - | ✓ | ✓ | - | ✓ | - | - | - |
| Video Tracking | 0.2m | 2.50 | 3 | ✓ | ✓ | - | ✓ | - | ✓ | ✓ | - | ✓ | - | - | - |
| Video Action Localization | 0.2m | 0.61 | 1 | ✓ | - | - | ✓ | - | ✓ | ✓ | - | ✓ | - | - | - |
| Video Sound Localization | 2.5k | 0.31 | 1 | ✓ | - | - | ✓ | - | ✓ | ✓ | - | ✓ | - | - | - |
| Audio Understanding | 2.2m | 2.50 | 10 | ✓ | - | - | ✓ | ✓ | ✓ | - | ✓ | - | - | - | - |
| Audio Tagging | 2.1m | 1.25 | 5 | ✓ | - | - | ✓ | ✓ | ✓ | - | ✓ | - | - | - | - |
| Audio Captioning | 75k | 1.25 | 5 | ✓ | - | - | - | ✓ | - | - | ✓ | - | - | - | - |
| Natural Language | 11m | 25.0 | 17 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Text Instruction Following | 11m | 12.5 | 10 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Language Modeling | - | 12.5 | 7 | ✓ | - | - | - | - | - | - | ✓ | - | - | - | - |
| Embodied AI | 7.2m | 4.33 | 23 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | ✓ | - | ✓ | - |
| Action Prediction | 4.3m | 3.37 | 12 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | - | - |
| Next Frame/State Prediction | 1.3m | 0.33 | 2 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | - | - | ✓ | - |
| Goal Generation | 0.7m | 0.33 | 3 | ✓ | - | - | ✓ | - | ✓ | - | - | - | - | ✓ | - |
| Embodied QA | 1.0m | 0.30 | 6 | ✓ | - | - | ✓ | - | ✓ | - | ✓ | ✓ | - | - | - |
| All Tasks | 775m | 100 | 227 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
In this section, we provide additional details about the instruction tuning data and individual tasks Unified-IO 2 supports. An overview of the instruction tuning data is shown in Table 11. We show a visualization including individual datasets in Figure 10. We sample broad categories of tasks evenly and then generally sample individual datasets in proportion to the square root of their size, although with some minor hand-engineered adjustments to downweight noisy datasets or upweight very rare tasks.
D.1 Natural Language
For natural language data we use the mixture from FlanV2 [122], which in turn includes data from Muffin [193], T0-SF [156], NIV2 [191], and CoT annotations, as well data from Alpaca [142], Dolly [33], Open Assistant [99], and MDPP [8]. In addition, we continue pre-training on our unsupervised NLP mixture from our fine-tuning stage to ensure the model does not forget information learned from unsupervised data during the extensive instruction-tuning stage.
D.2 Image Generation
For text-to-image generation, we use the same image/text pairs we used during pre-training, as well as localized narratives from Open Images [103] and captions from COCO [115] and Visual Genome (VG) [102]. Our prompts for these tasks specify that the image might be noisy or approximate for unsupervised corpora (e.g. “Generate an image that roughly matches this text: {caption}”) and give hints as to the style for supervised corpora (e.g. “What do you see in this image? Plainly describe the individual element you observe.” for localized narratives) to help disambiguate the stylistic differences between the datasets. We use simple prompts (e.g. “Caption this image.”) for the COCO captions.
We additionally train the model to generate images through view synthesis [194, 40] as was done during pre-training. We also integrate data for image editing [18, 217] and image editing based on various dense control signals such as depth maps, edges, segmentation, etc. Following [145], and the segmentation-based image generation from Unified-IO using data from COCO and LVIS [62]. Finally, we train on inpainting by masking a region of an input image that contains an object and training the model to generate the complete image given the object name and location. We derive data for this task from the object annotation data in COCO, Open Images, and VG.
During inference, we use top-p sampling, also known as nucleus sampling [75], for generating images with the temperature and . We also enable classifier-free guidance [74] by replacing the prompt with the un-informative prompt “An image of a random picture.” 10% of the time during training. That prompt is then used as the classifier-free prompt with a guidance scale of during inference.
