Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
Abstract
Visual text rendering poses a fundamental challenge for contemporary text-to-image generation models, with the core problem lying in text encoder deficiencies. To achieve accurate text rendering, we identify two crucial requirements for text encoders: character awareness and alignment with glyphs. Our solution involves crafting a series of customized text encoder, Glyph-ByT5, by fine-tuning the character-aware ByT5 encoder using a meticulously curated paired glyph-text dataset. We present an effective method for integrating Glyph-ByT5 with SDXL, resulting in the creation of the Glyph-SDXL model for design image generation. This significantly enhances text rendering accuracy, improving it from less than to nearly on our design image benchmark. Noteworthy is Glyph-SDXL’s newfound ability for text paragraph rendering, achieving high spelling accuracy for tens to hundreds of characters with automated multi-line layouts. Finally, through fine-tuning Glyph-SDXL with a small set of high-quality, photorealistic images featuring visual text, we showcase a substantial improvement in scene text rendering capabilities in open-domain real images. These compelling outcomes aim to encourage further exploration in designing customized text encoders for diverse and challenging tasks.
![[Uncaptioned image]](paragraph_1.png)
![[Uncaptioned image]](paragraph_2.png)
![[Uncaptioned image]](paragraph_3.png)
![[Uncaptioned image]](paragraph_4.png)
![[Uncaptioned image]](design_1.png)
![[Uncaptioned image]](design_5.png)
![[Uncaptioned image]](design_2.png)
![[Uncaptioned image]](design_3.png)
![[Uncaptioned image]](scene_1.png)
![[Uncaptioned image]](scene_2.png)
![[Uncaptioned image]](scene_3.png)
![[Uncaptioned image]](scene_5.png)
1 Introduction
Diffusion models have emerged as the predominant approach for image generation. Noteworthy contributions, like DALLE3 [3, 19] and Stable Diffusion series [24, 22], showcase remarkable proficiency in generating high-quality images in response to user prompts. However, a significant limitation persists in their ability to accurately render visual text, which is a critical element in various image generation applications. These applications range from producing design images for posters, cards, and brochures to synthesizing real-world images featuring scene text found in road signs, billboards, or text-laden T-shirts. The challenge of achieving precise text rendering accuracy has hindered the practical deployment of image generation models in these important domains.
We posit that the primary challenge hindering visual text rendering performance lies in the limitations of text encoders. The widely used CLIP text encoder, trained to align with visual signals, primarily focuses on grasping image concepts rather than delving into image details. Conversely, the commonly adopted T5 text encoder, designed for a comprehensive understanding of language, lacks alignment with visual signals. We argue that a text encoder capable of encoding character-level information and aligning with visual text signals, or glyphs, is essential for achieving high accuracy in visual text rendering. Drawing inspiration from the character-aware ByT5 encoder [16], our approach aims to customize it to better align with visual text or glyphs.
To construct the desired character-aware and glyph-aligned text encoder, we employ a fine-tuning approach based on the ByT5 model using paired text-glyph data. The main challenge arises from the scarcity of high-quality paired text-glyph data, which we overcome by establishing a scalable pipeline capable of generating virtually unlimited paired data based on graphic rendering. Additionally, we incorporate a glyph augmentation strategy to enhance the character awareness of the text encoder, addressing various error types commonly encountered in visual text rendering, as discussed in [16]. Leveraging our meticulously crafted dataset and employing an innovative box-level contrastive loss, we efficiently fine-tune ByT5 into a series of customized text encoder for glyph generation, named Glyph-ByT5.
| Method | #Params | Char-aware | Glyph-align | Precision () | |||
| 20 chars | 20-50 chars | 50-100 chars | 100 chars | ||||
| M | ✗ | ✗ | |||||
| + T5-L | + M | ✗ | ✗ | ||||
| + ByT5-S | + M | ✓ | ✗ | ||||
| + Glyph-ByT5-S | + M | ✓ | ✓ | ||||
| + | + M | ✓ | ✓ | ||||
| B | ✗ | ✗ | |||||
| DALLE3 | Unknown | ✗ | ✗ | ||||
Upon thorough training, Glyph-ByT5 is seamlessly integrated into the SDXL model using an efficient region-wise cross-attention mechanism, significantly enhancing the text rendering performance of the original diffusion model. The resultant Glyph-SDXL model showcases exceptional spelling accuracy, outperforming other state-of-the-art models in the generation of text-rich design images, as illustrated in Table 1. Furthermore, we fine-tuned Glyph-SDXL using a limited set of scene-text images, significantly bolstering its proficiency in generating scene-text images. The examples featured in Fig. 1 demonstrate that the refined model adeptly renders text paragraphs as scene text without perceptible degradation in the image generation capabilities of the original model.
Our investigation reveals that, through the training of a customized text encoder and the implementation of a suitable information injection mechanism, we can transform an open-domain image generator into an outstanding visual text renderer. When presented with a textual paragraph ranging from tens to hundreds of characters, our fine-tuned diffusion model achieves high spelling accuracy for rendering within the designated region, with fully automated handling of multi-line layouts. In essence, this work contributes in three distinct yet complementary ways. First, we train a character-aware, glyph-aligned text encoder, Glyph-ByT5, as the key solution to the accurate visual text rendering problem. Second, we elaborate on the architecture and training of Glyph-SDXL, a robust design image generator that integrates Glyph-ByT5 into SDXL through an efficient region-wise cross-attention mechanism. Lastly, we showcase the potential of fine-tuning Glyph-SDXL into a scene-text image generator, laying the groundwork for the development of a comprehensive, open-domain image generator equipped with exceptional visual text rendering capabilities.
2 Related Work
2.1 Visual Text Rendering
Rendering legible and visually coherent text poses a well-known limitation and a significant challenge for diffusion-based image generation models. It is worth noting that certain contemporary open-domain image generation models, such as Stable Diffusion 3 [10] and Ideogram 1.0111https://about.ideogram.ai/1.0, have dedicated considerable effort to enhance visual text rendering performance. However, the spelling accuracy of the rendered text remains unsatisfactory. Conversely, there have been endeavors focused on visual text rendering, such as GlyphControl, GlyphDraw, and the TextDiffuser series [29, 17, 16, 6, 7]. While these efforts have shown substantial improvements in spelling accuracy, it is disappointing to note that they are still focusing on rendering single words or text lines with fewer than approximately 20 characters. In this study, we aim to tackle the precise visual text rendering problem, particularly when dealing with textual content longer than a hundred characters, setting forth an ambitious goal in this domain.
2.2 Customized Text Encoder
Several recent efforts [12, 5, 32] have been made to train text-oriented diffusion models and replace or augment the original CLIP encoders with customized text encoders in different manners. However, these methods, like their predecessors, are limited to handling text sequences of a certain length, with UDiffText [32] supporting sequences of no more than 12 characters. In contrast, our methodology distinguishes itself by its ability to generate text sequences of more than 100 characters while achieving exceptionally high accuracy, reaching nearly word-level accuracy. This significant progress addresses the shortcomings of previous methods, providing wider applicability and improved performance in text generation tasks. Another closely related work is Counting-aware CLIP [21], which enhances the original CLIP text encoder with a specialized image-text counting dataset and a counting-focused loss function. However, a significant limitation of their approach is the lack of scalability in their dataset. They choose to replace the original text encoders and train diffusion models from scratch, whereas our data construction pipeline is scalable, and we prioritize integrating GlyphByT5 with the original text encoders to improve efficiency.
Our Contribution Our work aligns with the insights of the previously mentioned studies, identifying that one critical limitation in most current text-to-image generation models resides in the text encoder. The primary contribution of our work lies in presenting an effective strategy for systematically addressing the glyph rendering task. We first demonstrate that leveraging graphic rendering to create scalable and accurate glyph-text data is crucial for training a high-quality, glyph-aligned, character-aware text encoder. Then, we introduce a simple yet powerful method to integrate our Glyph-ByT5 text encoder with the original CLIP text encoder used in SDXL. Additionally, we illustrate how our approach can be applied to scene-text generation by performing design-to-scene alignment fine-tuning. We anticipate that training the customized text encoder on scalable, high-quality data represents a promising avenue for overcoming fundamental limitations, such as spatial awareness and numeracy.
3 Our Approach
We begin by illustrating the details of our customized glyph-aligned, character-aware text encoder, Glyph-ByT5, which is trained using a substantial dataset of paired glyph images and textual instructions. Subsequently, we demonstrate how Glyph-ByT5 significantly enhances the visual text rendering accuracy when integrated with the SDXL models for the design-text rendering task. Finally, we introduce a straightforward yet effective approach for design-to-scene alignment, enabling the adaptation of Glyph-SDXL for precise scene-text generation.
3.1 Glyph-ByT5: Customized Glyph-Aligned Character-Aware Text Encoder for Design-text Generation
A key factor contributing to inaccuracies in text rendering is the inherent limitations of text encoders in modern diffusion models, especially regarding their interpretation of glyph images. The original CLIP text encoder, for example, is tailored for broad visual-language semantic alignment at the conceptual level, while the T5/ByT5 text encoder focuses on deep language understanding. However, neither is explicitly fine-tuned for glyph image interpretation although the recent works show that T5/ByT5 text encoder is favorable for visual text rendering task. This lack of customized text encoder design can result in less accurate text rendering in various applications.
 (a)
(a)
 (b)
(b)
 (c)
(c)
 (d)
(d)
 (e)
(e)
 (f)
(f)
 (g)
(g)
 (h)
(h)








To bridge the gap between existing text encoders (such as the CLIP text encoder or the T5/ByT5 text encoder) and glyph images, we propose a innovative glyph-alignment methodology for training a series of glyph-aligned character-aware text encoders, i.e., Glyph-ByT5. Our approach is focused on training a series of glyph-aware text encoders, specifically designed to reconcile the disparity between glyph images and text. Drawing inspiration from the LiT framework [30], our strategy involves exclusively fine-tuning the text models while maintaining the pre-trained image models frozen. This approach effectively compels the text encoders to adapt, learning to identify the rich information encoded within the visual glyph representations extracted from the already trained image model. For the vision encoder component, we opt for the pre-trained CLIP vision encoders or the DINOv2 models, leveraging their advanced capabilities in handling visual data. We also explore the impact of employing vision encoders specifically tailored for scene text recognition or other tasks, and we consider the development and training of more advanced vision encoders for visual text rendering as a future avenue of research.
