SWAG: Storytelling With Action Guidance
Abstract
Automated long-form story generation typically employs long-context large language models (LLMs) for one-shot creation, which can produce cohesive but not necessarily engaging content. We introduce Storytelling With Action Guidance (SWAG), a novel approach to storytelling with LLMs. Our approach reduces story writing to a search problem through a two-model feedback loop: one LLM generates story content, and another auxiliary LLM is used to choose the next best “action” to steer the story’s future direction. Our results show that SWAG can substantially outperform previous end-to-end story generation techniques when evaluated by GPT-4 and through human evaluation, and our SWAG pipeline using only open-source models surpasses GPT-3.5-Turbo.
language=bash, keywordstyle=, basicstyle=, stringstyle=, showstringspaces=false
1 Introduction
Large language models (LLMs) have recently changed the landscape of content generation. A number of works have proposed techniques for short story generation (Fan et al., 2018; Wilmot & Keller, 2021; Rashkin et al., 2020; Xu et al., 2018). However, it has been a major challenge for AI to generate long-form stories that are both coherent and interesting (Oatley, 1995; Charniak, 2004; Alabdulkarim et al., 2021a). This remains a challenge with SoTA LLMs such as GPT-4 (OpenAI, 2023), Llama-2 (Touvron et al., 2023), and Mistral (Jiang et al., 2023).
While new LLMs have impressive content generation abilities, these models can have unstable outputs due to their unsupervised training objective. Recent advancements in alignment techniques for LLMs allow more control over output generation. Reinforcement Learning with Human Feedback (RLHF) (Christiano et al., 2023) is a popular alignment paradigm that requires training a reward model on a dataset of human preferences and fine-tuning the LLM to maximize the reward while ensuring that the model does not drift too far from the original pretrained model. This process can be complex and expensive, producing unstable results due to the imperfect reward model or other issues with approximating the KL divergence penalty. Direct Preference Optimization (DPO) (Rafailov et al., 2023) is another technique for aligning language models which optimizes the constrained reward maximization problem in RLHF in a single step of policy training. DPO is much more computationally efficient and stable, with similar or improved performance compared to existing RLHF techniques such as RLHF with proximal policy optimization (PPO) (Schulman et al., 2017).
We propose SWAG, an algorithm for iteratively generating engaging and captivating stories using LLMs. In our work, we structure storytelling as a search problem. This paradigm allows us to formulate the problem as finding the “optimal path” in a search space of possible stories given a story idea. By having another model guide the LLM during the story writing process, we can improve control over the story direction and create more engaging content. At a high level, we train an action discriminator LLM (AD LLM) to determine the next best action to take given the current state of a story. Using the generated action, we prompt another LLM to write the next part of the story based on the given action. This feedback loop can generate long-context stories that are fascinating and amusing to read. The main component of our system is the AD LLM, which helps pave the path for the story by selecting the next best “action” to continue the story. This AD LLM can be paired with any open-source model (e.g. Llama-2-7B, Mistral-7B) or closed models (e.g. OpenAI’s GPT-4) for generating the story. Our algorithm offers a simplified approach to storytelling, allowing for fine-grain control over the story content progression while providing the flexibility to integrate custom models for writing the story or using LLM services offered by other companies through APIs.
2 Related Work
Prior works have attempted to improve the quality and/or diversity of story generations in a variety of ways.
Storytelling with reinforcement learning
In the context of content generation, reinforcement is largely used for fine-tuning (Chang et al., 2023; Bai et al., 2022) or auxiliary model guidance (Peng et al., 2022; Castricato et al., 2022).
Perhaps most similar to our work are methods that involve dynamic inference-time option-selection and/or classification (Alabdulkarim et al., 2021b; Tambwekar et al., 2019; Peng et al., 2022). Our approach differs from prior ones in that our model (1) uses an adapted LLM to interpret an internal representation of the current story; (2) is highly modular; and (3) is prompting-based. These aspects contribute to our method’s diverse story generations despite having such a simple, flexible structure.
Controlled Text Generation (via prompting)
The recent advancements in language models have substantially increased the popularity of (simpler) prompting approaches such as chain of thought. Prompts may be manually designed (Brown et al., 2020) or automatically designed (Shin et al., 2020; Zou et al., 2021); prompting may also be an iterative process (Wei et al., 2022). Some works such as (Qin & Eisner, 2021; Lester et al., 2021) also explore continuous soft prompts. Compared to prior work, our contribution is an iterative feedback-prompting-based method that utilizes an auxiliary LLM for control, enabling more diverse storytelling.
Human-in-the-loop story generation
As opposed to automatic story generation, some previous works use human-in-the-loop methods to generate interesting long stories (Goldfarb-Tarrant et al., 2019; Coenen et al., 2021; Chung et al., 2022; Mirowski et al., 2022; Martin et al., 2017; Wang & Gordon, 2023; Lin & Riedl, 2021). We emphasize that although our method is completely automatic without any human intervention, the flexibility of the AD’s action space makes it quite intuitive for a human collaborator to “tune” our method towards their own liking.
3 Methods
Our creative storytelling method consists of two primary components: the story generation model and the action discriminator model (AD LLM). SWAG enables the use of any open-source LLM or LLM service for story generation. We create an AD LLM by collecting preference data for story actions, and aligning a pretrained LLM on our preference dataset. We visualize our training pipeline in Figure 1 below.
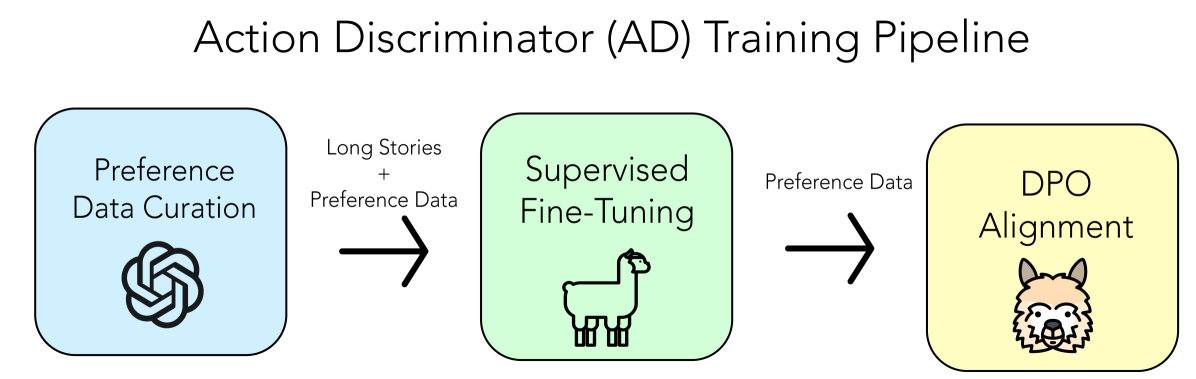
3.1 Preference Data Collection
We use a preference dataset of story actions to train a model to learn how to choose an action for the next part of the story. Given a list of actions, we want our AD LLM to select the best action that will keep the reader engaged with the story. Several datasets contain thousands of story prompts and ideas, but there are no preference datasets for choosing the next direction for a story.
To generate this data efficiently, we developed a pipeline that prompted OpenAI’s GPT-4 and Mixtral-87B (Jiang et al., 2024), to choose the next best action given a “story state”. We define the story state to be
where is the story prompt and is the current continuation of the story prompt. We use random subset of the Writing Prompts (Fan et al., 2018) dataset to acquire a diverse set of story prompts. For each story prompt from this subset, we prompt GPT-4 and Mixtral-87B to write an initial paragraph , forming the dataset
These story states provide a simple yet comprehensive starting point for the AD LLM to find the best path to continue generating the given story.