D.3 Audio Generation
Datasets for audio generation from text include AudioCaps [93], Clotho [47], MACS [131], MusicCaps [2], and LJSpeech [85]. During training, we divided the audio into 4-second-long segments and then generated one segment of the target audio, giving both the text and any previous segments as input. We also train on the next-frame prediction task, which aims to generate the audio for the next frame in a video from YT-Temporal-1B [215].
Our prompts for these tasks specify the characteristics of target audio; e.g., “Generate the sound/music based on the description: {caption}” for natural sound and music, respectively, and “Speak: {passage}” for speech. We use the same sampling method as the image generation, the top-p sampling with the temperature and . We do not use the classifier-free guidance because it can lead to poor performance. When generating audio longer than 4.08 seconds during inference, we generate an initial segment that is 4.08 seconds long and then extend it by generating additional segments using previous audio segments as the audio history input.
D.4 Image Understanding
These tasks require generating text in response to a query about an image or a pair of images. We use the data from MIT [112] and MIMIC-IT [108, 107], as well as a variety of other additional sources. For VQA, we add GQA [83], TallyQA [1], OK-VQA [130], A-OKVQA [160], OCR-based VQA datasets [133, 165], Visual Genome, ScienceQA [124], VCR [213] and VizWiz [67]. For image tagging we add Caltech Birds [195], iNaturalist [180], Sun397 [197], and Places365 [224]. For region classification, we add examples derived from object annotation from Open Images, VG, and COCO. We categorize datasets with open-ended responses such as LLaVa [119], Visual Storytelling [82], and Visual Dialog [36] as visual instruction following, and we categorize NLVR [171] and the “spot the differences” tasks from MIMIC-IT as image pair QA. For image pair QA tasks, we encode the second image in the image history modality.
We also add a grounded relationship prediction task using data from Visual Genome and VSR [116] as well as image captioning using the same supervised sources we use for image generation.
We again put stylistic hints in the prompts for these tasks. For example, in VQA and captioning datasets, we specify to return a short answer (e.g. “Answer this question very succinctly: {question}”), which we find is critical to allow the model to produce longer, more natural responses when asked user questions. Likewise, we roughly specify the kind of class to output for image tagging, e.g., “”What is the scientific name of this animal?” for the iNaturalist dataset.
D.5 Image Sparse Labelling
These tasks require outputting sparse coordinates based on an input image. We use Open Images, Visual Genome, and COCO for object detection and localization, which requires detecting all objects belonging to a specific class and three COCO referring expression datasets [91, 209, 136] for referring expressions.
In addition, we train on the OmniLabel [16] 3D detection dataset by generating the projected 3D center, virtual depth, log-normalized box size, and rotation of each 3D box, again by normalizing these values between 0 and 1 and then encoding them using the location tokens. We also added the camera pose prediction tasks using Objaverse objects that were used during pre-training.
We include 3 text detection datasets from COCO-Text [183], including finding the bounding box of an input text string for multiple text strings or finding and listing all text along with their bounding boxes in an image.
Lastly, we do keypoint detection using COCO pose data. For keypoint detection, we input a bounding box around a person in the image and train the model to return a list of keypoints for that person. During inference, we first localize all people in the image and then use each returned bounding box as a keypoint query to find that person’s keypoints. During training, the model predicts “MISSING” for keypoints that are not visible (e.g. “right elbow: MISSING”). During inference, we use a masking function over the model’s logit to force it to guess a valid point for each keypoint since the keypoint metric does not award points for correctly identifying a keypoint as being not visible.
D.6 Image Dense Labelling
We do several image labeling tasks, including surface normal estimation on FramNet [78], BlendedMVS [204] and Taskonomy [211], depth on NYU Depth [138], and optical flow on Flying Chairs [44] and MPI Sintel [21].
We additionally train on several segmentation tasks: semantic segmentation (segmenting a particular class), localization segmentation (segmenting an object in an input bounding box), and referring expression segmentation (segmenting an object matching a referring expression). Data comes from Open Images, COCO, LVIS, and referring expressions from the COCO refexp datasets [91, 209, 136]. To do instance segmentation, as needed for GRIT, we first do localization on the target class and then perform localized segmentation on each returned bounding box.
