LLM4EDA: Emerging Progress in Large Language Models for Electronic Design Automation
Abstract
Driven by Moore’s Law, the complexity and scale of modern chip design are increasing rapidly. Electronic Design Automation (EDA) has been widely applied to address the challenges encountered in the full chip design process. However, the evolution of very large-scale integrated circuits has made chip design time-consuming and resource-intensive, requiring substantial prior expert knowledge. Additionally, intermediate human control activities are crucial for seeking optimal solutions. In system design stage, circuits are usually represented with Hardware Description Language (HDL) as a textual format. Recently, Large Language Models (LLMs) have demonstrated their capability in context understanding, logic reasoning and answer generation. Since circuit can be represented with HDL in a textual format, it is reasonable to question whether LLMs can be leveraged in the EDA field to achieve fully automated chip design and generate circuits with improved power, performance, and area (PPA). In this paper, we present a systematic study on the application of LLMs in the EDA field, categorizing it into the following cases: 1) assistant chatbot, 2) HDL and script generation, and 3) HDL verification and analysis. Additionally, we highlight the future research direction, focusing on applying LLMs in logic synthesis, physical design, multi-modal feature extraction and alignment of circuits. We collect relevant papers up-to-date in this field via the following link: https://github.com/Thinklab-SJTU/Awesome-LLM4EDA.
1 Introduction
Over the past few decades, Electronic Design Automation (EDA) algorithms and tools have made significant strides, yielding substantial improvements in chip design productivity. At the same time, driven by Moore’s Law, circuit sizes have exponentially increased, presenting new challenges for chip engineers in achieving Very Large-Scale Integration (VLSI) with billions of transistors. In addition to the scale, it has become increasingly challenging to satisfy the demands of Power, Performance, and Area (PPA), specifications, and other constraints, especially throughout the entire and long EDA design flow. During this long design flow, the involvement of numerous intermediate processes necessitates time- and cost-intensive human intervention, often requiring iterative interactions with natural language or programming language interfaces. These processes generate abundant and various outputs and logs rich in textual information, demanding engineers’ understanding, processing, and decision-making for following guidance and commands. Consequently, the complete design flow remains far from being fully automated. Simultaneously, chip design also imposes high demands on engineers, and it typically takes several years to cultivate an experienced engineering professional in this field. How to achieve full automation of the circuit design process and reduce reliance on experienced circuit design engineers has become a key focus of research.
Deep learning, an ever-advancing technology, has found widespread application across diverse domains and scenarios, including classification, detection, forecasting, and generation. Notably, it exhibits great potential in generating high-quality solutions for many NP-complete (NPC) problems, which commonly arise in the EDA field. Traditional methods encounter challenges in effectively addressing these problems due to their demanding computational resources and time requirements, particularly in the realm of VLSI. Unlike traditional approaches that tackle each problem independently without the accumulation of knowledge, deep learning methods excel at extracting high-level features and representations shared among similar or related cases. Leveraging these features allows for their reuse and application throughout the problem-solving process, resulting in enhanced speed and improved solution quality. Consequently, the integration of deep learning techniques to aid and accelerate the resolution of EDA problems represents a highly promising direction of research.
At present, deep learning has found extensive applications through flow of chip design, including logic synthesis (Hosny et al., 2020; Yuan et al., 2023), floorplanning (Amini et al., 2022), placement (Lin et al., 2019; Mirhoseini et al., 2021; Cheng and Yan, 2021; Cheng et al., 2022; Lai et al., 2022), clock tree synthesis (Lu et al., 2021; Liang et al., 2023) routing (Cheng et al., 2022; Du et al., 2023a) and PPA prediction (Guo et al., 2022; Chai et al., 2023; Zhong et al., 2024). Simultaneously, many works focus on general representation learning of circuits (Li et al., 2022a; Shi et al., 2023; Wang et al., 2022). It embeds both functionality and structural information of a circuit as vectors, and these representations can be further utilized in various downstream tasks rather than learning a specific model for each task from scratch. To support the demand of neural network training for massive training data and achieve stronger generalization in EDA, open-sourced datasets such as Circuit (Chai et al., 2023) and Circuit 2.0 (Anonymous, 2024) have been made available to the research community. These datasets offer cross-stage and cross-design samples, facilitating comprehensive exploration of advancements in Artificial Intelligence for Electronic Design Automation (AI4EDA). We have collected papers and maintained real-time updates about AI4EDA 111https://github.com/Thinklab-SJTU/awesome-ai4eda.
Recently, Large Language Models (LLMs) demonstrated capability in various aspects, including context understand, Question and Answer (Q&A) and logic reasoning. Both commercial (ChatGPT, Bard, etc.) and open-source (LLaMA2 (Touvron et al., 2023)) schemes have achieved significant advancement in this field. Since circuits can be depicted in programming language, Hardware Description Language (HDL), specifications and many intermediate outputs through EDA flow are also represented in text format. It is natural to ask whether LLMs can be leveraged for EDA to assist engineers in chip design.
