Exploring Diverse Representations for Open Set Recognition
Abstract
Open set recognition (OSR) requires the model to classify samples that belong to closed sets while rejecting unknown samples during test. Currently, generative models often perform better than discriminative models in OSR, but recent studies show that generative models may be computationally infeasible or unstable on complex tasks. In this paper, we provide insights into OSR and find that learning supplementary representations can theoretically reduce the open space risk. Based on the analysis, we propose a new model, namely Multi-Expert Diverse Attention Fusion (MEDAF), that learns diverse representations in a discriminative way. MEDAF consists of multiple experts that are learned with an attention diversity regularization term to ensure the attention maps are mutually different. The logits learned by each expert are adaptively fused and used to identify the unknowns through the score function. We show that the differences in attention maps can lead to diverse representations so that the fused representations can well handle the open space. Extensive experiments are conducted on standard and OSR large-scale benchmarks. Results show that the proposed discriminative method can outperform existing generative models by up to 9.5% on AUROC and achieve new state-of-the-art performance with little computational cost. Our method can also seamlessly integrate existing classification models. Code is available at https://github.com/Vanixxz/MEDAF.
Introduction
Humans can realize what they have not learned, which provides a valuable basis for actively formulating questions and seeking information (Markman 1979). But this is quite challenging for artificial intelligence models: they will mistakenly identify samples of an unknown class as a known class, thereby preventing them from having the ability to think. To this end, open set recognition (OSR) is proposed to enable the models to recognize unknown samples while correctly identifying known samples (Scheirer et al. 2013).
Preliminary attempts on OSR have been made, in which existing methods can be categorized as discriminative methods and generative methods. Discriminative methods transform OSR into a classical discriminative task by imitating the open space using available data or features, such as explicitly estimating the probability of a test unknown sample (Bendale and Boult 2016), assigning placeholders to predict the distribution of unknown data (Zhou, Ye, and Zhan 2021), and utilizing supervised contrastive learning to improve the quality of representations (Xu, Shen, and Zhao 2023). These methods are simple and robust in various scenarios and easy to scale to large-scale tasks, but their performance is often limited due to the difficulty of modeling the open space. By contrast, generative methods encode known classes into various latent distributions using generative models and identify unknowns by measuring their distance to known distributions, such as mapping the latent known classes to prototypes (Yang et al. 2022), Gaussian distributions, and manifolds (Oza and Patel 2019). These methods have shown promising results and achieved state-of-the-art performance.
Despite effectiveness, generative methods are shown to be computationally infeasible or performatively unstable on complex tasks. (Xu, Shen, and Zhao 2023) pointed out that training generative models significantly increases the total training cost of the recognition system, and (Vaze et al. 2022) found it infeasible to train generative methods on large-scale benchmarks, e.g., ImageNet. Moreover, (Guo et al. 2021) and (Huang et al. 2023) empirically proved that generative methods suffer from significant performance degradation in recognizing unknowns when unknown classes are similar to known classes.
The aforementioned analysis raises a straightforward question: Is it possible to find the rationale of existing methods to design OSR models that are effective and robust as well as efficient and scalable?
In this paper, we first provide insights into OSR and theoretically find a key factor of generative methods is learning diverse representations that contain additional information to discriminative representations for identifying known classes. Subsequently, we propose a simple discriminative method that learns diverse representations using only vanilla discrimination models. Inspired by the mixture-of-experts model, we design multiple experts that share shallow layers and own expert-independent layers. To collaboratively learn diverse representations, the attention maps learned by the experts are constrained to be different using a diversity regularization term. Finally, the logits of each expert are adaptively fused by a gating network. The fused logits are used to classify knowns after the Softmax function as well as identifying unknowns in the score function. We show that the differences in attention maps can lead to diverse representations and the fused representations can reduce the open space risk, thereby boosting the ability to identify unknowns.
Extensive experiments on standard and large-scale OSR benchmarks demonstrate that the proposed method outperforms existing discriminative and generative models by up to 9.5% on AUROC and achieves new state-of-the-art performance. MEDAF is quite simple to implement and can seamlessly integrate existing classification models. The contributions of this study can be summarized as follows:
-
•
We provide theoretical insights into OSR and find that learning diverse representations is the key factor in reducing the open space risk.
-
•
We propose a simple yet effective method that learns multiple experts by constraining the learned attention map of each expert to be mutually different and fuses diverse representations to identify knowns and unknowns.
-
•
Experiments on standard and large-scale benchmarks demonstrate that the proposed method shows clear advantages over baselines with little computational cost.
Related Works
Discriminative OSR Methods
Since (Scheirer et al. 2013) provided a mathematical definition for OSR, (Hendrycks and Gimpel 2016) proposed a deep learning method that negates maximum softmax probability to reject unknowns. (Bendale and Boult 2016) demonstrated the instability of Softmax probabilities and designed an OpenMax function as a replacement for Softmax. (Zhou, Ye, and Zhan 2021) treated placeholders as representative points to address overconfidence in predictions for unknown classes. (Xu, Shen, and Zhao 2023) utilized supervised contrastive learning to enhance the efficacy of representations.