During inference, we do temperature sampling with a top-p of 0.95 as before, but without classifier-free guidance. For segmentation, we find it beneficial to increase the value of p to 0.97.
D.7 Video Understanding
These tasks require generating text in response to a query about a video. For video captioning, we add VATEX [190] and MSR-VTT [199]. For action classification (video tagging), we add UCF101 [168], Kinetics-710 [111], Something-Something v2 [58] and EPIC-KITCHENS-100 [35]. We also use examples from EPIC-KITCHENS-100 for action anticipation. For video question answering, we add MSRVTT-QA [198], MSVD-QA [198], STAR [196] and M4-ViteVQA [221]. Lastly, we use examples from MIT and MIMIC-IT for the video instruction following.
To cover the visual content of the entire video with a small number of frames (5), we use the segment-based sampling following [185]; we first divide the video into five segments of equal duration and then randomly sample one frame from each of the segments during training, and the middle frame at inference. We use the first four frames as the image history input and the final frame as the image input for action classification and video captioning. We empirically found that using the third frame as the image input while using the other frames as the image history input performs better for video question answering.
We use similar prompts to those for image understanding tasks, e.g., “Write a short description of this video.”, “The question {question} can be answered using the video. A short answer is” and “What are they doing in this video? Short answer:” in video captioning, video question answering, and video tagging, respectively, for ensuring a short answer.
D.8 Video Sparse Labelling
We do single object tracking and spatial-temporal action localization on video data. We train on YouTube-BB [151], LaSOT [50] and GOT-10k [79] by inputting bounding boxes around a target object in each of previous frames and having the model return the next location as a bounding box (“Anticipate the object’s next location from all previous images and the location of the object in those frames: {locations}.”). We also train the model on AVA [61] by inputting a video snippet consisting of five frames and requiring the model to detect all actions of humans appearing in the middle (third) frame of the video snippet (“Given the temporal context from the video, detect all of the humans performing actions in the image.”). Note that we provide the video snippet, not a single video frame, because some of the actions require temporal context to answer (e.g., stand and sit) correctly. We use the final/middle frame of five consecutive frames in the video as the image input and the other frames as the image history input for single object tracking and action localization, respectively.
D.9 Audio Understanding
We train the model on audio tagging and audio captioning tasks. For audio tagging, we add AudioSet [54], VGG-Sound [24], and MACS. For audio captioning, we use the same datasets as text-to-audio generation, that is, AudioCaps, Clotho, MACS, MusicCaps, and LJSpeech. For audio-visual action classification, we train on Kinetics-Sounds [7] and VGG-Sound.
We again use stylistic hints in the prompts for these tasks. For example, we specify the characteristics of target audio (e.g., “Describe the music.” and “Transcribe the audio to text.” for MusicCaps and LJSpeech, respectively), enforce a short answer (e.g., “What is this in the audio? Short answer:” and “Give a short description of this audio.”), and specify the kind of class to output for audio tagging, e.g., “This audio depicts a scene of a” for MACS. We use the same prompts as video tagging for audio-visual action classification.
We use the same sampling strategy as the video understanding; we sample five audio segments with uniform intervals from the whole audio and use the middle/final audio segment as the audio input while using the other segments as the audio history input for audio classification and audio captioning, respectively.
D.10 Embodied AI

While many robot manipulation tasks can be formulated by multimodal prompts that interleave language and images or video frames, we use VIMA-Bench [87] to evaluate the robot manipulation skills. We use the image input as the initial observation of the environment and the image history for the images or videos in the prompt. The text inputs, or the language instructions, also include special tokens to explicitly express the interleaved multimodal prompt. The action space consists of primitive actions of “pick and place” for tasks with a suction cup as the end effector or “push” for tasks with a spatula. Both primitive actions contain two poses and one rotation , specifying the start and target states of the end effector.
