Training embedding quantum kernels with data re-uploading quantum neural networks
Abstract
Kernel methods play a crucial role in machine learning and the Embedding Quantum Kernels (EQKs), an extension to quantum systems, have shown very promising performance. However, choosing the right embedding for EQKs is challenging. We address this by proposing a -qubit Quantum Neural Network (QNN) based on data re-uploading to identify the optimal -qubit EQK for a task (-to-). This method requires constructing the kernel matrix only once, offering improved efficiency. In particular, we focus on two cases: -to-, where we propose a scalable approach to train an -qubit QNN, and -to-, demonstrating that the training of a single-qubit QNN can be leveraged to construct powerful EQKs.
I Introduction
Quantum computing is a promising computational paradigm for tackling some complex computational problems which are classically intractable. In particular, its potential in enhancing machine learning tasks has garnered significant attention Biamonte et al. (2017); Carleo et al. (2019); Dunjko and Briegel (2018); Dalzell et al. (2023) with parametrized quantum circuits as the most common approach Benedetti et al. (2019); Skolik et al. (2022); Schuld et al. (2020); Farhi and Neven (2018). Although there are evidences of quantum advantage in some tailored problems Sweke et al. (2021); Jerbi et al. (2021); Pirnay et al. (2023); Gyurik and Dunjko (2023), advantage over classical counterparts for practical applications remains as an area of active research.
Amidst the exploration of quantum machine learning models, previous studies, particularly in Refs. Havlíček et al. (2019); Schuld and Killoran (2019), have delineated a categorization into explicit and implicit models. In explicit models, data undergoes encoding into a quantum state, and then a parametrized measurement is performed. In contrast, implicit or kernel models are based on a weighted summation of inner products between encoded data points. A specialized category within parametrized quantum circuits, which can be considered separately, consists of data re-uploading models Pérez-Salinas et al. (2020). This architecture features an alternation between encoding and processing unitaries, yielding expressive models that have found extensive use Schuld et al. (2021a); Caro et al. (2021); Ono et al. (2023). However, Ref. Jerbi et al. (2023) shows that these models can be mapped onto an explicit model, thereby unifying these three approaches within the framework of linear models within Hilbert space.
Beyond this overarching theoretical framework, significant effort has been devoted to studying the performance of quantum kernel methods Huang et al. (2021); Peters et al. (2021); Bartkiewicz et al. (2020); Kusumoto et al. (2021). Furthermore, theorizing about them as a way to explain quantum machine learning models has also been pursued Schuld and Killoran (2019); Schuld (2021); Schuld et al. (2021b). This interest is substantiated by several compelling factors. Firstly, the act of embedding data into quantum states provides direct access to the exponentially vast quantum Hilbert space, where inner products can be efficiently computed. Secondly, the creation of embedding quantum kernels that pose classical intractability yet offers the potential for quantum advantages Liu et al. (2021). Finally, in both classical machine learning and kernel methods, the representer theorem Schölkopf and Smola (2001) ensures that they consistently achieve a training loss lower than or equal to that of explicit models, provided the same encoding and training set are considered. However, it is worth noting that this enhanced expressivity may be accompanied by reduced generalization capability, a point explored and discussed in Ref. Jerbi et al. (2023).
While the arguments above might suggest a preference for kernel or implicit models over explicit ones, practical challenges persist. Firstly, the computational complexity associated with constructing the kernel matrix scales quadratically with the number of training samples. Additionally, selecting the appropriate embedding that defines the kernel function is contingent on the specific problem at hand, demanding careful consideration. Regarding the last one, two approaches to train kernels customized for the dataset in question have been considered: multiple kernel learning and kernel target alignment. In the former, a combination of kernel functions is trained to minimize an empirical risk function Vedaie et al. (2020); Ghukasyan et al. (2023). In the latter, it is defined a kernel using an embedding ansatz which is trained to align with an ideal kernel Hubregtsen et al. (2022). However, these techniques require the computation of the kernel matrix at each training iteration, incurring substantial computational costs.
In this Article, we employ a quantum neural network (QNN) to create an embedding quantum kernel (EQK). This strategy utilizes QNN training to construct the corresponding kernel matrix, significantly reducing the computational cost when compared to constructing the kernel matrix at each training step. In particular, we utilize the data re-uploading architecture for the QNN and propose a method to straightforwardly scale the training up to an qubit QNN. Following training on a given dataset, this QNN is used to generate a qubit EQK. This construction is denoted as the -to- approach. Here, we will focus on two specific cases: the -to- and the -to-. The former is fundamentally relevant, since we can prove that the classification accuracy of the QNN never decreases with and that entanglement plays a role in this accuracy. Additionally, we have empirically observed that the classification accuracy of the EQK not only is higher than the one of the QNN, as expected, but also that it does not decrease with . We also propose the use of the training of a single-qubit QNN to create an -qubit EQK with entanglement, referred to as the -to- approach. We substantiate our proposals with numerical evidence, demonstrating that the training of a small-sized QNN, potentially even simulatable classically, adeptly selects parameters to form a potent EQK tailored for a specific task. Our results consider up to 10 qubits, showing that our approach circumvents typical training challenges associated with scaling parametrized quantum circuits.
The article is organized into the following sections. We begin by introducing quantum kernel methods and EQKs. Afterwards, we present the data re-uploading architecture and our approach to scaling it up to an -qubit QNN. Subsequently, we detail the construction of EQKs derived from the training of these QNNs. Finally, we present numerical results supporting the practicability of our approach.
