Graph Foundation Models
Abstract
Graph Foundation Model (GFM) is a new trending research topic in the graph domain, aiming to develop a graph model capable of generalizing across different graphs and tasks. However, a versatile GFM has not yet been achieved. The key challenge in building GFM is how to enable positive transfer across graphs with diverse structural patterns. Inspired by the existing foundation models in the CV and NLP domains, we propose a novel perspective for the GFM development by advocating for a “graph vocabulary”, in which the basic transferable units underlying graphs encode the invariance on graphs. We ground the graph vocabulary construction from essential aspects including network analysis, theoretical foundations, and stability. Such a vocabulary perspective can potentially advance the future GFM design following the neural scaling laws.
1 Introduction
Foundation models (Bommasani et al., 2021), which are pre-trained on massive data and can be adapted to tackle a wide range of downstream tasks, have achieved inimitable success in various domains, e.g., computer vision (CV) (Radford et al., 2021) and natural language processing (NLP) (Bubeck et al., 2023; Touvron et al., 2023). Typically, foundation models can effectively utilize both the prior knowledge obtained from the pre-training stage and the data from downstream tasks to achieve better performance (Han et al., 2021) and even deliver promising efficacy with few-shot task demonstrations (Dong et al., 2022).
Meanwhile, graphs are vital and distinctive data structures that encapsulate non-Euclidean and intricate object relationships. Given that various graphs embody unique relations, most graph learning approaches are tailored to train from scratch for a single task on a particular graph. Such an approach requires data collection and deployment for each individual graph and task. Consequently, an intriguing question emerges: Is it possible to devise a Graph Foundation Model (GFM) capable of generalizing across different graphs and tasks?
Despite the significant advancements in foundation models in other domains, the development of GFMs remains in the infant stage. Recent research has demonstrated the potential of GFMs in specialized areas, such as knowledge graphs (Galkin et al., 2023) and molecular structures (Beaini et al., 2023). However, these models often concentrate on limited scenarios: they may be applied across multiple datasets but restricted to a single task, span various tasks within a single domain, or be confined to a small set of datasets and tasks. To date, a versatile GFM that can generalize across the broad spectrum of graph-based applications has yet to be realized.
The key difficulty in achieving the GFM is how to achieve positive transfer across diverse graph data ranging from social networks to molecule graphs with countless structure patterns. The answer from the CV and NLP domains is a shared vocabulary. In the NLP foundation models, the text is first broken down into smaller units based on the vocabulary, which can be words, phrases, or symbols. In the CV foundation models, the image is mapped to a series of discrete image tokens (Yu et al., 2023a; Bai et al., 2023) based on the vision token vocabulary. The vocabulary defines the basic units in the particular domain, transferable across different tasks and datasets. Therefore, the key challenges in achieving the GFM narrow down to how we can find the graph vocabulary, the basic transferable units underlying graphs to encode the invariance on graphs.
However, finding a suitable graph vocabulary that works across diverse graphs is challenging, which is the primary focus of this paper.
Our contributions: In this paper, we present a vocabulary perspective to clearly state the position of the GFM. In particular, we attribute the existing success of primitive GFMs to the suitable vocabulary construction guided by the particular transferability principle on graphs in Section 2. The comprehensive review of the transferability principles on graphs is illustrated in Section 3, serving us the principle for future vocabulary construction and the GFM design.
In Section 4, we discuss the potential for building the GFM following neural scaling laws from the vocabulary perspective and review the current progress towards advanced GFM. Finally, we introduce more insights and open questions to inspire constructive discussions on the GFM in Section 5.
Comparison with past relevant literature Concurrent to our position paper, Jin et al. (2023a); Li et al. (2023b); Zhang et al. (2023c) reviews those methods adapting large language model (LLM) for graph, which haven’t shown transferring capabilities and thus diverge from our scope to build a graph-centric GFM. Liu et al. (2023e) further discusses existing graph pre-training and adaption techniques with a focus on their implementations. Instead of technical details, our work focuses more on the fundamental principles, e.g., geometric invariance across datasets. With principle guidance, we depict the promising and relatively elusive directions for the development of GFMs.
2 Existing primitive GFMs and the key reasons for the existing success
The GFM is formally defined in Liu et al. (2023e), which expects a GFM with the capability to transfer across all the graph tasks and datasets.
Nonetheless, there remains no such GFM satisfying the above definition yet. In contrast, we have observed that existing models (Galkin et al., 2023; Zheng et al., 2023a) have achieved the initial success, obtaining the desired capability of the GFM on certain aspects.
In this work, we name them as the “primitive GFM”, which can further be categorized into task-specific, domain-specific, and prototype GFMs based on their transferability. Details can be found in Section 2.1. The key reasons for their success is then further discussed in Section 2.2.
2.1 Existing primitive GFMs
Based on the model transferability across domains and tasks, we can roughly distinguish the existing primitive GFMs into three categories: task-specific, domain-specific, and prototype GFMs. We provide definitions and examples for each category, with additional illustrations in Appendix B.
A task-specific/domain-specific GFM should be transferable across the specific task/domain and thus adapt to diverse downstream datasets and domain-specific tasks. A notable example of a task-specific GFM is ULTRA (Galkin et al., 2023), achieving superior zero-shot knowledge graph completion (KGC) performance across datasets from various domains. A domain-specific GFM instance, DiG (Zheng et al., 2023a), learns universal representations across various chemical tasks by leveraging domain-specific knowledge.
A Prototype GFM exhibits the capability to generalize towards a limited number of datasets and tasks. A notable example is PRODIGY (Huang et al., 2023a) which can perform few-shot in-context learning over node classification and link prediction on text-attributed graphs. However, since Huang et al. (2023a) employs a shallow GNN as its core model, the scalability and flexibility to additional datasets and tasks, given its modest model size, remains uncertain.
Concurrently, there have been efforts (Li et al., 2023b) to harness LLMs for graph-related tasks. Although LLMs excel in the NLP realm, directly simply flattening graph structures and prompting LLM yields suboptimal results, evidenced by studies on both text-attributed (Chen et al., 2023b) and non-text-attributed graphs (Wang et al., 2023a). A noteworthy approach is GraphText (Zhao et al., 2023b) employs a tree-based prompt design that retains structural semantics, delivering satisfactory few-shot in-context learning performance. However, the LLM meets fundamental issues (Saparov & He, 2022; Dziri et al., 2023) on addressing graph data. We provide a further discussion on the usage of LLM in the graph domain in Section 5.
2.2 The key reasons for the existing GFM success.
Despite the empirical success achieved by the primitive GFMs, the underlying reasons remain unclear. In particular, we investigate the mechanism on the ULTRA (Galkin et al., 2023), which is a task-specific GFM focusing on the knowledge graph completion (KGC) task. THe KGC task aims to infer the missing triplet (edge), denoted as , where is a query relationship, and are the head and tail entities, respectively. The KGC model aims to answer the query by predicting the tail entity .
The first reason for its success is to utilize the NBFNet (Zhu et al., 2021b) backbone model which enables the inductive generalization to new graphs with an expressive relational vocabulary. The NBFNet proposes a conditional message passing that can learn the pairwise-node representation conditioned on a head entity node and a query relation.
Huang et al. (2023c) demonstrates that this conditional message passing, grounded in the relational Weisfeiler-Leman algorithm, theoretically offers greater expressiveness in KGC compared to standard, unconditional GNNs (Li et al., 2022). Such expressiveness helps to distinguish the difference between knowledge graphs with different structural features, leading to a suitable relational vocabulary. In contrast, Barcelo et al. (2022) indicates that those unconditional GNNs, e.g., R-GCN (Schlichtkrull et al., 2018) and CompGCN (Vashishth et al., 2019), map non-isomorphic node pairs into the same representation, leading to a contracted relational vocabulary. Such contracted vocabulary may lead to negative transfer with inappropriately generalizing knowledge across non-isomorphic node pairs with inherent differences.
However, such expressive relational vocabulary only considers the pre-defined relation types which cannot generalize to the scenario with new relation types during inference. To extend the existing relational vocabulary including new relationship type, Galkin et al. (2023) constructs a graph of relations that captures fundamental interactions independent from any graph-specific relation types, serving as the second reason for its success. The graph of relations is theoretically grounded (Gao et al., 2023) which aims to learn the double permutation-equivariant representations. Such representation is equivariant to permutations of both node entities and edge relation types. Such equivariance can be an analogy to a shared relational vocabulary. It connects the new unseen relationship types to the existing ones and maps the equivariant node pairs into the same representation despite different relation types, leading to the positive transfer.
In summary, we can conclude the key for ULTRA to achieve good transferability is finding a suitable vocabulary for KGC satisfying two principles: (1) The vocabulary should not be compacted, which causes distinct node pairs to share representations, leading to potential negative transfer. (2) The vocabulary should be sufficiently inclusive to map new, unknown relationships onto the existing vocabulary, potentially enabling positive transfer.
The effectiveness of finding a suitable vocabulary for building the GFM can also be found in other existing primitive GFMs with the following evidence. GraphGPT (Zhao et al., 2023c) constructs a dataset-specific vocabulary where each node corresponds to a unique node ID. Notably, GraphGPT requires specific pre-training and fine-tuning on each dataset. MoleBERT (Xia et al., 2023), the foundation model for molecule graphs, manually designs a vocabulary that transforms atom attributes into chemically meaningful codes. Similarly, OFA (Liu et al., 2023b) manually converts all the node features into meaningful text descriptions.
3 The underlying transferability principle
In the last section, we investigate the key reason for the existing success of building the GFM. The key principle for building the GFM is to construct a suitable graph vocabulary, which keeps the essential invariance across datasets and tasks. Despite the existing success,
more graph transferability principles can discover different invariances and serve as guidance for constructing new suitable graph vocabulary for future GFMs.
The following discussions are organized as follows:
We first provide a general introduction to the graph transferability principles in Section 3.1. Detailed task-specific principles on node classification, link prediction, and graph classification tasks can be found in Section 3.2, 3.3, and 3.4, respectively. We finally discuss the principles for task transferability in Section 3.5. Notably, the following discussions majorly concentrate on the transferability of the graph structure.
3.1 Graph transferability principles
In this subsection, we introduce principles that enable transferability on graphs, focusing on three key aspects: network analysis, expressiveness, and stability.
