Prompt4Vis: Prompting Large Language Models with Example Mining and Schema Filtering for Tabular Data Visualization
Abstract.
Data visualization (DV) systems are increasingly recognized for their profound capability to uncover insights from vast datasets, gaining attention across both industry and academia. Crafting data queries is an essential process within certain declarative visualization languages (DVLs, e.g., Vega-Lite, EChart.). The evolution of natural language processing (NLP) technologies has streamlined the use of natural language interfaces to visualize tabular data, offering a more accessible and intuitive user experience. However, current methods for converting natural language questions into data visualization queries, such as Seq2Vis, ncNet, and RGVisNet, despite utilizing complex neural network architectures, still fall short of expectations and have great room for improvement.
Large language models (LLMs) such as ChatGPT and GPT-4, have established new benchmarks in a variety of NLP tasks, fundamentally altering the landscape of the field. Inspired by these advancements, we introduce a novel framework, Prompt4Vis, leveraging LLMs and in-context learning to enhance the performance of generating data visualization from natural language. Prompt4Vis comprises two key components: (1) a multi-objective example mining module, designed to find out the truly effective examples that strengthen the LLM’s in-context learning capabilities for text-to-vis; (2) a schema filtering module, which is proposed to simplify the schema of the database. Extensive experiments through 5-fold cross-validation on the NVBench dataset demonstrate the superiority of Prompt4Vis, which notably surpasses the state-of-the-art (SOTA) RGVisNet by approximately 35.9% and 71.3% on dev and test sets, respectively. To the best of our knowledge, Prompt4Vis is the first work that introduces in-context learning into the text-to-vis for generating data visualization queries.
1. Introduction
In the modern era, big data serves as the primary driving force across various sectors. The analysis of big data to uncover underlying patterns is increasingly critical (Luo et al., 2018a; Qian et al., 2021; Vartak et al., 2016). Data visualization emerges as a powerful tool in realizing this objective. Therefore, the topic of automatic data visualization has captured growing interest within the database and data mining communities (Savvides et al., 2019; Qian et al., 2021; Vartak et al., 2016). For example, RGVisNet (Song et al., 2022) in KDD’22 proposes a hybrid retrieval-revision framework towards automatically data visualization generation.
One essential step in conducting data visualization is the formulation of visualization specifications using declarative visualization languages (DVLs), such as Vega-Lite (Satyanarayan et al., 2017), ggplot2 (Wickham, 2009), ZQL (Siddiqui et al., 2016), ECharts (Li et al., 2018), and VizQL (Hanrahan, 2006). However, this composing specification demands users possess a thorough understanding of domain-specific data and familiarity with the syntax of these languages, which presents a significant challenge, especially for beginners. Thus, visualizing tabular data using natural language (or text-to-vis), which aims to directly transform natural language questions (NLs) to data visualization language (DVs) (Luo et al., 2018a, b, 2021), has garnered more and more attention within the community.
In an automatic text-to-vis system, it must first have a deep understanding of the natural language question and its corresponding database schema, then it needs to answer the given question with the correct data visualization language. To achieve this goal, a series of efforts (Cui et al., 2020; Dibia and Demiralp, 2019; Luo et al., 2018a, 2021; Narechania et al., 2021) have been made, such as DeepEye (Luo et al., 2018a), NL4DV (Narechania et al., 2021), Seq2Vis (Luo et al., 2021), ncNet (Luo et al., 2022) and RGVisNet (Song et al., 2022). Specifically, DeepEye and NL4DV rely on rule-based methodology or semantic parsing techniques in natural language processing, Seq2Vis (Luo et al., 2021) and ncNet (Luo et al., 2022) attempt to build encoding-decoding frameworks using deep neural networks for text-to-vis, and RGVisNet (Song et al., 2022) is retrieval-and-generation combined framework for data visualization language generation inspired by the concept of code reuse. Although these efforts have achieved a noticeable enhancement in the performance of text-to-vis, such performance still falls short of expectations, especially when dealing with test data from different domains.
Recently, large language models (LLMs), especially the GPT series (Brown et al., 2020; Chowdhery et al., 2023; OpenAI, 2022, 2023), have revolutionized the field of natural language processing (NLP). Leveraging their huge number of parameters and training data, LLMs learn substantial world knowledge and perform in pairs with humans (Bang et al., 2023; Qin et al., 2023). Meanwhile, with the development of LLMs, in-context learning that does not rely on large-scale labeled data and does not require parameter updates (Nguyen and Wong, 2023; Lyu et al., 2023; Nye et al., 2021; Wei et al., 2022) attracts researchers in various fields. In-context learning enables LLMs to make predictions about a new example by learning from only a few labeled examples. Hence, it is feasible and promising to leverage LLMs to realize text-to-vis and also to effectively alleviate the problem of insufficient generalization ability of existing methods.
To this end, this work attempts to adapt LLMs to generate data visualization queries from natural language questions and also proposes a novel prompting framework called Prompt4Vis with an in-context learning strategy. In order to maximize the ability of LLMs on the text-to-vis, this work introduces two key components aimed at generating clearer and more effective prompt text for LLMs. Firstly, as LLMs are sensitive to the choice of examples provided in the context (Lu et al., 2022; Liu et al., 2022), an example mining module is designed to find out truly effective demonstrations, wherein the similarity between the candidate examples and the target example, the influence of candidate examples on the target example, and the diversity among the candidate examples are all comprehensively considered, which indeed helps LLMs know what and how to perform well on this task. Specifically, the Euclidean distance between examples and the target input based on sentence vector representation is employed to measure the similarity and diversity of examples, and a contrastive learning-based influence model is trained to bring examples related to positive influence closer and push away from negative examples, this model can effectively measure the influence of examples. In the process of selecting the prompt example set, we attempt to maximize the similarity and influence scores between the candidate example set and the target example while ensuring diversity within the candidate example set. Secondly, given that encoding the entire schema for databases with numerous columns is not only expensive and impractical but also introduces irrelevant information to increase the difficulty of selecting the correct data for LLMs, a schema filtering module is also proposed to simplify the schema of database. Specifically, considering the all-round capabilities of LLMs, we prompt to LLMs via in-context examples to help us select the necessary table in the schema of database for the input question, eliminating irrelevant and redundant schema related to the current question.
Extensive experiments are conducted on the widely-used multi-domain dataset NVBench (Luo et al., 2021) to empirically verify the effectiveness of our Prompt4Vis framework. Evaluation results demonstrate that Prompt4Vis not only outperforms all baseline methods with obvious improvements but also shows better stability across different cross-domains. In summary, our contributions are as follows:
-
•
To the best of our knowledge, we are the first to introduce LLMs and in-context learning to generate data visualization for text-to-vis task. We believe this novel approach brings new insights to the text-to-vis task and will inspire further exploration of this promising new paradigm.
-
•
We propose a novel framework Prompt4Vis for the adaption of LLMs on tabular data visualization task, with two novel example mining and schema filtering components.
-
•
Extensive experiments demonstrate that Prompt4Vis bring around 36% and 71% relative improvements in overall accuracy on dev and test sets, respectively. Ablation studies also verify the effectiveness of all designed components in Prompt4Vis.
The rest of this paper is organized as follows: First, we introduced the background knowledge in section 2 to help realize this work. Then, section 3 gives the details of the proposed Prompt4Vis. Next, we present the experimental results and discuss the findings in section 4. Finally, the related work and conclusions of our work are introduced in section 5 and 6.
2. Background
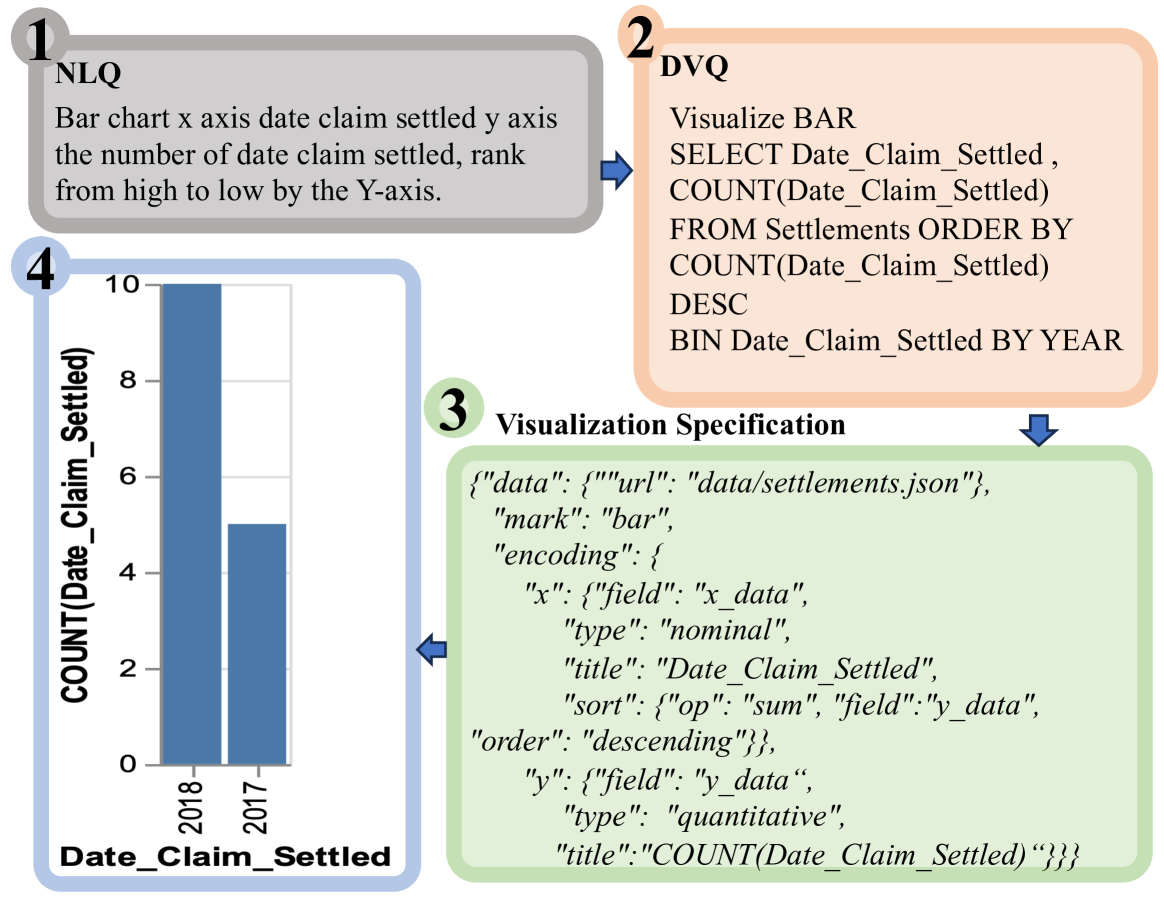
In this section, we introduce the preliminary concepts including the Natural Language Question and the Visualization Specification, and then we give the task definition to help realize the work.