With the action representation described in B.1, we seamlessly add large-scale manipulation datasets Language Table [127], BridgeData V2 [184], and FrankaKitchen [63] with the continuous control in both simulated and real-world environments. The model directly predicts the next action as the text target based on the current observation as image input, previous frames as image history, and language instruction and previous actions as text inputs.
Due to the non-causality of the model and limited sequence length for the image history, we only added the PointNav task from Habitat [157] Gibson scenes for the navigation. The model is required to predict the next action, with random augmentation for predicting the next position and rotation state, based on the point goal (positions ), visual observations, and previous actions and states, if any.
D.11 Task Augmentation
In addition to these sources, we derive several additional tasks that use the same supervised annotations as other tasks but require performing slightly different functions. We call this task augmentation. The new tasks include prompts that specify the desired output. These tasks serve to add diversity to our instruction following data. We review the task augmentation we construct below.
Segmentation. We build several augmentations of the segmentation tasks, including (1) segmenting pixels belonging to one of a set of 2-4 categories, possibly including categories that do not exist in the image, (2) segmenting pixels belonging to a class and are within an input bounding box and (3) build a map of pixels that do not belong to a set 1-4 classes. Prompts are designed for these that state the requirement, e.g., “Show pixels that are part of chair, paper and in <extra_id_289> <extra_id_871> <extra_id_781> <extra_id_1156>”.
| Prompt | Model Response |
|---|---|
| A video of a man (woman) saying Unified-IO 2 is a model that works with vision, language, audio, and action. | () |
A video of a man playing guitar.
![[Uncaptioned image]](x12.png)
|

Detection and Referring Expression. For detection, localization, and referring expressions, we also train the model to output various properties of the output bounding boxes instead of the boxes themselves. Properties include the width, height, area, left/right/top/bottom half, center coordinates, distance from the left/right/top/bottom edge of the image, or the coordinates of different corners of the bounding box. We also change the format of the output bounding box (e.g., instead of format), and change whether the model labels the boxes with the object category or not.
For detection, we train the model to detect any object belonging to a set of 1-4 classes. For referring expressions, we train the model to locate multiple referring expressions from a single query. In this case, we sometimes train the model to predict a property of both referenced boxes instead of outputting the directly, for example, which box is the smallest, which is the largest, the area of intersection, a box containing both boxes, etc.
Relationship Prediction. We train the model to list all relationships between a particular object in the image and any other object. A bounding box and category specify the target object. Similarly, we train the model to predict all relationships between any instance of a particular class of objects and any other object in the image.
Captioning. For captioning, we train the model to generate a caption that is longer or shorter than a given character or word length or contains a particular word or set of words. We also randomly require the caption to start with a particular prefix. Again, these requirements are specified in the prompt, for example, “Generate a caption longer than five words for this image. Start your output with the text ‘My caption is:’”.
Surface Normal Estimation. For surface normal estimation, we train the model to generate RGB images that encode the pixel orientation differently. This includes changing which RGB channels correspond to the x, y, and z orientations and only including a subset of those orientations. We also include tasks that require specifying the x, y, and z orientation at a particular point specified in the prompt using location tokens. Finally, we include tasks requiring segmentation masks over pixels with particular orientations, e.g., “Build a binary mask over surfaces with an upward orientation”.

Embodied AI. We further augment the embodiment datasets with the video QA and goal image generation tasks. The QA augmentation aims for the robot’s planning and affordance. For example, given a robot video trajectory, the model is supposed to predict the plan (caption), or whether a given action is reasonable from the language instruction. Applying image editing in embodied space, we further let the model generate the goal or subgoal images based on the initial visual observation in the image input and the language prompt in the text input. While recent works show that embodiment QA with VLM [46, 162] and (sub-)goal generation with diffusion model [134] are effective in the decision-making downstream tasks, our model combines the both augmentation strategies.