II Quantum kernel methods
Quantum machine learning models can be categorized into explicit and implicit models, as discussed in Refs. Schuld and Killoran (2019); Havlíček et al. (2019). Explicit models are based on parametrized quantum circuits Benedetti et al. (2019); Abbas et al. (2021); Cerezo et al. (2021); Bharti et al. (2022), which are tailored to process classical information encoded into a quantum state as , where refers to some quantum embedding. These models have proven resilient to noise Sharma et al. (2020), making them attractive for seeking quantum advantages in near-term quantum processors. However, they face scalability challenges due to the barren plateau problem during training McClean et al. (2018); Cerezo et al. (2021); Holmes et al. (2022); Anschuetz and Kiani (2022); Ragone et al. (2023). Implicit or kernel models, on the other hand, are defined by the linear combination
| (1) |
where is the kernel function and denotes training points from a training set . An important insight from classical machine learning theory is captured by the representer theorem. This theorem asserts that, when provided with a feature encoding and a training set, implicit models in the form of Eq. 1 consistently attain training losses that are either equal to or lower than those of explicit quantum models.
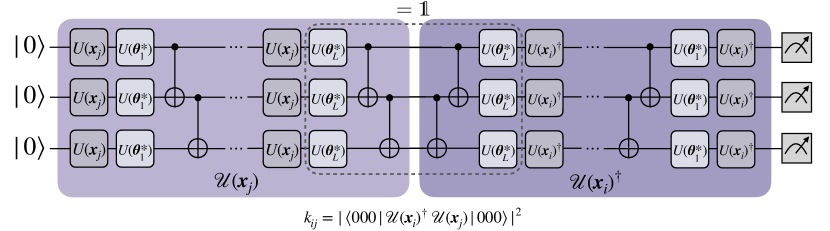
Determining the optimal parameters for implicit models involves solving a convex optimization problem, necessitating the construction of the kernel matrix with entries . To accomplish this, inner products between all training points must be evaluated on a quantum computer Buhrman et al. (2001); Fanizza et al. (2020); Cincio et al. (2018), involving evaluations. Although there are instances where these inner products can be computed without explicitly constructing the feature map, our primary focus here is on embedding quantum kernels (EQKs). EQKs, prevalent in quantum kernel literature and proven to be universal in Ref. Gil-Fuster et al. (2023), are constructed as follows:
| (2) |
where . These overlap evaluations serve as input for a support vector machine (SVM) algorithm. Although quantum SVM approaches have been explored Rebentrost et al. (2014); Park et al. (2023), we assume classical computation for this step in this work, incurring a time complexity of .
Given the representer theorem and the inherent capability of quantum devices to access exponentially large feature spaces, quantum kernel methods emerge as promising candidates for optimal quantum machine learning models Schuld (2021). However, they come with their challenges, such as the exponentially vanishing of kernel values Thanasilp et al. (2022); Kübler et al. (2021), and, as addressed in this work, the critical issue of selecting the appropriate kernel for a specific task.
To identify the optimal kernel, the common strategy involves employing a parametrized quantum embedding Lloyd et al. (2020), where represents the trainable parameters. This embedding defines a trainable quantum kernel , which is then optimized based on a specific figure of merit. In the study by Hubregtsen et al. Hubregtsen et al. (2022), the optimization problem is formulated using kernel target alignment. Another avenue explored in works such as Vedaie et al. (2020); Ghukasyan et al. (2023) involves multiple kernel learning, where the goal is to determine the optimal combination of different kernels for a specific task. However, these approaches require constructing the kernel matrix at each training step, which implies a high computational cost. In our work, we propose a novel method for training embedding quantum kernels that only necessitates constructing the kernel matrix once.
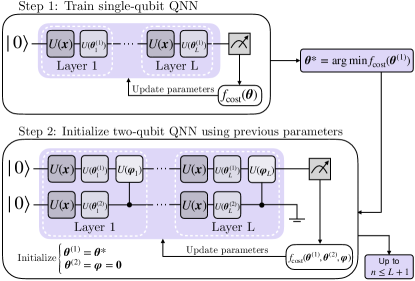
III Scaling data re-uploading for qubit QNN
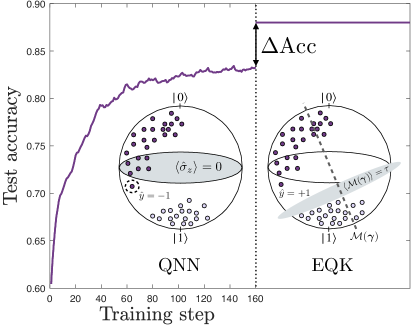
As reported by Pérez-Salinas et al. in Ref. Pérez-Salinas et al. (2020), the data re-uploading model incorporates layers composed of data-encoding and training unitaries. This approach effectively introduces non-linearities to the model allowing to capture complex patterns on data Schuld et al. (2021a); Casas and Cervera-Lierta (2023); Caro et al. (2021); Barthe and Pérez-Salinas (2023). In fact, it has been demonstrated that a single qubit quantum classifier possesses universal capabilities Pérez-Salinas et al. (2021).
While various encoding strategies could be considered for this architecture, we specifically adopt the easiest one defining
| (3) |
Here, denotes the number of layers, represents a generic unitary, and the vector encompasses the trainable parameters. To leverage this model to construct a binary classifier, one must select two label states that are maximally separated in Hilbert space. The training objective involves instructing the model to collectively rotate points belonging to the same class, bringing them closer to their corresponding label state.
Starting with the data re-uploading single-qubit QNN architecture, we can naturally extend it to create multi-qubit QNNs. The introduction of more qubits enhances the model’s expressivity by increasing the number of trainable parameters per layer and offering the potential for entanglement between qubits which enhances the expressivity of the model Panadero et al. (2023).
In this work, we propose an iterative training approach for multi-qubit QNNs. In our construction, the -qubit QNN is defined as
| (4) |
where denotes the controlled version of the general unitary with control in the -th qubit and target in the -th qubit, and and refer to the trainable parameters of single-qubit and two-qubit gates, respectively. The total number of trainable parameters in this architecture is .