Discriminative methods are efficient and scalable, but their performance is often inferior to generative methods.
Generative OSR Methods
Generation for known classes. (Oza and Patel 2019) proposed a two-stage approach, which trains an encoder for closed-set recognition and then adds class-conditional information to train a decoder for unknown detection. (Chen et al. 2020) developed RPL to identify if a sample is known or unknown based on its deviation from reciprocal points. (Sun et al. 2020) used a variational autoencoder (VAE) for constraining different latent space features to fit different Gaussian models for unknown detection. (Guo et al. 2021) combined VAE and capsule network to fit a predefined distribution, promoting consistency of features within the class. (Yang et al. 2022) proposed GCPL, which replaces the Softmax classifier with an open-world-oriented prototype model.
Generation for unknown information. (Neal et al. 2018) enriched the training dataset by generating samples similar to training examples but not belonging to any specific classes with GANs (Goodfellow et al. 2014). Based on RPL, (Chen et al. 2022) proposed ARPL, which enhances the ability of the model to differentiate by generating misleading samples. (Kong and Ramanan 2022) expanded the training set to improve the recognition of unknown samples using generated samples and auxiliary datasets. (Moon et al. 2022) considered generating samples of different difficulty levels to improve the robustness of the model. (Liu et al. 2023) proposed a label-to-prototype mapping function to construct prototypes for both known classes and unknown classes.
Generative methods presume and learn different distributions for known classes or synthesize pseudo-unknowns around the known samples. Recent works show outstanding performance but are shown to be unreliable in complex tasks, e.g., the unknowns being similar to the knowns, and computationally infeasible in large-scale datasets.
Delving Deep into Open Set Recognition
(Scheirer et al. 2013) aimed to find the optimal solution in the hypothesis space for OSR tasks by minimizing both empirical and open space risks. Since obtaining precise information about unknown samples during training is impossible, we analyze the potential risks on the test set to measure the performance of model.
Misclassifying samples in the known test set increases closed-set risk while accepting from the unknown set induces open space risk . To measure the performance of model with training set , we denote the test set as , the label of unknown samples as , and the proportion of unknown samples as , the potential risk can be formulated as
| (1) |
Closed-set risk can be approximated by the empirical risk using . We can transform into during training. Mathematically, can be formulated as Eq. (2) considering the cross-entropy loss function:
| (2) | ||||
where denotes the global representation.
A common way to reject an unknown sample is to measure the probability that the model predicts it belongs to any known class is higher than threshold :
| (3) |
| (4) |
Accordingly, the sample will be wrongly accepted if . Obviously, the open space risk of wrongly accepting an unknown sample will be reduced if the ’s probabilities of belonging to all the known classes decrease, making increased. Therefore, Eq. (1) can be formulated as follows:
Proposition 1.
With the test set and the model , as increases, the potential risk decreases.
| (5) | ||||
According to Eq. (5), mitigating potential risks requires enhancing .
Lemma 1.
(Cover and Thomas 2012) For a pair of random variables , the conditional entropy given is:
| (6) |
During the process of training models using cross-entropy, minimizing the conditional entropy between the true labels and the learned representations can optimize the value of cross-entropy. For binary classification between known and unknown, is negatively correlated with . Thus, we can reduce open space risk by decreasing , so the quality of given affects the model’s performance. However, DNNs often use a limited set of highly distinguishable features for classification, which is called “shortcut learning” (Geirhos et al. 2020). This may lead to confusion between unknowns and knowns when they share similar features learned by DNNs. Several researchers tried to enable the model to form more comprehensive attention, (Wang and Shen 2018) proposed to leverage multi-scale features. We mathematically define two kinds of representations and analyze the impact of them on the OSR task.
Definition 1.
Basic Discriminative Representations is the representations captured by the baseline model and further be utilized to obtain global representation , which is formalized by:
| (7) |
Definition 2.
Supplementary Discriminative Representations is the representations of class-relevant regions aside from the focal area is formalized by:
| (8) |
where denotes the feature map obtained with CNNs and indicates there is no overlap between and , while the representations of the focal area are denoted as .
Based on the above definitions, we have the following theorem.
Theorem 1.
With and its global representation , the conditional entropy of and with and additionally utilizing is expressed as , satisfying .
Proof.
According to Eq. (9), as is a constant, the difference between conditional entropy and is determined by the difference of mutual information term and .
| (9) | ||||
Since only considering , is equivalent to , while is equivalent to , and the difference is
| (10) | ||||
represents the reduction in conditional entropy from the knowledge of when is given, and it is significant to discuss its value.
Lemma 2.
(Cover and Thomas 2012) For any three random variables and ,
| (11) |
with equality if and only if and are conditionally independent given .
As is related with class and are representations of different regions, the equality condition of Eq. (11) does not hold, so we can derive that , which indicates that introducing can reduce the open space risk. ∎
As the model gives lower prediction probabilities on other non-corresponding classes with , it can predict a low probability of unknown samples belonging to any known class, thereby constraining the open space risk that induced by considering these samples as known.
