TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document
Abstract
We present TextMonkey, a large multimodal model (LMM) tailored for text-centric tasks. Our approach introduces enhancement across several dimensions: By adopting Shifted Window Attention with zero-initialization, we achieve cross-window connectivity at higher input resolutions and stabilize early training; We hypothesize that images may contain redundant tokens, and by using similarity to filter out significant tokens, we can not only streamline the token length but also enhance the model’s performance. Moreover, by expanding our model’s capabilities to encompass text spotting and grounding, and incorporating positional information into responses, we enhance interpretability. It also learns to perform screenshot tasks through finetuning. Evaluation on 12 benchmarks shows notable improvements: 5.2% in Scene Text-Centric tasks (including STVQA, TextVQA, and OCRVQA), 6.9% in Document-Oriented tasks (such as DocVQA, InfoVQA, ChartVQA, DeepForm, Kleister Charity, and WikiTableQuestions), and 2.8% in Key Information Extraction tasks (comprising FUNSD, SROIE, and POIE). It outperforms in scene text spotting with a 10.9% increase and sets a new standard on OCRBench, a comprehensive benchmark consisting of 29 OCR-related assessments, with a score of 561, surpassing previous open-sourced large multimodal models for document understanding. Code will be released at https://github.com/Yuliang-Liu/Monkey.
Index Terms:
Large Multi-modal Model, Document Analysis, Scene Text, Resolution, OCRBench1 Introduction
Extracting key information from a variety of sources, including documents like tables, forms, and invoices, as well as text in the wild is crucial for industries and academic research, aiming to automate and refine document-based and scene-text workflows. This field requires text detection and recognition in both document images and real-world scenes, language comprehension, and the integration of vision and language.
Many early methods [1, 2] attempt to address the task using a two-stage approach: 1) Detect and recognize the text using external systems; 2) Document understanding based on the fusion of text results and images. However, the individual step of text reading in the processing pipeline may lead to the accumulation of errors. Moreover, relying on off-the-shelf OCR Models/APIs (OCR-Models) introduces additional engineering complexity, limits the connection between the text and its surrounding context, and can potentially increase computational costs. To alleviate the drawbacks of external systems before understanding, OCR-Free solutions [3, 4] have attracted increasing attention recently.
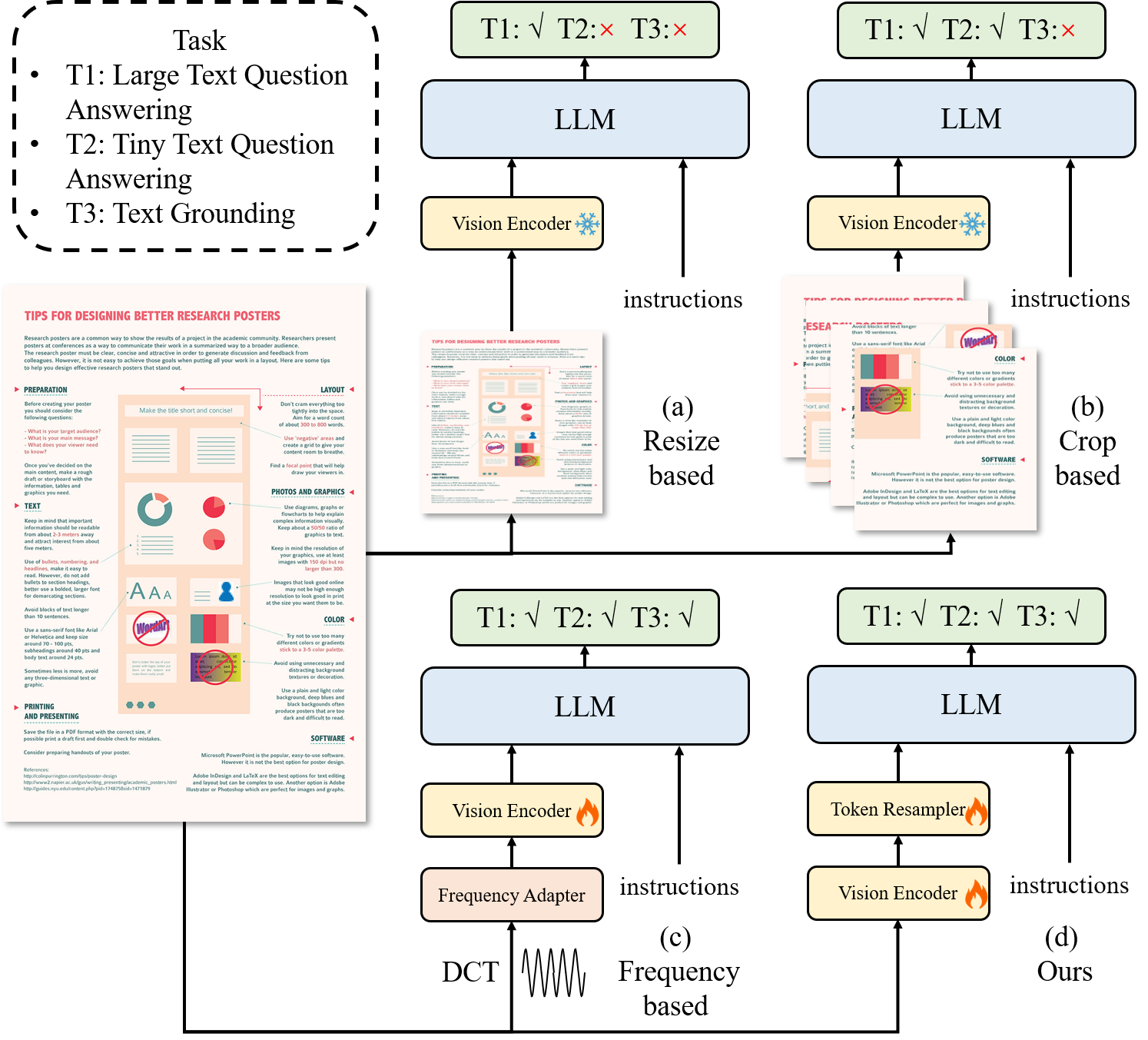
The field of large multimodal models (LMMs) [5, 6] is advancing rapidly due to its powerful ability to handle diverse types of data. However, they still have limitations when it comes to addressing text-related tasks. As depicted in Fig. 1 (a), several methods, including LLaVAR [7], UniDoc [8], TGDoc [9], and mPLUG-DocOwl [10] heavily rely on a pre-trained CLIP [11] for visual encoding. Nevertheless, these encoders have input resolutions of 224 or 336, which are insufficient to meet the demands of documents containing numerous small texts [12]. Therefore, they can only recognize large text and struggle with small text in images. To address the limitations of tiny text, UReaer [13] and Monkey [14] take a cropping strategy to expand the input resolution, as shown in Fig. 1 (b). However, this crop strategy may inadvertently split related words, resulting in semantic incoherence. For example, the word "Backup" may be divided into "Back" and "up," making it impossible to restore its original meaning even after fusion has been performed. Besides, the spatial separation caused by this splitting also makes it challenging to handle text position-related tasks, such as text grounding. As shown in Fig. 1 (c), DocPedia [15] directly processes visual input in the frequency domain rather than the pixel space. Due to the characteristics of the frequency domain, it can quickly expand the resolution without losing information. However, due to the transformation of the feature space, it is difficult to leverage existing pretrained models, increasing the demand for training resources.
We want to inherit the efficient image resolution scaling feature of Monkey [14] but address the missing cross-window context for the documents mentioned above. For this purpose, we introduce TextMonkey, as shown in Fig. 1 (d). TextMonkey utilizes a Split Module that divides high-resolution images into window patches using a sliding window method. Inspired by [16], we treat every self-attention layer in the CLIP as self-attention in non-overlapped windows. To introduce cross-window relationships while maintaining efficient computation, we use Shifted Window Attention with zero-initialization to build cross-window connections. This approach allows us to maintain the training data distribution for the encoder and deal with high-resolution document images while reducing the computational cost of training from scratch. On the other hand, the utilization of the Split Module still poses a significant challenge as it leads to a notable increase in token length. We have observed that there are numerous repetitive image features that align with the language space, similar to certain repeated elements in the language itself. Thus, we propose a token resampler to compress these features while keeping as many of the most important features as possible. We employ important tokens as queries and the original features as key-value pairs, facilitating the reaggregation of features. On the basis of reducing the number of tokens, our module can also significantly improve the performance compared to random queries.
On the other hand, due to the self-explanatory nature of the text, in most cases, humans are able to locate the position of the answer itself. To alleviate the issue of hallucination in large language models further, we require the model not only to provide accurate answers but also to locate specific visual evidence supporting its response. We also introduce a variety of text-related tasks to deepen the connection between text information and visual information, such as text spotting and text grounding. Besides, incorporating positional cues into the answers can further enhance the model’s reliability and interpretability.
We summarize the advantages of our method as follows:
-
•
Enhancing cross-window relations. We adopt Shfited Window Attention to successfully incorporate cross-window connectivity while expanding the input resolutions. Besides, we introduce zero initialization in the Shifted Window Attention mechanism, enabling the model to avoid drastic modifications to early training.
-
•
Token compression. We show enlarging resolution results in some redundant tokens. By using similarity as a criterion, we are able to find significant tokens that serve as queries for the token resampler. This module not only reduces the token length but also improves the model’s performance. Additionally, it significantly improves the performance compared to the use of random queries.
-
•
Support text grounding. We expand our scope to include tasks beyond text-based question answering, encompassing reading text, text spotting, and text grounding. Additionally, we found that incorporating positional information into the answers can improve the model’s interpretability. TextMonkey can also be finetuned to understand the command of screen-shot clicking.
