Shanghai Jiao Tong University, Shanghai, 200240, China
11email: yi.hong@sjtu.edu.cn
Med3DInsight: Enhancing 3D Medical Image Understanding with 2D Multi-Modal Large Language Models
Abstract
Understanding 3D medical image volumes is a critical task in the medical domain. However, existing 3D convolution and transformer-based methods have limited semantic understanding of an image volume and also need a large set of volumes for training. Recent advances in multi-modal large language models (MLLMs) provide a new and promising way to understand images with the help of text descriptions. However, most current MLLMs are designed for 2D natural images. To enhance the 3D medical image understanding with 2D MLLMs, we propose a novel pre-training framework called Med3DInsight, which marries existing 3D image encoders with 2D MLLMs and bridges them via a designed Plane-Slice-Aware Transformer (PSAT) module. Extensive experiments demonstrate our SOTA performance on two downstream segmentation and classification tasks, including three public datasets with CT and MRI modalities and comparison to more than ten baselines. Med3DInsight can be easily integrated into any current 3D medical image understanding network and improves its performance by a good margin. Our source code is publicly available at https://github.com/Qybc/Med3DInsight.
Keywords:
3D Medical Image Understanding Multi-modal Large Language Model Self Supervised Learning.1 Introduction
In medical research, analyzing and interpreting three-dimensional medical images is a critical task, which extracts valuable information for diagnosis, treatment planning, and other research in the field of healthcare. To understand 3D medical images, researchers often design different models according to specific purposes, e.g., 3D image classification models [14, 2], 3D medical image segmentation models [6, 10, 30]. Also, in the deep learning era, these models have limited semantic understanding of a 3D medical image, whose feature extraction is treated as a black box. We aim to design a pre-training framework for learning a general 3D medical image representation that has enhanced the semantic understanding of medical content in 3D scans, which can apply to multiple downstream tasks, including both image classification and segmentation.
Language description is an efficient way to improve image understanding through the integration of natural language processing and computer vision techniques. Recently, multi-modal large language models (MLLMs) [16, 1, 22] have demonstrated impressive capabilities in enabling natural language to discuss and comprehend various visual scenes. Despite MLLMs excelling at processing 2D image content, their comprehension of the more challenging 3D medical volumes remains an open question. A couple of works explore the potential of leveraging existing MLLMs for 3D medical understanding, such as MedBLIP [5], GTGM [7], and T3D [17]. These methods either project 3D images to 2D representation as inputs of MLLMs [7] or augment 2D MLLMs with 3D adaptors [5], which are not pure 3D representation learners with losing the whole understanding of a 3D image. Alslthough these methods align image and text features, unlike the image encoder in an MLLM, they lack the semantic understanding of a 3D image.
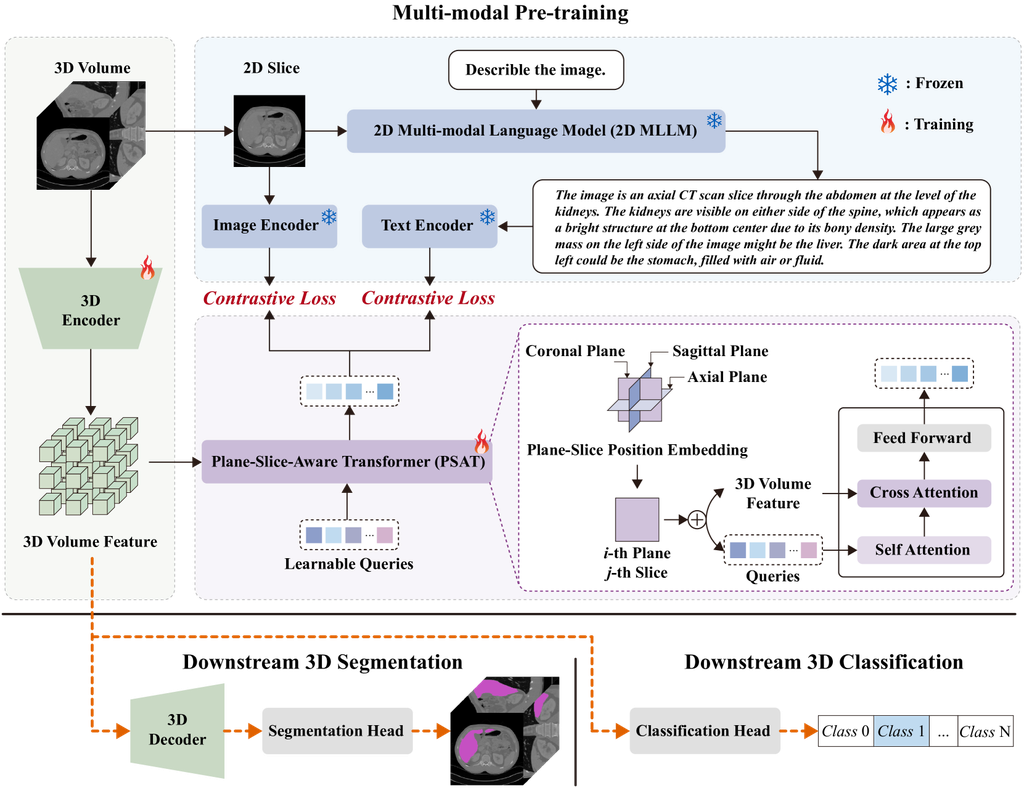
