API Pack: A Massive Multilingual Dataset for API Call Generation
Abstract
We introduce API Pack, a multilingual dataset featuring over one million instruction-API call pairs aimed at advancing large language models’ API call generation capabilities. Through experiments, we demonstrate API Pack’s efficacy in enhancing models for this specialized task while maintaining their overall proficiency at general coding. Fine-tuning CodeLlama-13B on just 20,000 Python instances yields over 10% and 5% higher accuracy than GPT-3.5 and GPT-4 respectively in generating unseen API calls. Scaling to 100k examples improves generalization to new APIs not seen during training. In addition, cross-lingual API call generation is achieved without needing extensive data per language. The dataset, fine-tuned models, and overall code base are publicly available at https://github.com/zguo0525/API-Pack.
1 Introduction
Large language models (LLMs) have shown promise in assisting with software engineering tasks (Hou et al., 2023; Ebert & Louridas, 2023), with a primary focus on code generation (Wang et al., 2023b; Liang et al., 2023; Zan et al., 2023; Shrivastava et al., 2023; Wei et al., 2023; Muennighoff et al., 2023). Our work builds on these advances but targets at the time-consuming task developers often face in finding API call code examples. Currently, developers typically seek out examples in documentation sites or API hubs (Sadowski et al., 2015), sifting through lengthy pages to locate relevant information (Meng et al., 2018). This process is recognized as cumbersome and inefficient. Our research aims to transform this workflow by exploring LLMs’ capabilities to identify appropriate API endpoints and generate corresponding API calls based on natural language prompts.
To achieve our research goal, we created API Pack, a dataset designed to advance LLMs’ API call generation capabilities. This multi-lingual dataset, comprising over one million instances with 10 programming languages, is by far the largest-open-source instruction dataset (see Table 1) for API call generation and API call intent-detection (identifying the appropriate API endpoint to solve a task based on a natural language prompt). We evaluated API Pack impact on API call generation in various ways (see Section 4). One of our fine-tuning experiments shows that CodeLlama-13B fine-tuned with only 20,000 instances of API Pack (all in Python) surpasses GPT-3.5 and GPT-4 for API call generation for unseen new APIs.
API Pack distinguishes itself from prior works (Xu et al., 2023b; Patil et al., 2023; Qin et al., 2023) in two different ways - scale and multilinguality. With over a million examples spanning more real-world APIs and use cases than predecessors, API Pack facilitates rigorously evaluating generalization capabilities by controlling training data volume. In addition, API Pack includes API calls across 10 different programming languages (see Table 1). This allows a rare assessment of cross-lingual skill transfer - how gains in one language apply to others. Such transfer is vital but underexplored in previous studies.
| Feature | API Pack (this work) | APIBench (Gorilla) | ToolBench | ToolBench (ToolLLM) | API Bank | ToolAlpaca | ToolFormer |
|---|---|---|---|---|---|---|---|
| API call intent detection? | ✓(*) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| API call code generation? | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Multi-lingual API calls? | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Multi-API call scenario? | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Data generation method: | custom | self-instruct | self-instruct | custom | custom | custom | custom |
| # of Sources | 4 | 3 | 8 | 1 | 53 | / | 5 |
| # of APIs / Tools | 11,213 | 1,645 | 8 | 16,464 | 53 | 400 | 5 |
| # of API calls | 1,128,599 | 16,450 | / | 37,204 | 568 | 3,938 | 9,400 |
| # of Instances | 1,128,599 | 16,450 | 2,746 | 12,657 | 264 | 3,938 | 22,453 |
We summarized three highlights from our experiments:
-
•
Fine-tuning CodeLlama-13B on 20,000 Python instances yields over 10% and 5% higher accuracy than GPT-3.5 and GPT-4 respectively for unseen API calls.
-
•
Scaling the instruction data to 100,000 Python instances improves generalization to new APIs, confirming the benefits of a larger dataset.
-
•
Cross-lingual API call generation can be achieved by fine-tuning models on a large amount of data in one language plus small amounts of data from other languages. An excessive amount of data for each target programming language is not crucial.
We also evaluated the performance of API Pack combined with other instruction datasets (Magicoder-OSS-Instruct-75K and Magicoder-Evol-Instruct-110K (Wei et al., 2023)). Our results show that API Pack improves API call generation without affecting the code generation performance on HumanEval+ (Liu et al., 2023a) and MBPP (Austin et al., 2021) benchmarks.
The paper is organized as follows: Section 2 reviews related work. Section 3 describes the construction of API Pack, our novel multilingual dataset. Section 4 outlines the experimental design for fine-tuning models on API Pack and evaluating performance. The key findings are presented in Section 5. We conclude the paper in Section 6, address limitations of the study in Section 7, and outline future work plans in Section 8.
2 Related Work
2.1 Methods to Generate Instruction Data with LLMs
As manually crafting instruction data is a labor-intensive process (Xu et al., 2023a), a growing trend of work has proposed the use of LLMs as a mean to reduce the human effort required to create instruction datasets. On the one hand, LLMs have made feasible to produce large amounts of instruction data in an automatic fashion. On the other hand, generating synthetic data with LLMs increases the risk of introducing incorrect data, instances that lack complexity or that are insufficiently diverse. Researches have work on these concerns and propose different methods to create and filter LLM-generated data. Two methods widely adopted are Self-Instruct (Wang et al., 2023a) and Evol-Instruct (Xu et al., 2023a). The latter, in particular, addresses the challenge of creating open-domain instructions.
Two phases, instance generation and filtering, are essential in creating synthetic instruction data with Self-Instruct (Wang et al., 2023a) and Evol-Instruct (Xu et al., 2023a). In Self-Instruct, a small pool of instances is created, and an LLM mutates selected instances with in-context examples. New instances are added back to the pool only if they pass filtering. Self-Instruct filters instances based on ROUGE-L similarity and other heuristics. Evol-Instruct generates new instances via LLM prompting with prompts that have a specific target. This method achieves instance filtering by classifying instructions based on a set of heuristics. For both methods, the heuristics for instance filtering are determined by manual analysis of the data. Even though Self-Instruct (Wang et al., 2023a) and Evol-Instruct (Xu et al., 2023a) have became a standard to create instruction data, custom versions of these methods are also employed to create instruction datasets for specific domains.