-
•
We evaluated TextMonkey’s performance across 12 recognized benchmarks, observing significant improvements in several areas. Firstly, in scene text-centric tasks such as STVQA, TextVQA, and OCRVQA, TextMonkey achieved a 5.2% increase in performance. For document-oriented tasks, including DocVQA, InfoVQA, ChartVQA, DeepForm, Kleister Charity, and WikiTableQuestions, it showed a 6.9% improvement. In the domain of key information extraction tasks, like FUNSD, SROIE, and POIE, we noted a 2.8% uplift. Particularly notable was its performance in scene text spotting tasks (Total-Text, CTW1500, and ICDAR 2015) focused on transcription accuracy, where it improved by 10.9%. Additionally, TextMonkey set a new high score of 561 on OCRBench, a comprehensive benchmark encompassing 29 OCR-related evaluations, significantly surpassing the performance of previous open-source, large-scale multimodal models designed for document understanding. This achievement underscores TextMonkey’s effectiveness and advances in the field of document analysis and understanding.
2 Related works
Models designed to comprehend images with text information can be broadly categorized into two types: OCR-Model-Driven and OCR-Free methods.
2.1 OCR-Model-Driven Methods
OCR-Model-Driven methods use OCR tools to acquire text and bounding box information. Subsequently, they rely on the models to integrate text, layout, and visual data. Meanwhile, diverse pre-training tasks are devised to enhance cross-modal alignment between visual and text inputs. StrucTexT [17] pays attention to the fine-grained semantic information and global layout information within the image in the design of pre-training tasks. Based on layout knowledge enhancement technology, ERNIE-Layout [18] innovatively proposes two self-supervised pre-training tasks: reading order prediction and fine-grained image-text matching. The LayoutLM [19, 20, 2] series continuously improves by integrating pre-trained text, layout, and visual features and introducing a unified model architecture and pre-training goals. This enhances the model’s performance in various document understanding tasks and simplifies overall design. UDOP [1] unifies vision, text, and layout through VTL Transformer and a unified generative pre-training task. Wukong-reader [21] proposes the Textline-Region Contrastive Learning and specially crafted pre-training tasks to extract fine-grained text line information. DocFormerv2 [22] designs an asymmetric pre-training method and a simplified visual branch for visual document understanding. DocLLM [23] focuses exclusively on position information to incorporate the spatial layout structure, using a decomposed attention mechanism to build a cross-alignment between text and spatial modalities.
While advancements have been achieved, OCR-Model-Driven methods depend on text extraction from external systems, which necessitates increased computational resources and extends processing durations. Additionally, these models may inherit OCR inaccuracies, presenting challenges to document understanding and analysis tasks.
2.2 OCR-Free Methods
OCR-Free methods do not require off-the-shelf OCR engines/APIs. Donut [3] first proposes an end-to-end training method based on a Transformer without OCR. Dessurt [24], based on an architecture similar to Donut, incorporates two-way cross-attention and employs distinct pre-training methods. Pix2Struct [4] is pre-trained by learning to parse masked screenshots of web pages into simplified HTML, introducing a variable-resolution input representation and a more flexible way to integrate language and visual input. StrucTexTv2 [25] introduces a novel self-supervised pre-training framework, employing text region-level document image masking to learn end-to-end visual-textual representations.
Although these methods do not require OCR tool limitations, they still need fine-tuning for specific tasks. In the fast-growing era of Multi-Modal Large Language Models (MLLMs), some models are explicitly trained on visual text understanding datasets and fine-tuned with instructions. LLaVAR [7], mPLUG-DocOwl [10] and UniDoc [8] create novel instruction-following datasets to enhance the tuning process and improve the comprehension of text-rich images. Additional efforts have been undertaken to capture more intricate textual details. UReader [13] designs a shape-adaptive cropping module that utilizes a frozen low-resolution visual encoder to process high-resolution images. DocPedia [15] processes visual input in the frequency domain rather than pixel space to process higher-resolution images with limited visual tokens. By training a visual vocabulary on a large amount of data, Vary [26] expands its resolution and achieves impressive results. Recently, TGDoc [9] uses text-grounding to enhance document understanding, suggesting that textual grounding can improve the model’s ability to interpret textual content, thereby enhancing its understanding of images rich in textual information.
3 Methodology
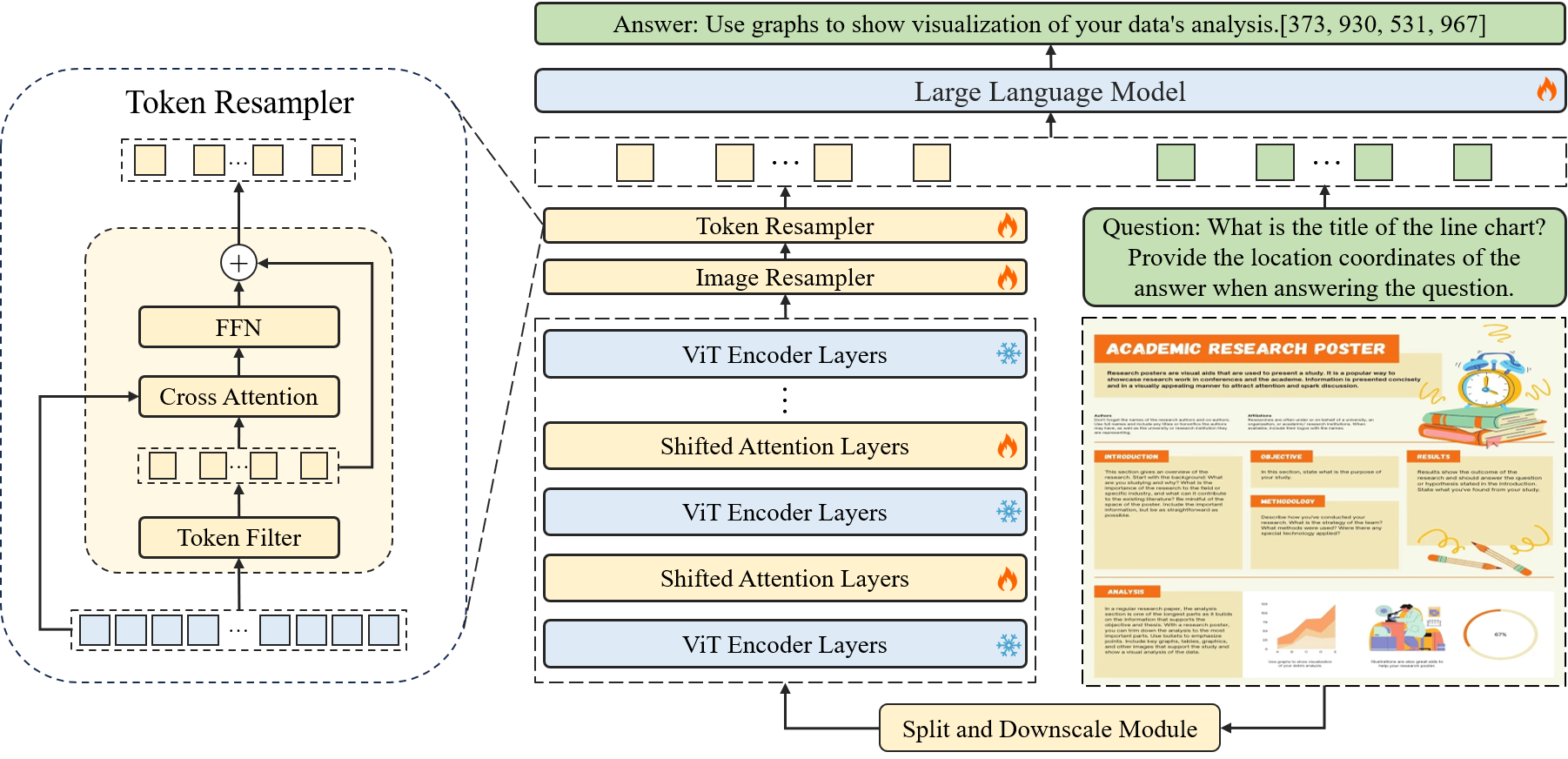
The method presented in Fig. 2 begins by dividing the input image into non-overlapping patches using a sliding window module, with each patch sized at 448x448 pixels. These patches are further subdivided into smaller patches of 14x14 pixels, each considered as a token. Utilizing Transformer blocks that inherit from the pre-trained CLIP model, we process these tokens on each window patch separately. To establish connections among various window patches, Shifted Window Attention is integrated at specific intervals within the Transformer blocks. To generate a hierarchical representation, the input image is resized to 448x448 and fed into CLIP to extract a global feature, as suggested by [14]. This global feature, alongside features from sub-images, is then processed by a shared image resampler to align with the language domain. Then, a Token Resampler is employed to further minimize redundancy in the language space by compressing the length of tokens. Ultimately, these processed features, combined with the input question, are analyzed by a Large Language Model (LLM) to produce the required answers.
3.1 Shifted Window Attention
Previous studies have underscored the significance of input resolution for precise document understanding [15, 12]. To enhance training efficiency, recent methods [14, 13] have adopted a sliding window technique to enhance image resolution. While effective in analyzing natural scenes due to their localized content, this strategy may lead to the fragmentation of connected text in document analysis, disrupting semantic continuity. Additionally, the spatial disjunction poses challenges for tasks that rely on text positioning, such as text grounding.
To alleviate the issue mentioned above, we adopt Shifted Window Attention [16] to augment the CLIP model’s visual processing capabilities. Specifically, for an input image , our approach slices the image into non-overlapping windows. This slice is achieved using a sliding window , where and indicate the window’s size. Within each window, we independently apply a transformer block from the CLIP architecture, which initially does not account for cross-window relationships. To incorporate interactions between different windows and enhance the model’s contextual understanding of the image, we adopt the Shifted Window Attention (SWA) mechanism. As mentioned in [16], the sliding window is cyclic-shifting toward the top-left direction, resulting in new windows. The self-attention computation by a masking mechanism, which limits self-attention computation to within new windows.
To achieve smoother training initialization, we have made modifications to the shifted window attention by allowing them to start learning from zero initialization, avoiding excessive transformation of early features during the initial stages. In particular, we modify the regular initialization in MLP to zero initialization to achieve smoother training, inspired by [27]:
| (1) |
where B and A refer to the weight of two linear layers. We use a random Gaussian initialization for A and zero initialization for B. This approach ensures that the image encoder’s parameters remain stable in the initial phase, facilitating a smoother training experience.