Network analysis provides a conventional understanding of the network system by identifying fundamental graph patterns, e.g., network motif (Menczer et al., 2020) and establishing the key principles, e.g., triadic closure principle (Huang et al., 2015) and homophily principle, which are generally valid across different domains. Those principles have been generally utilized to guide the design of advanced GNNs. For example, the state-of-the-art GNN for link prediction (Wang et al., 2023b) is a Neural Common Neighbor, inspired by the triadic closure principle. Despite its effectiveness, network analysis heavily relies on expert knowledge without a provable guarantee.
Expressiveness provides a theoretical background as to which functions graph neural architectures can model in general, e.g., a well-known connection that graph-level performance of GNNs is bounded by Weisfeiler-Leman tests (Xu et al., 2019; Morris et al., 2019, 2023). The most-expressive structural representation (Srinivasan & Ribeiro, 2019) is the key concept describing that the representation of two node sets should be invariant if and only if the node sets are symmetric with a permutation equivalence. Such most-expressive structural representation serves as an important principle to design a suitable graph vocabulary that perfectly distinguishes all non-isomorphic structural patterns in multi-ary prediction tasks.
Stability (Ruiz et al., 2023) assesses the representation sensitivity to graph perturbations. It aims to maintain a bounded gap in predictions for pairs under minor perturbations, rather than the expressiveness only distinguishing between isomorphic and non-isomorphic cases. The stability imposes a stricter constraint leading to better generalization. It can be an analogy to the constraint on the graph vocabulary where similar structure patterns should have similar representation.
Moreover, there are some other challenges that would affect the deeper GNN design to include more higher-order information. A deeper GNN may suffer from performance degradation and fail to capture higher-order structural information. There are majorly three issues: (i) The oversquashing problem (Topping et al., 2021) illustrates that the node representation is insensitive to information from important but distant nodes. (ii) The oversmoothing problem (Oono & Suzuki, 2019; Cai & Wang, 2020) illustrates that more aggregations lead to the node representations converging to a unique equilibrium, which loses the distinction between different nodes. (iii) The underreaching (Barceló et al., 2020) illustrates the failure to explore, cover, or affect all relevant nodes in the graph, leading to information loss. Various techniques are proposed to identify the root causes (Di Giovanni et al., 2023; Wu et al., 2023) and solve the expressiveness issues via new GNN (Yang et al., 2021) and graph transformer (Wu et al., 2022; Müller et al., 2023) architecture designs.
3.2 Transferability principles in node classification
Network analysis. Homophily (Khanam et al., 2020), which describes the phenomenon of linked nodes often sharing similar features (“birds of a feather flock together”), is a longstanding principle in social science. It serves as the principle guidance for methods ranging from conventional pagerank (Chien et al., 2021) and label propagation (Chawla & Karakoulas, 2005) to the recent advanced GNNs. Existing GNN architectures, often crafted based on the homophily principle, demonstrate strong performance on diverse homophilous graphs across various domains. This adherence to homophily not only enhances model effectiveness but also facilitates model transferability among homophilous graph datasets. Notably, successful transfers among such graphs are evidenced in Ying et al. (2018).
While homophily predominates in network analysis, it is not a universal rule. In many real-world scenarios, “opposites attract”, resulting in networks characterized by heterophily—where nodes are more likely to link with dissimilar nodes. GNNs built with the homophily principle often struggle with heterophilious networks, except in cases of “good heterophily” (Ma et al., 2021; Luan et al., 2021), where GNNs can identify and leverage consistent patterns in connections between dissimilar nodes. However, most heterophilious networks are complex and varied, posing challenges for GNNs due to their irregular and intricate interaction patterns (Luan et al., 2023; Wang et al., 2024; Mao et al., 2023a). Consequently, GNNs’ transferability, more assured in homophilous graphs, is facing significant challenges in heterophilous ones.
Stability. You et al. (2023) theoretically establishes the relationship between transferability and network stability, demonstrating that graph filters with enhanced spectral smoothness and a smaller maximum frequency response exhibit improved transferability in terms of node features and structure, respectively. In particular, spectral smoothness, characterized by the Lipschitz constant of the graph filter function of the corresponding GNN, indicates stability against edge perturbations. The maximum frequency response, reflecting the highest spectral frequency after applying a graph filter (essentially the largest eigenvalue of the Laplacian matrix), describes stability against feature perturbations.
3.3 Transferability principles in link prediction
Network Analysis. Important network analysis principles (Mao et al., 2023b) fall into three primary concepts including: (1) local structural proximity corresponding to the triadic closure principle (Huang et al., 2015), where friends of friends become friends themselves. It inspires well-known conventional methods including CN, RA, AA (Adamic & Adar, 2003). (2) global structural proximity corresponding to the decay factor principle, where two nodes with more short paths between them have a higher probability of being connected. It inspires well-known conventional methods e.g., Simrank and Katz (Katz, 1953; Jeh & Widom, 2002). (3) feature proximity corresponding to the homophily principle (Murase et al., 2019) where shared beliefs and thoughts can be found in connected individuals.
These principles guide the evolution of link prediction algorithms, from basic heuristics to sophisticated GNNs (Chamberlain et al., 2022; Li et al., 2023a). GNNs, inspired by these principles, perform well across diverse graphs in multiple domains. Moreover, Zheng et al. (2023b) provides empirical evidence supporting the beneficial transferability of these guiding principles.
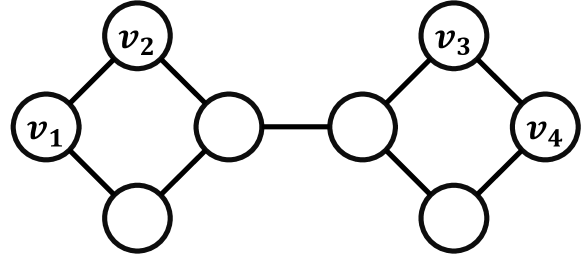
Expressiveness. A vanilla GNN, equipped with only single-node permutation equivalence, cannot achieve transferability for the link prediction task due to its lack of expressiveness. An example to showcase such failure is shown in Figure 1 with a featureless graph. and are represented identically by the vanilla GNN, as they possess identical neighborhood structures.
Therefore, the similarity between and will be the same as the one between and , leading to identical representations and predictions for both links and However, according to the global structural proximity, , with a shorter distance of 1, should be more likely to be connected. The vanilla GNN, computing ’s representation solely from its neighborhood, overlooks the structural dependence with . As a result, this potentially leads to negative transfer, where the GNN might erroneously predict both or neither link to exist, whereas it’s more likely that only has a link.
To consider all the possible dependencies between node pairs, we aim for the most expressive structural representation for the link prediction. This representation should be invariant if and only if links are symmetric. Zhang & Chen (2018) achieves such structural representation by incorporating node labeling features that depend on both the source and target nodes in a link. Zhang et al. (2021) further highlights the key aspects of node labeling design, including: (1) target-nodes-distinguishing, where the source and target nodes have distinct labels compared to other nodes; and (2) permutation equivariance. Node labeling methods that fulfill these criteria, such as double radius node labeling (DRNL) and zero-one (ZO) labeling, can produce the most expressive structural representations. The expressiveness representation can find the complete set of distinct relations to differentiate all non-isomorphic node pairs, thereby mitigating the risk of negative transfer in standard GNNs. Huang et al. (2023c) extends the relational Weisfeiler-Leman framework (Barcelo et al., 2022) to link prediction and incorporate the concept of labeling tricks to multi-relational graphs.
Stability. For those equally expressive structural representations, there may still be a gap in terms of their stability. For example, empirical evidence (Zhang et al., 2021) shows that GNNs with DRNL labeling outperform those with ZO labeling. From the perspective of stability, it is crucial to maintain a bounded gap in predictions for pairs under minor perturbations. Wang et al. (2021) provides a theoretical analysis identifying key properties of stable positional encoding (GNNs should be rotation and permutation equivariant to positional encodings) that enhance generalization.
3.4 Transferability principle in graph classification
Network Analysis. Network motifs, typically composed of small and recurrent subgraphs, are often considered the building blocks of a graph (Milo et al., 2002; Benson et al., 2016). A proper selection of the motif set can cover most essential knowledge on the specific datasets. Graph kernels (Vishwanathan et al., 2010) are proposed to quantify motif counts or other pre-defined graph structural features and then utilize the extracted features to build a classifier such as SVM. Despite the essential motif sets from different domains being generally different, there could exist a uniform set of motifs shared across different domains. In such cases, the positive transfer can be found on the uniform sets, where Battiston et al. (2020) shows the positive transfer across neuronal connectivity networks, food webs, and electronic circuits. Therefore, we conjecture that the network motif could be the base unit for the vocabulary (a set of invariant elements) for the graph classification as it is both explainable and potentially shared across graphs.
Expressiveness. Zhang et al. (2024) proposes a unified framework to understand the ability of different GNNs to detect and count graph substructures (motif). More expressive GNN which could detect more diverse motifs and construct a richer graph vocabulary. In analogy with the uniform motif sets, we conjecture that it is more possible for the expressive GNN to find the uniform motif sets and achieve better transferability.
Stability. Huang et al. (2023d) proposes a provably stable position encoding that surpasses the expressive sign and invariant encoding (Kreuzer et al., 2021) and modeling (Lim et al., 2022), enabling minimal changes to positional encodings on the minor modifications to the Laplacian. The key innovation is to apply a weighted sum of eigenvectors instead of treating each eigensubspace independently. Satisfying performance can be observed on the out-of-distribution molecular graph prediction.