Natural Language Question (NLQ) is a human-understandable expression used to describe the desired data visualization (DV), making it more user-friendly, particularly for novice users and those without a background in data science.
Visualization Specification usually follows the grammar of a common declarative visualization language (DVL), pointing out the details of visualization, eg., data mapping, chart typologies, stylistic configurations, interactivity features, and layout design. Utilizing advanced DVLs, e.g., Vega-Lite (Satyanarayan et al., 2017), ggplot2 (Wickham, 2009), ECharts (Li et al., 2018), the precise control of data visualization is achieved.
Data Visualization Query (DVQ) is proposed by Luo et al. (Luo et al., 2018b, a), involves initially executing a query on a database to retrieve the desired data, followed by defining the visualization details for presenting the acquired data. Importantly, DVQs are not limited to a single declarative visualization language (DVL). On the contrary, once the DVQ corresponding to a specific question is obtained, it can be seamlessly transformed to suit any DVL.
Text-to-Vis aims to translate NLQs into DVQs, which is a general step for tabular data visualization, as shown in Figure 1. Formally, given an NLQ and corresponding database schema , the text-to-vis task aims to character the corresponding DVQ to answer . Specifically, schema consists of a collection of tables , where represents table in , is the number of tables in . And is composed of a collection of columns, i.e., , where is the number of columns in .
3. Prompt4Vis
In this section, we are ready to describe the proposed prompt framework to LLMs for tabular data visualization.
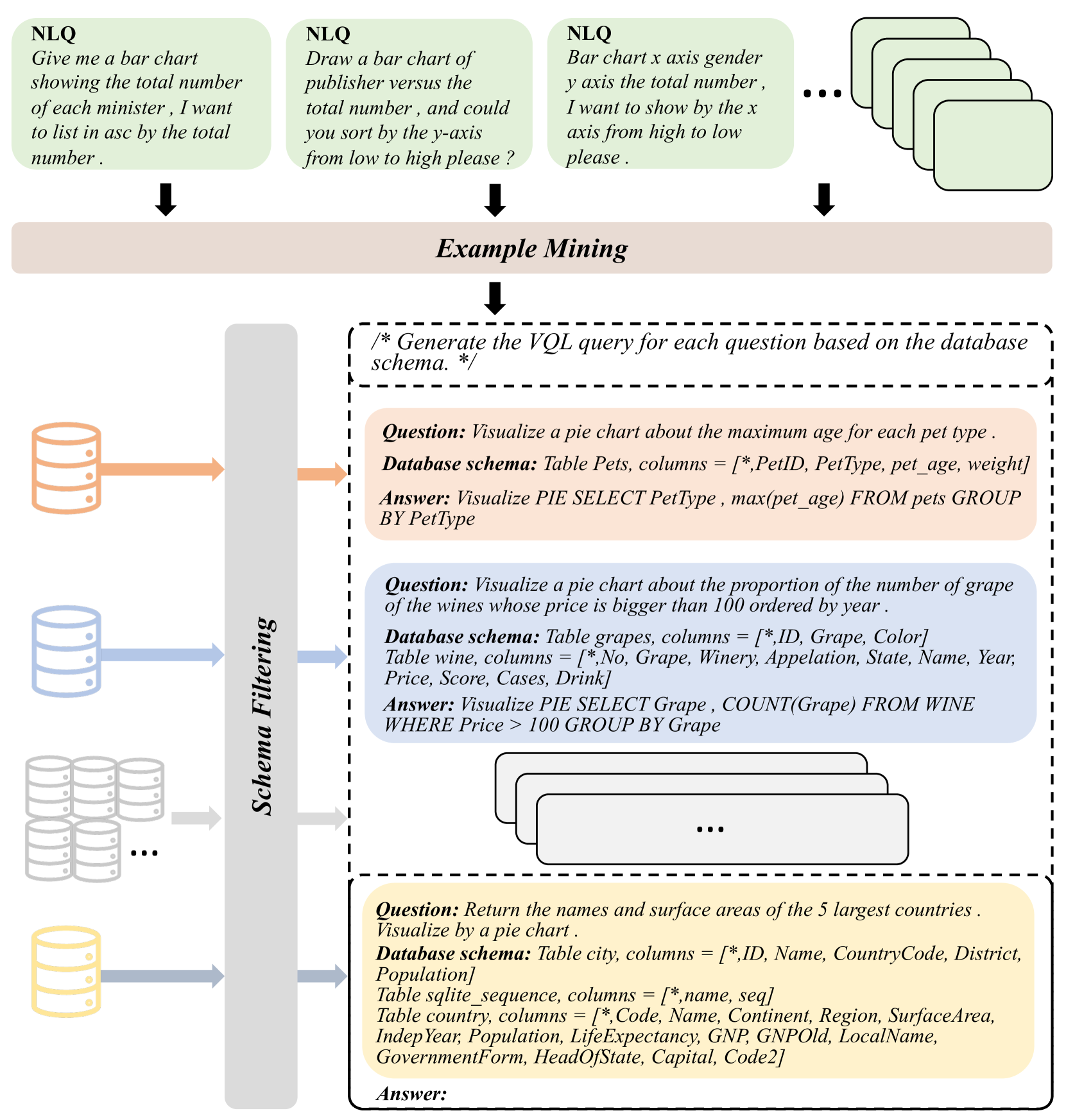
3.1. Overview
In in-context learning, the model is initially presented with a set of labeled examples as input, then it predicts the output for new examples based on the labeled examples. For text-to-vis, each labeled example can be formalization as a triple: , where is the natural language question asked by users, is the corresponding database for , and denotes the target DVQ. Therefore, given a dataset containing triples, a target question , and a LLM , in-context learning to generated DVQ based on database schema can be formulated as:
| (1) |
where is called prompt, which consists of examples, namely, . Additionally, in-context learning also provides some context as instructions to prompt the model to achieve the ideal output.
Figure 2 shows the workflow of Prompt4Vis. As shown in Figure 2, Prompt4Vis first finds effective examples with the example mining module, and then it conducts schema filtering to reduce the irrelevant information in the database. Finally, effective examples with filtered schemas are input into the LLMs to generate DVQs.
3.2. Example Mining
Previous research in in-context learning has demonstrated that similar examples of the target example can bring good performance (Zhang et al., 2023; Liu et al., 2022). However, they ignored the direct task-oriented influence of each example. To mitigate this gap, in addition to similarity, we propose to introduce influence in the process of example mining. At the same time, we introduce diversity to reduce the irrelevant information brought by similar candidate examples. In summary, our example mining method optimizes three different dimensions: influence, similarity, and diversity, to find out the most effective examples for text-to-vis.
In the following, we will first introduce the methodology for calculating the metrics of influence, similarity, and diversity in section 3.2.1. Then, we introduce the concentrate algorithm to find effective examples based on the aforementioned three measurements in section 3.2.2. Since there are no existing methods to directly calculate the influence scores, we design an influence model and introduce the details about it in section 3.2.3.
In particular, in in-context learning for text-to-vis, each prompt example consists of a question, a database schema, and a data visualization query. Since the goal of this task is to answer a given natural language question, with the data schema serving merely as auxiliary information, and considering the significant differences among data schemas of different databases, we opt to select examples based on questions as the unit.
3.2.1. Methodology for Calculating Metrics
In this section, we define to measure the similarity of in with the target question , to measure the rewards influence of . In the following, we introduce the detailed definitions and explanations of , , and .
Similarity .
The similarity metric is defined:
| (2) |
where measures the Euclidean distance of the vector representations between one single candidate question and the target question . is the min-max normalization. is the index of the question that minimizes :
| (3) |
and is the index of the question that maximizes :
| (4) |
Influence .
In relation to similarity measurement, we define influence sore as below:
| (5) |
where denotes the influence score of the candidate question to . The evaluation of is carried out with an influence model. We will go through the details of the designed influence model in section 3.2.3.
Diversity .
We define the diversity measurement as:
| (6) |
where is the Euclidean distance between one single candidate question and another candidate question . The greater the distance, the less similar the examples are to each other, indicating a higher diversity in the example subset.
3.2.2. Example Subset Mining Algorithm
The goal of example mining is to automatically select effective examples from the training dataset for a target question .
To achieve this goal, we employ an algorithm, Example Subset Mining (ESM) to find effective examples, it is composed of two phases including sorting and selecting. Initially, it considers only two criteria: similarity and influence, combing them for weight sorting. Subsequently, it further selects examples from the sorted list to maximize the diversity metric.
In other words, in the first step, the objective of example mining is to sort the training set ; Second, we find an effective example subset from the sorted training set by maximizing the diversity in it.
Formally, the sorting process is implemented based on the score function :
| (7) |
where is designed to measure the similarity and influence of , and it can be formalized in the following:
| (8) |
where measures the similarity of in with the target question , rewards influence of .
Then, in the second step, an example subset is selected by maximizing the diversity objective:
| (9) |
where measures the diversity of .
To this end, Example Subset Mining (ESM) Algorithm is illustrated in Algorithm 1. ESM first searches over questions in the training set for target questions and then sorts them with function . Next, the diversity of the examples is maximized to find Example Subset .
