ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
Abstract
As Large Language Models (LLMs) continue to advance in performance, their size has escalated significantly, with current LLMs containing billions or even trillions of parameters. However, in this study, we discovered that many layers of LLMs exhibit high similarity, and some layers play a negligible role in network functionality. Based on this observation, we define a metric called Block Influence (BI) to gauge the significance of each layer in LLMs. We then propose a straightforward pruning approach: layer removal, in which we directly delete the redundant layers in LLMs based on their BI scores. Experiments demonstrate that our method, which we call ShortGPT, significantly outperforms previous state-of-the-art (SOTA) methods in model pruning. Moreover, ShortGPT is orthogonal to quantization-like methods, enabling further reduction in parameters and computation. The ability to achieve better results through simple layer removal, as opposed to more complex pruning techniques, suggests a high degree of redundancy in the model architecture.
1 Introduction
The field of large language models (LLMs) has witnessed rapid development recently, with LLMs achieving impressive performance across various domains. Guided by the scaling laws identified in prior work (Kaplan et al., 2020; Hoffmann et al., 2022), current LLM research has tended to increase model parameters consistently to boost performance. However, the resulting massive models containing billions or even trillions of parameters pose stringent hardware requirements, hindering their practical deployment and use. To alleviate the demanding hardware requirements for deploying massive trained models, many researchers have focused on model compression techniques (Zhu et al., 2023) that reduce the inference cost. Model compression methods can be broadly categorized into two categories: quantization (Liu et al., 2021; Gholami et al., 2022; Dettmers et al., 2022, 2024) and pruning (LeCun et al., 1989; Han et al., 2015). Quantization methods quantize the weights and activations to lower precision. However, the acceleration benefits of quantization are dependent on hardware support and sometimes require additional fine-tuning to maintain good performance. In contrast, pruning methods remove redundant model parameters to reduce the overall parameter count. Pruning can be directly applied to a trained model without retraining and is generally more hardware-friendly than quantization approaches. While recently there has been significant progress in large language model compression methods based on model pruning, existing methods are often designed to be relatively complex. Some require the use of gradient information (Zhang et al., 2023) or only focus on compression in width (Ashkboos et al., 2024), rendering them overly sophisticated for practical applications. Therefore, there is a need to explore simple and efficient model pruning approaches tailored specifically for large language models. Identifying effective model pruning techniques necessitates studying model redundancy (Huang et al., 2021; Dalvi et al., 2020). Previous research on model redundancy has typically focused on relatively smaller models, such as convolutional neural networks (CNNs) or small-sized Transformers. For model pruning in LLMs, most previous works have concentrated on tensor-wise redundancy analysis, investigating the redundancy within each parameter tensor. However, a key finding in this paper is that LLMs exhibit significant redundancy at the layer level, enabling the simple removal of entire layers without substantially impacting downstream task performance. For instance, when deleting the last 10 layers (25% of the total 40 layers) from the LLaMA 2-13B model, the results on the MMLU benchmark (Hendrycks et al., 2020) only drop from 55.0 to 52.2 (a 95% retention). Furthermore, by removing the last 22 layers (55% of the total 40 layers), resulting in a 5.6 billion parameter model, we can still obtain a score of 47.2 on MMLU without any fine-tuning, even outperforming the LLaMA 2-7B model. In this paper, we propose to analyze the layer-wise redundancy through the lens of Block Influence (BI), which measures the hidden states transformations during the modeling process of LLMs. We find BI is a more relevant indicator of the layer’s importance in LLMs, and we can perform model pruning by simply deleting redundant layers with BI. This straightforward act of removing specific layers significantly outperforms previous more complex pruning methods. Our findings highlight substantial redundancy in current LLM architectures and shed light on opportunities for more efficient LLM training in the future. The main contributions of our paper are summarized as follows:
-
•
We analyze the redundancy in large language models (LLMs) and find that they exhibit significant redundancy at the layer level. This insight inspires us to prune LLMs by simply removing redundant layers.
-
•
We propose a metric called Block Influence (BI) as an effective indicator of layer importance. Through a quantitative analysis, we demonstrate that LLMs possess redundancy both in depth (layers) and width (parameters within layers).
-
•
Based on the BI metric, we propose a simple yet effective pruning strategy by removing layers with low BI scores. Experimental results show that our method maintains 92% performance while reducing approximately 25% of the parameters and computation, outperforming previous state-of-the-art methods.
-
•
Furthermore, we demonstrate that our layer pruning approach is orthogonal to quantization methods, meaning it can be combined with quantization techniques to further reduce the deployment overhead of LLMs.

2 Methodology
In this section, we present the methodological framework of our layer deletion approach for LLMs, elucidating the underlying principles and techniques employed. We first quantify the layer redundancy problem present in current prominent LLMs, such as LLaMA 2 and Baichuan 2. Then, we introduce a metric called Block Influence (BI), designed to assess the transformation of hidden states by each layer during LLM inference. Building upon BI, we apply layer deletion to LLMs, thereby reducing their inference cost without compromising their predictive accuracy or linguistic capabilities.
2.1 Layer redundancy
The predominant LLMs in current are primarily based on the Transformer (Vaswani et al., 2017). The transformer architecture is based on an attention mechanism, typically consisting of several residual layers stacked upon each other. Transformer is a sequence to sequence mapping, which can be defined as , where , , is the length of the sequence, is the vocabulary size, is the learnable parameters. The formal expression of an L-layer transformer is as follows:
| Y | (1) |
where is the word embedding matrix, is the output projection matrix of the transformer, which are sometimes tied with the (Chowdhery et al., 2023), is the hidden dim of the transformer. ATTN refers to the attention layer and FFN means the feed-forward layers, is the hidden states of the layers. Given that the transformer structure is composed of several identical layers, a natural question is what the differences and connections between the functionalities and roles of these identical layers are. Previous works found that the Transformer possesses certain semantic capabilities in earlier layers (Hasan et al., 2021). In this work, we uncover a significant level of redundancy between the layers of the transformer.
Layer Redundancy: A network with high redundancy should contain some redundant layers, which have a minimal impact on the network’s final performance. This may be due to these layers having homogenized functionalities compared to other layers in the network. We have found a high degree of redundancy in the current LLMs by omitting specific layers.

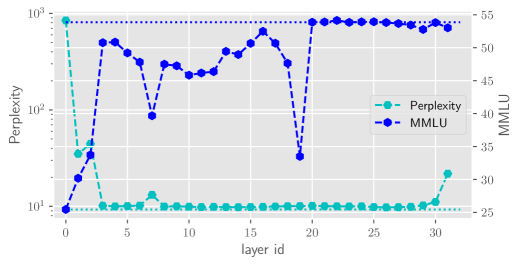
We observed that in many cases, the network’s prediction of remains largely unchanged. This phenomenon demonstrates a significant level of redundancy across the layers of the transformer. Figure 3 shows the perplexity and MMLU (Hendrycks et al., 2020) score of omitting a certain layer in the Llama2-7B-Base (Touvron et al., 2023), an English based LLMs, and Baichuan2-7B-Base (Yang et al., 2023) which is mainly focused on Chinese. For more benchmark results, please refer to the section 3. Figure 3 reveals that some layers do not play a crucial role in LLMs. Dropping a certain layer from the LLMs may have a minimal effect on the final results, and the same holds for the perplexity. Moreover, this redundancy is primarily manifested in the middle to later layers of the network, with the initial layers and the final layer often being more critical.
