Out-of-Distribution Detection using Neural
Activation Prior
Abstract
Out-of-distribution detection (OOD) is a crucial technique for deploying machine learning models in the real world to handle the unseen scenarios. In this paper, we first propose a simple yet effective Neural Activation Prior (NAP) for OOD detection. Our neural activation prior is based on a key observation that, for a channel before the global pooling layer of a fully trained neural network, the probability of a few neurons being activated with a large response by an in-distribution (ID) sample is significantly higher than that by an OOD sample. An intuitive explanation is that for a model fully trained on ID dataset, each channel would play a role in detecting a certain pattern in the ID dataset, and a few neurons can be activated with a large response when the pattern is detected in an input sample. Then, a new scoring function based on this prior is proposed to highlight the role of these strongly activated neurons in OOD detection. Our approach is plug-and-play and does not lead to any performance degradation on ID data classification and requires no extra training or statistics from training or external datasets. Notice that previous methods primarily rely on post-global-pooling features of the neural networks, while the within-channel distribution information we leverage would be discarded by the global pooling operator. Consequently, our method is orthogonal to existing approaches and can be effectively combined with them in various applications. Experimental results show that our method achieves the state-of-the-art performance on CIFAR benchmark and ImageNet dataset, which demonstrates the power of the proposed prior. Finally, we extend our method to Transformers and the experimental findings indicate that NAP can also significantly enhance the performance of OOD detection on Transformers, thereby demonstrating the broad applicability of this prior knowledge.
1 Introduction
Deep learning has developed rapidly in the last decade and become a crucial technique in various fields. However, neural networks would frequently make erroneous judgments in inference when encounter the data that differs greatly from their training data, which is known as out-of-distribution (OOD) data. This challenge is growing more prevalent and is particularly vital in safety-critical areas such as autonomous driving [11, 20] and medical diagnosis [33], which urges the development of effective OOD detection methods.
In practice, OOD data exhibits large diversity and is difficult to identify [49]. Existing studies typically formulate OOD detection as a one-class classification task, utilizing prior knowledge. They [14, 27, 51] propose various priors, based on which they further design scoring functions to distinguish OOD samples from ID samples. For example, Hendrycks et al. [14] observed that OOD samples always exhibit lower maximum softmax probabilities, and accordingly proposed using the maximal softmax probability output by a neural network as an OOD indicator. Liu et al. [27] found that OOD samples usually have lower logits values, and based on this, an energy function was proposed for OOD detection. Drawing from these precedents, it’s clear that existing methods largely rely on the introduction of certain priors. While some promising results highlight the effectiveness of these heuristics, a gap remains in meeting the practical requirements of real-world applications. Importantly, we note that the focus of these priors is narrowly concentrated on features and weights following global pooling, while the characteristics before the pooling layer are consistently ignored. Thus, we believe that finding and incorporating priors that can complement these existing focuses is essential, which will constitute the main contribution of our work.
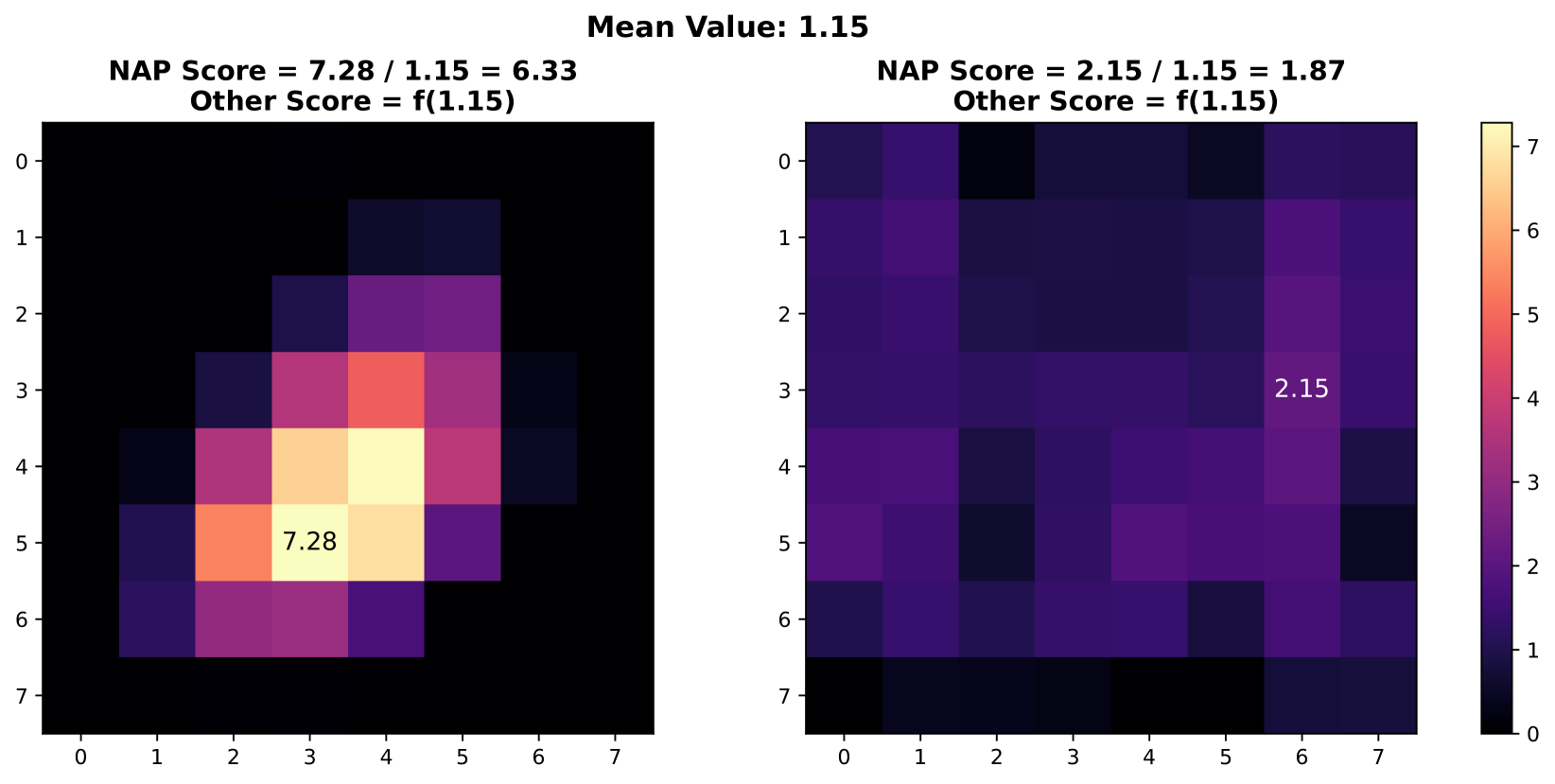
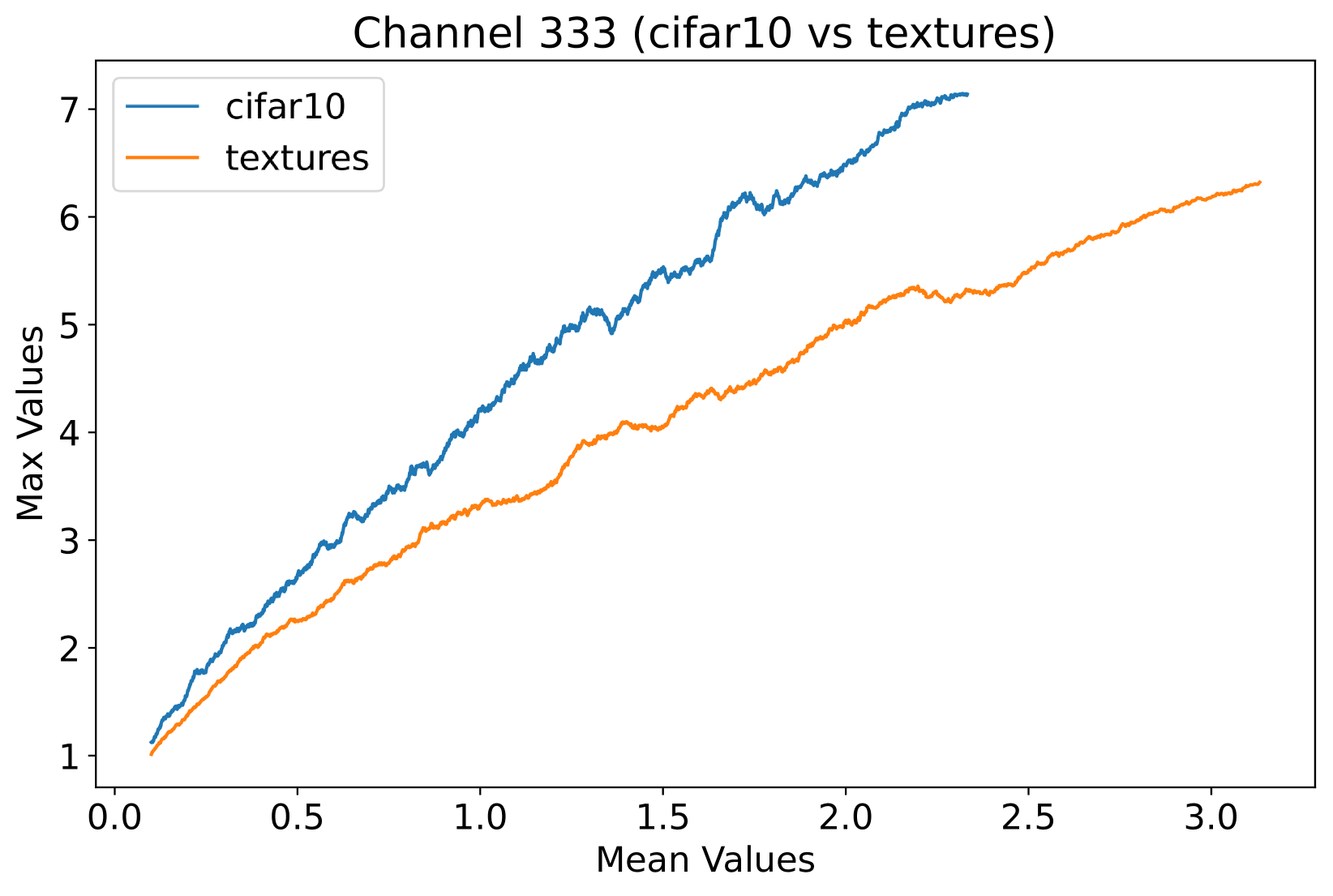
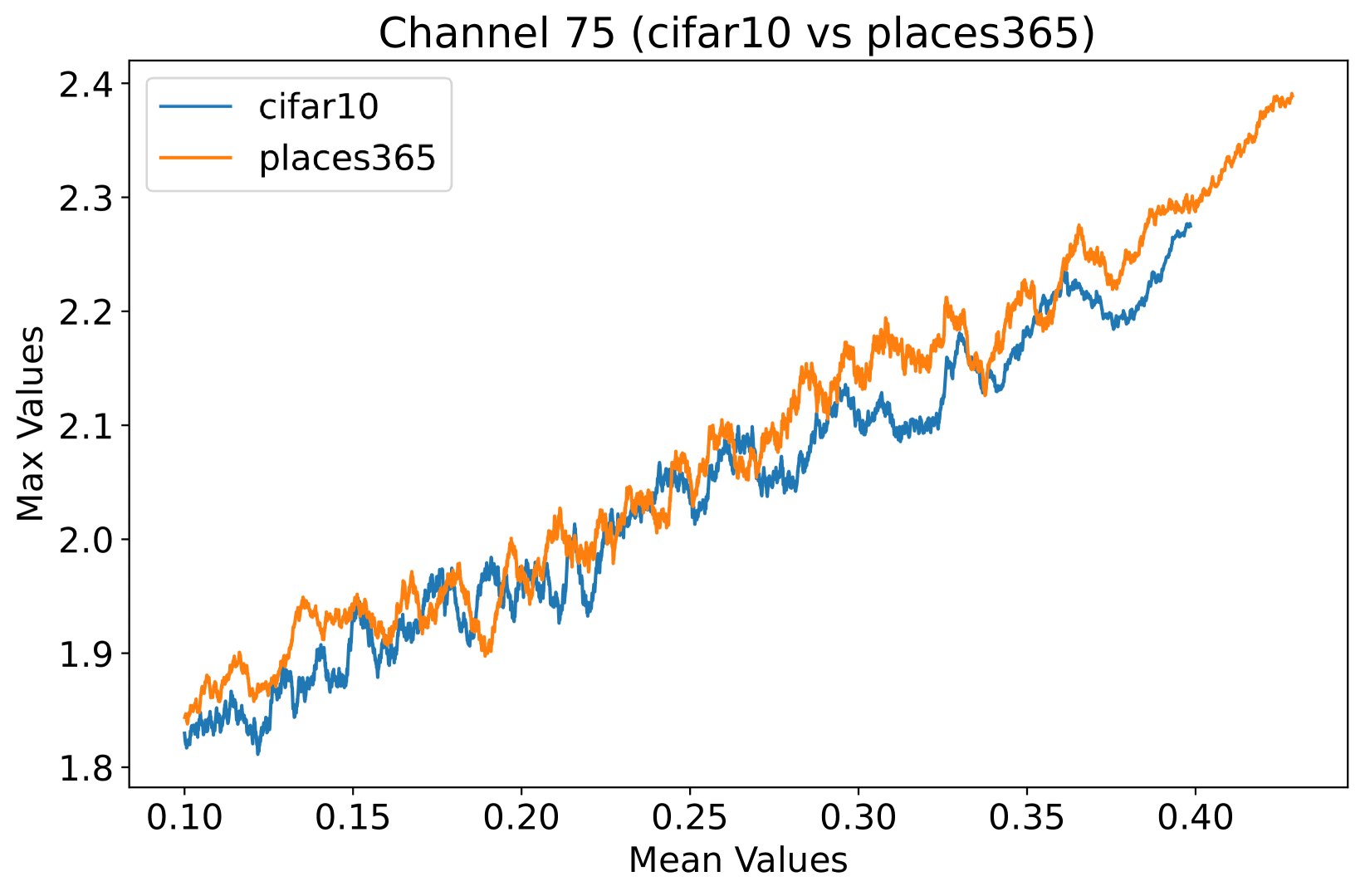
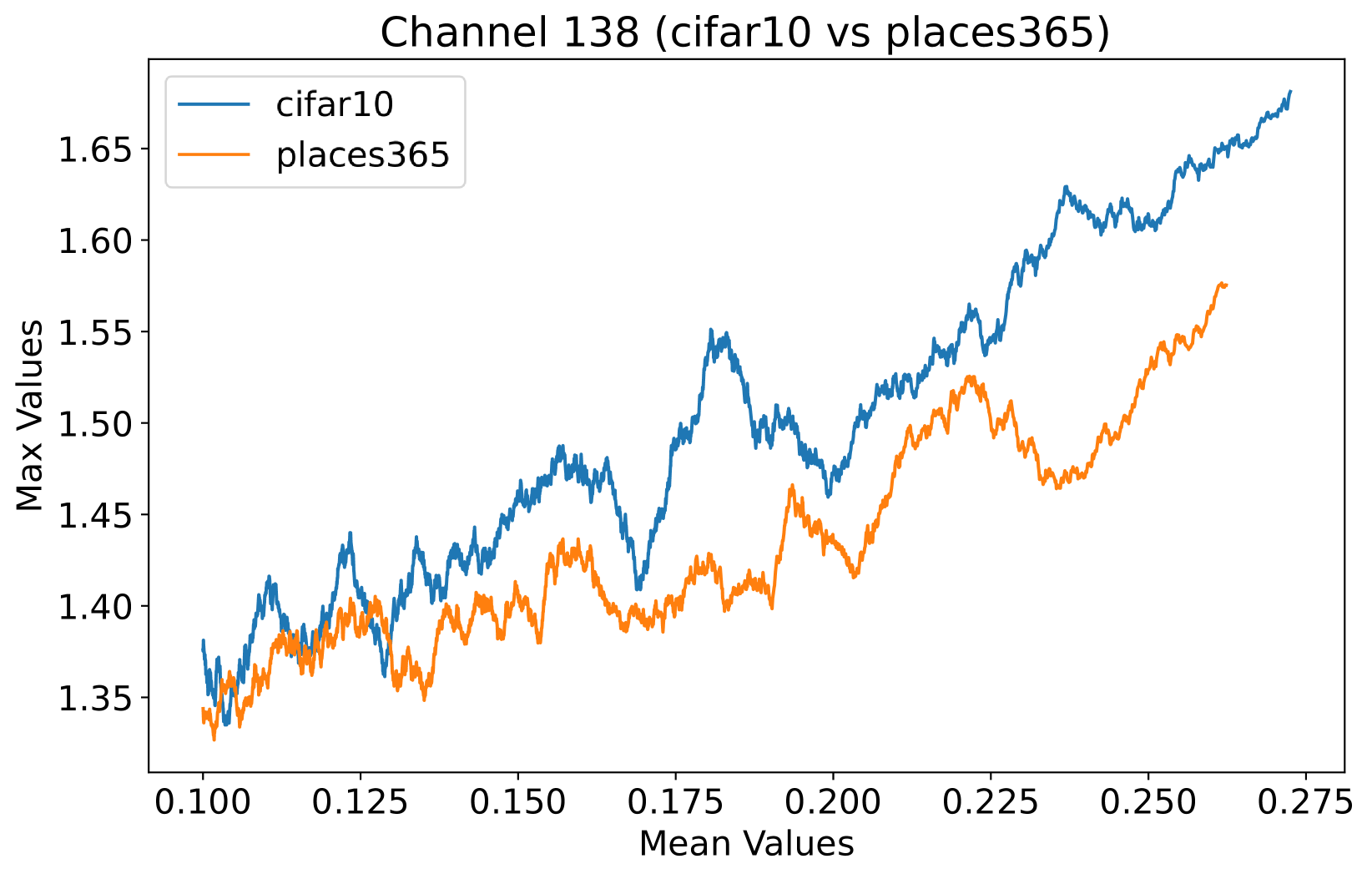
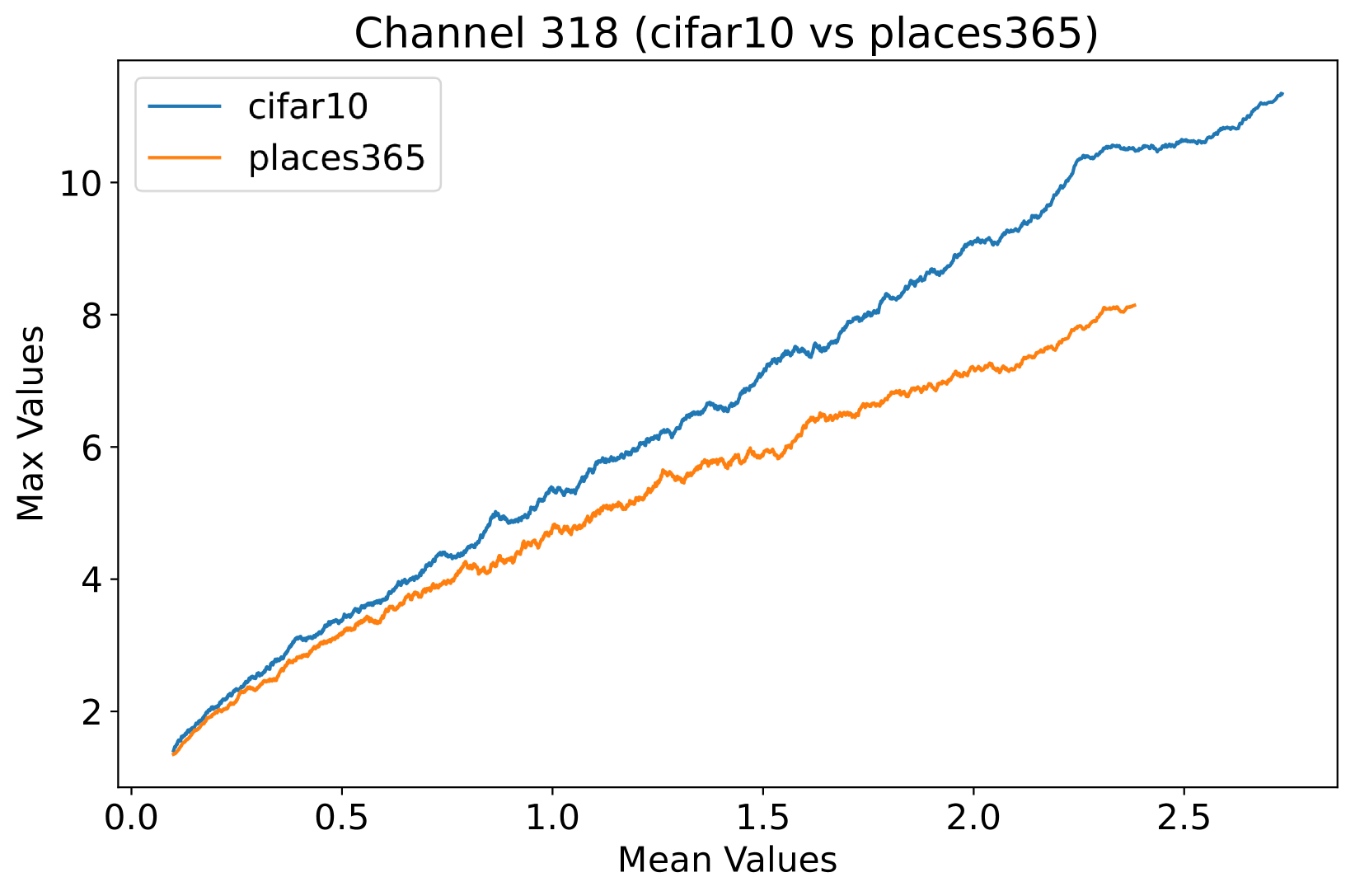
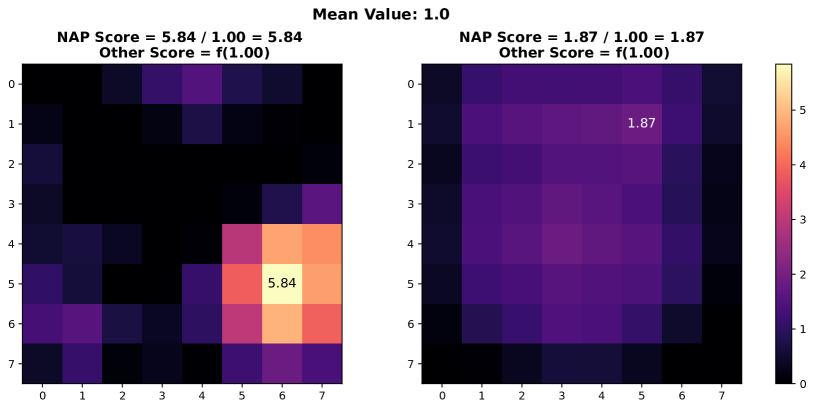
In this study, we propose a novel prior, called Neural Activation Prior (NAP), for OOD detection. NAP characterizes our key observation that for channels before the global pooling layer in a fully trained neural network (illustrated to Figure 3(a)), a few neurons have a significantly high probability to show a larger response when activated by in-distribution (ID) samples compared to OOD samples. An intuitive explanation for NAP is that channels in a model fully trained on an ID dataset play a role in detecting certain patterns in the input samples from the ID dataset. When such patterns are detected, a few neurons can be activated [16], resulting in larger responses. These large responses usually occur when the input sample is ID data, but when the input is OOD data, such responses are rarely observed. This is because the pattern that the neuron focuses on is unlikely to be present in the OOD data. To verify our proposed prior, we employed DenseNet architecture [18] on CIFAR-10 [23] and Texture [5] datasets, analyzing mean and maximum within-channel activations before global pooling at the penultimate layer. Figure 1 clearly demonstrates that ID samples exhibit significantly higher maximal activation values than OOD samples at equal average activation levels. Consequently, a series of methods, such as those in [14, 40, 27, 26, 25, 39, 8, 2, 38], based on pooled activation values are unable to effectively distinguish these OOD samples, given the non-discriminative nature of their average activation values.
It is worth noting that our proposed prior is orthogonal to that used in current OOD detection methods. In the OOD deteciton field, as shown in Figure 3(a), existing methods [14, 40, 27, 26, 25, 39, 8, 2, 38] mainly focus on the outputs and weights of the neural network after global pooling, and use them to design scoring functions for OOD detection. In contrast, the prior we proposed is focus within the channels of the penultimate layer before global pooling. Since the information carried in our prior can be easily lost during the global pooling process, this demonstrates that our NAP is essentially complementary to the priors used in current OOD detection studies. To this end, we would like to emphasize that the contribution of this paper would lie in how much improvement we can achieve by integrating our method with existing approaches, rather than a direct comparison with existing methods in the field.