Connections to existing methods.
The above finding can explain the working mechanisms of some existing generative methods, i.e., exploring diverse representations in addition to :
-
•
Prototype or auto-encoder based methods learn by mapping it to prototypical points or manifolds. But prototypes cannot provide much information of and even under learn due to the limited representation ability, and AEs may learn representations that are unrelated to classification (Huang et al. 2023).
-
•
Unknown sample generation methods enable by learning to distinguish knowns and pseudo unknowns. However, the generated unknowns are unreliable due to limited information, thereby learning unreliable (Kong and Ramanan 2022).
To learn reliable flexibly, we design a new model that obtains through fusing different representations learned by multiple local networks to output the final prediction, which can seamlessly build upon existing classification models and further enable them exploring diverse representations.
Multi-Expert Diverse Attention Fusion
Multi-Expert Architecture
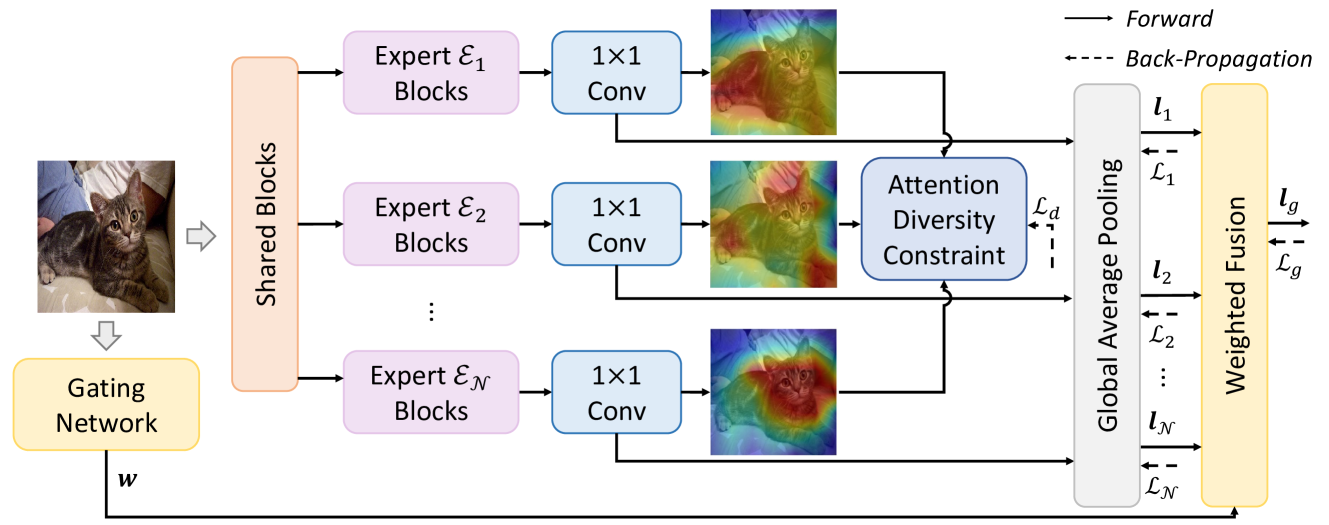
Inspired by the mixture of experts proposed by (Shazeer et al. 2017), we design multiple experts that share parameters in shallow layers and have individual parameters in deep layers. Each expert can specialize in capturing specific semantic features.
As shown in Figure 1, we set multi-experts represented as . Given a training sample , it first passes through the shared shallow layer to produce an intermediate representation with more detail, then is fed to various experts, which capture different discriminative regions.
Remark 1.
According to the specific demand and backbone, the number of expert-independent blocks and experts can be flexibly adjusted.
Learning Mutually Diverse Representations
The key to our method is to ensure multiple experts learn different representations. Simply constraining the learned representations to be different may lead to learning unnecessary information, so we use class activation mapping (CAM) (Zhou et al. 2016) that highlights the most critical regions in an image contributing to class .
Concretely, global averaging pooling (GAP) outputs global representation by calculating the average value of each pixel in feature map . By replacing the GAP-Linear with 11 Conv-GAP, we can obtain the feature map and the global representation . Given label , we can obtain the corresponding feature map , which is equivalent to CAM. With feature and its global representation , the GAP process can be formally described as Eq. (12), where denotes values on the nonsignificant regions (e.g., background).