Appendix E Experiment Details
| Categorization | Localization | VQA | Refexp | Segmentation | Keypoint | Normal | All | ||||||||||
| ablation | test | ablation | test | ablation | test | ablation | test | ablation | test | ablation | test | ablation | test | ablation | test | ||
| 0 | NLL-AngMF [11] | - | - | - | - | - | - | - | - | - | - | - | - | 49.6 | 50.5 | 7.2 | 7.1 |
| 1 | Mask R-CNN [70] | - | - | 44.7 | 45.1 | - | - | - | - | 26.2 | 26.2 | 70.8 | 70.6 | - | - | 20.2 | 20.3 |
| 2 | GPV-1 [65] | 33.2 | 33.2 | 42.8 | 42.7 | 50.6 | 49.8 | 25.8 | 26.8 | - | - | - | - | - | - | 21.8 | 21.8 |
| 3 | CLIP [146] | 48.1 | - | - | - | - | - | - | - | - | - | - | - | - | - | 6.9 | - |
| 4 | OFA [186] | 22.6 | - | - | - | 72.4 | - | 61.7 | - | - | - | - | - | - | - | 22.4 | - |
| 5 | GPV-2 [89] | 54.7 | 55.1 | 53.6 | 53.6 | 63.5 | 63.2 | 51.5 | 52.1 | - | - | - | - | - | - | 31.9 | 32.0 |
| 5 | DINO + SAM [94, 139] | - | - | 66.0 | 66.0 | - | - | - | - | 60.2 | 60.1 | - | - | - | - | 18.0 | 18.0 |
| 6 | Unified-IO | 42.6 | - | 50.4 | - | 52.9 | - | 51.1 | - | 40.7 | - | 46.5 | - | 33.5 | - | 45.4 | - |
| 7 | Unified-IO | 53.1 | - | 59.7 | - | 63.0 | - | 68.3 | - | 49.3 | - | 60.2 | - | 37.5 | - | 55.9 | - |
| 8 | Unified-IO | 57.0 | - | 64.2 | - | 67.4 | - | 74.1 | - | 54.0 | - | 67.6 | - | 40.2 | - | 60.7 | - |
| 9 | Unified-IO | 61.7 | 60.8 | 67.0 | 67.1 | 74.5 | 74.5 | 78.6 | 78.9 | 56.3 | 56.5 | 68.1 | 67.7 | 45.0 | 44.3 | 64.5 | 64.3 |
| 9 | UIO-2 | 70.1 | - | 66.1 | - | 67.6 | - | 66.6 | - | 53.8 | - | 56.8 | - | 44.5 | - | 60.8 | - |
| 10 | UIO-2 | 74.2 | - | 69.1 | - | 69.0 | - | 71.9 | - | 57.3 | - | 68.2 | - | 46.7 | - | 65.2 | - |
| 11 | UIO-2 | 74.9 | 75.2 | 70.3 | 70.2 | 71.3 | 71.1 | 75.5 | 75.5 | 58.2 | 58.8 | 72.8 | 73.2 | 45.2 | 44.7 | 66.9 | 67.0 |
E.1 Pre-training Visualization
In the main paper, we evaluate the effectiveness of our pre-training by evaluating Unified-IO 2 quantitively on a variety of benchmarks. Here, we qualitatively show the visualizations from the pre-trained UIO-2model. Table 12 shows audio generation from text (top) and text + video (bottom). We can see the pre-trained model learns text-to-speech synthesis through video pre-training, and the model can also synthesize music that matches the video input. Figure 12 shows the future frame prediction samples given the initial input image and action sequence. Figure 13 shows the image generation samples given prompts. The model has a good understanding of different objects. However, it struggles to generate the correct text from the given caption.
