[json]breaklines
API Pack: A Massive Multi-Programming Language Dataset for API Call Generation
Abstract
We introduce API Pack, a massive multi-programming language dataset containing more than 1 million instruction-API call pairs to improve the API call generation capabilities of large language models. By fine-tuning CodeLlama-13B on 20,000 Python instances from API Pack, we achieved around 10% and 5% higher accuracy compared to GPT-3.5 and GPT-4, respectively, in generating unseen API calls. Fine-tuning on API Pack enables cross-programming language generalization by leveraging a large amount of data in one language and small amounts of data from other languages. Scaling the training data to 1 million instances further improves the model’s generalization to new APIs not encountered during training. We open-source the API Pack dataset, trained models, and associated source code at https://github.com/zguo0525/API-Pack to facilitate further research.
1 Introduction
Large language models (LLMs) have shown promise in assisting with software engineering tasks [1, 2, 3, 4, 5, 6, 7, 8, 9], with a primary focus on code generation [10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26]. Our work builds on these advances but targets at the time-consuming task developers often face in finding application programming interface (API) call code examples. While finding an appropriate API is relatively easy with search, the challenge lies in generating the specific API call code. This involves understanding the API’s parameters, data types, and required operations, which can be complex and vary significantly across different APIs. Currently, developers typically seek out examples in documentations or API hubs [27], sifting through lengthy pages to locate relevant information [28]. This process is recognized as cumbersome and inefficient, as it requires developers to manually parse and adapt the example code to their specific use case. Our research aims to transform this workflow by using LLMs to identify appropriate API endpoints and generate corresponding API calls based on natural language instructions, thus automating the process of understanding and adapting API call code examples.
To achieve this research goal, we created API Pack, a dataset designed to improve the API call generation capabilities of LLMs. This massive multi-programming language dataset, containing over 1 million instances across 10 programming languages, is by far the largest open-source instruction dataset (see Table 1) for API call generation and API call intent detection. We evaluated the effectiveness of API Pack in improving API call generation through various experiments (see Section 4), and find that CodeLlama-13B, fine-tuned with only 20,000 Python instances from API Pack, surpasses the performance of GPT-3.5 and GPT-4 in generating API calls for entirely new APIs.
API Pack distinguishes itself from prior works [29, 30, 31] in two key aspects: multilinguality and scale. API Pack includes API calls across 10 different programming languages (see Table 1), allowing for a unique assessment of cross-lingual skill transfer - the extent to which improvements in one language apply to others. This is crucial for the practical application of LLMs in API call generation but has been underexplored in previous studies. Furthermore, with over a million instances spanning a wider range of real-world APIs and use cases compared to its predecessors, API Pack enables a more rigorous evaluation of generalization capabilities by controlling the volume of training data.
We summarize three key findings from our experiments:
| Feature | API Pack (this work) | APIBench (Gorilla) | ToolBench | ToolBench (ToolLLM) | API Bank | ToolAlpaca | ToolFormer |
|---|---|---|---|---|---|---|---|
| API call intent detection? | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| API call code generation? | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Multi-lingual API calls? | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Multi-API call scenario? | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Data generation method: | custom | self-instruct | self-instruct | custom | custom | custom | custom |
| # of Sources | 4 | 3 | 8 | 1 | 53 | / | 5 |
| # of APIs / Tools | 11,213 | 1,645 | 8 | 16,464 | 53 | 400 | 5 |
| # of API calls | 1,128,599 | 16,450 | / | 37,204 | 568 | 3,938 | 9,400 |
| # of Instances | 1,128,599 | 16,450 | 2,746 | 12,657 | 264 | 3,938 | 22,453 |
-
1.
Fine-tuning CodeLlama-13B on 20,000 Python instances from API Pack yields over 10% and 5% higher accuracy than GPT-3.5 and GPT-4, respectively, for unseen API calls.
-
2.
Cross-lingual API call generation can be achieved by fine-tuning models on a large amount of data in one language plus small amounts of data from other languages.
-
3.
Scaling the instruction data to 1 million instances improves generalization to new APIs, confirming the benefits of a larger dataset.
The paper is organized as follows: Section 2 reviews related works. Section 3 describes the construction of API Pack dataset. Section 4 outlines the experimental design for fine-tuning models on API Pack and evaluating their performance. The key findings are presented in Section 5. We conclude the paper in Section 6, and address the limitations in Section 7. API Pack dataset is licensed under the Creative Commons Attribution 4.0 International (CC BY 4.0) License. The associated source code is licensed under an MIT License.
2 Related Works
2.1 Methods to Generate Instruction Data with LLMs
Manually creating instruction data is labor-intensive [32]. To automate this process, researchers have proposed using LLMs, despite the risk of generating low-quality instances. Two popular methods are Self-Instruct [33] and Evol-Instruct [32], and both methods involve instance generation and filtering. Self-Instruct mutates seed instances using in-context examples and filters them based on ROUGE-L similarity and other heuristics. Evol-Instruct generates instances via targeted prompting and filters them using predefined heuristics. Quality checks are crucial when fine-tuning models with synthetic data. Expert annotators can determine instance correctness [33], or strong LLMs like ChatGPT can score or classify instances [34] based on heuristics derived from a small sample. This approach has also been used to assess instruction complexity [35, 36].
2.2 LLMs for API Call Code Generation and Intent Detection
LLMs for code generation primarily focus on general coding tasks, evaluated by benchmarks like MBPP [37], HumanEval [38], and its variants [39, 40, 41]. Recent research explores LLMs and APIs in two areas: API call intent detection and API call code generation. API call intent detection identifies the appropriate API endpoint for a natural language task. LLMs for this purpose [31, 42, 43, 44, 45] work in hybrid architectures, where the LLM finds the API endpoint(s) and other components generate the code. These studies explore single and multi-API intent scenarios, with few achieving good results in the latter [31]. Our work focuses on creating LLMs that generate code to invoke API functionality, which is less explored than API call intent detection. Gorilla [30] generates API calls for loading pre-trained machine learning models from known model hubs. ToolBench [29] benchmarks tool manipulation capabilities of open-source LLMs. Another line of work explores function calling in language models [46, 47, 48], including ChatGPT. These models require pre-defined functions before execution, differing from our scenario where developers rely on the language model to guide them to the appropriate function or API based on natural language input.