3.2 Image Resampler
To reduce the redundancy in image features initially, we inherited the image resampler from Qwen-VL [28], which is using upon every window. The module employs a set of trainable parameters as query vectors and utilizes the image features from the visual encoder as keys and values for cross-attention operations. This process helps compress the visual feature sequence to a fixed length of 256. Furthermore, to preserve positional information crucial for fine-grained image comprehension, 2D absolute positional encodings are integrated into the query-key pairs of the cross-attention mechanism.
3.3 Token Resampler
As the resolution increases, the number of tokens also significantly increases, using the slide window mechanism. However, due to limitations in the input length of some language models and training time constraints, reducing the number of tokens becomes necessary. In common visual scenarios, the previous method [29] has demonstrated the feasibility of merging token approaches.
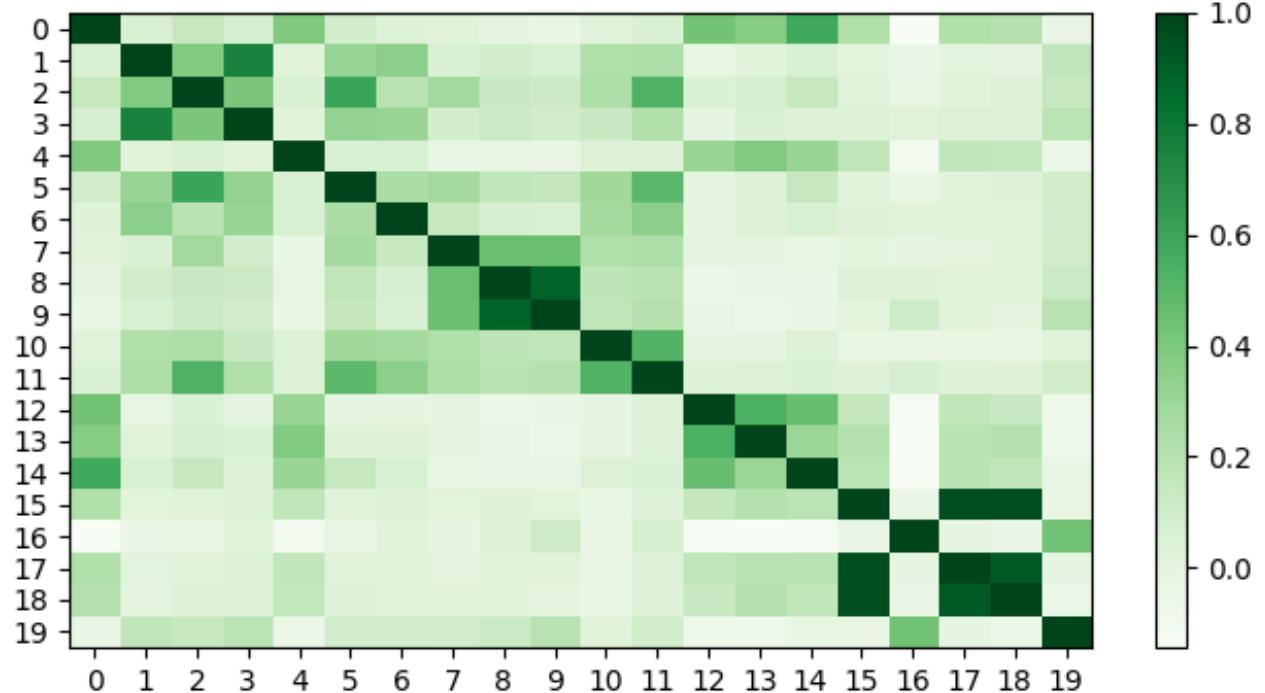
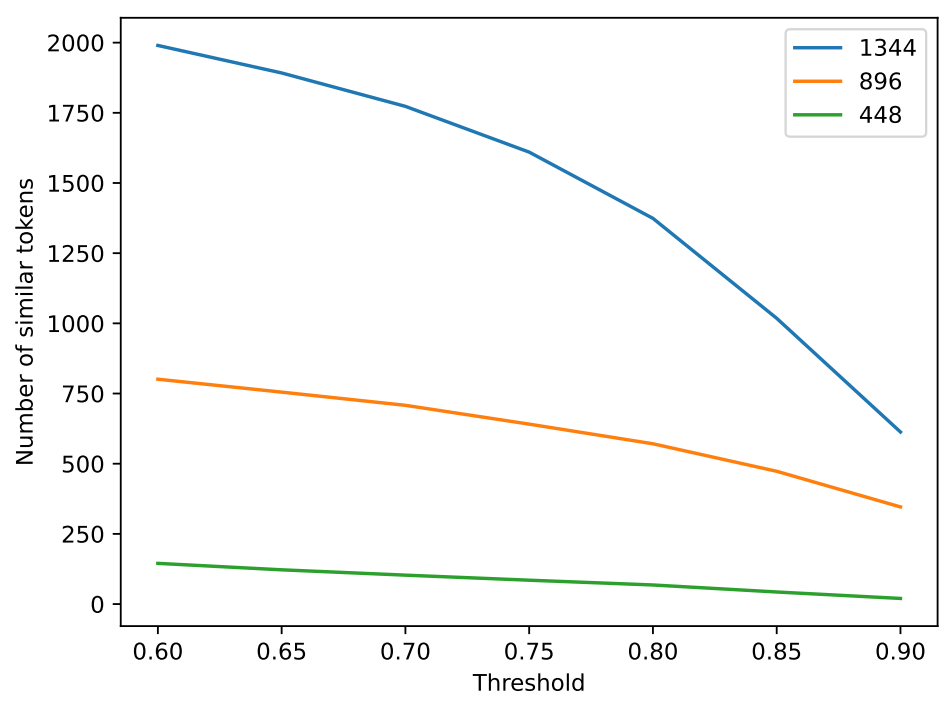
For natural language, redundant information could be repeated linguistic elements. Assuming that by expanding the resolution of the image, redundant visual information will exist. When determining the similarity between two linguistic elements, we often measure their embeddings’ similarity. To assess the redundancy of image features, we measure the similarity of image tokens already mapped to the language space. We randomly select 20 ordered features after the image resampler and compare pairwise similarities using cosine similarity, as shown in Fig. 3. Through the comparison of image tokens’ similarity, we can observe a pattern where many image tokens exhibit multiple similar tokens. Furthermore, we quantitatively compared the redundancy of tokens at different resolutions, as shown in Fig. 4. Empirically, we selected a threshold value of 0.8 as the similarity threshold, At resolutions of 448, 896, and 1334, we observed 68/256 (26.6%), 571/1024 (55.8%), and 1373/2304 (59.5%) redundant tokens, respectively. As presented in Fig. 4, with an increase in resolution, there is a higher occurrence of repeated tokens. This validates our hypothesis that while expanding the resolution can achieve clearer visibility, it also introduces some redundant features.
However, how can we identify important tokens and eliminate redundant ones? We have observed that certain tokens are highly unique and lack closely similar counterparts, such as the fifth token in Fig. 3. This suggests that this token is distinct. We hypothesize that these tokens carry crucial and distinctive information, which is further validated in subsequent experiments. Therefore, we utilize similarity as a metric to identify significant tokens.
Hence, we propose a Token Resampler to compress redundant tokens, as shown in the left part of Fig. 2. As shown in Algor. 1, we utilize a token filter algorithm to select the most valuable tokens.
To avoid information loss caused by directly discarding other tokens, we utilize important tokens as queries and employ cross-attention to further aggregate all the features. Based on the reduction of the token count, our module can also significantly improve the performance compared to random queries.
3.4 Position-Related Task
To alleviate the issue of hallucinations in Large Language Models (LLMs), where they can produce incorrect responses not related to the provided image, we aim to enhance their capability to analyze and incorporate visual information into their replies. Considering that answers to text-based tasks are often found within the image itself, we anticipate that the large model will not only produce precise responses but also identify the particular visual proof that underpins its answer.
Moreover, we have undertaken modifications to existing question-answering datasets. Specifically, we have found the positions with the majority of answers in the images. These positional cues have been extracted and seamlessly integrated into the answers themselves. To preserve the original capability of direct dialogue, we have also retained the original question-answering task.
For better perception of the spatial positions of the text, it requires the model to have a strong spatial understanding. Building upon the aforementioned model designs, we add additional training tasks to improve the model’s perception of text positions, such as text spotting and reading text. Specific tasks and prompts are shown in Tab. I. To guarantee a strong connection between text and location data, we strictly maintain their alignment, ensuring that text information always comes before any associated location details.
To standardize images of different ratios, we use a scale of (0, 1000) to represent positional information. Therefore, in an image with resolutions of (), the text coordinates (x, y) will be normalized to , and the same applies to y. The restoration process involves the inverse operation.
| Type | Prompt |
|---|---|
| Read All Text | Read all the text in the image. |
| Text Spotting | OCR with grounding: |
| Original Tasks | {Question}. Answer: |
| Position of text | <ref>text</ref> |
| Text Recognition | <ref>This</ref> |
| <box>(x1,y1),(x2,y2)</box>is | |
| VQA Grounding | {Question}. Provide the location coordinates |
| of the answer when answering the question. |
3.5 Dataset Construction
During our training process, we solely utilize open-source data and apply various task-specific augmentations to different datasets. By integrating various datasets and employing different instructions for different tasks, we enhance the model’s learning ability and training efficiency. For scene text scenario, we select COCOText [30], TextOCR [31], HierText [32], TextVQA [33], and MLT [34] for training. For document images, we select IIT-CDIP [35], DocVQA [36], ChartQA [37], InfoVQA [38], DeepForm [39], Kleister Charity (KLC) [40], and WikiTableQuestions (WTQ) [41]. To accelerate the training speed, we have transformed single-image question answering into multi-turn image-based question answering, significantly improving the utilization of image features, following the successful approach introduced in LLaVA [5]. The details of our training data are shown in Tab. II. We have a total of 409.1k pairs of dialogue data and 2.1M question-answering pairs in our dataset to train our model.