3.5 The transferability across tasks
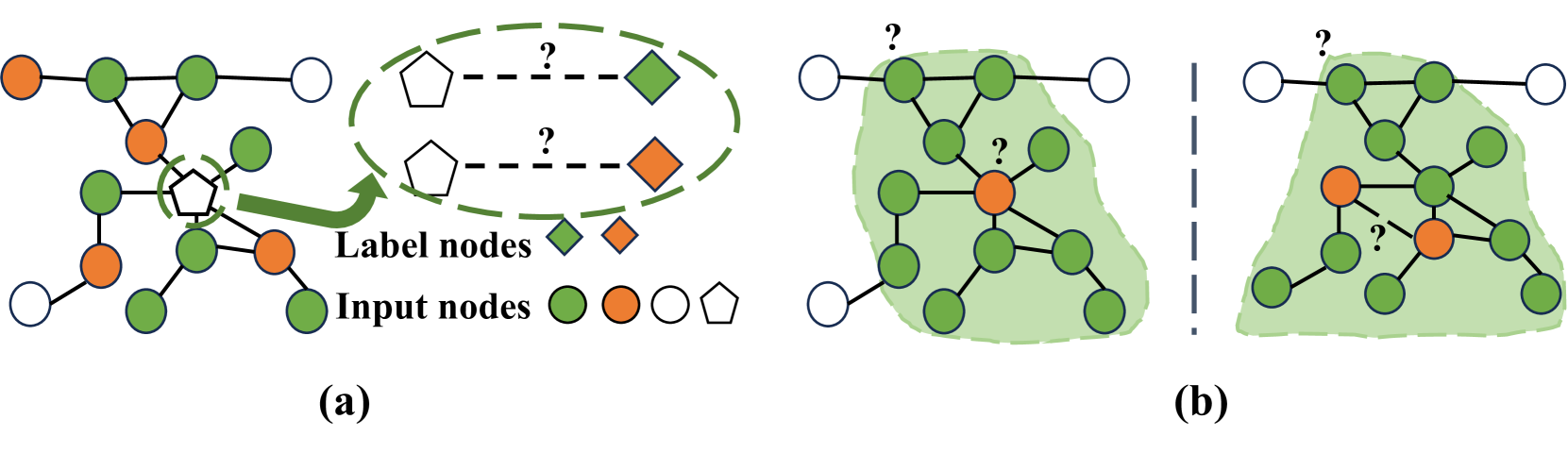
A unified task formulation is generally employed to facilitate transferability across various tasks. The significance of aligning task formulations is evident in the following example: Jin et al. (2020b) shows that using link prediction directly as a pretext task leads to negative transfer for node classification. However, by reformulating node classification into a link prediction problem (Sun et al., 2022; Huang et al., 2023a), where a node’s class membership is treated as the link likelihood between the node and label nodes, positive transfer is achieved.
Liu et al. (2023g); Sun et al. (2023) further propose a subgraph view to adapt the node classification as an ego graph classification, and link prediction as a binary classification on the induced subgraph of the target node pair.
Figure 2 provides illustrative examples for these two unified views. The unified task formulation enables (1) enlarging the dataset size via converting datasets for different downstream tasks as one and (2) utilizing one pre-training model to serve different tasks.
Surpassing the unified formulation, there are shared principles on different tasks listed as follows: (1) Node classification and link prediction tasks share the feature homophily as an important principle. (2) Liu et al. (2023d) indicates that the global structural proximity principle on the link prediction can improve the node classification performance on the non-homophilous graph. (3) The triadic closure in the link prediction is a particular network motif utilized in the graph classification. There are more shared motifs (Hibshman et al., 2021; Dong et al., 2017; AbuOda et al., 2020; Kriege et al., 2020) on both graph classification and link prediction tasks.
4 Towards GFM following neural scaling law
The success of the foundation model can be attributed to the validity of the neural scaling law (Kaplan et al., 2020) which shows performance enhancement with increasing model scale and data scale. In this section, we first discuss when the neural scaling law happens in Section 4.1 from a graph vocabulary perspective. We then discuss techniques towards successful data scaling and model scaling in Section 4.2 and 4.3, respectively. The pre-text task design is finally discussed in Section 4.4.
4.1 When neural scaling law happens
In section 3, we discuss the underlying transferable principles guiding future vocabulary construction. Such principle guidance has led to the successful scaling behavior in the material science domain (Shoghi et al., 2023; Zhang et al., 2023a; Batatia et al., 2023) with the help of the geometric prior. Nonetheless, we are still cautious about whether the existing success can be extended to the graph domain. The key concern is whether graphs can strictly follow those principles. Uncertainty can be found on the human-defined graph construction criteria (Brugere et al., 2018). For instance, the construction knowledge relying on expert knowledge may lead to uncertainty in edges (Ye et al., 2022). Chen et al. (2023b); Li et al. (2023c) observe that the mislabeled samples widely exist across datasets, where the popular CiteSeer dataset has more than 15 Despite the above uncertainty, different graph constructions with manual design can follow opposite principles. For instance, Ogbn-arxiv (Hu et al., 2020) and Arxiv-year (Lim et al., 2021) are two node classification datasets with identical graph information. The only difference lies in the label where Ogbn-arxiv employs paper categories, and Arxiv-year uses publication years as labels, resulting in conflicting homophily and heterophily properties (Mao et al., 2023a). Therefore, when uncertainties and opposite graph constructions exist, the scaling behavior may not happen as the data does not obey the graph transferable principles.
4.2 Data scaling
Chen et al. (2023a); Huang et al. (2023a) initially validate that GNNs trained in both supervised and self-supervised manners follow data scaling law on molecular property predictions, and node classification on text-attributed graphs. Xu et al. (2023) further exhibits that the similarity between pre-training data and downstream task data serves as a prerequisite for the data scaling on graphs. Specifically, Cao et al. (2023); Xu et al. (2023) provide concrete guidance on how to select the pre-training data via the graphon signal analysis and the essential network property, i.e. network entropy, respectively. The positive transfer can be found when the data exhibits similarity in the graphon space or with shared network properties.
A limitation in current research on data scaling is the small dataset size, particularly in contrast to the pre-training for LLMs (Raffel et al., 2019). This disparity may be attributed to the scarcity of high-quality data in the graph domain. NetworkRepository (Rossi & Ahmed, 2015), the largest graph database presently available, may support larger-scale pre-training, while burdensome pre-processing is required to clean those noisy and disordered data. Moreover, we illustrate a collection of useful datasets in Appendix A. We then show existing solutions as follows.
Tackling feature heterogeneity. Existing graph datasets cannot be uniformly utilized for pre-training due to the heterogeneous feature induced by missing features and different semantic spaces. Feature imputation techniques (Taguchi et al., 2021; Um et al., 2023; Gupta et al., 2023) are generally adapted to predict the missing attributes based on neighboring features. However, those techniques require each feature dimension to share the same semantic meaning. When features are not aligned in the same semantic space, Liu et al. (2023b) manually converts the original features with text descriptions and then encodes the embedding with LLMs. Moreover, feature misalignment can also be found in the inference stage between the pre-training model input and the test data. Jing et al. (2023) concatenates a learnable padding feature on the downstream task feature to align with the pre-trained GNN. However, such a technique cannot adapt to the case when the feature space is not aligned. Zhao et al. (2023b) directly abandons the original feature and utilizes the feature similarity as guidance.
Generating synthetic graphs is another path to enhance data scaling and enlarge the training data size. Traditional graph generative models (Albert & Barabási, 2002; Robins et al., 2007; Airoldi et al., 2008; Leskovec et al., 2010) are capable of generating graphs satisfying some certain statistical properties, which still plays an important role on node-level and link-level tasks.
Deep generative models on graph (Jin et al., 2020a; Luo et al., 2021; Jo et al., 2022; Vignac et al., 2023) have shown great success in generating high-quality synthetic graphs which helps graph-level tasks by providing a more comprehensive description of the graph distributions space.
Liu et al. (2023a) utilizes diffusion models to generate task-specific data argumentation to enhance the GNN on graph-level tasks with significant performance gain. With successful evidence of pre-training on synthetic data from other domains (Mishra et al., 2022; Trinh et al., 2024), we anticipate the potential to generate high-quality synthetic graphs for large-scale pre-training towards GFM.
4.3 Model scaling
Previous research in NLP indicates that apart from data, the backbone model constitutes a fundamental for scaling (Kaplan et al., 2020). Liu et al. (2024) primarily validates the neural scaling law on various graph tasks and model architectures under the supervised setting.
However, Kim et al. (2022) demonstrates that the GAT (Veličković et al., 2017) with a larger number of parameters underperforms on the graph regression tasks compared to the smaller-sized counterparts. As a comparison, geometric GNNs scale well to predict atomic potentials in material science (Shoghi et al., 2023; Zhang et al., 2023a; Batatia et al., 2023). The contradictory phenomenon indicates that the alignment between the geometric prior of GNNs and the specific task may influence model scaling.
Graph transformer is another popular choice for the model architecture, where geometric priors are explicitly modeled through either GNN or positional encoding (Müller et al., 2023). Masters et al. (2022); Lu et al. (2023) show that graph transformers show positive scaling capabilities for molecular data under a supervised setting. More recently, Zhao et al. (2023c) demonstrates vanilla transformer’s effectiveness in protein and molecular property prediction. Particularly, it views the graph as a sequence of tokens forming an Eulerian path (Edmonds & Johnson, 1973), which ensures the lossless serialization, and then adopts next-token prediction to pre-train transformers. After fine-tuning, it achieves promising results on the protein association prediction and molecular property prediction and shows that vanilla transformers also follow the model scaling law (Kaplan et al., 2020). Nonetheless, the effectiveness of such pure transformers on other tasks remains unclear.
4.4 Pretext task design
Given the scarcity of labeled data, a pretext task that can effectively utilize unsupervised data is the cornerstone for larger-scale neural scaling. We provide a brief review of the representative pretext designs.
Graph contrastive learning designs the pretext tasks (Sun et al., 2019; Veličković et al., 2018; Hassani & Khasahmadi, 2020; You et al., 2020) to obtain the equivalence via contrasting original and augmented views of the graph without materially changing the semantic content of the input. An initial unified understanding (Liu et al., 2022) on those pre-text tasks illustrates that existing pretext tasks focus on preserving the invariance with the low frequency on the graph spectrum. Nonetheless, different pretext tasks remain different where Zhu et al. (2021a) observes that satisfactory performance requires pretext tasks and downstream tasks share similar philosophies, such as homophily. To obtain a pre-training model that benefits different downstream tasks, Ju et al. (2023) adaptively combined pretext tasks with different philosophies via a multi-task learning framework.
The generative self-supervised learning designs the pre-text tasks (Hou et al., 2022; Hu et al., 2019; Kipf & Welling, 2016) to capture the shared data generation process among different tasks. Particularly, they attempt to predict the masked portions of the graph using the remaining structure and features. Liu et al. (2023f); Xia et al. (2023) further observe that task granularity also plays an important role in generative modeling. Specifically, employing node-level pretext tasks may lead the model to learn only low-level features (Liu et al., 2023f) while ignoring the global information essential for graph-level tasks. To address this issue, they adopt a GNN-based tokenizer to explicitly model high-level information in the pre-training stage and thus improve the downstream task performance.
More recently, the next token prediction (NTP) pre-text task (Zhao et al., 2023c) achieves initial success in the molecular graph. Notably, this is the first pretext task demonstrating empirical evidence of model scaling. The potential reason for its success may be (1) the construction of a fixed token set, narrowing down the problem space in a finite set to only predict a discrete token and (2) choosing transformers as the backbone model. However, it remains unclear whether the success can be easily extended to more tasks.
