KnowPhish: Large Language Models Meet Multimodal Knowledge Graphs for Enhancing Reference-Based Phishing Detection
Abstract
Phishing attacks have inflicted substantial losses on individuals and businesses alike, necessitating the development of robust and efficient automated phishing detection approaches. Reference-based phishing detectors (RBPDs), which compare the logos on a target webpage to a known set of logos, have emerged as the state-of-the-art approach. However, a major limitation of existing RBPDs is that they rely on a manually constructed brand knowledge base, making it infeasible to scale to a large number of brands, which results in false negative errors due to the insufficient brand coverage of the knowledge base. To address this issue, we propose an automated knowledge collection pipeline, using which we collect and release a large-scale multimodal brand knowledge base, KnowPhish, containing 20k brands with rich information about each brand. KnowPhish can be used to boost the performance of existing RBPDs in a plug-and-play manner. A second limitation of existing RBPDs is that they solely rely on the image modality, ignoring useful textual information present in the webpage HTML. To utilize this textual information, we propose a Large Language Model (LLM)-based approach to extract brand information of webpages from text. Our resulting multimodal phishing detection approach, KnowPhish Detector (KPD), can detect phishing webpages with or without logos. We evaluate KnowPhish and KPD on a manually validated dataset, and on a field study under Singapore’s local context, showing substantial improvements in effectiveness and efficiency compared to state-of-the-art baselines. 111Preprint. Under review. Codes and data will be released at a later date.
1 Introduction
Phishing attacks are one of the most impactful type of scams, harming both individuals and businesses: in 2023, an estimated $1.026 trillion was lost by consumers worldwide in scams [5], of which phishing scams are among the most common types. Phishing scams also account for about 90% of data breaches for organizations [11]. This problem has been exacerbated by the proliferation of automated phishing kits, enabling malicious actors to easily mimic genuine pages while evading detection using countermeasures [64]. Accordingly, the number of phishing attacks has increased by 47.2% in 2022 compared to the previous year [65]. These underscore the importance and urgency of tackling the issue, and the need for effective automatic phishing detection approaches.
Many efforts have been made to counter phishing attacks, including anti-phishing blacklists, heuristic-based, and feature-based models [14]. Blacklist-based methods [40, 42, 45] compare an input URL with a predefined blacklist of malicious URLs, but these are reactive approaches that require phishing sites to be first reported or detected through other means. Heuristic-based [13] and feature-based models [28, 37, 18, 61, 31, 54, 35] extract features to proactively identify new phishing webpages. However, as these do not utilize logo information, they are greatly limited in their ability to detect plentiful phishing pages which are mainly identifiable by the presence of a logo [33]. Moreover, as they depend on statistical features for detecting phishing pages, they are susceptible to distribution shift due to the constantly changing nature of phishing campaigns.
In contrast, reference-based phishing detectors (RBPDs), which work by comparing the logos on a target webpage to a known set of logos, have been established as the state-of-the-art phishing detection paradigm, garnering considerable research attention [1, 32, 33]. Specifically, a RBPD consists of brand knowledge base (BKB) containing brand information (the logos and legitimate domains of brands) and a detector backbone which uses information from this BKB for phishing detection. To detect if a webpage is a phishing or benign page, RBPDs first identify the webpage’s brand intention, i.e., the brand that the webpage presents itself as (e.g., a webpage with a Adobe logo and appearance has the brand intention of Adobe). Then, if the webpage is detected to have an intention of a certain brand, but its domain does not match the legitimate domains of that brand, the webpage is classified as a phishing. As virtually all phishing pages do not utilize the legitimate domains of the original brand, this approach typically obtains high precision. Moreover, as this approach is based on an invariant that does not change over time, it is relatively robust to distribution shift [32, 33].
Challenges.
Despite the advantages of RBPDs, they have two major limitations which we focus on. (1) The first limitation is Limited-Scale BKB: RBPDs fundamentally rely on their BKB to identify the brand intention of a website. However, it is labor-intensive to construct and maintain a large-scale BKB manually. Phishpedia [32] and PhishIntention [33] rely on manual curation, hence are limited to a small BKB of 277 brands. A recent method, DynaPhish [34], proposes to dynamically expand the BKB during deployment time. However, this leads to extremely long running time, e.g., averaging seconds per sample in our experiments. Moreover, it cannot recognize logo variants of those unseen brands, leading to potential false negatives. (2) The second limitation is Textual Brand Intention: Phishing webpages can convey their brand intention via text, instead of via logos. Figure 1 shows a webpage without a logo, but its target brand, Australia Post, is presented in the HTML. Its brand intention is clear to visitors of the page, but existing RBPDs cannot identify it because they solely operate within the image modality.
Present Work.
In this paper, we seek to address both of these issues. First, we propose an automated knowledge collection pipeline, with which we construct and publicly release a large-scale multimodal BKB named KnowPhish containing rich logo variants, aliases, and domain information of each brand. KnowPhish is constructed based on our empirical analysis which finds that phishing targets mostly belong to a few high-value industries, and this is stable over time. Hence, using brand-industry relations modelled from a publicly available knowledge base, Wikidata, we search for a set of potential phishing targets and their brand knowledge predictively, leading to a BKB covering around 20k potential phishing targets. KnowPhish can be used to boost the performance of existing RBPDs in a plug-and-play manner, as demonstrated in our experiments.
Next, to address the issue of textual brand intention, we develop a Large Language Model (LLM)-based approach to identify the brand intention of webpages in conjunction with the alias information in our KnowPhish KB. Our approach can be directly integrated with any standard visual RBPD [33], augmenting it to form a multimodal RBPD which detects brand intention through both visual and textual modalities. Our resulting multimodal phishing detection approach, named KnowPhish Detector (KPD), is able to detect phishing webpages with or without logos.
We then evaluate the effectiveness and efficiency of KnowPhish and KPD on TR-OP, a manually validated dataset that comprises 5k benign and 5k phishing webpages, which we release publicly. We also evaluate our approach on a field study under Singapore’s local context, to study how well different approaches generalize to such a local context. The resulting data, which we call SG-SCAN, contains 10k webpages from Singapore local webpage traffic over 6 months. On experiments on the two datasets, KnowPhish significantly boosts the effectiveness of RBPDs, and is 30 or more times faster than the on-deployment framework DynaPhish [34], when equipped with image-based RBPDs. Moreover, incorporating our multimodal approach, KPD, can substantially boost the number of detected phishing webpages.
In summary, our contributions are three-fold:
-
•
Multimodal Brand Knowledge Base. We propose KnowPhish, the first-of-its-kind large-scale multimodal BKB for phishing detection, and its automated construction approach. KnowPhish can be used in any RBPDs to boost their brand knowledge in a plug-and-play manner.
-
•
Multimodal Reference-based Phishing Detector. We propose an LLM-based approach to identify textual brands from HTML to handle logo-less phishing webpages. Our approach directly integrates with any existing RBPD, augmenting it to form a multimodal RBPD which can detect logo-less phishing webpages.
-
•
Effectiveness and Efficiency. Extensive experiments show that our approach significantly enhances effectiveness and efficiency of phishing detection compared to state-of-the-art baselines. We also demonstrate its effectiveness on a field study, and validate the robustness to adversarial attacks.
2 Formalization
Threat Model.
In a phishing attack, a malicious actor misleads visitors into believing that their webpage comes from a legitimate brand, misleading users into providing their credentials (such as username and password). Note that we do not consider other types of attacks, such as malware or miscellaneous scams that do not fit the above description, to be within our scope.
In our threat model, we assume the attacker has full control over their webpage. However, to maintain their webpage’s effectiveness in misleading users, the webpage needs to convey its brand intention, i.e., present itself as a particular recognizable brand to visitors. In addition, the webpage needs to be credential receiving in some way: e.g., via username and password fields, but less common approaches exist such as buttons or QR codes. Deviating from either of these two conditions makes it less likely for the phishing attack to succeed, and our empirical observations support that these two conditions hold consistently in phishing webpages.
Formally, consider a webpage , which consists of its screenshot (w.screenshot), its page HTML (w.html), and its domain (w.domain). As described above, the webpage needs to convey its brand intention, presenting itself as belonging to a brand . This can be done either in visual form (e.g., through logos in its screenshot) or textual form (e.g., through text in its HTML), so brand information may appear either in w.screenshot or w.html (or both).
Reference-Based Phishing Detection.
Since phishing webpages need to convey brand intention, the state-of-the-art RBPD approach relies on identifying this brand intention, by comparing images on the page to a set of known reference logos. Formally, an RBPD consists of a brand knowledge base (BKB) and a detector backbone utilizing this BKB.
A BKB [32, 33, 34] stores brand-related knowledge, taking the form of a list of brands: . For each brand , we store its name (b.name), its logo images (b.logos), and its legitimate domains (b.domains). In our work, to facilitate the detection of textual brand intention, we further add its list of textual aliases, i.e., a list of common alternate names used to refer to the brand (b.aliases), resulting in an augmented BKB. Formally, given a brand , the augmented BKB is:
For example, for the brand PayPal, this may contain: (PayPal, (logo1, logo2), (www.paypal.com), (PYPL)), where logo1 and logo2 are two PayPal logo images.
Next, given a webpage and a BKB , a detector backbone outputs either the brand intention that is predicted to have, or ‘null’ to indicate no predicted brand intention: .
Finally, an RBPD, denoted , classifies a webpage as phishing or benign. classifies as phishing if its detector backbone detects that presents a brand intention but ’s domain is inconsistent with any of the legitimate domains of brand recorded in (i.e., ). Otherwise, is classified as benign. Formally:
Evasion Attacks.
The attackers may attempt to bypass via the following methods:
T1: Phishing with Logo Variants. To circumvent the online knowledge expansion approach for (e.g., DynaPhish[34]), attackers can use other legitimate logo variants of instead of the one displayed on ’s official webpage.
T2: Phishing with Text Brands. Instead of using a logo to present their brand intention, the attacker can rely on text w.html to show its brand intention, making image-based phishing detectors completely fail.
T3: HTML Obfuscation. Phishing attackers may employ evasion techniques on HTML content to hinder effective information extraction by text-based methods.
We address T1 by constructing a large-scale multimodal BKB with rich logo information, i.e., multiple logos per brand. We address T2 by developing an LLM-based approach to extract text brands from HTML. For T3, we show in Section 5.5 that our LLM-based approach is robust to different types of adversarial noise in HTML.
