![[Uncaptioned image]](icon2.png) LLaMA Pro: Progressive LLaMA with Block Expansion
LLaMA Pro: Progressive LLaMA with Block Expansion
Abstract
Humans generally acquire new skills without compromising the old; however, the opposite holds for Large Language Models (LLMs), e.g., from LLaMA to CodeLLaMA. To this end, we propose a new post-pretraining method for LLMs with an expansion of Transformer blocks. We tune the expanded blocks using only new corpus, efficiently and effectively improving the model’s knowledge without catastrophic forgetting. In this paper, we experiment on the corpus of code and math, yielding LLaMA Pro-8.3B, a versatile foundation model initialized from LLaMA2-7B, excelling in general tasks, programming, and mathematics. LLaMA Pro and its instruction-following counterpart (LLaMA Pro - Instruct) achieve advanced performance among various benchmarks, demonstrating superiority over existing open models in the LLaMA family and the immense potential of reasoning and addressing diverse tasks as an intelligent agent. Our findings provide valuable insights into integrating natural and programming languages, laying a solid foundation for developing advanced language agents that operate effectively in various environments.
Chengyue Wu Yukang Gan Yixiao Ge††thanks: Correspondence to yixiaoge@tencent.com. Zeyu Lu Jiahao Wang Ye Feng Ping Luo Ying Shan The University of Hong Kong ARC Lab, Tencent PCG Shanghai Jiao Tong University Beijing Language and Culture University https://github.com/TencentARC/LLaMA-Pro
1 Introduction
The advent of Large Language Models (LLMs) has revolutionized the field of natural language processing, exhibiting remarkable proficiency in a variety of real-world tasks OpenAI (2023); Chowdhery et al. (2023). Despite the versatility, LLMs still fall short in certain domains, for example, programming, mathematics, biomedical, or finance. This limitation impedes the progress of developing generic language agents for broader applications.
Existing works Liu et al. (2023); Li et al. (2023a); Wu et al. (2023b) attempted to improve the multi-faceted capabilities of pre-trained LLMs with tailored data recipes. While feasible, they require substantial computational resources and vast amounts of data, which poses a challenge to the democratization of LLM research. Consequently, another line of research, known as domain-adaptive pretraining, focuses on post-pretraining with domain-specific corpora Gururangan et al. (2020). These approaches have demonstrated efficacy in adapting various LLMs to specific domains Roziere et al. (2023); Azerbayev et al. (2023); Wu et al. (2023b); Xu et al. (2023b), resulting in enhanced performance on downstream domain-specific tasks at a reduced computational cost.
Nonetheless, a considerable obstacle emerges in catastrophic forgetting De Lange et al. (2021). Post-pretraining often leads to a decline in the model’s original general abilities, inhibiting the fine-tuned performance of the model on diverse tasks Cheng et al. (2023); Dong et al. (2023). This necessitates a method that can inject domain-specific knowledge into LLMs while preserving their general abilities, thereby enhancing their comprehensive capabilities.

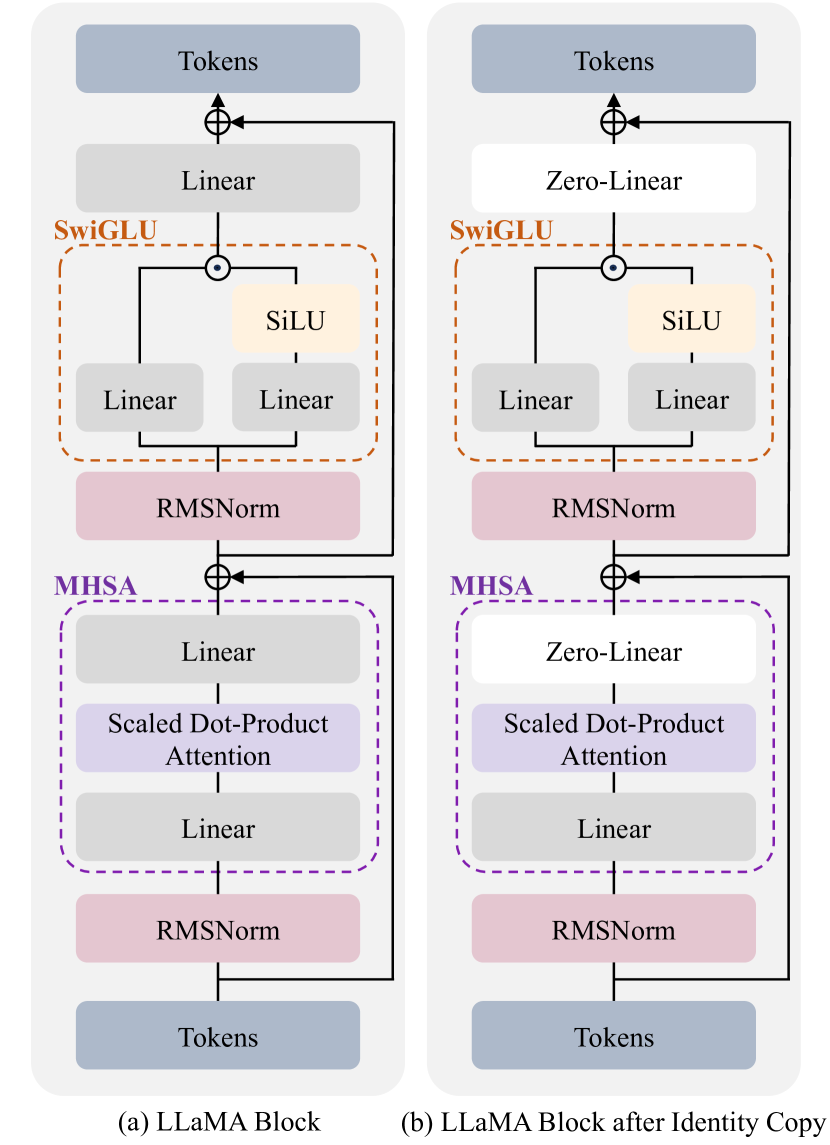
Towards this end, we introduce a simple yet effective post-pretraining method, termed block expansion. We expand the off-the-shelf pre-trained LLM using copied Transformer blocks, as illustrated in Figure 2. The newly added blocks, whose linear layers are zero-initialized to enable identity mapping, are further tuned with only domain-specific corpus while the remaining blocks are frozen. After tuning, the extended pre-trained model excels in both general and domain-specific tasks.
In practice, we extend the pre-trained LLaMA2-7B Touvron et al. (2023) by eight more blocks, yielding LLaMA Pro, a foundation model with 8.3B parameters, and enhanced performance in programming, coding, and reasoning. We pre-train LLaMA Pro’s expanded blocks on 80B tokens using open-source code and math data for 2830 GPU Hours (16 NVIDIA H800 GPUs for about 7 days). We further perform supervised instruction tuning (fully fine-tuning of all the blocks, aka SFT) on LLaMA Pro with approximately 80M tokens, yielding LLaMA Pro - Instruct. It is noted that pre-trained models produced by our block expansion method are well-compatible with the subsequent SFT techniques without specific modification.
