Non-autoregressive Generative Models for Reranking Recommendation
Abstract.
Contemporary recommendation systems are designed to meet users’ needs by delivering tailored lists of items that align with their specific demands or interests. In a multi-stage recommendation system, reranking plays a crucial role by modeling the intra-list correlations among items. The key challenge of reranking lies in the exploration of optimal sequences within the combinatorial space of permutations. Recent research proposes a generator-evaluator learning paradigm, where the generator generates multiple feasible sequences and the evaluator picks out the best sequence based on the estimated listwise score. The generator is of vital importance, and generative models are well-suited for the generator function. Current generative models employ an autoregressive strategy for sequence generation. However, deploying autoregressive models in real-time industrial systems is challenging. Firstly, the generator can only generate the target items one by one and hence suffers from slow inference. Secondly, the discrepancy between training and inference brings an error accumulation. Lastly, the left-to-right generation overlooks information from succeeding items, leading to suboptimal performance.
To address these issues, we propose a Non-AutoRegressive generative model for reranking Recommendation (NAR4Rec) designed to enhance efficiency and effectiveness. To tackle challenges such as sparse training samples and dynamic candidates, we introduce a matching model. Considering the diverse nature of user feedback, we employ a sequence-level unlikelihood training objective to differentiate feasible sequences from unfeasible ones. Additionally, to overcome the lack of dependency modeling in non-autoregressive models regarding target items, we introduce contrastive decoding to capture correlations among these items. Extensive offline experiments validate the superior performance of NAR4Rec over state-of-the-art reranking methods. Online A/B tests reveal that NAR4Rec significantly enhances the user experience. Furthermore, NAR4Rec has been fully deployed in a popular video app Kuaishou with over 300 million daily active users.
1. Introduction
Recommendation systems offer users personalized item lists tailored to their interests. Various approaches have been proposed to capture user interests, focusing on feature interactions(Cheng et al., 2016; Guo et al., 2017; Lian et al., 2018), user preference modeling(Zhou et al., 2018, 2019b), and so on. However, most existing methods treat individual items separately, neglecting their mutual influence and leading to suboptimal results. Acknowledging that user interactions with one item may correlate with others in the recommendation list(Pei et al., 2019), reranking is introduced to consider contextual information and generate an optimal sequence of recommendation items.
The main challenge in reranking is exploring optimal sequences within the vast space of permutations. Reranking methods are typically categorized into on-stage and two-stage approaches. One-stage methods (Ai et al., 2018; Pei et al., 2019) take candidates as input, estimating refined scores for each item within the permutation, and rerank them greedily based on these scores. However, one-stage methods encounter an inherent contradiction(Feng et al., 2021; Xi et al., 2021): the reranking operation inherently alters the permutation, introducing different mutual influences between items compared to the initial arrangement. Consequently, the refined score conditioned on the initial permutation is considered implausible.
To tackle this challenge, two-stage methods utilize a generator-evaluator framework. Here, the generator creates multiple feasible sequences, and the evaluator selects the optimal sequence based on the estimated listwise score. Within the generator-evaluator framework, the generator plays a crucial role. Generative models(Bello et al., 2018; Feng et al., 2021; Gong et al., 2022; Zhuang et al., 2018) are preferred over heuristic methods(Feng et al., 2021; Lin et al., 2023; Xi et al., 2021; Shi et al., 2023) for the generator function due to the expansive solution space of item permutations. Generative models commonly employ an autoregressive strategy for sequence generation.
However, deploying the autoregressive models in real-time industrial recommendation systems presents challenges. Firstly, autoregressive models suffer from inference efficiency. Autoregressive models adopt a sequential approach to generate target sequences item by item, resulting in slow inference as the time complexity increases linearly with the sequence length. Secondly, a critical issue arises from the training-inference discrepancy in autoregressive models. While these models are trained to predict the next item based on the ground truth up to that point. However, during inference, they receive their own previously generated outputs as input. This misalignment introduces an accumulated error, where inaccuracies generated in earlier timesteps propagate and accumulate over time. Consequently, this accumulation leads to sequences that deviate from the true distribution of the target sequence. Additionally, autoregressive models have limited information utilization. The sequential decoding process focuses solely on preceding items, neglecting information from succeeding items. This limitation results in suboptimal performance as the model fails to fully leverage the available context.
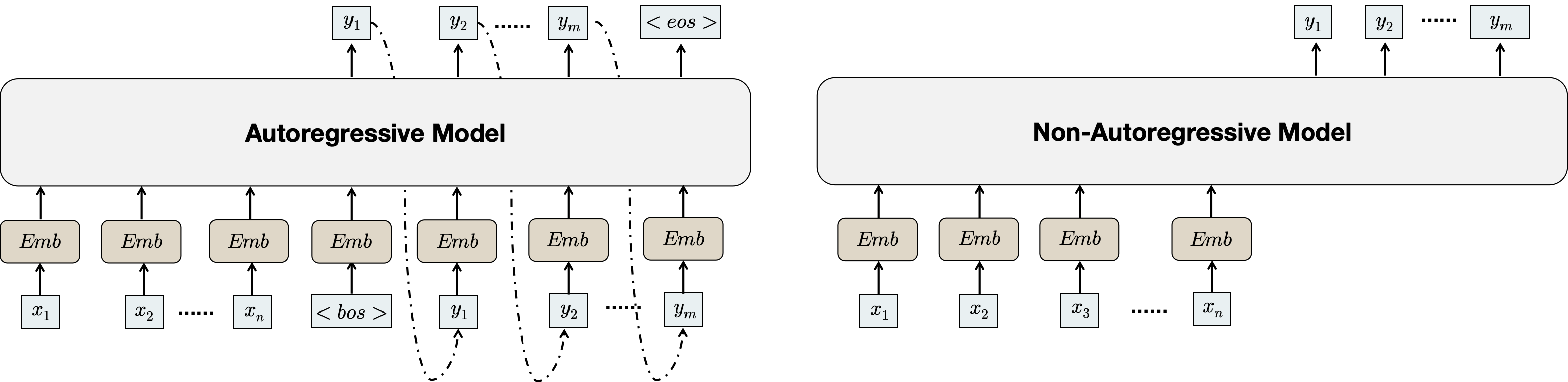
To address those challenges, we propose Non-AutoRegressive generative model for reranking Recommendation(NAR4Rec). Unlike autoregressive models, which generate sequences step by step, relying on their own previous outputs, NAR4Rec generates all items within the target sequence simultaneously.