Beyond data filtering, performing a quality check is still critical in order to use synthetic data to fine-tune models. A simple, but time-consuming way to perform this quality review is asking an expert annotator (a human) to determine the correctness of each instance generated (Wang et al., 2023a). An alternative to the human method is to prompt a strong LLM (i.e., ChatGPT) with either scoring or classifying instructions (Liu et al., 2023b) based on heuristics determined by manually reviewing a small sample of the data generated. This scoring approach has also being used to determine instructions complexity (Chen et al., 2023; Lu et al., 2023).
2.2 LLMs for API call Code Generation and Intent Detection
A growing body of research explores the integration of Large Language Models (LLMs) and Application Program Interfaces (APIs). Part of this work focuses on, API call intent-detection, accurately identifying the appropriate API endpoint to solve a natural language task. Other research work, however, centers on creating LLMs that generate code to invoke APIs functionality (e.g.,(Patil et al., 2023),(Xu et al., 2023b)). This second approach, which our work also contributes to, targets developers as end users, and seeks to improve their experience in finding API call code examples.
API call intent-detection LLMs (e.g., (Qin et al., 2023), (Li et al., 2023a), (Tang et al., 2023), (Yang et al., 2023), (Schick et al., 2023)) typically work as part of hybrid architectures in which LLMs find the appropriate API endpoint(s) to use, and other software components (e.g., retrievers, API code DBs, code generation libraries) generate the code to call them. In this hybrid approach, API calls are executed internally to return a final answer to the user. API call intent-detection studies have explored single and multi API-intent scenarios. For the latter, only a few studies have obtained good results (i.e., (Qin et al., 2023)).
API call code generation has been much less addressed in research as only a few studies have explored it. One of them is the Gorilla project (Patil et al., 2023), which created an LLM to generate API calls for loading pre-trained machine learning models from three known model hubs (Torch Hub, TensorFlow Hub v2, HuggingFace). Another important work is the ToolBench dataset (Xu et al., 2023b), which serves as benchmark to enhance the tool manipulation capabilities of open-source LLMs.
2.3 Datasets for Code-related Tasks
As it was a concern that only closed-source models (e.g., Code-Davinci002, Google’s Bard) performed well on popular code benchmarks (e.g., HumanEval (Chen et al., 2021), HumanEval+ (Liu et al., 2023a), MBPP (Austin et al., 2021)) the open-source community created open-source instruction datasets for code-related tasks in an attempt to even out the performance of open-source Code LLMs with their close-source counterparts. WizardCoder training set (Luo et al., 2023) is one of these attempts. This dataset was constructed by customizing the Evol-Instruct(Xu et al., 2023a) method to the realm of code, and it was used to fine-tune the StarCoder model (Li et al., 2023b). The resulting model, WizardCoder, achieved a performance very close to GPT4 and GPT3.5 models. In a similar vein, CommitPack (Muennighoff et al., 2023), an instruction dataset that comprises four terabytes of Git commits across 350 programming languages, was also used to fine tuned StarCoder. The resulting model achieved good performance on the HumanEval Python benchmark. Another important contribution motivated by the same goal is OSS-INSTRUCT (Wei et al., 2023), an approach to generate more diverse, realistic, and controllable coding instruction data. OSS-INSTRUCT was created based on a seed of open-source code snippets (outputs). Then, a teacher model was tasked with creating coding problems for the code snippets (inputs). This instruction dataset was used to fine tune the family of Magicoder models which surpassed ChatGPT on HumanEval+ (Liu et al., 2023a) benchmark.
3 API Pack
API Pack is an instruction dataset with more than one million instances. In API Pack, an instance contains an input-output pair plus additional information about the API and respective endpoints. Inputs are instructions to find an API call to solve a coding task. They include a task description in software engineering languages and the name of the API to be used. Conversely, outputs are API call examples, specifically HTTP request code snippets curated from OpenAPI specification (OAS) files.
API Pack curates data from four hubs that store OAS files: RapidAPI 111https://rapidapi.com/categories, APIGurus 222https://apis.guru/, the Swaggerhub 333https://app.swaggerhub.com/search, and a company’s public API Hub 444https://{anonymous_url}. Table 2 presents the total number of APIs, unique endpoints, and total instances (in different programming languages) that API Pack contains.
| Source | APIs | Unique Endpoints | Total Instances |
|---|---|---|---|
| Company API Hub | 73 | 2,884 | 17,206 |
| APIs Gurus | 1,980 | 37,097 | 495,533 |
| Swaggerhub | 5,045 | 26,747 | 345,765 |
| RapidAPI | 4,115 | 21,525 | 270,095 |
| Total | 11,213 | 88,253 | 1,128,599 |
The construction process of API Pack comprises four major stages: data pre-processing (3.1), API Database (DB) creation (3.2), instructions generation (3.3), and data validation (3.4). Figure 1 shows the overall pipeline.
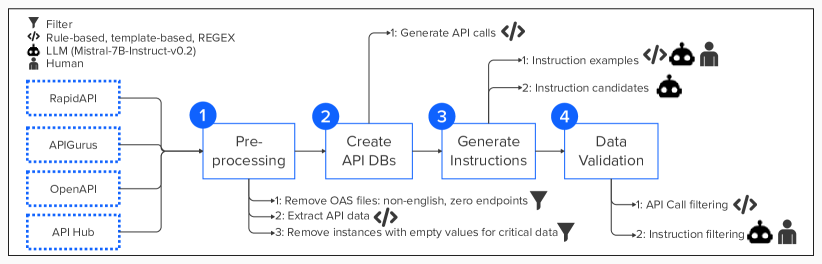
3.1 Data Pre-processing
First, we filter out files with non-English data or zero endpoints for all the OAS files collected. Second, we extracted information about the endpoints that each OAS file contains: name, functionality, description, method, and path. We also extracted information at the API level. Specifically, we collected the API name, the API description, and the API Provider. This information is the same for all the endpoints present in an OAS file. While OAS files provide a standard structure to document an API’s design, not all information fields are mandatory. Thus, we applied a second filter to remove instances with crucial data to generate API calls empty (e.g., method, either the path or the endpoint_name). We also filter out instances were the functionality, description and endpoint_name were empty as at least one of these values must exist to generate instructions.
