- AUROC
- area under the receiver operating characteristic curve
- BMI
- body mass index
- CXR
- chest X-ray
- LLM
- large language model
- MIM
- masked image modelling
- PHI
- protected health information
- PTX
- pneumothorax
- SSL
- self-supervised learning
- SOTA
- state-of-the-art
- ViT
- vision transformer
- VQA
- Visual Question Answering
: Exploring Scalable Medical Image Encoders Beyond Text Supervision
Abstract
Language-supervised pre-training has proven to be a valuable method for extracting semantically meaningful features from images, serving as a foundational element in multimodal systems within the computer vision and medical imaging domains. However, resulting features are limited by the information contained within the text. This is particularly problematic in medical imaging, where radiologists’ written findings focus on specific observations; a challenge compounded by the scarcity of paired imaging–text data due to concerns over leakage of personal health information. In this work, we fundamentally challenge the prevailing reliance on language supervision for learning general purpose biomedical imaging encoders. We introduce , a biomedical image encoder pre-trained solely on unimodal biomedical imaging data that obtains similar or greater performance than state-of-the-art biomedical language supervised models on a diverse range of benchmarks. Specifically, the quality of learned representations is evaluated on standard imaging tasks (classification and semantic segmentation), and a vision–language alignment task (text report generation from images). To further demonstrate the drawback of language supervision, we show that features from correlate with other medical records (e.g., sex or age) better than language-supervised models, which are generally not mentioned in radiology reports. Finally, we conduct a series of ablations determining the factors in ’s performance; notably, we observe that ’s downstream performance scales well with the quantity and diversity of training data, demonstrating that image-only supervision is a scalable approach for training a foundational biomedical image encoder.
††*Equal contribution. Corresponding author: ozan.oktay@microsoft.com1 Introduction
In the evolving landscape of vision–language deep learning, the prevalent use of textual supervision [1, 2] has been a cornerstone in learning novel visual descriptors for downstream applications [2, 3], including biomedical domains [4, 5, 6, 7]. With the emergence of large language models, these visual descriptors are increasingly being integrated as static input tokens for multimodal reasoning to perform Visual Question Answering (VQA) and text captioning tasks [8, 9, 10].
As the focus shifts towards achieving state-of-the-art (SOTA) performance with larger-scale datasets and models [11], the scalability of models in relation to increasing dataset sizes, along with the availability of high-quality datasets, have become increasingly vital [12, 13]. However, this shift presents practical challenges in domain-specific applications such as healthcare, particularly in the context of acquisition and curation of large-scale datasets of image–text pairs. Limited availability of public multimodal medical datasets and concerns around the anonymity of protected health information (PHI) hinders the research communities’ efforts to scale up medical foundation models. Moreover, the lack of pixel-level supervision, particularly when text data for image segmentation is not available, presents a substantial challenge. This absence of detailed textual annotations impedes the improvement of image encoder performance in tasks demanding precise image analysis, such as the detection and localisation of nodules in 2D or 3D medical scans.
Furthermore, in certain cases, the textual supervision can become a limiting factor, depending on the descriptiveness of captions, particularly when radiological findings, which describe radiologists’ key observations about images (target classes), are omitted. This can potentially lead to collapse of representations at the expense of image–text alignment [14, 15, 16], where intra-class variations may not be preserved. For instance, the radiological phrase “No cardiopulmonary process” is frequently used to report healthy chest X-rays in the MIMIC-CXR [17] dataset. Hence, its contrastive alignment [18, 19] with image features can introduce undesired invariances to anatomical variations seen across individuals. However, this information could be valuable for clinical applications beyond standard text generation, ranging from image segmentation to biomarker discovery for therapeutics that require understanding each individual’s uniqueness [20, 21]. Without this context, the applicability of learnt image encoders may not generalise to broader healthcare applications, eventually needing re-training of networks. Indeed, a recent study [15] has demonstrated that, whilst image–text data can establish correspondences between language and the visual world, it may not be precise and clean enough to result in SOTA image descriptors for downstream vision tasks. In a similar direction as [15], we explore the hypothesis that there may not be a need for text supervision to learn discriminative visual descriptors required for uni- and multimodal medical applications: The alignment across the two modalities can be performed subsequently depending on the downstream application, once the visual clustering of features is performed using large-scale imaging data alone.
For this purpose, we propose the image encoder, which is continually pre-trained with medical scans by adopting the DINOv2 image-only self-supervised learning (SSL) approach [22]. We assess its scalability with pre-training dataset size to downstream uni- and multimodal applications including both image- and pixel-level predictive tasks. It leverages two complementary training objectives: masked image modelling (MIM) and self-supervised contrastive learning. This hybrid design enables transferability of learned features to both global and local downstream tasks without requiring external text supervision [23, 24, 25]. In particular, we empirically verify the aforementioned hypothesis by benchmarking it against a series of SOTA baseline image encoders, trained with text supervision, on multiple medical datasets. On image classification, we demonstrate that similar performance levels can be consistently achieved or even surpassed for the majority of classes without the need for paired image–text datasets for training. These findings are generalised to downstream multimodal applications where image-to-text generation results are evaluated with frozen image backbone networks. Additionally, we demonstrate promising semantic segmentation performance, without using a hierarchical encoder architecture such as U-Net [26] or Swin Transformer [27], by training off-the-shelf decoder heads [28, 29] on top of pre-trained encoders, highlighting the reduced need for large-scale, densely annotated training datasets. Finally, we show that patient demographic information, which in general is not mentioned in text, can be more accurately predicted from ’s encodings than language supervised models, suggesting that image-only models such as are more useful for broader clinical applications.
More importantly, a series of ablations are conducted to understand the contribution of each component of to its performance, including: (I) the beneficial impact of domain-transfer with pre-trained weights from DINOv2, (II) the essential role of MIM for image segmentation, and (III) the importance of input image resolution for detecting certain classes. In particular, recent biomedical benchmarking efforts [30, 31] show that large general models (e.g., ViT-G [22]) show strong domain-transfer capabilities although solely trained on natural images. Lastly, we analyse how the presented approach scales with large and diverse image-only datasets, as this can enable a unified approach without reliance on hand-crafted SSL pretext tasks proposed for specific medical imaging modalities [32, 33].
In summary, our main findings are as follows:
-
•
We show that weak supervision with text data is not essential, and it could even be a hindrance for learning visual features required for downstream multimodal biomedical applications. Instead, one could employ self-supervision with imaging data only, such as with , to achieve comparable or better performance and further scale by leveraging the vast availability of imaging data.
-
•
Furthermore, ’s features show a stronger correlation with clinical information, e.g., patient medical records, which extends beyond the data typically found in radiology reports yet is routinely relied upon for diagnostic purposes. This capability could enable future multimodal applications that include EHR data.
-
•
Lastly, we demonstrate through a set of ablations that ’s performance scales with increased training dataset size, diversity, and higher input resolution, paving the way for a viable solution to train large-scale foundational biomedical image encoders.
2 Preliminaries and Experimental Setup
DINOv2:
In this work we leverage DINOv2, a state-of-the-art image-only self-supervised learning method, optimised for pre-training vision transformers [22]. This approach uses a siamese network, with predictions from a teacher network distilled into a student network. To learn image representations useful for both global and localised downstream tasks without requiring text captions, image-level and patch-level objectives are used concurrently [23, 24]. For the patch-level objective, masked image modelling (MIM) is used, where the student is fed an image with randomly masked patches, and must predict the teacher’s features for each patch. For the image-level objective, a contrastive training objective is used: the student is separately fed multiple crops (multi-crop) of an image, and must align its local feature representations with those predicted by the teacher network for the global views of the image. The teacher network is updated through the student’s parameters using exponential moving average (EMA) [34], with gradient back-propagation limited to the student network.
The combination of these objectives plays a key role in DINOv2’s SOTA performance over traditional SSL techniques that rely solely either on contrastive (e.g., CLIP [2], SimCLR [19]) or masked modelling objectives (BEiT [35]). Additionally, the use of multi-crop helps enable resultant backbone networks to learn distinctive local features required for dense predictive tasks [25], e.g., semantic segmentation and depth estimation. To prevent mode collapse, asymmetric design choices are applied across the two branches, including different augmentation views, centring, and temperature scaling (see [36] for further analysis). The asymmetry in centring techniques contributes to the robustness of the learning process. Furthermore, DINOv2 utilises a KoLeo regulariser [37], which promotes a uniform distribution of features. This is particularly beneficial for clustering-related tasks such as nearest-neighbour image retrieval.
Training setup:
We use a collection of large-scale radiology image-only datasets, namely Multi-CXR, composed of several public and private sources with a wide diversity in terms of findings and demographics (see outline in Table B.1). The pre-trained DINOv2 ViT-B model is continually trained with these chest X-ray (CXR) images for an additional 60k training steps with a batch size of 640. In contrast to the low-to-high-resolution two-phase learning schedule used in [22], the input resolution is kept the same throughout the training due to the shorter length of our continual training. The dual-view augmentations are adjusted to meet domain-specific requirements, as target classes (disease findings) need texture and contextual information, resulting in larger crop sizes and less severe blurring on the teacher branch (see Section C.1). This approach is consistent with the findings in [38] for X-rays and [23] for natural images.
| Model type | Model | Arch. | # Params. | Training dataset | # Images | # Text | Image resolution |
| Image & Text | CLIP@224 [2] | ViT-L/14 | 304 M | WebImageText | 400 M | 400 M | 224 224 |
| Image & Text | CLIP@336 [2] | ViT-L/14 | 304 M | WebImageText | 400 M | 400 M | 336 336 |
| Image & Text | BioViL-T [39] | ResNet50 | 27 M | MIMIC-CXR | 197 k | 174 k | 512 512 |
| Image & Text | BiomedCLIP [40] | ViT-B/16 | 86 M | PMC-15M | 15 M | 15 M | 224 224 |
| Image & Text | MRM [7] | ViT-B/16 | 86 M | MIMIC-CXR | 377 k | 227 k | 448 448 |
| Image Only | DINO-v2 [22] | ViT-G/14 | 1.1 B | LVD | 142 M | - | 518 518 |
| Image Only | -Control | ViT-B/14 | 87 M | MIMIC-CXR | 197 k | - | 518 518 |
| Image Only | ViT-B/14 | 87 M | Multi-CXR | 838 k | - | 518 518 |
Baseline approaches:
A range of baseline approaches (see Table 1) were selected for experimental analysis, as detailed in Table 1. Specifically, the prevalent use of image-text pairs in CLIP (BioViL-T [39] and BiomedCLIP [40]) and multimodal masked modelling (MRM [7]) guided our selection. We primarily aim to investigate the hypothesis that text supervision might not be essential to learn image encoders required for uni- and multi-modal downstream applications. Additionally, this varied selection facilitates the analysis of factors like input image resolution, training dataset size, and the need for domain-specific pre-training. Comparison with image-only SSL methods is left outside the scope of this study as it is extensively studied in prior art [22, 23, 41]. Moreover, evaluating CLIP@336 and CLIP@224 within the same framework highlights the current limitations of medical multimodal learning literature [8, 9], which largely depends on static CLIP-based image encoders. The experiments leveraged publicly available model checkpoints (see Section C.2), maintaining consistent train–test splits and evaluation metrics.
Downstream evaluation tasks:
Image-level and pixel-level predictive tasks often necessitate distinct feature invariances [42], thereby requiring complementary pre-training objectives [23, 22]. To evaluate the global and textural characteristics of the learned features, we employ semantic image segmentation and linear probing for image classification tasks with frozen backbone networks, incorporating external datasets and a few long-tail findings (less frequently observed cases). Crucially, we also evaluate the usefulness of learned features for multimodal prediction tasks, namely image-to-text generation; this additionally allows us to determine how well image-only tasks correlate with text-related tasks. For this purpose, Vicuna-1.5 7B LLM [43] is fine-tuned on each frozen image backbone in a LLaVA-style setting [44, 45] (more details in Section 4.2).
Evaluation datasets and metrics:
Across all applications, data splits are carefully constructed to ensure that images from each subject are confined to a single split, thereby preventing potential data leakage. Image classification is evaluated using external datasets, including VinDr-CXR [46], CANDID-PTX [47], and RSNA-Pneumonia [48]. For VinDr-CXR, a subset of six findings is selected, emphasising diversity (in-/out-patient) and prevalence, given the dataset’s long-tailed distribution. This dataset is particularly used for ablation studies due to its diverse data distribution, including a variety of findings and patient demographics, compared to other public datasets, see Section B.2 for further details on the datasets. Results are reported using the AUPRC metric, chosen over AUROC or threshold-dependent accuracy/F1 values due to significant class imbalance. It is noted that target classes are not mutually exclusive. For easier visualisation and comparison, macro AUPRC results are presented in the ablation studies.
In the segmentation tasks, a dedicated decoder head is trained from scratch. Evaluation is performed using Dice scores across various anatomical and pathological classes in chest X-rays, including left and right lungs [49], six lung zones [50], pneumothorax [47], chest tubes [47], and ribs [51]. For more information on their respective datasets, see Section B.2. For text report generation, the MIMIC-CXR [17] dataset was exclusively used, owing to the scarcity of publicly accessible, large-scale image–text pairs necessary for LLM fine-tuning. Performance is quantified using standard lexical and factuality metrics, and results are reported on the official test split.
3 Ablation Studies
Experimental analysis of different image networks can be confounded by factors such as image-resolution, training dataset and weight initialisation, which can lead to incomplete and sometimes misleading findings. Therefore, this study aims to first understand the impact of such factors on and its benchmark results in isolation, before performing extensive evaluation against baseline biomedical models, taking these factors into account. In that regard, the following subsections present our learnings from ablations performed by running a multi-class linear classification on the VinDr-CXR dataset.