5 Insights & open questions
The usage of LLM in the graph domain. With the existing success of LLMs (Bubeck et al., 2023) in the NLP domain, a natural question is whether we can directly apply its original language-centric ability on the graph. Primary exploration of the LLM focuses on text-attributed graphs. Chen et al. (2023b); He et al. (2023) treat node classification as the text classification on the target node, illustrating promising results on the zero-shot setting even without any structural information. For graphs without text attributes, Fatemi et al. (2023); Wang et al. (2023a) feed the data into LLM via describing graph structure with natural language. Observations show that LLMs present limited capability in understanding the essential graph structures. The key reason is that the LLM is required to tackle problems sequentially greedily (McCoy et al., 2023), leading to a shortcut solution (Saparov & He, 2022; Dziri et al., 2023) rather than a formal analysis on the graph structure. Moreover, Yue et al. (2023) points out the efficiency issue of utilizing LLM on the recommendation, the downstream link prediction task.
Tang et al. (2023); Ye et al. (2023); Chai et al. (2023) thus utilizes the GNN to encoder the graph structure knowledge and then introduces a linear layer to transform the embeddings obtained from the GNN into text space as a prompt token. Although these models can perform well, they still have two shortcomings: (1) The ability to process structures is bounded by the capabilities of GNN; (2) The instruction tuning can be costly while the tuned model can only tackle the corresponding downstream task and is not transferable to other tasks and datasets, which makes their capabilities distant from a GFM. We agree that LLM illustrates superior performance on textual node feature understanding. Nonetheless, it remains unclear whether LLM should play a key role in building GFM or just serve as a better textual feature encoder.
A potential strategy for equipping LLMs to effectively handle graph structures could be inspired by the success of multi-modal foundation models (Liu et al., 2023c). The key idea (Yu et al., 2023b) is to map the graph structure to a series of discrete tokens with a pre-trained tokenizer, which may convert graphs into a format comprehensible by LLMs. More discussion can be found in Appendix C.
Efficiency issue in subgraph-based methods. Subgraph-based extraction is a widely adopted technique to achieve inductive inference (Zeng et al., 2021) and unify different task formulations (Sun et al., 2023). Nonetheless, the subgraph-based extraction leads to the following issues: (1) information loss in high-order neighborhoods; (2) duplicate subgraph information with excessive memory consumption, and (3) the time complexity of vanilla subgraph extraction grows exponentially with the number of hops. Those issues hinder the applicability of subgraph-based methods. Graph sampling techniques like (Zeng et al., 2019) and global state vectors (Fey et al., 2021) can help to alleviate these issues.
Potential redundancy on pre-text task and architecture design. There are mainly two approaches to achieving transferability: (1) designing GNNs with specific geometric properties for transfer, e.g., ULTRA (Galkin et al., 2023), and (2) creating pretext tasks to automatically learn these properties. (Jin et al., 2020b) suggests an overlap between these approaches, indicating that pretext tasks targeting local structural information might be unnecessary, given that GNNs often inherently encode this information. Investigating the strengths and limitations of these techniques, along with providing practical guidance for their selection, could be a valuable research direction. A hypothesis might be that model design methods are more suitable for data that strictly adheres to geometric priors, while pretext task designs are more effective in the opposite scenario.
The necessity of GFM. Graphs can be defined in different ways based on different criteria like similarity or influence between node pairs (Brugere et al., 2018). We can then categorize graphs based on the observability of the criteria. The observable graph is unambiguously known, e.g., whether one paper cites another paper in a citation graph. Text and images can also be viewed as a specific case of observable graphs. In contrast, the unobservable ones are manually conducted with ambiguous descriptions of the relationship, e.g., whether one gene regulates the expression of another in a gene-regulate graph. These graphs may not naturally exist in the world, leading to uncertainty with a lack of invariant principle. We are not sure whether such graphs should be considered in the GFM.
Moreover, there are concerns about the benefit of training a GFM on graphs that are neither from the same domain nor share the same downstream task. On the one hand, it seems that training on them simultaneously shows no positive transfer benefit while increasing the risk of the negative transfer. On the other hand, we are not aware of potential undiscovered transferability leading to success.
GFMs on more applications. In this paper, we majorly focus on the conventional graph tasks, e.g., node classification, link prediction, graph classification, and the principle for building GFM on them. However, graph formulation is the universal representation ability, which can easily extend to different domains, e.g., scene graph for CV (Zhai et al., 2023; Zhong et al., 2021), bipartite graph for linear programming (Chen et al., 2022), and physical graphs for understanding physical mechanisms (Shi et al., 2022). Each domain can have its principle requiring specific graph vocabulary construction. Existing success can be found in material science (Zhang et al., 2023a; Batatia et al., 2023). For instance, (Batatia et al., 2023) utilizes the Equivariant Graph Tensor Network which can encode many-body information of atomic geometry can conduct molecular dynamics simulation across different chemistries. A potential application of GFM is to aid the generation of scene graphs (Zhong et al., 2021), involving predicting relationships between localized objects. Knowledge graph foundation models (Galkin et al., 2023) which can generalize to unseen entities and relations, may effectively model relationships and thus generate high-quality scene graphs.
6 Conclusion
From the transferability principles of graphs, we review existing GFMs and ground their effectiveness from a vocabulary view to find a set of basic transferrable units across graphs and tasks. Our key perspectives can be summarized as follows: (1) Constructing a universal GFM is challenging, but domain/task-specific GFMs are approachable with the usual availability of a specific vocabulary. (2) One challenge is developing GFM following the neural scaling law, which requires principle-driven design in data engineering, architecture, and pretext tasks. This paper summarizes the current position and challenges toward the next step, which may be a blueprint for GFM to inspire relevant research.
7 Impact Statements
In this paper, we provide principle guidance for the development of graph foundation models, which can be a pivotal infrastructure empowering diverse applications like nature science and E-commerce. The graph foundation model may reduce the resource consumption associated with training numerous task-specific models. Moreover, it may substantially curtail the requirement for manual annotation, particularly in domains such as molecular property prediction. We anticipate that our contributions will advance the ongoing efforts aimed at developing next-generation graph foundation models with better versatility and fairness.
References
- AbuOda et al. (2020) AbuOda, G., De Francisci Morales, G., and Aboulnaga, A. Link prediction via higher-order motif features. In Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2019, Würzburg, Germany, September 16–20, 2019, Proceedings, Part I, pp. 412–429. Springer, 2020.
- Adamic & Adar (2003) Adamic, L. A. and Adar, E. Friends and neighbors on the web. Social networks, 25(3):211–230, 2003.
- Airoldi et al. (2008) Airoldi, E. M., Blei, D., Fienberg, S., and Xing, E. Mixed membership stochastic blockmodels. Advances in neural information processing systems, 21, 2008.
- Albert & Barabási (2002) Albert, R. and Barabási, A.-L. Statistical mechanics of complex networks. Reviews of modern physics, 74(1):47, 2002.
- Bai et al. (2023) Bai, Y., Geng, X., Mangalam, K., Bar, A., Yuille, A., Darrell, T., Malik, J., and Efros, A. A. Sequential modeling enables scalable learning for large vision models. arXiv preprint arXiv:2312.00785, 2023.
- Barcelo et al. (2022) Barcelo, P., Galkin, M., Morris, C., and Orth, M. R. Weisfeiler and leman go relational. In Learning on Graphs Conference, pp. 46–1. PMLR, 2022.
- Barceló et al. (2020) Barceló, P., Kostylev, E. V., Monet, M., Pérez, J., Reutter, J., and Silva, J. P. The logical expressiveness of graph neural networks. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=r1lZ7AEKvB.
- Batatia et al. (2023) Batatia, I., Benner, P., Chiang, Y., Elena, A. M., Kovács, D. P., Riebesell, J., Advincula, X. R., Asta, M., Baldwin, W. J., Bernstein, N., Bhowmik, A., Blau, S. M., Cărare, V., Darby, J. P., De, S., Pia, F. D., Deringer, V. L., Elijošius, R., El-Machachi, Z., Fako, E., Ferrari, A. C., Genreith-Schriever, A., George, J., Goodall, R. E. A., Grey, C. P., Han, S., Handley, W., Heenen, H. H., Hermansson, K., Holm, C., Jaafar, J., Hofmann, S., Jakob, K. S., Jung, H., Kapil, V., Kaplan, A. D., Karimitari, N., Kroupa, N., Kullgren, J., Kuner, M. C., Kuryla, D., Liepuoniute, G., Margraf, J. T., Magdău, I.-B., Michaelides, A., Moore, J. H., Naik, A. A., Niblett, S. P., Norwood, S. W., O’Neill, N., Ortner, C., Persson, K. A., Reuter, K., Rosen, A. S., Schaaf, L. L., Schran, C., Sivonxay, E., Stenczel, T. K., Svahn, V., Sutton, C., van der Oord, C., Varga-Umbrich, E., Vegge, T., Vondrák, M., Wang, Y., Witt, W. C., Zills, F., and Csányi, G. A foundation model for atomistic materials chemistry, 2023.
- Battiston et al. (2020) Battiston, F., Cencetti, G., Iacopini, I., Latora, V., Lucas, M., Patania, A., Young, J.-G., and Petri, G. Networks beyond pairwise interactions: Structure and dynamics. Physics Reports, 874:1–92, 2020.
- Beaini et al. (2023) Beaini, D., Huang, S., Cunha, J. A., Moisescu-Pareja, G., Dymov, O., Maddrell-Mander, S., McLean, C., Wenkel, F., Müller, L., Mohamud, J. H., et al. Towards foundational models for molecular learning on large-scale multi-task datasets. arXiv preprint arXiv:2310.04292, 2023.
- Benson et al. (2016) Benson, A. R., Gleich, D. F., and Leskovec, J. Higher-order organization of complex networks. Science, 353(6295):163–166, 2016.
- Bommasani et al. (2021) Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- Brugere et al. (2018) Brugere, I., Gallagher, B., and Berger-Wolf, T. Y. Network structure inference, a survey: Motivations, methods, and applications. ACM Computing Surveys (CSUR), 51(2):1–39, 2018.
- Bubeck et al. (2023) Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- Cai & Wang (2020) Cai, C. and Wang, Y. A note on over-smoothing for graph neural networks. arXiv preprint arXiv:2006.13318, 2020.