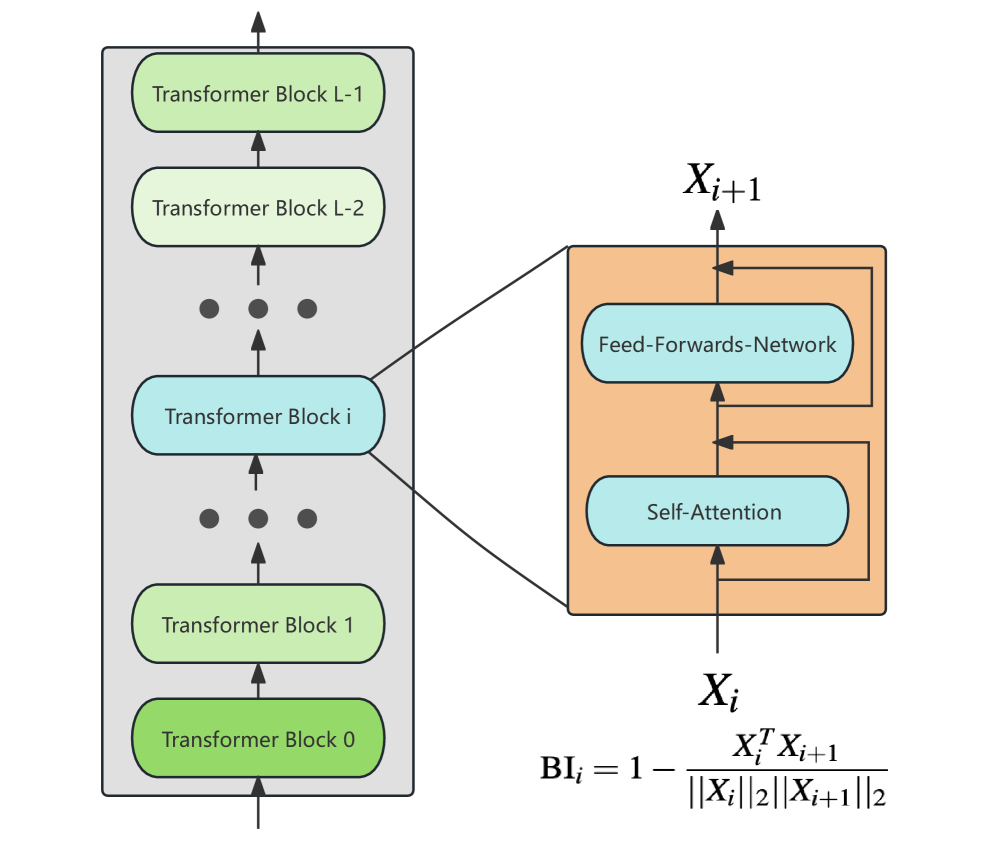
2.2 Layer importance
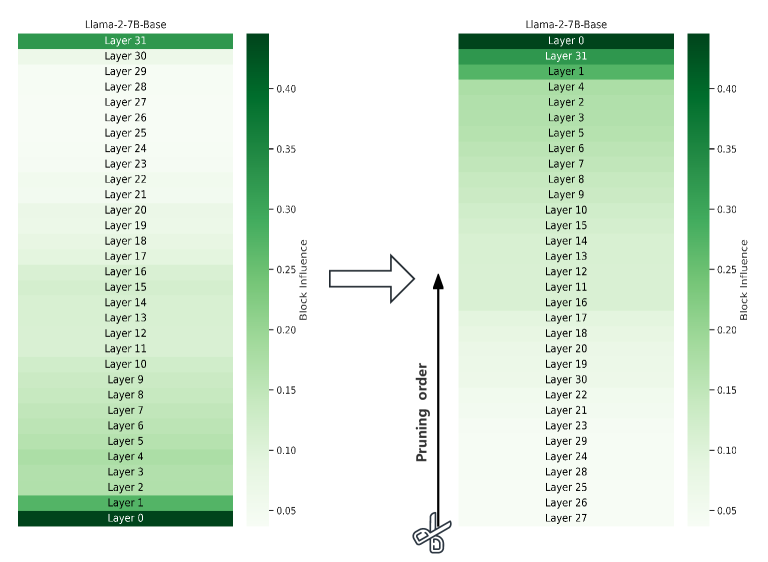
As outlined in the preceding section, the layers of LLMs exhibit redundancy, with varying degrees of redundancy across different layers. Notably, the deeper layers demonstrate a higher level of redundancy. To remove these redundant layers, we need a model-intrinsic metric to measure the importance of the layer. An intuitive method is to use the magnitude of each layer’s output as a measure of its importance, as a larger magnitude implies more activated neurons. In (Samragh et al., 2023), they proposed to use relative magnitude to measure the importance of layers. To characterize the influence of a certain layer. We defined a new metric, Block Influence (BI), under the assumption that the more a transformer block changes the hidden states, the more influential this layer is. As Figure 4 shows, the BI score of blocks can be calculated as follows:
| (2) |
where means the row of . Our empirical evidence supports that BI effectively reflects the importance of a layer. Figure 8 shows these different metrics in detail.
2.3 Layer Removal
The method we propose is straightforward: layer removal, which we simply referred as ShortGPT. We delete certain layers in LLMs based on BI score. Figure 2 illustrates our pruning method. First of all, we construct a calibration set, which is a set of unlabelled text samples such as PG19 (Rae et al., 2019). Then we collect the hidden states of each layer during inference on these samples. Next, we calculate the BI score based on the collected hidden states. Finally, we sort layers in ascending order according to the BI, and delete the layers with the smaller importance. The number of layers to be deleted can vary to trade off the speed and performance. The details of our layer remove setting can be found in Appendix B
3 Experiments
3.1 Experimental Setup
3.1.1 Models
To validate the effectiveness of our method, we conducted experiments on existing popular open-source language models, including Llama2-7B (Touvron et al., 2023), Llama2-13B, Baichuan2-7B, and Baichuan2-13B. They are all large language models based on the decoder-only Transformer architecture. LLaMA 2 was trained on more than 2 trillion tokens. Baichuan-series was mainly trained in Chinese and its 13-Billion model replaced the RoPE (Su et al., 2024) positional embedding with ALiBi (Press et al., 2021).
3.1.2 Benchmarks
In order to comprehensively evaluate the changes in the ability of large language models before and after pruning, we conducted evaluations on the most commonly used Benchmark MMLU (Hendrycks et al., 2020), CMMLU (Li et al., 2024) for evaluating large models. In addition, we also followed LaCo (Yang et al., 2024) to evaluate a wider dataset.
MMLU (Hendrycks et al., 2020) is a benchmark aimed at measuring the knowledge acquired during pre-training by specifically evaluating models in zero-shot and few-shot settings. This makes benchmarks more challenging and similar to the way we evaluate humans. This benchmark covers 57 subjects including STEM, humanities, social sciences, etc. Its difficulty ranges from beginner to advanced professional level, and it tests world knowledge and problem-solving ability.
CMMLU (Li et al., 2024) is a comprehensive Chinese language assessment dataset designed specifically to evaluate LLM’s advanced knowledge and reasoning abilities in the context of Chinese language and culture. CMMLU covers 67 topics, from elementary school to university or professional level. Including natural sciences, as well as humanities and social sciences, it also includes many contents with Chinese characteristics.
CMNLI (Xu et al., 2020) is part of the Chinese language understanding assessment benchmark. It consists of two parts: XNLI and MNLI. HellaSwag (HeSw) (Zellers et al., 2019) is a challenging dataset for evaluating commonsense NLI that is especially hard for state-of-the-art models, though its questions are trivial for humans. PIQA (Bisk et al., 2020) is a multi-choice question and answer dataset that focuses on daily scenarios. This dataset explores the model’s grasp of the laws of the real physical world through daily scenarios. CHID (Zheng et al., 2019) is an idiom cloze test dataset that mainly focuses on the selection of candidate words and the representation of idioms. CoQA (Reddy et al., 2019) is a large-scale dataset used for conversational question-answering tasks, containing over 127000 questions and their corresponding answers. BoolQ (Clark et al., 2019) is a question-answer dataset containing 15942 examples of yes/no questions. These problems occur naturally - they are generated in an environment that is silent and unconstrained. Race (Lai et al., 2017) is a large-scale reading comprehension dataset collected from English examinations in China, which are designed for middle school and high school students. XSum(Hasan et al., 2021) is used to evaluate abstract single document summarization systems. The goal is to create a short, one-sentence new summary of what the article is about. C3 (Sun et al., 2020) is a machine reading comprehension dataset with multiple choices, consisting of multiple-choice questions, reading materials from Chinese proficiency exams, and ethnic Chinese exams. PG19 (Rae et al., 2019) is a long document dataset from books used to test the effectiveness of language modeling.