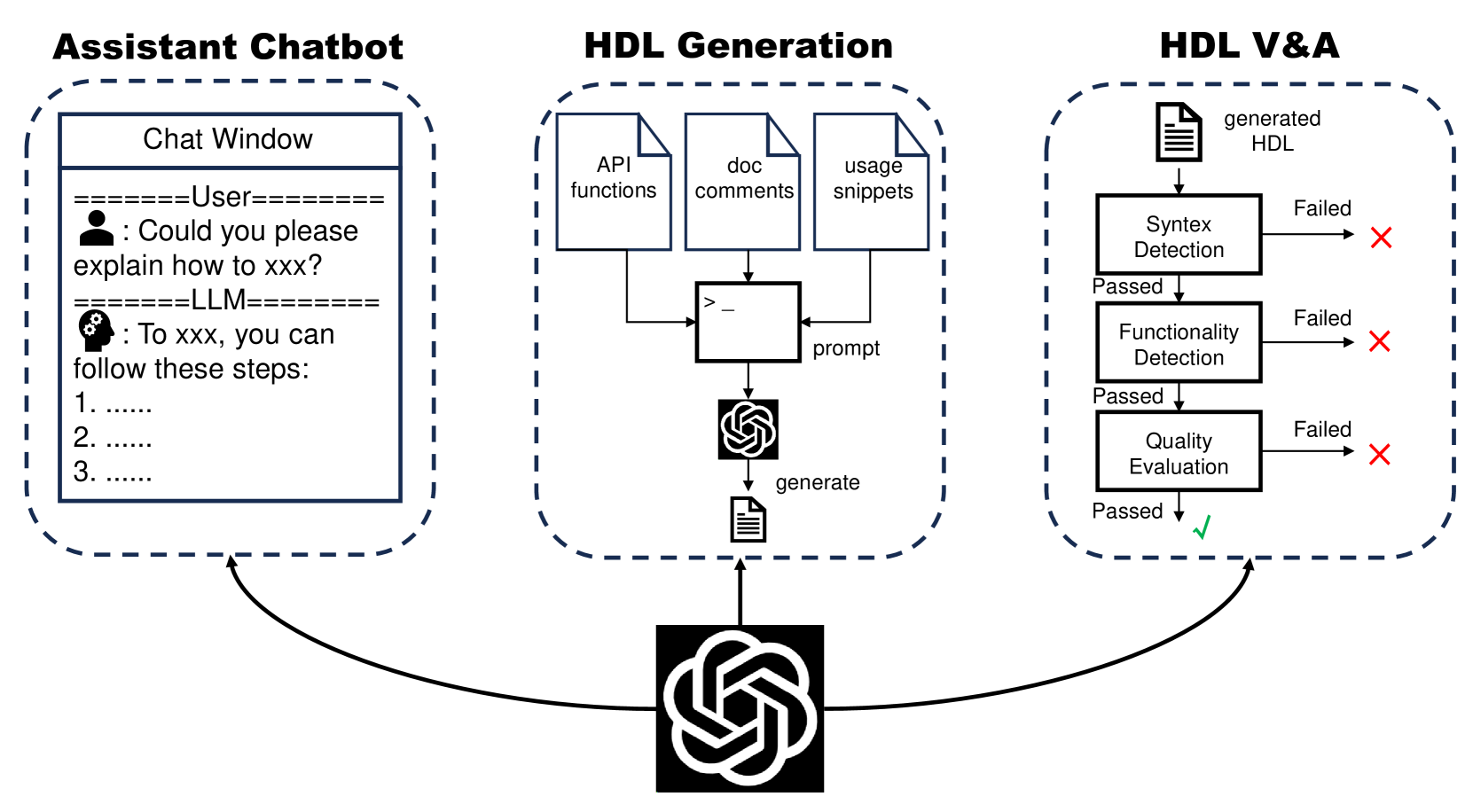
In this survey, we conduct a comprehensive and detailed investigation on the progress and application in Large Language Models for Electronic Design Automation (LLM4EDA). As shown in Fig. 1, we categorize current application and exploration of LLMs in EDA into the following three directions:
-
•
Assistant Chatbot. Users can interact with LLMs for knowledge acquisition and Q&A, without spending time in waiting or actively searching for answers. We present some notable works which aim to provide user-friendly and easy-interactively assistant chatbot and bring us new interaction paradigm with EDA software.
-
•
HDL and Script Generation. Given language format specification and requirements, LLMs will generate RTL codes and EDA controlling scripts. This automated process streamlines the development of circuit designs by reducing the manual effort traditionally involved in writing codes and scripts, thereby enhancing efficiency and productivity in the chip design. Besides, how to evaluate the quality of generated codes remains an open research focus, where syntax correctness and functionality equivalence are key factors. In EDA field there exist more metrics to consider, such as Power, Performance and Area (PPA) and security issues. Therefore, new evaluation framework considering various aspects are also essential.
-
•
HDL Verification and Analysis. We also investigate LLMs’ wide application in code analysis, such as bug detecting & fixing, code summarization and security checking. Besides, LLMs have also demonstrated strong ability for verification, e.g. Assertion Based Verification.
Apart from the aforementioned advancements, other key processes in EDA flow also exhibit promising potential when viewed from an LLM perspective. Specifically, we provide following overviews:
-
•
Logic Sythesis. LLM holds the potential to generate an optimization sequence, along with the corresponding arguments in logic synthesis, when Hardware Description Language (HDL) and prompts are considered as inputs.
-
•
Physical Design. The complexity of Placement and Routing (P&R) currently makes it challenging to directly apply LLMs. However, employing strategies such as graph partitioning and clustering can reduce the scale of the problem and accelerate the solving process, thereby making the use of LLMs feasible. LLMs could also be used to optimize modules or act as a reward system for reinforcement learning agents.
2 Preliminaries
2.1 Large Language Models
Large Language Models (LLMs) (OpenAI, 2023b; Touvron et al., 2023) are a type of artificial intelligence models characterized by their vast number of parameters. These models are trained on substantial amounts of text data over extended GPU time. The pioneer in this field is the GPT series (Brown et al., 2020; Ouyang et al., 2022; OpenAI, 2023b) from OpenAI, where GPT-3 (Brown et al., 2020) is an autoregressive language model with 175 billion parameters, significantly outperforming other contemporary models in terms of scale. On this basis, GPT-3.5 (Ouyang et al., 2022) focuses on the fine-tuning GPT-3, particularly incorporating the reinforcement learning from human feedback (RLHF) (Christiano et al., 2017; Stiennon et al., 2020) to enhance alignment with human preferences. While these models demonstrate impressive performance, the official surge in LLMs can be attributed to the advent of ChatGPT 222https://openai.com/blog/chatgpt/, which adapts GPT-3.5 to dialogue, achieving remarkable results and applications. In response to the widespread interest in ChatGPT, OpenAI developed GPT-4 (OpenAI, 2023b), a more capable LLM than ChatGPT, that supports multi-modal, longer, and more logical input/output.
The success of the GPT series has spurred the development of various other LLMs, such as LLaMA (Touvron et al., 2023) and Gemini 333https://deepmind.google/technologies/gemini/ by different corporations and institutes. Empowered by extensive data, a large number of parameters, and prolonged training time, LLMs can generate human-like text given certain inputs. They are not only capable of performing tasks like translation, character simulation, and generating creative content like poems and stories, but also answering questions and handling high-difficulty tasks such as generating executable code and scripts. The potential of LLMs is vast and far from being fully realized.
