sDPO: Don’t Use Your Data All at Once
Abstract
†† Corresponding AuthorAs development of large language models (LLM) progresses, aligning them with human preferences has become increasingly important. We propose stepwise DPO (sDPO), an extension of the recently popularized direct preference optimization (DPO) for alignment tuning. This approach involves dividing the available preference datasets and utilizing them in a stepwise manner, rather than employing it all at once. We demonstrate that this method facilitates the use of more precisely aligned reference models within the DPO training framework. Furthermore, sDPO trains the final model to be more performant, even outperforming other popular LLMs with more parameters.
sDPO: Don’t Use Your Data All at Once
Dahyun Kim, Yungi Kim, Wonho Song, Hyeonwoo Kim, Yunsu Kim, Sanghoon Kim Chanjun Park Upstage AI, South Korea {kdahyun, eddie, ynot, choco_9966, yoonsoo, limerobot, chanjun.park}@upstage.ai
1 Introduction
Large language models (LLMs) have revolutionized the field of natural language processing (NLP) through a training process that includes pre-training, supervised fine-tuning, and alignment tuning, with the latter ensuring the safety and usefulness of the model. Thus, reinforcement learning techniques Christiano et al. (2017); Bai et al. (2022), such as proximal policy optimization (PPO) Schulman et al. (2017), are key in this alignment phase, despite their complexity.
To address the complicated nature of reinforcement learning in LLM training, direct preference optimization (DPO) Rafailov et al. (2023), among other methods Yuan et al. (2023); Dong et al. (2023), have been popularized for its simplicity and effectiveness. DPO involves curating preference datasets using human or strong AI (e.g., GPT-4 OpenAI (2023)) judgement to select chosen and rejected responses to questions. These datasets are used to train LLMs by comparing log probabilities of chosen versus rejected answers. However, obtaining these probabilities can be challenging with proprietary models like GPT-4, since they do not offer log probabilities for inputs.
| Model | Reference Model | H4 |
|---|---|---|
| Mistral-7B-OpenOrca | N/A | 65.84 |
| Mistral-7B-OpenOrca + DPO | SFT Base | 68.87 |
| Mistral-7B-OpenOrca + DPO | SOLAR-0-70B | 67.86 |
| Mistral-7B-OpenOrca + DPO | Intel-7B-DPO | 70.13 |
| OpenHermes-2.5-Mistral-7B | N/A | 66.10 |
| OpenHermes-2.5-Mistral-7B + DPO | SFT Base | 68.41 |
| OpenHermes-2.5-Mistral-7B + DPO | SOLAR-0-70B | 68.90 |
| OpenHermes-2.5-Mistral-7B + DPO | Intel-7B-DPO | 69.72 |
Thus, in most practical scenarios, the reference model is simply set as the base SFT model Tunstall et al. (2023); Intel (2023b); Ivison et al. (2023), which is a much weaker alternative with potentially misaligned preferences. This reference model acts as a lower bound in DPO, i.e., the target model is optimized to be at least as aligned as the reference model. Thus, we argue that a reference model that is already more aligned will serve as a better lower bound for DPO training, which would be beneficial for the alignment tuning. One option would be to utilize the plethora of open source models Tunstall et al. (2023); Ivison et al. (2023) that have already undergone alignment tuning.
Note that the above may not be feasible due to the absence of such aligned models, or the fact that it renounces control over the reference model, leading to safety concerns. Instead, we propose ‘stepwise DPO’, named sDPO, where we use the preference datasets (or subsets of a preference dataset) in a step-by-step manner when undergoing DPO training. The aligned model in the previous step is used as the reference model for the current step, which results in utilizing a more aligned reference model (i.e., a better lower bound). Empirically, we show that using sDPO results in a more performant final aligned model as well.
While concurrent works (Yuan et al., 2024) that focus on an iterative pipeline of generating new preference data have been proposed, our method focuses on utilizing the currently available preference datasets. Thus, our approach is complementary as sDPO can be easily applied to any preference data and further combination with concurrent works would be an exciting future direction.