3.1 Dependence on Image Resolution
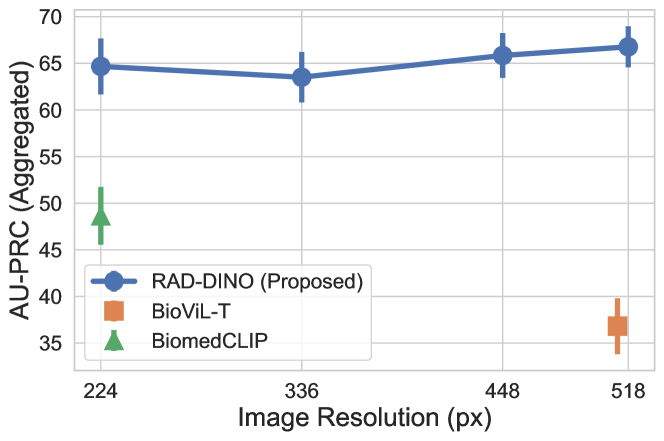
Image resolution has been shown to be an important factor in downstream prediction tasks [52, 53], and it can be a confounding factor on the performance gap between and baseline image encoders that we observe in our experiments. In this section, we examine the impact of image resolution on large-scale or conspicuous findings (such as cardiomegaly and opacity), found in the VinDr-CXR [46] dataset, across the input resolution range of 224 to 518 pixels. Linear probing is performed, and AUPRC results are aggregated across findings in each dataset and multiple runs with different seeds. is initialised from DINOv2 (ViT-B) for this ablation. Figure 1 shows that for such large scale findings, the performance improvement of is not necessarily attributed to its capability to encode higher resolution inputs—as long as input signal correlates with target objective, e.g. findings that manifest on large regions of the image. In contrast, in Section A.1, the same experiment is repeated for potentially small or subtle findings (including pneumothorax (PTX) and chest tubes), as found in the CANDID-PTX [47] dataset, where higher input resolution is required (see Figure A.1). In this scenario, we observe performance degradation as fine-granular details are lost, yet image-only learning still outperforms baseline approaches.
It is important to note that past research efforts on VQA [8, 9, 10] and text generation [10, 54], which leverage image backbones at lower resolutions, are likely hindered by the ambiguity of the input signal. This ambiguity may lead to hallucinations and performance limits, despite efforts to adapt large-scale text decoders with billions of model parameters on top of image embeddings.
3.2 Model Weight Initialisation
A series of ablations are carried out to inspect the role of pre-training on large-scale general domain datasets (e.g., LVD-142M) curated from over 1B images prior to in-domain training with chest X-ray images. Linear classification experiments are performed on the same VinDR benchmark by initialising the encoder parameters with random weights and ViT-B and comparing the large-scale DINO-v2 models (ViT-G and ViT-B) in the same setup.
| Model | LO | CM | PL-T | AE | PF | TB | Agg |
| DINOv2 (ViT-B) [22] | p m 1.36 | p m 1.62 | p m 3.71 | p m 1.4 | p m 1.06 | p m 0.9 | 39.46 |
| DINOv2 (ViT-G) [22] | p m 5.98 | p m 1.54 | p m 2.33 | p m 2.26 | p m 1.62 | p m 3.29 | 43.36 |
| (Random init.) | p m 2.8 | p m 1.13 | p m 3.91 | p m 0.86 | p m 1.78 | p m 2.47 | 59.82 |
| (Continual) | p m 2.96 | p m 1.66 | p m 4.98 | p m 0.73 | p m 2.29 | p m 3.51 | 66.63 |
LO: Lung Opacity, CM: Cardiomegaly, PL-T: Pleural Thickening, AE: Aortic Enlargement,
PF: Pulmonary Fibrosis, TB: Tuberculosis, Agg: Macro Average
The results provided in Tables 2 and 3 demonstrate that general-domain models transfer better to out-of-domain medical tasks with larger-scale architectures and training data, in particular compared to CLIP@336—and in some cases even better than small-scale backbones trained in-domain such as BioViL-T. This is in-line with the authors’ findings in [30, 55, 56]. However, continual pre-training with in-domain data leads to further gains (), which plays more crucial role as initialisation from random weights consistently performs better than the backbones trained on general domain data. In particular, the general-domain pre-training contributes to better discrimination of findings that are less commonly seen in in-domain ICU medical datasets such as tuberculosis (TB) and pulmonary fibrosis (PF).
3.3 Dependence on Training Dataset Size
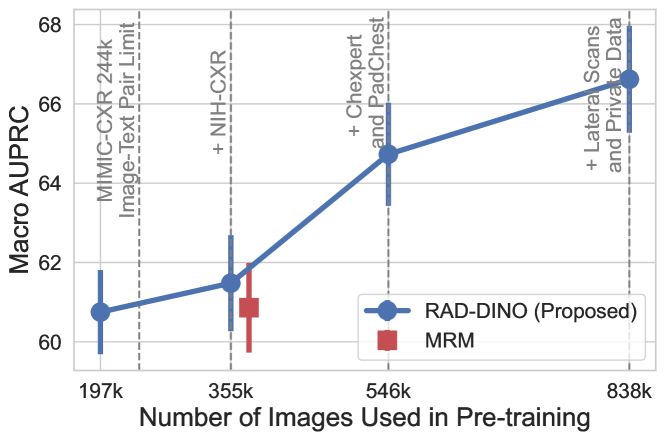
Here, we vary the diversity and size of the training dataset used for by systematically enriching it with more diverse examples, such as out-patient studies. This incremental addition of data enables comparison with different baseline methods that use paired image–text datasets. Despite a performance drop compared to using the full dataset (Tables 2 and 3), we observe that the model, trained with smaller-scale data (MIMIC-CXR: 197k), maintains its superior performance over baseline approaches without requiring text input for training (see Figure 2). For consistency with other ablation studies, we used the same backbone model, benchmark, and metric. Given that models tend to overfit with smaller dataset sizes, early stopping is applied by monitoring the validation loss computed on the CANDID-PTX classification task via linear probing.
For up to 546k samples, only the frontal chest X-ray scans (AP/PA) are utilised, as we empirically observe these to yield the maximal gain, given that the test set is composed exclusively of frontal images (see Figure 2). Similarly, the inclusion of the PadChest [57] dataset provides an additional performance boost, due to the increased diversity of findings in out-patient datasets. In the final stage, lateral scans and an additional private dataset are utilised to observe how the presented approach scales with increased dataset quantities.
4 Benchmark Results
4.1 Transfer to Image Classification
Experimental setup:
backbones are evaluated against other general-domain and domain-specific image networks using linear probing to compare different SSL approaches and assess their top-performance within each biomedical benchmark despite differences in pre-training datasets. All evaluations were performed on three external CXR datasets collected from both out-patient and in-patient settings (VinDr-CXR, CANDID-PTX and RSNA Pneumonia) and hence suitable to test the generalisation of networks. The analysis has not focused on comparing different image-only SSL methods as the existing studies have demonstrated that the combination of MIM [58] and contrastive approaches [41] as in the case of iBoT [59] and DINOv2 [22] lead to state-of-the-art performance.
| VinDr-CXR [46] (AUPRC) | |||||||
| Model | LO | CM | PL-T | AE | PF | TB | Agg |
| CLIP@224 [2] | p m 1.17 | p m 1.53 | p m 2.33 | p m 2.02 | p m 1.35 | p m 1.43 | 33.03 |
| CLIP@336 [2] | p m 1.05 | p m 1.40 | p m 3.61 | p m 1.62 | p m 0.69 | p m 1.99 | 34.54 |
| BioViL-T [39] | p m 3.20 | p m 1.94 | p m 4.32 | p m 1.19 | p m 2.38 | p m 3.65 | 34.19 |
| BiomedCLIP [40] | p m 1.93 | p m 0.95 | p m 3.57 | p m 1.9 | p m 3.85 | p m 4.85 | 45.42 |
| MRM [7] | p m 2.36 | p m 1.43 | p m 4.94 | p m 1.3 | p m 3.44 | p m 4.15 | 60.86 |
| p m 2.96 | p m 1.66 | p m 4.98 | p m 0.73 | p m 2.29 | p m 3.51 | 66.63 | |
| +4.17 | +0.47 | +1.08 | +8.39 | +14.55 | +5.94 | +5.77 | |
LO: Lung Opacity, CM: Cardiomegaly, PL-T: Pleural Thickening, AE: Aortic Enlargement,
PF: Pulmonary Fibrosis, TB: Tuberculosis, Agg: Macro Average
VinDr-CXR Benchmark:
The results in Table 3 collected on the benchmark demonstrate that masked-modelling approaches, including MRM [7], yield stronger performance compared to image–text contrastive-only approaches. The ablations in Section 3.3 show that also scales well with increasing dataset size and diversity, in line with existing literature [60]. Performance differences between MRM and (shown with ) are more pronounced on out-of-domain findings, such as chronic or incidental findings seen in out-patient studies; this is due to the limited availability of multimodal public datasets, with MRM therefore trained solely on MIMIC-CXR [17], which has a lack of diversity. In particular, a keyword search among all 227.8k study reports in MIMIC-CXR found that “fibrosis” (PF), “aortic enlargement” (AE), and “tuberculosis” (TB) are rarely reported (<1%). Nevertheless, -Control, obtained by training with the subset of MIMIC-CXR (197k images only, see Section 3.3) performs on par with MRM (60.75 vs 60.86 AUPRC) without requiring any text reports and with fewer training images (197k vs 377k). Note that the ablations in [7] show that MRM’s performance relies more on the image reconstruction and modelling pretext tasks than text modelling, supporting the thesis that text might not be necessary for strong image representations.
Furthermore, the baseline results emphasise the importance of data quality and its relevance for downstream tasks, as BiomedCLIP [40] was trained with over 10 more image–text pairs retrieved from PubMed articles, of which 222k contained X-rays. Lastly, the performance of general-domain encoder networks scales with increased capacity and training data [55, 56] when we compare DINOv2 (ViT-G) (Section 3.2) with CLIP@336 [2].
CANDID-PTX & RSNA Pneumonia Benchmarks:
Linear classification experiments on these two benchmarks (see Table 4) assess the generalisation of models to other external datasets and categorisation of more localised findings (e.g., pneumothorax). Note that the input image resolution plays an important role for CANDID-PTX as seen in the ablations in Figure A.1; nevertheless, we observe that ’s 224-pixel version still performs consistently better than image–text contrastive baselines despite the performance drop. The lower AUPRC values for rib fracture are mainly attributed to the availability of fewer positive examples (less than 2%) and the granularity of the finding, which might require encoding images at higher resolution. On the RSNA Pneumonia dataset, performs on par with the SOTA, despite not requiring text supervision. The lack of notable improvement over baselines may stem from the abundance of opacities and pneumonia-related images in public datasets, leading to a narrow performance gap.
| CANDID-PTX [47] (AUPRC) | RSNA Pneumonia [48] | |||||
| Model | Arch | PTX | Chest Tube | Fracture | AUPRC | AUROC |
| CLIP@224 [2] | ViT-L | p m 1.57 | p m 0.98 | p m 1.14 | p m 2.01 | p m 0.71 |
| CLIP@336 [2] | ViT-L | p m 1.15 | p m 1.67 | p m 1.97 | p m 1.7 | p m 0.37 |
| BioViL-T [39] | ResNet50 | p m 1.48 | p m 3.40 | p m 1.88 | p m 1.51 | p m 0.45 |
| BiomedCLIP [40] | ViT-B | p m 1.99 | p m 4.43 | p m 2.46 | p m 1.68 | p m 0.40 |
| MRM [7] | ViT-B | p m 2.37 | p m 4.89 | p m 7.11 | p m 1.49 | p m 0.51 |
| ViT-B | p m 1.55 | p m 1.56 | p m 4.10 | p m 1.75 | p m 0.63 | |
| +5.20 | +32.64 | +1.18 | -0.45 | -0.60 | ||
Lateral CXR scans:
For both classification experiments, only frontal chest X-rays are used. However, lateral scans capture certain abnormalities, and so are also commonly used to disambiguate findings, with the same text report used for both images. With many written findings not clearly visible in the lateral scan [61, 62], this substantially reduces the mutual information and adds noise into the learning process, making language supervised methods less effective. We evaluate this in Table A.1 similarly by training a linear classifier to detect abnormalities visible in lateral scans, and observe that the approaches based on MIM, and MRM, substantially outperform the CLIP-style models.
Impact of learning objectives:
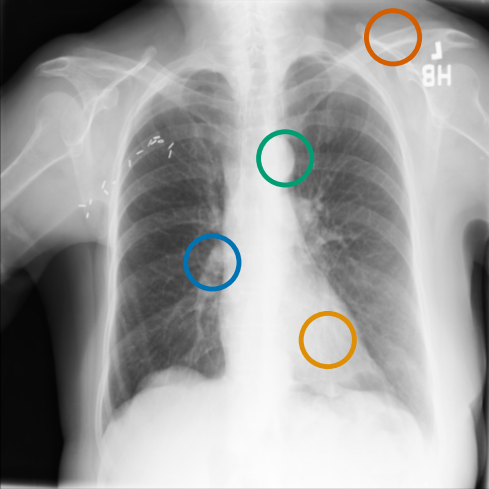
As can be evidenced by the self-attention maps, shown in Figure A.2, training is observed to pick up local texture, which we attribute to MIM [22, 59] and multi-crop contrastive training [63]. Similarly, Figure 3 shows the correspondences between patch embeddings across scans from different subjects where anatomical semantics are captured during training, see Section A.4 for additional examples showing matches between findings and anatomical landmarks. In particular, [25] show that DINO benefits from its multi-crop training setup since it is specifically trained to be invariant to both local and global scale of structures, and [24] emphasise the importance of MIM in learning high-frequency information present in images whilst contrastive objectives favour learning global-shape representations. Further, in the pneumonia linear-probing task, we observed that CLIP-style backbones demonstrate a warm start and faster convergence, attributable to the widespread availability of pneumonia-associated image findings (e.g. opacities) in public benchmarks and their detailed descriptions in radiology reports. This availability likely contributes to the narrower performance gap observed between different baselines.