3 KnowPhish Construction
In this section, we introduce how to construct KnowPhish, a large-scale multimodal BKB. We start by conducting empirical analysis on phishing feeds from different periods to find prospective indicators to proactively search for potential phishing targets. With our empirical findings, we then describe how to automatically construct KnowPhish using a publicly-accessible multimodal knowledge graph.
3.1 Empirical Motivation
Our empirical analysis seeks to address the following questions:
Question 1. How much do phishing targets change over time?
Question 2. What are the enduring characteristics shared by phishing feeds across different time intervals?
3.1.1 Data
To achieve this objective, we conducted a study using two distinct phishing datasets. The first dataset, , includes phishing webpages that were collected three years ago by [32]. It encompasses a total of 29,496 phishing instances targeting 283 different brands. The second dataset, , comprises phishing samples obtained from APWG[6] at the end of 2022. This dataset contains a total of 5,167 phishing examples targeting 391 unique brands.
Furthermore, we manually categorized each of these phishing targets into one of the following distinct industries, namely: 1) financial, 2) online service, 3) telecommunication, 4) e-commerce, 5) social media, 6) postal service, 7) government, 8) web portal, 9) video game, and 10) gambling. For the brands that cannot be classified into any of the ten categories, we categorize it as 11) other businesses. For instance, Bank of America is categorized into the financial category, while KFC is classified as other businesses.
3.1.2 Analysis
We conduct a thorough examination of the disparities in phishing targets and the distribution of their respective industries across the two phishing datasets. Our observations are as follows.
Observation 1. Phishing targets significantly change after three years.
In particular, in Figure 2 we observe significant changes in phishing targets when compared to three years ago, with only 118 of the 391 brands in being present in . Some previous phishing targets such as EMS and De Volksbank no longer exist, while new targets like Bitkub, and USPS, have emerged. This trend of changes aligns with the findings from a previous study by [34].
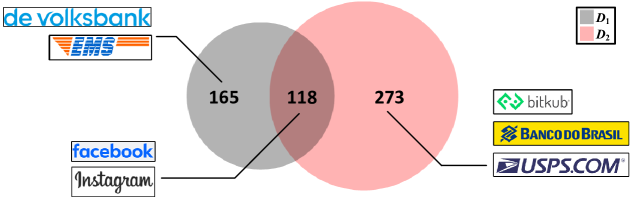
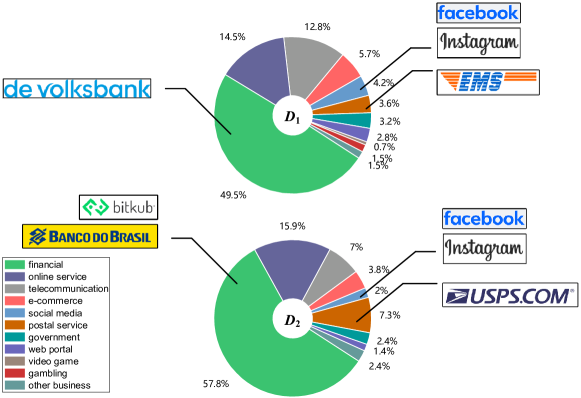
Observation 2. Even though a large number of emerging phishing targets appear, the industries of those phishing targets do not significantly change.
However, an intriguing revelation from Figure 3 is that despite the shifting landscape of phishing targets, the industries targeted by these phishing attacks have remained mostly consistent. For example, De Volksbank (in ), Bitkub, and Banco Do Brazil (in ) are all banking organizations, even though they became phishing targets at different times. Almost all the phishing targets in can still be categorized in the ten industries. The majority of these targets continue to belong to the same industries that have historically been the focus for phishing attacks, such as financial, telecommunication, and postal service, among others, while only a few brands such as KFC, Hydroquebec cannot be covered by the ten industries. We provide more examples of the phishing targets belonging to different industries in Table 8 in Appendix A.
It is worth noting that this observation echoes with the six Principles of Influence [10] upon which social engineering relies, namely the significance of authority in achieving successful persuasion. In the context of social engineering, threat actors, including phishing attackers, tend to focus their efforts on authorized and higher-value entities to maximize their gains from unlawful acquisition of sensitive information, rather than impersonate less-reputable and lower-value firms.
3.1.3 Connection to Wikidata Knowledge Graph
The consistent targeting of specific industries by phishing attacks can, in turn, serve as a valuable foundation for building a BKB predictively. The brand-industry relation can be regarded as a fact triplet stored within knowledge graphs. In this work, we use Wikidata [55], the largest publicly-accessible knowledge base[46, 43] to explore the connection between phishing targets and the knowledge graph. Our focus lies on examining the instance_of relationship within Wikidata, as we emprically find that it provides the most comprehensive information about the type or category to which an entity belongs. For example, the brand Bank of America belongs to the category bank can be represented as . Formally, we use to represent that brand belongs to category if there is such a fact in the knowledge graph .
To gain a deeper understanding on which Wikidata categories those phishing targets belong to, we perform searches within the dataset. Specifically, for each phishing target , we search for the categories associated with it, denoted as . This process yields a collection of categories, , comprising the categories for all phishing targets in the APWG phishing dataset. In Figure 4, we present a visualization of the 30 most frequently occurring categories within . Our observation reveals that some categories represent specific industries, such as bank, postal service, and internet service provider, while others, like business, public company, and enterprise, convey more general semantics.
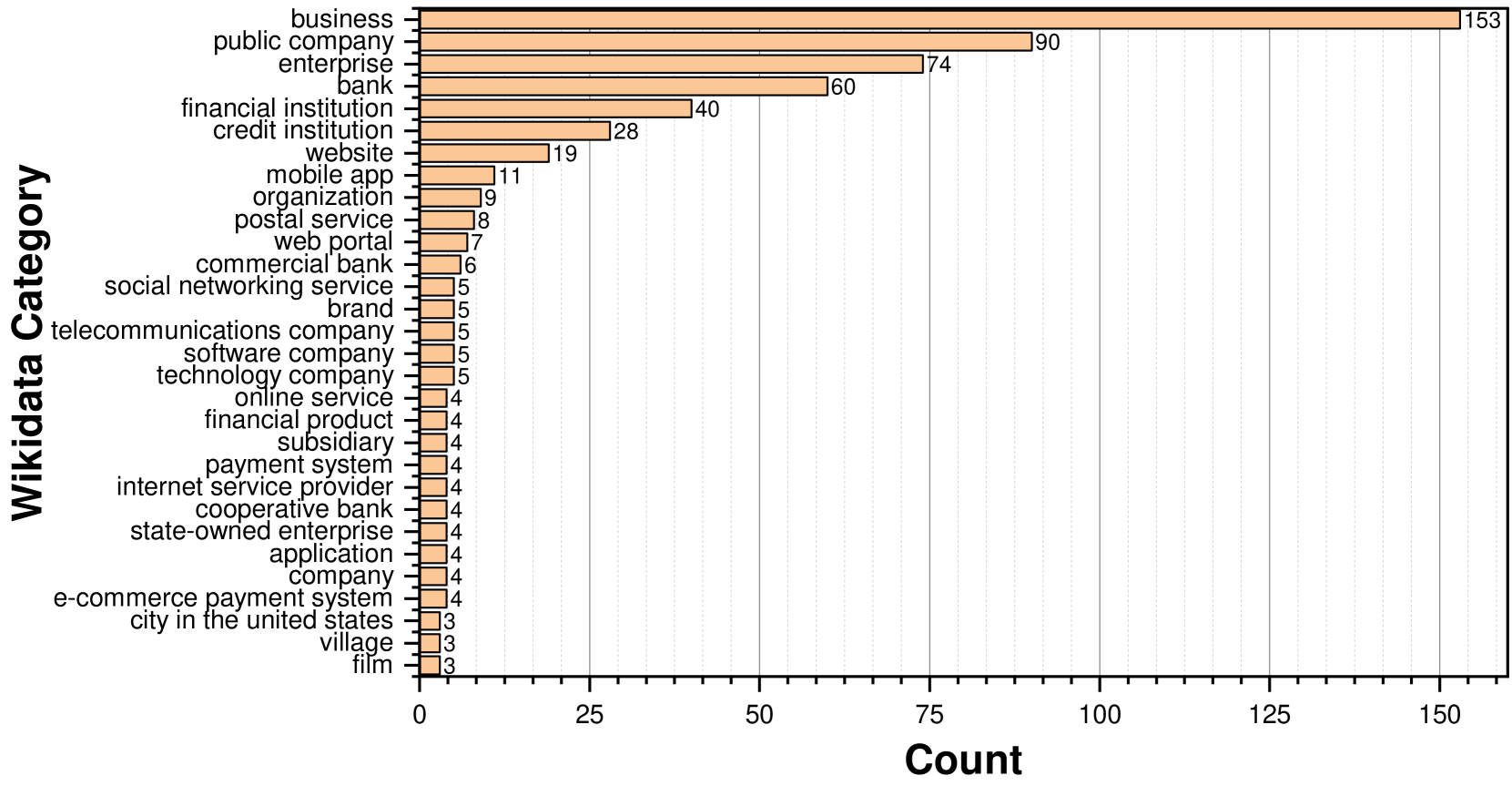
Based on this observation, we curate two lists of categories: 1) Narrow Categories such as ‘bank’ representing narrower industry segments, and 2) General Categories such as ‘business’, which will be used in constructing our brand knowledge base KnowPhish. The detailed lists can be found in Table 9 and Table 10 in Appendix A.