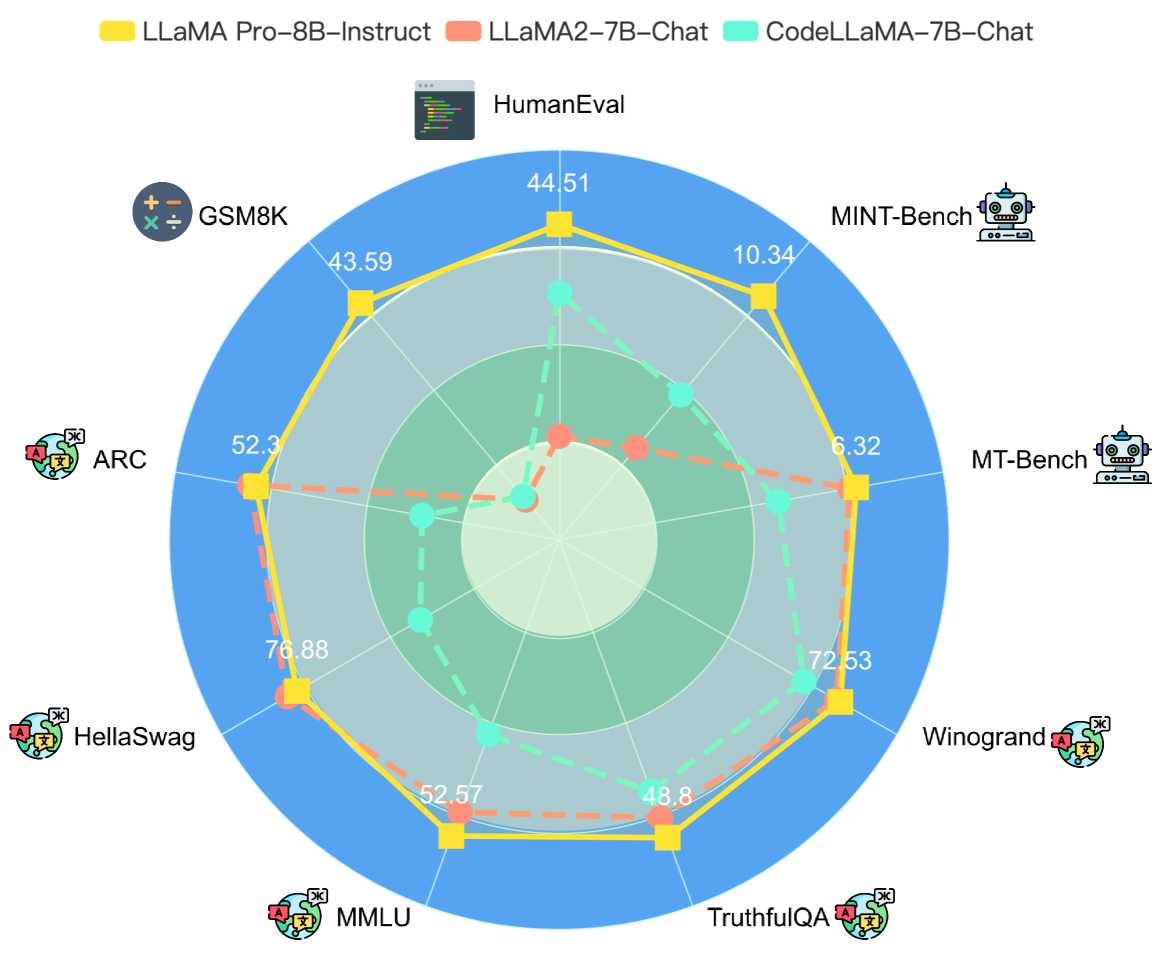
As shown in Figure 1, LLaMA Pro - Instruct reaches state-of-the-art performance across a broad range of general, code (i.e., HumanEval), and math (i.e., GSM8K) tasks. Furthermore, we assess the capabilities of LLaMA Pro - Instruct as a language agent across various scenarios (i.e., MINT-Bench), with a focus on the tool usage abilities and the capacity to ground in environmental and human feedback. We also employ GPT-4 OpenAI (2023) automatic evaluation to assess LLaMA Pro’s ability to serve as an effective assistant (i.e., MT-Bench). Comprehensive experimental results indicate the superiority of LLaMA Pro - Instruct over other models from the LLaMA family on both benchmarks and practical applications. Our contributions are three-fold:
-
•
We propose a novel post-pretraining method for LLMs, termed block expansion, enabling the injection of new knowledge while preserving the initial capabilities.
-
•
We introduce LLaMA Pro and LLaMA Pro - Instruct, versatile LLMs that well integrate natural and programming languages, excelling in general tasks, programming, and mathematics.
-
•
We benchmark the family of LLaMA Pro on extensive datasets, including both traditional and agent-oriented tasks, demonstrating its superiority and great potential in broader complex applications.
2 Related Work
Advancements in Large Language Models.
The field of large language models has witnessed significant progress in recent years. The growth in model and data scale has played a crucial role in achieving state-of-the-art performance across various tasks Hoffmann et al. (2022); Kaplan et al. (2020); Chowdhery et al. (2023). Concurrently, the development of more generalist models has led to the creation of models that can address diverse problems and quickly adapt to new tasks Radford et al. (2019); Brown et al. (2020). These advancements have been further bolstered by the open-source community, which has released powerful open large language models for research, such as LLaMA Touvron et al. (2023) and CodeLLaMA Roziere et al. (2023). Our work builds upon these developments by providing a methodology for specializing large language models in the domain of code, paving the way for future research and applications in this area.
Post-pretraining.
Language model applications typically involve a two-step process: an initial general-domain pretraining step, followed by domain-specific training Roziere et al. (2023); Azerbayev et al. (2023). The fine-tuning step is often aimed at enhancing instruction-following abilities Sanh et al. (2021); Wei et al. (2021); Wang et al. (2023d) or aligning the model’s outputs with human preferences Ziegler et al. (2019); Ouyang et al. (2022); Bai et al. (2022). Additionally, some studies explore adapting pretrained models to novel domains using parameter-efficient fine-tuning methods Houlsby et al. (2019); Hu et al. (2021); Wu et al. (2023a). Many works also focus on how to do continual learning after the pretraining phace Wang et al. (2023b); Gupta et al. (2023); Scialom et al. (2022). In our work, we propose an adaptation strategy that combines continued training with targeted general capability maintenance, allowing large language models to specialize in specific tasks without sacrificing their overall performance.
Progressive Learning.
In recent years, progressive training has gained attention for its ability to accelerate the training of large-scale models in both computer vision Zhang et al. (2023) and NLP research Yao et al. (2023); Li et al. (2023b). Gong et al. (2019) proposed a stacking method that doubles the model depth at each stage. CompoundGrow Gu et al. (2020) extends stacking by incorporating FeedForward Network (FFN) expansion into the schedule design. Shen et al. (2022) proposed a staged method that further supports expanding the hidden size of features. Bert2BERT Chen et al. (2021a) and LiGO Wang et al. (2023a) support all possible growth dimensions. Our method employs depth growth to preserve general performance while adapting to a specific domain.
3 Method
3.1 Preliminaries: The LLaMA Block
The LLaMA block consists of a multi-head self-attention (MHSA) mechanism followed by a position-wise feed-forward network (FFN) with residual connections and a Swish-Gated Linear Unit (SwiGLU) operation as Figure 3 shows. Given an input , the LLaMA block produces an output as described by the following equations:
| (1) |
The input has a dimension of , where is the sequence length and is the hidden size. The output has the same dimension as the input . The MHSA operation is a crucial component of the transformer, defined as:
| (2) |
where , , and are the query, key, and value matrices, respectively, and is the output weight matrix without bias . Each head is computed as:
| (3) |
with , , and being the corresponding weight matrices for the -th head.
The FFN block in the LLaMA model utilizes the SwiGLU activation function, which can be defined as:
| (4) |
where denotes element-wise multiplication, , , and are the weight matrices without bias, .
3.2 Block Expansion
Given a model with blocks , the block expansion incorporates an identity block after each block in the original model, ensuring that the expanded model maintains the same output after expansion. The identity block is defined as , where the input and output are identical.
Suppose we have an initial model with blocks that needs to be expanded to blocks. First, we partition the original blocks into groups, with each group containing blocks. For each group, we create identity copies of the top blocks and stack them on top of each group, as depicted in Figure 3. We arrange these blocks in an interleaved manner to maintain the structural characteristic of the transformer model, whose prior is that deeper blocks encode more complex information Van Aken et al. (2019); Tenney et al. (2019). This process leads to an increased depth in the model while maintaining its output behavior.
Shen et al. Shen et al. (2022) proposed the initialization of scale parameters in the Norm modules within the identity blocks to zero for the construction of the identity block. However, this approach may not be effective when applied to the LLaMA block. The reason lies in the fact that the gradient of the loss function with respect to the RMSNorm weight during backpropagation would be zero. This would prevent the training of RMSNorm, implying that when , the following condition will hold:
| (5) |
This equation signifies that the gradient of the loss function with respect to the weight of RMSNorm is zero, which would hinder the training of the RMSNorm module. This is further explained in Appendix A. Referring to the LLaMA block formulation in Equation 1, the identity can be achieved as long as and . We initialize the and weight matrices in the identity blocks to zero. Due to the presence of residual connections and the absence of bias terms in the LLaMA block, only the residual flows through the identity block. As a result, the entire block is reduced to an identity block at initialization, preserving the output from the initial model.
