Generative AI-driven Semantic Communication Networks: Architecture, Technologies and Applications
Abstract
Generative artificial intelligence (GAI) has emerged as a rapidly burgeoning field demonstrating significant potential in creating diverse contents intelligently and automatically. To support such artificial intelligence-generated content (AIGC) services, future communication systems should fulfill much more stringent requirements (including data rate, throughput, latency, etc.) with limited yet precious spectrum resources. To tackle this challenge, semantic communication (SemCom), dramatically reducing resource consumption via extracting and transmitting semantics, has been deemed as a revolutionary communication scheme. The advanced GAI algorithms facilitate SemCom on sophisticated intelligence for model training, knowledge base construction and channel adaption. Furthermore, GAI algorithms also play an important role in the management of SemCom networks. In this survey, we first overview the basics of GAI and SemCom as well as the synergies of the two technologies. Especially, the GAI-driven SemCom framework is presented, where many GAI models for information creation, SemCom-enabled information transmission and information effectiveness for AIGC are discussed separately. We then delve into the GAI-driven SemCom network management involving with novel management layers, knowledge management, and resource allocation. Finally, we envision several promising use cases, i.e., autonomous driving, smart city, and the Metaverse for a more comprehensive exploration.
Index Terms:
Semantic communication, AIGC, Generative AI, Intelligent wireless networks, Knowledge management.I Introduction
Generativeartificial intelligence (GAI), regarded as one of the most significant advancements in the field of artificial intelligence (AI), has recently achieved remarkable progress in many areas such as natural language processing (NLP) and multimedia content synthesis [1]. Intrinsically, GAI learns from external knowledge, categorizes data, analyzes examples, and comprehends patterns to produce human-like artifacts in digital content creation. The revolution brought by GAI is now reshaping industries and ushering in novel economic markets. From McKinsey’s estimation, GAI could add the equivalent of $2.6 trillion to $4.4 trillion annually, significantly increasing the impact of all AI [2].
I-A Background
Within the realm of GAI, AI-Generated Content (AIGC), i.e., digital content including text, image, audio and video is generated by machine learning (ML) algorithms automatically, stands as a notable application in information technology field. Recently, many AIGC products with high efficiency and knowledgeability meeting the huge demand from people on data acquisition, have attracted much attention. One of the most significant reasons is that AIGC services are capable to deal with large-scale database in a short time due to the advanced computing ability. For instance, Claude, delivered by Anthropic’s generative AI, could process 100,000 tokens of text (equal to about 75,000 words in a minute) by May 2023 [3]. Especially, some advanced AIGC services are realized by sophisticated multimodal GAI models which can cope with more than one data formats. A renowned example, ChatGPT-4 [4], allows users to share images and engage in voice conversations. It significantly enriches the user experience, offering a more dynamic and interactive form of communication compared to ChatGPT-3.5’s primarily text-based interactions.
In addition to enjoying benefits offered by GAI, it is anticipated that new challenges will come into the landscape of wireless communication networks [5]. To accommodate novel communication scenarios with GAI and AIGC services, the proliferation in traffic demands along with more stringent latency and reliability requirements are inevitable. Whereas, current wireless communication systems continue to operate under the framework of traditional Shannon’s theory, that is, regardless of the format (text, images, and video), all content is encoded into binary bits via pre-defined codebooks for transmission [6]. They concentrate solely on bits, neglecting the message’s meaning, thus leading to a low bandwidth utilization. Furthermore, these traditional systems focus on improving network performance in terms of data rate, latency, throughput, reliability, etc., which are tightly dependent on the amount of bits rather than content meaning. This rigid scheme is unable to exploit contextual information, customize content and make intelligent decisions based on the knowledge of the communication pairs, thus failing to adapt the knowledge-driven AIGC services [7].
Fortunately, semantic communication (SemCom), has been regarded as a groundbreaking paradigm shift. Compared with conventional communication systems, SemCom focuses on exchanging the meaning of information rather than reproducing the source data. Typically, a transmitter in SemCom begins by extracting the hidden semantics from source data and then adapting the encoding bits to the wireless channel condition [8, 9]. The information is then transmitted through a wireless channel, with the receiver working to recover the source’s meaning aiming to minimize semantic ambiguity. In this process, SemCom only conveys essential semantics and filters out irrelevant information, which leads to significant savings in wireless resource consumption. Moreover, the semantic encoder can personalize content creation based on the individual’s background knowledge. Further, aided by the mutual knowledge between the transmitter and receiver, the syntactic errors are corrected via context-based reasoning while recovering received semantics at the receiver. Thereby, SemCom can sustain good performance even under harsh channel conditions.
I-B Motivations
Considering the superiorities of SemCom, it should be expected as a promising paradigm for AIGC transmission. It is observed that the structure and logic of the AIGC are inherently tied to GAI models, making it possible for meaning inference according to immediate context. This is highly compatible with the framework of SemCom. Meanwhile, SemCom systems enable to handle high-volume data and diverse content types with sustainable resource consumption, sufficing the needs of intricate AIGC services while alleviating internet strain. By leveraging the knowledge collected from user’s history and sensing data, SemCom systems allow more intelligent personalized services.
On the other hand, GAI brings numerous benefits to SemCom design. At its core, the SemCom encoder and decoder are augmented by GAI. Through the generation of context-sensitive, adaptable, and semantically dense content, GAI greatly bolsters SemCom’s ability to effectively transmit content. Moreover, GAI can be employed to continuously refine the knowledge bases (KBs) and learning models, guaranteeing that the SemCom system is able to observe network environments and adapts to evolving dynamic network conditions.
Nevertheless, the synthesis of SemCom and GAI in intelligent wireless communication networks inevitably encounters many challenges, including:
-
•
Challenge 1: How to construct the SemCom systems fusing GAI to process any data format? The associated semantics are produced and interpreted by GAI through semantic encoder/decoder in SemCom. However, basic data processing falls short of meeting the demands posed by data-intensive AIGC services, necessitating the use of multimodal algorithms to handle diverse data types. Additionally, the computational time and power required for training must be factored in. During transmission, channel encoders and decoders should adaptively compress semantic information based on varying channel conditions.
-
•
Challenge 2: How to measure the effectiveness of information generated by GAI in SemCom-based networks? As SemCom emphasizes the conveyed message’s meaning rather than transmitted bits, conventional performance indicators derived from Shannon’s framework, are not suitable for evaluating SemCom networks [10]. To offer enhanced services, information effectiveness measurement is tied to the achievement of specific objectives and time. Additionally, interactions now incorporate both human-to-machine and machine-to-machine, moving beyond just human-to-human communication. Thus, determining appropriate metrics considering different goals and scenarios, poses another challenge.
-
•
Challenge 3: How to manage SemCom-based networks with GAI technologies? The rising ubiquity of GAI/ML tools across all network nodes necessitates coordinated management of resources for computation, communication, and control. Significantly, SemCom heavily depends on background knowledge for semantic representation and interpretation. Outdated or mismatched knowledge between communication parties can diminish semantic recovery accuracy. Hence, effective knowledge management strategies become essential in SemCom-based networks, presenting the third challenge.
| References | Contributions |
|
|
|
|
|
|||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [11] |
|
||||||||||||||||||
| [12] |
|
||||||||||||||||||
| [13] |
|
||||||||||||||||||
| [14] |
|
||||||||||||||||||
| [15] |
|
||||||||||||||||||
| [16] |
|
||||||||||||||||||
| [17] |
|
||||||||||||||||||
| [18] |
|
||||||||||||||||||
| This paper |
|
I-C Related Surveys, Contributions and Organization
Several brilliant works are conducted recently as listed in Table I. In the terms of SemCom, [12] presents a detailed survey on the recent technological trends in regard to SemCom for intelligent wireless networks. [11] provides a survey on the implementation of SemCom in 6G and discusses potential applications of 6G in SemCom-empowered network architectures. As for GAI and AIGC, [13] provides a review of recent challenges and results in the field of GAI with application to mobile telecommunications networks. [14, 15] provide surveys of techniques, applications and challenges of AIGC as the exploration of GAI. Furthermore, [16] presents a comprehensive survey on the definition, lifecycle, models, and evaluation metrics of AIGC within mobile edge networks through the combined efforts of mobile-edge-cloud communication, computing, and storage infrastructures. It also bridgs GAI technology with SemCom in the discussion on AIGC transmission. Considering the collaboration between GAI and SemCom, the authors in [17] propose a framework of GAI-assisted SemCom network that integrates global and local GAI with semantic coding models in a collaborative cloud-edge-mobile design. Moreover, the authors in [18] propose a GAI-aided SemCom framework without necessitating joint training with a reduction in both computational complexity and energy cost compared to conventional SemCom methods. These two works delve into the detailed frameworks of SemCom networks assisted by GAI, but without extensive discussions on information effectiveness and knowledge management in wireless networks. In this survey, compared with the relevant works in Table I, we present a comprehensive survey and focus specially on the interplay between GAI and SemCom in wireless communication networks involving GAI-assisted information creation, SemCom-enabled information transmission, information effectiveness, resource allocation and knowledge management.
The organization and our main contributions in this paper can be summarized as:
-
•
Section II- We primarily present a GAI-driven SemCom framework for AIGC delivery. It is the first paper to delve into the framework architecture, components, KPIs, and network management approaches of the synthesis of SemCom systems and GAI algorithms
-
•
Section III- We provide an extensive review of GAI models from the perspectives of unimodal and multimodal, then classify them into text-to-text, vision-to-vision, audio-to-audio, text-to-X (Text2X), X-to-text (X2Text) and voice bots perspectively.
-
•
Section IV- We conduct a comprehensive exploration into the benefits that SemCom can offer for the delivery of AIGC with the introduction of SemCom’s mathematical theory and transceiver design.
-
•
Section V- We conduct an investigation on AIGC’s information effectiveness for three perspectives: task-oriented systems, age of information (AoI), value of information (VoI) and causal control.
-
•
Section VI- We introduce new architecture and related algorithms for optimizing communication and computing resource allocation and knowledge management, including knowledge construction, update and sharing, to operate and maintain the GAI-driven SemCom networks.
-
•
Section VII- We present a discussion on several use cases and further conclude the benefits of the envisioned system in some scenarios.
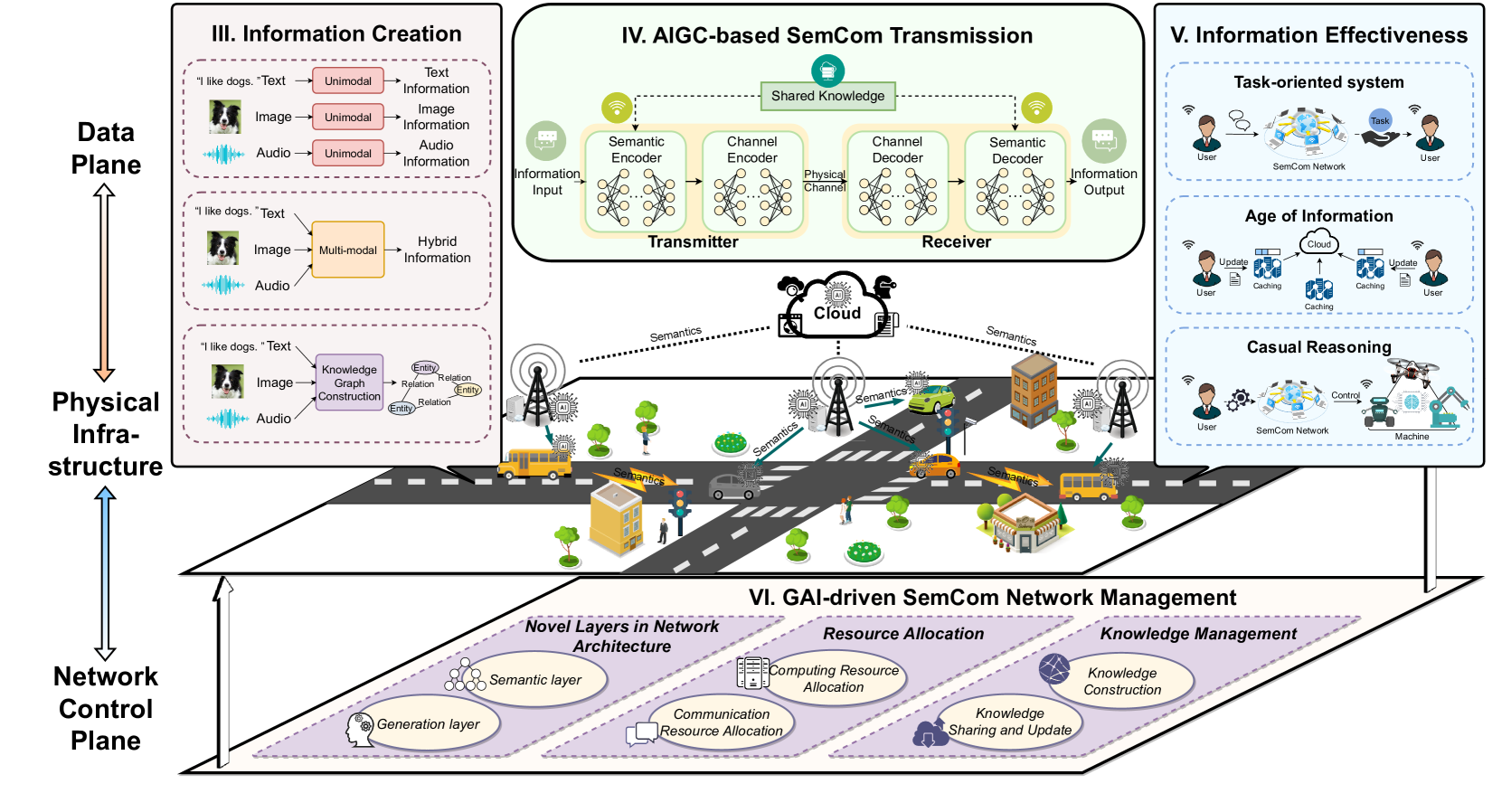
II Generative AI-driven Semantic Communication Network
In this section, we first present the basics of GAI and SemCom. In this context, we envision the GAI-driven SemCom networks from three perspectives: data plane, physical infrastructure and network control plane.