Furthermore, in this paper, we propose a simple yet effective scoring function for OOD detection based on our prior NAP. To be precise, our scoring function is based on the ratio of the maximal and averaged activation values within a channel. The rationale behind the scoring function can be understood from two primary perspectives: conceptual inspiration from the Signal-to-Noise (SNR) and empirical validation. On the conceptual front, inspired by the concept of SNR, we can consider the maximal activation value as signal strength, while the averaged activation value represents noise strength. Therefore, the ratio of the maximum to the average value can be used to measure the quality of information contained in the channel. On the empirical front, as shown in Figure 1, the ratio of the maximal and the averaged values for ID samples is significantly higher than that of OOD data. Regarding practical deployment, as previously mentioned, our scoring function complements and, when multiplied with existing metrics, improves OOD detection, as depicted in Figure 2. Also, it is noteworthy that this scoring function is a plug-and-play method, requiring no additional training, extra data, or reliance on pre-calculated statistical data from the training set, which makes it broadly applicable.
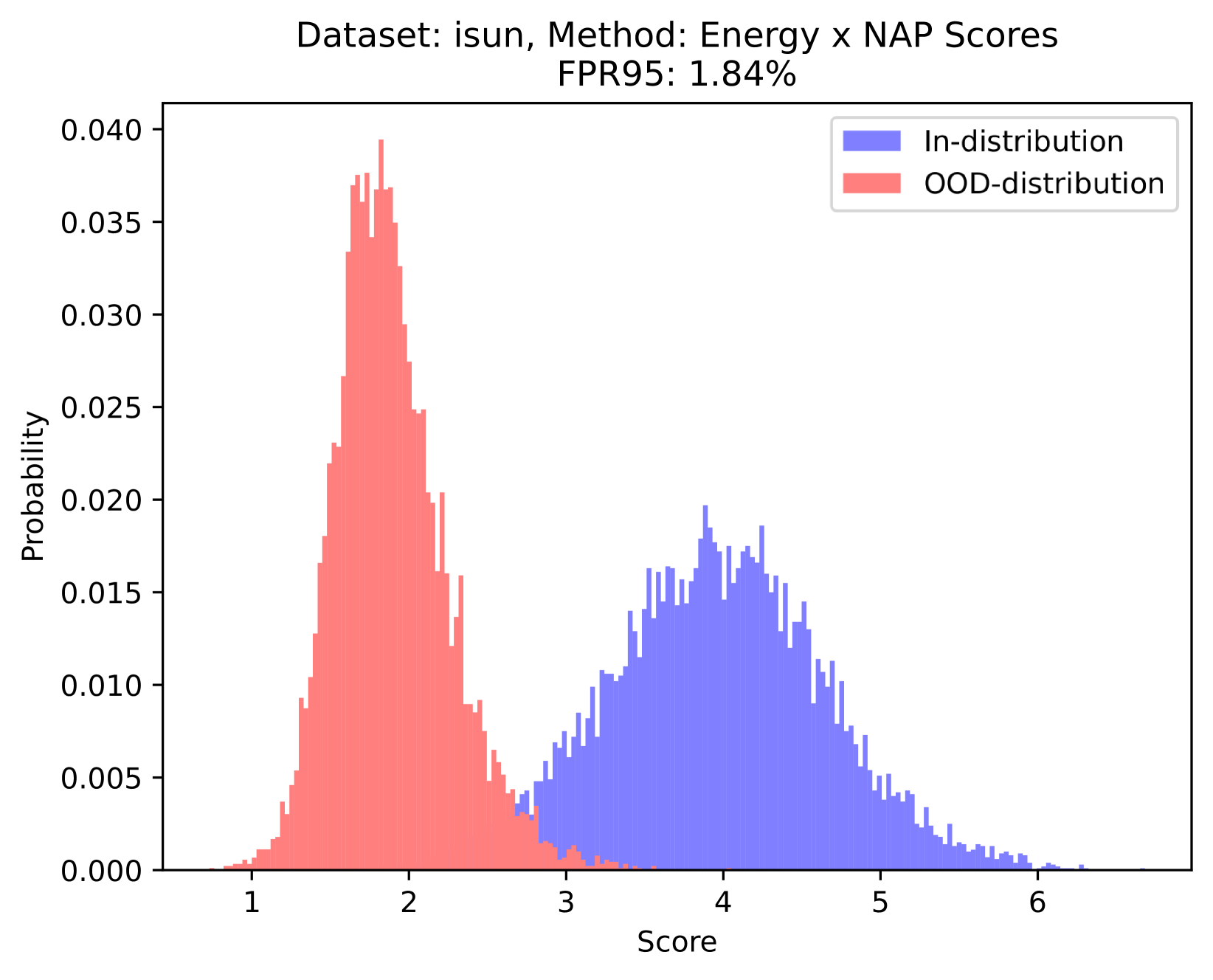
Experimental results show that our method achieves state-of-the-art performance on CIFAR-10 [23], CIFAR-100 [23] and ImageNet datasets. Specifically, our method significantly reduces the false positive rate by 48.23% (from 15.05 to 7.79) on the CIFAR-10 dataset [23], a reduction of 37.89% (from 41.40 to 25.71) on the CIFAR-100 dataset [23], and a reduction of 16.26% (from 35.66 to 29.86) on the ImageNet dataset. The large drop in FPR95 highlights the effectiveness of our approach in different environments. The above experimental results demonstrate the power of our proposed prior. We believe that these findings will provide inspiration for other researchers and thus promote progress in the field of OOD detection.
Additionally, while convolutional neural networks (CNNs) are predominantly employed in OOD detection tasks, the advent of Transformer architectures [46] and their variants has showcased substantial efficacy across a diverse array of applications. Motivated by this, we extend our method to ensure compatibility with Transformer models. The empirical evidence obtained from our experiments affirms the robustness of our approach, demonstrating its adaptability to various architectural paradigms.
In summary, our contributions are as follows:
-
•
We introduce the Neural Activation Prior (NAP), a novel contribution to OOD detection. Uniquely, NAP is orthogonal to priors utilized in existing methods, offering a distinct and complementary perspective that paves the way for advanced OOD detection research.
-
•
Based on the proposed prior, we develop a simple yet effective OOD detection scoring function. It can be readily integrated with many existing OOD detection techniques, enhancing their ability to balance OOD detection with ID accuracy.
-
•
We demonstrate the state-of-the-art performance of our approach through extensive experiments across various datasets, including a reduction in FPR95 by up to 48.23%. These results underscore the method’s operational efficiency, simplicity of deployment, and overall efficacy.
-
•
We extend the method to accommodate Transformer architectures. Experimental results are encouraging, validating the method’s efficacy across various architectural designs.
2 Related work
2.1 OOD detection
The OOD detection community has explored a variety of techniques to underscore the distinctions between ID and OOD samples. These methods encompass classification-based [19, 26, 3, 7, 15, 36, 42, 10], density-based [55, 1, 30, 54, 21, 32, 22, 34], and distance-based approaches [41, 25, 29, 4, 52, 44, 43, 28, 40], with classification-based techniques generally outperforming the other types [49]. In classification-based methods, the basic work of OOD detection starts with a simple and effective baseline: using the Maximum Softmax Probability (MSP) [15] to measure the probability that a certain sample is an ID sample. On this basis, early approaches [26, 17, 27] focused on developing enhanced OOD indicators derived from neural network outputs. In addition, some researchers have proposed strategies involving OOD sample generation [24, 10] and gradient-based [26] techniques. Among these, certain post-hoc methods [14, 26, 27, 38, 39, 8, 51, 10] are notable for their simplicity and because they do not necessitate changes in the training process or objectives. This feature is particularly valuable for implementing OOD detection in real production environments, where the additional cost and complexity associated with retraining would be unacceptable.
The MSP method, initially presented by Hendrycks et al. [14], was a formative step in post hoc OOD detection, using a neural network’s softmax output as a heuristic for distinguishing ID from OOD samples. Its straightforward application facilitated early adoption in OOD studies. Despite MSP’s influence, its limitations prompted further innovation, giving rise to the Energy method. This method, proposed by Liu et al. [27], refines the approach by assigning an energy score to network outputs, showing quantitative improvements over MSP with theoretical and empirical support. Advancements in post hoc OOD detection have led to diverse methodological branches stemming from MSP [15] and Energy [27] paradigms. LINe [2] innovates by reducing neuron-induced noise through the calculation of Shapley values. Yu et al. [51] distinguish ID from OOD data by identifying neural network blocks with optimal differentiation based on the norms of their features. DICE [39] improves discrimination by pruning weights in the fully connected layer according to the contribution units make during classification. On the other end of the spectrum, entirely computation-free post hoc methods such as ReAct [38] and ASH [8] have shown promise. ReAct [38] investigates activations prior to the fully connected layer, applying rectification to suppress extreme activations that OOD data tend to trigger, thereby achieving refined detection outcomes. Similarly, ASH [8] prunes the activations inputted to the fully connected layer, but it achieves even more enhanced results compared to DICE [39] by its selective pruning strategy. In this paper, our comparison mainly focuses on post hoc methods, since our method also belongs to this category.
3 Neural activation prior
Our NAP is based on the following observation for OOD detection: for a channel located before the global pooling layer in a fully trained neural network, the likelihood that a small number of its neurons activated with a stronger response to an ID sample is significantly higher compared to an OOD sample. For the behavior in other layers of the neural network, refer to the discussion around Figure 4 in Section 5.4.
To formally describe this observation, we first define the concept of neural activation. Consider a trained classification neural network , assuming it receives -dimensional input and outputs -dimensional logits. That is . We concentrate on the activation tensor , located at the penultimate layer just before the global pooling operation, as illustrated in Figure 3(a). Let the dimensions of be , where is the number of channels, and and are the spatial dimensions.
