Counting-Stars (★):
A Simple, Efficient, and Reasonable Strategy for Evaluating Long-Context Large Language Models
Abstract
While recent research endeavors have concentrated on developing Large Language Models (LLMs) with robust long-context capabilities, due to the lack of appropriate evaluation strategies, relatively little is known about how well the long-context processing abilities and performance of leading LLMs (e.g., ChatGPT and KimiChat). To address this gap, we propose a simple, efficient, and reasonable strategy for evaluating long-context LLMs as a new benchmark, named Counting-Stars. The Counting-Stars is designed to require LLMs to fully understand and capture long dependencies in long contexts and be able to collect inter-dependency across multiple pieces of evidence spanning the entire context to finish the task. Based on the Counting-Stars, we conduct experiments to evaluate the two leading long-context LLMs, i.e., GPT-4 Turbo and Kimi Chat. The experimental results indicate that GPT-4 Turbo and Kimi Chat achieve significant performance in the long context from 4K to 128K. We further present two intriguing analyses regarding the behavior of LLMs processing long context. Our code and data are released111https://github.com/nick7nlp/Counting-Stars.
1 Introduction
Large language models (LLMs) have demonstrated exceptional performance across a wide range of Natural Language Processing (NLP) downstream tasks Huang et al. (2023). A context window of 128K tokens is crucial for LLMs and enables LLMs to perform tasks that are significantly beyond the existing paradigm, such as multi-document question answering Caciularu et al. (2023), repository-level code understanding Bairi et al. (2023), etc. An increasing number of studies focus on extending the context window these models can handle to enable LLMs to support more intricate and diverse applications. Despite these developments, the efficacy of models in long-context settings still needs to be examined, primarily due to the lack of a robust evaluation benchmark An et al. (2023); Liu et al. (2023); Fu et al. (2024).
In contrast to the rapid evolution of the supported context length of LLMs, existing benchmarks have lagged behind Yuan et al. (2024). Meanwhile, it is worth mentioning that tasks in existing benchmarks are primarily short dependency tasks, which only require LLMs to retrieve answers from one specific sentence or paragraph without genuinely testing the capabilities of LLMs for handling long contexts. However, long dependency tasks require LLMs to collect pieces of key information from paragraphs across the entire document and summarize them into a cohesive answer Li et al. (2023); Fu et al. (2024). Recently, a few benchmarks have been proposed for evaluating long-context LLMs, including LongBench Bai et al. (2023), LooGLE Li et al. (2023), and Bench Zhang et al. (2024), which have been instrumental in evaluating the performance of long-context LLMs. Still, one inherent drawback is that the existing benchmarks may be previously used as the training data for LLMs or potentially used for training LLMs in the future, which may lead to data leakage in pre-trained LLMs and make the evaluation inaccurate.

A popular evaluation strategy for whether LLMs have the ability to utilize long context length is the Needle-in-a-Haystack test222https://github.com/gkamradt/LLMTest_NeedleInAHaystack, which asks LLMs to precisely recite the information in a given sentence where the sentence (the “needle”) is placed in an arbitrary location of a 128K long document (the “haystack”). The Needle-in-a-Haystack test asks LLMs to recite the key information in a “needle” sentence (e.g., “The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day”) that is inserted at designed locations in a long essay Kuratov et al. (2024). As mentioned before, this task can be used for testing the short dependency of LLMs in handling long contexts. However, only testing short dependency may not obtain a reasonable and comprehensive evaluation of the long-context modeling ability of LLMs.
To mitigate the shortcomings of existing benchmarks, in this paper, we propose a simple, efficient, and reasonable strategy for evaluating long-context LLMs as a new benchmark, named Counting-Stars. Suppose the Needle-in-a-Haystack test can be regarded as a short dependency task that assesses the long-context capability of LLMs. In that case, the Counting-Stars can be treated as a long dependency task for evaluating the long-context capability of LLMs. As the name suggests, the Counting-Stars test refers to scattering multiple stars (sentences describing the number of stars) in the sky (a 128K long context), requiring LLMs to collect and summarize them into a specified answer. Through this task, we expect to evaluate the long dependency of LLMs, i.e., the capability of understanding and gathering inter-dependency across multiple pieces of evidence spanning the entire long context. For the former, similar to Needle-in-a-Haystack, the inserted sentences and the long context are unrelated texts, which require LLMs to distinguish evidence and unrelated texts. The latter is evaluated by counting the number of sentences LLMs recited, which usually becomes more difficult as the input context becomes longer.
After constructing the Counting-Stars, we conduct experiments to evaluate the performance of two LLMs on different versions of the Counting-Stars to gauge their difficulty and evaluate the effectiveness of these LLMs. The experimental results show that GPT-4 Turbo and Kimi Chat have surprising capabilities in handling extremely long contexts but are not fully equipped to handle all settings within the Counting-Stars, highlighting the ongoing challenge of enabling LLMs to process long contexts effectively. Furthermore, we conduct intriguing analyses on the behavior of LLMs in such long contexts, including the length ablation, the absence of the lost-in-the-middle phenomenon, different long contexts, and etc.
2 Counting-Stars (★)
2.1 Preliminary
Before introducing the details and analysis of the Counting-Stars test, we first explain why this test is called Counting-Stars and why it ends with listing stars instead of counting. Initially, we expect LLMs to count the total number of stars in the sky, which aims to test the long dependency of LLMs. However, we find that if LLMs are required to count stars, they usually perform badly. Specifically, we analyze the reasons for the bad performance, which mainly include three points: (1) LLMs cannot discover stars; (2) LLMs can discover all the stars in the sky but cannot remember them all; (3) LLMs can remember all the stars but need better mathematical ability to calculate the total numbers of stars correctly. Therefore, in the end, we selected to let LLMs list all the numbers of stars because the test of Counting-Stars only wanted to better evaluate the long dependency ability of LLMs via a simple, efficient, and reasonable strategy.