II-A Basics of GAI and AIGC
GAI is a branch of AI designed to understand, learn, and apply knowledge across a wide array of tasks and domains [19]. Unlike specialized or narrow AI, which is tailored for specific tasks such as image recognition or natural language processing, GAI aims to exhibit cognitive abilities that are akin to human intelligence. This encompasses the capacity for logical reasoning, problem-solving, perception, language understanding, and even potentially emotional intelligence.
AIGC represents a cutting-edge approach to the creation, manipulation, and modification of various forms of content via GAI algorithms. GAI learns from the previous content including Professional Generated Content (PGC) and User Generated Content (UGC) to create AIGC [20, 21, 15]. Generally, AIGC’s benefits can be divided into five perspectives: low-latency, creativity, efficiency, scalability, and personalization [16]. With its capability to process and generate content at near real-time speed, AIGC significantly enhances operations in the environment where immediate responses are crucial, such as live chat interactions, real-time gaming, or instantaneous content recommendations [21]. Additionally, AIGC is redefining the boundaries of creativity, synthesizing entirely new content unbounded by the limitations of traditional human cognition. This creative capacity finds significant applications in areas ranging from digital art and music composition to advertising and product design [14]. Crucially, AIGC’s ability to generate large volumes of content rapidly and efficiently presents a marked advantage in the era of big data, streamlining operations in sectors like news reporting, social media content generation, and academic research. One of the most transformative aspects of AIGC is the capacity for personalization. By generating content tailored to individual preferences, past interactions, and specific contexts, AIGC is enhancing user experience across a multitude of fields, including e-commerce, education, entertainment, and customer service [15].
II-B Basics of SemCom
SemCom diverges from conventional Shannon communication by integrating human-like “comprehension” and “reasoning” into the data encoding and decoding processes, rather than striving for precise bits duplication [22]. It typically prioritizes transmitting the most significant and relevant information extracted from transmitter to receivers given constrained channel bandwidth, instead of focusing on maximizing bit throughput [23]. To be concrete, in semantic encoding, the original messages are first represented into semantic information (SI) carrying background knowledge and context-related information [24]. The KB of semantic encoder need to be shared with that in semantic decoder before transmission to ensure that the receiver can understand received message. Under equivalent background knowledge, the semantic decoding serves as the reverse operation of encoding to interpret received SI.
There are several pioneering works delivered recently. The authors in [25] first propose a model that integrates deep learning techniques to interpret and transmit the semantic essence of information in communication systems. In [26], the authors introduce a fresh perspective on future semantic and goal-oriented communication networks, and provide an overview of the architecture, underlying mathematical theories, and associated ML strategies. The authors in [27] identify two architectures for SemCom: the cross-layer design framework proposed before and the layer-coupling approach referred to SplitNet. Moreover, the authors in [12] present three categories of SemCom and the corresponding system design, as well as explore cutting-edge methods in the domains of SI extraction, SI transmission, and SI metrics in details. Nevertheless, the authors in [28] argue that the prior works focus less on the essential concepts and principles on semantic representation, language, reasoning, KPIs and scalability for SemCom, and then clearly distinguish the concept of SemCom from other frameworks and notions corresponding the mentioned accepts. Notably, they observe that the knowledge-driven and reasoning-driven AI-native networks is indeed required in 6G semantic networks instead of data-driven and information-driven AI-augmented networks.
II-C GAI-driven SemCom Network Architecture
Given the basics and features of GAI and SemCom, next, we present a synergistic interaction between GAI algorithms and SemCom networks. Thus, in this section, we present the vision of GAI-driven SemCom network architecture, as depicted in Fig. 1. We illustrate this architecture from the perspectives of physical infrastructure, data plane and network control plane.
II-C1 Physical Infrastructure
Similar to conventional communication networks, the physical infrastructure in GAI-driven SemCom networks consists of multiple wireless terminal devices (TDs), access points (APs), base stations (BSs), edge servers, and central cloud servers [29]. Besides performing conventional functions in communication systems, these entities are armed with additional intelligent techniques to support novel AIGC services. To be specific, TDs, such as smartphones, tablets, and laptops, are equipped with KBs and well-trained GAI models including encoder and decoder modules in SemCom system. Before transmission, TDs upload sensing data, as well as download knowledge and well-trained models through APs and BSs, thus integrating knowledge and updating KBs.
In GAI-driven SemCom networks, the edge nodes, including mobile edge computing (MEC) servers and BSs, enable to pre-train and fine-tune GAI models with the knowledge from themselves, connected TDs and central cloud servers. Then, edge nodes will offload the well-trained models to TDs corresponding to their tasks and environments. Additionally, the edge servers account for managing knowledge sharing and update with optimization of resource consumption (energy, bandwidth, etc.).
Due to the large storage and computing resource of central cloud servers, the large-scale GAI models can be employed and pre-trained. Virtually, most global AIGC services (e.g., ChatGPT) are trained in cloud utilizing the data from many data suppliers. Meanwhile, the centralized model will be updated, absorbing new knowledge to refresh models and adjusting resource allocation strategies.
II-C2 Data Plane
The AIGC data is generated, transmitted and evaluated on the data plane of this network. First, the AIGC information is created through GAI models, including unimodal and multimodal models, which will be discussed in Section III.
Then, AIGC data is transmitted through wireless channel in the approach of SemCom. To be concrete, the source messages are fed into semantic encoder and channel encoder at the transmitter to extract and compress their SI. Subsequently, the compressed SI passes through a wireless channel. At the other end, the distorted data are recovered by the channel decoder and semantic decoder based on the shared knowledge beforehand. Through this approach, SemCom could enhance the efficiency of AIGC transmission and resource utilization by transmitting only essential SI of AIGC data are transmitted.
Another function achieved by the data plane is to measure the AIGC information effectiveness from the perspectives of task completion, data freshness and relevance, as well as causal reasoning. First, some performance metrics on evaluating the task implementation for task-oriented systems are delivered [30]. Next, the AoI [31] is regarded as an important metric to measure how fresh the information is, which is significant in real-time supervision system and update system. If the information is expired, it may reduce the accuracy and reliability of system decision. Moreover, the VoI focusing on the importance and relevance of the information being transmitted is also an practicable metric for information effectiveness measurement in SemCom [32]. Finally, due to the dynamics in wireless environment, new measurements related to causal reasoning are envisioned considering the state of SemCom networks.
II-C3 Network Control Plane
Unlike conventional communication network, in GAI-driven SemCom networks, the network management should be more intelligent, knowledgeable and adaptive to GAI. Consequently, the network control plane encompasses network architecture, knowledge management, and resource allocation. First, the novel layers in the proposed networks are discussed including semantic level and generation level.
Next, the knowledge management features the utilization of KB which are essential in the processes of training both GAI and SemCom models containing public and private knowledge, especially for the personalized function. In this network, the key procedures consist of KB construction, sharing and update. To create a KB, the raw data, such as users’ history and channel status, is collected, classified, and encoded. In turn, KBs are continuously monitored by GAI automatically, updated based on new knowledge and users’ feedback, ensuring knowledge remain dynamic and reliable over time. Also, KBs in transceivers need to be aligned since the inconsistent KBs would lead to content misunderstanding.
Additionally, since the limited resource restricts the implementation of AIGC services with extensive data, new resource allocation methods for GAI-driven SemCom networks are urgently required. Beyond the conventionally utilized communication resources such as energy and bandwidth, some unprecedented issues are explored for SemCom networks, e.g., the matching degree of physical channel and KB. Furthermore, GAI acts as an add-on module to boost network performance. The strategies for resource allocation are decided by GAI automatically and they can be adjusted dynamically according to new network status.
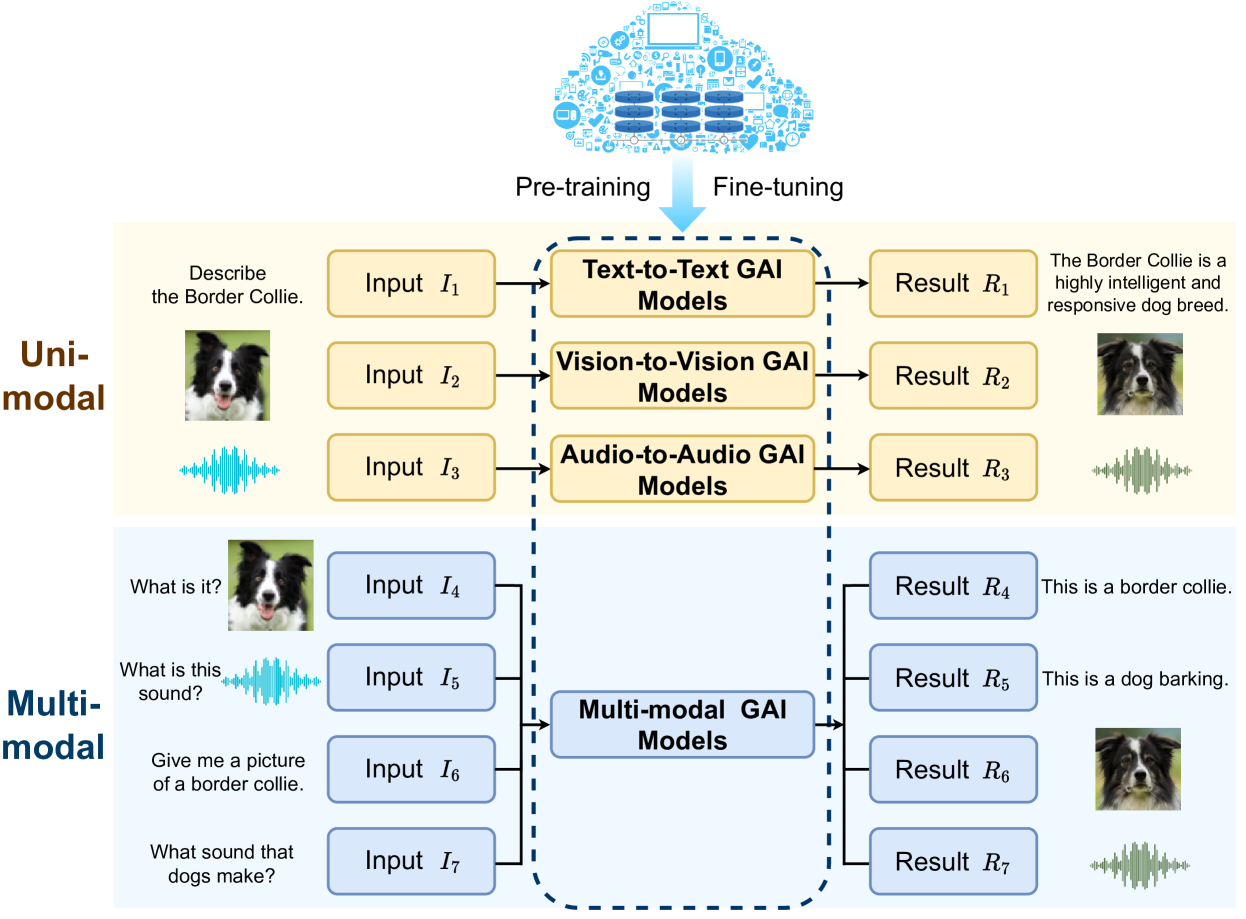
III Information Creation via Generative AI
This section introduces the overview of GAI models for information creation in AIGC with two categories: unimodal and multimodal as depicted in Fig. 2.
III-A Unimodal Models
We explore unimodal models based on a single type of input data (text, vision, and audio) to comprehend how they utilize information from a single source to generate a coherent output as shown in Table II.
III-A1 Text-to-Text
Text-to-Text GAI models are particularly effective in tasks like text generation, machine translation, summarization and question-answering. These models can be divided into four categories: sequence-to-sequence (Seq2Seq) models, variational autoencoder (VAE)-based models, generative adversarial network (GAN)-based models, and Transfromer-based models. Seq2Seq models [33, 34, 35, 36] are designed to handle variable-length input and output sequences with the architectures such as long short-term memory (LSTM) [37], recurrent neural networks (RNNs) [38] and gated recurrent unit (GRU) [39]. VAE-based models function by encoding an input sequence into a fixed-dimensional representation and subsequently decoding it. Some pertinent examples are presented in [40, 41, 42, 43]. GAN-based models [44, 45, 46, 47, 48] are featured by GAN which is a type of generative model consisting of two neural networks, a generator and a discriminator, that compete with each other during the training process. Transfromer-based models are stemed from Transformers [49], have become the backbone of many state-of-the-art GAI models (e.g., GPT [50], BERT [51], and T5 [52]) with their self-attention mechanism, excelling at handling long-range dependencies in text. Notably, several works such as VGAN [46] and TranGAN [48] integrate various technologies including GAN, VAEs, Transformers, and reinforcement learning (RL) to enhance performance.
| Model Type | AIGC Applications | AI Models |
|
|||||||||||||||
| Text-to-Text |
|
|
|
|||||||||||||||
|
Vision-to-Vision |
|
|
|
||||||||||||||
| Audio-to-Audio |
|
|
|
|||||||||||||||
| Text-to-Image |
|
|
|
|||||||||||||||
| Text2X | Text-to-Video |
|
CogVideo [84], Phenaki [85] |
|
||||||||||||||
| Text-to-Audio |
|
WaveNet [88], AudioLM [89] |
|
|||||||||||||||
|
Image-to-Text | Transkribus [90] |
|
|
||||||||||||||
| X2Text | Video-to-Text |
|
|
|
||||||||||||||
| Audio-to-Text | Speak AI [97] |
|
|
|||||||||||||||
|
|
|
|
|
||||||||||||||
III-A2 Vision-to-Vision
Vision-to-vision GAI models consist of image-based and video-based GAI models. Image-based GAI models can be broadly classified into five categories: convolutional neural network (CNN)-based models, VAE-based models, GAN-based models, flow-based models and diffusion-based models. CNN-based models [105, 106, 107, 108, 109] are constructed on CNNs which consist of multiple convolutional layers, pooling layers, and fully connected layers, enabling to learn spatial hierarchies of features from images. VAE-based models, such as Conditional VAEs [110] and IntroVAEs [111] can effectively modify images while retaining structural fidelity, useful for tasks like altering facial expressions or day-to-night conversions. Besides, the generators in GAN-based models can create synthetic images, while the discriminators attempt to distinguish between real and generated images. Some notable models such as DCGAN [112], CycleGAN [113] and StyleGAN [60] are utilized for various image synthesis tasks, such as image-to-image translation, super-resolution, and style transfer. Flow-based models [62] generate images by learning an invertible transformation between the data distribution and a known distribution (e.g., Gaussian distribution). Diffusion-based models primarily simulate stochastic diffusion processes to generate images. One of the most recent and prominent examples of diffusion models is the denoising diffusion probabilistic models (DDPM) proposed in [114]. Featured by diffusion, DALL-E 2 is promoted from DALL-E [115] with better processing ability created by [116].