After curating the initial story states, we generate preference data on the next best action for continuing the story. We model this preference data by having a “chosen” and “rejected” action for each story state. For the story state , the chosen action is what we would like the LLM to choose when deciding the next best direction for the story, and the rejected action is the path we would like the LLM to avoid for the next part of the story. This preference data allows our model to understand how to rank different actions for the diverse set of story prompts that it will encounter during test-time.
To generate the ranking data, we prompt GPT-4 and Mixtral-87B with an initial story state and a list of “actions” to choose the best direction for the next paragraph in the story. The action used by GPT-4 to generate the next paragraph is set as the chosen action, and we then randomly choose an action from the remaining actions as the rejected action. We distill multiple datasets for supervised fine-tuning (SFT), direct preference optimization (DPO), and evaluation.
3.2 Supervised Fine-Tuning (SFT)
In the SFT phase, we follow the typical set up of starting with a pre-trained LLM and fine-tuning it with supervised learning, effectively using a maximum likelihood objective. We fine-tune the LLM on our downstream task of action discrimination on the preference dataset we curated using GPT-4 and Mixtral-87B.
One problem with using open source LLMs is that they are not necessarily prepared to handle long-context inputs. For example, the Llama-2-7B model has a max context length of 4096 by default. In order to alleviate this issue, we use the approach to SFT presented in LongLoRA (Chen et al., 2023). We replace the default Llama-2-7B attention with shifted sparse attention to enable computationally efficient long-context fine-tuning. The standard self-attention algorithm requires computations, which results in high memory and time costs for long-context fine-tuning. The authors suggest that by using short attention across smaller groups of tokens, and by shifting the group partition by half group size in half attention heads, we can effectively approximate full self-attention at a much lower cost. This -Attn approach is easy to implement and removes any possibilities of overfitting on specific attention patterns due to the shifting mechanism (Chen et al., 2023). We set the embedding and normalization to be trainable parameters during the low rank adaptation (LoRA) training (Hu et al., 2021). This technique allows our model to better understand the best next story direction for longer stories without the need for extensive compute resources.
We conduct SFT in two stages. During the first stage, we fine-tune the AD LLM on a dataset of long stories. We train the model to take a prompt as an input and generate a long-context story. This process ensures that models like Llama-2-7B, with their shorter default context length, can accurately process longer data sequences. In the second stage, we fine-tune our new long-context AD LLM on a preference dataset with chosen and rejected actions for the next story direction. This stage helps the model better understand the downstream task for which we want to build a preference model.
3.3 Direct Preference Optimization (DPO)
We utilize DPO to further refine the results of our action discriminator model. In DPO, we want our policy to learn how to rank chosen responses over rejected responses in a preference model framework. In PPO, we use a learned reward model for which we estimate parameters by taking the maximum likelihood over our static preferences dataset. DPO instead allows us to define a mapping from the optimal reward model to our language model policy, enabling the training of our language model to satisfy our preferences directly with a single cross-entropy loss (Rafailov et al., 2023). More specifically, under an appropriate preference model, we can derive the optimal reward function in terms of the optimal language model policy , original SFT policy , a constant , and a partition function as follows:
We can then plug this reward into our preference model, providing a simple training procedure on our dataset of preferences :
|
|
(1) |
Thus, in the DPO procedure, we calculate the probabilities of and from both and the DPO model, and then we can compute Eq. 1 and backpropagate to update (Tunstall et al., 2023). Using DPO, we can refine the SFT model on our preferences dataset to generate actions that are better aligned with the actions chosen by GPT-4 and Mixtral-87B.
3.4 SWAG Feedback Loop
The main algorithm in our method is the SWAG feedback loop that enables the action guidance mechanism. This feedback loop is a three step process and can be configured to use open-source LLMs, closed-source LLMs, or a hybrid of both for inference (beyond story generation).
First, we generate an initial story state by passing the story prompt into the story generation model to yield the initial paragraph . Next, we pass into our AD LLM along with a list of (predefined) possible actions (included in Appendix B), and generates the next best action to continue the story.
After generating the next best action, we update our story state to be
To generate the story, we iteratively repeat this process of (1) generating the next paragraph in the story via and (2) generating the optimal subsequent action to take via . See Algorithm 1 for a pseudocode implementation of the SWAG feedback loop.
The SWAG feedback loop can be run as many times as needed until the desired story length is reached—we can freely choose . This feedback mechanism can be implemented between any two LLMs (for story and AD), allowing for enhanced modularity in content generation for stories.
3.5 Ablations
We perform several ablations on and to test the performance of our algorithm. Specifically, we run pairwise comparisons between different combinations of and models to gauge the quality of stories generated by SWAG.
In the ablation, we test different models to generate the story with a fixed . We run the SWAG inference loop with several open-source and closed-source LLMs as . This ablation provides insight into the level of improvement in story quality from different base models.
In the ablation, we test different models to generate the next story action with a fixed . We trained two different AD LLMs for this ablation with the same SFT and DPO preference datasets.
To test SWAG on closed-source LLMs, we also set up our inference pipeline with GPT-3.5-Turbo and GPT-4-Turbo. Here, we simply set GPT-3.5-Turbo and GPT-4-Turbo to be both and in the SWAG feedback loop. With these experiments, we aim to show the effectiveness of SWAG even without fine-tuning an AD as a preference model.
4 Experiments
4.1 Experimental Setup
In our experiments, we aimed to evaluate the quality of the stories generated by our inference pipeline with different combinations of models and AD settings. We also explored if GPT-4 had any bias in ranking story actions for the preference dataset and the effects of this bias on our AD LLM.
4.2 Dataset
In order to train an AD LLM that can process long-form content, we fine-tuned our model on a dataset of long stories. We distilled this dataset of long stories from Llama-2-7B, Mistral-7B, and Mixtral-87B using a sample of prompts from the WritingPrompts dataset. We generated 20,000 long stories from these models, providing a diverse distribution of stories for SFT. We fine-tuned Llama-2-7B and Mistral-7B on this long stories dataset, allowing them to have a context length of 32,768 tokens.