3 API Pack
API Pack is an instruction dataset with more than one million instances. Each instance contains an input-output pair plus additional information about the API and respective endpoints. The inputs are instructions for finding an API call to solve a coding task, including a task description in software engineering language and the name of the API to be used. The outputs are API call examples, specifically HTTP request code snippets curated from OpenAPI specification (OAS) files. The data in API Pack is sourced from four hubs that store OAS files: RapidAPI111https://rapidapi.com/categories, APIGurus222https://apis.guru/, Swaggerhub333https://app.swaggerhub.com/search, and IBM’s public API Hub444https://developer.ibm.com/apis/. Table 2 summarizes the total number of APIs, unique endpoints, and total instances (in different programming languages) contained within API Pack.
| Source | APIs | Unique Endpoints | Total Instances |
|---|---|---|---|
| IBM API Hub | 73 | 2,884 | 17,206 |
| APIs Gurus | 1,980 | 37,097 | 495,533 |
| Swaggerhub | 5,045 | 26,747 | 345,765 |
| RapidAPI | 4,115 | 21,525 | 270,095 |
| Total | 11,213 | 88,253 | 1,128,599 |
The construction of API Pack involves four main stages: data pre-processing (Section 3.1), API Database (DB) creation (Section 3.2), instruction generation (Section 3.3), and data validation (Section 3.4). Figure 1 illustrates the overall pipeline.
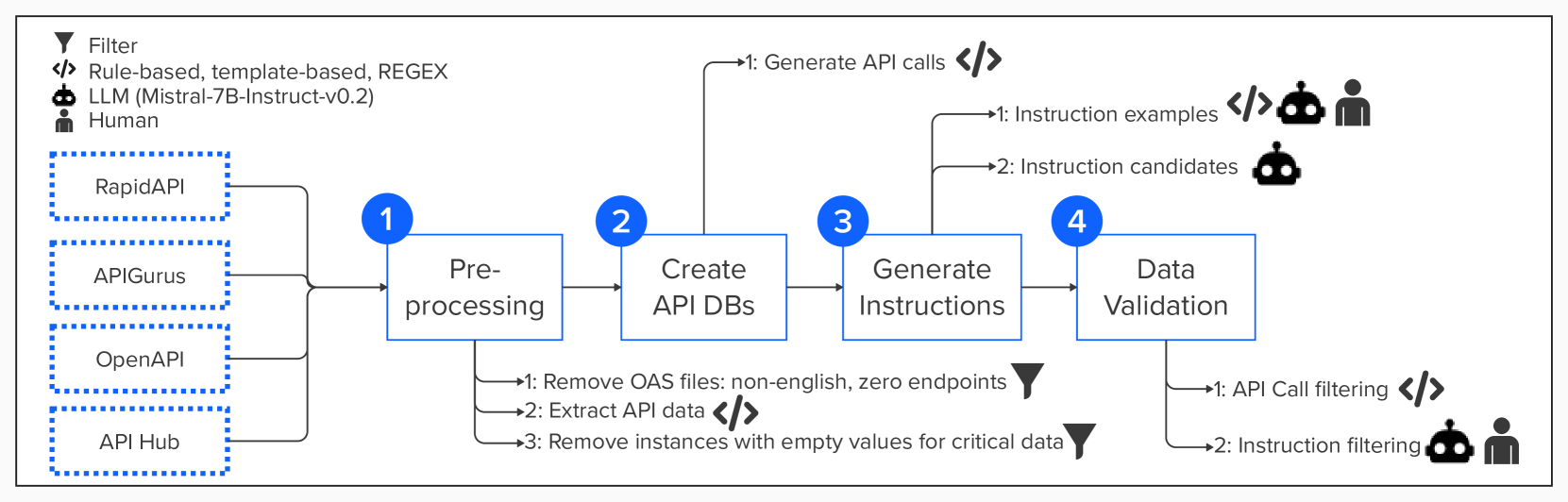
3.1 Data Pre-processing
The data pre-processing stage involves two main steps. First, we filter out OAS files with non-English data to maintain language consistency. We also remove OAS files with zero endpoints, as they lack the necessary information to generate meaningful API call examples or instructions. Next, we extract relevant information from the remaining OAS files. At the endpoint level, we collect the name, functionality, description, method, and path. At the API level, we gather the API name, description, and provider. To further ensure data quality, we apply a second filter to remove instances with missing crucial data for generating API calls (e.g., method, path, or endpoint name) and instructions (e.g., functionality, description, or endpoint name). This step guarantees that all instances in the dataset contain the necessary information for generating useful API call examples and instructions.
3.2 Create API Databases
We build an API database (DB) using the pre-processed data, with each instance containing endpoint information, API details, an API call example in a specific programming language, and a language identifier. We use OpenAPI Snippet555https://www.npmjs.com/package/openapi-snippet to generate API calls in 10 programming languages (cURL, libcurl, Java, Node.js, Python, Go, Ruby, PHP, Swift, JavaScript) for endpoints from RapidAPI, APIGurus, and OpenAPI, while directly extracting API calls from OAS files for IBM API Hub. Appendix 9.5 provides details on the API DB instance structure and the programming language diversity for each source.
3.3 Instructions Generation
The instruction generation process consists of two main steps: creating high-quality instruction examples and generating instruction candidates. This two-step process is essential to ensure the generation of precise, clear, and useful instructions.
First, we create high-quality instruction examples for each API DB file. We randomly select three endpoints from each API and use their information (e.g., functionality, description, endpoint_name, path) along with the respective API name to fill in a list of predefined instruction templates. This process yields three instruction examples per API DB file. For the API Gurus and IBM API Hub sources, three authors manually review and refine the generated instruction examples by correcting grammatical errors, removing unnecessary information, and ensuring that the API name is present in all examples. During this manual review, we identify common error patterns in the generated instructions. To streamline the refinement process for the Swaggerhub and RapidAPI sources, we replace human labor with an LLM (Mistral-7B-Instruct-v0.2666https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2). We create a prompt (Prompt 1 in Appendix 9.8) based on the common error patterns identified during the manual review of the API Gurus and IBM API Hub instruction examples. This prompt is used to guide the LLM in refining the instruction examples for the Swaggerhub and RapidAPI sources.
Next, we use the high-quality instruction examples to generate instruction candidates for each instance in the API DBs. We prompt an LLM (Mistral-7B-Instruct-v0.2) with the endpoint’s information as input and provide the high-quality instruction examples as in-context examples (Prompt 2 in Appendix 9.8). The LLM generates five instruction candidates for each instance in the API DBs. Figure 2 shows an example of a generated instruction candidate, while Appendix 9.7 presents all five candidates generated for the same instance.
