22institutetext: Depart. of Information Science and Technology, The University of Tokyo
33institutetext: Depart. of Mechanical Engineering, Columbia University
44institutetext: Depart. of Mechanical Engineering, The University of Tokyo
55institutetext: Depart. of Automation, Shanghai Jiao Tong University
SGS-SLAM: Semantic Gaussian Splatting For Neural Dense SLAM
Abstract
We present SGS-SLAM, the first semantic visual SLAM system based on Gaussian Splatting. It incorporates appearance, geometry, and semantic features through multi-channel optimization, addressing the oversmoothing limitations of neural implicit SLAM systems in high-quality rendering, scene understanding, and object-level geometry. We introduce a unique semantic feature loss that effectively compensates for the shortcomings of traditional depth and color losses in object optimization. Through a semantic-guided keyframe selection strategy, we prevent erroneous reconstructions caused by cumulative errors. Extensive experiments demonstrate that SGS-SLAM delivers state-of-the-art performance in camera pose estimation, map reconstruction, precise semantic segmentation, and object-level geometric accuracy, while ensuring real-time rendering capabilities.
Keywords:
SLAM 3D Reconstruction 3D Semantics 3D Segmentation1 Introduction

Dense Visual Simultaneous Localization and Mapping (SLAM) is a crucial problem in the field of computer vision. It aims to reconstruct a dense 3D map in an unseen environment while simultaneously tracking the camera poses in a real-time manner. Traditional visual SLAM systems [6, 29, 32, 27, 39, 9] stand out in sparse reconstruction using point clouds and voxels, but fall short in dense reconstruction. To extract dense geometric information for high-quality representation, learning-based SLAM methods [1, 36] have gained wild attention. They demonstrate proficiency in generating decent 3D global maps meanwhile exhibiting robustness on noises and outliers. In addition, drawing inspiration from the advancements in the neural radiance field (NeRF) [25], NeRF-based SLAM approaches [35, 47, 18, 44, 19, 37, 8] have made further progress. They excel in producing accurate and high-fidelity global reconstruction by capturing dense photometric information through differentiable rendering.
However, NeRF-based SLAM methods employ multi-layer perceptrons (MLPs) as the implicit neural representation of scenes, which introduces several challenging limitations. Primarily, MLP models struggle with over-smoothing issues at the edge of objects, leading to a lack of fine-grained details in the map. This challenge also brings difficulties in disentangling the representation of objects, making it non-trivial to segment, edit, and manipulate objects within the scene. Moreover, when applied to larger scenes, MLP models are prone to catastrophic forgetting. This means that incorporating new scenes can adversely affect the precision of previously learned models, thereby reducing overall performance. Additionally, NeRF-based methods are computationally inefficient. Since the entire scene is modeled through one or several MLPs, it necessitates extensive model tuning for adding or updating scenes.
In this context, as opposite to NeRF-based neural representation, our exploration shifts towards the volumetric representation based on the 3D Gaussian Radiance Field [17]. This approach marks a significant shift and offers notable advantages in the scene representation.
Benefits from its rasterization of 3D primitives, Gaussian Splatting exhibits remarkably fast rendering speeds and allows direct gradient flow to each Gaussian’s parameters. This results in an almost linear projection between the dense photometric loss and parameters during optimization, unlike the hierarchical pixel sampling and indirect gradient flow through multiple non-linear layers seen in NeRF models. Moreover, the direct projection capability simplifies the addition of new parameters to the Gaussian field as separate channels, thereby enabling dynamic multi-channel rendering. Crucially, we integrate a semantic map into the 3D Gaussian field, essential for applications in robotics and mixed reality. This integration allows real-time rendering of appearance, depth, and semantic color.
When compared with neural implicit semantic SLAM systems, such as DNS-SLAM [19] and SNI-SLAM [46], our system demonstrates remarkable superiority in terms of rendering speed, reconstruction quality, and segmentation accuracy. Leveraging these benefits, our method enables precise editing and manipulation of specific scene elements while preserving the high fidelity of the overall rendering. Furthermore, using explicit spatial and semantic information to identify scene content can be instrumental in optimizing camera tracking. Particularly, we incorporate a two-level adjustment based on geometric and semantic criteria for keyframes selection. This process relies on recognizing objects that have been previously seen in the trajectory. Extensive experiments are conducted on both synthetic and real-world scene benchmarks. These experiments compare our method against both implicit NeRF-based approaches [41, 47, 37, 15], and novel 3D-Gaussian-based methods [16], evaluating performance in mapping, tracking, and semantic segmentation.
Overall, our work presents several key contributions, summarized as follows:
-
•
We introduce SGS-SLAM, the first semantic dense visual SLAM system grounded in 3D Gaussians. SGS-SLAM employs an explicit volumetric representation, enabling swift and real-time camera tracking and scene mapping. More importantly, it utilizes 2D semantic maps to learn 3D semantic representations expressed by Gaussians. Compared with previous NeRF-based methods which offer over-smooth object edges, SGS-SLAM provides high-fidelity reconstruction and optimal segmentation precision.
-
•
In SGS-SLAM, semantic maps provide additional supervision for optimizing parameters and selecting keyframes. We employ a multi-channel parameter optimization strategy where appearance, geometric, and semantic signals collectively contribute to camera tracking and scene reconstruction. Furthermore, SGS-SLAM utilizes these diverse channels for keyframe selection during the tracking phase, concentrating on actively recognizing objects seen earlier in the trajectory. This approach results in efficient and high-quality map reconstruction based on the chosen keyframes.
-
•
Utilizing semantic representation, SGS-SLAM provides a highly accurate disentangled object representation in 3D scenes, laying a solid foundation for downstream tasks such as scene editing and manipulation. SGS-SLAM facilitates the dynamic moving, rotating, or removal of objects in the map in real time. This is achieved by grouping Gaussians by specifying the semantic labels of the objects.
2 Related Work
2.1 Semantic SLAM
Semantic information is of great importance for SLAM systems [27, 12, 38, 30], which is a crucial requirement for applications in robotics and VR or AR fields. Real-time dense semantic SLAM systems [32, 1, 31] integrate semantic information into 3D geometric representations. Traditional semantic SLAM systems rely on sparse 3D semantic expressions, such as voxel [13], point cloud [28], and signed distance field [28]. These methods struggle with accurately interpreting complex environments due to limited semantic understanding. This results in a simplified categorization of environmental features, which may not capture the full range of objects and their relationships within a space. Moreover, these methods exhibit limitations regarding reconstruction speed, high-fidelity model acquisition, and memory usage.