Creating Scalable and Accurate Glyph-Text Dataset To enable the training of the customized glyph-aware text encoder, we first create a high-quality glyph-text dataset, denoted as , consisting of approximately million pairs of synthetic data . This dataset was developed with the improved graphic render introduced in the recent work by [13]. We construct the initial glyph image set based on the original typographic attributes (including font types, colors, sizes, positions, and others) found in the crawled graphic design images. We compile a large text corpus that can be used to enrich the glyph image set by replacing the words with random text sampled from the corpus. Additionally, we randomly modify the font types and colors within each text box to further enlarge the dataset. Our glyph-text dataset encompasses nearly different font types and distinct font colors. To ensure the glyph-aligned text encoder focuses on only the difference on the visual text, we all use black colored background by default.
We present the example of glyph prompts corresponding to the glyph image shown in Figure 3 (a), detailing font types, colors, and text, as illustrated follows: {Text “oh! the places you’ll go!” in [font-color-39], [font-type-90]. Text “Happy Graduation Kim!” in [font-color-19] [font-type-181]}. In this process, special tokens are utilized to denote font colors and types. Prior to inputting it into the Glyph-ByT5 text encoder, we preprocess the prompt text by substituting special tokens, like the token ‘[font-color-39]’, with a series of global embeddings from the enriched codebook. We have conducted experiments on the Glyph-Text datasets at three distinct scales, expanding from 100K to 500K, and up to 1M. In the future, we aim to significantly expand our datasets, scaling up to 100M given access to more computing resources.
Creating Paragraph-Glyph-Text Dataset To enhance both the generation quality of small-sized fonts and the paragraph-level layout planning capability of customized text encoder, we have additionally compiled a dense-and-small paragraph-level glyph-text dataset, denoted as .
We define a ‘paragraph’ as a block of text content that cannot be accommodated within a single line, typically consisting of more than 10 words or 100 characters. The paragraph-glyph rendering task poses a greater challenge, as it demands not only very high word-level spelling accuracy but also meticulous planning of word-level and line-level layouts within the specified box region. This dataset is comprised of 100,000 pairs of synthetic data . Empirical findings suggest that fine-tuning the model, initially trained with , using markedly improves performance in rendering small-sized and paragraph-level visual text.
The capability for paragraph-level layout planning is non-trivial, and we empirically demonstrate that the diffusion model can effectively plan multi-line arrangements and adjust the line or word spacing according to the given text box, regardless of its size or aspect ratios. We display example images of the paragraph glyph-text data in Figure 3, illustrating that each image contains at least one text box with more than 100 characters. Some images even reach 400 characters, arranged into multiple lines with reasonable spacing. We also construct three scales of the paragraph-glyph-text datasets, comprising 100K, 500K, and 1M glyph-text pairs.
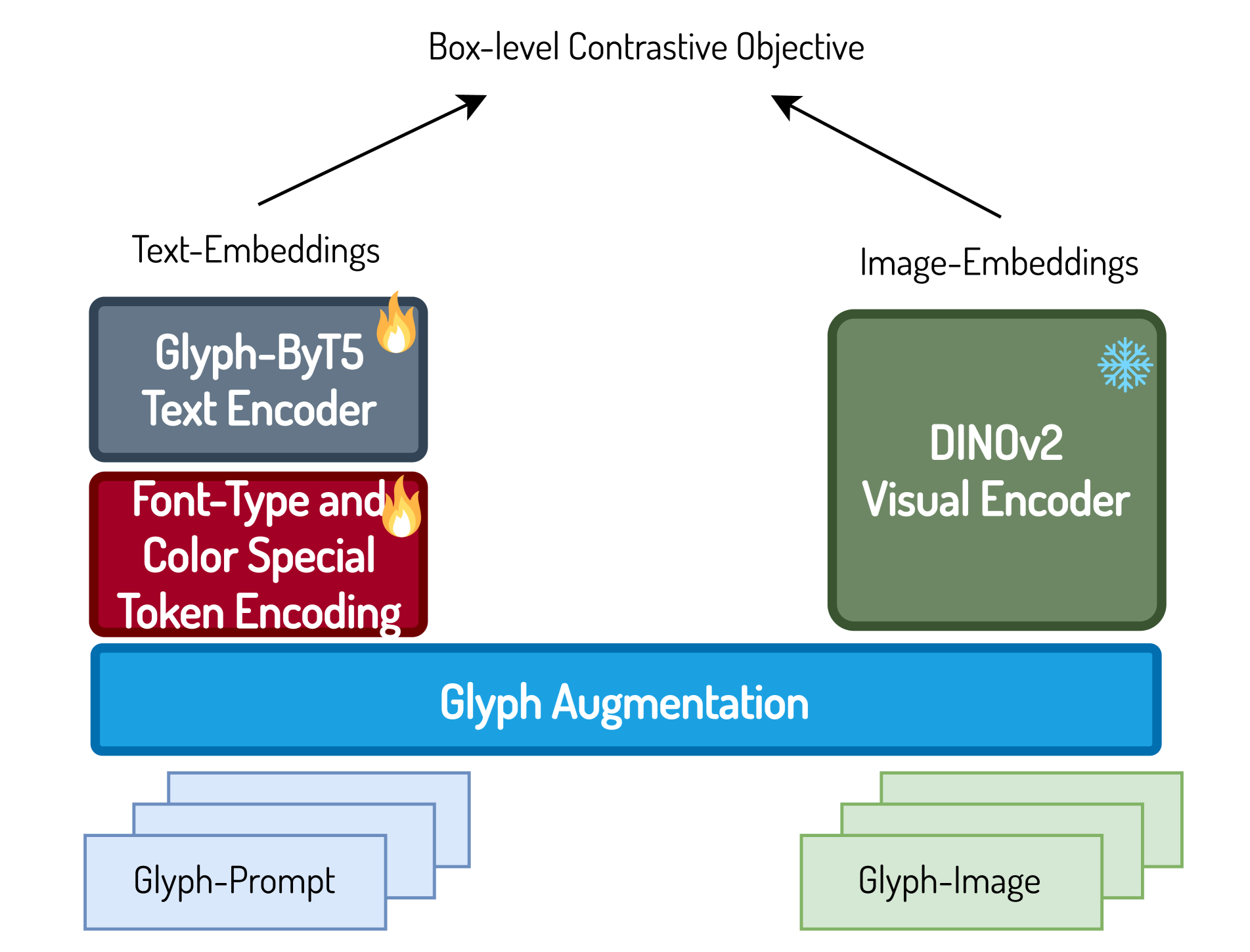
Glyph Augmentation Unlike conventional CLIP models, which only consider different glyph-text pairs as negative samples-thereby modeling only the relatively high-level differences caused by multiple words or even paragraphs consisting of more than characters-we propose a simple yet effective character-level and word-level glyph augmentation scheme. This approach constructs more informative negative samples, significantly enhancing training efficiency.
The proposed character-level and word-level augmentation scheme essentially consist of a combination of four different glyph augmentation strategies including glyph replacement, glyph repeat, glyph drop, and glyph add at both character-level and word-level. We apply these augmentations to both and to ensure consistency. Figure 3 shows some representative examples with these augmentation strategies. We also investigate the effect of constructing different ratios of informative negative samples for each sample. We independently apply these augmentations to each text box. We present statistics on the number of text boxes, words, and characters across the entire glyph-text dataset and the paragraph-glyph-text dataset in the supplementary material.
Glyph Text Encoder To efficiently capture the text features of each character, we have selected the character-aware ByT5 [28] encoder as the default text encoder for Glyph-CLIP. The original ByT5 model features a robust, heavy encoder paired with a lighter decoder. The ByT5 encoder is initialized using the official pre-trained checkpoints from the mC4 text corpus, as mentioned in [27].
Furthermore, we explore the impact of scaling the text encoders from smaller to larger sizes. This includes the evaluation of various ByT5 models such as ByT5-Small (217M parameters), ByT5-Base (415M parameters), and ByT5-Large (864M parameters) examining their performance enhancements. To distinguish from the original ByT5 series, we refer to these text encoders as Glyph-ByT5, indicating their specialized focus on bridging the gap between glyph images and their corresponding text prompts.
Glyph Vision Encoder For the exploration of the visual encoder, we analyzed the impact of using visual embeddings derived from CLIP [23], or DINOv2 [20, 9], or the variants [31, 1] tailored for visual text recognition task. Our observations revealed that DINOv2 yields the best performance. It was also noted that CLIP’s visual embeddings struggled to distinguish between different font types. This finding aligns with recent research efforts, as discussed by [8, 34], which demonstrate that DINOv2 excels in preserving identity information. As a result, DINOv2 has been chosen as our primary visual encoder. Furthermore, we explored the effect of scaling visual encoders from smaller to larger sizes on performance. This included assessing variations like ViT-B/14 (86M parameters), ViT-L/14 (300M parameters), and ViT-g/14 (1.1B parameters), aligning them with the above mentioned three ByT5 text encoders of varying scales.
Box-level Contrastive Loss Unlike conventional CLIP, which applies contrastive loss to the entire image, we propose applying a box-level contrastive loss that treats each text box and its corresponding text prompt as an instance. Based on the number of characters or words within the text box, we can categorize them into either a word text box, a sentence text box, or a paragraph text box. Therefore, our box-level contrastive loss is capable of aligning the text with glyph images at different levels of granularity. This alignment aids our customized text encoder in acquiring the capability for paragraph-level layout planning. We illustrate the mathmatical formulation as follows:
| (1) |
where represents all image-text pairs within the same batch, where the -th image-text pair consists of box-sub-text pairs. We compute the box embedding and sub-text embedding of -th box in -th image-text pair as follows: and . and represent the visual encoder and text encoder, respectively. We set the two normalization factors following and . is a learnable temperature parameter.
Hard-negative Contrastive Loss based on Glyph Augmentation: We additionally compute a contrastive loss for the hard-negative samples generated with our glyph augmentation and the mathematical formulatioin is shown as follows:
| (2) |
where and Here, represents the augmented training data based on box and sub-text . We investigate the impact of varying the number of augmented data points in the ablation experiments.
We combine the above two losses, i.e., , to facilitate the glyph-alignment pre-training process. We also empirically demonstrate that our design outperforms the image-level contrastive loss in the ablation experiments. We attribute the superior performance to two main factors: the availability of a significantly larger number of effective training samples, and the box-level visual features providing more accurate visual text information. These assertions are corroborated by the findings in two prior studies [4, 33]. Figure 4 depicts the complete framework of Glyph-ByT5, showcasing its glyph-alignment pre-training process that integrates the critical components previously mentioned.