[fontsize=, breaklines, breakanywhere] bash "instruction_candidates": [ "idx": 1, "candidate": "I’d like to confirm if 3D Secure is supported for a specific card brand or BIN using the Adyen BinLookup API. For 3D Secure 2, it will also provide device fingerprinting keys.", "input_tokens_mean": -0.5497539341557909, , … ], "api_call": "curl –request POST –url https://paltest.adyen.com/pal/servlet/BinLookup/v40/get3dsAvailability –header ’Authorization: Basic REPLACE_BASIC_AUTH’ –header ’content-type: application/json’ –data ’"additionalData":"property1":"string","property2":"string", "brands":["string"], "cardNumber":"string", "merchantAccount":"string", "recurringDetailReference":"string", "shopperReference":"string"’" …
3.4 Data Validation
The data validation process involves three main steps: 1) verifying the validity of API calls as HTTP request examples in a given programming language, 2) assessing the quality of generated instructions, and 3) selecting the highest-quality instruction for fine-tuning.
To verify the validity of API calls, we first compare the API call’s content with the instance data to ensure the correctness of the endpoint_name and the HTTP method (e.g., get, post, put, delete, custom method name). We then use regular expressions to validate the URL format, considering that placeholder strings may exist for the URL domain, path parameters, or query parameters. Additionally, we check that the programming language keywords in the API call match the language string ID assigned to each instance.
To validate the generated instructions for each API call, we randomly select a sample of 121 instances, each containing one API call and five instructions. These instances have unique functionality, description, and endpoint_name. One of the authors manually labels the 605 instructions (121 instances x 5 instructions) as good or bad. The analysis of the instructions labeled as bad reveals three common characteristics: 1) containing multiple instructions instead of a single one, b) including unnecessary text before or after the main instruction, and c) failing to accurately use the correct API name. Based on these characteristics, we create three prompts with a fixed set of in-context examples to automatically label instructions. To select the best prompt, we use an LLM (Mistral-7B-Instruct-v0.2) to label the 605 manually classified instructions and compare the results with human-labeled results. We choose the prompt with the best performance (Prompt 4 in Appendix 9.8) and instruct Mistral-7B-Instruct-v0.2 to classify all instructions in our dataset as good or bad. Instances with fewer than two good instructions are removed from the dataset.
To select the best candidate from the subset of good instructions, we calculate the likelihood of an LLM re-generating the input text used to generate the instruction. We prompt Mistral-7B-Instruct-v0.2 with each instruction candidate (Prompt 3 in Appendix 9.8) and obtain the log probability of each token for the re-generated input text. We calculate the mean of these log probabilities (input_tokens_mean). Appendix 9.7 shows five instruction candidates and their respective input_tokens_mean. We select instructions labeled as good with the best input_token_mean for fine-tuning. Our final dataset contains 1,128,599 instances, each with a valid API call example and at least two high-quality instructions. Appendix 9.1 shows the data instances filtered out at each stage of the pipeline.
4 Experiments and Evaluation Framework
To optimize the instruction-following capabilities of the language models, we post-processed API Pack into two instruction-tuning templates: zero-shot and three-shot. The zero-shot template targets scenarios where the output is expected to be a straightforward inference from the given input. The three-shot template emphasizes the model’s ability to learn and generate output with in-context learning. The three-shot template is available in Appendix 5.
4.1 Experimental Settings
A. Selecting the baseline: Our first experimental setting serves the purpose of selecting a base model for the rest of our experiments. We fine-tune Mistral 7b [49], CodeLlama 7b and 13b, as well as Llama 2 13b [50] on a subset of API Pack (20,000 instances in Python programming language). We evaluate the performance of each resulting model fine-tuned on the 20k subset and use the base model of the best-performing fine-tuned model in the rest of our experiments.
B. Inference with retrieval: Our second experiment aims to understand the influence of retrieval augmentation on model generalization. We evaluate the models under four distinct prompt settings during test time:
-
•
0-shot: No API examples provided for the model.
-
•
3-shot random: Three randomly selected API examples.
-
•
3-shot retrieved: Three retrieved relevant API examples.
-
•
3-shot retrieved & re-ranked: Five retrieved API examples, with three selected using a re-ranker model.
Note that these prompt settings are for testing/inference and differ from the instruction-tuning templates used in fine-tuning. We use bge-large-en-v1.5 [51] as the embedding model for retrieval and beg-reranker-large [52] for re-ranking. Appendix 9.4 illustrates the inference pipelines (0-shot, 3-shot) used to evaluate the models’ performance.
C. Cross-lingual generalization: To test the model’s ability to generalize to new programming languages, we supplement a cURL dataset of 100,000 instances with 1,000 instances from each of the nine additional languages in API Pack: Go, Java, JavaScript, libcurl, Node.js, PHP, Python, Ruby, and Swift. The goal is to determine if a model can generalize to new languages without requiring a large amount of multi-programming language data.
D. Scaling experiment: We conduct a scaling experiment to investigate whether more API data improves a model’s generalization ability for unseen API. We fine-tune models on progressively larger API datasets with unique API calls: 10k, 20k, 40k, 80k, 100k, and 1 million instances. Our hypothesis is that exposure to a greater scale and diversity of APIs during fine-tuning will improve the model’s ability to generalize to new, unseen APIs.
4.2 Evaluations
To measure the generalization capabilities enabled by API Pack, we establish a comprehensive evaluation framework spanning three levels of complexity for API call generation:
-
•
Level 1: Seen APIs and endpoints. This level assesses generalization to new instructions.
-
•
Level 2: Seen APIs and new endpoints. This level tests generalization to new endpoints of known APIs.
-
•
Level 3: Unseen APIs and endpoints. This level validates performance on entirely new APIs.
The process of data splitting is detailed in Appendix 9.2. Training hyperparameters are in Appendix 9.3. Endpoint and API call accuracy at each level is measured by SequenceMatcher, which identifies the longest matching subsequences while excluding insignificant elements. These elements refer to specific parts of the API requests that do not affect the overall functionality or purpose of the request, such as whitespace and formatting differences (e.g., variations in spaces, tabs, or newlines within the API requests) and specific naming conventions or variable names (i.e., the focus is on the structure and parameters of the API requests rather than the specific names used for variables or functions, as long as they serve the same purpose). A heuristic threshold of 0.9 is applied to compare the generated output with the ground truth Endpoint and API call, where the developers are expected to complete the API call based on the model response above this threshold.