| (12) | ||||
In addition to class-independent low-activation regions , regions with high activation values (e.g., ) in the CAM represent the location that the model focuses on, while regions with low activation values (e.g., ) are considered as supplementary representations. By forming diversity in and of each pair of experts, we can constrain differences in the regions that experts focus on and combine them to develop a comprehensive representation of the classification. We zero activation values lower than the mean to filter useless regions. Let denotes the processed CAM on expert , and it can be calculated as
| (13) |
We perform the cosine similarity between the processed CAM in a pairwise manner. The computed similarities are summed to compute the regularization loss for diversified expert attention, formulated as
| (14) |
| Method | SVHN | CIFAR10 | CIFAR+10 | CIFAR+50 | Tiny-ImageNet |
|---|---|---|---|---|---|
| Softmax (ICLR’16) | 0.886 | 0.677 | 0.816 | 0.805 | 0.577 |
| C2AE (CVPR’19) | 0.892 | 0.711 | 0.810 | 0.803 | 0.581 |
| CGDL (CVPR’20) | 0.896 | 0.681 | 0.794 | 0.794 | 0.653 |
| RPL (ECCV’20) | 0.931 | 0.784 | 0.885 | 0.881 | 0.711 |
| PROSER (CVPR’21) | 0.930 | 0.801 | 0.898 | 0.881 | 0.684 |
| CVAECap (ICCV’21) | 0.956 | 0.835 | 0.888 | 0.889 | 0.715 |
| ARPL (TPAMI’22) | 0.946 | 0.819 | 0.904 | 0.901 | 0.710 |
| NAS-OSR (AAAI’22) | 0.949 | 0.843 | 0.840 | 0.871 | - |
| DIAS (ECCV’22) | 0.943 | 0.850 | 0.920 | 0.916 | 0.731 |
| MEDAF | 0.957 | 0.860 | 0.960 | 0.955 | 0.800 |
Expert Fusion
To integrate predictions of different experts, we use a gating network to adaptively generate weights of experts. The gating network can consider expert-independent characteristics and relevance and allow fine-grained control over the contribution of each expert to the final result.
We adopt an identical feature extractor to those employed in the main network as the backbone of the gating network. Two fully connected layers are incorporated at the top of the backbone, culminating in deriving expert prediction weights. Let denotes the logits from expert , and represent the weights given by gating network. The final logits is calculated as follows:
| (15) |
where denotes the logits of the -th expert while denotes the integrated logits.
The overall loss function can be decomposed into global and expert-wise cross-entropy loss terms (denoted by and ) and the attention diversity regularization term , which can be formulated as
| (16) |
where and denote the scaling factors. The cross-entropy loss is formulated as
| (17) |
Rejecting Unknown Samples
According to open space risk in Eq. (3), the probability of an unknown sample being correctly rejected is inversely proportional to the mutual information between its feature and any known class . Unknown samples that share few discriminative features with known class samples are more likely to confuse the model (Moon et al. 2022).
By averaging multiple effective feature maps, we obtain a more comprehensive feature map that weakens the impact of a few similar features. The value is obtained through the L2 normalization of the averaged features:
| (18) |
To avoid degrading the original numerical difference with maximum softmax probability to reject unknowns, we use the maximum value of the logits as a term in and obtain the final result by linearly combining the above two terms according to Eq. (19), where is the weights of each term. When rejecting unknown samples, we use the value that ensures 95% of known samples are accepted as the threshold . According to Eq. (4), samples with scores lower than are considered unknown samples.
| (19) |
Experiments
Implementation Details
In experiments, we used ResNet18 (He et al. 2016) as the backbone. In terms of optimization, we used an SGD optimizer with a momentum value of 0.9 and set the initial learning rate to 0.1 with a fixed batch size of 128 for 150 epochs. For all the compared methods, we directly used the reported results if the settings were the same or the reproduced results using their official code if the settings were different. For methods that have not released their source code, we only reported the results of experiments they have done.
| Method | In:CIFAR10 / Out:CIFAR100 | In:CIFAR10 / Out:SVHN | ||||||
|---|---|---|---|---|---|---|---|---|
| DTACC | AUROC | AUIN | AUOUT | DTACC | AUROC | AUIN | AUOUT | |
| Softmax (ICLR’16) | 0.798 | 0.863 | 0.884 | 0.825 | 0.864 | 0.906 | 0.883 | 0.936 |
| RPL (ECCV’20) | 0.806 | 0.871 | 0.888 | 0.838 | 0.871 | 0.920 | 0.896 | 0.951 |
| CSI (NeuIPS’20) | 0.844 | 0.916 | 0.925 | 0.900 | 0.928 | 0.979 | 0.962 | 0.990 |
| GCPL (TPAMI’22) | 0.802 | 0.864 | 0.866 | 0.841 | 0.861 | 0.913 | 0.866 | 0.948 |
| ARPL (TPAMI’22) | 0.834 | 0.903 | 0.911 | 0.884 | 0.916 | 0.966 | 0.948 | 0.980 |
| MEDAF | 0.854 | 0.925 | 0.932 | 0.911 | 0.953 | 0.991 | 0.980 | 0.996 |
| Method | IMGN-C | IMGN-R | LSUN-C | LSUN-R |
|---|---|---|---|---|
| Softmax (ICLR’16) | 0.639 | 0.653 | 0.642 | 0.647 |
| CROSR (CVPR’19) | 0.721 | 0.735 | 0.720 | 0.749 |
| C2AE (CVPR’19) | 0.837 | 0.826 | 0.783 | 0.801 |
| GFROSR (CVPR’20) | 0.757 | 0.792 | 0.751 | 0.805 |
| CGDL (CVPR’20) | 0.840 | 0.832 | 0.806 | 0.812 |
| PROSER (CVPR’21) | 0.849 | 0.824 | 0.867 | 0.856 |
| ConOSR (AAAI’23) | 0.891 | 0.843 | 0.912 | 0.881 |
| MEDAF | 0.915 | 0.900 | 0.922 | 0.926 |
Unknown Detection
In this part, the model requires identifying samples from classes not learned during training on each dataset. Following the setting of (Moon et al. 2022), we conducted the experiments on five image datasets, including CIFAR10 (Krizhevsky 2009), CIFAR+10, CIFAR+50, SVHN (Netzer et al. 2011), and Tiny-ImageNet (Pouransari and Ghili 2014). The area under the receiver operating characteristic (AUROC) is a threshold-independent metric to measure the model’s ability to distinguish knowns and unknowns.