3.2 Approach Overview
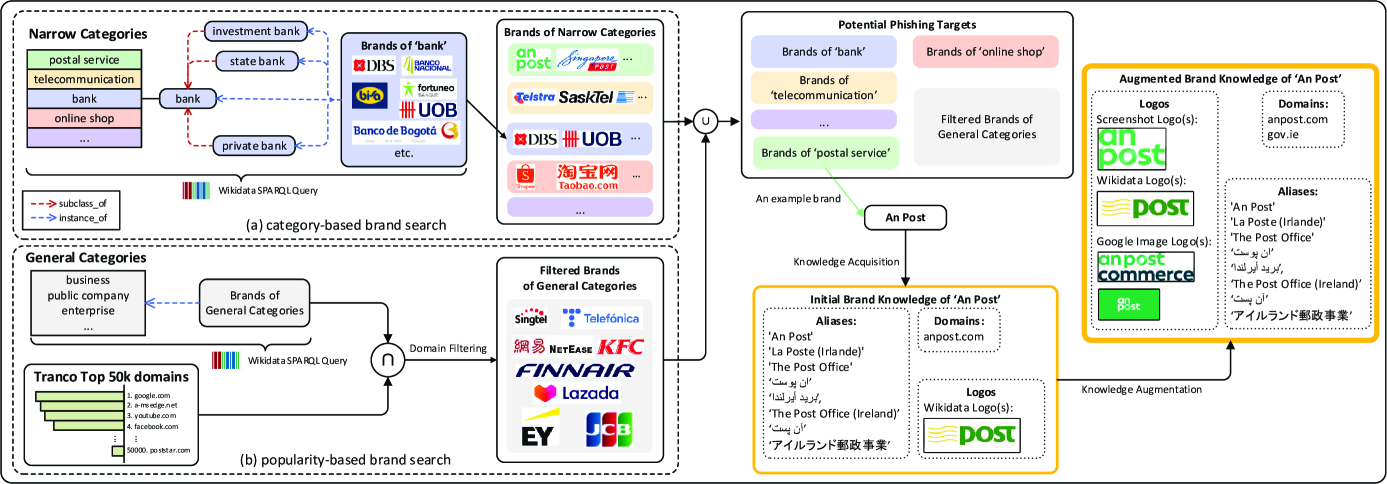
Building upon the empirical insights in Section 3.1, we introduce KnowPhish, a large-scale multimodal BKB prioritizing both comprehensive coverage of potential phishing targets and detailed brand knowledge. As Figure 5 shows, KnowPhish is constructed using an automatic pipeline, which starts from 1) Brand Search based on industries via Wikidata knowledge graph and proceeds with 2) Knowledge Acquisition and Augmentation to obtain relavant brand knowledge including logos, aliases, and domains. The complete construction algorithm is illustrated in Algorithm 2 in Appendix A.
3.3 Brand Search
Identifying a wide range of potential phishing targets is crucial for the construction of KnowPhish. If a phishing target is absent from the BKB, the RBPD may not be able to identify its corresponding phishing webpages, resulting in false negatives. Our brand search module is designed to prioritize brands that are higher-value phishing targets and consists of two concurrent components:
-
(a)
Category-based Brand Search identifies brands operating within specific industries, i.e., Narrow Categories , to find brands .
-
(b)
Popularity-based Brand Search considers a broader set of General Categories and ranks their brands by popularity to generate a brand list .
By combining (a) and (b), we obtain a more comprehensive list of potential phishing targets, denoted as .
3.3.1 Category-based Brand Search
Category-based brand search is motivated by our empirical observation that phishing attackers often choose to impersonate brands within high-value industries. Thus, we collect all brands associated with Narrow Categories . For instance, when focusing on the ‘bank’ category, we aim to find all the banks listed in Wikidata.
Hence, for each Narrow Category , we search for the corresponding brands belonging to and its subcategories , where subclass_of indicates a hierarchy relationship between two categories in the Wikidata graph . Formally, the brand list related to category is;
| (1) |
We introduce sub-categories here because the brands within a sub-category of a Narrow Category are also potential targets for phishing attackers. For example, National Bank of Costa Rica is categorized as state bank, a sub-category of bank, in Wikidata, although it unquestionably falls under the category of bank, and is a potential phishing target.
3.3.2 Popularity-based Brand Search
Although industry category is a key indicator of potential phishing targets, such information may not be accurately maintained in Wikidata for every brand. For example, Singtel, a Singaporean telco company, should logically fall into the telecommunication category. However, the only categories it has in Wikidata are ‘business’, ‘public company’, and ‘enterprise’. Hence, depending solely on Narrow Categories is insufficient.
To address this, we introduce popularity-based brand search that incorporates domain rank for selecting brands. We use domain rank-based filtering for two reasons: 1) not all the brands within General Categories are high-value entities, and 2) the more reputable a brand is, the more likely it is to be a phishing target. As a result, for each general category , we generate its corresponding brand list with a domain ranking constraint:
where is a popular domain ranking list, uses to compute the domain rank of the most popular domain in b.domains, and is a domain ranking threshold. Here, we instantiate with the Tranco domain ranking list [44].
The brands obtained through the category-based brand search, denoted as , and popularity-based brand search, denoted as , are combined into our final list .
3.4 Knowledge Acquisition and Augmentation
RBPDs fundamentally depend on their brand knowledge to allow for accurate phishing detection. Next, we augment our collected brands with knowledge about the 1) logos, 2) domains, and 3) aliases (or alternate names) associated with each brand. Note that aliases are not present in existing BKBs [32, 33, 34], but we introduce them to facilitate the detection of textual brand intention, as we describe in Section 4.
3.4.1 Knowledge Acquisition
Each brand we have collected is a Wikidata entity with rich property information. Therefore, we leverage this readily available data to establish initial brand knowledge. Specifically, for each , we acquire initial brand knowledge from the Wikidata graph :
where logo_image, official_website, and label222label is instantiated as ‘rdfs:label’ in SPARQL instead of a property relation. are the property relations in that indicate the logos, URL of official website, and alternative names in different languages of an entity, respectively.
3.4.2 Knowledge Augmentation
Information maintained in Wikidata may be incomplete, particularly for the logos and the domains. Brands may employ multiple legitimate logo variants and domain variants in its online presence. When a phishing page contains a logo variant not present in the knowledge base, the phishing detector may fail to identify its brand, leading to false negatives. Similarly, if our detector examines a benign webpage with a legitimate domain that is not documented in Wikidata, a false positive alarm may be raised. Thus, further augmentation to on the logos and domains is required to alleviate such false positives and false negatives.
Logo Variants.
To capture logo variants, we employ two methods. The first involves accessing the associated domain(s) of the brand and capturing the logo displayed on that webpage by a well-trained webpage layout detector[33], denoted . The second method utilizes Google Image Search[17]. We initiate a search query by combining the brand name with the term ‘logo’, then filter the results to include images with URLs matching the brand’s domain(s). In this way, we expand our logo collection beyond the Wikidata logo images:
| (2) |
Domain Variants.
To acquire additional domain variants, we utilize the Tranco domain ranking list and the Whois service[15]. Concretely, we run the Whois lookup on all the domains in KnowPhish and to gather the Whois information for each of their domains. Then for each brand , we expand the list of its legitimate domains by incorporating domains in that share identical organization details with the original :
| (3) |
Here, refers to the Whois information for domain . Note that the organization entry in the Whois information specifies the owner of a domain. Therefore, domains within owned by the same entity can effectively complement our list of domain variants.
Domain Propagation.
We further propose a method for propagating domain information among brand pairs that share subsidiary relationships, since the legitimate website of a brand may also display the logos of its subsidiary (or vice versa). For instance, ‘facebook.com’ can be seen as a domain variant for Meta. When visiting ‘facebook.com’, it is reasonable for a Meta logo to be present; but if we were not aware of this domain variant, we would classify it as having the brand intention of Meta, and thus a phishing attack, resulting in a false positive.
To address this problem, we use the subsidiary relationship under the owned_by and parent_organization property relations in . For each , its ‘propagated domains’ is defined as all domains in its 1-hop neighborhood over the graph of these relations; that is:
represents the domains from a collection of brands that share subsidiary relationships with the brand . At the end of domain propagation, we replace the original domains (b.domains) with the propagated domains as above.
By now KnowPhish has been constructed completely and is ready to be equipped with image-based [32, 33] and text-based phishing detectors (discussed in Section 4).
Adapting to Evolving Phishing Targets.
New brands are continuously emerging as new potential phishing targets. Since KnowPhish is built in a fully automatic manner, one can simply handle such information obsolescence by regularly reconstructing KnowPhish to search for new potential phishing targets outside . Such regular updates allow the RBPD method to remain effective in countering attacks targeting these emerging brands.
4 KnowPhish Detector
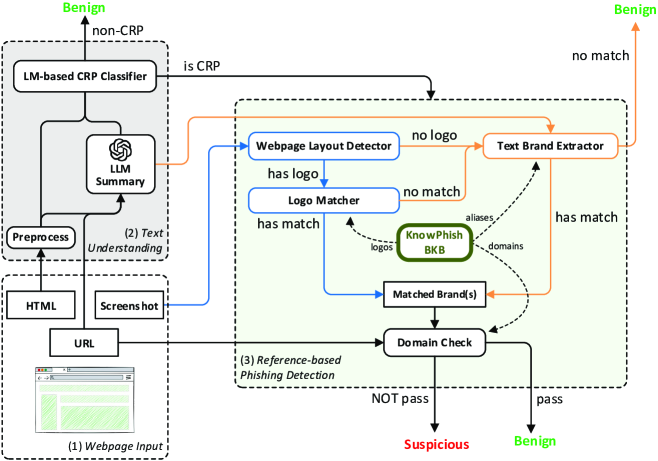
Incorporating our multimodal BKB KnowPhish, we further propose KnowPhish Detector (KPD), a multimodal RBPD with multi-stage analysis. Figure 6 offers an overview of KPD, and Algorithm 1 further elaborates on its analysis steps. Specifically, for an input webpage , KPD first leverages an LLM to generate a summary for using its HTML and URL. Then, the summary and the HTML are fed into a well-trained small language model to classify whether is a credential-requiring page (CRP). If is detected as a CRP, KPD will proceed to extract its brand intention from either the screenshot or the LLM summary. The extracted brand intention of are then used to retrieve a list of legitimate domains, which are compared with the domain of to decide whether is phishing or not. Notably, KPD features novel text-based modules to analyze implicit CRP and extract brand intention from logoless webpages, which will be discussed in Section 4.2 and Section 4.3, respectively.
4.1 LLM-based Webpage Summary
The LLM summary, as depicted in Figure 6, acts as crucial information for various subsequent tasks. To generate this summary, we first process the HTML by removing extraneous elements like JavaScript and CSS blocks. Subsequently, this processed HTML, along with the URL, will become the input of an LLM. We design a prompt template (Table 11 in Appendix B) with three in-context examples to understand the webpage from various aspects, such as what the brand intention of the webpage is, whether the webpage is a CRP, which elements in the HTML makes it a CRP, and the overall rationale for its CRP prediction. The generated summary will serve as an auxiliary text attribute of the webpage for the following CRP classification and text brand extraction tasks.
