WeakSAM: Segment Anything Meets Weakly-supervised Instance-level Recognition
Abstract
Weakly supervised visual recognition using inexact supervision is a critical yet challenging learning problem. It significantly reduces human labeling costs and traditionally relies on multi-instance learning and pseudo-labeling. This paper introduces WeakSAM and solves the weakly-supervised object detection (WSOD) and segmentation by utilizing the pre-learned world knowledge contained in a vision foundation model, i.e., the Segment Anything Model (SAM). WeakSAM addresses two critical limitations in traditional WSOD retraining, i.e., pseudo ground truth (PGT) incompleteness and noisy PGT instances, through adaptive PGT generation and Region of Interest (RoI) drop regularization. It also addresses the SAM’s problems of requiring prompts and category unawareness for automatic object detection and segmentation. Our results indicate that WeakSAM significantly surpasses previous state-of-the-art methods in WSOD and WSIS benchmarks with large margins, i.e. average improvements of 7.4% and 8.5%, respectively. Code is available at https://github.com/hustvl/WeakSAM.
1.20.1
1 Introduction
Weakly-supervised learning (WSL) (Zhou, 2018; Wang et al., 2013; Xu et al., 2014) is a crucial component of machine learning. It is particularly valuable in tasks where strong supervision is difficult to annotate due to the high cost of data labeling (Locatello et al., 2020; Schroeter et al., 2019; Fu et al., 2020). Due to the massive demand for annotated data in visual perception, WSL is essential in developing a label-efficient recognition system. In the standard weakly-supervised visual perception paradigm (Tang et al., 2018a; Sui et al., 2022), training commences with inexact supervision, such as image-level labels. Subsequently, the trained WSL network is employed to generate pseudo ground truth (PGT), which serves as a form of refined, albeit still inaccurate supervision. Finally, the PGT is used as inaccurate supervision to launch WSL retraining. Although the iterative WSL process achieves significant progress, it is still limited by the lack of external knowledge, which restricts the performance of WSL and hinders it from matching fully-supervised learning (FSL).
Nowadays, foundation models are gaining increasing attention because of their transferable pre-learned world knowledge, which can be regarded as powerful external knowledge for WSL. As a vision foundation model, SAM (Kirillov et al., 2023) achieves outstanding performance in interactive, class-agnostic segmentation. SAM owes its success to promptable training on a large-scale dataset. However, there are two main drawbacks to SAM: First, SAM requires interactive operations as input, which means it cannot work automatically without human prompts. Second, SAM produces class-agnostic segments and cannot assign class labels. These drawbacks severely restrict the application of SAM as a generic visual framework. As a strong complement, WSL is good at mining classification clues through inexact supervision, which can provide automatic prompts for SAM. Subsequently, WSL with SAM’s knowledge can further bring class-aware perception.
This motivates us to assimilate SAM within the WSL paradigm. The WeakSAM framework is designed to harness transferable knowledge from SAM, thereby enriching the WSL process. Simultaneously, it offers the capability to deliver automatic classification clues to SAM. This bidirectional enhancement constructs a promising foundation-model-based weakly-supervised visual perception framework. Specifically, in a weakly-supervised object detection (WSOD) setting, WeakSAM uses classification clues as SAM prompts to produce proposals automatically. These proposals are then used in WSOD training for class-aware perception.
Within the scope of the WeakSAM framework, our analysis identifies two prevailing limitations in the iterative WSOD retraining approach: the issue of pseudo ground truth (PGT) incompleteness and the presence of noisy PGT instances. The former, PGT incompleteness, refers to the tendency of WSOD-generated PGT to omit some objects or categories, leading to insufficient training for these categories. The latter, noisy PGT instances, pertain to the prevalent presence of noise within the PGT, which adversely impacts the retraining process. To effectively mitigate these challenges, we introduce two key strategies: adaptive PGT generation to address the PGT incompleteness problem, and Region of Interest (RoI) drop regularization to counteract the noise in PGT instances. Moreover, WeakSAM’s capability enables the extension in the realm of weakly-supervised instance segmentation (WSIS). In this context, SAM is employed to further refine WeakSAM-PGT, enabling the generation of pseudo instance segmentation labels. This approach exemplifies WeakSAM is promising to build a unified weakly-supervised instance-level recognition framework.
The main contributions of this paper can be summarized as follows:
-
•
We propose a weakly-supervised instance-level recognition framework (WeakSAM), which automatically prompts SAM by classification clues for proposals. The WeakSAM-proposals improve both the effectiveness and efficiency of WSOD.
-
•
We analyze the weaknesses in traditional WSOD retraining, and propose adaptive PGT generation and RoI drop regularization to address them, respectively. After the WeakSAM-WSOD is complete, the proposed WeakSAM can be easily applied to WSIS further.
-
•
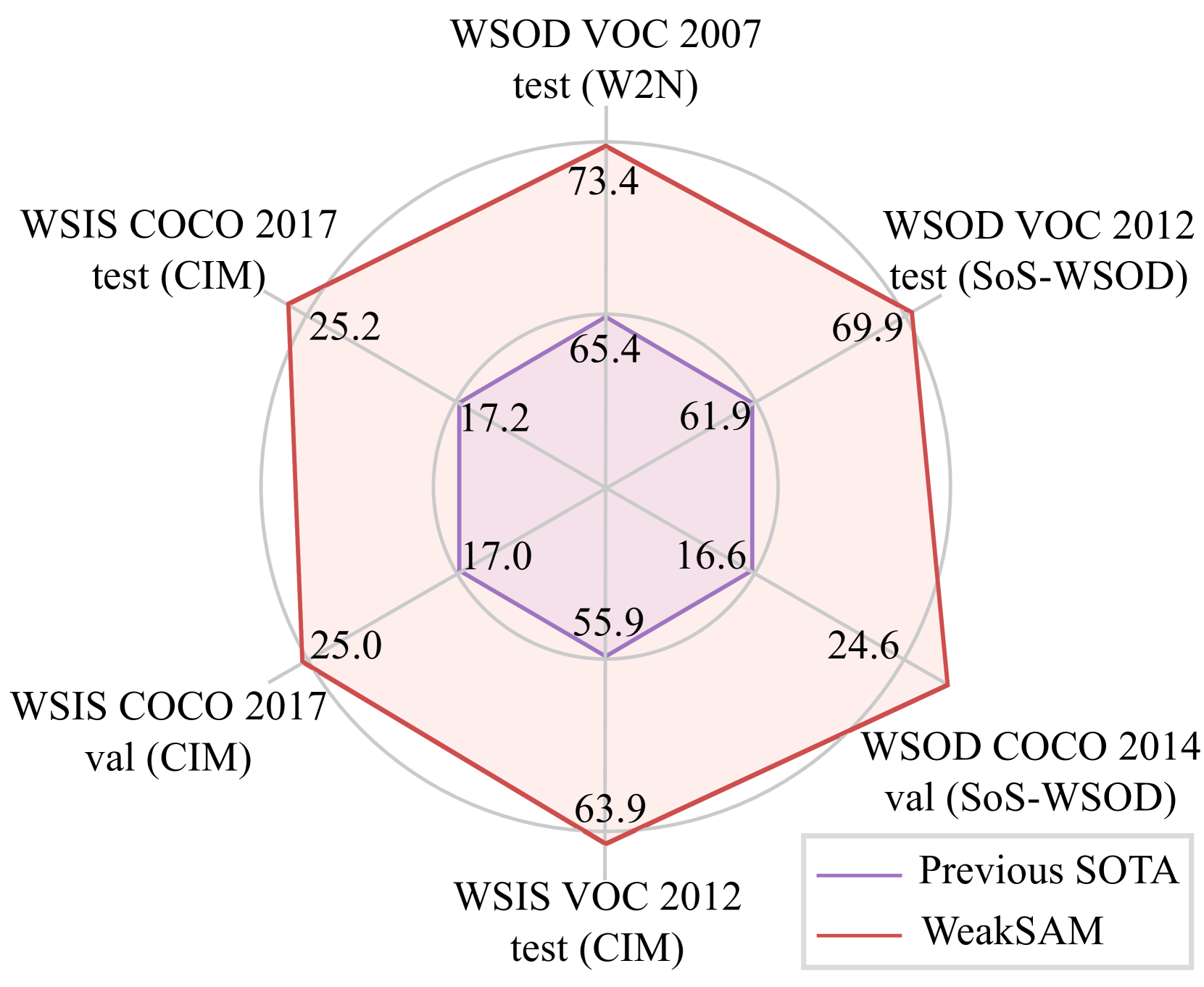
The proposed WeakSAM achieves state-of-the-art (SOTA) results on the WSOD and WSIS benchmarks, significantly surpassing previous SOTA methods as shown in Fig. 1.
2 Related Work
2.1 Segment Anything Model
The recent Segment Anything Model (SAM) (Kirillov et al., 2023) draws great attention from researchers. The SAM is trained on SA-1B with over 1 billion masks, following the model-in-the-loop manner. Besides, SAM performs superior zero-shot transfer capabilities and is applied in many visual tasks, e.g., FGVP (Yang et al., 2023) incorporates SAM to achieve zero-shot fine-grained visual prompting, MedSAM (Ma & Wang, 2023) adapts SAM into a large scale medical dataset to build a medical foundation model, and some methods (Sun et al., 2023; Jiang & Yang, 2023; Chen et al., 2023) utilize SAM to deal with the weakly-supervised semantic segmentation problem. However, SAM is an interactive segmentation method, which heavily relies on human prompts.