2 Methodology
2.1 Preliminary Investigation on Reference Models
To gauge the importance of using a well-aligned reference model in DPO, we perform preliminary experiments of DPO training with the Ultrafeedback dataset Cui et al. (2023) on Mistral-7B-OpenOrca Lian et al. (2023) and OpenHermes-2.5-Mistral-7B Teknium (2023) as the SFT base model, owing to their excellent performance and small size. We compare the following reference models: i) the SFT base model itself, same as the conventional DPO setup; ii) SOLAR-0-70B Upstage (2023), a larger and much more performant model; and iii) Intel-7B-DPO Intel (2023a), an already aligned reference model. The results are summarized in Tab. 1.
As the table shows, using Intel-7B-DPO as the reference model results in the best performance, even better than using SOLAR-0-70B, which is a much larger model that was trained with more data. Thus, whether the reference model is pre-aligned or not plays an important role in the resulting aligned model’s performance. Unfortunately, it is not always possible to simply use a open sourced pre-aligned model as the reference model due to technical and safety concerns, i.e., such a model may not exist yet or can be susceptible to various domain-specific harmfulness and fairness criteria. To remedy the above, we propose sDPO, which uses more aligned reference models as a part of the training framework.
2.2 Stepwise DPO
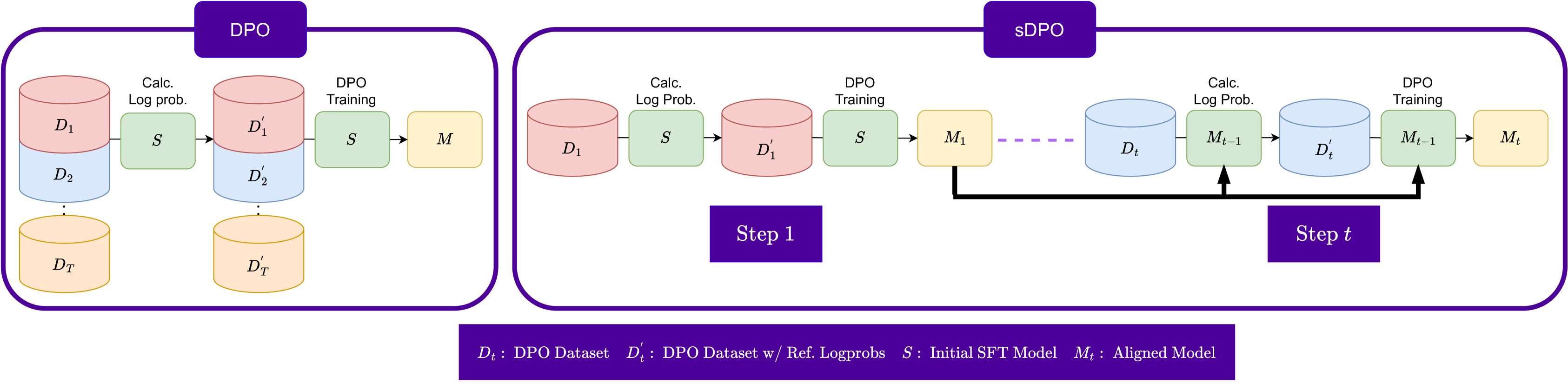
In sDPO, we propose to use the available preference datasets in a stepwise manner instead of using them all at once. The comparison of the overall flow of DPO and sDPO is presented in Fig. 1.
Reference model.
The reference model is used to calculate the log probabilities of the preference dataset. For each step, only a subset of the total data is used and the reference model is initialized as , i.e, the aligned model from the previous step. The initial reference model is set as , the SFT base model. This results in using a more aligned reference model than conventional DPO.
Target model.