2.2 Design Flow of Electronic Design Automation
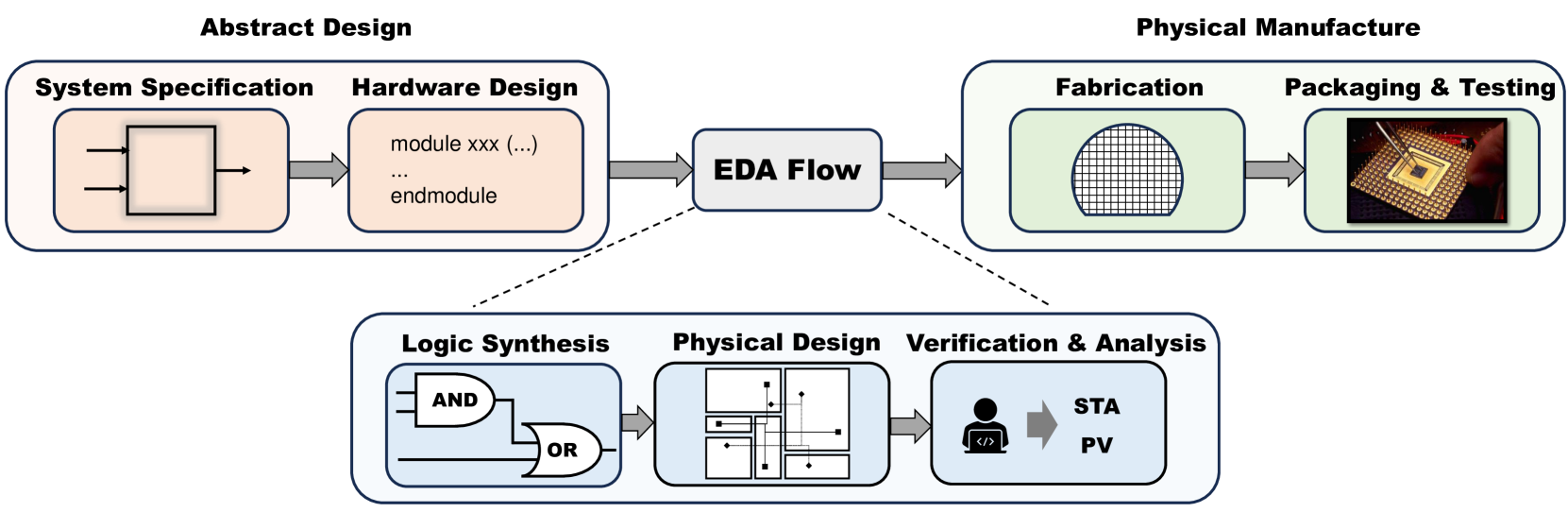
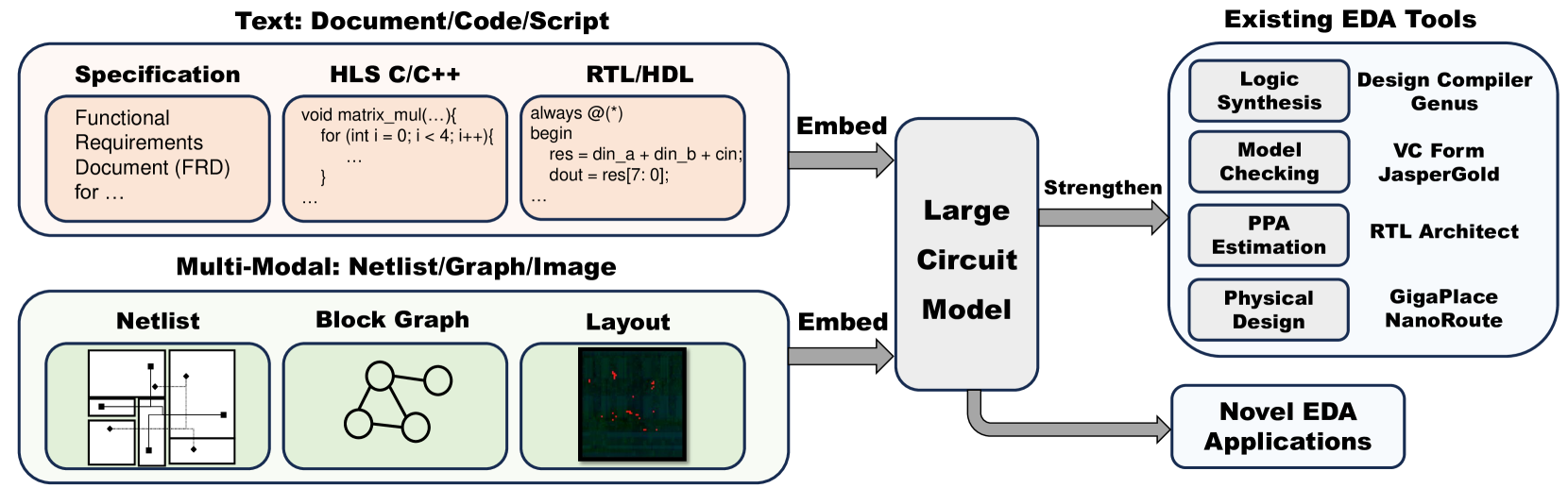
The process of chip design is intricate and multifaceted, typically segmented into several distinct stages (Anonymous, 2024). As shown in Fig. 2, these stages encompass abstract design, EDA flow, and physical manufacturing. The EDA flow itself can be further subdivided into logic synthesis, physical design, verification, and analysis, each of which plays a crucial role in the successful creation of a chip. We also envision that a large circuit model, regarded as an EDA-guided LLM, could union different stages and output a general solution in the EDA flow. Specifically, our approach utilizes a data-driven large model, where both text and multi-modal information are integrated into a latent space. The text data encompasses specification documents, HLS codes, and RTL scripts, while the multi-modal information comprises netlists, graphs, and images. The large circuit model is trained either from scratch or by fine-tuning an existing Language Large Model (LLM) using these data. Once trained, this model can enhance the capabilities of existing EDA tools and facilitate various downstream applications. The ideal workflow, based on the large circuit model, is depicted in Fig. 3. However, it’s important to note that achieving our ultimate goal is still a considerable journey ahead.
3 Application of LLM4EDA
According to the mainstream research interests, we synthesize recent literature into four aspects, including 1) assistant chatbot; 2) HDL and script generation; 3) evaluation of generated code, and 4) code verification and analysis. Related papers are listed in Fig. 4.
for tree= grow’=east, draw, rounded corners, node options=font=, fill=blue!20, edge=thick, color=blue!50, l sep+=0.8cm, s sep+=0.1cm, parent anchor=east, child anchor=west, anchor=west, edge path= [draw, edge] (!u.parent anchor) – +(5pt,0) |- (.child anchor)edge label; , [LLM4EDA, fill=black!20 [ Assistant Chatbot , for tree=fill=green!20 [ChipNeMo (Liu et al., 2023a), for tree=fill=black!5] [Smarton-AI (Han et al., 2023), for tree=fill=black!5] [RapidGPT (PrimisAI, 2023), for tree=fill=black!5] ] [ HDL Generation , for tree=fill=red!20 [ChatEDA (He et al., 2023), for tree=fill=black!5] [ChipGPT (Chang et al., 2023), for tree=fill=black!5] [VerilogEval (Liu et al., 2023b), for tree=fill=black!5] [GPT4AIGChip (Fu et al., 2023), for tree=fill=black!5] [Chip-Chat (Blocklove et al., 2023), for tree=fill=black!5] [AutoChip (Thakur et al., 2023c), for tree=fill=black!5] [RTLLM (Lu et al., 2023), for tree=fill=black!5] [Thakur et al. (2023a), for tree=fill=black!5] [VeriGen (Thakur et al., 2023b), for tree=fill=black!5] [RapidGPT (PrimisAI, 2023), for tree=fill=black!5] ] [ Code Verification & Analysis , for tree=fill=blue!20 [ChipNeMo (Liu et al., 2023a), for tree=fill=black!5] [RTLFixer (Tsai et al., 2023), for tree=fill=black!5] [AutoSVA (Orenes-Vera et al., 2021), for tree=fill=black!5] [Kande et al. (2023), for tree=fill=black!5] [NSPG (Meng et al., 2023), for tree=fill=black!5] [DIVAS (Paria et al., 2023), for tree=fill=black!5] [Ahmad et al. (2023), for tree=fill=black!5] ] ]
3.1 Assistant Chatbot
The full chip design flow necessitates extensive prior expert knowledge, which requires years of research and accumulation. To assist engineers in obtaining answers to their questions related to architecture, design, tools, and verification, an engineering assistant chatbot can effectively meet their needs. Although current LLMs are pre-trained on various types of text and serve as general chatbots, they may lack profound and accurate understanding in specific domains like the EDA field. Therefore, developing an engineering assistant chatbot that incorporates knowledge extracted from internal design documents, code, and recorded data pertaining to designs and technical communications could substantially enhance design productivity.