To further strengthen the model’s ability to handle structured text, we fine-tune one epoch on TextMonkey with structured data to enhance its structured capabilities, resulting in TextMonkey†. The fine-tuning data primarily consisted of 5% of the data from the previous stage, as well as a portion of structured data, including documents, tables, and charts. The structured data images are also sourced from publicly available datasets and are generated using their structure information. Therefore, we have a total of 55.7k of data in structured data.
| Task | Dataset | Samples |
| Scene Text | COCOText [30] | 16.2k |
| TextOCR [31] | 42.7k | |
| HierText [32] | 59.9k | |
| TextVQA [33] | 42.6k | |
| MLT [34] | 11.6k | |
| Document | IIT-CDIP [35] | 154.6k |
| DocVQA [36] | 22.7k | |
| ChartQA [37] | 36.6k | |
| InfoVQA [38] | 10.9k | |
| DeepForm [39] | 1.4k | |
| KLC [40] | 5.2k | |
| WTQ [41] | 4.7k | |
| Total | - | 409.1k |
3.6 Loss
Since TextMonkey is trained to predict the next tokens like other LLMs, it only requires maximizing the likelihood of loss at training time.
| (2) |
where I is the input image, Q is the question sequence, is the output sequence, s is the input sequence, is the length of the output sequence.
| Method | Scene Text-Centric VQA | Document-Oriented VQA | KIE | OCRBench | ||||||
| STVQA | TextVQA | OCRVQA | DocVQA | InfoVQA | ChartQA | FUNSD | SROIE | POIE | ||
| BLIP2-OPT-6.7B [42] | 20.9 | 23.5 | 9.7 | 3.2 | 11.3 | 3.4 | 0.2 | 0.1 | 0.3 | 235 |
| mPLUG-Owl [43] | 30.5 | 34.0 | 21.1 | 7.4 | 20.0 | 7.9 | 0.5 | 1.7 | 2.5 | 297 |
| InstructBLIP [44] | 27.4 | 29.1 | 41.3 | 4.5 | 16.4 | 5.3 | 0.2 | 0.6 | 1.0 | 276 |
| LLaVAR [7] | 39.2 | 41.8 | 24.0 | 12.3 | 16.5 | 12.2 | 0.5 | 5.2 | 5.9 | 346 |
| BLIVA [45] | 32.1 | 33.3 | 50.7 | 5.8 | 23.6 | 8.7 | 0.2 | 0.7 | 2.1 | 291 |
| mPLUG-Owl2 [46] | 49.8 | 53.9 | 58.7 | 17.9 | 18.9 | 19.4 | 1.4 | 3.2 | 9.9 | 366 |
| LLaVA1.5-7B [47] | 38.1 | 38.7 | 58.1 | 8.5 | 14.7 | 9.3 | 0.2 | 1.7 | 2.5 | 297 |
| TGDoc [9] | 36.3 | 46.2 | 37.2 | 9.0 | 12.8 | 12.7 | 1.4 | 3.0 | 22.2 | - |
| UniDoc [8] | 35.2 | 46.2 | 36.8 | 7.7 | 14.7 | 10.9 | 1.0 | 2.9 | 5.1 | - |
| DocPedia [15] | 45.5 | 60.2 | 57.2 | 47.1 | 15.2 | 46.9 | 29.9 | 21.4 | 39.9 | - |
| Monkey [14] | 54.7 | 64.3 | 64.4 | 50.1 | 25.8 | 54.0 | 24.1 | 41.9 | 19.9 | 514 |
| InternVL [48] | 62.2 | 59.8 | 30.5 | 28.7 | 23.6 | 45.6 | 6.5 | 26.4 | 25.9 | 517 |
| InternLM-XComposer2 [49] | 59.6 | 62.2 | 49.6 | 39.7 | 28.6 | 51.6 | 15.3 | 34.2 | 49.3 | 511 |
| TextMonkey | 61.8 | 65.9 | 71.3 | 64.3 | 28.2 | 58.2 | 32.3 | 47.0 | 27.9 | 561 |
| TextMonkey† | 61.2 | 64.3 | 72.2 | 66.7 | 28.6 | 59.9 | 42.9 | 46.2 | 32.0 | 558 |
4 Experiments
4.1 Implementation Details
Model Configuration. In our experiments, we utilized the well-trained Vit-BigG and LLM from Qwen-VL [28], which is a pre-trained large multimodal model. We configured the height and width (, ) of the image inputs to 448 to align with the encoder specifications of Qwen-VL. Our image resampler is equipped with 256 learnable queries, and the token resampler’s ratio (r) was set to 512 for images with a resolution of 896 and increased to 1024 for images with a resolution of 1344. To maximize training efficiency, our primary experimental focus was on using TextMonkey and evaluating outcomes at the 896 resolution setting.
TextMonkey consists of a large language model with 7.7B parameters, an image resampler module with 90M parameters, a token resampler module with 13M, an encoder with 1.9B parameters, and Shifted Window Attention with 45M parameters. Overall, TextMonkey has a total of 9.7B parameters.
Training. During the training phase, we utilized the AdamW [50] optimizer, setting the learning rate to 1e-5 for the initial stage and reducing it to 5e-6 for the subsequent stage, while adopting a cosine learning rate schedule. The parameters and were configured to 0.9 and 0.95, respectively. A warmup period comprising 150 steps was incorporated, and we processed the data in batches of 128. To mitigate the risk of overfitting, we applied a weight decay factor of 0.1. The comprehensive training procedure spanned across 12 A800 days to complete one epoch.
Evaluation. To facilitate a more equitable comparison with other approaches, we adopted the accuracy metric, where a response produced by our model is considered correct if it encompasses the ground truth. The selection of test datasets and the formulation of evaluation criteria were carried out in accordance with the methodology described in [12]. To ensure an even fairer comparison with other methods, we also performed supplementary evaluations on certain datasets utilizing their original metrics, such as F1 score and ANLS (Average Normalized Levenshtein Similarity).
| Method | Document | Table | Chart | Scene | ||
|---|---|---|---|---|---|---|
| DocVQA | DF | KLC | WTQ | ChartQA | TextVQA | |
| Donut [3] | 67.5 | 61.6 | 30.0 | 18.8 | 41.8 | 43.5 |
| Pix2Struct [4] | 72.1 | - | - | - | 56.0 | - |
| UReader [13] | 65.4 | 49.5 | 32.8 | 29.4 | 59.3 | 57.6 |
| Qwen-VL [28] | 65.1 | 3.1 | 13.9 | 21.6 | 65.7 | 63.8 |
| Monkey [14] | 66.5 | 40.5 | 33.9 | 25.3 | 65.1 | 67.6 |
| TextMonkey | 71.5 | 61.6 | 37.8 | 30.6 | 65.5 | 68.0 |
| TextMonkey† | 73.0 | 59.7 | 37.8 | 31.9 | 66.9 | 65.6 |
4.2 Results
OCRBench Results. We conduct a comparative analysis of our approach with recent large multimodal models. For our evaluation, we utilize three Scene Text-Centric VQA datasets: STVQA [51], TextVQA [33], and OCRVQA [52]; three Document-Oriented VQA datasets: DocVQA [36], InfoVQA [38], and ChartQA [37]; and three Key Information Extraction (KIE) datasets: FUNSD [53], SROIE [54], and POIE [55]. For a comprehensive assessment of performance, our evaluation includes OCRBench [12], a recent benchmark specifically developed to evaluate the Optical Character Recognition (OCR) capabilities of Large Multimodal Models. OCRBench spans a wide range of text-related visual tasks, encompassing 29 datasets, and is designed to generate an overall score.
As shown in Tab. III, our model demonstrates superior performance compared to existing large multimodal models, particularly in scenarios where the text is dense and small. Our method inherently enhances many current evaluation datasets, resulting in average performance improvements with numerous baseline methods by 5.2%, 6.9%, and 2.8% for Scene Text-Centric VQA, Document Oriented VQA and KIE, respectively. TextMonkey can achieve 64.3% on DocVQA and 58.2% on ChartQA. Specifically, our model achieved a score of 561 on OCRBench. The performance on both two challenging downstream tasks and OCRBench demonstrates its effectiveness in text-related tasks. We have found that our model tends to provide numerical answers without units, which results in a performance decrease on POIE.
| Method | Total-Text [56] | CTW1500 [57] | ICDAR 2015 [58] | |||
|---|---|---|---|---|---|---|
| Trans | Pos | Trans | Pos | Trans | Pos | |
| TOSS [59] | 61.5 | 65.1 | 51.4 | 54.2 | 47.1 | 52.4 |
| TTS [60] | - | 75.1 | - | - | - | 70.1 |
| SPTS v2 [61] | 64.7 | 75.5 | 55.4 | 63.6 | 55.6 | 72.6 |
| TextMonkey | 78.2 | 61.4 | 63.2 | 57.5 | 66.9 | 45.1 |
Document Benchmarks results. To further compare and assess the capabilities of our method, we conduct tests on additional datasets utilizing the specific evaluation metric provided in their paper: F1-score for Deepform and KLC, accuracy for WTQ, relaxed accuracy measure for ChartQA, ANLS for DocVQA, and VQA score for TextVQA.
The results, shown in Tab. IV, indicate that our model leads in performance on these datasets, outperforming other models. Across different domains, TextMonkey achieves a score of 71.5 in DocVQA, 30.6 in WTQ, 65.5 in ChartQA and 68.0 in TextVQA. It shows our model’s capability to handle documents, tables, charts, and scene text.
Text spotting results. To show the extensive capabilities of our model, we assessed its performance on text spotting datasets without finetuning, as detailed in Tab. V. Given our model’s focus on identifying complete text passages, we segmented the predicted content into individual words for analysis. We employed two evaluation methodologies to evaluate our model’s performance. In the “Trans” mode, text is considered correct if the answer contains this word. Conversely, the “Pos” mode requires the consideration of positional information in accordance with previous methods [62]. For both metrics, due to granularity issues of the output (TextMonkey often produces an integrated paragraph while others only produce desired words), the metric can not strictly follow the evaluation setup; however, both should be quite similar, as both the error and correct situations match in calculations.