3.2 Create API DBs
After extracting relevant data from the OAS files, we built an API DB with the data extracted. API DBs contain an array of independent instances in JSON format. Each instance contains all the information relevant to an endpoint (endpoint_name, functionality, description, path, method), and the API each endpoint belongs to (API name, API description, API provider). These information was extracted directly from the raw OAS files. Each instance also contains an API call example in a given programming language, and a string that identifies the programming language (e.g., cURL, python, java). We used openapi-snippet 555 https://www.npmjs.com/package/openapi-snippet to generate API calls (api_call) in 10 different programming languages (cURL, libcurl, java, node, python, go, ruby, php, swift, JavaScript) for the endpoints of three data sources. For one data source we directly extracted API calls from the OAS files. Appendix F shows the structure of an API DB instance and provides details on programming language diversity for each source.
Figure 2 shows an example of an API call in cURL. Note that this example does not include real argument values. Instead, a string (e.g., REPLACE_BASIC_AUTH, [“string”], “string”) serves as a placeholder to indicate the need of an argument. This is the standard way API documentation libraries integrate API call code examples into documentation (e.g, swagger-codegen 666https://github.com/swagger-api/swagger-codegen Sphinx documentation 777https://www.sphinx-doc.org/en/master/, DocFX 888https://github.com/dotnet/docfx). Developers usually copy these examples and replace the placeholder strings to test an API call code snippet.
3.3 Instructions Generation
The process to generate instructions comprises two steps: 1) creating high-quality instruction examples, and 2) generating instruction candidates.
We created instruction examples as follows. First, we randomly selected three endpoints from each API DB file. Then, we created an instruction example for each endpoint selected by bootstrapping its information (e.g., functionality, description, endpoint_name, path) and the respective API name into different templates. Through this method, we obtained three instruction examples for each API DB. Note that an LLM was not prompted to generate the initial version of these examples. We refined instruction examples in two ways. For API Gurus and the company’s API Hub, three people (all authors of this paper) corrected grammatical errors, removed unnecessary information (i.e., urls in the instruction), and verified that the API name was part of all the instruction examples. After manually reviewing the examples for these two sources, we noticed that the errors found were repetitive. Therefore, for the other two sources, the Swaggerhub and RapidAPI, we replaced human labor with a Large Language Model (LLM), Mistral-7B-Instruct-v0.2999https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2. The prompt used to refine these instruction examples (Prompt LABEL:lst:prompt_refinement in Appendix H) was distilled from the error patterns that the researchers identified by correcting instruction examples for API Gurus and the company’s API Hub.
We used these high-quality instruction examples to generate instruction candidates for the instances in each API DB. We prompted an LLM (Mistral-7B-Instruct-v0.2) to generate instructions by providing the endpoint’s information as input and the high-quality instructions created for each API DB (see previous paragraph) as in-context examples (see Prompt LABEL:lst:prompt_generation in Appendix H). For each API DB, we generated five instruction candidates per instance. Figure 2 shows one of the instruction candidates generated (Appendix G shows all the candidates generated for the same instance).
3.4 Data Validation
The data validation process comprises three steps: 1) verifying if API calls are valid HTTP request examples in a given programming language, 2) verifying if instructions are of high-quality, and 3) selecting the instruction with the best quality for training.
In order to verify that API calls were valid HTTP request examples, we first compared the API call’s content with the instance data to check the correctness of the endpoint_name and the method being used (e.g., get, post, put, delete, custom method name). Then, we used regular expressions to validate the url format. As these API calls are code examples, we considered that placeholder strings may exist for the url domain, path parameters, or query parameters. We also checked that the programming language keywords in the API call correspond to the language string id assigned to each instance.
To validate the set of instructions generated for each API call, we first selected a random sample of 121 instances, each instance contains one API call and five instructions. The 121 instances selected contain a unique functionality, description, and endpoint_name. One of the authors labeled the instructions for these 121 instances (605 instructions in total) as good or bad. By analyzing the instructions labeled as bad we noticed that they matched at least one of the following three characteristics:
-
•
Contains multiple instructions instead of a single one.
-
•
Include unnecessary text before or after the main instruction (e.g., ”User query”, ”query”, ”Instruction:”).
-
•
Fail to accurately use the correct API name.
We created three prompts to automatically label instructions considering these characteristics. All the prompts included a fixed set of in-context examples. To select a champion prompt, we used an LLM (Mistral-7B-Instruct-v0.2) to label the 605 instructions that one of the authors had manually classified as good or bad. We repeated this process with each prompt, and compare the results against our human-crafted oracle. We used the prompt that showed the best results (Prompt LABEL:lst:prompt_scoring in Appendix H) to task Mistral-7B-Instruct-v0.2 with classifying all the instructions in our dataset as good or bad. We removed instances with less than two good instructions from our dataset.
In order to select a best candidate to use for training from the (sub)set of good instructions, we calculated the likelihood of an LLM to recreate the input text used to generate each instruction. We prompted an LLM, Mistral-7B-Instruct-v0.2 to accomplish this task (see Prompt LABEL:lst:prompt_backtranslation in Appendix H); the text used as input was each instruction candidate itself. The LLM returned the log probability of each token for the re-generated input text. We calculated the mean of these log probabilities (input_tokens_mean), and link this metric to the respective instruction candidate. Appendix G shows five instruction candidates and their respective input_tokens_mean. We selected instructions labeled as good with the best input_token_mean (value closer to zero) for training.
Our final dataset contains 1,128,599 instances, each with a valid API call example and at least two high-quality instructions. Appendix A shows the data instances filtered out at each stage of the pipeline.
4 Experiments and Evaluation Framework
In this section, we introduce our experimental settings and evaluation framework.
4.1 Preamble
In order to optimize the instruction-following capabilities of the language models fine-tuned with our dataset, we post-processed API Pack into two instruction-tuning templates, which we refer to as zero-shot and three-shot templates. The first template (zero-shot) targets the scenario where the output is expected to be a straightforward inference from the given input, which highlights the model’s direct instruction-following capability. The second template (three-shot) emphasizes the model’s ability to learn and generate output with in-context learning. We provide the mathematical representation for each template below:
Zero-shot: this template models a direct probabilistic relationship between input (x) and output (y). The formula is expressed as:
| (1) |
In this formula, is the language model mapping of an input instruction to its corresponding output.
Three-shot: this template extends the model’s capacity by incorporating contextual pairs (). It is represented by the equation:
| (2) |
In this formulation, considers the primary input x as well as the context from three additional pairs . The three-shot template is available in Appendix LABEL:lst:prompt_eval.