For , the target model which is trained using the preference loss of DPO in each step of sDPO is also initialized as instead of . This ensures that the final model trained with sDPO has been directly trained with the same amount data as a model trained with DPO.
| Model | Size | Type | H4 (Avg.) | ARC | HellaSwag | MMLU | TruthfulQA |
|---|---|---|---|---|---|---|---|
| SOLAR 10.7B + SFT + sDPO | 11B | Alignment-tuned | 74.31 | 71.33 | 88.08 | 65.39 | 72.45 |
| SOLAR 10.7B + SFT + DPO | 11B | Alignment-tuned | 72.67 | 69.62 | 87.16 | 66.00 | 67.90 |
| SOLAR 10.7B + SFT + sDPO Strat. | 11B | Alignment-tuned | 72.56 | 69.20 | 87.27 | 65.96 | 67.81 |
| Mixtral 8x7B-Instruct-v0.1 | 47B | Alignment-tuned | 73.40 | 70.22 | 87.63 | 71.16 | 64.58 |
| SOLAR-0-70B-16bit | 70B | Instruction-tuned | 72.93 | 71.08 | 87.89 | 70.58 | 62.25 |
| Qwen 72B | 72B | Pretrained | 72.17 | 65.19 | 85.94 | 77.37 | 60.19 |
| Yi 34B | 34B | Pretrained | 70.72 | 64.59 | 85.69 | 76.35 | 56.23 |
| SOLAR 10.7B + SFT | 11B | Instruction-tuned | 69.51 | 67.32 | 85.96 | 65.95 | 58.80 |
| Mistral 7B-Instruct-v0.2 | 7B | Instruction-tuned | 69.27 | 63.14 | 84.88 | 60.78 | 68.26 |
| Falcon 180B | 180B | Pretrained | 68.57 | 69.45 | 88.86 | 70.50 | 45.47 |
| Mixtral 8x7B-v0.1 | 47B | Pretrained | 67.78 | 66.04 | 86.49 | 71.82 | 46.78 |
| Llama 2 70B | 70B | Pretrained | 67.35 | 67.32 | 87.33 | 69.83 | 44.92 |
| Zephyr | 7B | Alignment-tuned | 66.36 | 62.03 | 84.52 | 61.44 | 57.44 |
| Qwen 14B | 14B | Pretrained | 64.85 | 58.28 | 83.99 | 67.70 | 49.43 |
| SOLAR 10.7B | 11B | Pretrained | 64.27 | 61.95 | 84.60 | 65.48 | 45.04 |
| Mistral 7B | 7B | Pretrained | 62.40 | 59.98 | 83.31 | 64.16 | 42.15 |
Intuitive explanation.
To gain a deeper understanding of sDPO, we rearrange the DPO loss from Rafailov et al. (2023), as follows:
|
|
(1) |
where is the preference dataset, is the question, and are the chosen and rejected answers respectively, is the learnable parameters of the model, and , i.e., the logratio of the chosen and rejected samples w.r.t. the policy . As is a monotonically increasing function and is fixed before training, the minimization of leads to (on average). Thus, can be understood as a lower bound defined by the reference model, of which the target model is trained such that . In sDPO, increases as the steps progress because the reference model that defines it is more and more aligned. Hence, becomes a stricter lower bound as the steps pass, inducing a curriculum learning from easy to hard optimization tasks.
3 Experiments
3.1 Experimental Setup
Training details.
We use a supervised fine-tuned SOLAR 10.7B Kim et al. (2023) as our SFT base model as it delivers excellent performance with its uncommon 10.7B size. Further, the scarcity of 10.7B sized models leads to the absence of open source models that can be adopted as reference models, making the usage of sDPO more necessary. We use OpenOrca Mukherjee et al. (2023) ( samples) and Ultrafeedback Cleaned ( samples) Cui et al. (2023); Ivison et al. (2023) as our preference datasets. The training hyper-parameters closely follow that of Tunstall et al. (2023). We use two steps in sDPO, where we use OpenOrca as dataset in the first step and Ultrafeedback Cleaned as dataset in the second step.
Evaluation.
