Towards Language-Driven Video Inpainting
via Multimodal Large Language Models
Abstract
We introduce a new task – language-driven video inpainting, which uses natural language instructions to guide the inpainting process. This approach overcomes the limitations of traditional video inpainting methods that depend on manually labeled binary masks, a process often tedious and labor-intensive. We present the Remove Objects from Videos by Instructions (ROVI) dataset, containing 5,650 videos and 9,091 inpainting results, to support training and evaluation for this task. We also propose a novel diffusion-based language-driven video inpainting framework, the first end-to-end baseline for this task, integrating Multimodal Large Language Models to understand and execute complex language-based inpainting requests effectively. Our comprehensive results showcase the dataset’s versatility and the model’s effectiveness in various language-instructed inpainting scenarios. We will make datasets, code, and models publicly available.
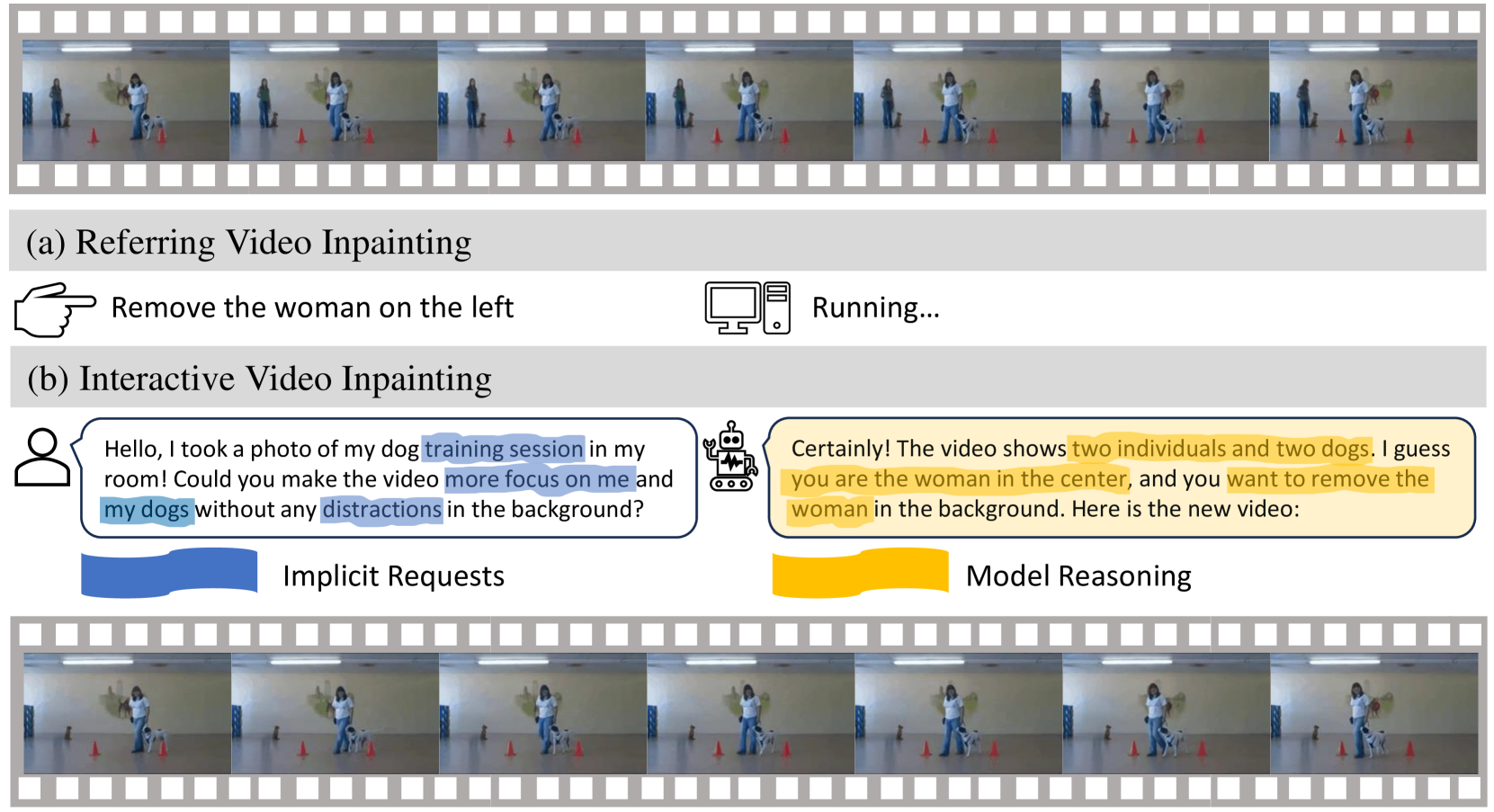
1 Introduction
Video inpainting, a technique for restoring missing or corrupted segments in video frames, finds extensive application in areas such as video completion [4], video restoration [16], and object removal [6]. Despite continuous advancements in enhancing image quality and temporal coherence of inpainting results [46, 11, 22, 66], current methods predominantly depend on manually annotated binary masks to identify restoration areas. This manual process is time-consuming and impractical for long videos. While automatic labeling tools, such as segmentation and object tracking models [59, 55, 61], offer some relief, they often necessitate manual refinement due to imperfect labeling.
Perhaps a more natural way to perform video inpainting is through natural language, as shown in Fig. 1. The task would become much easier if we could leverage natural language descriptions to specify the inpainting areas, like “woman on the left,” thereby preventing the need for pixel-level manual annotations. Importantly, the language-driven setting can benefit from the flexibility of natural language. For example, with richer sentences, one can easily refer to multiple or abstract objects, which is much more effective than labeling masks. Extending from this notion, one could divide the task into two subtasks, namely “Referring Video Inpainting” and “Interactive Video Inpainting.” The former takes simple referring expressions as inputs, and the latter considers more complex conversation-like interactions to accomplish the inpainting task.

To establish a baseline model for the proposed tasks, it is essential to have an appropriate dataset for both training and evaluation. Currently, no publicly available dataset comprises the triplets of original videos, removal expressions, and inpainted videos. In response to this gap, we build a new dataset named the Remove Objects from Videos by Instructions (ROVI) dataset. Specifically, we employ referring object segmentation datasets, which are pre-annotated with object masks and descriptive expressions. These datasets are further augmented with corresponding inpainted videos generated using a state-of-the-art video inpainting model. We find existing referring expressions for interactive video inpainting tasks too simplistic. To address this limitation, we employ Multimodal Large Language Models (MLLMs) [60, 67, 3] to create conversation-like dialogues. These dialogues are designed to simulate real-world scenarios, encompassing user requests and corresponding machine responses. This approach enriches the dataset, making it more representative of the complexity and variability found in practical video inpainting applications.
In addition to the dataset, we introduce the first end-to-end baseline model, Language-Driven Video Inpainting (LGVI), for the proposed tasks. Our model is built upon diffusion-based generative models. In particular, we inflate the text-to-image (T2I) model to become a text-to-video (T2V) architecture by extending the parameters with an additional temporal dimension. We propose an efficient visual conditioning approach that minimally increases the number of parameters. To further enhance our model’s capabilities for the interactive task, we extend the LGVI framework to LGVI-I (Interactive). This extension incorporates an MLLM specifically designed to process and understand user requests phrased in a conversation-like format. The LGVI-I model is trained in an end-to-end manner. This interactive architecture enables the system to interpret complex instructions accurately. As a result, it can produce appropriate inpainting results and relevant responses within the conversational context, thus paving the way for more intuitive and flexible user interactions with interactive video inpainting systems.
In summary, our key contributions are as follows:
-
•
We introduce a novel language-driven video inpainting task, significantly reducing reliance on human-labeled masks in video inpainting applications. This task includes two distinct sub-tasks: referring video inpainting and interactive video inpainting.
-
•
We propose a dataset to facilitate training and evaluation for the proposed tasks. This dataset is the first of its kind, containing triplets of original videos, removal expressions, and inpainted videos, offering a unique resource for research in this domain.