4.2 Experimental Settings
A. Selecting the baseline: our first experimental setting serves the purpose of selecting a base model for the rest of our experiments. To do so, we fine-tune Mistral 7b (Jiang et al., 2023), CodeLlama 7b and 13b, as well as Llama 2 13b (Touvron et al., 2023) on a subset of API Pack (20,000 instances in Python programming language). We evaluate the performance of each 20k fine-tuned resulting model. We use the respective base-model for the fine-tuned model that showed the best performance in the rest of our experiments.
B. Inference with retrieval: our second experiment has the goal of understanding the influence of retrieval augmentation on model generalization. Thus, we evaluate the models under four distinct prompt settings during the test time:
-
•
0-shot: no API examples provided for the model.
-
•
3-shot random: 3 randomly selected API examples.
-
•
3-shot retrieved: 3 retrieved relevant API examples.
-
•
3-shot retrieved & re-ranked: 5 retrieved API examples, selecting 3 out of 5 using a re-ranker model.
Note that these prompt settings are for testing/inference, different from the instruction-tuning templates used in fine-tuning. Here, we used bge-large-en-v1.5 (Zhang et al., 2023) as the embedding model for retrieval, and beg-reranker-large (Xiao et al., 2023) for re-ranking. Appendix C illustrates the inference pipelines (0-shot, 3-shot) we used to evaluate the performance of models.
C. Scaling experiment: we conduct a scaling experiment to investigate whether more API data improves a model’s generalization ability for unseen API data. For this experiment we fine-tune models on progressively larger API datasets, all with unique API calls in Python. Specifically, we fine-tuned models with 20k, 40k, 80k, and 100k instances respectively. Our hypothesis is that exposure to a greater diversity of APIs during fine-tuning will improve the model’s ability to generalize to new, unseen APIs.
D. Cross-lingual generalization: To test the model’s ability to generalize to new programming languages, we supplement a cURL dataset of 100,000 instances with 1000 instances from each of the nine additional languages: Go, Java, JavaScript, libcurl, Node.js, PHP, Python, Ruby, and Swift in API Pack. The goal is to see if a model generalizes to new languages without requiring a large amount of multi-lingual data.
E. Integration of API Pack with Magicoder: This experiment investigates the effect of combining API Pack with existing instruction datasets. We integrate a subset of 50,000 entries from API Pack into the Magicoder datasets (Magicoder-OSS-Instruct plus Magicoder-Evol-Instruct) and fine-tune the CodeLlama-13b model. The focus is on assessing improvements in API call code generation, especially for Level 3 tasks under a 3-shot prompting.
4.3 Evaluations
To measure the generalization capabilities enabled by API Pack, we establish a comprehensive evaluation framework spanning three levels of complexity for API call generation.
-
•
Level 1, seen APIs and Endpoints assess generalization to new instructions within familiar APIs.
-
•
Level 2, seen APIs and new Endpoints test generalization to new endpoints of known APIs.
-
•
Level 3, unseen APIs and Endpoints validate performance on entirely new APIs.
Endpoint and API call accuracy at each level is measured by SequenceMatcher, which identifies the longest matching subsequences while excluding insignificant elements. A threshold of 0.9 is applied to compare the generated output with the ground truth Endpoint and API call.
| Model | Fine-tuning | Testing | Evaluation Accuracy (%) | |||||
| template | Level 1 | Level 2 | Level 3 | |||||
| Intent | API Call | Intent | API Call | Intent | API Call | |||
| Mistral-7b | zero-shot | 0-shot | 17.2 | 10.9 | 14.1 | 11.4 | 14.3 | 11.2 |
| 3-shot (retre) | 42.0 | 29.7 | 35.4 | 28.7 | 39.1 | 29.1 | ||
| three-shot | 0-shot | 40.5 | 28.5 | 24.0 | 18.3 | 15.2 | 12.1 | |
| 3-shot (retre) | 64.1 | 55.4 | 49.1 | 42.8 | 50.8 | 42.5 | ||
| CodeLlama-7b | zero-shot | 0-shot | 8.1 | 6.1 | 10.0 | 7.0 | 11.0 | 7.8 |
| 3-shot (retre) | 52.6 | 42.6 | 43.6 | 35.9 | 50.2 | 40.1 | ||
| three-shot | 0-shot | 12.1 | 9.3 | 13.7 | 10.2 | 16.8 | 13.0 | |
| 3-shot (retre) | 60.6 | 52.7 | 54.1 | 47.3 | 55.9 | 49.1 | ||
| Llama-2-13b | zero-shot | 0-shot | 9.4 | 6.2 | 11.6 | 9.0 | 10.9 | 8.4 |
| 3-shot (retre) | 44.5 | 33.9 | 45.4 | 35.6 | 46.7 | 39.1 | ||
| three-shot | 0-shot | 15.7 | 10.2 | 14.0 | 11.2 | 11.7 | 9.6 | |
| 3-shot (retre) | 59.5 | 51.5 | 50.8 | 44.3 | 52.7 | 44.2 | ||
| CodeLlama-13b | zero-shot | 0-shot | 9.8 | 6.8 | 10.8 | 8.1 | 12.1 | 8.5 |
| 3-shot (retre) | 55.6 | 44.4 | 50.6 | 43.3 | 52.3 | 44.1 | ||
| three-shot | 0-shot | 14.4 | 10.3 | 15.9 | 13.3 | 14.2 | 8.9 | |
| 3-shot (retre) | 63.5 | 55.5 | 56.8 | 51.4 | 56.1 | 49.5 | ||
| gpt-3.5-1106 | none | 3-shot (retre) | - | - | - | - | 47.2 | 39.5 |
| gpt-4-1106 | none | 3-shot (retre) | - | - | - | - | 53.5 | 44.3 |
5 Results
In this section, we present and briefly discuss the results of the experiments described in Section 4.
5.1 Fine-tuned CodeLlama Excels in API call Generation
Table 3 shows the evaluation results for the four models fine-tuned with 20,000 API Pack instances in Python. Overall, note that the fine tuning of CodeLlama-13b excels in API call (code generation) for the three-shot retrieved setting, where it achieved the top rates for the three evaluation levels (55.5% in Level 1, 51.4% in Level 2, and 49.5% in Level 3). Also note that the models fine-tuned with the three-shot template consistently show better performance than those fine-tuned with the zero-shot template. This result suggests that bootstrapping data with the three-shot template is important to improve the model’s in-context learning abilities. Another key insight is the substantial improvement observed prompting with 3-shot (retre) versus 0-shot at testing time. This trend is consistent across all models and levels, indicating that providing models with relevant examples improves their accuracy in generating API calls. Finally, note that the fine-tuning of CodeLlama-13b with API Pack outperforms GPT-3.5 and GPT-4 models (not fine-tuned) for Level 3.