To address the above challenges, we propose to enhance a 3D image encoder using the image-text alignment technique as in MLLMs. However, unlike those in the computer vision domain, medical datasets with image-text pairs for 3D medical scans are extremely rare, even collecting a large set of 2D medical image-text pairs is a non-trivial task. In addition, there is a large gap between 3D medical image understanding with the current MLLMs designed for 2D nature images. Fortunately, GPT-4V(ision) [22] vision has already developed abilities for 2D medical imaging explanations [28]. Therefore, we introduce a novel 3D medical image representation learning framework, i.e., Med3DInsight, which aligns 3D image understanding with the help of 2D MLLMs, as shown in Fig. 1.
Mde3DInsight aligns 3D volume features with both 2D image and text features via contrastive learning [24]. To bridge the gap between 3D and 2D feature spaces, we design a Plane-Slice-Aware Transformer (PSAT) module, which embeds the plane and slice position of a slice in a 3D volume and adopts learnable query techinque [3] to project 3D features into 2D feature space for mapping. We adopt GPT-4V(ision) [22] to generate detailed text descriptions for 2D medical slices that are extracted from 3D image scans. To align image and text modalities in the same feature space [27], we fine-tune image and text encoders of CLIP [24] using the slice-text pairs generated by GPT-4V. During pre-training, we keep the GPT-4V and CLIP model frozen and train the 3D image encoder and PSAT module, resulting in a pretrained 3D image encoder for downstream segmentation and classification tasks.
Overall, our contributions are summarized as follows:
-
•
We propose a new framework Med3DInsight, which leverages 2D MLLMs to enhance medical image understanding of an existing 3D encoder. Our framework is general and improves multiple recent models, resulting in the state-of-the art (SOTA) performance for both 3D segmentation and classification on MM-WHS [31], CHAOS [15], and OASIS [20] datasets.
-
•
We design a Plane-Slice-Aware Transformer (PSAT) module that bridges the 3D medical image encoder with the 2D vision-language models. This module allows learning a mapping that is aware of the spatial orientation of visual features, which can be applied in other applications with need of establishing 2D and 3D feature mappings.
2 Methodology
Fig. 1 presents the overview of our Med3DInsight framework, which can be divided into pre-training and downstream tasks. Pre-training includes three components, i.e., the 3D image encoder, the 2D MLLMs, and the Plane-Slice-Aware Transformer (PSAT) module. Regarding the 3D image encoder, we can choose an encoder of an existing model, such as SETR [29], UNETR [10], nnFormer [30], Vit [8], Swin-ViT [18], etc. Based on the image volumes used for pre-training, we first create slice and text pairs for 2D MLLMs and then use the PSAT module to make the connection between 2D and 3D feature spaces.
Data Collection and 2D Feature Extraction. We choose a public 3D medical dataset 3DSeg-8 [6] for pre-training. This dataset has a collection of 2K images of various modalities, e.g., MRI, CT, and different body parts, including brain, heart, prostate, spleen, etc. These image scans are collected from multiple centers and have various spatial resolutions and intensity ranges. For each 3D medical volume image in this dataset, we create a triplet of a medical volume , an image slice extracted from the i-th plane (i.e., coronal, sagittal, or axial plane) and the j-th slice, and its corresponding text description .