3.1.3 Baselines
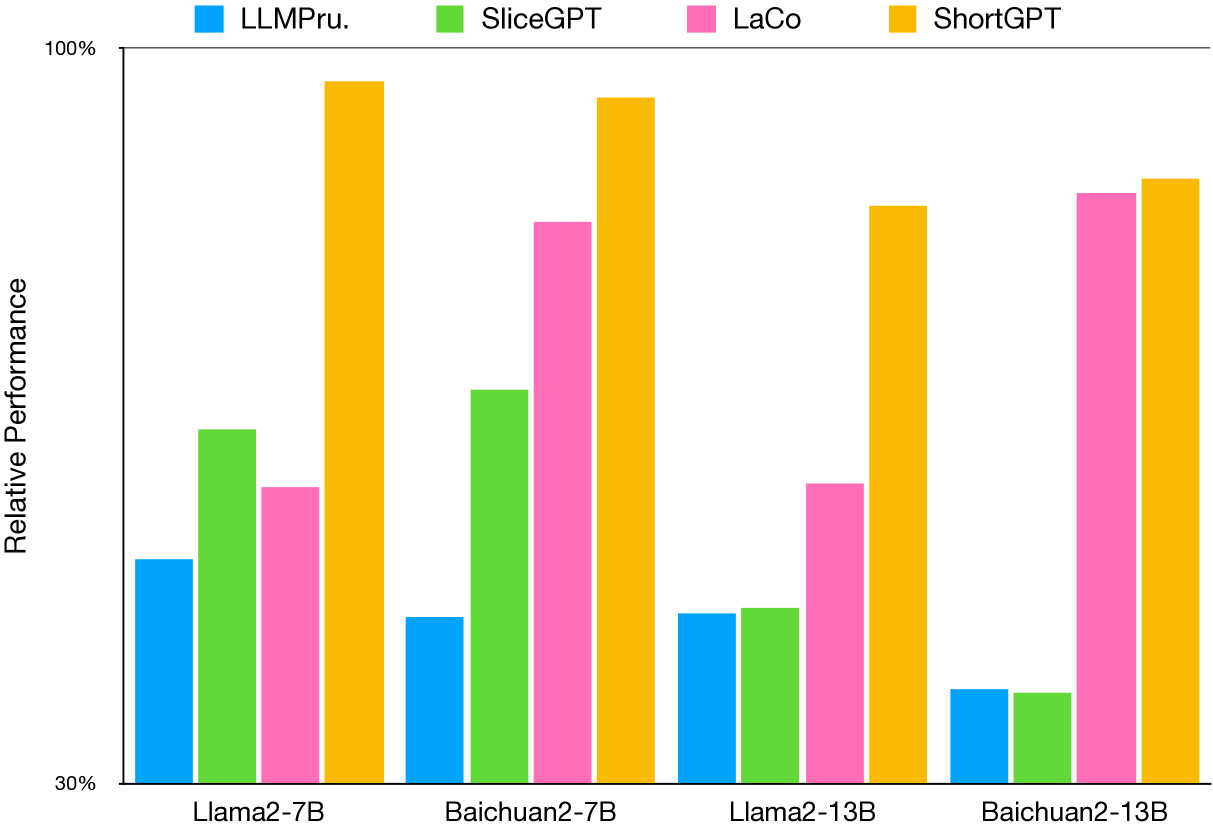
To evaluate the effectiveness of our method, we compared several structured pruning methods for large language models followed by LaCo (Yang et al., 2024). For our method, we use PG19 for layer importance and perplexity calculation.
LLMPru. (Ma et al., 2024) adopts structural pruning that selectively removes non-critical coupled structures based on gradient information, maximally preserving the majority of the LLM’s functionality. LLMPru. applies post training to the pruned model, but for fair comparison, we do not apply post training to it.
SliceGPT (Ashkboos et al., 2024) is a post-training sparsification scheme that replaces each weight matrix with a smaller matrix, reducing the embedding dimension of the network. Specifically, they applied PCA to the hidden representation from shallow to deep layers, and incorporated the dimension reduction matrix into existing network parameters.
LaCo (Yang et al., 2024) is a pruning method for large language models based on reducing layers. LaCo gradually merges similar layers from deep to shallow and sets a threshold to avoid continuously merging too many layers.
| LLM | Method | Ratio | Benchmarks | Ave. | Per. | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CMNLI | HeSw | PIQA | CHID | WSC | CoQA | BoolQ | Race-H | Race-M | XSum | C3 | MMLU | CMMLU | |||||
| Llama2-7B | Dense | 0.00% | 32.99 | 71.26 | 77.91 | 41.66 | 50.00 | 64.62 | 71.62 | 35.71 | 34.19 | 19.40 | 43.56 | 45.39 | 32.92 | 44.52 | 100.00 |
| LLMPrun. | 27.0% | 34.33 | 56.46 | 71.22 | 25.25 | 36.54 | 42.51 | 55.20 | 22.56 | 22.35 | 11.51 | 25.64 | 23.33 | 25.25 | 32.84 | 73.76 | |
| SliceGPT | 26.4% | 31.70 | 50.27 | 66.21 | 20.79 | 36.54 | 41.36 | 38.32 | 21.07 | 21.66 | 4.89 | 39.78 | 28.92 | 25.37 | 32.84 | 73.76 | |
| LaCo | 27.1% | 34.43 | 55.69 | 69.80 | 36.14 | 40.38 | 45.70 | 64.07 | 22.61 | 23.61 | 15.64 | 39.67 | 26.45 | 25.24 | 38.41 | 86.28 | |
| ShortGPT | 27.1% | 32.95 | 53.02 | 66.43 | 24.68 | 52.46 | 47.99 | 74.71 | 32.25 | 35.17 | 0.67 | 39.62 | 43.96 | 32.25 | 42.60 | 95.69 | |
| Llama2-13B | Dense | 0.00% | 32.99 | 74.78 | 79.71 | 47.35 | 50.00 | 66.91 | 82.39 | 57.95 | 60.38 | 23.45 | 47.51 | 55.00 | 38.40 | 51.91 | 100.00 |
| LLMPrun. | 24.4% | 33.03 | 67.76 | 76.66 | 35.64 | 40.38 | 50.86 | 56.42 | 22.47 | 22.08 | 19.17 | 32.33 | 25.21 | 24.71 | 38.97 | 75.07 | |
| SliceGPT | 23.6% | 29.82 | 55.71 | 69.04 | 19.31 | 36.54 | 47.26 | 37.86 | 23.41 | 24.03 | 5.27 | 41.92 | 37.14 | 25.79 | 34.84 | 67.11 | |
| LaCo | 24.6% | 32.86 | 64.39 | 74.27 | 40.10 | 52.88 | 52.66 | 63.98 | 54.49 | 56.55 | 14.45 | 44.93 | 45.93 | 32.62 | 48.30 | 93.05 | |
| ShortGPT | 24.6% | 33.00 | 66.64 | 73.45 | 36.61 | 50.00 | 58.64 | 62.48 | 58.35 | 60.17 | 17.59 | 46.90 | 54.69 | 38.38 | 50.53 | 97.34 | |
| Baichuan2-7B | Dense | 0.00% | 33.37 | 67.56 | 76.17 | 85.56 | 50.00 | 63.14 | 74.10 | 26.96 | 24.09 | 20.82 | 64.55 | 53.87 | 56.95 | 53.63 | 100.00 |
| LLMPrun. | 24.2% | 32.28 | 53.66 | 71.82 | 69.80 | 53.85 | 47.83 | 61.19 | 21.96 | 22.28 | 15.98 | 41.64 | 24.93 | 25.69 | 41.76 | 77.87 | |
| SliceGPT | 22.2% | 32.07 | 25.29 | 50.33 | 14.85 | 36.54 | 19.57 | 39.30 | 23.53 | 22.49 | 0.00 | 26.58 | 25.18 | 25.25 | 26.23 | 56.38 | |
| LaCo | 24.2% | 33.00 | 52.28 | 68.50 | 76.24 | 42.31 | 47.26 | 56.15 | 28.99 | 27.72 | 12.03 | 50.85 | 31.53 | 31.24 | 42.93 | 80.05 | |
| ShortGPT | 24.2% | 33.30 | 56.96 | 67.68 | 65.63 | 50.00 | 46.70 | 67.83 | 53.26 | 46.76 | 0.04 | 56.33 | 45.77 | 47.87 | 49.08 | 91.52 | |
| Baichuan2-13B | Dense | 0.00% | 33.21 | 71.10 | 78.07 | 86.51 | 50.00 | 65.6 | 77.89 | 67.27 | 68.94 | 25.02 | 65.64 | 59.50 | 61.30 | 62.31 | 100.00 |
| LLMPrun. | 24.3% | 33.80 | 53.57 | 71.82 | 72.77 | 37.50 | 38.82 | 56.54 | 21.17 | 21.61 | 13.67 | 39.89 | 23.19 | 25.18 | 39.20 | 62.91 | |
| SliceGPT | 22.8% | 32.07 | 25.85 | 51.03 | 10.40 | 36.54 | 18.02 | 37.83 | 21.56 | 21.52 | 0.00 | 24.99 | 22.95 | 25.26 | 25.03 | 40.17 | |
| LaCo | 24.7% | 33.03 | 60.71 | 68.88 | 76.73 | 44.23 | 55.45 | 62.35 | 56.92 | 57.80 | 12.32 | 61.10 | 51.35 | 53.65 | 53.43 | 85.75 | |
| ShortGPT | 24.7% | 32.81 | 60.55 | 71.60 | 80.17 | 47.13 | 54.30 | 62.54 | 55.77 | 56.41 | 15.14 | 60.16 | 52.11 | 58.86 | 54.43 | 87.33 | |
3.2 Main Results
To validate the efficacy of our proposed method, we conducted comparative experiments against benchmark and baseline techniques commonly employed in large language model evaluation. Considering the current structured pruning methods generally reduce parameters by no more than 30%, we performed experiments with approximately 1/4 of the parameters pruned. The experimental results are presented in Table 1. Additional experiments exploring different parameter reduction proportions will be discussed in the subsequent section.