In our approach, we innovatively propose to automatically prompt SAM using classification clues for extracting region proposals. This method results in high-recall proposals that surpass traditional methods like Selective Search in terms of both efficiency and effectiveness. This advancement represents a significant improvement in the domain of proposal generation within the WSOD framework.
2.2 Weakly-supervised Object Detection
Weakly-supervised object detection (WSOD) with image-level labels (Laptev et al., ; Diba et al., 2017; Tang et al., 2018b; Gao et al., 2018; Wan et al., 2018; Zhang et al., 2018a; Liu et al., 2019; Li et al., 2019; Arun et al., 2019; Sun et al., 2020; Arun et al., 2020; Jia et al., 2021; Wan et al., 2019) is important for reducing the human annotation burden. The previous works, i.e., WSDDN (Bilen & Vedaldi, 2016b) and OICR (Tang et al., 2017), proposed the Multiple Instance Learning and online refinement paradigms. The later works aimed to improve the WSOD performance from different perspectives. Such as WSOD (Zeng et al., 2019) introduced bottom-up object evidence, PCL (Tang et al., 2018a) proposed to cluster proposals, MIST (Ren et al., 2020) utilized a self-training algorithm, etc. Besides, some methods (Tang et al., 2018a; Jie et al., 2017; Li et al., 2016; Sui et al., 2022; Zhang et al., 2018b; Huang et al., 2022) also retrained a fully-supervised object detection network with generated pseudo ground truth (PGT). However, most of them used the proposals generated from low-level methods, i.e., Selective Search (Uijlings et al., 2013), EdgeBox (Zitnick & Dollár, 2014), and MCG (Pont-Tuset et al., 2016), which contain a great number of redundant proposals and bring an optimization challenge.
Different from previous methods, our WeakSAM-proposals have fewer numbers and higher recall, which reduces the difficulty of finding the correct proposals for WSOD methods. For the key problem of PGT incompleteness and noisy PGT instances, we propose adaptive PGT generation and Region of Interest (RoI) drop regularization to address them, respectively.
2.3 Weakly-supervised Instance Segmentation
Weakly-supervised instance segmentation (WSIS) aims to achieve instance segmentation through weak supervision, such as box-level supervision (Tian et al., 2021; Wang et al., 2021; Cheng et al., 2023; Hsu et al., 2019; Liao et al., 2019; Lee et al., 2021; Khoreva et al., 2017; Zhang et al., 2023; Zhu et al., 2023b; Li et al., 2022), and image-level supervision (Ge et al., 2019; Ou et al., 2021; Zhu et al., 2019; Liu et al., 2020; Hwang et al., 2021; Zhang et al., 2021; Hu et al., 2020; Hsieh et al., 2023; Laradji12 et al., ). The WSIS with image-level supervision is challenging because it lacks accurate instance locations. Some image-level WSIS methods use CAM to extract coarse object locations, such as PRM (Zhou et al., 2018), IAM (Zhu et al., 2019), IRNet (Ahn et al., 2019), BESTIE (Kim et al., 2022), etc. Some other image-level WSIS methods try to incorporate instance clues from extra priors, such as Fan et al. (Fan et al., 2018b), LIID (Liu et al., 2020), CIM (Li et al., 2023), etc. However, they always need complicated networks and lack high-quality instance segments.
Different from previous WSIS methods, the proposed WSIS extension using WeakSAM-PGT and SAM’s prediction is concise and effective. The generated pseudo instance labels can further be applied to any fully-supervised instance segmentation method.
3 Method
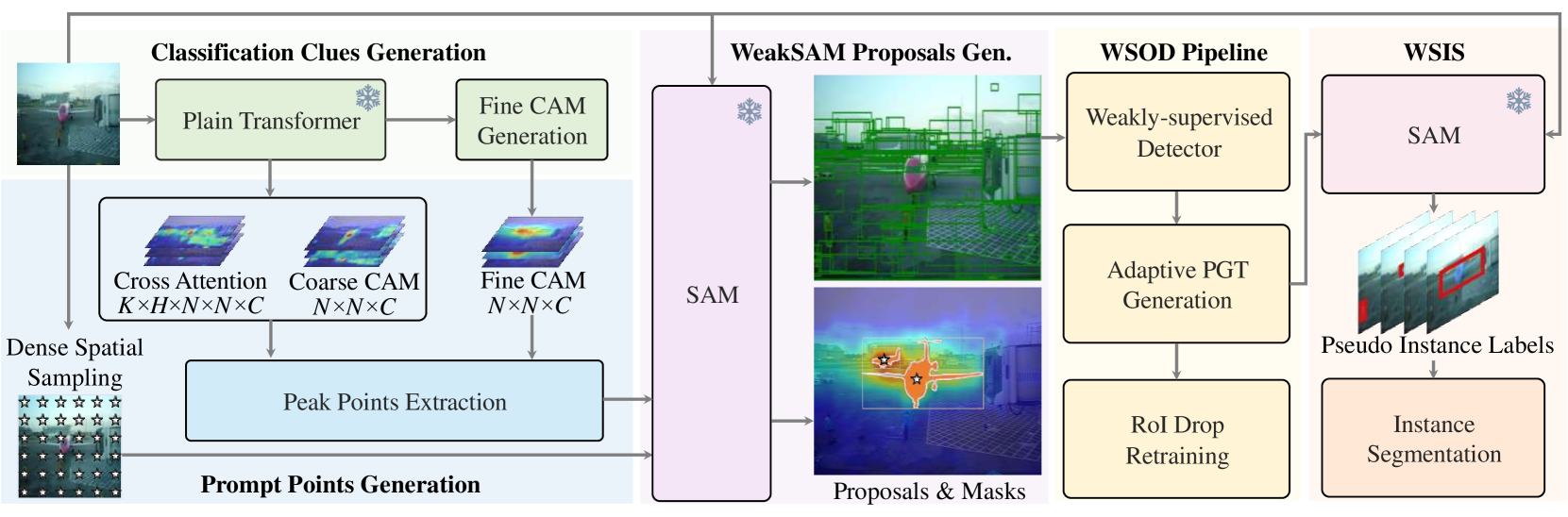
We present the WeakSAM framework as shown in Fig. 2. At first, WeakSAM automatically generates prompts from classification clues and spatial samples. Next, WeakSAM send the prompts to SAM for WeakSAM-proposals. Then, we launch the weakly-supervised object detection (WSOD) pipeline, which is enhanced by WeakSAM-proposals, adaptive pseudo ground truth (PGT) generation, and RoI drop regularization. Last, we use the PGT boxes generated by the WSOD pipeline to launch the weakly-supervised instance segmentation extension.
3.1 Classification Clues as Automatic Prompt
Previous WSOD methods face an optimization problem caused by the redundant proposals, e.g., Selective Search (Uijlings et al., 2013) and EdgeBox (Zitnick & Dollár, 2014), because these proposals are only based on low-level features. To address this problem, we propose to transfer knowledge in the foundation model, i.e., SAM, for proposal generation. We use classification clues to prompt SAM automatically, which also solves the shortcoming of SAM requiring interactive prompts
Classification Clues Generation
As shown in Fig. 2, we extract classification clues from a classification ViT. Specifically, we choose the pre-trained weakly-supervised semantic segmentation network, WeakTr (Zhu et al., 2023a), to provide classification clues because of its superior localization ability. At first, we extract cross-attention maps from the self-attention maps, where is the number of transformer encoding layers, is the number of attention heads in each layer, is the spatial size of the visual tokens, and represents the total number of classification categories. Then, we obtain coarse CAM, , from the convolutional CAM head, which takes visual tokens at the final transformer layer as input and produces coarse CAM. Last, we use WeakTr to produce fine CAM, .
Prompt Points Generation
As shown in Fig. 2, we extract prompts from dense sampling points, cross-attention maps, and CAMs. At first, the dense sampling requires splitting the image into patches and taking the center points as prompts. Notably, the dense sampling points provide spatial-aware prompts but lack explicit reference to objects and semantics, which means increasing the usually leads to a great number of invalid sampling points. Then, we get peak points from the cross-attention maps as prompts. We observe that these maps do not solely concentrate on objects from their corresponding categories but also give attention to objects from different categories. So, we mark these prompts as instance-aware ones. Last, we extract peak points from coarse CAM and fine CAM as semantic-aware prompts, which are more precise and focus on areas of foreground objects.
Specifically, we extract peak points from cross-attention maps and CAMs, as shown in Algorithm 1. Given cross-attention maps or CAMs as input, we first initialize the peak points list , peak values list , deleted lists , , and max pooling operation. Next, we reshape the input maps and ensure the last two dimensions correspond to the original image size and the others as the first dimension. Then, we apply max pooling on the input maps , and sort and in descending order based on . Last, we remove points with low activation values or close to high-score points.
WeakSAM Proposals Generation
At the WeakSAM proposal generation stage, we use the three kinds of prompts to prompt SAM automatically. We directly add semantic-aware prompts and spatial-ware prompts to the prompt list, because they usually have clear localization to foreground objects and spatial positions, respectively. For the instance-aware prompts that have some redundancy, we cluster them to filter the duplicated ones and then add them to the prompt list. Finally, all prompts in the prompt list are used to prompt SAM for proposals.