4.2 Text-based CRP Classification
As discussed in Section 2, phishing webpages always convey credential-requiring intentions. While a prior study has already developed an image-based CRP classifier[33], we empirically find that it leads to a significant number of false negatives during deployment by incorrectly classifying phishing webpages into non-CRP, in which most of these false negatives are implicit CRP. Figure 7 provides a comparison between explicit and implicit CRP, where explicit CRP directly shows credential-taking elements (e.g., the input fields of username and passwords), while implicit CRP only presents the elements (e.g., a login button) to redirect to a potential explicit CRP. While the credential-requiring intention is evident to page visitors, the CRP classifier from [33] cannot identify it because it exclusively focuses on identifying explicit CRPs.


In response to this limitation, we propose using a small LM (XLM-RoBERTa[12]) to identify credential-requiring intention from text. Specifically, the small LM takes both the processed HTML and the LLM summary as input and outputs a binary prediction of whether the webpage is a CRP or not. This design of integrating the original text and its LLM summary as input to a smaller LM aims to benefit from the general-purpose reasoning and instruction following ability of an LLM, along with the trainability of a small LM [20]. Consequently, our text-based classifier can better comprehend the credential-requiring intention from webpage text, facilitating the detection of both explicit and implicit CRP. Webpages classified as non-CRP are regarded as benign; for those classified as CRP, we proceed to the brand extractor step.
4.3 Brand Extractor
Next, we aim to extract the brand intention of the webpage. Recall that our approach integrates with an existing RBPD which identifies brands visually through logos, which we call a logo brand extractor (LBE). Specifically, existing LBEs [32, 33] consists of a webpage layout detector to locate a logo from the screenshot, and a logo matcher to match that logo to a brand in the BKB. We find that existing RBPDs encounter limitations in identifying brand intention when 1) the logo displayed in the webpage differs from the logos stored in the BKB, or 2) the logo cannot even be detected (e.g., Figure 1).
To cope with this problem, we introduce a text brand extractor (TBE), which acts as an extra component when the LBE fails to identify a brand from the screenshot. TBE directly extracts the text brand by parsing the LLM summary which already contains a brand intention prediction. The predicted text brand undergoes an exact matching process with all the aliases in KnowPhish. The brand associated with the matched alias becomes the identified brand during the brand identification step. In the event of multiple aliases matching, all corresponding brands become identified.
In situations where the LBE fails to detect a logo on the webpage or cannot find a matching logo, the TBE is activated to extract brand intention, leading to higher recall.
4.4 Domain Check
Once both the credential-requiring intention and the brand intention are confirmed, the final step is to perform a domain check. We retrieve all the legitimate domains of the matched brand(s) from KnowPhish and compare them with the domain of the input webpage. If the input domain is inconsistent with all the legitimate domains we retrieve, the webpage will be classified as phishing; otherwise, it is predicted as benign. Note that webpages classified as non-CRP or having no brand intention are also deemed benign.
5 Experiments
We conduct experiments to answer the following research questions:
-
•
[RQ1] Effectiveness and Efficiency: Can KnowPhish and KPD effectively improve the phishing detection performance of existing phishing detectors?
-
•
[RQ2] Field Study: How effective are KnowPhish and KPD when deployed in real-world scenarios?
-
•
[RQ3] Adversarial Robustness: How robust is the text-based phishing detector against adversarial noise in HTML texts?
-
•
[RQ4] Ablation Studies: How does each component of KPD contribute to its overall performance?
5.1 Datasets
We utilize two datasets for our main phishing detection experiments. 1) TR-OP: A manually labeled and balanced dataset where the benign samples are collected from Tranco[44] and the phishing samples are obtained from OpenPhish[40]. The phishing samples were crawled and validated within 6 months from July to December 2023 and covered 440 unique phishing targets. Note that the phishing samples here are different from the APWG phishing dataset from Section 3.1. 2) SG-SCAN: An unlabelled dataset where the samples come from Singapore’s local webpage traffic. We randomly sample 10k webpages dating from mid-August 2023 to mid-January 2024. It is used to evaluate the phishing detection approaches in the local setting. Table 1 offers an overview of both datasets.
| Dataset | #Samples | #Benign | #Phishing | Used in |
|---|---|---|---|---|
| TR-OP | 10k | 5000 | 5000 | RQ1,3, and 4 |
| SG-SCAN | 10k | Unknown | Unknown | RQ2 and 4 |
In addition, we also manually extracted and labelled 2555 samples to train a XLM-RoBERTa [12], our text-based CRP classifier. This dataset contains 1094 phishing samples from and 1461 benign samples from Alexa Ranking [4]. The 1094 phishing samples are all CRP. Among the 1461 benign samples, 1297 are non-CRP, while the remaining 164 are CRP. After combining these samples, they are divided into 0.8/0.1/0.1 train/valid/test splits.
5.2 Baselines
We select two state-of-the-art approaches, Phishpedia[32] and PhishIntention[33], together with our proposed KPD as the RBPD backbones. Both Phishpedia and PhishIntention can be either equipped with their original reference list (containing 277 brands), DynaPhish[34], or our proposed KnowPhish, as the BKB used for phishing detection. KPD will only be equipped with KnowPhish due to the requirement of alias information. For fair comparison, both KnowPhish and DynaPhish will construct their knowledge from an empty BKB, since one can always improve the performance of both knowledge expansion approaches by manually adding well-inspected brand knowledge.
We assume a static environment in all our experiments (i.e., the only data available on a webpage is its URL, screenshot, and HTML). In this case, the dynamic analysis module in PhishIntention and the webpage interaction module in DynaPhish will be disabled. Further details on the implementation can be found in Appendix C.
5.3 RQ1: Effectiveness and Efficiency
| Detector | BKB | ACC | F1 | Precision | Recall | Time |
|
Original |
68.17 |
53.54 |
99.08 |
36.68 |
0.22s |
|
|
Phishpedia |
DynaPhish |
66.40 |
52.52 |
89.50 |
37.16 |
10.92s |
|
KnowPhish |
85.79 |
83.67 |
98.27 |
72.80 |
0.22s |
|
|
Original |
64.97 |
46.15 |
99.73 |
30.02 |
0.24s |
|
|
PhishIntention |
DynaPhish |
62.51 |
41.16 |
95.62 |
26.22 |
10.67s |
|
KnowPhish |
77.84 |
71.60 |
99.67 |
55.84 |
0.26s |
|
|
KPD |
KnowPhish |
92.49 | 92.05 |
97.84 |
86.90 |
2.02s |
We evaluate the effectiveness of different RBPDs via accuracy, F1 score, precision, recall, number of brands detected, and efficiency based on the average running time per sample. Specifically, the number of brands detected is useful to understand how many unique brands each RBPD can identify from the phishing webpages, since identifying the target of a webpage is a crucial task for RBPDs.
Table 2 shows the phishing detection performance of the three RBPDs with different BKBs. We observed the following key advantages of KnowPhish and KPD:
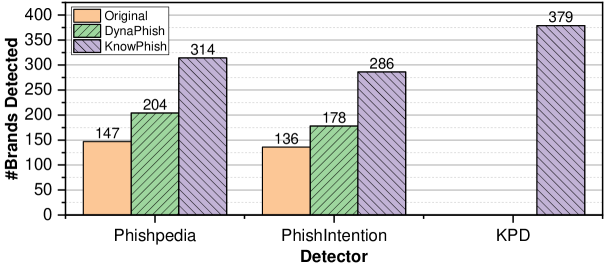
-
•
KnowPhish substantially boosts the F1 score of Phishpedia by 30% and PhishIntention by 25%, and also increases their recall by 25%, with only marginal impacts on precision, compared to other BKB baselines. The primary factor contributing to the superior performance of KnowPhish over DynaPhish is that KnowPhish contains more logo variants. In contrast, DynaPhish can only identify the logos identical to those displayed on official webpages (a few examples are provided in Figure 8).
-
•
KPD provides the highest F1 score of 92.02%, and recall of 86.90%, substantially outperforming other approaches. KPD benefits from the alias information from KnowPhish, allowing it to detect logo-less phishing pages. Consequently, KPD identifies more phishing targets than DynaPhish, as shown in Figure 9.
-
•
KnowPhish achieves runtime efficiency by decoupling the BKB construction from phishing detectors. Unlike DynaPhish which requires crawling additional webpages during deployment, KnowPhish identifies potential phishing targets locally, leading to about 50 times lower running time when integrated with Phishpedia and PhishIntention. Even when equipped with KPD with additional LLM query overhead, KnowPhish remains 5 times faster than DynaPhish with image-based RBPDs.
Overall, KnowPhish and KPD increase the coverage of brands and their logos, and allow us to detect logo-less pages, substantially improving detection performance, while maintaining acceptable runtime overhead.
5.4 RQ2: Field Study
To further understand how well the phishing detection performance of different RBPDs generalize to a local context, we conduct our field study on the SG-SCAN dataset. This field study also incorporates URLScan[53], a widely-recognized commercial phishing detector, as a baseline to assess the impact of KnowPhish and KPD within the industry. Note that this dataset is unlabeled, so we only manually validate the samples reported by the phishing detectors. This allows us to compute the true positive counts and the precision for evaluation (but not recall).
| Detector | BKB | #P | #TP | Precision | Time |
| Original | 54 | 17 | 31.48 | 0.16s | |
| Phishpedia | DynaPhish | 583 | 481 | 82.67 | 5.98s |
| KnowPhish | 353 | 333 | 94.33 | 0.16s | |
| Original | 25 | 8 | 32.00 | 0.18s | |
| PhishIntention | DynaPhish | 163 | 140 | 85.89 | 5.91s |
| KnowPhish | 138 | 133 | 96.37 | 0.19s | |
| URLScan | NA | 517 | 495 | 95.74 | NA |
| KPD | KnowPhish | 699 | 681 | 97.42 | 1.64s |
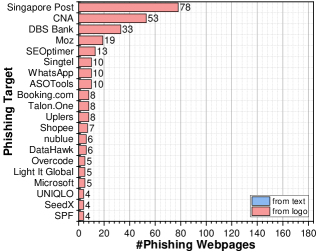
The main results are shown in Table 3 and Figure 10, leading to the following observations on our field study:
-
•
KPD detects the greatest number of phishing webpages while maintaining the highest precision over all the baselines, including the commercial phishing detector URLScan. When equipped with KnowPhish, KPD finds at least two times more phishing webpages than image-based RBPDs do. We find that the major reason for this large improvement is that logoless phishing webpages are very common in local webpage streams, which our LLM module in KPD can handle by extracting brand information from HTML. In contrast, image-based RBPDs cannot detect logoless phishing webpages. Additional examples of logoless phishing webpages can be found in Figure 13, located in Appendix C.