- Cao et al. (2023) Cao, Y., Xu, J., Yang, C., Wang, J., Zhang, Y., Wang, C., Chen, L., and Yang, Y. When to pre-train graph neural networks? an answer from data generation perspective! arXiv preprint arXiv:2303.16458, 2023.
- Chai et al. (2023) Chai, Z., Zhang, T., Wu, L., Han, K., Hu, X., Huang, X., and Yang, Y. Graphllm: Boosting graph reasoning ability of large language model. arXiv preprint arXiv:2310.05845, 2023.
- Chamberlain et al. (2022) Chamberlain, B. P., Shirobokov, S., Rossi, E., Frasca, F., Markovich, T., Hammerla, N., Bronstein, M. M., and Hansmire, M. Graph neural networks for link prediction with subgraph sketching. arXiv preprint arXiv:2209.15486, 2022.
- Chawla & Karakoulas (2005) Chawla, N. V. and Karakoulas, G. Learning from labeled and unlabeled data: An empirical study across techniques and domains. Journal of Artificial Intelligence Research, 23:331–366, 2005.
- Chen et al. (2023a) Chen, D., Zhu, Y., Zhang, J., Du, Y., Li, Z., Liu, Q., Wu, S., and Wang, L. Uncovering neural scaling laws in molecular representation learning. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023a. URL https://openreview.net/forum?id=Ys8RmfF9w1.
- Chen et al. (2022) Chen, Z., Liu, J., Wang, X., and Yin, W. On representing linear programs by graph neural networks. In The Eleventh International Conference on Learning Representations, 2022.
- Chen et al. (2023b) Chen, Z., Mao, H., Li, H., Jin, W., Wen, H., Wei, X., Wang, S., Yin, D., Fan, W., Liu, H., and Tang, J. Exploring the potential of large language models (llms) in learning on graphs. ArXiv, abs/2307.03393, 2023b.
- Chen et al. (2023c) Chen, Z., Mao, H., Wen, H., Han, H., Jin, W., Zhang, H., Liu, H., and Tang, J. Label-free node classification on graphs with large language models (llms). arXiv preprint arXiv:2310.04668, 2023c.
- Chien et al. (2021) Chien, E., Peng, J., Li, P., and Milenkovic, O. Adaptive universal generalized pagerank graph neural network. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=n6jl7fLxrP.
- Dessí et al. (2022) Dessí, D., Osborne, F., Recupero, D. R., Buscaldi, D., and Motta, E. Cs-kg: A large-scale knowledge graph of research entities and claims in computer science. In International Workshop on the Semantic Web, 2022. URL https://api.semanticscholar.org/CorpusID:253021556.
- Di Giovanni et al. (2023) Di Giovanni, F., Rusch, T. K., Bronstein, M. M., Deac, A., Lackenby, M., Mishra, S., and Veličković, P. How does over-squashing affect the power of gnns? arXiv preprint arXiv:2306.03589, 2023.
- Dong et al. (2022) Dong, Q., Li, L., Dai, D., Zheng, C., Wu, Z., Chang, B., Sun, X., Xu, J., and Sui, Z. A survey for in-context learning. arXiv preprint arXiv:2301.00234, 2022.
- Dong et al. (2017) Dong, Y., Johnson, R. A., Xu, J., and Chawla, N. V. Structural diversity and homophily: A study across more than one hundred big networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 807–816, 2017.
- Dziri et al. (2023) Dziri, N., Lu, X., Sclar, M., Li, X. L., Jian, L., Lin, B. Y., West, P., Bhagavatula, C., Bras, R. L., Hwang, J. D., et al. Faith and fate: Limits of transformers on compositionality. arXiv preprint arXiv:2305.18654, 2023.
- Edmonds & Johnson (1973) Edmonds, J. and Johnson, E. L. Matching, euler tours and the chinese postman. Mathematical Programming, 5:88–124, 1973. URL https://api.semanticscholar.org/CorpusID:15249924.
- Fatemi et al. (2023) Fatemi, B., Halcrow, J., and Perozzi, B. Talk like a graph: Encoding graphs for large language models. arXiv preprint arXiv:2310.04560, 2023.
- Fey & Lenssen (2019) Fey, M. and Lenssen, J. E. Fast graph representation learning with pytorch geometric. arXiv preprint arXiv:1903.02428, 2019.
- Fey et al. (2021) Fey, M., Lenssen, J. E., Weichert, F., and Leskovec, J. Gnnautoscale: Scalable and expressive graph neural networks via historical embeddings. In International conference on machine learning, pp. 3294–3304. PMLR, 2021.
- Freitas et al. (2021) Freitas, S., Duggal, R., and Chau, D. H. Malnet: A large-scale image database of malicious software. arXiv preprint arXiv:2102.01072, 2021.
- Galkin et al. (2023) Galkin, M., Yuan, X., Mostafa, H., Tang, J., and Zhu, Z. Towards foundation models for knowledge graph reasoning. arXiv preprint arXiv:2310.04562, 2023.
- Gao et al. (2023) Gao, J., Zhou, Y., Zhou, J., and Ribeiro, B. Double equivariance for inductive link prediction for both new nodes and new relation types. In NeurIPS 2023 Workshop: New Frontiers in Graph Learning, 2023.
- Gupta et al. (2023) Gupta, S., Manchanda, S., Ranu, S., and Bedathur, S. J. Grafenne: learning on graphs with heterogeneous and dynamic feature sets. In International Conference on Machine Learning, pp. 12165–12181. PMLR, 2023.
- Han et al. (2021) Han, X., Zhang, Z., Ding, N., Gu, Y., Liu, X., Huo, Y., Qiu, J., Yao, Y., Zhang, A., Zhang, L., et al. Pre-trained models: Past, present and future. AI Open, 2:225–250, 2021.
- Hassani & Khasahmadi (2020) Hassani, K. and Khasahmadi, A. H. Contrastive multi-view representation learning on graphs. In Proceedings of International Conference on Machine Learning, pp. 3451–3461. 2020.
- He et al. (2023) He, X., Bresson, X., Laurent, T., Perold, A., LeCun, Y., and Hooi, B. Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph representation learning, 2023.
- Hibshman et al. (2021) Hibshman, J. I., Gonzalez, D., Sikdar, S., and Weninger, T. Joint subgraph-to-subgraph transitions: Generalizing triadic closure for powerful and interpretable graph modeling. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, pp. 815–823, 2021.
- Hou et al. (2022) Hou, Z., Liu, X., Cen, Y., Dong, Y., Yang, H., Wang, C., and Tang, J. Graphmae: Self-supervised masked graph autoencoders. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 594–604, 2022.
- Hu et al. (2019) Hu, W., Liu, B., Gomes, J., Zitnik, M., Liang, P., Pande, V., and Leskovec, J. Strategies for pre-training graph neural networks. arXiv preprint arXiv:1905.12265, 2019.
- Hu et al. (2020) Hu, W., Fey, M., Zitnik, M., Dong, Y., Ren, H., Liu, B., Catasta, M., and Leskovec, J. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133, 2020.
- Huang et al. (2015) Huang, H., Tang, J., Liu, L., Luo, J., and Fu, X. Triadic closure pattern analysis and prediction in social networks. IEEE Transactions on Knowledge and Data Engineering, 27(12):3374–3389, 2015.
- Huang et al. (2023a) Huang, Q., Ren, H., Chen, P., Kržmanc, G., Zeng, D., Liang, P., and Leskovec, J. Prodigy: Enabling in-context learning over graphs. arXiv preprint arXiv:2305.12600, 2023a.
- Huang et al. (2023b) Huang, S., Poursafaei, F., Danovitch, J., Fey, M., Hu, W., Rossi, E., Leskovec, J., Bronstein, M., Rabusseau, G., and Rabbany, R. Temporal graph benchmark for machine learning on temporal graphs. arXiv preprint arXiv:2307.01026, 2023b.
- Huang et al. (2023c) Huang, X., Orth, M. R., Ceylan, İ. İ., and Barceló, P. A theory of link prediction via relational weisfeiler-leman. arXiv preprint arXiv:2302.02209, 2023c.
- Huang et al. (2023d) Huang, Y., Lu, W., Robinson, J., Yang, Y., Zhang, M., Jegelka, S., and Li, P. On the stability of expressive positional encodings for graph neural networks. arXiv preprint arXiv:2310.02579, 2023d.
- Jeh & Widom (2002) Jeh, G. and Widom, J. Simrank: a measure of structural-context similarity. In Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 538–543, 2002.
- Jin et al. (2023a) Jin, B., Liu, G., Han, C., Jiang, M., Ji, H., and Han, J. Large language models on graphs: A comprehensive survey. arXiv preprint arXiv:2312.02783, 2023a.
- Jin et al. (2023b) Jin, B., Zhang, W., Zhang, Y., Meng, Y., Zhang, X., Zhu, Q., and Han, J. Patton: Language model pretraining on text-rich networks. arXiv preprint arXiv:2305.12268, 2023b.
- Jin et al. (2020a) Jin, W., Barzilay, R., and Jaakkola, T. Hierarchical generation of molecular graphs using structural motifs. In International conference on machine learning, pp. 4839–4848. PMLR, 2020a.
- Jin et al. (2020b) Jin, W., Derr, T., Liu, H., Wang, Y., Wang, S., Liu, Z., and Tang, J. Self-supervised learning on graphs: Deep insights and new direction. arXiv preprint arXiv:2006.10141, 2020b.
- Jing et al. (2023) Jing, Y., Yuan, C., Ju, L., Yang, Y., Wang, X., and Tao, D. Deep graph reprogramming. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 24345–24354, 2023.
- Jo et al. (2022) Jo, J., Lee, S., and Hwang, S. J. Score-based generative modeling of graphs via the system of stochastic differential equations. In International Conference on Machine Learning, pp. 10362–10383. PMLR, 2022.
- Ju et al. (2023) Ju, M., Zhao, T., Wen, Q., Yu, W., Shah, N., Ye, Y., and Zhang, C. Multi-task self-supervised graph neural networks enable stronger task generalization. 2023.
- Kaplan et al. (2020) Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Katz (1953) Katz, L. A new status index derived from sociometric analysis. Psychometrika, 18(1):39–43, 1953.
- Khanam et al. (2020) Khanam, K. Z., Srivastava, G., and Mago, V. The homophily principle in social network analysis. arXiv preprint arXiv:2008.10383, 2020.
- Kim et al. (2022) Kim, J., Nguyen, T. D., Min, S., Cho, S., Lee, M., Lee, H., and Hong, S. Pure transformers are powerful graph learners. arXiv, abs/2207.02505, 2022. URL https://arxiv.org/abs/2207.02505.