3.2 WeakSAM WSOD Pipeline
To better describe the proposed weakly-supervised object detection (WSOD) pipeline, we first present the weakly-supervised detector training with WeakSAM-proposals. Then, we identify the PGT incompleteness problem and introduce the proposed adaptive PGT generation to address it. Last, we analyze the noise problem existing in the retraining phase, and propose Region of Interest (RoI) drop regularization to alleviate the effect of noise.
Weakly-supervised Detector Training
A primary challenge in traditional WSOD methods is the low training efficiency, largely attributed to the redundancy of proposals. Traditional approaches often involve the Region of Interest pooling layer processing thousands of proposals per image, which impairs both effectiveness and efficiency. To address this issue, our WeakSAM-proposals adopt transferred knowledge from SAM and classification clues. The proposed method focuses on generating a smaller quantity of proposals while maintaining high recall, thereby enhancing the overall efficiency and efficacy of the detection process in a WSOD context. We mainly apply the proposed WeakSAM on some convincing WSOD methods, including OICR (Tang et al., 2017) and MIST (Ren et al., 2020), which receive significant improvements. As shown in Table 1, quantitative results show that WeakSAM-enhanced WSOD can annotate bounding boxes for objects more precisely.
Adaptive PGT Generation
Generating high-quality pseudo ground truth (PGT) is the key to the WSOD paradigm. Traditional WSOD methods often encounter the issue of PGT incompleteness. This occurs because these methods typically select top-scoring proposals as PGT or apply a uniform threshold to filter proposals across all categories. Such approaches can lead to the omission of objects or entire categories, especially when proposals in certain categories score low. To address these problems, we propose an adaptive PGT generation method to normalize the score distribution of proposals, ensuring they fall within a similar range, as shown in Algorithm. 2.
For box list and corresponding score list , we first select them with a specific classification label and then normalize the scores. The is the number of predicted boxes, and the second dimension of is the combination of a category label and four coordinate values. Next, we keep boxes with scores higher than the threshold . Please note that the normalization enables the threshold to work for all categories adaptively, so we would not lose a ground truth category even if all boxes in this category have low scores. Then, we select the boxes whose main parts are not contained in some bigger boxes. Because the boxes that have more are often local components of some objects. Last, we return the box list as the final PGT.
RoI Drop Regularization
A recognized issue in the retraining phase of WSOD is noisy PGT instances. These noisy instances result in PGT acting as the inaccurate supervision. Alleviating this problem is critical for enhancing the performance of WSOD retraining. To analyze this problem in depth, we first divide the RoIs into different loss intervals. Then, we mark the RoIs whose corresponding PGTs do not have at least 70% IoU with the ground truth boxes as error ones. Last, we present the statistics as shown in Fig. 3, which demonstrates that the RoIs with larger losses are in a small amount and have a high error rate.
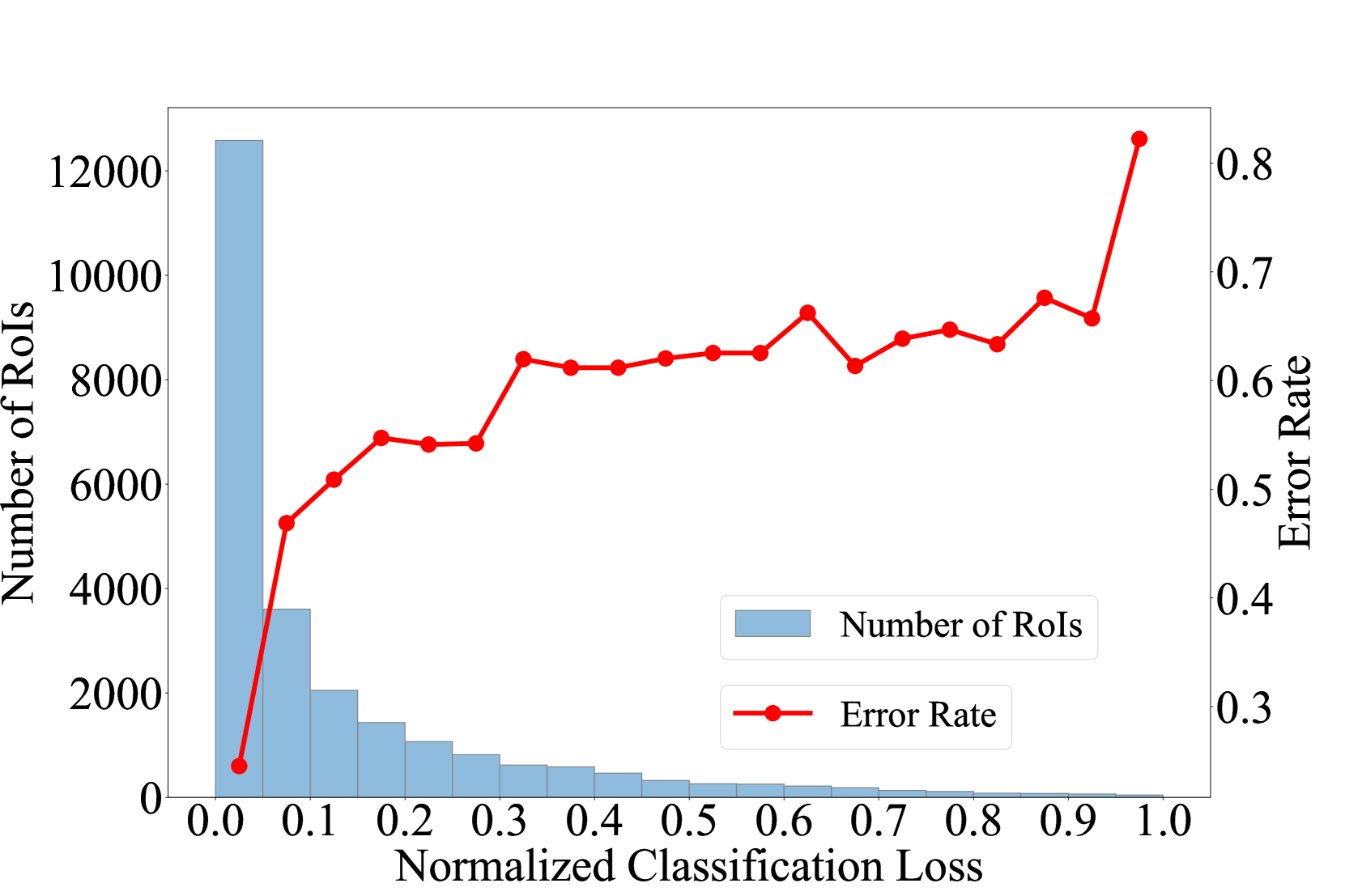
Intuitively, we propose a method, named RoI drop regularization, to adaptively drop the RoIs with larger losses. Notably, the proposed method is easy to implement and can further help the query-based detectors to alleviate the noisy PGT problem by its variant, query drop regularization. For anchor-based FSOD methods, e.g., Faster-RCNN (Ren et al., 2015), we first determine the thresholds and for classification loss and regression loss, respectively. Then, we compute the drop signal for RoI.
| (3) |
where the and represent the classification loss and regression loss for each RoI, respectively. When the two losses of a RoI are all below their thresholds, we set its drop signal as . Finally, we integrate the into the computation of final loss .
| (4) |
| Methods | Proposal | Retrain | VOC 07 | VOC 12 | COCO 14 | |||
| Fully-supervised object detection methods. | ||||||||
| Faster R-CNN (Ren et al., 2015) | RPN | – | 69.9 | – | 21.2 | 41.5 | – | |
| WSOD methods with point supervision. | ||||||||
| P2BNet (Chen et al., 2022) | RPN | – | 60.2 | – | 19.4 | 43.5 | – | |
| WSOD methods with image-level supervision. | ||||||||
| C-MIDN (Gao et al., 2019) | SS, MCG | – | 52.6 | 50.2 | 9.6 | 21.4 | – | |
| WSOD (Zeng et al., 2019) | SS | – | 53.6 | 47.2 | 10.8 | 22.7 | – | |
| SLV (Chen et al., 2020) | SS | – | 53.5 | 49.2 | – | – | – | |
| CASD (Huang et al., 2020) | SS | – | 56.8 | 53.6 | 12.8 | 26.4 | – | |
| IM-CFB (Yin et al., 2021) | SS | – | 54.3 | 49.4 | – | – | – | |
| OD-WSCL (Seo et al., 2022) | SS, MCG | – | 56.4 | 54.6 | 13.7 | 27.7 | 11.9 | |
| WSOD-CBL (Yin et al., 2023) | SS | – | 57.4 | 53.5 | 13.6 | 27.6 | – | |
| WSOVOD (Lin et al., 2024) | LO-WSRPN + SAM | – | 59.1 | 59.8 | 18.8 | 27.1 | 19.7 | |
| WSOVOD‡ | LO-WSRPN + SAM | – | 63.4 | 62.1 | 20.5 | 29.1 | 21.4 | |
| Baseline and ours. | ||||||||
| OICR (Tang et al., 2017) | SS, MCG | – | 41.2 | 37.9 | 8.0 | 18.9 | 7.0 | |
| WeakSAM (OICR) | WeakSAM | – | 58.9+17.7 | 58.4+20.5 | 19.9+11.9 | 32.1+13.2 | 20.6+13.6 | |
| Baseline and ours. | ||||||||
| MIST (Ren et al., 2020) | SS, MCG | – | 54.9 | 52.1 | 11.4 | 24.3 | 9.4 | |
| WeakSAM (MIST) | WeakSAM | – | 67.4+12.5 | 66.9+14.8 | 22.9+11.5 | 35.2+10.9 | 24.6+15.2 | |
| WSOD methods with image-level supervision. + Retrain | ||||||||
| W2F (Zhang et al., 2018b) | RPN | Faster R-CNN | 52.4 | 47.8 | – | – | – | |
| SoS-WSOD (Sui et al., 2022) | RPN | Faster R-CNN | 64.4 | 61.9 | 16.6 | 32.8 | 15.2 | |
| W2N (Huang et al., 2022) | RPN | Faster R-CNN | 65.4 | 60.8 | 15.9 | 33.3 | 13.4 | |
| Ours. + Retrain | ||||||||
| WeakSAM (OICR) | RPN | Faster R-CNN | 65.7 | 62.9 | 22.3 | 36.5 | 23.0 | |
| WeakSAM (MIST) | RPN | Faster R-CNN | 71.8 | 69.2 | 23.8 | 38.5 | 25.1 | |
| WeakSAM (OICR) | – | DINO | 66.1 | 63.7 | 24.9 | 36.9 | 26.8 | |
| WeakSAM (MIST) | – | DINO | 73.4 | 70.2 | 26.6 | 39.3 | 29.0 | |
where is 1 if the box is positive, and 0 if the box is negative. The is a balancing weight.