However, we find it nontrivial to deploy non-autoregressive in recommendation systems. Firstly, the sparse nature and dynamic candidates in recommendation systems pose difficulties for learning convergence, which we address by sharing position embedding and introducing a matching model. Secondly, the diverse nature of user feedback, including both positive and negative interactions, renders maximum likelihood training less suitable. We propose unlikelihood training to distinguish between desirable and undesirable sequences. Lastly, non-autoregressive models assume an independent selection of items at each position in a sequence, which is inadequate when modeling intra-list correlation. Hence we propose contrastive decoding to capture dependencies across items.
To summarize, our contributions are listed as follows:
-
•
We make the first attempt to adopt non-autoregressive models for reranking, which significantly speeds up the inference speed and meets the requirements of real-time recommendation systems.
-
•
We propose a matching model to enhance convergence, a sequence-level unlikelihood training method to guide the generated sequence towards improved overall utility, and a contrastive decoding method to refine current decoding strategies with intra-list correlation.
-
•
Extensive offline experiments demonstrate that NAR4Rec outperforms state-of-the-art methods. Online A/B tests further validate the effectiveness of NAR4Rec. Furthermore, NAR4Rec has been fully deployed in a real-world video app Kuaishou with over 300 million daily active users, notably improving the user experience.
2. Related work
2.1. Reranking in Recommendation Systems
In contrast to earlier phases like matching and ranking(Burges et al., 2005; Liu et al., 2009), which typically learn a user-specific itemwise scoring function, the core of reranking in recommendation systems lies in modeling correlations within the exposed list. Reranking(Pang et al., 2020; Pei et al., 2019; Xi et al., 2021), building upon candidate items from the ranking stage, selects a subset and determines their order to ensure exposing the most suitable items to the users. Existing research on reranking can be systematically classified into two principal categories: one-stage(Ai et al., 2018; Pei et al., 2019; Pang et al., 2020), and two-stage methods(Feng et al., 2021; Shi et al., 2023; Lin et al., 2023; Xi et al., 2021).
One-stage methods treat reranking as a retrieval task, recommending the top k items based on scores from a ranking model. These methods refine the initial list distribution using list-wise information, optimizing overall recommendation quality. Subsequently, the candidates are reranked by the refined itemwise score in a greedy manner. The distinction lies in the network architectures for capturing list-wise information, such as GRU in DLCM(Ai et al., 2018), and transformer in PRM(Pei et al., 2019). However, user feedback for the exposed list is influenced not just by item interest but also by arrangements and surrounding context(Joachims et al., 2017; Lorigo et al., 2008, 2006; Yang, 2017). The reranking operation modifies permutations, thereby introducing influences distinct from the initial permutation. Moreover, one-stage methods, which exclusively model the initial permutation, fall short of capturing alternative permutations. Consequently, those methods struggle to maximize overall user feedback(Xi et al., 2021).
Two-stage methods (Feng et al., 2021; Shi et al., 2023; Lin et al., 2023; Xi et al., 2021) embrace a generator-evaluator framework. In this framework, the generator initiates the process by generating multiple feasible sequences, and subsequently, the evaluator selects the optimal sequence based on the estimated listwise score. This framework allows for a comprehensive exploration of various feasible sequences, and an informed selection of the most optimal one based on listwise considerations. The role of the generator is particularly crucial for generating sequences. Common approaches for generators can be categorized into heuristic methods(Feng et al., 2021; Lin et al., 2023; Xi et al., 2021; Shi et al., 2023), such as beam search or item swapping, and generative models (Bello et al., 2018; Feng et al., 2021; Gong et al., 2022; Zhuang et al., 2018). Generative models are more suitable than heuristic methods for reranking given the vast permutation space. These generative models typically adopt a step-greedy strategy which autoregressively decides the display results of each position. However, the high computational complexity of online inferences limits their application in real-time recommendation systems.
To address the challenges linked with autoregressive generation models, our work investigates the viability of non-autoregressive generative models within the generator-evaluator framework. Non-autoregressive generative models generate the target sequence once to alleviate computational complexity.
2.2. Non-autoregressive Sequence Generation
Non-autoregressive sequence generation(Gu et al., 2018) was initially introduced in machine translation to speed up the decoding process. Then it has since gained increased attention in nature language processing, e.g. text summarization(Gu et al., 2019; Awasthi et al., 2019), text error correction(Leng et al., 2021b, a). Specifically, efforts have been focused on tackling the absence of target information in non-autoregressive models. Strategies include enhancing the training corpus to mitigate target-side dependencies(Gu et al., 2018; Zhou et al., 2019a) and refining training approaches(Ghazvininejad et al., 2019; Stern et al., 2019) to alleviate learning difficulties.
Although non-autoregressive generation has been explored in text, those conventional techniques are not directly applicable to recommendation systems. We tackle the challenges encountered in recommendation systems to improve the convergence and performance of non-autoregressive models and make the first attempt to integrate non-autoregressive models into reranking within real-time recommender systems.
3. Preliminary
3.1. Reranking problem Formulation
For each user within the set , a request encompasses a set of user profile features(such as user ID, gender, age), the recent interaction history, and candidates items denoted as , where is the number of candidates. Given candidates , the goal of reranking is to propose an item sequence that elicits the most favorable feedback for user , where is the sequence length and is the recommended list of the reranking model. We denote the reranking models as where the corresponding parameter is . In real-time recommendation systems, reranking acts as the last stage to deliver the ultimate list of recommended items. Typically, significantly exceeds , with being less than 10 and ranging from several tens to hundreds.