2.2 Neural Implicit SLAM
Methods based on NeRF [24], which handle complex topological structures and differentiable scene representation methods, have garnered significant attention, leading to the development of neural implicit SLAM methods [3, 21, 7, 20, 45]. iMAP [35] uses a single MLP for scene representation, which shows limitations in large-scale scenes. NICE-SLAM [47] uses pre-trained multiple MLPs for hierarchical scene representation. Co-SLAM [37] combines pixel set-based keyframe tracking with one-blob encoding. Go-SLAM [44] uses Droid-SLAM as a front-end tracking system and multi-resolution hash encoding [26] for mapping meanwhile integrated loop-closure detection and global optimization. However, these methods cannot utilize semantic information in maps. NIDS-SLAM [11] leverages the mature front-end tracking of ORB-SLAM3 [2] and Instant-NGP [26] for mapping but does not optimize joint semantic features for 3D reconstruction. DNS-SLAM [19] proposes a 2D semantic prior system that provides multi-view geometry constraints but does not optimize 3D reconstruction with semantic features. SNI-SLAM [46], a work parallel to ours, introduces semantic loss for geometric supervision but remains limited by the efficiency constraints of NeRF’s volume rendering.
2.3 3D Gaussian Splatting SLAM
The outstanding performance and fast rasterization capabilities of 3D Gaussian Splatting [17] enable higher efficiency and accuracy on scene reconstruction. However, existing 3D-Gaussian-based SLAM systems [40, 16, 14] lack traditional effective tracking optimization, limiting tracking accuracy and the ability to recognize semantic information in scenes. We fuse semantic features into geometry and appearance and integrate 3D semantic features during keyframe selection in the tracking process. This allows us to obtain more effective and higher-resolution scene segmentation results while maintaining real-time performance.
3 Method
SGS-SLAM is a Gaussian-based semantic visual SLAM system. Sec. 3.1 introduces its multi-channel Gaussian representation for joint parameter optimization. Like previous SLAM techniques, our method can be split into two processes: tracking and mapping. The tracking process estimates the camera pose of each frame while keeping the scene parameters fixed. Mapping optimizes the scene representations based on the estimated camera pose. Sec. 3.2 explains the breakdown steps in detail. In addition, Sec. 3.3 presents scene manipulation as a case study for downstream tasks. Fig. 1 shows an overview of our system.
3.1 Multi-Channel Gaussian Representation
The scene is represented using a Gaussian influence function on the map, For simplicity, these Gaussians are isotropic, as proposed in [16]:
| (1) |
Here, indicates opacity, represents the center position, and denotes the radius. Each Gaussian also carries RGB colors .
In order to optimize the parameters of Gaussians to represent the scene, we need to render the Gaussians into 2D images in a differentiable manner. We use the render method from [22], providing extended functionality of rendering depth in colors. It works by splatting 3D Gaussians into the image plane via approximating the integral projection of the influence function along the depth dimension in pixel coordinates. The center of the Gaussian , radius , and depth (in camera coordinates) is splatted using the standard point rendering formula:
| (2) |
where is the camera intrinsic matrix, is the extrinsic matrix capturing the rotation and translation of the camera at frame , is the focal length. The influence of all Gaussians on this pixel can be combined by sorting the Gaussians in depth order and performing front-to-back volume rendering using the Max volume rendering formula [23]:
| (3) |
The pixel-level rendered color is the sum over the colors of each Gaussian and weighted by the influence function (replace the 3D means and covariance matrices with the 2D splatted versions), multiplied by an occlusion term taking into account the effect of all Gaussians in front of the current Gaussian. Similarly, the depth can be rendered as:
| (4) |
where denotes the depth of each Gaussian. By setting , we can calculate a silhouette, , which assists in determining whether a pixel is visible in the current view [16]. This aspect of visibility is essential for camera pose estimation, as it relies on the current reconstructed map. Additionally, it is also employed in map reconstruction, where new Gaussians are introduced in pixels lacking sufficient information.
While acquiring 3D semantic information is challenging and usually demands extensive manual labeling, the 2D semantic label is more accessible prior. In our approach, we leverage 2D semantic labels, which are often provided in datasets or can be easily obtained using off-the-shelf methods. We assign distinct channels to the parameters of Gaussians to denote their semantic labels and colors. During the rendering process, the 2D semantic map can be rendered from the reconstructed 3D scene as follows:
| (5) |
where denotes the semantic color associated with the Gaussian. This semantic color is optimized jointly with the appearance color and depth during the mapping process.
The Gaussian representations employed in SGS-SLAM facilitate high-quality reconstructions at high rendering speed, offering exceptional accuracy in capturing complex textures and geometry with remarkable detail and efficiency. Furthermore, the integration of semantic features within our method significantly advances optimal scene interpretation and precise object-level geometry, effectively mitigating the oversmoothing issues prevalent in NeRF models.
3.2 Tracking and Mapping
3.2.1 Camera Pose Estimation
Given the first frame, the camera pose is set to identity and used as the reference coordinates for the following tracking and mapping procedure. While assessing the camera pose of an RGB-D view at a new timestep, the initial camera pose is determined by adding a displacement to the previous pose, assuming constant velocity, as . Following this, the current pose is iteratively refined by minimizing the tracking loss between the ground truth color (), depth images (), and semantic map () and their differentiably rendered views:
| (6) |
Here, only those rendered pixels with a sufficiently large silhouette are factored into the loss calculation. The threshold is designed to make use of the map that has been previously optimized and has high certainty to be visible in the current camera view.