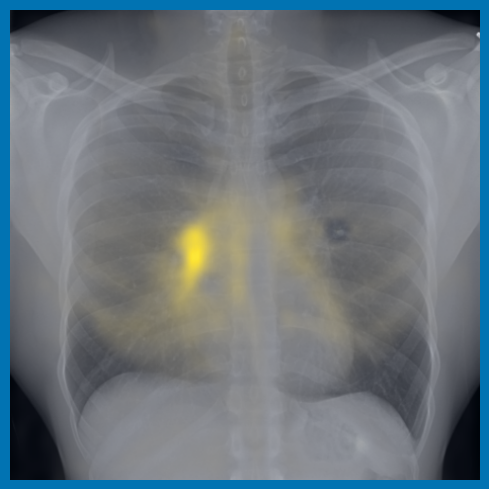
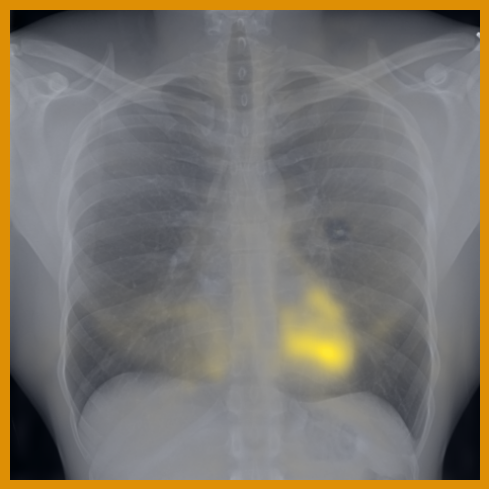
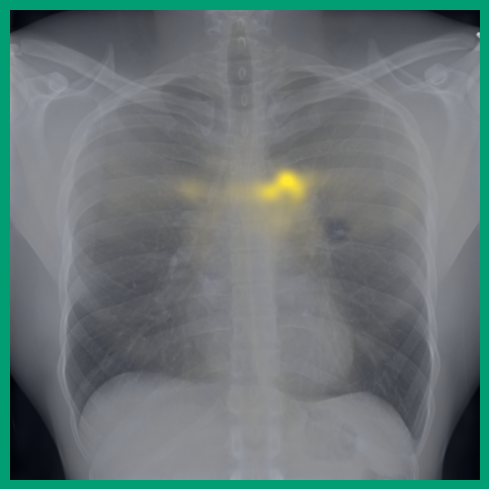
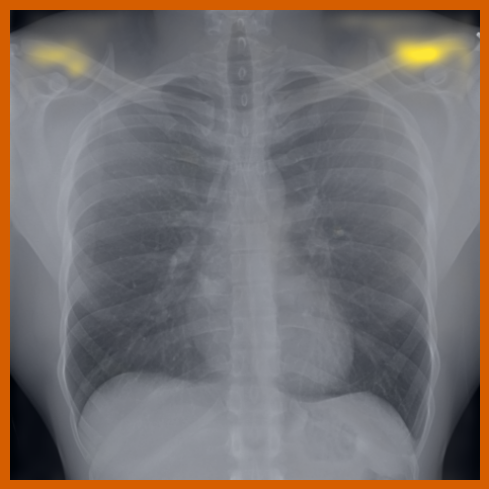
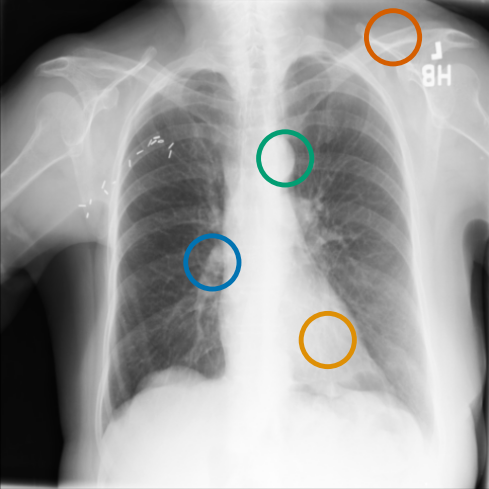
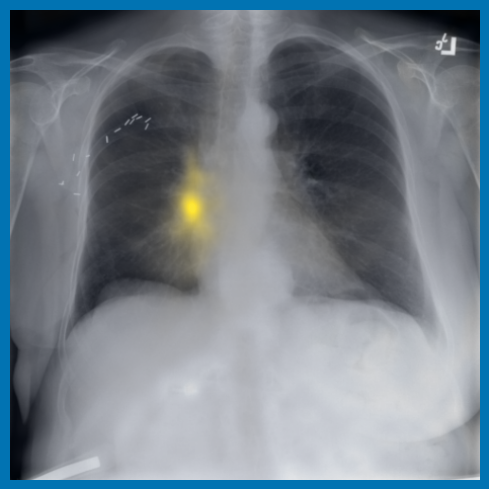
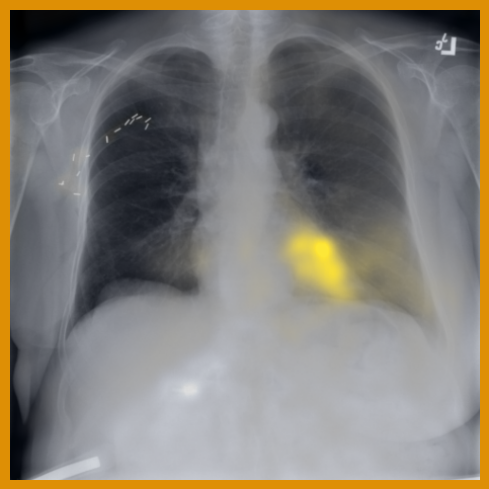
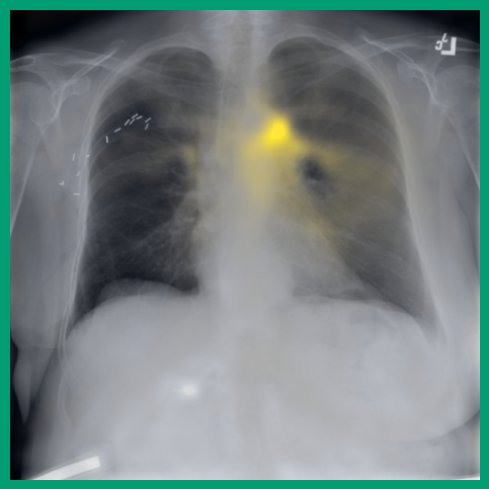
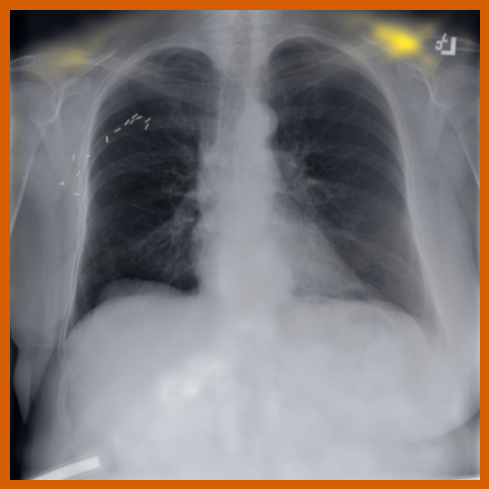
4.2 Transfer to Vision–Language Task: Text Report Generation from Images
Experimental setup:
CLIP-style multimodal pre-training [2] aims for symmetrical alignment between image and text embeddings. Here we ask whether this is a required procedure in the context of a vision–language downstream task, namely generation of the ‘Findings’ section of a frontal chest X-ray report. For this, we use the MIMIC-CXR dataset [17], following the official test and train splits in alignment with data used for , removing all non-AP/PA scans, and dropping samples without a findings section, resulting in 146,909 / 7,250 / 2,461 image–text pairs for training, validation, and testing of language decoder fine-tuning. The MRM baseline [7] is excluded in this analysis as the backbone network was trained with the complete set of image-text pairs in MIMIC-CXR.
We follow a LLaVA-style architecture [45, 44] to produce a multimodal model: patch embeddings from the frozen image encoder are projected and concatenated with an instruction to generate an output report: “image_tokens Provide a description of the findings in the radiology image.” Following LLaVA-1.5 [44], we use a two-layer fully connected (MLP) projector and Vicuna-7B (v1.5) [43] as the language model. The projection network is initialised with random weights and trained in conjunction with the decoder model whilst the image encoder is frozen. Input information to the LLM is kept minimal to focus evaluation on the quality of the image representations—further performance gains can be obtained by applying data augmentations [64] or providing additional clinical information, including prior reports [39].
Results analysis:
Table 5 shows detailed performance of the benchmarked image encoders. We report standard lexical metrics (ROUGE-L [65], BLEU-4 [66]) to measure word overlap of the generated findings and corresponding ground-truth findings sections, in addition to the radiology-specific RGER [67] and CheXbert-based [68] Macro-F1-14 [69] (with the ‘uncertain’ label mapped as negative). Macro-F1-14 metric measures the factuality of reported findings for 14 different classes. surpasses all other image encoders in terms of every computed lexical and clinical metric. In particular, we observe significant improvements over the specialised baselines, BiomedCLIP and BioViL-T, which are pre-trained with language supervision. The large increase in Macro-F1-14 indicates that the embeddings provided by the specialised encoder effectively capture the relevant pathologies, producing more factually correct reports. The results highlight the effectiveness of DINO-style image-only pre-training, which learns the relevant features required for generating accurate description of findings of chest X-rays. As an aside, these results also add some additional weight to the findings in [70], that image resolution is more important than the number of tokens; such architecture design may help enable greater scalability.
| Image encoder | Input resolution | # of Tokens | ROUGE-L | BLEU-4 | RGER | Macro-F1-14 |
| CLIP@224 | 224 224 | 23.0 [22.7, 23.4] | 8.3 [7.9, 8.6] | 20.3 [19.8, 20.7] | 24.7 [23.6, 26.0] | |
| CLIP@336 | 316 316 | 23.3 [22.9, 23.7] | 8.4 [8.0, 8.7] | 20.4 [19.9, 20.9] | 25.3 [24.2, 26.5] | |
| DINOv2 | 518 518 | 22.7 [22.4, 23.2] | 7.6 [7.3, 7.9] | 18.5 [18.1, 19.1] | 18.6 [17.8, 19.5] | |
| BiomedCLIP | 224 224 | 23.1 [22.8, 23.5] | 7.9 [7.5, 8.2] | 20.4 [19.9, 20.8] | 24.9 [23.8, 26.1] | |
| BioViL-T | 512 512 | 23.5 [23.2, 23.9] | 7.3 [7.0, 7.6] | 22.4 [21.9, 22.8] | 28.4 [27.2, 29.8] | |
| -Control | 518 518 | 24.2 [23.8, 24.6] | 9.0 [8.7, 9.4] | 22.4 [21.9, 22.9] | 31.5 [30.1, 32.9] | |
| 518 518 | 24.6 [24.2, 25.0] | 9.3 [8.9, 9.7] | 22.8 [22.3, 23.3] | 31.9 [30.4, 33.3] | ||
| +1.1 | +1.4 | +0.4 | +3.5 |
Balancing training datasets:
To assess the importance of training on in-domain data, in Table 5 we carry out a controlled experiment (referred to as -Control), training solely on a smaller set of in-domain MIMIC-CXR data, akin to BioViL-T. Once more, we witness enhanced performance in this scenario, indicating that the improvement over baselines is not merely due to training on extensive radiology data, but rather inherent to the power of masked image modelling. Moreover, we observe a minimal gap between the control and all-data regimes, likely because the control training data is already aligned with the MIMIC-CXR test set. Overall, these results suggest is a strong encoder option for downstream vision–language tasks in the radiology domain.
4.3 Transfer to Semantic Segmentation
Experiment setup:
To further probe the patch-level representation capabilities of , we assess its performance on downstream segmentation tasks using common chest X-ray datasets for anatomy or pathology segmentation (CANDID-PTX, and datasets derived from MIMIC-CXR; more details in Section B.2). We use each frozen backbone in an encoder–decoder framework with different decoder heads: linear [22], ViTDet [28], and UPerNet [29]. This selection is intended to measure linear discrimination of patch embeddings and their top-level performance using a feature-pyramid network [71] and standard vision transformer. Similar to the previous experiments, the same set of backbone networks are compared with in this new setup. To additionally understand the potential upper bound on performance [72], we end-to-end train and evaluate U-Net [26] encoder-decoder networks using different image encoders, NN-UNet [73] and EfficientNet-B6 [74], for each structure, primarily due to their ability to preserve high-resolution spatial information during downsampling through skip connections between encoder and decoder layers.
Results analysis:
Results shown in Tables 6 and A.5 highlight that image–text CLIP approaches do not yield transferable patch embeddings for downstream segmentation tasks, as the contrastive objective does not necessarily require pixel-level texture to identify correspondences between multimodal instances [24]. This is aligned with the findings in [22], where the DINOv2 pretrained encoder consistently outperforms the OpenCLIP encoder [75]. In particular, the performance gap widens for a fixed type decoder head (linear) as the segmentation task becomes more challenging with smaller target structures such as chest tubes. These results suggest that rich pixel-level features to represent fine-grained image information may not be suitably captured by image–text contrastive training, but are well captured by the encoder trained using large-scale image-only datasets.
Importance of masked image modelling (MIM):
By running an ablation on trained without the MIM objective, we further investigate the complementary nature [24] of the two training objectives discussed in Section 2, where the model is trained only with the contrastive term between global and multi-local crops. The contrastive objective focuses more on global relationships (e.g., shape) but MIM is more inclined towards local relationships (e.g., textures), thus, especially for dense downstream tasks such as semantic segmentation, MIM could be particularly important. As seen in Table 6, the MIM objective helps boost the segmentation performance for all the structures and datasets, showing that MIM yields effective representations for our dense tasks.