(1) Slice and Feature Extraction. To obtain the image slice set , we extract all image slices of each image volume from all three planes. During each iteration of pre-training, we randomly select one image slice from a plane of an image volume as and take it as input of the image encoder adopted from CLIP to extract the its feature , as shown in Fig. 1.
(2) Text Generation and Feature Extraction. We employ a 2D MLLM (e.g., GPT-4V [22]) to generate the text descriptions of a specific 2D slice , as shown in Fig. 1. Then, we input this text description into our text encoder adopted from CLIP and obtain the text feature representation of the image slice , i.e., .
In this way, we convert a triplet data into a triplet feature set , where and is the selected 3D image encoder.
PSAT Alignment. In the feature sets , we have both 3D image features and 2D image and text feature pairs , an alignment is desired to bridge the 2D and 3D gap and allow for the self-training based on contrastive learning. Here, we adopt the query techinque [3] augmented by knowing the plane-slice position of the randomly selected image slice.
As shown in Fig. 1, the PSAT module includes a set of learnable query embeddings. In the experiments, we set to 300 for a convenient projection into the image and text embedding space of the CLIP. These learnable queries interact with each other through a self-attention layer, then interact with the volume feature through a cross-attention layer and produces an output encoded visual vectors, one for each query embedding. These vectors then undergo processing through a multi-layer perceptron (MLP), resulting in the projection of the volume embedding, which is fed into the alignment with the image slice and text embedding via a contrastive loss [24].
Since the image slice is extracted from the image volume and located at the -th slice of the -th plane, the 3D-2D projection should be aware of this orientation relationship between image volume and slice. Therefore, we introduce a plane-slice position embedding for the volume feature to promote the model’s capacity of learning orientation and geometric relationships.
Specifically, we first construct the plane-slice position embedding with zero initial parameters, where is the embedding dim of model, is the number of planes, and is the number of slices. During pre-training, when dealing with a slice image , for instance, when a sample related to the eight slice (i.e., ) of the coronal plane (i.e., ), we only inject the eight slice at the coronal plane position embedding into volume feature and queries, following general positional encoding [26].
By aligning to 2D image slice and text features, we enhance the 3D medical image understanding in a self-learning way. Meanwhile, it has the potential to reduce the data requirement of image volumes, since the model is built upon pre-trained 2D MLLMs and we have millions of 2D image slices from the 2K image volumes of our pre-training dataset, which is demonstrated in our experiments.
3 Experiments
To demonstrate the effectiveness of our pre-training 3D framework Med3DInsight, we conduct experiments on two groups of downstream tasks: 3D segmentation, including cardiac structure segmentation, abdominal organ segmentation, and brain segmentation, and 3D classification of Alzherimer’s Disease (AD) and Normal Controls (NC). Then, we present detailed ablation studies and qualitative analysis to provide a deeper understanding of our approach.
3.1 Datasets and Experimental Settings
MM-WHS [31]. For cardiac segmentation, we used the Multi-Modality Whole Heart Segmentation (MM-WHS) Challenge 2017 dataset [31], consisting of unpaired 20 CT and 20 MRI scans with ground-truth pixel-level annotations acquired in the real clinical environment, including five labels, i.e., i.e., left ventricle blood cavity (LVC), right ventricle blood cavity (RVC), left atrium blood cavity (LAC), right atrium blood cavity (LAC), and ascending aorta (AA). In this experiment, we use CTs, consist of 177 to 363 slices with 512×512 pixels and voxel spacing ranging from 0.3 to 0.6 mm.
CHAOS [15]. For abdominal organ segmentation, we use the training dataset comprised of 20 abdominal CT images from the ISBI 2019 CHAOS Challenge [15], including only one abdominal organ, i.e., the liver, for segmentation. Each CT scan consist of 81 to 266 slices with 512×512 pixels and voxel spacing ranging from 0.6 to 2.0 mm.
OASIS [20]. For brain segmentation, we use the open-access OASIS1 dataset [20], including 414 subjects pre-processed with FreeSurfer [9] and SAMSEG [23]. Our method is applied to segment four brain substructures, i.e., Cortex, Gray-Matter (GM), White-Matter (WM), and Cerebrospinal fluid (CSF). Each MRI scan’s image size is 160×192×224 and voxel spacing is 1.0 mm. For alzheimer’s disease classification, we use the open-access OASIS2 dataset [19], consists of 335 T1-weighted sMRI scans collected from 135 subjects, including both AD subjects and healthy volunteers. Each MRI scan’s image size is 224×224×224 and voxel spacing is 1.75 mm.