For the training of the -qubit QNN, we propose an iterative construction starting from a single-qubit QNN. The initialization process is depicted in Figure 1. Initially, we train a single-qubit QNN and utilize its parameters to initialize the two-qubit QNN. During the initialization of the two-qubit QNN, we set for all , initializing the parameters of the first qubit with those obtained from the training of the single-qubit step. Consequently, the entangling layers do not have any action, ensuring that, with a local measurement on the first qubit, we commence in the output state of the single-qubit QNN training.
This process can be employed to scale up the QNN architecture, allowing the construction of QNNs with up to qubits. When adding an extra qubit, the supplementary entangling gates are initialized as identities, and the training begins with the optimal parameters obtained from the previous step. Essentially, this formalized approach signifies a systematic and scalable improvement in the QNN’s performance with the incorporation of each additional qubit.
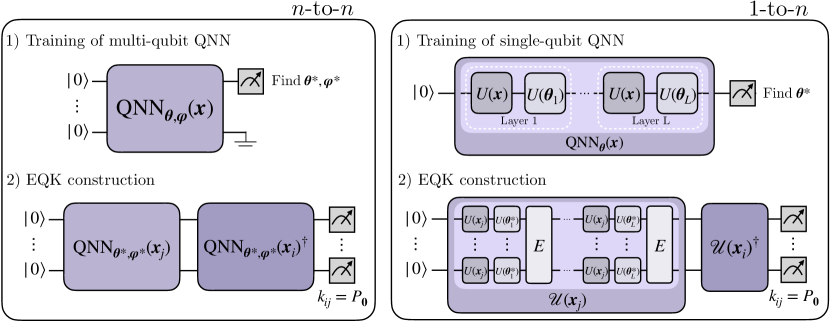
IV Constructing EQKs from QNN training
In this section, we propose a method for constructing trained embedding quantum kernels (EQK) using data re-uploading quantum neural networks (QNN). The idea is to train the QNN for a classification task and leverage its architecture to generate EQKs tailored to the specific task, thereby enhancing performance on the given dataset. The motivation for combining these two binary classification approaches, QNN and kernel methods, arises from two perspectives.
Firstly, we investigate whether the QNN can effectively select a suitable embedding kernel for a specific task. This approach may lead to more efficient kernel training compared to previous methods, as we only need to construct the kernel matrix once. Secondly, the QNN’s performance is contingent on its training. Utilizing the corresponding EQK construction might produce superior results compared to relying solely on the QNN, even in cases where the training process has not been optimal. Numerical results illustrating this can be found in Appendix E.
The underlying concept of this method is formalized in the Appendix and clarified in Figure 2, specifically for a single-qubit scenario. Initially, the QNN rotates data points of the same class near their label state while maintaining the decision hyperplane fixed. This hyperplane is taken as the equator of the Bloch sphere, i.e., . After training the QNN, the resulting feature map is obtained by preserving the parameters acquired during training. This feature map is then utilized to construct an EQK. The subsequent application of the SVM algorithm, using this kernel, aims to identify the optimal separation hyperplane in the feature space. In this context, the optimization is equivalent to adjusting the optimal measurement while keeping the data points fixed.
Building upon this insight, we propose constructing EQKs using QNN training in two ways: the -to- approach and the -to-. In the first one, an -qubit QNN is trained using the iterative method proposed earlier to directly construct the corresponding EQK of qubits. As depicted in Figure 3, a multi-qubit QNN of the form of Eq. 4 is trained while fixing the trainable parameters of the embedding and . Then, these parameters are subsequently used to construct an EQK which is defined by
| (5) |
This method allows us to scale the QNN as much as possible during training, and when it reaches a performance plateau, we can utilize the trained feature map to construct an EQK.
In the -to- construction, we train a single-qubit from Eq. 3, fixing the and we leverage this training to construct the kernel
| (6) |
where denotes an entangling operation, such as a cascade of or gates, among other possibilities. It is worth noting that the training is conducted for a single-qubit QNN and does not explicitly consider entanglement. Nevertheless, we will present numerical results demonstrating that this training alone is sufficient to select parameters for constructing a customized multi-qubit kernel tailored to a specific task.
Certainly, one can combine both the -to- and the -to- architectures and generalize it to -to-, where represents some integer. In this scenario, an -qubit QNN is trained and utilized to implement the same design as in the -to- construction. However, in this case, each qubit of the QNN is embedded into qubits, introducing entanglement between layers.
V Numerical results
Let us now explore the practical implementation of our approaches and evaluate their performance across various datasets detailed in Appendix F. Both the training and test sets consist of 500 data points each.
For the QNN training in this section, we employ the Adam optimizer with a batch size of 24. In the initial step for the QNN training (), we use a learning rate of 0.05 and consider 30 epochs. For , we use a learning rate of 0.005 and 10 epochs.
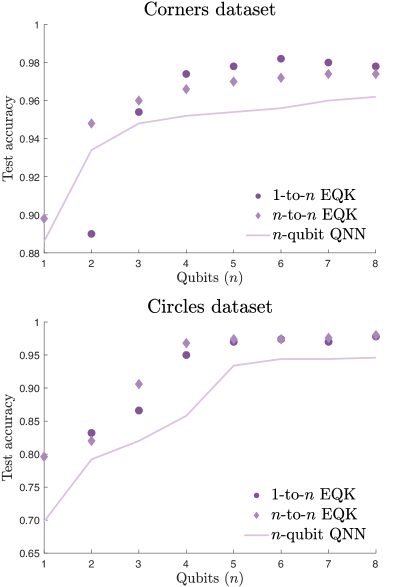
The results presented in Figure 4 demonstrate the test accuracies for two distinct datasets—the corners dataset and the circles dataset—for the -to- and the -to- constructions as functions of the number of qubits . These experiments consider layers, scaling up the QNN to . In the -to- construction, we introduce entanglement between layers using a cascade of CNOT gates, defined as
| (7) |
where the subscript refers to the control qubit, and the superscript refers to the target qubit.