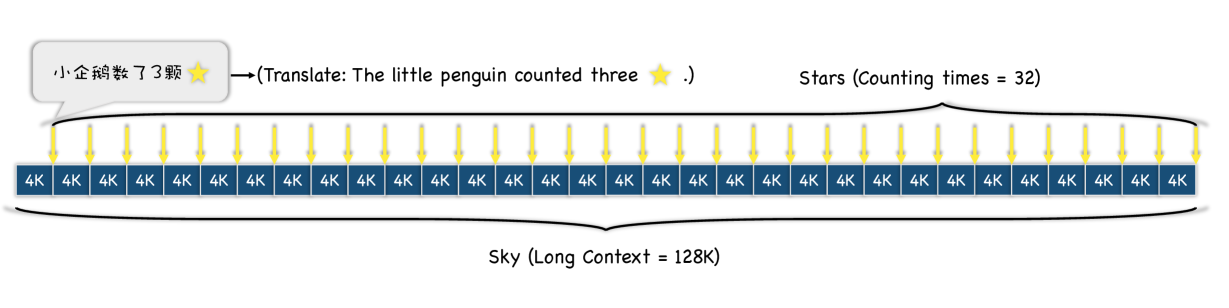
As shown in Figure 1 and Figure 2, the "sky" is the 128K input long-context333The input data used in this paper is The Story of the Stone, an 18th-century Chinese novel authored by Cao Xueqin, considered to be one of the Four Great Classical Novels of Chinese literature., the "stars" denotes sentences describing counting stars (sentences highlighted with yellow in the input text), and the answer is a list of numbers. Furthermore, we mainly evaluate the Chinese version of the Counting-Stars, while the English version can construct test data based on the translated content.
In the Counting-Stars, we change the experimental parameters from two perspectives and then set different versions of the Counting-Star test. For convenience, we add parameters into the name of the Counting-Star, namely Counting-Stars-(M-N). Specifically, the first parameter M is the number of inserted sentences with stars, and the second parameter N is the granularity of the input text length. Here, four versions of the Counting-Stars-(M-N) are designed as follows:
-
•
Counting-Stars-(32-32)
-
•
Counting-Stars-(64-32)
-
•
Counting-Stars-(16-32)
-
•
Counting-Stars-(32-16)
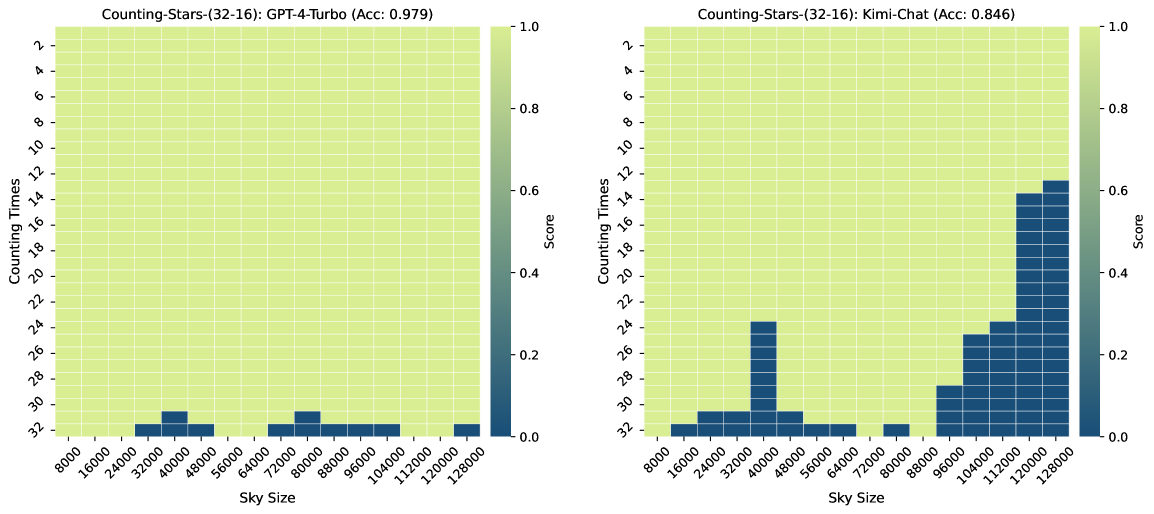
Among them, the Counting-Stars-(32-32) indicate the standard form of the Counting-Stars test. We set Counting-Stars-(16-32) and Counting Stars-(64-32) to adjust the difficulty. To verify the significance of fine-grained splitting context length, we set the interval granularity to be larger than the standard one, i.e., Counting-Stars-(32-16). In addition, as shown in Figure 1 (Ground Truth for M = 32), we randomly generated the number of stars counted each time because we found that LLMs easily slack off if a sequence of numbers is continuous or regular.

2.2 Baselines and Experimental Settings
Two popular used LLMs are selected for evaluation based on whether they can handle extremely long-context: (1) GPT-4-Turbo-128K444https://openai.com, the gpt-4-1106-preview model with a 128K context window size from OpenAI. (2) Kimi-Chat555https://kimi.moonshot.cn/, the Moonshot-v1-128K model with a 128K context window size from Moonshot AI.
Specifically, we utilize the number of prompt tokens returned by the GPT-4-Turbo-128K API to measure the context length. Therefore, it should also be noted that the position of inserting stars is actually somewhat biased. Firstly, it is due to the input context length being counted by the number of prompt tokens returned by GPT-4 Turbo, and secondly, it is precisely necessary to ensure some randomness.
To ensure the stability of the testing results, we generally set the temperature = 0 and conduct thrice for each experimental setting and observe that the differences are minimal. Therefore, we present and visualize only one set of results. Before evaluating, we truncate the results to the length of the ground truth, eliminate duplicates, and then adopt a binary metric to estimate the accuracy of the prediction generated by LLMs. For example, if the predicted list is [3, 6, 9] and the ground truth list is [3, 5, 9], then the result list is [1, 0, 1], where one is represented by yellow and zero is represented by blue in all figures of this paper.