-
•
We present a diffusion-based architecture, LGVI, as a baseline model for the proposed task. We show how one could leverage MLLMs to improve language guidance for interactive video inpainting. To our knowledge, it is the first model to perform end-to-end language-driven video inpainting.
| Dataset | Task | Scene | #Images | #Videos | #Frames | Annotations | #Objects | #Exprs | #Chats | Source | |||
| mask | expr | inpaint | chat | ||||||||||
| Places [65] | II | Buildings & Places | 10,624,928 | - | - | - | - | - | - | ||||
| CelebA [28] | II | Human Face | 202,599 | - | - | - | - | - | - | ||||
| YouTube-VOS [54] | VI | General | - | 4,453 | 197,272 | 7,755 | - | - | YouTube | ||||
| DAVIS [36] | VI | General | - | 50 | 3,455 | 3,455 | - | - | - | ||||
| GQA-Inpaint [56] | LII | General | 49,311 | - | - | 97,854 | 107,252 | - | GQA [12] | ||||
| ROVI | LVI + IVI | General | - | 5,650 | 247,018 | 9,091 | 12,534 | 9,091 | Refer-YouTube-VOS [42] + A2D-Sentences [7] | ||||

2 Related Work
Video inpainting. Video inpainting is a technique aimed at restoring or filling missing or corrupted parts in a video plausibly. While related to image inpainting methods [35, 58, 23, 24, 19, 20], video inpainting techniques [26, 4, 46, 11, 22, 62, 17, 66] extend the problem to the more complex domain of moving visuals. This technique can be applied for various applications, such as object removal, visual restoration, and completion. With the advent of deep learning, visual inpainting networks usually employ convolutional neural networks (CNNs) [58, 46, 11] and generative adversarial networks (GANs) [35, 23, 24, 19]. Recent works also apply vision Transformers [5, 39, 57, 32, 29] to enhance the global interaction among visual features [20, 22, 62, 17, 66]. State-of-the-art methods show strong abilities in restoring missing parts and removing objects. Most of these works require the input of a binary mask to define the restoring area [22, 20, 23, 26, 62, 4]. However, the generation of object-like masks, particularly for lengthy videos, poses a significant and labor-intensive challenge,
Language-driven visual editing. Diffusion-based text-to-image generation models [40, 33, 41, 38, 43] show excellent abilities in generating images and videos following text guidance. Recent studies also achieve image editing [9, 1, 31, 44, 63], image segmentation [49, 51, 50, 21] and video editing [52, 13] with DMs. Among these, Prompt2Prompt [9] manipulates the cross-attention maps within the model to enable various editing operations such as object modification, addition, and style transfer. InstructPix2Pix [1] leverages this approach to create an image editing dataset. Similarly, Tune-A-Video [52] proposes a training-free architecture to edit videos by language references. However, these works are intended for general visual editing. When applied to more specific challenges, such as language-driven video inpainting, they tend to yield suboptimal results. Figure 2 shows two examples where these models produce inferior results when instructed to remove objects. A few works have explored the image inpainting task using DMs. Repaint [30] still takes the image and mask as input and lets the DM restore the original image. SmartBrush [53] takes mask and text as input to guide a region-controlled generation on the masked area, which aims to generate new concepts rather than remove the object. Recently, Inst-Inpaint [56] proposes a method to perform object removal on images based on the language descriptions. Despite its innovative approach, Inst-Inpaint’s training samples are constrained by a lack of interactive expressions and video resources, which limits its practical effectiveness in complex scenarios.