3.2 Glyph-SDXL: Augmenting SDXL with Glyph-ByT5 for Design Image Generation
To verify the effectiveness of our approach in generating accurate text contents in design images and planning visual paragraph layouts within each text box, we have integrated our Glyph-ByT5 with the state-of-the-art, open-sourced text-to-image generation model, SDXL [22]. The primary challenge lies in integrating our customized text encoder with the existing one to harness the strengths of both without detracting from the original performance. Another challenge is the lack of high-quality graphic design datasets for training design-text generation model rendered in coherent background image layers.
 (a) Glyph-Alignment Pre-training
(a) Glyph-Alignment Pre-training
 (b) Region-wise Multi-Text-Encoder Fusion
(b) Region-wise Multi-Text-Encoder Fusion
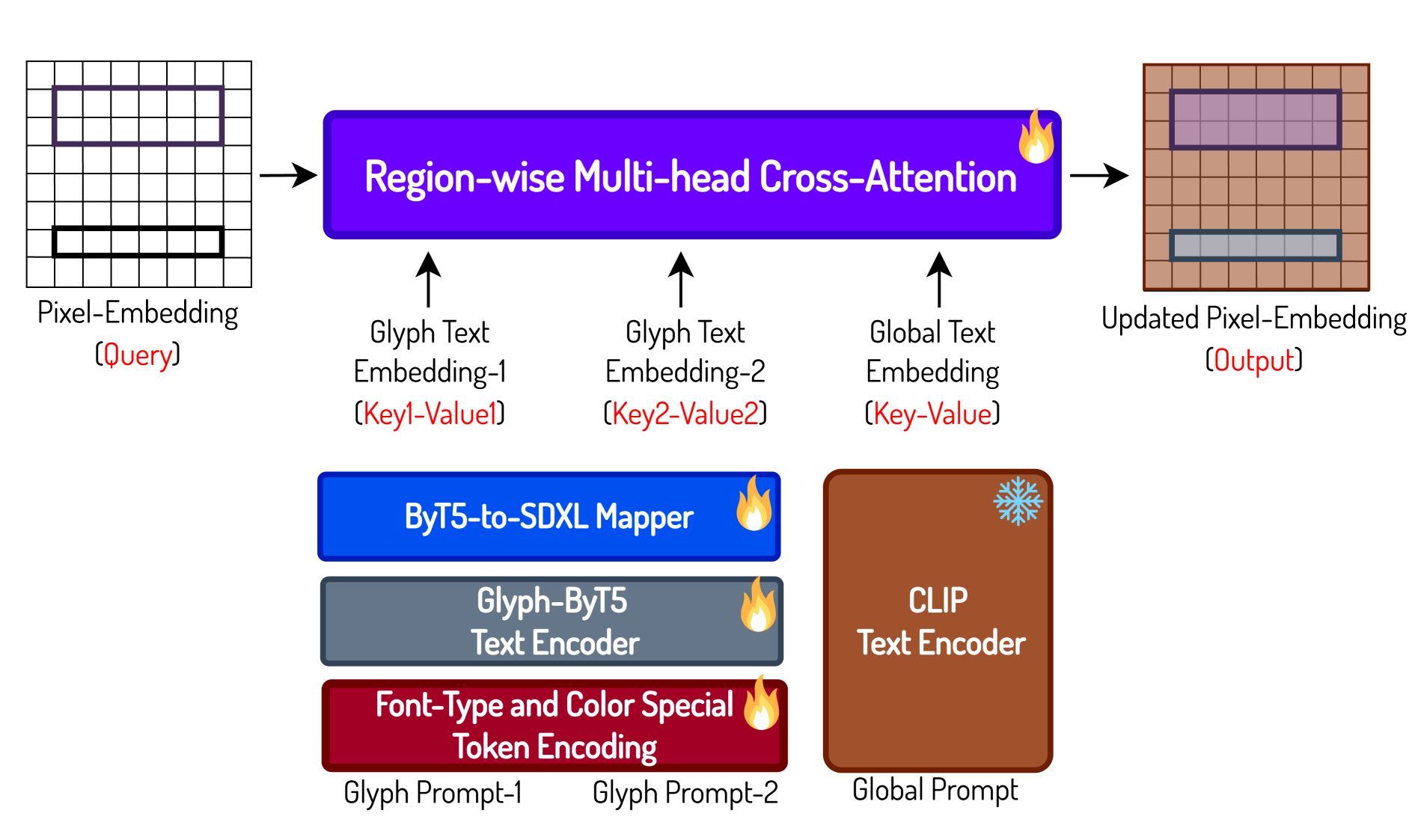
To address the two challenges mentioned above, we first introduce a region-wise multi-head cross-attention mechanism to seamlessly fuse the glyph knowledge encoded in our customized text encoder within the target typography boxes and the prior knowledge carried by the original text encoders in the regions outside of typography boxes. Additionally, we build a high-quality graphic design dataset to train our Glyph-SDXL generation model for accurate visual text rendering. Detailed discussions of these two pivotal contributions are provided in the subsequent sections.
Region-wise Multi-head Cross-Attention The original multi-head cross-attention is the core component responsible for mapping the rich semantic information of text-space into different positions in the image-space. In other words, it determines generate what object at where by continuely applying multi-head cross-attention across different layers and time steps.
The detailed framework of the region-wise multi-head cross-attention is displayed on the right side of Figure 4. In our region-wise multi-head cross-attention mechanism, we first partition the input pixel embeddings (Query) into multiple groups. These groups correspond to the target text boxes, which can be either specified by the user or automatically predicted by leveraging the planning capability of GPT-4. Simultaneously, we divide the text prompts (Key-Value) into corresponding sub-sections, which include a global prompt and several groups of glyph-specific prompts. We then specifically direct the pixel embeddings within the target text boxes to attend only to the glyph text embeddings extracted with Glyph-ByT5. Similarly, pixel embeddings outside the text boxes are made to attend exclusively to the global prompt embeddings extracted with the original two CLIP text encoders.
To close the gap between the output embedding space of Glyph-ByT5 with the original SDXL embedding space, we introduce a lightweight mapper, namely the ByT5-to-SDXL mapper. This mapper is equipped with four ByT5 transformer encoder layers, each initialized with random weights, and is applied to the output of the pre-trained Glyph-ByT5 text encoder. For efficiency, we implement the above-mentioned region-wise multi-head cross-attention by modulating the attention maps with a mask that ensures the mapping relations between the pixel embeddings and the multiple text encoder embeddings. We fine-tune the weights of both the Glyph-ByT5 text encoder and the ByT5-to-SDXL mapper during training, in line with previous research [16] which highlights that refining a character-aware text encoder within a diffusion model can significantly enhance performance.
Visual Design Dataset for Design-text Generation It is important to choose a reliable task to access the performance of design-text rendering performance. This work selects the design image generation as this is one of the most representative scenarios of text-intensive generation task. Therefore, we first build a high-quality visual design image dataset with dense paragraph-level visual text rendered on each image by crawling from a lot of graphic design websites following [13]. This task presents two significant challenges, as it demands not only the generation of dense visual text but also necessitates visually appealing background images. We have also created three versions of the graphic design datasets, encompassing sizes of 100K, 500K, and 1M, where we utilize LLaVA [15] based on Llama-B [25] to generate detailed captions for each graphic design image, with the ground-truth glyph text readily accessible in the raw data. We have also conducted data cleaning to ensure that few graphic design images share the same typography as the glyph-text images used for glyph-alignment pre-training.
Glyph-SDXL We train the Glyph-SDXL on the above constructed design-text dataset. To preserve the inherent capabilities of SDXL, we lock the entire model’s weights, encompassing both the UNet architecture and the dual CLIP text encoders. First, we implement LoRA [11] module exclusively on the UNet components. Second, we introduce a region-wise multi-text-encoder fusion mechanism designed to integrate the glyph-aware capabilities of the Glyph-ByT5 text encoder with the formidable strengths of the two original CLIP text encoders. This approach aims to synergize the unique features of each text encoder, enhancing the visual text rendering performance. In implementation, we only need to modify the original multi-head cross-attention module with our region-wise multi-head cross-attention accordingly.
We elaborate on the differences between our approach and traditional typography rendering tools in the supplementary material. Our tailored Glyph-ByT5 matches the rendering accuracy of conventional tools while leveraging the capabilities of fully diffusion-based models. This allows it to tackle scene-text generation tasks that beyond the capabilities of standard rendering tools.
3.3 Design-to-Scene Alignment: Fine-tuning Glyph-SDXL for Scene-text Generation
The previous constructed Glyph-SDXL, which was mainly trained on graphic design images, encounters difficulties in producing scene text that maintains a coherent layout. Furthermore, we have noticed a phenomenon known as ‘language drift’, which slightly undermines the model’s original proficiency. To tackle these issues and facilitate the creation of a superior scene text generation model, we propose the development of a hybrid design-to-scene alignment dataset. This dataset combines three types of high-quality data: 4,000 scene-text and design text images from TextSeg [26], 4,000 synthetic images generated using SDXL, and 4,000 design images. We simply fine-tune our Glyph-SDXL on the hybrid design-to-scene alignment dataset for epochs. We conduct thorough evaluations of the scene-text rendering capability of our method across three public benchmarks and report significant performance gains compared to previous state-of-the-art methods. To distinguish it from the original Glyph-SDXL, we designate the fine-tuned version on the design-to-scene alignment dataset as Glyph-SDXL-Scene. Additionally, we demonstrate that each subset is useful for three combined purposes: coherent layout, accurate text rendering, and visual quality, as detailed in the supplementary material.
4 Experiment
We assess our method’s ability to generate accurate design text in graphic design images, which often feature numerous paragraph-level text boxes, as well as scene text within photorealistic images. To facilitate the assessment of paragraph-level visual text rendering, we have developed the VisualParagraphy benchmark. This benchmark includes multi-line visual text within bounding boxes of diverse aspect ratios and scales.
Our evaluation compares our method against commercial products and the most advanced visual text rendering techniques, such as DALL·E, in the design-text generation task. We report objective OCR metrics and conduct a subjective user study to evaluate visual quality from other aspects. For the scene-text generation task, we compare our method with the representative models GlyphControl [29] and TextDiffuser-2[7] across three public benchmarks.