3 Discussion
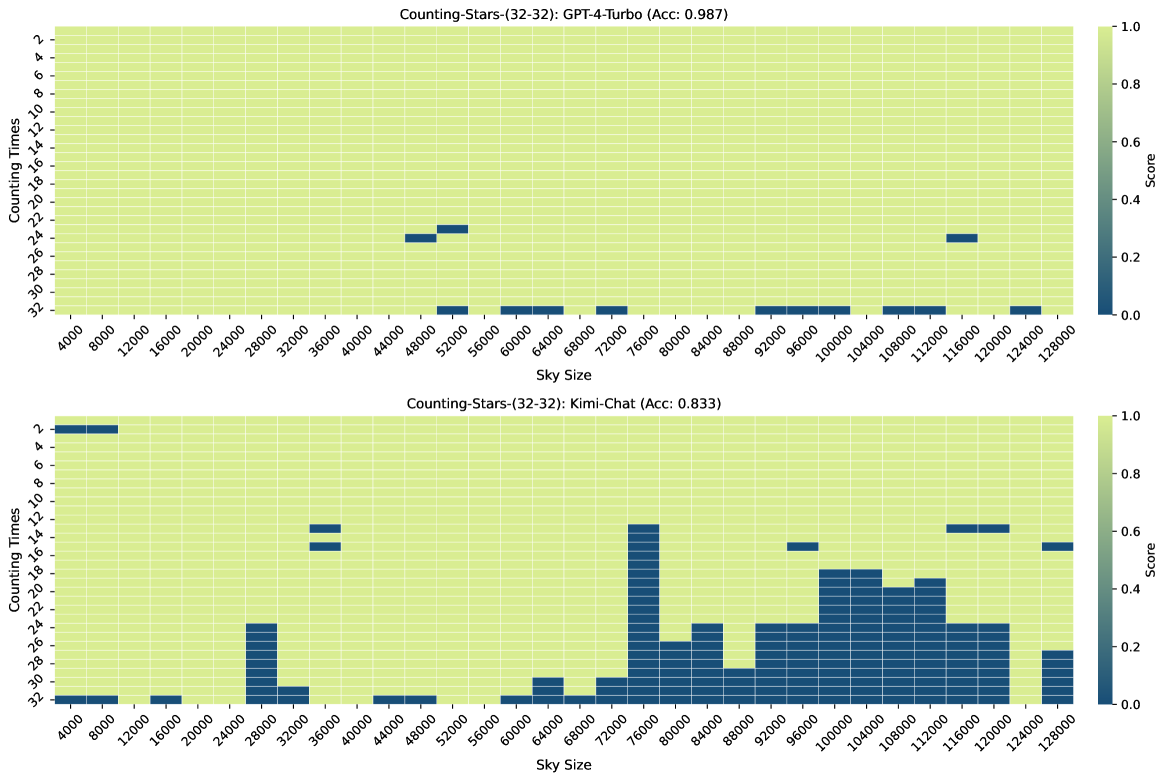
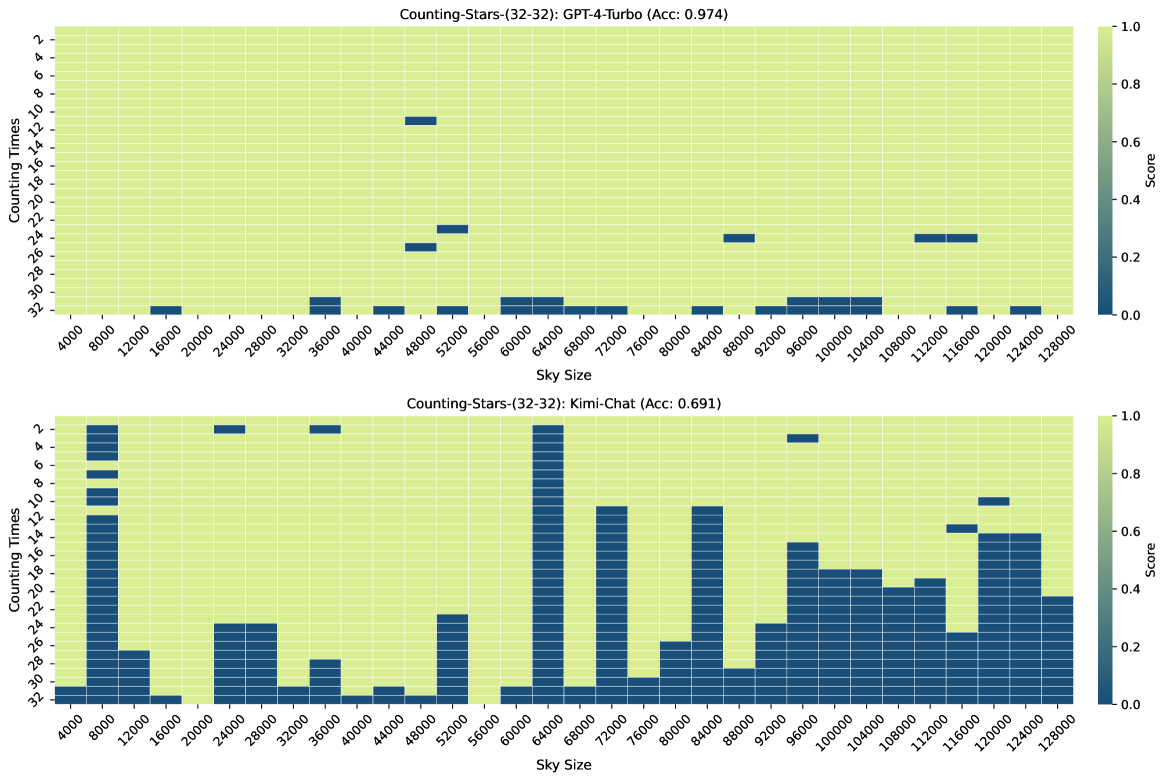
3.1 Overall Performance
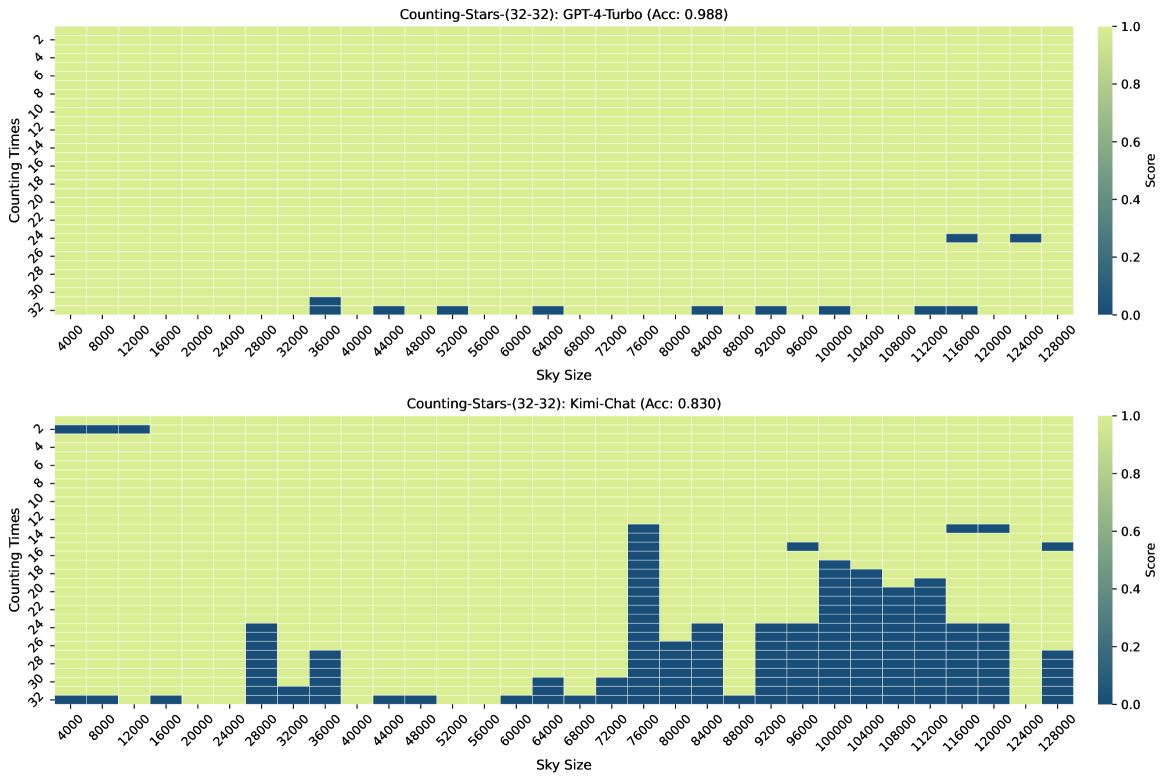
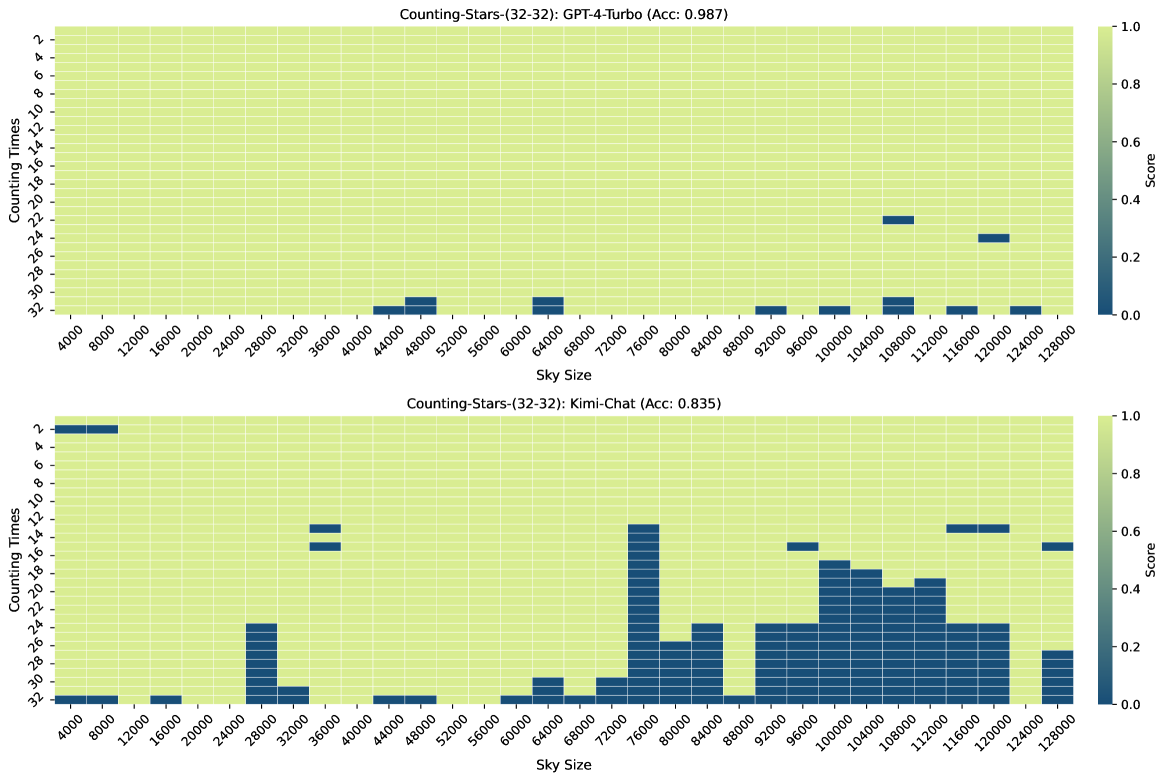
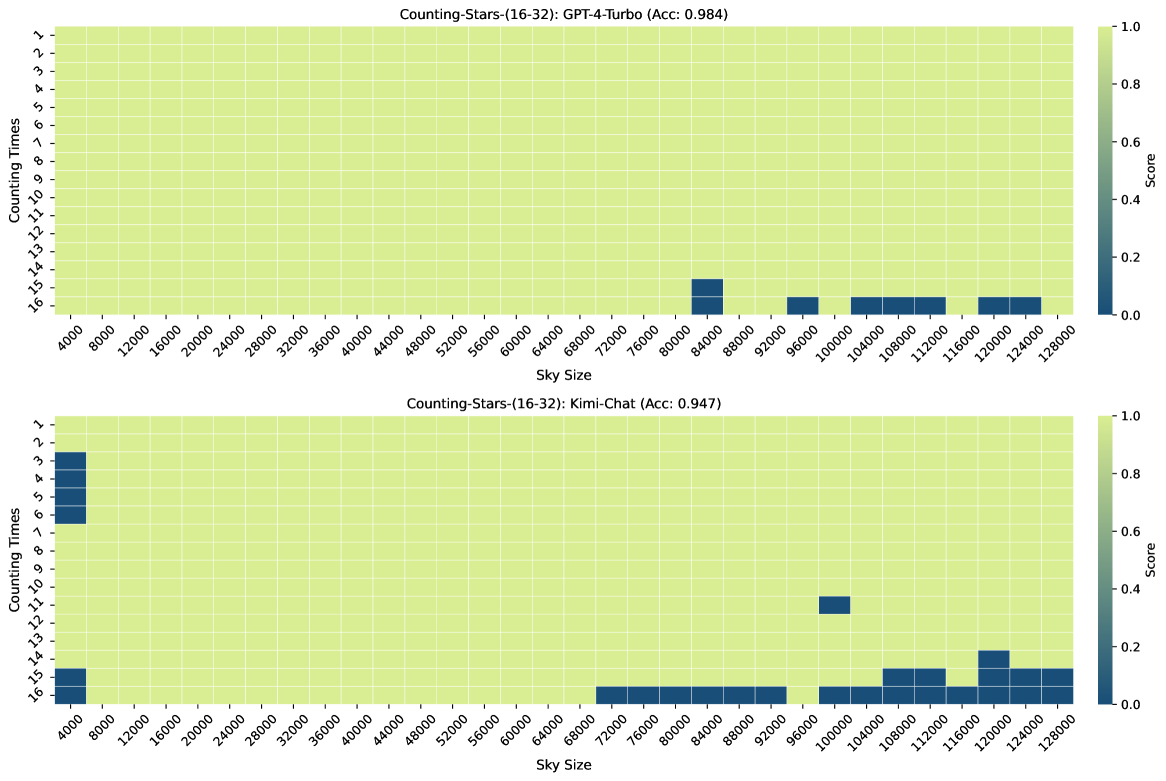
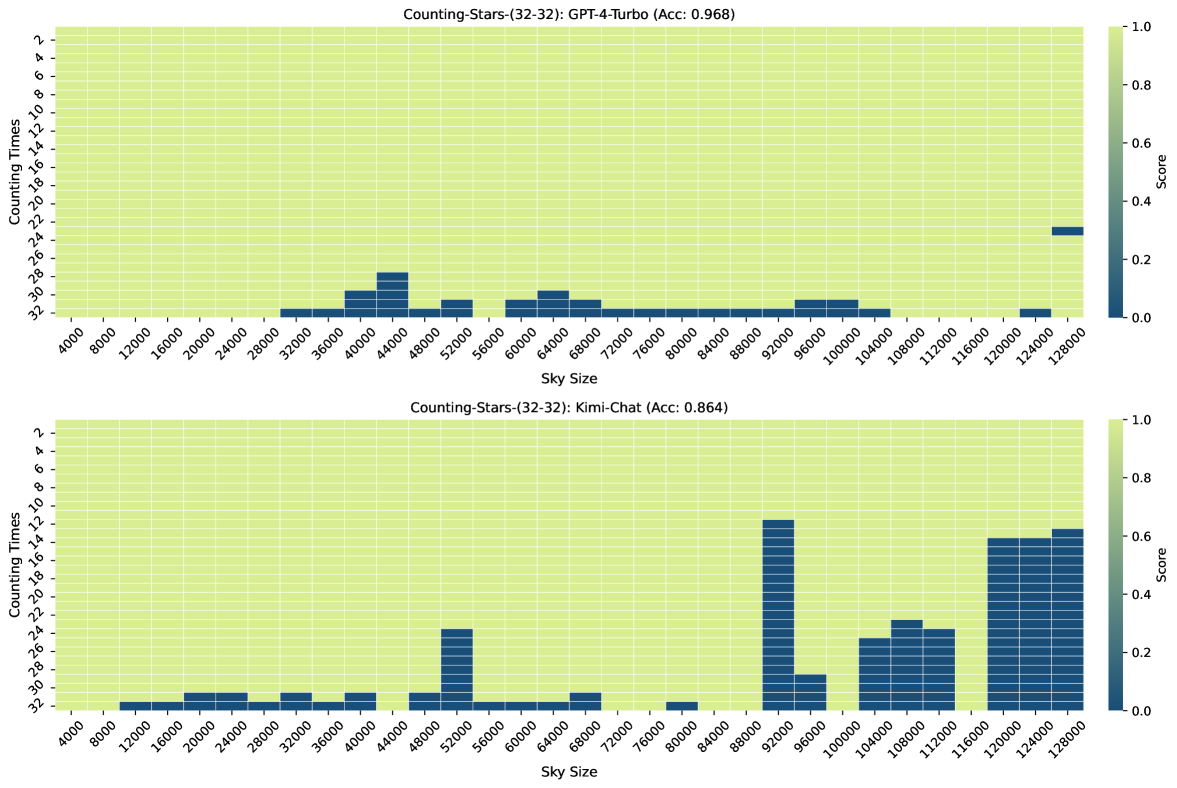
