Latency-Aware Generative Semantic Communications with Pre-Trained Diffusion Models
Abstract
Generative foundation AI models have recently shown great success in synthesizing natural signals with high perceptual quality using only textual prompts and conditioning signals to guide the generation process. This enables semantic communications at extremely low data rates in future wireless networks. In this paper, we develop a latency-aware semantic communications framework with pre-trained generative models. The transmitter performs multi-modal semantic decomposition on the input signal and transmits each semantic stream with the appropriate coding and communication schemes based on the intent. For the prompt, we adopt a re-transmission-based scheme to ensure reliable transmission, and for the other semantic modalities we use an adaptive modulation/coding scheme to achieve robustness to the changing wireless channel. Furthermore, we design a semantic and latency-aware scheme to allocate transmission power to different semantic modalities based on their importance subjected to semantic quality constraints. At the receiver, a pre-trained generative model synthesizes a high fidelity signal using the received multi-stream semantics. Simulation results demonstrate ultra-low-rate, low-latency, and channel-adaptive semantic communications.
Index Terms:
Generative AI, Semantic Communication, Pre-Trained Foundation Models, Stable Diffusion.I Introduction
Semantic Communication (SemCom) is poised to play a pivotal role in shaping the landscape of future AI/ML-driven communication systems. SemCom systems aim to significantly reduce the transmission rate by extracting and transmitting only the semantic message of interest based on the communication intent. Generative AI (GenAI) models have recently proved to significantly enhance communication at the semantic-level [2, 3, 4]. GenAI models such as Diffusion [5, 6], Flow-based [7], and GAN [8] models, can learn the general distribution of natural signals through training and can generate new samples at the inference time. This generative process can be guided or conditioned to synthesize outputs with a desired semantic content. In Generative Semantic Communications (Gen SemCom), the semantics of interest are extracted at the transmitter, communicated over the channel, and then used at the receiver to guide a generative model to synthesize a semantically consistent signal with high fidelity. GenAI models are trained to maximize the perceptual quality and the fundamental bounds on Generative SemCom are governed by the rate-distortion-perception theory [9, 10], which determines the threefold trade-off between rate, distortion, and perceptual quality of the reconstructed signal.
The recent advent of powerful Generative Foundation Models provides ample opportunities to develop ultra-low-rate semantic communication systems. The ultra low rate transmission can be achieved by transmitting data semantics in compressed format as a textual message or prompt. For instance, the prompt “Teddy bear surfer rides the wave in the tropics” can be used to generate a short video with its semantic content matching with the prompt. The generative foundation models such as Sora [11], Lumiere [12], and DALL.E [13] are pre-trained on large amount of data and can synthesize various types of AI Generated Content (AIGC) with high quality. The pre-trained nature of such models and their applicability to a vast range of multi-media synthesis tasks, has the potential to revolutionize generative semantic communications enabling universal intent and channel-adaptive SemCom systems empowered by pre-trained foundation models.
In this paper, we develop a universal generative semantic communications framework with pre-trained foundation models. We claim two key benefits in comparison with the existing semantic communication frameworks. Firstly, the foundation models possess a vast general knowledge leveraging the intensive self-supervised training process on huge amount of data. This alleviates the need for a shared knowledge base/graph between the semantic transmitter and receiver, obviating the need for corresponding knowledge sharing overheads imposed in current SemCom frameworks [14, 16, 17, 15, 18]. This vast general knowledge also makes the proposed Generative SemCom framework applicable to various datasets and tasks thereby achieving universality. Secondly, the adoption of pre-trained models allows a separation-based SemCom architecture, alleviating the need for end-to-end joint training of the transmitter and receiver, which is required in many SemCom frameworks [14, 16, 17, 15]. Such a separation-based architecture offers better compatibility with the existing design of wireless communication networks in comparison with the end-to-end methods. The proposed framework is specifically suitable for scenarios which require communication of huge multi-modal data with stringent latency and reliability requirements, e.g. the wireless metaverse, extended/mixed reality (XR/MR), holographic teleportation, and the internet of senses. The contributions of this work are three-fold:
-
•
We develop a semantic decomposition scheme at the transmitter which extracts the semantic content of the input signal in multiple semantic modalities. We extract the most important semantic contents as a compact textual message or prompt, along with multiple other modalities that act as conditioning signals to guide the synthesis process at the generative foundation model at the receiver.
-
•
To achieve semantic-aware communication, we design a multi-stream scheme that transmits each extracted semantic modality with appropriate coding and communication techniques based on communication intent. Due to the importance of the textual prompt, a re-transmission scheme is applied to ensure reliable reception, while other modalities are transmitted with a modulation scheme adapted to the varying wireless channel.
-
•
We design a semantic and latency-aware scheme to allocate the transmission power to different semantic streams based on semantic importance, and to adapt the modulation order to the varying wireless channels.
Notations: Boldface lower and upper-case symbols denote column vectors and matrices, respectively. denotes . and denote the -th element and the length of vector , respectively. Finally, is the dot production, and denotes probability of an event.
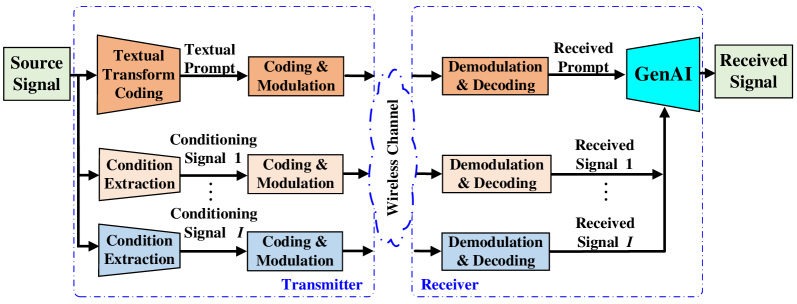
II Generative Foundation AI-based Semantic Communication
Fig. 1 depicts our proposed framework for generative semantic communication with pre-trained foundation models. This framework includes multi-modal semantic decomposition/synthesis, semantic-aware multi-stream transmission, and latency-aware semantic power allocation.