In a multi-interaction scenario, users may exhibit distinct types of interaction (e.g., clicks, likes, comments) for each item exposure. Formally, we define the set of user interactions as , and represents user ’s response to item concerning interaction . Given , each item has a multi-interaction response . For all items ,the overall user response is:
| (1) |
The overall utility is quantified as the summation of individual item utilities, denoted as . The utility associated with each item may correspond to a specific interaction type , such as clicks, watch time, or likes. In such cases, the item utility is expressed as . Alternatively, the item utility can be represented as the weighted sum of diverse interactions , where denotes the weight for each interaction.
The reranking objective is to maximum the overall utility for a given user :
| (2) |
Reranking introduces a permutation space with exponential size, represented as , where represents the number of candidates and represents the number of items to be selected and ordered. Each permutation represents a potential arrangement of items, and users provide unique feedback for each permutation. However, in practical scenarios, users typically encounter only one permutation. Thus, the main challenge in reranking lies in efficiently and effectively determining the optimal permutation given the vast solution space yet extremely sparse real user feedback as training samples.
3.2. Autoregressive sequence generation
Given a set of candidate items denoted as , autoregressive models decompose the distribution over potential generated sequences into a series of conditional probabilities:
| (3) |
where the special tokens (e.g., ¡bos¿) and (e.g., ¡eos¿) denote the beginning and end of target sequences. Importantly, the length of the generated sequence is predetermined and fixed, unlike variable lengths in text.
Factorizing the sequence generation output distribution autoregressively leads to a maximum likelihood training with a cross-entropy loss at each timestep:
| (4) |
The training objective aims to optimize individual conditional probabilities. In training, when the target sequence is known, these probabilities are calculated based on earlier target items rather than model-generated ones, enabling efficient parallelization. In inference, autoregressive models generate the target sequence item-by-item sequentially, efficiently capturing the distribution of the target sequence. This makes them well-suited for the reranking task, particularly considering the vast space of possible permutations.
While autoregressive models have proven effective, deploying them in industrial recommendation systems is challenging. Firstly, their sequential decoding process leads to slow inference, introducing latency that hinders real-time application. Secondly, these models, trained to predict based on ground truth, face a discrepancy during inference when they receive their own generated outputs as input. This misalignment may lead to compounded errors, as inaccuracies generated in earlier timesteps accumulate over time, resulting in inconsistent or divergent sequences that deviate from the true distribution of the target sequence. Thirdly, autoregressive models rely on a left-to-right causal attention mechanism, limiting the expressive power of hidden representations, as each item encodes information solely from preceding items(Sun et al., 2019). This constraint impedes optimal representation learning, resulting in suboptimal performance.
3.3. Non-autoregressive sequence generation
To address the aforementioned challenges, non-autoregressive sequence generation eliminates autoregressive dependencies from existing models. Each element’s distribution depends solely on the candidates :
| (5) |
Then the loss function for the non-autoregressive model is:
| (6) |
Despite the removal of the autoregressive structure, the models retain an explicit likelihood function. The training of models employs separate cross-entropy losses for each output distribution. Crucially, these distributions can be computed simultaneously during inference, which significantly differs from the sequential process of autoregressive models. This non-autoregressive approach reduces inference latency, thereby enhancing the efficiency of recommendation systems in real-world applications.
4. Approach
In this section, we present a detailed introduction of NAR4Rec. We will first discuss our non-autoregressive model structure, which estimates the probability by a matching model in section 4.1. Then, we delve into unlikelihood training, a method aimed at discerning feedback within the recommended sequence in section 4.2. Finally, we propose contrastive decoding to model the dependency in target sequence in section 4.3. The sequence evaluator in our generator-evaluator framework is introduced in section 4.4.
4.1. Matching model
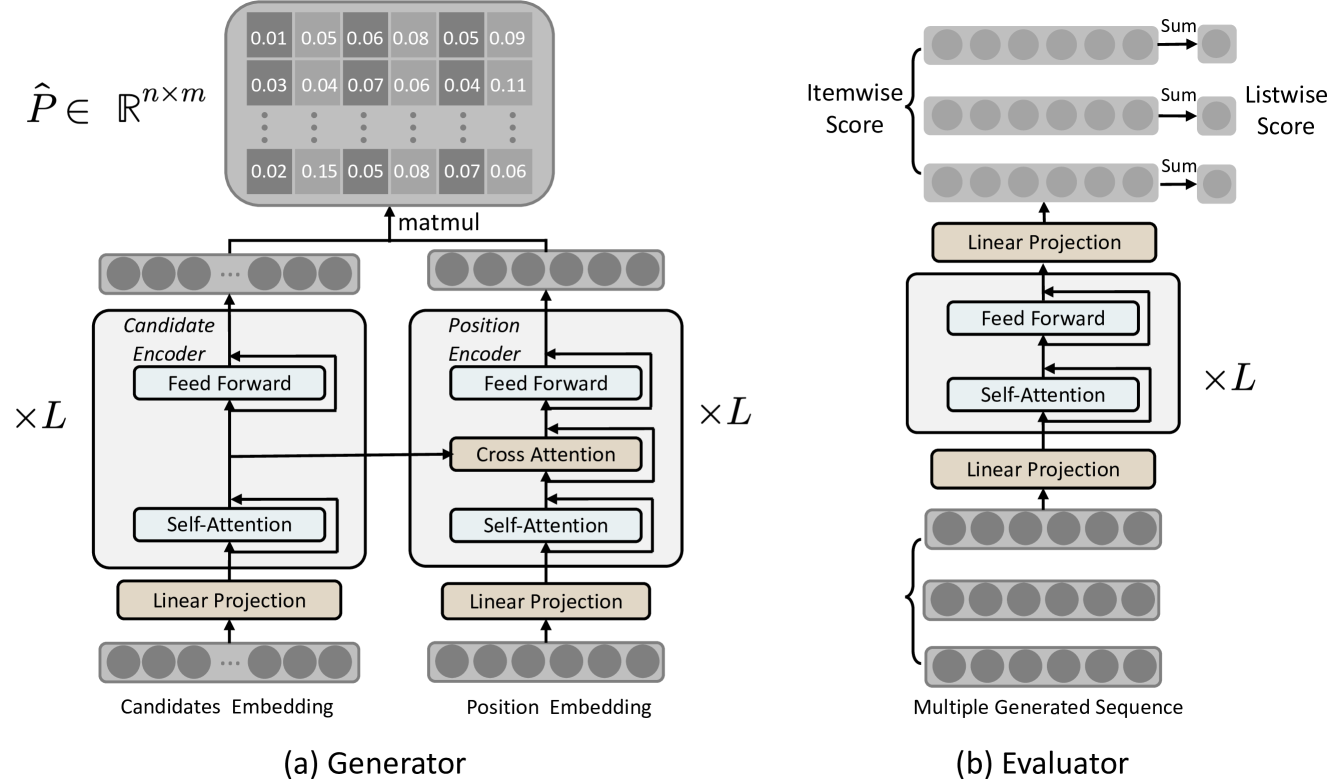
Non-autoregressive models encounter challenges in training convergence due to two main reasons. Firstly, the sparse nature of training sequences presents learning difficulties. Unlike text sequences that often share linguistic structures, recommended lists in training samples seldom have the same exposures, posing challenges for effective learning from limited data. Secondly, during the reranking stage, identical index for candidates may denote different items, leading to a variable vocabulary as the candidates to be ranked vary across samples.