5.2 Retrieval Augmentation Improves API Call Generation
The results of fine-tuning Mistral-7b and CodeLlama-13b models with the 20,000 Python API dataset using the three-shot template, highlights three-shot retrieval as the best approach to improve API call generation accuracy. See Appendix D for further details.
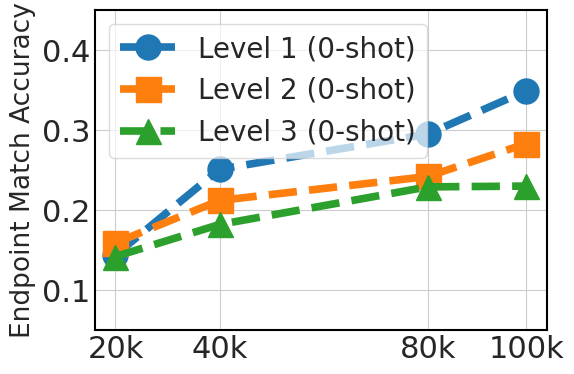
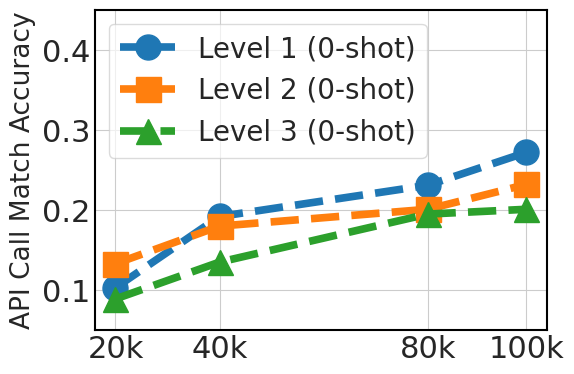
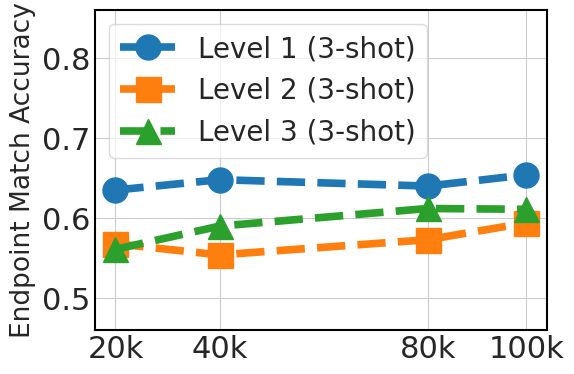
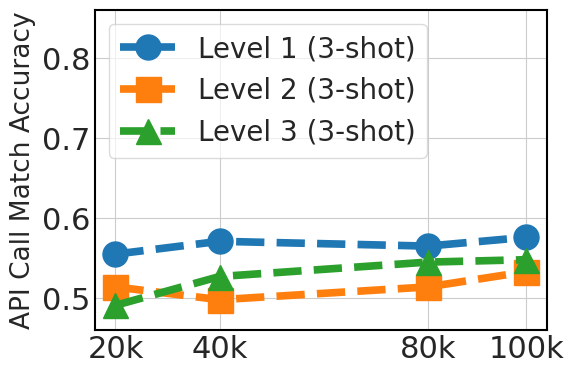
5.3 Scaling Instruction Dataset Helps Generalization
Fig. 3 clearly shows an upward trend in 0-shot performance that correlates with the dataset size (20k, 40k, 80k, and 100k Python API data). This improvement reflects the advantage of larger datasets in offering diverse examples, which is crucial in 0-shot prompting where the model relies exclusively on its pre-existing knowledge. For 3-shot, the graph also shows improvements as the dataset size increases, albeit less significantly than in the 0-shot case. This indicates that while additional fine-tuning data is beneficial, model pretraining is more instrumental for few-shot learning ability.
5.4 Multi-lingual Generalizations in API Call Performance
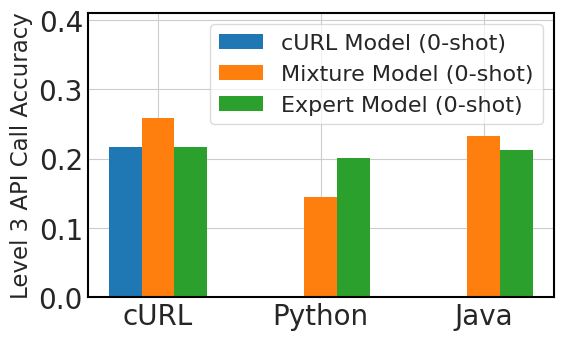
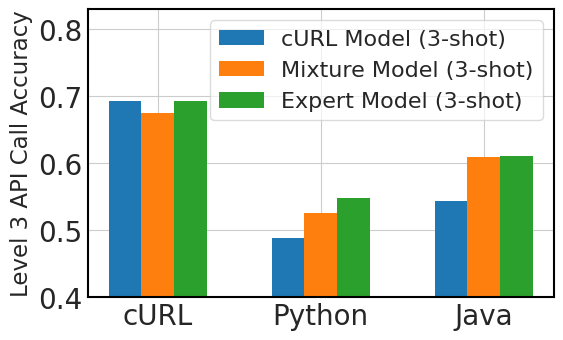
Figure 4 compares three fine-tuning approaches for multi-lingual API call performance: a model fine-tuned exclusively on 100,000 instances of ‘cURL’ data, or cURL Model, three expert models, each fine-tuned on 100,000 samples of ‘cURL’, ‘Python’, and ‘Java’ data separately, and a mixture model fine-tuned on 100,000 instances of ‘cURL’ data with additional samples of 9,000 instances each for nine different languages.
We distilled three key observations from this graph. First, generalizing to new programming languages without prior exposure remains a challenge in zero-shot scenarios. Second, despite the zero-shot limitations, the models demonstrate better-than-expected performance in three-shot contexts, indicating some degree of in-context learning adaptability, even without specific language fine-tuning. Third, mixed-language fine-tuning improves performance in both zero-shot and three-shot scenarios, which suggests that even a small amount of fine-tuning data in various languages can contribute to the model’s overall linguistic versatility and effectiveness in API call tasks.
We also analyzed the models’ adaptability across ten programming languages. We include the results of this analysis in Appendix E.