-
•
KnowPhish covers many local phishing targets in Singapore (e.g., DBS Bank, OCBC Bank, Shopee, Lazada, Singtel, Qoo10). These phishing targets all belong to the ten high-value industries we mentioned in Section 3.1, which further validates our empirical observation.
-
•
Phishpedia and PhishIntention detect slightly fewer phishing webpages when integrated with KnowPhish than with DynaPhish. Our manual inspection found that DynaPhish tends to be more effective when encountering less-known brands (e.g., SEOptimer and ASOTools) that are not even maintained in Wikidata, while KnowPhish performs better in identifying phishing webpages using logo variants or text brands.
To summarize, our field study highlights the need for RBPDs that can operate within the text modality, and demonstrates both the effectiveness and efficiency of KnowPhish and KPD in the local setting.
5.5 RQ3: Adversarial Robustness
We study the robustness of our text-based components against HTML obfuscation as an evasion technique. We design two approaches to obfuscate HTML:
-
•
Insertion. We follow the techniques introduced in [27] to generate random tokens. The 5 random noisy tokens will be placed as either prefixes or suffixes.
-
•
Typosquatting. Based on [33] and several motivating suspicious webpage examples (e.g., Figure 12 in Appendix C) that utilize obfuscation, we perform typosquatting on either the title only or all the text elements in the HTML. Here, we obfuscate one character in each word.
Both attack techniques aim to compromise the text-based models by introducing noise into the input texts while maintaining similarity to the original texts. Figure 11 shows several examples of the four settings of HTML obfuscation.
For brand extraction, we use 200 random phishing webpage samples from the TR-OP dataset to evaluate 1) NIR, the ratio of samples whose brand is not identifiable among the test samples, and 2) brand extraction accuracy. Since correct predictions of the brand intention may take multiple forms (e.g., ‘DBS’ or ‘DBS Bank’ are correct predictions of the brand DBS), evaluating the brand extraction accuracy requires human validation. Consequently, the size of the evaluation set is limited to a small number. For CRP classification, we sample and annotate 578 webpages from SG-SCAN dataset with a 148/276/154 explicit/implicit/non-CRP split, and the evaluation metric is classification accuracy.
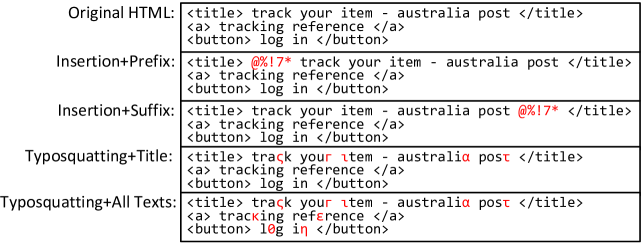
| Task | Attack Type | Position | NIR | ACC |
| None | None | 12.00 | 81.00 | |
| Brand | Insertion | Prefix | 13.00 | 79.00 |
| Extraction | Suffix | 14.00 | 78.50 | |
| Typosquatting | Title | 13.50 | 78.00 | |
| All Texts | 18.00 | 72.00 | ||
| CRP | None | None | NA | 93.94 |
| Classif. | Typosquatting | All Texts | NA | 91.00 |
Table 4 shows the results after employing adversarial attacks. Overall, our LLM-based approach is robust against such attacks. For the brand extraction task, insertion as an adversarial attack only leads to 2-3% drops in the ACC and 1-2% increase in NIR. The performance gap is slightly larger when we introduce typosquatting, especially when employing it to all the text in the HTML. However, the overall brand extraction ACC remains higher than 70% under all types of attacks. We believe this is because the LLM can seek useful information from multiple parts of HTML, or even use its internal knowledge to correct the brand name when tokens are corrupted. Similarly, for CRP classification, our LLM-based CRP classifier can retain a relatively high classification accuracy even when each word in the HTML text is typosquatted.
In summary, our adversarial attack experiments show that our LLM-based components are robust to the four types of HTML obfuscation.
5.6 RQ4: Ablation Studies
5.6.1 Ablation of KPD Components
Our multimodal phishing detector KPD is constructed with both LBE and TBE for brand identification. Therefore, we separately remove the LBE and TBE to investigate their individual utility in the pipeline. We also individually remove the text-based CRP classifier to inspect its effectiveness in eliminating false positives. We use both the TP-OP dataset and SG-SCAN dataset to evaluate our ablated models.
| Dataset | Detector | Recall | Precision | #P | #TP |
| TR-OP | KPD | 86.90 | 97.84 | 4441 | 4345 |
| w/o TBE | 69.96 | 98.54 | 3550 | 3498 | |
| w/o LBE | 71.72 | 98.35 | 3646 | 3586 | |
| w/o CRP Classifier | 91.20 | 97.42 | 4781 | 4560 | |
| SG-SCAN | KPD | Unknown | 97.42 | 699 | 681 |
| w/o CRP Classifier | Unknown | 85.11 | 873 | 743 |
Table 5 shows that the exclusion of either LBE or TBE undermines the recall notably on TR-OP. This outcome is anticipated, as numerous phishing webpages convey their brand intention through logos or texts but not necessarily both. Concerning the text-based CRP classifier, the results indicate that its removal does not severely compromise precision but substantially enhances recall on TR-OP. Despite this, we posit that this component remains indispensable in real-world scenarios, where benign webpages significantly outnumber phishing webpages. This is corroborated by the results from the SG-SCAN dataset, demonstrating that the absence of the text-based CRP classifier markedly impedes precision.
5.6.2 Effect of Different LLM Architectures
We also experiment with different LLM architectures to investigate their impacts on phishing detection.
| Detector | ACC | F1 | Precision | Recall |
|---|---|---|---|---|
| KPD (GPT-3.5-turbo-instruct) | 92.49 | 92.05 | 97.84 | 86.90 |
| w/ GPT-3.5-turbo | 91.84 | 91.29 | 97.94 | 85.48 |
| w/ GPT-4 | 92.31 | 91.82 | 98.05 | 86.34 |
| w/ LLaMA-2-7B | 91.23 | 90.68 | 96.69 | 85.38 |
The results are shown in Table 6. While GPT-4 yields the highest precision, our currently used LLM (GPT-3.5-turbo-instruct) gives the highest recall. In general, larger models do better than smaller ones such as LLaMA-2-7B on both precision and recall. Based on our observation, LLaMA-2-7B tends to mix up information from the in-context demonstrations more often and predict the target brand of the actual sample to be those from the demonstrations. Such mistakes, when happening to benign samples, can cause domain-brand inconsistency, resulting in false positive predictions. Additionally, smaller models have poorer instruction-following ability and cannot adhere to the required output format in more cases.
5.6.3 Analysis of CRP Classifier
Aside from the main components, we also take a closer look at the performance of different CRP classifers. Our text-based CRP classifier, a well-trained XLM-RoBERTa model, takes in the sample’s HTML and a CRP summary generated by the LLM (GPT-3.5-instruct). We replace our current LLM summarizer with other architectures to investigate whether the choice of CRP summarizer matters. Additionally, we also remove the CRP summary and use the HTML as the only input to our XLM-RoBERTa model, to check its performance in a standalone setting. Since [33] also proposes an image-based CRP classifier that generates CRP prediction from screenshot, we also include it as an individual baseline.
| Detector | ACC | F1 | Precision | Recall |
|---|---|---|---|---|
| Text-based CRP Classifier | 93.94 | 95.95 | 94.31 | 97.64 |
| w/ GPT-3.5-turbo Summary | 93.43 | 95.58 | 94.27 | 96.93 |
| w/ GPT-4 Summary | 94.12 | 96.05 | 94.72 | 97.41 |
| w/ LLaMA-2-7B Summary | 86.85 | 91.72 | 85.22 | 99.29 |
| w/o LLM Summary | 93.43 | 95.63 | 93.27 | 98.11 |
| Image-based CRP Classifier[33] | 51.90 | 51.91 | 97.40 | 35.38 |
Our models are then evaluated on the same CRP dataset in Section 5.5, and the results are shown in Table 7. Among the NLP-based methods, summaries generated by larger LLMs (GPT-3.5-instruct, GPT-3.5-turbo, GPT-4) give similar performances. However, there is a notable drop in precision and accuracy when switching the LLM summarizer to LLaMA-2-7B. This can be potentially caused by hallucinations in the summaries, which mislead our XLM-RoBERTa Classifier (See discussions in Section 6). Removing the LLM summary only slightly affects the precision and accuracy. This means our CRP classifier can function properly individually, while the LLM summary adds an extra safeguard against potential distributional shifts from our classifier’s training samples during inference. Compared with the image-based method, while our text-based method lags slightly on precision, it has a much higher recall and accuracy and can detect more CRPs, especially the implicit ones.
6 Limitations
6.1 Error Analysis
This section delves into a comprehensive analysis of the false positives and negatives of KnowPhish and KPD.
False Positives
By manually examining all 97 false positives made by KPD, we pinpointed two primary causes: brand representation collisions, and incomplete inclusion of domain variants, accounting for 45.36% and 43.30% of the total false positives, respectively.
Brand representation collision occurs either the webpage’s screenshot or HTML is matched to the wrong brand. Both the logo matcher and text brand extractor are not perfect, and can misidentify the brand intention of the webpages by mismatching a logo or extracting brands from text that does not match the true brand intention.
For the second issue, domain variants can be missing from KnowPhish because the Whois owner information is not available for all domains. We find that at most 30.79% of the domains in KnowPhish have their owner information available. This deficiency may lead to incomplete lists of domain variants for brands, leading to false positives when the current page’s domain is omitted as a legitimate domain in the knowledge base.
Finally, most remaining false positives align with common issues outlined in previous studies, such as the misidentification of an advertisement’s logo as the primary logo [32, 33].