Conventional models may struggle to handle such variations efficiently. To tackle these challenges, we introduce two key components to our models: a candidates encoder for effectively encoding representations of candidates and a position encoder to capture position-specific information within the target sequence. Initially, we randomly initialize an embedding for each position in the target sequences. Notably, we share these position embeddings across training data to enhance learning on sparse data. Subsequently, we integrate bidirectional self-attention and cross-attention modules to acquire representations for each position, leveraging information from the candidates.
Additionally, to address the challenge posed by the dynamic vocabulary arising from variations in candidates across samples, we employ a matching mechanism. Specifically, we match each candidate with each position in the target sequence, thereby yielding probabilities for each candidate at every position. In the following, we elaborate on the structure of NAR4Rec.
Given a user and candidates , the hidden representation of is . We stack together into matrix . Additionally, we randomly initialize an embedding vector for each position as . Also, we stack into . To align the embedding dimension of with that of , we project them into same hidden dimension by a linear projection layer. Then and . Consequently, is represented as and as .
Candidates Encoder. The candidates encoder adopts the standard Transformer architecture(Vaswani et al., 2017) by stacking Transformer layers. In each layer, the architecture mainly consists of two blocks, a self-attention block and a feed-forward network. An input for self-attention block is linearly transformed into query (), key () and value () as follows:
| (7) |
where , and denote the weight matrices. Then, the self-attention operation is applied as:
| (8) |
For a multi-head version of self-attention mechanism, the input is linearly projected into , and with times using individual linear projections to small dimensions(e.g. ). Finally, the output of self-attention(SAN) is
| (9) | SAN | |||
The feed-forward network is typically placed after the self-attention block,
| (10) |
where and denote the weight matrices of the two linear projection.
Position Encoder. The position encoder adopts a similar Transformer architecture as the candidates encoder. The key difference between them is that the position encoder inserts a cross-attention block between the self-attention block and the feed-forward network in each Transformer layer. As can be seen in Fig. 2, in each layer, the cross-attention block receives the hidden representation from the self-attention blocks of both encoders and processes them via cross-attention operation. Specifically, the hidden representation from the candidates encoder and position encoder are denoted as and , respectively. Similar to the self-attention block, we initially apply linear projection to them:
| (11) |
Then, we applies the formula in eq. 9 to , , and to get the output hidden representation. The cross-attention is introduced to capture the correlation between candidates and target sequence.
Probability Matrix. To compute the probability matrix, we perform a matrix multiplication on the output hidden representation from the candidates encoder (denoted as ) and position encoder (denoted as ). Subsequently, we apply a column-wise softmax function to normalize the scores. Formally, the probability score of placing the -th candidate item to the -th position is calculated as:
| (12) |
Training objectives NAR4Rec is trained via cross-entropy loss function, defined as follows:
| (13) |
where is 1 if is in position otherwise 0.
4.2. Unlikelihood Training
The discrepancy between text and item sequences hinders the direct application of generative models from text to item recommendation. This disparity arises from the unique characteristics of user interactions in recommendation scenarios. Unlike the structured nature of natural language text, the feedback within recommendation sequences is diverse due to the varied nature of user interactions. While text sequences typically follow conventional language structures to convey information or construct a coherent narrative, user feedback in recommendation sequences is characterized by diverse actions such as clicks or likes, reflecting a diverse and nuanced feedback.
Consequently, the difference in objectives between maximum likelihood training(as in eq. 5) and reranking (as in eq. 2) poses a significant challenge. Although maximum likelihood training effectively captures patterns in text sequences, its applicability diminishes in recommendation scenarios where user preferences are dynamic and subjective. The essence of high-quality recommendations lies not just in sequence patterns from training data but, more crucially, in the user utility of the recommended list. User interactions with recommended items are subjective and context-driven, adding complexity to aligning the training objective with the desired model behavior. To address this challenge, we propose unlikelihood training, guiding the model to assign lower probabilities to undesired generations. This adjustment aligns the training process with the intricate feedback patterns.
Unlikelihood training reduces the model’s probability of generating a negative sequence. Given candidates and a negative sequence , the unlikelihood loss is:
| (14) |
The loss decreases as decreases.
Unlike text generation, where messages are clear and content-focused, managing attributes like topic, style, and sentiment in the output text is straightforward(Li et al., 2020; Welleck et al., 2019). However, recommendation sequences involve user feedback with implicit signals. For instance, a lack of interaction with a recommended item may suggest disinterest. This highlights the model’s need to understand both explicit and implicit cues in user feedback. Effective control over generation in recommendation sequences becomes crucial to tailor the output based on user preferences and behaviors, thus enhancing the personalized recommendations. Specifically, we classify a item sequence as positive or negative based on the overall utility defined in section 3.1, and the corresponding loss is as follows:
| (15) |
where is the threshold for positive and negative sequences.