For query-based FSOD methods, e.g., DINO (Zhang et al., 2022), since queries can be regarded as dynamic RoIs, we apply query drop regularization on them. Because only a few matched queries need to calculate box loss and IoU loss , we only set a percentile threshold based on classification loss . Only when the query’s loss is less than the loss at % percentile, i.e., , will its corresponding be set to .
| (7) |
| (8) |
3.3 WeakSAM for WSIS
| Methods | Backbone | Retrain | VOC 12 | ||||
| Fully-supervised instance segmentation methods. | |||||||
| Mask R-CNN (He et al., 2017) | ResNet-101 | – | 76.7 | 67.9 | 52.5 | 44.9 | |
| WSIS methods with image-level supervision. + Retrain | |||||||
| WISE (Laradji et al., 2019) | ResNet-50 | Mask R-CNN | 49.2 | 41.7 | – | 23.7 | |
| IRNet (Ahn et al., 2019) | ResNet-50 | Mask R-CNN | – | 46.7 | 23.5 | – | |
| LIID (Liu et al., 2020) | ResNet-50 | Mask R-CNN | – | 48.4 | – | 24.9 | |
| Arun et al.(Arun et al., 2020) | ResNet-50 | Mask R-CNN | 59.7 | 50.9 | 30.2 | 28.5 | |
| WS-RCNN (Ou et al., 2021) | VGG-16 | Mask R-CNN | 62.2 | 47.3 | – | 19.8 | |
| BESTIE (Kim et al., 2022) | HRNet-W48 | Mask R-CNN | 61.2 | 51.0 | 31.9 | 26.6 | |
| CIM (Li et al., 2023) | ResNet-50 | Mask R-CNN | 68.7 | 55.9 | 37.1 | 30.9 | |
| Ours. | |||||||
| WeakSAM | ResNet-50 | Mask R-CNN | 70.3 | 59.6 | 43.1 | 36.2 | |
| WeakSAM | ResNet-50 | Mask2Former | 73.4 | 64.4 | 49.7 | 45.3 | |
| Methods | Backbone | Retrain | COCO val 2017 | COCO test-dev | |||||
| Fully-supervised instance segmentation methods. | |||||||||
| Mask R-CNN (He et al., 2017) | ResNet-50 | – | 34.4 | 55.1 | 36.7 | 33.6 | 55.2 | 35.3 | |
| WSIS methods with image-level supervision. | |||||||||
| WS-JDS (Shen et al., 2019) | VGG-16 | – | 6.1 | 11.7 | 5.5 | – | – | – | |
| PDSL (Shen et al., 2021) | ResNet18-WS | – | 6.3 | 13.1 | 5.0 | – | – | – | |
| Fan et al. (Fan et al., 2018a) | ResNet-101 | Mask R-CNN | – | – | – | 13.7 | 25.5 | 13.5 | |
| LIID (Liu et al., 2020) | ResNet-50 | Mask R-CNN | – | – | – | 16.0 | 27.1 | 16.5 | |
| BESTIE (Kim et al., 2022) | HRNet-W48 | Mask R-CNN | 14.3 | 28.0 | 13.2 | 14.4 | 28.0 | 13.5 | |
| CIM (Li et al., 2023) | ResNet-50 | Mask R-CNN | 17.0 | 29.4 | 17.0 | 17.2 | 29.7 | 17.3 | |
| Ours. | |||||||||
| WeakSAM | ResNet-50 | Mask R-CNN | 20.6 | 33.9 | 22.0 | 21.0 | 34.5 | 22.2 | |
| WeakSAM | ResNet-50 | Mask2Former | 25.2 | 38.4 | 27.0 | 25.9 | 39.9 | 27.9 | |
Thanks to the high-quality WeakSAM-PGT, we can directly use them to prompt SAM for precise segments as pseudo instance labels. Following the practices in the WeakSAM-WSOD pipeline, we evaluate the quality of WeakSAM-PGT using R-CNN-based and query-based instance segmentation methods, respectively. Notably, we do not introduce more techniques in the WeakSAM-WSIS, because the WeakSAM pseudo instance labels are accurate enough.
4 Experiment
4.1 Experimental Setup
Datasets and Metrics
We evaluate the proposed WeakSAM on both weakly-supervised object detection (WSOD) and weakly-supervised instance segmentation (WSIS) benchmarks. Notably, the same datasets for different tasks may have different settings. For WSOD, we use three datasets, i.e., PASCAL VOC 2007 (Everingham et al., 2015), PASCAL VOC 2012 (Everingham et al., 2015), and COCO 2014 (Lin et al., 2014). PASCAL VOC 2007 has 2501 images for training, 2510 images for evaluation, and 4592 images for testing. PASCAL VOC 2012 contains 5717 training images, 5823 validation images, and 10991 test images. COCO 2014 includes around 80,000 images for training and 40,000 images for validation. Following previous WSOD methods, we train WeakSAM on and sets and evaluate WeakSAM on the set for PASCAL VOC 2007 and 2012. For COCO 2014, we use the set for training and the set for evaluating. PASCAL VOC 2007 and 2012 datasets comprise 20 object categories and COCO 2014 comprises 80 ones. We report the average precision AP metrics for these benchmarks. For WSIS, we use two datasets, i.e., PASCAL VOC 2012, and COCO 2017. The PASCAL VOC 2012 dataset includes 10582 images for training, and 1449 images for evaluation, comprising 20 object categories. The COCO 2017 dataset includes 115K training images, 5K validation images, and 20K testing images, comprising 80 object categories. Following previous methods, we report the average precision AP metrics with different Intersection-over-Union (IoU) thresholds.
Implementation Details
For WeakSAM proposals generation, we adopt the WeakTr (Zhu et al., 2023a) with DeiT-S (Touvron et al., 2021) model for generating classification clues, the SAM (Kirillov et al., 2023) with ViT-H (Dosovitskiy et al., 2020) model to generate proposals. For WeakSAM WSOD pipeline, we use the WSOD networks, i.e., OICR (Tang et al., 2017), and MIST (Ren et al., 2020), with the VGG-16 (Han et al., 2021) backbone to generate pseudo ground truth (PGT), and FSOD networks, i.e., Faster R-CNN (Ren et al., 2015) and DINO (Zhang et al., 2022), with the ResNet-50 (He et al., 2016) backbone to retrain. As for the WeakSAM-WSIS, we use SAM-ViT-H to generate pseudo instance labels and train the R-CNN-based and query-based methods, i.e., Mask R-CNN (He et al., 2017) and Mask2former (Cheng et al., 2022), respectively. All hyper-parameters in Alg. 1 and Alg. 2 are following the default manners as Zhu et al. (2023a) and Sui et al. (2022).
4.2 Comparisons with State-of-the-art Methods
| SS | Dense Sample | CAM | CAM | Cross Attn. | Num. | Recall | |||
| IoU=0.50 | IoU=0.75 | IoU=0.90 | |||||||
| ✓ | 2001 | 92.6 | 57.7 | 19.2 | 54.9 | ||||
| ✓ | 129 | 79.6 | 50.7 | 24.3 | 45.2 | ||||
| ✓ | ✓ | 151 | 88.9 | 67.0 | 37.2 | 63.3+18.1 | |||
| ✓ | ✓ | ✓ | 174 | 90.6 | 70.1 | 40.1 | 65.5+20.3 | ||
| ✓ | ✓ | ✓ | ✓ | 213 | 95.6 | 75.0 | 42.1 | 67.4+22.2 | |
| Top-1 PGT | Adaptive PGT | RoI Drop | AP |
| ✓ | 68.4 | ||
| ✓ | 70.7+2.3 | ||
| ✓ | ✓ | 71.8+3.4 |
| Top-1 PGT | Adaptive PGT | Query Drop | AP |
| ✓ | 71.1 | ||
| ✓ | 72.8+1.7 | ||
| ✓ | ✓ | 73.4+2.3 |
Weakly-supervised object detection
We present the quantitative WSOD results in Table. 1. Compared with our WSOD baseline methods, i.e., OICR and MIST, the proposed WeakSAM achieves over 10% improvements on all metrics. The results of WeakSAM (MIST) surpass all WSOD methods on all metrics, which demonstrate the effectiveness of WeakSAM-proposals. Compared with WSOD methods retrained by pseudo ground truth (PGT), the WeakSAM (MIST) with Faster R-CNN retraining still outperforms the SoS-WSOD (Sui et al., 2022) and W2N (Huang et al., 2022) on all metrics, and the WeakSAM (MIST) with DINO retraining even has comparable performance with fully-supervised Faster R-CNN. The retraining results demonstrate the effectiveness of the proposed WSOD pipeline, which includes the adaptive PGT generation and RoI drop retraining. Compared with concurrent work, WSOVOD (Lin et al., 2024), which also incorporates SAM, our WeakSAM (MIST) also achieves better performance.