We utilize four of the six tasks in the HuggingFace Open LLM Leaderboard Beeching et al. (2023): ARC Clark et al. (2018), HellaSWAG Zellers et al. (2019), MMLU Hendrycks et al. (2020), TruthfulQA Lin et al. (2022). We also report the average scores for the four tasks, which is denoted as H4. Winogrande Sakaguchi et al. (2021) and GSM8K Cobbe et al. (2021) are excluded to control the complexity of the experiments, i.e., we excluded generation tasks in contrast to multiple choice tasks.
3.2 Main Results
Evaluation results for applying sDPO to the SFT base model, along with results for other top-performing models are shown in Tab. 2. Comparing the pretrained-only ‘SOLAR 10.7B’ to the instruction-tuned ‘SOLAR 10.7B + SFT’, we can see an increase of in terms of H4. Applying sDPO on SOLAR 10.7B + SFT further increases the H4 score upto , an improvement of . Notably, ‘SOLAR 10.7B + SFT + sDPO’ outperforms other larger models such as Mixtral 8x7B-Instruct-v0.1, despite the smaller number of parameters. This highlights that effective alignment tuning could be the key to unlocking next level performance for smaller LLMs. Further, applying sDPO results in substantially higher score of for TruthfulQA, which shows the effectiveness of the alignment tuning process.
3.3 Ablation Studies
We also report evaluation results for ablated models in Tab. 2. ‘SOLAR 10.7B + SFT + DPO’ uses all the DPO data at once, i.e., , same as the conventional DPO training setup. ‘SOLAR 10.7B + SFT + sDPO Strat.’ uses stratified sampling to sample of the data points from the union of OpenOrca and Ultrafeedback Cleaned to form and use the remaining as to mirror the dataset size of and used in SOLAR 10.7B + SFT + sDPO.
Comparing SOLAR 10.7B + SFT + DPO and SOLAR 10.7B + SFT + sDPO, we can see that using sDPO over DPO results in a higher H4 score overall, with noticeable improvements in ARC and TruthfulQA scores. Therefore, we believe sDPO could function as a drop-in replacement for DPO training with better performance. Looking at SOLAR 10.7B + SFT + sDPO and SOLAR 10.7B + SFT + sDPO Strat., we see that the specific way of splitting the available DPO data into multiple can also impact performance. We find that the natural split of using different preference datasets as works best in our experiments. We believe further exploration of how to define is an interesting direction for future research.
3.4 Reference Models in sDPO
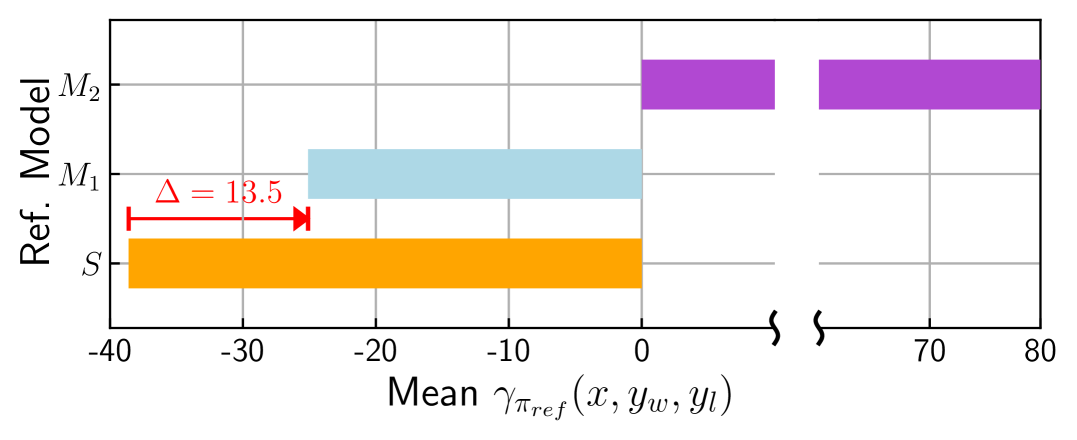
Effectiveness of sDPO in terms of alignment tuning.