In summary, beyond the primary goal of learning positive sequence patterns through sequence likelihood, unlikelihood training introduces an additional objective to reduce the likelihood of generating sequences with low utilities, effectively training recommendation models to discern feedback within recommendation sequences.
4.3. Contrastive Decoding
Compared with autoregressive generation, the non-autoregressive approach significantly enhances computation efficiency and makes it feasible to deploy in real-time recommendation systems. However, non-autoregressive generation introduce the conditional independence assumption: each target item’s distribution depends only on the candidates . This deviation from autoregressive models poses challenges in capturing the inherently multimodal nature of the distribution of valid target sequences. Take machine translation for example, when translating the phrase ”thank you” into German could result in multiple valid translations such as ”Vielen Dank” and ”Danke”. However, non-autoregressive models may generate unplausible translations like ”Danke Dank”. The conditional independence assumption in eq. 5 restricts the model’s ability to effectively grasp the multimodal distribution in target sequences.
Essentially, the assumption of conditional independence limits the model’s ability to navigate a vast solution space and identify the most suitable permutation from numerous valid options for a given set of candidates. This limitation is especially evident in recommendation where the number of reasonable target sequences far exceeds those encountered in text. Consequently, non-autoregressive frameworks grapple with the challenge of mitigating the impact of conditional independence to improve their capacity for generating diverse and contextually appropriate target sequences. To tackle this, we propose contrastive decoding to model the co-occurrence relationship between items and thereby improve the target dependency.
Contrastive decoding incorporates a diversity prior that regulates the sequence decoding procedure. This is grounded in the intuition that an effective recommended list needs to be composed of a wide variety of items. In fact, contrastive decoding leverages a similarity score function as a regulator when decoding, capturing the interdependence between various positions in the target sequence.
Formally, given the preceding context , at time step , the selection of the output follows
| (16) |
where . In eq. 16, the first term, termed as model confidence, denotes the probability of candidates predicted by the model. The second term, known as similarity penalty, quantifies the distinctiveness candidate concerning the previously selected items, where is computed as:
| (17) |
Specifically, the similarity penalty is defined as the maximum similarity between the representation of and all items in . NAR4Rec utilizes the dot product item embedding and position embedding to compute the probability matrix. Higher embedding similarity between items often means similar probability in a certain position. We introduce such penalty to introduce intra-list correlation.
Also, to encourage the language model to learn discriminative and isotropic item representations, we incorporate a contrastive objective into the training of the language model. Specifically, given a sequence , the and are defined as:
| (18) |
where is a pre-defined margin and is the hidden representation of item from candidates encoder.
| (19) |
where is the hidden representation of position from the position encoder. Intuitively, by training with , the model learns to pull away the distances between representations of distinct tokens.111By definition, the cosine similarity of the identical token is . Therefore, a discriminative and isotropic model representation space can be obtained.
The overall training objective is then defined as
| (20) |
where the unlikelihood training objective is described in eq. 15. Note that, when the margin in and equals to , the degenerates to the vanilla unlikelihood training objective .
4.4. Sequence Evaluator
The sequence evaluator model is designed to estimate the overall utility of a given sequence, as illustrated in fig. 2. The generated sequence from the generator is first encoded using a self-attention and a feed-forward layer to capture contextual information. The hidden representation then passes through the linear projection layer to predict the score for a specific target. The overall utility is calculated as the weighted sum of itemwise scores. Ultimately, the sequence with the highest overall utility is chosen for delivery to the users.
5. Experiments
In this section, we conduct extensive offline experiments and online A/B tests to demonstrate the effectiveness of NAR4Rec. We first describe our experiment setup and baselines in section 5.1. For offline experiments in section 5.2, we compare NAR4Rec with existing baselines on both performance and training and inference time. Then we alternate the hyper-parameter to analyse the hyper-parameter sensitivity of NAR4Rec. To further show the effectiveness of NAR4Rec in real-time recommendation system, we conduct online A/B tests to ablate our proposed methods in section 5.3.
5.1. Experiment details
| Dataset | #Requests | #Users | #Ads |
|---|---|---|---|
| Avito | 53,562,269 | 1,324,103 | 23,562,269 |
| Meituan | 230,525,531 | 3,201,922 | 98,525,531 |
Dataset: To evaluate reranking recommendation, we expect that each sample of the dataset is an exposed sequence to users rather than a manually constructed sequence. For public dataset, we choose Avito dataset. For industrial dataset, we use real-world data collected from Kuaishou short-video platform. The detailed introduction is given in table 1.
-
•
Avito222https://www.kaggle.com/c/avito-context-ad-clicks/data: The Avito dataset is a publicly available collection of user search logs from avito.ru. The dataset comprises over 53 million lists with 1.3 million users and 36 million ads. Each sample corresponds to a search page with multiple ads. The user search logs from first 21 days are used as training set and the search logs from the last 7 days are used as test set. The sequence length in Avito is 5.
-
•
Kuaishou: The Kuaishou dataset is derived from Kuaishou, a widely used short-video application with a user base of over 300 million daily active users. Each sample in the dataset represents an actual user request log, which contains user information(e.g. user id, age, gender), candidates items and user interaction to exposed items. The dataset consists of a total of 82,230,788 users, 26,835,337 items, and 1,811,625,438 requests. Each request contains 6 items in the exposed item sequence and 60 candidates from ranking.
5.2. Offline experiments
Baselines We compare the proposed NAR4Rec with 6 state-of-the-art reranking methods. We select DNN, DCN as pointwise baselines, PRM as one-stage listwise baselines, Edge-Rerank, PIER, Seq2slate as two-stage baselines. Crucially, Seq2slate is a autoregressive generative model. A brief overview of these baseline methods is as follows:
-
•
DNN(Covington et al., 2016): DNN is a basic method for click-through rate prediction, which applies a multi-layer perception to learn feature interaction.
-
•
DCN(Wang et al., 2017): DCN incorporates feature crossing at each layer, eliminating the need for manual feature engineering while keeping the added complexity to the DNN model minimal.
-
•
PRM(Pei et al., 2019): PRM models the mutual correlation among items by leveraging the self-attention mechanism and then rank the items by the estimated scores to generate the item sequence.