5.5 Improving Code Models with API Pack
We also evaluated the performance of mixing a subset of 50,000-entries of API Pack with Magicoder dataset and fine-tuned CodeLlama-13b model. The resulting model shows an increase of over 35.3% in API call code generation accuracy for Level 3, specifically with the 3-shot setting. This improvement does not come at the expense of general coding efficiency, as the resulting model still performs well on benchmarks such as HumanEval+ and MBPP. See Table 4 for further details.
| Data Mixture | Bench. (pass@10) | Level 3 (3-shot) | |
|---|---|---|---|
| HumanEval+ | MBPP | Endpoint | |
| - | 47.8 | 58.3 | - |
| Magicoder | 60.8 | 66.4 | 17.0 |
| Magicoder + API Pack | 61.3 | 64.3 | 52.3 |
6 Conclusion
In this paper, we introduce API Pack, a multilingual dataset of more than one million instruction-API call instances that seeks to improve models’ code generation ability. Leveraging this unprecedented scale and diversity, we explore two critical research questions: (1) Does exposure to a greater diversity of APIs during fine-tuning improve the model’s generalization to new API data? (2) Can models generalize to new languages without requiring a large amount of multi-lingual data? Our results demonstrate that increasing data volume does improve generalization capabilities, and that cross-lingual code generation can be achieved by training in only one programming language plus small amounts of data from other languages. Moreover, we also explored the usability of API Pack with other code instruction datasets. Our results show that API Pack improves API call code generation without affecting the general performance of other code generation tasks.
7 Limitations
While advancing the field of code generation with API call integration our research presents limitations:
-
•
API Pack instructions must include the API name to achieve correct intent-detection. This limitation hinders the model’s ability to intuitively interpret and respond incomplete queries.
-
•
Challenges with Multi-API Call Scenarios. As API Pack is not a multi-API call dataset, the models fine-tuned with this dataset will potentially struggle with scenarios involving multiple, interdependent API calls. This restricts API Pack effectiveness in complex, real-world software development tasks.
8 Future Work
Building upon these promising findings, we propose three future research directions:
-
•
Enriched API Classification. Eliminating the explicit need of API names in dataset instructions to allow intuitive context-based translation that better resembles natural coding workflows.
-
•
Argument Augmentation. Incorporating API calls with arguments for comprehensive, functional examples. This expanded scope enables models to generate detailed, actionable code that developers can test.
-
•
Multi-Step API Scenarios. Including multi-API call sequences to mirror real-world complexity and dependencies in advanced development settings.
9 Broader Impact Statement
Our research has a broader impact on Software Productivity as it aims to accelerate software development workflows by automating routine coding tasks. Alongside promising productivity gains, the integration of advanced LLMs into software development workflows raises sociotechnical concerns (e.g., job displacement, developers’ continuous oversight to ensure accuracy). Therefore, a responsible innovation lens assessing and responding to potential harms remains vital.
References
- Austin et al. (2021) Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., and Sutton, C. Program Synthesis with Large Language Models, August 2021. URL http://arxiv.org/abs/2108.07732. arXiv:2108.07732 [cs].
- Chen et al. (2023) Chen, L., Li, S., Yan, J., Wang, H., Gunaratna, K., Yadav, V., Tang, Z., Srinivasan, V., Zhou, T., Huang, H., and Jin, H. AlpaGasus: Training A Better Alpaca with Fewer Data, November 2023. URL http://arxiv.org/abs/2307.08701. arXiv:2307.08701 [cs].
- Chen et al. (2021) Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. d. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F. P., Cummings, D., Plappert, M., Chantzis, F., Barnes, E., Herbert-Voss, A., Guss, W. H., Nichol, A., Paino, A., Tezak, N., Tang, J., Babuschkin, I., Balaji, S., Jain, S., Saunders, W., Hesse, C., Carr, A. N., Leike, J., Achiam, J., Misra, V., Morikawa, E., Radford, A., Knight, M., Brundage, M., Murati, M., Mayer, K., Welinder, P., McGrew, B., Amodei, D., McCandlish, S., Sutskever, I., and Zaremba, W. Evaluating Large Language Models Trained on Code, July 2021. URL http://arxiv.org/abs/2107.03374. arXiv:2107.03374 [cs].
- Ebert & Louridas (2023) Ebert, C. and Louridas, P. Generative AI for Software Practitioners. IEEE Software, 40(4):30–38, July 2023. ISSN 1937-4194. doi: 10.1109/MS.2023.3265877. URL https://ieeexplore.ieee.org/abstract/document/10176168?casa_token=JPr1zeiL9IYAAAAA:noU0xEJ-kpRsoaLTTNiSFttcQ_Fw1lBtZRQWnykXIz6rRNvIW4qW-5nljQZYP7H_dH1yJ-3qc-bW. Conference Name: IEEE Software.
- Hou et al. (2023) Hou, X., Zhao, Y., Liu, Y., Yang, Z., Wang, K., Li, L., Luo, X., Lo, D., Grundy, J., and Wang, H. Large Language Models for Software Engineering: A Systematic Literature Review, September 2023. URL http://arxiv.org/abs/2308.10620. arXiv:2308.10620 [cs].
- Jiang et al. (2023) Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. d. l., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. Mistral 7B, October 2023. URL http://arxiv.org/abs/2310.06825. arXiv:2310.06825 [cs].
- Li et al. (2023a) Li, M., Song, F., Yu, B., Yu, H., Li, Z., Huang, F., and Li, Y. API-Bank: A Benchmark for Tool-Augmented LLMs, April 2023a. URL http://arxiv.org/abs/2304.08244. arXiv:2304.08244 [cs].
- Li et al. (2023b) Li, R., Allal, L. B., Zi, Y., Muennighoff, N., Kocetkov, D., Mou, C., Marone, M., Akiki, C., Li, J., Chim, J., Liu, Q., Zheltonozhskii, E., Zhuo, T. Y., Wang, T., Dehaene, O., Davaadorj, M., Lamy-Poirier, J., Monteiro, J., Shliazhko, O., Gontier, N., Meade, N., Zebaze, A., Yee, M.-H., Umapathi, L. K., Zhu, J., Lipkin, B., Oblokulov, M., Wang, Z., Murthy, R., Stillerman, J., Patel, S. S., Abulkhanov, D., Zocca, M., Dey, M., Zhang, Z., Fahmy, N., Bhattacharyya, U., Yu, W., Singh, S., Luccioni, S., Villegas, P., Kunakov, M., Zhdanov, F., Romero, M., Lee, T., Timor, N., Ding, J., Schlesinger, C., Schoelkopf, H., Ebert, J., Dao, T., Mishra, M., Gu, A., Robinson, J., Anderson, C. J., Dolan-Gavitt, B., Contractor, D., Reddy, S., Fried, D., Bahdanau, D., Jernite, Y., Ferrandis, C. M., Hughes, S., Wolf, T., Guha, A., von Werra, L., and de Vries, H. StarCoder: may the source be with you!, December 2023b. URL http://arxiv.org/abs/2305.06161. arXiv:2305.06161 [cs].