3.2.3. Contrastive Learning-based Influence Model
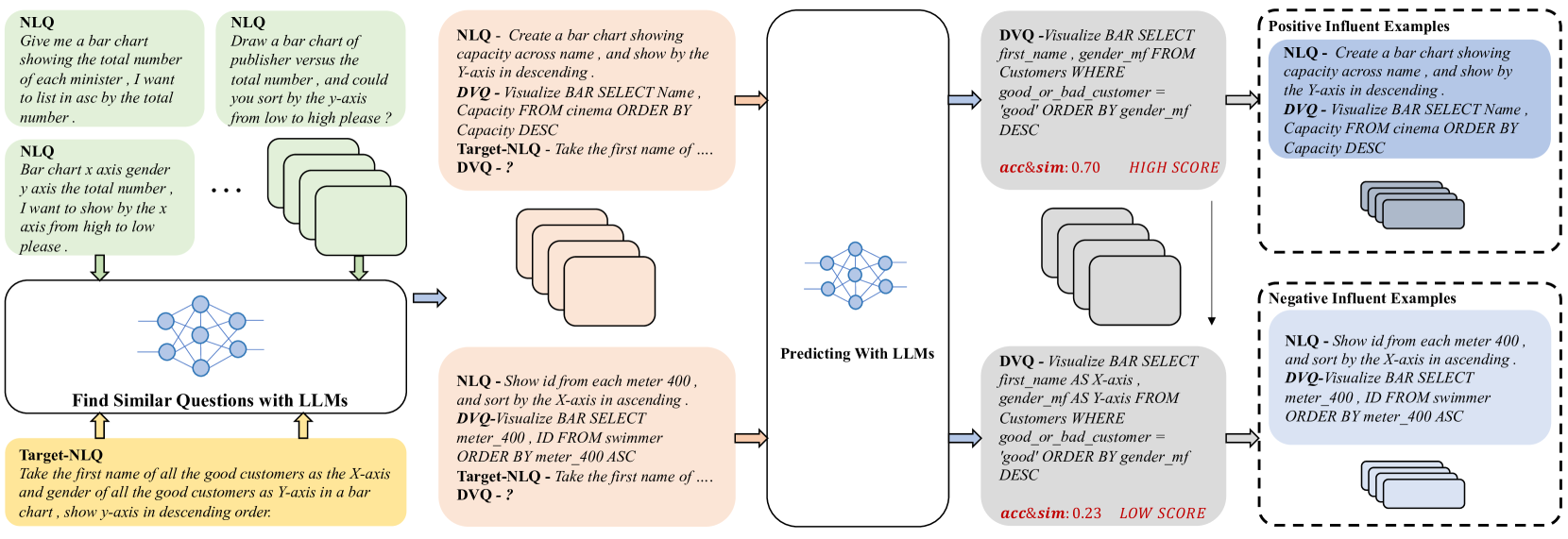
As mentioned above, similarity and diversity are realized through sentence vector representation and Euclidean distance calculation. However, the influence of each example can not obtained by the existing methods. Therefore we designed a contrastive learning-based influence learning model.
In this section, we will provide a detailed introduction to the training data construction for the influence model and training objective.
Training Data Construction for Influence Model. To train the contrastive learning-based influence model, we need to construct the training data in the first step. In other words, we need to find a positive and negative set for each example in the training set of the influence model. Recall that in-context learning is defined as in Equation 1. For each example, given the question and the schema , we predict where is the large language model and is the question in the prompt example, is the corresponding database schema for , noted that . In particular, is extracted from a set that includes the top- similar questions to . Since we have the ground truth for for , we can measure the performance by comparing the predicted and ground truth . Then the performance will be set as the influence score of on in in-context learning of text-to-vis.
Concretely, the influence score consists of two aspects, i.e., the average accuracy of the predicted , and the semantic similarity between the predicted and the ground truth . Formally, it can be formalized as:
| (10) | ||||
| (11) |
where is measured by Euclidean distance function . is the average score of the four metrics described in section 4.1.3.
For each , we extract the top- questions with the highest influence score and their corresponding database schema to form the positive examples, while the lowest as the negative examples. The workflow of training data construction for the influence model is shown in Figure 3.
Training Objective. In the influence model, we first encode the input questions with a pre-trained language model BERT (Devlin et al., 2019): , and then fine-tune the parameters using the contrastive learning objective. Inspired by (Gao et al., 2021), we train the influence model to follow the contrastive framework with a cross-entropy objective. Let denote the representation of target question, and denote the representations of positive and negative questions for , then the training objective for within a mini-batch of pairs is:
| (12) |
where is a temperature hyper-parameter and denotes the cosine similarity .
3.3. Schema Filtering
Apart from the natural language question , the input in the prompt examples includes a database schema consisting of a set of tables , with each table comprising of a set of columns . The gold DVQ query for the target question mentions a subset of schema elements from . Schema elements can be either tables or columns. In the schema filtering process, we propose to filter a subset from covering , i.e., and . In this work, we adopt a table as the basic unit in the schema filtering for two reasons. First, extracting precise column information is challenging because sometimes there is no direct semantic connection between the natural language description and the database column names. Additionally, at times, the operations of DVQ are performed across multiple column names in multiple tables. Providing relatively coarse-grained base units can help prevent the omission of information.
To be specific, we use state-of-the-art LLMs with few-shot prompting to produce . We employ GPT-3.5-Turbo with a fixed prompt comprising of ten in-context examples as shown in Table 1 to create the desired corresponding to .
| Select the related tables for generating SQL queries for each question based on the database schema. |
|---|
|
Question: Give me a bar chart showing the total number of each minister , I want to list in asc by the total number . |
|
Schema: Table region, columns = [*,Region_ID, Region_name, Date, Label, Format, Catalogue] |
|
Table party, columns = [*,Party_ID, Minister, Took_office, Left_office, Region_ID, Party_name] |
|
Table member, columns = [*,Member_ID, Member_Name, Party_ID, In_office] |
|
Table party_events, columns = [*,Event_ID, Event_Name, Party_ID, Member_in_charge_ID] |
|
Selected Table: Table party |
|
… |
|
Question: Which catalog contents has price above 700 dollars ? Show their catalog entry names and capacities , list by the X in ascending . |
|
Schema: Table Attribute_Definitions, columns = [*,attribute_id, attribute_name, attribute_data_type] |
|
Table Catalog_Structure, columns = [*,catalog_level_number, catalog_id, catalog_level_name] |
|
Table Catalog_Contents, columns = [*,catalog_entry_id, catalog_level_number, parent_entry_id, previous_entry_id, next_entry_id, catalog_entry_name, product_stock_number, price_in_dollars, price_in_euros, price_in_pounds, capacity, length, height, width] |
|
Table Catalog_Contents_Additional_Attributes, columns = [*,catalog_entry_id, catalog_level_number, attribute_id, attribute_value] |
| Selected Table: |
4. Experiments
4.1. Experimental Setup
4.1.1. Dataset
In this work, we utilize NVBench, a public text-to-vis dataset, to conduct our experiments. It is initially created to evaluate text-to-vis systems. In particular, NVBench contains 7247 DVQs, each corresponding to several natural language questions and a specific database schema. Following the previous work (Song et al., 2022), we partitioned the dataset with the training set, development set, and test set containing 98, 29, and 14 databases, respectively. Furthermore, to thoroughly validate the effectiveness of the experiments and mitigate the impact of different database partitions, we conducted a 5-fold cross-validation.
4.1.2. Baselines
In this work, we compare four widely recognized baselines with our method for evaluation, including Seq2Vis (Luo et al., 2021), Transformer (Vaswani et al., 2017), ncNet (Luo et al., 2022), and RGVisNet(Song et al., 2022).
4.1.3. Evaluation Metrics
Following the prior works (Song et al., 2022), we use four popular metrics to evaluate the models in the experiments including Vis Accuracy, Axis Accuracy, Data Accuracy, and Overall Accuracy.
| Test Set | Dev Set | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | Vis Acc | Axis Acc | Data Acc | Overall Acc | Vis Acc | Axis Acc | Data Acc | Overall Acc |
| Seq2Vis | 86.97% | 0.02% | 11.88% | 0.01% | 84.10% | 0.81% | 11.31% | 0.32% |
| Transformer | 98.82% | 0.58% | 12.16% | 0.42% | 98.31% | 2.54% | 11.11% | 1.71% |
| ncNet | 98.86% | 41.34% | 40.62% | 23.61% | 98.27% | 37.44% | 45.79% | 23.97% |
| RGVisNet | 95.46% | 44.80% | 37.35% | 30.75% | 95.38% | 60.06% | 52.37% | 44.44% |
| Prompt4Vis (ours) | 98.37% | 79.23% | 58.64% | 52.69% | 97.77% | 79.23% | 65.68% | 60.39% |
4.2. Experimental Results
4.2.1. Main results
We first compare the proposed method with baselines on the aforementioned metrics in a 5-fold cross-validation set, and we report the average scores in Table 2. As is shown, Prompt4Vis outperforms the SOTA RGVisNet with obvious improvements. Specifically, Prompt4Vis method surpasses the current SOTA RGVisNet by relatively 71.3% and 35.9% on test and dev set in terms of overall accuracy, respectively, which indicates the absolute effectiveness of the proposed method. This finding shows a novel paradigm of text-to-vis different from the previous designing of complex neural networks.