To maintain TextMonkey’s consistent performance, we refrained from fine-tuning it with downstream text spotting data, unlike other methods that were optimized for either the “Trans” or “Pos” metrics. Our results reveal that, for the “Trans” metric, TextMonkey outperformed SPTS v2 by a margin of 10.9%. Regarding the “Pos” metric, it demonstrated competent text spotting capabilities, showing its ability in understanding both text content and spatial positioning.
4.3 Visualization
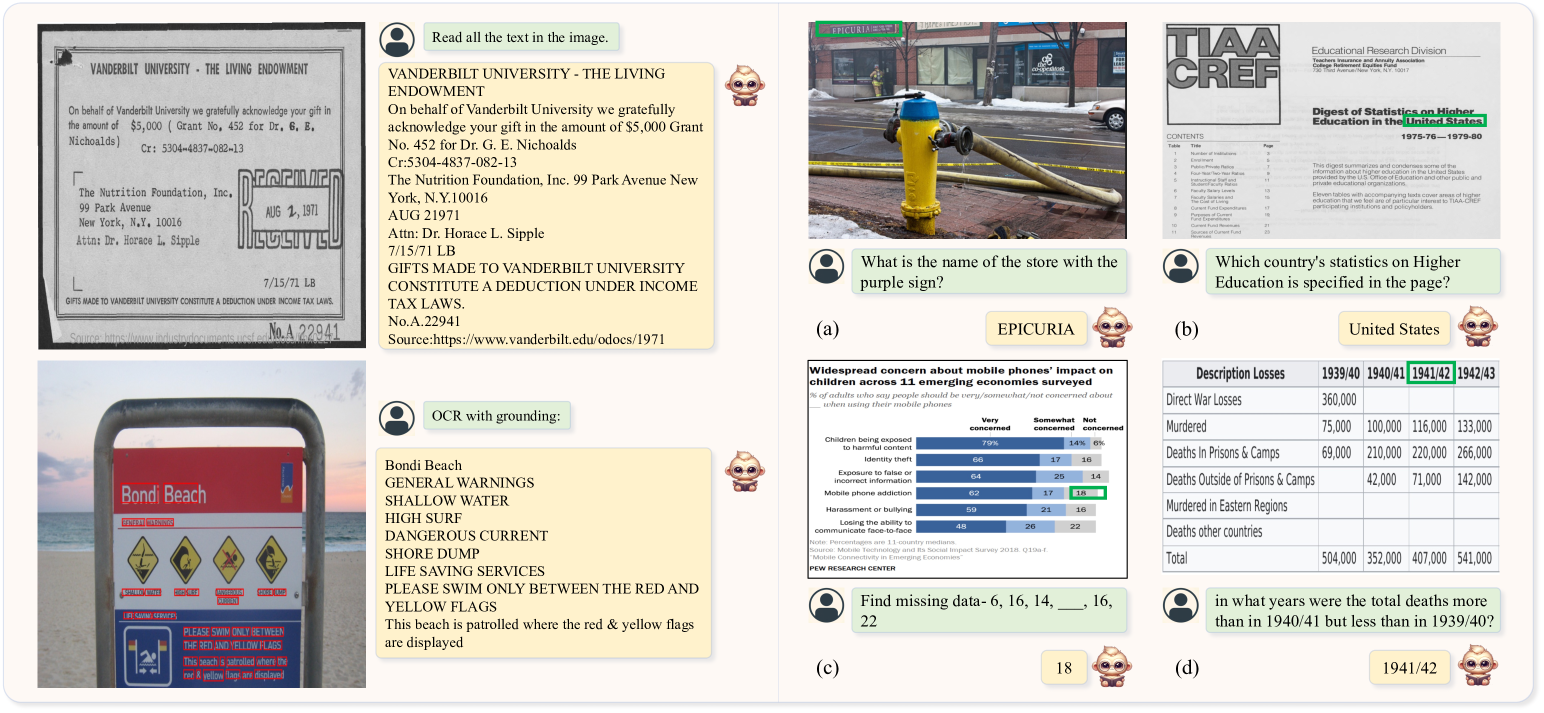
We conduct a qualitative evaluation of TextMonkey across various scenarios, including natural scenes and document images. As shown in the left part of Fig. 5, TextMonkey accurately locates and identifies text in both scene and document images. Besides, natural images in Fig. 5 (a), documents in Fig. 5 (b), charts in Fig. 5 (c), and tables in Fig. 5 (d) exemplify TextMonkey’s adeptness at discerning and interpreting visual and textual information within a wide range of scenarios. Overall, TextMonkey’s performance across diverse scenarios demonstrates its effectiveness in perceiving and comprehending textual information in various visual contexts.
| Zero Initialization | SROIE | DocVQA | TextVQA | ChartVQA |
|---|---|---|---|---|
| 46.8 | 64.1 | 65.7 | 57.6 | |
| 47.0 | 64.3 | 65.9 | 58.2 |
| W-Attn | T-Resampler | SROIE | DocVQA | TextVQA |
|---|---|---|---|---|
| 45.9 | 62.6 | 62.4 | ||
| 46.0 | 64.1 | 64.8 | ||
| 47.0 | 64.3 | 65.9 |
| Method | SROIE | DocVQA | TextVQA |
|---|---|---|---|
| w/o token filter | 32.9 | 46.7 | 59.5 |
| w/o resampler | 44.9 | 63.5 | 62.5 |
| w unsorted token filter | 46.8 | 62.1 | 64.2 |
| ours | 47.0 | 64.3 | 65.9 |
4.4 Ablation Study
Ablation study on zero initialization. Since CLIP is already pretrained, it is advisable to avoid drastic changes in features during the early training stages. As shown in Tab. VI, incorporating this zero initialization method can yield 0.6% performance gain on ChartQA.
Ablation study on different components. As shown in Tab. VII, by introducing cross-window connections, we achieved an improvement of 0.1% on SROIE, 1.5% on DocVQA, and 2.4% on TextVQA. It can be observed that cross-window connections partially compensate for the discontinuity caused by chunking and contribute to a better understanding of the images. Based on the Token Resampler, our method demonstrates better performance, achieving 1.0%, 0.2%, and 1.1% performance gain on the SROIE, DocVQA, and TextVQA. This suggests that our approach effectively preserves essential information while eliminating redundant tokens, thereby simplifying the learning process for the model.
Ablation study on strategies of reducing token length. As demonstrated in Tab. VIII, substituting important tokens with random ones (without token filter) leads to an average decline in performance by roughly 12.7%. This decline is attributed to the increased complexity of optimizing random queries, which necessitates more datasets to achieve a generalized representation compared to utilizing significant tokens. Solely focusing on pivotal features (without resampler) and directly eliminating features incurs a loss of some information, showing a decrease in performance, such as a 2.1% drop in SROIE. Additionally, neglecting the order of tokens (with unsorted token filter) does not markedly impair performance, owing to the language model’s inherent ability to organize unordered tokens. Nevertheless, the lack of token order can still lead to decrease, especially evident in the result of DocVQA, with a 2.2% decrease in performance.
Interaction between input resolution and the number of tokens remained. As shown in Tab. IX, Directly increasing the resolution without compressing tokens can actually lead to consistent worse performance, especially with a decrease of 9.2% performance in DocVQA. We speculate that the increase in resolution results in a significant increase in redundant tokens, making it more difficult to find crucial information in our setting. Therefore, compressing tokens reasonably can lead to higher performance. Considering the sparsity of information in large-sized images, it is also necessary to consider selecting an appropriate value of “r” for different input resolutions. Besides, increasing the input resolution brings benefits to the dataset, which contains many large-sized images, with 0.2% performance gain for DocVQA and 3.2% performance gain for InfoVQA. However, for datasets like TextVQA and SROIE, which contain much smaller images, increasing the input resolution directly does not yield any gains.