The results demonstrate that the performance of the model pruned by our method significantly surpasses that of the baseline method, maintaining most of the large language model’s capabilities, such as reasoning, language understanding, knowledge retention, and examination performance, to the greatest extent possible. Furthermore, we note that the approach of reducing the number of layers (ShortGPT/LaCo) outperforms the method of reducing the embedding dimensions (LLMPru./SliceGPT), implying that the model exhibits more redundancy in-depth than in width. Further experimental analysis will be presented in the ensuing section.
4 Analysis
4.1 Varying prune ratio
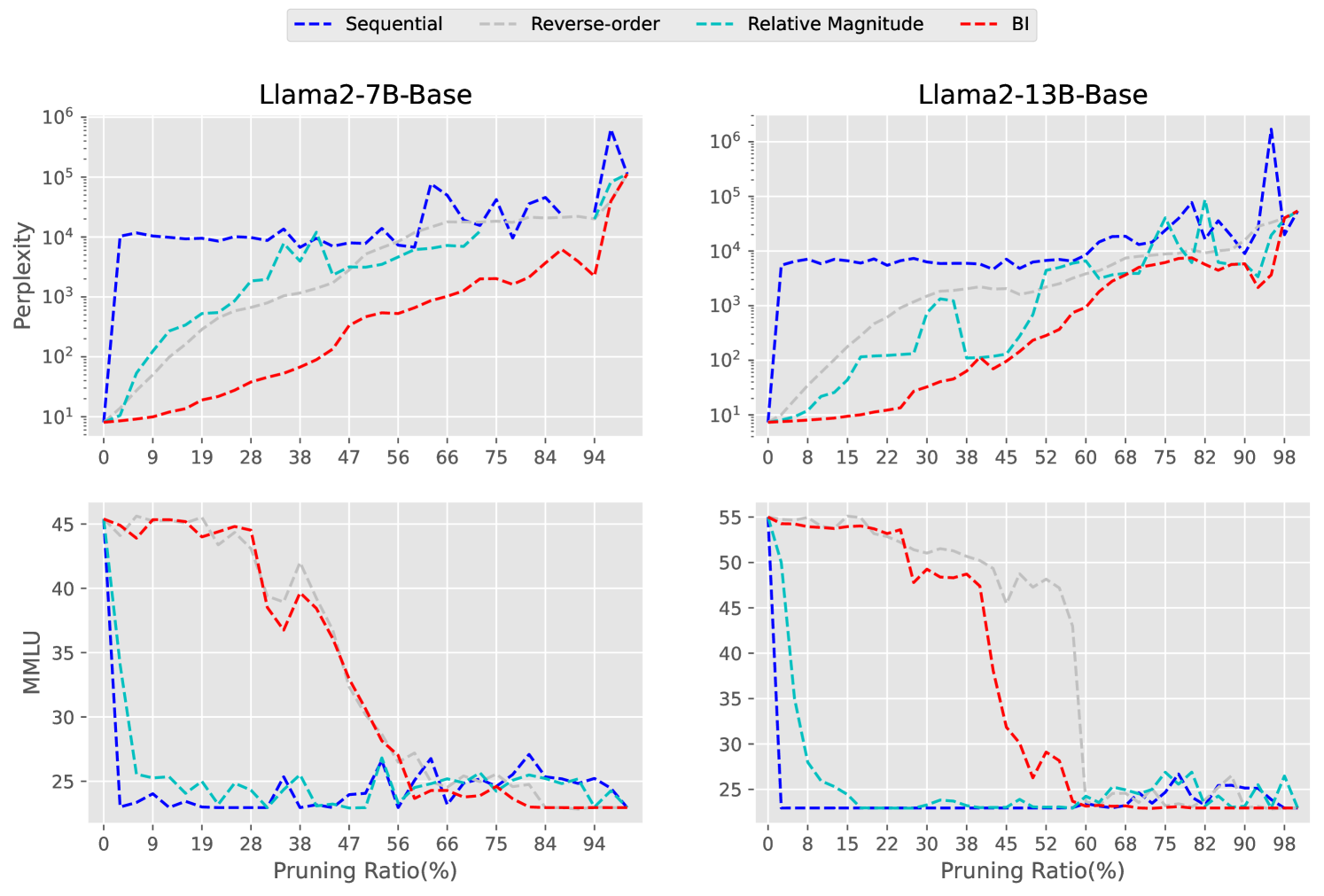
As a pruning method, we further validated the effects of different pruning ratios on model performance. Experiments were conducted on the Llama2-7B-Base and Baichuan2-7B-Base models, observing the Perplexity and MMLU. The pruning ratios ranged from 0% to 97%, employing the strategy of deleting layers based on the importance proposed in this paper, resulting in models with 1 to 32 layers. The results in Figure 5 indicate that as the pruning ratio increases, the performance of the model declines. However, the MMLU score drops significantly at a certain layer, which may imply the existence of certain special layers within the network that play a critically important role.