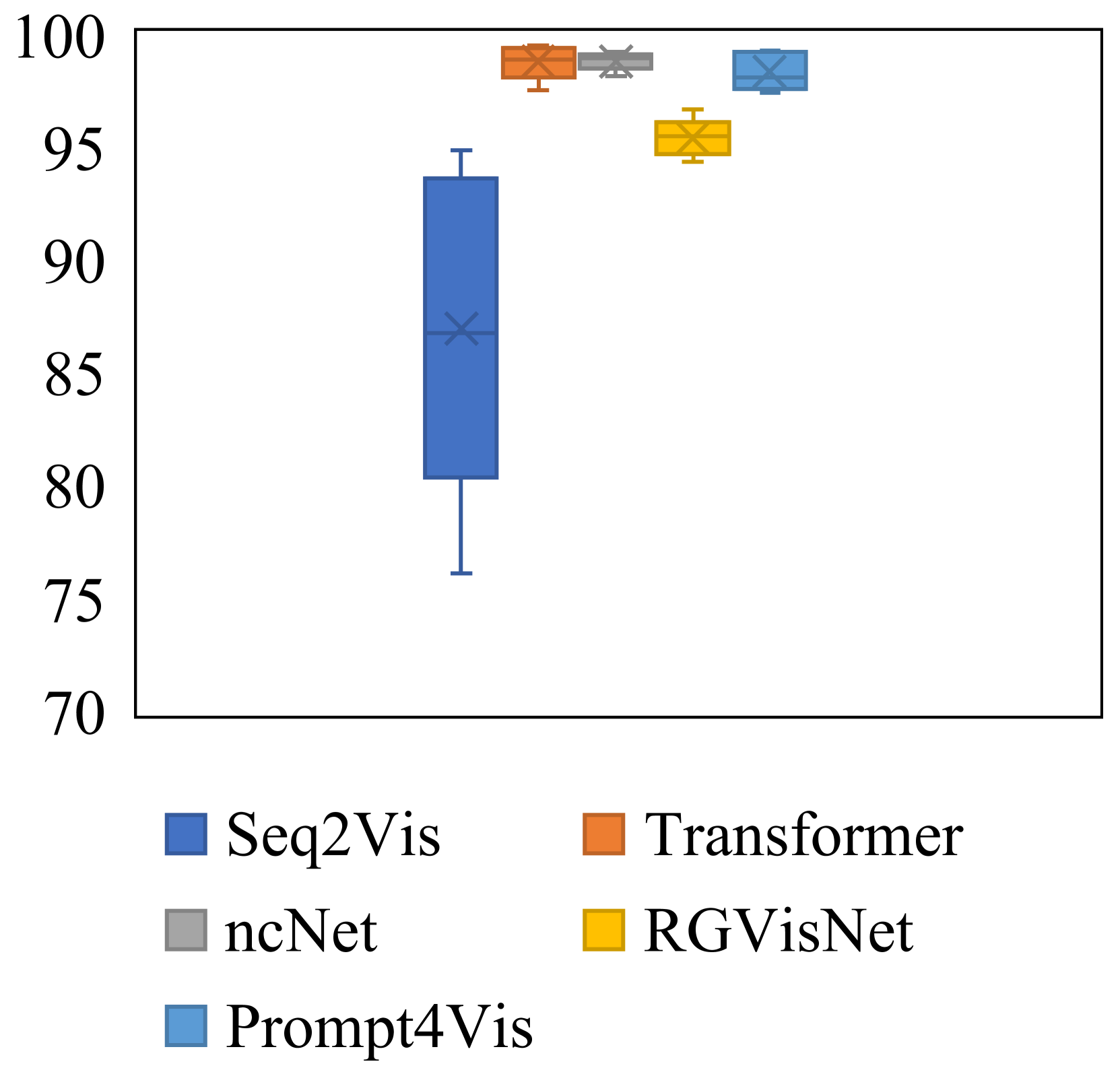
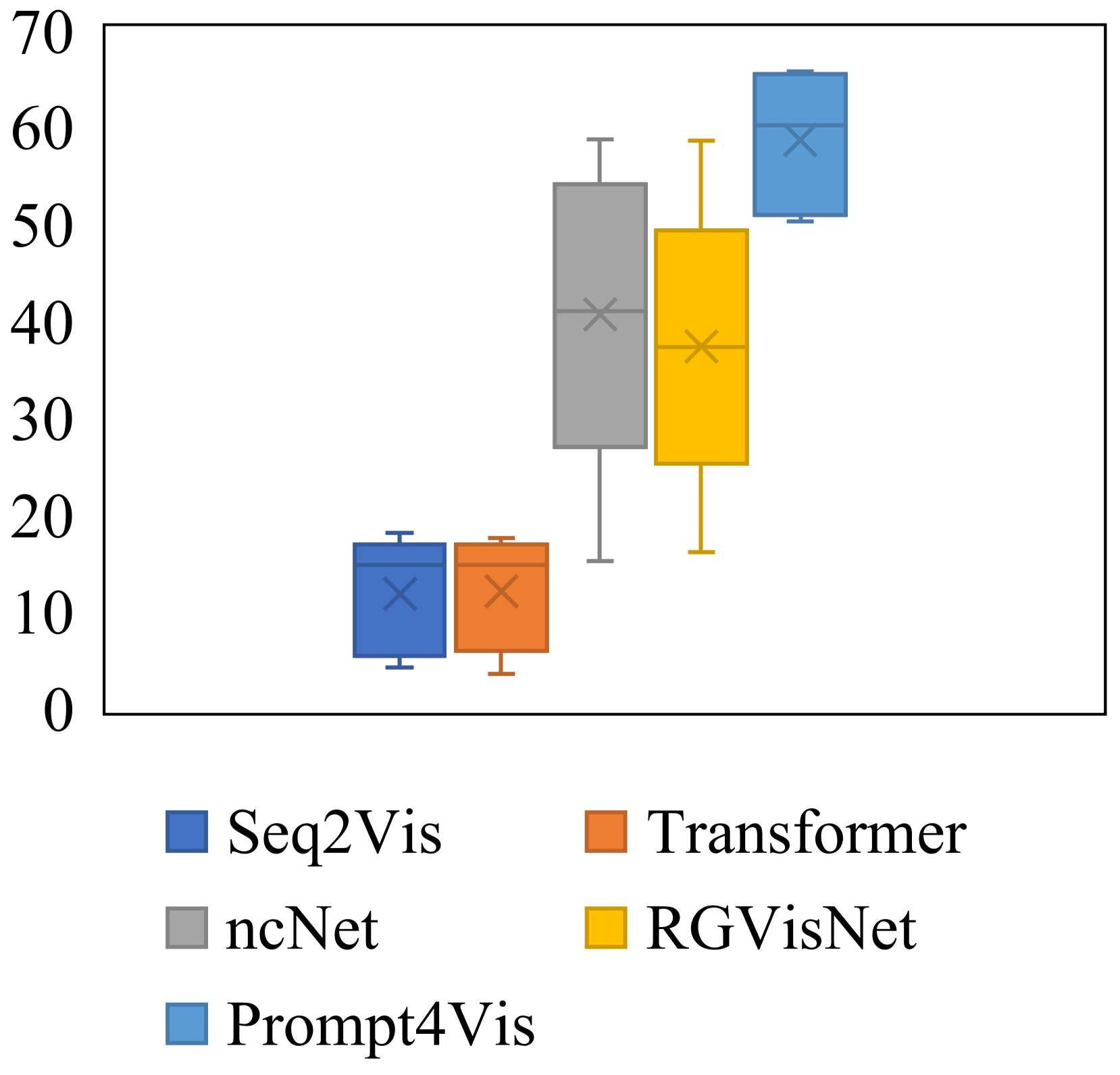
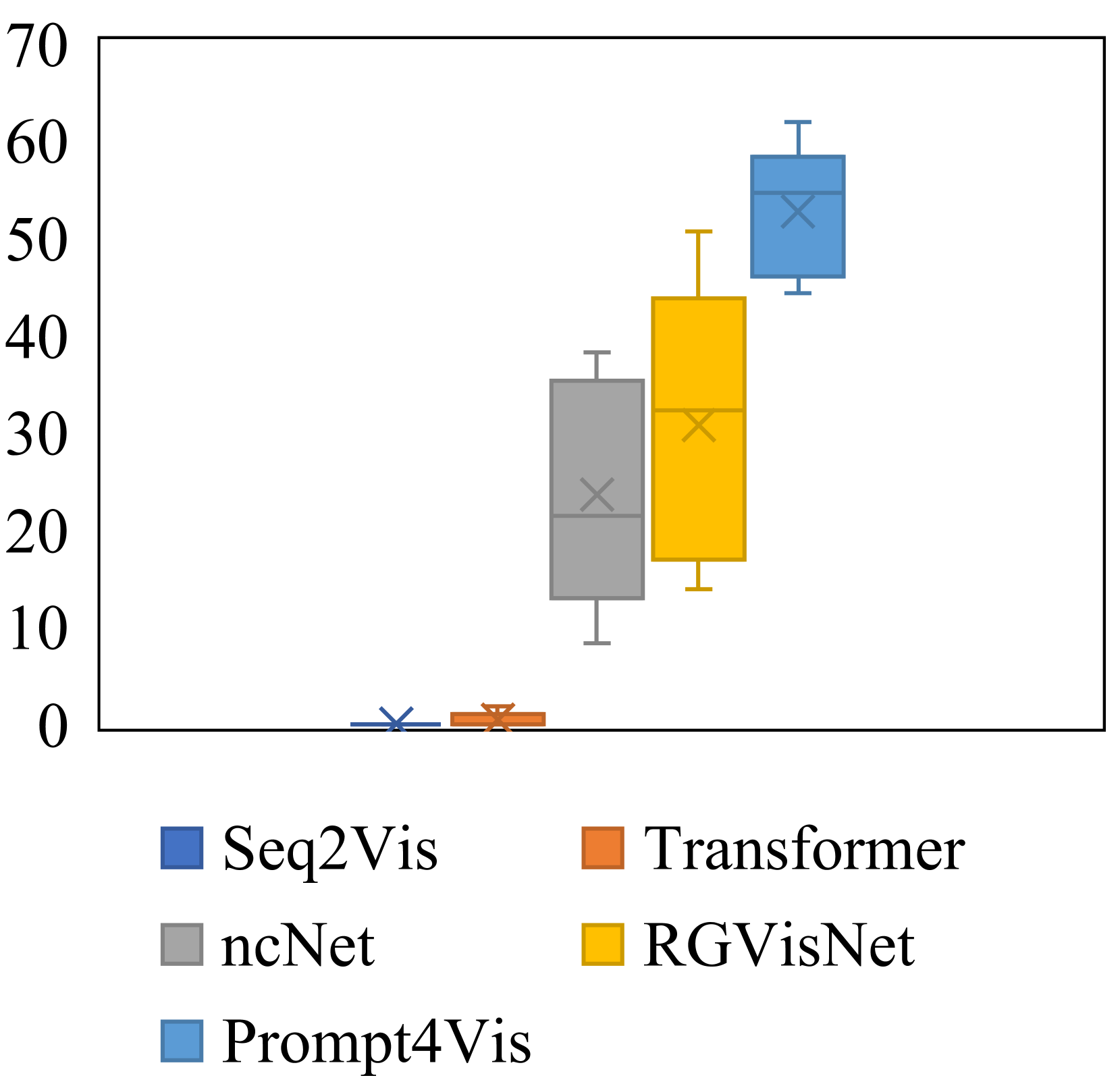
Then, we present the performance range in 5-fold cross-validation across different models and metrics with box charts in Figure 4. As is shown, Prompt4Vis demonstrates better stability across domains. To be specific, when compared to other baseline models such as ncNet and RGVisNet, the box height for Prompt4Vis is consistently the shortest across various metrics. In other words, Prompt4Vis exhibits the least fluctuation in terms of all accuracy metrics. It indicates that our model has the best stability in cross-domain settings. Moreover, for each subplot, we can see that our model is always located in the top-right corner of the subplots, which means that the performance of Prompt4Vis consistently exceeds the baseline models.