It is widely acknowledged that LLMs may generate inaccurate answers, giving the impression of correctness while often leading to a high level of misunderstanding. This phenomenon is commonly referred to as hallucination (Ji et al., 2023). While the exact causes of hallucination are not yet fully comprehended, it is imperative to address this issue, particularly in engineering, with a specific emphasis on the EDA field. The accuracy of these generated answers holds significant importance in engineering, underscoring the need to mitigate the occurrence of hallucination.
A representative work is ChipNeMo (Liu et al., 2023a). They propose to leverage retrieval augmented generation (RAG) (Lewis et al., 2020) method to mitigate hallucination. Also, they find that fine-tuning an off-the-shelf unsupervised pre-trained dense retrieval model with a modest amount of domain specific training data significantly improves retrieval accuracy. They utilize these techniques to fine-tune a pre-trained LLM to construct a chip-design-specific assistant chatbot. As a consequence, engineers can focus more on brainstorming, designing, and writing codes, instead of waiting answers or searching knowledge they lack. RapidGPT (PrimisAI, 2023) is another notable work and it is the industry’s first AI-based pair-designer tailored for FPGA engineers. Serving as an intelligent code assistant, RapidGPT leverages AI algorithms to provide accurate and context-aware code suggestions, allowing FPGA engineers to write Verilog code more efficiently. RapidGPT also provides conversational capabilities to the next level by offering a chat panel, allowing users to easily communicate with the tool. This chat panel can be used to write or improve HDL code in a conversational manner.
From the perspective of interacting with LLMs, Smarton-AI (Han et al., 2023) propose a new interaction paradigm for leveraging LLMs in complex software, including main-sub GPTs and a Q&A GPT. The main GPT identifies most relevant tasks according to user input in natural language format. All sub-GPTs form a Mixture of Experts (MoE) (Masoudnia and Ebrahimpour, 2014) system. Each sub-GPT is dedicated to a identified task from main-GPT and generates learning documents for this task. The Q&A GPT is responsible for processing the generated learning documents produced by the sub-GPTs. It serves as an assistant chatbot, leveraging the input derived from these documents to facilitate user interactions and provide relevant information in a question-and-answer format.
3.2 HDL Generation & Evaluation
3.2.1 HDL Generation
Modern chip design often originates from the specifications given by human natural language and then turns to translations into Hardware Description Languages (HDLs) such as Verilog. These translations typically require highly-skilled hardware engineers and suffer from man-made errors and loads of labors. Automating the hardware design could effectively reduce human errors and accelerate the process of design translations. Equipped with LLMs which are empirically proved to be effective to generate high-quality contexts, it is natural to apply LLMs to language translations and other related script generation.
Recent works of LLMs for HDL and script generation mainly emphasize on two aspects: 1) which flow to work on, and 2) what the goal is.
Among the works, ChatEDA (He et al., 2023) endeavors to automate the flow from Register-Transfer Level (RTL) to Graphic Data System Version II (GDSII), which splits the flow stream into task planning, script generation, and task execution due to the complexity of the whole flow. Specifically, ChatEDA treats the natural language as input and then generates effective codes for task execution with EDA tools. Similar flow splitting can also been observed in ChipGPT (Chang et al., 2023) that reports a four-stage logic design framework, including generating prompts, producing initial Verilog programs, correcting and optimizing these programs, and selecting the optimal design according to the target metrics. GPT4AIGChip (Fu et al., 2023) constructs a framework that intends to democratize AI accelerator design. By investigating the weaknesses of current LLMs, especially the inability to handle lengthy codes, GPT4AIGChip also decouples various hardware modules and functionalities of the AI accelerator design to enable the LLM-driven design automation. Chip-Chat (Blocklove et al., 2023) targets the case for the novel 8-bit accumulator-based microprocessor architecture and partitions the task into generating Verilog code and producing most of the processor’s specification.
To enable the generated code to be more functionally accurate, AutoChip (Thakur et al., 2023c) focuses more on the context from compilation errors and dubugging contents when incorporating the interactions from LLMs into the output of the Verilog simulations. Unlike AutoChip (Thakur et al., 2023c) and most other LLM-baesd approaches that targets the design correctness, RTLLM (Lu et al., 2023), as an instruction for generating design RTL, concerns more about the design qualities, which is fairer in practice. In addition to the metric-based goals, Chip-Chat (Blocklove et al., 2023) seeks a von Neumann type design with 32 bytes of memory considering the space restriction. For the security issues and vulnerabilities in hardware design, Nair et al. (2023) constructs robust prompt for ChatGPT to generate design resistant Common Vulnerability Enumerations (CWEs).
VerilogEval (Liu et al., 2023b) constructed a synthetic supervised fine-tuning dataset by leveraging GPT-3.5 (Ouyang et al., 2022) to generate problem descriptions paired with Verilog code. RTLCoder (Liu et al., 2023c) follows this synthetic method, and proposes a new LLM fine-tuning algorithm leveraging quality score feedback. Furthermore, they also quantize LLM to 4-bit with a total size of 4GB, enabling it to function on a single laptop with only slight performance degradation. Simultaneously, many works focus on prompt engineering and feedback, directly utilizing existed general LLMs without further fine-tuning. ChipGPT (Chang et al., 2023) uses template-based prompts, providing details and purpose of original specification. It also contains an output manager to provide LLM with PPA or other human-specified targets as feedback. Du et al. (2023b) proposes to utilize In-Context Learning and Chain-of-Thought prompting techniques in complex FPGA design to tackle challenges, including sub-task scheduling and multi-step thinking problems. Chip-Chat (Blocklove et al., 2023) proposes the conversation flow technique, breaking large design into sub-tasks and giving output from previous sub-task to LLM as base specification and feedback.
3.2.2 HDL Evaluation
Once the LLMs have been developed for code generation, it becomes essential to evaluate their quality. This evaluation process involves checking for both syntax correctness and functionality correctness. Syntax correctness ensures that the generated code follows the proper programming language syntax rules, while functionality correctness ensures that the code performs the intended tasks accurately.
In addition to these checks, when dealing with codes in the EDA field, it is crucial to conduct further testing to evaluate their final power, performance, and area (PPA) characteristics. This testing process typically takes place after the completion of the entire design flow. They are utilized to verify whether the final circuit design meets the specified requirements and corresponding constraints, such as area utilization and timing constraints.