Video-based GAI models, including image-to-video and video-to-video models, consider the time dimension in the contrast of image processing. The image-to-video models synthesize new video content based on a single image or a sequence of images, e.g., the works in [117, 118]. The video-to-video models are video processing models that focus on enhancing video quality, such as video super-resolution, video inpainting, or video denoising. These models employ DL techniques such as CNN, GAN, VAE, transformer and diffusion model, with notable examples including video diffusion model [63], and EDVR [119].
III-A3 Audio-to-Audio
Audio-to-audio GAI models can generate new sounds based on the input audio which includes four categories: GAN-based models, VAE-based models, autoregressive models and transformer-based models. Models based on GAN, such as WaveGAN [67] and SpecGAN [68], are utilized for creating realistic, high-fidelity audio. VAE-based models, like VAE-VC [70], are particularly effective for tasks that require the modeling of a continuous latent space. Autoregressive models, including WaveNet [88] and WaveRNN [69], employ DL techniques like CNNs and RNNs to generate highly authentic speech and music audio sequentially. Meanwhile, Transformer-based models, exemplified by OpenAI’s Jukebox [72], utilize attention mechanisms to efficiently process long-range sequences in musical compositions.
III-B Multimodal Models
The majority of current popular AIGC services such as DALL-E 2 are empowered by multimodal GAI models. Compared with unimodal GAI models, multimodal ones are more complex and versatile to process multiple types of input and output. We categorize multimodal GAI models based on their input and output types: text input (text2X), text output (X2text), and voice conversation (voice bots) as shown in Table II.
III-B1 Text-to-X
Text-to-X GAI models convert textual input into various forms of output including images, video and audio. First, in terms of text-to-image models, DALL-E [76] is one of the most famous products that generates images based on textual descriptions. It is built on the GPT-3 architecture and has demonstrated an impressive ability to create coherent and contextually relevant images from a wide range of textual inputs. Also developed by OpenAI, CLIP [77] can learn from text-image pairs and perform various tasks such as zero-shot image classification, image captioning, and even text-to-image generation employing a transformer architecture and CNN. Integrating CLIP and VQGAN, VQGAN-CLIP is proposed in [78], utilizing a multimodal encoder to create images of high visual quality from prompts without any training. The ensemble of diffusion models delivered in [79] is called eDiff-I, which enhances text synchronization while keeping the computational cost of inference constant and sustaining superior visual quality. The authors in [80] merge the capabilities of two well-known pre-trained models, a text-based model (GPT-3) and an image-generation model (Stable Diffusion [120]), to edit images from human instructions.
Second, for text-to-video models, Cogvideo is proposed in [84] utilizing 9B-parameter transformer to produce video. The authors in [85] present Phenaki which has the ability to produce videos of indefinite length based on a series of textual cues, such as time-sensitive text or a narrative in open domain.
Third, in the audio domain, WaveNet is proposed in [88] to predict the next sample in a sequence given the previous samples via CNN. Another example provided in [121] is AudioLM, which can produce speech extensions that are both syntactically and semantically coherent through a multi-stage Transformer-based language model, while also preserving speaker identity and prosody for unseen speakers.
III-B2 X-to-Text
Different from the text-to-X models, the X-to-text GAI models convert various forms of inputs into textual outputs. In the realm of image-to-text, GAI models are able to accurately interpret visual elements within images and generate descriptive textual content. CLIP is an example mentioned before utilized for producing text according to the text-to-image alignments. In addition, neural image caption (NIC), proposed in [91] is used to generate natural sentences describing an image relied on a vision CNN followed by a language generating RNN. The authors in [92] introduce VisualGPT which leverages a novel self-resurrecting encoder-decoder attention mechanism aiming to swiftly fine-tune the large pre-trained language model (PLM) using a limited set of domain-specific image-text data. Vision Transformer (ViT) in [93] is a straightforward transformer model applied to a series of image segments, which excels in image categorization tasks.
The video-to-text models enable to extract context from a sequence of frames and generate coherent textual content. VideoCLIP in [94] trains a transformer for both video and text by contrasting temporally correlated positive video-text combinations against challenging negatives, identified through nearest-neighbor searches. Also, the authors in [96] propose a unified video and language pre-training model (UniVL) with the pipelines consisting of two single-modal encoders, a cross encoder, and a decoder with the Transformer backbone. Furthermore, the authors in [95] expand the BERT framework to learn bidirectional joint distributions over sequences of visual and linguistic tokens for the tasks including action classification and video captioning.
Last, audio-to-text conversion is a well-established field in GAI, wherein spoken language is transcribed into written text. DeepSpeech [98] is an RNN-based speech recognition system using significant simple end-to-end deep learning. Additionally, wav2vec 2.0 in [99] masks speech input in the latent space, and learns powerful representations from speech audio alone followed by fine-tuning transcribed speech based on a Transformer architecture.
III-B3 Voice Bots
Voice bots, also known as voice-based chatbots or voice assistants, enable voice conversation in human-computer interaction [122]. Several products have been widely used, like Amazon’s Alexa [103], Apple’s Siri [100], and Google Assistant [102]. Basically, voice bots interpret user’s spoken input through automatic speech recognition (ASR) algorithms, and convert the audio into text. This text is then processed using natural language understanding (NLU) techniques to understand the intent and context behind the user’s query. Once understood, the bot generates a response, converting the text back into human-like speech through natual language generation (NLG) algorithms [104].
IV Semantic Communication for AIGC Transmission
With the goal of going into SemCom for AIGC delivery, we first present a literature review on the advanced information theory used for SemCom. Subsequently, relevant works on SemCom transceiver design are discussed as per four categories (text, image, audio and video delivery). Finally, we explore the intricacies of GAI and SemCom’s interaction and potential implications.
IV-A Information Theory for SemCom
Information theory plays a crucial role in understanding and modeling communication systems. It provides a mathematical framework to quantify the amount of information being exchanged, assess the capacity of communication channels, and determine the optimal coding schemes to minimize errors and maximize efficiency. Because the transmission content has changed in SemCom, SIT is a paradigm shift which focuses on how to measure SI related to the context and external knowledge.
Semantic information theory (SIT) is derived from Shannon’s classical information theory (CIT), merging insights from linguistics and cognitive science [25, 12]. The idea of semantics traces back to [123], the authors introduce a triad: syntactics, semantics, and pragmatics, as foundational elements in sign theory. Later, the authors in [124] present a three-level communication framework, delving deeper into the distinctions of syntactic, semantic, and pragmatic aspects. In [125], the authors develop a theory centered on SI by using propositional logic and incorporating a probability measure for the information’s semantics. The authors in [126] take SIT a step further by integrating situational logic. Additionally, the universal SemCom situation between two intelligent entities without common knowledge is investigated in [127]. More conditions related to general “goals of communication” are further explored in [128]. The authors in [129] address the challenge of accurately measuring contradictions, while the authors in [130] utilize the notion of truth-likeness to measure SI, catering to a wider array of applications.
Recently, SIT has evolved over offering a broader range of perspectives on the core nature of SI. The authors in [131] introduce a unique theory on SI, emphasizing its distinct position within the information trinity. From a physics standpoint, the work of [132] characterizes SI as the syntactic data between a system and its surroundings, which causally aids the system’s ongoing operation. The work of [132] later provides a layered interpretation of SI across various strata of communication systems, and employs semantic entropy used in [133] for its assessment.
IV-B Transceiver Design in SemCom
Transceivers within a SemCom system can be significantly enhanced by GAI models on optimizing the understanding, transmission, and management of information. Essentially, the purpose of semantic transceivers is to extract semantics at the sender’s end and restore it at the receiver’s end with minimum semantic errors over different channel conditions. Learned from KB, the semantic features are first distilled by semantic encoder, then compressed by channel encoder. After passing through a physical channel, these distorted semantic features are restored by channel decoder and semantic decoder. Recently, this prevalent architecture has been enhanced and refined through numerous pioneering works with diverse tasks. In this part, SemCom’s transceiver designs are categorized based on the type of source data, including text, images, speech, and video.
IV-B1 Text delivery
In most cases, each word in a message is converted into tokens, which serve as the fundamental units of semantic representation. The transformer structure is widely utilized. In this regard, the position and attention weight of each token can be factored into semantic encoding. Developed by a Transformer-based system, an end-to-end SemCom system for text delivery named DeepSC is proposed in [25], which establishes a significant milestone in DL-based transceiver design of SemCom. Inspired by DeepSC, many variations have emerged. The authors in [134] integrate semantic encoding with Reed-Solomon coding and a hybrid automatic repeat request (called SC-RS-HARQ) to enhance the reliability of transmitting textual semantics, as well as propose a similarity detection network for semantic errors. The authors in [135] also propose a Transformer-based SemCom system with a new loss function to quantify the impact of semantic distortion, allowing for a dynamic balance between semantic compression loss and semantic accuracy. In order to adapt the trained model for Internet-of-Things (IoT) devices with limited capability, the authors in [136] come up with a lite version of DeepSC through pruning and quantizing the fully trained DeepSC models to achieve as large as 40× compression ratio without performance degradation.
Furthermore, different from that KBs in aforementioned researches merely acting as corpora with unprocessed text, the KGs consisting of structured and interconnected entities and their relations enhance reasoning ability and improve personalization of SemCom. The KG-based SemCom systems are capable of predicting words based on the relationships delineated by KG, rather than solely relying on context, hence enhancing the accuracy of prediction. For example, [137] introduces a KG-driven SemCom system and utilizes Text2KG and KG2Text networks in semantic encoder and semantic decoder. Additionally, [138] delivers a more reliable SemCom system cooperating extracted semantics and KG. Specifically, it aggregates context in KG extraction and semantic restoration, which shows great robustness especially when the channel quality is poor.
IV-B2 Audio Delivery
Utilizing cutting-edge NLP techniques, spoken words can be efficiently converted to text, which can then be channeled into SemCom. However, compared to text, which is purely composed of characters, the intricacies of speech signals make them more challenging to handle. This complexity arises from factors beyond just the fidelity and volume of the speech, encompassing its frequency and tone as well. The authors in [139] introduce a speech-focused variant of DeepSC, called DeepSC-S. Mean squared error (MSE) is utilized as the loss function to minimize discrepancies between the original and recovered speech signals. Moreover, signal-to-distortion ratio (SDR) and perceptual evaluation of speech quality (PESQ) are used as performance indicators to assess the quality of the reconstructed speech signals. The authors in [140] expand this framework to accommodate multiple users, deploying federated learning to collaboratively train a CNN-based encoder and decoder across various local devices and a central server. Although MSE can be serve as the performance metric in this case, it does not adequately capture the semantic content at the receiver. Responding to the growing needs for intelligent tasks, DeepSC-ST [141] leverages RNNs to extract textual semantic content from speech signals at the transmitting end and reconstructs the text sequence at the receiving end for speech synthesis. This approach significantly cuts down the resources needed for transmission. Connectionist temporal classification (CTC) [142] serves as the loss function, with character-error-rate (CER) and word error rate (WER) as performance metrics to evaluate the accuracy of the transcribed text.
IV-B3 Image Delivery
In SemCom systems for image transmission, commonly, the relevance between adjacent pixels would be calculated to classify and segment images with semantic labels. In this case, the minimum semantic representation unit is pixel. Transformer, CNN, GAN are usually used for transceiver design of image delivery. For example, the authors in [143] develop an end-to-end SemCom system for image transmission, where a pre-trained GAN at the receiver reconstructs a realistic image from the semantically segmented image input. The authors in [144] propose a coarse-to-fine image compression framework employing GANs and better portable graphics (BPG) residual coding. In [145], a RL-based adaptive semantic coding (RL-ASC) approach for image SemCom is proposed, employing a convolutional semantic encoder and an attention-based generative semantic decoder.
Furthermore, specialized solutions are explored for task-oriented SemCom systems tailored to specific vision-related tasks. In [146], a unified transmission-classification system is designed for image transmission, where the receiver directly produces image classification results. The authors in [147] develop a task-oriented SemCom system for simultaneous transmission and classification of scenes in UAV scenarios, utilizing deep reinforcement learning (DRL) algorithms to precisely identify essential semantic features. In addition, in [148], the authors present an energy-efficient SemCom-based framework for UAVs, incorporating a personalized semantic encoder to selectively transmit images that align with the user’s specific interests.
IV-B4 Video Delivery
Compared to image delivery, video delivery requires maintaining temporal consistency between sequential frames to account for the time dimension. Meanwhile, the frames can be reasoned according to the action/trajectory logic and behavior patterns via understanding the video content. Specifically, the authors in [149] design a joint source-channel coding (JSCC) strategy to optimize the trade-off between transmission rate and distortion for over-the-air video transmission. The authors in [150] introduce a unique method for video conferencing that employs a semantic error detector, and uses a still photo of the speaker as prior information to assist in reconstructing the speaker’s facial expressions, thereby significantly reducing the need for wireless resources. The authors in [151] introduce a novel framework which segments each frame in a video into environment and action parts, then extracts semantics and transmits them separately, in order to reduce redundancy in repeated environmental images and unnecessary action images. The authors in [152] develop a mobile video transmission framework to ensure a high Quality of Experience (QoE), creating an extensive dataset to understand the correlation between subjective QoE scores and neural network parameters. Moreover, the authors in [153] introduce a method for editing talking-head videos through text modification, and those in [154] propose transmitting only text instead of video to substantially relieve network traffic.