5 Results
| Model | Fine-tuning | Testing | Evaluation Accuracy (%) | |||||
| template | Level 1 | Level 2 | Level 3 | |||||
| Intent | API Call | Intent | API Call | Intent | API Call | |||
| Mistral-7b | zero-shot | 0-shot | 17.2 | 10.9 | 14.1 | 11.4 | 14.3 | 11.2 |
| 3-shot (retre) | 42.0 | 29.7 | 35.4 | 28.7 | 39.1 | 29.1 | ||
| three-shot | 0-shot | 40.5 | 28.5 | 24.0 | 18.3 | 15.2 | 12.1 | |
| 3-shot (retre) | 64.1 | 55.4 | 49.1 | 42.8 | 50.8 | 42.5 | ||
| CodeLlama-7b | zero-shot | 0-shot | 8.1 | 6.1 | 10.0 | 7.0 | 11.0 | 7.8 |
| 3-shot (retre) | 52.6 | 42.6 | 43.6 | 35.9 | 50.2 | 40.1 | ||
| three-shot | 0-shot | 12.1 | 9.3 | 13.7 | 10.2 | 16.8 | 13.0 | |
| 3-shot (retre) | 60.6 | 52.7 | 54.1 | 47.3 | 55.9 | 49.1 | ||
| Llama-2-13b | zero-shot | 0-shot | 9.4 | 6.2 | 11.6 | 9.0 | 10.9 | 8.4 |
| 3-shot (retre) | 44.5 | 33.9 | 45.4 | 35.6 | 46.7 | 39.1 | ||
| three-shot | 0-shot | 15.7 | 10.2 | 14.0 | 11.2 | 11.7 | 9.6 | |
| 3-shot (retre) | 59.5 | 51.5 | 50.8 | 44.3 | 52.7 | 44.2 | ||
| CodeLlama-13b | zero-shot | 0-shot | 9.8 | 6.8 | 10.8 | 8.1 | 12.1 | 8.5 |
| 3-shot (retre) | 55.6 | 44.4 | 50.6 | 43.3 | 52.3 | 44.1 | ||
| three-shot | 0-shot | 14.4 | 10.3 | 15.9 | 13.3 | 14.2 | 8.9 | |
| 3-shot (retre) | 63.5 | 55.5 | 56.8 | 51.4 | 56.1 | 49.5 | ||
| gpt-3.5-1106 | none | 0-shot | - | - | - | - | 1.0 | 0.7 |
| none | 3-shot (retre) | - | - | - | - | 47.2 | 39.5 | |
| gpt-4-1106 | none | 0-shot | - | - | - | - | 0.2 | 0.1 |
| none | 3-shot (retre) | - | - | - | - | 53.5 | 44.3 | |
5.1 Fine-tuned CodeLlama Excels in API call Generation
Table 3 presents the evaluation results for the four models fine-tuned with 20,000 Python instances from API Pack. The fine-tuned CodeLlama-13b model demonstrates superior performance in API call generation for the three-shot retrieved setting, achieving the highest API call accuracy across all evaluation levels. Models fine-tuned with the three-shot template consistently outperform those fine-tuned with the zero-shot template, showing the importance of using the three-shot template to improve the model’s in-context learning abilities. Furthermore, prompting with 3-shot (retre) at testing time leads to substantial improvements compared to 0-shot, a trend observed across all models and levels. This finding highlights the significance of providing relevant examples to improve the models’ accuracy in generating API calls. Notably, the fine-tuned CodeLlama-13b model with API Pack surpasses the performance of GPT-3.5 and GPT-4 models (not fine-tuned) for Level 3, both 0-shot and 3-shot (retre).
| Model | Testing | Evaluation Accuracy (%) | |||||
| Level 1 | Level 2 | Level 3 | |||||
| Endpoint | API Call | Endpoint | API Call | Endpoint | API Call | ||
| Mistral-7b | 3-shot (rand) | 54.5 | 41.8 | 48.2 | 41.2 | 45.2 | 37.0 |
| 3-shot (retre) | 64.1 | 55.4 | 49.1 | 42.8 | 50.8 | 42.5 | |
| 3-shot (retre & rerank) | 63.0 | 53.6 | 49.0 | 42.2 | 51.5 | 43.9 | |
| CodeLlama-13b | 3-shot (rand) | 49.2 | 38.6 | 49.8 | 43.6 | 50.0 | 41.4 |
| 3-shot (retre) | 63.5 | 55.5 | 56.8 | 51.4 | 56.1 | 49.5 | |
| 3-shot (retre & rerank) | 61.0 | 52.9 | 55.1 | 49.2 | 55.9 | 49.3 | |
5.2 Retrieval Augmentation Improves API Call Generation
Table 4 illustrates the impact of different retrieval methods on three-shot API call generation, highlighting the significance of retrieval augmentation in improving the models’ performance. The results of fine-tuning Mistral-7b and CodeLlama-13b models with 20,000 Python instances from API Pack using the three-shot template demonstrate that three-shot retrieval is the most effective approach.
5.3 Cross-lingual Generalizations in API Call Performance
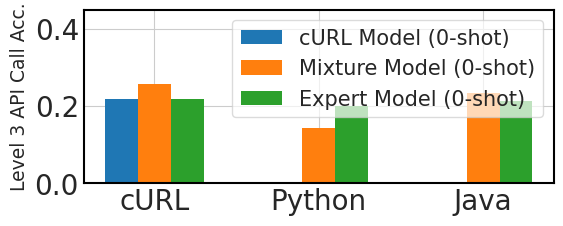
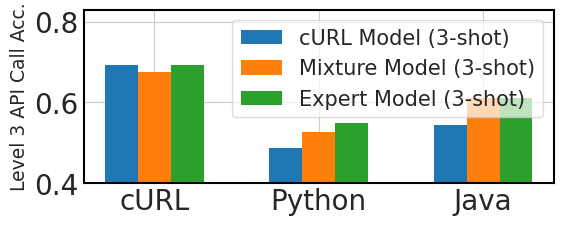

Figure 3 compares three fine-tuning approaches for cross-lingual API call performance: a model fine-tuned exclusively on 100,000 instances of ‘cURL’ data, or cURL Model, three expert models, each fine-tuned on 100,000 samples of ‘cURL’, ‘Python’, and ‘Java’ data separately, and a mixture model fine-tuned on 100,000 instances of ‘cURL’ data with additional samples of 1,000 instances each for nine different languages.