E.2 NLP Results
| HellaSwag | MMLU | Arc Easy | Arc Cha. | BoolQ | |
|---|---|---|---|---|---|
| UIO-2 | 39.4 | 28.4 | 41.8 | 26.2 | 66.6 |
| UIO-2 | 49.9 | 29.7 | 49.5 | 31.3 | 72.8 |
| UIO-2 | 52.7 | 30.4 | 55.3 | 33.5 | 77.3 |
| Open LLaMA 3B | 52.0 | 23.9 | 69.3 | 33.8 | 67.0 |
| LLaMA 7B | 57.1 | 42.6 | 76.4 | 43.5 | 77.7 |
| LLaMA 7B Chat | 57.7 | 47.6 | 74.4 | 44.0 | 80.7 |
We present results on a set of NLP tasks to evaluate the model’s language understanding abilities. We evaluate using the EleutherAI LM-Eval harness [51], tasks are evaluated zero-shot using the default prompts without any adjustments aside from adding the [Text] [S] prefix used for all text generation tasks. We evaluate on HellaSwag [214] and a selection of other question answering benchmarks: MMLU [72], ARC [31], and BoolQ [30]. Results are shown in Table 14. Baselines were evaluated in the same setting, i.e., zero-shot, with the default prompts, and using LM-Eval. Unified-IO 2 is generally ahead of Open LLaMA 3B but behind LLaMA.
E.3 GRIT Details
We present GRIT results in more detail in Table 13. Notably, Unified-IO 2 is the first unified model to pass the Masked R-CNN baseline for localization and goes a long way toward closing the gap between SAM and unified models on segmentation.
For GRIT VQA, looking at the scores from GRIT on different VQA subsets, we find that Unified-IO 2 does better on the same-source subset (84.6 vs 58.5) but worse on the new-source subset (57.7 vs 67.2). Same-source questions come from VQA 2.0, and new-source questions come from VG, so the difference can be attributed to the kinds of questions being asked. Qualitatively, it is hard to understand why the scores differ on these subsets since the GRIT ablation questions lack ground truth annotations. However, we notice the models often produce different answers when faced with ambiguous questions (e.g. “What color is black on the horse”, “hair” for Unified-IO vs. “mane” for Unified-IO 2), so one possibility is that Unified-IO 2 does not match the VG answer style as well as Unified-IO, which would likely be due to differences in the kind of VQA training data the models were trained on.
For GRIT localization, we find the model can struggle with images with many instances of the target class, particularly when using beam search. We hypothesize that this is because the probability mass can get split between many similar location tokens, resulting in EOS becoming the most probable token even if its probability is low. As a solution, during inference, we only output EOS if the EOS token itself has a probability of over 0.5, which we find significantly improves the performance on crowded images. In rare cases, we observe this leads to the model generating bounding boxes for the same instance multiple times. As a solution, we apply Non-maximum suppression with a higher threshold of 0.8 to remove these duplicates. We apply this inference trick for localization and when doing the initial localization step for the keypoint and segmentation tasks.
E.4 Multimodal Benchmark Details
| Splits | Metrics | UIO-2 | UIO-2 | UIO-2 | [206] | [207] | [26] |
|---|---|---|---|---|---|---|---|
| Random | Accuracy () | 90.90 | 88.27 | 84.03 | 88.28 | 90.24 | 86.90 |
| Precision () | 94.30 | 97.44 | 77.73 | 94.34 | 97.72 | 94.40 | |
| Recall () | 87.07 | 78.60 | 95.40 | 82.20 | 83.00 | 79.27 | |
| F1-Score () | 90.54 | 87.01 | 85.66 | 87.85 | 89.76 | 86.19 | |
| % Yes | 46.17 | 40.33 | 61.37 | 44.91 | 43.78 | 43.26 | |
| Popular | Accuracy () | 88.17 | 87.47 | 77.27 | 86.20 | 84.90 | 83.97 |
| Precision () | 89.13 | 95.69 | 70.03 | 89.46 | 88.24 | 87.55 | |
| Recall () | 86.93 | 78.47 | 95.33 | 82.06 | 80.53 | 79.20 | |
| F1-Score () | 88.02 | 86.23 | 80.75 | 85.60 | 84.21 | 83.16 | |
| % Yes | 48.77 | 41.00 | 68.07 | 45.86 | 45.63 | 45.23 | |
| Adversarial | Accuracy () | 84.17 | 85.77 | 72.00 | 84.12 | 82.36 | 83.10 |
| Precision () | 82.17 | 92.01 | 65.00 | 85.54 | 83.60 | 85.60 | |
| Recall () | 87.27 | 78.33 | 95.33 | 82.13 | 80.53 | 79.60 | |
| F1-Score () | 84.64 | 84.62 | 77.30 | 83.80 | 82.00 | 82.49 | |
| % Yes | 53.10 | 42.57 | 73.30 | 48.00 | 48.18 | 46.50 |
| Img | Video | All | |
| InstructBLIP [34] | 58.8 | 38.1 | 53.4 |
| VideoChat-7B [110] | 39.0 | 33.9 | 37.6 |