Weakly-supervised instance segmentation
We first present the quantitative WSIS results of the PASCAL VOC 2012 set in Table 2. The proposed WeakSAM with Mask R-CNN retraining achieves the best performance, which demonstrates the WeakSAM can benefit WSIS effectively. Furthermore, the pseudo instance labels generated by WeakSAM can also be used by the modern query-based methods, e.g., Mask2Former (Cheng et al., 2022), which achieves the best results.
We then show the quantitative WSIS results on COCO 2017 and sets. On these more challenging benchmarks, WeakSAM with Mask R-CNN retraining achieves better results than CIM (Li et al., 2023). Besides, the WeakSAM with Mask2Former also presents the best results.
4.3 Ablation Studies
In this section, we present the ablation studies to evaluate the improvements brought by the proposed methods, i.e., WeakSAM prompts, adaptive PGT generation, and RoI drop retraining.
Due to the limitation of pages, we leave more ablation studies in the supplementary material, including efficiency analysis, sensitivity analysis, qualitative analysis, etc.
Improvements of WeakSAM Prompts
To further analyze the improvements brought by the proposed WeakSAM prompts, we conduct ablation experiments for different prompts in Table 4. Here, we use the Selective Search (Uijlings et al., 2013) as the baseline method. When only using the densely sampled points, the generated proposals can achieve 5.1% higher Recall (IoU=0.90), and 9.7% lower AP for MIST. After adding peak CAM points and peak cross attention points as prompts, we can achieve higher recall and AP through only 213 proposals on average.
Improvements of WSOD Pipeline
To further analyze the improvements brought by the proposed WeakSAM-WSOD pipeline, we conduct ablation experiments for adaptive PGT generation and RoI drop regularization in Table 5(b). Here, we set a baseline that uses the predicted boxes with the top-1 score as PGT and plain Faster R-CNN as the retraining network. It shows that adaptive PGT generation and RoI drop can both improve the retraining results of Faster R-CNN (Ren et al., 2015) and DINO (Zhang et al., 2022), respectively.
5 Conclusion
In this paper, we introduce WeakSAM, a novel framework utilizing the Segment Anything Model (SAM) for weakly-supervised instance-level recognition, demonstrating leading performance in WSOD and WSIS benchmarks. Different from the original SAM, which requires interaction and can not be aware of categories, WeakSAM represents an innovative fusion of SAM with weakly-supervised learning (WSL), overcoming the redundancy problem of WSOD proposals. To further address WSOD issues such as pseudo ground truth (PGT) incompleteness and noisy PGT instances, our approach includes adaptive PGT generation and a Region of Interest (RoI) drop regularization. The adaptability of WeakSAM is further showcased through its extension to weakly-supervised instance segmentation (WSIS). Our work aims to inspire further research with SAM and WSL, contributing significantly to the development of a universal framework for weakly-supervised recognition.
References
- Ahn et al. (2019) Ahn, J., Cho, S., and Kwak, S. Weakly supervised learning of instance segmentation with inter-pixel relations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- Arun et al. (2019) Arun, A., Jawahar, C., and Kumar, M. P. Dissimilarity coefficient based weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- Arun et al. (2020) Arun, A., Jawahar, C., and Kumar, M. P. Weakly supervised instance segmentation by learning annotation consistent instances. In European Conference on Computer Vision, pp. 254–270. Springer, 2020.
- Bilen & Vedaldi (2016a) Bilen, H. and Vedaldi, A. Weakly supervised deep detection networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2846–2854, 2016a.
- Bilen & Vedaldi (2016b) Bilen, H. and Vedaldi, A. Weakly supervised deep detection networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2846–2854, 2016b.
- Chen et al. (2022) Chen, P., Yu, X., Han, X., Hassan, N., Wang, K., Li, J., Zhao, J., Shi, H., Han, Z., and Ye, Q. Point-to-box network for accurate object detection via single point supervision. In European Conference on Computer Vision, pp. 51–67. Springer, 2022.
- Chen et al. (2023) Chen, T., Mai, Z., Li, R., and Chao, W.-l. Segment anything model (sam) enhanced pseudo labels for weakly supervised semantic segmentation. arXiv preprint arXiv:2305.05803, 2023.
- Chen et al. (2020) Chen, Z., Fu, Z., Jiang, R., Chen, Y., and Hua, X.-S. Slv: Spatial likelihood voting for weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- Cheng et al. (2022) Cheng, B., Misra, I., Schwing, A. G., Kirillov, A., and Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1290–1299, 2022.
- Cheng et al. (2023) Cheng, T., Wang, X., Chen, S., Zhang, Q., and Liu, W. Boxteacher: Exploring high-quality pseudo labels for weakly supervised instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3145–3154, 2023.
- Diba et al. (2017) Diba, A., Sharma, V., Pazandeh, A., Pirsiavash, H., and Van Gool, L. Weakly supervised cascaded convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 914–922, 2017.
- Dosovitskiy et al. (2020) Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Everingham et al. (2015) Everingham, M., Eslami, S. A., Van Gool, L., Williams, C. K., Winn, J., and Zisserman, A. The pascal visual object classes challenge: A retrospective. International journal of computer vision, 111:98–136, 2015.
- Fan et al. (2018a) Fan, R., Hou, Q., Cheng, M.-M., Yu, G., Martin, R. R., and Hu, S.-M. Associating inter-image salient instances for weakly supervised semantic segmentation. In Proceedings of the European conference on computer vision (ECCV), pp. 367–383, 2018a.
- Fan et al. (2018b) Fan, R., Hou, Q., Cheng, M.-M., Yu, G., Martin, R. R., and Hu, S.-M. Associating inter-image salient instances for weakly supervised semantic segmentation. In Proceedings of the European conference on computer vision (ECCV), pp. 367–383, 2018b.
- Fu et al. (2020) Fu, D., Chen, M., Sala, F., Hooper, S., Fatahalian, K., and Re, C. Fast and three-rious: Speeding up weak supervision with triplet methods. In III, H. D. and Singh, A. (eds.), Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pp. 3280–3291. PMLR, 13–18 Jul 2020. URL https://proceedings.mlr.press/v119/fu20a.html.
- Gao et al. (2018) Gao, M., Li, A., Yu, R., Morariu, V. I., and Davis, L. S. C-wsl: Count-guided weakly supervised localization. In Proceedings of the European conference on computer vision (ECCV), pp. 152–168, 2018.
- Gao et al. (2019) Gao, Y., Liu, B., Guo, N., Ye, X., Wan, F., You, H., and Fan, D. C-midn: Coupled multiple instance detection network with segmentation guidance for weakly supervised object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9834–9843, 2019.
- Ge et al. (2019) Ge, W., Guo, S., Huang, W., and Scott, M. R. Label-penet: Sequential label propagation and enhancement networks for weakly supervised instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3345–3354, 2019.
- Han et al. (2021) Han, K., Xiao, A., Wu, E., Guo, J., Xu, C., and Wang, Y. Transformer in transformer. Advances in Neural Information Processing Systems, 34:15908–15919, 2021.
- He et al. (2016) He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- He et al. (2017) He, K., Gkioxari, G., Dollár, P., and Girshick, R. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pp. 2961–2969, 2017.
- Hsieh et al. (2023) Hsieh, Y.-H., Chen, G.-S., Cai, S.-X., Wei, T.-Y., Yang, H.-F., and Chen, C.-S. Class-incremental continual learning for instance segmentation with image-level weak supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 1250–1261, October 2023.
- Hsu et al. (2019) Hsu, C.-C., Hsu, K.-J., Tsai, C.-C., Lin, Y.-Y., and Chuang, Y.-Y. Weakly supervised instance segmentation using the bounding box tightness prior. Advances in Neural Information Processing Systems, 32, 2019.
- Hu et al. (2020) Hu, Z., Liu, Z., Li, G., Ye, L., Zhou, L., and Wang, Y. Weakly supervised instance segmentation using multi-stage erasing refinement and saliency-guided proposals ordering. Journal of Visual Communication and Image Representation, 73:102957, 2020.
- Huang et al. (2020) Huang, Z., Zou, Y., Kumar, B., and Huang, D. Comprehensive attention self-distillation for weakly-supervised object detection. Advances in neural information processing systems, 33:16797–16807, 2020.
- Huang et al. (2022) Huang, Z., Bao, Y., Dong, B., Zhou, E., and Zuo, W. W2n:switching from weak supervision to noisy supervision for object detection, 2022.