4.2 Depth Redundancy v.s. Width Redundancy
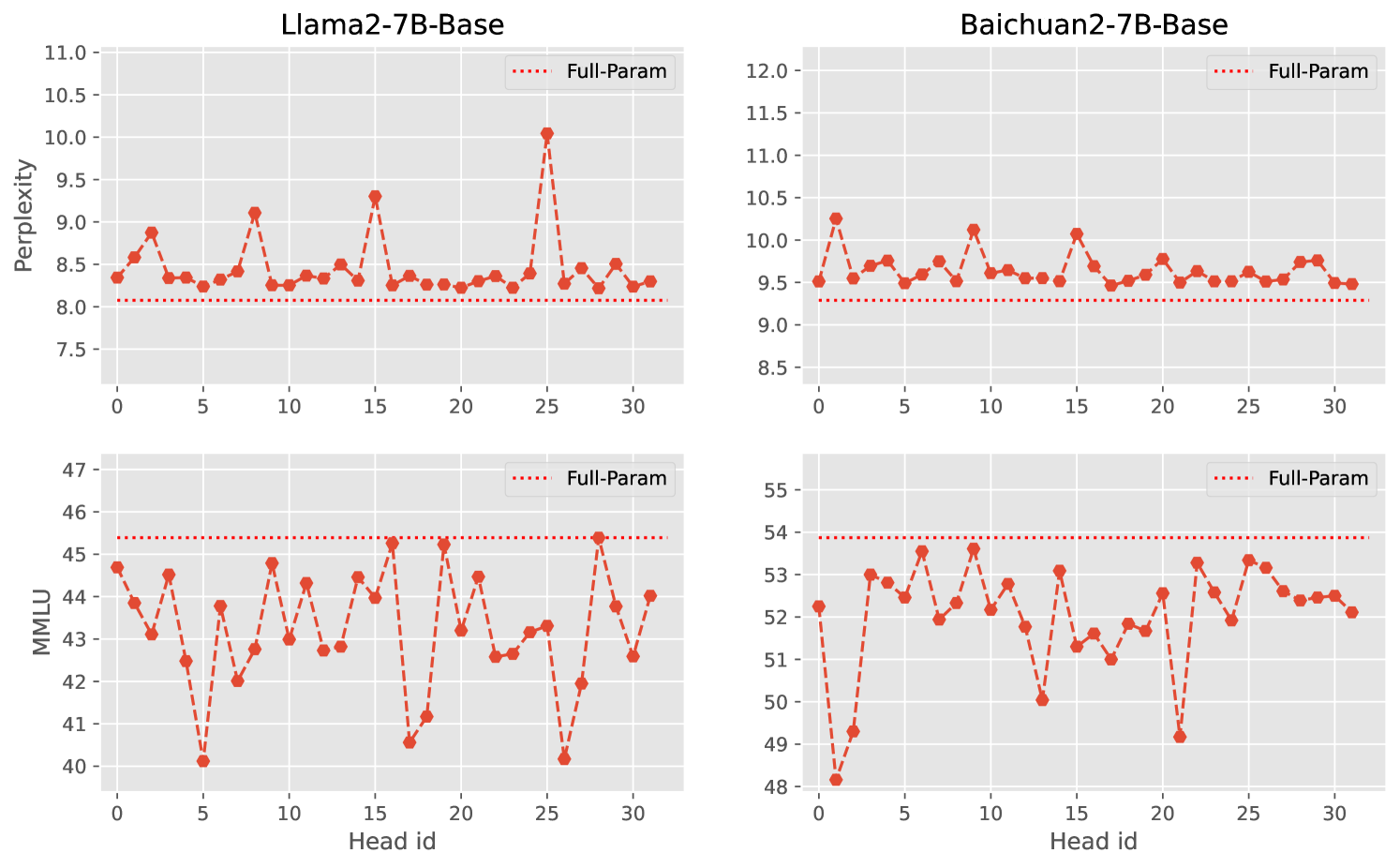
In the preceding sections, we analyzed and explored the redundancy of large language models (LLMs) in terms of depth (layers). However, we also investigated redundancy in terms of width, specifically focusing on the attention heads. Our method involves sequentially removing each head from the multi-head attention mechanism and adjusting the parameters of the attention output projection to ensure the output shape of the Attention block remains unchanged. The Feed-Forward Network (FFN) remains unaltered. Similar to the approach in Section 2.1, we observe the impact of each head’s removal on the final performance of the network. Figure 6 illustrates the changes in Perplexity and MMLU scores after each head is removed. The results indicate that LLMs exhibit a high degree of redundancy in width, comparable to their redundancy in depth. However, this width redundancy does not follow any discernible pattern and varies across different models. We hypothesize that this variation may be attributed to the symmetry among heads.
4.3 Redundancy on non-transformer LLM

We further investigate whether the redundancy observed in depth is a result of the Transformer’s architecture. Given that the vast majority of popular LLMs are based on the Transformer structure. We selected the RWKV-7B model proposed in (Peng et al., 2023), a formidable competitor to the Transformer architecture which indeed consists of identical layers to a certain extent. We analyzed this model using the methodology from 2.1. Figure 7 shows the redundancy of the RWKV-7B 111 We use rwkv-v5-world-7B from https://huggingface.co/BlinkDL/rwkv-5-world model. Through this figure, we can observe that the RWKV-7B model also exhibits a high level of redundancy. This may suggest that the redundancy is universal across LLMs.
4.4 Importance metric
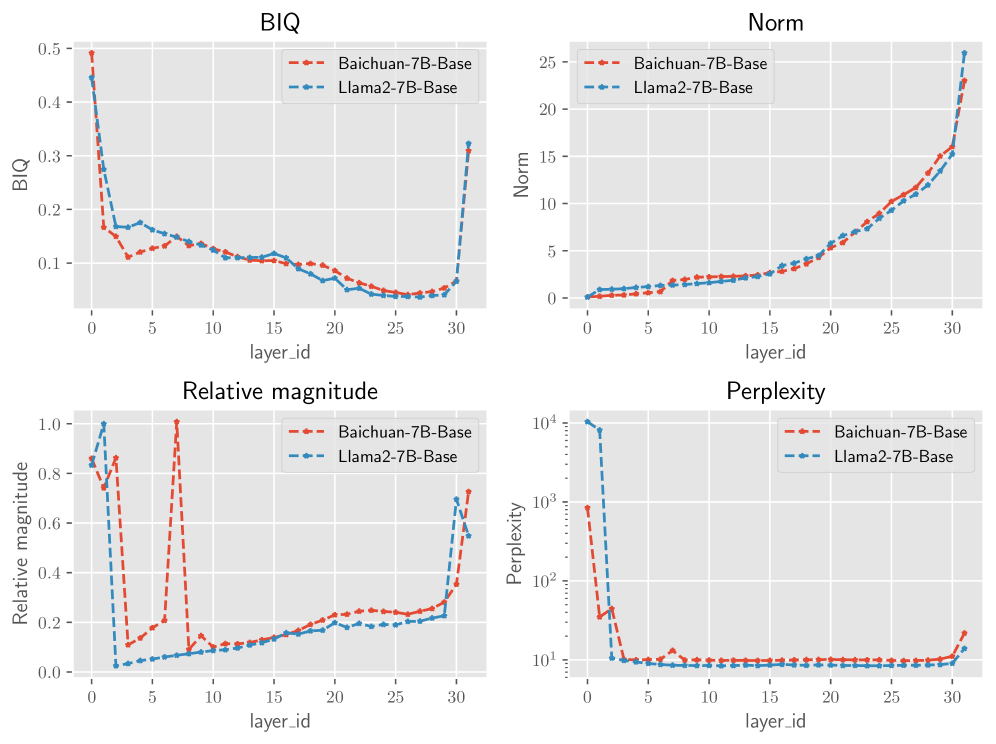
The overarching concept of our method is to rank layers by importance and remove the less significant ones. The definition of importance metrics has a profound impact on the outcome. In this section, we define and compare various important metrics:
Sequential: The importance is directly proportional to the sequence order, with shallower layers being more important. This can be implemented by taking the negative of each layer’s index as the importance metric.
Reverse-order/Norm: This metric posits that importance is inversely proportional to the sequence order. It assigns higher importance scores to the shallower layers Inspired by Figure 3. This method gives the same order as measuring importance by hidden states norm mentioned in LABEL:layerimportacne. Here, the importance metric is the layer’s index itself.
Relative Magnitude: Proposed in (Samragh et al., 2023), this metric assumes layers with larger are of higher importance, where is the layer transformation function.
BI: BI mentioned in previous section 2.2.