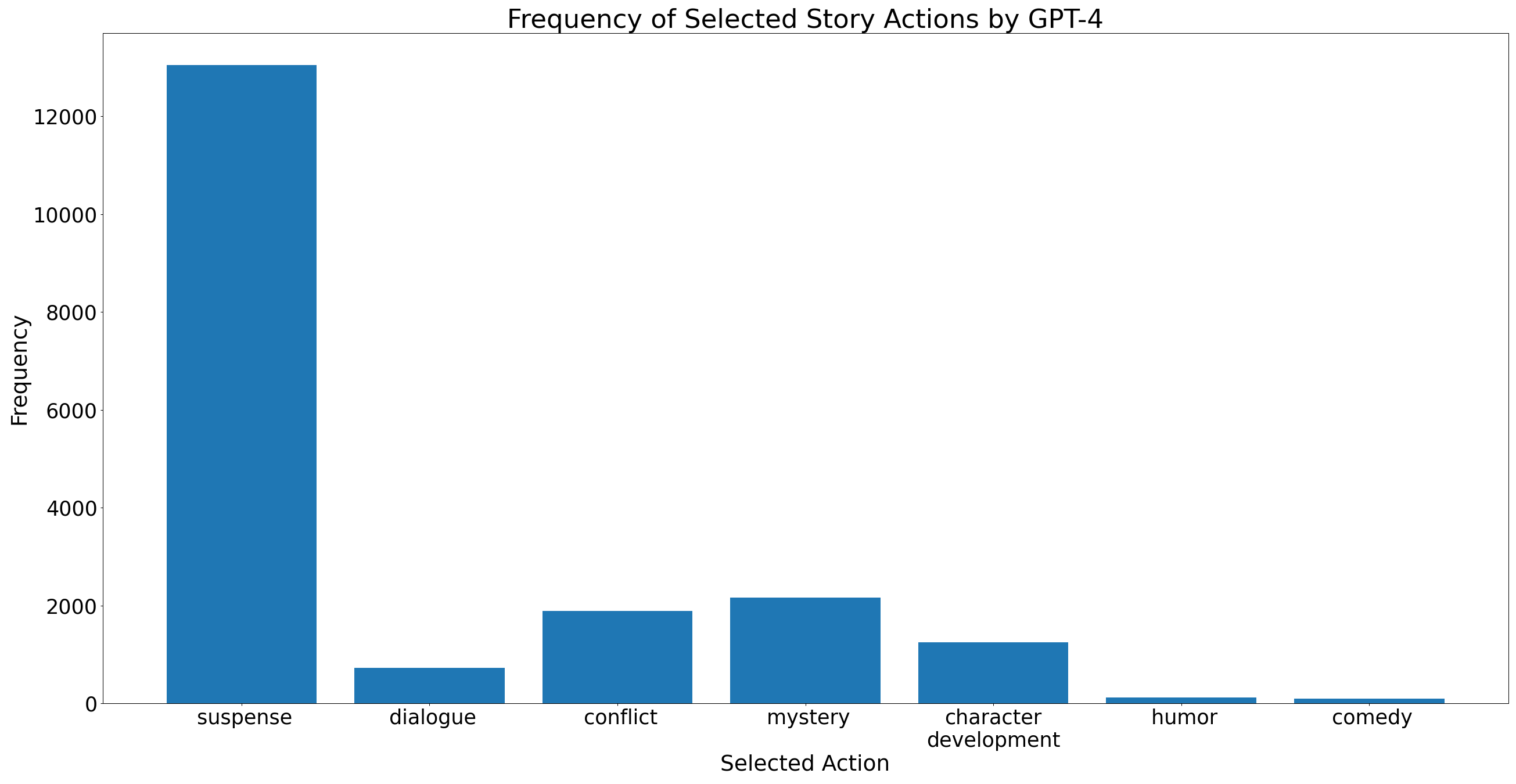
For our DPO preference dataset, we prompted GPT-4 and Mixtral-87B to generate preference data on a sample of approximately 60,000 prompts from the WritingPrompts dataset. One key aspect of this preference data is the potential options for story actions. We distilled a list of 50 different story actions from GPT-4 and used this set of actions for all training experiments. Some examples of actions in the set include “add suspense”, “add mystery”, “add character development”, etc. We used 34,000 preference data samples for fine-tuning the AD LLM to understand the downstream task of choosing the next story direction, and we used 25,000 samples to train the preference model using DPO. In the DPO dataset, we noticed an imbalance in the distribution of chosen actions by GPT-4. In Figure 2, we can see the substantial difference in the number of stories for which “add suspense” was selected compared to other options. This observation implies that GPT-4 has an inherent bias while selecting actions to continue the story.
In order to mitigate this effect, we generated more preference data from GPT-4, but this time, we removed the option to add suspense to the story. This would force GPT-4 to focus on other actions as well, resulting in a more spread out distribution of actions. After generating the new data, we took a random sample of 3,000 prompts from the original preference dataset with “add suspense” as the chosen action and merged it with our new dataset. In Figure 3, we can view the new distribution of story actions and notice that it is much more spread out, allowing for more variability in future story directions.
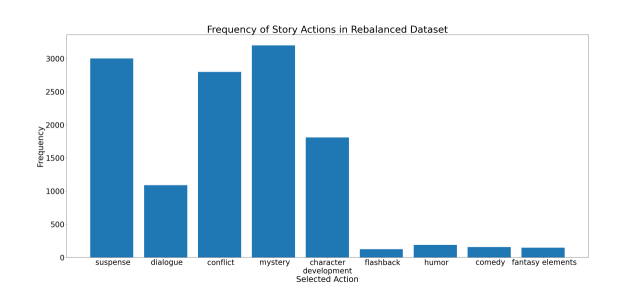
We collected three different datasets for SFT, DPO, and evaluation. Rebalancing was only done on the DPO dataset, but a similar approach could have been used on the SFT dataset as well. Due to constraints with the GPT-4 API, we were unable to generate enough data for rebalancing the SFT dataset. However, it is worth noting that the SFT process allows our model to better understand the downstream task, but the DPO procedure is more critical for generating a preference model that produces useful results as shown in later experiments.
4.3 Training
For our AD LLM training, we first used a dataset of long stories to fine-tune our model to process long-context sequences. Then, we use a separate preference dataset collected for SFT to fine-tune our base AD LLM. We used approximately 34,000 ranking samples for SFT, and we trained the model to predict the next best action given the initial story state. We fine-tuned Llama-2-7B on this dataset for 5300 steps, with a mini-batch size of 1 and 64 gradient accumulation steps using 8 A100 80GB GPUs (so one step processes 64 stories, and 530 steps is about one epoch). Completing the SFT process for each model required about 36 hours. We used the LongLoRA (Chen et al., 2023) approach with Flash Attention 2.0 (Dao, 2023) for SFT to enable fast fine-tuning on limited compute. We used the AdamW optimizer (Loshchilov & Hutter, 2019) with , a learning rate of 3e-5, and 30 warm-up steps with a constant learning rate scheduler.
We used DPO to train a preference model on two SFT model checkpoints, which were trained for 2650 and 5300 steps, respectively. The DPO training ran for 1000 steps for each model on approximately 25,000 samples of our preference dataset. We used a learning rate of 5e-4 with an AdamW optimizer and cosine annealing scheduler, both on default settings of . We also used LoRA in our DPO training for both checkpoints, with , , and a dropout of 0.05. We conducted the DPO training using the Hugging Face Transformers Reinforcement Learning (TRL) (von Werra et al., 2020) library in a similar setting as SFT with 8 A100 80GB GPUs but with a mini-batch size of 1 and 8 gradient accumulation steps. Each DPO training required approximately 12 hours with this setup on the rebalanced preference dataset, and we checkpointed our model at every 100 training steps. DPO for both checkpoints displayed convergence after approximately 800 steps of training.
4.4 Inference
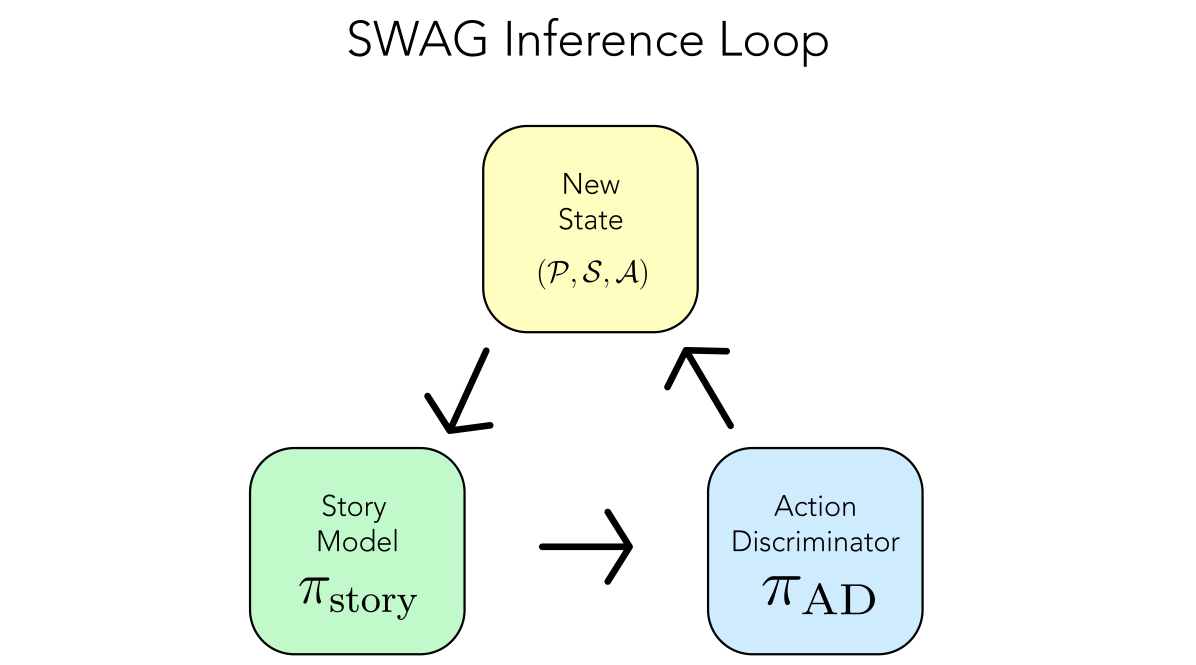
Our inference pipeline requires two models: the action discriminator and the story generation model . We create a feedback loop between these two models to generate our story.