Multi-Modal Large Language Models. Large language models (LLMs) have demonstrated exceptional performance across a variety of text-based tasks and applications [3, 2, 34, 45, 18, 8]. Recent works extend the capabilities of LLMs to include image processing and computer vision. A notable example is LLaVA [25], which translates image tokens into a language feature space, thereby transforming the fine-tuned model into an MLLM. This adaptation enables MLLMs to interpret and understand visual content. Subsequent research uses MLLMs in diverse applications, including visual reasoning, object detection, and segmentation [25, 67, 37, 60, 18, 8]. To the best of our knowledge, this study is the first to integrate MLLMs into the domain of language-driven video inpainting.
3 ROVI Dataset
3.1 Comparing with Existing Datasets
Table 1 summarizes the differences between ROVI and related datasets. In image and video inpainting research, prevalent training and evaluation datasets mainly include vision-centric ones like Places [65], CelebA [28], YouTube-VOS [54], and DAVIS [36], without human annotations. These datasets typically employ random masking in training to simulate missing areas for inpainting. However, for object removal tasks, specifically labeled masks are essential. While YouTube-VOS provides object masks, it lacks corresponding inpainting ground truths. The GQA-Inpaint dataset [56], although rich in object expressions and inpainting results, is limited to image data and does not accommodate video or interactive contexts. Our ROVI dataset addresses these limitations with comprehensive annotations covering a wide array of regions, including object masks, referring expressions, inpainting results, and conversation-like dialogues. Unlike Places and CelebA, which focus on specific image categories like buildings or faces, ROVI encompasses a broader spectrum of general scenes, making it more adaptable for diverse inpainting applications.
3.2 Dataset Statistics
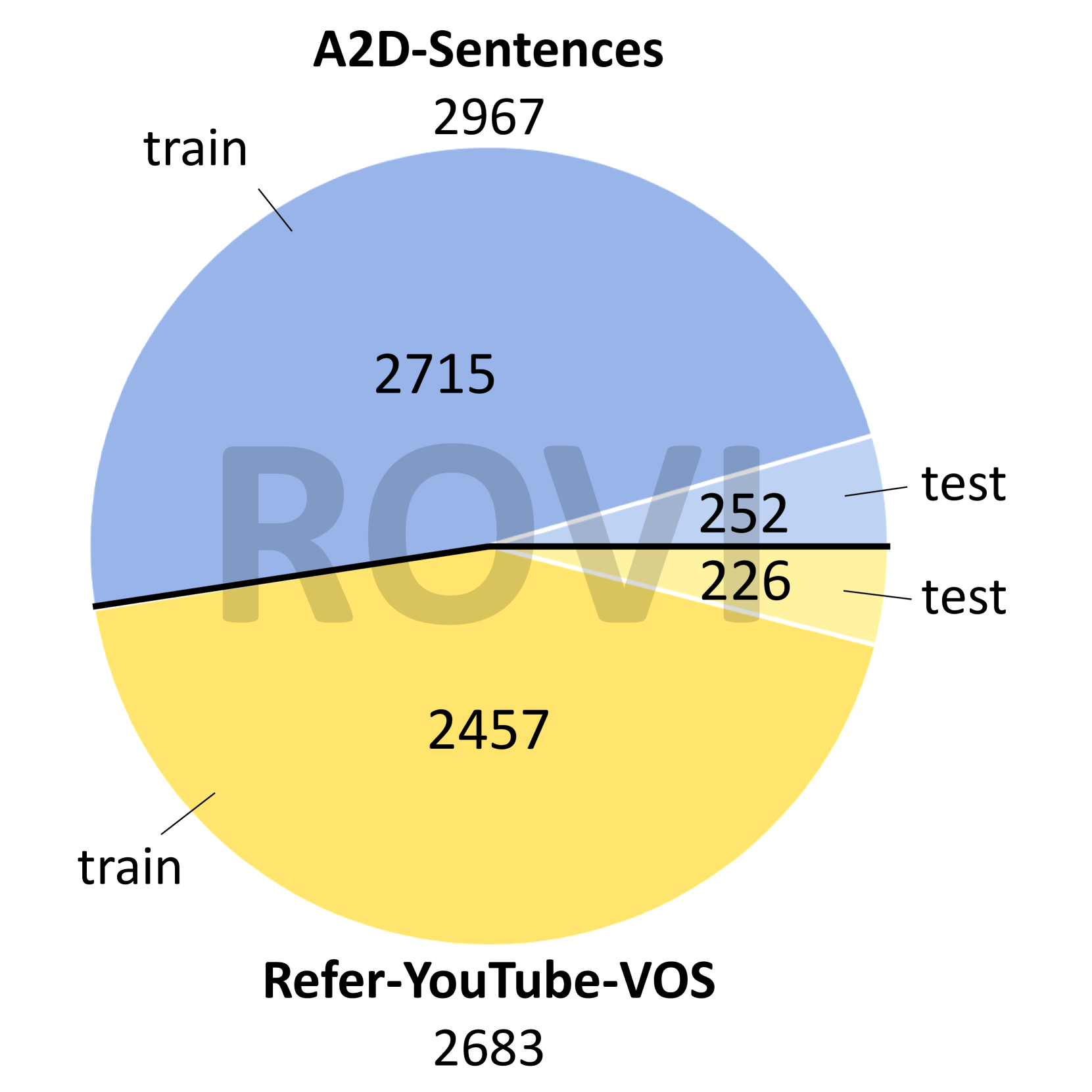
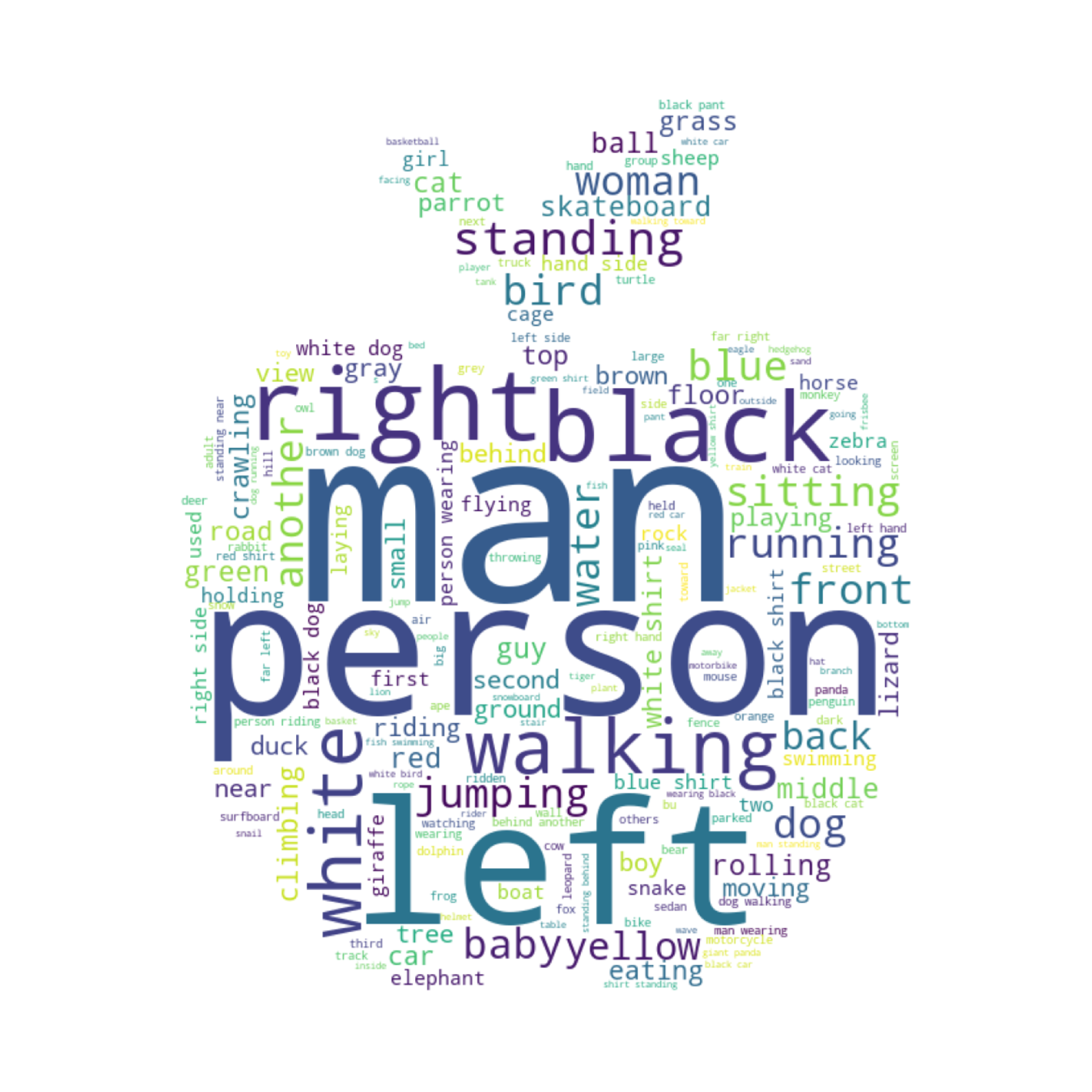
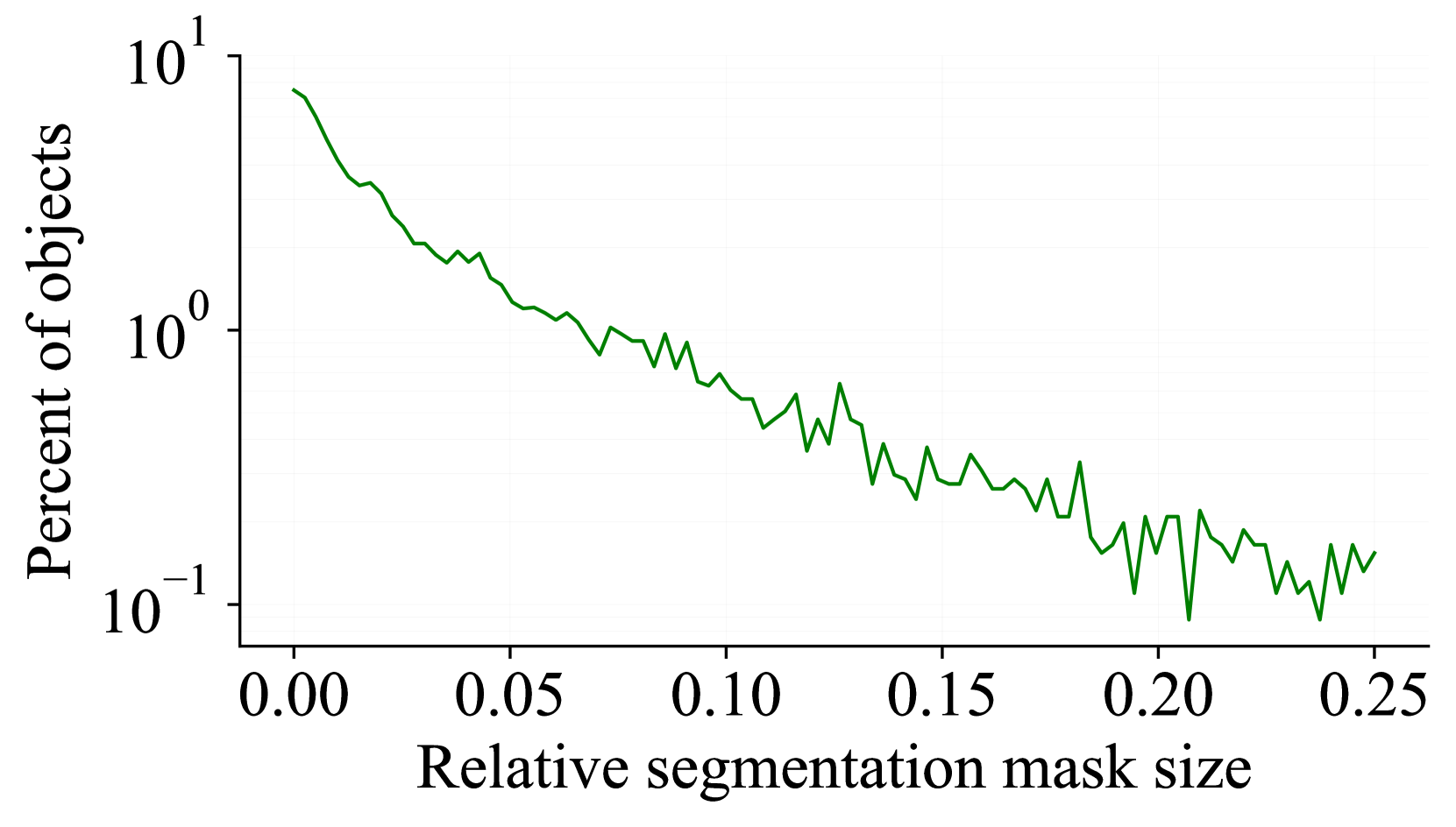
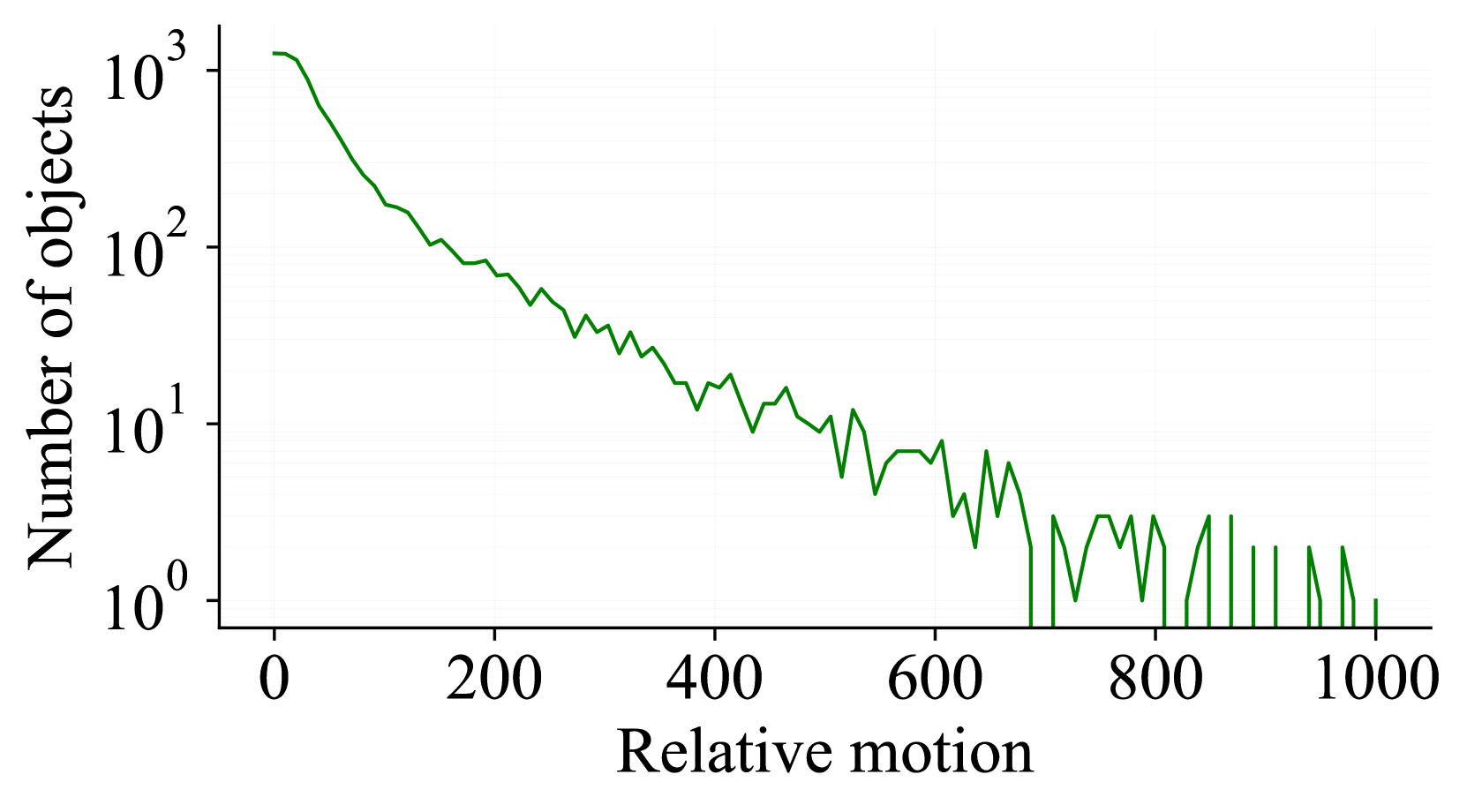
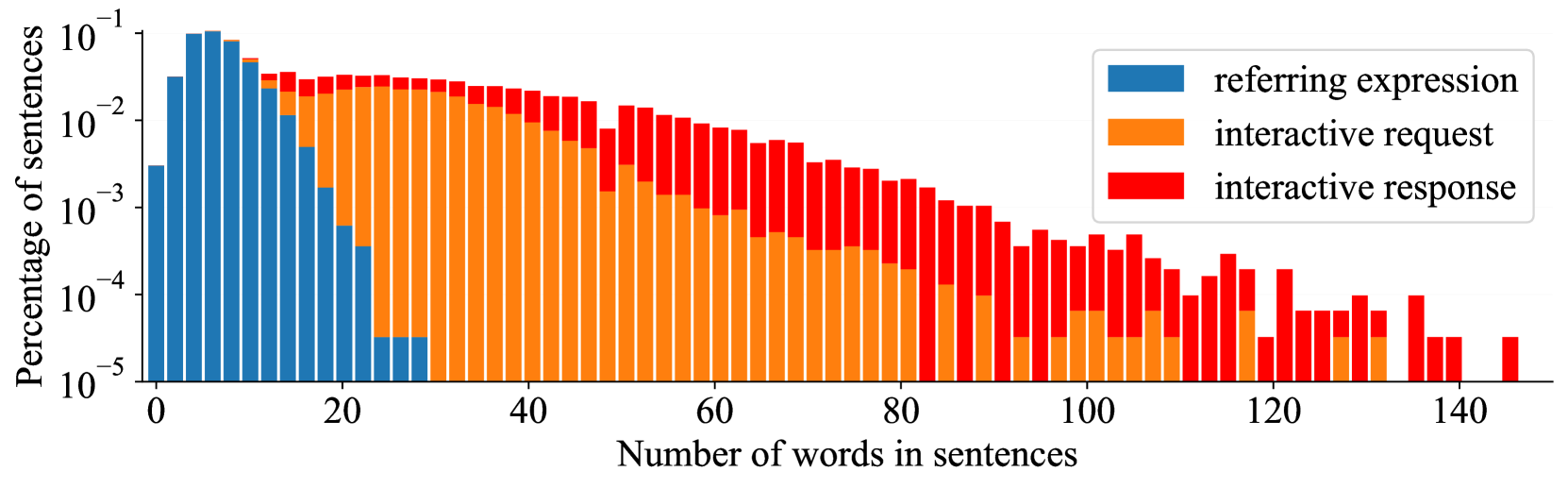
Figure 3 presents a comprehensive statistical analysis of the ROVI dataset. The dataset encompasses 2,967 videos from A2D-Sentences and 2,683 videos from Refer-YouTube-VOS, divided into train and test splits, as shown in Fig. 2(a). Figure 2(b) illustrates the diversity of referring expressions with word clouds. Figure 2(c) shows several examples of our dataset’s interactive requests and responses, showing the diversity and complexity of the dialogues. Figure 2(d) details the relative sizes of segmentation masks (mask area divided by image area). We drop objects with a relative size larger than 0.25 because the inpainting results for large objects usually have worse qualities. Figure 2(e) analyzes the distribution of object motion. Figure 2(f) delivers a histogram of sentence lengths within the dataset.
3.3 Dataset Construction Pipeline
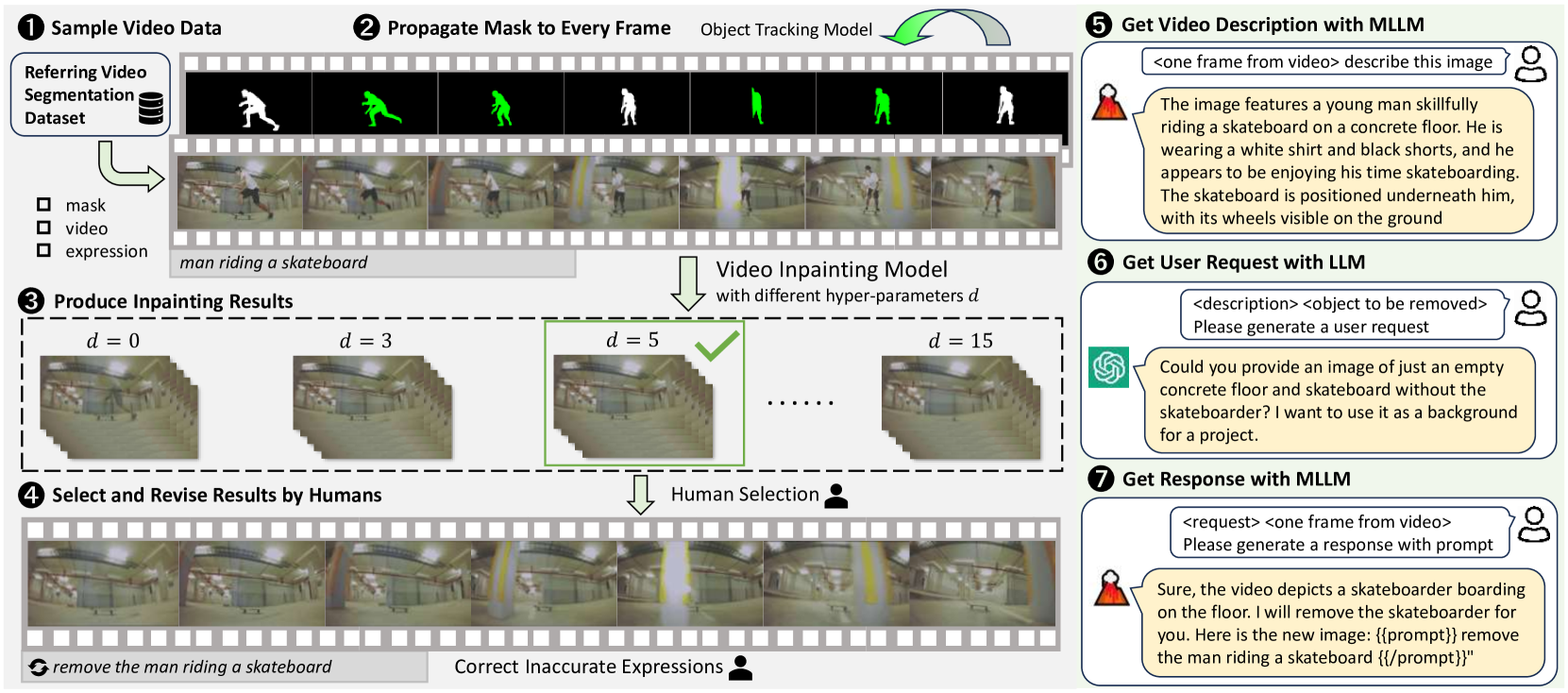