- Hwang et al. (2021) Hwang, J., Kim, S., Son, J., and Han, B. Weakly supervised instance segmentation by deep community learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 1020–1029, January 2021.
- Jia et al. (2021) Jia, Q., Wei, S., Ruan, T., Zhao, Y., and Zhao, Y. Gradingnet: Towards providing reliable supervisions for weakly supervised object detection by grading the box candidates. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp. 1682–1690, 2021.
- Jiang & Yang (2023) Jiang, P.-T. and Yang, Y. Segment anything is a good pseudo-label generator for weakly supervised semantic segmentation. arXiv preprint arXiv:2305.01275, 2023.
- Jie et al. (2017) Jie, Z., Wei, Y., Jin, X., Feng, J., and Liu, W. Deep self-taught learning for weakly supervised object localization. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1377–1385, 2017.
- Khoreva et al. (2017) Khoreva, A., Benenson, R., Hosang, J., Hein, M., and Schiele, B. Simple does it: Weakly supervised instance and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- Kim et al. (2022) Kim, B., Yoo, Y., Rhee, C. E., and Kim, J. Beyond semantic to instance segmentation: Weakly-supervised instance segmentation via semantic knowledge transfer and self-refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4278–4287, June 2022.
- Kirillov et al. (2023) Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W.-Y., Dollár, P., and Girshick, R. Segment anything. arXiv:2304.02643, 2023.
- (35) Laptev, I., Kantorov, V., Oquab, M., and Cho, M. Contextlocnet: Context-aware deep network models for weakly supervised localization.
- Laradji et al. (2019) Laradji, I. H., Vazquez, D., and Schmidt, M. Where are the masks: Instance segmentation with image-level supervision. arXiv preprint arXiv:1907.01430, 2019.
- (37) Laradji12, I. H., Vazquez, D., Schmidt, M., and Element, A. Where are the masks: Instance segmentation with image-level supervision.
- Lee et al. (2021) Lee, J., Yi, J., Shin, C., and Yoon, S. Bbam: Bounding box attribution map for weakly supervised semantic and instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2643–2652, June 2021.
- Li et al. (2016) Li, D., Huang, J.-B., Li, Y., Wang, S., and Yang, M.-H. Weakly supervised object localization with progressive domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3512–3520, 2016.
- Li et al. (2022) Li, W., Liu, W., Zhu, J., Cui, M., Hua, X.-S., and Zhang, L. Box-supervised instance segmentation with level set evolution. In European conference on computer vision, pp. 1–18. Springer, 2022.
- Li et al. (2019) Li, X., Kan, M., Shan, S., and Chen, X. Weakly supervised object detection with segmentation collaboration. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019.
- Li et al. (2023) Li, Z., Zeng, Z., Liang, Y., and Yu, J.-G. Complete instances mining for weakly supervised instance segmentation. In International Joint Conference on Artificial Intelligence, 2023.
- Liao et al. (2019) Liao, S., Sun, Y., Gao, C., KP, P. S., Mu, S., Shimamura, J., and Sagata, A. Weakly supervised instance segmentation using hybrid networks. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1917–1921. IEEE, 2019.
- Lin et al. (2024) Lin, J., Shen, Y., Wang, B., Lin, S., Li, K., and Cao, L. Weakly supervised open-vocabulary object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, 2024.
- Lin et al. (2014) Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., and Zitnick, C. L. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pp. 740–755. Springer, 2014.
- Lin et al. (2017) Lin, T.-Y., Goyal, P., Girshick, R., He, K., and Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pp. 2980–2988, 2017.
- Lin et al. (2023) Lin, Y., Chen, M., Wang, W., Wu, B., Li, K., Lin, B., Liu, H., and He, X. Clip is also an efficient segmenter: A text-driven approach for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15305–15314, 2023.
- Liu et al. (2019) Liu, B., Gao, Y., Guo, N., Ye, X., Wan, F., You, H., and Fan, D. Utilizing the instability in weakly supervised object detection. In CVPR Workshops, 2019.
- Liu et al. (2020) Liu, Y., Wu, Y.-H., Wen, P., Shi, Y., Qiu, Y., and Cheng, M.-M. Leveraging instance-, image-and dataset-level information for weakly supervised instance segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(3):1415–1428, 2020.
- Locatello et al. (2020) Locatello, F., Poole, B., Rätsch, G., Schölkopf, B., Bachem, O., and Tschannen, M. Weakly-supervised disentanglement without compromises. In International Conference on Machine Learning, pp. 6348–6359. PMLR, 2020.
- Loshchilov & Hutter (2017) Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Ma & Wang (2023) Ma, J. and Wang, B. Segment anything in medical images. arXiv preprint arXiv:2304.12306, 2023.
- Ou et al. (2021) Ou, J.-R., Deng, S.-L., and Yu, J.-G. Ws-rcnn: Learning to score proposals for weakly supervised instance segmentation. Sensors, 21(10):3475, 2021.
- Pont-Tuset et al. (2016) Pont-Tuset, J., Arbelaez, P., Barron, J. T., Marques, F., and Malik, J. Multiscale combinatorial grouping for image segmentation and object proposal generation. IEEE transactions on pattern analysis and machine intelligence, 39(1):128–140, 2016.
- Ren et al. (2015) Ren, S., He, K., Girshick, R., and Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 2015.
- Ren et al. (2020) Ren, Z., Yu, Z., Yang, X., Liu, M.-Y., Lee, Y. J., Schwing, A. G., and Kautz, J. Instance-aware, context-focused, and memory-efficient weakly supervised object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10598–10607, 2020.
- Schroeter et al. (2019) Schroeter, J., Sidorov, K., and Marshall, D. Weakly-supervised temporal localization via occurrence count learning. In International Conference on Machine Learning, pp. 5649–5659. PMLR, 2019.
- Seo et al. (2022) Seo, J., Bae, W., Sutherland, D. J., Noh, J., and Kim, D. Object discovery via contrastive learning for weakly supervised object detection. In European Conference on Computer Vision, pp. 312–329. Springer, 2022.
- Shen et al. (2019) Shen, Y., Ji, R., Wang, Y., Wu, Y., and Cao, L. Cyclic guidance for weakly supervised joint detection and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 697–707, 2019.
- Shen et al. (2020) Shen, Y., Ji, R., Wang, Y., Chen, Z., Zheng, F., Huang, F., and Wu, Y. Enabling deep residual networks for weakly supervised object detection. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VIII 16, pp. 118–136. Springer, 2020.
- Shen et al. (2021) Shen, Y., Cao, L., Chen, Z., Zhang, B., Su, C., Wu, Y., Huang, F., and Ji, R. Parallel detection-and-segmentation learning for weakly supervised instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8198–8208, 2021.
- Sui et al. (2022) Sui, L., Zhang, C.-L., and Wu, J. Salvage of supervision in weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14227–14236, 2022.
- Sun et al. (2020) Sun, G., Wang, W., Dai, J., and Van Gool, L. Mining cross-image semantics for weakly supervised semantic segmentation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16, pp. 347–365. Springer, 2020.
- Sun et al. (2023) Sun, W., Liu, Z., Zhang, Y., Zhong, Y., and Barnes, N. An alternative to wsss? an empirical study of the segment anything model (sam) on weakly-supervised semantic segmentation problems. arXiv preprint arXiv:2305.01586, 2023.
- Tang et al. (2017) Tang, P., Wang, X., Bai, X., and Liu, W. Multiple instance detection network with online instance classifier refinement. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2843–2851, 2017.
- Tang et al. (2018a) Tang, P., Wang, X., Bai, S., Shen, W., Bai, X., Liu, W., and Yuille, A. Pcl: Proposal cluster learning for weakly supervised object detection. IEEE transactions on pattern analysis and machine intelligence, 42(1):176–191, 2018a.
- Tang et al. (2018b) Tang, P., Wang, X., Wang, A., Yan, Y., Liu, W., Huang, J., and Yuille, A. Weakly supervised region proposal network and object detection. In Proceedings of the European conference on computer vision (ECCV), pp. 352–368, 2018b.
- Tian et al. (2021) Tian, Z., Shen, C., Wang, X., and Chen, H. Boxinst: High-performance instance segmentation with box annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5443–5452, 2021.
- Touvron et al. (2021) Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., and Jégou, H. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, pp. 10347–10357. PMLR, 2021.
- Uijlings et al. (2013) Uijlings, J. R. R., van de Sande, K. E. A., Gevers, T., and Smeulders, A. W. M. Selective search for object recognition. International Journal of Computer Vision, 104:154 – 171, 2013. URL https://api.semanticscholar.org/CorpusID:216077384.
- Wan et al. (2018) Wan, F., Wei, P., Jiao, J., Han, Z., and Ye, Q. Min-entropy latent model for weakly supervised object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1297–1306, 2018.
- Wan et al. (2019) Wan, F., Liu, C., Ke, W., Ji, X., Jiao, J., and Ye, Q. C-mil: Continuation multiple instance learning for weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2199–2208, 2019.
- Wang et al. (2013) Wang, X., Wang, B., Bai, X., Liu, W., and Tu, Z. Max-margin multiple-instance dictionary learning. In International conference on machine learning, pp. 846–854. PMLR, 2013.
- Wang et al. (2021) Wang, X., Feng, J., Hu, B., Ding, Q., Ran, L., Chen, X., and Liu, W. Weakly-supervised instance segmentation via class-agnostic learning with salient images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10225–10235, 2021.