False Negatives
We also examined all 655 false negative samples by KPD on the TR-OP dataset, uncovering three primary reasons behind these erroneous predictions.
A majority (53.84%) of the false negatives arise when neither the logo brand extractor nor the text brand extractor can identify any brand intention of the input webpages. This may occur when the logo displayed on the webpage differs from the ones in KnowPhish, the logo is not identifiable from the screenshot, the text brand is extracted incorrectly by the LLM, or the text brand cannot be extracted from the HTML entirely. If no brand intention can be identified from a webpage, KPD, and any existing RBPD, will classify that webpage as benign.
Additionally, negative classifications by the CRP classifier also leads to 30.2% of the false negatives. Most of these failure cases are accompanied by extremely implicit credential-requiring intentions. Figure 14 in Appendix C shows an example, where our text brand extractor detected the brand intention as Telegram, but our CRP classifier classifies it as non-CRP.
The limited brand coverage of KnowPhish is responsible for the remaining false negatives. Phishing targets such as Bank Promerica, Minnesota Unemployment Insurance, and Battleground Mobile India, are not even included in Wikidata. While KnowPhish enhances the performance of existing RBPDs, surpassing even DynaPhish, some phishing targets will be beyond the BKB. In such cases, any RBPD will face challenges in detecting the phishing webpages.
6.2 Incompleteness of External Databases
Our error analysis in Section 6.1 points to brand knowledge limitations (including logos, aliases, and domain variants) as a major source of errors, arising from limitations of Wikidata and the Whois service. The most straightforward solution is to integrate other brand databases, such as the WIPO Global Brand Database [60]. Alternatively, we can rely on the implicit knowledge from LLMs [50, 39, 36, 23] or methods integrating LLMs with online search [56, 48, 38, 26].
To further handle false positives, we can also introduce a secondary validator, such as a search engine-based filter to validate the popularity of a webpage before the RBPDs report it as phishing: i.e., if a webpage is reported as phishing by RBPDs but found to be a popular webpage by search engines, it is likely to be benign. Previous studies have shown that a search engine-based validator can identify more than 60% of benign webpages[13, 34] with negligible runtime overhead.
6.3 Errors Made by LLMs
We observe two major types of errors made by our LLMs. Firstly, they occasionally extract the wrong brands (See Table 4) when the HTML contains multiple brand names. This can potentially be addressed by better prompting or eliciting better reasoning from LLMs. Text spans for target brands usually have morphological (e.g., capitalization of every character) or contextual characteristics that distinguish them from non-brands. Therefore, we can use existing techniques [58, 57, 62] to guide the LLMs to identify and reason about these characteristics for more accurate target brand extraction. Secondly, we observe that LLMs can make up nonexistent HTML elements such as input fields and redirect buttons that are indicative of a credential-taking intention. This points to hallucination, a known issue for LLMs [22]. To address this issue, many strategies [51, 49, 8] can be used to direct our models’ attention to the parts of HTML that are pertinent to credential-taking intention and make their generations better anchored on page content.
7 Related Work
Phishing Detection
The simplest phishing detection methods rely on blacklists of malicious URLs [45, 40, 42], which are reactive approaches. Proactive approaches include feature engineering-based methods, which rely on hand-crafted features from URLs [28, 37, 54], HTML [18, 61], or both [31, 35, 29]. These methods are limited by their inability to use logos, and are susceptible to distribution shift. RBPDs extract brand intention of webpages through screenshots [16, 3, 1] or logos[32, 33], relying on small, manually collected BKBs. Recently, DynaPhish [34] proposed to dynamically expand the BKB during deployment. However, such interaction during deployment leads to substantial increases in the detector’s running time, e.g., 10.6 seconds per sample. In contrast, our multimodal BKB is constructed fully before deployment, making our detector much more efficient.
LLMs and Knowledge-Intensive Applications
LLMs have shown remarkable performance on a wide range of language and code-related tasks [2, 9], and have been extended to large multimodal models (LMMs) [63]. A few recent works apply LLMs for phishing detection [25, 59]. However, these are non-RBPD methods, and cannot use logos. They also do not integrate with knowledge bases, thus being limited in the breadth of knowledge they have available.
To enhance LLMs’ performance on knowledge-intensive tasks, a rich line of work combines them with knowledge graphs [21, 41]. This can reduce hallucination [52], improves interpretability, and allows for knowledge updating [41]. Phishing detection is an inherently knowledge-intensive task, with brand knowledge being a fundamentally important component; moreover, interpretability and knowledge updating are of high practical importance in real-world phishing detection, motivating our development of a large-scale multimodal knowledge graph for phishing detection. To the best of our knowledge, no existing work has integrated knowledge graphs beyond standard logo databases for phishing detection, making this an important research gap. On the detector side, no existing work has developed multimodal RBPDs utilizing both image and textual modalities.
Concerningly, LLMs have also been misused to develop phishing attacks [24], notably spear phishing emails [19, 7], phishing webpages imitating certain brands, and evading current anti-phishing tools [47]. Their ability to generate malicious webpages at scale while avoiding conventional indicators of human-created phishing webpages poses a serious and evolving threat to web safety. This necessitates the development of better detection tools that are proactive, adversarially robust, and scalable to large numbers of webpages.
8 Conclusions
In this work, we propose KnowPhish, a large-scale multimodal brand knowledge base covering more than 20k potential phishing targets, which can be integrated with any RBPD in a plug-and-play manner. We further propose KPD, a multimodal RBPD operating within both text and image modalities to detect phishing webpages with or without logos. Extensive experiments demonstrate the effectiveness and efficiency of KnowPhish and KPD under multiple settings. Moving forward, we foresee that integrating additional knowledge sources and LLM-related enhancements such as retrieval augmentation [30] can further enhance performance.
Acknowledgement
This research is supported by the National Research Foundation, Singapore, and the Smart Nation and Digital Government Office under its Smart Nation & Digital Government Translational R&D Funding Initiative (TRANS) 2.0 (TRANS2023-TGC01), and by National Research Foundation Singapore, NCS Pte. Ltd. and National University of Singapore under the NUS-NCS Joint Laboratory (Grant A-0008542-00-00).
References
- [1] Sahar Abdelnabi, Katharina Krombholz, and Mario Fritz. Visualphishnet: Zero-day phishing website detection by visual similarity. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, CCS ’20, page 1681–1698, New York, NY, USA, 2020. Association for Computing Machinery.
- [2] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [3] Sadia Afroz and Rachel Greenstadt. Phishzoo: Detecting phishing websites by looking at them. In 2011 IEEE Fifth International Conference on Semantic Computing, pages 368–375, 2011.
- [4] Alexa ranking. https://www.alexa.com/siteinfo.
- [5] Global Anti-Scam Alliance. The global state of scams report, 2023.
- [6] Anti-phishing working group. https://apwg.org/.
- [7] Mazal Bethany, Athanasios Galiopoulos, Emet Bethany, Mohammad Bahrami Karkevandi, Nishant Vishwamitra, and Peyman Najafirad. Large language model lateral spear phishing: A comparative study in large-scale organizational settings. arXiv preprint arXiv:2401.09727, 2024.
- [8] Chung-Ching Chang, David Reitter, Renat Aksitov, and Yun-Hsuan Sung. Kl-divergence guided temperature sampling, 2023.
- [9] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [10] Robert Cialdini and Brad J. B. Sagarin. Psychological Insights and Perspectives. Sage Publications, Inc, 2005.
- [11] Cisco. Cybersecurity threat trends report, 2022.
- [12] Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Francisco Guzmán Guillaume Wenzek, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. Unsupervised cross lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020.
- [13] Yan Ding, Nurbol Luktarhan, Keqin Li, and Wushour Slamu. A keyword-based combination approach for detecting phishing webpages. Comput. Secur., 84(C):256–275, jul 2019.
- [14] D. Divakaran and A. Oest. Phishing detection leveraging machine learning and deep learning: A review. IEEE Security & Privacy, 20(5):2–11, jun 5555.
- [15] Free whois lookup. https://www.whois.com/whois/.
- [16] Anthony Y. Fu, Liu Wenyin, and Xiaotie Deng. Detecting phishing web pages with visual similarity assessment based on earth mover’s distance (emd). IEEE Transactions on Dependable and Secure Computing, 3(4):301–311, 2006.
- [17] Google images search. https://pypi.org/project/Google-Images-Search/.
- [18] Bingyang Guo, Yunyi Zhang, Chengxi Xu, Fan Shi, Yuwei Li, and Min Zhang. Hinphish: An effective phishing detection approach based on heterogeneous information networks. Applied Sciences, 11(20), 2021.
- [19] Julian Hazell. Large language models can be used to effectively scale spear phishing campaigns. arXiv preprint arXiv:2305.06972, 2023.
- [20] Xiaoxin He, Xavier Bresson, Thomas Laurent, Adam Perold, Yann LeCun, and Bryan Hooi. Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph representation learning, 2023.
- [21] Linmei Hu, Zeyi Liu, Ziwang Zhao, Lei Hou, Liqiang Nie, and Juanzi Li. A survey of knowledge enhanced pre-trained language models. IEEE Transactions on Knowledge and Data Engineering, 2023.
- [22] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1––38, 2022.
- [23] Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. Large language models struggle to learn long-tail knowledge. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 15696–15707. PMLR, 23–29 Jul 2023.
- [24] Rabimba Karanjai. Targeted phishing campaigns using large scale language models. arXiv preprint arXiv:2301.00665, 2022.
- [25] Takashi Koide, Naoki Fukushi, Hiroki Nakano, and Daiki Chiba. Detecting phishing sites using chatgpt, 2023.
- [26] Mojtaba Komeili, Kurt Shuster, and Jason Weston. Internet-augmented dialogue generation. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8460–8478, Dublin, Ireland, May 2022. Association for Computational Linguistics.
- [27] Aounon Kumar, Chirag Agarwal, Suraj Srinivas, Aaron Jiaxun Li, Soheil Feizi, and Himabindu Lakkaraju. Certifying llm safety against adversarial prompting, 2023.
- [28] Hung Le, Quang Pham, Doyen Sahoo, and Steven C. H. Hoi. Urlnet: Learning a url representation with deep learning for malicious url detection, 2018.