Take RTLLM (Lu et al., 2023) as instance: it provides an public benchmark to evaluate the generated codes from following three perspectives:
-
1.
Syntax goal. It means that the generated RTL design should as least be correct, which can be verified by checking whether the design can correctly synthesized into netlist.
-
2.
Functionality goal. It means the functionality of generated RTL should be exactly the same as user’s expectation. This goal can be checked with a comprehensive testbench.
-
3.
Design quality goal. If the generated RTL pass both above-mentioned unit tests, we need to further check its design quality, e.g. PPA. It can be verified by checking the PPA values after the synthesis and layout of RTL.
Dataset Task Size Description Chat Gen. V&A ChipNeMo (Liu et al., 2023a) 24.1 B tokens Data from NVBugs (NVIDIA’s internal bug database), bug summary, design source, documentation, verification. LLaMA2 tokenizer is adapted and approximately 9K new tokens are added to improve tokenization efficiency. ChatEDA (He et al., 2023) ✓ 1,500 instructions Instruction tuning: Query GPT-4 to generate and collect instructions. The core controller, AutoMage is further fine-tuned on these instructions. GPT4AIGChip (Fu et al., 2023) ✓ 7,000 snippets Open-source HLS code snippets from GitHub and customized HLS templates with implementation instructions to fine-tune LLMs. VeriGen (Thakur et al., 2023b) ✓ 400 MB From Verilog textbooks and open-source GitHub repositories. Training samples are further generated through overlapped sliding windows on module blocks. Dehaerne et al. (2023) ✓ 100,000 files Verilog and SystemVerilog from GitHub open-source repositories. The dataset consists of two unlabeled subsets, file-level data and snippet-level data, and a labeled subset of snippet definition and body pairs VerilogEval (Liu et al., 2023b) ✓ 8,502 samples Designs generated from GPT-3.5 for SFT data, containing description and corresponding code. MinHash algorithm with Jaccard similarity is also performed to realize approximate deduplication. RTLCoder (Liu et al., 2023c) ✓ 10,000 designs Generated from GPT-3.5, each sample consists of an description and corresponding RTL code. Conditional log probability based quality score is also incorporated for fine-tuning. NSPG (Meng et al., 2023) ✓ 20,000 sentences Documentation collected from OpenTitan, RISC-V, OpenRISC, MIPS, OpenSPARC. This dataset is further augmented with Random Deletion, Random Swap, Synonym Replacement and Random Insertion.
Based on above-mentioned unit tests, VerilogEval (Liu et al., 2023b) proposes to use pass@k metric to further reflect the correctness of generated RTL codes:
| (1) |
where we generate samples per task in which samples pass the unit test.
Some prior works, including AutoChip (Thakur et al., 2023c), ChipGPT (Chang et al., 2023), Thakur et al. (2023a), categorize the problem set into kinds of difficulty: e.g. easy, intermediate and hard. Under different difficulty settings, they evaluate the generated RTL codes with syntax goal and functionality goal, design quality goal.
3.3 HDL Verification and Analysis
Another promising application of LLMs for EDA is to leverage LLMs to understand, analyse and summarize the input RTL codes. Different from Sec. 3.2.2 evaluating the generated codes through external tools, LLMs take input as RTL codes and user-specified queries, and provide responses to the user based on this input. This approach allows users to directly interact with the LLMs, reaching out to the analysis of input codes.
To assist engineers in bug summarization and analysis, ChipNeMo (Liu et al., 2023a) constructs a domain-specific SFT dataset based on NVIDIA’s internal bug database, NVBugs. Considering bug descriptions could be too large for context windows, they replace long path names with short alias, and split the summarization tasks into an incremental task.
Besides bug summarization and analysis, RTLFixer (Tsai et al., 2023) proposes a paradigm for fixing erroneous Verilog codes directly. Formulating an input prompt and followed by utilizing Retrieval Augmented Generation (RAG) and ReAct prompting mechanism (Yao et al., 2022), the agent revises the erroneous Verilog codes. If syntax errors persist, error logs from the compiler as well as retrieved human guidance from the database are provided as feedback.
LLMs also demonstrate the capability in assertion checking, which is effective at finding intricate RTL bugs and security issues. It is a popular verification technique, where the specification of design under test in coded into assertions or properties in hardware description language. Each assertion will focus on verifying individual functionality and logic. Besides, it is also able to detect security vulnerabilities to defense attacks. Orenes-Vera et al. (2023) proposes an iterative methodology based on formal property verification to generate SystemVerilog Assertions (SVA) from a given RTL module. They also integrate this assertion generation flow in open-source framework, AutoSVA (Orenes-Vera et al., 2021). Kande et al. (2023) realizes SVA with a similar flow, including prompt construction, LLMs-based assertions generation and simulation. They also lexical tools to automatically fix minor mistakes based on qualitative analysis about ’common pitfalls’ made by LLMs.
Considering the security problems in hardware designs, NSPG (Meng et al., 2023) proposes a framework to identify essential properties from Intellectual Property (IP) cores documentations. They fine-tune a pre-trained LLM and a sequence classification model on datasets consisting of hardware documentations, where the latter is responsible to identify whether a sentence in documentation is a property or not, which contains essential information of operator behaviour and security. DIVAS (Paria et al., 2023) proposes a LLM-based end-to-end framework for identify the CWEs for a given System-on-Chip (SoC) specification and employs a novel LLM-based technique to determine the relevant CWEs, which are finally converted into SystemVerilog Assertions using LLMs for verification. (Ahmad et al., 2023) utilizes a detector tool to extract or directly get the location and CWE type of bug. These bug information, codes before the bug and buggy code in comments are combined as LLM prompt, assisting LLM to fix this hardware bug.
4 Datasets of LLM4EDA
Fine-tuning general-purpose LLMs with extensive and accurate domain-specific data would yield better performance. Some works have evolved in constructing corresponding datasets through collecting existed data, including public design source codes, documentation, internal error logs, and bug summaries. Simultaneously, other works generate synthesis dataset by querying existed general LLMs for circuits or design instructions. In Table 1, we present some representative works that have explored the fine-tuning of LLMs utilizing domain-specific datasets.
5 Backbones for LLM4EDA
We demonstrate the tasks, backbone and fine-tuning techniques for LLMs applied in EDA in Table 2. Due to limitations in computational resources and available datasets, current efforts are primarily focused on utilizing APIs of existing LLMs. For domain specific data, they either collect existed RTL codes (Liu et al., 2023a; Fu et al., 2023; Thakur et al., 2023b; Dehaerne et al., 2023; Meng et al., 2023), or generate synthesis designs from pre-trained general LLMs (Liu et al., 2023c, b).