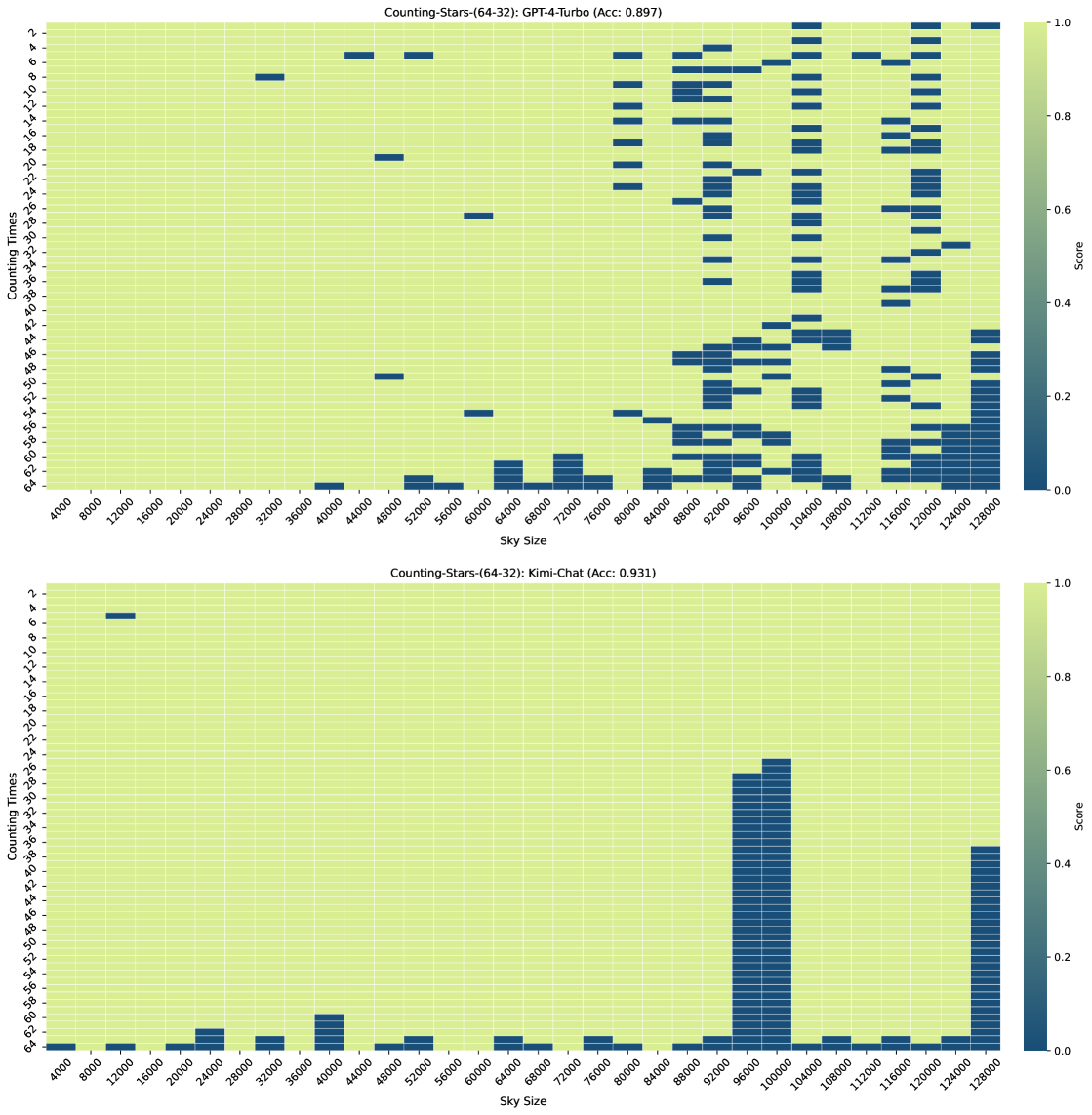
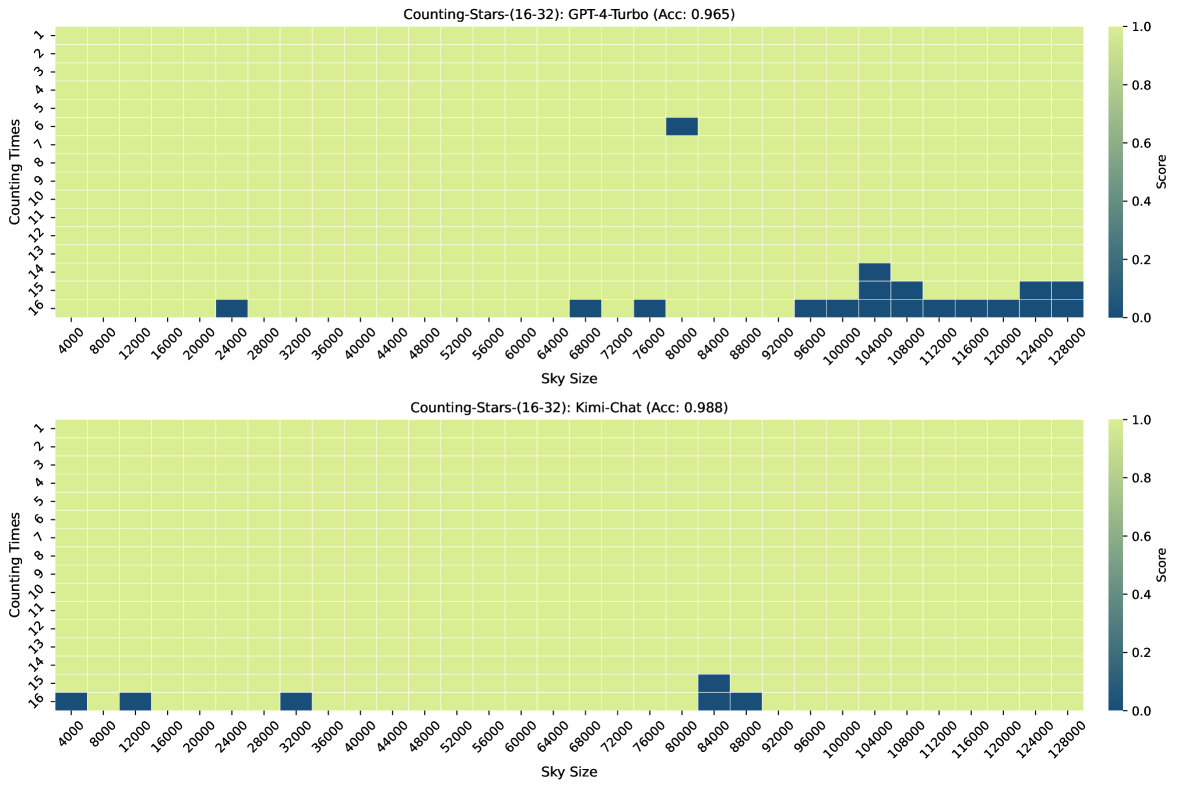
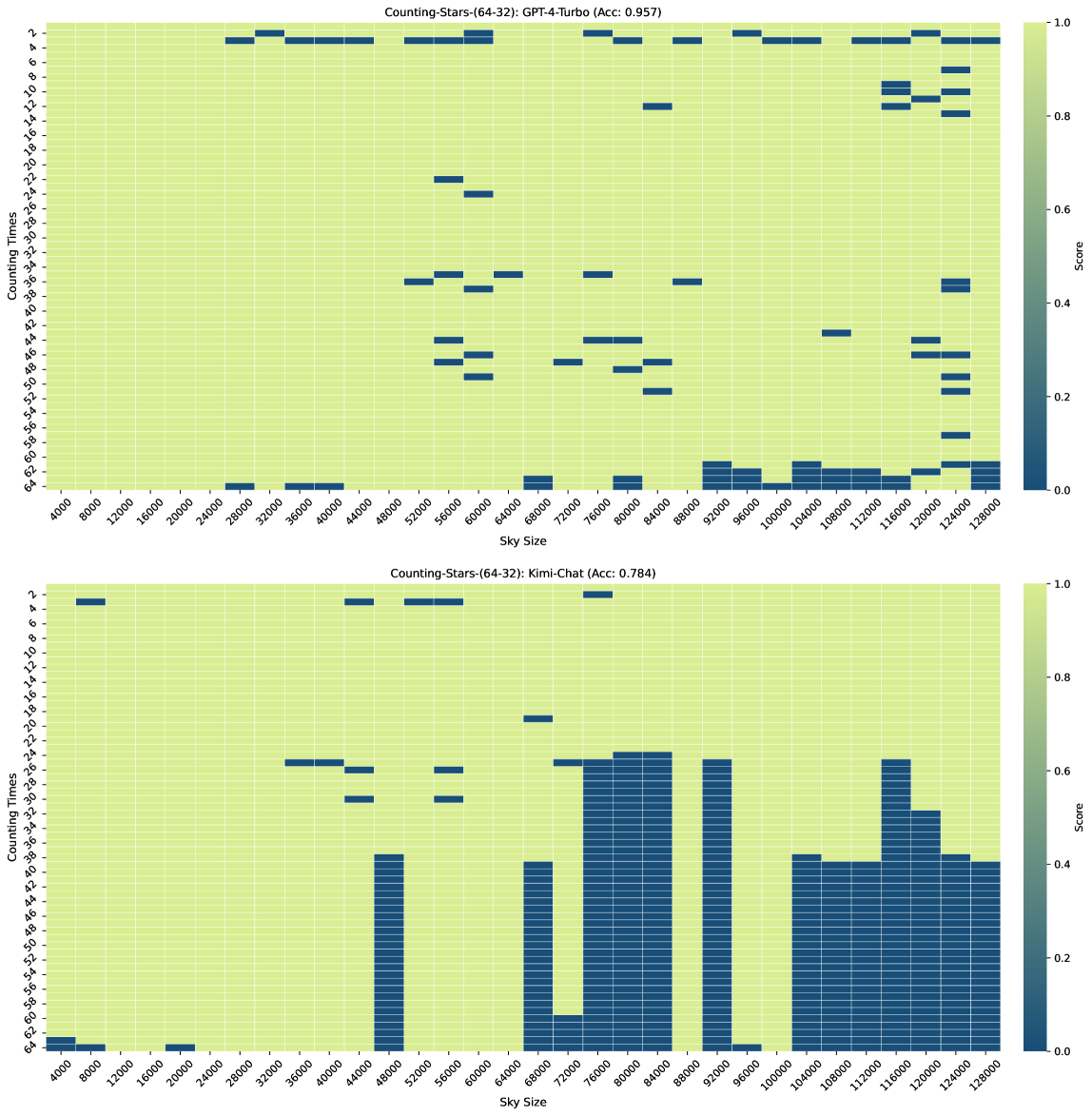
Figure 3, Figure 7, Figure 6, and Figure 4 show the results of the Counting-Stars-(32-32), Counting-Stars-(32-16), Counting-Stars-(16-32), Counting-Stars-(64-32) tests. Overall, Kimi Chat shows surprising performance, although there is still a bit lacking compared to the GPT-4 Turbo, significantly when increasing the amount of evidence to model the long inter-dependency spanning the entire long context (e.g., the results in the Counting-Stars-(32-32) test, as shown in Figure 3). Furthermore, we present a detailed analysis of some lousy performance in the results, as follows:
-
•
As shown in Figure 4, when the context length is 120K, we observe that the results of GPT-4 Turbo are not good since it does not list the number of stars correctly but generates some random numbers.