![[Uncaptioned image]](ours_1.png)
![[Uncaptioned image]](ours_2.png)
![[Uncaptioned image]](ours_3.png)
![[Uncaptioned image]](ours_4.png)
![[Uncaptioned image]](ours_5.png)
![[Uncaptioned image]](dalle_1.jpg)
![[Uncaptioned image]](dalle_2.jpg)
![[Uncaptioned image]](dalle_3.jpg)
![[Uncaptioned image]](dalle_4.jpg)
![[Uncaptioned image]](dalle_5.jpg) Figure 5: Qualitative comparison results. We show the results generated with our Glyph-SDXL and DALLE3 in the first row and second row, respectively.
Figure 5: Qualitative comparison results. We show the results generated with our Glyph-SDXL and DALLE3 in the first row and second row, respectively.
Additionally, we conduct thorough ablation experiments to study the effect of each component within our approach and visualize the cross-attention maps to demonstrate that our customized text encoder can provide a glyph prior to the diffusion model. We detail the training settings and provide additional comparison results in the supplementary material.
4.1 Metrics
In the majority of our experiments, we default to reporting case-sensitive word-level precision, except for comparisons involving GlyphControl and TextDiffuser. In these instances, we align with their original methodologies by reporting case-agnostic metrics and image-level metrics. For instance, as indicated in Table 8, Case-Recall is used as a case-sensitive metric to differentiate between uppercase and lowercase letters. Conversely, all other metrics are case-agnostic. Accuracy [IMG] is utilized to denote image-level accuracy, which depends on the accurate spelling of every visual word within the entire image to achieve a favorable evaluation. Furthermore, we identified a direct correspondence between the OCR Accuracy metric in GlyphControl and the Recall metric in TextDiffuser. As a result, to ensure consistency in metrics reporting for both SimpleBench and CreativeBench, we have unified the approach by selecting Recall as the principal metric.
4.2 VisualParagraphy Benchmark
We have constructed a benchmark for design-text generation task, amassing approximately design-text prompts covering varying number of characters with different difficulty, rendering less than 20 characters, rendering 20 to 50 characters, rendering 50 to 100 characters, and rendering more than 100 characters. We provide some representative examples of prompts in the supplementary material. We use approximately 1,000 design-text prompts in the comparison with the commercial product, DALLE3, while by default, a smaller subset of approximately 400 design-text prompts are used in all subsequent ablation experiments for efficiency.
4.3 Comparison to Commercial-Product DALLE3
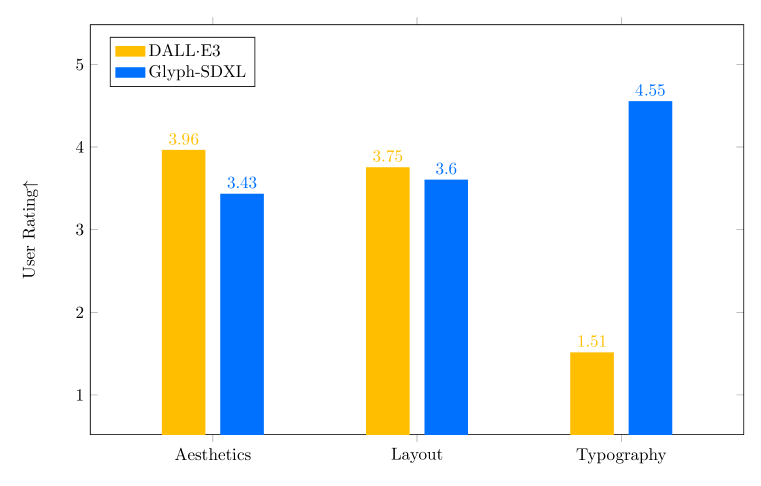
We compare our approach with the most powerful commercial product in the visual text rendering task, namely, DALLE3 on VisualParagraphy benchmark. We conducted a user study to assess the results from three critical aspects: visual aesthetics, layout quality, and typography accuracy. We hired 10 users with a design background to rate the generated images on a scale from 1 to 5. The results of the user study are illustrated in Figure 6. We can see the users give significantly higher scores on typography and slightly lower scores on other two aspects. Additionally, we show some representative qualitative visual comparison results in Figure 5. We find that our approach demonstrates significant advantages in the design-text rendering task.
| Method | SimpleBench | CreativeBench | MARIO-Eval | |||||||
| Recall | Case-Recall | Edit-Dis. | Recall | Case-Recall | Edit-Dis. | Accuracy [IMG] | Precision | Recall | F-measure | |
| DeepFloyd IF [14] | ||||||||||
| GlyphControl [29] | - | - | - | - | ||||||
| TextDiffuser [6] | - | - | - | - | - | - | ||||
| TextDiffuser-2 [7] | - | - | - | - | - | - | ||||
| Glyph-SDXL | ||||||||||
| Glyph-SDXL-Scene | ||||||||||
| Loss design | Precision () | |||
| 20 chars | 20-50 chars | 50-100 chars | 100 chars | |
| IL-CL | ||||
| BL-CL | ||||
| IL-CL + BL-CL | ||||
| Glyph aug. ratio | Precision () | |||
| 20 chars | 20-50 chars | 50-100 chars | 100 chars | |
| None | ||||
| 1:8 | ||||
| 1:16 | ||||
| 1:32 | ||||
| ByT5-to-SDXL mapper | Precision () | |||
| 20 chars | 20-50 chars | 50-100 chars | 100 chars | |
| w/o mapper | ||||
| w/ mapper | ||||
| Text encoder | #Params | Precision () | |||
| 20 chars | 20-50 chars | 50-100 chars | 100 chars | ||
| Glyph-ByT5-S | M | ||||
| Glyph-ByT5-B | M | ||||
| Glyph-ByT5-L | M | ||||
4.4 Comparison to State-of-the-Art
Our foremost goal was to confirm the broad applicability of our visual text generation model. To this end, we have carefully detailed the outcomes obtained by applying our methodology to the representative scene-text rendering benchmarks outlined in earlier research, such as TextDiffuser [6], TextDiffuser-2 [7] and GlyphControl [29]. This encompassed comprehensive testing on benchmarks like MARIO-Eval, SimpleBench, and CreativeBench. The comparison results are summarized in Table 8. According to these comparison results, it is evident that our Glyph-SDXL-Scene significantly outperforms the previous state-of-the-art by a substantial margin across these three benchmarks. All of the results of our method represent zero-shot performance.
4.5 Typography Editing on DALLE3
We demonstrate that our Glyph-SDXL is capable of editing typography in images generated by DALLE3 following the SDEdit [18] in the supplementary material.
4.6 Ablation Experiments
We carry out all ablation studies by initially undertaking glyph-alignment pre-training, followed by training the Glyph-SDXL model on our graphic design benchmarks. Furthermore, all ablations are carried out on K glyph image-text pairs for Glyph-ByT5 and Glyph-SDXL models respectively unless specified.
Pre-trained Visual Encoder Choice We study the effect of choosing four different pre-trained visual encoders: CLIP visual encoder [23], DINOv2 [9], ViTSTR [1], and CLIP4STR visual encoder [31]. We report the detailed comparison results in Table 8. Notably, we also observe that accurate font type and color controls only occur when using DINOv2 as the pre-trained visual encoder.
Loss Design We study the effect of choosing different training loss designs and report the detailed comparison results in Table 8. It is evident that the proposed box-level contrastive loss achieves favorable performance.





Glyph Augmentation We study the effect of glyph augmentation during Glyph-Alignment pretraining. As indicated in Table 8, glyph augmentation provides a notable improvement compared with non-augmented settings, peaking at around 1:16. Notably, we also observe that font-type and color control only occur when the ratio reaches or exceeds 1:16, also indicating its effectiveness.
Mapper, Scaling Glyph-Text Dataset and Text Encoder Size, and More Table 8 shows the importance of using the ByT5-to-SDXL mapper to align the gap. Table 8 and Table 8 verify the benefits of scaling up the glyph-text dataset size and text encoder size. We provide more ablation experiments of the Glyph-SDXL-Scene in the supplementary material.
Qualitative Analysis To gain a deeper understanding of how our Glyph-ByT5 excels at the visual text rendering task, we further visualize the cross-attention maps between glyph text prompts and rendered images, providing an example in Figure 7. This visualization confirms that the diffusion model effectively utilizes the glyph-alignment prior encoded within our Glyph-ByT5 text encoder.
5 Conclusion
This paper presents the design and training of the Glyph-ByT5 text encoder, tailored for accurate visual text rendering with diffusion models. Central to this endeavor are two key developments: the creation of a scalable, high-quality glyph-text dataset and the implementation of pre-training techniques for glyph-text alignment. These critical advancements efficiently bridge the gap between glyph imagery and text prompts, facilitating the generation of accurate text for both text-rich design images and open-domain images with scene text. The compelling performance achieved by our proposed Glyph-SDXL model suggests that the development of specialized text encoders represents a promising avenue for overcoming some of the fundamental challenges associated with diffusion models, indicating a significant trend in the domain.
References
- Atienza [2021] Rowel Atienza. Vision transformer for fast and efficient scene text recognition. In International Conference on Document Analysis and Recognition, pages 319–334. Springer, 2021.
- Avrahami et al. [2023] Omri Avrahami, Ohad Fried, and Dani Lischinski. Blended latent diffusion. ACM Transactions on Graphics (TOG), 42(4):1–11, 2023.
- Betker et al. [2023] James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, Wesam Manassra, Prafulla Dhariwal, Casey Chu, Yunxin Jiao, and Aditya Ramesh. Improving image generation with better captions. 2023.
- Bica et al. [2024] Ioana Bica, Anastasija Ilić, Matthias Bauer, Goker Erdogan, Matko Bošnjak, Christos Kaplanis, Alexey A Gritsenko, Matthias Minderer, Charles Blundell, Razvan Pascanu, et al. Improving fine-grained understanding in image-text pre-training. arXiv preprint arXiv:2401.09865, 2024.
- [5] Haoxing Chen, Zhuoer Xu, Zhangxuan Gu, Jun Lan, Xing Zheng, Yaohui Li, Changhua Meng, Huijia Zhu, and Weiqiang Wang. Diffute: Universal text editing diffusion model.
- Chen et al. [2023a] Jingye Chen, Yupan Huang, Tengchao Lv, Lei Cui, Qifeng Chen, and Furu Wei. Textdiffuser: Diffusion models as text painters. arXiv preprint arXiv:2305.10855, 2023a.