3.2.2 Keyframes Selection and Weighting
During the tracking phase of SLAM systems, keyframes are identified and stored simultaneously. These keyframes, providing different views of objects, are critical for mapping to refine 3D scene reconstruction. SGS-SLAM captures and stores keyframes at constant time intervals. Subsequently, keyframes associated with the current frame are chosen based on geometric and semantic constraints. Specifically, we randomly select pixels from the current frame and extract their corresponding Gaussians in the 3D scene. These Gaussians, , are then projected onto the camera views of keyframes as . The are evaluated based on the geometric overlap ratio:
| (7) |
It represents the proportion of Gaussians captured within the camera view of the keyframes. and are the width and height of the camera view. The candidates with lower than a certain threshold are removed. After the initial geometric-based selection, a second filter is conducted based on semantic criteria. We discard keyframes whose semantic maps are identical to the current frame’s semantic map, as indicated by a high mIoU score. This threshold, denoted as intends to enhance map optimization from varying viewpoints, preferring views with low mIoU overlap. The remaining candidates are randomly sampled to serve as the selected keyframes associated with the current frame. In addition, we compute an uncertainty score for each keyframe, defined as , with representing the timestamp of the keyframe and being a decay coefficient. This uncertainty score is used to weight the mapping loss . The intuition behind this is that keyframes with a later timestamp index carry a higher uncertainty in reconstruction due to the accumulation of camera tracking errors along the trajectory.
3.2.3 Map Reconstruction
The scene is modeled using Gaussians across three distinct channels: (1) their mean coordinates represent the geometric information of the scene, (2) their appearance colors depict the scene’s visual appearance, and (3) their semantic colors indicate the semantic labels of objects. These parameters across the channels are jointly optimized during the process of Gaussian densification and optimization, whereas the camera pose, ascertained from tracking, remains fixed.
Starting with the first frame, all pixels contribute to initializing the map. In the process of map reconstruction at a new timestep, new Gaussians are introduced to areas of the map that are either insufficiently dense or display new geometry in front of the previously estimated map. The addition of new Gaussians is regulated by applying a mask to the pixels where either (ii) the silhouette value falls below a certain threshold, signifying a high uncertainty in visibility, or (ii) the ground-truth depth is much smaller than the estimated depth, suggesting the presence of new geometric entities.
After densification, the parameters of the map are optimized by minimizing the mapping loss:
| (8) |
where and are weighted SSIM loss [17] with respect to appearance image and semantic image:
| (9) |
, , , and are predefined hyperparameters, and is the uncertainty score defined in Sec. 3.2.2.
Compared to existing NeRF-based approaches [47, 15, 19, 46] that necessitate complex model architectures and feature fusion strategies, SGS-SLAM adopts explicit Gaussian representation for mapping. This approach allows for direct gradient flow to each parameter, resulting in high rendering speeds and optimal reconstruction quality. Compared to recent Gaussian-based methods [16, 40], SGS-SLAM incorporates geometric, appearance, and semantic features for multi-channel rendering. This enables the joint optimization of parameters across different channels, remarkably enhancing the efficiency and effectiveness of both mapping and segmentation processes.
3.3 Scene Manipulation via Object-level Geometry
Given that the scene is represented explicitly by Gaussians, it becomes feasible to directly edit and manipulate a targeted group of Gaussians. In our case, Gaussian groups are identified based on their semantic labels. The mapping process generates these Gaussians, as defined in Eq. 1, allowing for further manipulation in the following manner:
| (10) |
where the edited Gaussians, , are influenced by the visibility mask , transition function , and the Gaussian’s semantic label . The visibility mask determines if the Gaussians should be retained (1) or removed (0) based on . The transition function applies a transformation to the Gaussian’s coordinates on selected , enabling spatial manipulation.
4 Experiment
4.1 Experimental Setup
4.1.1 Datasets
We evaluate our method on both synthetic and real-world datasets. To compare with other neural implicit SLAM methods, we evaluate synthetic scenes from Replica dataset [34] and real-world scenes from ScanNet [4] and ScanNet++ [43] datasets. The ground-truth camera pose and semantic map of Replica are offered from simulation, and the ground-truth camera pose of ScanNet is generated by BundleFusion [5]. The ground-truth 2D semantic label is provided by the dataset.
4.1.2 Metrics
We use PSNR, Depth-L1 (on 2D depth maps), SSIM, and LPIPS to evaluate the reconstruction quality. For the evaluation of camera pose, we adopt the average absolute trajectory error (ATE RMSE). For semantic segmentation, we calculate mIoU score.
4.1.3 Baselines
We compare the tracking and mapping with state-of-the-art methods iMap [35], NICE-SLAM [47], Co-SLAM [37], ESLAM [15], and SplaTAM [16]. For semantic segmentation accuracy, we compare with NIDS-SLAM [11], DNS-SLAM [19], and SNI-SLAM [46].
4.2 Evaluation of Mapping and Localization
We show quantitative measures of reconstruction quality using the Replica dataset [34] in Tab. 1. Our method demonstrates state-of-the-art performance. Compared to other baseline methods, our approach attains notably superior outcomes, outperforming them by a margin of 10dB in PSNR.