In Sec. 2.2, we explain that the reference models in sDPO are more aligned, resulting in higher , i.e., a stricter lower bound. We verify the above empirically in Fig. 2 by comparing the mean on the Ultrafeedback Cleaned dataset for the reference models in steps 1 and 2 of sDPO, i.e., and . Note that these two models have not been trained on the aforementioned dataset. Using the SFT base model as the reference model, the mean of is . On the other hand, using the aligned model from step 1 of sDPO as the reference model, the mean of is , an increase of in log scale. Thus, a single step of sDPO greatly increases , which results in a more performant aligned model as seen in Tab. 2.
Adopting open source models as reference models could be dangerous.
We also show mean of , the aligned model from step 2 of sDPO. Unlike and , is trained on the Ultrafeedback Cleaned dataset, i.e., is used as a reference model on data that was already used to train it. Note that such a case could happen commonly when adopting various open source models as reference models. This is because the datasets that were used in training those models are often unclear and could overlap with the preference datasets unintentionally. Mean of is , which is staggeringly higher than either or . The strikingly high value for likely points to overfitting of to the Ultrafeedback Cleaned dataset. This result highlights the potential danger of merely adopting open source models as reference models instead of using sDPO.
3.5 Target Model Initialization in sDPO
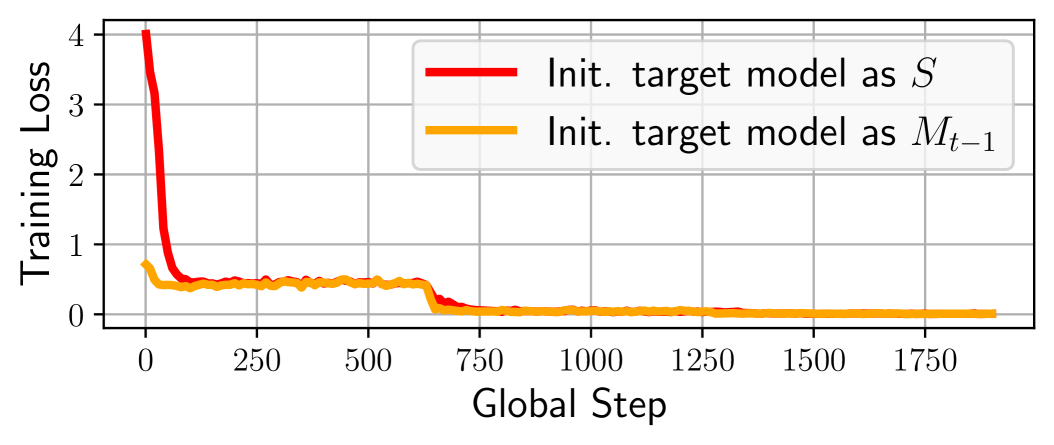
The target model in each step of sDPO is also initialized with , the aligned model from the last step. This ensures that the final model in sDPO has undergone training with the same amount of data as the final model in DPO. On the other hand, one concern of such design choice is that it may become increasingly difficult to stabilize the training of the target model as the steps progress, since it has already undergone training with a decreasing learning rate schedule in the preceding steps. Thus, another option is to use the initial SFT base model as the target model for all steps of sDPO.
However, as shown in Fig. 3, initializing the target model as results in a much bigger initial loss than that of , which could lead to an unstable training. The main reason is that DPO training is usually done where the reference and target models are the same. In contrast, initializing the target model as creates a differential in the reference and target models, which may be amplified as the steps progress. Thus, for stable training, initializing the target model as was chosen for sDPO.
4 Conclusion
We propose sDPO where we use the preference data in a stepwise way instead of all at once. We show that applying sDPO results in more performant models than DPO in terms of H4 score. We also empirically exhibit that sDPO results in more aligned reference models by comparing mean .
Limitations
While we have demonstrated the effectiveness of employing different datasets in distinct stages of sDPO, identifying an optimal strategy for segmenting more intricate DPO data collections remains an area for further exploration. This task is particularly challenging due to the complexities within these datasets. Our approach, while promising, necessitates a more deeper understanding of dataset characteristics and their impact on the performance of sDPO.