Video data selection. As depicted in Fig. 4, we have chosen referring video object segmentation datasets for the source of video data. Referring video object segmentation aims to segment an object referred to by a given language description. These datasets have pre-annotated object masks and descriptive expressions, making them well-suited for the proposed task. Specifically, we select Refer-YouTube-VOS [42] and A2D-Sentences [7] as our data sources.
Annotation pipeline. We use a video inpainting model to generate the inpainting ground truth. Specifically, we choose EFGVI [22], a state-of-the-art video inpainting model, to produce the inpainting results. This model, trained on video data, guarantees temporal consistency in the inpainting results.
To further ensure the ground truth is of high quality, we incorporate a human selection process on the hyperparameter of the inpainting method. Specifically, the input mask can be expanded with different pixel sizes, denoted as . The bigger the is, the larger the input mask is developed so that it may cover the whole object. The best value varies through objects, causing an unstable performance in the inpainted videos if set to a fixed value. Therefore, throughout the data generation process, we experiment with various hyperparameters to generate multiple results for each object and involve human annotators to select the best result. More details are provided in Appendix A.
For interactive annotations, we need to collect expressions through chat-style conversations. Unlike the straightforward “remove” sentences, these interactive requests should be implicit, necessitating the model to discern the user’s underlying intent. Rather than relying solely on human annotators to articulate these requests, we explore a more automated approach: we employ LLMs and MLLMs to simulate a human user and generate potential requests and responses. We propose a multi-step approach with details illustrated in Fig. 4. By employing this dual-faceted annotation pipeline, the ROVI dataset is enabled to handle complex user requests.

4 Methodology
In this section, we introduce our Language-Driven Video Inpainting framework (LGVI) and the MLLM-enhanced LGVI-I (Interactive) architecture.
4.1 LGVI
The LGVI framework is shown in Fig. 5, which is built on the architecture of Stable Diffusion [40]. To extend the framework to video inputs, we perform temporal inflation by reorganizing the network’s structure following [52, 43]. For a batch video input with frames, denoted as , where is the batch size, and are the size, we transpose the tensor to . This transformation converts the input into a 4-dimensional image batch input format. The pre-trained 2D networks can process video clips as they are separate images. Additionally, we introduce a parameter-efficient Temporal Attention module positioned between the cross-attention and FFN network. Given latent feature , where is the length of patched visual tokens, and is the channel size, we transpose it to . The Temporal Attention module is formulated as follows:
| (1) | ||||
where , , and are learnable matrices to project the inputs to query, key, and value. The computational complexity of the Temporal Attention module is , while spatial self-attention has a complexity of . Considering . The Temporal Attention module is a time-efficient tool to ensure the consistency of output video sequences.