Encoder Decoder # Features Frozen backbone Lungs Lung zones Pneumothorax Chest tubes Ribs NN-UNet [73] Unet — ✗ 98.0 (1.1) 92.6 (10.2) 89.3 (27.3) 93.1 (21.8) 86.2 (2.8) EfficientNet-B6 [74] Unet — ✗ 98.3 (1.1) 92.7 (10.1) 89.5 (26.9) 95.2 (17.2) 88.9 (2.6) BioViL-T [39] Linear 2048 ✓ 83.2 (3.2) 69.4 (9.0) 76.0 (39.9) 83.0 (37.0) 59.1 (4.7) BiomedCLIP [40] Linear 768 ✓ 90.4 (2.6) 76.2 (10.2) 27.4 (41.3) 67.6 (46.4) 67.4 (4.5) (no MIM) Linear 768 ✓ 91.3 (2.5) 78.8 (9.6) 37.5 (45.4) 78.5 (39.6) 67.3 (4.7) Linear 768 ✓ 95.9 (1.5) 85.7 (9.8) 47.4 (46.7) 90.4 (26.8) 73.4 (3.6) ViTDet 4 768 ✓ 97.8 (1.2) 90.7 (10.0) 52.5 (46.9) 85.6 (32.7) 83.6 (2.9) UPerNet 4 768 ✓ 98.0 (1.1) 91.2 (10.1) 87.2 (29.4) 94.4 (20.0) 85.3 (2.6)
Role of encoder–decoder choice:
Variants of image feature pyramid networks (FPNs) [71], including the U-Net approach used to set the performance upper bound, have been consistently applied to dense localisation and segmentation tasks as they efficiently leverage low- and high-level semantic features simultaneously. In that regard, ViT is not an optimal selection for this purpose due to its single-scale feature map throughout the network, and here we combined with FPN-based decoder heads (e.g., UPerNet) to observe its maximal performance.
We observe that pre-training alone is a good candidate for learning transferable frozen features—similarly to how DINOv2 features were shown to perform well out-of-the-box without the need for fine-tuning [22]—and is competitive with end-to-end networks trained specifically for the downstream tasks, such as the U-Net in Table 6 and other recent chest X-ray segmentation models [76, 77, 78, 79]. Similarly, large performance gains are noted for smaller structures with the use of intermediate activations and FPN-based decoder heads, and we conjecture that further gains can be achieved by introducing feature pyramids at image encoding stage with an architecture like Swin Transformer [27].
Fewer segmentation labels are required:
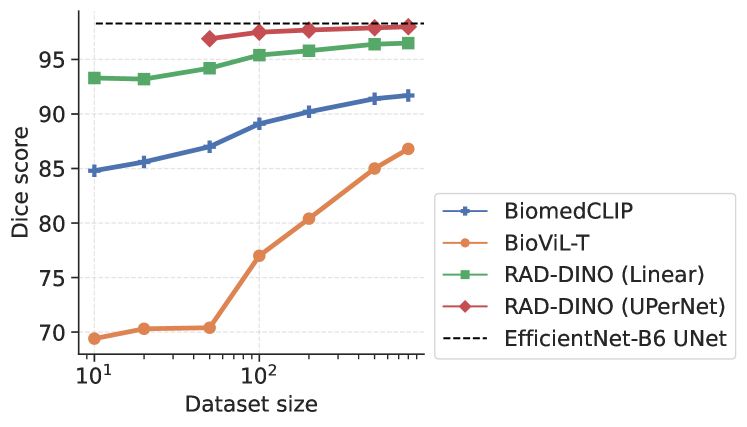
Additional ablations are performed to understand few-shot transfer of image networks to segmentation tasks; as such, the previous set of experiments are repeated only for the segmentation of left and right lungs for varying size of manual annotations used for training. Figure 4 shows that the few-shot transfer of baseline approaches (BioViL-T and BiomedCLIP) is sub-optimal compared to the vision-only pre-trained encoder with a linear decoder [22]. We see lower variation in the Dice scores for across increasing training dataset sizes, reaching near-optimal segmentation performance even with very few samples. The performance further improves when is combined with a UPerNet decoder. This implies that large scale image-only pre-training can potentially reduce the need for densely annotated medical scans for downstream semantic segmentation applications, which require medical expertise and are time-consuming to collect.
4.4 Correlation of Imaging Features with Patient Metadata
Experimental setup:
While patient demographics and medical records, such as sex, age, weight, and body mass index (BMI), are not routinely included in chest X-ray reports, they are considered by radiologists during image interpretation, radiation dose decisions [80], and follow-up interventions. However, the patients’ metadata is often correlated with imaging features, for example in 3D-tomographic scans, where 2D scout images can provide a useful approximation [81, 82]. Our hypothesis is that image encoders trained with text-based weak supervision (e.g., BiomedCLIP and BioViL-T) may not capture this patient information, even though it is present in the pixel data. We compare the performance of a linear classifier using a frozen encoder with those using frozen BiomedCLIP and BioViL-T encoders. We select a subset of the MIMIC-CXR dataset (N = 60.1k) where the radiology reports noted “no findings”. We then link the anonymised subject information with the medical records provided in the MIMIC-IV dataset [83].
Encoder Sex Age Weight BMI BioViL-T [39] 75.1 (0.3) 60.8 (0.5) 43.8 (0.5) 47.6 (0.1) BiomedCLIP [40] 86.0 (0.3) 56.5 (0.5) 52.8 (0.4) 54.2 (0.1) 99.6 (0.1) 72.3 (0.3) 62.4 (0.4) 71.3 (0.2)
Results analysis:
As shown in Table 7, significantly outperforms baselines in predicting sex, age, weight, and BMI. This suggests that self-supervised learning captures a more comprehensive set of imaging information. It’s important to note that differences in image resolution and training data are expected to have less impact on these variables, as global image characteristics (e.g., size of mediastinum, AP/PA view, appearance of bones, and width of fat layer) play a more significant role. While in some applications, invariance to metadata factors such as ethnicity can be a desired attribute to avoid unwanted bias, it is important to consider that other factors, such as age and sex, are commonly used in the clinical decision-making process, and so it is important for an image encoder to capture them. For instance, similar abnormalities may be interpreted differently, and with different levels of concern for different patient age groups.
5 Related Work
Representation learning:
Advances in representation learning come from a variety of directions, with recent approaches obtaining desired properties by combining methods. For image-only pre-training, contrastive objectives are powerful for learning useful global representations [19]; more recently, reliance on negative samples has been replaced with asymmetric architectures [84, 85] and clustering [63, 41]. For local feature learning, useful for tasks such as segmentation, generative tasks, namely masked image modelling has shown to be more useful [35, 86] and its data scaling characteristics studied in [60]. Such local MIM and global contrastive objectives can be combined effectively to capture features useful for more diverse tasks [59, 22, 23]. Recently [58] has shown that MIM-only learning coupled with advanced masking and latent-prediction strategies can improve the model convergence and reduce the reliance on multi-view contrastive objectives. Contrastive methods are similarly popular for image-text pre-training, mapping the two modalities to the same global feature space (CLIP; [2]), and have been shown to be effective for various downstream tasks. Proposals for improvements include using external knowledge bases [87], encouraging finer-level alignment [88], and binding multiple modalities [89]. Additional granularity in learned representations can be obtained via generative tasks such as captioning [90, 91, 92, 93]. Combining image-only objectives and image-text objectives has also been shown to be beneficial [15, 94, 95, 96].
Biomedical vision–language models:
A number of other works have developed foundation models specialised for medical tasks. Many of these are based on multimodal contrastive learning [6], with ChexZero [97], GLoRIA [5], and BioViL [4] training solely on X-ray datasets, showing image- and patch-level variants of the CLIP objective. BioViL-T [39] introduces temporal knowledge into the learning process to make use of multiple X-rays and conditional reports. Med-UniC [31] has extended these approaches to multi-lingual datasets achieving superior performance. In [98], authors have introduced a joint space for multimodal samples by extracting clinical entity triplets from each modality and aligning them. A set of studies have focused on building new larger scale paired image-text datasets in order to match the scaling observed for natural image CLIP models: BiomedCLIP [40] build a larger dataset of image-text pairs by extracting figures from PubMed articles; PMC-CLIP [99] do similar, with additional data curation stages to filter for primarily X-ray images. MedCLIP [100] addresses medical data scarcity by decoupling image and text for multimodal contrastive learning, thus vastly scaling usable training data at a low cost. Similarly, masked-modelling has found its applications in this domain as well, achieving strong performance on various benchmarks [7]. Lastly, vision-language models have been developed based on generative captioning [90], with Med-Flamingo [9] fine-tuning a Flamingo [101] model on paired/interleaved image-text data.
Image-based self-supervised learning:
Image-only pre-training for medical data has been extensively studied, with many recent works focusing on selecting pre-training objectives useful for the class of downstream applications of interest. For example, for classification, [38, 102, 103] demonstrated the use of SimCLR [19] and DINO-v.1 [41] contrastive approaches to learn transferable image features for downstream fine-tuning (also build more informative positive pairs); while for segmentation, Tang et al. [33] learn local features useful for CT and MR image segmentation by applying contrastive/predictive objectives to local regions, and [32, 104] use pixel-wise masked image modelling [86, 105] demonstrating strong performance across different imaging modalities. To learn features useful for medical tasks at multiple scales, Hosseinzadeh Taher et al. [106] decompose images in a coarse-to-fine manner and utilise contrastive predictive coding [18], while Zhou et al. [7] combine masked image modelling with masked language modelling, to learn a joint distribution and improve the fusion of modalities. Also of relevance are recent large-scale pre-trained image networks, specialised for the histopathology domain, which is notable for its abundant availability of imaging data; in similar research, authors in [107, 108] train iBoT [59] and DINOv2 [22] models respectively, arguing that contrastive methods are less suitable for rare pathologies since the linear separability of learned representations is poor for class-imbalanced data.
Applications of deep networks in radiology:
A survey study [109] on chest X-Rays outlines various applications and benchmark datasets used in past studies. Sellergren et al. [110] have studied the transfer of pre-trained SSL features to classification tasks in reducing the requirement for manual labels. Similarly, early work [69, 111] explored the use of neural networks for image classification on large-scale datasets (NIH-CXR-14 and Chexpert). In these benchmarks, diagnostic labels were extracted from radiology reports using a parser, resulting in significant label noise [112, 113]. Consequently, and baselines are evaluated only on benchmarks containing expert annotations. For medical image segmentation, in particular, U-Net [26] models remain widespread [72], whilst domain-specific approaches [114] used priors tailored towards chest X-Rays. Segmentation of findings have been also used to mitigate potential short-cuts and biases learnt by networks to disentangle abnormalities from treatment interventions [115]. Lastly, image backbones have been utilised for radiology report generation [10, 39, 116, 117] and VQA applications [8, 9] to extract visual descriptors that can be reasoned in conjunction with other clinical input data or textual prompts to generate text outputs.
6 Discussion and Conclusion
In this study we demonstrated that high quality general purpose biomedical image encoders useful for a diverse range of downstream tasks, can be trained solely using unimodal imaging data. This is in contrast to prior state-of-the-art biomedical methods which rely on language supervision. Towards this goal, we developed by continually pre-training DINOv2 with domain-specific augmentations and datasets, without specialising on a specific set of modalities or task-specific supervisory objectives, instead using the raw imaging data alone. The experimental results across multiple benchmarks demonstrated that achieves comparable or superior performance to state-of-the-art methods, a distinction attributed to its independence from text supervision quality and its ability to capture a wider range of imaging features at scale.
To explain ’s performance, we postulated that reliance on additional modalities can not only not be necessary, but actually become a potential limitation in learning rich visual representations of medical scans; in the case of textual reports this depends on their descriptiveness and completeness. Moreover, language supervised models may not generalise beyond the content reported in findings. For instance, by mapping scans without any abnormalities to the same latent representation, CLIP-style image networks can fail to link imaging data with other clinical data modalities, explore new imaging biomarkers, and enable prognosis that require medical scans. Strengthening these findings, we performed a number of ablations where we found that: pre-existing large-scale Vision Transformer-based image encoders with no in-domain biomedical knowledge already generalise surprisingly well to chest X-ray datasets, yielding results that are on par with some established biomedical baselines, echoing findings in [30, 31]; ’s imaging features correlate better with patient medical records than CLIP-style models; and that unlike CLIP-style models, can naturally handle the challenge of learning from both frontal and lateral scans simultaneously without fusing multiple views or associating textual phrases with each view separately.
A further advantage of the approach is that it allows the vast amounts of medical imaging-only data to be leveraged, enabling larger-scale models to be trained. This circumvents the well known problems of scarcity of paired image–text pairs in public datasets, while also opening up application areas including histopathology and sonography, where text is rarely available. Relying only on image self-supervision also enables applications with increased resolution and dimension (e.g., full-body 3D CT images); there, the weak supervision signal from text data can become sparse and less reliable, requiring multiple-instance learning or ad-hoc pre-processing solutions, limiting their scalability. For this reason, we conjecture that self-supervised training, using or other MIM approaches, will scale more easily with the addition of data from other imaging modalities, whilst achieving similar or better results than current SOTA approaches. Additionally, our analysis on input image resolution emphasises the importance of breaking down analysis of results per target class: some subsets of findings require fine-grained analysis of texture; for instance in this work pneumothorax and chest tubes, where shows no major limitations. The importance of image resolution is expected to be further pronounced in the context of describing attributes of findings, e.g., severity and temporal progression, which is partly quantified within our report generation experiments. However, while demonstrably important, ’s superior performance is not solely attributed to image resolution.