The entire training pipeline is depicted in Figure 2. Our method concentrates on the post-pretraining stage, targeting specific domain corpora such as code corpora. We begin by initializing our model with large language models trained on extensive unlabeled general corpora, where all blocks will be fine-tuned. To enhance the model’s capacity for accommodating additional domain knowledge while retaining its general knowledge, we employ block expansion to increase the number of blocks in the LLM. During this process, we only fine-tune the newly added blocks while freezing the original blocks, thereby preserving the general abilities of the model.
4 Experiments
This section presents our key experimental findings. We begin with experimental settings (described in Sec. 4.1), and then verify the effectiveness of block expanded tuning after pretraining (described in Sec. 4.2). Next, we give the supervised finetuning (SFT) results (described in Sec. 5). Finally, ablation studies of the key design choices are presented (described in Sec. 6).
4.1 Experimental Settings
Pretrain details.
We construct a dataset that concentrates on code and math. For the code component, we rely on the Stack-dedup dataset, which is a compilation of permissively licensed source codes from GitHub. Among all the programming languages available in Stack-dedup, we specifically utilize the Python split. As for the math component, we opt for the Proof-pile-2 dataset Azerbayev et al. (2023), a 55-billion-token amalgamation of scientific papers, web data containing mathematical content, and mathematical code.
| Data source | Tokens | Weight |
|---|---|---|
| Proof-Pile-2 | 55B | 1.00 |
| AlgebraicStack | 11B | |
| OpenWebMath | 15B | |
| ArXiv | 29B | |
| The-Stack-Dedup | ||
| Python | 22B | 1.50 |
We initialize our base model with LLaMA2-7B and expand the number of blocks from 32 to 40 using an interleaved approach. In the block expansion process, we configure the parameters as , , and , resulting in 8 groups where each group expands from 4 blocks to 5 blocks. For the code and math corpus pretraining, we employ a batch size of 1024, a sequence length of 4096, a warmup ratio of 6%, a learning rate of 2e-4, and a Cosine learning rate scheduler. We also use bf16 mixed precision, a weight decay of 0.1, and gradient clipping at 1.0. To speed up the training process, we apply the flash-attention mechanism.
Our experiment is conducted on 16 NVIDIA H800 GPUs. LLaMA Pro is trained for a total of 15,900 steps. This training process corresponds to approximately 2830 H800 GPU hours.
SFT details.
During the instruction fine-tuning phase, we combine five data sources to create LLaMA Pro - Instruct. These sources include ShareGPT111https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered, which contains real user and ChatGPT chat history records, and the WizardLM evolution instruction dataset Xu et al. (2023a), offering a wealth of instruction data with varying complexity levels. We also incorporate the evolution CodeAlpaca dataset Luo et al. (2023), which includes complex coding tasks generated by ChatGPT and their corresponding solutions. Additionally, we use MetaMath Yu et al. (2023), which reframes questions from multiple perspectives, and SlimOrca Lian et al. (2023), a curated subset of our OpenOrca data. SlimOrca provides an efficient route to achieve performance comparable to using larger data slices, while only incorporating approximately 500,000 GPT-4 completions.
| Datasets | Query Source | Response Source | # Instances | |||
|---|---|---|---|---|---|---|
| ShareGPT | User prompts | GPT-3.5/GPT-4 | 63,817 | 2.9 | 293.2 | 1157.1 |
| WizardLM_evol_instruct_V2 | GPT-4 | GPT-4 | 143,000 | 1.0 | 602.6 | 1704.9 |
| SlimOrca | Human-written | GPT-4 | 517,982 | 1.0 | 574.3 | 599.3 |
| MetaMath | Human-written/GPT-4 | GPT-4 | 395,000 | 1.0 | 209.4 | 498.2 |
| Evol-CodeAlpaca | GPT-4 | GPT-4 | 111,272 | 1.0 | 652.5 | 1552.0 |
The final sft dataset consists of approximately 1M samples. To fine-tune the basic models, we employ specific configurations, including a batch size of 128, a sequence length of 4096, 0.03 warmup ratio, a learning rate of 2e-5, a Cosine learning rate scheduler, and bf16 mixed precision.
Evaluation details.
We conduct a comparative analysis of LLaMA Pro with the latest state-of-the-art (SOTA) Large Language Models (LLMs). The evaluation is performed on six key general benchmarks using the Eleuther AI Language Model Evaluation Harness222https://github.com/EleutherAI/lm-evaluation-harness, a unified framework designed to test generative language models across a vast array of evaluation tasks. For code-related tasks, we employ the BigCode Evaluation Harness333https://github.com/bigcode-project/bigcode-evaluation-harness to evaluate HumanEval and MBPP, and we report the pass@1 rate of code tasks with greedy decoding.
The benchmarks used for evaluation include:
-
•
AI2 Reasoning Challenge Clark et al. (2018) (25-shot): a set of grade-school science questions.
-
•
HellaSwag (10-shot) Zellers et al. (2019): a test of commonsense inference, which is easy for humans (approximately 95%) but challenging for SOTA models.
-
•
MMLU (5-shot) Hendrycks et al. (2020): a test to measure a text model’s multitask accuracy. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more.
-
•
TruthfulQA (0-shot) Lin et al. (2021): a test to measure a model’s propensity to reproduce falsehoods commonly found online.
-
•
Winogrande (5-shot) Sakaguchi et al. (2021): an adversarial and difficult Winograd benchmark at scale, for commonsense reasoning.
-
•
GSM8k (5-shot) Cobbe et al. (2021): diverse grade school math word problems to measure a model’s ability to solve multi-step mathematical reasoning problems. Additionally, we assess the models in the context of the Program of Thought (PoT) setting Chen et al. (2023a). The PoT setting utilizes Python code to solve mathematical problems, which serves to evaluate the code generation capabilities of the models.
-
•
HumanEval (0-shot) Chen et al. (2021b): 164 handwritten Python programming problems with a function signature, docstring, body, and several unit tests.
-
•
MBPP (3-shot) Austin et al. (2021): crowd-sourced Python programming problems, designed to be solvable by entry-level programmers. Each problem consists of a task description in English, a code solution and 3 automated test cases.