Furthermore, our experiments predominantly utilized SOLAR 10.7B models, driven by the state-of-the-art performance at the time of experimentation along with its unique 10.7 billion parameter size. The unique size of SOLAR 10.7B models made the usage of sDPO more necessary as there are far fewer open source LLMs that can be adopted as reference models.
Additionally, as with most research on LLMs, we operated within our limitations in computational resources. Although this focus has yielded significant insights, expanding our experimental framework to incorporate a broader range of Large Language Models (LLMs) could potentially unveil more comprehensive understanding of the strengths and limitations of sDPO. Such an expansion would allow for a more robust comparison across different model architectures and sizes, further enriching our findings.
Evaluating the efficacy of LLMs is an evolving challenge in the field. In our study, we primarily employed tasks from the Huggingface Open LLM Leaderboard as benchmarks for evaluation. While this provided comparative results, future research could benefit from incorporating a wider array of tasks and benchmarks. These could include tasks that judge actual human or strong AI preference alignment. Such additional evaluation would not only enhance the validity of our findings but also contribute to the broader discourse on LLM assessment methodologies.
Ethics Statement
In this study, we strictly adhered to ethical standards in the conduct of our research. Our experiments were based entirely on open models and open datasets, ensuring transparency and accessibility. We took meticulous care to avoid any biases or data contamination, thereby maintaining the integrity of our research process. The experimental environment was rigorously designed to be objective, ensuring that all comparisons conducted were fair and impartial. This approach reinforces the reliability and validity of our findings, contributing positively to the field while upholding the highest ethical standards. We confirmed that all the data used in our experiments were free of licensing issues.
References
- Anil et al. (2023) Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. 2023. Palm 2 technical report. arXiv preprint arXiv:2305.10403.
- Bai et al. (2022) Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 2022. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073.
- Beeching et al. (2023) Edward Beeching, Clémentine Fourrier, Nathan Habib, Sheon Han, Nathan Lambert, Nazneen Rajani, Omar Sanseviero, Lewis Tunstall, and Thomas Wolf. 2023. Open llm leaderboard. https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Christiano et al. (2017) Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Cui et al. (2023) Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. 2023. Ultrafeedback: Boosting language models with high-quality feedback. arXiv preprint arXiv:2310.01377.
- Dong et al. (2023) Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. 2023. Raft: Reward ranked finetuning for generative foundation model alignment. arXiv preprint arXiv:2304.06767.
- Hendrycks et al. (2020) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. In International Conference on Learning Representations.
- Hernandez et al. (2021) Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish. 2021. Scaling laws for transfer. arXiv preprint arXiv:2102.01293.
- Intel (2023a) Intel. 2023a. Intel/neural-chat-7b-v3-1. https://huggingface.co/Intel/neural-chat-7b-v3-1.
- Intel (2023b) Intel. 2023b. Supervised fine-tuning and direct preference optimization on intel gaudi2.
- Ivison et al. (2023) Hamish Ivison, Yizhong Wang, Valentina Pyatkin, Nathan Lambert, Matthew Peters, Pradeep Dasigi, Joel Jang, David Wadden, Noah A. Smith, Iz Beltagy, and Hannaneh Hajishirzi. 2023. Camels in a changing climate: Enhancing lm adaptation with tulu 2.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
- Kim et al. (2023) Dahyun Kim, Chanjun Park, Sanghoon Kim, Wonsung Lee, Wonho Song, Yunsu Kim, Hyeonwoo Kim, Yungi Kim, Hyeonju Lee, Jihoo Kim, Changbae Ahn, Seonghoon Yang, Sukyung Lee, Hyunbyung Park, Gyoungjin Gim, Mikyoung Cha, Hwalsuk Lee, and Sunghun Kim. 2023. Solar 10.7b: Scaling large language models with simple yet effective depth up-scaling.
- Lian et al. (2023) Wing Lian, Bleys Goodson, Guan Wang, Eugene Pentland, Austin Cook, Chanvichet Vong, and "Teknium". 2023. Mistralorca: Mistral-7b model instruct-tuned on filtered openorcav1 gpt-4 dataset. https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca.