- Chen et al. [2023b] Jingye Chen, Yupan Huang, Tengchao Lv, Lei Cui, Qifeng Chen, and Furu Wei. Textdiffuser-2: Unleashing the power of language models for text rendering. arXiv preprint arXiv:2311.16465, 2023b.
- Chen et al. [2023c] Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-level image customization. arXiv preprint arXiv:2307.09481, 2023c.
- Darcet et al. [2023] Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers, 2023.
- Esser et al. [2024] Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024.
- Hu et al. [2021] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Ji et al. [2023] Jiabao Ji, Guanhua Zhang, Zhaowen Wang, Bairu Hou, Zhifei Zhang, Brian Price, and Shiyu Chang. Improving diffusion models for scene text editing with dual encoders. arXiv preprint arXiv:2304.05568, 2023.
- Jia et al. [2023] Peidong Jia, Chenxuan Li, Zeyu Liu, Yichao Shen, Xingru Chen, Yuhui Yuan, Yinglin Zheng, Dong Chen, Ji Li, Xiaodong Xie, et al. Cole: A hierarchical generation framework for graphic design. arXiv preprint arXiv:2311.16974, 2023.
- Lab [2023] DeepFloyd Lab. Deepfloyd if. https://github.com/deep-floyd/IF, 2023.
- Liu et al. [2024] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024.
- Liu et al. [2022] Rosanne Liu, Daniel H Garrette, Chitwan Saharia, William Chan, Adam Roberts, Sharan Narang, Irina Blok, R. J. Mical, Mohammad Norouzi, and Noah Constant. Character-aware models improve visual text rendering. In Annual Meeting of the Association for Computational Linguistics, 2022.
- Ma et al. [2023] Jian Ma, Mingjun Zhao, Chen Chen, Ruichen Wang, Di Niu, Haonan Lu, and Xiaodong Lin. Glyphdraw: Learning to draw chinese characters in image synthesis models coherently. arXiv preprint arXiv:2303.17870, 2023.
- Meng et al. [2021] Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073, 2021.
- OpenAI [2023] OpenAI. Dall·e 3 system card. 2023.
- Oquab et al. [2023] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- Paiss et al. [2023] Roni Paiss, Ariel Ephrat, Omer Tov, Shiran Zada, Inbar Mosseri, Michal Irani, and Tali Dekel. Teaching clip to count to ten. arXiv preprint arXiv:2302.12066, 2023.