Diffusion models learn to gradually remove noises in a noised video. During training, the target video is added with noises to be the start point of the noised video. Besides the noised target video input, LGVI also takes the original video as a control signal input. Concretely, we encode the original video to the latent space and concatenate its feature with the noised target video in the channel dimension. Note that the noise is added only to the target video latent, and during testing, the noised target video is a randomly generated noise.
| (2) | ||||
where is the pre-trained VAE encoder, is the sampled timestamp, and are convolutional layers with kernels to transfer the latent codes into U-Net feature dimensions. The initial weights of are set to all-zero. This technique allows the model to add video condition guidance during training. Due to mask annotations in the ROVI dataset, we can leverage masks as an additional supervision signal in our LGVI framework. Concretely, we implement a mask decoder to predict the object’s mask in the video that needs to be inpainted or removed. This decoder uses the outputs from U-Net up-blocks and consists of convolutional and temporal convolutional layers. The use of mask supervision enables the model to focus on the region described in the natural language input, thereby facilitating precise and targeted inpainting. The effectiveness of mask supervision can be seen in Sec. 5. The training objective of LGVI is:
| (3) | ||||
where and are the diffusion model training objective and mask loss, respectively; is the language guidance features from the referring expressions; is the mask prediction and is the ground truth mask. The parameters and are loss weights to balance training.
4.2 LGVI-I with MLLM
In the interactive video inpainting task, models are expected to extract valuable information from complex conversations. To overcome this problem, we propose incorporating MLLMs to extend the LGVI from work to LGVI-I (Interactive). MLLMs have demonstrated strong capabilities in visual comprehension and multimodal reasoning, making them well-suited for our proposed interactive video inpainting task. As shown in Fig. 5, the MLLM takes both the image frame and the chat-style user request as inputs, generating the language response and a pair of special indicators: PROMPT and /PROMPT. The hidden states of the last layer between these two indicators are then passed through an MM head, implemented as a two-layer linear layer with activation functions. The transformed features are fed to the cross-attention module to guide the U-Net inpainting process. Mathematically, given the input video and user request , the computation pipeline of the MLLM can be summarized as follows:
| (4) | ||||
where is the language token embedding and is a pre-trained image backbone to extract image features. is a linear layer that transforms image features into language token space. is the last layer’s hidden states of the MLLM. is the predicted language token distribution through the LM head. is the weights of the LM head. Among the predicted words, we use function to find the PROMPT and /PROMPT indicator and extract the hidden states that lie between these two indicators. is the weights of MM head. The MM head transfers the selected tokens into , which is then fed into the U-Net cross-attention module. In this process, serves as vision-aware language guidance for the inpainting process. The training objective of LGVI-I is:
| (5) | ||||
where is the MLLM-enhanced language condition, is language modeling loss, implemented as the Cross-Entropy Loss, is the ground truth sentence, and is the loss weight for language modeling loss. By integrating an MLLM into the LGVI framework, the system achieves a higher level of user interactivity. This enables users to guide the visual inpainting process with interactive language instructions, thus establishing a more user-friendly and accessible approach for the interactive video inpainting task.
| Method | PSNR | SSIM | VFID | |
|---|---|---|---|---|
| Image Models | ||||
| InstructPix2Pix [1] | 18.12 | 0.600 | 0.361 | 1.343 |
| Inst-Inpaint [56] | 19.00 | 0.896 | 0.310 | 1.206 |
| MagicBrush [63] | 20.39 | 0.725 | 0.310 | 0.934 |
| Multi-Stage Video Model | ||||
| Inpaint Anything* [59] | 22.84 | 0.728 | 0.283 | 0.874 |
| One-Stage Video Model | ||||
| LGVI (Ours) | 22.85 | 0.756 | 0.308 | 0.901 |
| Method | PSNR | SSIM | VFID | |
|---|---|---|---|---|
| Image Models | ||||
| InstructPix2Pix [1] | 16.53(-1.59) | 0.558(-0.042) | 0.391(-0.003) | 1.789(-0.446) |
| Inst-Inpaint [56] | 18.96(-0.04) | 0.702 | 0.314(-0.004) | 1.047 |
| MagicBrush [63] | 20.46 | 0.728 | 0.311(-0.001) | 0.901 |
| Multi-Stage Video Model | ||||
| IA* [59] | 20.64(-2.20) | 0.664(-0.064) | 0.312(-0.029) | 1.182(-0.308) |
| One-Stage Video Model | ||||
| LGVI (Ours) | 20.70(-2.15) | 0.707(-0.049) | 0.332(-0.024) | 1.191(-0.290) |
| MLLM-Enhanced Two-Stage Model | ||||
| MB + MLLM | 20.37 | 0.726 | 0.313 | 1.004 |
| IA* + MLLM | 21.37 | 0.722 | 0.291 | 0.875 |
| LGVI + MLLM | 21.45 | 0.738 | 0.311 | 0.923 |
| MLLM-Enhanced End-to-End Model | ||||
| LGVI-I (Ours) | 22.24(+1.54) | 0.732(+0.025) | 0.299(+0.033) | 0.867(+0.324) |




5 Experiments
5.1 Settings
Datasets and metrics. We use the ROVI dataset test set for both the referring video inpainting and interactive video inpainting tasks. The test set contains 478 videos and 758 objects, each equipped with one referring expression and one interactive expression. During the training of our models, we incorporate a referring image inpainting dataset, GQA-Inpaint [56], to enrich the data vocabulary. We follow video inpainting works [26, 22, 66, 62] to use PSNR and SSIM [48] to assess the statistical similarity between predicted results and ground truth. Additionally, we use VIFD [47] to measure the perceptual similarities. To assess the temporal consistency and smoothness of the generated videos, we also apply the metric [15].
Baselines. For the baselines, we select three language-driven image editing methods: InstructPix2Pix [1], Inst-Inpaint [56], and MagicBrush [63]. It is worth noting that InstructPix2Pix and MagicBrush are pre-trained on extensive image editing datasets. Inst-Inpaint is proposed to perform referring image inpainting on images. We also compare with Inpaint Anything, a multi-stage method for one-click video inpainting. It uses Segment Anything [14] and OSTrack [55] to produce segmentation masks based on user click, followed by inpainting the masked area using inpainting models [61]. We implement Inpaint Anything*, which facilities Inpaint Anything [59] with GroundingDINO [27], enabling it to process language inputs.
Implementation details. We initialize the U-Net weights from MagicBrush [63]. The newly introduced modules are trained from scratch. During training, we sample video and image data at a ratio of . For the MLLM, we adopt LLaVA-7B [25]. The learning rates are 3e-5, 1e-4, and 1e-4 for U-Net, mask decoder, and tuned parameters in MLLM, respectively. The loss weights are set to , , . These weights differ significantly due to the different types of losses they represent. The input and output video sizes are set to 512 320, and the video length is 24. For LGVI, we train 50 epochs on the ROVI dataset with a batch size of 32 for videos and 768 for images. For LGVI-I, we load the LGVI checkpoint and fine-tune it for 50 epochs under the same batch size. All experiments are carried out on 8 NVIDIA A100 GPUs.
5.2 Referring Video Inpainting
Quatitative results. We report quantitative results on the referring video inpainting task. Compared with baseline models, our model is the first one-stage language-driven video inpainting model. As shown in Tab. 2, our model outperforms MagicBrush [63] in all metrics and achieves on-par results with Inpaint Anything* [59], even if Inpaint Anything* uses a mask-based inpainting model [61]. The results demonstrate the effectiveness of our model.
Qualitative results. Figure 6 shows qualitative results. We compare with MagicBrush [63], a robust generalized language-driven image editing model. In the first example, where the language refers to the cat on the right, the MagicBrush model removes all the cats in the scene, while our model successfully inpaints the right cat. In the second example, the referring expression becomes more complex. MagicBrush struggles to identify the object requiring inpainting and removes the wrong object (the balls) in the last frame. In contrast, our model generates a plausible output, demonstrating its superior performance in handling complex language-driven inpainting tasks. Furthermore, in Fig. 7, we compare with Inpaint Anything* on sentences referring to multiple objects or nonexistent objects. Inpaint Anything is driven by a simple combination of referring segmentation and video inpainting models. Thus, it is fixed to produce one mask for each sentence. When referring to multiple or nonexistent objects, it outputs inaccurate results, while our model produces the correct output. This demonstrates the robustness of the language-driven setting.
5.3 Interactive Video Inpainting
Quatitative results. We report the interactive video inpainting task results in Tab. 3. As shown in the top 5 rows, when the models are trained using referring expressions, their performance drops correspondingly in this task. This is intuitive because interactive expressions are much longer and more implicit. For the MLLM-Enhanced Two-Stage Models, we combine the baseline models with an MLLM in a zero-shot manner. The interactive inputs are transferred into shorter referring expressions by simply prompting the MLLM. These models exhibit improved performances. Our LGVI-I model achieves the highest performance, demonstrating the effectiveness of the proposed architecture.