For our experiments, we evaluated the performance of different combinations of and across a set of test story prompts. For each story prompt , we ask to write the initial paragraph, and then, with this initial story state , we instruct to select the optimal action for the subsequent paragraph.
In the action discriminator model ablation, we used our own fine-tuned and aligned Llama-2-7B and Mistral-7B AD LLMs and GPT-4-Turbo. For the story generation model ablation, we used the base Llama-2-7B, Mistral-7B, GPT-3.5-Turbo, and GPT-4-Turbo models. For our open-source model generations, we also compare the performance when using a that was tuned with a different base model as .
To analyze the baseline performance for story generation, we generated stories with each by giving an initial story prompt and repeatedly prompting it to continue the story. The results of these end-to-end (E2E) generation ablations are shown in Table 2.
Finally, we analyze if our models are better in choosing actions than a random selection. Our AD LLMs, trained using DPO, had a choice of only 30 actions during SFT and DPO. Using these 30 actions, we generated stories from the base Llama-2-7B and Mistral-7B models using our SWAG pipeline. However, in this ablation, we replaced and instead selected an action randomly from the list for each step of the loop.
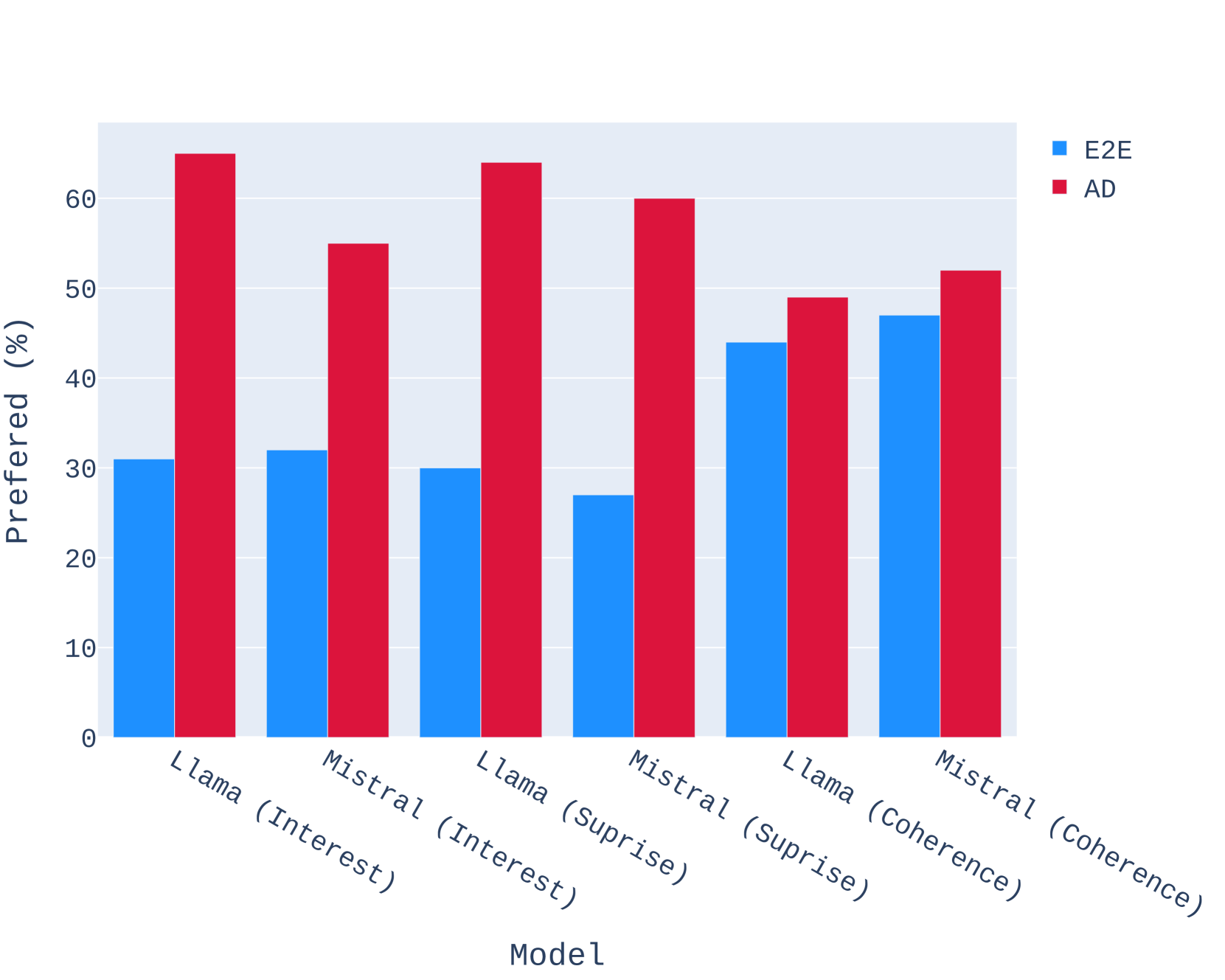
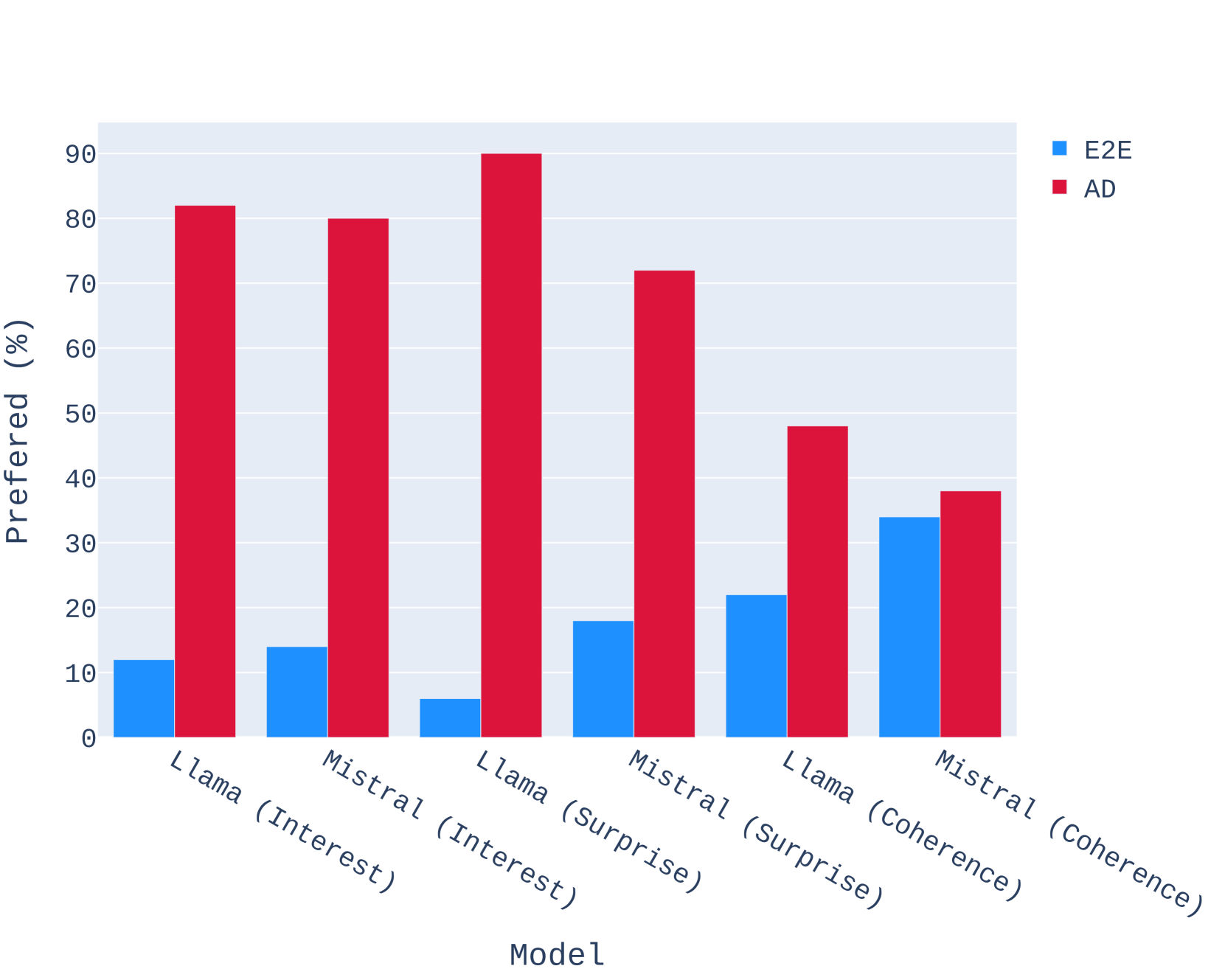
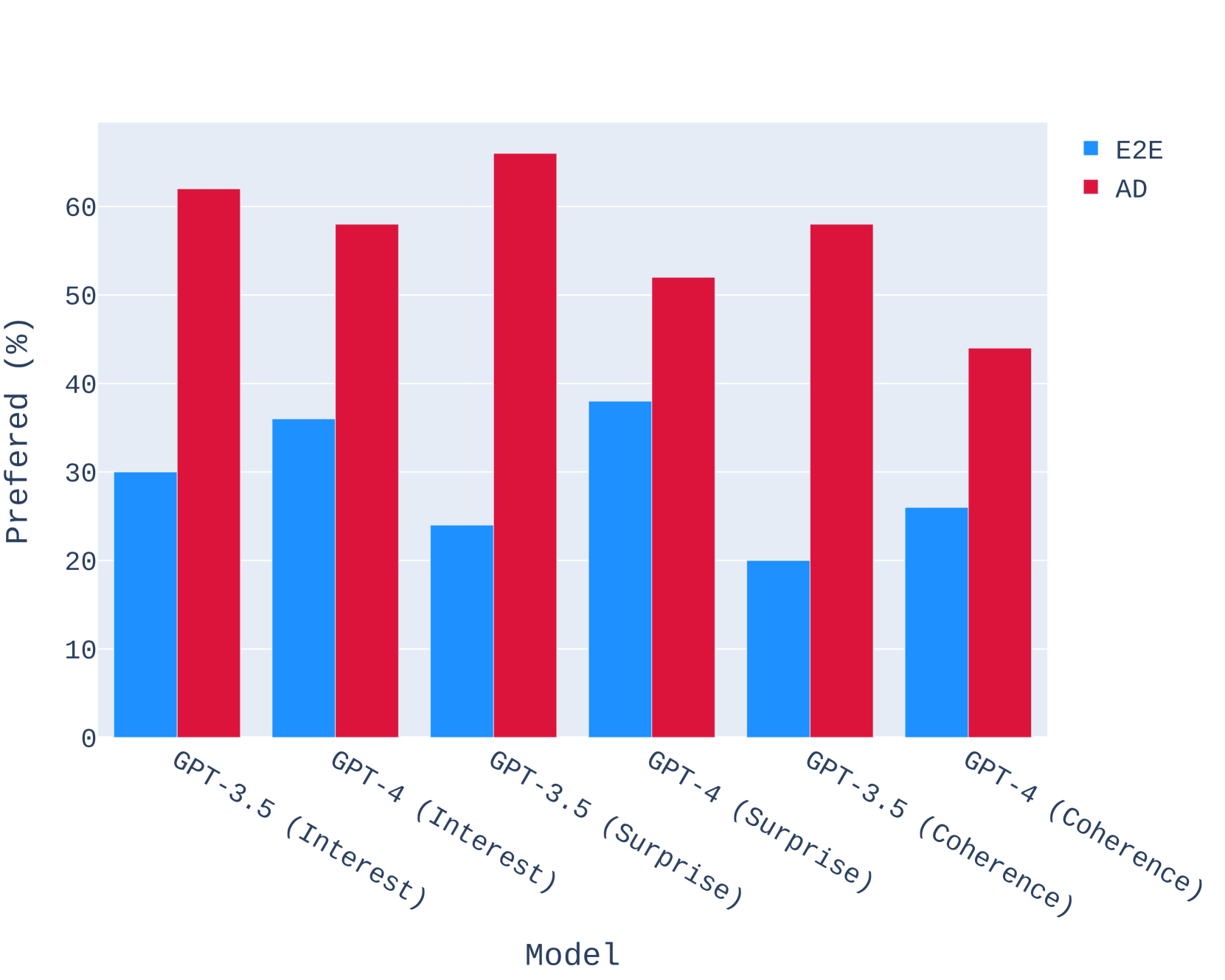
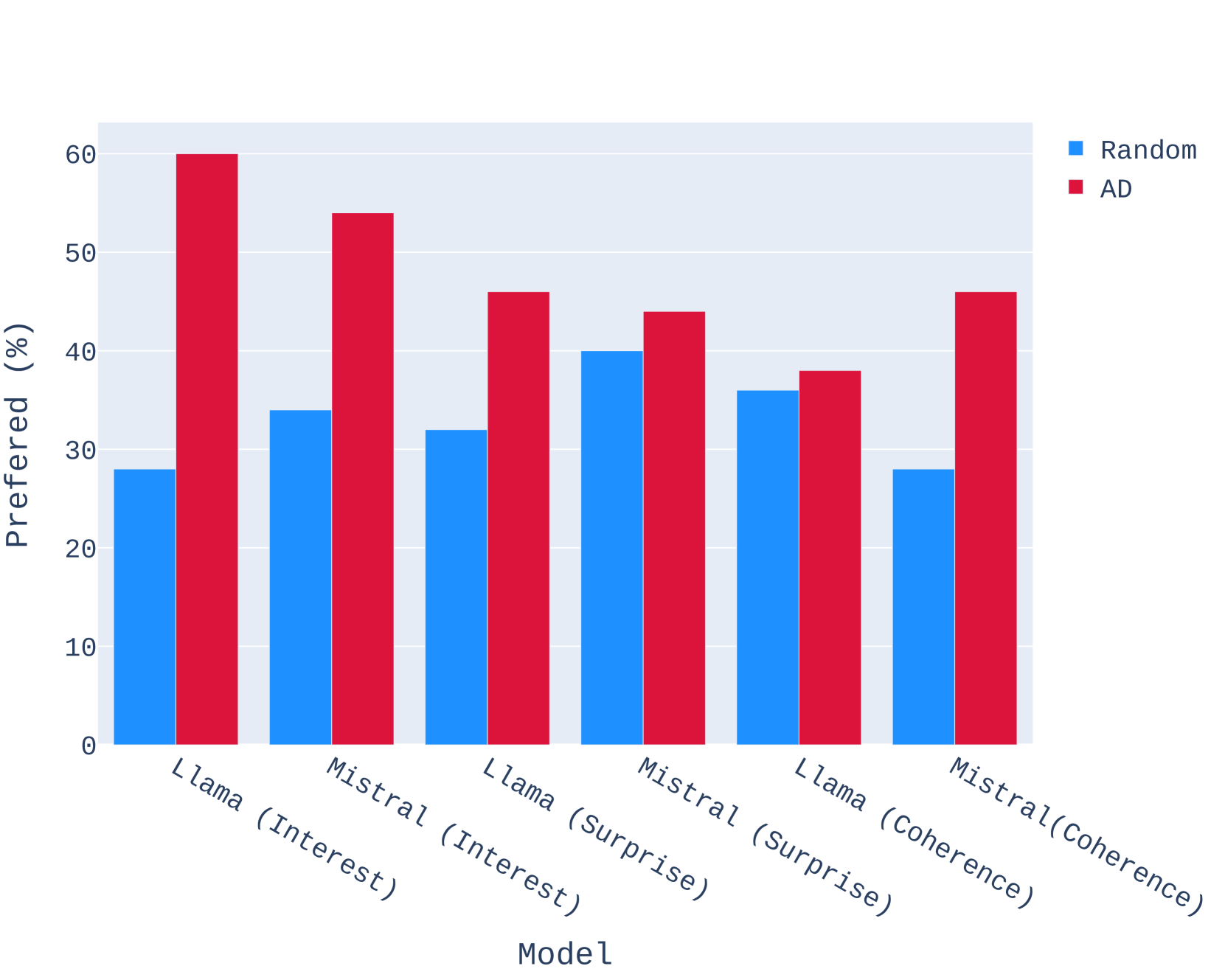
4.5 Human Evaluation
Our human evaluation setup is heavily inspired by (Zhu et al., 2023). We run human evaluations comparing stories generated by various methods across three aspects: interesting-ness, surprise, and coherence. For each of 12 pairwise comparisons of two methods, we ask Surge AI workers to answer three preference questions about 50 pairs of stories generated by the methods we compare. We display the preference questions in Table 1, where each question corresponds to an aspect of story quality. We display our human annotation results in Figures 5-8.