However, we observed that although our model surpasses the current SOTA baseline model RGVisNet by relatively 35.9% to 71.3%, there remains considerable potential for enhancing performance in the text-to-vis task. This finding highlights the difficulty of text-to-vis and suggests further efforts are required in this field.
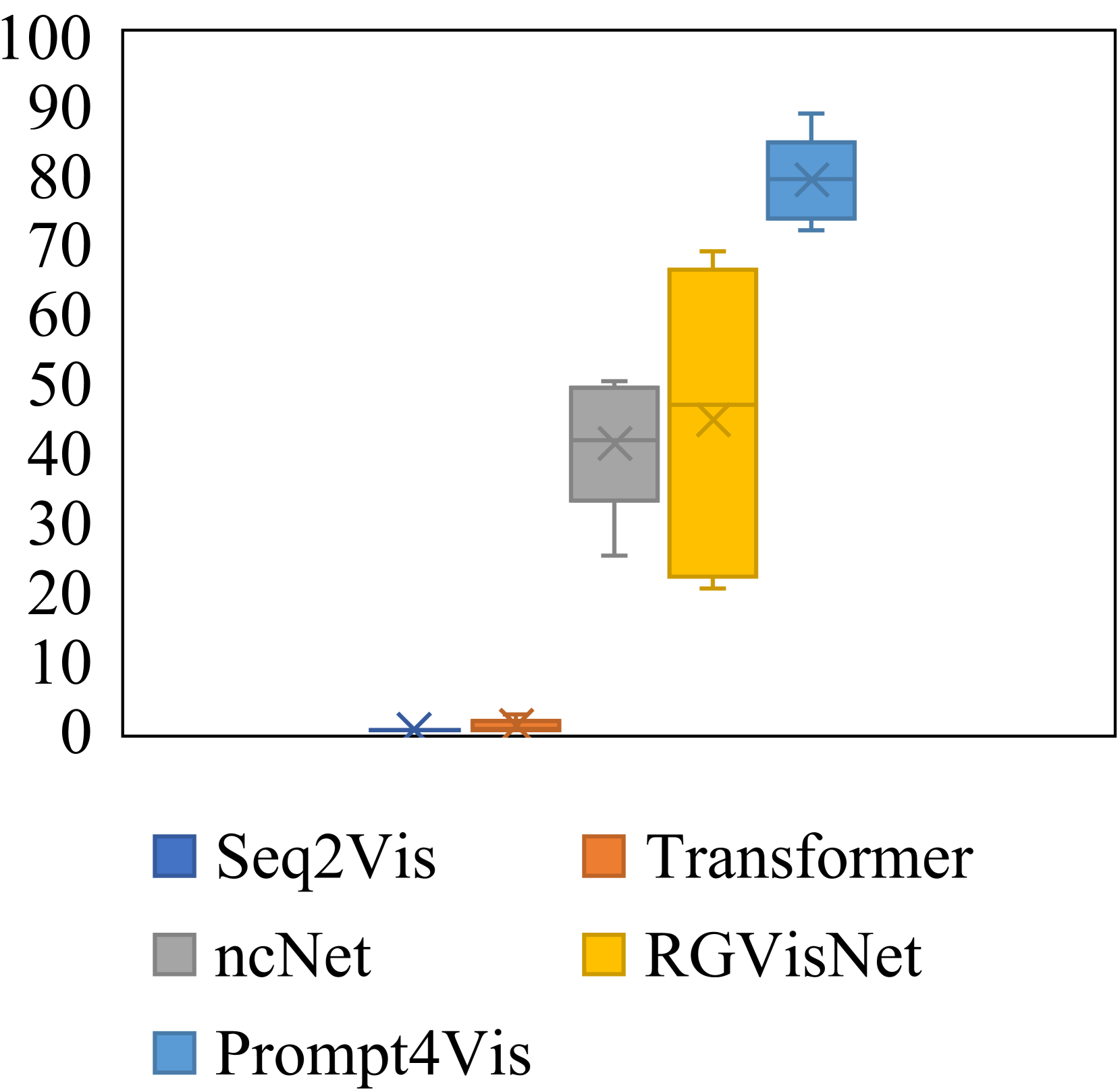
| Test Set | Dev Set | |||||||
| Method | Vis Acc | Axis Acc | Data Acc | Overall Acc | Vis Acc | Axis Acc | Data Acc | Overall Acc |
| Prompt4Vis (ours) | 98.37% | 79.23% | 58.64% | 52.69% | 97.77% | 79.23% | 65.68% | 60.39% |
| w. random | 90.68% | 58.67% | 45.09% | 33.51% | 89.97% | 59.67% | 53.72% | 39.65% |
| w. sim | 96.96% | 76.57% | 57.33% | 50.15% | 96.48% | 76.58% | 63.35% | 56.75% |
| w/o inf | 97.72% | 77.01% | 57.64% | 50.72% | 97.12% | 77.73% | 64.33% | 58.75% |
| w/o div | 97.22% | 78.61% | 58.25% | 51.65% | 97.11% | 78.36% | 64.18% | 58.32% |
| w/o sim | 98.29% | 79.79% | 58.59% | 52.16% | 97.74% | 80.65% | 64.98% | 59.40% |
| w. all schemas | 98.20% | 76.10% | 57.02% | 50.42% | 97.60% | 74.53% | 63.81% | 56.40% |
| w/o schema | 98.68% | 76.69% | 57.76% | 50.78% | 97.99% | 76.97% | 63.45% | 57.34% |
| w. RAT | 97.92% | 76.77% | 57.11% | 50.46% | 97.61% | 74.99% | 63.72% | 56.72% |
| w. RATLink | 98.14% | 58.14% | 48.86% | 38.33% | 97.23% | 60.90% | 57.65% | 46.83% |
4.2.2. Ablation Study
We conduct experiments to verify the effectiveness of each component in Prompt4Vis. To be specific, we set Prompt4Vis with all designed components as the baseline. Then we create variants of Prompt4Vis by either removing or replacing the designed components and then compare their performance with Prompt4Vis. The experimental results are presented in Table 3. In the following, we will introduce the details of these variants and analyze their performance.
First, we investigate if the improvements of our method are brought by only the ability of large language models. Therefore, we propose to prompt GPT-3.5-Turbo with 5 random examples sampling from the training set and name it as w. random. Then, as prior studies demonstrate selecting similar examples can benefit in-context learning (Zhang et al., 2023; Liu et al., 2022). We propose a variant, w. sim as a baseline to verify the proposed multi-objective example mining method. As shown in Table 3, besides the superior ability of LLMs, our prompt method makes obvious contributions to the improvements. In particular, Prompt4Vis outperforms LLMs prompting with random examples with large margins, 57.2% and 52.3% on test and dev set, respectively, which shows the effectiveness of our method. In other words, directly employing LLMs with random examples can not obtain the ideal performance. What’s more, compared with the results in Table 2, LLMs prompting with random examples even performs worse than the RGVisNet on the dev set. Additionally, the proposed method also achieves better performance than prompting with similar examples with obvious margins.
Second, we investigate the utility of three elements in an example mining module. We remove similarity, influence, and diversity elements, respectively, and name them w/o sim, w/o influence, and w/o diversity. As shown in Table 3, experimental results show the effectiveness of each element in the example mining module, when removing any element in it, the performance drops.
Finally, we verify the effectiveness of the second module, schema filtering. We first remove the scheme filtering module, which means we provide full schemes for each example (w. all schemas). Then, we only provide the schema for the target question and name this method as w/o schema. Next, we replace the schema filtering with a representative schema linking method RAT (Wang et al., 2020), and give tables filtered by this method to LLMs (w. RAT). Finally, we also explore providing the schema linking, which means the concentrate columns that the target query may mention with RAT, and name it w. RATLink. As shown in Table 3, we can see that w. all schemas hurts the performance, which drops relatively by 4.3% on the test set and 6.6% on the dev set compared with Prompt4Vis. The reason may be that a large number of tables bring irrelevant information to the model. What’s more, when replacing the schema filtering module proposed in this work with the RAT method, the performances also drop around 4.2% to 6.1%, which further indicates the effectiveness of the schema filtering module in Prompt4Vis.
4.2.3. Parameter Study.
In this section, we investigate the number of in-context examples for Prompt4Vis. Following the approach of (Bar et al., 2022), we vary the number of in-context examples from 1 to 7 and test the performance of Prompt4Vis on the test sets of 5-fold cross-validation setting. The average scores of overall accuracy are presented in Figure 5. The experimental results demonstrate that more examples can provide richer context, thereby enhancing model performance. However, when the number of examples reaches a certain threshold, such as 7 examples, the model performance is similar and even lower than 5 examples. This may be because too many examples could bring irrelevant information, implying that in in-context learning, choosing an optimal number of sample examples can result in a higher cost-effectiveness ratio rather than indiscriminately increasing the number of examples.