Figure 8 demonstrates the different metrics. We observe that shallower layers in the LLM network are more crucial than deeper ones. Figure 5 shows the results of removing layers by different metrics, demonstrating that Our proposed BI outperforms other metrics. The method of (Samragh et al., 2023) is highly competitive, indicating that relative values can also reflect the importance to a certain extent. It is worth noting that the hidden states norm seems to be a good metric when only considering the MMLU benchmark, but the perplexity is relatively poor, which significantly impacts tasks related to text generation. This also indicates the limitations of the current LLMs evaluation methods.
4.5 Orthogonal to Quantization
In this section, we show that our method is orthogonal to quantization methods. We apply our method to a model 222We take the model from https://huggingface.co/TheBloke/Llama-2-7B-GPTQ quantized by GPTQ algorithm. Table 2 shows that our method is compatible with the quantization-like method, which could reduce the footprint further.
| Model | Ratio/Layer | Perplexity | MMLU |
|---|---|---|---|
| Baseline | 0%/32 | 8.4999 | 37.99 |
| ShortGPT | 27.1%/23 | 42.6951 | 36.69 |
5 Limitation
Although our method demonstrates strong competitiveness compared to current pruning methods, with some benchmarks even suggesting that deleting certain layers has no impact on the final result, this does not imply that layer removal comes without drawbacks. Due to the limitations of benchmarking, current evaluations may not fully capture the impact of layer removal on model performance. Our experiments reveal that the effect of layer removal is significantly more pronounced on generative tasks compared to multiple-choice tasks. On benchmarks such as GSM8K (Cobbe et al., 2021) and HumanEval (Chen et al., 2021), removing 25% of the layers often leads to a severe performance drop, with scores approaching zero. Nevertheless, this study proves that models maintain strong semantic understanding and processing capabilities after layer removal. Post-training techniques could potentially further mitigate performance losses, which is an area of ongoing research.
6 Related works
To reduce the inference cost of large language models and increase their practical applications, there have been many recent works on compressing models, which can be classified into four categories: model pruning, knowledge distillation, quantization, and low-rank factorization.
Model pruning: model pruning (LeCun et al., 1989; Han et al., 2015) is a classic and effective method of reducing model redundancy modules to compress models. The model pruning methods mainly include unstructured pruning and structured pruning. The unstructured pruning simplifies an LLM by removing specific parameters without considering its internal structure, such as SparseGPT (Frantar and Alistarh, 2023) and LoRAPrune (Zhang et al., 2023). However, this method disregards the overall LLM structure, resulting in an irregular sparse model composition. Another more practical approach is structured pruning, GUM(Syed et al., 2023) makes an analysis of several structured pruning methods for decoder-only LLMs. LLM-Pruner (Ma et al., 2024) selectively removes non-critical structures according to gradient information. ShearedLLaMA (Xia et al., 2023) employs targeted structured pruning and dynamic batch loading. LaCo (Yang et al., 2024) used layer merging to compress the model. Compared to the previous method, our method is a simple and efficient structured pruning method.
Knowledge distillation: Knowledge distillation (KD) (Hinton et al., 2015; Gou et al., 2021) is another way of compressing models, where a larger teacher network provides knowledge to a smaller student network. Using the prompt response pairs by LLM APIs to fine-tune small models can get promised results (Li et al., 2022). In addition, when we can access transparent teacher models, the result can be improved more. MiniLLM (Gu et al., 2023) uses reverse Kullback-Leibler divergence to prevent the student model from overestimating the low-probability regions of the teacher distribution. DistlLLM (Ko et al., 2024) uses an adaptive off-policy approach designed to enhance the efficiency in utilizing student-generated outputs. However, compared to model pruning, this method often requires higher computational resources.
Quantization: quantization (Liu et al., 2021; Gholami et al., 2022; Dettmers et al., 2022, 2024) is a widely accepted technique in the field of model compression, which can significantly save the storage and computational costs of deep learning models. Traditional models are generally stored as floating-point numbers, but quantization converts them into integers or other discrete forms. LUT-GEMM (Park et al., 2022) quantifies only weights and optimizes matrix multiplication in LLM using BCQ format. SPQR (Dettmers et al., 2023) identifies and isolates abnormal weights, stores them with higher accuracy, and compresses all other weights into 3-4 bits. Our model pruning method and quantization method are orthogonal, which means quantification based on our pruned model can further compress the model.
Low-rank factorization: low-rank decomposition (Cheng et al., 2017; Povey et al., 2018) is a model compression technique aimed at approximating a given weight matrix by decomposing it into two or more smaller matrices with significantly lower dimensions. TensorGPT (Xu et al., 2023) stores large embeddings in a low-rank tensor format, reducing the space complexity of LLMs and making them available on edge devices. Recently, SliceGPT (Ashkboos et al., 2024) has also implemented structured compression of models based on matrix factorization of hidden states and absorbed the new matrix into the parameters of the origin networks.
Model redundancy: researchers have long noticed the significant redundancy in nonlinear models (Catchpole and Morgan, 1997). In recent years, the transformer model architecture has been widely applied, and researchers have also studied its redundancy. In (Bian et al., 2021), researchers analyzed redundancy in attention mechanisms, in which clear and similar redundancy patterns (cluster structure) are observed among attention heads. In (Dalvi et al., 2020), researchers dissect two pre-trained models, BERT (Devlin et al., 2018) and XLNet (Yang et al., 2019), studying how much redundancy they exhibit at a representation level and a more fine-grained neuron-level. However, the redundancy in current large language models based on decoder-only structures still needs to be explored.
7 Conclusion
This work has introduced a novel approach to pruning Large Language Models (LLMs) based on layer redundancy and an "importance" metric defined as attention entropy. Our study reveals a significant degree of layer-wise redundancy in LLMs, indicating that certain layers contribute minimally to the overall network function and can thus be removed without substantially compromising model performance. By employing a straightforward layer removal strategy guided by the calculated importance of each layer, we have demonstrated that it is possible to maintain up to 95% of an LLM’s performance while reducing the model’s parameter count and computational requirements by approximately 25%. This achievement not only surpasses previous state-of-the-art pruning methods but also underscores the potential for further optimizations in LLM deployment strategies.
Our findings suggest that the redundancy inherent in LLMs is largely depth-based rather than width-based, highlighting an avenue for future research into the structural efficiency of neural networks. Moreover, our pruning approach, characterized by its simplicity and effectiveness, is compatible with other compression techniques such as quantization, offering a composite pathway to model size reduction that is both significant and versatile.
The implications of our research extend beyond academic interest, offering practical solutions for deploying advanced LLMs in resource-constrained environments. By enabling more efficient model architectures without the need for extensive retraining, our pruning method facilitates broader access to cutting-edge AI capabilities across a variety of platforms and devices.
In conclusion, our investigation into layer redundancy and the development of an importance-based pruning strategy represent a meaningful advancement in the optimization of Large Language Models. As the demand for sophisticated AI tools continues to grow, approaches like ours will play a crucial role in making these technologies more accessible and sustainable. Future work will focus on refining our understanding of model redundancy and exploring additional methods for enhancing the efficiency of neural network models.
References
- Ashkboos et al. (2024) Saleh Ashkboos, Maximilian L Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, and James Hensman. 2024. Slicegpt: Compress large language models by deleting rows and columns. arXiv preprint arXiv:2401.15024.
- Bian et al. (2021) Yuchen Bian, Jiaji Huang, Xingyu Cai, Jiahong Yuan, and Kenneth Church. 2021. On attention redundancy: A comprehensive study. In Proceedings of the 2021 conference of the north american chapter of the association for computational linguistics: human language technologies, pages 930–945.
- Bisk et al. (2020) Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. 2020. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, pages 7432–7439.
- Catchpole and Morgan (1997) Edward A Catchpole and Byron JT Morgan. 1997. Detecting parameter redundancy. Biometrika, 84(1):187–196.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
- Cheng et al. (2017) Yu Cheng, Duo Wang, Pan Zhou, and Tao Zhang. 2017. A survey of model compression and acceleration for deep neural networks. arXiv preprint arXiv:1710.09282.
- Chowdhery et al. (2023) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113.