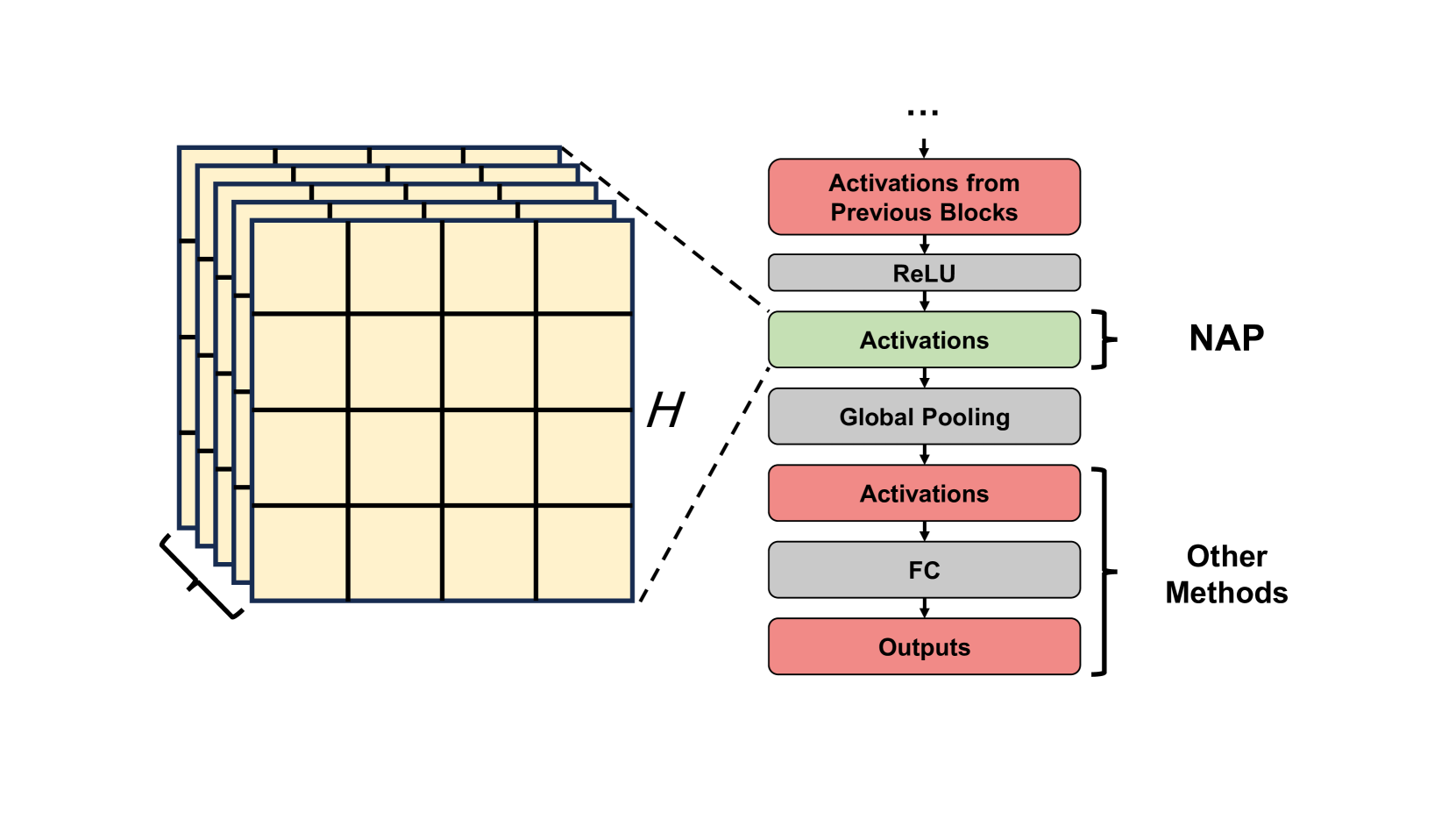
Let represent the activation tensor of the -th channel. We define two key statistical indicators of as follows:
-
•
Maximum activation value:
(1) where is the maximum value among all elements in the activation vector . Here, and index the spatial dimensions (height and width) of the activation map, respectively. Notice that is processed by ReLU (as shown in Figure 3(a)), hence .
-
•
Mean activation value:
(2) where is the average of all activation values in the -th channel.
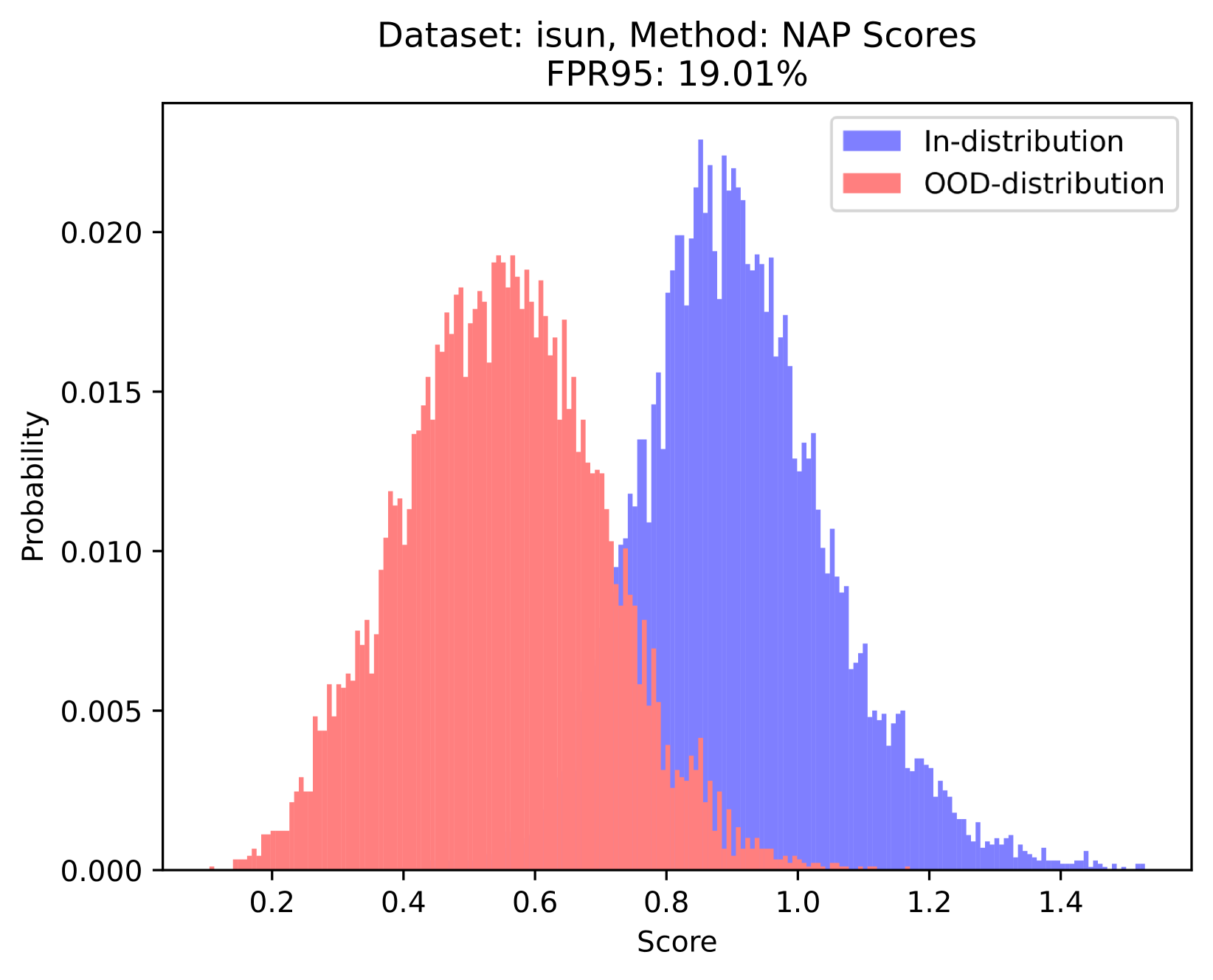
Inspired by the concept of signal-to-noise ratio, we interpret as the signal strength and as the noise strength. The ratio of these values can be viewed as an indicator of the quality of the activation vector . Note that we calculate this metric separately for each channel in the network, since different channels are usually used to detect different patterns. In the context of OOD detection, this quality measure can be used to assess whether the neural network recognizes the input sample — in other words, this measure can be used to judge whether a sample is within the training set distribution. As shown in Figure 1, this phenomenon is termed as the neural activation prior.
It is worth noting that our proposed prior is orthogonal to existing OOD detection methods. As illustrated in Figure 3(a), existing methods mainly focus on the network output and weight of the penultimate layer after global pooling, and leverage them to design various scoring functions for OOD detection. In contrast, the prior we propose focuses on the channels of the penultimate layer before global pooling. Since the distribution information within these channels is inevitably lost during the global pooling process, our proposed prior is complementary to existing work.
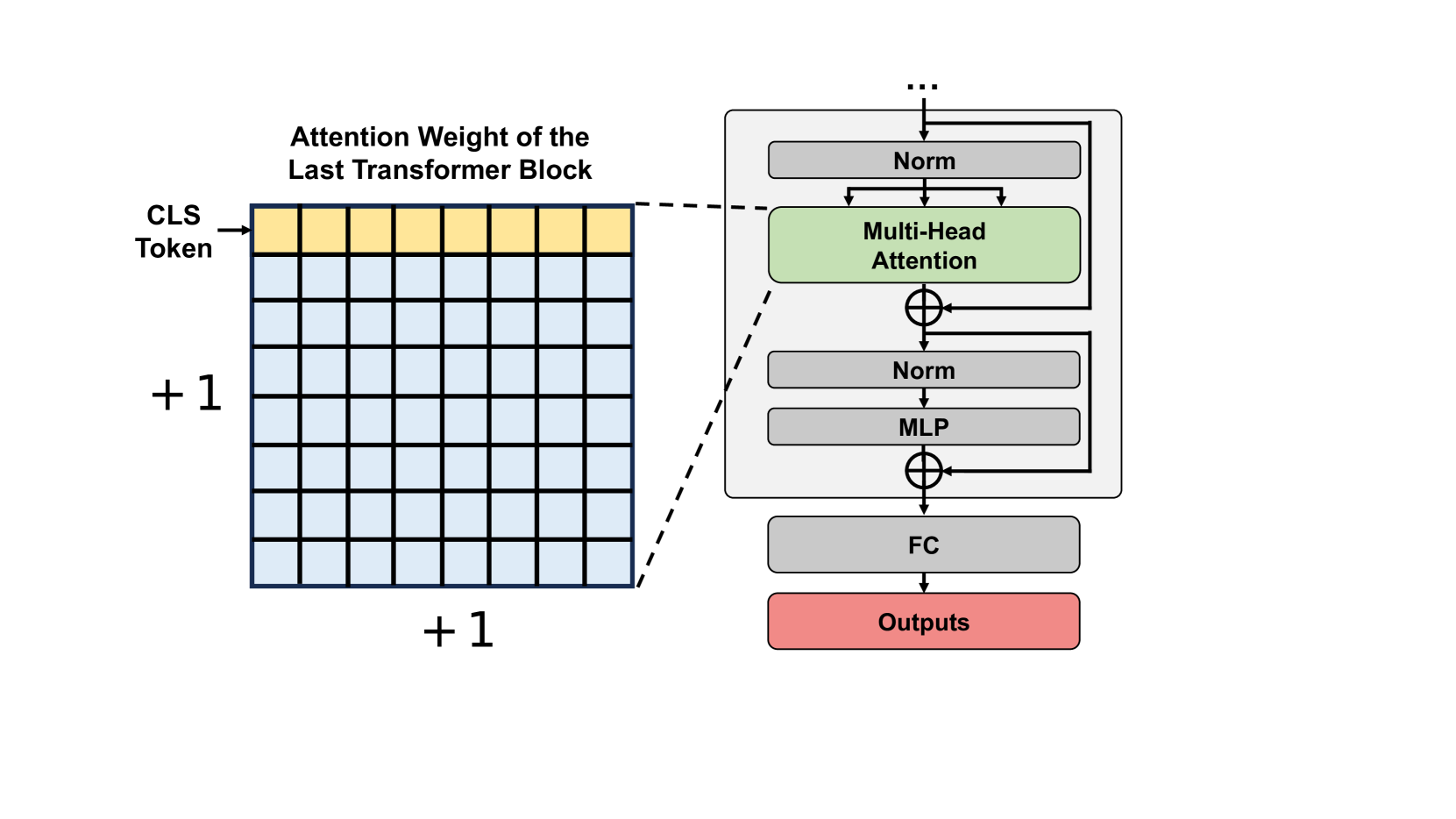
Extension to Transformer backbones. We observe that the classify (cls) token in the last block of Transformers can be effectively utilized as an analogue to the pooled activations used in CNNs for our method. Consequently, as illustrated in Figure 3(b), we calculate NAP score by employing the attention vectors associated with the cls token from the final Transformer block. This approach mirrors our methodological framework in CNNs, facilitating a coherent extension across both architectures. The specifics of the scoring function for NAP, applicable to both CNNs and Transformers, will be further elucidated in Section 4.2.
4 OOD Detection with NAP
4.1 Basics
First, we will provide a brief overview of typical settings for OOD detection in image classification networks. Typically, classification networks use ID data, that is, known training data sets, to train a classification model. Once training is completed, the model’s parameters are fixed, enabling it to effectively classify the categories within the training data set. In the testing phase, to identify OOD samples, researchers usually introduce a scoring function into the model. During the inference, samples mixed with OOD data are fed into this trained model. The model not only classifies each sample, but also uses a scoring function to generate a score for each one. This score is used to predict whether a sample belongs to an ID class in the training set, or an unknown OOD class.
4.2 Design of scoring function
Based on our prior proposed previously in Section 3, we propose a SNR-like scoring function. In our formulation, the mean activation value is interpreted as the noise intensity, while the maximal activation value is regarded as the signal strength. This conceptual framework leads to the following scoring function:
| (3) |
where represents the number of channels before global pooling. Note that a small constant is added to ensure the numerical stability of the computation.
Scoring function for Transformers. Consistent with the NAP score used in CNNs, we calculate the mean and maximum values of the attention that the cls token has towards all other tokens. The attention vector, denoted as , has a dimensionality of , where represents the sequence length. To maintain consistency with the NAP score calculation method used in CNN networks, we would typically divide the maximum value by the mean. However, we note that the mean value of the attention vector is always , rendering the denominator superfluous. Therefore, for simplicity, we design the NAP score function for Transformers as .
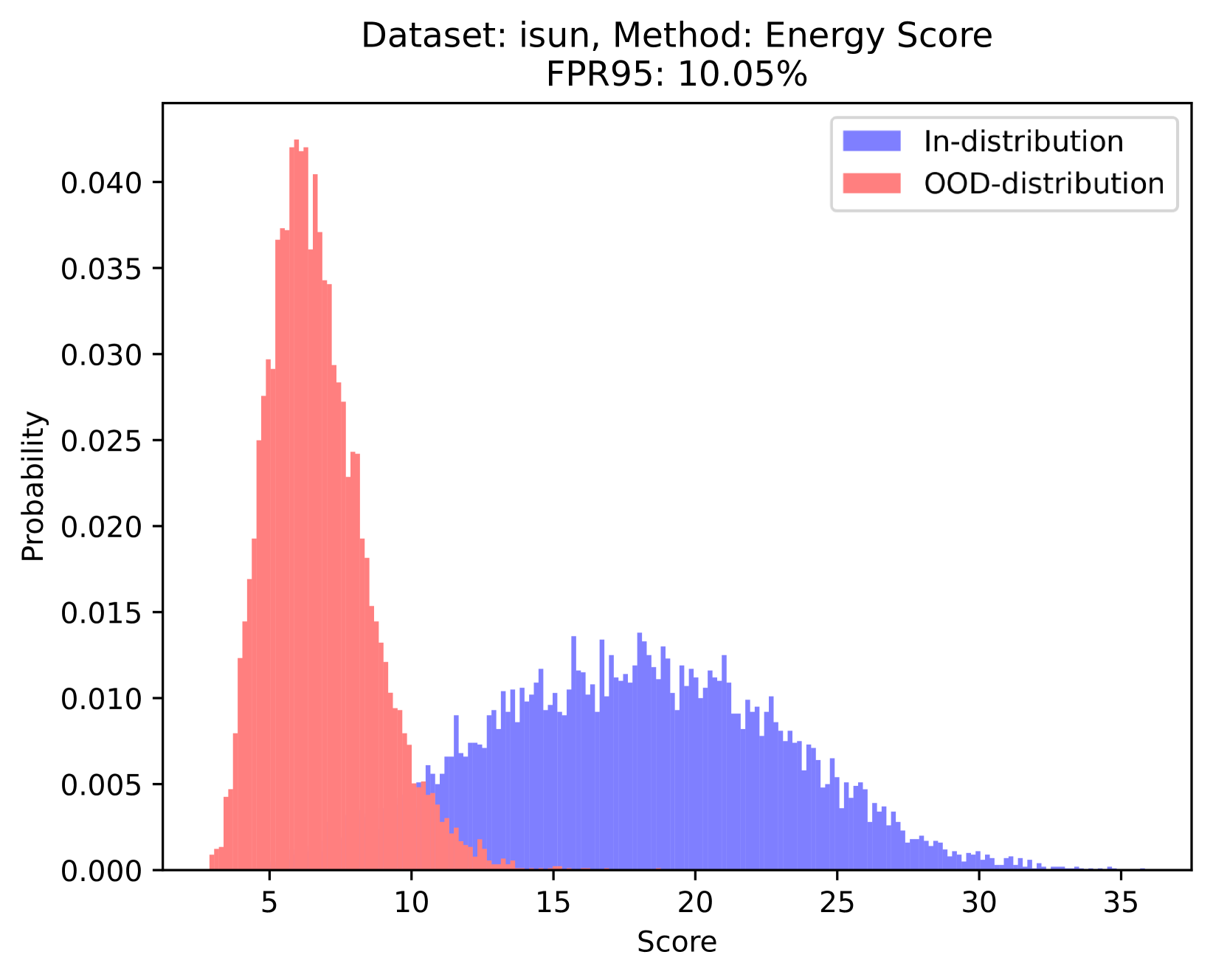
OOD detection. The usage of scoring function in this paper is similar to that of the energy score . The energy scoring function converts the logits output of the classification network into a scalar , where is the logits output of category . In OOD detection, the score employed for OOD detection is the negative energy score, . Therefore, ID data is given a higher score, while OOD data is assigned a lower score.
We can combine these two scoring functions. In this paper, we adopt the weighted geometric mean method to combine them:
| (4) |
And when using to enhance other energy score based OOD methods, we simply replace the function in the above formula with the specific function of the corresponding method, such as , , , etc.
How to find a optimal parameter ? When combining NAP with different OOD detection methods, the optimal weight parameter varies. To obtain the optimal parameter, we utilized a set of data transformation techniques (such as Gaussian noise, glass blur, motion blur, etc., more details in the Appendix H) to generate a corrupted dataset based on the ID dataset, serving as pseudo OOD data. For the choice of transformation types, we referred to [13]. Utilizing this set of OOD data, we employed a binary search method to find the optimal . Through experimentation with various datasets and methods, we found that this search approach quickly identifies the optimal , which generalizes well to real OOD datasets. Refer to Appendix H for more details about this process.
Discussion.
-
•
Plug-and-play simplicity: The scoring function we proposed is a plug-and-play approach that can be easily integrated into existing neural network architectures. It requires no additional training or external data and retains the model’s inherent classification capabilities. These properties make it practical and suitable for a variety of applications.