MEDAF has a clear advantage on challenging tasks with more unknown samples and high intra-similarity of classes. To avoid unfair comparisons arising from different splits, we adopted unified split information with (Moon et al. 2022; Neal et al. 2018) and can be found in the supplementary. Results in Table 1 demonstrate that MEDAF outperforms existing discriminative and generative methods on all datasets. It is worth noting that a significant improvement of 9.5% is obtained on TinyImageNet compared with the recent generative method, which has high variability in object appearance, and some classes in it visually resemble others.
Out-of-Distribution Detection
For measuring the performance of MEDAF in identifying samples that deviate from the learned in-distribution, we conducted OOD detection experiments. Following the setup proposed in (Chen et al. 2020), we employed CIFAR-100 and SVHN as near- and far-OOD datasets, with CIFAR-10 as the in-distribution dataset. We used the AUROC, DTACC, and AUPR to evaluate the performance. DTACC refers to the highest probability of classification across various thresholds. AUPR measures the performance in a data-imbalanced scenario, and AUIN and AUOUT denote the AUPR value when in- or out-of-distribution samples are positive.
MEDAF can well handle near-OOD samples. Under the settings of near-OOD and far-OOD, the model requires to distinguish between samples with slight or significant differences with in-distribution data. Therefore, the former has stronger requirements for the discriminative ability of model and higher difficulty. Results in Table 2 show that MEDAF achieves comparable performance with SOTA methods. It is worth noting that MEDAF exhibits superior capabilities when dealing with near-OOD task, demonstrating it can effectively reject samples similar to in-distribution samples, thereby having greater practical significance.
Open Set Recognition
To evaluate the model’s ability to classify on closed-set and detect samples in the open space, we conducted a class classification experiment.
Following the protocol introduced by (Yoshihashi et al. 2019), we used the entire CIFAR10 as the knowns and use processed images derived from LSUN (Yu et al. 2015) or ImageNet (Deng et al. 2009) as unknown samples. We adopted the macro-averaged F1-score as the metric, calculated by averaging the F1-scores of classes.