| Q1 |
Which story plot is more interesting to you overall? |
|---|---|
| Q2 |
Which story created more suspense and surprise? |
| Q3 |
Which story is more coherent and consistent in terms of plot structure? |
4.6 Machine (GPT-4-Turbo) Evaluation
Recent development in open-ended benchmarks shows promising results in evaluating LLM’s response, with increasing utilization of GPT-4 in place of human judges, such as MT-Bench (Zheng et al., 2023) and AlpacaEval (Dubois et al., 2023). Employing a similar strategy, we conduct evaluations with GPT-4-Turbo as a judge to pairwise compare two stories and pick the more interesting, engaging, and consistent story or a tie. The system prompt can be found in Appendix A.3. We evaluated several open and proprietary variants of AD LLMs against different baselines (random action, GPT-3.5-Turbo, etc.), with results presented in Table 2.
| AD vs E2E | Win-Rate (AD) | AD | E2E | Tie |
|---|---|---|---|---|
| Mistral-7B | 68.0% | 58 | 22 | 20 |
| Llama-2-7B | 54.5% | 47 | 38 | 15 |
| GPT-3.5-Turbo | 77.5% | 66 | 8 | 23 |
| GPT-4-Turbo | 61.5% | 49 | 24 | 25 |
| AD vs Random | Win-Rate (AD) | AD | Random | Tie |
| Llama-2-7B | 53.0% | 45 | 39 | 16 |
| Mistral-7B | 67.5% | 61 | 26 | 13 |
| AD vs GPT-3.5 | Win-Rate (AD) | AD | GPT-3.5 | Tie |
| Mistral-7B | 19.5% | 11 | 72 | 17 |
| Llama-2-7B | 31.0% | 19 | 57 | 24 |
| E2E vs GPT-3.5 | Win-Rate (E2E) | E2E | GPT-3.5 | Tie |
| Mistral-7B | 9.5% | 3 | 84 | 13 |
| Llama-2-7B | 23.5% | 14 | 67 | 19 |
5 Discussion
5.1 Machine Evaluation Results
Table 2 displays the pairwise evaluation results using GPT-4-Turbo as a judge. The win-rate column specifies the percentage of stories generated by SWAG that were preferred by the LM judge in the comparison. For the AD vs. Random comparisons, GPT-4 preferred Llama-2-7B and Mistral-7B with SWAG over using randomly selected actions. This shows that the AD LLM in SWAG provides useful signals to the story generation LLM for guiding the story direction.
In the AD vs. E2E comparisons, SWAG outperforms the E2E approach across all models. We note a significantly large win-rate in SWAG results for Mistral-7B, GPT-3.5-Turbo, and GPT-4-Turbo and a slightly higher win-rate than E2E with Llama-2-7B. This indicates that SWAG is greatly improves story engagement compared to generating long-form stories with no guidance.
The results across the ablations exhibit the effectiveness of SWAG and how a simple feedback loop improves content quality in stories. In each evaluation, GPT-4-Turbo provides reasoning for its story preference ranking. The stories generated with SWAG are consistently rated to have better suspense, surprise, and engagement. Examples of GPT-4-Turbo’s reasoning can be seen in Appendix E.
5.2 Human Evaluation Results
We then evaluate these stories once again in terms of interesting-ness, surprise, and coherence with humans as the judge. The human evaluators were specifically asked to rate each aspect separately by answering the questions in Table 1. We provide the full results in Appendix C. For both open-source and closed-source models, SWAG produces stories that overwhelmingly beat their E2E counterparts. We find that both SWAG Llama-2-7B’s stories and SWAG Mistral-7B’s stories were significantly more preferred over GPT-3.5-Turbo’s stories along interest and surprise while being equivalent in coherence.
Comparing GPT-4-Turbo and human evaluation, AD consistently outperform its baseline regardless of judges, demonstrating SWAG’s effectiveness. However, the gap in preferences is greater in human evaluation in comparison to GPT-4-Turbo as judge. As shown in Table 2 and Table 4, there is a significant difference in preferences on pairwise comparisons between open source AD LLMs and GPT-3.5-Turbo, with only 14% of Llama-2-7B AD being preferred over GPT-3.5-Turbo when GPT-4-Turbo is judge, while over 50% of Llama-2-7B AD being preferred across the 3 aspects. This is most likely due to GPT-4-Turbo inherent bias towards GPT-3.5-Turbo while human evaluators does not have a bias towards any particular LLM. These inconsistencies between GPT-4-Turbo and human judges reveal that even the strongest propriety models continue to lag behind human evaluators in terms of quality and trustworthiness.
5.3 Extensions
Beyond generating the story automatically using SWAG, users can also intervene in the story generation process. Our method can be “paused” at any time, after which a human can continue writing the story or even collaborate back-and-forth with the story model via SWAG. We are excited to explore new forms of human-LLM interaction as automated generation capabilities progress.
To further customize the SWAG inference loop, the user can also tailor the list of actions for the AD LLM to their own needs. For example, if a user would like their AD LLM to specialize in directing stories that focus on a specific genre like horror, they can add actions that better fit this theme. The flexibility to choose actions allows SWAG to be a versatile system for a wide variety of content generation tasks across various genres.
Based on our experiments and evaluations, we believe that our results could be further improved given more fine-grained actions during SFT and DPO training and inference time. Fine-grained actions would enable consistent control and can add depth and complexity to stories to increase engagement with the reader. Using more detailed actions can lead to richer narratives by allowing for more nuanced character development, plot twists, and detailed settings.