The numerical experiments illustrate a consistent improvement in the performance of the -qubit QNN as more qubits are introduced for both datasets. Additionally, the corresponding kernel, represented by the -to- construction, exhibits enhanced performance compared to the QNN alone. Interestingly, the -to- construction performs remarkably well, showing a rapid increase in performance with a small number of qubits, although it eventually plateaus. While the improvement in the -to- scenario is slower, its performance consistently surpasses that of the QNN, and the scaling of this model is consistent and rigorous. For additional numerical experiments, refer to Appendix G.
These results demonstrate, on one hand, the scalability of a data re-uploading QNN and the improved performance achieved by constructing the corresponding EQK. On the other hand, they highlight the capability to create complex kernels through the training of simple QNN architectures. Despite the small QNNs being trainable using a classical computer, the obtained parameters could be utilized to construct a classically hard embedding quantum kernel.
VI Conclusions
We have addressed the challenge of training a -qubit embedding quantum kernel by introducing a practical approach that constructs them from a data re-uploading -qubit quantum neural network. This method significantly reduces computational costs compared to previous techniques in which the kernel matrix was constructed at each training step. We focus on two specific cases for constructing embedding quantum kernels, namely, the -to- and the -to- cases. The first involves using the output of the training of an -qubit QNN directly as a feature map (referred to as the -to- approach), for which we have proposed a scalable training method. The second approach enables the creation of multi-qubit EQKs with entanglement from the training of a single-qubit QNN (referred to as the -to- approach). Given the current limitations in scaling parametrized quantum circuits, our combined approach offers an alternative for creating trainable scalable kernels as quantum machine learning models, mitigating the challenges associated with their scalability and reducing the dependence on the training for model success. Moreover, the -to- approach can be considered a quantum inspired proposal, paving the way for exploring the construction of classically hard-to-estimate kernels from the training of small architectures, even those that can be simulated with a classical computer.
VII Acknowledgements
The authors would like to thank Maria Schuld for her valuable comments which led to a more solid presentation of the results and Sofiene Yerbi and Adrián Pérez-Salinas for their worthy insights during QTML 2023. PR and YB acknowledge financial support from the CDTI within the Misiones 2021 program and the Ministry of Science and Innovation under the Recovery, Transformation and Resilience Plan—Next Generation EU under the project “CUCO: Quantum Computing and its Application to Strategic Industries”. PR and MS acknowledge support from EU FET Open project EPIQUS (899368) and HORIZON-CL4- 2022-QUANTUM01-SGA project 101113946 OpenSuperQPlus100 of the EU Flagship on Quantum Technologies, the Spanish Ramón y Cajal Grant RYC-2020-030503-I, project Grant No. PID2021-125823NA-I00 funded by MCIN/AEI/10.13039/501100011033 and by “ERDF A way of making Europe” and “ERDF Invest in your Future”, and from the IKUR Strategy under the collaboration agreement between Ikerbasque Foundation and BCAM on behalf of the Department of Education of the Basque Government. This project has also received support from the Spanish Ministry of Economic Affairs and Digital Transformation through the QUANTUM ENIA project call - Quantum Spain, and by the EU through the Recovery, Transformation and Resilience Plan - NextGenerationEU. YB acknowledges support from the Spanish Government via the project PID2021-126694NA- C22 (MCIU/AEI/FEDER, EU).
References
- Biamonte et al. (2017) J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, Nature 549, 195 (2017).
- Carleo et al. (2019) G. Carleo, I. Cirac, K. Cranmer, L. Daudet, M. Schuld, N. Tishby, L. Vogt-Maranto, and L. Zdeborová , Reviews of Modern Physics 91 (2019), 10.1103/revmodphys.91.045002.
- Dunjko and Briegel (2018) V. Dunjko and H. J. Briegel, Reports on Progress in Physics 81, 074001 (2018).
- Dalzell et al. (2023) A. M. Dalzell, S. McArdle, M. Berta, P. Bienias, C.-F. Chen, A. Gilyén, C. T. Hann, M. J. Kastoryano, E. T. Khabiboulline, A. Kubica, G. Salton, S. Wang, and F. G. S. L. Brandão, “Quantum algorithms: A survey of applications and end-to-end complexities,” (2023), arXiv:2310.03011 [quant-ph] .
- Benedetti et al. (2019) M. Benedetti, E. Lloyd, S. Sack, and M. Fiorentini, Quantum Science and Technology 4, 043001 (2019).
- Skolik et al. (2022) A. Skolik, S. Jerbi, and V. Dunjko, Quantum 6, 720 (2022).
- Schuld et al. (2020) M. Schuld, A. Bocharov, K. M. Svore, and N. Wiebe, Physical Review A 101 (2020), 10.1103/physreva.101.032308.
- Farhi and Neven (2018) E. Farhi and H. Neven, “Classification with quantum neural networks on near term processors,” (2018), arXiv:1802.06002 [quant-ph] .
- Sweke et al. (2021) R. Sweke, J.-P. Seifert, D. Hangleiter, and J. Eisert, Quantum 5, 417 (2021).
- Jerbi et al. (2021) S. Jerbi, L. M. Trenkwalder, H. Poulsen Nautrup, H. J. Briegel, and V. Dunjko, PRX Quantum 2 (2021), 10.1103/prxquantum.2.010328.