The graph shows that generalizing to new programming languages without fine-tuning is challenging in zero-shot scenarios. However, the models perform better than expected in three-shot settings, indicating some in-context learning adaptability. Mixed-language fine-tuning improves performance in both zero-shot and three-shot scenarios, suggesting that even a small amount of fine-tuning data in various languages can improve the model’s effectiveness in cross-lingual API call tasks. These findings demonstrate that cross-lingual API call generation can be achieved by fine-tuning models on a large amount of data in one language plus small amounts of data from other languages, without requiring an extensive dataset for each target programming language. Figure 4 illustrates the models’ adaptability across ten programming languages, with the Mixture Model performing on par with Expert Models in three-shot testing, highlighting their potential in multi-lingual programming applications.
5.4 Scaling Instruction Dataset Helps Generalization
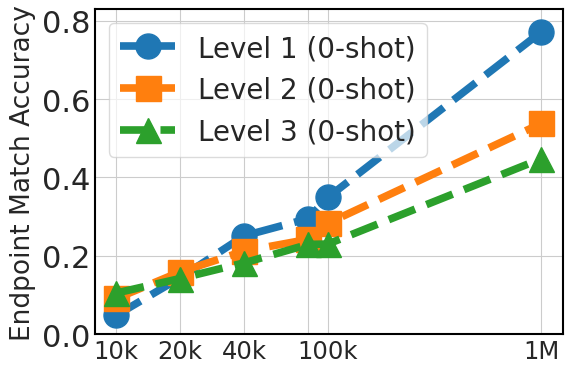
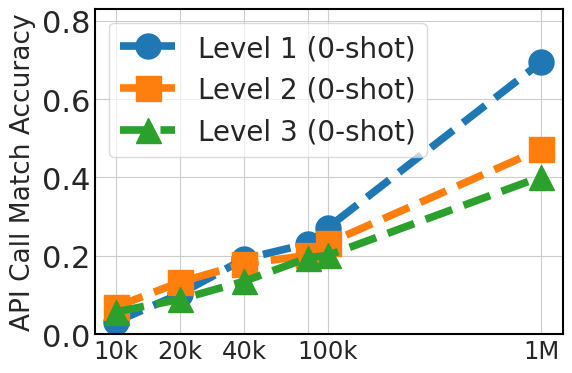
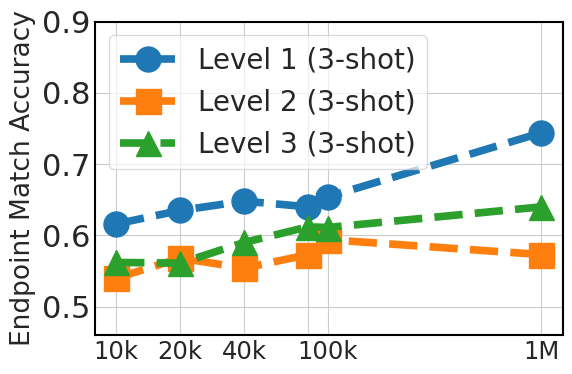
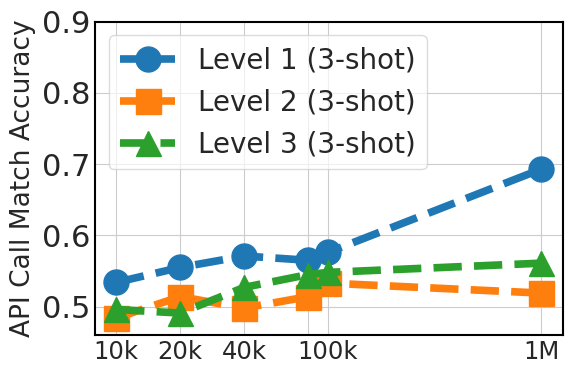
Fig. 5 clearly demonstrates an upward trend in zero-shot performance that correlates with the fine-tuning dataset size (20k, 40k, 80k, 100k, and 1 million instances from API Pack). This improvement highlights the advantage of larger datasets in providing diverse examples, which is crucial in zero-shot prompting where the model relies solely on its pre-existing knowledge. For three-shot prompting, the graph also shows improvements as the dataset size increases, although less significantly than in the zero-shot case, particular for level 3 cases. This suggests that while additional fine-tuning data is beneficial, model pretraining plays a more critical role in in-context learning ability.
5.5 Additional Ablation Experiments
| Train | Testing | Evaluation Accuracy | |||||
| Level 1 Endpoint | Level 1 API Call | Level 2 Endpoint | Level 2 API Call | Level 3 Endpoint | Level 3 API Call | ||
| ToolBench | 0-shot | 5.7 | 5.7 | 8.1 | 8.0 | 7.3 | 7.0 |
| 3-shot | 44.5 | 37.8 | 40.7 | 36.4 | 43.7 | 38.1 | |
| API Pack | 0-shot | 14.4 | 10.3 | 15.9 | 13.3 | 14.2 | 8.9 |
| 3-shot | 63.5 | 55.5 | 56.8 | 51.4 | 56.1 | 49.1 | |
To verify API Pack’s quality, we evaluated a fine-tuned CodeLlama-13b model on 20k instances of ToolBench dataset, which only contains APIs from RapidAPI. Results in Table 5 show that using APIs from a single source like in TollBench decreases model performance in both 0-shot and 3-shot settings compared to API Pack, which curates data from four different sources.
| Train | Testing | Evaluation Accuracy | |||||
| Level 1 Endpoint | Level 1 API Call | Level 2 Endpoint | Level 2 API Call | Level 3 Endpoint | Level 3 API Call | ||
| none-filtered | 0-shot | 10.3 | 8.3 | 12.8 | 10.3 | 12.2 | 8.4 |
| 3-shot | 62.4 | 54.9 | 54.9 | 48.7 | 55.7 | 49.5 | |
| with-filtered | 0-shot | 14.4 | 10.3 | 15.9 | 13.3 | 14.2 | 8.9 |
| 3-shot | 63.5 | 55.5 | 56.8 | 51.4 | 56.1 | 49.1 | |
Furthermore, to demonstrate the effectiveness of our data filtering pipeline, we replaced 45% of the filtered instructions with non-filtered ones and fine-tuned CodeLlama-13b with 20k instances of each. The results in Table 6 confirm that the 0-shot and 3-shot performances indeed drop with the introduction of non-filtered instructions.