6 Limitations
Due to compute restraints, we were only able to use DPO for AD LLM alignment. DPO is much more lightweight than PPO as it is an offline RL algorithm. However, it is possible that through the online sampling process of PPO and with a strong reward model, we would be able to achieve better results. We also would have preferred to increase the scope of our ablations, potentially experimenting with a greater variety open-source and closed-source models and a larger set of diverse and fine-grained actions.
For our evaluations, we were only able to generate machine evaluations on 100 test story prompts and human evaluations on 50 test story prompts due to resource constraints. Evaluating on a larger set of stories, especially for machine evaluation, would give us better insight into the quality of the stories generated by SWAG.
7 Conclusion
This paper proposes SWAG, a simple feedback-based framework for creative story generation. The fine-tuned action discriminator LLM enables more interesting and exciting plot development with little to no sacrifice in coherence or consistency. Both machine and human evaluation exemplify our method’s effectiveness compared to SoTA end-to-end generation methods, even with the strongest closed-source models. We anticipate that our contribution will further advancements in content generation, particularly through the lens of iterative feedback mechanisms.
References
- Alabdulkarim et al. (2021a) Alabdulkarim, A., Li, S., and Peng, X. Automatic story generation: Challenges and attempts, 2021a.
- Alabdulkarim et al. (2021b) Alabdulkarim, A., Li, W., Martin, L. J., and Riedl, M. O. Goal-directed story generation: Augmenting generative language models with reinforcement learning, 2021b.
- Bai et al. (2022) Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., Joseph, N., Kadavath, S., Kernion, J., Conerly, T., El-Showk, S., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Hume, T., Johnston, S., Kravec, S., Lovitt, L., Nanda, N., Olsson, C., Amodei, D., Brown, T., Clark, J., McCandlish, S., Olah, C., Mann, B., and Kaplan, J. Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022.
- Brown et al. (2020) Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. Language models are few-shot learners. CoRR, abs/2005.14165, 2020. URL https://arxiv.org/abs/2005.14165.
- Castricato et al. (2022) Castricato, L., Havrilla, A., Matiana, S., Pieler, M., Ye, A., Yang, I., Frazier, S., and Riedl, M. Robust preference learning for storytelling via contrastive reinforcement learning, 2022.
- Chang et al. (2023) Chang, J. D., Brantley, K., Ramamurthy, R., Misra, D., and Sun, W. Learning to generate better than your llm, 2023.
- Charniak (2004) Charniak, E. Toward a model of children’s story comprehension. 10 2004.
- Chen et al. (2023) Chen, Y., Qian, S., Tang, H., Lai, X., Liu, Z., Han, S., and Jia, J. Longlora: Efficient fine-tuning of long-context large language models, 2023.
- Christiano et al. (2023) Christiano, P., Leike, J., Brown, T. B., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences, 2023.
- Chung et al. (2022) Chung, J. J. Y., Kim, W., Yoo, K. M., Lee, H., Adar, E., and Chang, M. Talebrush: Sketching stories with generative pretrained language models. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, pp. 1–19, 2022.
- Coenen et al. (2021) Coenen, A., Davis, L., Ippolito, D., Reif, E., and Yuan, A. Wordcraft: a human-ai collaborative editor for story writing, 2021.
- Dao (2023) Dao, T. Flashattention-2: Faster attention with better parallelism and work partitioning, 2023.
- Dubois et al. (2023) Dubois, Y., Li, X., Taori, R., Zhang, T., Gulrajani, I., Ba, J., Guestrin, C., Liang, P., and Hashimoto, T. B. Alpacafarm: A simulation framework for methods that learn from human feedback. arXiv preprint arXiv:2305.14387, 2023.
- Fan et al. (2018) Fan, A., Lewis, M., and Dauphin, Y. Hierarchical neural story generation, 2018.
- Goldfarb-Tarrant et al. (2019) Goldfarb-Tarrant, S., Feng, H., and Peng, N. Plan, write, and revise: an interactive system for open-domain story generation. In Ammar, W., Louis, A., and Mostafazadeh, N. (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), pp. 89–97, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-4016. URL https://aclanthology.org/N19-4016.
- Hu et al. (2021) Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lora: Low-rank adaptation of large language models, 2021.
- Jiang et al. (2023) Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. Mistral 7b, 2023.
- Jiang et al. (2024) Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., de las Casas, D., Hanna, E. B., Bressand, F., Lengyel, G., Bour, G., Lample, G., Lavaud, L. R., Saulnier, L., Lachaux, M.-A., Stock, P., Subramanian, S., Yang, S., Antoniak, S., Scao, T. L., Gervet, T., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. Mixtral of experts, 2024.
- Lester et al. (2021) Lester, B., Al-Rfou, R., and Constant, N. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021.
- Lin & Riedl (2021) Lin, Z. and Riedl, M. O. Plug-and-blend: A framework for plug-and-play controllable story generation with sketches. In Artificial Intelligence and Interactive Digital Entertainment Conference, 2021. URL https://api.semanticscholar.org/CorpusID:236470168.
- Loshchilov & Hutter (2019) Loshchilov, I. and Hutter, F. Decoupled weight decay regularization, 2019.
- Martin et al. (2017) Martin, L. J., Ammanabrolu, P., Wang, X., Singh, S., Harrison, B., Dhuliawala, M., Tambwekar, P., Mehta, A., Arora, R., Dass, N., et al. Improvisational storytelling agents. In Workshop on Machine Learning for Creativity and Design (NeurIPS 2017), volume 8, 2017.
- Mirowski et al. (2022) Mirowski, P., Mathewson, K. W., Pittman, J., and Evans, R. Co-writing screenplays and theatre scripts with language models: An evaluation by industry professionals, 2022.
- Oatley (1995) Oatley, K. Book reviews: The creative process: A computer model of storytelling and creativity. Computational Linguistics, 21(4), 1995. URL https://aclanthology.org/J95-4007.
- OpenAI (2023) OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023. URL https://arxiv.org/abs/2303.08774.
- Peng et al. (2022) Peng, X., Xie, K., Alabdulkarim, A., Kayam, H., Dani, S., and Riedl, M. O. Guiding neural story generation with reader models, 2022.
- Qin & Eisner (2021) Qin, G. and Eisner, J. Learning how to ask: Querying lms with mixtures of soft prompts. arXiv preprint arXiv:2104.06599, 2021.
- Rafailov et al. (2023) Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., and Finn, C. Direct preference optimization: Your language model is secretly a reward model, 2023.
- Rashkin et al. (2020) Rashkin, H., Celikyilmaz, A., Choi, Y., and Gao, J. Plotmachines: Outline-conditioned generation with dynamic plot state tracking, 2020.
- Schulman et al. (2017) Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms, 2017.
- Shin et al. (2020) Shin, T., Razeghi, Y., au2, R. L. L. I., Wallace, E., and Singh, S. Autoprompt: Eliciting knowledge from language models with automatically generated prompts, 2020.
- Tambwekar et al. (2019) Tambwekar, P., Dhuliawala, M., Martin, L. J., Mehta, A., Harrison, B., and Riedl, M. O. Controllable neural story plot generation via reward shaping. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-2019. International Joint Conferences on Artificial Intelligence Organization, August 2019. doi: 10.24963/ijcai.2019/829. URL http://dx.doi.org/10.24963/ijcai.2019/829.
- Touvron et al. (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V., Khabsa, M., Kloumann, I., Korenev, A., Koura, P. S., Lachaux, M.-A., Lavril, T., Lee, J., Liskovich, D., Lu, Y., Mao, Y., Martinet, X., Mihaylov, T., Mishra, P., Molybog, I., Nie, Y., Poulton, A., Reizenstein, J., Rungta, R., Saladi, K., Schelten, A., Silva, R., Smith, E. M., Subramanian, R., Tan, X. E., Tang, B., Taylor, R., Williams, A., Kuan, J. X., Xu, P., Yan, Z., Zarov, I., Zhang, Y., Fan, A., Kambadur, M., Narang, S., Rodriguez, A., Stojnic, R., Edunov, S., and Scialom, T. Llama 2: Open foundation and fine-tuned chat models, 2023.