- Liang et al. (2023) Liang, J., Huang, W., Xia, F., Xu, P., Hausman, K., Ichter, B., Florence, P., and Zeng, A. Code as Policies: Language Model Programs for Embodied Control. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 9493–9500, May 2023. doi: 10.1109/ICRA48891.2023.10160591. URL https://ieeexplore.ieee.org/abstract/document/10160591?casa_token=NZCPW7T2O5QAAAAA:lnnQxWsEhgimKw52mjcQJ-GMER2nOCA11yJHSUvZGA_VZiHcM_qYfKBnd2GCRDbNcLGakL2SgQ.
- Liu et al. (2023a) Liu, J., Xia, C. S., Wang, Y., and Zhang, L. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation, October 2023a. URL http://arxiv.org/abs/2305.01210. arXiv:2305.01210 [cs].
- Liu et al. (2023b) Liu, W., Zeng, W., He, K., Jiang, Y., and He, J. What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, December 2023b. URL http://arxiv.org/abs/2312.15685. arXiv:2312.15685 [cs].
- Lu et al. (2023) Lu, K., Yuan, H., Yuan, Z., Lin, R., Lin, J., Tan, C., Zhou, C., and Zhou, J. #InsTag: Instruction Tagging for Analyzing Supervised Fine-tuning of Large Language Models, August 2023. URL http://arxiv.org/abs/2308.07074. arXiv:2308.07074 [cs].
- Luo et al. (2023) Luo, Z., Xu, C., Zhao, P., Sun, Q., Geng, X., Hu, W., Tao, C., Ma, J., Lin, Q., and Jiang, D. WizardCoder: Empowering Code Large Language Models with Evol-Instruct, June 2023. URL http://arxiv.org/abs/2306.08568. arXiv:2306.08568 [cs].
- Meng et al. (2018) Meng, M., Steinhardt, S., and Schubert, A. Application Programming Interface Documentation: What Do Software Developers Want? Journal of Technical Writing and Communication, 48(3):295–330, July 2018. ISSN 0047-2816. doi: 10.1177/0047281617721853. URL https://doi.org/10.1177/0047281617721853. Publisher: SAGE Publications Inc.
- Muennighoff et al. (2023) Muennighoff, N., Liu, Q., Zebaze, A., Zheng, Q., Hui, B., Zhuo, T. Y., Singh, S., Tang, X., von Werra, L., and Longpre, S. OctoPack: Instruction Tuning Code Large Language Models, August 2023. URL http://arxiv.org/abs/2308.07124. arXiv:2308.07124 [cs].
- Patil et al. (2023) Patil, S. G., Zhang, T., Wang, X., and Gonzalez, J. E. Gorilla: Large Language Model Connected with Massive APIs, May 2023. URL http://arxiv.org/abs/2305.15334. arXiv:2305.15334 [cs].
- Qin et al. (2023) Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., Lu, Y., Lin, Y., Cong, X., Tang, X., Qian, B., Zhao, S., Tian, R., Xie, R., Zhou, J., Gerstein, M., Li, D., Liu, Z., and Sun, M. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, July 2023. URL http://arxiv.org/abs/2307.16789. arXiv:2307.16789 [cs].
- Sadowski et al. (2015) Sadowski, C., Stolee, K. T., and Elbaum, S. How developers search for code: a case study. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, ESEC/FSE 2015, pp. 191–201, New York, NY, USA, August 2015. Association for Computing Machinery. ISBN 978-1-4503-3675-8. doi: 10.1145/2786805.2786855. URL https://dl.acm.org/doi/10.1145/2786805.2786855.
- Schick et al. (2023) Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., and Scialom, T. Toolformer: Language Models Can Teach Themselves to Use Tools, February 2023. URL http://arxiv.org/abs/2302.04761. arXiv:2302.04761 [cs].
- Shrivastava et al. (2023) Shrivastava, D., Larochelle, H., and Tarlow, D. Repository-Level Prompt Generation for Large Language Models of Code. In Proceedings of the 40th International Conference on Machine Learning, pp. 31693–31715. PMLR, July 2023. URL https://proceedings.mlr.press/v202/shrivastava23a.html. ISSN: 2640-3498.
- Tang et al. (2023) Tang, Q., Deng, Z., Lin, H., Han, X., Liang, Q., Cao, B., and Sun, L. ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases, September 2023. URL http://arxiv.org/abs/2306.05301. arXiv:2306.05301 [cs].
- Touvron et al. (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V., Khabsa, M., Kloumann, I., Korenev, A., Koura, P. S., Lachaux, M.-A., Lavril, T., Lee, J., Liskovich, D., Lu, Y., Mao, Y., Martinet, X., Mihaylov, T., Mishra, P., Molybog, I., Nie, Y., Poulton, A., Reizenstein, J., Rungta, R., Saladi, K., Schelten, A., Silva, R., Smith, E. M., Subramanian, R., Tan, X. E., Tang, B., Taylor, R., Williams, A., Kuan, J. X., Xu, P., Yan, Z., Zarov, I., Zhang, Y., Fan, A., Kambadur, M., Narang, S., Rodriguez, A., Stojnic, R., Edunov, S., and Scialom, T. Llama 2: Open Foundation and Fine-Tuned Chat Models, July 2023. URL http://arxiv.org/abs/2307.09288. arXiv:2307.09288 [cs].
- Wang et al. (2023a) Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., and Hajishirzi, H. Self-Instruct: Aligning Language Models with Self-Generated Instructions, May 2023a. URL http://arxiv.org/abs/2212.10560. arXiv:2212.10560 [cs].
- Wang et al. (2023b) Wang, Y., Le, H., Gotmare, A. D., Bui, N. D. Q., Li, J., and Hoi, S. C. H. CodeT5+: Open Code Large Language Models for Code Understanding and Generation, May 2023b. URL http://arxiv.org/abs/2305.07922. arXiv:2305.07922 [cs].