- Xu et al. (2014) Xu, C., Tao, D., Xu, C., and Rui, Y. Large-margin weakly supervised dimensionality reduction. In International conference on machine learning, pp. 865–873. PMLR, 2014.
- Xu et al. (2022) Xu, L., Ouyang, W., Bennamoun, M., Boussaid, F., and Xu, D. Multi-class token transformer for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4310–4319, 2022.
- Yang et al. (2019) Yang, K., Li, D., and Dou, Y. Towards precise end-to-end weakly supervised object detection network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8372–8381, 2019.
- Yang et al. (2023) Yang, L., Wang, Y., Li, X., Wang, X., and Yang, J. Fine-grained visual prompting. arXiv preprint arXiv:2306.04356, 2023.
- Yin et al. (2021) Yin, Y., Deng, J., Zhou, W., and Li, H. Instance mining with class feature banks for weakly supervised object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp. 3190–3198, 2021.
- Yin et al. (2023) Yin, Y., Deng, J., Zhou, W., Li, L., and Li, H. Cyclic-bootstrap labeling for weakly supervised object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7008–7018, 2023.
- Zeng et al. (2019) Zeng, Z., Liu, B., Fu, J., Chao, H., and Zhang, L. Wsod2: Learning bottom-up and top-down objectness distillation for weakly-supervised object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 8292–8300, 2019.
- Zhang et al. (2022) Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L. M., and Shum, H.-Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection, 2022.
- Zhang et al. (2023) Zhang, J., Su, H., He, Y., and Zou, W. Weakly supervised instance segmentation via category-aware centerness learning with localization supervision. Pattern Recognition, 136:109165, 2023.
- Zhang et al. (2021) Zhang, K., Yuan, C., Zhu, Y., Jiang, Y., and Luo, L. Weakly supervised instance segmentation by exploring entire object regions. IEEE Transactions on Multimedia, 2021.
- Zhang et al. (2018a) Zhang, X., Feng, J., Xiong, H., and Tian, Q. Zigzag learning for weakly supervised object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4262–4270, 2018a.
- Zhang et al. (2018b) Zhang, Y., Bai, Y., Ding, M., Li, Y., and Ghanem, B. W2f: A weakly-supervised to fully-supervised framework for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 928–936, 2018b.
- Zhou et al. (2018) Zhou, Y., Zhu, Y., Ye, Q., Qiu, Q., and Jiao, J. Weakly supervised instance segmentation using class peak response. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3791–3800, 2018.
- Zhou (2018) Zhou, Z.-H. A brief introduction to weakly supervised learning. National science review, 5(1):44–53, 2018.
- Zhu et al. (2023a) Zhu, L., Li, Y., Fang, J., Liu, Y., Xin, H., Liu, W., and Wang, X. Weaktr: Exploring plain vision transformer for weakly-supervised semantic segmentation. arXiv preprint arXiv:2304.01184, 2023a.
- Zhu et al. (2023b) Zhu, L., Peng, L., Ding, S., and Liu, Z. An encoder-decoder framework with dynamic convolution for weakly supervised instance segmentation. IET Computer Vision, 2023b.
- Zhu et al. (2019) Zhu, Y., Zhou, Y., Xu, H., Ye, Q., Doermann, D., and Jiao, J. Learning instance activation maps for weakly supervised instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- Zitnick & Dollár (2014) Zitnick, C. L. and Dollár, P. Edge boxes: Locating object proposals from edges. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pp. 391–405. Springer, 2014.
Appendix A More Details of WeakSAM Proposals
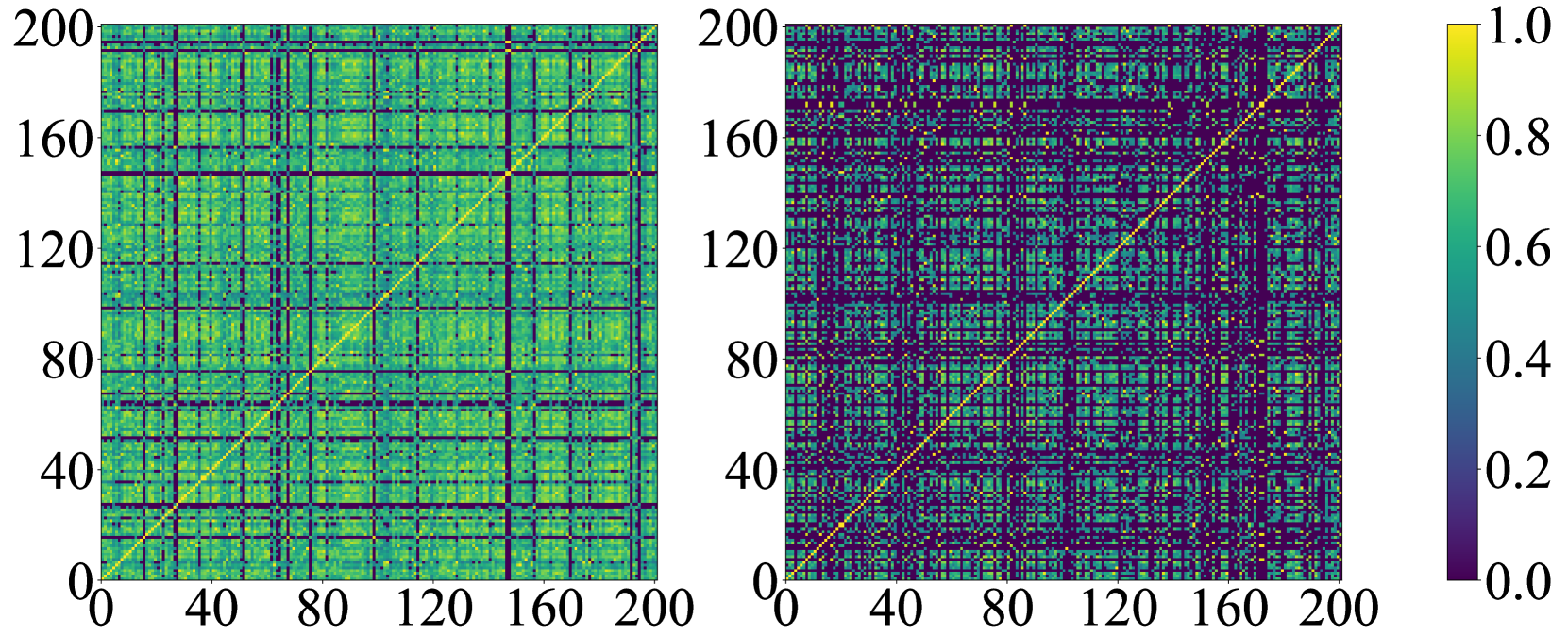
We further analyze the proposal similarity in the different weakly-supervised object detection (WSOD) proposals, as shown in Fig. 4. We randomly sample 200 proposal features each from Selective Search (Uijlings et al., 2013) proposals and WeakSAM-proposals, and then compute their cosine similarity, respectively. Please note that all the features are output by the RoI pooling layer. It can be seen that the features from Selective Search tend to have higher similarity with other ones. In contrast, the features from WeakSAM-proposals show lower similarity, which usually means it has less overlap and redundancy.
Appendix B More Details of RoI Drop Regularization
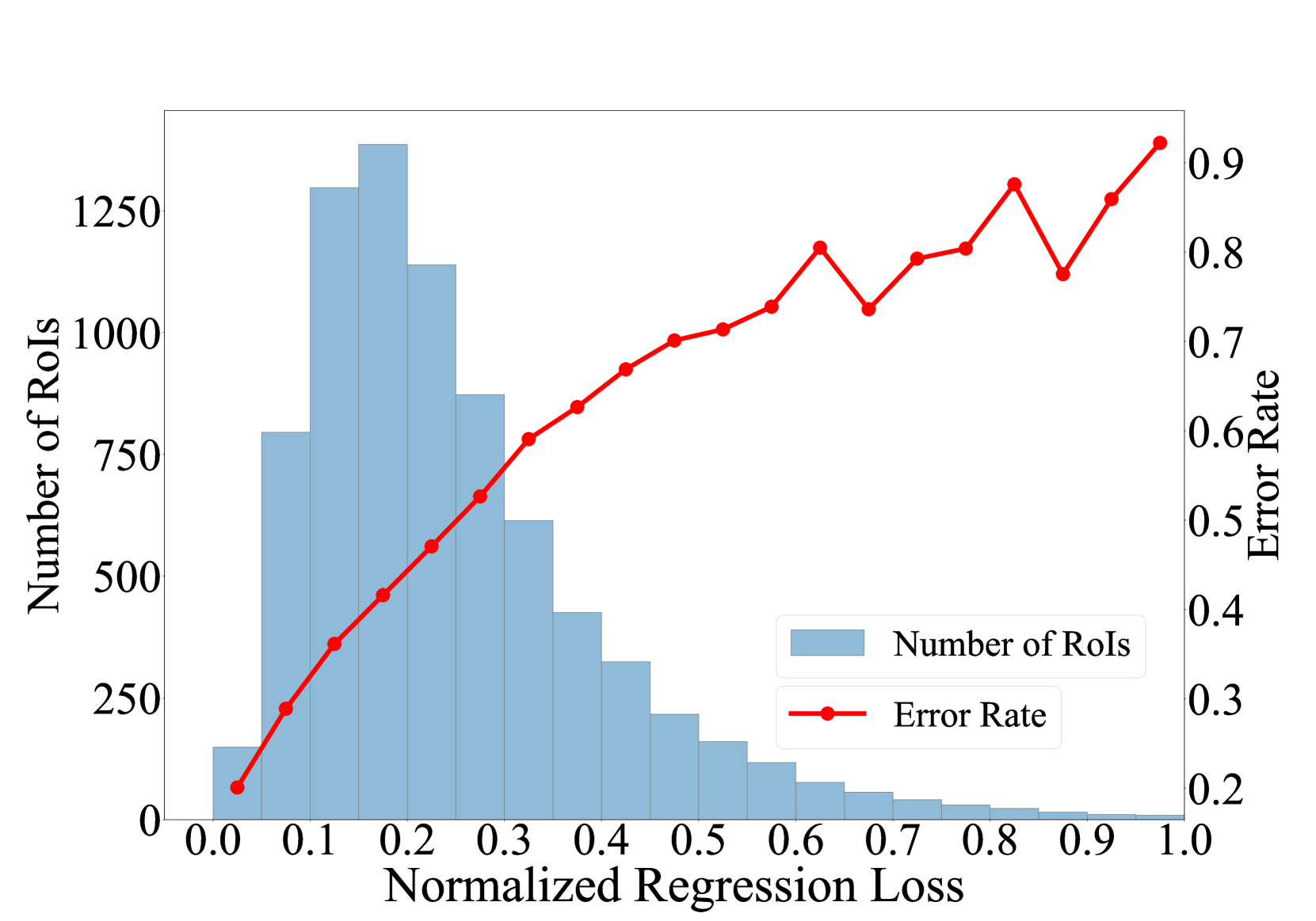
We further present the relationship between the normalized regression loss, the corresponding number of RoIs, and the corresponding error rate in Fig. 5. It shows that the regression losses of RoIs have different number distributions compared to the classification losses. However, they exhibit similar error rate curves. This observation further demonstrates the necessity of RoI drop regularization with a regression threshold .