- Tunstall et al. (2023) Tunstall, L., Beeching, E., Lambert, N., Rajani, N., Rasul, K., Belkada, Y., Huang, S., von Werra, L., Fourrier, C., Habib, N., Sarrazin, N., Sanseviero, O., Rush, A. M., and Wolf, T. Zephyr: Direct distillation of lm alignment, 2023.
- von Werra et al. (2020) von Werra, L., Belkada, Y., Tunstall, L., Beeching, E., Thrush, T., Lambert, N., and Huang, S. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl, 2020.
- Wang & Gordon (2023) Wang, T. S. and Gordon, A. S. Playing story creation games with large language models: Experiments with gpt-3.5. In International Conference on Interactive Digital Storytelling, pp. 297–305. Springer, 2023.
- Wei et al. (2022) Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., and Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. 2022. doi: 10.48550/ARXIV.2201.11903. URL https://arxiv.org/abs/2201.11903.
- Wilmot & Keller (2021) Wilmot, D. and Keller, F. A temporal variational model for story generation, 2021.
- Xu et al. (2018) Xu, J., Ren, X., Zhang, Y., Zeng, Q., Cai, X., and Sun, X. A skeleton-based model for promoting coherence among sentences in narrative story generation, 2018.
- Zheng et al. (2023) Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., and Stoica, I. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
- Zhu et al. (2023) Zhu, H., Cohen, A., Wang, D., Yang, K., Yang, X., Jiao, J., and Tian, Y. End-to-end story plot generator, 2023.
- Zou et al. (2021) Zou, X., Yin, D., Zhong, Q., Yang, H., Yang, Z., and Tang, J. Controllable generation from pre-trained language models via inverse prompting. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, KDD ’21, pp. 2450–2460, New York, NY, USA, 2021. Association for Computing Machinery. ISBN 9781450383325. doi: 10.1145/3447548.3467418. URL https://doi.org/10.1145/3447548.3467418.
Appendix A Prompts
A.1 AD LLM Prompt
A.2 Story Model Prompt
A.3 System Prompt for Evaluation
To further avoid positional bias, we also randomly shuffle the position of the stories presented to GPT-4-Turbo judge. For example, in 100 pairwise comparisons between E2E and AD, 50 comparisons are randomly chosen to present E2E as story A while the other 50 present AD as story A.
Appendix B Actions
Our action space consists of the following 30 phrases:
Appendix C Full Human Evaluation Results
| Llama-2_E2E (A) vs GPT-3.5_E2E (B) | Mistral_E2E (A) vs GPT-3.5_E2E (B) | |||||
| Aspect | Story A | Story B | Tie | Story A | Story B | Tie |
| Interest |
22% |
60% |
18% |
26% |
62% |
12% |
| Surprise |
24% |
64% |
12% |
22% |
68% |
10% |
| Coherence |
36% |
48% |
16% |
38% |
44% |
18% |
| Llama-2_AD_Llama-2_GEN (A) vs GPT-3.5_E2E (B) | Mistral_AD_Mistral_GEN (A) vs GPT-3.5_E2E (B) | |||||
| Aspect | Story A | Story B | Tie | Story A | Story B | Tie |
| Interest |
62% |
32% |
6% |
48% |
38% |
14% |
| Surprise |
56% |
30% |
16% |
52% |
36% |
16% |
| Coherence |
34% |
36% |
30% |
38% |
34% |
28% |
| Rnd_AD_Llama-2_GEN vs Llama-2_AD_Llama-2_GEN | Rnd_AD_Mistral_GEN vs Mistral_AD_Mistral_GEN | |||||
| Aspect | Story A | Story B | Tie | Story A | Story B | Tie |
| Interest |
28% |
60% |
12% |
34% |
54% |
12% |
| Surprise |
32% |
46% |
22% |
40% |
44% |
16% |
| Coherence |
36% |
38% |
26% |
28% |
46% |
26% |
| GPT-4_E2E vs GPT-4_AD_GPT-4_GEN | GPT-3.5_E2E vs GPT-3.5_AD_GPT-3.5_GEN | |||||
| Aspect | Story A | Story B | Tie | Story A | Story B | Tie |
| Interest |
36% |
58% |
6% |
30% |
62% |
8% |
| Surprise |
38% |
52% |
10% |
24% |
66% |
10% |
| Coherence |
26% |
44% |
30% |
20% |
58% |
22% |
| Llama-2_E2E vs Llama-2_AD_Llama_GEN | Mistral_E2E vs Mistral_AD_Mistral_GEN | |||||
| Aspect | Story A | Story B | Tie | Story A | Story B | Tie |
| Interest |
12% |
82% |
6% |
14% |
80% |
6% |
| Surprise |
6% |
90% |
4% |
18% |
72% |
10% |
| Coherence |
22% |
48% |
30% |
34% |
38% |
24% |
| Llama-2_AD_Llama_GEN vs Llama-2_AD_Mistral_GEN | Mistral_AD_Mistral_GEN vs Mistral_AD_Llama_GEN | |||||
| Aspect | Story A | Story B | Tie | Story A | Story B | Tie |
| Interest |
52% |
30% |
18% |
40% |
34% |
26% |
| Surprise |
50% |
34% |
16% |
44% |
32% |
24% |
| Coherence |
44% |
30% |
26% |
38% |
28% |
34% |
Appendix D Human Evaluation Experimental Details
For each of the 12 method combinations, we asked a group of human workers on the Surge AI platform to compare 50 pairs of generated stories across 3 aspects. See Tables 9 for a set of instructions we gave to the workers in the experiment.
We paid the participants according to our estimate of $18/hr, which we believe is reasonable compensation given the task and the U.S. demographic of the workers. The data collection protocol was determined to be exempt from an ethics review board.
|
We are a group of AI/NLP researchers working on methods to improve the quality and creativity of stories generated by language models. In this task we ask you to look at pairs of (lengthy) stories written by different AI based on the same initial premise, and respond to the following comparison questions about each story pair: (1) Which story is more interesting to you overall? (2) Which story created more suspense and surprise? (3) Which story is more coherent and consistent in terms of plot structure? For all these questions, we just need high-level judgements, so please quickly skim both stories. In other words, there is no need to read each story carefully (they can be up to 5000 words in length); we expect you to spend at most ten minutes per story. |
Appendix E GPT-4-Turbo Reasoning
Example 1: An example judgment from GPT-4-Turbo on a pairwise comparison between GPT-3.5-Turbo E2E as story A and GPT-3.5-Turbo AD as story B.
Example 2: An example judgment from GPT-4-Turbo on a pairwise comparison between GPT-3.5-Turbo E2E as story A and GPT-3.5-Turbo AD as story B.
Appendix F Full Story
Example: GPT-4-Turbo’s response, with action guidance to the following writing prompt: “Humans lost the war in under thirty minutes … the worst part is the Izdrazi Empire ’s Technology is so advanced even as their servants humans live better than kings before the war.”
Appendix G Models Used
We used Llama-2-7B, Mistral-7B, Mixtral-8x7B, GPT-3.5-Turbo, GPT-4, and GPT-4-Turbo.
Appendix H Licenses and Software
The WritingPrompts dataset uses the MIT License.
All models are implemented in PyTorch; Llama-2 uses the GPL license and Mistral uses the Apache 2.0 license. Mixtral-8x7B is utilized from Huggingface, which is under the Apache License 2.0.
Our use of datasets and models is consistent with their intended use.