- Clark et al. (2019) Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. Boolq: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2924–2936.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Dalvi et al. (2020) Fahim Dalvi, Hassan Sajjad, Nadir Durrani, and Yonatan Belinkov. 2020. Analyzing redundancy in pretrained transformer models.
- Dettmers et al. (2022) Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. Llm. int8 (): 8-bit matrix multiplication for transformers at scale. arXiv preprint arXiv:2208.07339.
- Dettmers et al. (2024) Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2024. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36.
- Dettmers et al. (2023) Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh. 2023. Spqr: A sparse-quantized representation for near-lossless llm weight compression. arXiv preprint arXiv:2306.03078.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Frantar and Alistarh (2023) Elias Frantar and Dan Alistarh. 2023. Massive language models can be accurately pruned in one-shot. arXiv preprint arXiv:2301.00774.
- Gholami et al. (2022) Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W Mahoney, and Kurt Keutzer. 2022. A survey of quantization methods for efficient neural network inference. In Low-Power Computer Vision, pages 291–326. Chapman and Hall/CRC.
- Gou et al. (2021) Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. 2021. Knowledge distillation: A survey. International Journal of Computer Vision, 129:1789–1819.
- Gu et al. (2023) Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. 2023. Knowledge distillation of large language models. arXiv preprint arXiv:2306.08543.
- Han et al. (2015) Song Han, Jeff Pool, John Tran, and William Dally. 2015. Learning both weights and connections for efficient neural network. Advances in neural information processing systems, 28.
- Hasan et al. (2021) Tahmid Hasan, Abhik Bhattacharjee, Md Saiful Islam, Kazi Mubasshir, Yuan-Fang Li, Yong-Bin Kang, M Sohel Rahman, and Rifat Shahriyar. 2021. Xl-sum: Large-scale multilingual abstractive summarization for 44 languages. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4693–4703.
- Hendrycks et al. (2020) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300.
- Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.
- Hoffmann et al. (2022) Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre. 2022. Training compute-optimal large language models.
- Huang et al. (2021) Feiqing Huang, Yuefeng Si, Yao Zheng, and Guodong Li. 2021. A new measure of model redundancy for compressed convolutional neural networks.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.
- Ko et al. (2024) Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun. 2024. Distillm: Towards streamlined distillation for large language models. arXiv preprint arXiv:2402.03898.
- Lai et al. (2017) Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. 2017. Race: Large-scale reading comprehension dataset from examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 785–794.
- LeCun et al. (1989) Yann LeCun, John Denker, and Sara Solla. 1989. Optimal brain damage. Advances in neural information processing systems, 2.
- Li et al. (2024) Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. 2024. Cmmlu: Measuring massive multitask language understanding in chinese.
- Li et al. (2022) Shiyang Li, Jianshu Chen, Yelong Shen, Zhiyu Chen, Xinlu Zhang, Zekun Li, Hong Wang, Jing Qian, Baolin Peng, Yi Mao, et al. 2022. Explanations from large language models make small reasoners better. arXiv preprint arXiv:2210.06726.
- Liu et al. (2021) Zhenhua Liu, Yunhe Wang, Kai Han, Wei Zhang, Siwei Ma, and Wen Gao. 2021. Post-training quantization for vision transformer. Advances in Neural Information Processing Systems, 34:28092–28103.
- Ma et al. (2024) Xinyin Ma, Gongfan Fang, and Xinchao Wang. 2024. Llm-pruner: On the structural pruning of large language models. Advances in neural information processing systems, 36.
- Park et al. (2022) Gunho Park, Baeseong Park, Se Jung Kwon, Byeongwook Kim, Youngjoo Lee, and Dongsoo Lee. 2022. nuqmm: Quantized matmul for efficient inference of large-scale generative language models. arXiv preprint arXiv:2206.09557.
- Peng et al. (2023) Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, Kranthi Kiran GV, et al. 2023. Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048.
- Povey et al. (2018) Daniel Povey, Gaofeng Cheng, Yiming Wang, Ke Li, Hainan Xu, Mahsa Yarmohammadi, and Sanjeev Khudanpur. 2018. Semi-orthogonal low-rank matrix factorization for deep neural networks. In Interspeech, pages 3743–3747.
- Press et al. (2021) Ofir Press, Noah A Smith, and Mike Lewis. 2021. Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409.
- Rae et al. (2019) Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, Chloe Hillier, and Timothy P Lillicrap. 2019. Compressive transformers for long-range sequence modelling. In International Conference on Learning Representations.
- Reddy et al. (2019) Siva Reddy, Danqi Chen, and Christopher D Manning. 2019. Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7:249–266.
- Samragh et al. (2023) Mohammad Samragh, Mehrdad Farajtabar, Sachin Mehta, Raviteja Vemulapalli, Fartash Faghri, Devang Naik, Oncel Tuzel, and Mohammad Rastegari. 2023. Weight subcloning: direct initialization of transformers using larger pretrained ones.
- Su et al. (2024) Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063.
- Sun et al. (2020) Kai Sun, Dian Yu, Dong Yu, and Claire Cardie. 2020. Investigating prior knowledge for challenging chinese machine reading comprehension. Transactions of the Association for Computational Linguistics, 8:141–155.
- Syed et al. (2023) Aaquib Syed, Phillip Huang Guo, and Vijaykaarti Sundarapandiyan. 2023. Prune and tune: Improving efficient pruning techniques for massive language models. Arxiv.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30.
- Xia et al. (2023) Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, and Danqi Chen. 2023. Sheared llama: Accelerating language model pre-training via structured pruning. arXiv preprint arXiv:2310.06694.
- Xu et al. (2020) Liang Xu, Hai Hu, Xuanwei Zhang, Lu Li, Chenjie Cao, Yudong Li, Yechen Xu, Kai Sun, Dian Yu, Cong Yu, et al. 2020. Clue: A chinese language understanding evaluation benchmark. In Proceedings of the 28th International Conference on Computational Linguistics, pages 4762–4772.
- Xu et al. (2023) Mingxue Xu, Yao Lei Xu, and Danilo P Mandic. 2023. Tensorgpt: Efficient compression of the embedding layer in llms based on the tensor-train decomposition. arXiv preprint arXiv:2307.00526.
- Yang et al. (2023) Aiyuan Yang, Bin Xiao, Bingning Wang, Borong Zhang, Ce Bian, Chao Yin, Chenxu Lv, Da Pan, Dian Wang, Dong Yan, et al. 2023. Baichuan 2: Open large-scale language models. arXiv preprint arXiv:2309.10305.
- Yang et al. (2024) Yifei Yang, Zouying Cao, and Hai Zhao. 2024. Laco: Large language model pruning via layer collapse.
- Yang et al. (2019) Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. 2019. Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems, 32.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800.
- Zhang et al. (2023) Mingyang Zhang, Chunhua Shen, Zhen Yang, Linlin Ou, Xinyi Yu, Bohan Zhuang, et al. 2023. Pruning meets low-rank parameter-efficient fine-tuning. arXiv preprint arXiv:2305.18403.
- Zheng et al. (2019) Chujie Zheng, Minlie Huang, and Aixin Sun. 2019. Chid: A large-scale chinese idiom dataset for cloze test. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 778–787.
- Zhu et al. (2023) Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. 2023. A survey on model compression for large language models.