With the growth of large-scale computation and availability of extensive training data, we have begun to witness the potential of large-scale models for tasks beyond their initial scope, able to learn ad-hoc from a few examples [118, 119]. We expect a similar trend to unfold in the medical domain [120]. Our work makes progress in this direction; rather than fine-tuning such large networks for a narrow set of applications, producing multiple resultant encoders, we advocate for reusing them with task-specific heads (e.g., segmentation, language decoding) in different contexts as a more effective and efficient strategy to enable AI solutions in wider healthcare settings. This also requires complementary benchmarking efforts across a broad set of applications, as in the case of our study, not focusing solely on unimodal evaluations [7, 31] but also including multimodal tasks like textual report generation. Due to the limited scope of our study, we have not studied alternative encoder architecture adaptions, such as Swin Transformers; however, we expect that use of such a multi-scale backbone within our approach would provide further performance gains for image segmentation, without compromising on performance for the other benchmarks. Similarly, performance of the image backbone for report generation could be further enhanced by aggregating intermediate layers and fine-tuning a higher-capacity adaptation layer, as in [121], to better adapt image representations for the LLM. We leave this for the future work.
References
- Desai and Johnson [2021] Karan Desai and Justin Johnson. Virtex: Learning visual representations from textual annotations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11162–11173, 2021.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Yu et al. [2022a] Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models. Trans. Mach. Learn. Res., 2022, 2022a. URL https://openreview.net/pdf?id=Ee277P3AYC.
- Boecking et al. [2022] Benedikt Boecking, Naoto Usuyama, Shruthi Bannur, Daniel C Castro, Anton Schwaighofer, Stephanie Hyland, Maria Wetscherek, Tristan Naumann, Aditya Nori, Javier Alvarez-Valle, et al. Making the most of text semantics to improve biomedical vision–language processing. In European conference on computer vision, pages 1–21. Springer, 2022.
- Huang et al. [2021] Shih-Cheng Huang, Liyue Shen, Matthew P Lungren, and Serena Yeung. Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3942–3951, 2021.
- Zhang et al. [2022] Yuhao Zhang, Hang Jiang, Yasuhide Miura, Christopher D Manning, and Curtis P Langlotz. Contrastive learning of medical visual representations from paired images and text. In Machine Learning for Healthcare Conference, pages 2–25. PMLR, 2022.
- Zhou et al. [2023] Hong-Yu Zhou, Chenyu Lian, Liansheng Wang, and Yizhou Yu. Advancing radiograph representation learning with masked record modeling. In The Eleventh International Conference on Learning Representations, 2023.
- Li et al. [2023] Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. arXiv preprint arXiv:2306.00890, 2023. URL https://arxiv.org/pdf/2306.00890.pdf.
- Moor et al. [2023a] Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Cyril Zakka, Yash Dalmia, Eduardo Pontes Reis, Pranav Rajpurkar, and Jure Leskovec. Med-flamingo: a multimodal medical few-shot learner. arXiv preprint arXiv:2307.15189, 2023a. URL https://arxiv.org/pdf/2307.15189.pdf.
- Tu et al. [2023] Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Chuck Lau, Ryutaro Tanno, Ira Ktena, et al. Towards generalist biomedical ai. arXiv preprint arXiv:2307.14334, 2023. URL https://arxiv.org/pdf/2307.14334.pdf.
- Moor et al. [2023b] Michael Moor, Oishi Banerjee, Zahra Shakeri Hossein Abad, Harlan M Krumholz, Jure Leskovec, Eric J Topol, and Pranav Rajpurkar. Foundation models for generalist medical artificial intelligence. Nature, 616(7956):259–265, 2023b.
- Dehghani et al. [2023] Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, et al. Scaling vision transformers to 22 billion parameters. In International Conference on Machine Learning, pages 7480–7512. PMLR, 2023.
- Zhai et al. [2022a] Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12104–12113, 2022a.
- Yang et al. [2022] Jinyu Yang, Jiali Duan, Son Tran, Yi Xu, Sampath Chanda, Liqun Chen, Belinda Zeng, Trishul Chilimbi, and Junzhou Huang. Vision-language pre-training with triple contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15671–15680, 2022.
- Zhai et al. [2022b] Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18123–18133, 2022b.
- Liang et al. [2022] Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Processing Systems, 35:17612–17625, 2022.
- Johnson et al. [2019] Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data, 6(1):317, 2019. URL https://physionet.org/content/mimic-cxr/2.0.0/.
- Oord et al. [2018] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018. URL https://arxiv.org/pdf/1807.03748.pdf.
- Chen et al. [2020] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020. URL https://proceedings.mlr.press/v119/chen20j/chen20j.pdf.
- Acosta et al. [2022] Julián N Acosta, Guido J Falcone, Pranav Rajpurkar, and Eric J Topol. Multimodal biomedical ai. Nature Medicine, 28(9):1773–1784, 2022.
- Langlotz [2023] Curtis P Langlotz. The future of ai and informatics in radiology: 10 predictions, 2023.
- Oquab et al. [2023] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, and Piotr Bojanowski. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. URL https://arxiv.org/pdf/2304.07193.pdf.
- Huang et al. [2023] Zhicheng Huang, Xiaojie Jin, Chengze Lu, Qibin Hou, Ming-Ming Cheng, Dongmei Fu, Xiaohui Shen, and Jiashi Feng. Contrastive masked autoencoders are stronger vision learners. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- Park et al. [2023] Namuk Park, Wonjae Kim, Byeongho Heo, Taekyung Kim, and Sangdoo Yun. What do self-supervised vision transformers learn? In The Eleventh International Conference on Learning Representations, 2023.
- Shekhar et al. [2023] Shashank Shekhar, Florian Bordes, Pascal Vincent, and Ari S Morcos. Objectives matter: Understanding the impact of self-supervised objectives on vision transformer representations. In ICLR 2023 Workshop on Mathematical and Empirical Understanding of Foundation Models, 2023.
- Ronneberger et al. [2015] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer, 2015.
- Liu et al. [2021] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021.
- Li et al. [2022] Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. Exploring plain vision transformer backbones for object detection. In European Conference on Computer Vision, pages 280–296. Springer, 2022.
- Xiao et al. [2018] Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. Unified perceptual parsing for scene understanding. In Proceedings of the European conference on computer vision (ECCV), pages 418–434, 2018. URL https://openaccess.thecvf.com/content_ECCV_2018/papers/Tete_Xiao_Unified_Perceptual_Parsing_ECCV_2018_paper.pdf.
- Huix et al. [2024] Joana Palés Huix, Adithya Raju Ganeshan, Johan Fredin Haslum, Magnus Söderberg, Christos Matsoukas, and Kevin Smith. Are natural domain foundation models useful for medical image classification? In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 7634–7643, 2024.
- Wan et al. [2023] Zhongwei Wan, Che Liu, Mi Zhang, Jie Fu, Benyou Wang, Sibo Cheng, Lei Ma, Cesar C’esar Quilodr’an-Casas, and Rossella Arcucci. Med-unic: Unifying cross-lingual medical vision-language pre-training by diminishing bias. Advances in Neural Information Processing Systems, 2023.
- Zhou et al. [2019] Zongwei Zhou, Vatsal Sodha, Md Mahfuzur Rahman Siddiquee, Ruibin Feng, Nima Tajbakhsh, Michael B Gotway, and Jianming Liang. Models genesis: Generic autodidactic models for 3d medical image analysis. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13–17, 2019, Proceedings, Part IV 22, pages 384–393. Springer, 2019.
- Tang et al. [2022] Yucheng Tang, Dong Yang, Wenqi Li, Holger R Roth, Bennett Landman, Daguang Xu, Vishwesh Nath, and Ali Hatamizadeh. Self-supervised pre-training of swin transformers for 3d medical image analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20730–20740, 2022.
- Tarvainen and Valpola [2017] Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Advances in neural information processing systems, 30, 2017.
- Bao et al. [2021] Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers. In International Conference on Learning Representations, 2021.
- Wang et al. [2022a] Xiao Wang, Haoqi Fan, Yuandong Tian, Daisuke Kihara, and Xinlei Chen. On the importance of asymmetry for siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16570–16579, 2022a.
- Sablayrolles et al. [2018] Alexandre Sablayrolles, Matthijs Douze, Cordelia Schmid, and Hervé Jégou. Spreading vectors for similarity search. In International Conference on Learning Representations, 2018.
- Park et al. [2022] Sangjoon Park, Gwanghyun Kim, Yujin Oh, Joon Beom Seo, Sang Min Lee, Jin Hwan Kim, Sungjun Moon, Jae-Kwang Lim, Chang Min Park, and Jong Chul Ye. Self-evolving vision transformer for chest x-ray diagnosis through knowledge distillation. Nature communications, 13(1):3848, 2022.
- Bannur et al. [2023] Shruthi Bannur, Stephanie Hyland, Qianchu Liu, Fernando Perez-Garcia, Maximilian Ilse, Daniel C Castro, Benedikt Boecking, Harshita Sharma, Kenza Bouzid, Anja Thieme, et al. Learning to exploit temporal structure for biomedical vision-language processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15016–15027, 2023.
- Zhang et al. [2023a] Sheng Zhang, Yanbo Xu, Naoto Usuyama, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, Cliff Wong, et al. Large-scale domain-specific pretraining for biomedical vision-language processing. arXiv preprint arXiv:2303.00915, 2023a. URL https://arxiv.org/pdf/2303.00915.pdf.
- Caron et al. [2021] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021.
- Bardes et al. [2022] Adrien Bardes, Jean Ponce, and Yann LeCun. Vicregl: Self-supervised learning of local visual features. Advances in Neural Information Processing Systems, 35:8799–8810, 2022.
- Chiang et al. [2023] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Liu et al. [2023a] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2023a. URL http://arxiv.org/pdf/2310.03744.pdf.
- Liu et al. [2023b] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023b. URL http://arxiv.org/abs/2304.08485.
- Nguyen et al. [2022] Ha Q Nguyen, Khanh Lam, Linh T Le, Hieu H Pham, Dat Q Tran, Dung B Nguyen, Dung D Le, Chi M Pham, Hang TT Tong, Diep H Dinh, et al. Vindr-cxr: An open dataset of chest x-rays with radiologist’s annotations. Scientific Data, 9(1):429, 2022.
- Feng et al. [2021] Sijing Feng, Damian Azzollini, Ji Soo Kim, Cheng-Kai Jin, Simon P Gordon, Jason Yeoh, Eve Kim, Mina Han, Andrew Lee, Aakash Patel, et al. Curation of the candid-ptx dataset with free-text reports. Radiology: Artificial Intelligence, 3(6):e210136, 2021.
- MD et al. [2018] Anouk Stein MD, Carol Wu, Chris Carr, George Shih, Jamie Dulkowski, kalpathy, Leon Chen, Luciano Prevedello, Marc Kohli MD, Mark McDonald, Peter, Phil Culliton, Safwan Halabi MD, and Tian Xia. Rsna pneumonia detection challenge, 2018. URL https://kaggle.com/competitions/rsna-pneumonia-detection-challenge.
- Chen et al. [2022] Li-Ching Chen, Po-Chih Kuo, Ryan Wang, Judy Gichoya, and Leo Anthony Celi. Chest x-ray segmentation images based on mimic-cxr, 2022. URL https://physionet.org/content/lung-segment-mimic-cxr/1.0.0/.
- Wu et al. [2021] Joy T Wu, Nkechinyere N Agu, Ismini Lourentzou, Arjun Sharma, Joseph A Paguio, Jasper S Yao, Edward C Dee, William Mitchell, Satyananda Kashyap, Andrea Giovannini, et al. Chest imagenome dataset (version 1.0. 0). PhysioNet, 5:18, 2021.
- Nguyen et al. [2021] Hoang C. Nguyen, Tung T. Le, Hieu H. Pham, and Ha Q. Nguyen. Vindr-ribcxr: A benchmark dataset for automatic segmentation and labeling of individual ribs on chest x-rays, 2021.
- Haque et al. [2023] Md Inzamam Ul Haque, Abhishek K Dubey, Ioana Danciu, Amy C Justice, Olga S Ovchinnikova, and Jacob D Hinkle. Effect of image resolution on automated classification of chest x-rays. Journal of Medical Imaging, 10(4):044503–044503, 2023.
- Sabottke and Spieler [2020] Carl F Sabottke and Bradley M Spieler. The effect of image resolution on deep learning in radiography. Radiology: Artificial Intelligence, 2(1):e190015, 2020.
- Tanno et al. [2023] Ryutaro Tanno, David GT Barrett, Andrew Sellergren, Sumedh Ghaisas, Sumanth Dathathri, Abigail See, Johannes Welbl, Karan Singhal, Shekoofeh Azizi, Tao Tu, et al. Consensus, dissensus and synergy between clinicians and specialist foundation models in radiology report generation. arXiv preprint arXiv:2311.18260, 2023. URL https://arxiv.org/pdf/2311.18260.pdf.
- Cherti and Jitsev [2022] Mehdi Cherti and Jenia Jitsev. Effect of pre-training scale on intra-and inter-domain, full and few-shot transfer learning for natural and x-ray chest images. In 2022 International Joint Conference on Neural Networks (IJCNN), pages 1–9. IEEE, 2022. URL https://arxiv.org/pdf/2106.00116.pdf.
- Mustafa et al. [2021] Basil Mustafa, Aaron Loh, Jan Freyberg, Patricia MacWilliams, Megan Wilson, Scott Mayer McKinney, Marcin Sieniek, Jim Winkens, Yuan Liu, Peggy Bui, et al. Supervised transfer learning at scale for medical imaging. arXiv preprint arXiv:2101.05913, 2021. URL https://arxiv.org/pdf/2101.05913.pdf.