| Otter-7B [108] | 42.9 | 30.6 | 39.7 |
| Qwen-VL-7B [12] | 62.3 | 39.1 | 56.3 |
| Qwen-VL-chat-7B [12] | 65.4 | 37.8 | 58.2 |
| mPLUG-Owl2-7B [206] | 64.1 | 39.8 | 57.8 |
| LLaVA-1.5-7B [118] | - | - | 58.6 |
| LLaVA-1.5-13B [118] | 68.2 | 42.7 | 61.6 |
| Unified-IO 2 | 56.0 | 37.5 | 51.1 |
| Unified-IO 2 | 64.1 | 45.6 | 60.2 |
| Unified-IO 2 | 65.7 | 46.8 | 61.8 |
We now provide the breakdown results for the evaluation-only multimodal benchmarks, POPE [113] and SEED-Bench [106]. POPE is the object hallucination benchmark, requiring ‘yes’ or ‘no’ answers. As shown in Table 15, our largest model achieves the highest F1 score in all 3 dimensions. Interestingly, smaller models favored ‘no’ responses, possibly due to a bias from negative examples encountered during the instruction tuning phase. SEED-Bench offers 19k multiple-choice questions with human annotations for evaluating multimodal models across 12 dimensions, including spatial (Image) and temporal (Video) understanding. As shown in Table 16, our XXL model outperforms all other 7B vision/video language models, and is even slightly better than the LLaVA-1.5 13B model. Notably, our XL (3B) model has already outperformed all other counterparts in the temporal understanding split. While recent video language models [128, 110, 108] have shown proficiency in conventional video tasks like video tagging and captioning, their performance in SEED-Bench’s temporal understanding is even worse than that of vision language models, which might be attributed to their limited instruction-following capabilities.
E.5 Image Generation Details


Figure 15 shows generated images for the TIFA benchmark captions [76] using several baselines as well as UIO-2. We use the official implementation code (Emu [172] and CoDi [174]) or the images shared in the official GitHub repository of TIFA555https://github.com/Yushi-Hu/tifa/tree/main/human_annotations (Stable Diffusion v1.5 [154] and miniDALL-E [37]) for baselines. All the baselines except miniDALL-E use the Stable Diffusion decoder trained on large-scale, high-quality image datasets, generating images of high fidelity. However, they often generate images that do not fully follow the input captions while Unified-IO 2 generates faithful images.
For text-to-image generation on MS COCO [115], we follow the standard convention [226]; we evaluate on a subset of 30K captions sampled from the validation set.666We use the evaluation code at https://github.com/MinfengZhu/DM-GAN Following [43], we generate 8 images for each caption and select the best one using CLIP text-image similarity [146]. Despite classifier-free guidance [74] resulting in generated images of qualitatively higher quality, the computed FID score [73] is significantly worse compared to what would have been achieved without employing it (33.77 vs 13.39); see Figure 14.
E.6 Audio Generation Details
![[Uncaptioned image]](x17.png)
![[Uncaptioned image]](x18.png)
![[Uncaptioned image]](x19.png)
![[Uncaptioned image]](x20.png)
![[Uncaptioned image]](x21.png)
![[Uncaptioned image]](x22.png)
![[Uncaptioned image]](x23.png)
![[Uncaptioned image]](x24.png)
![[Uncaptioned image]](x25.png)
![[Uncaptioned image]](x26.png)
![[Uncaptioned image]](x27.png)
![[Uncaptioned image]](x28.png)
For text-to-audio generation, we evaluate on the AudioCaps [93] test set. Note that we cannot do an apples-to-apples comparison with other methods because AudioCaps consists of 10-second audio clips while our model can generate 4.08-second audio at a time. Instead, we evaluate the dataset in the following setup: we first sample four 2-second audio segments, convert them to log-mel-spectrograms with zero-padding, and generate the following audio with the prompt “Generate the following sound based on what you heard and the description: {caption}”. We convert the model output, that is, a log-mel-scaled spectrogram, into a waveform using the pretrained HiFi-GAN, and compare the ground-truth audio and generated audio using computational metrics including Fréchet Audio Distance [92], Inception Score [155] and Kullback–Leibler divergence. We use the same evaluation code as AudioLDM777https://github.com/haoheliu/audioldm_eval [117]. We show the audio generation examples in Table 17 and audio-visual qualitative examples in Table 18.