| Resolution | r | SROIE | DocVQA | TextVQA | InfoVQA |
|---|---|---|---|---|---|
| 896 | - | 46.0 | 64.1 | 64.8 | 29.1 |
| 896 | 256 | 47.0 | 60.9 | 65.2 | 25.9 |
| 896 | 512 | 47.0 | 64.3 | 65.9 | 28.2 |
| 1344 | - | 42.9 | 54.9 | 62.5 | 28.9 |
| 1344 | 512 | 44.9 | 59.7 | 64.2 | 28.0 |
| 1344 | 1024 | 46.0 | 64.5 | 65.1 | 31.4 |
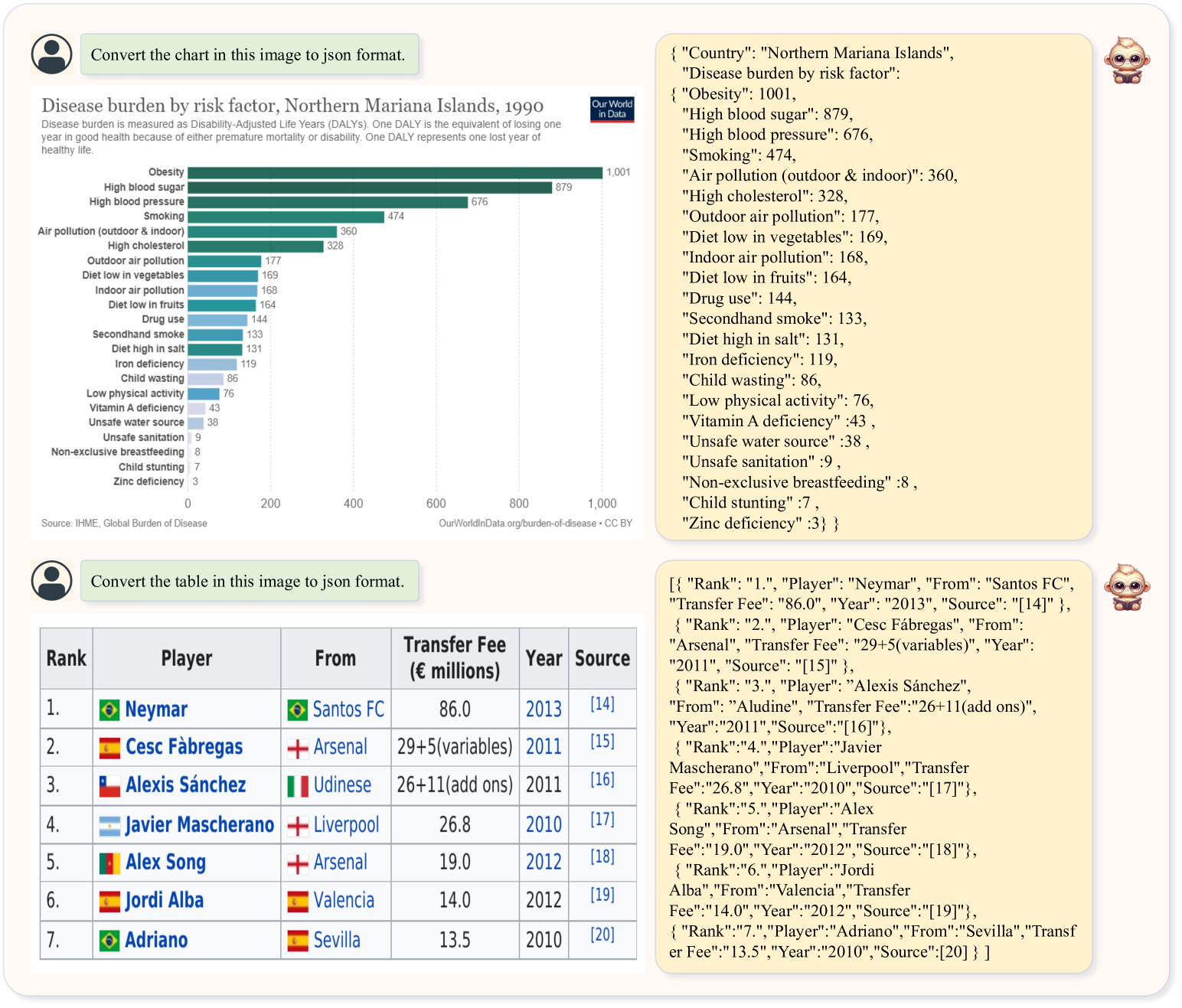
4.5 Structuralization
The structuralization of charts and tables holds substantial practical value. Structured charts and tables present data in a clear format, and by extracting structural information from images, computers can accurately parse and extract the data. This makes data analysis, statistics, and modeling more efficient and precise. It also helps reduce the complexity of information and improves its comprehensibility. As depicted in Fig. 6, our model is capable of structuring charts and tables into JSON format, demonstrating its potential for downstream applications. According to Tab. IV, TextMonkey† exhibits a performance improvement of 1.3% and 1.4% on tables and charts, respectively. This underscores that high-quality data not only enables the model’s structuralization capabilities but also amplifies the effectiveness of the related benchmarks. However, it is worth noting that this type of data will primarily benefit the data within its own domain, thus leading to a performance decrease for cross-domain TextVQA.
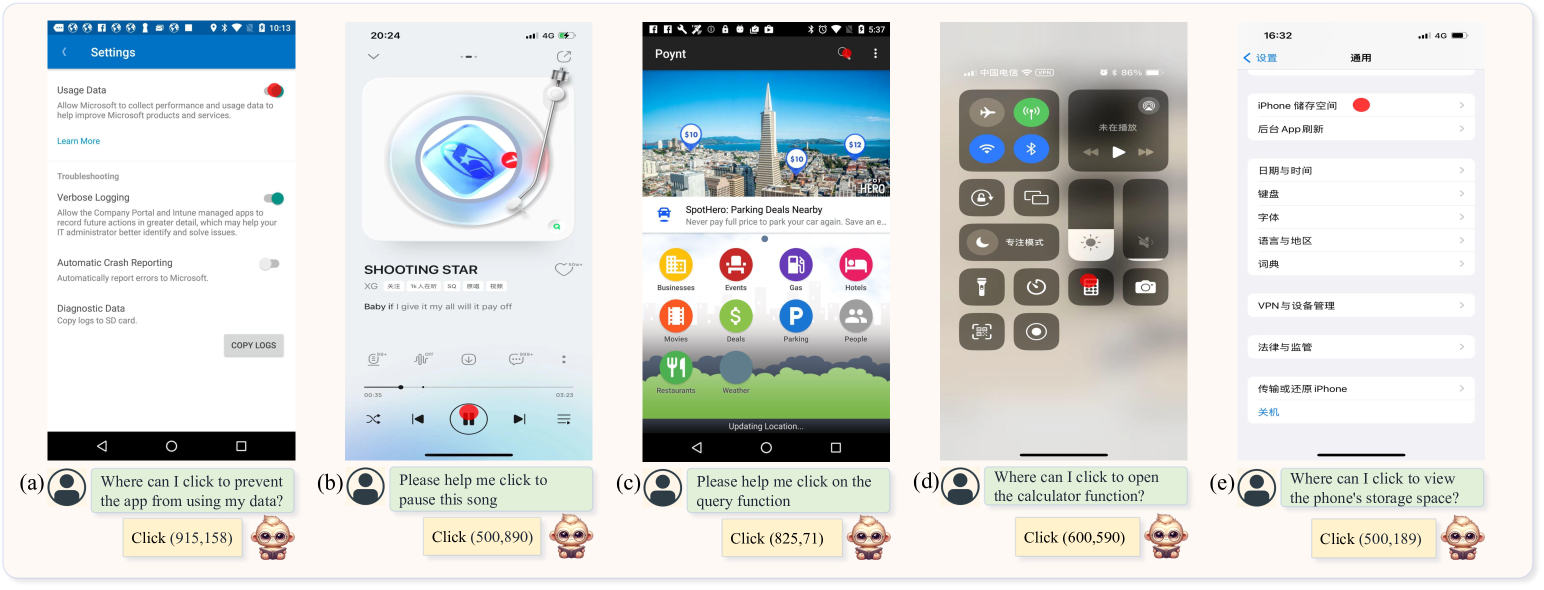
4.6 App Agent
Recently, there has been a lot of attention on using LMMs for the task of acting as agents for smartphone applications [63, 64, 65]. Unlike existing intelligent phone assistants like Siri, which operate through system back-end access and function calls, this agent interacts with smartphone applications in a human-like manner, using low-level operations such as clicking and swiping on the graphical user interface (GUI). It eliminates the need for system back-end access, enhancing security and privacy as the agent does not require deep system integration. The GUI primarily consists of icons and text, and we explore the feasibility of TextMonkey on this aspect. We transformed 15k user click data from the Rico [66] dataset and performed downstream fine-tuning using TextMonkey. As qualitatively shown in Fig. 7, our model is able to understand user intent and click on the corresponding icons, which suggests the potential of the model to serve as an app agent by using downstream data.
| Method | DocVQA | SROIE | ChartQA | InfoVQA |
|---|---|---|---|---|
| w position | 64.5 | 47.2 | 57.8 | 27.7 |
| w/o position | 64.3 | 47.0 | 58.2 | 28.2 |
5 Discussion
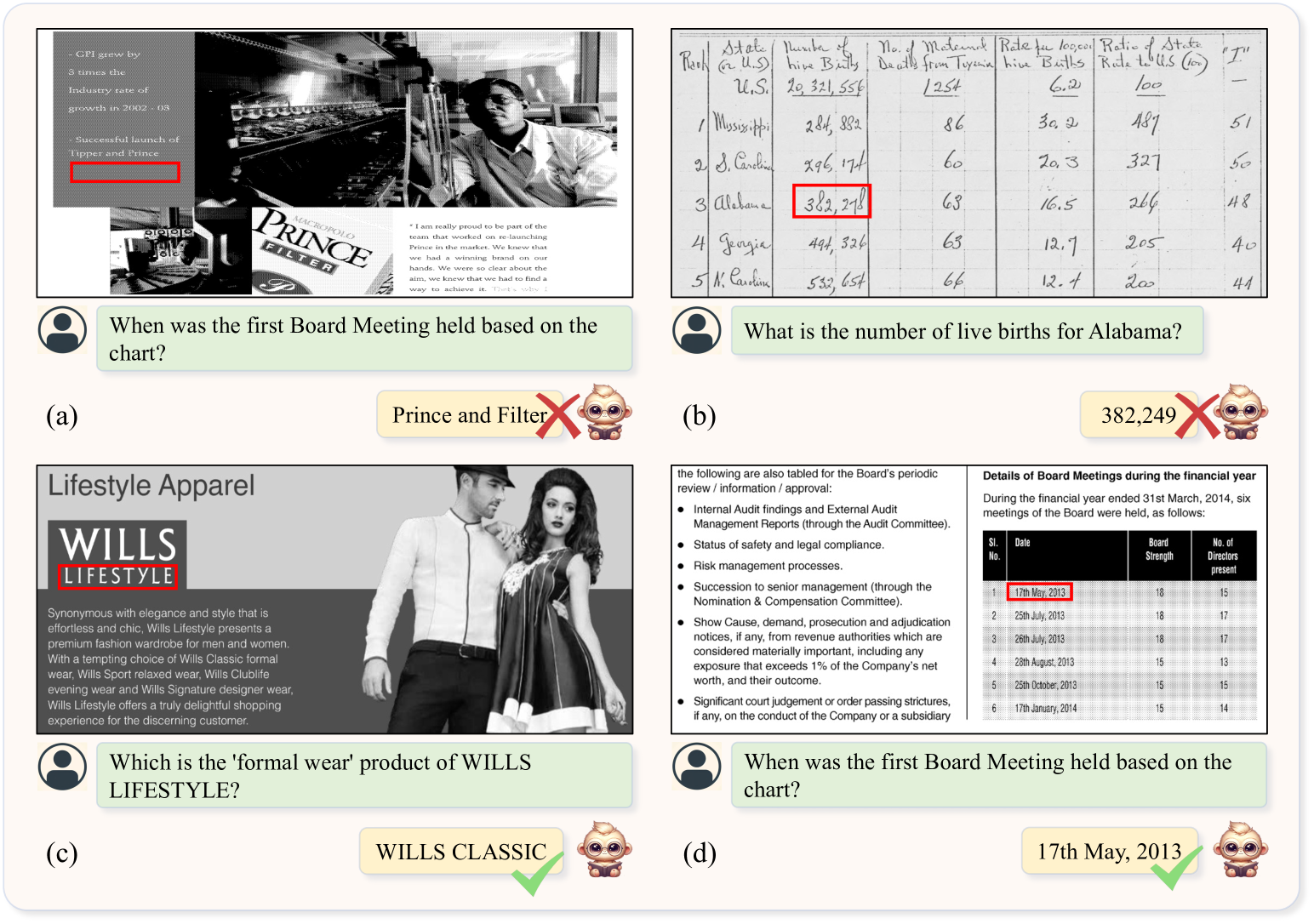
5.1 Interpretability
By examining the grounding information, we can identify the reasons behind the model’s errors, enhancing a better understanding of the model’s behavior. As shown in Fig. 8 (a), we ground to the white region, indicating that the model might be engaging in hallucination. We correctly identify the location but recognize it wrongly in Fig. 8 (b). Fig. 8 (c) highlights a scenario where the model grounds to incorrect text but still provides the correct answer. This could imply that there is some level of randomness or uncertainty in the model’s responses at this point. In Fig. 8 (d), the alignment between the position and text indicates that the model is more confident in its predictions. Therefore, based on these analyses, we can gain a better understanding of the model’s behavior and have a better awareness of the model’s hallucination, thus reducing the model’s hallucination.