-
•
Orthogonal to existing approaches: Based on our proposed priors, the scoring function we design is orthogonal to existing methods. As shown in Figure 1, the value ranges of the within-channel activation mean values of ID samples and OOD samples overlap. This puts existing methods into trouble when distinguishing between ID and OOD samples with close means values. Based on the prior we proposed, this kind of dilemma can be solved naturally, which illustrates the power of our proposed priors to provide new perspectives for identifying OOD data.
5 Experiments
In this section, we conduct experiments on various real-world datasets. In our experiments, we use NAP-[initial] to denote the combination of NAP with another method, where [initial] represents the initial letter of the method’s name (e.g., NAP-A for the combination with ASH). Specifically, we combine NAP with a series of common OOD detection methods, including ASH, DICE, Energy, KNN, MSP, and ReAct, denoted as NAP-A, NAP-D, NAP-E, NAP-K, NAP-M, and NAP-R, respectively. CIFAR-10, CIFAR-100, and ImageNet are used as ID datasets. For each combination of NAP with other methods, we use the approach described in Section 4.2 to determine the optimal combination parameter . Detailed optimal values for different experimental setups can be found in Appendix H. It’s noted that the value of in our scoring functions is consistently set to for numerical stability. All experiments were conducted on an NVIDIA GeForce RTX 3090 GPU.
5.1 Evaluation on CIFAR benchmarks
Implementation details. In our experiments, consistent with recent studies [38, 39, 8], we utilized 10,000 test images from both CIFAR-10 [23] and CIFAR-100 [23] as ID data. To gauge the performance of the model, six widely-used OOD datasets were employed as benchmarks. These datasets include SVHN [31], Textures [5], iSUN [48], LSUN-Crop [50], LSUN-Resize [50], and Places365 [53]. As for pre-trained model, we employed DenseNet [18], and we follow the training setting of DenseNet introduced in [39].
| Method | ASH | NAP-A | DICE | NAP-D | Energy | NAP-E | KNN | NAP-K | MSP | NAP-M | ReAct | NAP-R | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F. | 15.05 | 11.14 | 20.83 | 11.66 | 26.55 | 9.02 | 16.12 | 7.79 | 48.69 | 19.09 | 26.45 | 9.18 | |
| CIFAR-10 | A. | 96.91 | 97.48 | 95.24 | 97.47 | 94.67 | 98.15 | 96.79 | 98.38 | 92.52 | 95.11 | 94.67 | 98.02 |
| F. | 41.40 | 35.40 | 49.72 | 32.34 | 68.45 | 32.61 | 44.91 | 33.63 | 80.13 | 48.20 | 62.27 | 25.71 | |
| CIFAR-100 | A. | 90.02 | 91.21 | 87.23 | 92.23 | 81.19 | 92.84 | 86.58 | 91.54 | 74.36 | 88.45 | 84.47 | 93.18 |
Experimental results. Table 1 presents the comparison of NAP combined with other post hoc OOD detection methods on the CIFAR-10 and CIFAR-100 benchmarks. As shown in the table, our approach significantly enhances the performance of all methods on both CIFAR-10 and CIFAR-100 datasets. Notably, the maximum reductions in FPR95 on CIFAR-10 and CIFAR-100 are 66.03% (NAP-E) and 58.71% (NAP-R), respectively. Note that the table showcases the average performance across six OOD datasets; for complete performance details, please refer to Appendix G.
| Method | OOD Datasets | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| iNaturalist [45] | SUN [47] | Places [53] | Textures [5] | |||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| ASH [8] | 31.46 | 94.28 | 38.45 | 91.61 | 51.80 | 87.56 | 20.92 | 95.07 | 35.66 | 92.13 |
| NAP-A | 26.26 | 95.10 | 32.89 | 92.77 | 48.69 | 87.92 | 11.60 | 97.32 | 29.86 | 93.28 |
| DICE [39] | 43.09 | 90.83 | 38.69 | 90.46 | 53.11 | 85.81 | 32.80 | 91.30 | 41.92 | 89.60 |
| NAP-D | 27.48 | 94.13 | 36.14 | 90.66 | 51.84 | 85.03 | 9.02 | 97.92 | 31.12 | 91.94 |
| Energy [27] | 59.50 | 88.91 | 62.65 | 84.50 | 69.37 | 81.19 | 58.05 | 85.03 | 62.39 | 84.91 |
| NAP-E | 29.90 | 94.47 | 39.69 | 90.46 | 55.17 | 85.15 | 11.74 | 97.28 | 34.12 | 91.84 |
| KNN [40] | 85.91 | 72.67 | 90.49 | 65.39 | 93.18 | 60.08 | 14.08 | 96.98 | 70.92 | 73.78 |
| NAP-K | 38.23 | 89.80 | 56.55 | 80.01 | 70.89 | 71.35 | 7.02 | 98.39 | 43.17 | 84.89 |
| MSP [14] | 64.29 | 85.32 | 77.02 | 77.10 | 79.23 | 76.27 | 73.51 | 77.30 | 73.51 | 79.00 |
| NAP-M | 35.47 | 92.53 | 51.19 | 86.51 | 63.77 | 80.61 | 15.14 | 97.09 | 41.39 | 89.19 |
| ReAct [38] | 42.40 | 91.53 | 47.69 | 88.16 | 51.56 | 86.64 | 38.42 | 91.53 | 45.02 | 89.47 |
| NAP-R | 24.58 | 95.55 | 38.47 | 91.12 | 53.32 | 86.24 | 9.57 | 97.60 | 31.49 | 92.63 |
5.2 Evaluation on ImageNet
Implementation details. In real-world applications, models are confronted with high-resolution images spanning a diverse range of scenes and features. Evaluations on large-scale datasets can provide insights into the performance of models in practical deployments. Thus, in line with recent research [38, 39, 8], we conduct experiments with NAP on the expansive ImageNet-1k [6] dataset in this study. Four dataset subsets, with all overlapping categories with ImageNet-1k eliminated, were employed as OOD benchmarks. These OOD datasets comprise Textures [5], Places365 [53], iNaturalist [45], and SUN [47]. We used MobileNetV2 [35] architecture, which pre-trained on ImageNet-1k [6]. The architecture and parameters remain unchanged during the OOD detection stage.
Experimental results. Table 2 shows the comparison results of NAP with other post-hoc OOD detection methods on the ImageNet-1k [6] benchmark. As shown in the table, our approach significantly enhances the performance of all methods on the ImageNet-1k dataset [6]. We have observed that our method brings significant performance improvements on the iNaturalist and Textures datasets, which is particularly notable. Intuitively, most of the pictures in the Textures [5] dataset are of a texture nature, so there is a small probability of obtaining a large response value. And while samples in iNaturalist have a relatively simple background, and the animals and plants in the foreground have certain semantic differences from the samples in ImageNet-1k, therefor, a sample in iNaturalist [45] is not likely to trigger large response values. The reason why existing methods do not perform well on this dataset may be due to their focus on activation values after global pooling. We speculate that although texture pictures cannot cause large activation values, they can excite small-amplitude noise on the entire feature map. Since large response values tend to only appear in a small area on the feature map, after global pooling, ID samples and texture class samples are likely to obtain similar average activation values. This may compromise the separability of the two types of samples, causing existing work to perform poorly on such samples.
5.3 Evaluation on Transformer
Following the experimental setup described in Section 5.2, we conduct experiments on the Vision Transformer [9] (ViT-B/16) using ImageNet-1k as the ID dataset. Energy [27] and MSP [14] were selected as baseline methodologies for this analysis. The study further explores the enhancement of these baseline methods through the integration of NAP, resulting in two variants: NAP-E and NAP-M. Comparative results detailed in Table 3 demonstrate that the NAP method substantially boosts the performance on Transformer architectures beyond the baselines, affirming the utility and versatility of NAP within such contexts.
| Method | OOD Datasets | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| iNaturalist [45] | SUN [47] | Places [53] | Textures [5] | |||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| Energy [27] | 64.08 | 79.24 | 72.77 | 70.25 | 74.30 | 68.44 | 58.46 | 79.30 | 67.40 | 74.31 |
| NAP-E | 60.97 | 80.77 | 64.05 | 77.34 | 69.34 | 73.30 | 45.04 | 86.93 | 59.85 | 79.58 |
| MSP [14] | 51.47 | 88.16 | 66.53 | 80.93 | 68.65 | 80.38 | 60.21 | 82.99 | 61.72 | 83.12 |
| NAP-M | 47.09 | 88.23 | 59.45 | 82.78 | 63.38 | 80.48 | 47.70 | 87.93 | 54.40 | 84.85 |
Discussion. We compare only with MSP [14] and Energy [27] because methods such as ASH [8] and ReAct [38] are specifically designed for CNNs and fail completely when applied to ViT. For fairness, we do not include these methods in our comparison.
5.4 Does NAP work across all network layers?
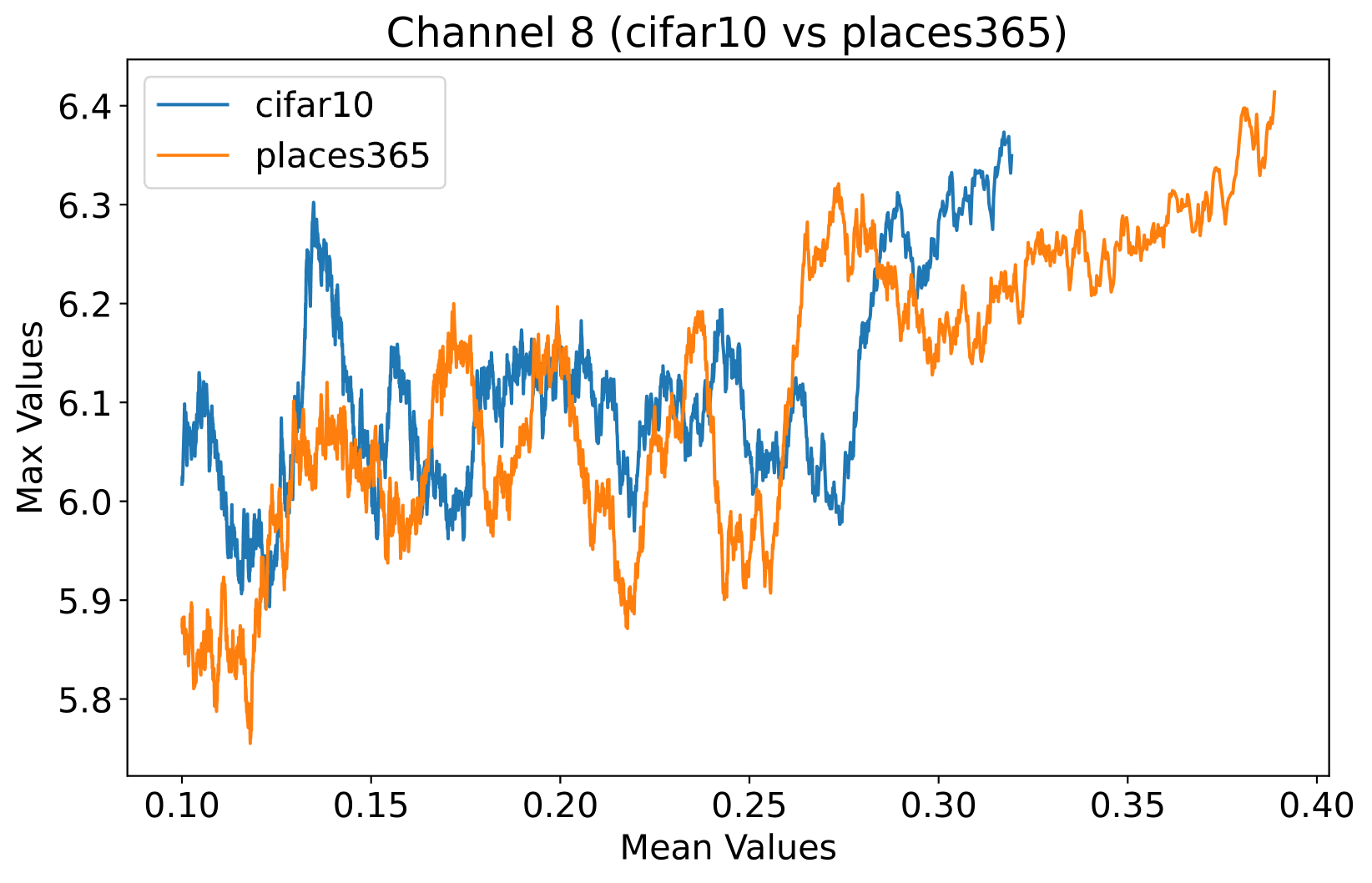
To assess the efficacy of the NAP across various layers within the DenseNet architecture, we conduct a detailed examination of activation distributions utilizing the CIFAR-10 [23] and Places365 datasets [53]. Analysis focused on four pivotal points within the network: post-first convolutional layer, pre-pooling in the first and second transition blocks, and immediately preceding the final global pooling layer. Selected instances from the empirical findings are illustrated in Selected examples from our tests are shown in Figure 4, with more detailed visuals in the Appendix C. From these figures, it’s clear that the deeper the layer, the easier it is to tell apart ID and OOD samples based on the maximum and average activation values. In the network’s early layers, neurons pick up basic features common to both ID and OOD samples, which explains why the lines cross in Figures 4(a) and 4(b). Moving to deeper layers, neurons start capturing more complex, meaningful features. As seen in Figures 4(c) and 4(d), ID samples with specific meanings trigger larger responses. This indicates that NAP works best closer to the end of the network, especially before the global pooling layer, highlighting its value in making models more reliable for OOD detection.
6 Conclusion
This paper proposes a novel Neural Activation Prior (NAP) for OOD detection in machine learning models. Our proposed prior is grounded on the observation that in a fully trained neural network, ID samples typically induce stronger activation responses in some neurons of a channel compared to OOD samples. This discovery led to our novel scoring function based on within-channel distribution. Its main advantage lies in its simplicity and easy integration. It necessitates neither additional training nor external data and does not compromise the classification performance on ID data. Experimental results on various datasets and architectures show that our method achieves state-of-the-art performance in OOD detection. This not only verifies the effectiveness of neural activation priors, but also demonstrates the potential of rethinking the way neural network features are utilized in OOD scenarios.
References
- [1] D. Abati, A. Porrello, S. Calderara, and R. Cucchiara. Latent space autoregression for novelty detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 481–490, 2019.
- [2] Y. H. Ahn, G.-M. Park, and S. T. Kim. Line: Out-of-distribution detection by leveraging important neurons. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19852–19862, 2023.
- [3] A. Bendale and T. E. Boult. Towards open set deep networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1563–1572, 2016.
- [4] X. Chen, X. Lan, F. Sun, and N. Zheng. A boundary based out-of-distribution classifier for generalized zero-shot learning. In European conference on computer vision, pages 572–588. Springer, 2020.
- [5] M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, and A. Vedaldi. Describing textures in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3606–3613, 2014.
- [6] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- [7] T. DeVries and G. W. Taylor. Learning confidence for out-of-distribution detection in neural networks. stat, 1050:13, 2018.
- [8] A. Djurisic, N. Bozanic, A. Ashok, and R. Liu. Extremely simple activation shaping for out-of-distribution detection. In The Eleventh International Conference on Learning Representations, 2022.
- [9] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2020.
- [10] X. Du, Z. Wang, M. Cai, and Y. Li. Vos: Learning what you don’t know by virtual outlier synthesis. arXiv preprint arXiv:2202.01197, 2022.
- [11] A. Filos, P. Tigkas, R. McAllister, N. Rhinehart, S. Levine, and Y. Gal. Can autonomous vehicles identify, recover from, and adapt to distribution shifts? In International Conference on Machine Learning, pages 3145–3153. PMLR, 2020.
- [12] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [13] D. Hendrycks and T. Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. In International Conference on Learning Representations, 2018.
- [14] D. Hendrycks and K. Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. In International Conference on Learning Representations, 2016.
- [15] D. Hendrycks and K. Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. In International Conference on Learning Representations, 2016.
- [16] T. Hoefler, D. Alistarh, T. Ben-Nun, N. Dryden, and A. Peste. Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks. The Journal of Machine Learning Research, 22(1):10882–11005, 2021.
- [17] Y.-C. Hsu, Y. Shen, H. Jin, and Z. Kira. Generalized odin: Detecting out-of-distribution image without learning from out-of-distribution data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10951–10960, 2020.
- [18] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017.
- [19] R. Huang and Y. Li. Mos: Towards scaling out-of-distribution detection for large semantic space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8710–8719, 2021.
- [20] J. Janai, F. Güney, A. Behl, A. Geiger, et al. Computer vision for autonomous vehicles: Problems, datasets and state of the art. Foundations and Trends® in Computer Graphics and Vision, 12(1–3):1–308, 2020.
- [21] D. Jiang, S. Sun, and Y. Yu. Revisiting flow generative models for out-of-distribution detection. In International Conference on Learning Representations, 2021.
- [22] P. Kirichenko, P. Izmailov, and A. G. Wilson. Why normalizing flows fail to detect out-of-distribution data. Advances in neural information processing systems, 33:20578–20589, 2020.
- [23] A. Krizhevsky, G. Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [24] K. Lee, H. Lee, K. Lee, and J. Shin. Training confidence-calibrated classifiers for detecting out-of-distribution samples. In International Conference on Learning Representations, 2018.
- [25] K. Lee, K. Lee, H. Lee, and J. Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. Advances in neural information processing systems, 31, 2018.
- [26] S. Liang, Y. Li, and R. Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. In International Conference on Learning Representations, 2018.
- [27] W. Liu, X. Wang, J. Owens, and Y. Li. Energy-based out-of-distribution detection. Advances in neural information processing systems, 33:21464–21475, 2020.
- [28] F. Lu, K. Zhu, W. Zhai, K. Zheng, and Y. Cao. Uncertainty-aware optimal transport for semantically coherent out-of-distribution detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3282–3291, 2023.