E.7 Video and Audio Understanding Details


We consider classification and question-answering tasks as open-ended answer generation and use the Exact Match (EM) to measure the performance. We also tried to formulate the classification task as multiple-choice answering and generate answers by computing the logit for each dataset label and selecting the one with the highest logit, but the performance boost was quite marginal. Note that we do not train our model directly on the Kinetics-400 [90]; we instead train on Kinetics-710, a mixture of three different datasets belonging to the Kinetics family, that is, Kinetics-400, 600, and 700. Our model achieves top-1 accuracy 79.1 (vs. instruction tuning only: 73.8) when further finetuning on Kinetics-400 for 5 epochs, following [111]. For Kinetics-Sounds, leveraging both audio and visual inputs largely improves performance (audio-visual: 89.3 vs. video-only: 87.4 vs. audio-only: 38.2). For captioning tasks, we use CIDEr [182] as the evaluation metric. Figure 17 shows the qualitative examples for video understanding tasks.
E.8 Embodiment Details

| L1 | L2 | L3 | L4 | Avg. | |
| VIMA [87] | 81.5 | 81.5 | 78.7 | 48.6 | 72.6 |
| VIMA-Gato [152] | 57.0 | 53.9 | 45.6 | 13.5 | 42.5 |
| VIMA-Flamingo [5] | 47.4 | 46.0 | 40.7 | 12.1 | 36.6 |
| VIMA-GPT [19] | 46.9 | 46.9 | 42.2 | 12.1 | 37.0 |
| Unified-IO 2 | 66.9 | 63.8 | 57.5 | 12.6 | 50.2 |
| Unified-IO 2 | 70.3 | 69.8 | 64.5 | 13.1 | 54.2 |
| Unified-IO 2 | 71.3 | 70.4 | 68.0 | 15.5 | 56.3 |
In VIMA-Bench [87], there are 4 levels of evaluation protocols: L1 object placement, L2 novel combination, L3 novel object, and L4 novel task. Results and comparisons are shown in Table 19. The inputs for the autoregressive transformer model VIMA [87] are object tokens consisting of cropped images and bounding boxes; image patch tokens encoded by ViT for VIMA-Gato [152]; image patch tokens encoded by ViT, further downsampled by a perceiver module for VIMA-Flamingo [5]; and single image token encoded by ViT for VIMA-GPT [19]. The output of those baselines is all next-step action prediction. Since our model has to predict all actions at once only with the initial observation, the task setting is then more challenging than the casual policy learning baselines. Nevertheless, our models still outperform counterparts that input image or image patches for all 4 levels and are only behind the object-centric method [87]. In Figure 18, we show the future state prediction examples on robotic manipulation tasks. Given the input state image and natural language prompt, our model can successfully synthesize the target image state.
E.9 Other Tasks


Figure 16 shows single object tracking examples from the LaSOT [50] dataset. Note that Unified-IO 2 does not use specific class labels for tracking and tracks small moving objects such as a table tennis paddle well. Figure 19 presents qualitative examples of 3D object detection from the Objectron dataset [3]. As outlined in our main paper, Unified-IO 2 exhibits suboptimal performance in benchmarks for multi-object 3D detection. Additionally, Figure 20 illustrates examples of image-based 3D view synthesis using the Objaverse dataset [40]. While the model produces coherent results, it faces challenges in accurately representing relative camera transformations.