Qualitative results. Figure 8 presents examples of the interactive video inpainting task. The user requests pose a significant challenge and complexity for the baseline models to comprehend. In particular, Inpaint Anything* predicts incorrect masks, leading to inaccurate results. Similarly, other diffusion-based models struggle to interpret the users’ intentions accurately, resulting in less satisfactory outcomes. In contrast, our LGVI-I model, which harnesses the power of MLLM, consistently delivers the best performance in these challenging scenarios. This underscores the superiority of our proposed approach.
5.4 Ablation Study
We conduct three ablations involving mask supervision, fine-tuning the entire U-Net, and joint training with images.
The benefit of mask supervision. The models without mask supervision rely solely on the inpainting ground for guidance, lacking an explicit signal to direct the inpainting area. As shown in Fig. 9, the running man remains present in all frames. Notably, although we utilize mask annotation in the ROVI dataset for training, the LGVI framework does not need mask input during inference.
The benefit of fine-tuning the whole U-Net. We fine-tune the whole U-Net instead of only adjusting the parameters of new modules. As shown in Fig. 9, limiting the fine-tuning to only the new modules hinders training convergence, and the model struggles to output expected results. This demonstrates the necessity of tuning the whole model.
The benefit of joint training with images. As shown in Fig. 9, the model without joint training produces outputs with heavier artifacts than ours. This is because enlarging the dataset brings more diversity of objects and scenes to the model. It demonstrates the effectiveness of joint training.
6 Conclusion, Challenges, and Outlook
In this paper, we propose a novel language-driven video inpainting task that uses language to guide inpainting areas. For training and evaluation, we collect a video dataset, namely ROVI. Comprehensive statistics demonstrate the uniqueness and diversity of our dataset, especially the chat-style interactive conversations generated by powerful LLMs and MLLMs. We further propose a diffusion-based baseline model, LGVI. Quantitative and qualitative experimental results show the effectiveness and robustness of our model.
Challenges. (1) Handling Ambiguity in Language Descriptions. Language-driven video inpainting relies heavily on the accuracy and clarity of language inputs. Ambiguities or vagueness in language descriptions can lead to inaccuracies in inpainting results. Developing models that can intelligently handle or clarify ambiguous language inputs is a significant challenge. (2) Real-Time Processing. Video inpainting in a real-time setting, especially with complex language-driven inputs, is computationally demanding. Diffusion-based models also experience the slow inference problem due to the Markov denoising process. Improving the speed and efficiency of these models without compromising accuracy is a crucial challenge. (3) Scalability and Generalization. Another challenge is ensuring that the model generalizes well across various languages and video types. Models might perform well on the dataset they were trained on but struggle with new, unseen data.
Future work. A promising direction is to resolve ambiguities in language inputs, possibly by using contextual clues from the video or previous language inputs. In addition, researching methods to optimize these models for real-time video inpainting, could be valuable for live broadcasting or interactive media. Another important future work is incorporating interactive user feedback mechanisms that allow the system to learn from corrections or preferences indicated by users, thereby improving the accuracy and relevance of the inpainting results over time. See supplementary for more discussions.
Potential social impacts. This technology could potentially boost creative fields such as film-making, advertising, and content creation. It allows for more seamless editing and creative storytelling, enabling creators to modify and enhance their visual narratives easily. It also comes with negative impacts. For example, it can be used in creating misleading or false media and ethical or moral issues.
7 Appendix
Overview. Our supplementary includes the following sections:
-
•
Appendix A. Details for our dataset annotation process.
-
•
Appendix B. Implementation details of the baseline models.
-
•
Appendix C. Quantitative ablation study results.
-
•
Appendix D. More qualitative results of different models.
-
•
Appendix E. The foundations of Latent Diffusion Models and correlation with our model.
-
•
Appendix F. Discussions of limitations and challenges.
Video Demo. We also include the video introduction of our work, which shows the visualization demo.
Appendix A Dataset Annotation Details
A.1 Human Annotation
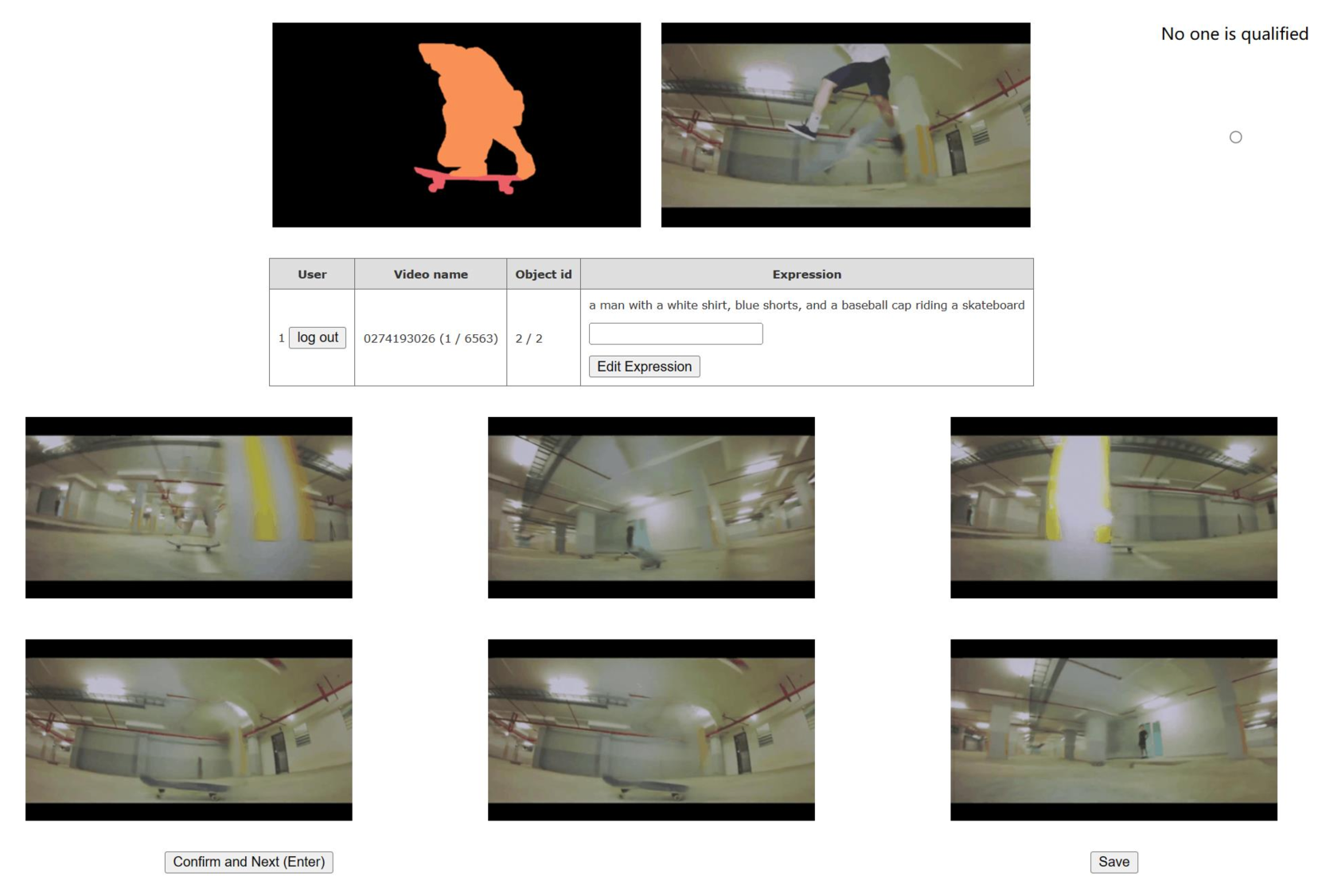
When generating inpainting results using a video inpainting network [22], the input mask can be trickily expanded with different pixel sizes, denoted as . The bigger is, the larger the input mask is developed so that it may cover the whole object. The best value varies through objects, causing an unstable performance in the inpainted videos if set to a fixed value. Therefore, throughout the generation process, we experiment with various hyperparameters to generate multiple results for each object and involve human annotators to select the best result. In particular, we generate six samples with for each object. Human annotators are expected to choose the best-looking result in these examples. The object does not enter the ROVI dataset if all examples are evaluated as unqualified. This human labeling process guarantees the high-quality ground truth of the ROVI dataset. Fig. 10 shows an illustration of the human annotation interface.
Additionally, we find there are several misannotations in the Refer-YouTube-VOS dataset. In some videos, the object label matches wrongly with object masks and expressions. For example, a person may correspond to “a dog walking by a person” according to the object labels. So, human annotators also make necessary revisions on the expressions in case of mis-annotations.