-
•
Edge-Rerank(Gong et al., 2022): Edge-Rerank generates the context-aware sequence with adaptive beam search on estimate scores.
-
•
Seq2Slate(Bello et al., 2018): Seq2Slate leverages pointer networks, which are seq2seq models with an attention mechanism to predict the next item given the items already selected.
-
•
PIER(Shi et al., 2023): PIER applies hashing algorithm to slect top-k candidates from the full permutation based on user interests. Then the generator and evaluator are jointly trained to generate better permutations.
Metrics As there is not common sequence generation metrics for recommendation, we follow previous work(Shi et al., 2023; Lin et al., 2023) and evaluate these models using three commonly adopted metrics: AUC, LogLoss, and NDCG on Avito dataset. For Avito dataset, where and are equal(5), the task is to predict the itemwise click-through rate given a listwise input. For Kuaishou dataset, where and are and respectively, we employ Recall@6, Recall@10, and LogLoss as evaluation metrics. The task for Kuaishou dataset is to predict whether an item is chosen to be one of the exposed items.
Hyperparameters For Avito dataset, the learning rate is 10-3, the optimizer is Adam and the batch size is 1024. For Kuaishou dataset, the learning rate and optimizer is the same as Avito, but the batch size is 256.
5.2.1. Performance comparison
Here we show the results of our proposed method NAR4Rec. As can be seen in in table 2 and table 3, NAR4Rec outperforms 5 baslines including recent strong reranking methods(Pei et al., 2019; Bello et al., 2018; Shi et al., 2023). PRM outperforms DNN and DCN by effectively capturing the mutual influence between items. Additionally, Edge-rerank surpass DNN and DCN with an adative beam search with previous item information. PIER demonstrates superiority over other baselines by the interaction per category. Notably, our proposed method exhibits the highest improvement with a significant increase of 0.0125 in the AUC metric compared to other baseline models. table 3 shows the results of our offline experiments on Kuaishou. The evaluation metrics used in this experiment include Recall@6, Recall@10, and Loss. Our method achieves superior results on all metrics compared to other baseline models as well.
| AUC | LogLoss | NDCG | |
|---|---|---|---|
| DNN | 0.6614 | 0.0598 | 0.6920 |
| DCN | 0.6623 | 0.0598 | 0.7004 |
| PRM | 0.6881 | 0.0594 | 0.7380 |
| Edge-rerank | 0.6953 | 0.0574 | 0.7203 |
| PIER | 0.7109 | 0.0409 | 0.7401 |
| Seq2Slate | 0.7034 | 0.0486 | 0.7225 |
| NAR4Rec | 0.7234 | 0.0384 | 0.7409 |
| Recall@6 | Recall@10 | LogLoss | |
|---|---|---|---|
| DNN | 66.47% | 86.65% | 0.6764 |
| DCN | 68.22% | 87.95% | 0.6809 |
| PRM | 73.17% | 92.25% | 0.5328 |
| Edge-rerank | 73.63 % | 92.90% | 0.5252 |
| PIER | 73.50% | 92.44% | 0.5361 |
| NAR4Rec | 74.86% | 93.16% | 0.5199 |
5.2.2. Training and Inference Time comparison
Given that NAR4Rec is closely related to autoregressive models, we conduct a comparison with autoregressive models Seq2Slate. We compare the training and inference time on the Avito dataset between Seq2slate and NAR4Rec. We also give training and inference time for generators in other baselines in table 4. Since Seq2slate utilizes recurrent neural networks as its backbone network, both training and inference processes adopt an autoregressive manner. The inference speedup of NAR4Rec over Seq2slate is almost the same as training. NAR4Rec only requires 58 minutes to complete the training while Seq2Slate requires 283 minutes. Such a significant reduction in training time (i.e. approximately 5 speedup) highlights the computational efficiency of NAR4Rec. The autoregressive model represented by Seq2Slate generates target sequences item by item, while our Non-autoregressive NAR4Rec generates all items at once. So when generating a sequence with length 5, NAR4Rec shows approximately 5 speedup.
| Training Time | Inference Time | |
|---|---|---|
| DNN | 0.102s | 0.034s |
| DCN | 0.106s | 0.035s |
| PRM | 0.109s | 0.036s |
| Edge-rerank | 0.105s | 0.035s |
| PIER | 0.160s | 0.053s |
| Seq2Slate | 0.558s | 0.186s |
| NAR4Rec | 0.112s | 0.037s |
5.2.3. Hyper-parameter Analysis of NAR4Rec
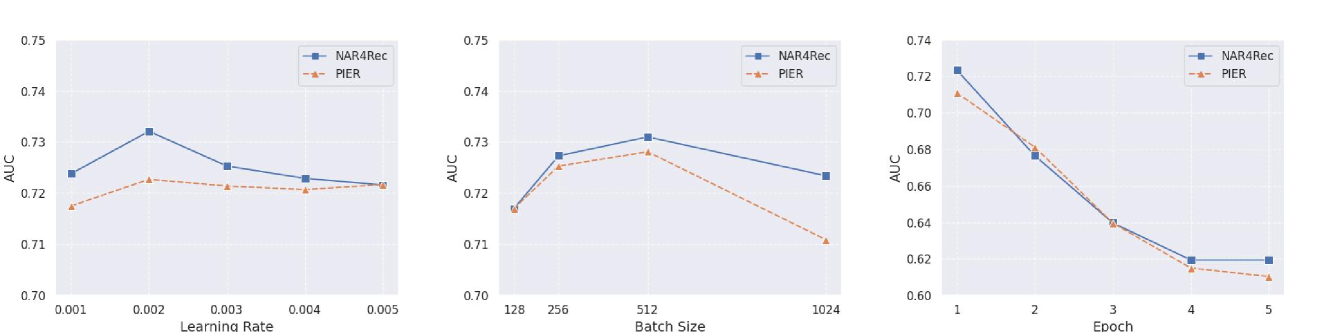
We further analyze the hyper-parameter sensitivity on NAR4Rec. Here, we conduct a series of experiments on NAR4Rec and PIER. As shown in fig. 3, we demonstrate that our experimental results exhibit insensitivity to variations in the learning rate, batch size, and epoch.