4.2 Pretrain Results
| Model | Language Tasks | Math Tasks | Code Tasks | Avg. | ||||||
| ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K | GSM8K-PoT | HumanEval | MBPP | ||
| Pretrained comparison | ||||||||||
| LLaMA Pro (8B) | 54.10 | 77.94 | 47.88 | 39.04 | 73.95 | 17.89 | 25.42 | 28.66 | 33.20 | 44.23 |
| CrystalCoder (7B) | 47.01 | 71.97 | 48.78 | 35.91 | 67.17 | 10.77 | 24.96 | 28.38 | 36.38 | 41.26 |
| LLaMA2-7B | 53.07 | 78.59 | 46.87 | 38.76 | 74.03 | 14.48 | 17.68 | 13.05 | 20.09 | 39.62 |
| CodeLLaMA-7B | 39.93 | 60.80 | 31.12 | 37.82 | 64.01 | 5.16 | 25.20 | 33.50 | 41.40 | 37.66 |
| StarCoder-15B | 30.38 | 47.93 | 29.96 | 41.28 | 56.12 | 9.48 | 25.09 | 33.63 | 43.28 | 35.24 |
| LLaMA-7B | 50.94 | 77.81 | 35.69 | 34.33 | 71.43 | 8.04 | 10.46 | 10.61 | 17.04 | 35.15 |
| OpenLLaMA-v2-7B | 43.69 | 72.20 | 41.29 | 35.54 | 69.38 | 3.49 | 5.46 | 15.32 | 12.69 | 33.23 |
| Falcon-7B | 47.87 | 78.13 | 27.79 | 34.26 | 72.38 | 4.62 | 4.32 | 9.42 | 13.39 | 32.46 |
| SFT comparison | ||||||||||
| LLaMA Pro - Instruct | 52.30 | 76.88 | 52.57 | 48.80 | 72.53 | 43.59 | 55.61 | 44.51 | 37.88 | 53.85 |
| LLaMA2-7B-Chat | 52.90 | 78.55 | 48.32 | 45.57 | 71.74 | 7.35 | 19.73 | 14.63 | 21.60 | 40.04 |
| CodeLLaMA-7B-Instruct | 36.52 | 55.44 | 34.54 | 41.25 | 64.56 | 7.96 | 34.67 | 34.80 | 44.4 | 39.35 |
| WizardCoder-Python-7B | 41.81 | 65.06 | 32.29 | 36.32 | 61.72 | 4.70 | 17.60 | 42.07 | 47.20 | 38.75 |
| WizardMath-7B | 54.10 | 79.55 | 45.97 | 43.65 | 72.69 | 2.73 | 25.57 | 12.20 | 18.00 | 39.38 |
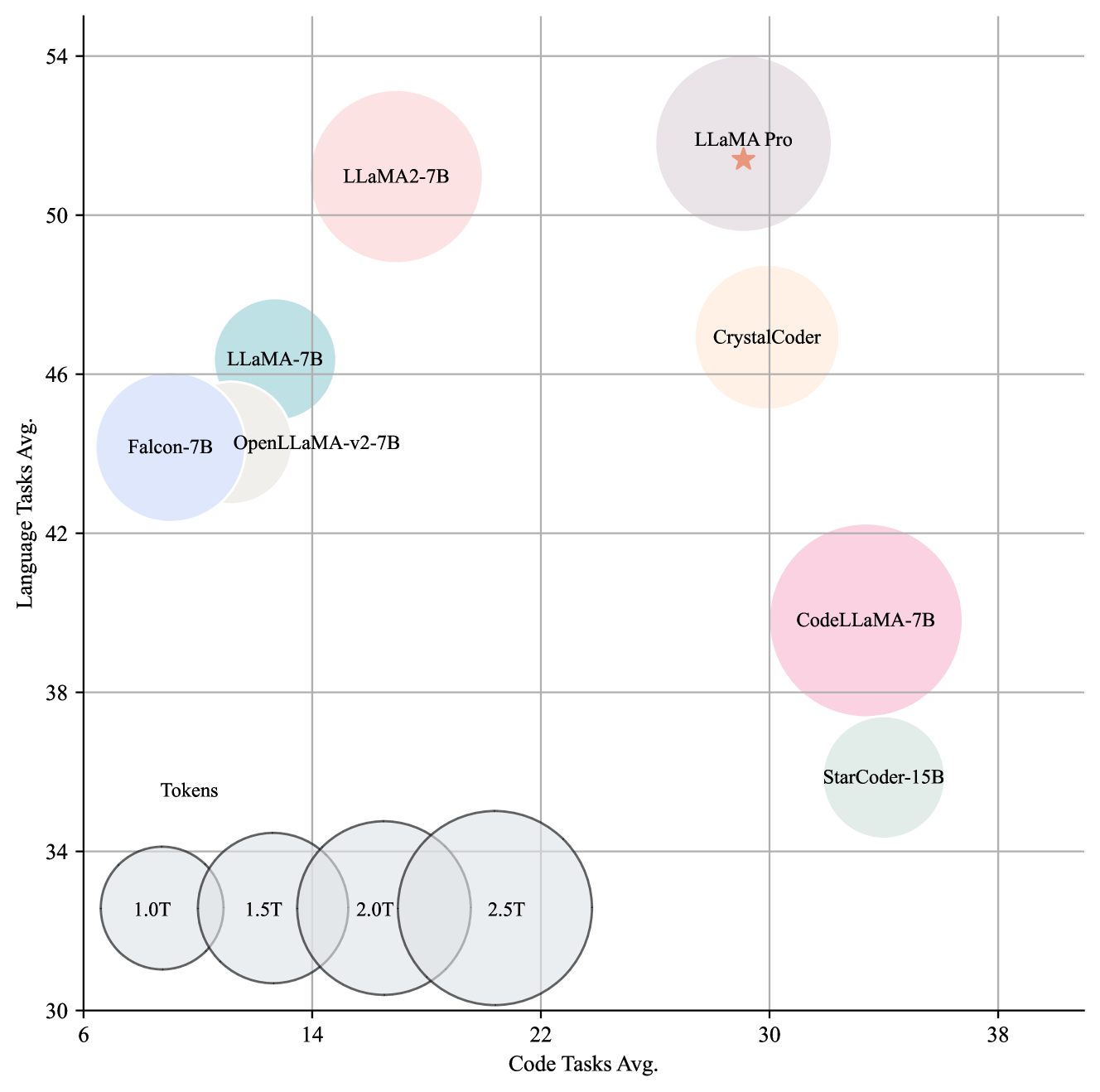
We evaluate LLaMA Pro’s performance with benchmark datasets from the Open LLM Leaderboard. Furthermore, we incorporate coding benchmark datasets, including HumanEval pass@1 and MBPP pass@1, as well as the math benchmark GSM8K, to provide a comprehensive evaluation. We compare the performance of LLaMA Pro with a selection of state-of-the-art pretrained models that were trained around the same period with similar size. This includes general-purpose pretrained models like LLaMA2 and code-oriented pretrained models like CodeLLaMA. The results are presented in Table 3.
The results highlight that LLaMA Pro effectively balances natural language processing and coding capabilities. It not only preserves the general performance of its base model, LLaMA2-7B, but also surpasses it in the average performance of general language tasks. Conversely, CodeLLaMA-7B sacrifices general performance to enhance its code ability. We attribute this improvement to our expansion design, which freezes the initial LLaMA blocks to maintain their capabilities and increases the blocks to accommodate more domain-specific knowledge.
As depicted in Figure 4, LLaMA Pro shows robust general performance alongside code performance that is on par with code-oriented LLMs. Situated on the Pareto frontier, LLaMA Pro has undergone fine-tuning with an additional 80B tokens in conjunction with LLaMA2, which more than doubles the code tasks average performance. In contrast, CodeLLaMA is fine-tuned with 500B tokens. LLaMA Pro excels in general performance while maintaining code performance that is competitive with code-oriented LLMs, whether they are trained from scratch, such as StarCoder-15B and CrystalCoder, or fine-tuned like CodeLLaMA-7B.
4.3 SFT Results
| Model | MT Bench |
|---|---|
| Alpaca-13B | 4.53 |
| CodeLLaMA-7B-Instruct | 5.71 |
| Vicuna-7B | 6.17 |
| LLaMA2-7B-Chat | 6.27 |
| LLaMA Pro - Instruct | 6.32 |
Modern LLMs typically undergo supervised fine-tuning or instruction tuning after pretraining on vast amounts of unlabeled data. In this section, we aim to demonstrate that our expansion strategy can adapt to this widely used training pipeline, just as traditional LLMs do.
Table 3 presents a comparison of evaluation results among several prominent supervised fine-tuning (SFT) LLMs from the LLaMA community, across general tasks, math tasks, and code tasks benchmarks. As a singular SFT model, LLaMA Pro - Instruct attains state-of-the-art performance, even when compared to specifically tuned models such as WizardCoder and WizardMath. This demonstrates its more comprehensive capabilities.
As seen in Figure 1, LLaMA Pro - Instruct boosts both code and math tasks to state-of-the-art performances while maintaining reliable general performance. We enhance the average performance of LLaMA2-7B-chat and CodeLLaMA-7B-instruct by 13.81% and 14.50% respectively, which highlights the benefits of balancing textual and coding abilities.
To assess the comprehensive conversational performance of the LLaMA Pro - Instruct assistant, we evaluate it using the MT-Bench with GPT-4 automatic scoring, as proposed by Vicuna Zheng et al. (2023). As depicted in Table 4, LLaMA Pro - Instruct surpasses widely used chatbots from the LLaMA community. This indicates its potential as a chatbot capable of providing helpful responses, in addition to its impressive performance in traditional benchmarks. The details of MT-Bench can be found in the Appendix C.