Since the image volumes used in the downstream datasets have various image resolutions and spacing, all image volumes are re-sampled into the isotropic voxel spacing of 1.0 mm in each dimension, and the image size of volumes ranges from 144×144×161 to 400×400×256. The voxel intensities of the images are then normalized to the range [0,1]. To simplify the preprocessing step, all images are first padded to a cube shape and then scaled to a unified size of 128 × 128 × 128 as inputs. We subject-wisely split the data into training, validation, and testing with a ratio of 7:1:2.
Backbones, Baselines, and Other Settings. For the 3D image encoder, we employ the SOTA 3D backbone, e.g., SETR [29], UNETR [10], and nnFormer [30] for segmentation, ViT [8] and Swin-ViT [18] for classification. For the segmentation task, we utilize both cross entropy loss and dice loss by simply averaging them. For the classification task, we utilize the cross-entropy loss. All experiments are conducted on NVIDIA GeForce RTX 3090 GPUs. For comparison, we select five baselines for 3D image segmentation, including UNet [25], AttUNet [21], Med3D [6], TransUNet [4], nnUNet [13], and also five baselines for classification, including 3D ResNet50 [11], 3D DenseNet121 [12], MRNet [2], MedicalNet [6], and M3T [14]. For the PSAT module, we set the token number of learnable queries to 300, and the dimension of the token is 512. Med3DInsight is trained for 300 epochs. We set the batch size as 32 and the learning rate as . AdamW is our optimizer for training Med3DInsight.
| Methods | MM-WHS | CHAOS | OASIS | |||||||||
| LVC | RVC | LAC | RAC | AA | Avg. | Liver | Cortex | GM | WM | CSF | Avg. | |
| UNet [25] | 80.9 | 78.1 | 76.6 | 72.3 | 74.7 | 76.5 | 79.9 | 70.9 | 83.3 | 83.2 | 80.5 | 79.5 |
| AttUNet [21] | 81.0 | 78.9 | 77.1 | 74.2 | 75.2 | 77.3 | 79.7 | 70.8 | 83.1 | 83.1 | 79.8 | 79.2 |
| Med3D [6] | 83.0 | 77.1 | 81.6 | 74.9 | 77.9 | 78.9 | 81.2 | 76.4 | 85.5 | 87.7 | 84.5 | 83.5 |
| TransUNet [4] | 82.9 | 76.9 | 80.8 | 76.1 | 78.6 | 79.1 | 82.6 | 76.6 | 85.6 | 87.3 | 84.7 | 83.6 |
| nnUNet [13] | 83.9 | 76.6 | 78.9 | 76.8 | 81.9 | 79.6 | 84.8 | 77.2 | 86.0 | 88.0 | 85.5 | 84.2 |
| SETR [29] | 85.1 | 77.2 | 80.5 | 75.7 | 81.7 | 80.0 | 86.2 | 81.5 | 86.9 | 84.5 | 87.2 | 85.0 |
| +Med3DInsight | 85.2 | 81.5 | 81.6 | 80.4 | 85.7 | 82.9 | 89.8 | 82.6 | 89.1 | 88.3 | 90.1 | 87.5 |
| +2.9 | +3.6 | +2.5 | ||||||||||
| UNetr [10] | 85.9 | 81.0 | 83.4 | 80.2 | 87.2 | 83.5 | 89.9 | 80.3 | 88.0 | 89.5 | 88.2 | 86.5 |
| +Med3DInsight | 86.5 | 81.2 | 85.3 | 83.5 | 89.7 | 85.2 | 91.2 | 83.0 | 90.1 | 91.3 | 90.4 | 88.7 |