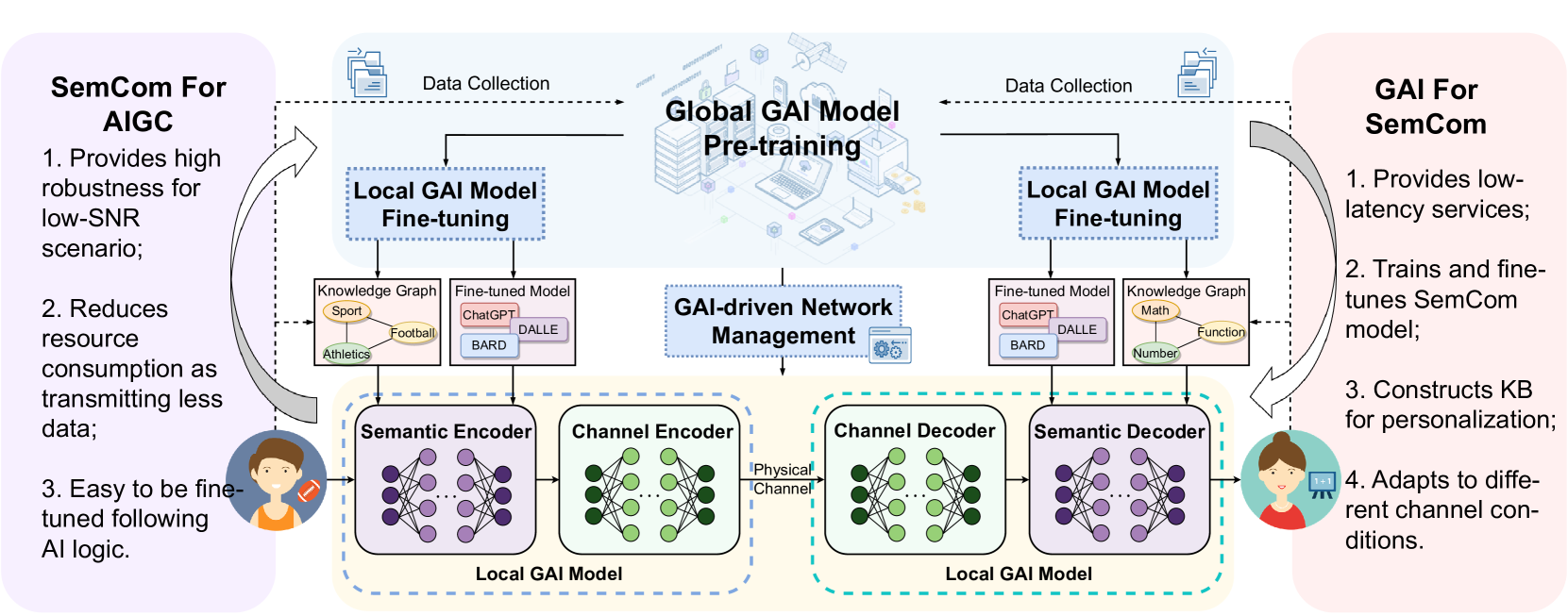
IV-C GAI’s Role in SemCom
Via the aforementioned review, we observe that GAI technologies can significantly enhance SemCom systems as illustrated in Fig. 3. The benefits can be concluded in following aspects:
-
•
Models training and fine-tuning: GAI’s proficiency in efficiently generating massive amounts of content provides a scalable solution to SemCom systems, enabling them to handle large datasets. This feature is incredibly useful in generating training data for ML models, augmenting databases with contextually meaningful content, and facilitating large-scale semantic analysis [15]. Moreover, GAI’s speed and efficiency make it well-suited for the low-latency requirement of semantic analysis, a critical attribute in applications requiring real-time language translation or immediate response generation [14]. Furthermore, GAI can create personalized content aligned with individual preferences and contexts for fine-tuning [16]. This ability can substantially enhance the precision and personal relevance of semantic analysis, leading to a more individualized user experience and services based on semantic understanding of user needs and interests.
-
•
KB construction: GAI streamlines KB construction by automating the identification and structuring of information from diverse data sources. GAI improves the accuracy and depth of KBs by continuously learning to better recognize and integrate varied data types. These advances result in dynamic, self-updating KBs that enhance semantic analysis and decision-making, making them not only more comprehensive but also contextually intelligent.
-
•
Channel adaption: GAI can significantly bolster the adaptability of communication channels by enabling dynamic adjustments based on content, context, and user behavior. GAI models analyze real-time data streams to optimize channel performance, adjusting parameters like bandwidth and signal modulation to maintain high-quality transmission under varying conditions. They can predict and preemptively mitigate potential disruptions, ensuring seamless communication. Furthermore, GAI’s predictive capabilities allow for anticipatory resource allocation, reducing latency and enhancing the overall user experience. This intelligence-driven adaptability is especially crucial in dynamic networks with unstable wireless channels, ensuring reliability and efficiency in data exchange.
V Information Effectiveness for AIGC
Clearly, the conventional network performance metrics, such as throughput, latency/delay, packet loss and bit error rate (BER), are no longer adaptive for the brand-new GAI-driven SemCom networks which are content oriented and sensitive to data freshness. Thus, how to evaluate information effectiveness for such networks is imperative. In this section, we shed light on new views considering the communication goal, data freshness and causal reasoning for three varieties of AIGC regimes, i.e., task-oriented systems, AoI, VoI and causal control systems.
V-1 Task-Oriented System
A task-oriented SemCom system is designed to focus not just on transmitting data but ensuring that the communicated data are efficiently used to fulfill a specific task or objective. This approach goes beyond merely delivering information to guarantee that the communicated information is of maximum utility in achieving the recipient’s goals. For instance, in a manufacturing setting, a task-oriented SemCom system might be used to transmit machine sensing data. Rather than merely sending raw sensor readings, the system could be designed to only transmit when readings indicate a potential issue – such as a sudden spike in temperature or vibration – that could signify a problem requiring intervention.
Some related works propose various methods for measuring information effectiveness in task-oriented SemCom systems. Focusing on transmitting single and multiple modality data, task-oriented multi-user SemComs with image and text sources input are explored in [155]. Three intelligent tasks are chosen as representative case studies: image retrieval and machine translation for single-modality data transmission, and the more complex visual question answering (VQA) task for multimodal data transmission. Moreover, the authors in [148] present an energy-efficient SemCom-based framework for UAVs, incorporating a personalized semantic encoder to selectively transmit images that align with the user’s specific interests. The task involves optimizing objectives to enhance resource utilization in the proposed multi-user resource allocation scheme, which is grounded in game theory.
V-2 Age of Information (AoI) and Value of Information (VoI)
AoI is a concept in communication systems that quantifies the freshness or timeliness of information received at the destination proposed in [31]. AoI can be utilized in some applications which deeply require recipients to receive the most recent status updates to ensure the correctness of the actions taken, such as IoT networks [156], wireless sensor networks (WSN) [157], cloud gaming [158], etc.
Therefore, AoI is deemed as a useful criteria in SemCom system optimization considering its emphasis on time sensitivity [12, 159]. The authors in [160] regard AoI as a semantic measure for an age-aware SemCom system from data significance perspective. Furthermore, a new age-related metric named Age of Incorrect Information (AoII) is presented in [161]. In contrast to AoI, AoII represents an advancement by incorporating an information-penalty aspect and a time-related function, thereby enhancing SemCom systems.
Besides, VoI refers to the importance and relevance of the information being transmitted proposed in [32], as opposed to merely focusing on the quantity of data. Its emphasis is on ensuring that the information shared is meaningful and useful for the intended purpose or recipient, which is a suitable metric for SemCom [162]. VoI can also be regarded as a nonlinear relationship between the value and freshness denoted by at a given time , where represent the AoI penalty function describing how VoI evolves as AoI grows [163]. For instance, in [164], the authors utilize VoI to formulate a rate-regulation tradeoff between the packet rate and the regulation cost with an event trigger and a controller in networked control systems.
V-3 Causal Reasoning
Causal reasoning techniques has gained popularity by providing a structured framework to understand the mechanism of cause-and-effect for reasoning and inference. Central to this approach is causal inference, also known as counterfactual inference, which aims at addressing questions like “What if I had acted differently?”. While causality stands out for its interpretability and capacity to extrapolate data, traditional causal models struggle with high-dimensional, unstructured data, making the identification of causal structures a complex and computationally demanding task. Fortunately, GAI models can approximate complex and high-dimensional data with relative ease, therefore complementing the strengths of causal models. Moreover, SemCom systems ensure that the causal analysis conducted is not just data-driven but meaning-driven with low latency, leading to more accurate and real-time inferences. In addition, the knowledge update and sharing in SemCom networks can to be monitored dynamically through casual reasoning.
In this regard, the wireless network state and dynamics are novel perspectives to be considered in the information effectiveness measurement for SemCom networks. The authors in [165] propose an emergent SemCom (ESC) framework composed of a signaling game for emergent language design and a neuro-symbolic (NeSy) AI approach for causal reasoning. They also present the metrics on causal influence in ESC which capture the semantic effectiveness (SI measures over classical mutual information metrics). In the work of [166], a new information measures for the learned structural causal models (SCM) at the imitator is introduced in the causal semantic communication (CSC) framework. Also, it presents a new semantic state abstraction concept based on the dynamic network states, which utilizes the intrinsic information concept from integrated information theory. Furthermore, the GAI architecture and components for “Network State Model” in the proposed framework are discussed.
VI Generative AI-driven Semantic Communication Network Management
This section delves into the management of GAI-driven SemCom networks. We first illustrate the novel layers introduced in the network to manage resources from architecture perspective. Then, we discuss the knowledge management, including knowledge construction and knowledge sharing and update. Finally, we investigate the computing and communication resource allocation strategies.
VI-A Novel Layers in GAI-driven SemCom Architecture
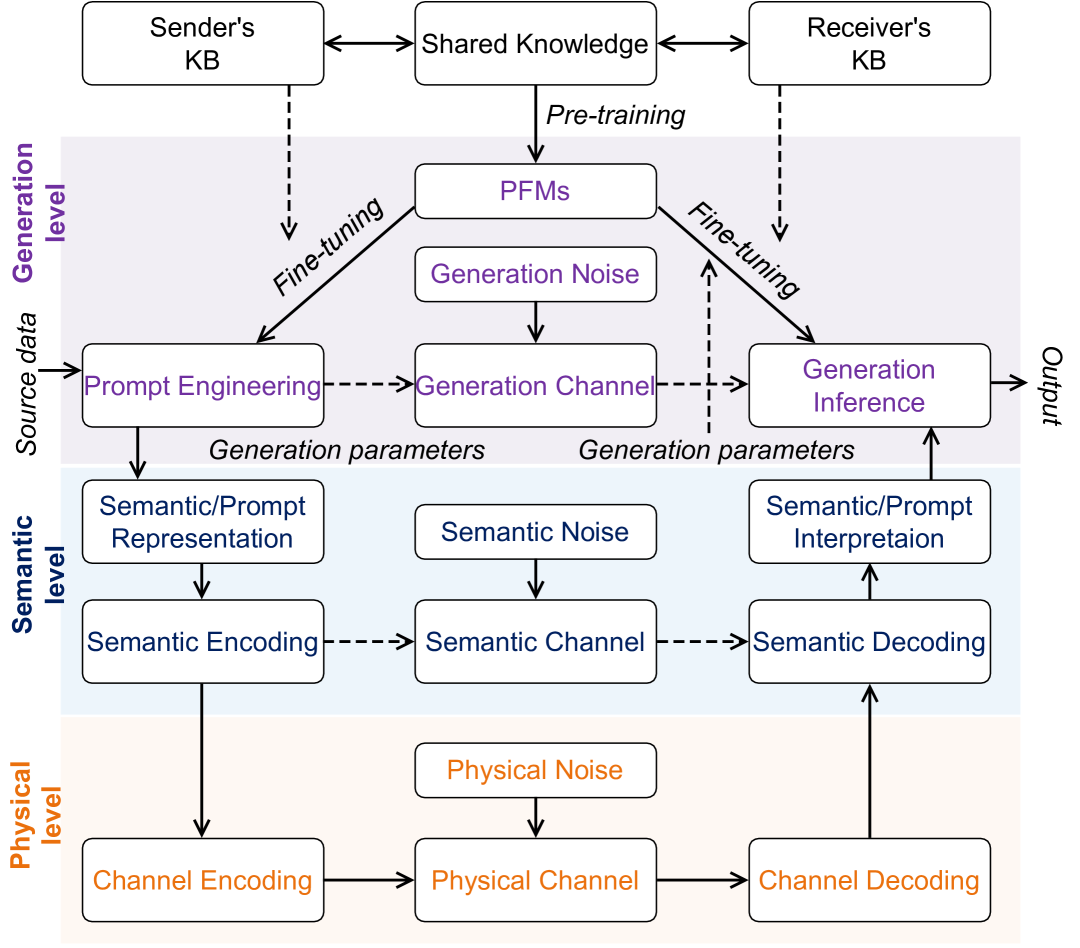
To manage the GAI-driven SemCom networks, some research works propose novel layers for dedicatedly dealing with semantics message. A novel GAI-assisted SemCom network framework in a cloud-edge-mobile design is proposed in [17], which enables multimodal semantic content provisioning, semantic-level joint-source-channel coding, and AIGC acquisition. The authors in [12] come up with a two-tier architecture primarily including physical and semantic levels in the semantic-aware network management and communications realm.
Drawing inspiration from previous research, the proposed network architecture, as depicted in Fig. 4, comprises three distinct layers: the physical layer, the semantic layer, and the newly introduced generation layer. The physical layer handles the actual data transmission, encompassing the encoding and decoding of signals. The semantic layer focuses on the meaning or context of the transmitted information. The innovative generation layer utilizes SI and algorithmic parameters to guide GAI models, producing content that aligns with specific communication goals. Crucially, knowledge is shared between the sender and receiver beforehand to pre-train the GAI foundation models. The sender employs prompt engineering, based on the sender’s KB, to create generation parameters from source data. Once transmitted through a channel, these signals are processed into generation inferences at the receiver end, guided by the receiver’s KB, and then interpreted into the final output. This architecture represents a cohesive integration of physical transmission, semantic understanding, and content generation, tailored to enhance communication efficacy for AIGC services.