- Bustos et al. [2020] Aurelia Bustos, Antonio Pertusa, Jose-Maria Salinas, and Maria de la Iglesia-Vayá. PadChest: A large chest x-ray image dataset with multi-label annotated reports. Medical Image Analysis, 66:101797, December 2020. ISSN 1361-8415. doi:10.1016/j.media.2020.101797. URL http://dx.doi.org/10.1016/j.media.2020.101797.
- Assran et al. [2023] Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023.
- Zhou et al. [2022] Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. iBOT: image BERT pre-training with online tokenizer. In International Conference on Learning Representations, 2022.
- Xie et al. [2023] Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Yixuan Wei, Qi Dai, and Han Hu. On data scaling in masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10365–10374, 2023.
- Bertrand et al. [2019] Hadrien Bertrand, Mohammad Hashir, and Joseph Paul Cohen. Do lateral views help automated chest x-ray predictions? arXiv preprint arXiv:1904.08534, 2019. URL https://arxiv.org/pdf/1904.08534.pdf.
- Hashir et al. [2020] Mohammad Hashir, Hadrien Bertrand, and Joseph Paul Cohen. Quantifying the value of lateral views in deep learning for chest x-rays. In Medical Imaging with Deep Learning, pages 288–303. PMLR, 2020. URL https://proceedings.mlr.press/v121/hashir20a/hashir20a.pdf.
- Caron et al. [2020] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. Advances in neural information processing systems, 33:9912–9924, 2020.
- Yang et al. [2023] Ziyu Yang, Santhosh Cherian, and Slobodan Vucetic. Data augmentation for radiology report simplification. In Findings of the Association for Computational Linguistics: EACL 2023, pages 1877–1887, 2023.
- Lin [2004] Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81. Association for Computational Linguistics, July 2004. URL https://aclanthology.org/W04-1013.
- Papineni et al. [2002] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318. Association for Computational Linguistics, July 2002. doi:10.3115/1073083.1073135.
- Delbrouck et al. [2022] Jean-Benoit Delbrouck, Pierre Chambon, Christian Bluethgen, Emily Tsai, Omar Almusa, and Curtis Langlotz. Improving the factual correctness of radiology report generation with semantic rewards. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 4348–4360. ACL, December 2022. doi:10.18653/v1/2022.findings-emnlp.319.
- Smit et al. [2020] Akshay Smit, Saahil Jain, Pranav Rajpurkar, Anuj Pareek, Andrew Ng, and Matthew Lungren. Combining automatic labelers and expert annotations for accurate radiology report labeling using BERT. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1500–1519. ACL, November 2020. doi:10.18653/v1/2020.emnlp-main.117.
- Irvin et al. [2019] Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn L. Ball, Katie Shpanskaya, Jayne Seekins, David A. Mong, Safwan S. Halabi, Jesse K. Sandberg, Ricky Jones, David B. Larson, Curtis P. Langlotz, Bhavik N. Patel, Matthew P. Lungren, and Andrew Y. Ng. CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI 2019), volume 33, pages 590–597. AAAI Press, July 2019. doi:10.1609/aaai.v33i01.3301590.
- Lin et al. [2023a] Ji Lin, Hongxu Yin, Wei Ping, Yao Lu, Pavlo Molchanov, Andrew Tao, Huizi Mao, Jan Kautz, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models. arXiv preprint arXiv:2312.07533, 2023a. URL https://arxiv.org/pdf/2312.07533.pdf.
- Lin et al. [2017] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017.
- Azad et al. [2022] Reza Azad, Ehsan Khodapanah Aghdam, Amelie Rauland, Yiwei Jia, Atlas Haddadi Avval, Afshin Bozorgpour, Sanaz Karimijafarbigloo, Joseph Paul Cohen, Ehsan Adeli, and Dorit Merhof. Medical image segmentation review: The success of u-net, 2022.
- Isensee et al. [2018] Fabian Isensee, Jens Petersen, Andre Klein, David Zimmerer, Paul F. Jaeger, Simon Kohl, Jakob Wasserthal, Gregor Koehler, Tobias Norajitra, Sebastian Wirkert, and Klaus H. Maier-Hein. nnu-net: Self-adapting framework for u-net-based medical image segmentation. arXiv preprint arXiv:1809.10486, 2018. URL https://arxiv.org/pdf/1809.10486.pdf.
- Tan and Le [2020] Mingxing Tan and Quoc V. Le. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv preprint arXiv:1905.11946, 2020. URL https://arxiv.org/pdf/1905.11946.pdf.
- Ilharco et al. [2022] Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. OpenCLIP, September 2022. URL https://doi.org/10.5281/zenodo.7086307.
- Wang et al. [2024] Hongyu Wang, Dandan Zhang, Jun Feng, Lucia Cascone, Michele Nappi, and Shaohua Wan. A multi-objective segmentation method for chest x-rays based on collaborative learning from multiple partially annotated datasets. Information Fusion, 102:102016, 2024.
- Zhang et al. [2023b] Dandan Zhang, Hongyu Wang, Jiahui Deng, Tonghui Wang, Cong Shen, and Jun Feng. Cams-net: An attention-guided feature selection network for rib segmentation in chest x-rays. Computers in Biology and Medicine, 156:106702, 2023b.
- Pal et al. [2023] Debojyoti Pal, Tanushree Meena, and Sudipta Roy. A fully connected reproducible se-uresnet for multiorgan chest radiographs segmentation. In 2023 IEEE 24th International Conference on Information Reuse and Integration for Data Science (IRI), pages 261–266. IEEE, 2023.
- Brioso et al. [2023] Ricardo Coimbra Brioso, João Pedrosa, Ana Maria Mendonça, and Aurélio Campilho. Semi-supervised multi-structure segmentation in chest x-ray imaging. In 2023 IEEE 36th International Symposium on Computer-Based Medical Systems (CBMS), pages 814–820. IEEE, 2023.
- Boos et al. [2016] Johannes Boos, Rotem S Lanzman, Philipp Heusch, Joel Aissa, Christoph Schleich, Christoph Thomas, Lino M Sawicki, Gerald Antoch, and Patric Kröpil. Does body mass index outperform body weight as a surrogate parameter in the calculation of size-specific dose estimates in adult body ct? The British Journal of Radiology, 89(1059):20150734, 2016.
- Demircioğlu et al. [2023] Aydin Demircioğlu, Anton S Quinsten, Lale Umutlu, Michael Forsting, Kai Nassenstein, and Denise Bos. Determining body height and weight from thoracic and abdominal ct localizers in pediatric and young adult patients using deep learning. Scientific Reports, 13(1):19010, 2023.
- Ichikawa et al. [2021] Shota Ichikawa, Misaki Hamada, and Hiroyuki Sugimori. A deep-learning method using computed tomography scout images for estimating patient body weight. Scientific reports, 11(1):15627, 2021.
- Johnson et al. [2023] Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Steven Horng, Leo Anthony Celi, and Roger Mark. Mimic-iv, 2023. URL https://physionet.org/content/mimiciv/2.2/.
- Grill et al. [2020] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33:21271–21284, 2020.
- Chen and He [2021] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15750–15758, 2021.
- He et al. [2022] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022.
- Shen et al. [2022] Sheng Shen, Chunyuan Li, Xiaowei Hu, Yujia Xie, Jianwei Yang, Pengchuan Zhang, Zhe Gan, Lijuan Wang, Lu Yuan, Ce Liu, et al. K-lite: Learning transferable visual models with external knowledge. Advances in Neural Information Processing Systems, 35:15558–15573, 2022.
- Yao et al. [2021] Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: Fine-grained interactive language-image pre-training. In International Conference on Learning Representations, 2021.
- Girdhar et al. [2023] Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15180–15190, 2023.
- Yu et al. [2022b] Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models. Transactions on Machine Learning Research, 2022b. ISSN 2835-8856.
- Wang et al. [2022b] Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, and Yuan Cao. SimVLM: Simple visual language model pretraining with weak supervision. In International Conference on Learning Representations, 2022b.
- Singh et al. [2022] Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela. Flava: A foundational language and vision alignment model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15638–15650, 2022.
- Tschannen et al. [2023] Michael Tschannen, Manoj Kumar, Andreas Steiner, Xiaohua Zhai, Neil Houlsby, and Lucas Beyer. Image captioners are scalable vision learners too. arXiv preprint arXiv:2306.07915, 2023. URL https://arxiv.org/pdf/2306.07915.pdf.
- Li et al. [2021] Yangguang Li, Feng Liang, Lichen Zhao, Yufeng Cui, Wanli Ouyang, Jing Shao, Fengwei Yu, and Junjie Yan. Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm. In International Conference on Learning Representations, 2021.
- Weers et al. [2023] Floris Weers, Vaishaal Shankar, Angelos Katharopoulos, Yinfei Yang, and Tom Gunter. Masked autoencoding does not help natural language supervision at scale. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23432–23444, 2023.
- Mu et al. [2022] Norman Mu, Alexander Kirillov, David Wagner, and Saining Xie. Slip: Self-supervision meets language-image pre-training. In European Conference on Computer Vision, pages 529–544. Springer, 2022.
- E. et al. [2022] Tiu E., Talius E., Patel P., et al. Expert-level detection of pathologies from unannotated chest x-ray images via self-supervised learning. Nat. Biomed. Eng 6, 1399–1406, 2022.
- Wu et al. [2023] Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 21372–21383, October 2023. URL https://openaccess.thecvf.com/content/ICCV2023/papers/Wu_MedKLIP_Medical_Knowledge_Enhanced_Language-Image_Pre-Training_for_X-ray_Diagnosis_ICCV_2023_paper.pdf.
- Lin et al. [2023b] Weixiong Lin, Ziheng Zhao, Xiaoman Zhang, Chaoyi Wu, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc-clip: Contrastive language-image pre-training using biomedical documents. arXiv preprint arXiv:2303.07240, 2023b. URL https://arxiv.org/pdf/2303.07240.pdf.
- Wang et al. [2022c] Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medical images and text, 2022c. URL https://arxiv.org/pdf/2210.10163.pdf.
- Alayrac et al. [2022] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716–23736, 2022.
- Azizi et al. [2021] Shekoofeh Azizi, Basil Mustafa, Fiona Ryan, Zachary Beaver, Jan Freyberg, Jonathan Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, et al. Big self-supervised models advance medical image classification. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3478–3488, 2021.
- Azizi et al. [2023] Shekoofeh Azizi, Laura Culp, Jan Freyberg, Basil Mustafa, Sebastien Baur, Simon Kornblith, Ting Chen, Nenad Tomasev, Jovana Mitrović, Patricia Strachan, et al. Robust and data-efficient generalization of self-supervised machine learning for diagnostic imaging. Nature Biomedical Engineering, pages 1–24, 2023.
- Chen et al. [2023] Zekai Chen, Devansh Agarwal, Kshitij Aggarwal, Wiem Safta, Mariann Micsinai Balan, and Kevin Brown. Masked image modeling advances 3d medical image analysis. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1970–1980, 2023.
- Xie et al. [2022] Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9653–9663, 2022.
- Hosseinzadeh Taher et al. [2023] Mohammad Reza Hosseinzadeh Taher, Michael B Gotway, and Jianming Liang. Towards foundation models learned from anatomy in medical imaging via self-supervision. In MICCAI Workshop on Domain Adaptation and Representation Transfer, pages 94–104. Springer, 2023.
- Filiot et al. [2023] Alexandre Filiot, Ridouane Ghermi, Antoine Olivier, Paul Jacob, Lucas Fidon, Alice Mac Kain, Charlie Saillard, and Jean-Baptiste Schiratti. Scaling self-supervised learning for histopathology with masked image modeling. medRxiv, pages 2023–07, 2023. URL https://www.medrxiv.org/content/10.1101/2023.07.21.23292757v2.full.pdf.
- Vorontsov et al. [2023] Eugene Vorontsov, Alican Bozkurt, Adam Casson, George Shaikovski, Michal Zelechowski, Siqi Liu, Philippe Mathieu, Alexander van Eck, Donghun Lee, Julian Viret, Eric Robert, Yi Kan Wang, Jeremy D. Kunz, Matthew C. H. Lee, Jan Bernhard, Ran A. Godrich, Gerard Oakley, Ewan Millar, Matthew Hanna, Juan Retamero, William A. Moye, Razik Yousfi, Christopher Kanan, David Klimstra, Brandon Rothrock, and Thomas J. Fuchs. Virchow: A million-slide digital pathology foundation model. arXiv preprint arXiv:2309.07778, 2023. URL https://arxiv.org/pdf/2309.07778.pdf.
- Çallı et al. [2021] Erdi Çallı, Ecem Sogancioglu, Bram van Ginneken, Kicky G van Leeuwen, and Keelin Murphy. Deep learning for chest x-ray analysis: A survey. Medical Image Analysis, 72:102125, 2021.
- Sellergren et al. [2022] Andrew B Sellergren, Christina Chen, Zaid Nabulsi, Yuanzhen Li, Aaron Maschinot, Aaron Sarna, Jenny Huang, Charles Lau, Sreenivasa Raju Kalidindi, Mozziyar Etemadi, et al. Simplified transfer learning for chest radiography models using less data. Radiology, 305(2):454–465, 2022.
- Wang et al. [2017] Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M Summers. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2097–2106, 2017.
- Oakden-Rayner [2020] Luke Oakden-Rayner. Exploring large-scale public medical image datasets. Academic radiology, 27(1):106–112, 2020.
- Majkowska et al. [2020] Anna Majkowska, Sid Mittal, David F Steiner, Joshua J Reicher, Scott Mayer McKinney, Gavin E Duggan, Krish Eswaran, Po-Hsuan Cameron Chen, Yun Liu, Sreenivasa Raju Kalidindi, et al. Chest radiograph interpretation with deep learning models: assessment with radiologist-adjudicated reference standards and population-adjusted evaluation. Radiology, 294(2):421–431, 2020.