- [29] Jehyun Lee, Farren Tang, Pingxiao Ye, Fahim Abbasi, Phil Hay, and Dinil Mon Divakaran. D-fence: A flexible, efficient, and comprehensive phishing email detection system. In 2021 IEEE European Symposium on Security and Privacy (EuroS&P), pages 578–597, 2021.
- [30] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- [31] Yukun Li, Zhenguo Yang, Xu Chen, Huaping Yuan, and Wenyin Liu. A stacking model using url and html features for phishing webpage detection. Future Gener. Comput. Syst., 94(C):27–39, may 2019.
- [32] Yun Lin, Ruofan Liu, Dinil Mon Divakaran, Jun Yang Ng, Qing Zhou Chan, Yiwen Lu, Yuxuan Si, Fan Zhang, and Jin Song Dong. Phishpedia: A hybrid deep learning based approach to visually identify phishing webpages. In 30th USENIX Security Symposium (USENIX Security 21), pages 3793–3810. USENIX Association, August 2021.
- [33] Ruofan Liu, Yun Lin, Xianglin Yang, Siang Hwee Ng, Dinil Mon Divakaran, and Jin Song Dong. Inferring phishing intention via webpage appearance and dynamics: A deep vision based approach. In 31st USENIX Security Symposium (USENIX Security 22), pages 1633–1650, Boston, MA, August 2022. USENIX Association.
- [34] Ruofan Liu, Yun Lin, Yifan Zhang, Penn Han Lee, and Jin Song Dong. Knowledge expansion and counterfactual interaction for Reference-Based phishing detection. In 32nd USENIX Security Symposium (USENIX Security 23), pages 4139–4156, Anaheim, CA, August 2023. USENIX Association.
- [35] Christian Ludl, Sean McAllister, Engin Kirda, and Christopher Kruegel. On the effectiveness of techniques to detect phishing sites. In Bernhard M. Hämmerli and Robin Sommer, editors, Detection of Intrusions and Malware, and Vulnerability Assessment, pages 20–39, Berlin, Heidelberg, 2007. Springer Berlin Heidelberg.
- [36] Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9802–9822, Toronto, Canada, July 2023. Association for Computational Linguistics.
- [37] Pranav Maneriker, Jack W. Stokes, Edir Garcia Lazo, Diana Carutasu, Farid Tajaddodianfar, and Arun Gururajan. Urltran: Improving phishing url detection using transformers. In MILCOM 2021 - 2021 IEEE Military Communications Conference (MILCOM), pages 197–204, 2021.
- [38] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback, 2022.
- [39] Reham Omar, Omij Mangukiya, Panos Kalnis, and Essam Mansour. Chatgpt versus traditional question answering for knowledge graphs: Current status and future directions towards knowledge graph chatbots, 2023.
- [40] Openphish - phishing intelligence. https://openphish.com/.
- [41] Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu. Unifying large language models and knowledge graphs: A roadmap. IEEE Transactions on Knowledge and Data Engineering, 2024.
- [42] Phishtank | join the fight against phishing. https://phishtank.org/.
- [43] Sini Govinda Pillai, Lay-Ki Soon, and Su-Cheng Haw. Comparing dbpedia, wikidata, and yago for web information retrieval. In Vincenzo Piuri, Valentina Emilia Balas, Samarjeet Borah, and Sharifah Sakinah Syed Ahmad, editors, Intelligent and Interactive Computing, pages 525–535, Singapore, 2019. Springer Singapore.
- [44] Victor Le Pochat, Tom Van Goethem, Samaneh Tajalizadehkhoob, Maciej Korczynski, and Wouter Joosen. Tranco: A research-oriented top sites ranking hardened against manipulation. In Proceedings 2019 Network and Distributed System Security Symposium. Internet Society, 2019.
- [45] Niels Provos, Dean McNamee, Panayiotis Mavrommatis, Ke Wang, and Nagendra Modadugu. The ghost in the browser: Analysis of web-based malware. In First Workshop on Hot Topics in Understanding Botnets (HotBots 07), Cambridge, MA, April 2007. USENIX Association.
- [46] Daniel Ringler and Heiko Paulheim. One knowledge graph to rule them all? analyzing the differences between dbpedia, yago, wikidata & co. In Gabriele Kern-Isberner, Johannes Fürnkranz, and Matthias Thimm, editors, KI 2017: Advances in Artificial Intelligence, pages 366–372, Cham, 2017. Springer International Publishing.
- [47] Sayak Saha Roy, Poojitha Thota, Krishna Vamsi Naragam, and Shirin Nilizadeh. From chatbots to phishbots?–preventing phishing scams created using chatgpt, google bard and claude. arXiv preprint arXiv:2310.19181, 2023.
- [48] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools, 2023.
- [49] Weijia Shi, Xiaochuang Han, Mike Lewis, Luke Zettlemoyer Yulia Tsvetkov, and Scott Wen tau Yih. Trusting your evidence: Hallucinate less with context-aware decoding, 2023.
- [50] Kai Sun, Yifan Ethan Xu, Hanwen Zha, Yue Liu, and Xin Luna Dong. Head-to-tail: How knowledgeable are large language models (llm)? a.k.a. will llms replace knowledge graphs?, 2023.
- [51] Ran Tian, Shashi Narayan, Thibault Sellam, and Ankur P Parikh. Sticking to the facts: Confident decoding for faithful data-to-text generation., 2019.
- [52] SM Tonmoy, SM Zaman, Vinija Jain, Anku Rani, Vipula Rawte, Aman Chadha, and Amitava Das. A comprehensive survey of hallucination mitigation techniques in large language models. arXiv preprint arXiv:2401.01313, 2024.
- [53] Url and website scanner - urlscan.io. https://urlscan.io/.
- [54] Rakesh Verma and Keith Dyer. On the character of phishing urls: Accurate and robust statistical learning classifiers. In Proceedings of the 5th ACM Conference on Data and Application Security and Privacy, CODASPY ’15, page 111–122, New York, NY, USA, 2015. Association for Computing Machinery.
- [55] Denny Vrandečić and Markus Krötzsch. Wikidata: A free collaborative knowledgebase. Commun. ACM, 57(10):78–85, sep 2014.
- [56] Xintao Wang, Qianwen Yang, Yongting Qiu, Jiaqing Liang, Qianyu He, Zhouhong Gu, Yanghua Xiao, and Wei Wang. Knowledgpt: Enhancing large language models with retrieval and storage access on knowledge bases, 2023.
- [57] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In Proceedings of the 11th International Conference on Learning Representations (ICLR)., 2023.
- [58] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In Conference on Neural Information Processing Systems (NeurIPS), 2022.
- [59] What does chatgpt know about phishing? https://securelist.com/chatgpt-anti-phishing/109590/.
- [60] Wipo global brand database. https://www.wipo.int/portal/en/index.html.
- [61] Guang Xiang, Jason Hong, Carolyn P. Rose, and Lorrie Cranor. Cantina+: A feature-rich machine learning framework for detecting phishing web sites. ACM Trans. Inf. Syst. Secur., 14(2), sep 2011.
- [62] Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, Xu Zhao, Min-Yen Kan, and Junxian He. Decomposition enhances reasoning via self-evaluation guided decoding. In CoRR, 2023.
- [63] Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models. arXiv preprint arXiv:2306.13549, 2023.
- [64] Rasha Zieni, Luisa Massari, and Maria Carla Calzarossa. Phishing or not phishing? a survey on the detection of phishing websites. IEEE Access, 11:18499–18519, 2023.
- [65] Zscaler. Zscaler threatlabz 2023 phishing report, 2023.
Appendix A Additional Details on KnowPhish Construction
Phishing Targets of Different Industries
We provide more details of the brands from the eleven industries on each dataset in Table 8.
| Industries | ||
|---|---|---|
|
financial |
Bank of America, Paypal, Credit Agricole, PostFinance |
Bitkub, Credit Saison, Denizbank, Banco Do Brasil, GCash |
|
online services |
Outlook, Microsoft 365, Dropbox, Adobe, Onedrive |
WeTransfer, Booking.com, Intuit, Biglobe, Mailchimp |
|
telecommunication |
AT&T, BT Group, Orange, Cox Communication |
Shaw Communication, Swisscom, Singtel, Bell, Etisalat |
|
e-commerce |
Amazon, eBay, Rakuten, Americanas |
Brooks Sports, Tesco, Loungefly, Shopee |
|
social media |
Instagram, Facebook, LinkedIn |
WeChat, VKontakte |
|
postal service |
DHL, EMS, FedEx, La Poste |
Australia Post, USPS, UPS, An Post, DPD |
|
government |
UK Gov, IRS, French Health Insurance, |
Turkey Gov, Australia Gov, LTA Singapore |
|
web portal |
Google, Daum, AOL |
Naver |
|
video game |
Steam, RuneScape, League of Legends |
/ |
|
gambling |
Bet365 |
/ |
|
other business |
Delta Airline |
KFC, AirNZ, Hydroqubec |
Wikidata Categories for KnowPhish Construction
We provide the full list of Narrow Categories in Table 9 and General Categories in Table 10. We put two Wikidata categories ‘online service’ and ‘government organization’ into because we empirically find that it will lead to an excessively large number of brands. We handle this by conditioning on their popularity, which is identical to put them into .
| Industries | Wikidata Category | Wikidata ID |
|
financial |
bank |
Q22687 |
|
financial institution |
Q650241 |
|
|
credit institution |
Q730038 |
|
|
federal credit union |
Q116763799 |
|
|
payment system |
Q986008 |
|
|
digital wallet |
Q1147226 |
|
|
cryptocurrency exchange |
Q25401607 |
|
|
online service |
webmail |
Q327618 |
|
web service |
Q193424 |
|
|
mobile app |
Q620615 |
|
|
office suite |
Q207170 |
|
|
telecommunication |
telecommunication company |
Q2401749 |
|
mobile network |
Q15360302 |
|
|
mobile network operator |
Q1941618 |
|
|
internet service provider |
Q11371 |
|
|
e-commerce |
online shop |
Q4382945 |
|
online marketplace |
Q3390477 |
|
|
social media |
social media |
Q202833 |
|
social networking service |
Q3220391 |
|
|
online video platform |
Q559856 |
|
|
postal service |
postal service |
Q1529128 |
|
package delivery |
Q1447463 |
|
|
government |
government |
Q7188 |
|
web portal |
web portal |
Q186165 |
|
web search engine |
Q4182287 |
|
|
video game |
video game distribution platform |
Q81989119 |
|
gambling |
gambling |
Q11416 |
| Industries | Wikidata Category | Wikidata ID |
|---|---|---|
|
other business |
business |
Q4830453 |
|
public company |
Q891723 |
|
|
enterprise |
Q6881511 |
|
|
online service |
Q19967801 |
|
|
government organization |
Q2659904 |
KnowPhish Construction Algorithm
The complete KnowPhish construction algorithm is illustrated in Algorithm 2.