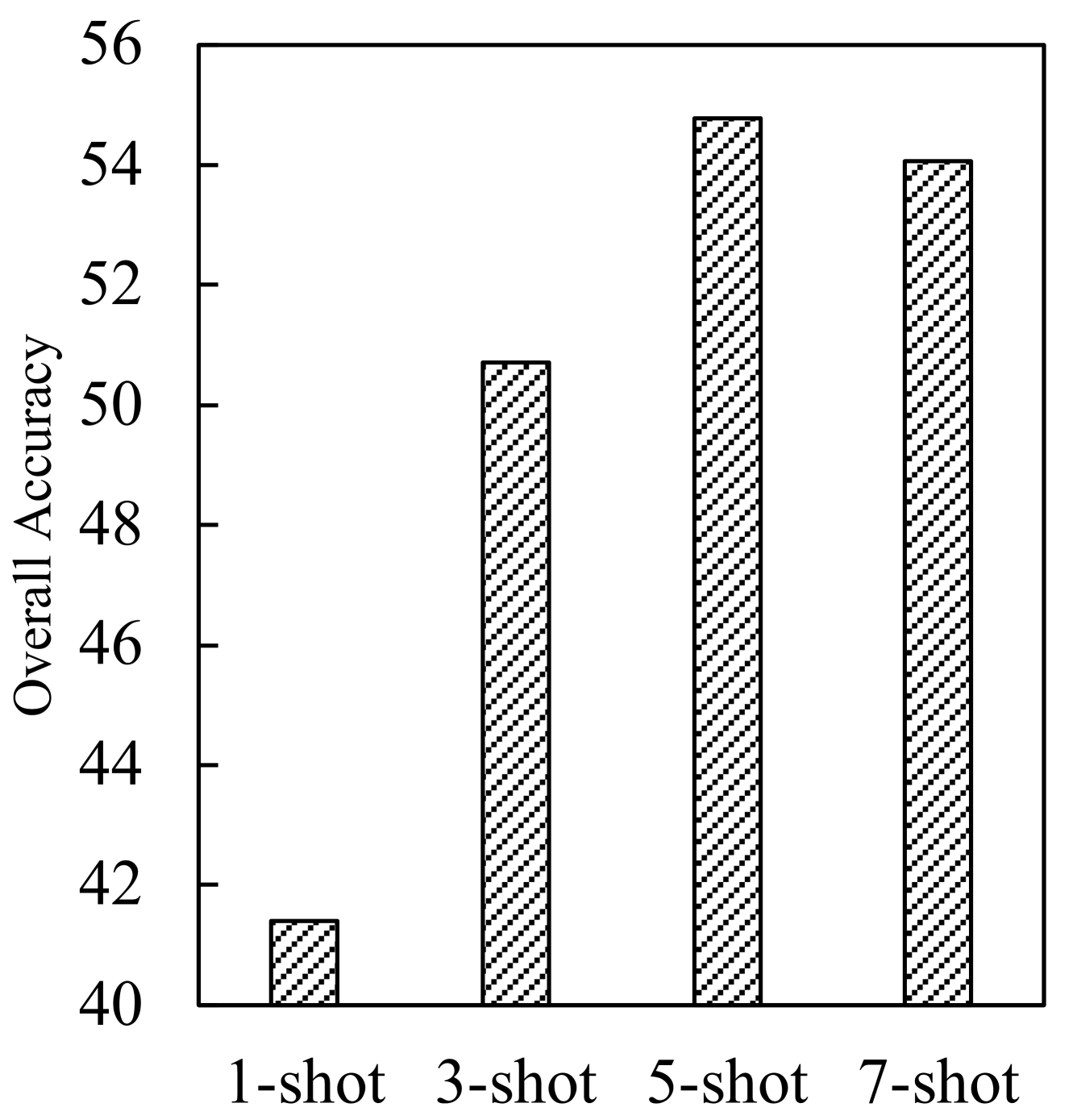
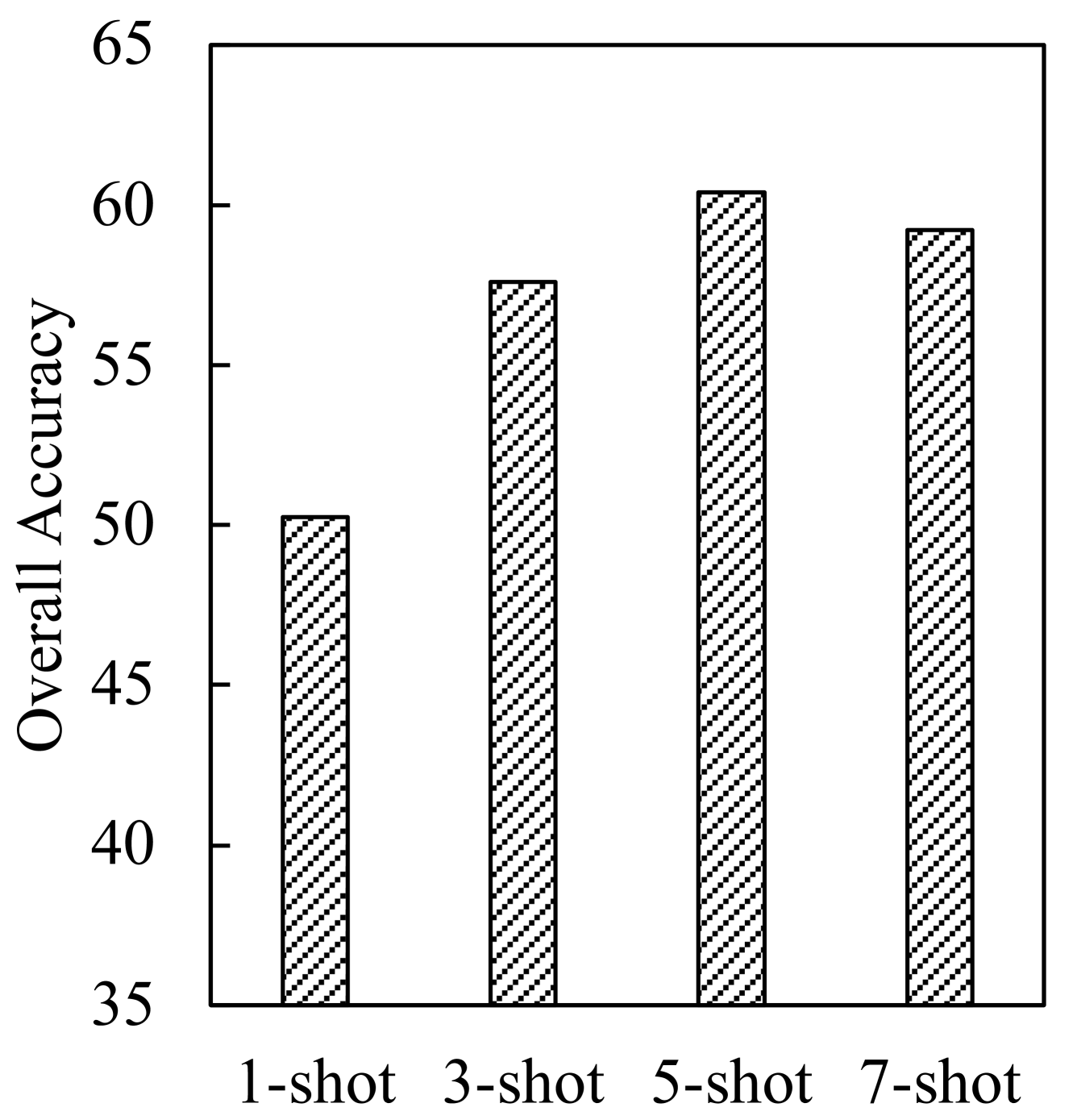
4.2.4. Case Study
| NL Question |
Return the names and surface areas of the 5 largest countries. Visualize by a pie chart. |
|
| Target DVQ |
VISUALIZE PIE SELECT Name, SurfaceArea FROM country ORDER BY SurfaceArea DESC LIMIT 5 |
|
| Seq2Vis |
VISUALIZE BAR SELECT Surface, COUNT(*) FROM hiring GROUP BY Surface ORDER BY surface ASC Figure (a) |
|
| Transformer |
VISUALIZE PIE SELECT Area, COUNT(Area) FROM appellations GROUP BY Area Figure (a) |
|
| ncNet |
VISUALIZE PIE SELECT Name, COUNT(*) FROM country Figure (b) |
|
| RGVisNet |
VISUALIZE PIE SELECT Name, SurfaceArea FROM country Figure (c) |
|
| Prompt4Vis (ours) |
VISUALIZE PIE SELECT Name, SurfaceArea FROM country ORDER BY SurfaceArea DESC LIMIT 5 Figure (d) |

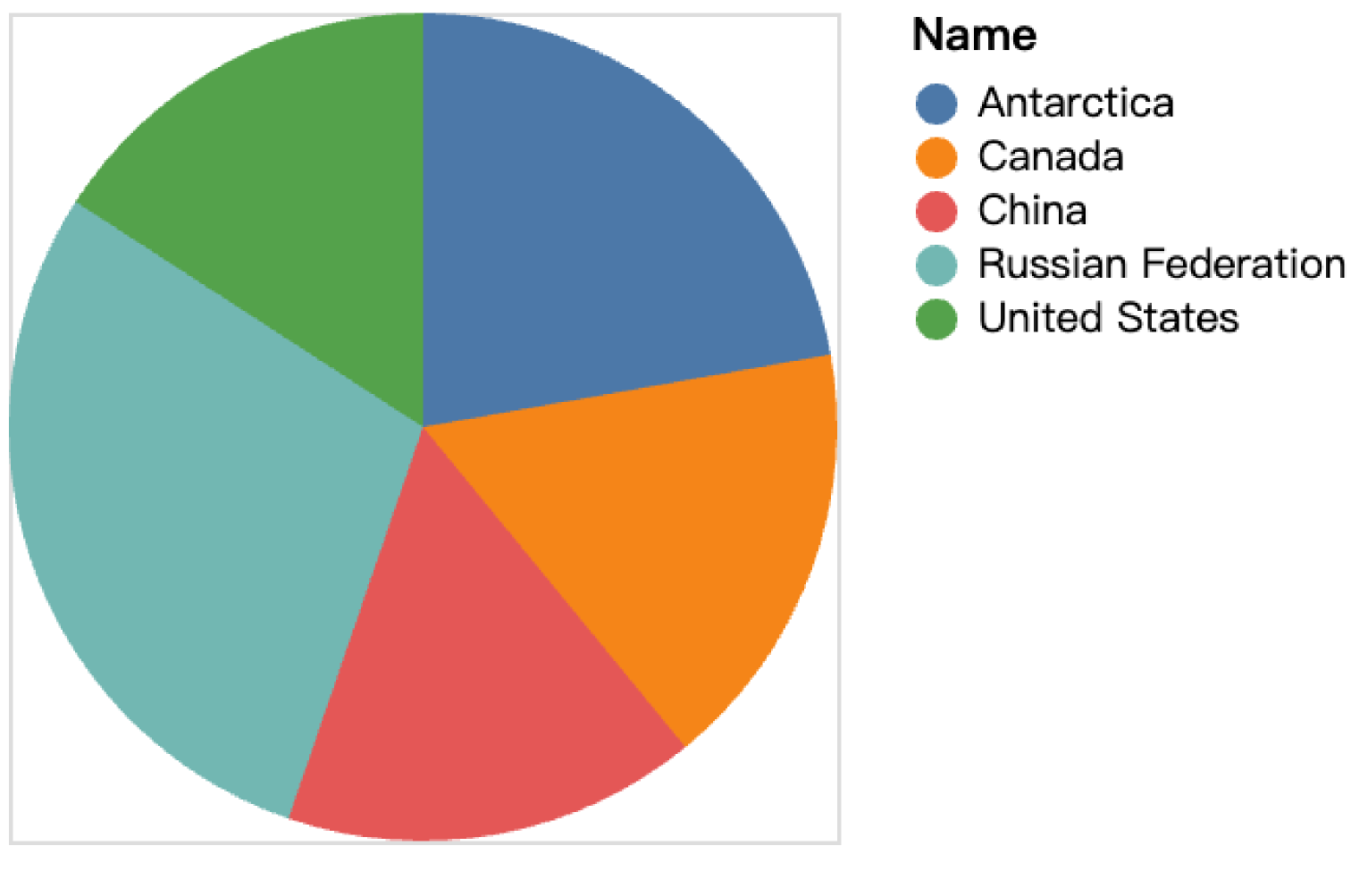
Table 4 presents a case to concretely show the DVQs generated by Prompt4Vis and the baselines. The corresponding charts generated by these models are also displayed in Table 4. As shown in Table 4, Seq2Vis and Transformer produce wrong table names, which leads to no image generated in Table 5(a). ncNet produce the DVQ with correct table country, however, it selects COUNT(*) from country, which results in a wrong image in Table 5(b). The first half of the DVQ generated by RGVisNet is completely correct, as it can learn the prototype close to the gold query by retrieval and obtain the DVQ for the current NLQ through revision. However, it lacks ORDER BY SurfaceArea DESC LIMIT 5, which may be due to the rarity of this expression in the training set, not enabling the neural network to learn this pattern. Different from the aforementioned models, Prompt4Vis is able to accurately produce the DVQ as the same as the target query, which results in the correct charts presented in Table 5(d).
5. Related Work
5.1. In-context Learning
Recently, LLMs, represented by ChatGPT and GPT-4, have demonstrated remarkable ability in comprehending natural language and have made significant advancements in a series of NLP tasks (Bang et al., 2023; Qin et al., 2023). In-context learning is a novel learning-free paradigm that originally emerged in LLMs. Recently, it has inspired the passion of database researchers (Narayan et al., 2022; Dong et al., 2023; Pourreza and Rafiei, 2023; Gao et al., 2023). For instance, Narayan et al. (Narayan et al., 2022) explore the ability of in-context learning in data cleaning and integration tasks including error detection, entity matching, and data transformation. Dong et al. (Dong et al., 2023) propose a zero-shot method for text-to-SQL, named C3, which first formulates clear task prompts, then devises calibration techniques to address incorrect outputs, and finally orders the large language model to produce consistent outputs to enhance the quality of the generated SQL.
Different from the above works, our work mainly focuses on text-to-vis and explores how to find effective examples for in-context learning of text-to-vis.
What’s more, researchers in NLP and CV have found that the examples selected of in-context learning have a great influence on the performance of downstream tasks (Liu et al., 2022; Zhang et al., 2023). They have made efforts to find good examples of in-context learning. For instance, Liu et al. (Liu et al., 2022) supposed that good examples should be semantically similar to the target example. Rubin et al. (Rubin et al., 2022) and Zhang et al. (Zhang et al., 2023) retrieve examples that can maximize the performance of downstream tasks for in-context learning. Different from the aforementioned works, we find effective examples from three different dimensions for text-to-vis and conduct schema filtering to give clean prompts to LLMs.
5.2. Text-to-Vis
Text-to-vis has garnered significant interest from the database and visualization communities as it enables non-experts to interact with the visualization systems through natural language questions. Existing typical works for text-to-vis can be divided into rule-based methods and neural network-based methods.
Rule-based methods represent the main trend at the beginning of text-to-vis. For instance, a rule-based approach to transform textual commands into infographics is employed in text-to-vis by Cui et al. (Cui et al., 2020). Moritz et al. (Moritz et al., 2019) design a set of constraints to model the knowledge in visualization and then optimize these constraints. DeepEye (Luo et al., 2018a) is an automatic visualization system that employs semantic parsing tools in NL. It consists of three components including visualization recognition, visualization ranking, and visualization selection. NL4DV (Narechania et al., 2021) is also implemented based on parsing tools and offers a Python toolkit that supports various high-level operations to assist users in creating NL-based DV systems.