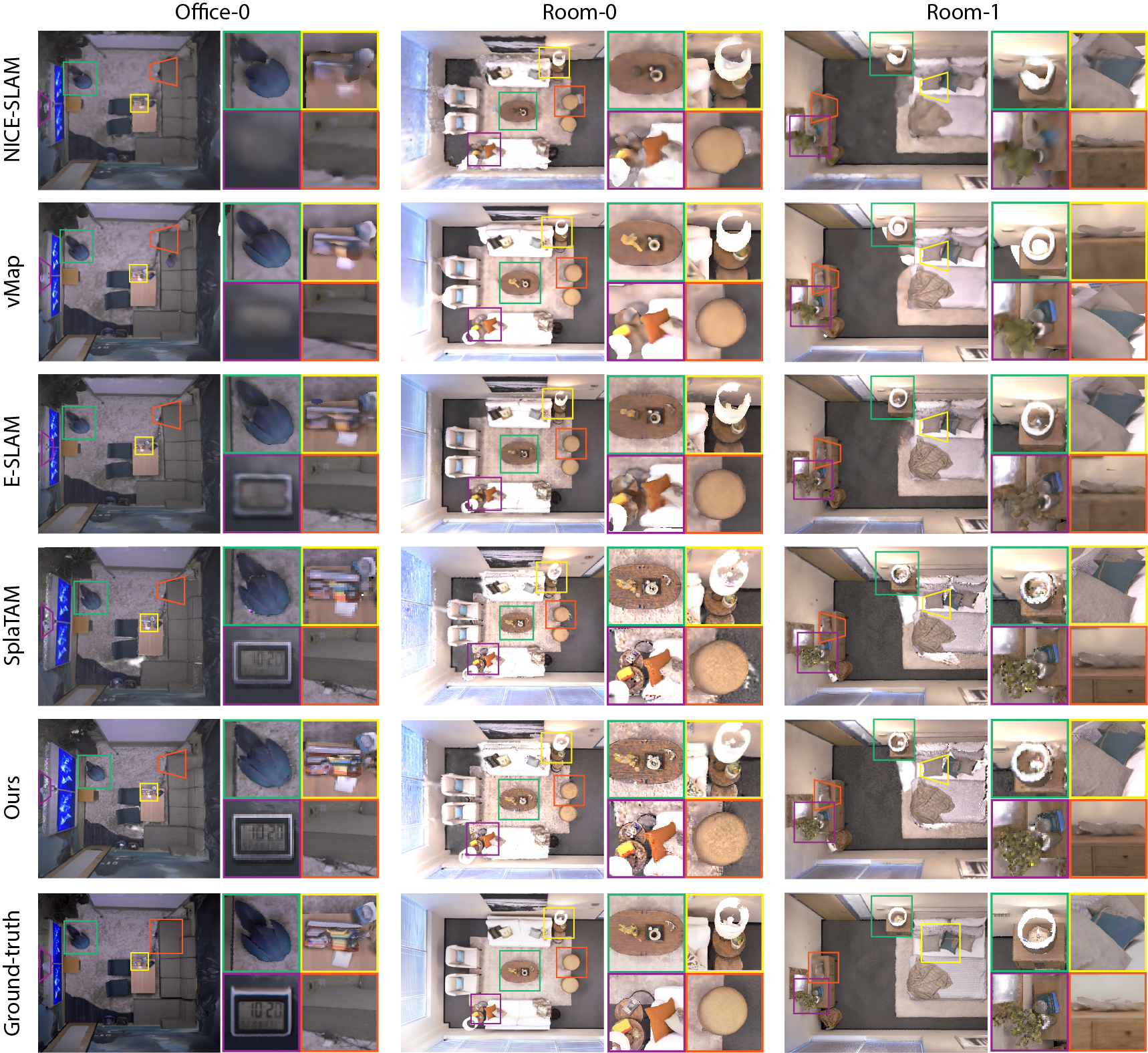
In Fig. 2, we present the reconstruction results of three chosen scenes, where regions of interest are accentuated with boxes in various colors. Our method exhibits high-fidelity reconstruction outcomes. Specifically, for small, intricately textured objects like a clock, socket, books on a tea table, and a lamp, our approach shows remarkable accuracy over NeRF-based methods. This is because Gaussians are capable of representing objects with complex textures and surfaces. Furthermore, NeRF-based methods often struggle with the over-smoothing issue, resulting in blurred edges on objects. In contrast, by utilizing an explicit Gaussian representation, SGS-SLAM precisely captures objects with clear edges, irrespective of their sizes. Compared with SplaTAM [16], which is also a Gaussian-based model, our approach utilizes semantic information for discerning object categories, recognizing visual appearance to determine texture, and applying geometric constraints to preserve accurate shapes. This combination enables our method to achieve thorough modeling of both objects and their surrounding environment. The combination of these constraints allows SGS-SLAM to capture fine-grained details of objects, offering high-fidelity and accurate reconstruction.
| Methods | Metrics | Avg. | Room0 | Room1 | Room2 | Office0 | Office1 | Office2 | Office3 | Office4 |
| PSNR | 24.42 | 22.12 | 22.47 | 24.52 | 29.07 | 30.34 | 19.66 | 22.23 | 24.94 | |
| NICE-SLAM | SSIM | 0.809 | 0.689 | 0.757 | 0.814 | 0.874 | 0.886 | 0.797 | 0.801 | 0.856 |
| LPIPS | 0.233 | 0.330 | 0.271 | 0.208 | 0.229 | 0.181 | 0.235 | 0.209 | 0.198 | |
| PSNR | 30.24 | 27.27 | 28.45 | 29.06 | 34.14 | 34.87 | 28.43 | 28.76 | 30.91 | |
| Co-SLAM | SSIM | 0.939 | 0.910 | 0.909 | 0.932 | 0.961 | 0.969 | 0.938 | 0.941 | 0.955 |
| LPIPS | 0.252 | 0.324 | 0.294 | 0.266 | 0.209 | 0.196 | 0.258 | 0.229 | 0.236 | |
| PSNR | 29.08 | 25.32 | 27.77 | 29.08 | 33.71 | 30.20 | 28.09 | 28.77 | 29.71 | |
| ESLAM | SSIM | 0.929 | 0.875 | 0.902 | 0.932 | 0.960 | 0.923 | 0.943 | 0.948 | 0.945 |
| LPIPS | 0.336 | 0.313 | 0.298 | 0.248 | 0.184 | 0.228 | 0.241 | 0.196 | 0.204 | |
| PSNR | 33.98 | 32.48 | 33.72 | 34.96 | 38.34 | 39.04 | 31.90 | 29.70 | 31.68 | |
| SplaTAM | SSIM | 0.969 | 0.975 | 0.970 | 0.982 | 0.982 | 0.982 | 0.965 | 0.950 | 0.946 |
| LPIPS | 0.099 | 0.072 | 0.096 | 0.074 | 0.083 | 0.093 | 0.100 | 0.118 | 0.155 | |
| PSNR | 34.66 | 32.50 | 34.25 | 35.10 | 38.54 | 39.20 | 32.90 | 32.05 | 32.75 | |
| Ours | SSIM | 0.973 | 0.976 | 0.978 | 0.981 | 0.984 | 0.980 | 0.967 | 0.966 | 0.949 |
| LPIPS | 0.096 | 0.070 | 0.094 | 0.070 | 0.086 | 0.087 | 0.101 | 0.115 | 0.148 | |
| Methods | Depth L1 [cm] | ATE Mean [cm] | ATE RMSE [cm] | Track. FPS Unit | Map. FPS Unit | SLAM FPS Unit |
| iMAP | 4.645 | 3.118 | 4.153 | 9.92 | 2.23 | 1.82 |
| NICE-SLAM | 1.903 | 1.795 | 2.503 | 13.70 | 0.20 | 0.20 |
| Co-SLAM | 1.513 | 0.935 | 1.059 | 17.24 | 10.20 | 6.41 |
| ESLAM | 1.180 | 0.520 | 0.630 | 18.11 | 3.62 | 3.02 |
| Ours | 0.356 | 0.327 | 0.412 | 5.27 | 3.52 | 2.11 |
Tab. 2 displays the tracking evaluation results on the Replica dataset [34]. Our method excels in achieving the highest level of depth L1 loss (cm) and minimal ATE error, surpassing baseline methods by 70% in terms of depth loss and 34% in terms of ATE RMSE (cm). This exceptional performance can be attributed to our precise scene reconstruction, which provides finely-detailed rendering results. The high-quality rendering, in turn, contributes to accurate camera pose estimation based on the established map by preventing incorrect geometric reconstruction, which could otherwise result in inaccurate tracking outcomes. Additionally, utilizing features from different channels of Gaussians, such as geometry, appearance, and semantic information, provides multiple levels of supervision, resulting in a more robust and accurate tracking capability.