- [29] Y. Ming, Y. Sun, O. Dia, and Y. Li. Cider: Exploiting hyperspherical embeddings for out-of-distribution detection. arXiv preprint arXiv:2203.04450, 7(10), 2022.
- [30] E. Nalisnick, A. Matsukawa, Y. W. Teh, D. Gorur, and B. Lakshminarayanan. Do deep generative models know what they don’t know? In International Conference on Learning Representations, 2018.
- [31] Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y. Ng. Reading digits in natural images with unsupervised feature learning. 2011.
- [32] S. Pidhorskyi, R. Almohsen, and G. Doretto. Generative probabilistic novelty detection with adversarial autoencoders. Advances in neural information processing systems, 31, 2018.
- [33] E. H. Pooch, P. Ballester, and R. C. Barros. Can we trust deep learning based diagnosis? the impact of domain shift in chest radiograph classification. In Thoracic Image Analysis: Second International Workshop, TIA 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, October 8, 2020, Proceedings 2, pages 74–83. Springer, 2020.
- [34] M. Sabokrou, M. Khalooei, M. Fathy, and E. Adeli. Adversarially learned one-class classifier for novelty detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3379–3388, 2018.
- [35] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4510–4520, 2018.
- [36] C. S. Sastry and S. Oore. Detecting out-of-distribution examples with gram matrices. In International Conference on Machine Learning, pages 8491–8501. PMLR, 2020.
- [37] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In 3rd International Conference on Learning Representations (ICLR 2015). Computational and Biological Learning Society, 2015.
- [38] Y. Sun, C. Guo, and Y. Li. React: Out-of-distribution detection with rectified activations. Advances in Neural Information Processing Systems, 34:144–157, 2021.
- [39] Y. Sun and Y. Li. Dice: Leveraging sparsification for out-of-distribution detection. In European Conference on Computer Vision, pages 691–708. Springer, 2022.
- [40] Y. Sun, Y. Ming, X. Zhu, and Y. Li. Out-of-distribution detection with deep nearest neighbors. In International Conference on Machine Learning, pages 20827–20840. PMLR, 2022.
- [41] Y. Sun, Y. Ming, X. Zhu, and Y. Li. Out-of-distribution detection with deep nearest neighbors. In International Conference on Machine Learning, pages 20827–20840. PMLR, 2022.
- [42] J. Tack, S. Mo, J. Jeong, and J. Shin. Csi: Novelty detection via contrastive learning on distributionally shifted instances. Advances in neural information processing systems, 33:11839–11852, 2020.
- [43] E. Techapanurak, M. Suganuma, and T. Okatani. Hyperparameter-free out-of-distribution detection using cosine similarity. In Proceedings of the Asian conference on computer vision, 2020.
- [44] J. Van Amersfoort, L. Smith, Y. W. Teh, and Y. Gal. Uncertainty estimation using a single deep deterministic neural network. In International conference on machine learning, pages 9690–9700. PMLR, 2020.
- [45] G. Van Horn, O. Mac Aodha, Y. Song, Y. Cui, C. Sun, A. Shepard, H. Adam, P. Perona, and S. Belongie. The inaturalist species classification and detection dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8769–8778, 2018.
- [46] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [47] J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In 2010 IEEE computer society conference on computer vision and pattern recognition, pages 3485–3492. IEEE, 2010.
- [48] P. Xu, K. A. Ehinger, Y. Zhang, A. Finkelstein, S. R. Kulkarni, and J. Xiao. Turkergaze: Crowdsourcing saliency with webcam based eye tracking. arXiv preprint arXiv:1504.06755, 2015.
- [49] J. Yang, K. Zhou, Y. Li, and Z. Liu. Generalized out-of-distribution detection: A survey. arXiv preprint arXiv:2110.11334, 2021.
- [50] F. Yu, A. Seff, Y. Zhang, S. Song, T. Funkhouser, and J. Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365, 2015.
- [51] Y. Yu, S. Shin, S. Lee, C. Jun, and K. Lee. Block selection method for using feature norm in out-of-distribution detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15701–15711, 2023.
- [52] A. Zaeemzadeh, N. Bisagno, Z. Sambugaro, N. Conci, N. Rahnavard, and M. Shah. Out-of-distribution detection using union of 1-dimensional subspaces. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 9452–9461, 2021.
- [53] B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba. Places: A 10 million image database for scene recognition. IEEE transactions on pattern analysis and machine intelligence, 40(6):1452–1464, 2017.
- [54] E. Zisselman and A. Tamar. Deep residual flow for out of distribution detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13994–14003, 2020.
- [55] B. Zong, Q. Song, M. R. Min, W. Cheng, C. Lumezanu, D. Cho, and H. Chen. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In International conference on learning representations, 2018.
Appendix
In this appendix, we provide comprehensive additional materials to supplement the main text. The contents include:
-
•
Broader impacts (Section A): A discussion on the broader implications of our research.
-
•
Pseudo code for NAP (Section B): The algorithmic representation of the Neural Activation Prior (NAP) methodology.
-
•
Why is the penultimate layer more effective for NAP? (Section C): An exploration of the reasons behind the superior effectiveness of the penultimate layer in the context of NAP.
-
•
Evaluating multi-layer integration with NAP for OOD detection (Section D): Investigation into the effects of integrating multiple layers along with NAP in detecting OOD data.
-
•
On transferability to other architectures (Section E): To ascertain the versatility and robustness of NAP across different CNN architectures, we conducted extensive experiments on various backbones, including VGG, DenseNet, and ResNet.
-
•
Pareto frontier of ID accuracy and OOD detection performance (Section F):Evaluation on Pareto Frontier of ID accuracy and OOD Detection Performance.
-
•
Full CIFAR benchmark results: enhancing methods with NAP (Section G): Comprehensive evaluation of NAP’s effectiveness in enhancing existing models, as demonstrated through detailed results on the CIFAR benchmark.
-
•
How to find an optimal parameter ? (Section H): A guide on determining the optimal parameter for NAP.
-
•
Performance on Near-OOD detection (Section I): Investigating the capability of the NAP in distinguishing between closely related datasets provides insight into its utility in nuanced OOD detection scenarios.
-
•
More examples of activation map visualizaiton. (Section J): Additional visual examples showcasing the activation maps.
-
•
Limitations (Section K): A critical analysis of the limitations of our approach.
-
•
Discussion (Section L): A concluding section that summarizes the key findings and outlines future directions for research based on our work.
-
•
Licenses for existing assets (Section M): Credits and licenses for all existing assets used in this research.
Appendix A Broder impacts
The proposed Neural Activation Prior for OOD detection has significant implications for the deployment of machine learning models in real-world scenarios. By enhancing the ability to detect OOD samples, our method contributes to improving the reliability and safety of AI systems, particularly in critical applications such as autonomous driving, healthcare, and security, where encountering unexpected inputs could have severe consequences.
Appendix B Pseudo code for NAP
As illustrated in Algorithm 1, we present a detailed pseudo-code representation of our proposed method for OOD detection, which is integrated into the DenseNet architecture. The key modification involves the calculation of NAP score within the DenseNet’s processing pipeline (highlighted in green font in the algorithm), which is then followed by calculating the OOD score using the model’s logits together with . These calculations do not alter the logits output by the model, thereby ensuring no degradation in classification accuracy for the ID dataset.
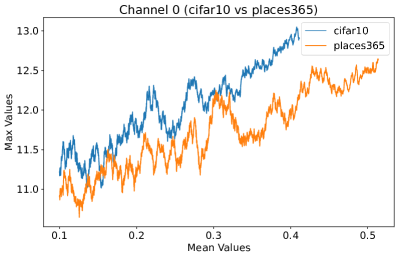
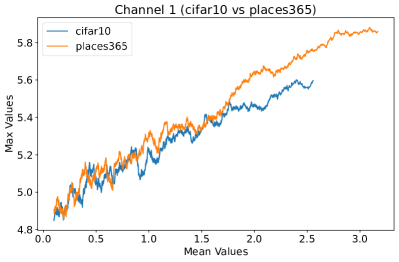
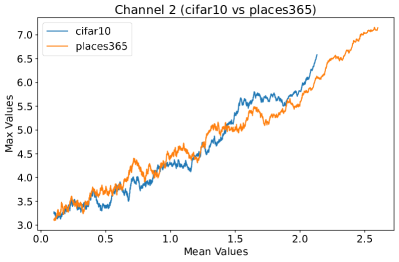
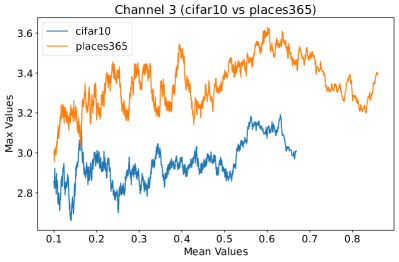
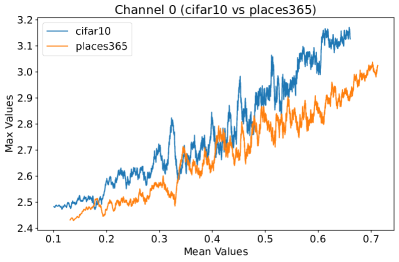
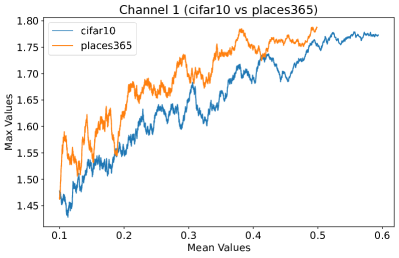
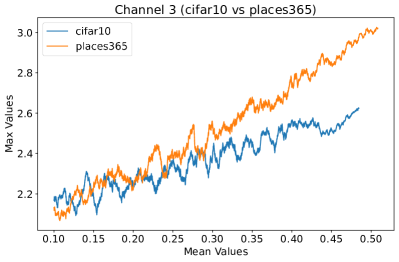
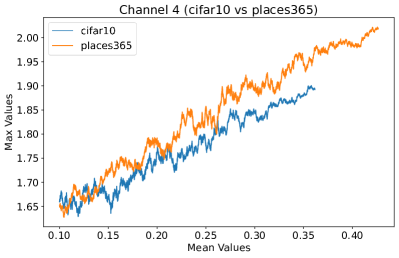
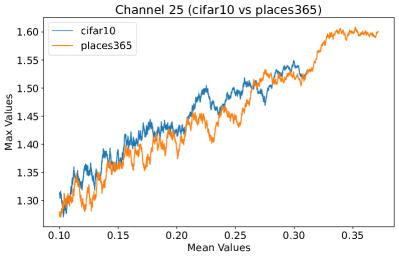
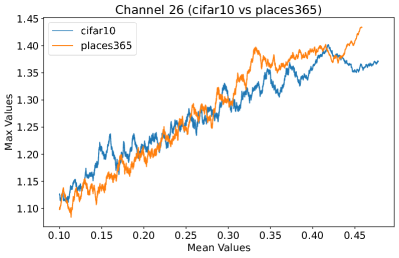
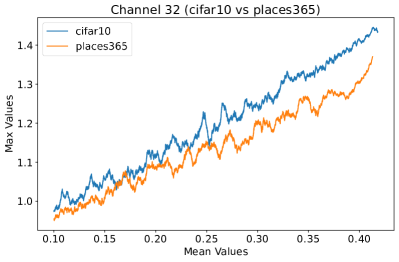
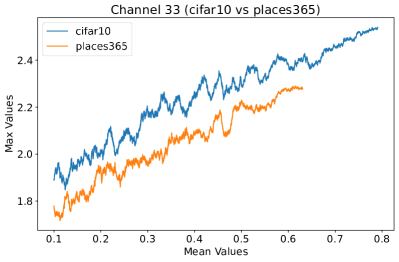
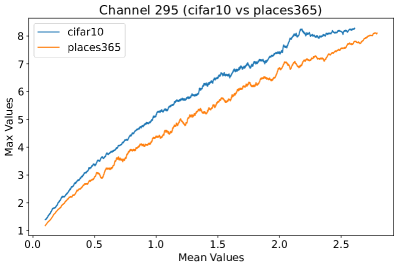
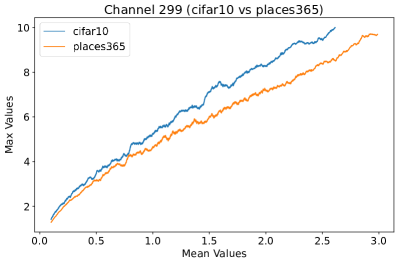
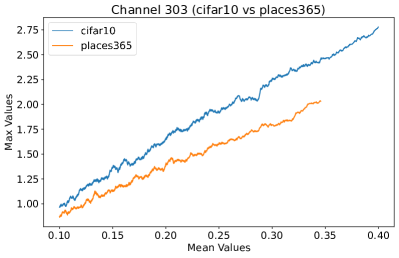
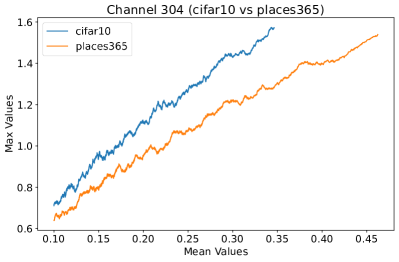
Appendix C Why is the penultimate layer more effective for NAP?
We provide an extensive collection of visualizations showcasing the activations within the DenseNet architecture when applied to the CIFAR-10 (ID) dataset and Places365 (OOD) dataset. These visualizations are crucial for understanding how the network processes both ID and OOD data, revealing the distinct patterns of neural activations at various layers of the network. Our analysis focuses on four critical layers within DenseNet: (1) after the first convolutional layer, (2) before the pooling operation in the first transition block, (3) before pooling in the second transition block, and (4) before the final global pooling layer. Each layer offers four visualizations, providing a comprehensive view of the network’s response to different datasets.
These detailed visualizations enhance the discussion in the main text, offering deeper insights into how NAP effectively distinguishes between ID and OOD samples within the network. As depicted in Figure 5, the first three selected layers, which focus primarily on low-level features, exhibit a less pronounced distinction between ID and OOD samples. This is likely because low-level features, such as edges and textures, are common to both ID and OOD datasets, making them less distinctive. However, the contrast between ID and OOD samples becomes more evident and stable in the fourth selected layer, located before the final global pooling layer. This layer, concentrating on high-level semantic information, captures features more unique to the ID dataset, leading to clearer separability and enhanced stability in activation values compared to earlier layers. This layer’s focus on distinctive semantic features makes it particularly suitable for developing a scoring function for OOD detection. Therefore, since the penultimate layer is the most informative layer in the neural network, we utilize this layer in our method to develop our scoring function.
| Method | CIFAR-10 | CIFAR-100 | ||
|---|---|---|---|---|
| FPR95 | AUROC | FPR95 | AUROC | |
| NAP(c1) | 83.22 | 51.99 | 84.13 | 50.34 |
| NAP(t1) | 69.10 | 50.47 | 86.82 | 54.92 |
| NAP(t2) | 56.53 | 78.44 | 88.85 | 53.08 |
| NAP(c1,t1,t2,p) | 68.33 | 58.99 | 82.66 | 56.96 |
| NAP(t1,t2,p) | 56.84 | 64.26 | 83.35 | 57.97 |
| NAP(t2,p) | 34.41 | 87.81 | 82.74 | 58.31 |
| NAP(p) | 26.57 | 92.45 | 54.91 | 85.86 |
Appendix D Evaluating multi-layer integration with NAP for OOD detection
In an additional exploration presented in the appendix, we investigate the effects of incorporating values from both the penultimate layer and earlier layers on OOD detection. Our experiments, detailed in Table 4, suggest that the integration of earlier layers with the penultimate layer, where NAP is primarily applied, does not yield significant improvements in OOD detection. This phenomenon could partly stem from the inherent limitations of earlier layers in differentiating between ID and OOD data. Additionally, there is a possibility that the scoring function, specifically optimized for the penultimate layer, may not align optimally with the feature representation characteristics of the preceding layers. Considering the constraints of space in this paper, a comprehensive analysis of multi-layer integration using NAP is not presented. Nonetheless, the potential of combining multiple layers in OOD detection, especially in the context of NAP, remains an intriguing aspect for future research. We anticipate that further investigations, potentially involving the creation of new scoring functions suitable for a broader range of layers, could provide substantial contributions to the field. Thus, we propose this as an avenue for future work, aiming to stimulate further advancements within the research community.