Appendix B Additional Details on KnowPhish Detector
Prompt Template for LLM Summary Generation Table 11 provides the complete prompt template to generate the LLM summary for the input webpage.
Instruction: Define targeted brand as a brand that a webpage belongs to. Define credential-taking intention as a webpage’s intention to take users’ credentials, such as their email addresses, passwords, and so on. A credential-taking intention can be explicit or implicit, where explicit means having forms and input fields to submit user credentials directly, and implicit means not having explicit credential-taking intention, but instead having buttons or links redirecting users to another credential-taking webpage. Additionally, keywords related to user credentials, such as "Sign in", "Log in", "Register", "Account", "Assets", and "Password", are usually strong indicators of a credential-taking intention. Note that the texts in the HTML may be obfuscated into similar characters (e.g., ’a’ is obfuscated into ’’, or ’b’ is obfuscated into ’’). If such obfuscation exists, please deobfuscate it and correctify your output. Given the URL and HTML of a webpage P, answer (1) What the targeted brand of P is. If it is not identifiable, put "Not identifiable". Extract the brand name only and do not include extra details such as affiliated products, countries, or additional abbreviations; (2) What forms or input fields to submit user credentials are present; (3) What buttons or links are present that redirect users to another credential-taking webpage; (4) What important keywords are present; (5) Whether there is a credential-taking intention; (6) Reason to the answer in (5). Start the answer to each of (1) to (6) on a new line.
URL: https://1staskyoude2-gopnumze9.top/
HTML: <title> Adobe-PDF Singapore sell everything you need </title> <a> </a> <a> </a> © 2023 Adobe. All brands are the property of their respective owners.
Answer:
(1) Adobe
(2) There are no forms or input fields to submit user credentials.
(3) There are no buttons or links directing the user to another credential-taking page.
(4) There are no important keywords.
(5) no intention
(6) The answer is according to (2), (3), and (4).
URL: https://cryptoinex.com/h5/
HTML: <title> Home - Cryptoin Online For Business - CPT </title> 本站点必须要开启JavaScript才能运行 Cryptoin currency Total assets equivalent (USD) 0.00 Announcement on Delisting SGB/USDT Token Pair Announcement on Delisting Selected Token Pairs Announcement on Supporting Ethereum London Hard Fork locked mining more 3day USDT lock up to earn coins 10 start 3% Daily rate of return 1day USDT lock up to earn coins 100 start 7% Daily rate of return 15day USDT lock up to earn coins 1000 start 15% Daily rate of return 30day USDT lock up to earn coins 10000 start 30% Daily rate of return 60day USDT lock up to earn coins 100000 start 60% Daily rate of return Quote more BTC/USDT -0.54% 22437.79000 DTC/USDT -0.49% 1570.48000 XRP/USDT +0.87% 0.37054 LTC/USDT -1.39% 87.52000 EOS/USDT -1.00% 1.21330 YMT/USDT -0.61% 1.26965 BCH/USDT +0.02% 124.50000 Quote more trading pair Latest Price Today change XRP /USDT 24H: 11681739.60651 0.37054 +0.87% LTC /USDT 24H: 5219.74600 87.52000 -1.39% EOS /USDT 24H: 204125.08287 1.21330 -1.00% YMT /USDT 24H: 490.15695 1.26965 -0.61% BCH /USDT 24H: 1079.22726 124.50000 +0.02% Home Markets Trade Finance Assets Cancel OK
Answer:
(1) Cryptoin
(2) There are no forms or input fields to submit user credentials.
(3) There are no buttons or links directing the user to another credential-taking page.
(4) There is a keyword "Assets" related to user assets.
(5) implicit intention
(6) The answer is according to (4).
URL: https://app.afe-n2jhk.com/index/login/login/token
HTML: English Chinese English <form> <inputtxt> </inputtxt> <inputpwd> </inputpwd> The account or password is wrong, please re-enter!! <button> Login </button> </form> <a> Open an account now </a> <a> Online service </a> <a> ©1998-2021 Rights Reserved </a> <a> AFE ©1998-2021 Rights Reserved </a>
Answer:
(1) AFE
(2) There is a form containing account and password input fields.
(3) There is a button with the label "Login" and a link with the text "Open an account now".
(4) There are keywords "account", "password", and "Login" related to user credentials.
(5) explicit intention
(6) The answer is according to (2).
URL: {U}
HTML: {H}
Answer:
Estimated Cost for LLM Query
The LLM Summarizer in KPD leverages GPT-3.5-turbo-instruct as its LLM backbone. Here, we provide an estimation of the cost incurred by this LLM query. Take our TR-OP dataset as an example: on average, each webpage sample has 2,588 input tokens and 108 output tokens. With the API pricing at $0.0015 per 1,000 input tokens and $0.0020 per 1,000 output tokens, the estimated price for LLM summary per webpage sample is calculated as follows:
| Cost | |||
Hence, the estimated cost for running KPD on the entire TR-OP dataset is approximately 41 USD.
Appendix C Additional Details on Experiments
Implementation Details
For KnowPhish construction, we use the same webpage layout detector from [33] to extract the logo image from the webpage, as the instantiation of the DetectLogo() function. We limit the size of the top domain list to 50k (i.e., =50k). The brand search algorithm thereby returns us 20514 potential phishing targets. For KPD, we also instantiate the webpage layout detector and logo matcher with the same modules from [33], and use GPT-3.5-turbo-instruct as the LLM backbone.
All the experiments are conducted within a Ubuntu server with 2 AMD EPYC 7543 32-Core Processor @ 2.8GHz and 8 Nvidia A40 48GB GPU available.
Motivating Examples for HTML Obfuscation
Figure 12 provides an example of typosquatting, based on which we develop the HTML obfuscation techniques studies in this paper.
Logoless Phishing Webpages in Field Study
Figure 13 shows a few examples of logoless phishing webpages detected by KPD on SG-SCAN dataset.
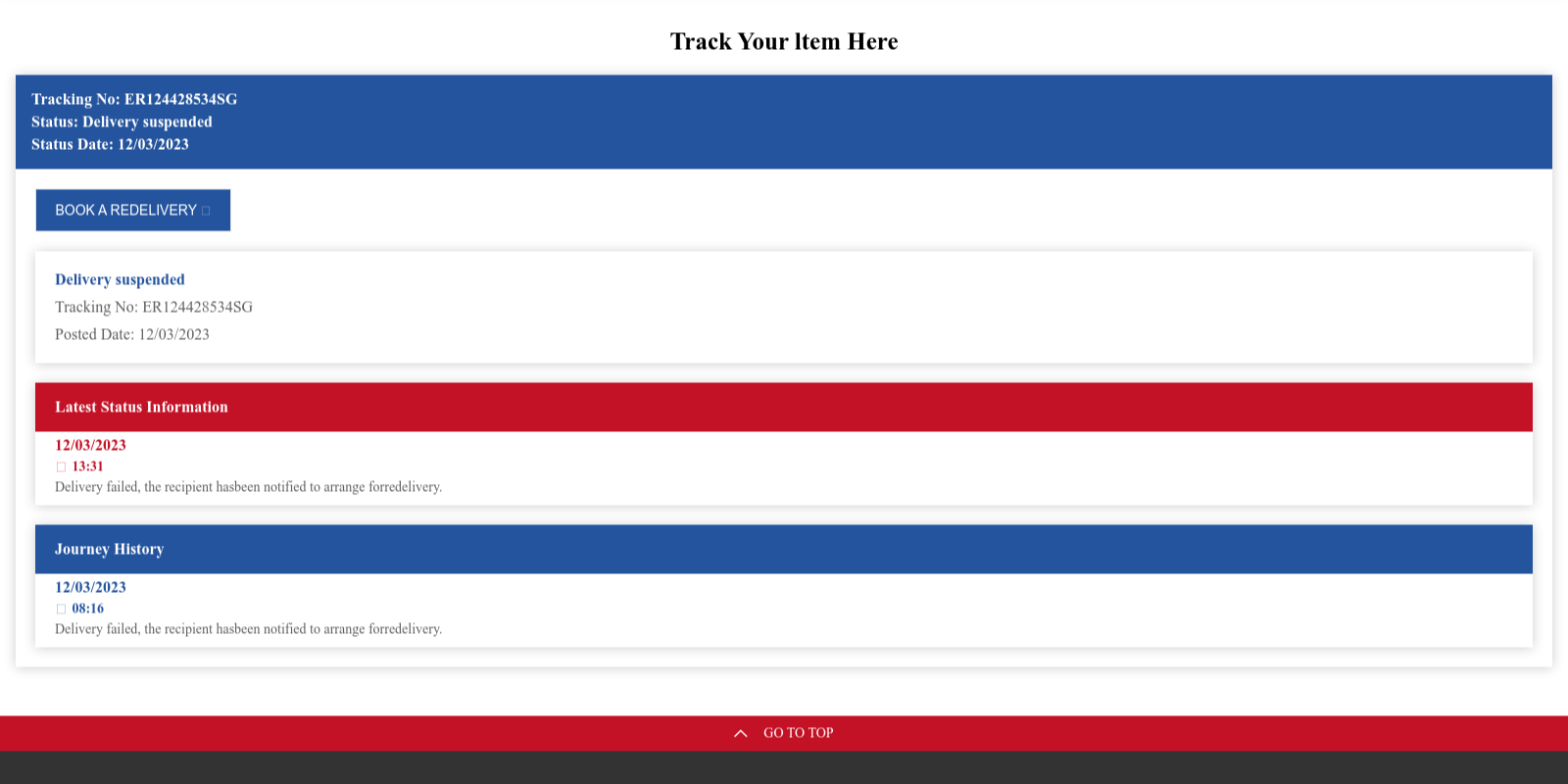
Error Analysis
Figure 14 is an example of extremely implicit CRP that our text-based CRP classifier fails to detect.