4.3 Evaluation of Semantic Segmentation
Tab. 3 shows a quantitative evaluation of our method in comparison to other neural semantic SLAM approaches. It’s worth noting that we only show four scenes because previous NeRF-based semantic models only reported results on these scenes. In comparison to these previous methods, SGS-SLAM demonstrates state-of-the-art performance, outperforming the initial baseline by more than 10%. Substantial enhancement highlights the crucial advantage of explicit Gaussian representation over NeRF-based approaches. Gaussians can precisely isolate object boundaries, resulting in highly accurate 3D scene segmentation. In contrast, NeRF-based methods often struggle to recognize individual objects and typically require complex muti-level model designs and extensive feature fusion. Our approach offers an unparalleled ability to identify 3D objects in decomposed representations, which can serve as 3D priors for tracking and mapping in future time steps, and is well-suited for further downstream tasks.
| Methods | Avg. mIoU | Room0 [%] | Room1 [%] | Room2 [%] | Office0 [%] |
| NIDS-SLAM | 82.37 | 82.45 | 84.08 | 76.99 | 85.94 |
| DNS-SLAM | 84.77 | 88.32 | 84.90 | 81.20 | 84.66 |
| SNI-SLAM | 87.41 | 88.42 | 87.43 | 86.16 | 87.63 |
| Ours | 92.72 | 92.95 | 92.91 | 92.10 | 92.90 |
4.4 Evaluation of Keyframe Optimization

In real-world datasets, tracking errors tend to accumulate along a trajectory, making pose estimations at later timestamps less reliable. Such inaccuracies can compromise the quality of map reconstructions, negatively impacting the previously well-established scenes. A case in point is scene0000 from the ScanNet dataset [4], where objects such as bike and guitar are revisited at early and late stages in the trajectory. Keyframes from later sequences, influenced by inaccurate camera poses, can disrupt the previously accurate reconstructions. Fig. 3 illustrates the novel view evaluation for scene0000. In comparison to ESLAM [15] and SplaTAM [16], which are based on NeRF and 3D Gaussians, our method delivers more accurate reconstruction outcomes. The bike, garbage bin, and guitar are accurately rendered, meanwhile details are preserved. Our method facilitates the selection of keyframes based on geometric and semantic constraints, incorporating uncertainty weighting during the optimization of selected keyframes. This strategy demonstrates its effectiveness in map optimization from different views meanwhile preventing the unreliable keyframse with high uncertainty to significantly altering the earlier accurately reconstructed map.
4.5 Scene Manipulation
The obtained semantic mask within the 3D scene has a range of applications for subsequent tasks. As an illustrative example, we demonstrate a straightforward but efficient Gaussian editing method defined by Eq. 10, which is crucial for enabling scene manipulation for robotics or mixed reality applications.

Utilizing the decoupled scene representation, in contrast to NeRF-based approaches that demand fine-tuning of the entire network, SGS-SLAM can edit specific objects within the scene while keeping the remainder of the well-trained, irrelevant environment fixed. As shown in Fig. 4, we can directly manipulate the Gaussians associated with the editing target, such as erasing, moving, and rotating the jar and flowers on the table. In addition, we can group objects by selecting their semantic masks and applying a transition, such as rotating both the table and the above objects as shown in the supplementary material. This editing capability requires no training or fine-tuning, making it readily available for downstream applications.
4.6 Ablation Study
We perform the ablation of SGS-SLAM on the scene0000 of the ScanNet dataset [4] to evaluate the effectiveness of multi-channel feature supervision, and the keyframe optimization strategies.
| Settings | Depth L1 [cm] | ATE RMSE [cm] | PSNR [dB] | mIoU [%] |
| without color image () | 7.44 | 24.59 | ✗ | 68.19 |
| without depth map () | 47.66 | 40.47 | 15.14 | 54.52 |
| without semantic map () | 9.15 | 13.81 | 17.52 | ✗ |
| without silhouette threshold () | 29.12 | 357.48 | 12.06 | 28.07 |
| with multi-channel optimization | 6.18 | 11.26 | 19.47 | 70.27 |
| Settings | Depth L1 [cm] | ATE RMSE [cm] | PSNR [dB] | mIoU [%] |
| without geometric threshold () | 6.66 | 15.55 | 19.21 | 68.93 |
| without semantic threshold () | 8.44 | 12.89 | 17.84 | 69.85 |
| without uncertainty weighting () | 6.87 | 11.43 | 18.72 | 70.12 |
| with keyframe selection | 6.18 | 11.26 | 19.47 | 70.27 |
4.6.1 Effect of Multi-channel Optimization
Tab. 4 shows the ablation study on multi-channel parameter optimization. The results reveal that our optimization strategy can significantly improve the localization and mapping performance. Specifically, the system without appearance color cannot provide rendered views, whereas camera pose and depth can still be estimated by leveraging depth and semantic input. The absence of depth data leads to the poorest depth estimation, highlighting the importance of geometric supervision. Furthermore, the absence of an input semantic map disables 3D semantic segmentation and remarkably diminishes the performance of tracking and mapping. Additionally, the silhouette threshold, essential for assessing scene visibility, is crucial for the system stability. Without this threshold, the system shows a significant decline in the effectiveness of tracking and mapping.