6 Conclusion
In this paper, we introduce API Pack, a massive multi-programming language dataset with over 1 million instruction-API call instances. Using this dataset, we investigate if models can generalize to new languages without extensive multi-language data and whether exposure to diverse APIs during fine-tuning improves generalization. Our results show that cross-lingual API call is achievable by training on a large amount of single-language data supplemented with small amounts of data from other languages. Furthermore, increasing data volume improves generalization. These findings highlight the potential of large-scale, diverse datasets in enabling LLMs to effectively identify appropriate API endpoints and generate corresponding API calls based on natural language instructions.
7 Limitations
API Pack is not designed for multi-API call scenarios, so models fine-tuned with this dataset may struggle with tasks involving multiple, interdependent API calls. This limitation restricts API Pack’s effectiveness in complex, real-world software development tasks that often require multi-API integrations. Future work should focus on creating datasets and models that can effectively handle multi-API call scenarios, enabling the generation of more sophisticated and practical code solutions.
8 Broader Impact Statement
Our research has a broader impact on Software Productivity as it aims to accelerate software development workflows by automating routine coding tasks. Alongside promising productivity gains, the integration of advanced LLMs into software development workflows raises sociotechnical concerns (e.g., job displacement, developers’ continuous oversight to ensure accuracy). Therefore, a responsible innovation lens assessing and responding to potential harms remains vital.
Acknowledgments and Disclosure of Funding
This work was supported by MIT-IBM Watson AI Lab and IBM Research.
References
- [1] Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, and ZHAO-XIANG ZHANG. Sheetcopilot: Bringing software productivity to the next level through large language models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 4952–4984. Curran Associates, Inc., 2023.
- [2] Ipek Ozkaya. Application of large language models to software engineering tasks: Opportunities, risks, and implications. IEEE Software, 40(3):4–8, 2023.
- [3] Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M Zhang. Large language models for software engineering: Survey and open problems. arXiv preprint arXiv:2310.03533, 2023.
- [4] Lenz Belzner, Thomas Gabor, and Martin Wirsing. Large language model assisted software engineering: prospects, challenges, and a case study. In International Conference on Bridging the Gap between AI and Reality, pages 355–374. Springer, 2023.
- [5] Steven I Ross, Fernando Martinez, Stephanie Houde, Michael Muller, and Justin D Weisz. The programmer’s assistant: Conversational interaction with a large language model for software development. In Proceedings of the 28th International Conference on Intelligent User Interfaces, pages 491–514, 2023.
- [6] Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. Large Language Models for Software Engineering: A Systematic Literature Review, September 2023. arXiv:2308.10620 [cs].
- [7] Christof Ebert and Panos Louridas. Generative AI for Software Practitioners. IEEE Software, 40(4):30–38, July 2023. Conference Name: IEEE Software.
- [8] Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 15(3):1–45, 2024.
- [9] Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. Software testing with large language models: Survey, landscape, and vision. IEEE Transactions on Software Engineering, 2024.
- [10] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [11] Frank F Xu, Uri Alon, Graham Neubig, and Vincent Josua Hellendoorn. A systematic evaluation of large language models of code. In Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, pages 1–10, 2022.
- [12] Sami Sarsa, Paul Denny, Arto Hellas, and Juho Leinonen. Automatic generation of programming exercises and code explanations using large language models. In Proceedings of the 2022 ACM Conference on International Computing Education Research-Volume 1, pages 27–43, 2022.
- [13] Priyan Vaithilingam, Tianyi Zhang, and Elena L Glassman. Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models. In Chi conference on human factors in computing systems extended abstracts, pages 1–7, 2022.
- [14] Gabriel Poesia, Oleksandr Polozov, Vu Le, Ashish Tiwari, Gustavo Soares, Christopher Meek, and Sumit Gulwani. Synchromesh: Reliable code generation from pre-trained language models. arXiv preprint arXiv:2201.11227, 2022.
- [15] Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi D. Q. Bui, Junnan Li, and Steven C. H. Hoi. CodeT5+: Open Code Large Language Models for Code Understanding and Generation, May 2023. arXiv:2305.07922 [cs].
- [16] Disha Shrivastava, Hugo Larochelle, and Daniel Tarlow. Repository-level prompt generation for large language models of code. In International Conference on Machine Learning, pages 31693–31715. PMLR, 2023.
- [17] Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as Policies: Language Model Programs for Embodied Control. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9493–9500, May 2023.
- [18] Daoguang Zan, Bei Chen, Fengji Zhang, Dianjie Lu, Bingchao Wu, Bei Guan, Wang Yongji, and Jian-Guang Lou. Large Language Models Meet NL2Code: A Survey. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7443–7464, Toronto, Canada, July 2023. Association for Computational Linguistics.
- [19] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and LINGMING ZHANG. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 21558–21572. Curran Associates, Inc., 2023.
- [20] Disha Shrivastava, Hugo Larochelle, and Daniel Tarlow. Repository-Level Prompt Generation for Large Language Models of Code. In Proceedings of the 40th International Conference on Machine Learning, pages 31693–31715. PMLR, July 2023. ISSN: 2640-3498.
- [21] Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Source Code Is All You Need, December 2023. arXiv:2312.02120 [cs].
- [22] Niklas Muennighoff, Qian Liu, Armel Zebaze, Qinkai Zheng, Binyuan Hui, Terry Yue Zhuo, Swayam Singh, Xiangru Tang, Leandro von Werra, and Shayne Longpre. OctoPack: Instruction Tuning Code Large Language Models, August 2023. arXiv:2308.07124 [cs].
- [23] Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161, 2023.
- [24] Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. Starcoder 2 and the stack v2: The next generation. arXiv preprint arXiv:2402.19173, 2024.
- [25] Shailja Thakur, Baleegh Ahmad, Hammond Pearce, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri, and Siddharth Garg. Verigen: A large language model for verilog code generation. ACM Transactions on Design Automation of Electronic Systems, 29(3):1–31, 2024.
- [26] Mayank Mishra, Matt Stallone, Gaoyuan Zhang, Yikang Shen, Aditya Prasad, Adriana Meza Soria, Michele Merler, Parameswaran Selvam, Saptha Surendran, Shivdeep Singh, et al. Granite code models: A family of open foundation models for code intelligence. arXiv preprint arXiv:2405.04324, 2024.
- [27] Caitlin Sadowski, Kathryn T. Stolee, and Sebastian Elbaum. How developers search for code: a case study. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, ESEC/FSE 2015, pages 191–201, New York, NY, USA, August 2015. Association for Computing Machinery.