- Pirnay et al. (2023) N. Pirnay, R. Sweke, J. Eisert, and J.-P. Seifert, Physical Review A 107 (2023), 10.1103/physreva.107.042416.
- Gyurik and Dunjko (2023) C. Gyurik and V. Dunjko, “On establishing learning separations between classical and quantum machine learning with classical data,” (2023), arXiv:2208.06339 [quant-ph] .
- Havlíček et al. (2019) V. Havlíček, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, Nature 567, 209 (2019).
- Schuld and Killoran (2019) M. Schuld and N. Killoran, Physical review letters 122, 040504 (2019).
- Pérez-Salinas et al. (2020) A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, Quantum 4, 226 (2020).
- Schuld et al. (2021a) M. Schuld, R. Sweke, and J. J. Meyer, Physical Review A 103 (2021a), 10.1103/physreva.103.032430.
- Caro et al. (2021) M. C. Caro, E. Gil-Fuster, J. J. Meyer, J. Eisert, and R. Sweke, Quantum 5, 582 (2021).
- Ono et al. (2023) T. Ono, W. Roga, K. Wakui, M. Fujiwara, S. Miki, H. Terai, and M. Takeoka, Physical Review Letters 131 (2023), 10.1103/physrevlett.131.013601.
- Jerbi et al. (2023) S. Jerbi, L. J. Fiderer, H. Poulsen Nautrup, J. M. Kübler, H. J. Briegel, and V. Dunjko, Nature Communications 14, 517 (2023).
- Huang et al. (2021) H.-Y. Huang, M. Broughton, M. Mohseni, R. Babbush, S. Boixo, H. Neven, and J. R. McClean, Nature Communications 12 (2021), 10.1038/s41467-021-22539-9.
- Peters et al. (2021) E. Peters, J. Caldeira, A. Ho, S. Leichenauer, M. Mohseni, H. Neven, P. Spentzouris, D. Strain, and G. N. Perdue, “Machine learning of high dimensional data on a noisy quantum processor,” (2021), arXiv:2101.09581 [quant-ph] .
- Bartkiewicz et al. (2020) K. Bartkiewicz, C. Gneiting, A. Černoch, K. Jiráková, K. Lemr, and F. Nori, Scientific Reports 10 (2020), 10.1038/s41598-020-68911-5.
- Kusumoto et al. (2021) T. Kusumoto, K. Mitarai, K. Fujii, M. Kitagawa, and M. Negoro, npj Quantum Information 7 (2021), 10.1038/s41534-021-00423-0.
- Schuld (2021) M. Schuld, arXiv preprint arXiv:2101.11020 (2021).
- Schuld et al. (2021b) M. Schuld, F. Petruccione, M. Schuld, and F. Petruccione, Machine Learning with Quantum Computers , 217 (2021b).
- Liu et al. (2021) Y. Liu, S. Arunachalam, and K. Temme, Nature Physics 17, 1013 (2021).
- Schölkopf and Smola (2001) B. Schölkopf and A. Smola, Smola, A.: Learning with Kernels - Support Vector Machines, Regularization, Optimization and Beyond. MIT Press, Cambridge, MA, Vol. 98 (2001).
- Vedaie et al. (2020) S. S. Vedaie, M. Noori, J. S. Oberoi, B. C. Sanders, and E. Zahedinejad, “Quantum multiple kernel learning,” (2020), arXiv:2011.09694 [quant-ph] .
- Ghukasyan et al. (2023) A. Ghukasyan, J. S. Baker, O. Goktas, J. Carrasquilla, and S. K. Radha, “Quantum-classical multiple kernel learning,” (2023), arXiv:2305.17707 [quant-ph] .
- Hubregtsen et al. (2022) T. Hubregtsen, D. Wierichs, E. Gil-Fuster, P.-J. H. S. Derks, P. K. Faehrmann, and J. J. Meyer, Physical Review A 106 (2022), 10.1103/physreva.106.042431.
- Abbas et al. (2021) A. Abbas, D. Sutter, C. Zoufal, A. Lucchi, A. Figalli, and S. Woerner, Nature Computational Science 1, 403–409 (2021).
- Cerezo et al. (2021) M. Cerezo, A. Sone, T. Volkoff, L. Cincio, and P. J. Coles, Nature Communications 12 (2021), 10.1038/s41467-021-21728-w.
- Bharti et al. (2022) K. Bharti, A. Cervera-Lierta, T. H. Kyaw, T. Haug, S. Alperin-Lea, A. Anand, M. Degroote, H. Heimonen, J. S. Kottmann, T. Menke, et al., Reviews of Modern Physics 94, 015004 (2022).
- Sharma et al. (2020) K. Sharma, S. Khatri, M. Cerezo, and P. J. Coles, New Journal of Physics 22, 043006 (2020).
- McClean et al. (2018) J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Babbush, and H. Neven, Nature Communications 9 (2018), 10.1038/s41467-018-07090-4.
- Holmes et al. (2022) Z. Holmes, K. Sharma, M. Cerezo, and P. J. Coles, PRX Quantum 3 (2022), 10.1103/prxquantum.3.010313.
- Anschuetz and Kiani (2022) E. R. Anschuetz and B. T. Kiani, Nature Communications 13 (2022), 10.1038/s41467-022-35364-5.
- Ragone et al. (2023) M. Ragone, B. N. Bakalov, F. Sauvage, A. F. Kemper, C. O. Marrero, M. Larocca, and M. Cerezo, “A unified theory of barren plateaus for deep parametrized quantum circuits,” (2023), arXiv:2309.09342 [quant-ph] .
- Buhrman et al. (2001) H. Buhrman, R. Cleve, J. Watrous, and R. de Wolf, Physical Review Letters 87 (2001), 10.1103/physrevlett.87.167902.