- Kipf & Welling (2016) Kipf, T. N. and Welling, M. Variational graph auto-encoders. arXiv preprint arXiv:1611.07308, 2016.
- Kreuzer et al. (2021) Kreuzer, D., Beaini, D., Hamilton, W., Létourneau, V., and Tossou, P. Rethinking graph transformers with spectral attention. Advances in Neural Information Processing Systems, 34:21618–21629, 2021.
- Kriege et al. (2020) Kriege, N. M., Johansson, F. D., and Morris, C. A survey on graph kernels. Applied Network Science, 5(1):1–42, 2020.
- Leskovec & Krevl (2014) Leskovec, J. and Krevl, A. SNAP Datasets: Stanford large network dataset collection. http://snap.stanford.edu/data, June 2014.
- Leskovec et al. (2010) Leskovec, J., Chakrabarti, D., Kleinberg, J., Faloutsos, C., and Ghahramani, Z. Kronecker graphs: an approach to modeling networks. Journal of Machine Learning Research, 11(2), 2010.
- Li et al. (2022) Li, J., Shomer, H., Ding, J., Wang, Y., Ma, Y., Shah, N., Tang, J., and Yin, D. Are graph neural networks really helpful for knowledge graph completion? arXiv preprint arXiv:2205.10652, 2022.
- Li et al. (2023a) Li, J., Shomer, H., Mao, H., Zeng, S., Ma, Y., Shah, N., Tang, J., and Yin, D. Evaluating graph neural networks for link prediction: Current pitfalls and new benchmarking. arXiv preprint arXiv:2306.10453, 2023a.
- Li et al. (2023b) Li, Y., Li, Z., Wang, P., Li, J., Sun, X., Cheng, H., and Yu, J. X. A survey of graph meets large language model: Progress and future directions. arXiv preprint arXiv:2311.12399, 2023b.
- Li et al. (2023c) Li, Y., Xiong, M., and Hooi, B. Graphcleaner: Detecting mislabelled samples in popular graph learning benchmarks. arXiv preprint arXiv:2306.00015, 2023c.
- Lim et al. (2021) Lim, D., Hohne, F., Li, X., Huang, S. L., Gupta, V., Bhalerao, O., and Lim, S. N. Large scale learning on non-homophilous graphs: New benchmarks and strong simple methods. Advances in Neural Information Processing Systems, 34:20887–20902, 2021.
- Lim et al. (2022) Lim, D., Robinson, J. D., Zhao, L., Smidt, T., Sra, S., Maron, H., and Jegelka, S. Sign and basis invariant networks for spectral graph representation learning. In The Eleventh International Conference on Learning Representations, 2022.
- Liu et al. (2023a) Liu, G., Inae, E., Zhao, T., Xu, J., Luo, T., and Jiang, M. Data-centric learning from unlabeled graphs with diffusion model. arXiv preprint arXiv:2303.10108, 2023a.
- Liu et al. (2023b) Liu, H., Feng, J., Kong, L., Liang, N., Tao, D., Chen, Y., and Zhang, M. One for all: Towards training one graph model for all classification tasks. arXiv preprint arXiv:2310.00149, 2023b.
- Liu et al. (2023c) Liu, H., Li, C., Wu, Q., and Lee, Y. J. Visual instruction tuning. In NeurIPS, 2023c.
- Liu et al. (2023d) Liu, H., Liao, N., and Luo, S. Simga: A simple and effective heterophilous graph neural network with efficient global aggregation. arXiv preprint arXiv:2305.09958, 2023d.
- Liu et al. (2023e) Liu, J., Yang, C., Lu, Z., Chen, J., Li, Y., Zhang, M., Bai, T., Fang, Y., Sun, L., Yu, P. S., et al. Towards graph foundation models: A survey and beyond. arXiv preprint arXiv:2310.11829, 2023e.
- Liu et al. (2024) Liu, J., Mao, H., Chen, Z., Zhao, T., Shah, N., and Tang, J. Neural scaling laws on graphs. 2024.
- Liu et al. (2022) Liu, N., Wang, X., Bo, D., Shi, C., and Pei, J. Revisiting graph contrastive learning from the perspective of graph spectrum. Advances in Neural Information Processing Systems, 35:2972–2983, 2022.
- Liu et al. (2023f) Liu, Z., Shi, Y., Zhang, A., Zhang, E., Kawaguchi, K., Wang, X., and Chua, T.-S. Rethinking tokenizer and decoder in masked graph modeling for molecules. In NeurIPS, 2023f. URL https://openreview.net/forum?id=fWLf8DV0fI.
- Liu et al. (2023g) Liu, Z., Yu, X., Fang, Y., and Zhang, X. Graphprompt: Unifying pre-training and downstream tasks for graph neural networks. In Proceedings of the ACM Web Conference 2023, pp. 417–428, 2023g.
- Lu et al. (2023) Lu, S., Gao, Z., He, D., Zhang, L., and Ke, G. Highly accurate quantum chemical property prediction with uni-mol+. arXiv preprint arXiv:2303.16982, 2023.
- Luan et al. (2021) Luan, S., Hua, C., Lu, Q., Zhu, J., Zhao, M., Zhang, S., Chang, X.-W., and Precup, D. Is heterophily a real nightmare for graph neural networks to do node classification? arXiv preprint arXiv:2109.05641, 2021.
- Luan et al. (2023) Luan, S., Hua, C., Xu, M., Lu, Q., Zhu, J., Chang, X.-W., Fu, J., Leskovec, J., and Precup, D. When do graph neural networks help with node classification: Investigating the homophily principle on node distinguishability. arXiv preprint arXiv:2304.14274, 2023.
- Luo et al. (2021) Luo, Y., Yan, K., and Ji, S. Graphdf: A discrete flow model for molecular graph generation. In International Conference on Machine Learning, pp. 7192–7203. PMLR, 2021.
- Ma et al. (2021) Ma, Y., Liu, X., Shah, N., and Tang, J. Is homophily a necessity for graph neural networks? arXiv preprint arXiv:2106.06134, 2021.
- Mao et al. (2023a) Mao, H., Chen, Z., Jin, W., Han, H., Ma, Y., Zhao, T., Shah, N., and Tang, J. Demystifying structural disparity in graph neural networks: Can one size fit all? arXiv preprint arXiv:2306.01323, 2023a.
- Mao et al. (2023b) Mao, H., Li, J., Shomer, H., Li, B., Fan, W., Ma, Y., Zhao, T., Shah, N., and Tang, J. Revisiting link prediction: A data perspective. arXiv preprint arXiv:2310.00793, 2023b.
- Masters et al. (2022) Masters, D., Dean, J., Klaser, K., Li, Z., Maddrell-Mander, S., Sanders, A., Helal, H., Beker, D., Rampášek, L., and Beaini, D. Gps++: An optimised hybrid mpnn/transformer for molecular property prediction. arXiv preprint arXiv:2212.02229, 2022.
- McCoy et al. (2023) McCoy, R. T., Yao, S., Friedman, D., Hardy, M., and Griffiths, T. L. Embers of autoregression: Understanding large language models through the problem they are trained to solve. arXiv preprint arXiv:2309.13638, 2023.
- Menczer et al. (2020) Menczer, F., Fortunato, S., and Davis, C. A. A First Course in Network Science. Cambridge University Press, 2020.
- Milo et al. (2002) Milo, R., Shen-Orr, S., Itzkovitz, S., Kashtan, N., Chklovskii, D., and Alon, U. Network motifs: simple building blocks of complex networks. Science, 298(5594):824–827, 2002.
- Mishra et al. (2022) Mishra, S., Panda, R., Phoo, C. P., Chen, C.-F. R., Karlinsky, L., Saenko, K., Saligrama, V., and Feris, R. S. Task2sim: Towards effective pre-training and transfer from synthetic data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9194–9204, 2022.
- Morris et al. (2019) Morris, C., Ritzert, M., Fey, M., Hamilton, W. L., Lenssen, J. E., Rattan, G., and Grohe, M. Weisfeiler and leman go neural: Higher-order graph neural networks. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pp. 4602–4609, 2019.
- Morris et al. (2020) Morris, C., Kriege, N. M., Bause, F., Kersting, K., Mutzel, P., and Neumann, M. Tudataset: A collection of benchmark datasets for learning with graphs. In ICML 2020 Workshop on Graph Representation Learning and Beyond (GRL+ 2020), 2020. URL www.graphlearning.io.
- Morris et al. (2023) Morris, C., Lipman, Y., Maron, H., Rieck, B., Kriege, N. M., Grohe, M., Fey, M., and Borgwardt, K. Weisfeiler and leman go machine learning: The story so far. Journal of Machine Learning Research, 24(333):1–59, 2023. URL http://jmlr.org/papers/v24/22-0240.html.
- Müller et al. (2023) Müller, L., Galkin, M., Morris, C., and Rampášek, L. Attending to graph transformers. arXiv preprint arXiv:2302.04181, 2023.
- Murase et al. (2019) Murase, Y., Jo, H. H., Török, J., Kertész, J., Kaski, K., et al. Structural transition in social networks. 2019.
- Oono & Suzuki (2019) Oono, K. and Suzuki, T. Graph neural networks exponentially lose expressive power for node classification. In International Conference on Learning Representations, 2019.
- (100) Project, U. C. R. Recommender systems and personalization datasets. URL https://cseweb.ucsd.edu/~jmcauley/datasets.html.
- Radford et al. (2021) Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PMLR, 2021.
- Raffel et al. (2019) Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv e-prints, 2019.
- Ramsundar et al. (2019) Ramsundar, B., Eastman, P., Walters, P., Pande, V., Leswing, K., and Wu, Z. Deep Learning for the Life Sciences. O’Reilly Media, 2019. https://www.amazon.com/Deep-Learning-Life-Sciences-Microscopy/dp/1492039837.
- Robins et al. (2007) Robins, G., Pattison, P., Kalish, Y., and Lusher, D. An introduction to exponential random graph (p*) models for social networks. Social networks, 29(2):173–191, 2007.
- Rossi & Ahmed (2015) Rossi, R. A. and Ahmed, N. K. The network data repository with interactive graph analytics and visualization. In AAAI, 2015. URL http://networkrepository.com.
- Ruiz et al. (2023) Ruiz, L., Chamon, L. F. O., and Ribeiro, A. Transferability properties of graph neural networks. IEEE Transactions on Signal Processing, 71:3474–3489, 2023. doi: 10.1109/TSP.2023.3297848.