To further promote the field of text-to-vis, Luo et al. (Luo et al., 2021) create a cross-domain text-to-vis dataset, NVBench, based on a popular text-to-SQL benchmark. Meanwhile, with the development of neural networks, the Seq2Vis model (Luo et al., 2021) is proposed based on the encoder-decoder framework and neural networks. Inspired by the way developers reuse previously validated code snippets from code search engines or large codebases during software development, Song et al. (Song et al., 2022) introduce a novel hybrid retrieval-generation framework for text-to-vis called RGVisNet. It retrieves the most relevant DVQ candidate as a prototype from the DVQ codebase and then refines this prototype to generate the desired DVQ.
Most recently, visualization researchers have also been attracted by large language models, which further promote the development of data visualization (Maddigan and Susnjak, 2023; Dibia, 2023; Wang et al., 2024; Ko et al., 2023; Wang et al., 2023). For instance, Chat2Vis system (Maddigan and Susnjak, 2023) makes efforts to prompt LLMs to produce Python code for data visualization. LIDA (Dibia, 2023) is a tool to visualize with the assistance of large language models and image generation models, which provides a novel Python API and a user interface to interact with users. Ko et al. (Ko et al., 2023) aim at promoting the development of visualization by enriching the datasets in this field. Therefore, they propose a novel framework based on LLMs to generate natural language datasets taking Vega-Lite specifications. What’s more, Wang et al. (Wang et al., 2023) propose to leverage LLMs as a recommendation tool for visualization.
Several of the aforementioned methods utilize LLMs as integral components within their frameworks for various visualization tasks, including recommendation (Wang et al., 2023) and concept binding (Wang et al., 2024). Additionally, some approaches leverage LLMs for generating programming code (Maddigan and Susnjak, 2023; Dibia, 2023; Ko et al., 2023), such as Python, specifically tailored to data visualization. However, our approach differs from these existing methods by proposing to use LLMs as a comprehensive pipeline to generate queries for data visualization. This approach breaks the constraints of a singular declarative visualization language, offering a broader way for automatic data visualization.
6. Conclusion
Our work is a timely study of in-context learning for text-to-vis tasks in the era of large language models. We systematically study how to perform in-context learning for text-to-vis and propose a novel framework, Prompt4Vis, which includes an example mining module and a schema filtering module. Compared to the previous SOTA models and methods that randomly select examples for in-context learning, our model achieved significant results, demonstrating the immense potential of in-context learning in the field of text-to-vis even data science.
We also discover some interesting findings in this work, such as in the process of example selection for text-to-vis, aside from the similarity between examples, the influence and diversity of examples also play important roles. Moreover, for each test case, the full database schema may introduce redundant information. Hence, a good schema filtering module can reduce the irrelevant schema information and further enhance the performance. We believe that it is valuable to attempt and practice these approaches in other data science fields as well.
References
- (1)
- Bang et al. (2023) Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, Quyet V. Do, Yan Xu, and Pascale Fung. 2023. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. CoRR abs/2302.04023 (2023).
- Bar et al. (2022) Amir Bar, Yossi Gandelsman, Trevor Darrell, Amir Globerson, and Alexei A. Efros. 2022. Visual Prompting via Image Inpainting. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Chowdhery et al. (2023) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. 2023. PaLM: Scaling Language Modeling with Pathways. J. Mach. Learn. Res. 24 (2023), 240:1–240:113.
- Cui et al. (2020) Weiwei Cui, Xiaoyu Zhang, Yun Wang, He Huang, Bei Chen, Lei Fang, Haidong Zhang, Jian-Guang Lou, and Dongmei Zhang. 2020. Text-to-Viz: Automatic Generation of Infographics from Proportion-Related Natural Language Statements. IEEE Trans. Vis. Comput. Graph. 26, 1 (2020), 906–916.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), Jill Burstein, Christy Doran, and Thamar Solorio (Eds.). Association for Computational Linguistics, 4171–4186.
- Dibia (2023) Victor Dibia. 2023. LIDA: A Tool for Automatic Generation of Grammar-Agnostic Visualizations and Infographics using Large Language Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics: System Demonstrations, ACL 2023, Toronto, Canada, July 10-12, 2023, Danushka Bollegala, Ruihong Huang, and Alan Ritter (Eds.). Association for Computational Linguistics, 113–126.