- Fanizza et al. (2020) M. Fanizza, M. Rosati, M. Skotiniotis, J. Calsamiglia, and V. Giovannetti, Physical Review Letters 124 (2020), 10.1103/physrevlett.124.060503.
- Cincio et al. (2018) L. Cincio, Y. Subaşı, A. T. Sornborger, and P. J. Coles, New Journal of Physics 20, 113022 (2018).
- Gil-Fuster et al. (2023) E. Gil-Fuster, J. Eisert, and V. Dunjko, arXiv preprint arXiv:2309.14419 (2023).
- Rebentrost et al. (2014) P. Rebentrost, M. Mohseni, and S. Lloyd, Physical review letters 113, 130503 (2014).
- Park et al. (2023) S. Park, D. K. Park, and J.-K. K. Rhee, Scientific Reports 13, 3288 (2023).
- Thanasilp et al. (2022) S. Thanasilp, S. Wang, M. Cerezo, and Z. Holmes, “Exponential concentration and untrainability in quantum kernel methods,” (2022), arXiv:2208.11060 [quant-ph] .
- Kübler et al. (2021) J. M. Kübler, S. Buchholz, and B. Schölkopf, “The inductive bias of quantum kernels,” (2021), arXiv:2106.03747 [quant-ph] .
- Lloyd et al. (2020) S. Lloyd, M. Schuld, A. Ijaz, J. Izaac, and N. Killoran, “Quantum embeddings for machine learning,” (2020), arXiv:2001.03622 [quant-ph] .
- Casas and Cervera-Lierta (2023) B. Casas and A. Cervera-Lierta, Physical Review A 107 (2023), 10.1103/physreva.107.062612.
- Barthe and Pérez-Salinas (2023) A. Barthe and A. Pérez-Salinas, “Gradients and frequency profiles of quantum re-uploading models,” (2023), arXiv:2311.10822 [quant-ph] .
- Pérez-Salinas et al. (2021) A. Pérez-Salinas, D. López-Núñez, A. García-Sáez, P. Forn-Díaz, and J. I. Latorre, Physical Review A 104 (2021), 10.1103/physreva.104.012405.
- Panadero et al. (2023) I. Panadero, Y. Ban, H. Espinós, R. Puebla, J. Casanova, and E. Torrontegui, “Regressions on quantum neural networks at maximal expressivity,” (2023), arXiv:2311.06090 [quant-ph] .
- Holmes and Jain (2006) D. E. Holmes and L. C. Jain, Innovations in machine learning (Springer, 2006).
Appendix A Related work on quantum kernel training
One of the main drawbacks of quantum kernel methods is determining the best kernel which depends on the specific problem. In cases where no prior knowledge about the input data is available, approaches have been developed to construct parametrized embedding quantum kernels that are trained for a specific task. These kernel training methods are based on multiple kernel learning Vedaie et al. (2020); Ghukasyan et al. (2023) and kernel target alignment Hubregtsen et al. (2022).
A.1 Multiple kernel learning
Multiple kernel learning methods involve the creation of a combined kernel
| (8) |
where represents a set of parametrized embedding quantum kernels, and is a combination function. Two common choices for this function result in either a linear kernel combination
| (9) |
or a multiplicative kernel combination
| (10) |
When it comes to choosing model parameters, in Ref. Vedaie et al. (2020) they use an empirical risk function to minimize, while in Ref. Ghukasyan et al. (2023) the authors opt for a convex minimization problem. However, in both constructions a complete kernel matrix is computed at each optimization step.
A.2 Kernel target alignment
Training kernels using kernel target alignment is based on the similarity measure between two kernel matrices, denoted as and . This similarity measure, known as kernel alignment Holmes and Jain (2006), is defined as
| (11) |
and corresponds to the cosine of the angle between kernel matrices if we see them as vectors in the space of matrices with the Hilbert-Schmidt inner product. The use of kernel alignment to train kernels is by defining the ideal kernel matrix whose entries are . Given a parametrized quantum embedding kernel whose kernel matrix is named as , the kernel-target alignment is defined as the kernel alignment between and the ideal kernel, i.e.
| (12) |
where we used that independently from the label and is the number of training points. Thus, authors in Ref. Hubregtsen et al. (2022) use this quantity as cost function which is minimized using gradient descent over the parameters. This strategy is closely related to the approach outlined in Ref. Lloyd et al. (2020), where the authors explore the construction of quantum feature maps with the aim of maximizing the separation between different classes in Hilbert space. However, in the case of the kernel target alignment strategy, similar to multiple kernel learning, the construction of the kernel matrix (or at least a subset of it) at each training step is required.
Appendix B Data re-uploading
To construct a data re-uploading QNN for binary classification, each label is associated with a unique quantum state, aiming to maximize the separation in the Bloch sphere. For the single qubit quantum classifier, the labels +1 and -1 are represented by the computational basis states and , respectively. The objective is to appropriately tune the parameters that define the state
| (13) |
to rotate the data points of the same class close to their corresponding label state. To achieve this, we use the fidelity cost function
| (14) |
where represents the correct label state for the data point . This optimization process occurs on a classical processor. Once the model is trained, the quantum circuit is applied to a test data point , and the probability of obtaining one of the label states is measured. If this probability surpasses a certain threshold (set as 1/2 in this case), the data point is classified into the corresponding label state class. Formally, the decision rule can be expressed as
| (15) |
When consider a multi-qubit architecture, the idea is the same but we need to properly choose the corresponding label states. In this work, for a -qubit QNN we consider as label states the ones defined by the projectors and , which corresponds to a local measurement in the first qubit.