Appendix E On transferability to other architectures
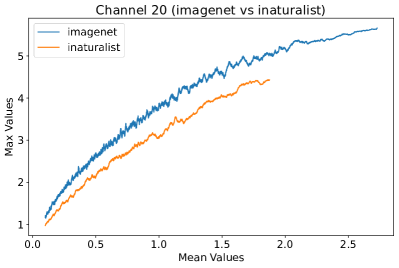
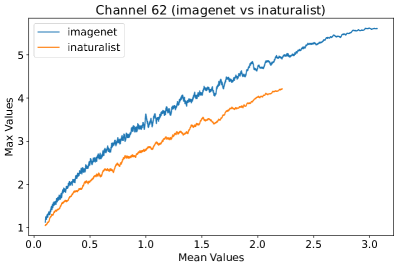
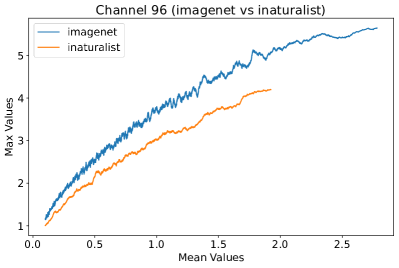
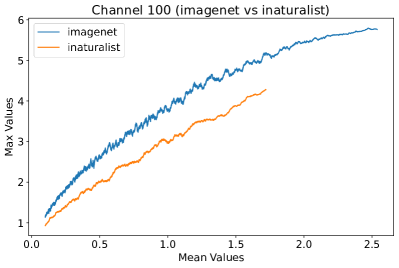
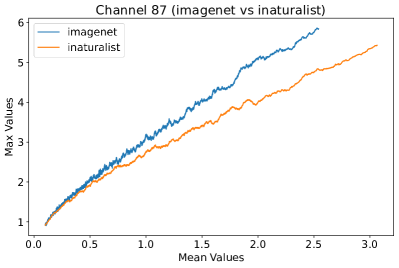
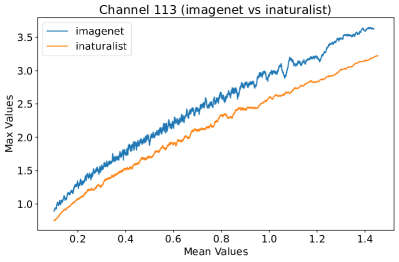
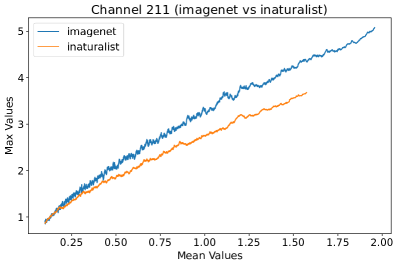
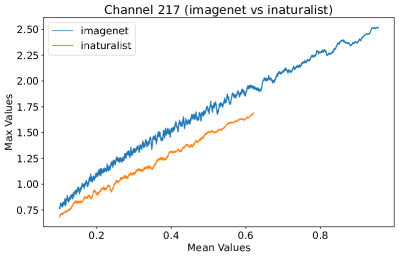
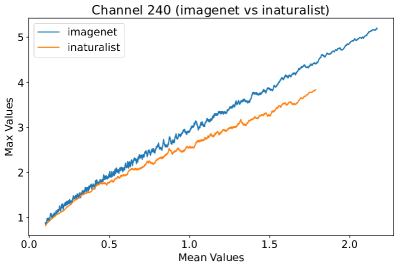
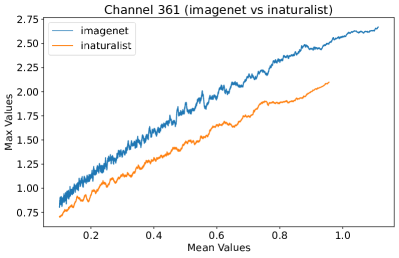
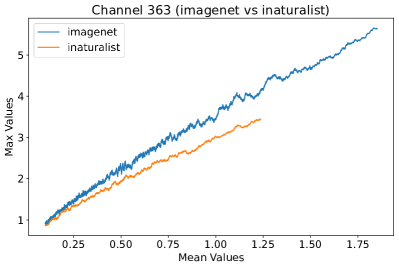
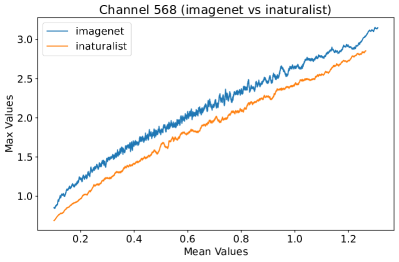
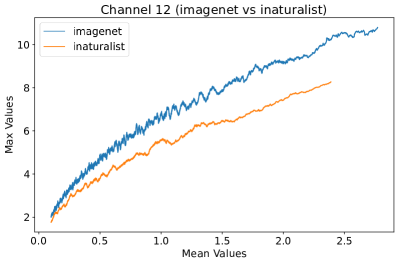
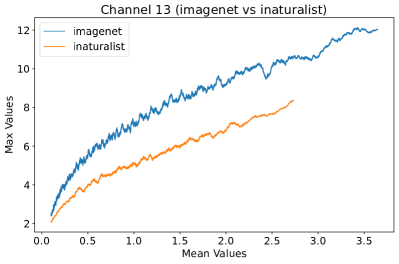
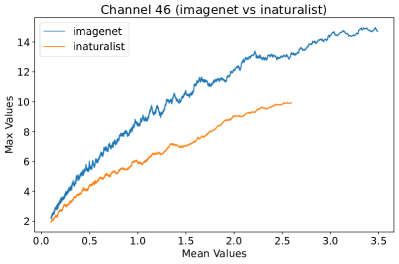
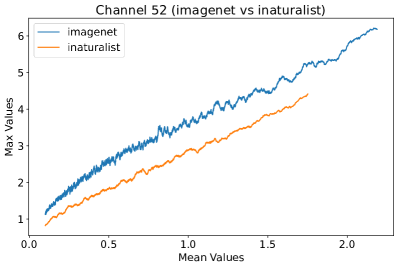
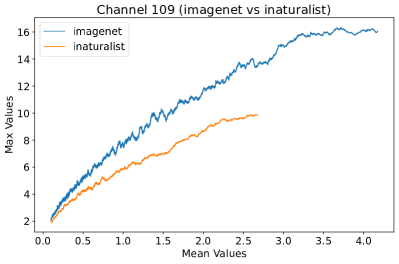
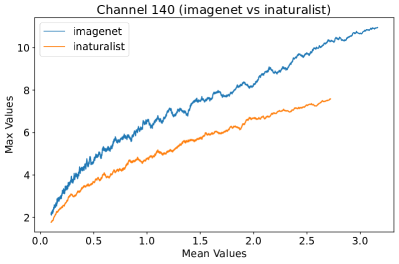
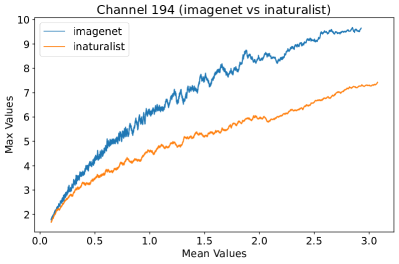
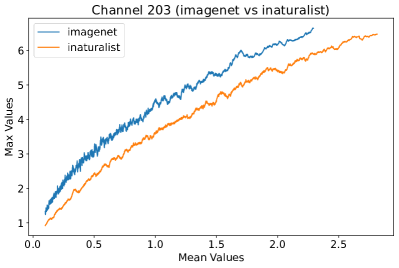
In Figure 8, 9, and 10, we present detailed visualizations of the activation patterns within three distinct architectures: MobileNetV2 [35], ResNet50 [12], and VGG16 [37]. These visualizations clearly demonstrate a remarkable gap between ID samples, depicted with blue lines, and OOD samples, represented with orange lines. This distinction is evident across all three architectures, underscoring the versatility and effectiveness of the proposed NAP. The consistent separability observed in these diverse architectures confirms the adaptability and potential of NAP for broad application in different neural network models.
In order to validate the effectiveness of NAP across different Convolutional Neural Network (CNN) architectures, we conducted experiments on a variety of CNN backbones. As depicted in Table 5, our proposed NAP method significantly enhances the OOD detection performance across various CNN structures. These results underscore the adaptability of NAP to various CNN models, demonstrating its potential as a versatile tool for enhancing the reliability and accuracy of OOD detection in neural network applications.
| Energy | NAP | NAP-E | ||||
|---|---|---|---|---|---|---|
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| VGG | 54.34 | 88.17 | 29.23 | 93.46 | 23.23 | 95.00 |
| DenseNet | 50.40 | 87.66 | 49.89 | 88.40 | 32.95 | 91.68 |
| ResNet | 57.47 | 87.05 | 48.77 | 82.76 | 32.12 | 92.02 |
Appendix F Pareto frontier of ID accuracy and OOD detection performance
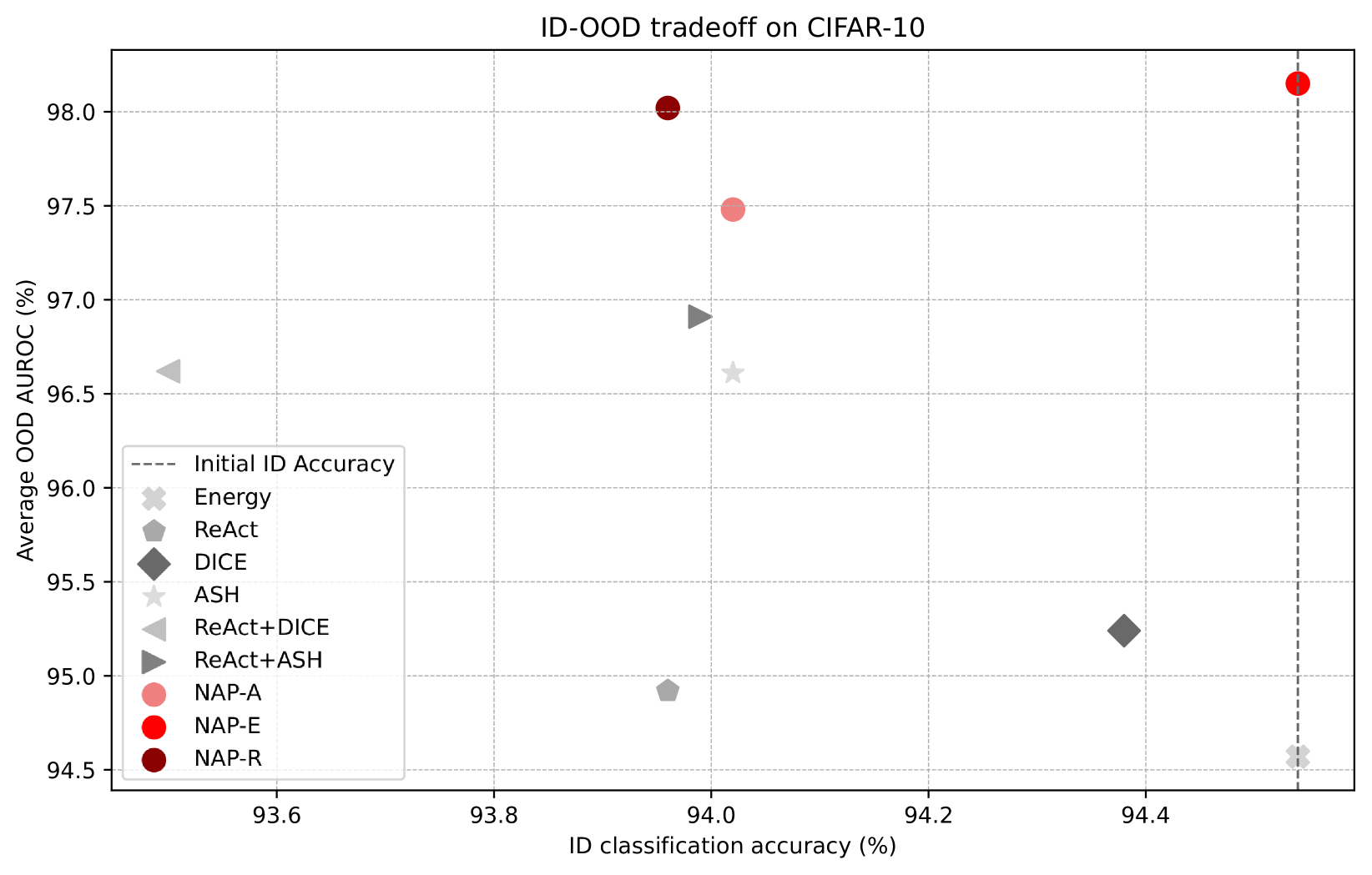
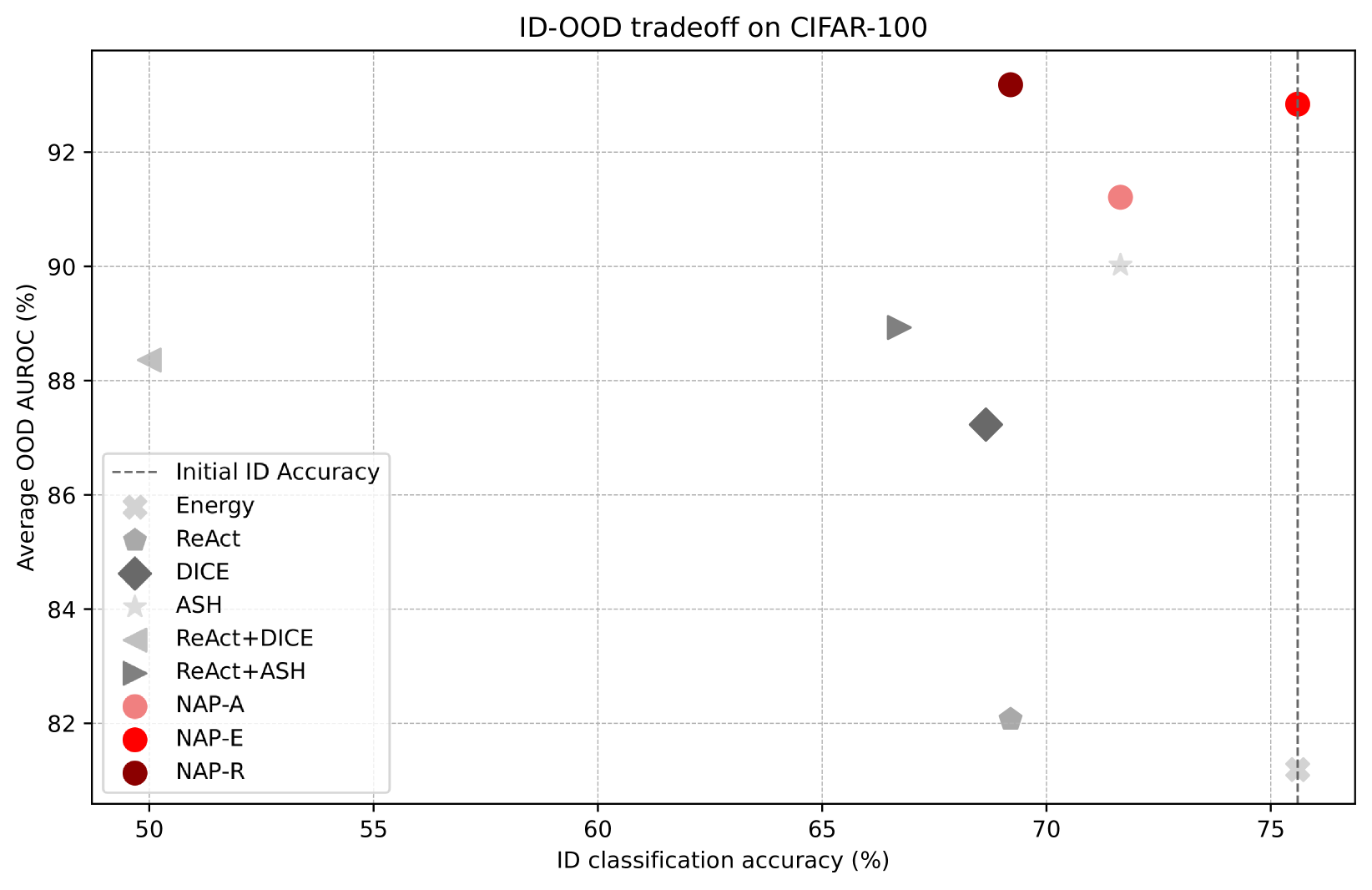
Some existing methods negatively affect ID accuracy; however, we have found that integrating these methods with the NAP approach can mitigate or reduce this impact, achieving a more optimal balance. The NAP approach establishes an ideal equilibrium between ID classification accuracy and OOD detection efficacy (measured in AUROC), thereby positioning it favorably on the Pareto front for superior performance. This demonstrates our method’s ability to enhance OOD detection without additional costs while maintaining the model’s classification performance, as illustrated in Figures 6(a) and 6(b) using the CIFAR benchmark [23].
Appendix G Full CIFAR benchmark results: enhancing methods with NAP
This section focuses on the significant enhancements brought by the Neural Activation Prior (NAP) to existing out-of-distribution detection methods in the context of the CIFAR-10 (in Table 6) and CIFAR-100 (in Table 7) dataset. The incorporation of NAP into established methods like Energy [27], ASH [8], DICE [39], KNN [40], MSP [14] and ReAct [38], resulting in NAP-E, NAP-A, NAP-D, NAP-K, NAP-Mand NAP-R respectively, showcases the potential of NAP in augmenting existing approaches. Our experimental results demonstrate that NAP-based variants consistently outperform their corresponding traditional methods across all six OOD datasets. Notably, our experimental results reveal some extremely substantial decreases in FPR95 values, indicative of the profound impact of NAP integration. For instance, on the CIFAR-100 dataset, the FPR95 value of NAP-R, compared to ReAct, dropped by 83.06% (from 83.81 to 14.19), highlighting a notable reduction in false alarms while maintaining high detection accuracy and affirming the enhanced capability of these methods in distinguishing between in-distribution and OOD samples.