MEDAF can accurately identify both known and unknown samples. Results in Table 3 demonstrate that, compared to recently proposed methods, we improve the macro-F1 up to 6.7%. When faced with different unknown samples, MEDAF has stable classification performance, thus validating the effectiveness of the design in enhancing the distinguishing capability.
| Gating | Acc. | IMGN-R | IMGN-F | LSUN-R | LSUN-F | |
|---|---|---|---|---|---|---|
| - | - | 0.936 | 0.944 | 0.915 | 0.952 | 0.901 |
| ✓ | - | 0.950 | 0.977 | 0.951 | 0.987 | 0.946 |
| ✓ | ✓ | 0.954 | 0.983 | 0.953 | 0.990 | 0.950 |
Ablation Study
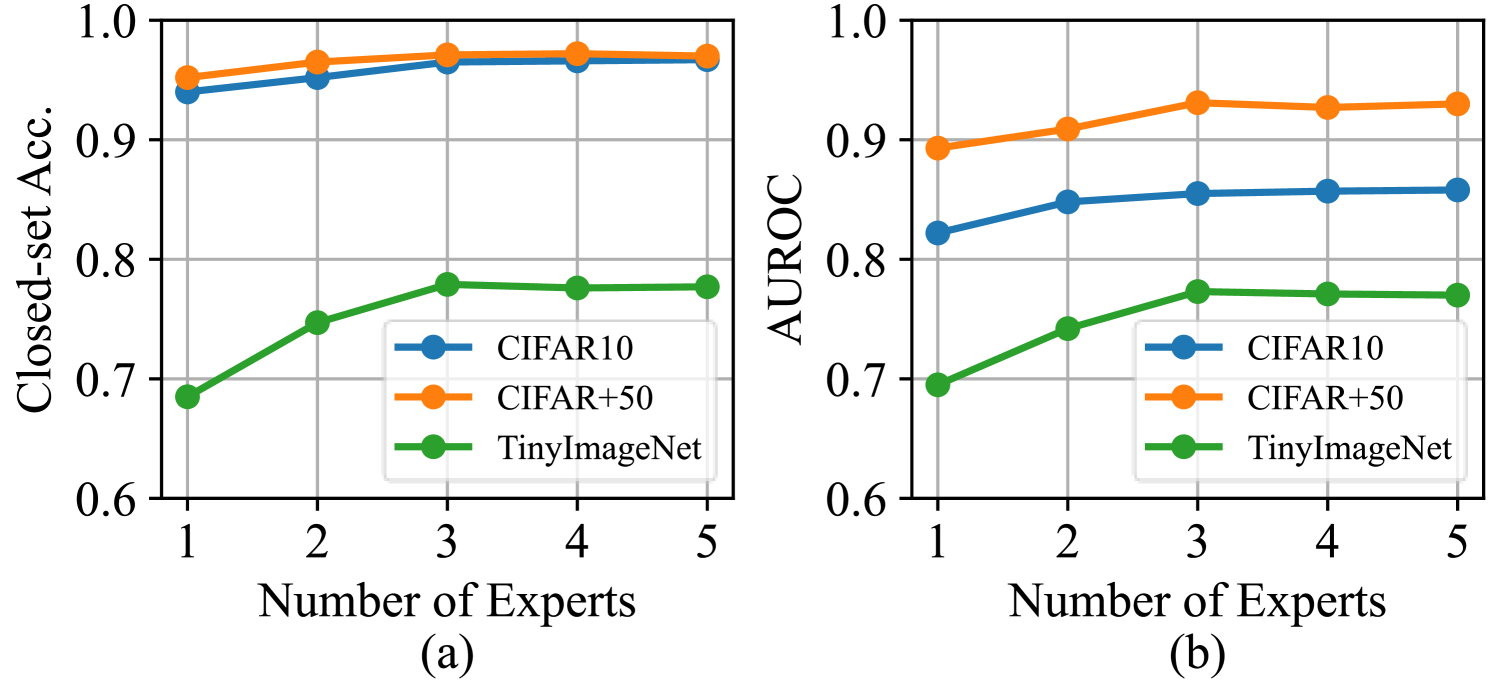
Fusion on a few experts can achieve outstanding performance.
As shown in Figure 2, we tested the closed-set classification accuracy and AUROC with different expert numbers. We found that the performance is initially better with more experts but then stabilizes or decreases, which indicates that expanding the model structure has diminishing returns, given the ability to extract comprehensive features.
Diverse representations and adaptive weighting are both beneficial for OSR.
We conducted ablation experiments on the gating network and diversity loss, which helped the model explore and fuse diverse features. We used CIFAR10 as the known dataset, while variations of LSUN and ImageNet as the unknown datasets. Results in Table 4 demonstrate that the gating network improves the performance of the model compared to using prediction from a single expert or a simple combination. Moreover, the diversity loss effectively enhances the model’s ability in both known class classification and unknown class detection compared to the baseline.
| Method | AUROC | TNR@TPR95 | DTACC |
|---|---|---|---|
| Softmax | 0.797 | 0.448 | 0.735 |
| GCPL | 0.823 | - | - |
| ARPL | 0.836 | 0.486 | 0.782 |
| MEDAF | 0.928 | 0.583 | 0.867 |
| Method | CIFAR10 | CIFAR100 | Tiny-ImageNet |
|---|---|---|---|
| Plain CNN | 0.940 | 0.716 | 0.637 |
| ARPL | 0.941 | 0.721 | 0.657 |
| ConOSR | 0.946 | 0.730 | 0.661 |
| MEDAF | 0.954 | 0.770 | 0.706 |
Further Analysis
Large-Scale Benchmark.
To evaluate the scalability of different methods, we conducted experiments on ImageNet 1k (Russakovsky et al. 2015). We selected the first 100 classes as known classes, and the remaining 900 are unknown classes. Experimental results are recorded in Table 5. MEDAF operates effectively even in challenging scenarios where more unknown samples appear. Furthermore, with these classes requiring detailed differentiation, MEDAF still has outstanding closed-set accuracy.