II-A Multi-modal Semantic Decomposition and Synthesis
At the transmitter, a pre-trained textual transform encoder performs ultra-low-rate source-to-text transformation, extracting the textual message which acts as a prompt for the GenAI process at the receiver. Depending on the source signal (e.g. voice, image, video, point cloud, etc.), various large, medium, and small scale pre-trained AI models can be used for prompt extraction. The prompt contains the most important semantic contents of the source signal. At the same time, additional semantic information is extracted from the source signal based on communication intent. They are typically extracted in modalities other than text and provide additional conditioning signals to guide the GenAI process at the receiver. For example, if the source signal to be transmitted is a short video, the initial frame of that video can be a good conditioning signal to be transmitted along with the prompt to guide the generation process at the receiver. As another example, if the source signal is an image and the receiver is interested in the relative location of different objects in the image, an edge map can be a good conditioning signal, as discussed later in Section III.
The decomposed multi-modal semantics, i.e., prompt and conditioning signals, are then compressed, coded, and modulated, and transmitted over the wireless channel. At the receiver, after demodulation, decoding, and decompression, the received multi-modal semantics are simultaneously fed into a pre-trained generative model for high-fidelity synthesis of the source signal. We note that state-of-the-art generative models, e.g. stable diffusion (SD) [5], allow generation using only the prompt, which results in a relatively high distortion. On the other hand, some semantic information content of the source signal can be more efficiently communicated using other modalities. The conditioning signals improve the semantic fidelity as well as distortion at additional communication costs. Finally, the desired dimensions of the signal to be synthesized by GenAI are assumed to be fixed and known to the receiver.
II-B Semantic-aware Multi-Stream Transmission
The transmitter sends the extracted multi-modal semantics, i.e., prompt and conditioning signals, in multiple streams over orthogonal frequency channels to enable semantic-aware design of specific transmission mechanisms, e.g. coding rate, modulation order, for different semantic modalities. Since the prompt is a compact textual message and contains the most important semantic content of the source signal, we use lossless compression for prompt to obtain a bit-stream . However, for other semantic modalities we use state-of-the-art Deep Neural Network (DNN)-based techniques for lossy compression as will be discussed in Section III. The bit-stream of the -th conditioning signal is denoted by , .
We consider the Rayleigh fading channel and assume that the channels experience block fading within the transmit duration of each semantic modality. In particular, the channel gain of the -th semantic modality is expressed as
| (1) |
where (resp. ) denotes the prompt (resp. conditioning signals), is a random scattering element captured by zero-mean and unit-variance circularly symmetric complex Gaussian (CSCG) variables, is the path loss at the reference distance m, is the path loss exponent, is the distance. Furthermore, the received signal-to-noise ratio (SNR) at the receiver for the -th semantic modality is given by , where and denote the transmit power and the bandwidth allocated for the -th modality, respectively, and is the noise power spectral density. For notational simplicity, we use instead of , , in the sequel.
II-B1 Re-transmission-based Communication of the Textual Prompt
The textual prompt is a super compact message that is highly sensitive to errors. Even a single bit error can change a character/word causing a significant semantic error. Thereby, our framework uses re-transmissions if the prompt is received with any error. Based on this, we propose a cyclic redundancy check (CRC)-based re-transmission mechanism for the prompt to guarantee its reliable communication. Assuming the prompt is transmitted in packets of length bits, the packet error rate (PER) can be expressed as [19]
| (2) |
where and are parameters determined by the channel coding scheme and the modulation order. We denote the coding rate and the modulation order as and , respectively. Hence, the expected total transmission delay for the prompt is given by
| (3) |
where , , denote the number of packets, the number of re-transmissions, and the transmission delay of each packet, respectively.
II-B2 Adaptive Modulation and Coding for other Semantic Modalities
For the transmission of the other semantic modalities, we adopt an adaptive MQAM modulation and coding scheme to cope with varying wireless channel. Denote the bit error rate (BER) of the -th, , conditioning signal as , where denotes the corresponding received data stream of the conditioning signal. With such a scheme, the achievable rate can be generally expressed as [20]
| (4) |
where and are parameters determined by the coding schemes. Thereby, the transmission delay of -th semantic stream is , .
II-C Latency-aware Adaptive Semantic Communication
In this subsection, we propose a semantic and latency-aware approach for selecting the optimal communication parameters such as the transmission power, and modulation order, for various semantic modalities, tailored to the prevailing channel quality as well as the specified semantic quality requirements. We formulate the problem as minimizing the transmission delay under the power and semantic quality constraints given as
| (5) | ||||||
| s.t. | ||||||
where is the maximum transmit power budget, and denote the -th semantic quality metric and its requirement111It is assumed that a larger value of the metric represents improved semantic quality. Many common metrics can be easily transformed to satisfy this., respectively. Since reliable transmission of the prompt is assumed via re-transmissions, , , is a multi-variable function of the BERs of the conditioning signals, denoted as . The quality requirements can represent any semantic distortion or perception [9, 10] requirement of the signal synthesized at the receiver, and can be enforced by various metrics, e.g. MS-SSIM [21], LPIPS [22], FID [23], CLIP [24], etc. The semantic quality constraints represent epigraphs of the metrics, and in the most general case, convexity of problem (5) depends on the behaviour of the selected metrics in terms of . In the typical scenario, where the prompt is transmitted along with only one additional modality, (5) is convex with a straightforward solution as given in Lemma 1.
Lemma 1.
For the case of one conditioning signal, i.e., , if , , are monotonically non-increasing with respect to , (5) is a convex problem. The optimal solution can be achieved if and only if , , and , where denotes the generalized inverse function of , .
Proof.