- Wei et al. (2023) Wei, Y., Wang, Z., Liu, J., Ding, Y., and Zhang, L. Magicoder: Source Code Is All You Need, December 2023. URL http://arxiv.org/abs/2312.02120. arXiv:2312.02120 [cs].
- Xiao et al. (2023) Xiao, S., Liu, Z., Zhang, P., and Muennighoff, N. C-Pack: Packaged Resources To Advance General Chinese Embedding, December 2023. URL http://arxiv.org/abs/2309.07597. arXiv:2309.07597 [cs].
- Xu et al. (2023a) Xu, C., Sun, Q., Zheng, K., Geng, X., Zhao, P., Feng, J., Tao, C., and Jiang, D. WizardLM: Empowering Large Language Models to Follow Complex Instructions, June 2023a. URL http://arxiv.org/abs/2304.12244. arXiv:2304.12244 [cs].
- Xu et al. (2023b) Xu, Q., Hong, F., Li, B., Hu, C., Chen, Z., and Zhang, J. On the Tool Manipulation Capability of Open-source Large Language Models, May 2023b. URL https://arxiv.org/abs/2305.16504v1.
- Yang et al. (2023) Yang, R., Song, L., Li, Y., Zhao, S., Ge, Y., Li, X., and Shan, Y. GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction, May 2023. URL http://arxiv.org/abs/2305.18752. arXiv:2305.18752 [cs].
- Zan et al. (2023) Zan, D., Chen, B., Zhang, F., Lu, D., Wu, B., Guan, B., Yongji, W., and Lou, J.-G. Large Language Models Meet NL2Code: A Survey. In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 7443–7464, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.411. URL https://aclanthology.org/2023.acl-long.411.
- Zhang et al. (2023) Zhang, P., Xiao, S., Liu, Z., Dou, Z., and Nie, J.-Y. Retrieve Anything To Augment Large Language Models, October 2023. URL http://arxiv.org/abs/2310.07554. arXiv:2310.07554 [cs].
Appendix
Appendix A Data Filtering at each Stage of the Pipeline
| Source/Instances | Before Data Validation | After Removing Invalid API calls | After Removing Instances without Good Instructions |
|---|---|---|---|
| API Hub | 27,635 | 17,712 | 17,206 |
| APIs Gurus | 500,160 | 499,250 | 495,533 |
| Swaggerhub | 351,756 | 351,756 | 345,765 |
| RapidAPI | 274,014 | 273,388 | 270,095 |
| Total | 1,153,565 | 1,142,106 | 1,128,599 |
Appendix B Hyperparameters for Training
We fine-tune the models using the HuggingFace Transformers library on a cluster consisting of 1 node with 8 NVIDIA H100 80GB GPUs, with Fully Shared Data Parallelism (FSDP). Techniques such as mixed precision, gradient checkpointing, and AdaFactor optimizer are used to improve training efficiency. The key hyperparameters are summarized in Table 6.
| Hyperparameter Name | Value |
|---|---|
| Learning rate | |
| Batch size | 128 |
| Max seq length | 4096 |
| Number of epochs | 2 |
| Warmup ratio | 0.03 |
Appendix C Testing Pipeline
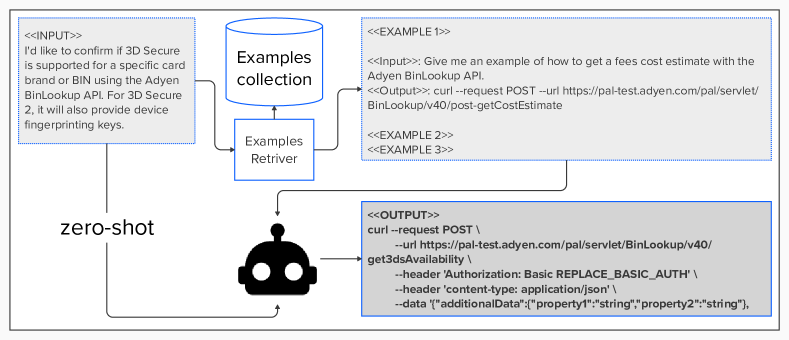
Figure 5 shows an example of our testing pipeline including zero and few-shot.
Appendix D Retrieval methods comparison
Figure 7 illustrates the impact of different retrieval methods for three-shot API call generation.
| Model | Testing | Evaluation Accuracy (%) | |||||
| Level 1 | Level 2 | Level 3 | |||||
| Endpoint | API Call | Endpoint | API Call | Endpoint | API Call | ||
| Mistral-7b | 3-shot (rand) | 54.5 | 41.8 | 48.2 | 41.2 | 45.2 | 37.0 |
| 3-shot (retre) | 64.1 | 55.4 | 49.1 | 42.8 | 50.8 | 42.5 | |
| 3-shot (retre & rerank) | 63.0 | 53.6 | 49.0 | 42.2 | 51.5 | 43.9 | |
| CodeLlama-13b | 3-shot (rand) | 49.2 | 38.6 | 49.8 | 43.6 | 50.0 | 41.4 |
| 3-shot (retre) | 63.5 | 55.5 | 56.8 | 51.4 | 56.1 | 49.5 | |
| 3-shot (retre & rerank) | 61.0 | 52.9 | 55.1 | 49.2 | 55.9 | 49.3 | |
Appendix E Analysis of Cross-linguistic Flexibility
Figure 6 illustrates the models’ adaptability across ten programming languages. The mixture model is on par with expert models in three-shot testing, highlighting the models’ potential in multi-lingual programming applications.

Appendix F API DB instance
Figure 7 shows and the structure of an API DB instance. We used openapi-snippet 101010https://www.npmjs.com/package/openapi-snippet, an open-source package that takes as input an OpenAPI v2.0 or v3.0.x specification file (OAS file) and translates it into an HTTP Archive 1.2 request object, to generate API calls. We generated API calls (api_call) in 10 different programming languages (cURL, libcurl, java, node, python, go, ruby, php, swift, JavaScript) for RapidAPI, API Gurus, and the Swaggerhub. For the company’s public API Hub API calls were extracted directly from the OAS files. We extracted API calls in eight different programming languages from this source (cURL, java, node, python, go, ruby, php, swift).
Appendix G Instruction Candidates
Figure 8 shows all the candidates generated for an instance with their respective id and input_tokens_mean.