| Method | OOD Datasets | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVHN | Textures | iSUN | LSUN | LSUN-Crop | Places365 | |||||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| ASH | 6.51 | 98.65 | 24.34 | 95.09 | 5.17 | 98.90 | 4.96 | 98.92 | 0.90 | 99.73 | 48.45 | 88.34 | 15.05 | 96.91 |
| NAP-A | 5.55 | 98.86 | 10.51 | 97.90 | 3.04 | 99.32 | 2.68 | 99.40 | 0.80 | 99.80 | 44.28 | 89.59 | 11.14 | 97.48 |
| DICE | 29.62 | 94.66 | 0.38 | 99.90 | 4.43 | 99.03 | 5.14 | 98.97 | 45.87 | 86.97 | 45.32 | 90.29 | 21.79 | 94.97 |
| NAP-D | 10.60 | 97.75 | 0.41 | 99.88 | 2.03 | 99.48 | 2.69 | 99.41 | 13.85 | 96.98 | 40.40 | 91.31 | 11.66 | 97.47 |
| Energy | 40.57 | 93.99 | 56.29 | 86.42 | 10.07 | 98.07 | 9.28 | 98.12 | 3.81 | 99.15 | 39.50 | 92.01 | 26.59 | 94.63 |
| NAP-E | 8.32 | 98.36 | 11.65 | 97.72 | 1.77 | 99.57 | 1.50 | 99.60 | 0.99 | 99.76 | 29.89 | 93.91 | 9.02 | 98.15 |
| KNN | 4.31 | 99.20 | 7.71 | 98.62 | 9.45 | 98.22 | 10.08 | 98.15 | 19.31 | 96.46 | 45.83 | 90.09 | 16.12 | 96.79 |
| NAP-K | 2.39 | 99.56 | 2.29 | 99.55 | 1.76 | 99.57 | 2.45 | 99.47 | 3.58 | 99.34 | 34.27 | 92.80 | 7.79 | 98.38 |
| MSP | 47.34 | 93.48 | 33.66 | 95.54 | 42.21 | 94.51 | 42.42 | 94.52 | 64.52 | 88.14 | 61.98 | 88.95 | 48.69 | 92.52 |
| NAP-M | 14.09 | 96.05 | 7.33 | 98.35 | 10.91 | 97.72 | 11.20 | 97.55 | 16.42 | 96.23 | 54.61 | 84.76 | 19.09 | 95.11 |
| ReAct | 41.64 | 93.87 | 43.58 | 92.47 | 12.72 | 97.72 | 11.46 | 97.87 | 5.96 | 98.84 | 43.31 | 91.03 | 26.45 | 94.67 |
| NAP-R | 8.07 | 98.31 | 8.10 | 98.17 | 2.81 | 99.35 | 2.35 | 99.43 | 3.04 | 99.33 | 30.70 | 93.50 | 9.18 | 98.02 |
| Method | OOD Datasets | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVHN | Textures | iSUN | LSUN | LSUN-Crop | Places365 | |||||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| ASH | 25.02 | 95.76 | 34.02 | 92.35 | 46.67 | 91.30 | 51.33 | 90.12 | 5.52 | 98.84 | 85.86 | 71.62 | 41.40 | 90.02 |
| NAP-A | 17.41 | 96.72 | 22.70 | 94.99 | 38.22 | 93.34 | 43.05 | 92.17 | 5.25 | 98.94 | 85.76 | 72.08 | 35.40 | 91.32 |
| DICE | 59.25 | 88.57 | 0.91 | 99.74 | 51.63 | 89.32 | 49.48 | 89.51 | 61.42 | 77.12 | 80.29 | 77.08 | 50.50 | 86.89 |
| NAP-D | 23.63 | 95.28 | 1.22 | 99.68 | 33.86 | 94.25 | 28.56 | 95.02 | 24.59 | 92.04 | 82.12 | 77.13 | 32.34 | 92.23 |
| Energy | 87.46 | 81.85 | 84.15 | 71.03 | 74.54 | 78.95 | 70.65 | 80.14 | 14.72 | 97.43 | 79.20 | 77.72 | 68.45 | 81.19 |
| NAP-E | 19.03 | 96.40 | 21.72 | 95.47 | 33.24 | 94.15 | 43.38 | 92.11 | 2.60 | 99.38 | 75.70 | 79.54 | 32.61 | 92.84 |
| KNN | 16.27 | 96.65 | 28.06 | 92.69 | 58.74 | 82.09 | 52.77 | 84.55 | 26.01 | 93.53 | 87.59 | 69.94 | 44.91 | 86.58 |
| NAP-K | 10.26 | 97.84 | 12.24 | 97.76 | 45.56 | 91.57 | 36.45 | 93.22 | 9.84 | 98.04 | 87.42 | 70.83 | 33.63 | 91.54 |
| MSP | 81.70 | 75.40 | 60.49 | 85.60 | 85.24 | 69.18 | 85.99 | 70.17 | 84.79 | 71.48 | 82.55 | 74.31 | 80.13 | 74.36 |
| NAP-M | 35.58 | 93.32 | 15.29 | 96.94 | 66.86 | 86.62 | 57.64 | 88.98 | 27.85 | 93.93 | 86.00 | 70.89 | 48.20 | 88.45 |
| ReAct | 83.81 | 81.41 | 77.78 | 78.95 | 65.27 | 86.55 | 60.08 | 87.88 | 25.55 | 94.92 | 82.65 | 74.04 | 62.27 | 84.47 |
| NAP-R | 14.19 | 96.52 | 17.22 | 96.16 | 16.72 | 96.54 | 17.16 | 96.64 | 5.73 | 98.76 | 82.54 | 74.46 | 25.71 | 93.18 |
Appendix H How to find an optimal parameter ?
When combining NAP with different OOD detection methods, the optimal weight parameter varies. To obtain the optimal parameter, we utilized a set of data transformation techniques (including Gaussian noise, shot noise, impulse noise, defocus blur, glass blur, motion blur, zoom blur, snow, frost, fog, brightness, contrast, elastic transform, pixelate, jpeg compression) to generate a corrupted dataset based on the ID dataset, serving as pseudo OOD data. Utilizing this set of OOD data, we employed a binary search method to find the optimal . Through experimentation with various datasets and methods, we found that this search approach quickly identifies the optimal , which generalizes well to real OOD datasets. The values of used in our experiments are summarized in the Table 8.
| Method | CIFAR-10 | CIFAR-100 | ImageNet-1k |
|---|---|---|---|
| ASH | 0.5 | 0.6 | 0.8 |
| DICE | 0.5 | 0.6 | 0.6 |
| Energy | 0.4 | 0.4 | 0.6 |
| KNN | 0.8 | 0.8 | 0.6 |
| MSP | 0.5 | 0.3 | 0.3 |
| ReAct | 0.4 | 0.5 | 0.8 |
Appendix I Performance on Near-OOD detection
Given the context of existing research, where CIFAR-10 is commonly used as the ID dataset and datasets such as SVHN and Texture are utilized as OOD datasets, the distinction in data distribution is markedly evident due to the difference in data sources. This conventional setup, however, does not adequately challenge the model with closely related distributions. Therefore, we embark on an experiment utilizing CIFAR-10 and CIFAR-100 as ID and OOD datasets, respectively, to explore the performance of NAP in scenarios where the data distributions are more closely aligned. This approach aims to assess the robustness of NAP in distinguishing between datasets with subtle differences in distribution yet distinct semantic features.
Conclusion: Our findings confirm that NAP is capable of effectively functioning in scenarios where the ID and OOD data distributions are closely related, showcasing its utility in near-OOD detection tasks. Table 9 demonstrates the effectiveness of NAP variants (NAP-E, NAP-R, and NAP-A) in comparison to baseline methods (Energy, ReAct, and ASH) for the task of near-OOD detection between CIFAR-10 and CIFAR-100 datasets.
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |||
|---|---|---|---|---|---|---|---|---|
| Energy | 50.74 | 89.76 | ReAct | 48.77 | 90.55 | ASH | 48.74 | 89.93 |
| NAP-E | 44.38 | 90.69 | NAP-R | 42.94 | 90.66 | NAP-A | 44.92 | 90.07 |
To understand the mechanism by which NAP achieves this, it is essential to delve into how neural networks process and distinguish between different types of data. Neural network classifiers are adept at detecting various semantic features through different channels in the penultimate layer. It is this capability that NAP leverages to differentiate between ID and OOD data. NAP distinguishes between ID and OOD data based on the neural network’s high response to specific semantic features of ID data. Thus, in principle, NAP is well-suited for semantic OOD detection, capable of effectively distinguishing between samples from closely related distributions but with different semantics (e.g., CIFAR-10 vs CIFAR-100, as shown in the table below). However, it is important to note that NAP is not intended for more fine-grained tasks, such as pixel-level industrial surface defect detection.
Appendix J More examples of activation map visualizaiton
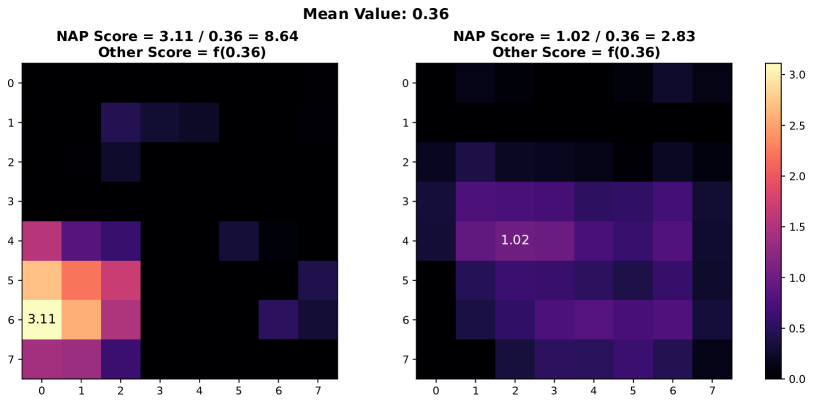
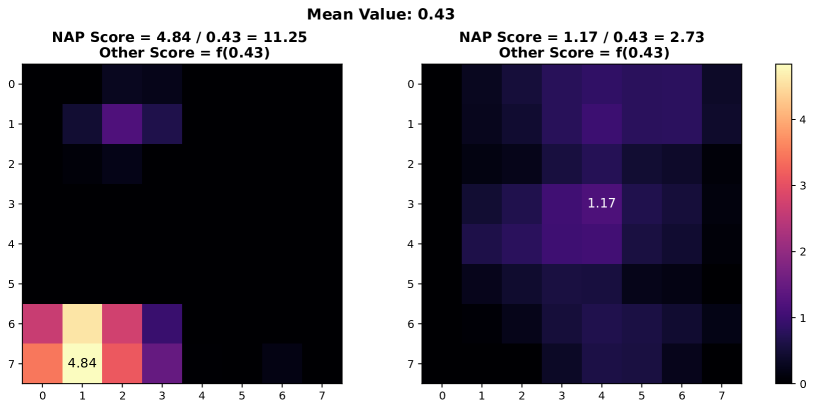
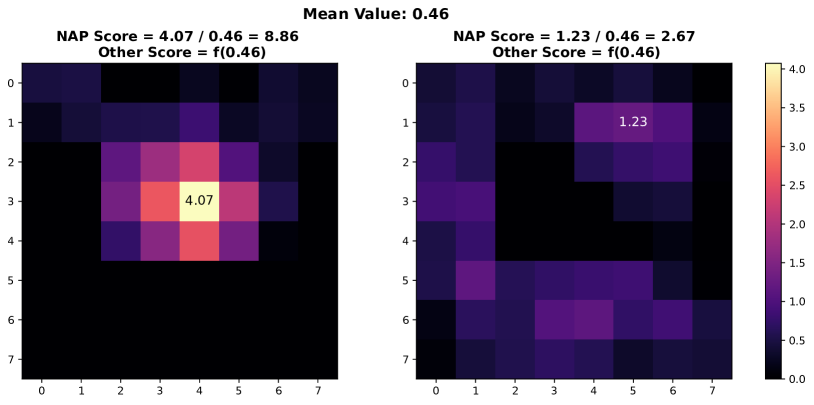
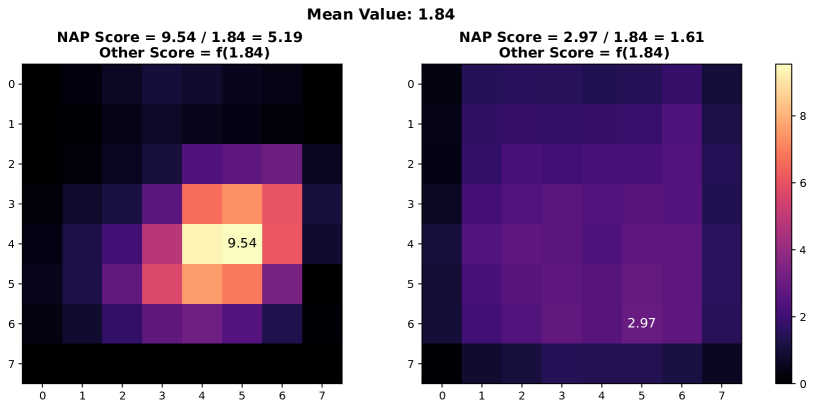
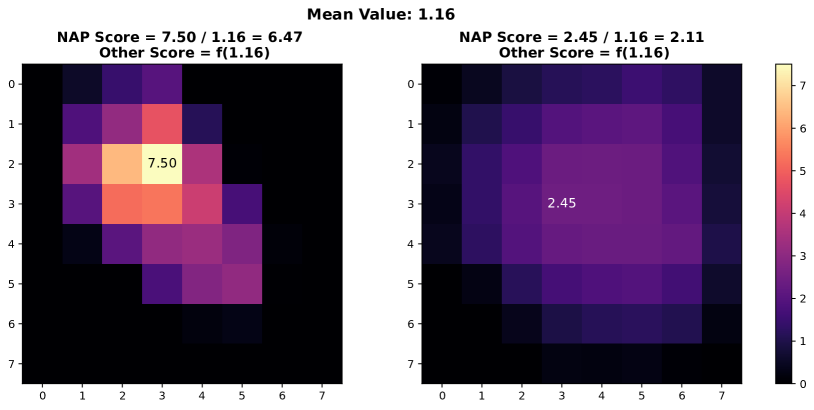
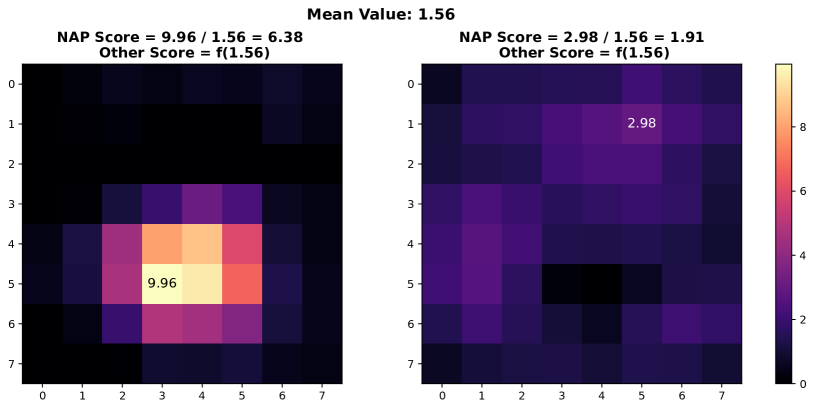
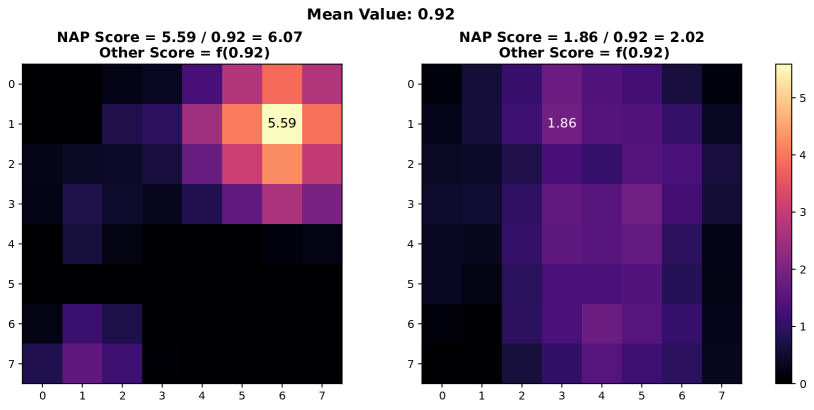
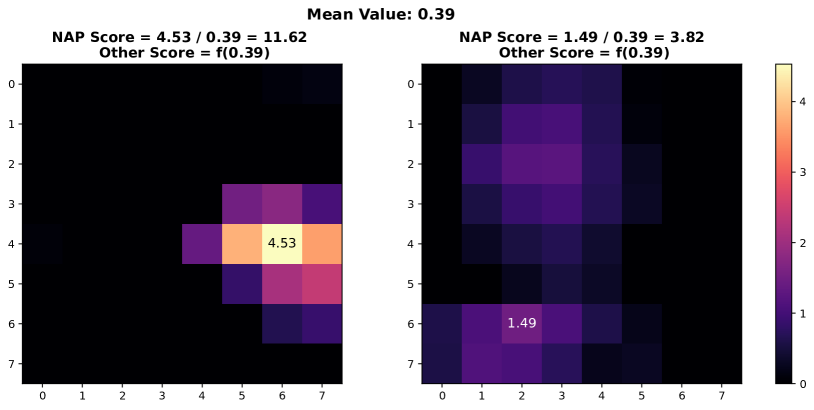
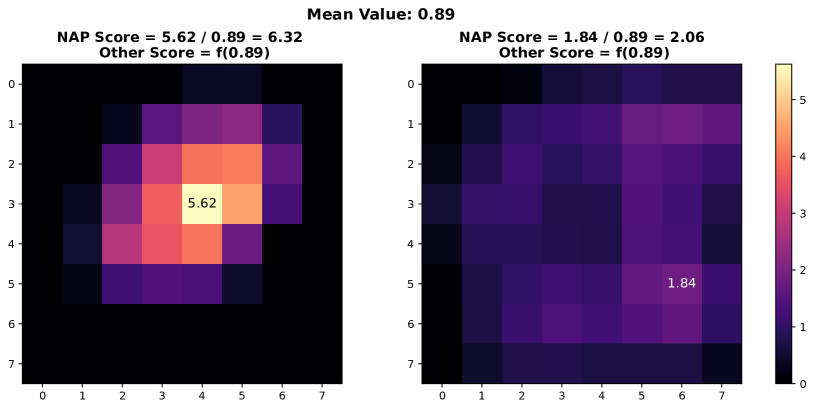
In this section, we present additional examples of activation map visualizations to further illustrate the challenges and phenomena discussed in our work. Specifically, we examine the penultimate layer’s activation maps for both in-distribution (ID) and out-of-distribution (OOD) samples. The visualizations provide insights into how global pooling methods can obscure important distinctions between ID and OOD samples by averaging out the spatial distribution of activation values within channels.
As shown in Figure 7, each pair of images displays the activation maps for a given channel. The left image in each pair corresponds to an ID sample, while the right image corresponds to an OOD sample. Different channels in the penultimate layer are typically tuned to capture specific semantic features present in the training data. For ID samples, these features often result in high activation values in particular regions of the activation map. For example, certain regions in the left images of each pair exhibit very high activation values when the corresponding semantic features are present in the ID sample.
In contrast, OOD samples, which do not contain these specific semantic features, may still produce activation responses due to the model’s unfamiliarity with such data. This can result in weak noise activations, as observed in the right images of each pair. This phenomenon highlights the difficulty faced by traditional OOD detection methods that rely on aggregated activation values, as discussed by [38]. These methods often fail to differentiate between ID and OOD samples because the average channel activations do not provide sufficient discriminative power.