Appendix C More Details of Query Drop Regularization
Because DINO (Zhang et al., 2022) employs Focal loss (Lin et al., 2017) as the classification loss, queries associated with background classes tend to have higher predicted probabilities and lower losses. This results in the inadvertent omission of most foreground category queries when directly dropping queries. To mitigate this issue, our first step involves normalizing the unweighted Focal loss, which is essentially the binary cross-entropy loss, for both foreground and background queries within each training batch. Normalizing at the batch level broadens the sampling scope from a single image to the size of the batch. In the second step, queries are dropped based on their loss ranking post-normalization. This approach avoids making the model converge slowly due to the dropping of the most foreground queries.
Appendix D Efficiency Comparison
| Num. | T | T | M | |
| SS (Uijlings et al., 2013) | 2001 | 11.6 hrs | 16 hrs | 17810 MiB |
| Ours | 213-89.4% | 4 hrs-65.5% | 9 hrs-43.8% | 5667 MiB-68.2% |
To further analyze the efficiency improvement brought by the WeakSAM, we present the efficiency comparison between Selective Search (Uijlings et al., 2013) and our WeakSAM on a machine with 4 GPU cards, as shown in Table 6. Our WeakSAM reduces the number of proposals by 89.4%, the proposal generation time by 65.5%, the WSOD network training time by 43.8%, and the GPU memory cost by 68.2%. The results demonstrate the significant efficiency improvement brought by the proposed WeakSAM.
Appendix E Additional Quantitative Results
| Methods | Proposal | CorLoc | |
| WSDDN (Bilen & Vedaldi, 2016a) | EB (Zitnick & Dollár, 2014) | 53.5 | |
| Yang et al. (Yang et al., 2019) | SS (Uijlings et al., 2013) | 68.0 | |
| C-MIL (Wan et al., 2019) | SS | 65.0 | |
| C-MIDN (Gao et al., 2019) | SS | 53.5 | |
| WSOD2 (Zeng et al., 2019) | SS | 69.5 | |
| CASD (Huang et al., 2020) | SS | 70.4 | |
| OD-WSCL (Seo et al., 2022) | SS | 69.8 | |
| WSOD-CBL (Yin et al., 2023) | SS | 71.8 | |
| WSOVOD (Lin et al., 2024) | LO-WSRPN+SAM | 77.2 | |
| WSOVOD‡ | LO-WSRPN+SAM | 80.1 | |
| OICR (Tang et al., 2017) | SS | 60.6 | |
| WeakSAM (OICR) | WeakSAM | 74.5+13.9 | |
| MIST (Ren et al., 2020) | SS | 68.8 | |
| WeakSAM (MIST) | WeakSAM | 82.9+14.1 |
We present the comparison on PASCAL VOC 2007 set in terms of CorLoc, as shown in Table 7. It can be seen that the WeakSAM achieves the 13.9% and 14.1% CorLoc improvements on OICR and MIST, respectively. The WeakSAM (OICR) outperforms the WSOD-CBL (Yin et al., 2023) by 11.1% CorLoc. The results demonstrate the significant effectiveness improvement brought by our WeakSAM.
Appendix F Additional Ablation Studies
F.1 Improvements of Classification Methods
| CLS Methods | Num. | Recall | ||
| IoU=0.50 | IoU=0.75 | IoU=0.90 | ||
| None | 2001 | 92.6 | 57.7 | 19.2 |
| WeakTr (Zhu et al., 2023a) | 213 | 95.6 | 75.0 | 42.1 |
| MCTformer (Xu et al., 2022) | 173 | 93.2 | 74.8 | 43.7 |
| CLIP-ES (Lin et al., 2023) | 205 | 93.8 | 75.6 | 44.5 |
To further analyze the impact of methods that generate classification clues, we replaced WeakTr in WeakSAM with MCTformer and CLIP-ES. As indicated in Table 8, WeakSAM (MCTformer) achieves a 1.6% higher Recall (IoU=90) than WeakSAM (WeakTr). Furthermore, WeakSAM (CLIP-ES) records increases of 0.6% and 2.4% in Recall over WeakSAM (WeakTr) at IoU thresholds of 75 and 90, respectively. These results demonstrate the versatility of the WeakSAM proposal-generating method across different classification methods. Please note that all classification methods employed in this study are CAM networks from weakly-supervised semantic segmentation (WSSS) methods. Since these networks are typically well-tuned on specific datasets, such as PASCAL VOC 2012 and COCO 2014, they are adept at providing rich classification clues.
F.2 Ablation Studies for RoI Drop Regularization
| 0.8 | 1.0 | 1.2 | |
| 71.0 | 71.8 | 71.3 | |
| 3.0 | 4.0 | 5.0 | |
| 71.2 | 71.8 | 71.1 | |
To further analyze the impact of the regression threshold and classification threshold in RoI drop regularization, we conduct experiments as shown in Table 9(b). It is observed that the best regression threshold and classification threshold for RoI drop regularization is 1.0 and 4.0, respectively.
F.3 Ablation Studies for Query Drop Regularization
| Baseline | AP | ||
| ✓ | 72.8 | ||
| ✓ | 73.4+0.6 | ||
| ✓ | ✓ | 73.3+0.5 |


To analyze the impact of dropping queries corresponding to foreground categories and background categories , we conduct ablations as shown in Table 10. Experimental results indicate that dropping only the foreground queries () leads to the best performance, whereas dropping both types of queries results in a slight decrease in performance. We maintain the viewpoint that dropping more background queries may also lead to slower convergence. Consequently, we choose to drop only to achieve better performance.
We further analyze the impact of classification threshold in query drop regularization, as shown in Table 11. Quantitative results demonstrate that 90 is the best percentile classification threshold.
| (%) | 100 | 90 | 80 |
| 72.8 | 73.4 | 71.8 | |
Appendix G Additional Visualization Results


Fig.6 compares the Selective Search proposals with those generated by WeakSAM. The WeakSAM-proposals exhibit less redundancy than Selective Search proposals. Fig.7 contrasts the Top-1 PGT with adaptive PGT, demonstrating that adaptive PGT generation captures a greater number of objects, which might be missed by the Top-1 approach. Additionally, adaptive PGT can be seamlessly integrated to generate pseudo instance labels. Fig.8 presents the object detection results using WeakSAM (MIST), showing its capability to accurately capture entire objects without generating excessive noisy bounding boxes. In Fig.9, the instance segmentation results of WeakSAM-Mask2Former retraining are showcased. The results indicate effective segmentation of entire instances with a notable reduction in overlapping segments.
Appendix H More Implementation Details
For Algorithm 1, we set the kernel size to 128 and activation threshold to 0.9 following default parameters from WeakTr (Zhu et al., 2023a). And for Algorithm 2, we follow the default manners similar to SoS-WSOD (Sui et al., 2022), in which score threshold is set to 0.3, and overlap threshold is set to 0.85.
For Faster R-CNN (Ren et al., 2015) retraining, we adopt the same training strategy and hyper-parameters as the Fully-supervised ones. For DINO (Zhang et al., 2022) retraining, we use a learning rate of 9e-5 with the AdamW (Loshchilov & Hutter, 2017) optimizer, and a max epoch of 14. Moreover, we apply multi-scale augmentation and horizontal flips in both training and testing.
For implementations of Mask R-CNN (He et al., 2017) and Mask2Former (Cheng et al., 2022), we follow their default hyper-parameters.