Moreover, the pre-trained foundation models (PFMs) can be fine-tuned for the specific tasks such as feature extraction and parameter optimization, to provide personalized services and meet the unique demands of various applications [167]. The introduced novel layers also restrict the exposure of sensitive information as only semantic instructions and prompts are transmitted. Hence, the integration of GAI into SemCom models is envisioned to herald a new era of unparalleled personalization, adaptability, and security.
VI-B Knowledge Management in GAI-driven SemCom Networks
As shown in Fig. 4, knowledge, regarded as the foundation of GAI, comprises two categories as follow:
-
•
Background Knowledge: Task-specific parameters at the transmitter end and required expertise for model fine-tuning at the receiver end form the components of this tier.
-
•
Common Knowledge: A shared database enables both the transmitter and receiver to pull relevant data, facilitating the use of PFMs for further refinements.
In this sense, knowledge management is significant in the proposed networks since GAI relies on accumulative knowledge for learning, while the network hinges on constant knowledge sharing and updating for seamless operation [168, 169]. To be concrete, knowledge is first constructed from raw data, then shared and updated between each communication entity.
VI-B1 Knowledge Construction
The repository of knowledge, KB, contains a variety of data, e.g., model parameters, sensing data, knowledge graph (KG), as well as comprehensive corpuses of text, images, audio, and video. Especially, the KG sophisticates the data framework by weaving in entity and relation triples, thereby enhancing the structure of the stored information. Prominent examples of KGs, such as Freebase [170], DBpedia [171], Wikidata [172], and Google’s Knowledge Graph [173], have bolstered GAI’s deductive prowess requiring a high degree of personalization, like recommendation engines and question-answering (QA) systems [174, 175, 176].
In terms of knowledge construction in GAI-driven SemCom networks, KBs are compiled from an amalgamation of public and proprietary data sources, processed through GAI algorithms. These sources are diverse, ranging from crowdsourced content to data marketplaces, from the input of IoT sensors to passive collections, as well as encompassing user histories and records [177]. This expansive data assimilation is vital for the effective operation of the proposed networks.
Besides, the KG creation is more complex, which has three fundamental processes: knowledge extraction (KE), knowledge representation learning (KRL), and knowledge graph completion (KGC) [176]. The initial stage in the knowledge management process involves leveraging algorithms for named entity recognition (NER) and relation extraction to distill valuable entities and their connections from unstructured data, forming a network of triples. These triples consist of head entities, relations, and tail entities, denoted as and organized by the resource description framework (RDF) [178]. GAI algorithms then employ KRL to convert these triples into compact, low-dimensional vectors, rendering complex knowledge into a machine-interpretable format. Finally, KGC algorithms are responsible for inferring and inserting the missing pieces within these triples via triple and relation based reasoning to ensure data integrity and completeness [179].
VI-B2 Knowledge Sharing and Update
After collecting the knowledge in various communication nodes, knowledge sharing and update are crucial for maintaining high accuracy and relevance of knowledge in SemCom systems. The processes of knowledge sharing and updating ensure that GAI’s decisions are created from the latest data, fostering efficiency and innovation. Regularly refreshing KBs is vital to enable quick adaptation to new market trends, technologies, and user demands. Especially in customer-centric services, it enhances personalization and dedicated user experience.
-
•
Knowledge Sharing: Sharing among edge nodes enables collective learning and cooperative knowledge creation, often facilitated by methods like federated learning [180, 181, 182]. Additionally, a specific application for knowledge sharing in the context of the Industrial Internet of Things (IIoT) is presented via edge GAI platforms [180].
-
•
Knowledge Update: To sustain the accuracy and relevance of the KB community, periodic audits are employed to identify and excise outdated or incorrect data, while concurrently integrating new research and insights [183, 184, 185]. Tracking KB version periodically is advisable to streamline the management of these updates. Such a system allows for the archiving of significant updates as separate versions, providing users the flexibility to compare changes and revert to prior versions if needed [180].
Through these multifaceted strategies, the KB community maintains high integrity, adaptability, and utility, thereby serving as a robust asset in GAI-driven networks.
VI-C GAI-driven Resource Allocation
In GAI-driven SemCom networks, resource allocation strategies prioritize knowledge-related metrics, focusing on the intelligent use of bandwidth, spectrum, and energy, rather than only optimizing traditional bit-related metrics such as data throughput and bandwidth efficiency. This section highlights the intricacies of computing and communication resources allocation, emphasizing a more intelligent and strategic approach to managing network resources.
VI-C1 Computing Resource Allocation
Computing resources, encompassing processing power, storage, and memory, are fundamental to the operation of GAI-driven SemCom networks. Intuitively, GAI can dynamically allocate computing resources based on real-time network demands, effectively responding to network traffic and load changes [18]. Specifically, the works in [186, 187] present that GAI can learn from historical network behaviors, predict future resource consumption patterns, and consequently generate judicious decisions for resource allocation. Within a diverse wireless network environment that supports various applications, GAI algorithms can continuously monitor network status and application-specific resource demands. For example, while high-definition video streaming may necessitate robust processing power and memory, IoT sensor data transmission might require less computational effort but greater storage capacity. GAI can use real-time and historical data to predict such diverse requirements and adaptively reallocate computing resources [188]. In [12], the authors point out that GAI-driven SemCom can mitigate resource wastage through this dynamic strategy and boost overall network performance and user satisfaction.
Following this idea, the authors in [18] introduce the AI-Generated Optimal Decision (AGOD) algorithm, which leverages diffusion model-based GAI techniques. This algorithm serves as a fundamental component in an AIGC-as-a-Service (AaaS) architecture, deployed over wireless edge networks to enable ubiquitous access to AIGC functionalities, particularly tailored for Metaverse users. To be concrete, the users’ requests are continuously arrived and allocated to different AIGC service providers (ASPs) for processing. Subsequently, the results of the AIGC are delivered to the users.
VI-C2 Communication Resource Allocation
By focusing on the semantics or meaning of data, GAI-driven SemCom networks require more intelligent, context-aware and user-centric allocation of communication resources [189]. Employing reasonable resource management schemes can prioritize the transmission of important and relevant semantics, ensuring timely and reliable information delivery. This can be achieved through GAI algorithms to understand, interpret, and prioritize data based on its semantic value.
Existing research showcases a range of communication resource allocation strategies tailored for GAI-driven SemCom networks. The works in [187, 18, 190] utilize the diffusion model-based joint resource allocation strategies. Specifically, in [187], the authors propose two schemes for resource allocation: the confidence-based scheme and the artificial intelligence-generated scheme, both designed to improve the quality of transmitting vital semantic information. The authors in [18] introduce multimodal (visual and textual) prompts to address the instability of SemCom or generative decoder-based GAI-driven SemCom system in message recovery. The visual prompts aim to restore the image’s structural fidelity, while textual prompts encapsulate its semantic context. They also evaluate the effectiveness of a generative diffusion model (GDM)-based resource allocation scheme to achieve a high Structural Similarity Index Measure (SSIM) while maintaining secure covert communications [191]. The research in [190] explores resource allocation for AIGC services in GAI-driven SemCom. Edge devices collect raw data and extract SI, which AIGC providers use to create meaningful content via GAI models. This content then helps multimedia service providers produce customized digital content. Efficiency is measured by the balance between resources used for these processes and the overall system demands.
Furthermore, since different knowledge-matching degrees in SemCom can lead to differentiated semantic performance observed by mobile users, some recent related works have focused on the resource allocation problem from a knowledge-matching perspective. In [10], the authors develop a bit-to-message transformation function based on the specific knowledge-matching degree between transceivers for the first time to optimize resource management in SemCom-enabled cellular networks. Besides, the authors in [177] propose an efficient and low-latency semantic service provisioning solution in SemCom-enabled vehicular networks for the knowledge-matching problem between pairing vehicles.
VII Case Study
In this section, we conceive important cases for GAI-driven SemCom networks, including autonomous driving, smart city and Metaverse.
VII-A Autonomous Driving
In the realm of autonomous driving, autonomous vehicles (AVs) need to actively gather sensing data and swiftly analyze the data to form a perception of their surrounding environment. However, the data collection and transmission processes for AVs are often cumbersome and expensive [16]. Moreover, it is noteworthy that the current perception models in AVs offer a rather rudimentary understanding which informs AVs’ control decisions. In GAI-driven SemCom networks, the costs of data transmission would be reduced via advanced GAI algorithms. Cumulative history and sensing data provide valuable semantic details, enhancing the contextual reasoning abilities of AVs within GAI-driven SemCom networks. They facilitate more accurate interpretations of complex traffic situations and environmental cues, which further leads to smarter decision-making in real-time driving scenarios.
Several prominent studies have been conducted on SemCom systems for autonomous driving. In [192], the authors present a semantic model to capture the relevant SI in autonomous vehicle systems for improving autonomous driving via enhancing information exchange and integration and enrich background knowledge. The authors in [193] develop a SemCom framework for a high altitude platform (HAP)-supported AV network, where traffic infrastructure can transmit its SI to BSs whenever it observes a connected AV. In [194], a multimodal semantic-aware framework is proposed to generative enhanced guidance to recipient vehicles on the basis of both text and images, with a DRL-based resource allocation strategy.
VII-B Smart City
Smart city represents intricate socio-technical networks made up of various interrelated components like IoT devices, mobile phones, other portable devices, physical infrastructures, services, applications, and the data shared among these elements [195]. The high complexity of smart city networks comes from dealing with numerous data, diverse content types, spatial and dynamic network structures, distributed control systems, and the intricate interconnections between various urban subsystems spanning physical, digital, organizational, and societal spheres [196]. In this regard, GAI-driven SemCom networks are anticipated to extract semantics from various sensing data types, enhance data exchanging efficiency, and precisely make decisions to achieve heterogeneous goals under various scenarios. The software and algorithms in the GAI-driven SemCom networks are capable to enhance urban performance in areas like transportation efficiency and energy conservation, aid in urban planning such as zoning, and bolster resilience through control methods and risk management strategies.
There are some related works encompassing both GAI technologies and semantic models in smart city. The authors in [197] put forward some preliminary thoughts for creating a semantic description model to describe and help discover, index and query smart city data. In [198], a smart city digital twin architecture is introduced, which facilitates the representation and reasoning of semantic knowledge, collaborating closely with ML methodologies. The authors in [199] provide a detailed overview of semantic interoperability techniques used in smart city applications for a holistic integration of IoT semantic data. Additionally, the authors in [200] focus on the application of semantic technologies aming at enhancing interoperability among Internet-of-Everything components in smart cities.
VII-C Metaverse
Metaverse is a collective virtual shared space, emerging from the fusion of enhanced virtual depictions of our physical world and persistent digital realms. Advancements in GAI technologies have led to a significant increase in Metaverse applications, notably in augmented reality (AR), virtual reality (VR), and extended reality (XR) [201, 202, 203, 204]. Both academia and industry are exploring the Metaverse to create immersive, dynamic virtual landscapes that can adapt in real-time, reflecting user interactions and inclinations. However, to authentically mirror our physical world within these virtual domains, vast amounts of data, spanning text, images, and videos, are essential. Classical communication infrastructures, constrained by their data compression and transmission capacities, are ill-equipped to support such data-intensive services. In this context, GAI-driven SemCom networks stand out by extracting meaningful semantic data and eliminating superfluous information in alignment with user preferences and auxiliary KB. This novel network paradigm has the potential to alleviate the data demands of the Metaverse applications on Internet, thus enhancing overall resource efficiency.
Recent studies have started to explore potential solutions to implementing the Metaverse applications through SemCom networks ensuring a satisfactory service experience. The authors in [205] introduce a framework dividing the Metaverse into agent-specific semantic multiverses (SMs), based on distributed learning and multi-agent RL. The framework in [206] facilitates the transmission of sensing information from the physical world to the Metaverse, incorporating semantic bases and a contest-based strategy for incentivized data upload. In [188], the authors explore content contest theory within SemCom to optimize resource allocation by the Metaverse service providers. In [190], an integrated framework is presented which applies a diffusion model for resource allocation in semantic extraction and content generation. Additionally, given the limitations of traditional metrics for SemCom networks, the authors in [207] adopt the AoI as a metric to measure data timeliness for virtual service providers creating digital twins of the physical world. Increasingly powered by GAI technologies which depend on shared knowledge from multiple service providers and individual users, the importance of data privacy and security in the Metaverse services becomes paramount. To address these, the authors in [208] design a trustworthy SemCom system for the Metaverse, leveraging the distributed decision-making and privacy-preserving capabilities of a federated learning architecture.
VIII Conclusion
In this survey, we have investigated the integration of GAI with SemCom, leading to the GAI-driven SemCom networks. We have detailed the fundamentals of GAI and SemCom, emphasizing their synergy and its impact on AIGC services. We have also delved into network management, covering aspects of novel layers, knowledge management, and resource allocation. The comprehensive exploration in this work not only underscores the revolutionary potential of GAI-driven SemCom networks in various domains but also highlights the emerging trends and future directions in wireless communications. The insights gained from this survey could pave the way for innovative solutions in enhancing network efficiency and user experience. We further explored practical applications in fields of autonomous driving, smart cities, and the Metaverse, showcasing the real-world potential of these technologies in GAI-driven SemCom networks.
References
- [1] M. Jovanovic and M. Campbell, “Generative Artificial Intelligence: Trends and Prospects,” Computer, vol. 55, no. 10, pp. 107–112, 2022.
- [2] M. Chui, E. Hazan, R. Roberts, A. Singla, K. Smaje, A. Sukharevsky, L. Yee, and R. Zemmel, “The Economic Potential of Generative AI: The Next Productivity Frontier,” June 2023. [Online]. Available: https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/the-economic-potential-of-generative-AI-the-next-productivity-frontier#key-insights
- [3] Anthropic PBC. Video AI. Accessed: Jul. 19, 2023. [Online]. Available: https://www.promptengineering.org/claudes-100k-context-window-how-this-will-transform-business-education-and-research/
- [4] OpenAI. ChatGPT Can Now See, Hear, and Speak. Accessed: Dec. 9, 2023. [Online]. Available: https://openai.com/blog/chatgpt-can-now-see-hear-and-speak
- [5] H. Du, Z. Li, D. Niyato, J. Kang, Z. Xiong, D. I. Kim et al., “Enabling AI-generated Content (AIGC) Services in Wireless Edge Networks,” arXiv preprint arXiv:2301.03220, 2023.