Method Task Type Size Fine-tune Chat Gen. V&A RTLCoder (Liu et al., 2023c) ✓ Zephyr 7 B Quality Score VerilogEval (Liu et al., 2023b) ✓ CodeGen 16 B SFT Ahmad et al. (2023) ✓ CodeGen 16 B Thakur et al. (2023a) ✓ CodeGen 16 B AI21 Studio ChipNeMo (Liu et al., 2023a) ✓ ✓ ✓ LLaMA2 13 B SFT ChatEDA (He et al., 2023) ✓ LLaMA2 70 B QLoRA ChipGPT (Chang et al., 2023) ✓ GPT-3.5 DIVAS (Paria et al., 2023) ✓ GPT-3.5 Schäfer et al. (2023) ✓ GPT-3.5 Nair et al. (2023) ✓ GPT-3.5 Du et al. (2023b) ✓ ✓ GPT-3.5 Kande et al. (2023) ✓ GPT-3.5 RTLFixer (Tsai et al., 2023) ✓ GPT-3.5 RTLLM (Lu et al., 2023) ✓ GPT-4 GPT4AIGChip (Fu et al., 2023) ✓ GPT-4 AutoChip (Thakur et al., 2023c) ✓ GPT-4 Chip-Chat (Blocklove et al., 2023) ✓ GPT-4 VeriGen (Thakur et al., 2023b) ✓ GPT-4 Orenes-Vera et al. (2023) ✓ GPT-4
6 Outlook
6.1 LLM in Logic Synthesis
Logic synthesis transforms a high-level description of a design, e.g. Verilog, into an optimized gate-level representation. It mainly consists of three steps, namely pre-mapping optimization, technology mapping, and post-mapping optimization. Extensive tuning of the synthesis optimization flow is required, including which optimizations to use, their corresponding arguments and the order of invocation. This process can be treated as a sequential decision making problem in parameterized action space (Fan et al., 2019). Efficient design space exploration is challenging due to the exponential number of possible optimization permutations. Therefore, it heavily relies on experienced engineers.
Current works utilize heuristics (Li et al., 2022b), Bayesian Optimization (BO) (Grosnit et al., 2022) Reinforcement Learning (RL) (Hosny et al., 2020; Yuan et al., 2023) to search the well-performed optimization sequence. With respect to LLM, taking HDL of design and appropriate prompts as input (e.g., containing target PPA), LLM can generate the sequence of optimization along with their respective arguments. Furthermore, final or estimated PPA can serve as the feedback for LLM, enabling iteratively enhancement of the Quality of Results (QoR).
6.2 LLM in Physical Design
In physical design, placement algorithm determines location for each module, including macro module and standard cell. It aims to minimize wirelength cost subjecting to density constraints. After placement, the (wire) routing step adds wires needed to properly connect the placed components while obeying all design rules. The main objective is to connect all the required connections and on this basis, reduce the routing wirelength and overflow. Placement and Routing (P&R) consumes major part of time and computational resources during physical design, and has a significant impact on final PPA.
The utilization of LLMs in Placement and Routing (P&R) remains relatively unexplored due to the inherent challenges posed by large-scale problems. Contemporary designs typically comprise millions of cells and nets (Lin et al., 2019), making it impractical for LLMs to directly address the location and wire assignment of each component. Employing graph partitioning and clustering algorithms provides feasible approaches to reduce the problem’s scale. While these methods may result in a loss of fine-grained details and potential constraint violations, the resulting ‘coarse’ layouts can serve as initial solutions for traditional P&R algorithms, thereby expediting the solving process.
An alternative strategy could involve optimizing the modules, which are few in number but subject to numerous complex constraints. In this scenario, LLMs could serve dual purposes: they could be employed to generate the optimal outcome, or they could act as a black-box reward system, providing feedback to the reinforcement learning agent.
6.3 Feature Extraction and Alignment
Currently, circuits are typically expressed using hardware description languages, representing them in a textual format. Once the synthesis process is completed, the circuit is transformed into an equivalent netlist, commonly represented as a directed acyclic graph (DAG). Subsequently, placement and routing operations are performed to generate a layout, establishing the physical positions and interconnections of components.
These representations stem from the same underlying entity and correspond to language-based, graph-based, and image-based representations, respectively. However, extraction and alignment of these multi-modal contents has not been thoroughly investigated to date. Large Graph Models (Zhang et al., 2023; Tang et al., 2023) and Large Vision Models (Wang et al., 2023a; OpenAI, 2023a) have demonstrate strong potential to extract informative feature and representation from netlist and layout respectively. We could also build a large-scale multi-modal pre-trained model (Wang et al., 2023b) to realize alignment of there features from different modalities. Techniques such as contrastive learning, e.g. CLIP (Contrastive Language-Image Pretraining) (Radford et al., 2021), or methods involving masking and reconstructing some modalities from others, can be employed to achieve content alignment.
6.4 Long Chain Feedback for PPA
With the assistance of LLMs, our aim is to improve the PPA in chip design. However, there is still a significant gap in predicting and optimizing PPA at the system design stage due to the necessity of numerous intermediate processes such as synthesis, placement, and routing. This lengthy feedback chain poses challenges in optimizing PPA from the initial stages. We believe this problem could be addressed from following perspectives:
-
1.
Domain specific datasets with PPA. Domain-specific datasets incorporating PPA metrics have garnered attention. Existing datasets utilized for fine-tuning general pre-trained LLMs typically include source codes and corresponding descriptions. However, they lack awareness of PPA considerations (Chang et al., 2023). By augmenting these datasets with final PPA metrics, they can serve as more accurate design specifications or targets, as well as providing supervised labels. This augmentation would bridge the gap between RTL designs and their corresponding final PPA, enhancing the effectiveness and applicability of the datasets for fune-tuning PPA-aware LLMs.
-
2.
Utilize PPA as feedback. For a human engineer, PPA is an essential feedback serving as guidance in the iterative and repetitive design process. Similarly, during the interaction with LLMs, we can either 1) evaluate the final PPA with high accuracy through external verification tools or 2) predict PPA with enhanced computational speed, e.g. with neural network based methods (Guo et al., 2022; Yang et al., 2022; Zhong et al., 2024). These PPA could serve as feedback for LLMs, guiding them to generate or refine designs with improved quality.
-
3.
Prompt engineering and task planning. Prompt matters in interacting with LLMs especially for querying in EDA field (Chang et al., 2023; He et al., 2023; Pearce et al., 2020). We could construct more informative prompts by specifying PPA targets, incorporating cost constraints, and integrating design rules, facilitating LLMs to better understand and realize our purposes. To make full use of the context window, it is beneficial to break down large design through task planning into sub-tasks, where each has its own interface communicating with others. Additionally, the output generated from previous tasks could serve as a fundamental specification and guidance for subsequent sub-tasking processing, thus facilitating a coherent and efficient design workflow.
7 Conclusion
This paper presents a comprehensive survey on the integration of Language Models (LLMs) in the Electronic Design Automation (EDA) field. The survey encompasses a range of applications of LLMs in EDA, namely: 1) assistant chatbot, 2) generation of HDL code and EDA flow scripts, 3) verification and analysis of HDL code. Additionally, we highlight the future research direction, focusing on applying LLMs in logic synthesis and physical design, addressing long feedback of PPA, multi-modal feature extraction and alignment of circuits. We firmly anticipate the eventual realization of large-scale multi-modal pre-trained models, for but not only for EDA.