The epigraph of a single-variable function is convex iff the function is (weakly) monotonic. Hence, if , , are monotonically non-increasing, then the intersection of their epigraphs determines a convex region with respect to , given by where exists because is (weakly) monotonic. Moreover, since is a decreasing function of itself, the constraints collectively determine a convex feasible region in terms of . Using (3) and (4), the latency functions are also convex in , and thereby the optimization is convex with a global solution. Finally, it is straightforward to show that in the optimum solution, all constraints hold with equality and we have . Hence, the optimum solution can be found by solving the non-linear system of equations , , and in . The overall transmission delay is then . ∎
III Simulation Results
III-A System setup
We consider a generative image semantic communication setting, where the receiver is interested in the main objects inside the image, e.g. “car”, “building”, and its general structure, i.e. object shapes and locations. In this context, we consider a two-modal semantic decomposition framework, including a textual prompt to convey the main objects, and an edge map as the conditioning signal to convey the general image structure. To extract the prompt, we adopt the GPT-4 model [25] in this work. We also adopt the holistically-nested edge detection model [29], to extract a gray-scale edge map from the original image at the transmitter. The prompt is encoded to bits using UFT-8 [30], and the edge map is compressed to bits using learned nonlinear transform coding [31]. At the receiver, we adopt the state-of-the-art pre-trained SD model [5] for conditional image generation from the received prompt and the edge map. The wireless transmission parameters for the two semantic streams are listed in Table I.
| Parameters | Values |
| Packet length of prompt, | bits |
| Coding rate of prompt, | 1/2 (convolutional code) |
| Modulation order of prompt, | 4 (QPSK) |
| in (2) | |
| in (4) | |
| Transmit power budget, | 10 mW |
| Path loss at m, | -30 dB |
| Path loss exponent, | 3.4 |
| Noise power density, | -174 dBm/Hz |
| Bandwidth, | 1 MHz |
III-B Semantic quality metrics