- [6] D. Gündüz, Z. Qin, I. E. Aguerri, H. S. Dhillon, Z. Yang, A. Yener, K. K. Wong, and C.-B. Chae, “Beyond Transmitting Bits: Context, Semantics, and Task-Oriented Communications,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 5–41, 2023.
- [7] R. Cheng, Y. Sun, D. Niyato, L. Zhang, L. Zhang, and M. A. Imran, “A Wireless AI-Generated Content (AIGC) Provisioning Framework Empowered by Semantic Communication,” arXiv preprint arXiv:2310.17705, 2023.
- [8] X. Luo, H.-H. Chen, and Q. Guo, “Semantic Communications: Overview, Open Issues, and Future Research Directions,” IEEE Wireless Communications, vol. 29, no. 1, pp. 210–219, 2022.
- [9] Z. Qin, X. Tao, J. Lu, W. Tong, and G. Y. Li, “Semantic Communications: Principles and Challenges,” arXiv preprint arXiv:2201.01389, 2021.
- [10] L. Xia, Y. Sun, D. Niyato, X. Li, and M. A. Imran, “Joint User Association and Bandwidth Allocation in Semantic Communication Networks,” IEEE Transactions on Vehicular Technology, 2023.
- [11] S. Iyer, R. Khanai, D. Torse, R. J. Pandya, K. M. Rabie, K. Pai, W. U. Khan, and Z. Fadlullah, “A Survey on Semantic Communications for Intelligent Wireless Networks,” Wireless Personal Communications, vol. 129, no. 1, pp. 569–611, 2023.
- [12] W. Yang, H. Du, Z. Q. Liew, W. Y. B. Lim, Z. Xiong, D. Niyato, X. Chi, X. S. Shen, and C. Miao, “Semantic Communications for Future Internet: Fundamentals, Applications, and Challenges,” IEEE Communications Surveys & Tutorials, 2022.
- [13] A. Karapantelakis, P. Alizadeh, A. Alabassi, K. Dey, and A. Nikou, “Generative AI in Mobile Networks: A Survey,” Annals of Telecommunications, pp. 1–19, 2023.
- [14] Y. Cao, S. Li, Y. Liu, Z. Yan, Y. Dai, P. S. Yu, and L. Sun, “A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT,” arXiv preprint arXiv:2303.04226, 2023.
- [15] J. Wu, W. Gan, Z. Chen, S. Wan, and H. Lin, “AI-Generated Content (AIGC): A Survey,” arXiv preprint arXiv:2304.06632, 2023.
- [16] M. Xu, H. Du, D. Niyato, J. Kang, Z. Xiong, S. Mao, Z. Han, A. Jamalipour, D. I. Kim, V. Leung et al., “Unleashing the Power of Edge-Cloud Generative AI in Mobile Networks: A Survey of AIGC Services,” arXiv preprint arXiv:2303.16129, 2023.
- [17] L. Xia, Y. Sun, C. Liang, L. Zhang, M. A. Imran, and D. Niyato, “Generative AI for Semantic Communication: Architecture, Challenges, and Outlook,” arXiv preprint arXiv:2308.15483, 2023.
- [18] H. Du, G. Liu, D. Niyato, J. Zhang, J. Kang, Z. Xiong, B. Ai, and D. I. Kim, “Generative AI-aided Joint Training-free Secure Semantic Communications via Multi-modal Prompts,” arXiv preprint arXiv:2309.02616, 2023.
- [19] R. Gozalo-Brizuela and E. C. Garrido-Merchán, “A Survey of Generative AI Applications,” arXiv preprint arXiv:2306.02781, 2023.
- [20] A. Z. Bahtar and M. Muda, “The Impact of User–Generated Content (UGC) on Product Reviews towards Online Purchasing–A Conceptual Framework,” Procedia Economics and Finance, vol. 37, pp. 337–342, 2016.
- [21] Y. Li, L. Feng, J. Xu, T. Zhang, Y. Liao, and J. Li, “Full-Reference and No-Reference Quality Assessment For Compressed User-Generated Content Videos,” in 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), 2021, pp. 1–6.
- [22] W. Yang, Z. Q. Liew, W. Y. B. Lim, Z. Xiong, D. Niyato, X. Chi, X. Cao, and K. B. Letaief, “Semantic Communication Meets Edge Intelligence,” IEEE Wireless Communications, vol. 29, no. 5, pp. 28–35, 2022.
- [23] P. Basu, J. Bao, M. Dean, and J. Hendler, “Preserving quality of information by using semantic relationships,” in 2012 IEEE International Conference on Pervasive Computing and Communications Workshops, 2012, pp. 58–63.
- [24] F. Zhao, Y. Sun, R. Cheng, and M. A. Imran, “Background Knowledge Aware Semantic Coding Model Selection,” in 2022 IEEE 22nd International Conference on Communication Technology (ICCT), 2022, pp. 84–89.
- [25] H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep Learning Enabled Semantic Communication Systems,” IEEE Transactions on Signal Processing, vol. 69, pp. 2663–2675, 2021.
- [26] E. C. Strinati and S. Barbarossa, “6G Networks: Beyond Shannon Towards Semantic and Goal-Oriented Communications,” Computer Networks, vol. 190, p. 107930, 2021.
- [27] Q. Lan, D. Wen, Z. Zhang, Q. Zeng, X. Chen, P. Popovski, and K. Huang, “What is Semantic Communication? A View on Conveying Meaning in the Era of Machine Intelligence,” Journal of Communications and Information Networks, vol. 6, no. 4, pp. 336–371, 2021.
- [28] C. Chaccour, W. Saad, M. Debbah, Z. Han, and H. V. Poor, “Less Data, More Knowledge: Building Next Generation Semantic Communication Networks,” arXiv preprint arXiv:2211.14343, 2022.
- [29] K. B. Letaief, W. Chen, Y. Shi, J. Zhang, and Y.-J. A. Zhang, “The Roadmap to 6G: AI Empowered Wireless Networks,” IEEE Communications Magazine, vol. 57, no. 8, pp. 84–90, 2019.
- [30] C. Cai, X. Yuan, and Y.-J. A. Zhang, “Multi-Device Task-Oriented Communication via Maximal Coding Rate Reduction,” arXiv preprint arXiv:2309.02888, 2023.
- [31] S. Kaul, R. Yates, and M. Gruteser, “Real-time Status: How Often Should One Update?” in 2012 Proceedings IEEE INFOCOM, 2012, pp. 2731–2735.
- [32] R. A. Howard, “Information Value Theory,” IEEE Transactions on Systems Science and Cybernetics, vol. 2, no. 1, pp. 22–26, 1966.
- [33] D. Bahdanau, K. Cho, and Y. Bengio, “Neural Machine Translation by Jointly Learning to Align and Translate,” arXiv preprint arXiv:1409.0473, 2014.
- [34] A. See, P. J. Liu, and C. D. Manning, “Get to the Point: Summarization with Pointer-Generator Networks,” arXiv preprint arXiv:1704.04368, 2017.
- [35] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to Sequence Learning with Neural Networks,” Advances in Neural Information Processing Systems, vol. 27, 2014.
- [36] O. Vinyals and Q. Le, “A Neural Conversational Model,” arXiv preprint arXiv:1506.05869, 2015.
- [37] S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- [38] T. Mikolov, M. Karafiát, L. Burget, J. Cernockỳ, and S. Khudanpur, “Recurrent Neural Network Based Language Model.” in Interspeech, vol. 2, no. 3. Makuhari, 2010, pp. 1045–1048.
- [39] R. Dey and F. M. Salem, “Gate-variants of Gated Recurrent Unit (GRU) neural networks,” in 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), 2017, pp. 1597–1600.
- [40] S. R. Bowman, L. Vilnis, O. Vinyals, A. M. Dai, R. Jozefowicz, and S. Bengio, “Generating Sentences from a Continuous Space,” arXiv preprint arXiv:1511.06349, 2015.
- [41] W. Wang, Z. Gan, H. Xu, R. Zhang, G. Wang, D. Shen, C. Chen, and L. Carin, “Topic-guided Variational Autoencoders for Text Generation,” arXiv preprint arXiv:1903.07137, 2019.
- [42] S. Semeniuta, A. Severyn, and E. Barth, “A Hybrid Convolutional Variational Autoencoder for Text Generation,” arXiv preprint arXiv:1702.02390, 2017.
- [43] W. Xu, H. Sun, C. Deng, and Y. Tan, “Variational Autoencoder for Semi-Supervised Text Classification,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31, no. 1, 2017.
- [44] L. Yu, W. Zhang, J. Wang, and Y. Yu, “SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient,” in Proceedings of the AAAI conference on artificial intelligence, vol. 31, no. 1, 2017.
- [45] Y. Zhang, Z. Gan, K. Fan, Z. Chen, R. Henao, D. Shen, and L. Carin, “Adversarial Feature Matching for Text Generation,” in International conference on machine learning. PMLR, 2017, pp. 4006–4015.
- [46] H. Wang, Z. Qin, and T. Wan, “Text Generation Based on Generative Adversarial Nets with Latent Variable,” in Advances in Knowledge Discovery and Data Mining: 22nd Pacific-Asia Conference, PAKDD 2018, Melbourne, VIC, Australia, June 3-6, 2018, Proceedings, Part II 22. Springer, 2018, pp. 92–103.
- [47] J. Guo, S. Lu, H. Cai, W. Zhang, Y. Yu, and J. Wang, “Long Text Generation via Adversarial Training with Leaked Information,” in Proceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018.
- [48] C. Zhang, C. Xiong, and L. Wang, “A research on generative adversarial networks applied to text generation,” in 2019 14th International Conference on Computer Science & Education (ICCSE), 2019, pp. 913–917.
- [49] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is All You Need,” Advances In Neural Information Processing Systems, vol. 30, 2017.
- [50] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language Models are Unsupervised Multitask Learners,” OpenAI Blog, vol. 1, no. 8, p. 9, 2019.
- [51] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [52] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the Limits of Transfer Learning with A Unified Text-To-Text Transformer,” The Journal of Machine Learning Research, vol. 21, no. 1, pp. 5485–5551, 2020.
- [53] OpenAI. ChatGPT: Optimizing Language Models for Dialogue. Accessed: Jul. 13, 2023. [Online]. Available: https://openai.com/blog/chatgpt/
- [54] M. Corporation. Reinventing Search with A New AI-powered Microsoft Bing and Edge, your Copilot for the Web. Accessed: Jul. 13, 2023. [Online]. Available: https://blogs.microsoft.com/blog/2023/02/07/reinventing-search-with-a-new-ai-powered-microsoft-bing-and-edge-your-copilot-for-the-web/
- [55] S. Smith, M. Patwary, B. Norick, P. LeGresley, S. Rajbhandari, J. Casper, Z. Liu, S. Prabhumoye, G. Zerveas, V. Korthikanti et al., “Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model,” arXiv preprint arXiv:2201.11990, 2022.
- [56] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language Models are Few-shot Learners,” Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020.
- [57] PaintMe. PaintMe AI: Home. Accessed: Jul. 19, 2023. [Online]. Available: https://www.paintme.ai/index.php
- [58] Vizcom. The Next Generation of Product Visualization. Accessed: Jul. 19, 2023. [Online]. Available: https://www.vizcom.ai/
- [59] Steve.AI. Convert Photos to Videos Instantly Using Steve.AI. Accessed: Jul. 19, 2023. [Online]. Available: https://www.steve.ai/photo-video-maker
- [60] T. Karras, S. Laine, and T. Aila, “A Style-Based Generator Architecture for Generative Adversarial Networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4401–4410.
- [61] A. Van Den Oord, O. Vinyals et al., “Neural Discrete Representation Learning,” Advances in Neural Information Processing Systems, vol. 30, 2017.
- [62] D. Rezende and S. Mohamed, “Variational Inference with Normalizing Flows,” in International conference on machine learning. PMLR, 2015, pp. 1530–1538.
- [63] J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet, “Video Diffusion Models,” arXiv:2204.03458, 2022.
- [64] Murf.AI. Transform Your Voiceover from A Home Recording to A Professional AI Voice. Accessed: Jul. 19, 2023. [Online]. Available: https://murf.ai/voice-changer
- [65] Resemble.AI. Real-time Speech-to-Speech Voice Conversion. Accessed: Jul. 19, 2023. [Online]. Available: https://www.resemble.ai/speech-to-speech/
- [66] MetaVoice. Accessed: Jul. 19, 2023. [Online]. Available: https://themetavoice.xyz/
- [67] C. Donahue, J. McAuley, and M. Puckette, “Adversarial Audio Synthesis,” arXiv preprint arXiv:1802.04208, 2018.
- [68] Y. Meng, W. Li, S. Lei, Z. Zou, and Z. Shi, “Large-Factor Super-Resolution of Remote Sensing Images With Spectra-Guided Generative Adversarial Networks,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–11, 2022.
- [69] N. Kalchbrenner, E. Elsen, K. Simonyan, S. Noury, N. Casagrande, E. Lockhart, F. Stimberg, A. Oord, S. Dieleman, and K. Kavukcuoglu, “Efficient Neural Audio Synthesis,” in International Conference on Machine Learning. PMLR, 2018, pp. 2410–2419.
- [70] K. Akuzawa, K. Onishi, K. Takiguchi, K. Mametani, and K. Mori, “Conditional Deep Hierarchical Variational Autoencoder for Voice Conversion,” in 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2021, pp. 808–813.
- [71] K. Zhou, B. Sisman, and H. Li, “VAW-GAN for Disentanglement and Recomposition of Emotional Elements in Speech,” in 2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 415–422.
- [72] P. Dhariwal, H. Jun, C. Payne, J. W. Kim, A. Radford, and I. Sutskever, “Jukebox: A Generative Model for Music,” arXiv preprint arXiv:2005.00341, 2020.