4.6.2 Effect of Keyframe Optimization
Tab. 5 presents the results of keyframe selection ablation. Our two-level keyframe selection strategy reveals that omitting either geometric or semantic constraints results in a significant drop in both tracking and mapping performance. Additionally, without incorporating uncertainty weighting, the system demonstrates a decrease in performance compared to its full implementation.
5 Conclusion and Limitations
We presented SGS-SLAM, the first semantic dense visual SLAM system based on the 3D Gaussian representation. We propose to leverage multi-channel parameter optimization where appearance, geometric, and semantic constraints are combined to enforce high-accurate 3D semantic segmentation, and high-fidelity dense map reconstruction meanwhile effectively producing a robust camera pose estimation. SGS-SLAM takes advantage of optimal keyframe optimization, resulting in reliable reconstruction quality. Extensive experiments show that our method provides state-of-the-art tracking and mapping results, meanwhile maintaining rapid rendering speeds. Furthermore, the high-quality reconstruction of scenes and precise 3D semantic labeling generated by our system establish a strong foundation for downstream tasks such as scene editing, offering solid prior for robotics or mixed reality applications.
5.0.1 Limitations
SGS-SLAM replies on depth and 2D semantic signal inputs for tracking and mapping. In scenarios where this information is scarce or difficult to access, the system’s effectiveness will be compromised. Additionally, our method incurs large memory consumption when deployed to large scenes. Addressing these limitations will be an objective for future research.
References
- [1] Bloesch, M., Czarnowski, J., Clark, R., Leutenegger, S., Davison, A.J.: Codeslam—learning a compact, optimisable representation for dense visual slam. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2560–2568 (2018)
- [2] Campos, C., Elvira, R., Rodríguez, J.J.G., Montiel, J.M., Tardós, J.D.: Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Transactions on Robotics 37(6), 1874–1890 (2021)
- [3] Chung, C.M., Tseng, Y.C., Hsu, Y.C., Shi, X.Q., Hua, Y.H., Yeh, J.F., Chen, W.C., Chen, Y.T., Hsu, W.H.: Orbeez-slam: A real-time monocular visual slam with orb features and nerf-realized mapping. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). pp. 9400–9406. IEEE (2023)
- [4] Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5828–5839 (2017)
- [5] Dai, A., Nießner, M., Zollhöfer, M., Izadi, S., Theobalt, C.: Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface reintegration. ACM Transactions on Graphics (ToG) 36(4), 1 (2017)
- [6] Davison, A.J., Reid, I.D., Molton, N.D., Stasse, O.: Monoslam: Real-time single camera slam. IEEE transactions on pattern analysis and machine intelligence 29(6), 1052–1067 (2007)
- [7] Deng, T., Liu, S., Wang, X., Liu, Y., Wang, D., Chen, W.: Prosgnerf: Progressive dynamic neural scene graph with frequency modulated auto-encoder in urban scenes. arXiv preprint arXiv:2312.09076 (2023)
- [8] Deng, T., Shen, G., Qin, T., Wang, J., Zhao, W., Wang, J., Wang, D., Chen, W.: Plgslam: Progressive neural scene represenation with local to global bundle adjustment. arXiv preprint arXiv:2312.09866 (2023)
- [9] Deng, T., Xie, H., Wang, J., Chen, W.: Long-term visual simultaneous localization and mapping: Using a bayesian persistence filter-based global map prediction. IEEE Robotics and Automation Magazine 30(1), 36–49 (2023)
- [10] Freda, L.: Plvs: A slam system with points, lines, volumetric mapping, and 3d incremental segmentation. arXiv preprint arXiv:2309.10896 (2023)
- [11] Haghighi, Y., Kumar, S., Thiran, J.P., Van Gool, L.: Neural implicit dense semantic slam. arXiv preprint arXiv:2304.14560 (2023)
- [12] He, J., Li, M., Wang, Y., Wang, H.: Ovd-slam: An online visual slam for dynamic environments. IEEE Sensors Journal (2023)
- [13] Hermans, A., Floros, G., Leibe, B.: Dense 3d semantic mapping of indoor scenes from rgb-d images. In: 2014 IEEE International Conference on Robotics and Automation (ICRA). pp. 2631–2638. IEEE (2014)
- [14] Huang, H., Li, L., Cheng, H., Yeung, S.K.: Photo-slam: Real-time simultaneous localization and photorealistic mapping for monocular, stereo, and rgb-d cameras. arXiv preprint arXiv:2311.16728 (2023)
- [15] Johari, M.M., Carta, C., Fleuret, F.: Eslam: Efficient dense slam system based on hybrid representation of signed distance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17408–17419 (2023)
- [16] Keetha, N., Karhade, J., Jatavallabhula, K.M., Yang, G., Scherer, S., Ramanan, D., Luiten, J.: Splatam: Splat, track & map 3d gaussians for dense rgb-d slam. arXiv preprint arXiv:2312.02126 (2023)
- [17] Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics 42(4) (2023)
- [18] Kong, X., Liu, S., Taher, M., Davison, A.J.: vmap: Vectorised object mapping for neural field slam. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 952–961 (2023)
- [19] Li, K., Niemeyer, M., Navab, N., Tombari, F.: Dns slam: Dense neural semantic-informed slam. arXiv preprint arXiv:2312.00204 (2023)
- [20] Li, M., He, J., Jiang, G., Wang, H.: Ddn-slam: Real-time dense dynamic neural implicit slam with joint semantic encoding. arXiv preprint arXiv:2401.01545 (2024)
- [21] Li, M., He, J., Wang, Y., Wang, H.: End-to-end rgb-d slam with multi-mlps dense neural implicit representations. IEEE Robotics and Automation Letters 8(11), 7138–7145 (2023)
- [22] Luiten, J., Kopanas, G., Leibe, B., Ramanan, D.: Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis. In: 3DV (2024)
- [23] Max, N.: Optical models for direct volume rendering. IEEE Transactions on Visualization and Computer Graphics 1(2), 99–108 (1995)
- [24] McCormac, J., Clark, R., Bloesch, M., Davison, A., Leutenegger, S.: Fusion++: Volumetric object-level slam. In: 2018 international conference on 3D vision (3DV). pp. 32–41. IEEE (2018)
- [25] Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM 65(1), 99–106 (2021)
- [26] Müller, T., Evans, A., Schied, C., Keller, A.: Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics (ToG) 41(4), 1–15 (2022)