5.2 Chain-of-Thought
We also conduct experiments on several datasets and observe inconsistent improvements if we require a model to provide the answer’s position, as shown in Tab. X. In datasets where the majority of answers are based on information within the images, such as DocVQA and SROIE, there is a noticeable benefit in requiring the model to provide the answer’s position. However, for datasets that involve reasoning tasks, such as ChartQA and InfoVQA, where questions require comparisons or quantitative analysis (e.g., "How much more is A than B?"), demanding positional answers can actually result in a detrimental effect. Upon further examination of the wrong answer, we consider that the requirement of grounding might have partially affected certain reasoning needs. Hence, it is essential to consider the nature of the dataset and the type of questions being asked when deciding whether to impose the requirement of positional answers.
Additionally, we believe that automating the process of constructing a thinking chain [67] in subsequent steps could be a promising direction for future research. By developing mechanisms to generate a coherent chain of reasoning automatically, we can potentially enhance the overall performance and reasoning capabilities of our models.
| Representation | SROIE | DocVQA | TextVQA | ChartVQA |
|---|---|---|---|---|
| Polygon | 47.2 | 64.0 | 65.7 | 57.9 |
| Rect | 47.0 | 64.3 | 65.9 | 58.2 |
| Point | 47.9 | 65.0 | 66.0 | 58.3 |
5.3 Comparison Between Different Representations of Position
Recently, some methods [61] have used points to represent positions instead of rectangles and polygons. Firstly, intuitively, the cost of generating points during inference would be lower compared to generating rectangles and polygons, as generating Nx points is required for other forms of bounding boxes. We aim to further investigate and experimentally validate which form is more suitable for LMMs to learn. To maintain strict consistency in our experiments, we only applied transformations to the data while keeping the other training hyperparameters the same. For the points, we selected the center points of the bounding boxes that were the most meaningful.
As demonstrated in Table XI, employing points as visual cues significantly enhances performance over rectangles. In the case of Docvqa, there was an improvement of 0.7%, while for SROIE, the enhancement reached 0.9%. Furthermore, rectangles often surpass polygons in performance. This might be attributed to the previously discussed issue that redundant image tokens could increase the complexity of the model’s learning process. Similarly, extensive position representations might face comparable obstacles. Given these considerations, along with the associated inference costs, utilizing points as representations can be a viable strategy for appropriate tasks.
6 Conclusion
This paper introduces TextMonkey to address the challenges associated with text-heavy tasks such as document question answering and fine-grained text analysis. We adopt Shifted Window Attention with zero initialization to help establish relationships while increasing input resolutions using a sliding window. Increasing the resolution simultaneously increases the number of tokens. Through analyzing the redundancy of tokens, our proposed Token Resampler effectively reduces the number of tokens. Furthermore, by engaging in multiple text-oriented tasks simultaneously, TextMonkey enhances its perception and understanding of spatial relationships, leading to improved interpretability and support for clicking screen-shots. By comparing our model with various LMMs, our model achieved excellent results on multiple benchmarks. It is worth mentioning that we also find that directly increasing the input resolution does not always lead to improvements, particularly for much smaller images. This underscores the necessity of creating an efficient method for scaling resolution in documents where size changes can be dramatic.
References
- [1] Z. Tang, Z. Yang, G. Wang, Y. Fang, Y. Liu, C. Zhu, M. Zeng, C. Zhang, and M. Bansal, “Unifying vision, text, and layout for universal document processing,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 254–19 264.
- [2] Y. Huang, T. Lv, L. Cui, Y. Lu, and F. Wei, “Layoutlmv3: Pre-training for document AI with unified text and image masking,” in MM ’22: The 30th ACM International Conference on Multimedia, Lisboa, Portugal, October 10 - 14, 2022. ACM, 2022, pp. 4083–4091.
- [3] G. Kim, T. Hong, M. Yim, J. Nam, J. Park, J. Yim, W. Hwang, S. Yun, D. Han, and S. Park, “Ocr-free document understanding transformer,” in European Conference on Computer Vision. Springer, 2022, pp. 498–517.
- [4] K. Lee, M. Joshi, I. R. Turc, H. Hu, F. Liu, J. M. Eisenschlos, U. Khandelwal, P. Shaw, M.-W. Chang, and K. Toutanova, “Pix2struct: Screenshot parsing as pretraining for visual language understanding,” in International Conference on Machine Learning. PMLR, 2023, pp. 18 893–18 912.
- [5] H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- [6] D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: Enhancing vision-language understanding with advanced large language models,” The International Conference on Learning Representations (ICLR), 2024.
- [7] Y. Zhang, R. Zhang, J. Gu, Y. Zhou, N. Lipka, D. Yang, and T. Sun, “Llavar: Enhanced visual instruction tuning for text-rich image understanding,” arXiv preprint arXiv:2306.17107, 2023.
- [8] H. Feng, Z. Wang, J. Tang, J. Lu, W. Zhou, H. Li, and C. Huang, “Unidoc: A universal large multimodal model for simultaneous text detection, recognition, spotting and understanding,” arXiv preprint arXiv:2308.11592, 2023.
- [9] Y. Wang, W. Zhou, H. Feng, K. Zhou, and H. Li, “Towards improving document understanding: An exploration on text-grounding via mllms,” arXiv preprint arXiv:2311.13194, 2023.
- [10] J. Ye, A. Hu, H. Xu, Q. Ye, M. Yan, Y. Dan, C. Zhao, G. Xu, C. Li, J. Tian et al., “mplug-docowl: Modularized multimodal large language model for document understanding,” arXiv preprint arXiv:2307.02499, 2023.
- [11] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [12] Y. Liu, Z. Li, H. Li, W. Yu, M. Huang, D. Peng, M. Liu, M. Chen, C. Li, L. Jin et al., “On the hidden mystery of ocr in large multimodal models,” arXiv preprint arXiv:2305.07895, 2023.
- [13] J. Ye, A. Hu, H. Xu, Q. Ye, M. Yan, G. Xu, C. Li, J. Tian, Q. Qian, J. Zhang et al., “Ureader: Universal ocr-free visually-situated language understanding with multimodal large language model,” in The 2023 Conference on Empirical Methods in Natural Language Processing, 2023.
- [14] Z. Li, B. Yang, Q. Liu, Z. Ma, S. Zhang, J. Yang, Y. Sun, Y. Liu, and X. Bai, “Monkey: Image resolution and text label are important things for large multi-modal models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- [15] H. Feng, Q. Liu, H. Liu, W. Zhou, H. Li, and C. Huang, “Docpedia: Unleashing the power of large multimodal model in the frequency domain for versatile document understanding,” arXiv preprint arXiv:2311.11810, 2023.
- [16] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022.
- [17] Y. Li, Y. Qian, Y. Yu, X. Qin, C. Zhang, Y. Liu, K. Yao, J. Han, J. Liu, and E. Ding, “Structext: Structured text understanding with multi-modal transformers,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 1912–1920.
- [18] Q. Peng, Y. Pan, W. Wang, B. Luo, Z. Zhang, Z. Huang, Y. Cao, W. Yin, Y. Chen, Y. Zhang et al., “Ernie-layout: Layout knowledge enhanced pre-training for visually-rich document understanding,” in Findings of the Association for Computational Linguistics: EMNLP 2022, 2022, pp. 3744–3756.
- [19] Y. Xu, M. Li, L. Cui, S. Huang, F. Wei, and M. Zhou, “Layoutlm: Pre-training of text and layout for document image understanding,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020, pp. 1192–1200.
- [20] Y. Xu, Y. Xu, T. Lv, L. Cui, F. Wei, G. Wang, Y. Lu, D. A. F. Florêncio, C. Zhang, W. Che, M. Zhang, and L. Zhou, “Layoutlmv2: Multi-modal pre-training for visually-rich document understanding,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021. Association for Computational Linguistics, 2021, pp. 2579–2591.
- [21] H. Bai, Z. Liu, X. Meng, W. Li, S. Liu, Y. Luo, N. Xie, R. Zheng, L. Wang, L. Hou, J. Wei, X. Jiang, and Q. Liu, “Wukong-reader: Multi-modal pre-training for fine-grained visual document understanding,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023. Association for Computational Linguistics, 2023, pp. 13 386–13 401.