Various reference-based or no-reference metrics can be adopted to evaluate the quality of the synthesized signal based on the semantic communication intent. In this work, we adopt two metrics, one to measure the semantic similarity, and the other to measure the structural similarity between the original and the synthesized images at the Gen SemCom receiver. In order to assess the quality of the most important semantic information conveyed by the prompt, we use the contrastive language-image pretraining (CLIP) model [24]. Specifically, we define the CLIP metric as the cosine similarity between the CLIP embedding of the original and synthesized images, i.e. and , given by . For structural similarity, we use the multi-scale structural similarity (MS-SSIM) [21] metric.
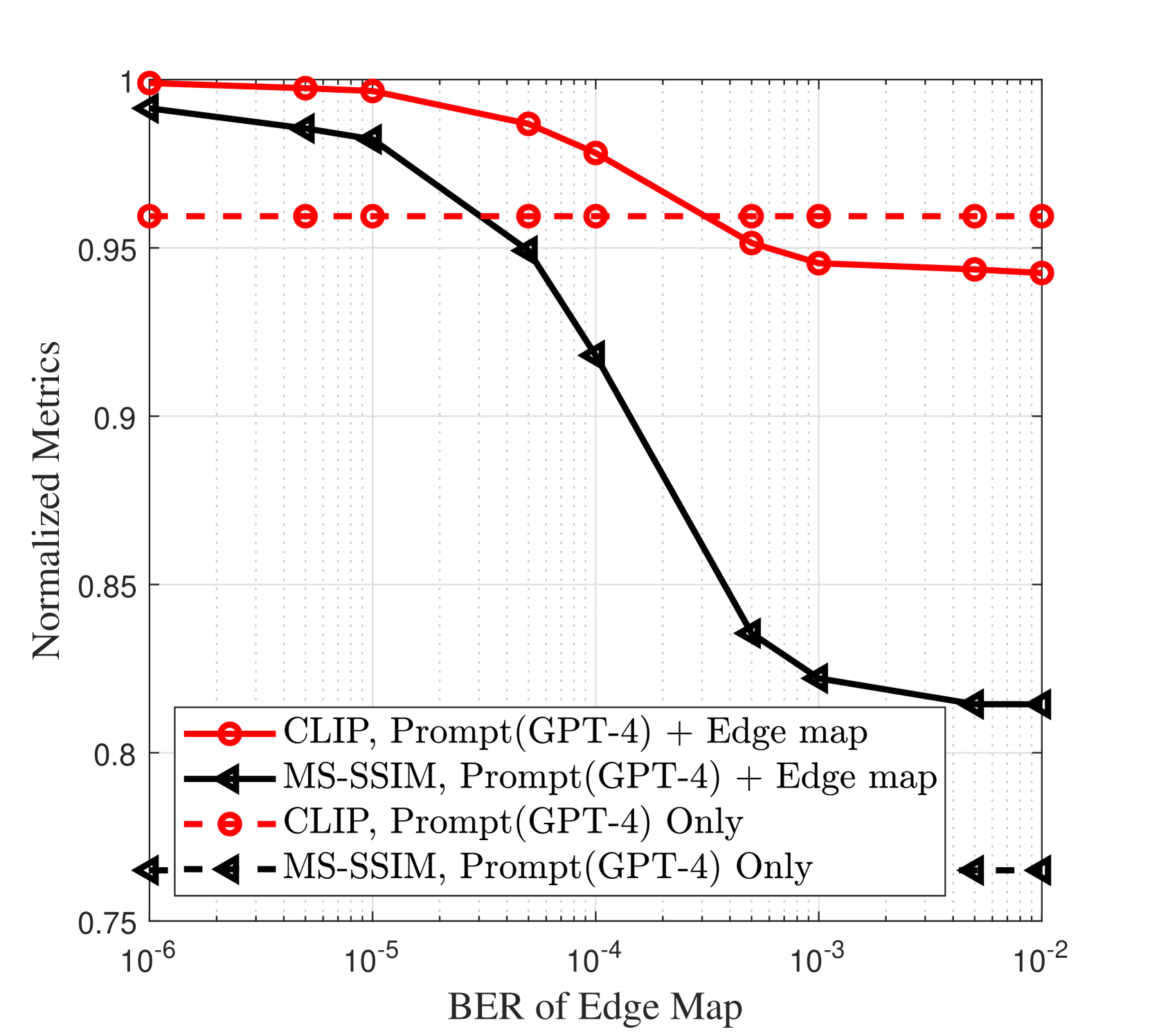
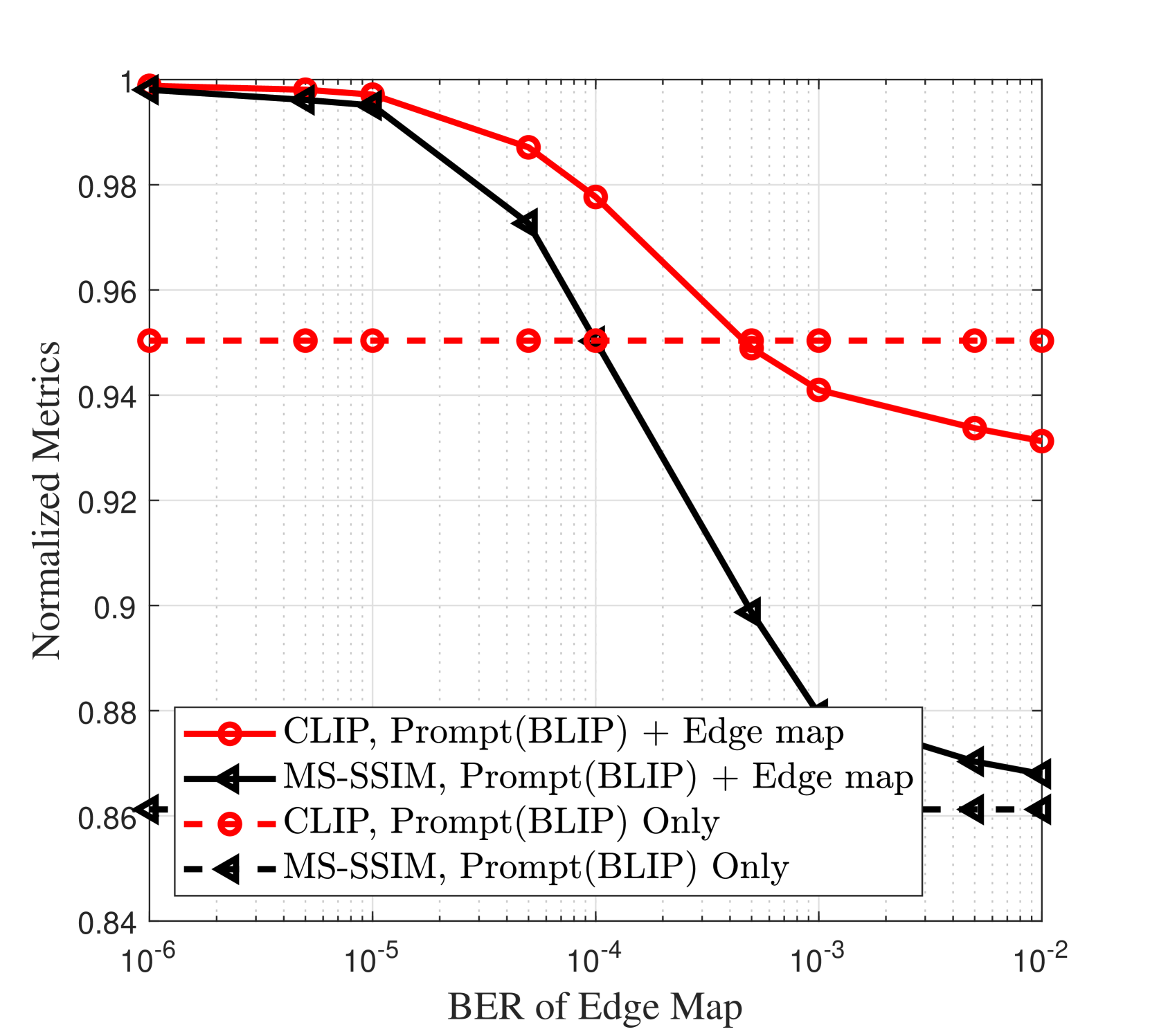
III-C Monotonicity of the quality metrics
The end-to-end performance of the proposed framework depends on behaviour of the pre-trained GenAI model at the receiver, i.e. its sensitivity to the BER of the conditioning signal, and the requirements of the semantic quality metrics. Hence, we investigate monotonicity of the CLIP and MS-SSIM metrics to apply Lemma 1 for latency-aware adaptive SemCom. Specifically, through intensive simulations in presence of random bit errors in the proposed framework, we demonstrate that the normalized CLIP/MS-SSIM metrics are monotonically non-increasing functions of the BER of the edge map, as depicted in Fig. 2. Note that the proposed framework works independent of the choice of the AI models adopted at the transmitter and receiver. For example, the GPT-4 model can be replaced by smaller image-to-text models, e.g. BLIP [26], Oscar [27], UNIMO [28], at the cost of a slight degradation of the semantic quality metrics. These smaller models can be implemented locally on-device. The absolute CLIP values achieved with GPT-4 and BLIP, under error-free transmission of the edge map, are and , respectively, while the resulting MS-SSIM values are similar. The normalized CLIP and MS-SSIM are defined as and , respectively, where CLIP0 and MS-SSIM0 are the reference values of these metrics for perfect transmission of the edge map. We note that “CLIP, Prompt + Edge Map” surpasses “CLIP, Prompt Only” when , indicating that transmitting the edge map enhances the semantic quality as interpreted by the SD model. On the contrary, when , the inaccuracies in the received edge map due to the communication errors become detrimental, causing the SD model to misinterpret the prompt semantics. For example in Fig. 3, the “fence” is missing in the generated image due to the inaccuracies of the received edge map at , despite the word “fence” being part of the prompt. Moreover, transmitting the edge map alongside the prompt invariably boosts the MS-SSIM in comparison to relying solely on prompt.