Appendix C Connection with the representer theorem
In this section, we aim to leverage the representer theorem to demonstrate that the kernels derived from the data re-uploading Quantum Neural Network (QNN) will be at least as effective as the corresponding QNN. In our construction, the -qubit QNN is defined in Eq. 4 in the main text. There, we can extract the last layer to separate it into a variational part, which will be absorbed into the measurement when we define the corresponding quantum model, and the encoding part which will define the quantum feature map for the construction of the kernel. This corresponds to
| (16) |
where we defined and . This formulation aligns with the definition of a quantum model from Ref. Schuld (2021),
| (17) |
In our case, , and the variational measurement .
Once this model is trained over a dataset, we determine the parameters that minimize the defined in the previous section, fixing , and . If we now use the corresponding feature map to construct an embedding quantum kernel, we are effectively replacing the measurement from the optimization by the optimal measurement
| (18) |
which, by the representer theorem, defines the optimal quantum model
| (19) |
that minimizes the regularized empirical risk function. Thus, we proved that constructing the embedding quantum kernel from QNN training will perform equally or better in terms of training loss than the QNN alone.
Appendix D Hyperplane defined in the Bloch sphere
The objective of the data re-uploading quantum neural network (QNN) is to map all points with label +1 to the state on the Bloch sphere, while mapping points with label -1 to the state. In an ideal scenario, all +1 points would be rotated to the state and all -1 points to the state. Using this feature map to construct the embedding quantum kernel, all points would be support vectors associated to the same Lagrange multiplier . The SVM generates a separating hyperplane defined by the equation
| (20) |
In this scenario, assuming a balanced dataset translates to an equal number of support vectors, denoted as , for each class, and results in due to symmetry. Working with this equation by considering the sum of support vectors separately for the +1 class () and -1 class (), we obtain
| (21) |
which is equivalent to the hyperplane defined by
| (22) |
mirroring the decision boundary of the QNN part. Therefore, in the case of a perfect training, the SVM becomes redundant. Even if the points are not perfectly mapped to their label states and the separating hyperplane of the SVM is not exactly the one from Eq. 22, as long as all points are correctly classified by the QNN, the SVM will yield the same results. Thus, the SVM part is only meaningful for the single-qubit QNN to construct a single-qubit EQK case when the QNN training is suboptimal and requires to adjust the measurement of the decision boundary.
Appendix E Noisy simulations
We have introduced a combined protocol for binary classification. It is worth noting that the kernel estimation part involves the utilization of a quantum circuit with twice the depth of the QNN part. In practical implementations on current noisy intermediate-scale quantum devices, the consideration of a larger circuit warrants careful attention. This is due to the susceptibility of larger circuits to elevated noise levels, potentially affecting the overall performance.
As previously mentioned, increasing the number of layers in the model enhances its expressivity. However, when constructing the kernel using a high number of layers, noise can have a detrimental impact on the performance, resulting in poorer results for the combined protocol compared to using only the QNN. Therefore, in this section, our objective is to perform simulations to visualize the trade-off between the number of layers in the QNN and using the combined protocol.
To characterize the noise incorporated into these simulations, we employ the operator sum representation of the noise channel acting on a quantum state ,
| (23) |
where represents the respective Kraus operators. In our simulations, we account for two single-qubit noise channels that are applied after each quantum gate. Firstly, we consider amplitude damping error which is described by the Kraus operators
| (24) | ||||
| (25) |
Here, is the amplitude damping probability, which can be defined as , with representing the thermal relaxation time and denoting the duration of application of a quantum gate. The second noise source under consideration is the phase flip error, which can be described by the following Kraus operators
| (26) | ||||
| (27) |
In this case, represents the probability of a phase flip error, which can be defined as , with denoting the spin-spin relaxation time or dephasing time. The value of also falls within the interval .
The current state-of-the-art experimental values for the noise parameters of a superconducting quantum processor are as follows: falls within the range of , is in the range of , and varies from . It is important to note that noise becomes more pronounced when and decrease and/or when increases. To explore the scenario with the worst noise, we consider the extreme values within these ranges, leading to and .
In our simulations, we simplify the noise characterization by defining a noise strength parameter for the sake of simplicity. We choose the single-qubit data re-uploading quantum neural network (QNN) as the kernel selection part. To observe a transition where it is no longer advantageous to include the support vector machine (SVM) part, we explore values of ranging from to in steps of , while also including the noiseless case where . These values correspond to examining the range and . Notably, even in these highly adverse conditions, which are significantly worse than those of current real hardware quantum devices, we find that the combined protocol remains suitable. This conclusion aligns with expectations since the protocol utilizes only a small number of qubits and quantum gates.
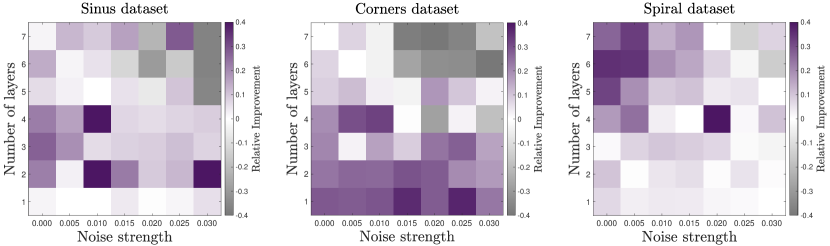
In Figure E.1, we present the relative improvement, denoted as
| (28) |
plotted as a function of the noise strength parameter and the number of layers . The architecture employed corresponds to the -to- case, utilizing gates for entanglement between layers. For QNN training in this instance, we limit it to two epochs with a learning rate of 0.05. The objective is to demonstrate that the resulting EQK is not highly dependent on the training specifics of the corresponding QNN and even a sub-optimal QNN training can lead to a powerful EQK for the specific task.