- [27] Mur-Artal, R., Montiel, J.M.M., Tardos, J.D.: Orb-slam: a versatile and accurate monocular slam system. IEEE transactions on robotics 31(5), 1147–1163 (2015)
- [28] Narita, G., Seno, T., Ishikawa, T., Kaji, Y.: Panopticfusion: Online volumetric semantic mapping at the level of stuff and things. In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 4205–4212. IEEE (2019)
- [29] Newcombe, R.A., Lovegrove, S.J., Davison, A.J.: Dtam: Dense tracking and mapping in real-time. In: 2011 international conference on computer vision. pp. 2320–2327. IEEE (2011)
- [30] Qin, T., Li, P., Shen, S.: Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Transactions on Robotics 34(4), 1004–1020 (2018)
- [31] Rosinol, A., Abate, M., Chang, Y., Carlone, L.: Kimera: an open-source library for real-time metric-semantic localization and mapping. In: 2020 IEEE International Conference on Robotics and Automation (ICRA). pp. 1689–1696. IEEE (2020)
- [32] Salas-Moreno, R.F., Newcombe, R.A., Strasdat, H., Kelly, P.H., Davison, A.J.: Slam++: Simultaneous localisation and mapping at the level of objects. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1352–1359 (2013)
- [33] Sandström, E., Li, Y., Van Gool, L., Oswald, M.R.: Point-slam: Dense neural point cloud-based slam. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 18433–18444 (2023)
- [34] Straub, J., Whelan, T., Ma, L., Chen, Y., Wijmans, E., Green, S., Engel, J.J., Mur-Artal, R., Ren, C., Verma, S., et al.: The replica dataset: A digital replica of indoor spaces. arXiv preprint arXiv:1906.05797 (2019)
- [35] Sucar, E., Liu, S., Ortiz, J., Davison, A.J.: imap: Implicit mapping and positioning in real-time. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6229–6238 (2021)
- [36] Sucar, E., Wada, K., Davison, A.: Nodeslam: Neural object descriptors for multi-view shape reconstruction. In: 2020 International Conference on 3D Vision (3DV). pp. 949–958. IEEE (2020)
- [37] Wang, H., Wang, J., Agapito, L.: Co-slam: Joint coordinate and sparse parametric encodings for neural real-time slam. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13293–13302 (2023)
- [38] Whelan, T., Leutenegger, S., Salas-Moreno, R., Glocker, B., Davison, A.: Elasticfusion: Dense slam without a pose graph. In: Proceedings of Robotics: Science and Systems. Robotics: Science and Systems (2015)
- [39] Xie, H., Deng, T., Wang, J., Chen, W.: Robust incremental long-term visual topological localization in changing environments. IEEE Transactions on Instrumentation and Measurement 72, 1–14 (2023)
- [40] Yan, C., Qu, D., Wang, D., Xu, D., Wang, Z., Zhao, B., Li, X.: Gs-slam: Dense visual slam with 3d gaussian splatting. arXiv preprint arXiv:2311.11700 (2023)
- [41] Yang, X., Li, H., Zhai, H., Ming, Y., Liu, Y., Zhang, G.: Vox-fusion: Dense tracking and mapping with voxel-based neural implicit representation. In: 2022 IEEE International Symposium on Mixed and Augmented Reality (ISMAR). pp. 499–507. IEEE (2022)
- [42] Ye, M., Danelljan, M., Yu, F., Ke, L.: Gaussian grouping: Segment and edit anything in 3d scenes. arXiv preprint arXiv:2312.00732 (2023)
- [43] Yeshwanth, C., Liu, Y.C., Nießner, M., Dai, A.: Scannet++: A high-fidelity dataset of 3d indoor scenes. In: Proceedings of the International Conference on Computer Vision (ICCV) (2023)
- [44] Zhang, Y., Tosi, F., Mattoccia, S., Poggi, M.: Go-slam: Global optimization for consistent 3d instant reconstruction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3727–3737 (2023)
- [45] Zhou, H., Guo, Z., Liu, S., Zhang, L., Wang, Q., Ren, Y., Li, M.: Mod-slam: Monocular dense mapping for unbounded 3d scene reconstruction. arXiv preprint arXiv:2402.03762 (2024)
- [46] Zhu, S., Wang, G., Blum, H., Liu, J., Song, L., Pollefeys, M., Wang, H.: Sni-slam: Semantic neural implicit slam. arXiv preprint arXiv:2311.11016 (2023)
- [47] Zhu, Z., Peng, S., Larsson, V., Xu, W., Bao, H., Cui, Z., Oswald, M.R., Pollefeys, M.: Nice-slam: Neural implicit scalable encoding for slam. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12786–12796 (2022)
SGS-SLAM: Semantic Gaussian Splatting For Neural Dense SLAM
— Supplementary Material —
6 Experiment Settings
In this section, we outline the experimental setup and hyperparameters applied in our studies. The experiments were conducted on a server with NVIDIA A100-40GB GPU. However, our method typically takes less than 12 GB of memory for the scenes presented in this study, making it compatible with any GPU that has more than this amount of memory. The ground-truth results we compared, particularly for the novel view rendering, were obtained from the ground-truth mesh provided in the dataset, which was generated in an offline manner. Therefore, some defects can be observed in the ground-truth results. The code will be released soon.
6.0.1 SGS-SLAM
By default, both mapping and tracking operations are conducted for each frame. During the tracking phase, we set the silhouette visibility threshold, , to 0.99. The multi-channel optimization involves three parameters: for depth, for colors, and for semantic loss, with the semantic loss weight being comparatively low due to the typical noisiness of real-world semantic labels. Throughout the tracking, the multi-channel Gaussian parameters remain constant, adjusting only the camera parameters with a learning rate of 2e-3 for transition. Key-frames are initially chosen at intervals of every 5 frames, then refined based on geometric and semantic criteria. The geometric overlap threshold, , is defined at 0.05, and the semantic mean Intersection over Union (mIoU) threshold, , at 0.7. The maximum number of keyframes per frame is limited to 25, considering the computation speed. The uncertainty decay coefficient, scales with the length of the input frame series. In the mapping process, the silhouette threshold is adjusted to 0.5. The weights of photometric loss are set to , , and . Here, camera parameters are fixed, and Gaussian parameters are optimized, with specific learning rates for 3D position at 1e-4, color 2.5e-3, Gaussian rotation at 1e-3, logit opacity at 0.05, and log scale at 1e-3. Performance metrics of tracking and mapping are assessed every 5 frames, with mIoU scores evaluated at the same frequency.