- [73] OpenAI. DALL·E 2: Exploring the Limits of Data-Driven Image Generation with Transformers. Accessed: Jul. 19, 2023. [Online]. Available: https://openai.com/dall-e-2
- [74] NightCafe Studio. NightCafe Studio - AI Art Generator. Accessed: Jul. 19, 2023. [Online]. Available: https://creator.nightcafe.studio/
- [75] DreamStudio. DreamStudio - Image Generator. Accessed: Jul. 19, 2023. [Online]. Available: https://dreamstudio.ai/generate
- [76] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, “Zero-Shot Text-to-Image Generation,” in International Conference on Machine Learning. PMLR, 2021, pp. 8821–8831.
- [77] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning Transferable Visual Models From Natural Language Supervision,” arXiv preprint arXiv:2103.00020, 2021.
- [78] K. Crowson, S. Biderman, D. Kornis, D. Stander, E. Hallahan, L. Castricato, and E. Raff, “VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance,” in European Conference on Computer Vision. Springer, 2022, pp. 88–105.
- [79] Y. Balaji, S. Nah, X. Huang, A. Vahdat, J. Song, K. Kreis, M. Aittala, T. Aila, S. Laine, B. Catanzaro et al., “eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers,” arXiv preprint arXiv:2211.01324, 2022.
- [80] T. Brooks, A. Holynski, and A. A. Efros, “InstructPix2Pix: Learning to Follow Image Editing Instructions,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 392–18 402.
- [81] Synthesia. Create Professional Videos without Mics, Cameras, or Actors. Accessed: Jul. 19, 2023. [Online]. Available: https://www.synthesia.io/
- [82] Pictory. Script To Video Creation In Minutes. Accessed: Jul. 19, 2023. [Online]. Available: https://pictory.ai/pictory-features/script-to-video
- [83] Meta AI. Accessed: Jul. 19, 2023. [Online]. Available: https://makeavideo.studio/
- [84] W. Hong, M. Ding, W. Zheng, X. Liu, and J. Tang, “CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers,” arXiv preprint arXiv:2205.15868, 2022.
- [85] R. Villegas, M. Babaeizadeh, P.-J. Kindermans, H. Moraldo, H. Zhang, M. T. Saffar, S. Castro, J. Kunze, and D. Erhan, “Phenaki: Variable Length Video Generation From Open Domain Textual Description,” arXiv preprint arXiv:2210.02399, 2022.
- [86] Murf.AI. Go from Text to Speech with A Versatile AI Voice Generator. Accessed: Jul. 19, 2023. [Online]. Available: https://murf.ai/
- [87] PlayHT. AI Powered Text to Voice Generator. Accessed: Jul. 19, 2023. [Online]. Available: https://play.ht/blog/ai-text-to-speech-voice-cloning-technology-overview/
- [88] A. v. d. Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “WaveNet: A Generative Model for Raw Audio,” arXiv preprint arXiv:1609.03499, 2016.
- [89] Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, D. Roblek, O. Teboul, D. Grangier, M. Tagliasacchi et al., “AudioLM: A Language Modeling Approach to Audio Generation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023.
- [90] READ-COOP. Unlock Historical Documents with AI. Accessed: Jul. 19, 2023. [Online]. Available: https://readcoop.eu/transkribus/
- [91] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and Tell: A Neural Image Caption Generator,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015.
- [92] J. Chen, H. Guo, K. Yi, B. Li, and M. Elhoseiny, “VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18 030–18 040.
- [93] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” arXiv preprint arXiv:2010.11929, 2020.
- [94] H. Xu, G. Ghosh, P.-Y. Huang, D. Okhonko, A. Aghajanyan, F. Metze, L. Zettlemoyer, and C. Feichtenhofer, “VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding,” arXiv preprint arXiv:2109.14084, 2021.
- [95] C. Sun, A. Myers, C. Vondrick, K. Murphy, and C. Schmid, “VideoBERT: A Joint Model for Video and Language Representation Learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019.
- [96] H. Luo, L. Ji, B. Shi, H. Huang, N. Duan, T. Li, J. Li, T. Bharti, and M. Zhou, “UniVL: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation,” arXiv preprint arXiv:2002.06353, 2020.
- [97] SpeakAI. Turn Your Language Data into Insights, Fast and with No Code. Accessed: Jul. 19, 2023. [Online]. Available: https://speakai.co/
- [98] A. Hannun, C. Case, J. Casper, B. Catanzaro, G. Diamos, E. Elsen, R. Prenger, S. Satheesh, S. Sengupta, A. Coates et al., “Deep Speech: Scaling Up End-to-End Speech Recognition,” arXiv preprint arXiv:1412.5567, 2014.
- [99] A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations,” Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020.
- [100] Apple: Siri. Accessed: Jul. 19, 2023. [Online]. Available: http://www.apple.com/ios/siri/
- [101] XiaoIce. Accessed: Jul. 19, 2023. [Online]. Available: https://www.xiaoice.com/
- [102] Google: Google Assistant. Accessed: Jul. 19, 2023. [Online]. Available: https://assistant.google.com/
- [103] Amazon Inc.: Alexa. Accessed: Jul. 19, 2023. [Online]. Available: https://developer.amazon.com/public/solutions/alexa/
- [104] L. Zhou, J. Gao, D. Li, and H.-Y. Shum, “The Design and Implementation of XiaoIce, an Empathetic Social Chatbot,” Computational Linguistics, vol. 46, no. 1, pp. 53–93, 2020.
- [105] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-Based Learning Applied to Document Recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- [106] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017.
- [107] K. Simonyan and A. Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [108] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [109] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely Connected Convolutional Networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4700–4708.
- [110] K. Sohn, H. Lee, and X. Yan, “Advances in Neural Information Processing Systems,” Advances in neural information processing systems, vol. 28, 2015.
- [111] H. Huang, R. He, Z. Sun, T. Tan et al., “Advances in Neural Information Processing Systems,” Advances in neural information processing systems, vol. 31, 2018.
- [112] A. Radford, L. Metz, and S. Chintala, “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks,” arXiv preprint arXiv:1511.06434, 2015.
- [113] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 2223–2232.
- [114] J. Song, C. Meng, and S. Ermon, “Denoising Diffusion Implicit Models,” arXiv preprint arXiv:2010.02502, 2020.
- [115] M. D. M. Reddy, M. S. M. Basha, M. M. C. Hari, and M. N. Penchalaiah, “DALL-E: Creating Images from Text,” UGC Care Group I Journal, vol. 8, no. 14, pp. 71–75, 2021.
- [116] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical Text-Conditional Image Generation with CLIP Latents,” arXiv preprint arXiv:2204.06125, 2022.
- [117] M. Dorkenwald, T. Milbich, A. Blattmann, R. Rombach, K. G. Derpanis, and B. Ommer, “Stochastic Image-to-Video Synthesis using cINNs,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 3742–3753.
- [118] L. Zhao, X. Peng, Y. Tian, M. Kapadia, and D. Metaxas, “Learning to Forecast and Refine Residual Motion for Image-to-Video Generation,” in Proceedings of the European Conference on Computer Vision (ECCV), September 2018.
- [119] X. Wang, K. C. Chan, K. Yu, C. Dong, and C. Change Loy, “EDVR: Video Restoration with Enhanced Deformable Convolutional Networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019, pp. 0–0.
- [120] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-Resolution Image Synthesis with Latent Diffusion Models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695.
- [121] J. Finnie-Ansley, P. Denny, B. A. Becker, A. Luxton-Reilly, and J. Prather, “The Robots are Coming: Exploring the Implications of OpenAI Codex on Introductory Programming,” in Australasian Computing Education Conference, 2022, pp. 10–19.
- [122] R. Batish, Voicebot and Chatbot Design: Flexible Conversational Interfaces with Amazon Alexa, Google Home, and Facebook Messenger. Packt Publishing Ltd, 2018.
- [123] C. W. Morris, “Foundations of the Theory of Signs,” in International Encyclopedia of Unified Science. Chicago University Press, 1938, pp. 1–59.
- [124] C. E. Shannon and W. Weaver, The Mathematical Theory of Communication. University of Illinois Press, 1949.
- [125] R. Carnap and Y. Bar-Hillel, “An Outline of a Theory of Semantic Information,” Journal of Symbolic Logic, vol. 19, no. 3, pp. 230–232, 1954.
- [126] J. Barwise and J. Perry, Situations and Attitudes, J. Perry, Ed. Cambridge, Mass.: MIT Press, 1983.
- [127] B. Juba and M. Sudan, “Universal Semantic Communication I,” in Proceedings of the fortieth annual ACM symposium on theory of computing, 2008, pp. 123–132.
- [128] Juba, Brendan and Sudan, Madhu, “Universal Semantic Communication II: A Theory of Goal-oriented Communication,” in Electronic Colloquium on Computational Complexity (ECCC), vol. 15, no. 095, 2008.
- [129] L. Floridi, “Outline of A Theory of Strongly Semantic Information,” Minds and Machines, vol. 14, pp. 197–221, 2004.
- [130] S. D’Alfonso, “On Quantifying Semantic Information,” Information, vol. 2, no. 1, pp. 61–101, 2011.
- [131] Y. Zhong, “A Theory of Semantic Information,” China Communications, vol. 14, no. 1, pp. 1–17, 2017.
- [132] A. Kolchinsky and D. H. Wolpert, “Semantic Information, Autonomous Agency and Non-equilibrium Statistical Physics,” Interface Focus, vol. 8, no. 6, p. 20180041, 2018.
- [133] A. Rényi, “On Measures of Entropy and Information,” in Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, vol. 4. University of California Press, 1961, pp. 547–562.
- [134] P. Jiang, C.-K. Wen, S. Jin, and G. Y. Li, “Deep Source-Channel Coding for Sentence Semantic Transmission With HARQ,” IEEE Transactions on Communications, vol. 70, no. 8, pp. 5225–5240, 2022.
- [135] M. Sana and E. C. Strinati, “Learning Semantics: An Opportunity for Effective 6G Communications,” in 2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC), 2022, pp. 631–636.
- [136] H. Xie and Z. Qin, “A Lite Distributed Semantic Communication System for Internet of Things,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 1, pp. 142–153, 2021.
- [137] F. Zhou, Y. Li, X. Zhang, Q. Wu, X. Lei, and R. Q. Hu, “Cognitive Semantic Communication Systems Driven by Knowledge Graph,” in ICC 2022-IEEE International Conference on Communications. IEEE, 2022, pp. 4860–4865.
- [138] S. Jiang, Y. Liu, Y. Zhang, P. Luo, K. Cao, J. Xiong, H. Zhao, and J. Wei, “Reliable Semantic Communication System Enabled by Knowledge Graph,” Entropy, vol. 24, no. 6, p. 846, 2022.
- [139] Z. Weng and Z. Qin, “Semantic Communication Systems for Speech Transmission,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 8, pp. 2434–2444, 2021.
- [140] H. Tong, Z. Yang, S. Wang, Y. Hu, O. Semiari, W. Saad, and C. Yin, “Federated Learning for Audio Semantic Communication,” Frontiers in communications and networks, vol. 2, p. 734402, 2021.
- [141] Z. Weng, Z. Qin, X. Tao, C. Pan, G. Liu, and G. Y. Li, “Deep Learning Enabled Semantic Communications with Speech Recognition and Synthesis,” IEEE Transactions on Wireless Communications, pp. 1–1, 2023.
- [142] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks,” in Proceedings of the 23rd International Conference on Machine Learning, 2006, pp. 369–376.
- [143] M. U. Lokumarambage, V. S. S. Gowrisetty, H. Rezaei, T. Sivalingam, N. Rajatheva, and A. Fernando, “Wireless End-to-End Image Transmission System using Semantic Communications,” IEEE Access, 2023.
- [144] D. Huang, X. Tao, F. Gao, and J. Lu, “Deep Learning-Based Image Semantic Coding for Semantic Communications,” in 2021 IEEE Global Communications Conference (GLOBECOM), 2021, pp. 1–6.
- [145] D. Huang, F. Gao, X. Tao, Q. Du, and J. Lu, “Toward Semantic Communications: Deep Learning-Based Image Semantic Coding,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 55–71, 2023.
- [146] C.-H. Lee, J.-W. Lin, P.-H. Chen, and Y.-C. Chang, “Deep Learning-Constructed Joint Transmission-Recognition for Internet of Things,” IEEE Access, vol. 7, pp. 76 547–76 561, 2019.
- [147] X. Kang, B. Song, J. Guo, Z. Qin, and F. R. Yu, “Task-Oriented Image Transmission for Scene Classification in Unmanned Aerial Systems,” IEEE Transactions on Communications, vol. 70, no. 8, pp. 5181–5192, 2022.
- [148] J. Kang, H. Du, Z. Li, Z. Xiong, S. Ma, D. Niyato, and Y. Li, “Personalized Saliency in Task-Oriented Semantic Communications: Image Transmission and Performance Analysis,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 186–201, 2023.
- [149] S. Wang, J. Dai, Z. Liang, K. Niu, Z. Si, C. Dong, X. Qin, and P. Zhang, “Wireless Deep Video Semantic Transmission,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 214–229, 2023.
- [150] P. Jiang, C.-K. Wen, S. Jin, and G. Y. Li, “Wireless Semantic Communications for Video Conferencing,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 230–244, 2023.
- [151] C. Liang, X. Deng, Y. Sun, R. Cheng, L. Xia, D. Niyato, and M. A. Imran, “VISTA: Video Transmission over A Semantic Communication Approach,” in 2023 IEEE International Conference on Communications Workshops (ICC Workshops), 2023, pp. 1777–1782.
- [152] X. Tao, Y. Duan, M. Xu, Z. Meng, and J. Lu, “Learning QoE of Mobile Video Transmission With Deep Neural Network: A Data-Driven Approach,” IEEE Journal on Selected Areas in Communications, vol. 37, no. 6, pp. 1337–1348, 2019.
- [153] O. Fried, A. Tewari, M. Zollhöfer, A. Finkelstein, E. Shechtman, D. B. Goldman, K. Genova, Z. Jin, C. Theobalt, and M. Agrawala, “Text-based Editing of Talking-Head Video,” ACM Transactions on Graphics (TOG), vol. 38, no. 4, pp. 1–14, 2019.