- [28] Michael Meng, Stephanie Steinhardt, and Andreas Schubert. Application Programming Interface Documentation: What Do Software Developers Want? Journal of Technical Writing and Communication, 48(3):295–330, July 2018. Publisher: SAGE Publications Inc.
- [29] Qiantong Xu, Fenglu Hong, Bo Li, Changran Hu, Zhengyu Chen, and Jian Zhang. On the Tool Manipulation Capability of Open-source Large Language Models, May 2023.
- [30] Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large Language Model Connected with Massive APIs, May 2023. arXiv:2305.15334 [cs].
- [31] Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, July 2023. arXiv:2307.16789 [cs].
- [32] Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. WizardLM: Empowering Large Language Models to Follow Complex Instructions, June 2023. arXiv:2304.12244 [cs].
- [33] Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-Instruct: Aligning Language Models with Self-Generated Instructions, May 2023. arXiv:2212.10560 [cs].
- [34] Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, December 2023. arXiv:2312.15685 [cs].
- [35] Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, and Hongxia Jin. AlpaGasus: Training A Better Alpaca with Fewer Data, November 2023. arXiv:2307.08701 [cs].
- [36] Keming Lu, Hongyi Yuan, Zheng Yuan, Runji Lin, Junyang Lin, Chuanqi Tan, Chang Zhou, and Jingren Zhou. #InsTag: Instruction Tagging for Analyzing Supervised Fine-tuning of Large Language Models, August 2023. arXiv:2308.07074 [cs].
- [37] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program Synthesis with Large Language Models, August 2021. arXiv:2108.07732 [cs].
- [38] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating Large Language Models Trained on Code, July 2021. arXiv:2107.03374 [cs].
- [39] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation, October 2023. arXiv:2305.01210 [cs].
- [40] Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Zihan Wang, Lei Shen, Andi Wang, Yang Li, Teng Su, Zhilin Yang, and Jie Tang. Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x, 2023.
- [41] Qiwei Peng, Yekun Chai, and Xuhong Li. Humaneval-xl: A multilingual code generation benchmark for cross-lingual natural language generalization. arXiv preprint arXiv:2402.16694, 2024.
- [42] Minghao Li, Feifan Song, Bowen Yu, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-Bank: A Benchmark for Tool-Augmented LLMs, April 2023. arXiv:2304.08244 [cs].
- [43] Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases, September 2023. arXiv:2306.05301 [cs].
- [44] Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, and Ying Shan. GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction, May 2023. arXiv:2305.18752 [cs].
- [45] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools, February 2023. arXiv:2302.04761 [cs].
- [46] Venkat Krishna Srinivasan, Zhen Dong, Banghua Zhu, Brian Yu, Damon Mosk-Aoyama, Kurt Keutzer, Jiantao Jiao, and Jian Zhang. Nexusraven: a commercially-permissive language model for function calling. In NeurIPS 2023 Foundation Models for Decision Making Workshop, 2023.
- [47] Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Yongliang Shen, Ren Kan, Dongsheng Li, and Deqing Yang. Easytool: Enhancing llm-based agents with concise tool instruction. arXiv preprint arXiv:2401.06201, 2024.
- [48] Wei Chen, Zhiyuan Li, and Mingyuan Ma. Octopus: On-device language model for function calling of software apis. arXiv preprint arXiv:2404.01549, 2024.
- [49] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7B, October 2023. arXiv:2310.06825 [cs].
- [50] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open Foundation and Fine-Tuned Chat Models, July 2023. arXiv:2307.09288 [cs].
- [51] Peitian Zhang, Shitao Xiao, Zheng Liu, Zhicheng Dou, and Jian-Yun Nie. Retrieve Anything To Augment Large Language Models, October 2023. arXiv:2310.07554 [cs].
- [52] Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-Pack: Packaged Resources To Advance General Chinese Embedding, December 2023. arXiv:2309.07597 [cs].
9 Appendix
9.1 Data Filtering at each Stage of the Pipeline
| Source/Instances | Before Data Validation | After Removing Invalid API calls | After Removing Instances without Good Instructions |
|---|---|---|---|
| IBM API Hub | 27,635 | 17,712 | 17,206 |
| APIs Gurus | 500,160 | 499,250 | 495,533 |
| Swaggerhub | 351,756 | 351,756 | 345,765 |
| RapidAPI | 274,014 | 273,388 | 270,095 |
| Total | 1,153,565 | 1,142,106 | 1,128,599 |
9.2 Data Spliting for Level 1, Level 2, and Level 3 Testing
To split the data, first copy the total dataset into total_training and calculate the occurrence of each API. For the first level of testing data, select up to 1,000 data points from the first 20,000 entries where instruction_test is not "None" and the API appears more than four times. For the second level, iterate through the first 20,000 entries, selecting data points with APIs not yet selected, until 1,000 unique APIs are collected, then remove these from the training dataset. For the third level, from the 80,000th entry onwards, select data points with APIs not used in Level 2, collecting up to 1,000 data points, and remove data points with these APIs from the training dataset.
9.3 Hyperparameters for Training
We fine-tune the models using the HuggingFace Transformers library on a cluster consisting of 1 node with 8 NVIDIA H100 80GB GPUs, with Fully Shared Data Parallelism (FSDP). Techniques such as mixed precision, gradient checkpointing, and AdaFactor optimizer are used to improve training efficiency. The key hyperparameters are summarized in Table 8.