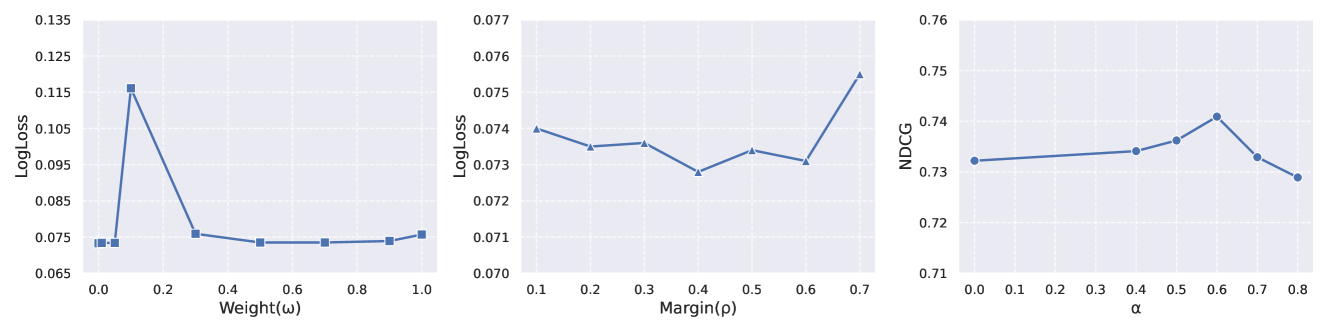
Then, we analyze the impact of weight and margin in contrastive loss and the impact of penalty parameter in contrastive decoding. Figure 4 shows the results of our experiments. We change while fixing =0.5, and change while fixing =0.01 in contrastive loss. When changing in contrastive decoding, we set =0.5 and =0.01 as the default parameters.
5.3. Online experiments
Text sequence generation often is evaluated by human labeling. In recommendation, we resort to online A/B experiments to obtain the feedback from users to demonstrate our effectiveness.
5.3.1. Experiments setup
In online A/B experiments, we evenly divide the traffic of the entire app into ten buckets. The online baseline is Edge-rerank(Gong et al., 2022), with 20% of the traffic assigned to NAR4Rec, while the remaining traffic is assigned to Edge-rerank.
5.3.2. Experimental Results
The experiments have been launched on the system for ten days, and the result is listed in table 5. NAR4Rec outperforms Edge-rerank(Gong et al., 2022) by a large margin. NAR4Rec shows users watch more(i.e a higher Views) videos, spend more time on each video(i.e. more Long Views and Complete Views) and a more positive user feedback(i.e. a improvement on like, follows) over (Gong et al., 2022).
| Views | Likes | Follows | Long Views | Complete Views |
| +1.161% | +1.71% | +1.15% | +1.82% | +2.45% |
5.3.3. Ablation Study on Unlikelihood Training
To show the effectiveness of unlikelihood training, we compare vanilla training on all exposed sequences with unlikelihood training. Unlikelihood shows more Views and a longer Watch Time.
| Views | Watch Time | |
| Vanilla training | -0.370%* | -0.277%* |
5.3.4. Ablation Study on Contrastive Decoding
Here we compare the common decoding algorithm in text sequence and a diversity-based algorithm(i.e. Deep DPP)with contrastive decoding. Those decoding algorithms shows a significant drop in View and Watch time, suggesting a poorer user feedback.
| Views | Watch Time | |
|---|---|---|
| Deep DPP | -0.363%* | -0.361%* |
| Beam Search | -0.327%* | -0.214%* |
| Greedy Search | -0.216%* | -0.178%* |
| Top-k Sampling | -0.254%* | -0.131% |
6. Conclusion
In this paper, we provide an overview of the current formulation and challenges associated with reranking in recommendation systems. Although non-autoregressive generation has been explored in natural language processing, conventional techniques are not directly applicable to recommendation systems. We tackle the challenges in recommendations to improve the convergence and performance of non-autoregressive models and make the first attempt to integrate non-autoregressive models into reranking in real-time recommender systems. Extensive online and offline A/B experiments have demonstrated the effectiveness and efficiency of NAR4Rec as a versatile framework for generating sequences with enhanced utility. Moving forward, our future work will focus on refining the modeling of sequence utility to further enhance the capabilities of NAR4Rec.
References
- (1)
- Ai et al. (2018) Qingyao Ai, Keping Bi, Jiafeng Guo, and W Bruce Croft. 2018. Learning a deep listwise context model for ranking refinement. In The 41st international ACM SIGIR conference on research & development in information retrieval. 135–144.
- Awasthi et al. (2019) Abhijeet Awasthi, Sunita Sarawagi, Rasna Goyal, Sabyasachi Ghosh, and Vihari Piratla. 2019. Parallel Iterative Edit Models for Local Sequence Transduction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 4260–4270.
- Bello et al. (2018) Irwan Bello, Sayali Kulkarni, Sagar Jain, Craig Boutilier, Ed Chi, Elad Eban, Xiyang Luo, Alan Mackey, and Ofer Meshi. 2018. Seq2Slate: Re-ranking and slate optimization with RNNs. arXiv preprint arXiv:1810.02019 (2018).
- Burges et al. (2005) Chris Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Greg Hullender. 2005. Learning to rank using gradient descent. In Proceedings of the 22nd international conference on Machine learning. 89–96.
- Cheng et al. (2016) Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems. 7–10.
- Covington et al. (2016) Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM conference on recommender systems. 191–198.
- Feng et al. (2021) Yufei Feng, Binbin Hu, Yu Gong, Fei Sun, Qingwen Liu, and Wenwu Ou. 2021. GRN: Generative Rerank Network for Context-wise Recommendation. arXiv preprint arXiv:2104.00860 (2021).
- Ghazvininejad et al. (2019) Marjan Ghazvininejad, Omer Levy, Yinhan Liu, and Luke Zettlemoyer. 2019. Mask-Predict: Parallel Decoding of Conditional Masked Language Models. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 6112–6121.