- [154] P. Tandon, S. Chandak, P. Pataranutaporn, Y. Liu, A. M. Mapuranga, P. Maes, T. Weissman, and M. Sra, “Txt2Vid: Ultra-Low Bitrate Compression of Talking-Head Videos via Text,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 107–118, 2023.
- [155] H. Xie, Z. Qin, X. Tao, and K. B. Letaief, “Task-Oriented Multi-User Semantic Communications,” IEEE Journal on Selected Areas in Communications, vol. 40, no. 9, pp. 2584–2597, 2022.
- [156] J. Hribar, M. Costa, N. Kaminski, and L. A. DaSilva, “Updating Strategies in the Internet of Things by Taking Advantage of Correlated Sources,” in GLOBECOM 2017 - 2017 IEEE Global Communications Conference, 2017, pp. 1–6.
- [157] Q. Abbas, S. A. Hassan, H. K. Qureshi, K. Dev, and H. Jung, “A Comprehensive Survey on Age of Information in Massive IoT Networks,” Computer Communications, vol. 197, pp. 199–213, 2023.
- [158] R. D. Yates, M. Tavan, Y. Hu, and D. Raychaudhuri, “Timely Cloud Gaming,” in IEEE INFOCOM 2017 - IEEE Conference on Computer Communications, 2017, pp. 1–9.
- [159] R. D. Yates, Y. Sun, D. R. Brown, S. K. Kaul, E. Modiano, and S. Ulukus, “Age of Information: An Introduction and Survey,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 5, pp. 1183–1210, 2021.
- [160] E. Uysal, O. Kaya, A. Ephremides, J. Gross, M. Codreanu, P. Popovski, M. Assaad, G. Liva, A. Munari, T. Soleymani et al., “Semantic Communications in Networked Systems: A Data Significance Perspective,” arXiv preprint arXiv:2103.05391, 2021.
- [161] A. Maatouk, M. Assaad, and A. Ephremides, “The Age of Incorrect Information: An Enabler of Semantics-Empowered Communication,” IEEE Transactions on Wireless Communications, 2022.
- [162] E. Uysal, O. Kaya, A. Ephremides, J. Gross, M. Codreanu, P. Popovski, M. Assaad, G. Liva, A. Munari, B. Soret et al., “Semantic Communications in Networked Systems: A Data Significance Perspective,” IEEE Network, vol. 36, no. 4, pp. 233–240, 2022.
- [163] A. Li, S. Wu, S. Meng, and Q. Zhang, “Towards Goal-Oriented Semantic Communications: New Metrics, Open Challenges, and Future Research Directions,” arXiv preprint arXiv:2304.00848, 2023.
- [164] T. Soleymani, J. S. Baras, and S. Hirche, “Value of Information in Feedback Control: Quantification,” IEEE Transactions on Automatic Control, vol. 67, no. 7, pp. 3730–3737, 2021.
- [165] C. K. Thomas and W. Saad, “Neuro-Symbolic Causal Reasoning Meets Signaling Game for Emergent Semantic Communications,” IEEE Transactions on Wireless Communications, pp. 1–1, 2023.
- [166] C. K. Thomas, W. Saad, and Y. Xiao, “Causal Semantic Communication for Digital Twins: A Generalizable Imitation Learning Approach,” arXiv preprint arXiv:2304.12502, 2023.
- [167] G. Liu, H. Du, D. Niyato, J. Kang, Z. Xiong, D. I. Kim et al., “Semantic Communications for Artificial Intelligence Generated Content (AIGC) Toward Effective Content Creation,” arXiv preprint arXiv:2308.04942, 2023.
- [168] Q. Hu, G. Zhang, Z. Qin, Y. Cai, G. Yu, and G. Y. Li, “Robust Semantic Communications with Masked VQ-VAE Enabled Codebook,” IEEE Transactions on Wireless Communications, pp. 1–1, 2023.
- [169] G. Shi, Y. Xiao, Y. Li, and X. Xie, “From Semantic Communication to Semantic-Aware Networking: Model, Architecture, and Open Problems,” IEEE Communications Magazine, vol. 59, no. 8, pp. 44–50, 2021.
- [170] K. Bollacker, C. Evans, P. Paritosh, T. Sturge, and J. Taylor, “Freebase: A Collaboratively Created Graph Database for Structuring Human Knowledge,” in Proceedings of the 2008 ACM SIGMOD international conference on Management of data, 2008, pp. 1247–1250.
- [171] S. Auer, C. Bizer, G. Kobilarov, J. Lehmann, R. Cyganiak, and Z. Ives, “DBpedia: A Nucleus for A Web of Open Data,” in Proceedings of the 6th International The Semantic Web and 2nd Asian Conference on Asian Semantic Web Conference, ser. ISWC’07/ASWC’07. Berlin, Heidelberg: Springer-Verlag, 2007, p. 722–735.
- [172] D. Vrandečić and M. Krötzsch, “Wikidata: A Free Collaborative Knowledgebase,” Communications of the ACM, vol. 57, no. 10, pp. 78–85, 2014.
- [173] Google. Introducing the Knowledge Graph: Things, not Strings. Accessed: Jul. 19, 2023. [Online]. Available: https://blog.google/products/search/introducing-knowledge-graph-things-not/
- [174] X. Wang, D. Wang, C. Xu, X. He, Y. Cao, and T.-S. Chua, “Explainable Reasoning over Knowledge Graphs for Recommendation,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 5329–5336.
- [175] W. Zheng, L. Yin, X. Chen, Z. Ma, S. Liu, and B. Yang, “Knowledge Base Graph Embedding Module Design for Visual Question Answering Model,” Pattern recognition, vol. 120, p. 108153, 2021.
- [176] X. Chen, S. Jia, and Y. Xiang, “A Review: Knowledge Reasoning over Knowledge Graph,” Expert Systems with Applications, vol. 141, p. 112948, 2020.
- [177] L. Xia, Y. Sun, D. Niyato, D. Feng, L. Feng, and M. A. Imran, “xURLLC-Aware Service Provisioning in Vehicular Networks: A Semantic Communication Perspective,” arXiv preprint arXiv:2302.11993, 2023.
- [178] S. Ji, S. Pan, E. Cambria, P. Marttinen, and S. Y. Philip, “A Survey on Knowledge Graphs: Representation, Acquisition, and Applications,” IEEE transactions on neural networks and learning systems, vol. 33, no. 2, pp. 494–514, 2021.
- [179] T. Vu, T. D. Nguyen, D. Q. Nguyen, D. Phung et al., “A Capsule Network-based Embedding Model for Knowledge Graph Completion and Search Personalization,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019, pp. 2180–2189.
- [180] Y. Lin, X. Wang, H. Ma, L. Wang, F. Hao, and Z. Cai, “An Efficient Approach to Sharing Edge Knowledge in 5G-Enabled Industrial Internet of Things,” IEEE Transactions on Industrial Informatics, vol. 19, no. 1, pp. 930–939, 2023.
- [181] H. Chai, S. Leng, Y. Chen, and K. Zhang, “A Hierarchical Blockchain-Enabled Federated Learning Algorithm for Knowledge Sharing in Internet of Vehicles,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 7, pp. 3975–3986, 2021.
- [182] Z. Cai and X. Zheng, “A Private and Efficient Mechanism for Data Uploading in Smart Cyber-Physical Systems,” IEEE Transactions on Network Science and Engineering, vol. 7, no. 2, pp. 766–775, 2020.
- [183] R. Mullins and M. T. Barros, “Cognitive Network Management for 5G,” 5GPPP Working Group on Network Management and QoS, Tech. Rep., 2017.
- [184] T. Maksymyuk, S. Dumych, M. Brych, D. Satria, and M. Jo, “An IoT Based Monitoring Framework for Software Defined 5G Mobile Networks,” in Proceedings of the 11th international conference on ubiquitous information management and communication, 2017, pp. 1–4.
- [185] H. Du, J. Wang, D. Niyato, J. Kang, Z. Xiong, and D. I. Kim, “AI-generated Incentive Mechanism and Full-duplex Semantic Communications for Information Sharing,” arXiv preprint arXiv:2303.01896, 2023.
- [186] H. Du, R. Zhang, Y. Liu, J. Wang, Y. Lin, Z. Li, D. Niyato, J. Kang, Z. Xiong, S. Cui et al., “Beyond Deep Reinforcement Learning: A Tutorial on Generative Diffusion Models in Network Optimization,” arXiv preprint arXiv:2308.05384, 2023.
- [187] B. Du, H. Du, H. Liu, D. Niyato, P. Xin, J. Yu, M. Qi, and Y. Tang, “YOLO-based Semantic Communication with Generative AI-aided Resource Allocation for Digital Twins Construction,” arXiv preprint arXiv:2306.14138, 2023.
- [188] G. Liu, H. Du, D. Niyato, J. Kang, Z. Xiong, and B. H. Soong, “Vision-based Semantic Communications for Metaverse Services: A Contest Theoretic Approach,” arXiv preprint arXiv:2308.07618, 2023.
- [189] Y. Xu, G. Gui, H. Gacanin, and F. Adachi, “A Survey on Resource Allocation for 5G Heterogeneous Networks: Current Research, Future Trends, and Challenges,” IEEE Communications Surveys & Tutorials, vol. 23, no. 2, pp. 668–695, 2021.
- [190] Y. Lin, Z. Gao, H. Du, D. Niyato, J. Kang, A. Jamalipour, and X. S. Shen, “A Unified Framework for Integrating Semantic Communication and AI-Generated Content in Metaverse,” arXiv preprint arXiv:2305.11911, 2023.
- [191] H. Du, J. Wang, D. Niyato, J. Kang, Z. Xiong, M. Guizani, and D. I. Kim, “Rethinking Wireless Communication Security in Semantic Internet of Things,” IEEE Wireless Communications, vol. 30, no. 3, pp. 36–43, 2023.
- [192] S. Zhang, I.-L. Yen, F. Bastani, H. Moeini, and D. Moore, “A Semantic Model for Information Sharing in Autonomous Vehicle Systems,” in 2017 IEEE 11th International Conference on Semantic Computing (ICSC), 2017, pp. 32–39.
- [193] A. Deb Raha, M. Shirajum Munir, A. Adhikary, Y. Qiao, S.-B. Park, and C. Seon Hong, “An Artificial Intelligent-Driven Semantic Communication Framework for Connected Autonomous Vehicular Network,” in 2023 International Conference on Information Networking (ICOIN), 2023, pp. 352–357.
- [194] R. Zhang, K. Xiong, H. Du, D. Niyato, J. Kang, X. Shen, and H. V. Poor, “Generative AI-enabled Vehicular Networks: Fundamentals, Framework, and Case Study,” arXiv preprint arXiv:2304.11098, 2023.
- [195] L. Carvalho, “Smart Cities from Scratch? A Socio-technical Perspective,” Cambridge Journal of Regions, Economy and Society, vol. 8, no. 1, pp. 43–60, 2015.
- [196] S. Rinaldi, J. Peerenboom, and T. Kelly, “Identifying, Understanding, and Analyzing Critical Infrastructure Interdependencies,” IEEE Control Systems Magazine, vol. 21, no. 6, pp. 11–25, 2001.
- [197] S. Bischof, A. Karapantelakis, C.-S. Nechifor, A. P. Sheth, A. Mileo, and P. Barnaghi, “Semantic Modelling of Smart City Data,” in W3C Workshop on the Web of Things, 2014.
- [198] M. Austin, P. Delgoshaei, M. Coelho, and M. Heidarinejad, “Architecting Smart City Digital Twins: Combined Semantic Model and Machine Learning Approach,” Journal of Management in Engineering, vol. 36, no. 4, p. 04020026, 2020.
- [199] S. Balakrishna, V. K. Solanki, V. K. Gunjan, and M. Thirumaran, “A Survey on Semantic Approaches for IoT Data Integration in Smart Cities,” in ICICCT 2019–System Reliability, Quality Control, Safety, Maintenance and Management: Applications to Electrical, Electronics and Computer Science and Engineering. Springer, 2020, pp. 827–835.
- [200] P. Antonios, K. Konstantinos, and G. Christos, “A Systematic Review on Semantic Interoperability in the IoE-enabled Smart cities,” Internet of Things, p. 100754, 2023.
- [201] L. Xia, Y. Sun, C. Liang, D. Feng, R. Cheng, Y. Yang, and M. A. Imran, “WiserVR: Semantic Communication Enabled Wireless Virtual Reality Delivery,” IEEE Wireless Communications, vol. 30, no. 2, pp. 32–39, 2023.
- [202] C. Wang, Y. Li, F. Gao, D. Deng, J. Xu, Y. Liu, and W. Wang, “Adaptive Semantic-Bit Communication for Extended Reality Interactions,” IEEE Journal of Selected Topics in Signal Processing, pp. 1–13, 2023.
- [203] B. Zhang, Z. Qin, Y. Guo, and G. Y. Li, “Semantic Sensing and Communications for Ultimate Extended Reality,” arXiv preprint arXiv:2212.08533, 2022.
- [204] B. Zhang, Z. Qin, and G. Y. Li, “Semantic Communications with Variable-Length Coding for Extended Reality,” arXiv preprint arXiv:2302.08645, 2023.
- [205] J. Park, J. Choi, S.-L. Kim, and M. Bennis, “Enabling the Wireless Metaverse via Semantic Multiverse Communication,” in 2023 20th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON). IEEE, 2023, pp. 85–90.
- [206] J. Wang, H. Du, Z. Tian, D. Niyato, J. Kang, and X. Shen, “Semantic-Aware Sensing Information Transmission for Metaverse: A Contest Theoretic Approach,” IEEE Transactions on Wireless Communications, 2023.
- [207] Z. Q. Liew, H. Du, W. Y. B. Lim, Z. Xiong, D. Niyato, C. Miao, and D. I. Kim, “Economics of Semantic Communication System: An Auction Approach,” IEEE Transactions on Vehicular Technology, 2023.
- [208] J. Chen, J. Wang, C. Jiang, Y. Ren, and L. Hanzo, “Trust-Worthy Semantic Communications for the Metaverse Relying on Federated Learning,” arXiv preprint arXiv:2305.09255, 2023.