Appendix A Detailed Strategy for Layer Removal
| Strategy |
Description |
|---|---|
| Sequential |
Layers are removed sequentially from the beginning of the model. The process starts with layer 0 and progressively includes more layers for removal (e.g., {0}, {0, 1}, …). |
| Reverse-order |
This strategy involves starting from the model’s final layer and progressively removing layers in reverse order (e.g., {-1}, {-1, -2}, …). |
| Relative Magnitude |
Layers are removed in ascending order based on their Relative Magnitude values. The removal process accumulates layers from those with the smallest to the largest values, mirroring the sequential strategy’s accumulation method. |
| BI (Block Influence) |
Follows a similar accumulation approach as the Sequential strategy, but layers are ordered and removed according to their BI values, starting from the lowest and moving to the highest. |
Appendix B Benchmark Setup for Removed Layers
Before delineating the specific layer removal configurations in the benchmarked models, a concise overview of the structural modifications is warranted. The Llama-2-7B and Baichuan-2-7B models, initially designed with 32 layers, have been streamlined by excising 9 layers, corresponding to a 28% reduction of the total layer framework. The 13B variants, originally constituted of 40 layers, experienced a decrement of 10 layers, marking a 25% diminution. The selection criterion for layer removal was based on ascending Block Influence (BI) values, ensuring a data-driven approach to minimization. This premise underpins the benchmark configurations.
| Model | Removed Layers |
|---|---|
| Llama-2-7B | 27, 26, 25, 28, 24, 29, 23, 21, 22 |
| Llama-2-13B | 33, 31, 32, 30, 29, 34, 28, 35, 27, 26 |
| Baichuan-2-7B | 26, 27, 25, 28, 24, 29, 23, 22, 30 |
| Baichuan-2-13B | 32, 31, 33, 30, 34, 29, 28, 35, 27, 26 |
Appendix C Layer Removal on Baichuan2-series Model
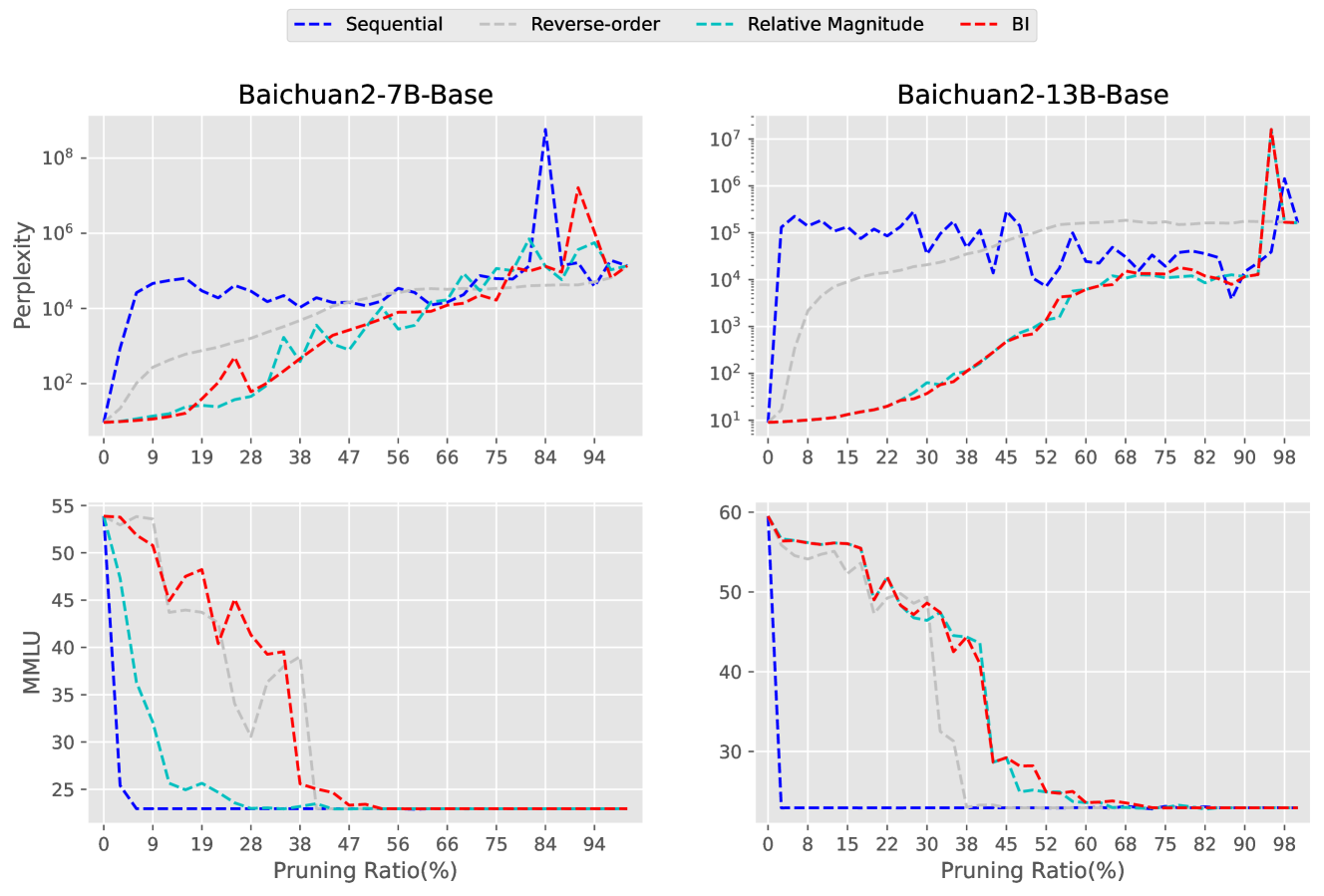
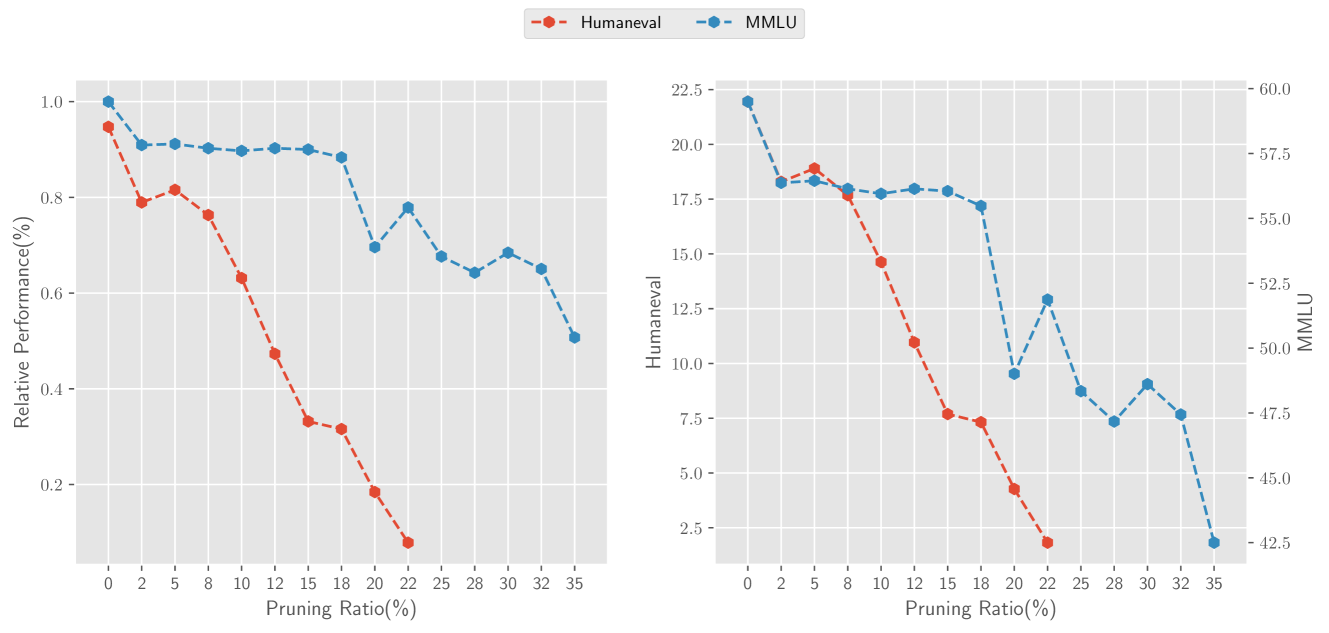
Appendix D Layer Removal on HumanEval.
We also found that layer removal has a significant impact on the performance of the model in generative tasks. Specifically, we conducted experiments on the Baichuan2-13B model on HumanEval (Chen et al., 2021), which is a dataset used to evaluate the performance of code generation models. The results are shown in Figure 10. After removing 10 layers, the performance on HumanEval almost completely degraded. We speculate that it may be due to significant cumulative errors in generative tasks.