III-D Visual quality of the proposed framework
In Fig. 3, we provide illustrations to demonstrate the visual quality of our proposed framework on a sample natural image. These results demonstrate a good semantic quality for the proposed framework for ultra-low-rate transmission at bit per pixel (bpp) values as low as and for the prompt and the edge map, respectively.
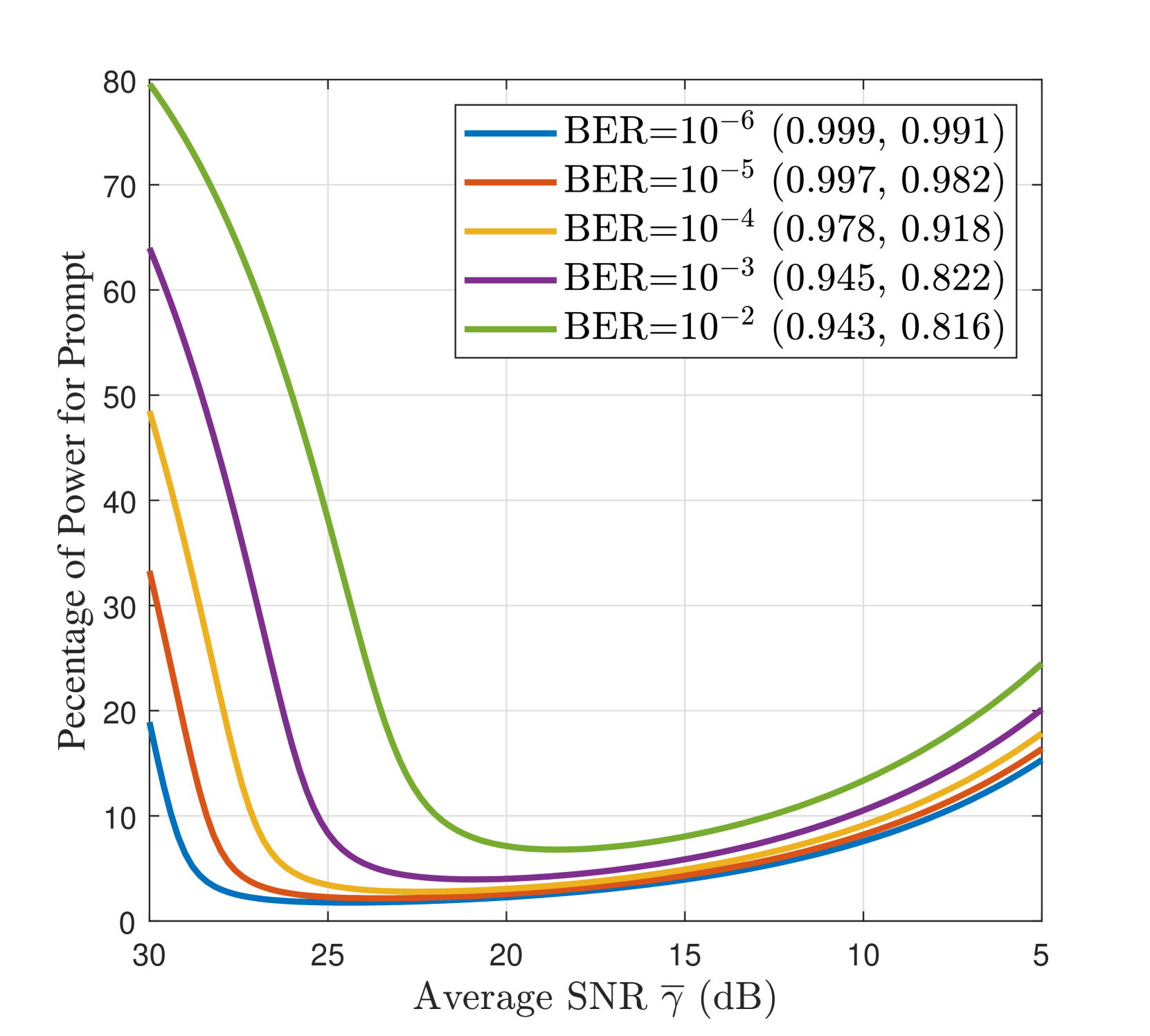
III-E Latency-aware Adaptive Semantic Communication
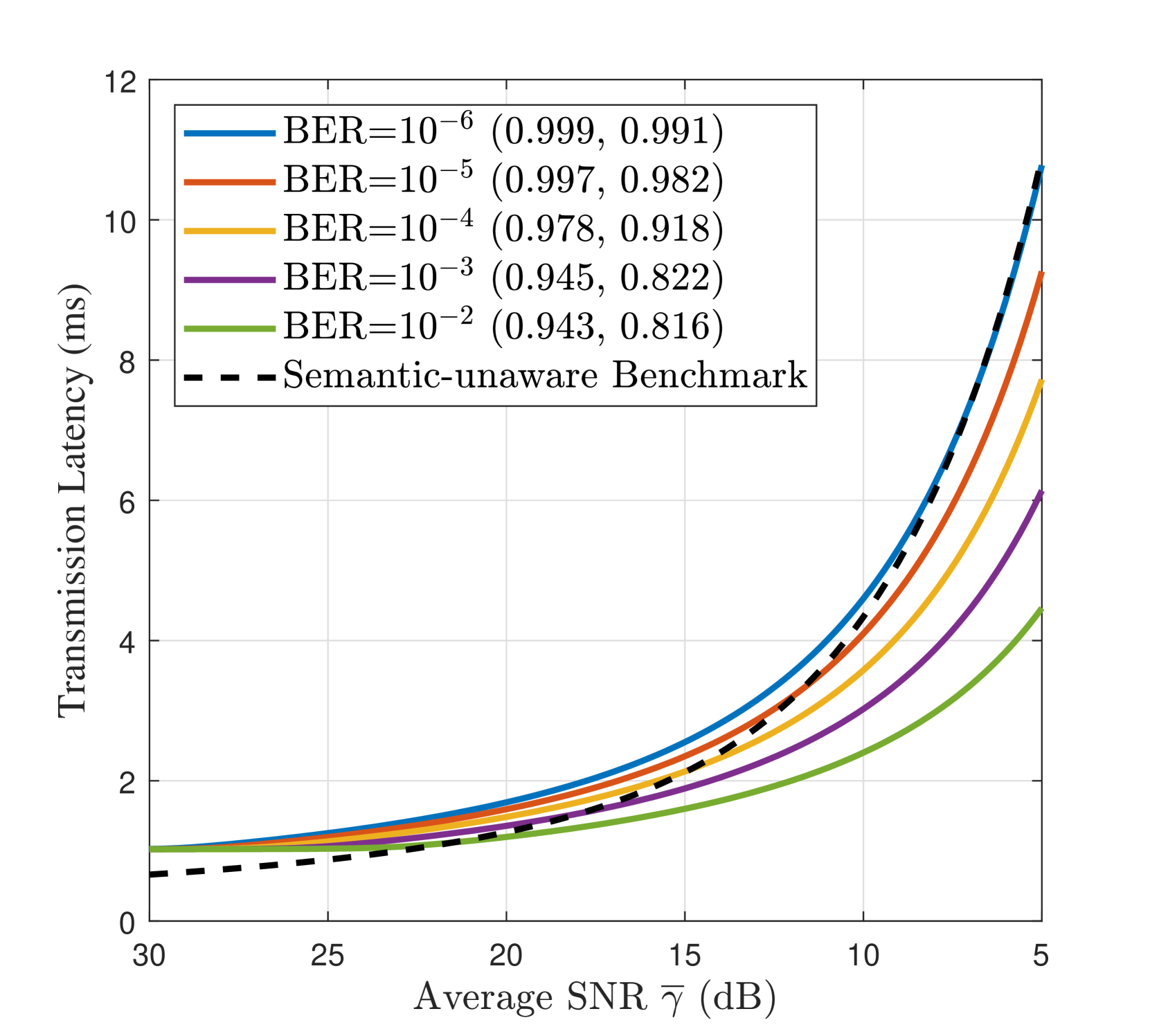
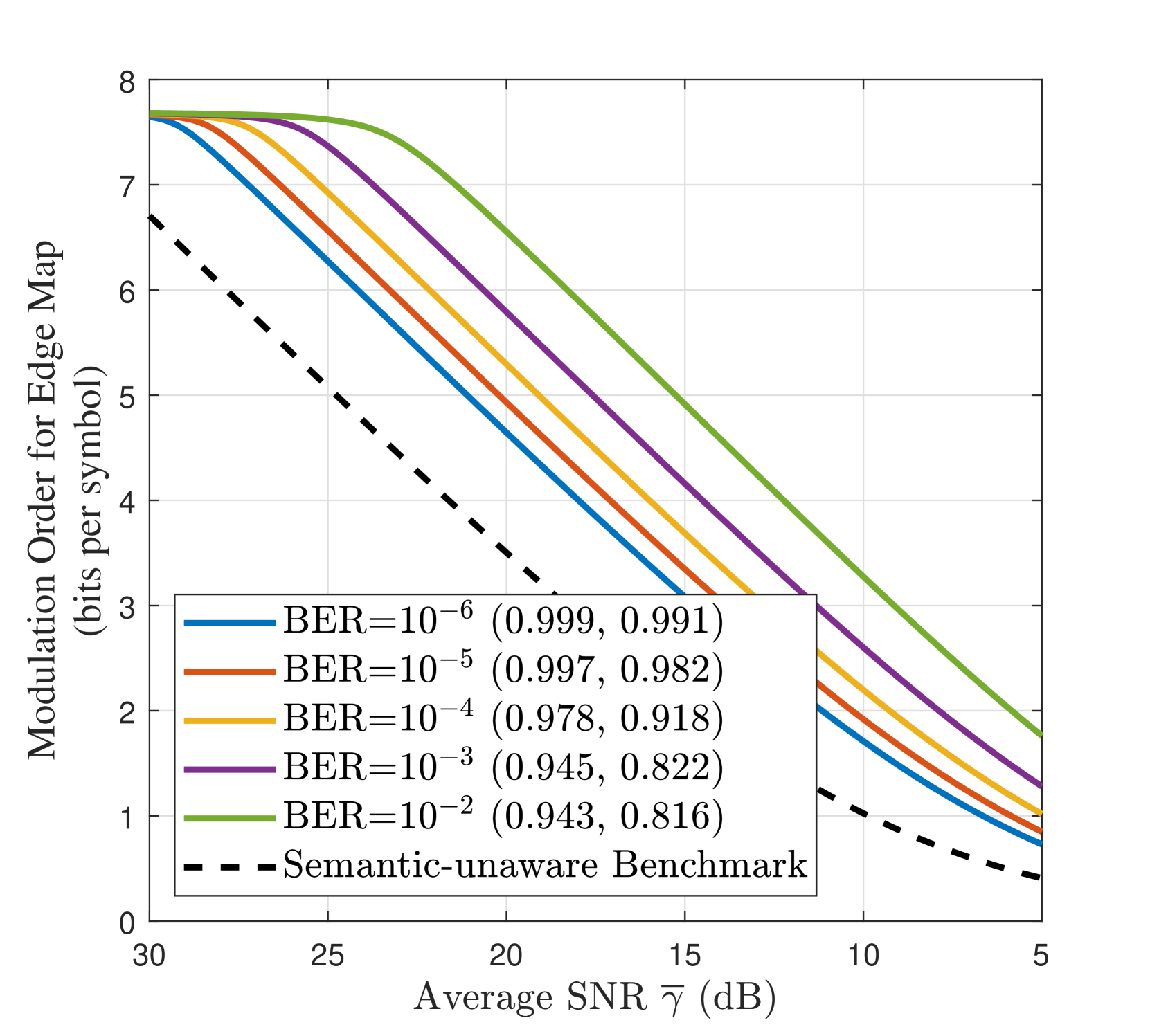
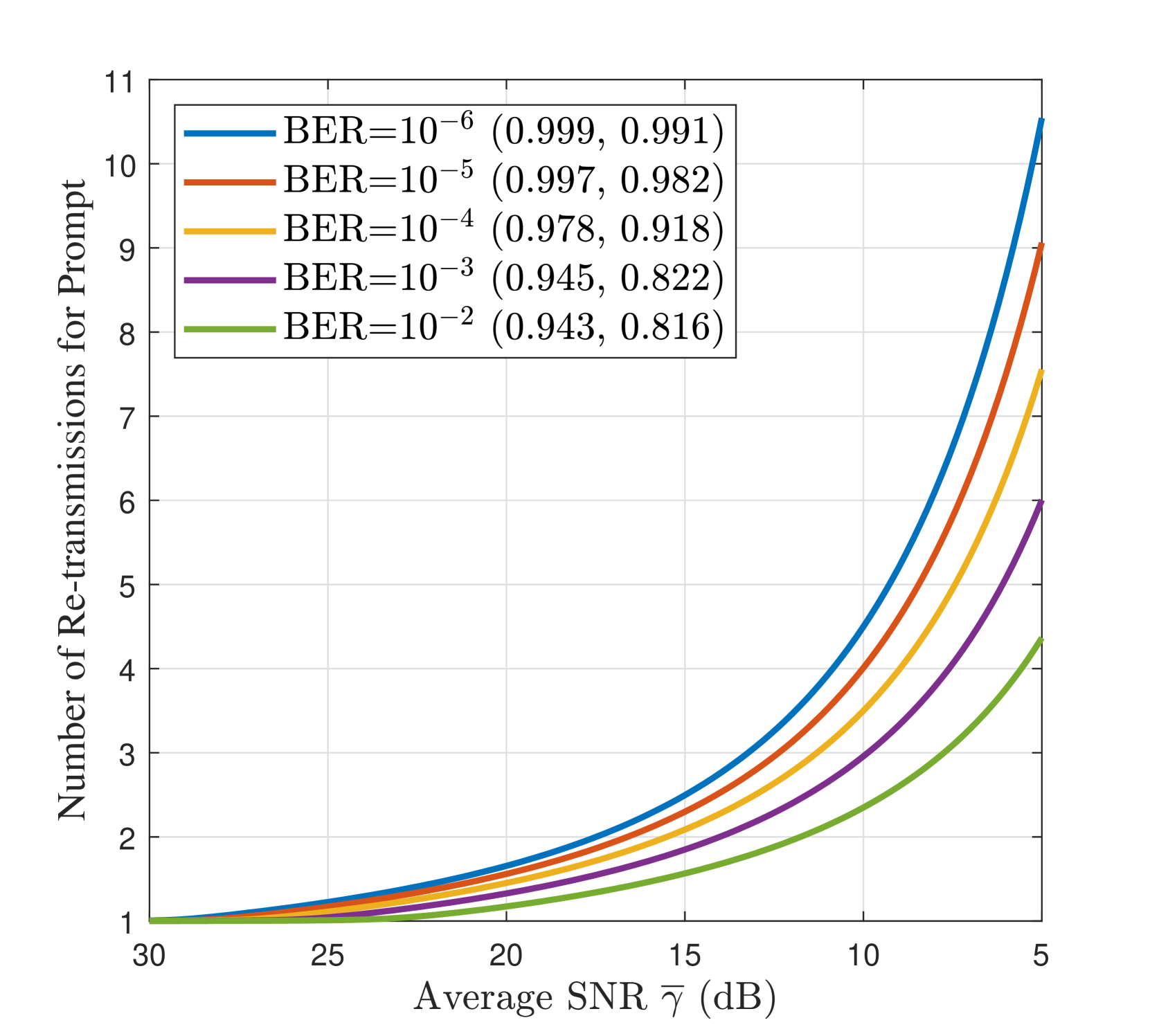
We evaluate the optimal semantic latency in terms of the average SNR, i.e. , as a channel quality indicator. With the investigation in subsection III-C, we apply Lemma 1 and solve the resulting nonlinear system of equations numerically. Fig. 4 quantifies the semantic quality-latency trade-off for the proposed Gen SemCom framework, and illustrates the optimal wireless parameters versus average SNR at various target semantic quality, i.e. normalized (CLIP, MS-SSIM), and