We use MINT-Bench Wang et al. (2023c) to evaluate our model’s ability to solve multi-turn interactions by using tools. MINT-Bench tests LLMs’ ability to use tools by generating and executing Python code, focusing on tool-augmented task-solving and leveraging natural language feedback. MINT includes eight datasets covering reasoning, code generation, and decision-making. The details of MINT can be found in the Appendix B. The results are shown in Table 5. LLaMA Pro - Instruct achieves SOTA performance compared to similar size models in multi-turn interactions with the use of tools.
| Model | Interaction Turns | Avg. | ||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| AgentLM-7B | 0.0 | 4.44 | 5.29 | 6.48 | 7.34 | 4.71 |
| CodeLLaMA-7B-Instruct | 0.34 | 7.85 | 10.24 | 9.73 | 8.70 | 7.37 |
| LLaMA2-7B-Chat | 1.02 | 4.27 | 6.66 | 6.48 | 7.34 | 5.77 |
| Mistral-Instruct-v0.1 | 1.54 | 12.12 | 13.31 | 14.16 | 13.99 | 11.02 |
| LLaMA Pro - Instruct | 0.68 | 12.63 | 11.95 | 11.95 | 14.68 | 10.38 |
4.4 Ablation Study
| Method | Overall Performance (OP) | Backward Transfer (BWT) |
|---|---|---|
| LoRA | 37.1 | -17.3% |
| SeqFT | 45.5 | -14.7% |
| Block Expansion | 46.5 | -14.3% |
| Method | Language Tasks | Law Task | Avg. | |||||
|---|---|---|---|---|---|---|---|---|
| ARC | HellaSwag | MMLU | TruthfulQA | Winogrand | Avg. | Unfair-ToS | ||
| Add 1 Block | 52.30 | 77.92 | 38.62 | 37.80 | 73.16 | 55.96 | 67.45 | 61.71 |
| Add 2 Block | 53.16 | 77.91 | 39.62 | 38.92 | 73.01 | 56.52 | 69.57 | 63.05 |
| Add 4 Block | 52.39 | 76.92 | 37.30 | 40.53 | 72.22 | 55.87 | 71.31 | 63.59 |
| Add 8 Block | 52.90 | 76.63 | 41.74 | 39.83 | 72.38 | 56.70 | 75.11 | 65.91 |
| Add 16 Block | 51.88 | 76.59 | 41.35 | 40.13 | 71.82 | 56.35 | 75.17 | 65.76 |
| Add 32 Block | 50.77 | 76.72 | 40.68 | 41.66 | 72.77 | 56.52 | 73.93 | 65.23 |
| Mixture-of-Expert (MoE) | 51.45 | 76.51 | 42.47 | 40.13 | 72.23 | 56.56 | 67.27 | 61.92 |
| Prefix Stacking (8 Block) | 27.82 | 26.12 | 23.12 | 22.52 | 47.20 | 29.36 | 0.81 | 15.08 |
| Suffix Stacking (8 Block) | 52.56 | 77.89 | 39.10 | 39.03 | 72.38 | 56.19 | 60.98 | 58.59 |
We evaluate various training strategies, including LoRA, fine-tuning, and the block expansion training approach that we propose, using the TRACE benchmark Wang et al. (2023b). TRACE is designed to assess continual learning in LLMs and comprises eight distinct datasets that span challenging tasks such as domain-specific tasks, multilingual capabilities, code generation, and mathematical reasoning. We assess the ability of different strategies to retain the model’s existing knowledge while incorporating new skills. Details are provided in the Appendix 13.
We employ Overall Performance (OP Chaudhry et al. (2018)) and Backward Transfer (BWT Lopez-Paz and Ranzato (2017)) scores as evaluation metrics. After incrementally learning the -th task, the model’s score on the -th task (where ) is denoted as . The OP and BWT scores are calculated using the following formulas:
| (6) |
| (7) |
Table 6 presents the performance of different strategies on the TRACE benchmark following their continual learning phase with LLaMA2-7B. The results show that block expansion training exhibits superior task-specific adaptability compared to sequential fine-tuning and LoRA, as evidenced by its better OP and BWT scores.
Apart from the aspect of code corpus, we explore our method on another domain: law, with the freelaw subset of Pile dataset as our pretrain corpus Gao et al. (2020). We evaluate on UNFAIR-ToS Lippi et al. (2019) of the LexGLUE benchmark Chalkidis et al. (2021). The details can be found in the Appendix 14.
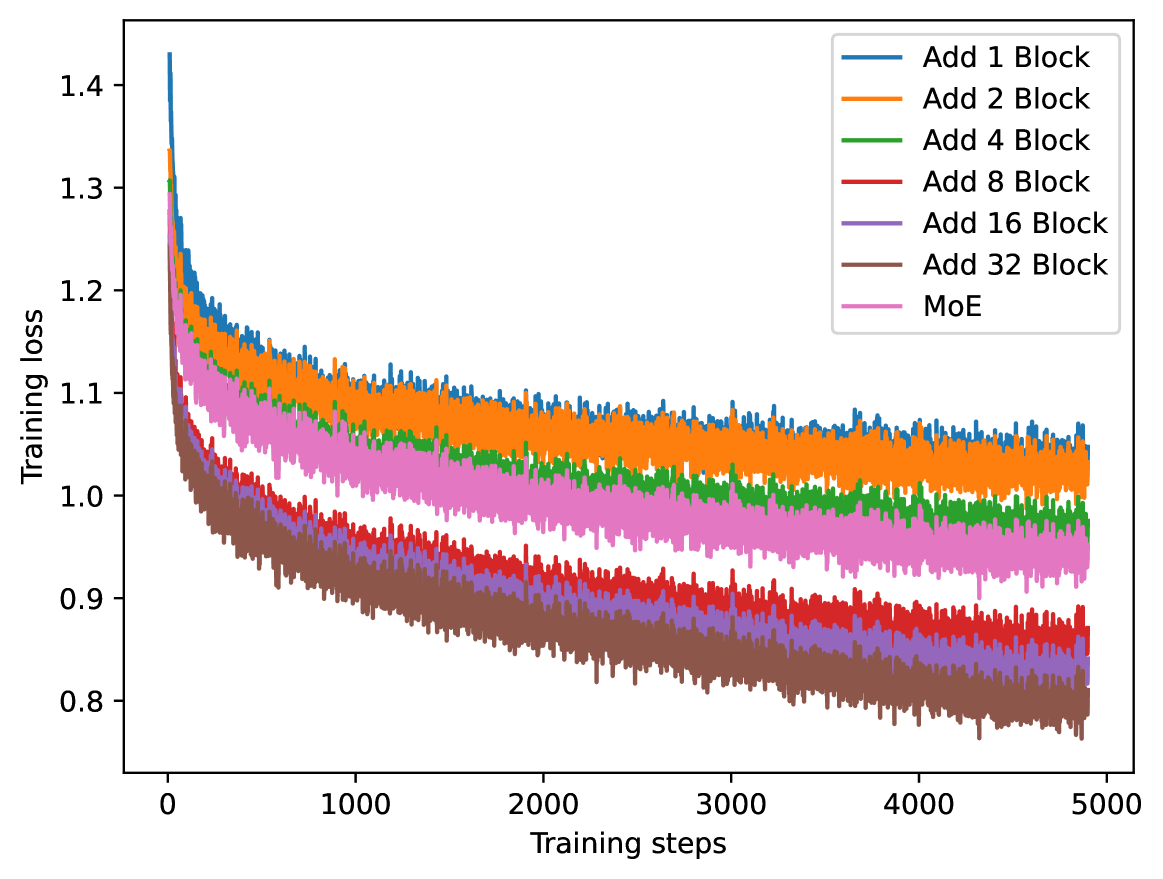
In our experiment, we assess the scalability of our block expansion method in terms of training loss and downstream task performance as we increase the number of added blocks. We also compare our method with the Mixture-of-Expert (MoE) expansion method Fedus et al. (2022).
We first examine the training loss with varying added blocks. As seen in Figure 5, the training loss of the models consistently decreases as training progresses, regardless of the number of added blocks. Moreover, the loss decreases more rapidly as we increase the size of the model. These findings suggest that our method exhibits strong scalability with larger models and more data. The training loss of MoE is comparable to our method with four added blocks.
However, a lower overall training loss does not necessarily guarantee superior performance on domain-specific tasks. Therefore, we evaluate models of different sizes on both general language tasks and Unfair-ToS, as shown in Table 7. All the expanded models effectively preserve the general capabilities of the initial model. For the domain-specific task, larger models achieve better performance. We find that adding eight blocks provides optimal performance with minimal cost compared to larger models, hence we adopt this as our default strategy.
We also analyze the impact of the position where the identity blocks are added, either at the bottom or the top of the model, compared to adding them interleaved, as shown in Table 7. We observe that adding blocks at the bottom results in poor evaluation performance, likely because it disrupts the model’s foundation, causing errors to propagate throughout the model. Adding blocks at the top of the model Gong et al. (2019) preserves the initial model’s performance, but its performance on domain-specific tasks is lower than when adding blocks interleaved.