The mapping and tracking iteration steps are specific to each dataset, In the case of the Replica dataset [34], the number of iterations for tracking and mapping are set to 40 and 60. For the ScanNet dataset [4], tracking and mapping are set to 120 and 40. In the enhanced ScanNet++ dataset [43], where the camera transition is large between each frame, the tracking and mapping iterations are adjusted to 220 and 50.
6.0.2 Baselines
We adhere to the default configurations for each baseline as reported in their papers. The evaluation metrics for tracking and mapping are consistent with those applied to our method. For baselines whose implementations are not publicly available, we present the results as reported in their papers.
7 Additional Experiment Results
We provide additional quantitative analysis of camera tracking in Sec. 7.1. The visualization of semantic segmentation compared with NeRF-based method is presented in Sec. 7.2. More qualitative novel view rendering results are illustrated in Sec. 7.3. We compared our method with Vox-Fusion [41], NICE-SLAM [47], Co-SLAM [37], ESLAM [15], and Point-SLAM [33] for ATE RMSE evaluation. For 3D semantic segmentation, we visualized the comparison with DNS-SLAM [19].
7.1 Camera Tracking
In this section, we break down the quantitative analysis on ATE RMSE [cm] on Replica [34], ScanNet [4], and ScanNet++ [43] datasets. Tab. 6, Tab. 7, and Tab. 8 present the evaluation our SGS-SLAM against baseline models on each dataset. Our method of estimating camera poses by directly optimizing the gradient on dense photometric loss achieves state-of-the-art tracking performance on datasets with high-quality RGB-D images. In particular, on the ScanNet++ dataset [43], where there is a large camera transition between successive frames, NeRF-based methods like ESLAM failed to track. Conversely, SGS-SLAM demonstrated robust and accurate tracking capability.
| Methods | Avg. | Room0 | Room1 | Room2 | Office0 | Office1 | Office2 | Office3 | Office4 |
| Vox-Fusion | 3.09 | 1.37 | 4.70 | 1.47 | 8.48 | 2.04 | 2.58 | 1.11 | 2.94 |
| NICE-SLAM | 2.50 | 2.25 | 2.86 | 2.34 | 1.98 | 2.12 | 2.83 | 2.68 | 2.96 |
| Co-SLAM | 0.86 | 0.65 | 1.13 | 1.43 | 0.55 | 0.50 | 0.46 | 1.40 | 0.77 |
| ESLAM | 0.63 | 0.71 | 0.70 | 0.52 | 0.57 | 0.55 | 0.58 | 0.72 | 0.63 |
| Point-SLAM | 0.52 | 0.61 | 0.41 | 0.37 | 0.38 | 0.48 | 0.54 | 0.69 | 0.72 |
| Ours | 0.41 | 0.46 | 0.45 | 0.29 | 0.46 | 0.23 | 0.45 | 0.42 | 0.55 |
| Methods | Avg. | 0000 | 0059 | 0106 | 0169 | 0181 | 0207 |
| Vox-Fusion | 26.90 | 68.84 | 24.18 | 8.41 | 27.28 | 23.30 | 9.41 |
| NICE-SLAM | 10.70 | 12.00 | 14.00 | 7.90 | 10.90 | 13.40 | 6.20 |
| Co-SLAM | 9.73 | 12.29 | 9.57 | 6.62 | 13.43 | 7.13 | 9.37 |
| ESLAM | 7.88 | 8.47 | 8.70 | 7.58 | 7.45 | 8.87 | 6.20 |
| Point-SLAM | 12.19 | 10.24 | 7.81 | 8.65 | 22.16 | 14.77 | 9.54 |
| Ours | 9.87 | 11.15 | 9.54 | 10.43 | 10.70 | 11.28 | 6.11 |
| Methods | Avg. [cm] | 8b5caf3398 [cm] | b20a261fdf [cm] |
| ESLAM | 170.06 | 185.15 | 156.96 |
| Ours | 1.62 | 0.65 | 2.34 |
7.2 Semantic Segmentation

In this section, the outcomes of semantic segmentation on the Replica dataset [34] are visualized and compared with DNS-SLAM [19], a NeRF-based approach. As illustrated, our method offered accurate and detailed segmentation, whereas DNS-SLAM faces challenges in edges due to the over-smoothing issue of NeRF.
7.3 Novel View Rendering
We present additional results of novel view rendering using our method across the Replica [34], ScanNet [4], and ScanNet++ [43] datasets, with comparisons to ESLAM [15]. Visualizations are provided in Fig. 6, Fig. 7, Fig. 8, and Fig. 9 with semantic segmentation outcomes. Our method consistently delivers high-quality rendering results for both synthesized and real-world datasets. Notably, on the challenging real-world ScanNet++ dataset, ESLAM [15] struggled to reconstruct the scene. By contrast, SGS-SLAM provides accurate high-fidelity scene reconstructions along with precise segmentation outcomes. Note that the ground-truth segmentation labels are retrieved from the ground-truth mesh at the instance level, and therefore, our results also show instance-level segmentation.




7.4 Scene Manipulation
In this section, we visualize scene manipulation results by grouping the Gaussians using the semantic mask. As shown in Fig. 10, for object removal, we can directly erase the Gaussians associated with the editing target, such as removing the table while preserving all the items on it. In addition, we can group objects by selecting their semantic masks and applying translation and rotation, such as moving and rotating both the table and the above objects to a different place.
It is worth noting that we can observe holes left in the place when removing or transitioning the objects. Such as the hole left on the ground when we removed the table. This is due to the explicit scene representation using 3D Gaussians where the unobserved geometry in the multi-views from the trajectory are inevitably missing. This defect, stemming from the characteristics of the 3D Gaussian representation, poses a challenging problem. It is identified as an area for future research, with the potential solution through the use of 3D geometry priors [10] or scene inpainting [42] techniques.