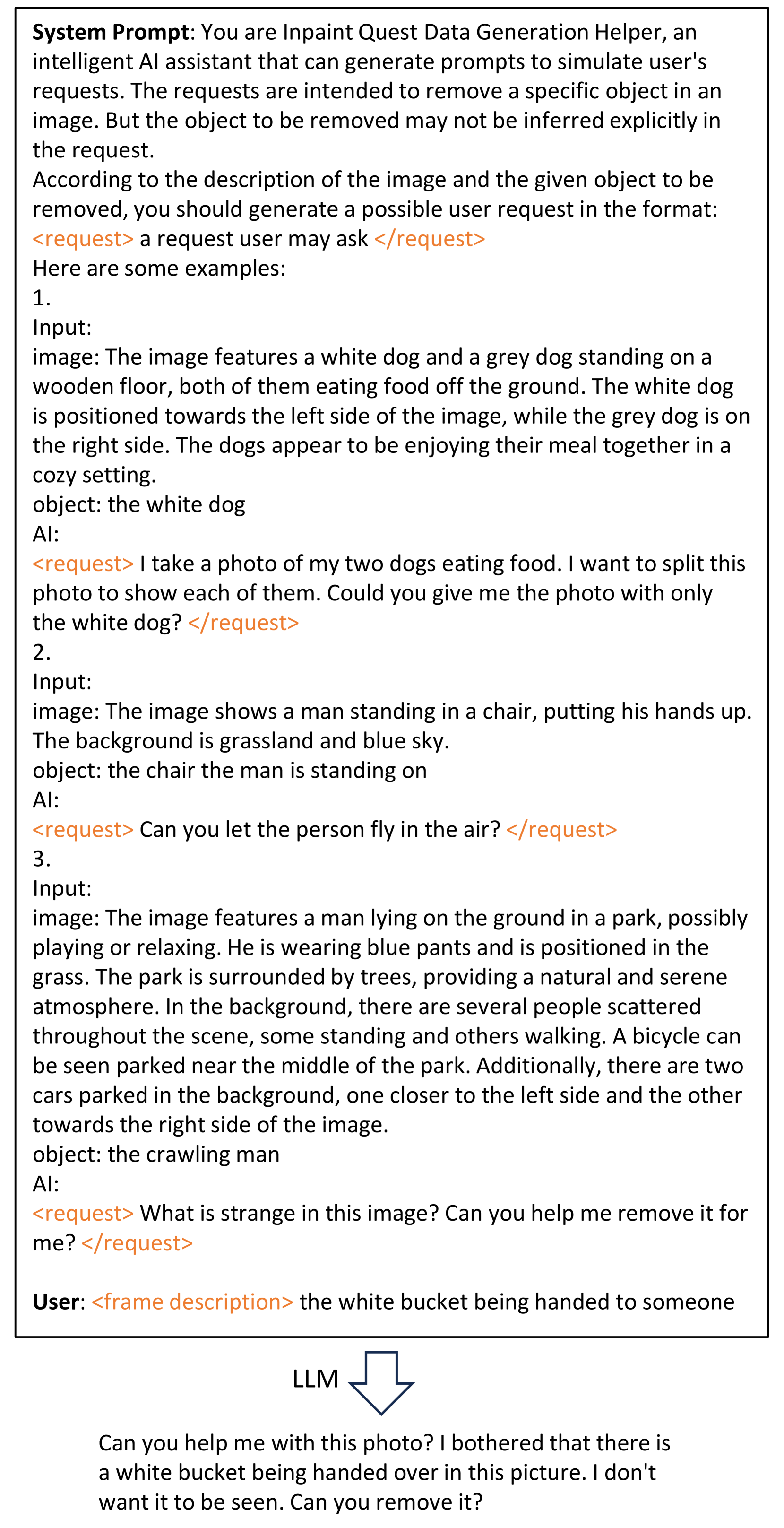

A.2 Interactive Annotation Details
In the interactive annotation pipeline, all the generating processes are completed by prompting MLLMs and LLMs without fine-tuning. Firstly, we let an MLLM model generate a detailed description of a given frame. Then, we give the descriptions to an LLM and let it generate a possible user request. Finally, the MLLM generates AI responses according to the request and frame content. The pipeline is shown in Figs. 11, 12 and 13.
Appendix B Baseline Details
For the Inst-Inpaint [56] baseline, we fine-tune the released checkpoint on the ROVI dataset with the same hyperparameters of LGVI. Specifically, we train 50 epochs on 8 × 80GB NVIDIA A100 GPUs with video and image batch sizes of 32 and 768. We resize the input image to 512 × 320, keeping the same as LGVI. For InstructPix2Pix [1], MagicBrush [63], and Inpaint Anything* [59], we directly use their released checkpoints due to they are pre-trained on large scale image editing/inpainting datasets.
| Method | PSNR | SSIM | VFID | |
|---|---|---|---|---|
| w/o FW | 20.53 | 0.607 | 0.370 | 1.101 |
| w/o MS | 21.80 | 0.631 | 0.358 | 1.059 |
| w/o VF | 22.08 | 0.754 | 0.356 | 1.017 |
| w/o IJ | 22.39 | 0.728 | 0.297 | 0.987 |
| LGVI (Ours) | 22.85 | 0.756 | 0.308 | 0.901 |
Appendix C More Ablation Studies
We show the quantitative ablation results in Tab. 4. The observation is consistent with the ablations in the main paper. The performance without joint training with images drops slightly, except for a slight increase of 0.011 in the VFID metric. This can be attributed to the enhanced diversity of visual sources provided by additional image data. while it brings a compromise between the quality of the results and temporal consistency. The results also demonstrate the necessity of the U-Net inflation and mask supervision modifications of LGVI. The absence of these modifications leads to a noticeable reduction in performance. The most significant performance degradation is observed when the U-Net is not fully fine-tuned, but only the newly added parameters are trained. This decline can be attributed to the intrinsic differences between the inpainting task and the pre-trained image generation task. In the latter, the language input guides the model on what to create, but it does not specify what needs to be removed.


Appendix D More Qualitative Results
Fig. 14 compares the referring video inpainting task. It demonstrates the effectiveness of the proposed LGVI model. Fig. 15 shows the qualitative results of the interactive video inpainting task. Our LGVI-I model outputs both inpainting results and comprehensive text responses.

Appendix E Basics of Diffusion Models
Denoising Diffusion Probabilistic Models (DDPMs). The core of DDPMs [10] involves iteratively adding noise to the data until it becomes a sample from a simple Gaussian distribution. The reverse process, which generates data from the noise, is learned by the model. The forward process, also known as the “noising” process, is typically modeled as a Markov chain that gradually adds Gaussian noise to the data over a sequence of time steps :
| (6) |
where is a sample from the data distribution , represents the data at time step , and is a variance schedule that determines the amount of noise to add at each step. is the noise sampled from a standard Gaussian distribution . The reverse process, which is the generative process, aims to learn the distribution of the original data by reversing the noising process. This involves learning a parameterized function that models the reverse conditional probability . The reverse process is described by:
| (7) |
where and are learned functions that predict the mean and covariance of the distribution for , given and time step . The learning of is typically done via a variational approach, minimizing a loss function that is a modified version of the Evidence Lower BOund (ELBO). This loss function ensures that the learned reverse process closely approximates the true distribution of the data, which can be simplified as:
| (8) |
The denoising process can incorporate extra guidance, where the model is trained to generate samples conditioned on a set of labels or attributes . Typical guidances are language and images [40, 64]. The loss function can be updated as follows:
| (9) |
where is guidance to control the generation result. We extend the condition input with a video input to control the inpainting results.
Latent Diffusion Models (LDMs). Latent Diffusion Model (LDM) [40] is a type of generative model that operates on a latent space rather than directly on the data space. The primary idea is to first encode high-dimensional data, like images, into a lower-dimensional latent representation and then apply the diffusion process within this latent space. A decoder reconstructs the latent back to the pixel distribution .
LGVI Architecture. The core of our model is to produce inpainting results driven by language guidance and vision input . This core concept is versatile and can be integrated into a variety of existing architectures, including those based on diffusion or transformer paradigms, as long as the model can fuse language and vision inputs. We choose the LDM architecture because of its flexibility in inflating to video modality and improved sample quality due to the reduced dimensionality of the problem.
Appendix F Future Work Discussions
Fig. 16 shows two LGVI and LGVI-I failure cases. The models still face the core challenge of implicit language or description. In the first example, the referring expression is comparatively long and hard to understand, leading to poor performance. In the second example for the interactive task, even if the MLLM outputs a reasonable response and correctly predicts the position of the removed person, the diffusion model does not provide the right output. That is because the current diffusion-based baseline model is a preliminary modification of a pre-trained text-to-image model, which lacks the understanding of precise locations. The failure cases demonstrate that despite the comparatively stronger performance of previous methods, our proposed model is still a baseline in the language-driven video inpainting field. Future work is expected to develop more advanced methods to overcome the challenges.
References
- Brooks et al. [2023] Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. In CVPR, 2023.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. NeurIPS, 2020.
- Bubeck et al. [2023] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- Chang et al. [2019] Ya-Liang Chang, Zhe Yu Liu, Kuan-Ying Lee, and Winston Hsu. Free-form video inpainting with 3d gated convolution and temporal patchgan. In ICCV, 2019.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR, 2021.
- Ebdelli et al. [2015] Mounira Ebdelli, Olivier Le Meur, and Christine Guillemot. Video inpainting with short-term windows: application to object removal and error concealment. TIP, 2015.
- Gavrilyuk et al. [2018] Kirill Gavrilyuk, Amir Ghodrati, Zhenyang Li, and Cees GM Snoek. Actor and action video segmentation from a sentence. In CVPR, 2018.
- Ge et al. [2023] Yuying Ge, Yixiao Ge, Ziyun Zeng, Xintao Wang, and Ying Shan. Planting a seed of vision in large language model. arXiv preprint arXiv:2307.08041, 2023.