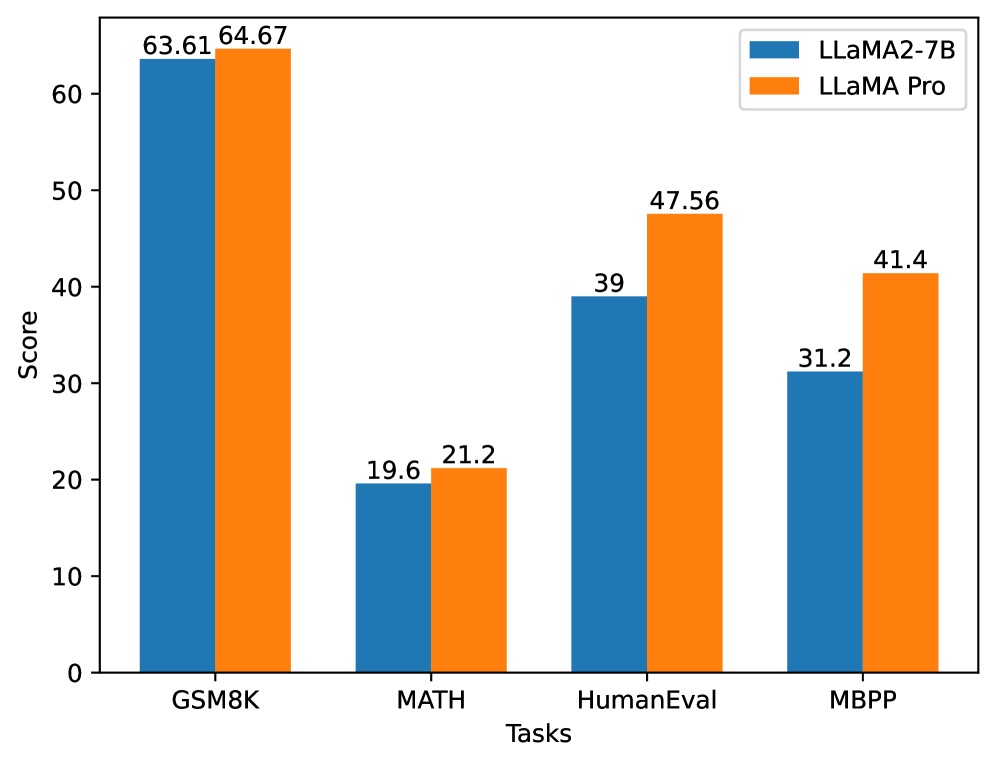
As highlighted in the LIMA study Zhou et al. (2023), the majority of knowledge in large language models is acquired during pretraining, with only a limited amount of instruction tuning data required to generate high-quality output. To investigate the extent of knowledge encoded during pretraining, we conducted a comparative analysis between LLaMA2-7B and LLaMA Pro using the same instruction dataset, as illustrated in Figure 6. Our results showed that LLaMA Pro consistently outperforms LLaMA2-7B across all tasks, indicating that our method effectively enables LLaMA Pro to encode more domain-specific knowledge during the pretraining phase.
5 Conclusion
In this study, we introduced a novel block expansion method for Large Language Models (LLMs) post-pretraining, aiming to enhance domain-specific abilities while preserving the original general capabilities. Our approach effectively balances the model’s performance across both general and domain-specific tasks. We demonstrated the effectiveness of our method through LLaMA Pro, an LLM initialized from LLaMA2-7B with 8 added blocks, which outperformed other LLaMA-series models on comprehensive benchmarks.
The work highlights the importance of balancing general and domain-specific abilities in LLMs and offers a promising approach to achieving this balance. Future research could explore broader applications of our block expansion method in other domains, for instance, it is an important task for multimodal large language models Ge et al. (2023); Bai et al. (2023) to preserve the original language ability.
Acknowledgements
We sincerely acknowledge Qingyue Zhao (Tsinghua University; ARC Lab, Tencent PCG) and Xiaohu Jiang (Tsinghua University; ARC Lab, Tencent PCG) for their engaging discussions.
References
- Austin et al. (2021) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732.
- Azerbayev et al. (2023) Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Albert Q Jiang, Jia Deng, Stella Biderman, and Sean Welleck. 2023. Llemma: An open language model for mathematics. arXiv preprint arXiv:2310.10631.
- Bai et al. (2023) Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966.
- Bai et al. (2022) Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Chalkidis et al. (2021) Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion Androutsopoulos, Daniel Martin Katz, and Nikolaos Aletras. 2021. Lexglue: A benchmark dataset for legal language understanding in english. arXiv preprint arXiv:2110.00976.
- Chaudhry et al. (2018) Arslan Chaudhry, Puneet K Dokania, Thalaiyasingam Ajanthan, and Philip HS Torr. 2018. Riemannian walk for incremental learning: Understanding forgetting and intransigence. In Proceedings of the European conference on computer vision (ECCV), pages 532–547.
- Chen et al. (2021a) Cheng Chen, Yichun Yin, Lifeng Shang, Xin Jiang, Yujia Qin, Fengyu Wang, Zhi Wang, Xiao Chen, Zhiyuan Liu, and Qun Liu. 2021a. bert2bert: Towards reusable pretrained language models. arXiv preprint arXiv:2110.07143.
- Chen et al. (2021b) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021b. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
- Chen et al. (2023a) Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2023a. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. Transactions on Machine Learning Research.
- Chen et al. (2023b) Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. 2023b. Theoremqa: A theorem-driven question answering dataset. arXiv preprint arXiv:2305.12524.
- Cheng et al. (2023) Daixuan Cheng, Shaohan Huang, and Furu Wei. 2023. Adapting large language models via reading comprehension. arXiv preprint arXiv:2309.09530.
- Chowdhery et al. (2023) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- De Lange et al. (2021) Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. 2021. A continual learning survey: Defying forgetting in classification tasks. IEEE transactions on pattern analysis and machine intelligence, 44(7):3366–3385.
- Dong et al. (2023) Guanting Dong, Hongyi Yuan, Keming Lu, Chengpeng Li, Mingfeng Xue, Dayiheng Liu, Wei Wang, Zheng Yuan, Chang Zhou, and Jingren Zhou. 2023. How abilities in large language models are affected by supervised fine-tuning data composition. arXiv preprint arXiv:2310.05492.
- Fedus et al. (2022) William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. The Journal of Machine Learning Research, 23(1):5232–5270.
- Gao et al. (2020) Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. 2020. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027.
- Ge et al. (2023) Yuying Ge, Sijie Zhao, Ziyun Zeng, Yixiao Ge, Chen Li, Xintao Wang, and Ying Shan. 2023. Making llama see and draw with seed tokenizer. arXiv preprint arXiv:2310.01218.
- Gong et al. (2019) Linyuan Gong, Di He, Zhuohan Li, Tao Qin, Liwei Wang, and Tieyan Liu. 2019. Efficient training of bert by progressively stacking. In International conference on machine learning, pages 2337–2346. PMLR.
- Gu et al. (2020) Xiaotao Gu, Liyuan Liu, Hongkun Yu, Jing Li, Chen Chen, and Jiawei Han. 2020. On the transformer growth for progressive bert training. arXiv preprint arXiv:2010.12562.
- Gupta et al. (2023) Kshitij Gupta, Benjamin Thérien, Adam Ibrahim, Mats L Richter, Quentin Anthony, Eugene Belilovsky, Irina Rish, and Timothée Lesort. 2023. Continual pre-training of large language models: How to (re) warm your model? arXiv preprint arXiv:2308.04014.
- Gururangan et al. (2020) Suchin Gururangan, Ana Marasović, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A Smith. 2020. Don’t stop pretraining: Adapt language models to domains and tasks. arXiv preprint arXiv:2004.10964.
- Hendrycks et al. (2020) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset. NeurIPS.
- Hoffmann et al. (2022) Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. 2022. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556.
- Houlsby et al. (2019) Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR.
- Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
- Li et al. (2023a) Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023a. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161.
- Li et al. (2023b) Xiang Li, Yiqun Yao, Xin Jiang, Xuezhi Fang, Xuying Meng, Siqi Fan, Peng Han, Jing Li, Li Du, Bowen Qin, et al. 2023b. Flm-101b: An open llm and how to train it with $100 k budget. arXiv preprint arXiv:2309.03852.
- Lian et al. (2023) Wing Lian, Guan Wang, Bleys Goodson, Eugene Pentland, Austin Cook, Chanvichet Vong, and "Teknium". 2023. Slimorca: An open dataset of gpt-4 augmented flan reasoning traces, with verification.
- Lin et al. (2021) Stephanie Lin, Jacob Hilton, and Owain Evans. 2021. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958.