- Dibia and Demiralp (2019) Victor Dibia and Çagatay Demiralp. 2019. Data2Vis: Automatic Generation of Data Visualizations Using Sequence-to-Sequence Recurrent Neural Networks. IEEE Computer Graphics and Applications 39, 5 (2019), 33–46.
- Dong et al. (2023) Xuemei Dong, Chao Zhang, Yuhang Ge, Yuren Mao, Yunjun Gao, Lu Chen, Jinshu Lin, and Dongfang Lou. 2023. C3: Zero-shot Text-to-SQL with ChatGPT. CoRR abs/2307.07306 (2023).
- Gao et al. (2023) Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2023. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation. CoRR abs/2308.15363 (2023). https://doi.org/10.48550/ARXIV.2308.15363 arXiv:2308.15363
- Gao et al. (2021) Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. SimCSE: Simple Contrastive Learning of Sentence Embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (Eds.). Association for Computational Linguistics, 6894–6910.
- Hanrahan (2006) Pat Hanrahan. 2006. VizQL: a language for query, analysis and visualization. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Chicago, Illinois, USA, June 27-29, 2006, Surajit Chaudhuri, Vagelis Hristidis, and Neoklis Polyzotis (Eds.). ACM, 721.
- Ko et al. (2023) Hyung-Kwon Ko, Hyeon Jeon, Gwanmo Park, Dae Hyun Kim, Nam Wook Kim, Juho Kim, and Jinwook Seo. 2023. Natural Language Dataset Generation Framework for Visualizations Powered by Large Language Models. CoRR abs/2309.10245 (2023). https://doi.org/10.48550/ARXIV.2309.10245 arXiv:2309.10245
- Li et al. (2018) Deqing Li, Honghui Mei, Yi Shen, Shuang Su, Wenli Zhang, Junting Wang, Ming Zu, and Wei Chen. 2018. ECharts: A declarative framework for rapid construction of web-based visualization. Vis. Informatics 2, 2 (2018), 136–146.
- Liu et al. (2022) Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. 2022. What Makes Good In-Context Examples for GPT-3?. In Proceedings of Deep Learning Inside Out: The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, DeeLIO@ACL 2022, Dublin, Ireland and Online, May 27, 2022, Eneko Agirre, Marianna Apidianaki, and Ivan Vulic (Eds.). Association for Computational Linguistics, 100–114.
- Lu et al. (2022) Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computational Linguistics, 8086–8098.
- Luo et al. (2018a) Yuyu Luo, Xuedi Qin, Nan Tang, and Guoliang Li. 2018a. DeepEye: Towards Automatic Data Visualization. In 34th IEEE International Conference on Data Engineering, ICDE 2018, Paris, France, April 16-19, 2018. IEEE Computer Society, 101–112.
- Luo et al. (2018b) Yuyu Luo, Xuedi Qin, Nan Tang, Guoliang Li, and Xinran Wang. 2018b. DeepEye: Creating Good Data Visualizations by Keyword Search. In Proceedings of the 2018 International Conference on Management of Data, SIGMOD Conference 2018, Houston, TX, USA, June 10-15, 2018, Gautam Das, Christopher M. Jermaine, and Philip A. Bernstein (Eds.). ACM, 1733–1736.
- Luo et al. (2021) Yuyu Luo, Nan Tang, Guoliang Li, Chengliang Chai, Wenbo Li, and Xuedi Qin. 2021. Synthesizing Natural Language to Visualization (NL2VIS) Benchmarks from NL2SQL Benchmarks. In SIGMOD ’21: International Conference on Management of Data, Virtual Event, China, June 20-25, 2021, Guoliang Li, Zhanhuai Li, Stratos Idreos, and Divesh Srivastava (Eds.). ACM, 1235–1247.
- Luo et al. (2022) Yuyu Luo, Nan Tang, Guoliang Li, Jiawei Tang, Chengliang Chai, and Xuedi Qin. 2022. Natural Language to Visualization by Neural Machine Translation. IEEE Trans. Vis. Comput. Graph. 28, 1 (2022), 217–226.
- Lyu et al. (2023) Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. 2023. Faithful Chain-of-Thought Reasoning. CoRR abs/2301.13379 (2023). https://doi.org/10.48550/ARXIV.2301.13379
- Maddigan and Susnjak (2023) Paula Maddigan and Teo Susnjak. 2023. Chat2VIS: Generating Data Visualizations via Natural Language Using ChatGPT, Codex and GPT-3 Large Language Models. IEEE Access 11 (2023), 45181–45193.
- Moritz et al. (2019) Dominik Moritz, Chenglong Wang, Greg L. Nelson, Halden Lin, Adam M. Smith, Bill Howe, and Jeffrey Heer. 2019. Formalizing Visualization Design Knowledge as Constraints: Actionable and Extensible Models in Draco. IEEE Trans. Vis. Comput. Graph. 25, 1 (2019), 438–448.
- Narayan et al. (2022) Avanika Narayan, Ines Chami, Laurel J. Orr, and Christopher Ré. 2022. Can Foundation Models Wrangle Your Data? Proc. VLDB Endow. 16, 4 (2022), 738–746.
- Narechania et al. (2021) Arpit Narechania, Arjun Srinivasan, and John T. Stasko. 2021. NL4DV: A Toolkit for Generating Analytic Specifications for Data Visualization from Natural Language Queries. IEEE Trans. Vis. Comput. Graph. 27, 2 (2021), 369–379.
- Nguyen and Wong (2023) Tai Nguyen and Eric Wong. 2023. In-context Example Selection with Influences. CoRR abs/2302.11042 (2023). https://doi.org/10.48550/ARXIV.2302.11042 arXiv:2302.11042
- Nye et al. (2021) Maxwell I. Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, and Augustus Odena. 2021. Show Your Work: Scratchpads for Intermediate Computation with Language Models. CoRR abs/2112.00114 (2021). arXiv:2112.00114 https://arxiv.org/abs/2112.00114
- OpenAI (2022) OpenAI. 2022. Introducing chatgpt. https://openai.com/blog/chatgpt.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report. arXiv:2303.08774 [cs.DL]
- Pourreza and Rafiei (2023) Mohammadreza Pourreza and Davood Rafiei. 2023. DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction. CoRR abs/2304.11015 (2023). https://doi.org/10.48550/ARXIV.2304.11015 arXiv:2304.11015
- Qian et al. (2021) Xin Qian, Ryan A. Rossi, Fan Du, Sungchul Kim, Eunyee Koh, Sana Malik, Tak Yeon Lee, and Joel Chan. 2021. Learning to Recommend Visualizations from Data. In KDD ’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, Singapore, August 14-18, 2021, Feida Zhu, Beng Chin Ooi, and Chunyan Miao (Eds.). ACM, 1359–1369.
- Qin et al. (2023) Chengwei Qin, Aston Zhang, Zhuosheng Zhang, Jiaao Chen, Michihiro Yasunaga, and Diyi Yang. 2023. Is ChatGPT a General-Purpose Natural Language Processing Task Solver?. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, 1339–1384.
- Rubin et al. (2022) Ohad Rubin, Jonathan Herzig, and Jonathan Berant. 2022. Learning To Retrieve Prompts for In-Context Learning. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2022, Seattle, WA, United States, July 10-15, 2022, Marine Carpuat, Marie-Catherine de Marneffe, and Iván Vladimir Meza Ruíz (Eds.). Association for Computational Linguistics, 2655–2671.
- Satyanarayan et al. (2017) Arvind Satyanarayan, Dominik Moritz, Kanit Wongsuphasawat, and Jeffrey Heer. 2017. Vega-Lite: A Grammar of Interactive Graphics. IEEE Trans. Vis. Comput. Graph. 23, 1 (2017), 341–350.
- Savvides et al. (2019) Rafael Savvides, Andreas Henelius, Emilia Oikarinen, and Kai Puolamäki. 2019. Significance of Patterns in Data Visualisations. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA, August 4-8, 2019, Ankur Teredesai, Vipin Kumar, Ying Li, Rómer Rosales, Evimaria Terzi, and George Karypis (Eds.). ACM, 1509–1517.
- Siddiqui et al. (2016) Tarique Siddiqui, Albert Kim, John Lee, Karrie Karahalios, and Aditya G. Parameswaran. 2016. Effortless Data Exploration with zenvisage: An Expressive and Interactive Visual Analytics System. Proc. VLDB Endow. 10, 4 (2016), 457–468.
- Song et al. (2022) Yuanfeng Song, Xuefang Zhao, Raymond Chi-Wing Wong, and Di Jiang. 2022. RGVisNet: A Hybrid Retrieval-Generation Neural Framework Towards Automatic Data Visualization Generation. In KDD ’22: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, August 14 - 18, 2022, Aidong Zhang and Huzefa Rangwala (Eds.). ACM, 1646–1655.
- Vartak et al. (2016) Manasi Vartak, Silu Huang, Tarique Siddiqui, Samuel Madden, and Aditya G. Parameswaran. 2016. Towards Visualization Recommendation Systems. SIGMOD Rec. 45, 4 (2016), 34–39.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA. 5998–6008.
- Wang et al. (2020) Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, and Matthew Richardson. 2020. RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020. Association for Computational Linguistics, 7567–7578.
- Wang et al. (2024) Chenglong Wang, John Thompson, and Bongshin Lee. 2024. Data Formulator: AI-Powered Concept-Driven Visualization Authoring. IEEE Trans. Vis. Comput. Graph. 30, 1 (2024), 1128–1138.
- Wang et al. (2023) Lei Wang, Songheng Zhang, Yun Wang, Ee-Peng Lim, and Yong Wang. 2023. LLM4Vis: Explainable Visualization Recommendation using ChatGPT. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: EMNLP 2023 - Industry Track, Singapore, December 6-10, 2023, Mingxuan Wang and Imed Zitouni (Eds.). Association for Computational Linguistics, 675–692.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh (Eds.).
- Wickham (2009) Hadley Wickham. 2009. ggplot2 - Elegant Graphics for Data Analysis. Springer. https://doi.org/10.1007/978-0-387-98141-3
- Zhang et al. (2023) Yuanhan Zhang, Kaiyang Zhou, and Ziwei Liu. 2023. What Makes Good Examples for Visual In-Context Learning?