BER values. It is evident that to achieve a higher target semantic quality (i.e. higher CLIP/MS-SSIM and lower BER) one should allocate more power to the transmission of the edge map, which in turn, increases the latency. Furthermore, when the channel SNR deteriorates, the sender should use a lower modulation order for the edge map to maintain the semantic quality at a target acceptable level. This will also increase the expected number of re-transmissions for the prompt.
For performance comparison, we adopt a semantic-unaware transmission benchmark, in which the prompt and edge map are treated equally and transmitted as one data stream regardless of the unequal importance of each semantic modality. For a fair comparison, the maximum power and bandwidth are allocated for the transmission of this single stream with adaptive MQAM employed. The prompt BER becomes the bottleneck for single-stream transmission, and hence, the BER is kept at to ensure reliable reception of the prompt. From Fig. 4(b), the proposed semantic-aware multi-stream transmission significantly reduces the transmission latency at the lower SNR region, i.e., dB. Finally, in Table II, we provide modulation adaptation guidelines to achieve various semantic qualities (CLIP, MS-SSIM) in varying channel qualities. Here, is the modulation order for the edge map, and is the transmission latency.
| (0.999, 0.991) | (0.997, 0.982) | (0.978, 0.918) | (ms) | |
| 64 | () | () | () | 1.31 |
| 16 | () | () | () | 1.97 |
| 4 | () | () | () | 3.93 |
| 0 | / |
III-F Computation latency
The computation latency depends on the choice of the AI models and the implementation scenario. For the on-device implementation scenario, smaller models like BLIP (55 GFLOPs) [26] and mobile diffusion (153 GFLOPs) [32] are used. Using a state-of-the-art A17 Pro chip (35 TFLOPS/s), the resulting computation latencies are 1.6 ms for BLIP and 4.6 ms for mobile diffusion. These are comparable to the transmission latencies as reported in Fig. 4(b) and TABLE II, emphasizing the need to minimize the transmission latency for reduced end-to-end latency.