| +1.7 | +1.3 | +2.2 | ||||||||||
| nnFormer [30] | 85.2 | 83.3 | 85.5 | 85.0 | 90.6 | 85.9 | 91.9 | 89.1 | 93.1 | 94.6 | 92.8 | 92.4 |
| +Med3DInsight | 89.3 | 89.1 | 86.5 | 87.4 | 90.5 | 88.6 | 94.1 | 92.6 | 94.2 | 96.8 | 95.3 | 94.7 |
| +2.7 | +2.2 | +2.3 | ||||||||||
| Methods | OASIS | |
| Accuracy(%) | AUC(%) | |
| 3D ResNet50 [11] | 66.2 | 65.9 |
| 3D DenseNet121 [12] | 72.3 | 72.7 |
| MRNet [2] | 70.8 | 71.9 |
| MedicalNet [6] | 73.9 | 72.7 |
| M3T [14] | 80.2 | 81.7 |
| ViT [8] | 80.5 | 82.6 |
| +Med3DInsight | 81.4 | 84.3 |
| +0.9 | +1.7 | |
| Swin-ViT [18] | 82.8 | 84.4 |
| +Med3DInsight | 84.1 | 85.7 |
| +1.3 | +1.3 | |
3.2 Experimental Results And Ablation Study
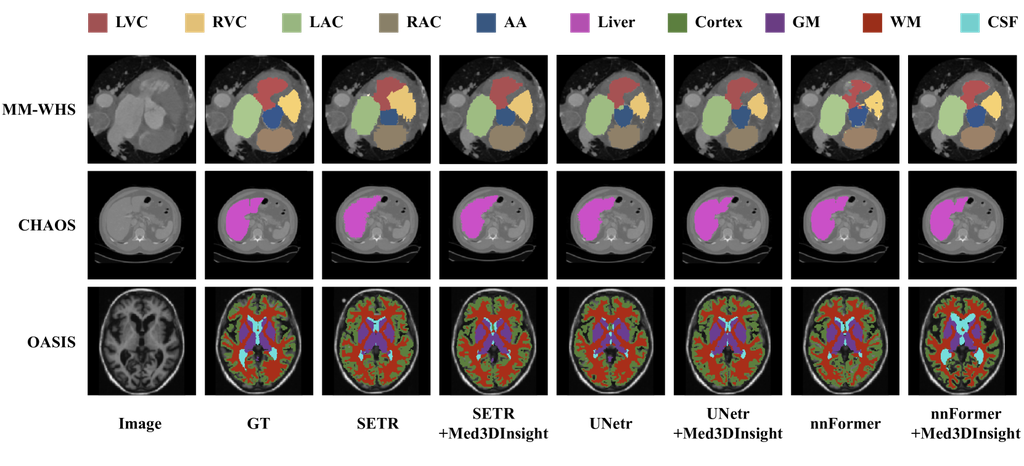
Table 1 reports the 3D segmentation results on the MM-WHS, CHAOS, and OASIS datasets, and Table 2 reports the 3D classification results on OASIS. Experimental results show that Med3DInsight enhances all backbones and improves both segmentation and classification results by over 2% mean Dice and 1% classification accuracy, respectively. Also, all Med3DInsight-augmented methods outperform all baselines. For 3D segmentation, the combination of Med3DInsight with nnFormer achieves the SOTA performance on all three segmentation tasks. For 3D classification, the combination of Swin-ViT with Med3DInsight performs the best on the OASIS dataset. Fig. 2 visualizes the qualitative comparison of 3D segmentation results. Med3DInsight shows improved segmentation performance of baselines. Specifically, our model demonstrates better performance in capturing the fine-grained details of organs or substructures.
Effectiveness of the PSAT Model. To demonstrate the effectiveness of each component in PSAT, we perform an ablation study on the OASIS 3D segmentation task. As shown in Table 3, denotes the absence of any transformer structure and position embedding. In this case, the 3D image feature is directly input to a projection layer to align the dimensions and is then fed to the calculate contrastive loss to align with the features of 2D vision-language of CLIP. In , with the use of Query Transformer, we observe that the dice score achieves 93.9%. The results demonstrate that the structure of the Query Transformer can better align 3D medical image features with 2D vision-language features. Compared with and , the introduction of the Plane-Slice Position embedding achieves an 0.8% dice score improvement. This set of results affirms that incorporating the Plane-Slice Position embedding aids the model in better understanding 3D scenes and spatial relationships.