However, the NAP score proposed in this paper addresses this issue by effectively distinguishing between ID and OOD samples based on a more nuanced analysis of activation patterns. The following visualizations exemplify the described behavior and underscore the importance of considering the distribution of activation values within channels for robust OOD detection.
Appendix K Limitations
The proposed method relies on the neural network’s ability to effectively learn specific semantic features of the ID dataset in the penultimate layer, and the assumption that OOD samples do not possess these features. If OOD samples exhibit similar semantic features or if the neural network is not well-trained, the effectiveness of the proposed method may be compromised.
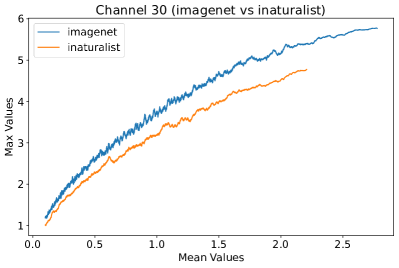
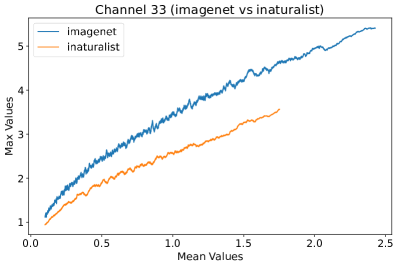
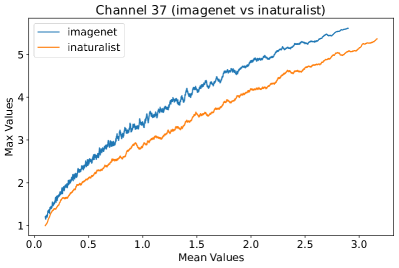
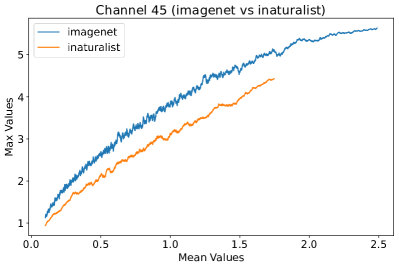
Appendix L Discussion
Based on the ultra effectiveness of our prior, shown in the visualization results presented in Figure 1 in the main text and Figure 8, 9, and 10 in this appendix, we are confident that more effective scoring functions exist. Due to space limitations, the primary focus and contribution of this paper is to introduce this prior and and validate its effectiveness by proposing a new score function. We leave the development of optimal scoring functions based on our prior for future work, aiming to further contribute to the community. We also hope this paper could encourage the researchers in this community to build upon our work and advance the field.
Appendix M Licenses for existing assets
We use several datasets and external code libraries in our research. To maintain anonymity, explicit references and detailed license information are not included in the submitted code. However, all creators and original owners of these assets are properly credited, and their licenses and terms of use are respected. The datasets used include CIFAR-10 [23], CIFAR-100 [23], ImageNet-1k [6], CIFAR-10-C [13], CIFAR-100-C [13], ImageNet-1k-C [13], SVHN [31], iSUN [48], LSUN [50], LSUN-crop [50], iNaturalist [45], SUN [47], Places [53], Textures [5], and Places365 [53]. We also utilize DenseNet [18], ResNet [12], VGG [37], and ViT [9] architectures in our experiments. Our codebase for Neural Activation Prior (NAP) includes original code under the MIT License, with additional components from other sources. External code sources include ASH [8], DICE [39], and [40] under the MIT License.
NeurIPS Paper Checklist
-
1.
Claims
-
Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope?
-
Answer: [Yes]
-
Justification: The abstract and introduction clearly state the main contributions and scope of the paper, which are supported by the theoretical and experimental results presented.
-
Guidelines:
-
•
The answer NA means that the abstract and introduction do not include the claims made in the paper.
-
•
The abstract and/or introduction should clearly state the claims made, including the contributions made in the paper and important assumptions and limitations. A No or NA answer to this question will not be perceived well by the reviewers.
-
•
The claims made should match theoretical and experimental results, and reflect how much the results can be expected to generalize to other settings.
-
•
It is fine to include aspirational goals as motivation as long as it is clear that these goals are not attained by the paper.
-
•
-
2.
Limitations
-
Question: Does the paper discuss the limitations of the work performed by the authors?
-
Answer: [Yes]
-
Justification: The limitations of this work are discussed in detail in Appendix K
-
Guidelines:
-
•
The answer NA means that the paper has no limitation while the answer No means that the paper has limitations, but those are not discussed in the paper.
-
•
The authors are encouraged to create a separate "Limitations" section in their paper.
-
•
The paper should point out any strong assumptions and how robust the results are to violations of these assumptions (e.g., independence assumptions, noiseless settings, model well-specification, asymptotic approximations only holding locally). The authors should reflect on how these assumptions might be violated in practice and what the implications would be.
-
•
The authors should reflect on the scope of the claims made, e.g., if the approach was only tested on a few datasets or with a few runs. In general, empirical results often depend on implicit assumptions, which should be articulated.
-
•
The authors should reflect on the factors that influence the performance of the approach. For example, a facial recognition algorithm may perform poorly when image resolution is low or images are taken in low lighting. Or a speech-to-text system might not be used reliably to provide closed captions for online lectures because it fails to handle technical jargon.
-
•
The authors should discuss the computational efficiency of the proposed algorithms and how they scale with dataset size.
-
•
If applicable, the authors should discuss possible limitations of their approach to address problems of privacy and fairness.
-
•
While the authors might fear that complete honesty about limitations might be used by reviewers as grounds for rejection, a worse outcome might be that reviewers discover limitations that aren’t acknowledged in the paper. The authors should use their best judgment and recognize that individual actions in favor of transparency play an important role in developing norms that preserve the integrity of the community. Reviewers will be specifically instructed to not penalize honesty concerning limitations.
-
•
-
3.
Theory Assumptions and Proofs
-
Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof?
-
Answer: [N/A]
-
Justification: Our paper does not include theoretical results.
-
Guidelines:
-
•
The answer NA means that the paper does not include theoretical results.
-
•
All the theorems, formulas, and proofs in the paper should be numbered and cross-referenced.
-
•
All assumptions should be clearly stated or referenced in the statement of any theorems.
-
•
The proofs can either appear in the main paper or the supplemental material, but if they appear in the supplemental material, the authors are encouraged to provide a short proof sketch to provide intuition.
-
•
Inversely, any informal proof provided in the core of the paper should be complemented by formal proofs provided in appendix or supplemental material.
-
•
Theorems and Lemmas that the proof relies upon should be properly referenced.
-
•
-
4.
Experimental Result Reproducibility
-
Question: Does the paper fully disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and/or conclusions of the paper (regardless of whether the code and data are provided or not)?
-
Answer: [Yes]
-
Justification: The experimental setup, datasets used, and evaluation metrics are thoroughly described, ensuring that the main experimental results can be reproduced.
-
Guidelines:
-
•
The answer NA means that the paper does not include experiments.
-
•
If the paper includes experiments, a No answer to this question will not be perceived well by the reviewers: Making the paper reproducible is important, regardless of whether the code and data are provided or not.
-
•
If the contribution is a dataset and/or model, the authors should describe the steps taken to make their results reproducible or verifiable.
-
•
Depending on the contribution, reproducibility can be accomplished in various ways. For example, if the contribution is a novel architecture, describing the architecture fully might suffice, or if the contribution is a specific model and empirical evaluation, it may be necessary to either make it possible for others to replicate the model with the same dataset, or provide access to the model. In general. releasing code and data is often one good way to accomplish this, but reproducibility can also be provided via detailed instructions for how to replicate the results, access to a hosted model (e.g., in the case of a large language model), releasing of a model checkpoint, or other means that are appropriate to the research performed.
-
•
While NeurIPS does not require releasing code, the conference does require all submissions to provide some reasonable avenue for reproducibility, which may depend on the nature of the contribution. For example
-
(a)
If the contribution is primarily a new algorithm, the paper should make it clear how to reproduce that algorithm.
-
(b)
If the contribution is primarily a new model architecture, the paper should describe the architecture clearly and fully.
-
(c)
If the contribution is a new model (e.g., a large language model), then there should either be a way to access this model for reproducing the results or a way to reproduce the model (e.g., with an open-source dataset or instructions for how to construct the dataset).
-
(d)
We recognize that reproducibility may be tricky in some cases, in which case authors are welcome to describe the particular way they provide for reproducibility. In the case of closed-source models, it may be that access to the model is limited in some way (e.g., to registered users), but it should be possible for other researchers to have some path to reproducing or verifying the results.
-
(a)
-
•
-
5.
Open access to data and code
-
Question: Does the paper provide open access to the data and code, with sufficient instructions to faithfully reproduce the main experimental results, as described in supplemental material?
-
Answer: [Yes]
-
Guidelines:
-
•
The answer NA means that paper does not include experiments requiring code.
-
•
Please see the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
-
•
While we encourage the release of code and data, we understand that this might not be possible, so “No” is an acceptable answer. Papers cannot be rejected simply for not including code, unless this is central to the contribution (e.g., for a new open-source benchmark).
-
•
The instructions should contain the exact command and environment needed to run to reproduce the results. See the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
-
•
The authors should provide instructions on data access and preparation, including how to access the raw data, preprocessed data, intermediate data, and generated data, etc.
-
•
The authors should provide scripts to reproduce all experimental results for the new proposed method and baselines. If only a subset of experiments are reproducible, they should state which ones are omitted from the script and why.
-
•
At submission time, to preserve anonymity, the authors should release anonymized versions (if applicable).
-
•
Providing as much information as possible in supplemental material (appended to the paper) is recommended, but including URLs to data and code is permitted.
-
•
-
6.
Experimental Setting/Details
-
Question: Does the paper specify all the training and test details (e.g., data splits, hyperparameters, how they were chosen, type of optimizer, etc.) necessary to understand the results?
-
Answer: [Yes]
-
Guidelines:
-
•
The answer NA means that the paper does not include experiments.
-
•
The experimental setting should be presented in the core of the paper to a level of detail that is necessary to appreciate the results and make sense of them.
-
•
The full details can be provided either with the code, in appendix, or as supplemental material.
-
•
-
7.
Experiment Statistical Significance
-
Question: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments?
-
Answer: [No]
-
Justification: The proposed method is deterministic and does not involve any stochastic components or random initialization that would require error bars or statistical significance testing. Therefore, error bars are not applicable in this context.
-
Guidelines:
-
•
The answer NA means that the paper does not include experiments.
-
•
The authors should answer "Yes" if the results are accompanied by error bars, confidence intervals, or statistical significance tests, at least for the experiments that support the main claims of the paper.
-
•
The factors of variability that the error bars are capturing should be clearly stated (for example, train/test split, initialization, random drawing of some parameter, or overall run with given experimental conditions).
-
•
The method for calculating the error bars should be explained (closed form formula, call to a library function, bootstrap, etc.)
-
•
The assumptions made should be given (e.g., Normally distributed errors).
-
•
It should be clear whether the error bar is the standard deviation or the standard error of the mean.
-
•
It is OK to report 1-sigma error bars, but one should state it. The authors should preferably report a 2-sigma error bar than state that they have a 96% CI, if the hypothesis of Normality of errors is not verified.
-
•
For asymmetric distributions, the authors should be careful not to show in tables or figures symmetric error bars that would yield results that are out of range (e.g. negative error rates).
-
•
If error bars are reported in tables or plots, The authors should explain in the text how they were calculated and reference the corresponding figures or tables in the text.
-
•
-
8.
Experiments Compute Resources
-
Question: For each experiment, does the paper provide sufficient information on the computer resources (type of compute workers, memory, time of execution) needed to reproduce the experiments?
-
Answer: [Yes]
-
Justification: Detailed information about the compute resources used for the experiments is provided in Section 5 of the paper.
-
Guidelines:
-
•
The answer NA means that the paper does not include experiments.
-
•
The paper should indicate the type of compute workers CPU or GPU, internal cluster, or cloud provider, including relevant memory and storage.
-
•
The paper should provide the amount of compute required for each of the individual experimental runs as well as estimate the total compute.
-
•
The paper should disclose whether the full research project required more compute than the experiments reported in the paper (e.g., preliminary or failed experiments that didn’t make it into the paper).
-
•
-
9.
Code Of Ethics
-
Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics https://neurips.cc/public/EthicsGuidelines?
-
Answer: [Yes]
-
Justification: The research presented in this paper adheres to the NeurIPS Code of Ethics. All experiments were conducted with integrity and transparency, ensuring fairness, accountability, and inclusivity.
-
Guidelines:
-
•
The answer NA means that the authors have not reviewed the NeurIPS Code of Ethics.
-
•
If the authors answer No, they should explain the special circumstances that require a deviation from the Code of Ethics.
-
•
The authors should make sure to preserve anonymity (e.g., if there is a special consideration due to laws or regulations in their jurisdiction).
-
•
-
10.
Broader Impacts
-
Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed?
-
Answer: [Yes]
-
Justification: The broader impacts of this work are discussed in Appendix A.
-
Guidelines:
-
•
The answer NA means that there is no societal impact of the work performed.
-
•
If the authors answer NA or No, they should explain why their work has no societal impact or why the paper does not address societal impact.
-
•
Examples of negative societal impacts include potential malicious or unintended uses (e.g., disinformation, generating fake profiles, surveillance), fairness considerations (e.g., deployment of technologies that could make decisions that unfairly impact specific groups), privacy considerations, and security considerations.
-
•
The conference expects that many papers will be foundational research and not tied to particular applications, let alone deployments. However, if there is a direct path to any negative applications, the authors should point it out. For example, it is legitimate to point out that an improvement in the quality of generative models could be used to generate deepfakes for disinformation. On the other hand, it is not needed to point out that a generic algorithm for optimizing neural networks could enable people to train models that generate Deepfakes faster.
-
•
The authors should consider possible harms that could arise when the technology is being used as intended and functioning correctly, harms that could arise when the technology is being used as intended but gives incorrect results, and harms following from (intentional or unintentional) misuse of the technology.
-
•
If there are negative societal impacts, the authors could also discuss possible mitigation strategies (e.g., gated release of models, providing defenses in addition to attacks, mechanisms for monitoring misuse, mechanisms to monitor how a system learns from feedback over time, improving the efficiency and accessibility of ML).
-
•
-
11.
Safeguards
-
Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pretrained language models, image generators, or scraped datasets)?
-
Answer: [N/A]
-
Justification: This paper poses no such risks.
-
Guidelines:
-
•
The answer NA means that the paper poses no such risks.
-
•
Released models that have a high risk for misuse or dual-use should be released with necessary safeguards to allow for controlled use of the model, for example by requiring that users adhere to usage guidelines or restrictions to access the model or implementing safety filters.
-
•
Datasets that have been scraped from the Internet could pose safety risks. The authors should describe how they avoided releasing unsafe images.
-
•
We recognize that providing effective safeguards is challenging, and many papers do not require this, but we encourage authors to take this into account and make a best faith effort.
-
•
-
12.
Licenses for existing assets
-
Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected?
-
Answer: [Yes]
-
Justification: The paper properly credits all creators and original owners of assets used, including datasets and code in Appendix M. Additionally, the licenses and terms of use for these datasets are explicitly mentioned and respected. For code and models, appropriate references and acknowledgments are included, and the licenses under which they are released are adhered to, ensuring compliance with their terms of use.
-
Guidelines:
-
•
The answer NA means that the paper does not use existing assets.
-
•
The authors should cite the original paper that produced the code package or dataset.
-
•
The authors should state which version of the asset is used and, if possible, include a URL.
-
•
The name of the license (e.g., CC-BY 4.0) should be included for each asset.
-
•
For scraped data from a particular source (e.g., website), the copyright and terms of service of that source should be provided.
-
•
If assets are released, the license, copyright information, and terms of use in the package should be provided. For popular datasets, paperswithcode.com/datasets has curated licenses for some datasets. Their licensing guide can help determine the license of a dataset.
-
•
For existing datasets that are re-packaged, both the original license and the license of the derived asset (if it has changed) should be provided.
-
•
If this information is not available online, the authors are encouraged to reach out to the asset’s creators.
-
•
-
13.
New Assets
-
Question: Are new assets introduced in the paper well documented and is the documentation provided alongside the assets?
-
Answer: [N/A]
-
Justification: This paper does not release new assets.
-
Guidelines:
-
•
The answer NA means that the paper does not release new assets.
-
•
Researchers should communicate the details of the dataset/code/model as part of their submissions via structured templates. This includes details about training, license, limitations, etc.
-
•
The paper should discuss whether and how consent was obtained from people whose asset is used.
-
•
At submission time, remember to anonymize your assets (if applicable). You can either create an anonymized URL or include an anonymized zip file.
-
•
-
14.
Crowdsourcing and Research with Human Subjects
-
Question: For crowdsourcing experiments and research with human subjects, does the paper include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)?
-
Answer: [N/A]
-
Justification: This paper does not involve crowdsourcing nor research with human subjects.
-
Guidelines:
-
•
The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
-
•
Including this information in the supplemental material is fine, but if the main contribution of the paper involves human subjects, then as much detail as possible should be included in the main paper.
-
•
According to the NeurIPS Code of Ethics, workers involved in data collection, curation, or other labor should be paid at least the minimum wage in the country of the data collector.
-
•
-
15.
Institutional Review Board (IRB) Approvals or Equivalent for Research with Human Subjects
-
Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or institution) were obtained?
-
Answer: [N/A]
-
Justification: This paper does not involve crowdsourcing nor research with human subjects.
-
Guidelines:
-
•
The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
-
•
Depending on the country in which research is conducted, IRB approval (or equivalent) may be required for any human subjects research. If you obtained IRB approval, you should clearly state this in the paper.
-
•
We recognize that the procedures for this may vary significantly between institutions and locations, and we expect authors to adhere to the NeurIPS Code of Ethics and the guidelines for their institution.
-
•
For initial submissions, do not include any information that would break anonymity (if applicable), such as the institution conducting the review.
-
•