| Hyperparameter Name | Value |
|---|---|
| Learning rate | |
| Batch size | 128 |
| Max seq length | 4096 |
| Number of epochs | 2 |
| Warmup ratio | 0.03 |
9.4 Testing Pipeline
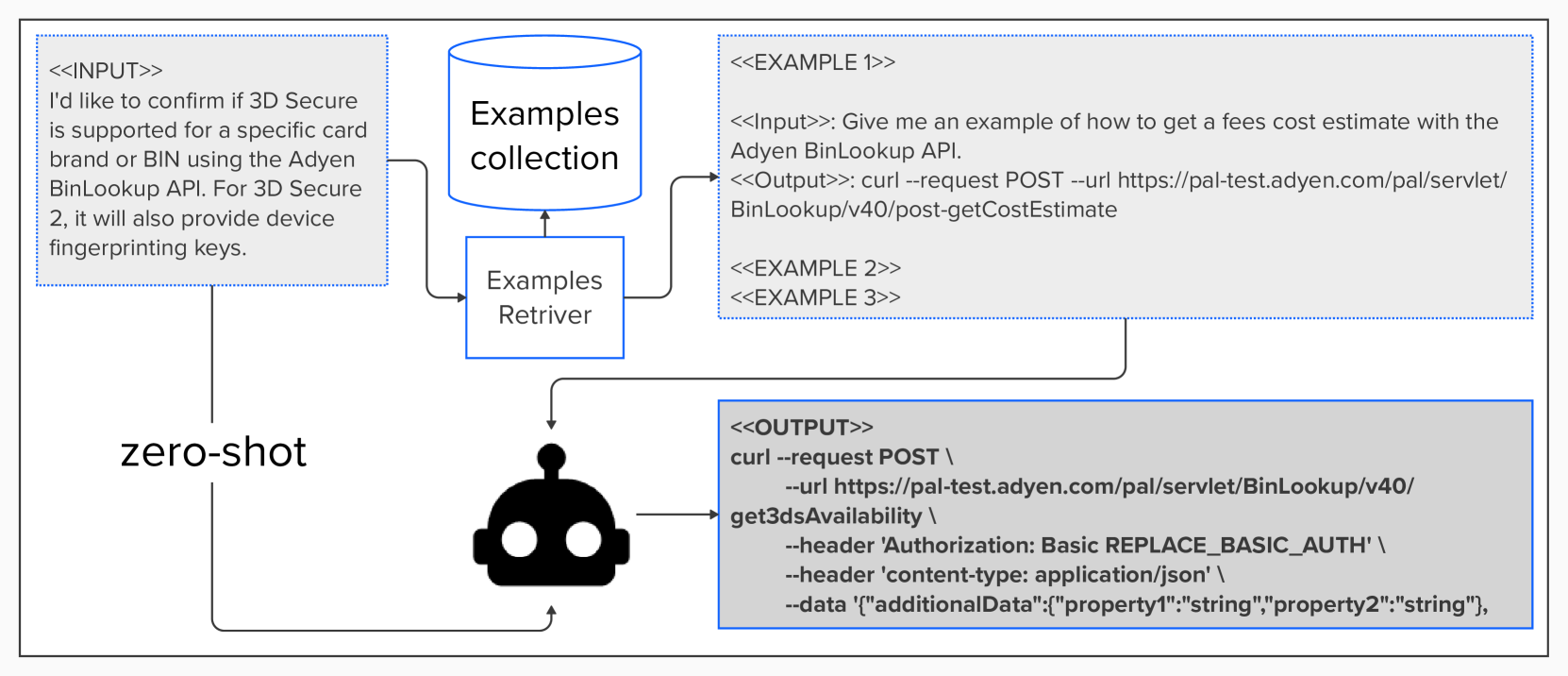
Figure 6 shows an example of our testing pipeline including zero and few-shot.
9.5 API DB instance
Figure 7 shows and the structure of an API DB instance. We used openapi-snippet 777https://www.npmjs.com/package/openapi-snippet, an open-source package that takes as input an OpenAPI v2.0 or v3.0.x specification file (OAS file) and translates it into an HTTP Archive 1.2 request object, to generate API calls. We generated API calls (api_call) in 10 different programming languages (cURL, libcurl, java, node, python, go, ruby, php, swift, JavaScript) for RapidAPI, API Gurus, and the Swaggerhub. For the company’s public API Hub API calls were extracted directly from the OAS files. We extracted API calls in eight different programming languages from this source (cURL, java, node, python, go, ruby, php, swift).
[fontsize=] json "api_name" : "The name of the API the endpoint belongs to", "api_description": "The description of the API the enpoint belongs to", "api_provider": "The API’s provider name", "endpoint_name": "The name of the function to call", "functionality": "A brief description of endpoint’s functionality", "description": "A long description of endpoint’s functionality", "path": "The enpoint’s name plus specific versioning as it appears in the API call’s URL", "method": "HTTP method used in the API call (e.g., get, post, put, delete)", "api_call": "HTTP request code example to invoke an endpoint", "lang": "The programming language in which the API call is written",
9.6 Improving Code Models with API Pack
We evaluated the performance of mixing a subset of 50,000-entries of API Pack with Magicoder dataset and fine-tuned CodeLlama-13b model. The resulting model shows an increase of over 35.3% in API call code generation accuracy for Level 3, specifically with the 3-shot setting. This improvement does not come at the expense of general coding efficiency, as the resulting model still performs well on benchmarks such as HumanEval+ and MBPP. See Table 9 for further details.
| Data Mixture | Bench. (pass@10) | Level 3 (3-shot) | |
|---|---|---|---|
| HumanEval+ | MBPP | Endpoint | |
| - | 47.8 | 58.3 | - |
| Magicoder | 60.8 | 66.4 | 17.0 |
| Magicoder + API Pack | 61.3 | 64.3 | 52.3 |
9.7 Instruction Candidates
Figure 8 shows all the candidates generated for an instance with their respective id and input_tokens_mean.
[fontsize=] json "instruction_candidates": [ "idx": 1, "candidate": "I’d like to confirm if 3D Secure is supported for a specific card brand or BIN using the Adyen BinLookup API. For 3D Secure 2, it will also provide device fingerprinting keys.", "input_tokens_mean": -0.5497539341557909 , "idx": 2, "candidate": "To confirm if 3D Secure is enabled for a specific card brand or BIN number using the Adyen BinLookup API, you can make use of the ‘post-get3dsAvailability‘ endpoint. This API call will provide you with information about the availability of 3D Secure, along with device fingerprinting keys for 3D Secure 2 transactions. Let me know if you need assistance in forming the request or handling the response.", "input_tokens_mean": -0.5088001283229344 , "idx": 3, "candidate": "To confirm if a specific card brand or BIN supports 3D Secure and retrieves device fingerprinting keys for 3D Secure 2, please utilize the Adyen BinLookup API’s post-get3dsAvailability endpoint.", "input_tokens_mean": -0.5554471563123543 , "idx": 4, "candidate": "To confirm if 3D Secure is supported for a specific card brand or BIN number using the Adyen BinLookup API, please make a POST request to the endpoint ’post-get3dsAvailability’. This API will return whether 3D Secure is enabled and for 3D Secure 2, it will also provide device fingerprinting keys.", "input_tokens_mean": -0.5466722401065375 , "idx": 5, "candidate": "To confirm if 3D Secure is supported by Adyen for a given card brand or BIN number, you can utilize the Adyen BinLookup API. Simply send a POST request to the post-get3dsAvailability endpoint with the required card details. If 3D Secure is available, the response will include device fingerprinting keys for 3D Secure 2.", "input_tokens_mean": -0.5726057469087047 ]