References
- Ahmad et al. [2023] Baleegh Ahmad, Shailja Thakur, Benjamin Tan, Ramesh Karri, and Hammond Pearce. Fixing hardware security bugs with large language models. arXiv preprint arXiv:2302.01215, 2023.
- Amini et al. [2022] Mohammad Amini, Zhanguang Zhang, Surya Penmetsa, Yingxue Zhang, Jianye Hao, and Wulong Liu. Generalizable floorplanner through corner block list representation and hypergraph embedding. In SIGKDD, 2022.
- Anonymous [2024] Anonymous. Circuitnet 2.0: An advanced dataset for promoting machine learning innovations in realistic chip design environment. In Submitted to The 12th ICLR, 2024. URL https://openreview.net/forum?id=nMFSUjxMIl. Under Review.
- Blocklove et al. [2023] Jason Blocklove, Siddharth Garg, Ramesh Karri, and Hammond Pearce. Chip-chat: Challenges and opportunities in conversational hardware design. arXiv preprint arXiv:2305.13243, 2023.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. NeurIPS, 2020.
- Chai et al. [2023] Zhuomin Chai, Yuxiang Zhao, Wei Liu, Yibo Lin, Runsheng Wang, and Ru Huang. Circuitnet: An open-source dataset for machine learning in vlsi cad applications with improved domain-specific evaluation metric and learning strategies. TCAD, 2023.
- Chang et al. [2023] Kaiyan Chang, Ying Wang, Haimeng Ren, Mengdi Wang, Shengwen Liang, Yinhe Han, Huawei Li, and Xiaowei Li. Chipgpt: How far are we from natural language hardware design. arXiv preprint arXiv:2305.14019, 2023.
- Cheng and Yan [2021] Ruoyu Cheng and Junchi Yan. On joint learning for solving placement and routing in chip design. NeurIPS, 2021.
- Cheng et al. [2022] Ruoyu Cheng, Xianglong Lyu, Yang Li, Junjie Ye, Jianye Hao, and Junchi Yan. The policy-gradient placement and generative routing neural networks for chip design. NeurIPS, 2022.
- Christiano et al. [2017] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. NeurIPS, 2017.
- Dehaerne et al. [2023] Enrique Dehaerne, Bappaditya Dey, Sandip Halder, and Stefan De Gendt. A deep learning framework for verilog autocompletion towards design and verification automation. arXiv preprint arXiv:2304.13840, 2023.
- Du et al. [2023a] Xingbo Du, Chonghua Wang, Ruizhe Zhong, and Junchi Yan. Hubrouter: Learning global routing via hub generation and pin-hub connection. In NeurIPS, 2023a.
- Du et al. [2023b] Yuyang Du, Soung Chang Liew, Kexin Chen, and Yulin Shao. The power of large language models for wireless communication system development: A case study on fpga platforms. arXiv preprint arXiv:2307.07319, 2023b.
- Fan et al. [2019] Zhou Fan, Rui Su, Weinan Zhang, and Yong Yu. Hybrid actor-critic reinforcement learning in parameterized action space. In IJCAI, 2019.
- Fu et al. [2023] Yonggan Fu, Yongan Zhang, Zhongzhi Yu, Sixu Li, Zhifan Ye, Chaojian Li, Cheng Wan, and Yingyan Celine Lin. Gpt4aigchip: Towards next-generation ai accelerator design automation via large language models. In ICCAD, 2023.
- Grosnit et al. [2022] Antoine Grosnit, Cedric Malherbe, Rasul Tutunov, Xingchen Wan, Jun Wang, and Haitham Bou Ammar. Boils: Bayesian optimisation for logic synthesis. In DATE. IEEE, 2022.
- Guo et al. [2022] Zizheng Guo, Mingjie Liu, Jiaqi Gu, Shuhan Zhang, David Z Pan, and Yibo Lin. A timing engine inspired graph neural network model for pre-routing slack prediction. In DAC, 2022.
- Han et al. [2023] Boyu Han, Xinyu Wang, Yifan Wang, Junyu Yan, and Yidong Tian. New interaction paradigm for complex eda software leveraging gpt. arXiv preprint arXiv:2307.14740, 2023.
- He et al. [2023] Zhuolun He, Haoyuan Wu, Xinyun Zhang, Xufeng Yao, Su Zheng, Haisheng Zheng, and Bei Yu. Chateda: A large language model powered autonomous agent for eda. In MLCAD, 2023.
- Hosny et al. [2020] Abdelrahman Hosny, Soheil Hashemi, Mohamed Shalan, and Sherief Reda. Drills: Deep reinforcement learning for logic synthesis. In ASP-DAC, 2020.
- Ji et al. [2023] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 2023.
- Kande et al. [2023] Rahul Kande, Hammond Pearce, Benjamin Tan, Brendan Dolan-Gavitt, Shailja Thakur, Ramesh Karri, and Jeyavijayan Rajendran. Llm-assisted generation of hardware assertions. arXiv preprint arXiv:2306.14027, 2023.
- Lai et al. [2022] Yao Lai, Yao Mu, and Ping Luo. Maskplace: Fast chip placement via reinforced visual representation learning. NeurIPS, 35, 2022.
- Lewis et al. [2020] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. NeurIPS, 2020.
- Li et al. [2022a] Min Li, Sadaf Khan, Zhengyuan Shi, Naixing Wang, Huang Yu, and Qiang Xu. Deepgate: Learning neural representations of logic gates. In DAC, 2022a.
- Li et al. [2022b] Xing Li, Lei Chen, Fan Yang, Mingxuan Yuan, Hongli Yan, and Yupeng Wan. Himap: A heuristic and iterative logic synthesis approach. In DAC, 2022b.
- Liang et al. [2023] Rongjian Liang, Siddhartha Nath, Anand Rajaram, Jiang Hu, and Haoxing Ren. Bufformer: A generative ml framework for scalable buffering. In ASP-DAC, 2023.
- Lin et al. [2019] Yibo Lin, Shounak Dhar, Wuxi Li, Haoxing Ren, Brucek Khailany, and David Z Pan. Dreamplace: Deep learning toolkit-enabled gpu acceleration for modern vlsi placement. In DAC, 2019.
- Liu et al. [2023a] Mingjie Liu, Teodor-Dumitru Ene, Robert Kirby, Chris Cheng, Nathaniel Pinckney, Rongjian Liang, Jonah Alben, Himyanshu Anand, Sanmitra Banerjee, Ismet Bayraktaroglu, et al. Chipnemo: Domain-adapted llms for chip design. arXiv preprint arXiv:2311.00176, 2023a.
- Liu et al. [2023b] Mingjie Liu, Nathaniel Pinckney, Brucek Khailany, and Haoxing Ren. Verilogeval: Evaluating large language models for verilog code generation. In ICCAD, 2023b.