- Gaggion et al. [2023] Nicolás Gaggion, Candelaria Mosquera, Lucas Mansilla, Martina Aineseder, Diego H Milone, and Enzo Ferrante. Chexmask: a large-scale dataset of anatomical segmentation masks for multi-center chest x-ray images. arXiv preprint arXiv:2307.03293, 2023. URL https://arxiv.org/pdf/2307.03293.pdf.
- Rueckel et al. [2021] Johannes Rueckel, Christian Huemmer, Andreas Fieselmann, Florin-Cristian Ghesu, Awais Mansoor, Balthasar Schachtner, Philipp Wesp, Lena Trappmann, Basel Munawwar, Jens Ricke, et al. Pneumothorax detection in chest radiographs: optimizing artificial intelligence system for accuracy and confounding bias reduction using in-image annotations in algorithm training. European radiology, pages 1–13, 2021.
- Endo et al. [2021] Mark Endo, Rayan Krishnan, Viswesh Krishna, Andrew Y Ng, and Pranav Rajpurkar. Retrieval-based chest x-ray report generation using a pre-trained contrastive language-image model. In Machine Learning for Health, pages 209–219. PMLR, 2021.
- Miura et al. [2021] Yasuhide Miura, Yuhao Zhang, Emily Tsai, Curtis Langlotz, and Dan Jurafsky. Improving factual completeness and consistency of image-to-text radiology report generation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5288–5304, 2021.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Achiam et al. [2023] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023. URL https://arxiv.org/pdf/2303.08774.pdf.
- Nori et al. [2023] Harsha Nori, Yin Tat Lee, Sheng Zhang, Dean Carignan, Richard Edgar, Nicolo Fusi, Nicholas King, Jonathan Larson, Yuanzhi Li, Weishung Liu, et al. Can generalist foundation models outcompete special-purpose tuning? case study in medicine. arXiv preprint arXiv:2311.16452, 2023. URL https://arxiv.org/pdf/2311.16452.pdf.
- Jiang et al. [2023] Dongsheng Jiang, Yuchen Liu, Songlin Liu, Xiaopeng Zhang, Jin Li, Hongkai Xiong, and Qi Tian. From clip to dino: Visual encoders shout in multi-modal large language models, 2023. URL https://arxiv.org/pdf/2310.08825v1.pdf.
- Reis et al. [2022] Eduardo P Reis, Joselisa PQ de Paiva, Maria CB da Silva, Guilherme AS Ribeiro, Victor F Paiva, Lucas Bulgarelli, Henrique MH Lee, Paulo V Santos, Vanessa M Brito, Lucas TW Amaral, et al. BRAX, Brazilian labeled chest x-ray dataset. Scientific Data, 9(1):487, 2022.
- Pedregosa et al. [2011] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
Appendix A Further Analysis on Model Behaviour and Results
A.1 Impact of Image Resolution on Subtle Findings
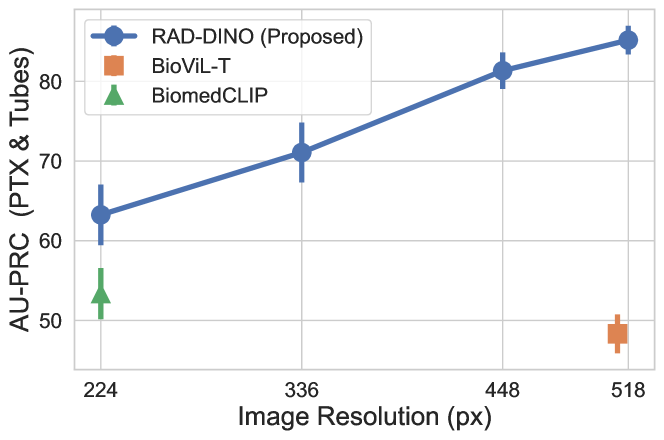
We also extend our resolution ablation studies, reported in Section 3.1, to include subtle findings like pneumothorax and chest tubes using the CANDID-PTX dataset [47]. As detailed in Figure A.1, the results reveal that the encoders’ performance diminishes at lower resolutions due to the ambiguity and loss of detail in the input images, highlighting the necessity of high resolution for accurately detecting such nuanced findings. In comparison to other baseline methods like BiomedCLIP and BioViL-T, the image-only pretrained encoder demonstrates consistently superior performance across various resolutions (224 px and 512 px, respectively). This suggests that the encoder’s effective utilisation of higher resolutions could lead to enhanced performance in downstream tasks such as VQA and text generation, surpassing encoders trained at limited resolutions [9, 10]. Furthermore, it’s crucial to analyse the results breakdown across different findings to fully understand the impact of input resolution.
A.2 Experiments with Lateral Chest X-Ray Scans
We hypothesise that image–text alignment can be challenging for lateral scans and radiology text data, as there is often limited mutual information shared between these two data modalities. Specifically, certain findings reported in radiology textual reports may not be visible in lateral scans, or they are assessable by relying solely on the frontal scans. In this context, image-only SSL techniques, such as , can be a useful alternative to simultaneously learn a rich set of imaging features from both frontal and lateral imaging views during pre-training.
To this end, we used a subset of studies from the PadChest dataset, selecting only the lateral scans containing specific findings, and excluded these studies from pre-training. The selection of findings was guided by the feasibility of detecting them solely based on the lateral scans, in order to reduce task ambiguity. For these reasons, the following findings were selected based on prior research work [61, 62] that demonstrate the unique value of lateral scans in identifying them: “vertebral degenerative changes” (VDC), “pleural effusion” (PE), and “costophrenic angle blunting” (CAB). The positive and negative class distribution of each binary task is kept balanced by randomly sampling negative lateral scans from the rest of the dataset. The total dataset size is N=11.9k, and the dataset is split across train/val/test at 80/10/10% for each random allocation by subject identifier. Since not all class labels were present for each image in this dataset, a subset of the dataset was used for the testing of models for each finding: N=373 for VDC, N=542 for PE, and N=503 for CAB.
The results in Table A.1 indicate that BioViL-T performs nearly comparably to a random classifier on previously unseen findings, such as VDC, likely because it was predominantly trained with frontal scans from MIMIC-CXR. In contrast, the training dataset of BiomedCLIP includes a more balanced mix of frontal and lateral scans. In conclusion, we observe that approaches based on masked modelling, such as MRM and , consistently deliver strong classification results. This demonstrates the effectiveness of the MIM objective in adapting to various imaging views. Furthermore, it is important to note that can achieve this performance without requiring text supervision during pre-training.
| PadChest [57] (AUPRC) | |||||
| Image Encoder | Pre-trained with Laterals | Vertebral Deg. Changes | Pleural Effusion | Costophrenic Angle Blunting | Agg |
| BioViL-T [39] | ✗ | p m 2.44 | p m 2.36 | p m 2.21 | 69.64 |
| BiomedCLIP [40] | ✓ | p m 1.24 | p m 1.02 | p m 2.92 | 78.62 |
| MRM [7] | ✓ | p m 1.75 | p m 0.98 | p m 2.85 | 85.50 |
| ✓ | p m 1.32 | p m 0.95 | p m 2.63 | 86.14 | |
A.3 Qualitative Results
A.3.1 Visualisation of Self-Attentions
Figure A.2 shows the self-attention of the [CLS] token with respect to patch embeddings extracted with the encoder. The top row demonstrates ’s ability to accurately attend and trace different types of support devices. The bottom row shows that on images with pleural effusion and opacities, attention heads are concentrated within the lung fields including the base and hilar regions.


A.4 Patch Embedding Correspondences
Figures A.3 and A.4 provide additional qualitative examples of patch embedding matching between pairs of chest X-ray images collected from different subjects. In particular, we see that the anatomical correspondences (Figure A.3) are well preserved despite the presence of findings such as loculated right pleural effusion.
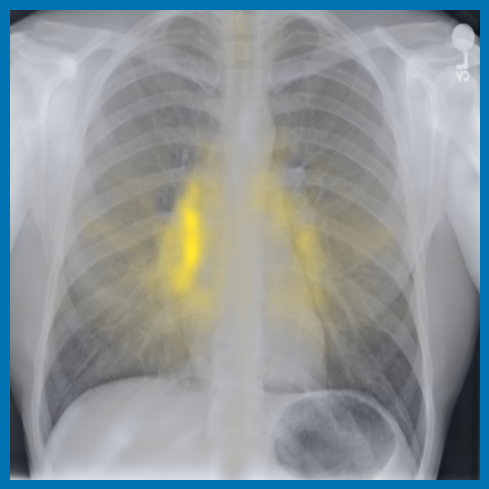
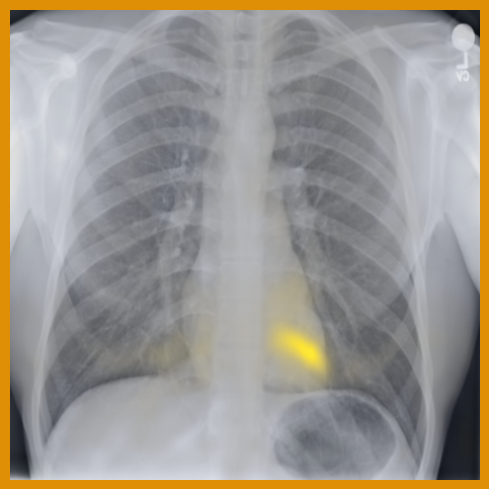
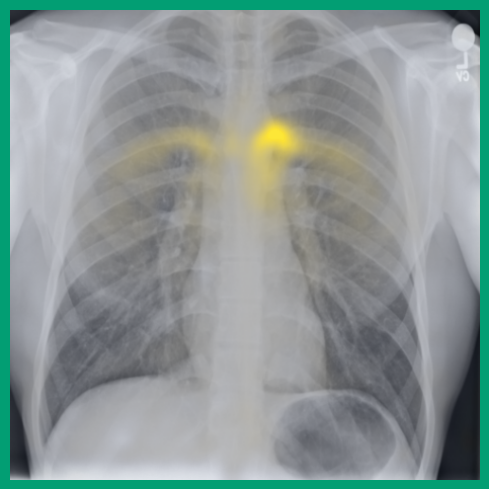
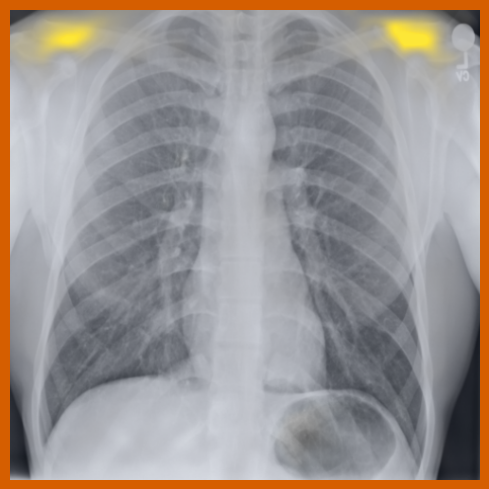
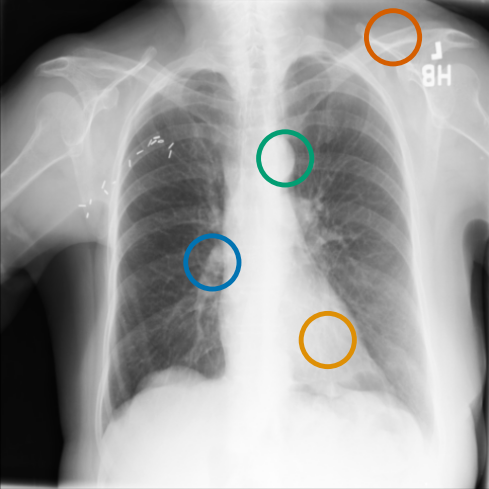
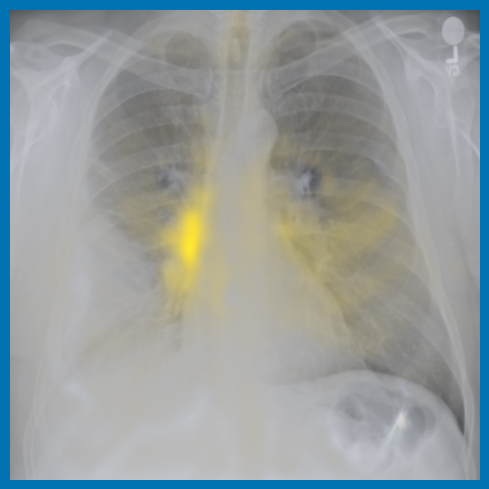
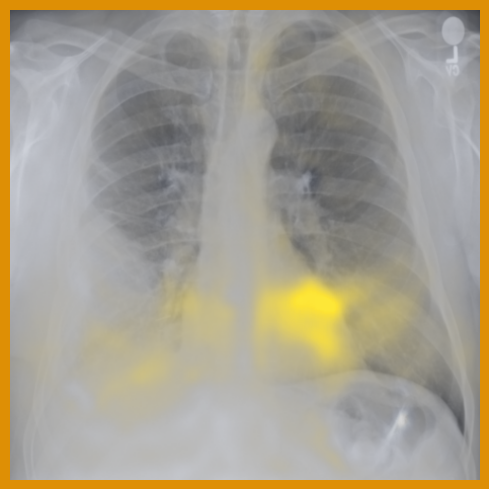
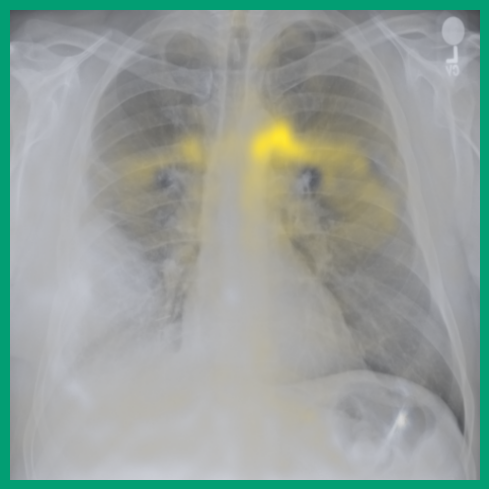
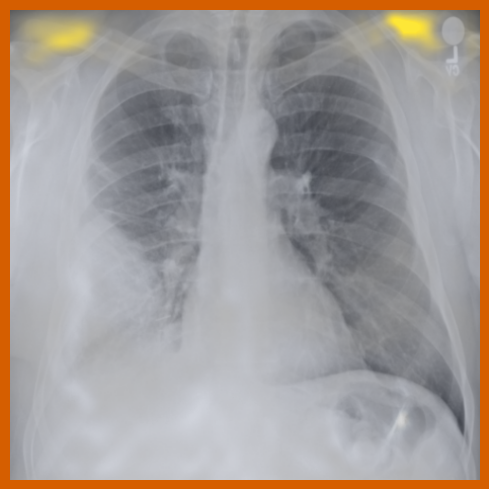

Similarly, local patch embeddings for abnormal findings such as consolidation and nodules can be well aligned across scans, see Figure A.4. We also observe that when there is an overlap between an anatomical region and an abnormal finding (e.g., pleural effusion in the costophrenic angle), the nearest-neighbour match between anatomically corresponding points is affected. This leads to embeddings that capture both types of information simultaneously.