- Lippi et al. (2019) Marco Lippi, Przemysław Pałka, Giuseppe Contissa, Francesca Lagioia, Hans-Wolfgang Micklitz, Giovanni Sartor, and Paolo Torroni. 2019. Claudette: an automated detector of potentially unfair clauses in online terms of service. Artificial Intelligence and Law, 27:117–139.
- Liu et al. (2023) Zhengzhong Liu, Aurick Qiao, Willie Neiswanger, Hongyi Wang, Bowen Tan, Tianhua Tao, Junbo Li, Yuqi Wang, Suqi Sun, Omkar Pangarkar, et al. 2023. Llm360: Towards fully transparent open-source llms. arXiv preprint arXiv:2312.06550.
- Lopez-Paz and Ranzato (2017) David Lopez-Paz and Marc’Aurelio Ranzato. 2017. Gradient episodic memory for continual learning. Advances in neural information processing systems, 30.
- Luo et al. (2023) Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. 2023. Wizardcoder: Empowering code large language models with evol-instruct.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Roziere et al. (2023) Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
- Sakaguchi et al. (2021) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106.
- Sanh et al. (2021) Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al. 2021. Multitask prompted training enables zero-shot task generalization. arXiv preprint arXiv:2110.08207.
- Scialom et al. (2022) Thomas Scialom, Tuhin Chakrabarty, and Smaranda Muresan. 2022. Fine-tuned language models are continual learners. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 6107–6122.
- Shen et al. (2022) Sheng Shen, Pete Walsh, Kurt Keutzer, Jesse Dodge, Matthew Peters, and Iz Beltagy. 2022. Staged training for transformer language models. In International Conference on Machine Learning, pages 19893–19908. PMLR.
- Shridhar et al. (2020) Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2020. Alfworld: Aligning text and embodied environments for interactive learning. arXiv preprint arXiv:2010.03768.
- Tenney et al. (2019) Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019. Bert rediscovers the classical nlp pipeline. arXiv preprint arXiv:1905.05950.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Van Aken et al. (2019) Betty Van Aken, Benjamin Winter, Alexander Löser, and Felix A Gers. 2019. How does bert answer questions? a layer-wise analysis of transformer representations. In Proceedings of the 28th ACM international conference on information and knowledge management, pages 1823–1832.
- Wang et al. (2023a) Peihao Wang, Rameswar Panda, Lucas Torroba Hennigen, Philip Greengard, Leonid Karlinsky, Rogerio Feris, David Daniel Cox, Zhangyang Wang, and Yoon Kim. 2023a. Learning to grow pretrained models for efficient transformer training. arXiv preprint arXiv:2303.00980.
- Wang et al. (2023b) Xiao Wang, Yuansen Zhang, Tianze Chen, Songyang Gao, Senjie Jin, Xianjun Yang, Zhiheng Xi, Rui Zheng, Yicheng Zou, Tao Gui, et al. 2023b. Trace: A comprehensive benchmark for continual learning in large language models. arXiv preprint arXiv:2310.06762.
- Wang et al. (2023c) Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. 2023c. Mint: Evaluating llms in multi-turn interaction with tools and language feedback.
- Wang et al. (2023d) Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Raghavi Chandu, David Wadden, Kelsey MacMillan, Noah A. Smith, Iz Beltagy, and Hannaneh Hajishirzi. 2023d. How far can camels go? exploring the state of instruction tuning on open resources.
- Wei et al. (2021) Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. 2021. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652.
- Wu et al. (2023a) Chengyue Wu, Teng Wang, Yixiao Ge, Zeyu Lu, Ruisong Zhou, Ying Shan, and Ping Luo. 2023a. -tuning: Transferring multimodal foundation models with optimal multi-task interpolation. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 37713–37727. PMLR.
- Wu et al. (2023b) Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. 2023b. Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564.
- Xu et al. (2023a) Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. 2023a. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244.
- Xu et al. (2023b) Yiheng Xu, Hongjin Su, Chen Xing, Boyu Mi, Qian Liu, Weijia Shi, Binyuan Hui, Fan Zhou, Yitao Liu, Tianbao Xie, et al. 2023b. Lemur: Harmonizing natural language and code for language agents. arXiv preprint arXiv:2310.06830.
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600.
- Yao et al. (2022) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629.
- Yao et al. (2023) Yiqun Yao, Zheng Zhang, Jing Li, and Yequan Wang. 2023. 2x faster language model pre-training via masked structural growth. arXiv preprint arXiv:2305.02869.
- Yu et al. (2023) Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. 2023. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830.
- Zhang et al. (2023) Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685.
- Zhou et al. (2023) Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. 2023. Lima: Less is more for alignment. arXiv preprint arXiv:2305.11206.
- Ziegler et al. (2019) Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 2019. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593.
Appendix A Gradient Derivation
To calculate the gradient of the RMSNorm weight during backpropagation, we first need to consider the forward pass equation for the Llama RMSNorm:
| (8) |
where is the input tensor, is the weight parameter, is the variance of across the last dimension, and is a small constant for numerical stability.
Now, let’s consider the chain rule for the gradient of the loss function with respect to the RMSNorm weight during backpropagation. Denote the loss function as , and the output of the FFN as . We have:
| (9) |
To compute the gradient, we need to find the partial derivative . From the FFN equation, we have:
| (10) |
Taking the derivative with respect to , we get:
| (11) |
Now, let’s differentiate the RMSNorm function with respect to :
| (12) |
Using the chain rule, we can compute the gradient of the loss function with respect to the RMSNorm weight:
| (13) |
Given that , we need to find the derivative of the FFN with respect to . Recall the FFN equation:
| (14) |
Now we want to find the partial derivative of the FFN with respect to . Recall the SwiGLU activation function:
| (15) |
Taking the derivative of the SwiGLU function with respect to , we get:
| (16) |
Now, recall the SiLU activation function:
| (17) |
Thus, the gradient of the FFN with respect to when is also zero:
| (18) |
In conclusion, when , the gradient of the FFN with respect to is zero, which demonstrates that the gradient is zero when the input to the FFN is zero.
Appendix B MINT-Bench
| Task Type | Task Name | # Instances |
|---|---|---|
| Code Generation | HumanEval (Chen et al., 2021b) | 45 |
| MBPP (Austin et al., 2021) | 91 | |
| Decision Making | ALFWorld (Shridhar et al., 2020) | 134 |
| Reasoning | GSM8K (Cobbe et al., 2021) | 48 |
| HotpotQA (Yang et al., 2018) | 43 | |
| MATH (Hendrycks et al., 2021) | 100 | |
| MMLU (Hendrycks et al., 2020) | 76 | |
| TheoremQA (Chen et al., 2023b) | 49 | |
| Total | 586 | |
| Model | Code Generation | Decision Making | Reasoning | Micro Avg. |
|---|---|---|---|---|
| AgentLM-7B | 1.47 | 9.70 | 8.86 | 7.34 |
| CodeLLaMA-7B-Instruct | 2.21 | 17.16 | 7.91 | 8.70 |
| LLaMA2-7B-Chat | 0.00 | 0.00 | 13.61 | 7.34 |
| Mistral-Instruct-v0.1 | 6.62 | 34.33 | 8.54 | 13.99 |
| LLaMA Pro - Instruct | 11.76 | 29.10 | 9.81 | 14.68 |

The MINT-Bench Wang et al. (2023c) details are provided in this section. MINT-Bench comprises eight datasets spanning code generation, decision-making, and reasoning tasks, totaling 586 instances, as shown in Table 8.
We use the Success Rate (SR) as our evaluation metric, which measures the percentage of successful task instances. For an interaction limit of , MINT-Bench starts from scratch and allows each LLM to interact up to the -th turn, measuring the corresponding . Unless specified otherwise, MINT-Bench limits , where indicates no interaction, and maximizes interaction turns within the context window (4,096 tokens) of most modern LLMs.
In each turn, the LLM is instructed to perform the following steps: (1) Optionally express its reasoning process (referred to as "Thought," similar to Yao et al. (2022)); (2) Either interact with tools by generating Python code and executing it through a Python interpreter (referred to as "Execute"), or propose a solution to the user (referred to as "Propose Solution").
Table 9 displays the success rate for each model evaluated on various task type benchmarks, as well as the micro average when . The LLaMA Pro - Instruct model demonstrates robust performance across all task types compared to other models of similar size. Figure 7 provides a case study to compare LLaMA Pro - Instruct and LLaMA2-7B-Chat where LLaMA Pro - Instruct successfully utilizes Python program to solve the given question in the multi-round interaction.