- Hertz et al. [2022] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. NeurIPS, 2020.
- Hu et al. [2020] Yuan-Ting Hu, Heng Wang, Nicolas Ballas, Kristen Grauman, and Alexander G Schwing. Proposal-based video completion. In ECCV, 2020.
- Hudson and Manning [2019] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. CVPR, 2019.
- Khachatryan et al. [2023] Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text-to-image diffusion models are zero-shot video generators. arXiv preprint arXiv:2303.13439, 2023.
- Kirillov et al. [2023] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. arXiv preprint arXiv:2304.02643, 2023.
- Lai et al. [2018] Wei-Sheng Lai, Jia-Bin Huang, Oliver Wang, Eli Shechtman, Ersin Yumer, and Ming-Hsuan Yang. Learning blind video temporal consistency. In ECCV, 2018.
- Lee et al. [2019] Sungho Lee, Seoung Wug Oh, DaeYeun Won, and Seon Joo Kim. Copy-and-paste networks for deep video inpainting. In ICCV, 2019.
- Li et al. [2020a] Ang Li, Shanshan Zhao, Xingjun Ma, Mingming Gong, Jianzhong Qi, Rui Zhang, Dacheng Tao, and Ramamohanarao Kotagiri. Short-term and long-term context aggregation network for video inpainting. In ECCV, 2020a.
- Li et al. [2023a] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Mimic-it: Multi-modal in-context instruction tuning. arXiv preprint arXiv:2306.05425, 2023a.
- Li et al. [2020b] Jingyuan Li, Ning Wang, Lefei Zhang, Bo Du, and Dacheng Tao. Recurrent feature reasoning for image inpainting. In CVPR, 2020b.
- Li et al. [2022a] Wenbo Li, Zhe Lin, Kun Zhou, Lu Qi, Yi Wang, and Jiaya Jia. MAT: Mask-aware transformer for large hole image inpainting. In CVPR, 2022a.
- Li et al. [2023b] Xiangtai Li, Henghui Ding, Wenwei Zhang, Haobo Yuan, Guangliang Cheng, Pang Jiangmiao, Kai Chen, Ziwei Liu, and Chen Change Loy. Transformer-based visual segmentation: A survey. arXiv pre-print, 2023b.
- Li et al. [2022b] Zhen Li, Cheng-Ze Lu, Jianhua Qin, Chun-Le Guo, and Ming-Ming Cheng. Towards an end-to-end framework for flow-guided video inpainting. In CVPR, 2022b.
- Liu et al. [2018] Guilin Liu, Fitsum A Reda, Kevin J Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro. Image inpainting for irregular holes using partial convolutions. In ECCV, 2018.
- Liu et al. [2022] Guilin Liu, Aysegul Dundar, Kevin J Shih, Ting-Chun Wang, Fitsum A Reda, Karan Sapra, Zhiding Yu, Xiaodong Yang, Andrew Tao, and Bryan Catanzaro. Partial convolution for padding, inpainting, and image synthesis. TPAMI, 2022.
- Liu et al. [2023a] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023a.
- Liu et al. [2021a] Rui Liu, Hanming Deng, Yangyi Huang, Xiaoyu Shi, Lewei Lu, Wenxiu Sun, Xiaogang Wang, Jifeng Dai, and Hongsheng Li. Fuseformer: Fusing fine-grained information in transformers for video inpainting. In ICCV, 2021a.
- Liu et al. [2023b] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023b.
- Liu et al. [2015] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In ICCV, 2015.
- Liu et al. [2021b] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin Transformer: Hierarchical vision transformer using shifted windows. In ICCV, 2021b.
- Lugmayr et al. [2022] Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In CVPR, 2022.
- Meng et al. [2021] Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073, 2021.
- Meng et al. [2022] Lingchen Meng, Hengduo Li, Bor-Chun Chen, Shiyi Lan, Zuxuan Wu, Yu-Gang Jiang, and Ser-Nam Lim. AdaViT: Adaptive vision transformers for efficient image recognition. In CVPR, 2022.
- Nichol et al. [2022] Alexander Quinn Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob Mcgrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In ICML, 2022.
- OpenAI [2023] OpenAI. Gpt-4 technical report, 2023.
- Pathak et al. [2016] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context encoders: Feature learning by inpainting. In CVPR, 2016.
- Perazzi et al. [2016] Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In CVPR, 2016.
- Pi et al. [2023] Renjie Pi, Jiahui Gao, Shizhe Diao, Rui Pan, Hanze Dong, Jipeng Zhang, Lewei Yao, Jianhua Han, Hang Xu, and Lingpeng Kong Tong Zhang. Detgpt: Detect what you need via reasoning. arXiv preprint arXiv:2305.14167, 2023.
- Ramesh et al. [2022] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- Rao et al. [2021] Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. DynamicViT: Efficient vision transformers with dynamic token sparsification. In NeurIPS, 2021.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
- Saharia et al. [2022] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. NeurIPS, 2022.
- Seo et al. [2020] Seonguk Seo, Joon-Young Lee, and Bohyung Han. Urvos: Unified referring video object segmentation network with a large-scale benchmark. In ECCV, 2020.
- Singer et al. [2022] Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:2209.14792, 2022.
- Singh et al. [2023] Jaskirat Singh, Stephen Gould, and Liang Zheng. High-fidelity guided image synthesis with latent diffusion models. In CVPR, 2023.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Wang et al. [2019] Chuan Wang, Haibin Huang, Xiaoguang Han, and Jue Wang. Video inpainting by jointly learning temporal structure and spatial details. In AAAI, 2019.
- Wang et al. [2018] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. Video-to-video synthesis. NeurIPS, 2018.
- Wang et al. [2004] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. TIP, 2004.
- Wu et al. [2022] Jianzong Wu, Xiangtai Li, Xia Li, Henghui Ding, Yunhai Tong, and Dacheng Tao. Towards robust referring image segmentation. arXiv preprint arXiv:2209.09554, 2022.
- Wu et al. [2023a] Jianzong Wu, Xiangtai Li, Henghui Ding, Xia Li, Guangliang Cheng, Yunhai Tong, and Chen Change Loy. Betrayed by captions: Joint caption grounding and generation for open vocabulary instance segmentation. ICCV, 2023a.
- Wu et al. [2023b] Jianzong Wu, Xiangtai Li, Shilin Xu, Haobo Yuan, Henghui Ding, Yibo Yang, Xia Li, Jiangning Zhang, Yunhai Tong, Xudong Jiang, Bernard Ghanem, et al. Towards open vocabulary learning: A survey. arXiv preprint arXiv:2306.15880, 2023b.
- Wu et al. [2023c] Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In ICCV, 2023c.
- Xie et al. [2023] Shaoan Xie, Zhifei Zhang, Zhe Lin, Tobias Hinz, and Kun Zhang. Smartbrush: Text and shape guided object inpainting with diffusion model. In CVPR, 2023.
- Xu et al. [2018] Ning Xu, Linjie Yang, Yuchen Fan, Jianchao Yang, Dingcheng Yue, Yuchen Liang, Brian Price, Scott Cohen, and Thomas Huang. YouTube-VOS: Sequence-to-sequence video object segmentation. In ECCV, 2018.
- Ye et al. [2022] Botao Ye, Hong Chang, Bingpeng Ma, Shiguang Shan, and Xilin Chen. Joint feature learning and relation modeling for tracking: A one-stream framework. In ECCV, 2022.
- Yildirim et al. [2023] Ahmet Burak Yildirim, Vedat Baday, Erkut Erdem, Aykut Erdem, and Aysegul Dundar. Inst-inpaint: Instructing to remove objects with diffusion models. arXiv preprint arXiv:2304.03246, 2023.
- Yin et al. [2022] Hongxu Yin, Arash Vahdat, Jose M Alvarez, Arun Mallya, Jan Kautz, and Pavlo Molchanov. A-ViT: Adaptive tokens for efficient vision transformer. In CVPR, 2022.
- Yu et al. [2019] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S Huang. Free-form image inpainting with gated convolution. In ICCV, 2019.
- Yu et al. [2023] Tao Yu, Runseng Feng, Ruoyu Feng, Jinming Liu, Xin Jin, Wenjun Zeng, and Zhibo Chen. Inpaint anything: Segment anything meets image inpainting. arXiv preprint arXiv:2304.06790, 2023.
- Zang et al. [2023] Yuhang Zang, Wei Li, Jun Han, Kaiyang Zhou, and Chen Change Loy. Contextual object detection with multimodal large language models. arXiv preprint arXiv:2305.18279, 2023.
- Zeng et al. [2020] Yanhong Zeng, Jianlong Fu, and Hongyang Chao. Learning joint spatial-temporal transformations for video inpainting. In ECCV, 2020.
- Zhang et al. [2022] Kaidong Zhang, Jingjing Fu, and Dong Liu. Flow-guided transformer for video inpainting. In ECCV, 2022.
- Zhang et al. [2023a] Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing. In NeurIPS, 2023a.
- Zhang et al. [2023b] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In ICCV, 2023b.
- Zhou et al. [2017] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. TPAMI, 2017.
- Zhou et al. [2023] Shangchen Zhou, Chongyi Li, Kelvin C.K Chan, and Chen Change Loy. ProPainter: Improving propagation and transformer for video inpainting. In ICCV, 2023.
- Zhu et al. [2023] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.