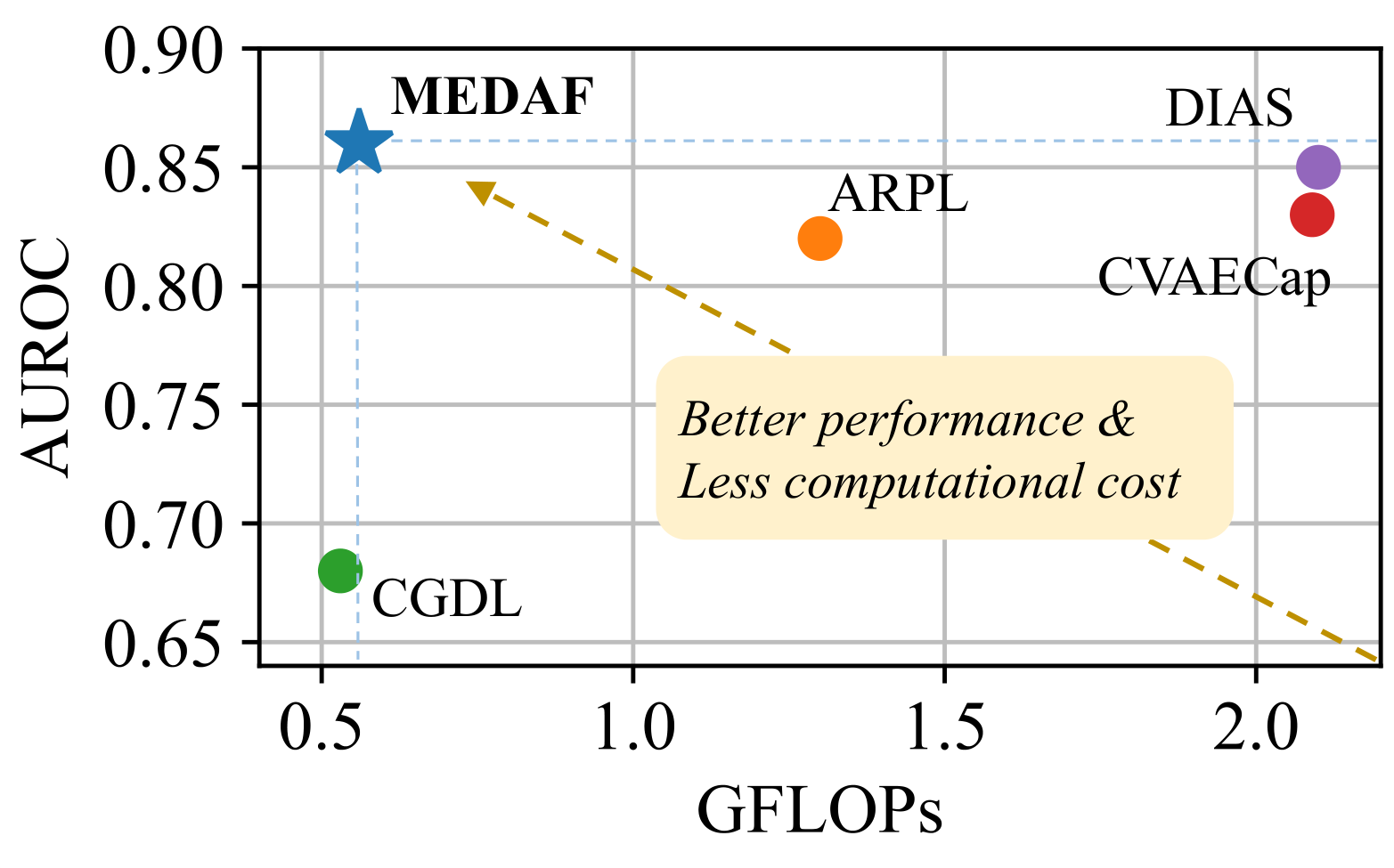
Efficiency.
We compared the computational cost of MEDAF and other methods on CIFAR10. Figure 3 clearly shows that MEDAF achieves the best performance with little cost. By contrast, most generative models have high GFLOPs, which verifies that they are computationally expensive and difficult to scale to large-scale tasks.
Closed-Set Accuracy.
Following the setting in (Xu, Shen, and Zhao 2023), we trained the models on CIFAR10, CIFAR100, and the first 100 classes of TinyImagenet to test their closed-set accuracy. Table 6 shows that MEDAF significantly outperforms other methods, especially when the number of classes and task difficulty increases, demonstrating great potential in both closed and open scenarios.

Visualizations.
Figure 4 shows attention visualizations of the baseline method (plain classification model) and the proposed MEDAF. It can be observed that the attention regions are notably more precise and comprehensive when compared to those of a plain classification model. MEDAF learns more diverse features, yielding effective unknown detection as well as robust known recognition.
Conclusion
In this paper, we analyzed the challenges OSR tasks and found that propose a novel method called Multi-Expert Diverse Attention Fusion (MEDAF). The key insight is that diverse representations that contain supplementary representations in addition to basic ones learned by baselines can effectively reduce the open space risk in OSR. To achieve the goal, MEDAF uses an architecture of multiple experts that share shallow layers while having expert-independent layers. An attention diversity regularization loss is proposed to ensure the learned attention map of each expert is mutually different. By adaptively fusing the logits learned by each expert with a feature-based score function, MEDAF can accurately identify and reject unknown samples. Experiments on both standard and large-scale benchmarks show that MEDAF significantly outperforms other methods with little computational cost.
References
- Bendale and Boult (2016) Bendale, A.; and Boult, T. E. 2016. Towards Open Set Deep Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1563–1572.
- Chen et al. (2022) Chen, G.; Peng, P.; Wang, X.; and Tian, Y. 2022. Adversarial Reciprocal Points Learning for Open Set Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(11): 8065–8081.
- Chen et al. (2020) Chen, G.; Qiao, L.; Shi, Y.; Peng, P.; Li, J.; Huang, T.; Pu, S.; and Tian, Y. 2020. Learning open set network with discriminative reciprocal points. In Proceedings of the European Conference on Computer Vision, 507–522.
- Cover and Thomas (2012) Cover, T. M.; and Thomas, J. A. 2012. Elements of Information Theory. John Wiley & Sons.
- Deng et al. (2009) Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; and Fei-Fei, L. 2009. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 248–255.