- Lin et al. (2022) Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252.
- Mukherjee et al. (2023) Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. 2023. Orca: Progressive learning from complex explanation traces of gpt-4. arXiv preprint arXiv:2306.02707.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Rafailov et al. (2023) Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290.
- Sakaguchi et al. (2021) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
- Teknium (2023) Teknium. 2023. teknium/openhermes-2.5-mistral-7b. https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B.
- Tunstall et al. (2023) Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, et al. 2023. Zephyr: Direct distillation of lm alignment. arXiv preprint arXiv:2310.16944.
- Upstage (2023) Upstage. 2023. upstage/solar-0-70b-16bit. https://huggingface.co/upstage/SOLAR-0-70b-16bit.
- Wei et al. (2022) Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. 2022. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682.
- Yuan et al. (2024) Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. 2024. Self-rewarding language models. arXiv preprint arXiv:2401.10020.
- Yuan et al. (2023) Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. 2023. Rrhf: Rank responses to align language models with human feedback without tears. arXiv preprint arXiv:2304.05302.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800.
- Ziegler et al. (2019) Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 2019. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593.
Appendix A Related Work
A.1 Large Language Models
Recent research has highlighted a "scaling law" in the field of context-based language models Kaplan et al. (2020); Hernandez et al. (2021); Anil et al. (2023), showing a proportional relationship between the size of the model plus the training data and the resulting performance improvements. Consequently, this has led to the advent of Large Language Models (LLMs). In contrast to earlier models, LLMs can perform in-context learning, which includes abilities such as zero-shot learning Radford et al. (2019) and few-shot learning Brown et al. (2020), allowing them to adapt and perform tasks without the need for weight adjustments. These emergent abilities of LLMs, absent in their smaller counterparts, signal a significant evolution in language model capabilities Wei et al. (2022).
A.2 Alignment Tuning
LLMs have been recognized to produce text that may seem linguistically inconsistent to human interpreters because their pretraining is based not on an understanding of human intentions but on a broad spectrum of domain-specific knowledge, as indicated in Ziegler et al. (2019). In an effort to rectify this issue and better mirror human intentions, prior research Ziegler et al. (2019) has suggested the adoption of Reinforcement Learning with Human Feedback (RLHF). RLHF seeks to refine the LLM’s output by constructing a reward model that aligns with human preferences and applying reinforcement learning to direct the LLM towards selections that garner the most favorable reward metrics. This approach is intended to bolster the safety, decorum, and general excellence of the responses produced by the LLM. Nonetheless, despite showing promising results, RLHF is confronted with challenges, such as the intricate handling of an extensive set of hyperparameters and the necessity to amalgamate several models (policy, value, reward, and reference models).
To address these issues, there have been proposals for supervised fine-tuning methodologies such as Rank Responses to align Human Feedback (RRHF) Yuan et al. (2023), Reward rAnked FineTuning (RAFT) Dong et al. (2023), and Direct Preference Optimization (DPO) Rafailov et al. (2023). These methods circumvent the intricacies inherent in reinforcement learning and have been shown to yield empirical results on par with RLHF. Notably, the DPO technique straightforwardly encourages the LLM to favor positive responses and discourage negative ones. DPO has been observed to yield performant learning outcomes, in spite of its uncomplicated training procedure.
Concurrent to our work, Yuan et al. (2024) have developed an iterative framework for generating new preference datasets and performing DPO training on the resulting datasets. They empirically demonstrated the superiority of their iterative framework in terms of AlpacaEval 2.0. In contrast, our work is complementary to the above in the sense that we focus on utilizing the current preference data and does not undergo new data generation. Thus, our method can also be applied to Yuan et al. (2024) by changing the DPO training part to using sDPO instead. We leave the above combination as an interesting future work. Additionally, the evaluation used in Yuan et al. (2024) is also different to ours as we utilize tasks from Open LLM Leaderboard whereas Yuan et al. (2024) uses AlpacaEval 2.0.