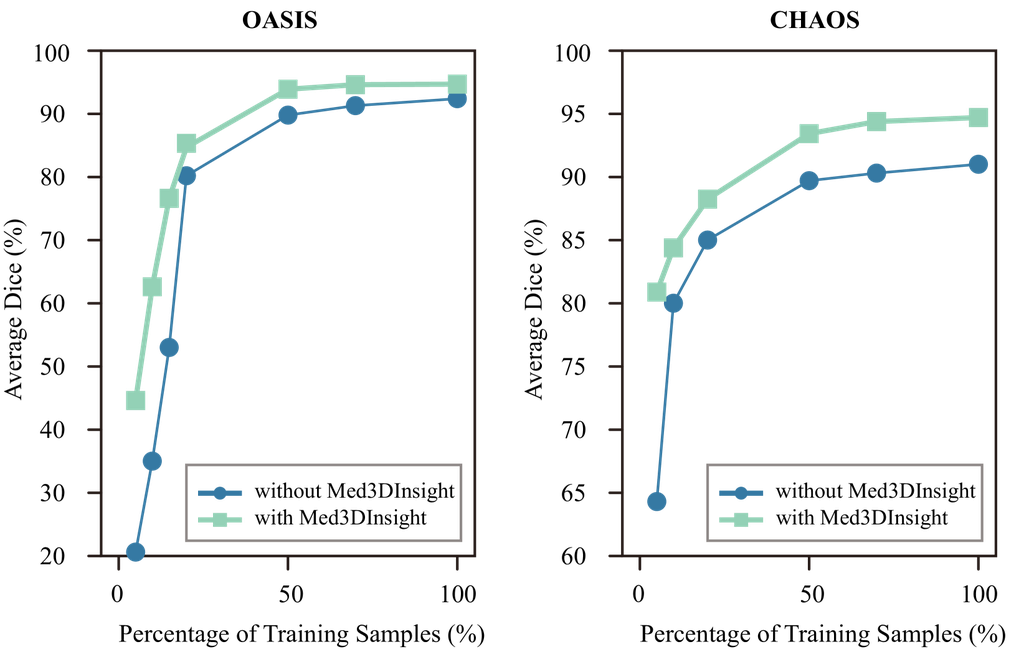
Data Efficiency. Model pre-training can potentially reduce the demand for labeled data in downstream tasks. We validate the data efficiency by comparing the effectiveness of using our Med3DInsight based on nnFormer, under a varying number of fine-tuning samples. Fig. 3 presents the comparison results, showing that the nnFormer’s performance is largely improved in the low data regime when being pre-trained under the Med3DInsight framework. We observe that Med3DInsight performs better on CHAOS than on the OASIS dataset when using less than 20% training data. This is probably because our model is pre-trained on the 3DSeg-8 dataset, which has a large amount of abdominal CT images. Even in this situation, Med3DInsight still improves the performance on OASIS by a good margin.
4 Conclusion and Discussion
In this paper, we propose a new pre-training framework Med3DInsight, which utilizes 2D MLLMs to enhance medical image understanding and improve the downstream segmentation and classification performance of multiple current 3D image understanding networks. To bridge the feature space gap between the 3D image encoder and 2D MLLMs, we introduce the Plane-Slice-Aware Transformer (PSAT) based on the learnable query technique. Experimental results demonstrate the consistent improvements of our method in downstream tasks. In future work, we consider further exploring the semantic understanding of the 3D image volume in our framework, by integrating with large language models for 3D image caption or 3D visual question answering.
References
- [1] Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems 35, 23716–23736 (2022)
- [2] Bien, N., Rajpurkar, P., Ball, R.L., Irvin, J., Park, A., Jones, E., Bereket, M., Patel, B.N., Yeom, K.W., Shpanskaya, K., et al.: Deep-learning-assisted diagnosis for knee magnetic resonance imaging: development and retrospective validation of mrnet. PLoS medicine 15(11), e1002699 (2018)
- [3] Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020)
- [4] Chen, J., Lu, Y., Yu, Q., Luo, X., Adeli, E., Wang, Y., Lu, L., Yuille, A.L., Zhou, Y.: Transunet: Transformers make strong encoders for medical image segmentation. arXiv preprint arXiv:2102.04306 (2021)
- [5] Chen, Q., Hu, X., Wang, Z., Hong, Y.: Medblip: Bootstrapping language-image pre-training from 3d medical images and texts. arXiv preprint arXiv:2305.10799 (2023)
- [6] Chen, S., Ma, K., Zheng, Y.: Med3d: Transfer learning for 3d medical image analysis. arXiv preprint arXiv:1904.00625 (2019)
- [7] Chen, Y., Liu, C., Huang, W., Cheng, S., Arcucci, R., Xiong, Z.: Generative text-guided 3d vision-language pretraining for unified medical image segmentation. arXiv preprint arXiv:2306.04811 (2023)
- [8] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
- [9] Fischl, B.: Freesurfer. Neuroimage 62(2), 774–781 (2012)
- [10] Hatamizadeh, A., Tang, Y., Nath, V., Yang, D., Myronenko, A., Landman, B., Roth, H.R., Xu, D.: Unetr: Transformers for 3d medical image segmentation. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 574–584 (2022)
- [11] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
- [12] Iandola, F., Moskewicz, M., Karayev, S., Girshick, R., Darrell, T., Keutzer, K.: Densenet: Implementing efficient convnet descriptor pyramids. arXiv preprint arXiv:1404.1869 (2014)