- Podell et al. [2023] Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- Touvron et al. [2023] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Xu et al. [2021] Xingqian Xu, Zhifei Zhang, Zhaowen Wang, Brian Price, Zhonghao Wang, and Humphrey Shi. Rethinking text segmentation: A novel dataset and a text-specific refinement approach. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12045–12055, 2021.
- Xue et al. [2020] Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. mt5: A massively multilingual pre-trained text-to-text transformer. arXiv preprint arXiv:2010.11934, 2020.
- Xue et al. [2022] Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, and Colin Raffel. Byt5: Towards a token-free future with pre-trained byte-to-byte models. Transactions of the Association for Computational Linguistics, 10:291–306, 2022.
- Yang et al. [2023] Yukang Yang, Dongnan Gui, Yuhui Yuan, Haisong Ding, Han Hu, and Kai Chen. Glyphcontrol: Glyph conditional control for visual text generation, 2023.
- Zhai et al. [2022] Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18123–18133, 2022.
- Zhao et al. [2023] Shuai Zhao, Xiaohan Wang, Linchao Zhu, and Yi Yang. Clip4str: A simple baseline for scene text recognition with pre-trained vision-language model. arXiv preprint arXiv:2305.14014, 2023.
- Zhao and Lian [2023] Yiming Zhao and Zhouhui Lian. Udifftext: A unified framework for high-quality text synthesis in arbitrary images via character-aware diffusion models. arXiv preprint arXiv:2312.04884, 2023.
- Zhong et al. [2022] Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region-based language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16793–16803, 2022.
- Zhou et al. [2023] Yufan Zhou, Ruiyi Zhang, Jiuxiang Gu, and Tong Sun. Customization assistant for text-to-image generation. arXiv preprint arXiv:2312.03045, 2023.
Supplementary Material
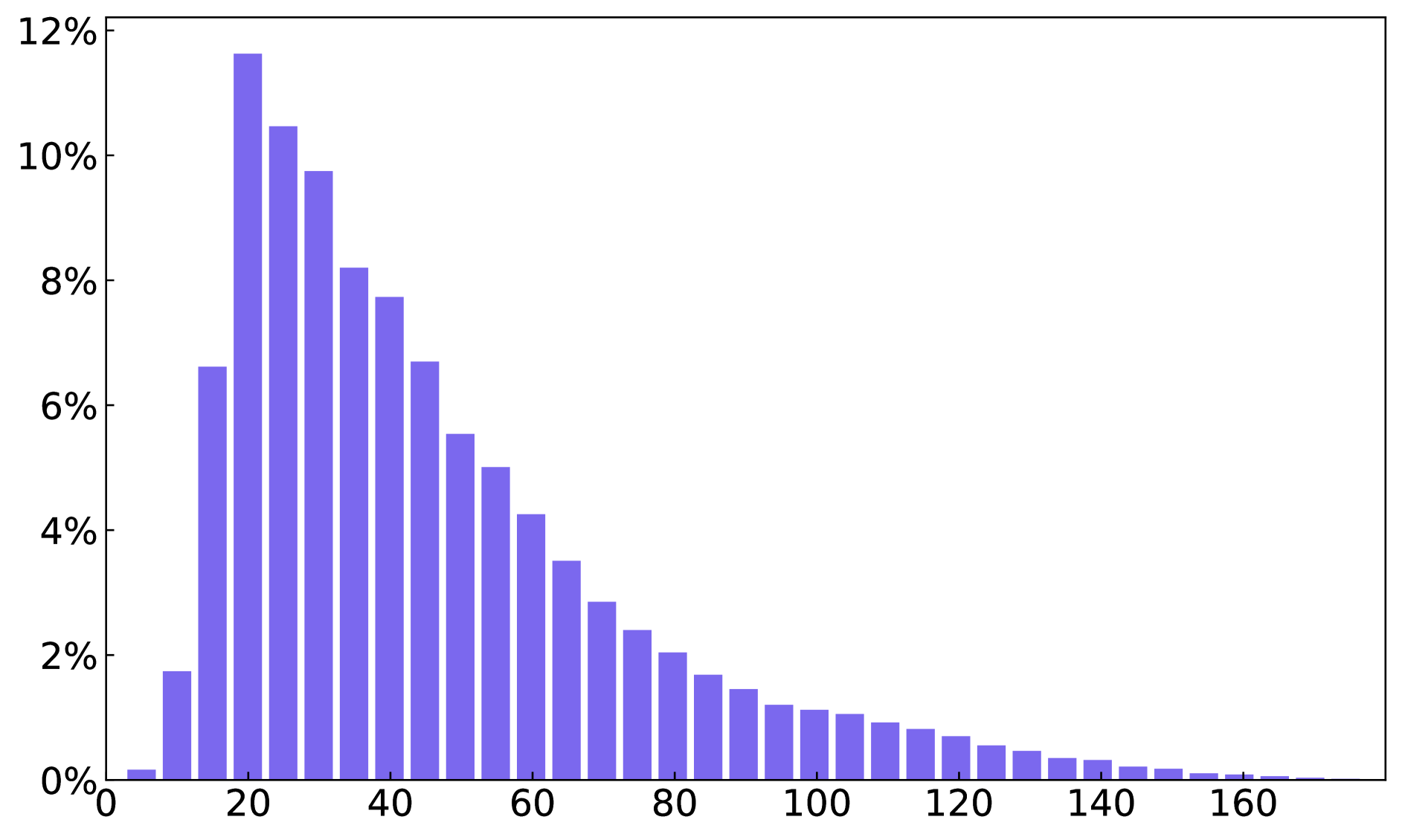
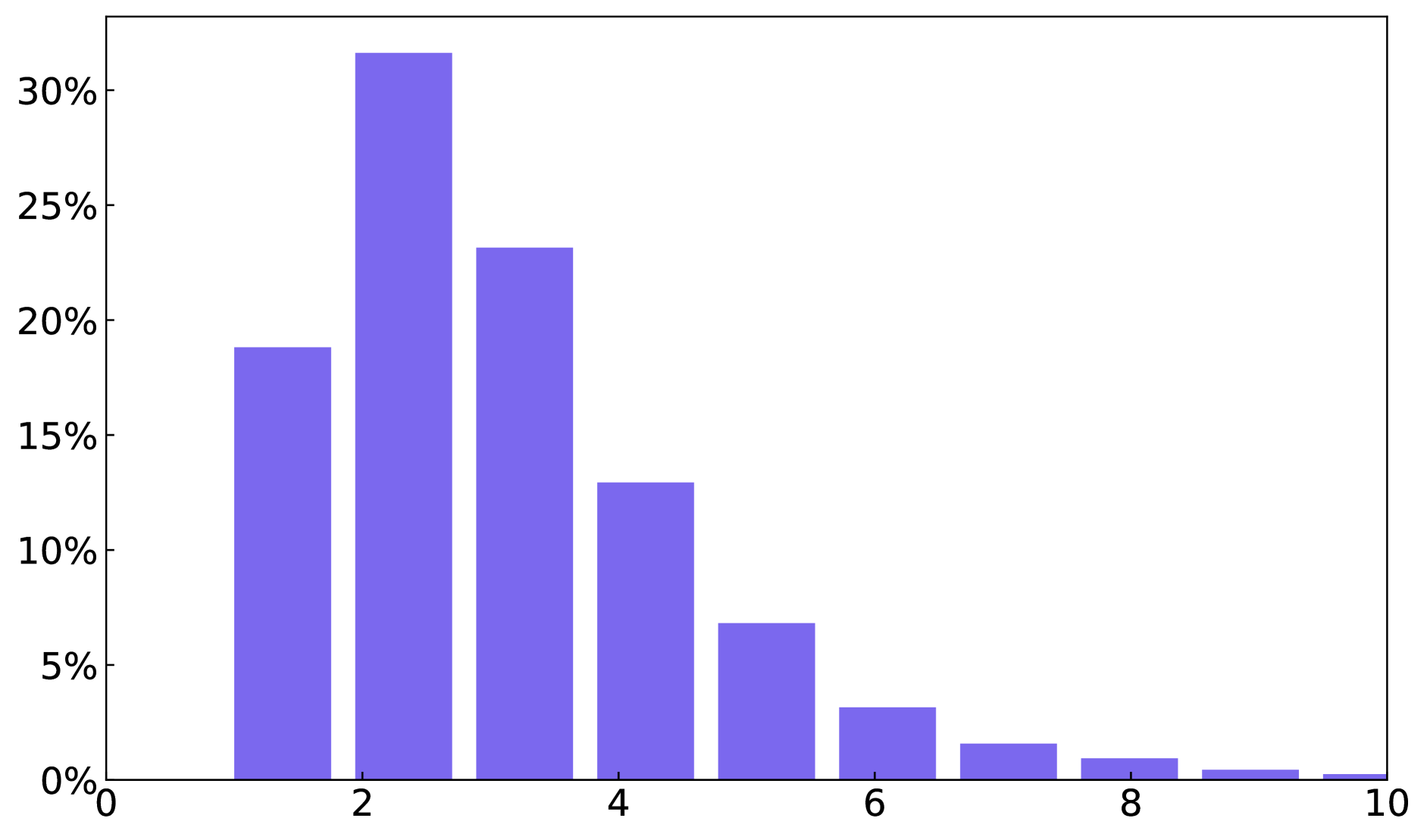
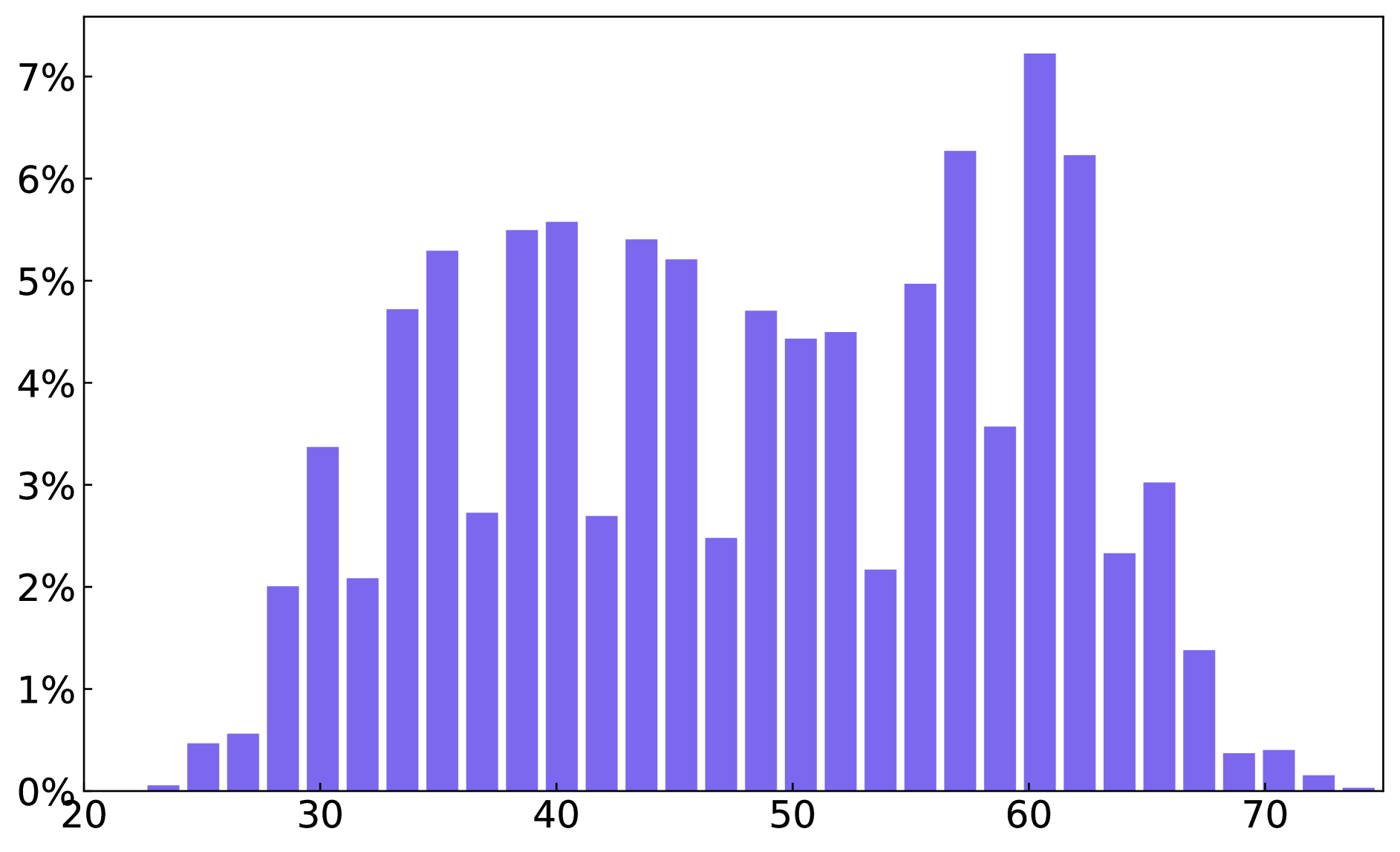
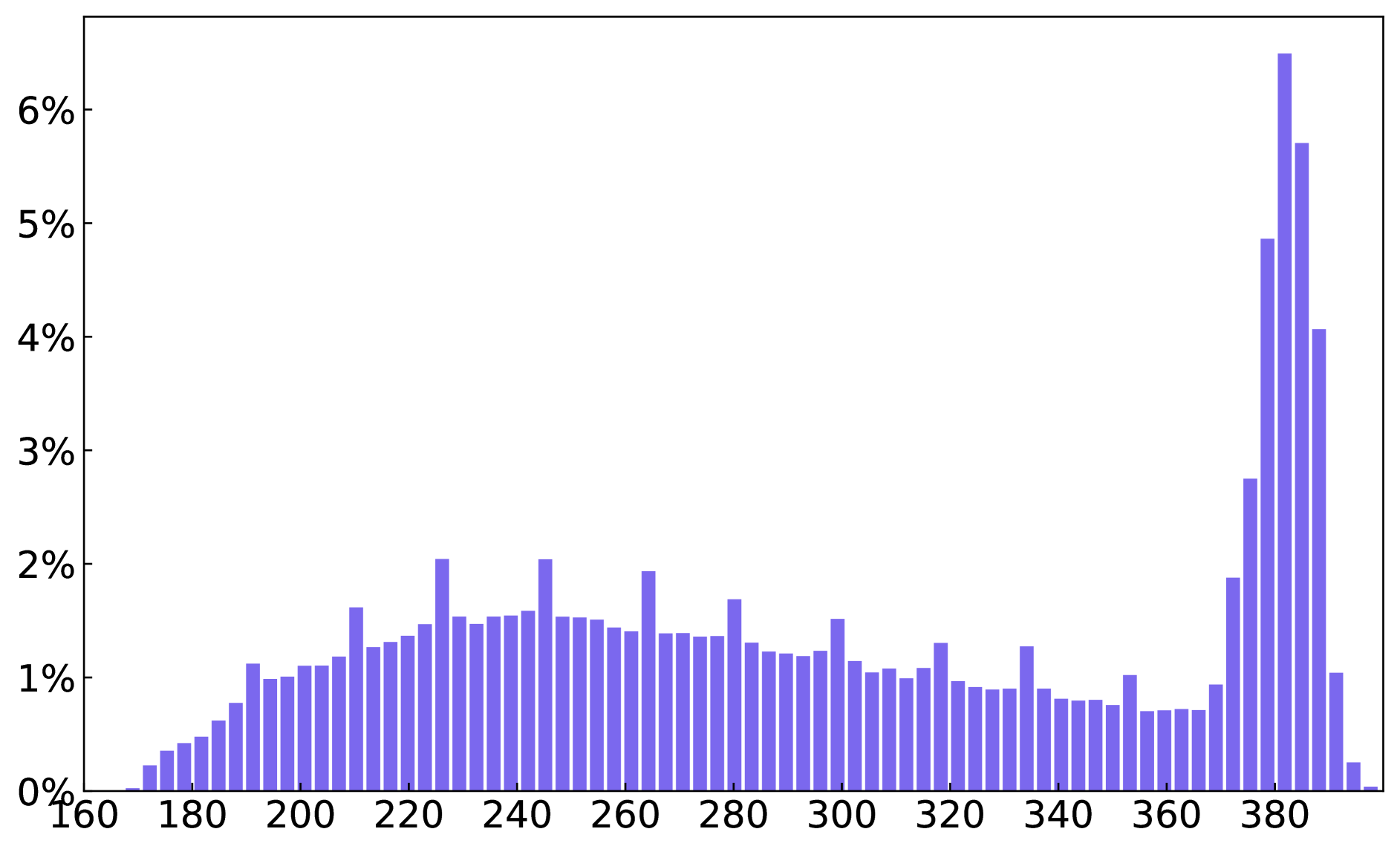
A. Dataset Statistics
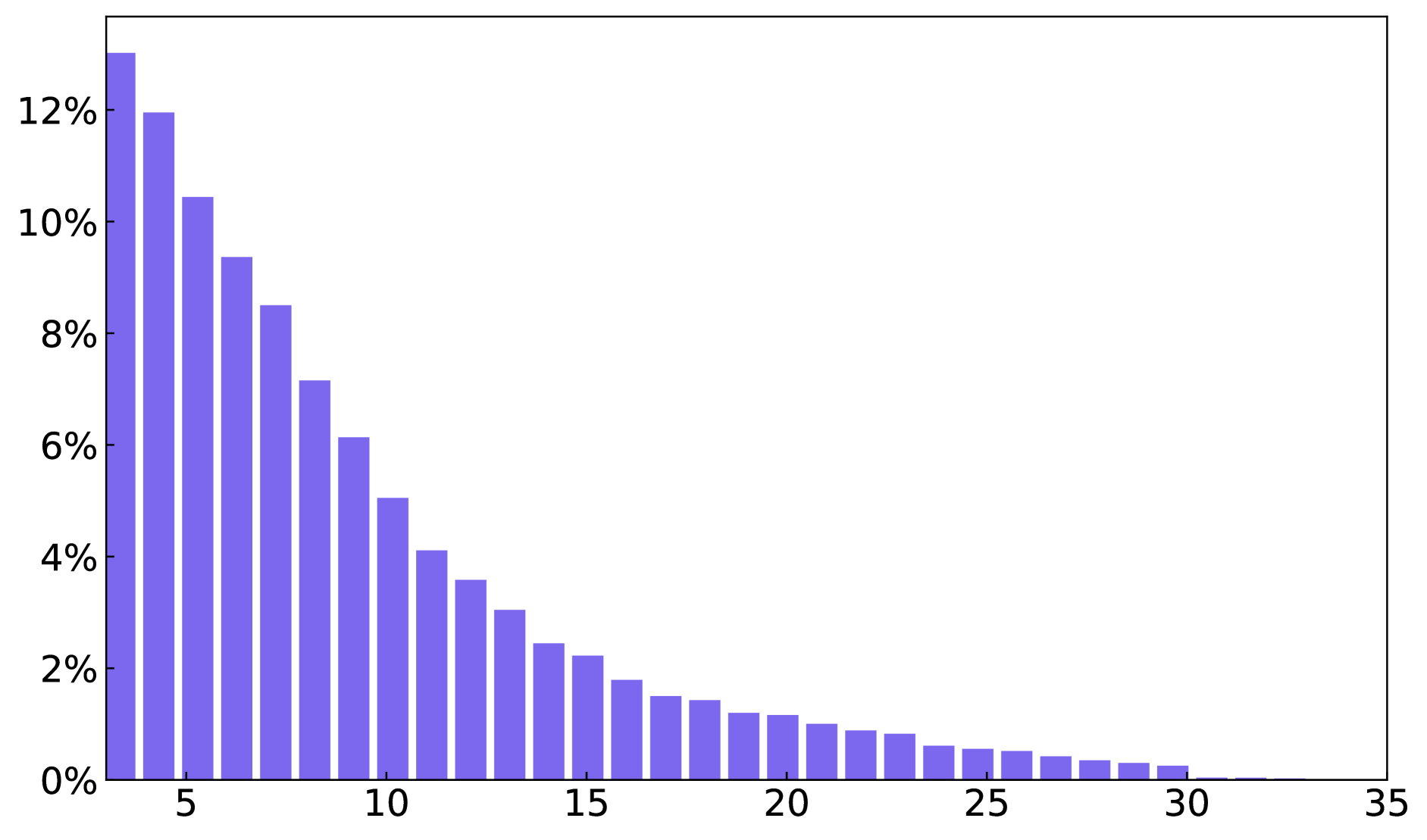
We present statistics on the number of text boxes, words, and characters across the entire glyph-text dataset and the paragraph-glyph-text dataset in Figure 8.