Appendix C MT-Bench

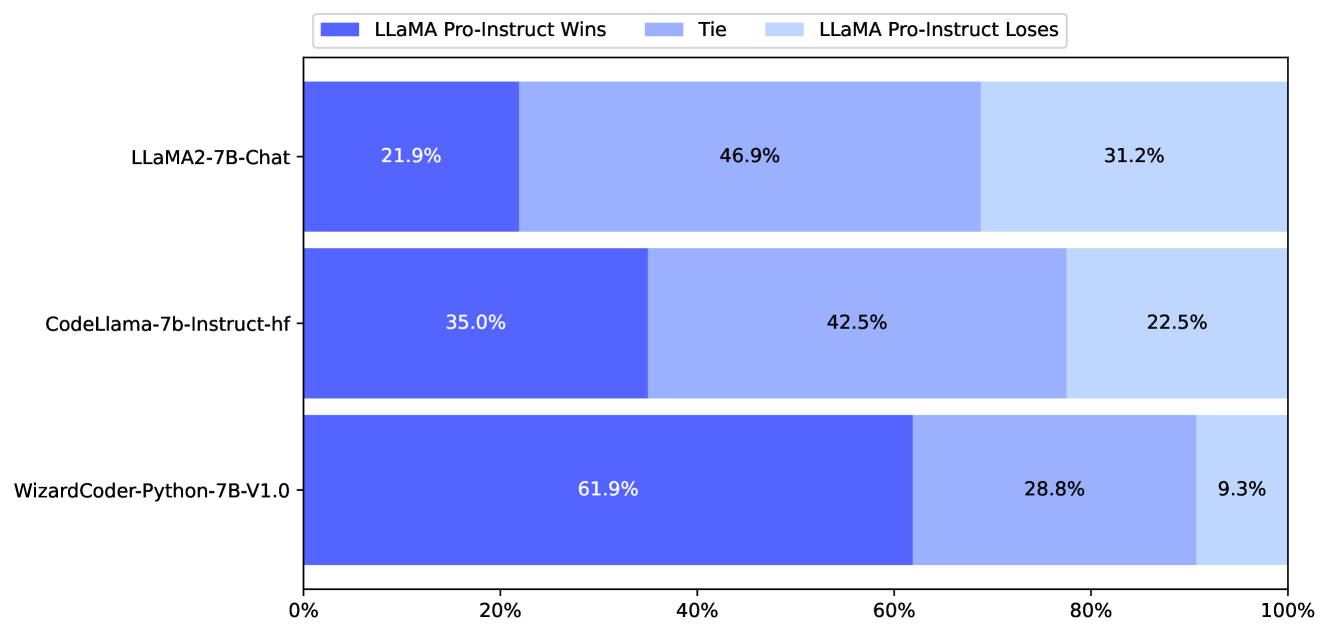
MT-bench is a collection of demanding multi-turn open-ended questions designed for evaluating chat assistants. In order to automate the evaluation process, we employ powerful LLMs, such as GPT-4, to act as judges and assess the quality of the models’ responses. We present the detailed pairwise comparison in the Figure 8 and Figure 9. Figure 10 shows the case study of the comparison between LLaMA Pro - Instruct and LLaMA2-7B-Chat.

Appendix D TRACE-Bench
| Dataset | Source | Avg len | Metric | Language | #data |
|---|---|---|---|---|---|
| Domain-specific | |||||
| ScienceQA | Science | 210 | Accuracy | English | 5,000 |
| FOMC | Finance | 51 | Accuracy | English | 5,000 |
| MeetingBank | Meeting | 2853 | ROUGE-L | English | 5,000 |
| Multi-lingual | |||||
| C-STANCE | Social media | 127 | Accuracy | Chinese | 5,000 |
| 20Minuten | News | 382 | SARI | Germany | 5,000 |
| Code completion | |||||
| Py150 | Github | 422 | Edim similarity | Python | 5,000 |
| Mathematical reasoning | |||||
| NumGLUE-cm | Math | 32 | Accuracy | English | 5,000 |
| NumGLUE-ds | Math | 21 | Accuracy | English | 5,000 |
| Task\Round | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| C-STANCE | 0.5 | 0.27 | 0.28 | 0.31 | 0.01 | 0.51 | 0.44 | 0.27 |
| FOMC | - | 0.69 | 0.61 | 0.57 | 0.0 | 0.44 | 0.51 | 0.46 |
| MeetingBank | - | - | 0.472 | 0.287 | 0.159 | 0.111 | 0.14 | 0.139 |
| Py150 | - | - | - | 0.61 | 0.294 | 0.551 | 0.547 | 0.364 |
| ScienceQA | - | - | - | - | 0.68 | 0.6 | 0.59 | 0.54 |
| NumGLUE-cm | - | - | - | - | - | 0.395 | 0.309 | 0.272 |
| NumGLUE-ds | - | - | - | - | - | - | 0.59 | 0.51 |
| 20Minuten | - | - | - | - | - | - | - | 0.414 |
| OP | 0.371 | |||||||
| BWT | -0.173 |
| Task\Round | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| C-STANCE | 0.6 | 0.43 | 0.49 | 0.49 | 0.5 | 0.49 | 0.48 | 0.53 |
| FOMC | - | 0.8 | 0.46 | 0.47 | 0.0 | 0.47 | 0.5 | 0.51 |
| MeetingBank | - | - | 0.523 | 0.338 | 0.344 | 0.392 | 0.396 | 0.371 |
| Py150 | - | - | - | 0.594 | 0.265 | 0.561 | 0.566 | 0.575 |
| ScienceQA | - | - | - | - | 0.87 | 0.83 | 0.58 | 0.55 |
| NumGLUE-cm | - | - | - | - | - | 0.383 | 0.198 | 0.210 |
| NumGLUE-ds | - | - | - | - | - | - | 0.64 | 0.49 |
| 20Minuten | - | - | - | - | - | - | - | 0.407 |
| OP | 0.455 | |||||||
| BWT | -0.147 |
| Task\Round | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| C-STANCE | 0.65 | 0.52 | 0.52 | 0.52 | 0.28 | 0.52 | 0.5 | 0.57 |
| FOMC | - | 0.8 | 0.49 | 0.45 | 0.0 | 0.44 | 0.46 | 0.45 |
| MeetingBank | - | - | 0.512 | 0.363 | 0.338 | 0.383 | 0.393 | 0.38 |
| Py150 | - | - | - | 0.593 | 0.366 | 0.531 | 0.53 | 0.548 |
| ScienceQA | - | - | - | - | 0.89 | 0.8 | 0.6 | 0.63 |
| NumGLUE-cm | - | - | - | - | - | 0.333 | 0.185 | 0.198 |
| NumGLUE-ds | - | - | - | - | - | - | 0.68 | 0.54 |
| 20Minuten | - | - | - | - | - | - | - | 0.408 |
| OP | 0.465 | |||||||
| BWT | -0.143 |
Table 10 shows the statistics of TRACE. We evaluate the performance of different training strategies after sequential tasks. Table 11-13 shows the detailed performance of different training strategies of each round during the continual learning with LLaMA2-7B.
Appendix E Domain of Law
| Hyperparameter | Assignment |
|---|---|
| Batch size | 1024 |
| Maximum sequence length | 2,048 |
| Maximum learning rate | 2e-4 |
| Optimizer | Adam |
| Adam beta weights | 0.9, 0.95 |
| Learning rate scheduler | cosine |
| Warmup ratio | 0.06 |
| Gradient clipping | 1.0 |
Table 14 shows the hyper-parameters we use to do the ablation study in the domain of law. We use the freelaw subset of Pile dataset as our pretrain corpus Gao et al. (2020) in the domain of law. This subset has 51.2 GiB raw size and 16.7B tokens with 3.6M documents.
The Unfair-ToS dataset, which we use to evaluate the performance of law, contains Terms of Service (ToS) from online platforms (e.g., YouTube, Ebay, Facebook, etc.). The dataset has been annotated on the sentence-level with 8 types of unfair contractual terms (sentences), meaning terms that potentially violate user rights according to the European consumer law. The UNFAIR-ToS task is a multilabel classification task. To get model predictions for this task, we categorize it as a multiple-choice question as the method Cheng et al. (2023) uses. The accuracy of an individual data example is considered true if the model prediction (i.e., the option with the highest per-token likelihood) belongs to the label(s) set. We evaluate the Unfair-ToS dataset in a 4-shot scenario just like Cheng et al. (2023).