- Gong et al. (2022) Xudong Gong, Qinlin Feng, Yuan Zhang, Jiangling Qin, Weijie Ding, Biao Li, Peng Jiang, and Kun Gai. 2022. Real-time Short Video Recommendation on Mobile Devices. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 3103–3112.
- Gu et al. (2018) Jiatao Gu, James Bradbury, Caiming Xiong, Victor OK Li, and Richard Socher. 2018. Non-Autoregressive Neural Machine Translation. In International Conference on Learning Representations.
- Gu et al. (2019) Jiatao Gu, Changhan Wang, and Junbo Zhao. 2019. Levenshtein transformer. Advances in Neural Information Processing Systems 32 (2019).
- Guo et al. (2017) Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence. 1725–1731.
- Joachims et al. (2017) Thorsten Joachims, Laura Granka, Bing Pan, Helene Hembrooke, and Geri Gay. 2017. Accurately interpreting clickthrough data as implicit feedback. In Acm Sigir Forum, Vol. 51. Acm New York, NY, USA, 4–11.
- Leng et al. (2021a) Yichong Leng, Xu Tan, Rui Wang, Linchen Zhu, Jin Xu, Wenjie Liu, Linquan Liu, Xiang-Yang Li, Tao Qin, Edward Lin, et al. 2021a. FastCorrect 2: Fast Error Correction on Multiple Candidates for Automatic Speech Recognition. In Findings of the Association for Computational Linguistics: EMNLP 2021. 4328–4337.
- Leng et al. (2021b) Yichong Leng, Xu Tan, Linchen Zhu, Jin Xu, Renqian Luo, Linquan Liu, Tao Qin, Xiangyang Li, Edward Lin, and Tie-Yan Liu. 2021b. Fastcorrect: Fast error correction with edit alignment for automatic speech recognition. Advances in Neural Information Processing Systems 34 (2021), 21708–21719.
- Li et al. (2020) Margaret Li, Stephen Roller, Ilia Kulikov, Sean Welleck, Y-Lan Boureau, Kyunghyun Cho, and Jason Weston. 2020. Don’t Say That! Making Inconsistent Dialogue Unlikely with Unlikelihood Training. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 4715–4728.
- Lian et al. (2018) Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1754–1763.
- Lin et al. (2023) Xiao Lin, Xiaokai Chen, Chenyang Wang, Hantao Shu, Linfeng Song, Biao Li, et al. 2023. Discrete Conditional Diffusion for Reranking in Recommendation. arXiv preprint arXiv:2308.06982 (2023).
- Liu et al. (2009) Tie-Yan Liu et al. 2009. Learning to rank for information retrieval. Foundations and Trends® in Information Retrieval 3, 3 (2009), 225–331.
- Lorigo et al. (2008) Lori Lorigo, Maya Haridasan, Hrönn Brynjarsdóttir, Ling Xia, Thorsten Joachims, Geri Gay, Laura Granka, Fabio Pellacini, and Bing Pan. 2008. Eye tracking and online search: Lessons learned and challenges ahead. Journal of the American Society for Information Science and Technology 59, 7 (2008), 1041–1052.
- Lorigo et al. (2006) Lori Lorigo, Bing Pan, Helene Hembrooke, Thorsten Joachims, Laura Granka, and Geri Gay. 2006. The influence of task and gender on search and evaluation behavior using Google. Information processing & management 42, 4 (2006), 1123–1131.
- Pang et al. (2020) Liang Pang, Jun Xu, Qingyao Ai, Yanyan Lan, Xueqi Cheng, and Jirong Wen. 2020. Setrank: Learning a permutation-invariant ranking model for information retrieval. In Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 499–508.
- Pei et al. (2019) Changhua Pei, Yi Zhang, Yongfeng Zhang, Fei Sun, Xiao Lin, Hanxiao Sun, Jian Wu, Peng Jiang, Junfeng Ge, Wenwu Ou, et al. 2019. Personalized re-ranking for recommendation. In Proceedings of the 13th ACM conference on recommender systems. 3–11.
- Shi et al. (2023) Xiaowen Shi, Fan Yang, Ze Wang, Xiaoxu Wu, Muzhi Guan, Guogang Liao, Wang Yongkang, Xingxing Wang, and Dong Wang. 2023. PIER: Permutation-Level Interest-Based End-to-End Re-ranking Framework in E-commerce. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4823–4831.
- Stern et al. (2019) Mitchell Stern, William Chan, Jamie Kiros, and Jakob Uszkoreit. 2019. Insertion transformer: Flexible sequence generation via insertion operations. In International Conference on Machine Learning. PMLR, 5976–5985.
- Sun et al. (2019) Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management. 1441–1450.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- Wang et al. (2017) Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & cross network for ad click predictions. In Proceedings of the ADKDD’17. 1–7.
- Welleck et al. (2019) Sean Welleck, Ilia Kulikov, Stephen Roller, Emily Dinan, Kyunghyun Cho, and Jason Weston. 2019. Neural Text Generation With Unlikelihood Training. In International Conference on Learning Representations.
- Xi et al. (2021) Yunjia Xi, Weiwen Liu, Xinyi Dai, Ruiming Tang, Weinan Zhang, Qing Liu, Xiuqiang He, and Yong Yu. 2021. Context-aware reranking with utility maximization for recommendation. arXiv preprint arXiv:2110.09059 (2021).
- Yang (2017) Ziying Yang. 2017. Relevance judgments: Preferences, scores and ties. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1373–1373.
- Zhou et al. (2019a) Chunting Zhou, Jiatao Gu, and Graham Neubig. 2019a. Understanding Knowledge Distillation in Non-autoregressive Machine Translation. In International Conference on Learning Representations.
- Zhou et al. (2019b) Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019b. Deep interest evolution network for click-through rate prediction. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948.
- Zhou et al. (2018) Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068.
- Zhuang et al. (2018) Tao Zhuang, Wenwu Ou, and Zhirong Wang. 2018. Globally optimized mutual influence aware ranking in e-commerce search. arXiv preprint arXiv:1805.08524 (2018).