 (a)
(a)
 (b)
(b)
 (c)
(c)
 (d)
(d)
 (e)
(e)
 (f)
(f)
B. Training Settings
Table 9 and Table 11 detail the hyperparameters for training Glyph-CLIP and Glyph-SDXL, respectively. Glyph-CLIP is trained with A100 GPUs while Glyph-SDXL is trained with MI200 GPUs.
| Hyperparameter | Glyph-CLIP-Small | Glyph-CLIP-Base | Glyph-CLIP-Large |
| Text Encoder | ByT5-Small | ByT5-Base | ByT5-Large |
| Vision Encoder | DINOv2 ViT-B/14 | DINOv2 ViT-L/14 | DINOv2 ViT-g/14 |
| Peak Learning-rate | 5.00E-04 | 5.00E-04 | 5.00E-04 |
| Batch Size | 1536 | 1024 | 768 |
| Epochs | 5 | 5 | 5 |
| Warmup Iterations | 100 | 100 | 100 |
| Weight Decay | 0.2 | 0.2 | 0.2 |
| Text-Encoder Dropout | 0.1 | 0.1 | 0.1 |
| Hyperparameter | Glyph-SDXL-Small | Glyph-SDXL-Base | Glyph-SDXL-Large |
| Text Encoder | Glyph-ByT5-Small | Glyph-ByT5-Base | Glyph-ByT5-Large |
| UNet Learning-rate | 5.00E-05 | 5.00E-05 | 5.00E-05 |
| Text Enoder Learning-rate | 1.00E-04 | 1.00E-04 | 1.00E-04 |
| Batch Size | 256 | 256 | 256 |
| Epochs | 10 | 10 | 10 |
| Weight Decay | 0.01 | 0.01 | 0.01 |
| Text-Encoder Weight Decay | 0.2 | 0.2 | 0.2 |
| Text-Encoder Dropout | 0.1 | 0.1 | 0.1 |
| Gradient Clipping | 1.0 | 1.0 | 1.0 |
| Text encoder fusion method | Precision () | |||
| 20 chars | 20-50 chars | 50-100 chars | 100 chars | |
| concatnate text embeddings | ||||
| region-wise cross-attention | ||||
C. Typography Editing with Region-wise SDEdit
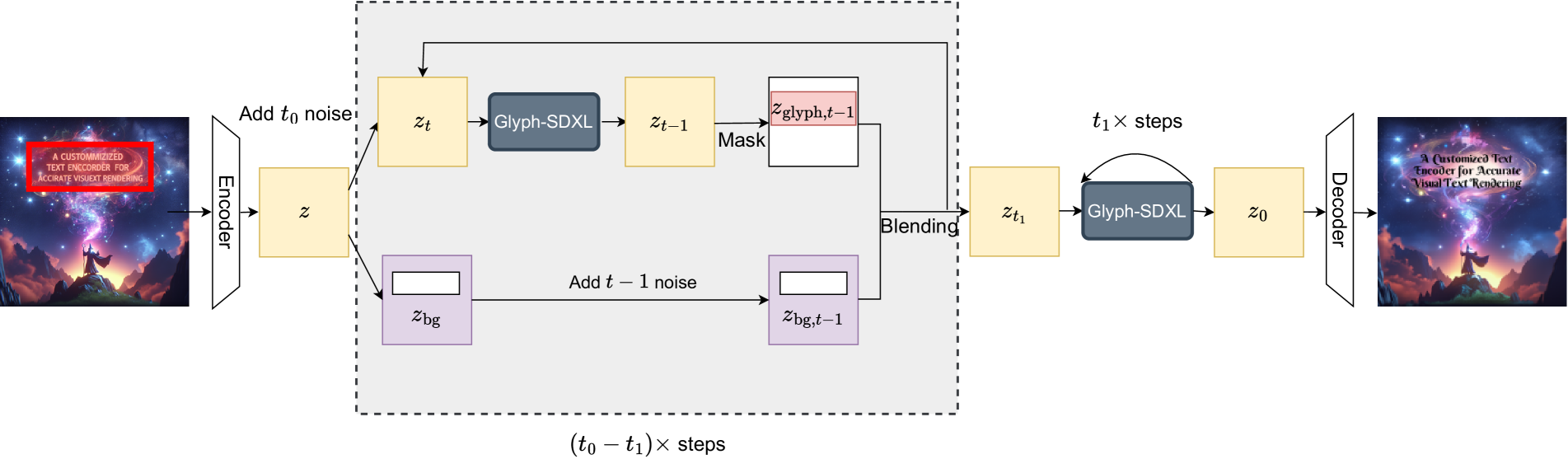
Inspired by the success of SDEdit [18] and Blended Latent Diffusion [2], we introduce a region-wise SDEdit scheme, transforming our Glyph-SDXL into a precise and adaptable visual text editor. This enables the refinement of visual text in high-quality images produced by state-of-the-art (SOTA) generation models, such as DALLE3. The typography editing outcomes are displayed in Figure 10, showcasing our approach’s robust capability for precise typography editing.
Region-wise SDEdit Scheme: For any given input image, steps of noise are initially added. Beginning at , the Glyph-SDXL model is employed iteratively on the noised image to perform denoising. To ensure modifications are confined exclusively to glyph pixels—thereby keeping background pixels untouched—only glyph areas undergo denoising throughout this phase. The process progresses until timestep , at which point the entire image undergoes denoising to guarantee overall coherence. Figure 10 depicts the framework of our region-wise SDEdit scheme.
Effect of parameter choice: We study the effect of different choices for and .
We first fix and study the effect of different . As illustrated in Figure 13, a large is crucial to ensure that the glyph latents are fully edited. Smaller keeps a larger proportion of the original latents, resulting in conflicts and degrading performance.
Furthermore, we fix and study the effect of different choices of . As illustrated in Figure 13, larger ensures better coherence between the pixels inside and outside the glyph boxes, but significantly changes the background image. Smaller , on the contrary, maintains the background image while sacrificing coherence.

















 (a)
(a)
 (b)
(b)
 (c)
(c)
 (d)
(d)
 (e)
(f) original
(e)
(f) original






 (a)
(a)
 (b)
(b)
 (c)
(c)
 (d)
(d)
 (e)
(e)
 (f)
(f)


















D.Ablation on the Design-to-Scene Alignment









































We examine the impact of employing three types of high-quality data, as shown in Figure 15, Figure 13, and Figure 15.
First, Figure 15 presents a comparison that confirms the importance of fine-tuning Glyph-SDXL with synthetic images created by SDXL. This process significantly mitigates the ’language drift’ phenomenon observed when fine-tuning solely with graphic design data. Furthermore, our analysis reveals that fine-tuning with a combined dataset of TextSeg and graphic design images is beneficial, even in the absence of images generated by SDXL.
Then, we illustrate the impact of incorporating graphic design images in Figure 13, highlighting their importance for ensuring accurate font rendering. This is evident from comparing the results displayed in the second and third rows. Last, in Figure 15, we confirm the critical role of incorporating the TextSeg dataset in generating scene text that seamlessly blends with background objects. For instance, without the TextSeg dataset, the placement of scene text often appears illogical, occasionally even situated outside intended boards or sign placeholders.
E. Ablation on other Text Encoder Fusion Scheme
One might question the effectiveness of a basic approach that concatenates the text embeddings from different text encoders. The comparison results are detailed in Table 11. Empirically, we find that this baseline underperforms significantly due to the substantial discrepancies among the text encoders.
F. Font Type Blending
We illustrate the effect of blending different font types to create new unseen font types in order to demonstrate the extrapolation abilities of our Glyph-SDXL model. As illustrated in Figure 18, we interpolate the embeddings of the italic Brightwall-Italic font type with the distinctive Creepster-Regular font type to create a new blended font type that is italic and contains the special effect of Creepster-Regular.