- Saparov & He (2022) Saparov, A. and He, H. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought. arXiv preprint arXiv:2210.01240, 2022.
- Schlichtkrull et al. (2018) Schlichtkrull, M., Kipf, T. N., Bloem, P., Van Den Berg, R., Titov, I., and Welling, M. Modeling relational data with graph convolutional networks. In The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June 3–7, 2018, Proceedings 15, pp. 593–607. Springer, 2018.
- Shi et al. (2022) Shi, H., Ding, J., Cao, Y., Liu, L., Li, Y., et al. Learning symbolic models for graph-structured physical mechanism. In The Eleventh International Conference on Learning Representations, 2022.
- Shoghi et al. (2023) Shoghi, N., Kolluru, A., Kitchin, J. R., Ulissi, Z. W., Zitnick, C. L., and Wood, B. M. From molecules to materials: Pre-training large generalizable models for atomic property prediction, 2023.
- Srinivasan & Ribeiro (2019) Srinivasan, B. and Ribeiro, B. On the equivalence between positional node embeddings and structural graph representations. arXiv preprint arXiv:1910.00452, 2019.
- Sun et al. (2019) Sun, F.-Y., Hoffmann, J., Verma, V., and Tang, J. Infograph: Unsupervised and semi-supervised graph-level representation learning via mutual information maximization. arXiv preprint arXiv:1908.01000, 2019.
- Sun et al. (2022) Sun, M., Zhou, K., He, X., Wang, Y., and Wang, X. Gppt: Graph pre-training and prompt tuning to generalize graph neural networks. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’22, pp. 1717–1727, New York, NY, USA, 2022. Association for Computing Machinery. ISBN 9781450393850. doi: 10.1145/3534678.3539249. URL https://doi.org/10.1145/3534678.3539249.
- Sun et al. (2023) Sun, X., Cheng, H., Li, J., Liu, B., and Guan, J. All in one: Multi-task prompting for graph neural networks. 2023.
- Taguchi et al. (2021) Taguchi, H., Liu, X., and Murata, T. Graph convolutional networks for graphs containing missing features. Future Generation Computer Systems, 117:155–168, 2021.
- Tang (2016) Tang, J. Aminer: Toward understanding big scholar data. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, WSDM ’16, pp. 467, New York, NY, USA, 2016. Association for Computing Machinery. ISBN 9781450337168. doi: 10.1145/2835776.2835849. URL https://doi.org/10.1145/2835776.2835849.
- Tang et al. (2023) Tang, J., Yang, Y., Wei, W., Shi, L., Su, L., Cheng, S., Yin, D., and Huang, C. Graphgpt: Graph instruction tuning for large language models. arXiv preprint arXiv:2310.13023, 2023.
- Topping et al. (2021) Topping, J., Di Giovanni, F., Chamberlain, B. P., Dong, X., and Bronstein, M. M. Understanding over-squashing and bottlenecks on graphs via curvature. In International Conference on Learning Representations, 2021.
- Touvron et al. (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Trinh et al. (2024) Trinh, T. H., Wu, Y., Le, Q. V., He, H., and Luong, T. Solving olympiad geometry without human demonstrations. Nature, 625(7995):476–482, 2024.
- Um et al. (2023) Um, D., Park, J., Park, S., and young Choi, J. Confidence-based feature imputation for graphs with partially known features. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=YPKBIILy-Kt.
- Vashishth et al. (2019) Vashishth, S., Sanyal, S., Nitin, V., and Talukdar, P. Composition-based multi-relational graph convolutional networks. In International Conference on Learning Representations, 2019.
- Veličković et al. (2017) Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., and Bengio, Y. Graph attention networks. arXiv preprint arXiv:1710.10903, 2017.
- Veličković et al. (2018) Veličković, P., Fedus, W., Hamilton, W. L., Liò, P., Bengio, Y., and Hjelm, R. D. Deep graph infomax. arXiv preprint arXiv:1809.10341, 2018.
- Vignac et al. (2023) Vignac, C., Krawczuk, I., Siraudin, A., Wang, B., Cevher, V., and Frossard, P. Digress: Discrete denoising diffusion for graph generation. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=UaAD-Nu86WX.
- Vishwanathan et al. (2010) Vishwanathan, S. V. N., Schraudolph, N. N., Kondor, R., and Borgwardt, K. M. Graph kernels. Journal of Machine Learning Research, 11:1201–1242, 2010.
- Wang et al. (2021) Wang, H., Yin, H., Zhang, M., and Li, P. Equivariant and stable positional encoding for more powerful graph neural networks. In International Conference on Learning Representations, 2021.
- Wang et al. (2023a) Wang, H., Feng, S., He, T., Tan, Z., Han, X., and Tsvetkov, Y. Can language models solve graph problems in natural language? In Thirty-seventh Conference on Neural Information Processing Systems, 2023a. URL https://openreview.net/forum?id=UDqHhbqYJV.
- Wang et al. (2024) Wang, J., Guo, Y., Yang, L., and Wang, Y. Understanding heterophily for graph neural networks. arXiv preprint arXiv:2401.09125, 2024.
- Wang et al. (2023b) Wang, X., Yang, H., and Zhang, M. Neural common neighbor with completion for link prediction. arXiv preprint arXiv:2302.00890, 2023b.
- Wu et al. (2022) Wu, Q., Zhao, W., Li, Z., Wipf, D. P., and Yan, J. Nodeformer: A scalable graph structure learning transformer for node classification. Advances in Neural Information Processing Systems, 35:27387–27401, 2022.
- Wu et al. (2023) Wu, X., Ajorlou, A., Wu, Z., and Jadbabaie, A. Demystifying oversmoothing in attention-based graph neural networks. arXiv preprint arXiv:2305.16102, 2023.
- Xia et al. (2023) Xia, J., Zhao, C., Hu, B., Gao, Z., Tan, C., Liu, Y., Li, S., and Li, S. Z. Mole-BERT: Rethinking pre-training graph neural networks for molecules. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=jevY-DtiZTR.
- Xie et al. (2023) Xie, H., Zheng, D., Ma, J., Zhang, H., Ioannidis, V. N., Song, X., Ping, Q., Wang, S., Yang, C., Xu, Y., et al. Graph-aware language model pre-training on a large graph corpus can help multiple graph applications. arXiv preprint arXiv:2306.02592, 2023.
- Xu et al. (2023) Xu, J., Huang, R., Jiang, X., Cao, Y., Yang, C., Wang, C., and Yang, Y. Better with less: A data-active perspective on pre-training graph neural networks. arXiv preprint arXiv:2311.01038, 2023.
- Xu et al. (2019) Xu, K., Hu, W., Leskovec, J., and Jegelka, S. How powerful are graph neural networks? In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=ryGs6iA5Km.
- Yang et al. (2021) Yang, Y., Liu, T., Wang, Y., Zhou, J., Gan, Q., Wei, Z., Zhang, Z., Huang, Z., and Wipf, D. Graph neural networks inspired by classical iterative algorithms. In International Conference on Machine Learning, pp. 11773–11783. PMLR, 2021.
- Yasunaga et al. (2022a) Yasunaga, M., Bosselut, A., Ren, H., Zhang, X., Manning, C. D., Liang, P., and Leskovec, J. Deep bidirectional language-knowledge graph pretraining. In Neural Information Processing Systems (NeurIPS), 2022a.
- Yasunaga et al. (2022b) Yasunaga, M., Leskovec, J., and Liang, P. Linkbert: Pretraining language models with document links. arXiv preprint arXiv:2203.15827, 2022b.
- Ye et al. (2022) Ye, H., Zhang, N., Chen, H., and Chen, H. Generative knowledge graph construction: A review. arXiv preprint arXiv:2210.12714, 2022.
- Ye et al. (2023) Ye, R., Zhang, C., Wang, R., Xu, S., and Zhang, Y. Natural language is all a graph needs. arXiv:2308.07134, 2023.
- Ying et al. (2018) Ying, R., He, R., Chen, K., Eksombatchai, P., Hamilton, W. L., and Leskovec, J. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pp. 974–983, 2018.
- You et al. (2020) You, Y., Chen, T., Sui, Y., Chen, T., Wang, Z., and Shen, Y. Graph contrastive learning with augmentations. Advances in neural information processing systems, 33:5812–5823, 2020.
- You et al. (2023) You, Y., Chen, T., Wang, Z., and Shen, Y. Graph domain adaptation via theory-grounded spectral regularization. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=OysfLgrk8mk.
- Yu et al. (2023a) Yu, L., Lezama, J., Gundavarapu, N. B., Versari, L., Sohn, K., Minnen, D., Cheng, Y., Gupta, A., Gu, X., Hauptmann, A. G., et al. Language model beats diffusion–tokenizer is key to visual generation. arXiv preprint arXiv:2310.05737, 2023a.
- Yu et al. (2023b) Yu, L., Lezama, J., Gundavarapu, N. B., Versari, L., Sohn, K., Minnen, D., Cheng, Y., Gupta, A., Gu, X., Hauptmann, A. G., et al. Language model beats diffusion–tokenizer is key to visual generation. arXiv preprint arXiv:2310.05737, 2023b.
- Yue et al. (2023) Yue, Z., Rabhi, S., Moreira, G. d. S. P., Wang, D., and Oldridge, E. Llamarec: Two-stage recommendation using large language models for ranking. arXiv preprint arXiv:2311.02089, 2023.
- Zeng et al. (2019) Zeng, H., Zhou, H., Srivastava, A., Kannan, R., and Prasanna, V. Graphsaint: Graph sampling based inductive learning method. arXiv preprint arXiv:1907.04931, 2019.
- Zeng et al. (2021) Zeng, H., Zhang, M., Xia, Y., Srivastava, A., Malevich, A., Kannan, R., Prasanna, V., Jin, L., and Chen, R. Decoupling the depth and scope of graph neural networks. In Beygelzimer, A., Dauphin, Y., Liang, P., and Vaughan, J. W. (eds.), Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=d0MtHWY0NZ.
- Zhai et al. (2023) Zhai, G., Örnek, E. P., Wu, S.-C., Di, Y., Tombari, F., Navab, N., and Busam, B. Commonscenes: Generating commonsense 3d indoor scenes with scene graphs. arXiv preprint arXiv:2305.16283, 2023.