The relative improvements vary depending on the dataset under consideration and range from to . As expected, the worst performance of the combined protocol is observed at higher noise levels and for a greater number of layers, corresponding to a longer-depth quantum circuit. It is crucial to emphasize once more that these high noise strength values significantly surpass the noise parameters of current quantum devices. Therefore, even though the combined protocol necessitates running a double-depth circuit with more qubits, considering the noise model described earlier, it remains suitable for actual quantum devices.
Appendix F Datasets
In this work we utilized four artificial datasets for evaluating the performance of the proposed embedded quantum kernels. Here we explain how they were created:
-
•
Sinus Dataset: The sinus dataset is defined by a sinusoidal function, specifically . Points located above this sinusoidal curve are categorized as class -1, while points below it are assigned to class +1.
-
•
Corners Dataset: The corners dataset comprises four quarters of a circumference with a radius of 0.75, positioned at the corners of a square. Points located inside these circular regions are labeled as class -1, while points outside are classified as class +1.
-
•
Spiral Dataset: The spiral dataset features two spirals formed by points arranged along a trajectory defined by polar coordinates. The first spiral, denoted as class +1, originates at the origin (0, 0) and spirals outward in a counter-clockwise direction, forming a curve. The second spiral, labeled class -1, mirrors the first spiral but spirals inward in a clockwise direction. These spirals are generated by varying the polar angle, selected randomly to create the data points. The radial distance from the origin for each point depends on the angle, creating the characteristic spiral shape. Noise is added to the data points by introducing random perturbations to ensure they do not align perfectly along the spirals.
-
•
Circles Dataset: The circles dataset is created using two concentric circles that define an annular region. The inner circle has a radius of , while the outer circle has a radius of . Data points located within the annular region are labeled as -1, while those outside the region are labeled as +1.
Appendix G Numerical experiments
In the main we provide numerical results for two datasets for the -to- and -to- constructions up to 8 qubits. Here we provide the tables of more numerical experiments with the same hyperparameters: learning rate of 0.05 and 30 epochs for the QNN and learning rate of 0.005 and 10 epochs for . Here we provide more results for different datasets and considering also CZ as source of entanglement. All accuracies refer to test accuracies.
| Dataset | QNN accuracy | EQK type | EQK accuracy |
|---|---|---|---|
| Sinus | 0.890 | 0.960 | |
| Sinus | 0.948 | ||
| Corners | 0.886 | 0.954 | |
| Corners | 0.940 | ||
| Spiral | 0.800 | 0.994 | |
| Spiral | 0.866 | ||
| Circles | 0.698 | 0.866 | |
| Circles | 0.864 |
In Table 1, the outcomes demonstrate striking similarity when introducing entanglement through gates or gates, with the exception of the spiral dataset. Given the ambiguity surrounding the method of entanglement introduction, one might contemplate utilizing controlled rotations with random parameters as a potential source of entanglement. Notably, it is observed that even starting from a single-qubit QNN achieving accuracies of less than , the construction of EQKs yields accuracies surpassing .
| Dataset | n=2 | n=3 | n=4 | n=5 | n=6 | n=7 | n=8 | n=9 | n=10 |
|---|---|---|---|---|---|---|---|---|---|
| Corners | 0.890 | 0.954 | 0.974 | 0.978 | 0.982 | 0.980 | 0.978 | 0.978 | 0.978 |
| Circles | 0.832 | 0.866 | 0.950 | 0.970 | 0.974 | 0.970 | 0.978 | 0.966 | 0.962 |
In the -to- construction presented in Table 2 for the corners and circles datasets, we observe that the accuracy rises rapidly as qubits are added, reaching a peak at . Subsequently, the accuracy plateaus, attaining a maximum at for the corners dataset and for the circles dataset. After reaching these points, the accuracy gradually decreases with additional qubits.
| Dataset | n=1 | n=2 | n=3 | n=4 | n=5 | n=6 | n=7 | n=8 |
|---|---|---|---|---|---|---|---|---|
| Corners (QNN) | 0.886 | 0.934 | 0.948 | 0.952 | 0.954 | 0.956 | 0.960 | 0.962 |
| Corners (EQK) | 0.898 | 0.948 | 0.960 | 0.966 | 0.970 | 0.972 | 0.974 | 0.974 |
| Circles (QNN) | 0.698 | 0.792 | 0.820 | 0.858 | 0.934 | 0.944 | 0.944 | 0.946 |
| Circles (EQK) | 0.796 | 0.820 | 0.906 | 0.968 | 0.974 | 0.974 | 0.976 | 0.980 |
In the -to- approach, as presented in Table 3, the accuracy consistently increases with the addition of qubits for both the QNN and the EQK. Additionally, as discussed in the main text, the EQK consistently outperforms the corresponding QNN architecture for the same value of .
| Dataset | Layers | QNN accuracy | EQK accuracy |
|---|---|---|---|
| Sinus | 0.948 | 0.970 | |
| Sinus | 0.956 | 0.964 | |
| Sinus | 0.966 | 0.972 | |
| Sinus | 0.958 | 0.964 | |
| Corners | 0.948 | 0.970 | |
| Corners | 0.936 | 0.950 | |
| Corners | 0.934 | 0.948 | |
| Corners | 0.916 | 0.920 | |
| Spiral | 0.952 | 0.996 | |
| Spiral | 0.974 | 0.998 | |
| Spiral | 0.978 | 1.000 | |
| Spiral | 0.980 | 0.998 | |
| Circles | 0.786 | 0.812 | |
| Circles | 0.808 | 0.814 | |
| Circles | 0.792 | 0.820 | |
| Circles | 0.844 | 0.902 |
Finally, in Table 4, we present results for the four datasets considering different numbers of layers for the -to- architecture with . Adding layers increases the expressivity of the QNN but does not guarantee better accuracies, as we can observe. Again, we see that the EQK consistently outperforms the QNN.