- [22] S. Appalaraju, P. Tang, Q. Dong, N. Sankaran, Y. Zhou, and R. Manmatha, “Docformerv2: Local features for document understanding,” arXiv preprint arXiv:2306.01733, 2023.
- [23] D. Wang, N. Raman, M. Sibue, Z. Ma, P. Babkin, S. Kaur, Y. Pei, A. Nourbakhsh, and X. Liu, “Docllm: A layout-aware generative language model for multimodal document understanding,” arXiv preprint arXiv:2401.00908, 2023.
- [24] B. Davis, B. Morse, B. Price, C. Tensmeyer, C. Wigington, and V. Morariu, “End-to-end document recognition and understanding with dessurt,” in European Conference on Computer Vision. Springer, 2022, pp. 280–296.
- [25] Y. Yu, Y. Li, C. Zhang, X. Zhang, Z. Guo, X. Qin, K. Yao, J. Han, E. Ding, and J. Wang, “Structextv2: Masked visual-textual prediction for document image pre-training,” in The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023.
- [26] H. Wei, L. Kong, J. Chen, L. Zhao, Z. Ge, J. Yang, J. Sun, C. Han, and X. Zhang, “Vary: Scaling up the vision vocabulary for large vision-language models,” arXiv preprint arXiv:2312.06109, 2023.
- [27] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” in The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022.
- [28] J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A frontier large vision-language model with versatile abilities,” arXiv preprint arXiv:2308.12966, 2023.
- [29] D. Bolya, C.-Y. Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman, “Token merging: Your vit but faster,” in The Eleventh International Conference on Learning Representations, 2022.
- [30] A. Veit, T. Matera, L. Neumann, J. Matas, and S. Belongie, “Coco-text: Dataset and benchmark for text detection and recognition in natural images,” 2016.
- [31] A. Singh, G. Pang, M. Toh, J. Huang, W. Galuba, and T. Hassner, “Textocr: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8802–8812.
- [32] S. Long, S. Qin, D. Panteleev, A. Bissacco, Y. Fujii, and M. Raptis, “Towards end-to-end unified scene text detection and layout analysis,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1049–1059.
- [33] A. Singh, V. Natarajan, M. Shah, Y. Jiang, X. Chen, D. Batra, D. Parikh, and M. Rohrbach, “Towards vqa models that can read,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8317–8326.
- [34] N. Nayef, Y. Patel, M. Busta, P. N. Chowdhury, D. Karatzas, W. Khlif, J. Matas, U. Pal, J.-C. Burie, C.-l. Liu et al., “Icdar2019 robust reading challenge on multi-lingual scene text detection and recognition—rrc-mlt-2019,” in 2019 International conference on document analysis and recognition (ICDAR). IEEE, 2019, pp. 1582–1587.
- [35] D. Lewis, G. Agam, S. Argamon, O. Frieder, D. Grossman, and J. Heard, “Building a test collection for complex document information processing,” in Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval, 2006, pp. 665–666.
- [36] M. Mathew, D. Karatzas, and C. Jawahar, “Docvqa: A dataset for vqa on document images,” in Proceedings of the IEEE/CVF winter conference on applications of computer vision, 2021, pp. 2200–2209.
- [37] A. Masry, X. L. Do, J. Q. Tan, S. Joty, and E. Hoque, “Chartqa: A benchmark for question answering about charts with visual and logical reasoning,” in Findings of the Association for Computational Linguistics: ACL 2022, 2022, pp. 2263–2279.
- [38] M. Mathew, V. Bagal, R. Tito, D. Karatzas, E. Valveny, and C. Jawahar, “Infographicvqa,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 1697–1706.
- [39] S. Svetlichnaya, “Deepform: Understand structured documents at scale,” 2020.
- [40] T. Stanisławek, F. Graliński, A. Wróblewska, D. Lipiński, A. Kaliska, P. Rosalska, B. Topolski, and P. Biecek, “Kleister: key information extraction datasets involving long documents with complex layouts,” in International Conference on Document Analysis and Recognition. Springer, 2021, pp. 564–579.
- [41] P. Pasupat and P. Liang, “Compositional semantic parsing on semi-structured tables,” in Annual Meeting of the Association for Computational Linguistics, 2015.
- [42] J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” in International conference on machine learning. PMLR, 2023, pp. 19 730–19 742.
- [43] Q. Ye, H. Xu, G. Xu, J. Ye, M. Yan, Y. Zhou, J. Wang, A. Hu, P. Shi, Y. Shi et al., “mplug-owl: Modularization empowers large language models with multimodality,” arXiv preprint arXiv:2304.14178, 2023.
- [44] W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, and S. Hoi, “InstructBLIP: Towards general-purpose vision-language models with instruction tuning,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- [45] W. Hu, Y. Xu, Y. Li, W. Li, Z. Chen, and Z. Tu, “Bliva: A simple multimodal llm for better handling of text-rich visual questions,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2024.
- [46] Q. Ye, H. Xu, J. Ye, M. Yan, H. Liu, Q. Qian, J. Zhang, F. Huang, and J. Zhou, “mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- [47] H. Liu, C. Li, Y. Li, and Y. J. Lee, “Improved baselines with visual instruction tuning,” arXiv preprint arXiv:2310.03744, 2023.
- [48] Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, B. Li, P. Luo, T. Lu, Y. Qiao, and J. Dai, “Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- [49] X. Dong, P. Zhang, Y. Zang, Y. Cao, B. Wang, L. Ouyang, X. Wei, S. Zhang, H. Duan, M. Cao et al., “Internlm-xcomposer2: Mastering free-form text-image composition and comprehension in vision-language large model,” arXiv preprint arXiv:2401.16420, 2024.
- [50] I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in International Conference on Learning Representations, 2017.
- [51] A. F. Biten, R. Tito, A. Mafla, L. Gomez, M. Rusinol, E. Valveny, C. Jawahar, and D. Karatzas, “Scene text visual question answering,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 4291–4301.
- [52] A. Mishra, S. Shekhar, A. K. Singh, and A. Chakraborty, “Ocr-vqa: Visual question answering by reading text in images,” in 2019 international conference on document analysis and recognition (ICDAR). IEEE, 2019, pp. 947–952.
- [53] G. Jaume, H. Kemal Ekenel, and J.-P. Thiran, “Funsd: A dataset for form understanding in noisy scanned documents,” in 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW), vol. 2, 2019, pp. 1–6.
- [54] Z. Huang, K. Chen, J. He, X. Bai, D. Karatzas, S. Lu, and C. V. Jawahar, “ICDAR 2019 competition on scanned receipt ocr and information extraction,” in 2019 International Conference on Document Analysis and Recognition (ICDAR), 2019, pp. 1516–1520.
- [55] J. Kuang, W. Hua, D. Liang, M. Yang, D. Jiang, B. Ren, and X. Bai, “Visual information extraction in the wild: practical dataset and end-to-end solution,” in International Conference on Document Analysis and Recognition. Springer, 2023, pp. 36–53.
- [56] C. K. Ch’ng and C. S. Chan, “Total-text: A comprehensive dataset for scene text detection and recognition,” in 2017 14th IAPR international conference on document analysis and recognition (ICDAR), vol. 1. IEEE, 2017, pp. 935–942.
- [57] Y. Liu, L. Jin, S. Zhang, C. Luo, and S. Zhang, “Curved scene text detection via transverse and longitudinal sequence connection,” Pattern Recognition, vol. 90, pp. 337–345, 2019.
- [58] D. Karatzas, L. Gomez-Bigorda, A. Nicolaou, S. Ghosh, A. Bagdanov, M. Iwamura, J. Matas, L. Neumann, V. R. Chandrasekhar, S. Lu et al., “Icdar 2015 competition on robust reading,” in 2015 13th international conference on document analysis and recognition (ICDAR). IEEE, 2015, pp. 1156–1160.
- [59] J. Tang, S. Qiao, B. Cui, Y. Ma, S. Zhang, and D. Kanoulas, “You can even annotate text with voice: Transcription-only-supervised text spotting,” in Proceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 4154–4163.
- [60] Y. Kittenplon, I. Lavi, S. Fogel, Y. Bar, R. Manmatha, and P. Perona, “Towards weakly-supervised text spotting using a multi-task transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4604–4613.
- [61] Y. Liu, J. Zhang, D. Peng, M. Huang, X. Wang, J. Tang, C. Huang, D. Lin, C. Shen, X. Bai et al., “Spts v2: single-point scene text spotting,” arXiv preprint arXiv:2301.01635, 2023.
- [62] Y. Liu, C. Shen, L. Jin, T. He, P. Chen, C. Liu, and H. Chen, “ABCNet v2: Adaptive bezier-curve network for real-time end-to-end text spotting,” vol. 44, no. 11, pp. 8048–8064, 2022.
- [63] Z. Yang, J. Liu, Y. Han, X. Chen, Z. Huang, B. Fu, and G. Yu, “Appagent: Multimodal agents as smartphone users,” arXiv preprint arXiv:2312.13771, 2023.
- [64] J. Wang, H. Xu, J. Ye, M. Yan, W. Shen, J. Zhang, F. Huang, and J. Sang, “Mobile-agent: Autonomous multi-modal mobile device agent with visual perception,” arXiv preprint arXiv:2401.16158, 2024.
- [65] R. Niu, J. Li, S. Wang, Y. Fu, X. Hu, X. Leng, H. Kong, Y. Chang, and Q. Wang, “Screenagent: A vision language model-driven computer control agent,” arXiv preprint arXiv:2402.07945, 2024.
- [66] B. Deka, Z. Huang, C. Franzen, J. Hibschman, D. Afergan, Y. Li, J. Nichols, and R. Kumar, “Rico: A mobile app dataset for building data-driven design applications,” in Proceedings of the 30th annual ACM symposium on user interface software and technology, 2017, pp. 845–854.
- [67] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou et al., “Chain-of-thought prompting elicits reasoning in large language models,” Advances in Neural Information Processing Systems, vol. 35, pp. 24 824–24 837, 2022.