- Zhang et al. (2024) Zhang, B., Gai, J., Du, Y., Ye, Q., He, D., and Wang, L. Beyond weisfeiler-lehman: A quantitative framework for gnn expressiveness. arXiv preprint arXiv:2401.08514, 2024.
- Zhang et al. (2023a) Zhang, D., Liu, X., Zhang, X., Zhang, C., Cai, C., Bi, H., Du, Y., Qin, X., Huang, J., Li, B., Shan, Y., Zeng, J., Zhang, Y., Liu, S., Li, Y., Chang, J., Wang, X., Zhou, S., Liu, J., Luo, X., Wang, Z., Jiang, W., Wu, J., Yang, Y., Yang, J., Yang, M., Gong, F.-Q., Zhang, L., Shi, M., Dai, F.-Z., York, D. M., Liu, S., Zhu, T., Zhong, Z., Lv, J., Cheng, J., Jia, W., Chen, M., Ke, G., E, W., Zhang, L., and Wang, H. Dpa-2: Towards a universal large atomic model for molecular and material simulation. arXiv preprint arXiv:2312.15492, 2023a.
- Zhang et al. (2023b) Zhang, F., Liu, X., Tang, J., Dong, Y., Yao, P., Zhang, J., Gu, X., Wang, Y., Kharlamov, E., Shao, B., Li, R., and Wang, K. Oag: Linking entities across large-scale heterogeneous knowledge graphs. IEEE Transactions on Knowledge and Data Engineering, 35(9):9225–9239, 2023b. doi: 10.1109/TKDE.2022.3222168.
- Zhang & Chen (2018) Zhang, M. and Chen, Y. Link prediction based on graph neural networks. Advances in neural information processing systems, 31, 2018.
- Zhang et al. (2021) Zhang, M., Li, P., Xia, Y., Wang, K., and Jin, L. Labeling trick: A theory of using graph neural networks for multi-node representation learning. Advances in Neural Information Processing Systems, 34:9061–9073, 2021.
- Zhang et al. (2023c) Zhang, Z., Li, H., Zhang, Z., Qin, Y., Wang, X., and Zhu, W. Graph meets llms: Towards large graph models. In NeurIPS 2023 Workshop: New Frontiers in Graph Learning, 2023c.
- Zhang et al. (2023d) Zhang, Z., Luo, B., Lu, S., and He, B. Live graph lab: Towards open, dynamic and real transaction graphs with nft. arXiv preprint arXiv:2310.11709, 2023d.
- Zhao et al. (2023a) Zhao, H., Liu, S., Ma, C., Xu, H., Fu, J., Deng, Z.-H., Kong, L., and Liu, Q. Gimlet: A unified graph-text model for instruction-based molecule zero-shot learning. bioRxiv, pp. 2023–05, 2023a.
- Zhao et al. (2023b) Zhao, J., Zhuo, L., Shen, Y., Qu, M., Liu, K., Bronstein, M., Zhu, Z., and Tang, J. Graphtext: Graph reasoning in text space. arXiv preprint arXiv:2310.01089, 2023b.
- Zhao et al. (2023c) Zhao, Q., Ren, W., Li, T., Xu, X., and Liu, H. Graphgpt: Graph learning with generative pre-trained transformers. arXiv preprint arXiv:2401.00529, 2023c.
- Zheng et al. (2023a) Zheng, S., He, J., Liu, C., Shi, Y., Lu, Z., Feng, W., Ju, F., Wang, J., Zhu, J., Min, Y., Zhang, H., Tang, S., Hao, H., Jin, P., Chen, C., Noé, F., Liu, H., and Liu, T.-Y. Towards predicting equilibrium distributions for molecular systems with deep learning. arXiv preprint arXiv:2306.05445, 2023a.
- Zheng et al. (2023b) Zheng, W., Huang, E. W., Rao, N., Wang, Z., and Subbian, K. You only transfer what you share: Intersection-induced graph transfer learning for link prediction. arXiv preprint arXiv:2302.14189, 2023b.
- Zhong et al. (2021) Zhong, Y., Shi, J., Yang, J., Xu, C., and Li, Y. Learning to generate scene graph from natural language supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1823–1834, 2021.
- Zhu et al. (2021a) Zhu, Y., Xu, Y., Liu, Q., and Wu, S. An empirical study of graph contrastive learning. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021a.
- Zhu et al. (2021b) Zhu, Z., Zhang, Z., Xhonneux, L.-P., and Tang, J. Neural bellman-ford networks: A general graph neural network framework for link prediction. Advances in Neural Information Processing Systems, 34:29476–29490, 2021b.
Appendix A A collection of datasets to support large-scale pre-training
In this section, we show a collection of large-scale graph datasets from various fields to support pre-training massive-scale graph foundation models.
| Name | URL | Description |
|---|---|---|
| TU-Dataset (Morris et al., 2020) | https://chrsmrrs.github.io/datasets/ | A collection of graph-level prediction datasets |
| NetworkRepository (Rossi & Ahmed, 2015) | https://networkrepository.com/ | The largest graph datasets, with graphs coming from 30+ different domains |
| Open Graph Benchmark (Hu et al., 2020) | https://ogb.stanford.edu/ | Contains a bunch of large-scale graph benchmarks |
| Pyg (Fey & Lenssen, 2019) | https://pytorch-geometric.readthedocs.io | Official datasets provided by PYG, containing popular datasets for benchmark |
| SNAP (Leskovec & Krevl, 2014) | https://snap.stanford.edu/data/ | Mainly focus on social network |
| Aminer (Tang, 2016) | https://www.aminer.cn/data/ | A collection of academic graphs |
| OAG (Zhang et al., 2023b) | https://www.aminer.cn/open-academic-graph | A large-scale academic graph |
| MalNet (Freitas et al., 2021) | https://www.mal-net.org/#home | A large-scale function calling graph for malware detection |
| ScholKG (Dessí et al., 2022) | https://scholkg.kmi.open.ac.uk/ | A large-scale scholarly knowledge graph |
| Graphium (Beaini et al., 2023) | https://github.com/datamol-io/graphium | A massive dataset for molecular property prediction |
| Live Graph Lab (Zhang et al., 2023d) | https://livegraphlab.github.io/ | A large-scale temporal graph for NFT transactions |
| Temporal Graph Benchmark (Huang et al., 2023b) | https://docs.tgb.complexdatalab.com/ | A large-scale benchmark for temporal graph learning |
| MoleculeNet (Ramsundar et al., 2019) | https://moleculenet.org/ | A benchmark for molecular machine learning |
| Recsys data (Project, ) | https://cseweb.ucsd.edu/~jmcauley/datasets.html | A collection of datasets for recommender systems |
| LINKX (Lim et al., 2021) | https://github.com/CUAI/Non-Homophily-Large-Scale | A collection of large-scale non-homophilous graphs |
Appendix B Existing GFMs
In this section, we demonstrate existing representative GFMs and categorize them into prototype GFM, domain-specific GFM, and task-specific GFM, as shown in Table 2.
| Name | Domain | Task | |||||
| Prototype GFM | PRODIGY (Huang et al., 2023a) |
|
|
||||
| OneForAll (Liu et al., 2023b) |
|
|
|||||
| GraphText (Zhao et al., 2023b) | General graph | Node classification | |||||
| Domain-specific GFM | DIG (Zheng et al., 2023a) | Molecule |
|
||||
| MACE-MP-0 (Batatia et al., 2023) | Material Science |
|
|||||
| JMP-1 (Shoghi et al., 2023) | Material Science | Atomic property prediction | |||||
| DPA-2 (Zhang et al., 2023a) | Material Science | Molecular simulation | |||||
| MoleBERT (Xia et al., 2023) | Molecule | Molecule property prediction | |||||
|
ULTRA (Galkin et al., 2023) | Knowledge graph | Knowledge graph reasoning |
Appendix C A more comprehensive discussion on applying LLMs to graph
In this position paper, we mainly discuss how to build a graph-centric foundation model. Many people also understand the graph foundation model as the combination of graphs and other foundation models (Jin et al., 2023a; Li et al., 2023b; Liu et al., 2023e). In this part, we provide an introduction to those representative works. Specifically, the current integration of graph and foundational models follows two primary pathways. The first involves using graphs to augment the capabilities of other foundational models. The second employs foundational models to address challenges encountered in graph machine learning.
The first type of work focuses on enhancing the capabilities of foundation models by graphs. Yasunaga et al. (2022a, b); Jin et al. (2023b); Xie et al. (2023) further pre-train LLMs on text-attributed graphs with a structure-aware pretext task. For example, Yasunaga et al. (2022b) trains an LLM to predict masked edges, which is formalized as pair classification on two end nodes’ attributes. Structure-aware training can effectively enhance language models’ capability on those tasks requiring structure reasoning, such as multi-hop reasoning. These works still view the graph as a second-class citizen providing auxiliary information and put more emphasis on text-centric tasks like question answering (Yasunaga et al., 2022a, b). Tang et al. (2023); Ye et al. (2023); Chai et al. (2023) improves LLMs’ capabilities tackling graph-related problems with instruction tuning. They adopt a linear map to inject the embedding generated by GNNs as a prompt token, then tune LLMs according to downstream tasks. A notable drawback of these works lies in that the tuned models don’t present capabilities beyond GNNs while introducing computation overhead.
The second line of work adopts LLMs’ capabilities to solve challenges in the graph domain. Chen et al. (2023b); He et al. (2023) adopts LLMs as encoders to augment the node attributes and enhance GNNs’ performance on node classification. Chen et al. (2023c) aims at solving the cold-start problem in node classification, and shows that actively annotating nodes with LLMs can significantly improve GNNs’ zero-shot inference capability. Zhao et al. (2023a) unifies graph and text representations of molecules via instruction-tuning, which then achieves promising zero-shot performance on property prediction.
We then provide a more comprehensive discussion on the positive potential of graphs on LLM. As discussed in Section 2.1, the straightforward application of LLms to graph learning by natural language description is less than ideal. The primary issue is that LLMs tend to approach problems with a sequentially greedy mindset (McCoy et al., 2023), which often results in superficial, ’shortcut’ solutions (Saparov & He, 2022; Dziri et al., 2023) rather than in-depth structural analysis. Thus, the principal challenge in adapting LLMs to serve as GFMs is enabling them to comprehend graph structures effectively. One promising solution involves structurally formatted prompts that LLMs can process. For instance, GraphText (Zhao et al., 2023b) introduces a tree-based prompt format that may allow LLMs to perform graph reasoning while preserving structural semantics. It remains positive potential for LLM to serve as a GFM.