A.4.1 Qualitative Segmentation Results
The qualitative results using the pre-trained encoder are notably better for all tasks, compared to the image-text contrastively trained encoders BioViL-T and BiomedCLIP using a linear decoder head (Fig. 4(a)). Specifically, we see more detailing of shapes and edges for the predicted segmentation mask (more prominently seen in smaller structures such as chest tubes and lung zones). In contrast, the fine-grained edge and shape details are not preserved in the masks predicted by both BioViL-T and BiomedCLIP. The segmentation masks produced by BiomedCLIP show disconnected components (similar to OpenCLIP segmentation qualitative results in [22]). Moreover, the segmentation masks predicted using the encoder with a UPerNet decoder preserve fine-granular details of each structure and are close in visual quality to the masks predicted by the best-performing segmentation model EfficientNet-B6 UNet (Fig. 4(b)).
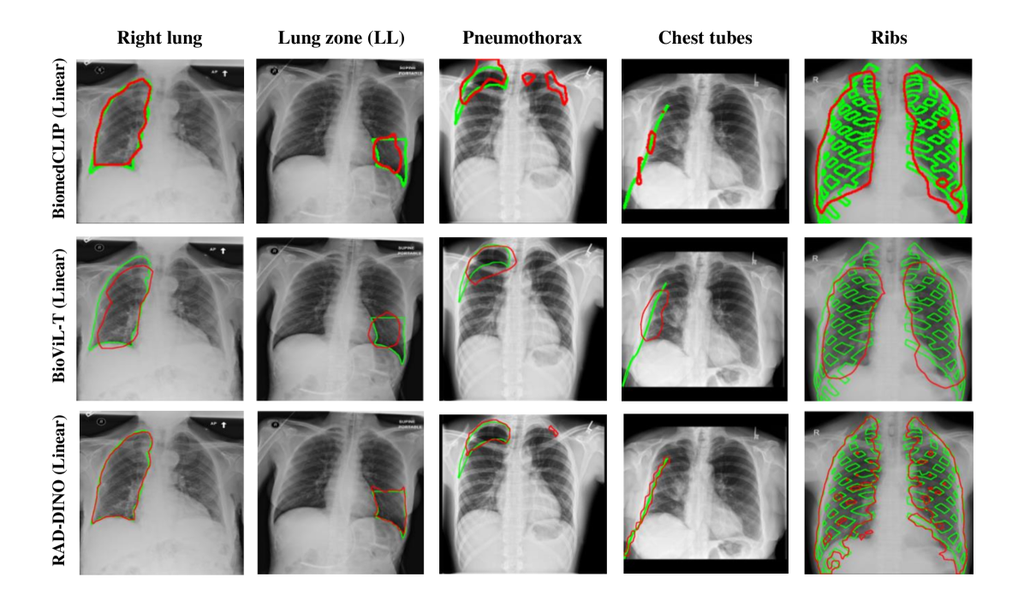
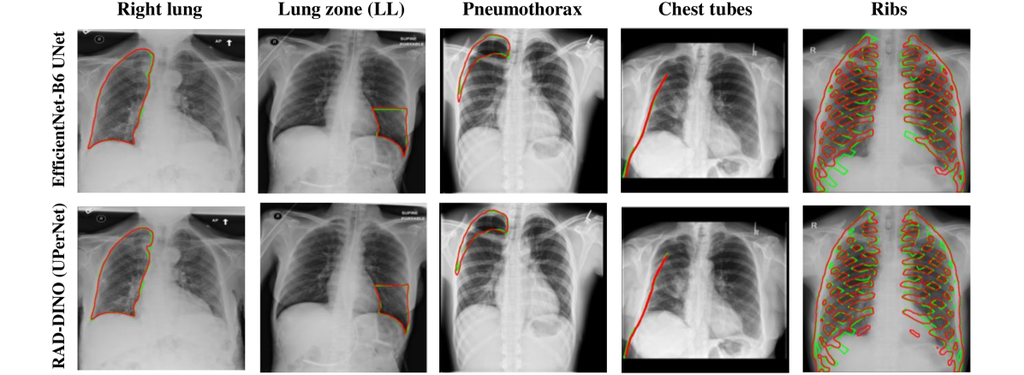
Appendix B Datasets
B.1 Pre-training
To train the image encoder, we use a combination of chest X-ray datasets that are outlined in Table B.1. The BRAX dataset [122] consists of 24,959 high-quality digital chest radiography studies acquired prior to the COVID-19 pandemic from 19,351 patients from a large general Brazilian hospital. Being sourced from a Brazilian hospital, BRAX can help address the under-representation of certain populations in medical datasets. MIMIC-CXR [17] consists of chest X-ray studies including radiology reports collected from intensive care unit (ICU), where a subset of clinical findings are observed. It has been the main pre-training data resource in prior art [5, 39, 7]. Similarly, NIH-CXR [111] is compiled by the NIH and is composed of chest X-ray scans from more than 30,000 patients, including many with advanced lung disease. PadChest [57] consists of medical images along with their associated reports of subjects reporting at San Juan Hospital (Spain), where the reports were labelled with 174 different radiographic findings, 19 differential diagnoses, and 104 anatomic locations organised as a hierarchical taxonomy. Since the PadChest dataset is comprised of studies collected from both in- and out-patient wards, its diversity is quite valuable in generalising to findings seen outside the ICU settings. Note that lateral scans are not excluded from training although evaluations heavily assess the findings seen on frontal scans. Lastly, we utilise a set of in-house chest X-ray imaging dataset collected from outpatient clinics to further assess the scalability model with training dataset size.
In summary, the large-scale combined pre-training dataset comprises of chest X-ray images obtained from subjects with diverse reported radiological findings, collected from different patient cohorts across different geographical locations and time durations. All images are used for pre-training from the given datasets, except MIMIC-CXR [17] where their recommended training split is used.
| Dataset | View | Patient cohort | Number of subjects | Number of images |
| BRAX [122] | frontal, lateral | all available in institutional PACS | 19,351 | 41,620 |
| CheXpert [69] | frontal, lateral | inpatient and outpatient | 65,240 | 223,648 |
| MIMIC-CXR [17] | frontal | ICU | 188,546 | 210,491 |
| NIH-CXR [111] | frontal | not specified | 32,717 | 112,120 |
| PadChest [57] | frontal, lateral | all available | 67,000 | 160,817 |
| Private | frontal, lateral | outpatient | 66,323 | 90,000 |
| Total | 439,177 | 838,336 |
B.2 Downstream Evaluation Tasks
For the image classification task, we use VinDr-CXR [46], CANDID-PTX [47], and RSNA-Pneumonia [48]. The VinDr-CXR subset for the six reported findings consists of 18,000 images from the same number of subjects. CANDID-PTX [47] contains 19,237 images from the same number of subjects. RSNA-Pneumonia [48] contains 26,684 images from the same number of subjects. For the semantic segmentation task, we train and evaluate the encoder-decoder networks for left and right lungs, lung zones, pneumothorax, chest tubes, and ribs. For lung and lung zone segmentations, lung masks are provided in a lung segmentation dataset based on MIMIC-CXR [49]. To extract lung zone masks from lung masks, bounding boxes for six lung zones (left upper, left mid, left lower, right upper, right mid, right lower) are obtained from the Chest Imagenome dataset [50] based on MIMIC-CXR. Corresponding chest X-ray images are directly extracted from the MIMIC-CXR database [17]. The lung and lung zone segmentation datasets contain 1,138 images from the same number of subjects. For pneumothorax and chest tubes, we use the chest X-ray images and masks from CANDID-PTX [47] consisting of of 19,237 images from the same number of subjects. The VinDR-RibCXR dataset [51] consists of rib segmentations for 20 ribs (L1-L10, R1-R10) of images collected from 245 subjects.
Appendix C Implementation Details
C.1 Pre-training
We train the encoders on 4 compute nodes of 4 NVIDIA A100 GPUs each. To pre-train the encoder (ViT-B/14), we use a training batch size of 640 (40 per GPU), the AdamW optimizer, base learning rate 0.001 and a cosine learning rate scheduler with linear warmup. For an input image of size 518 518, we generate a global view by extracting a random crop with a size sampled from (259, 518), and upsampling it back to 518 518. For local views, we use (104, 259) and upsample to 196 196. The encoder is trained for 100 epochs. More details including augmentations are provided in Section 2.
C.2 Baseline Image Encoders
The source code and pretrained weights of the baseline image encoders were obtained from public resources: CLIP@224 111https://huggingface.co/openai/clip-vit-large-patch14, CLIP@336 222https://huggingface.co/openai/clip-vit-large-patch14-336, BioViL-T 333https://huggingface.co/microsoft/BiomedVLP-BioViL-T, BiomedCLIP 444https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224, MRM 555https://github.com/RL4M/MRM-pytorch, and DINOv2 666https://github.com/facebookresearch/dinov2. For each baseline, we used its corresponding image preprocessing pipeline and image inference implementation, if provided. If a network used a special token, such as [CLS], during pre-training for contrastive learning, it is used in linear probing experiments for better baseline performance. For the MRM baseline, we observed better downstream performance when probing was applied on the pooled patch embeddings, which were used for both masked image and text modelling objectives during pre-training. Since the baseline evaluations focused on interpreting single images, the BioViL-T model was evaluated in static mode, rather than in a temporal analysis of two consecutive scans.
C.3 Downstream Evaluation Tasks
The implementation details for the training and evaluation of each downstream network presented in Section 4 is provided below:
Image classification:
We use a training batch size of 96 (12 per GPU), AdamW optimizer, base learning rate , and a cosine learning rate scheduler. We use the following preprocessing and augmentations: centre-cropping and resizing (518 518 for all encoders except BiomedCLIP, where we resize to 224 224), random horizontal flip, random cropping, random affine transform, random colour jittering, and random Gaussian noise. For the experiments, we normalise the intensities using statistics computed from all images in MIMIC-CXR [17]. The classification models are trained for 100 epochs. The last checkpoint is selected for inference on the test set as we did not observe overfitting while monitoring the validation loss
Semantic image segmentation:
We use a training batch size 80 (10 per GPU), Adam optimizer, base learning rate , and a cosine learning rate scheduler. We use the following preprocessing and augmentations: centre-cropping and resizing (518 518 for all encoders except BiomedCLIP where we resize to 224 224), random horizontal flip (except left–right lungs and lung zones), random affine transform, elastic transform, random brightness and contrast jittering, and random gamma adjustments. For experiments, we normalise the intensities using statistics computed from all images in MIMIC-CXR [17]. The segmentation models are trained for 100 epochs. We use a 70/15/15 split by subjects for train, validation and test sets, respectively, and report metrics on the test set (for ribs segmentation, we use the provided data splits, i.e., 196 train, 49 test). The model with minimum loss on the validation set is used for inference on the test set.
Textual report generation:
Training is performed on compute nodes of 4 NVIDIA A100 GPUs with 80GB RAM. We use the same hyperparameters set in LLaVa-1.5 [44]. Namely, we use a batch size of 128 (32 per GPU), and a cosine learning rate scheduler with warmup during 3% of the training steps, and base learning rate . We only perform single-stage fine-tuning for three epochs, where the image encoder is frozen while the LLM, along with the adaptor, are updated. Finally, we use 32-bit full precision for decoding up to 150 tokens with a batch size of 1 during inference.
Experiments with patient metadata:
First, we select a subset of the MIMIC-CXR dataset where the radiology reports noted “No findings”. We then link the anonymised subject information with the medical records provided in the MIMIC-IV dataset. The resulting dataset consists of 60.1k images with AP/PA view. Second, we compute the embeddings for BioViL-T, BiomedCLIP, and . Third, we train a logistic regression model to predict the metadata variables: sex, age, weight and BMI using the image embeddings. The model is evaluated using five-fold cross-validation with an 80/20 split and trained for 100 epochs with default settings (we used the LogisticRegression module from scikit-learn [123]). Sex was a binary variable with categories Female (N = 29.3k) and Male (N = 30.8k). The continuous variables, age, weight, and BMI, were discretised into five bins each. The distribution of the dataset across these bins is as follows:
-
•
Age (years): < 20 (N = 0.8k), 20–40 (N = 11.1k), 40–60 (N = 23.2k), 60–80 (N = 20.4k), > 80 (N = 4.6k)
-
•
Weight (kg): < 50 (2.7k), 50–65 (11.3k), 65–80 (17.9k), 80–95 (14.2k), > 95 (13.8k)
-
•
BMI (): < 18.5 (1.9k), 18.5–25 (17.4k), 25–30 (18.8k), 30–35 (11.4k), > 35 (10.4k)