IV Conclusions
This paper proposed a latency-aware and channel-adaptive semantic communication framework with pre-trained foundation generative AI models. In this framework, the transmitter extracts multi-modal semantic content of the input signal including a textual prompt and conditioning signals. The extracted semantics are then transmitted in multiple streams with semantic-aware appropriate coding and communication schemes and then input to a generative diffusion model at the receiver. Simulation results on natural images showcase the efficacy of the proposed framework in achieving ultra-low-rate, low-latency, and channel-adaptive semantic communications.
References
- [1]
- [2] L. Xia et al., “Generative AI for semantic communication: Architecture, challenges, and outlook,” arXiv preprint arXiv:2308.15483v2, 2024.
- [3] G. Grassucci et al., “Generative AI meets semantic communication: Evolution and revolution of communication tasks,” arXiv preprint arXiv:2401.06803v1, 2024.
- [4] B. Li et al., “Extreme video compression with pre-trained diffusion models,” arXiv preprint arXiv:2402.08934, 2024.
- [5] R. Rombach et al., “High-resolution image synthesis with latent diffusion models,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 10 674–10 685.
- [6] P. Dhariwal et al., “Diffusion models beat GANs on image synthesis,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 34, 2021, pp. 8780–8794.
- [7] D. P. Kingma et al., “Glow: Generative flow with invertible 1×1 convolutions,” Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2018.
- [8] I. Goodfellow et al., “Generative adversarial nets,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 27, 2014.
- [9] J. Chen et al., “On the rate-distortion-perception function,” IEEE J. Sel. Areas Inf. Theory, vol. 3, no. 4, pp. 664–673, 2022.
- [10] Y. Blau et al., “Rethinking lossy compression: The rate-distortion-perception tradeoff,” Proc. Int. Conf. Mach. Learn. (ICML), pp. 675–685, 2019.
- [11] T. Brooks et al., “Video generation models as world simulators,” 2024. [Online]. Available: https://openai.com/research/video-generation-models-as-world-simulators
- [12] O. Bar-Tal et al., “Lumiere: A space-time diffusion model for video generation,” arXiv preprint arXiv:2401.12945, 2024.
- [13] A. Ramesh et al., “Zero-shot text-to-image generation,” in Proc. Int. Conf. Mach. Learn. (ICML), vol. 139, 18–24 Jul 2021, pp. 8821–8831.
- [14] D. Gündüz et al., “Beyond transmitting bits: Context, semantics, and task-oriented communications,” IEEE J. Select. Areas Commun., vol. 41, no. 1, pp. 5–41, 2023.
- [15] Y. Wang et al., “Transformer-empowered 6G intelligent networks: From massive MIMO processing to semantic communication,” IEEE Wirel. Commun., vol. 30, no. 6, pp. 127-135, Dec. 2023.
- [16] W. Yang et al., “Semantic communications for future internet: Fundamentals, applications, and challenges,” IEEE Commun. Surv. Tutor., vol. 25, no. 1, pp. 213–250, 2023.
- [17] H. Xie et al., “Deep learning enabled semantic communication systems,” IEEE Trans. Signal Processing, vol. 69, pp. 2663–2675, 2021.
- [18] Z. Zhao, Z. Yang, M. Chen, Z. Zhang, and H. V. Poor, “A joint communication and computation design for probabilistic semantic communications,” arXiv preprint arXiv: 2402.16328, 2024.
- [19] J. Wu, G. Wang, and Y. R. Zheng, “Energy efficiency and spectral efficiency tradeoff in type-I ARQ systems,” IEEE J. Select. Areas Commun., vol. 32, no. 2, pp. 356–366, 2014.
- [20] A. J. Goldsmith et al., “Variable-rate variable-power MQAM for fading channels,” IEEE Trans. Commun., vol. 45, no. 10, pp. 1218–1230, 1997.
- [21] Z. Wang et al., “Multiscale structural similarity for image quality assessment,” in The Thrity-Seventh Asilomar Conference on Signals, Systems Computers, 2003, vol. 2, 2003, pp. 1398–1402 Vol.2.
- [22] R. Zhang et al., “The unreasonable effectiveness of deep features as a perceptual metric,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 586–595.
- [23] M. Heusel et al., “GANs trained by a two time-scale update rule converge to a local Nash equilibrium,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 30, 2017.
- [24] A. Radford et al., “Learning transferable visual models from natural language supervision,” in Proc. Int. Conf. Mach. Learn. (ICML). PMLR, 2021.
- [25] J. Achiam et al., “GPT-4 technical report,” arXiv preprint arXiv:2303.08774, 2023.
- [26] J. Li et al., “BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” in Proc. Int. Conf. Mach. Learn. (ICML). PMLR, 2022, pp. 12 888–12 900.
- [27] X. Li et al., “Oscar: Object-semantics aligned pre-training for vision-language tasks,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2020, pp. 121–137.
- [28] W. Li et al., “UNIMO: Towards unified-modal understanding and generation via cross-modal contrastive learning,” arXiv preprint arXiv:2012.15409, 2020.
- [29] S. Xie and Z. Tu, “Holistically-nested edge detection,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2015, pp. 1395–1403.
- [30] F. Yergeau, “UTF-8, a transformation format of ISO 10646,” Tech. Rep., 2003.
- [31] J. Ballé et al., “Nonlinear transform coding,” IEEE J. Sel. Topics Signal Process., vol. 15, no. 2, pp. 339–353, 2020.
- [32] Y. Zhao et al., “MobileDiffusion: Subsecond text-to-image generation on mobile devices,” arXiv preprint arXiv:2311.16567, 2023.