G. Detailed Prompt List
We illustrate the detailed prompts for generated images shown in Figure 1 and Figure 5 in Table 12.
| Image |
Prompt |
| Fig 1, Row 1, Col1 | Background: Cards and invitations. The image features a white card adorned with blue flowers and greenery. Tags: blue, white, modern, simple, elegant, floral, illustration, professional, aesthetic, announcement. Text: Text ”It was the best of times, it was the worst of times. It was the age of wisdom, it was the age of foolishness.” in color-1, font-421. |
| Fig 1, Row 1, Col2 | Background: Cards and invitations. The image features a white card adorned with blue flowers and greenery. Tags: blue, white, modern, simple, elegant, floral, illustration, professional, aesthetic, announcement. Text: Text ”It was the best of times, it was the worst of times. It was the age of wisdom, it was the age of foolishness.” in color-1, font-469. |
| Fig 1, Row 1, Col3 | Background: Cards and invitations. The image features an endless lush green forest. Tags: elegant, illustration, professional, aesthetic, announcement. Text: Text ”It was the best of times, it was the worst of times.” in color-36, font-126. Text ”It was the age of wisdom, it was the age of foolishness.” in color-19, font-42. |
| Fig 1, Row 1, Col4 | Background: Blue Modern Stars Bookmark. The image features the stary universe with saturn, mars and other planets in aesthetic oil painting style. Tags: elegant, illustration, professional, aesthetic. Text: Text ”It was the best of times, it was the worst of times.” in color-0, font-47. Text ”It was the age of wisdom, it was the age of foolishness.” in color-38, font-420. |
| Fig 1, Row 2, Col1 | Background: Instagram Posts. The image features a stack of pancakes with syrup and strawberries on top. The pancakes are arranged in a visually appealing manner, with some pancakes placed on top of each other. The syrup is drizzled generously over the pancakes, and the strawberries are scattered around, adding a touch of color and freshness to the scene. The overall presentation of the pancakes is appetizing and inviting. Tags: brown, peach, grey, modern, minimalist, simple, colorful, illustration, Instagram post, instagram, post, national pancake day, international pancake day, happy pancake day, pancake day, pancake, sweet, cake, discount, sale. Text: Text ”Get 75% Discount for your first order” in color-3, font-25. Text ”Order Now” in color-0, font-97. Text ”National Pancake Day” in color-4, font-97. |
| Fig 1, Row 2, Col2 | Background: Cards and invitations. The image features a large gray elephant sitting in a field of flowers, holding a smaller elephant in its arms. The scene is quite serene and picturesque, with the two elephants being the main focus of the image. The field is filled with various flowers, creating a beautiful and vibrant backdrop for the elephants. Tags: Light green, orange, Illustration, watercolor, playful, Baby shower invitation, baby boy shower invitation, baby boy, welcoming baby boy, koala baby shower invitation, baby shower invitation for baby shower, baby boy invitation, background, playful baby shower card, baby shower, card, newborn, born, Baby Shirt Baby Shower Invitation. Text: Text ”RSVP to +123-456-7890” in color-18, font-100. Text ”Olivia Wilson” in color-99, font-210. Text ”Baby Shower” in color-53, font-210. Text ”Please Join Us For a” in color-18, font-100. Text ”In Honoring” in color-18, font-100. Text ”23 November, 2021 — 03:00 PM Fauget Hotels” in color-18, font-100. |
| Fig 1, Row 2, Col3 | Background: Flyers. The image features a purple background with a witch flying on a broomstick, surrounded by several pumpkins. The pumpkins are scattered throughout the scene, with some positioned closer to the witch and others further away. The combination of the purple background, the witch, and the pumpkins creates a festive and spooky atmosphere. Tags: purple, orange, colorful, illustration, creative, fun, dark, bold, playful, cute, cartoon, flyer, halloween, trick or treat, costume, party, spooky, pumpkin, trick, event. Text: Text ”Games” in color-27, font-197. Text ”Costume Party” in color-27, font-197. Text ”Candies” in color-27, font-197. Text ”October 31st 6 p.m. - 9 p.m. 123 Anywhere St., Any City, ST 12345” in color-51, font-197. Text ”Treat” in color-51, font-371. Text ”or” in color-51, font-371. Text ”Trick” in color-51, font-371. |
| Fig 1, Row 2, Col4 | Background: Instagram Posts. The image features a purple witch’s hat on a pumpkin, which is placed in front of a graveyard. The pumpkin is positioned in the center of the scene, and the hat is slightly tilted to the left. There are three ghosts in the background, with one on the left side, one on the right side, and another one in the middle. The ghosts are positioned at different heights, with the one on the left being the tallest, the one in the middle being the shortest, and the one on the right being slightly taller than the middle ghost. Tags: purple, orange, yellow, illustration, halloween, halloween day, halloween party, happy halloween, pumpkins, trick or treats, spooky, haunted, event, party, festive, witch, monster, scary, ghost, instagram post. Text: Text ”Big deals” in color-14. Text ”31 October 2022” in color-14. Text ”HALLOWEEN SALE” in color-57, font-252. Text ”ONLY FOR TODAY” in color-57, font-252. Text ”50% OFF” in color-57, font-252. |
| Fig 1, Row 1, Col4 | Background: A photo of a cute squirrel holding a sign, 4k, dslr. Text: Text ”Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering”. |
| Fig 1, Row 1, Col4 | Background: A man standing in the midst of a vibrant sunflower field with a mountain range in the background under a blue sky, holding a sign that reads ”Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering” Vincent van Gogh style. Text: Text ”Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering”. |
| Fig 1, Row 1, Col4 | Background: An intriguing scene of a blank sign standing amidst a rocky landscape, with a backdrop of a clear sky and a palm tree. Text: Text ”Words on sign are”. Text ”CORRECT”. Text ”exactly with Glyph ByT5”. |
| Fig 1, Row 1, Col4 | Background: The image shows a sign with a stylized design, featuring a bird and branches. The sign is hanging from a ceiling, and it appears to be located outside a building. The design is simple and modern, with a limited color palette that includes shades of brown and white. The bird and branches are depicted in a minimalist style, with clean lines and a lack of detail that gives the sign a contemporary feel. The sign is likely intended to provide information or direction to passersby, but the specific content of the sign is not visible in the image. Text ”Glyph ByT5: A Customized Text Encoder for Accurate”. Text ”Visual Text Rendering”. |
| Fig 5, Row 1, Col1 | Background: The image features a decorative frame with a floral design, showcasing a variety of flowers. The frame is adorned with a combination of pink, yellow, and white flowers, creating a visually appealing and colorful display. The flowers are arranged in a way that fills the frame, giving the impression of a vibrant and lively scene. Text: Text ” ”Marriage does not guarantee you will be together forever, it’s only paper. It takes love, respect, trust, understanding, friendship, and faith in your relationship to make it last.”” in color-10, font-358. |
| Fig 5, Row 1, Col2 | Background: The image features a white background with a few plants and flowers scattered across it. There are three main plants in the scene, with one located on the left side, another in the middle, and the third on the right side. Additionally, there are two smaller plants in the upper part of the image. The plants are of various sizes and shapes, adding a sense of diversity to the scene. Text: Text ”Give yourself the same amount of care you selflessly give to others.” in color-7, font-196. |
| Fig 5, Row 1, Col3 | Background: Instagram Posts. The image features a woman sitting in a lotus position, also known as a yoga pose, with her legs crossed and her hands resting on her knees. She is surrounded by a serene environment, with trees in the background and a sun in the sky above her. The woman appears to be meditating or practicing yoga in a peaceful outdoor setting. Tags: WHITE, BROWN, BLUE, MODERN, meditation, exercise, fitness, yoga day, poster, health, illustration, international, position, concept, relaxation, yoga, woman. Text: Text ”” letś move to find healthy”” in color-2, font-30. Text ”YOGA DAY” in color-2, font-30. Text ”International” in color-2, font-500. |
| Fig 5, Row 1, Col4 | Background: The image features a white background with a circular frame made of colored pencils. The frame is filled with a variety of colored pencils, creating a visually appealing and artistic design. The pencils are arranged in different positions, with some overlapping and others standing alone. The combination of colors and the circular shape of the frame make the image a unique and creative piece of art. Text: Text ”I TOTALLY REMEMBERED YOUR BIRTHDAY!” in color-14, font-101. |
| Fig 5, Row 1, Col5 | Background: Facebook Post. The image features a man wearing a black shirt and blue overalls, holding a brown box. He is standing in front of a blue background, which has a few speech bubbles scattered around. The man appears to be smiling, possibly indicating that he is happy or excited about the box he is holding. Tags: Violet, purple, illustration, illustrated, corporate, professional, Courier, delivery, parcel, package, fast, free, express, shipping, vehicle, transportation, pickup, centre, man, character. Text: Text ”EXPRESS PARCEL SHIPPING” in color-0, font-4. Text ”www.reallygreatsite.comïn color-0, font-4. Text ”tel.: +123-456-7890” in color-0, font-4. Text ”over 1000 Delivery Centres” in color-0, font-4. Text ”Online Tracking” in color-0, font-4. Text ”10% off for New Clients” in color-0, font-4. Text ”FOR BUSINESS AND INDIVIDUALS” in color-123, font-4. Text ”DELIVERY” in color-123, font-54. Text ”COURIER” in color-0, font-54. |
H. Typography Layout Planning with GPT-4
To reduce reliance on manually provided typography layouts, such as target text boxes, we utilize the visual planning capabilities of GPT-4 to automate layout generation and subsequently display images based on these layouts. Additionally, we employ the layout prediction capabilities of TextDiffuser-2’s LLM to determine target text boxes. Following these predictions, we implement our Glyph-SDXL model to generate visual text images, as shown in Figure 18. The results indicate that GPT-4’s layout capabilities are significantly more reliable than those of TextDiffuser-2’s layout LLM.
Moreover, we present several typical failure cases encountered with GPT-4 in Figure 18. Notably, GPT-4 tends to uniformly distribute all text boxes within the same column (Columns 1 & 2), cluster text boxes into one corner (Columns 3 & 4), or overlook layout constraints implied by text semantics, such as placing ”Happy” and ”Father” together (Columns 5 & 6).
























 GPT4
GPT4
 Human
Human
 GPT4
GPT4
 Human
Human
 GPT4
GPT4
 Human
Human