- Geirhos et al. (2020) Geirhos, R.; Jacobsen, J.-H.; Michaelis, C.; Zemel, R.; Brendel, W.; Bethge, M.; and Wichmann, F. A. 2020. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11): 665–673.
- Goodfellow et al. (2014) Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; and Bengio, Y. 2014. Generative Adversarial Nets. In Proceedings of the Conference on Neural Information Processing Systems, 2672–2680.
- Guo et al. (2021) Guo, Y.; Camporese, G.; Yang, W.; Sperduti, A.; and Ballan, L. 2021. Conditional Variational Capsule Network for Open Set Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 103–111.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 770–778.
- Hendrycks and Gimpel (2016) Hendrycks, D.; and Gimpel, K. 2016. A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks. In Proceedings of the International Conference on Learning Representations, 1–12.
- Huang et al. (2023) Huang, H.; Wang, Y.; Hu, Q.; and Cheng, M.-M. 2023. Class-Specific Semantic Reconstruction for Open Set Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4): 4214–4228.
- Kong and Ramanan (2022) Kong, S.; and Ramanan, D. 2022. OpenGAN: Open-Set Recognition Via Open Data Generation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1–10.
- Krizhevsky (2009) Krizhevsky, A. 2009. Learning Multiple Layers of Features from Tiny Images. Technical report.
- Liu et al. (2023) Liu, C.; Yang, C.; Qin, H.-B.; Zhu, X.; Liu, C.-L.; and Yin, X.-C. 2023. Towards open-set text recognition via label-to-prototype learning. Pattern Recognition, 134: 109109.
- Markman (1979) Markman, E. M. 1979. Realizing that you don’t understand: Elementary school children’s awareness of inconsistencies. Child development, 643–655.
- Moon et al. (2022) Moon, W.; Park, J.; Seong, H. S.; Cho, C.-H.; and Heo, J.-P. 2022. Difficulty-aware simulator for open set recognition. In Proceedings of the European Conference on Computer Vision, 365–381.
- Neal et al. (2018) Neal, L.; Olson, M. L.; Fern, X. Z.; Wong, W.-K.; and Li, F. 2018. Open Set Learning with Counterfactual Images. In Proceedings of the European Conference on Computer Vision, 620–635.
- Netzer et al. (2011) Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; and Ng, A. Y. 2011. Reading Digits in Natural Images with Unsupervised Feature Learning. In Neural Information Processing Systems, 1–9.
- Oza and Patel (2019) Oza, P.; and Patel, V. M. 2019. C2AE: Class Conditioned Auto-Encoder for Open-Set Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2302–2311.
- Pouransari and Ghili (2014) Pouransari, H.; and Ghili, S. 2014. Tiny ImageNet Visual Recognition Challenge. CS 231N.
- Russakovsky et al. (2015) Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; Berg, A. C.; and Fei-Fei, L. 2015. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision, 115(3): 211–252.
- Scheirer et al. (2013) Scheirer, W. J.; de Rezende Rocha, A.; Sapkota, A.; and Boult, T. E. 2013. Toward Open Set Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(7): 1757–1772.
- Shazeer et al. (2017) Shazeer, N.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q. V.; Hinton, G. E.; and Dean, J. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In Proceedings of the International Conference on Learning Representations, 1–12.
- Sun et al. (2020) Sun, X.; Yang, Z.; Zhang, C.; Ling, K.-V.; and Peng, G. 2020. Conditional Gaussian Distribution Learning for Open Set Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13477–13486.
- Vaze et al. (2022) Vaze, S.; Han, K.; Vedaldi, A.; and Zisserman, A. 2022. Open-Set Recognition: A Good Closed-Set Classifier is All You Need. In Proceedings of the International Conference on Learning Representations, 1–14.
- Wang and Shen (2018) Wang, W.; and Shen, J. 2018. Deep Visual Attention Prediction. IEEE Transactions on Image Processing, 27(5): 2368–2378.
- Xu, Shen, and Zhao (2023) Xu, B.; Shen, F.; and Zhao, J. 2023. Contrastive Open Set Recognition. In AAAI Conference on Artificial Intelligence, 1–11.
- Yang et al. (2022) Yang, H.-M.; Zhang, X.-Y.; Yin, F.; Yang, Q.; and Liu, C.-L. 2022. Convolutional Prototype Network for Open Set Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(5): 2358–2370.
- Yoshihashi et al. (2019) Yoshihashi, R.; Shao, W.; Kawakami, R.; You, S.; Iida, M.; and Naemura, T. 2019. Classification-reconstruction learning for open-set recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4016–4025.
- Yu et al. (2015) Yu, F.; Zhang, Y.; Song, S.; Seff, A.; and Xiao, J. 2015. LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop. arXiv:1506.03365.
- Zhou et al. (2016) Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; and Torralba, A. 2016. Learning deep features for discriminative localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2921–2929.
- Zhou, Ye, and Zhan (2021) Zhou, D.-W.; Ye, H.-J.; and Zhan, D.-C. 2021. Learning Placeholders for Open-Set Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4399–4408.