-
•
As shown in Figure 4, when the context length is 128K, we observe that the results of Kimi Chat are not good because the LLMs cannot search all sentences that count stars from the long context.
- •
- •
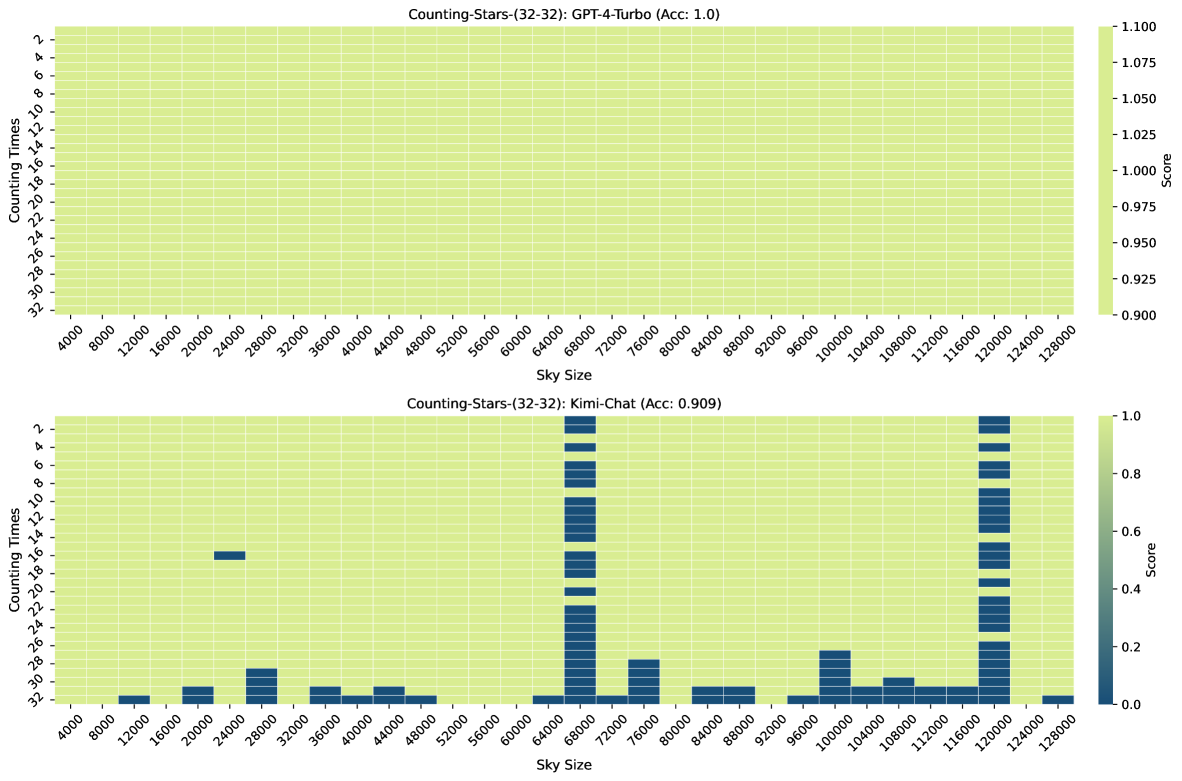
In addition, the results are presented in Figure 8, Figure 9, Figure 10, Figure 11, Figure 12, Figure 13 using Journey to the West666Journey to the West is a Chinese novel published in the 16th century during the Ming dynasty and attributed to Wu Cheng’en. It is regarded as one of the greatest Classic Chinese Novels and has been described as arguably the most famous literary work in East Asia. as the input long context instead of The Story of the Stone. Among them, the provided results also include the thrice testing on the Counting-Stars-(32-32), i.e., Counting-Stars-(32-32)-v1, Counting-Stars-(32-32)-v2, and Counting-Stars-(32-32)-v3.
Additionally, the results are shown in Figure 14 using the English long context777The using data is similar to the Needle-in-a-Haystack testhttps://opencompass.org.cn/doc. to do the English-version Counting-Stars. Specifically, in the English version, the context length is at the character level. It can be seen that in the English version, GPT-4 Turbo is significantly better than Kimi Chat.
3.2 Lost in the Middle
Prior research indicates a performance decline in some LLMs when answers are positioned around the middle of the long context Liu et al. (2023). Similar to Zhang et al. (2024), however, our findings do not strongly corroborate the lost-in-the-middle phenomenon. One possible reason why we obtain different observations from Liu et al. (2023) is that they find the phenomenon via the test at most 16K length contexts, which is not long enough. In our experiments based on the Counting-Stars, we discover that the bad cases usually appeared in the tail rather than the middle of the long context (the lost-in-the-tail phenomenon). Hence, we hypothesize that the lost-in-the-middle phenomenon only occurs in specific tasks or length contexts.