- [13] Isensee, F., Jaeger, P.F., Kohl, S.A., Petersen, J., Maier-Hein, K.H.: nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods 18(2), 203–211 (2021)
- [14] Jang, J., Hwang, D.: M3t: three-dimensional medical image classifier using multi-plane and multi-slice transformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20718–20729 (2022)
- [15] Kavur, A.E., Gezer, N.S., Barış, M., Aslan, S., Conze, P.H., Groza, V., Pham, D.D., Chatterjee, S., Ernst, P., Özkan, S., et al.: Chaos challenge-combined (ct-mr) healthy abdominal organ segmentation. Medical Image Analysis 69, 101950 (2021)
- [16] Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597 (2023)
- [17] Liu, C., Ouyang, C., Chen, Y., Quilodrán-Casas, C.C., Ma, L., Fu, J., Guo, Y., Shah, A., Bai, W., Arcucci, R.: T3d: Towards 3d medical image understanding through vision-language pre-training. arXiv preprint arXiv:2312.01529 (2023)
- [18] Liu, Z., Ning, J., Cao, Y., Wei, Y., Zhang, Z., Lin, S., Hu, H.: Video swin transformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3202–3211 (2022)
- [19] Marcus, D.S., Fotenos, A.F., Csernansky, J.G., Morris, J.C., Buckner, R.L.: Open access series of imaging studies: longitudinal mri data in nondemented and demented older adults. Journal of cognitive neuroscience 22(12), 2677–2684 (2010)
- [20] Marcus, D.S., Wang, T.H., Parker, J., Csernansky, J.G., Morris, J.C., Buckner, R.L.: Open access series of imaging studies (oasis): cross-sectional mri data in young, middle aged, nondemented, and demented older adults. Journal of cognitive neuroscience 19(9), 1498–1507 (2007)
- [21] Oktay, O., Schlemper, J., Folgoc, L.L., Lee, M., Heinrich, M., Misawa, K., Mori, K., McDonagh, S., Hammerla, N.Y., Kainz, B., et al.: Attention u-net: Learning where to look for the pancreas. arXiv preprint arXiv:1804.03999 (2018)
- [22] OpenAI: Gpt-4v(ision) system card (2023)
- [23] Puonti, O., Iglesias, J.E., Van Leemput, K.: Fast and sequence-adaptive whole-brain segmentation using parametric bayesian modeling. NeuroImage 143, 235–249 (2016)
- [24] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021)
- [25] Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. pp. 234–241. Springer (2015)
- [26] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30 (2017)
- [27] Xue, L., Gao, M., Xing, C., Martín-Martín, R., Wu, J., Xiong, C., Xu, R., Niebles, J.C., Savarese, S.: Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1179–1189 (2023)
- [28] Yang, Z., Yao, Z., Tasmin, M., Vashisht, P., Jang, W.S., Ouyang, F., Wang, B., Berlowitz, D., Yu, H.: Performance of multimodal gpt-4v on usmle with image: Potential for imaging diagnostic support with explanations. medRxiv pp. 2023–10 (2023)
- [29] Zheng, S., Lu, J., Zhao, H., Zhu, X., Luo, Z., Wang, Y., Fu, Y., Feng, J., Xiang, T., Torr, P.H., et al.: Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6881–6890 (2021)
- [30] Zhou, H.Y., Guo, J., Zhang, Y., Han, X., Yu, L., Wang, L., Yu, Y.: nnformer: Volumetric medical image segmentation via a 3d transformer. IEEE Transactions on Image Processing (2023)
- [31] Zhuang, X., Shen, J.: Multi-scale patch and multi-modality atlases for whole heart segmentation of mri. Medical image analysis 31, 77–87 (2016)