- Liu et al. [2023c] Shang Liu, Wenji Fang, Yao Lu, Qijun Zhang, Hongce Zhang, and Zhiyao Xie. Rtlcoder: Outperforming gpt-3.5 in design rtl generation with our open-source dataset and lightweight solution. arXiv preprint arXiv:2312.08617, 2023c.
- Lu et al. [2023] Yao Lu, Shang Liu, Qijun Zhang, and Zhiyao Xie. Rtllm: An open-source benchmark for design rtl generation with large language model. arXiv preprint arXiv:2308.05345, 2023.
- Lu et al. [2021] Yi-Chen Lu, Jeehyun Lee, Anthony Agnesina, Kambiz Samadi, and Sung Kyu Lim. A clock tree prediction and optimization framework using generative adversarial learning. TCAD, 2021.
- Masoudnia and Ebrahimpour [2014] Saeed Masoudnia and Reza Ebrahimpour. Mixture of experts: a literature survey. Artificial Intelligence Review, 2014.
- Meng et al. [2023] Xingyu Meng, Amisha Srivastava, Ayush Arunachalam, Avik Ray, Pedro Henrique Silva, Rafail Psiakis, Yiorgos Makris, and Kanad Basu. Unlocking hardware security assurance: The potential of llms. arXiv preprint arXiv:2308.11042, 2023.
- Mirhoseini et al. [2021] Azalia Mirhoseini, Anna Goldie, Mustafa Yazgan, Joe Wenjie Jiang, Ebrahim Songhori, Shen Wang, Young-Joon Lee, Eric Johnson, Omkar Pathak, Azade Nazi, et al. A graph placement methodology for fast chip design. Nature, 2021.
- Nair et al. [2023] Madhav Nair, Rajat Sadhukhan, and Debdeep Mukhopadhyay. Generating secure hardware using chatgpt resistant to cwes. Cryptology ePrint Archive, 2023.
- OpenAI [2023a] OpenAI. Gpt-vision. https://platform.openai.com/docs/guides/vision, 2023a.
- OpenAI [2023b] OpenAI. Gpt-4 technical report, 2023b.
- Orenes-Vera et al. [2021] Marcelo Orenes-Vera, Aninda Manocha, David Wentzlaff, and Margaret Martonosi. Autosva: Democratizing formal verification of rtl module interactions. In DAC, 2021.
- Orenes-Vera et al. [2023] Marcelo Orenes-Vera, Margaret Martonosi, and David Wentzlaff. Using llms to facilitate formal verification of rtl. arXiv e-prints, 2023.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In NeurIPS, 2022.
- Paria et al. [2023] Sudipta Paria, Aritra Dasgupta, and Swarup Bhunia. Divas: An llm-based end-to-end framework for soc security analysis and policy-based protection. arXiv preprint arXiv:2308.06932, 2023.
- Pearce et al. [2020] Hammond Pearce, Benjamin Tan, and Ramesh Karri. Dave: Deriving automatically verilog from english. In MLCAD, 2020.
- PrimisAI [2023] PrimisAI. Rapidgpt: Your ultimate hdl pair-designer. https://primis.ai/, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021.
- Schäfer et al. [2023] Max Schäfer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. An empirical evaluation of using large language models for automated unit test generation. IEEE Transactions on Software Engineering, 2023.
- Shi et al. [2023] Zhengyuan Shi, Hongyang Pan, Sadaf Khan, Min Li, Yi Liu, Junhua Huang, Hui-Ling Zhen, Mingxuan Yuan, Zhufei Chu, and Qiang Xu. Deepgate2: Functionality-aware circuit representation learning. arXiv preprint arXiv:2305.16373, 2023.
- Stiennon et al. [2020] Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. NeurIPS, 2020.
- Tang et al. [2023] Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. Graphgpt: Graph instruction tuning for large language models. arXiv preprint arXiv:2310.13023, 2023.
- Thakur et al. [2023a] Shailja Thakur, Baleegh Ahmad, Zhenxing Fan, Hammond Pearce, Benjamin Tan, Ramesh Karri, Brendan Dolan-Gavitt, and Siddharth Garg. Benchmarking large language models for automated verilog rtl code generation. In DATE, 2023a.
- Thakur et al. [2023b] Shailja Thakur, Baleegh Ahmad, Hammond Pearce, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri, and Siddharth Garg. Verigen: A large language model for verilog code generation. arXiv preprint arXiv:2308.00708, 2023b.
- Thakur et al. [2023c] Shailja Thakur, Jason Blocklove, Hammond Pearce, Benjamin Tan, Siddharth Garg, and Ramesh Karri. Autochip: Automating hdl generation using llm feedback. arXiv preprint arXiv:2311.04887, 2023c.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Tsai et al. [2023] YunDa Tsai, Mingjie Liu, and Haoxing Ren. Rtlfixer: Automatically fixing rtl syntax errors with large language models. arXiv preprint arXiv:2311.16543, 2023.
- Wang et al. [2023a] Jiaqi Wang, Zhengliang Liu, Lin Zhao, Zihao Wu, Chong Ma, Sigang Yu, Haixing Dai, Qiushi Yang, Yiheng Liu, Songyao Zhang, et al. Review of large vision models and visual prompt engineering. Meta-Radiology, 2023a.
- Wang et al. [2023b] Xiao Wang, Guangyao Chen, Guangwu Qian, Pengcheng Gao, Xiao-Yong Wei, Yaowei Wang, Yonghong Tian, and Wen Gao. Large-scale multi-modal pre-trained models: A comprehensive survey. Machine Intelligence Research, 2023b.
- Wang et al. [2022] Ziyi Wang, Chen Bai, Zhuolun He, Guangliang Zhang, Qiang Xu, Tsung-Yi Ho, Bei Yu, and Yu Huang. Functionality matters in netlist representation learning. In DAC, 2022.
- Yang et al. [2022] Zhihao Yang, Dong Li, Yingxueff Zhang, Zhanguang Zhang, Guojie Song, Jianye Hao, et al. Versatile multi-stage graph neural network for circuit representation. NeurIPS, 2022.
- Yao et al. [2022] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Yuan et al. [2023] Jianyong Yuan, Peiyu Wang, Junjie Ye, Mingxuan Yuan, Jianye Hao, and Junchi Yan. Easyso: Exploration-enhanced reinforcement learning for logic synthesis sequence optimization and a comprehensive rl environment. In ICCAD, 2023.
- Zhang et al. [2023] Ziwei Zhang, Haoyang Li, Zeyang Zhang, Yijian Qin, Xin Wang, and Wenwu Zhu. Large graph models: A perspective. arXiv preprint arXiv:2308.14522, 2023.
- Zhong et al. [2024] Ruizhe Zhong, Junjie Ye, Zhentao Tang, Shixiong Kai, Mingxuan Yuan, Jianye Hao, and Junchi Yan. Preroutgnn for timing prediction with order preserving partition: Global circuit pre-training, local delay learning and attentional cell modeling. In AAAI, 2024.