By observing the results of multiple experiments, we guess that the lost-in-the-middle phenomenon of LLMs is determined by their reasoning or thinking patterns when dealing with specific tasks or length contexts. Interestingly, as illustrated in Figure 5 (case 3), when counting stars from the input long context, LLMs first attempt to memorize and recite relevant sentences and then further summarize them into the final result. According to the above findings, we guess this kind of reasoning or thinking patterns may alleviate the lost-in-the-middle phenomenon.
3.3 Stars or A Needle?
The essential difference between Counting-Stars and Needle-in-a-Haystack is that the former can be treated as a long dependency task, and the latter can be treated as a short dependency task. Similar to the prior work Li et al. (2023), we refer to long dependency tasks as those that require understanding inter-dependency across multiple pieces of evidence spanning the entire long-context. Since stars are distributed throughout the entire long context, it is expected that other abilities behind LLMs could be analyzed, such as the long-context processing strategies and attention mechanisms. However, it is essential to note that, based on their analysis Li et al. (2023), both short and long dependencies are equally crucial in analyzing the long-context processing ability of LLMs.
In addition, the Counting-Stars costs less than the Needle-in-a-Haystack, which is beneficial for reducing carbon emissions.
| Model | Counting-Stars (★) | |||
|---|---|---|---|---|
| 32-16 | 16-32 | 32-32 | 64-32 | |
| GPT-4 Turbo | 0.979 | 0.965 | 0.968 | 0.897 |
| Kimi Chat | 0.846 | 0.988 | 0.864 | 0.931 |
3.4 The Length-Stability Dilemma
One phenomenon that puzzles us the most among the test results of both Needle-in-a-Haystack and Counting-Stars is why the same task performs well when the input context length is long but badly at the shorter context (e.g., 100K and 92K in Figure 3). It is important to note that this phenomenon becomes more pronounced as the length of the context increases. In other words, hiding the answer in different positions within different contexts results in LLMs failing to search it. Is this due to the different contexts surrounding the answer? Or is it because the distribution of the input context length of the training data is not uniform, leading to differences in the capabilities of LLMs across various context lengths? Therefore, could increase the robustness of LLMs help? However, based on the experiments in this paper, we cannot yet determine the specific reasons, which is also a goal that the next version of Counting-Stars aims to achieve. We consider that the most intuitive idea behind this is that the long-context capability of LLMs is still relatively weak, so in the case of limited resources, part of stability needs to be sacrificed. Addressing this issue may aid researchers in better analyzing and enhancing the long-context modeling capabilities of LLMs, benefiting specific NLP tasks, such as multi-document question answering.
3.5 Counting-Stars (★★)
As mentioned before, the Counting-Stars initially requires LLMs to calculate the number of stars directly. Still, through experiments, we find that even if it is a simple mathematical problem of calculating “1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1”, the probability of LLMs calculating correctly is lower. Therefore, counting may be a simple and direct extension of the Counting-Stars in the future.
4 Conclusion
We introduce a simple, efficient, and reasonable strategy for evaluating long-context LLMs called Counting-Stars. Based on the Counting-Stars, we conduct intriguing analyses on the behavior of LLMs in such long contexts, including the length ablation, the absence of the lost-in-the-middle phenomenon, and different long contexts as the sky. Additionally, our testing and analysis provide valuable insights into the behavior of leading LLMs when dealing with long contexts, which can inform and guide future research endeavors.
5 Limitations
While this paper offers some insights into the performance of long-context LLMs, it may not be sufficiently diverse or extensive to provide a comprehensive evaluation of the long-context capabilities, a constraint common to most analyses and benchmarks. In addition, through our experiments, two main findings are: (1) the design of prompts had a significant impact on the performance of LLMs; (2) different long texts used as the sky can also have a significant impact on the performance. Meanwhile, we set the temperature to 0 to ensure stability and fairness, impacting the performance.
References
- An et al. (2023) Chenxin An, Shansan Gong, Ming Zhong, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. 2023. L-eval: Instituting standardized evaluation for long context language models. CoRR, abs/2307.11088.
- Bai et al. (2023) Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2023. Longbench: A bilingual, multitask benchmark for long context understanding. CoRR, abs/2308.14508.
- Bairi et al. (2023) Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, Vageesh D. C, Arun Iyer, Suresh Parthasarathy, Sriram K. Rajamani, Balasubramanyan Ashok, and Shashank Shet. 2023. Codeplan: Repository-level coding using llms and planning. CoRR, abs/2309.12499.
- Caciularu et al. (2023) Avi Caciularu, Matthew E. Peters, Jacob Goldberger, Ido Dagan, and Arman Cohan. 2023. Peek across: Improving multi-document modeling via cross-document question-answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 1970–1989. Association for Computational Linguistics.
- Fu et al. (2024) Yao Fu, Rameswar Panda, Xinyao Niu, Xiang Yue, Hannaneh Hajishirzi, Yoon Kim, and Hao Peng. 2024. Data engineering for scaling language models to 128k context. CoRR, abs/2402.10171.
- Huang et al. (2023) Yunpeng Huang, Jingwei Xu, Zixu Jiang, Junyu Lai, Zenan Li, Yuan Yao, Taolue Chen, Lijuan Yang, Zhou Xin, and Xiaoxing Ma. 2023. Advancing transformer architecture in long-context large language models: A comprehensive survey. CoRR, abs/2311.12351.
- Kuratov et al. (2024) Yuri Kuratov, Aydar Bulatov, Petr Anokhin, Dmitry Sorokin, Artyom Sorokin, and Mikhail Burtsev. 2024. In search of needles in a 11m haystack: Recurrent memory finds what llms miss.
- Li et al. (2023) Jiaqi Li, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. 2023. Loogle: Can long-context language models understand long contexts? CoRR, abs/2311.04939.
- Liu et al. (2023) Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the middle: How language models use long contexts. CoRR, abs/2307.03172.
- Yuan et al. (2024) Tao Yuan, Xuefei Ning, Dong Zhou, Zhijie Yang, Shiyao Li, Minghui Zhuang, Zheyue Tan, Zhuyu Yao, Dahua Lin, Boxun Li, Guohao Dai, Shengen Yan, and Yu Wang. 2024. Lv-eval: A balanced long-context benchmark with 5 length levels up to 256k. CoRR, abs/2402.05136.
- Zhang et al. (2024) Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Khai Hao, Xu Han, Zhen Leng Thai, Shuo Wang, Zhiyuan Liu, and Maosong Sun. 2024. bench: Extending long context evaluation beyond 100k tokens.