![[Uncaptioned image]](x1.png) PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
Abstract
To parameter-efficiently fine-tune (PEFT) large language models (LLMs), the low-rank adaptation (LoRA) method approximates the model changes through the product of two matrices and , where , is initialized with Gaussian noise, and with zeros. LoRA freezes the original model and updates the “Noise & Zero” adapter, which may lead to slow convergence. To overcome this limitation, we introduce Principal Singular values and Singular vectors Adaptation (PiSSA). PiSSA shares the same architecture as LoRA, but initializes the adaptor matrices and with the principal components of the original matrix , and put the remaining components into a residual matrix which is frozen during fine-tuning. Compared to LoRA, PiSSA updates the principal components while freezing the “residual” parts, allowing faster convergence and enhanced performance. Comparative experiments of PiSSA and LoRA across 12 different models, ranging from 184M to 70B, encompassing 5 NLG and 8 NLU tasks, reveal that PiSSA consistently outperforms LoRA under identical experimental setups. On the GSM8K benchmark, Mistral-7B fine-tuned with PiSSA achieves an accuracy of 72.86%, surpassing LoRA’s 67.7% by 5.16%. Due to the same architecture, PiSSA is also compatible with quantization to further reduce the memory requirement of fine-tuning. Compared to QLoRA, QPiSSA (PiSSA with 4-bit quantization) exhibits smaller quantization errors in the initial stages. Fine-tuning LLaMA-3-70B on GSM8K, QPiSSA attains an accuracy of 86.05%, exceeding the performances of QLoRA at 81.73%. Leveraging a fast SVD technique, PiSSA can be initialized in only a few seconds, presenting a negligible cost for transitioning from LoRA to PiSSA.

1 Introduction
Fine-tuning large language models (LLMs) is a highly effective technique for boosting their capabilities in various tasks [1, 2, 3, 4], ensuring models to follow instructions [5, 6, 7], and instilling models with desirable behaviors while eliminating undesirable ones [8, 9]. However, the fine-tuning process for very large models is accompanied by prohibitive costs. For example, regular 16-bit fine-tuning of a LLaMA 65B parameter model requires over 780 GB of GPU memory [10], and the VRAM consumption for training GPT-3 175B reaches 1.2TB [11]. Consequently, various parameter-efficient fine-tuning (PEFT) [12, 13] methods have been proposed to reduce the number of parameters and memory usage required for fine-tuning. Due to the ability to maintain the performance of full fine-tuning without adding additional inference latency, Low-Rank Adaptation (LoRA) [11] has emerged as a popular PEFT method.
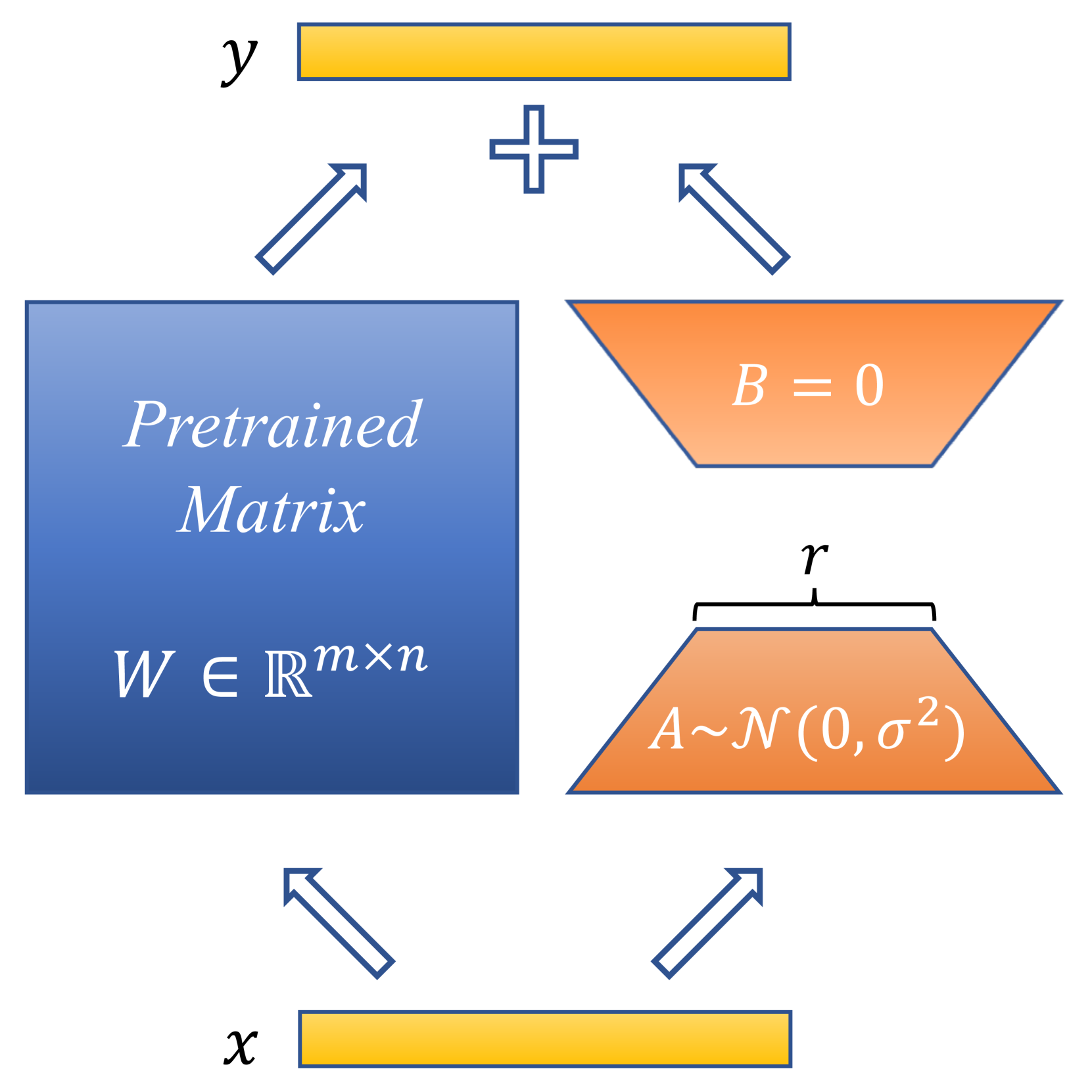
LoRA [11] hypothesizes that the modifications to parameter matrices during fine-tuning exhibit low-rank properties. As depicted in Figure 1(b), for a pre-trained weight matrix , LoRA substitutes the updates with a low-rank decomposition , where and , and the rank . For , the modified forward pass is as follows:
| (1) |
where , , and represents the batch size of input data. A random Gaussian initialization is used for and zero for , making at the beginning of training, thereby the injection of adapters does not affect the model’s output initially. LoRA avoids the need to compute gradients or maintain the optimizer states for the original matrix , instead optimizing the injected, significantly smaller low-rank matrices . Thus, it could reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times [11]. Moreover, LoRA often achieves comparable or superior performance to full parameter fine-tuning, indicating that fine-tuning “parts” of the full parameters can be enough for downstream tasks. By integrating the quantization of pre-trained matrices , LoRA also enables reducing the average memory requirements by 16 times [10]. Meanwhile, the adapters are still allowed to utilize higher precision weights; thus, the quantization usually does not significantly degrade the performance of LoRA.
According to Equation 1, the gradients of A and B are and . Compared to full fine-tuning, using LoRA initially does not change the output for the same input , so the gradient magnitude is primarily determined by the values of and . Since and are initialized with Gaussian noise and zeros in LoRA, the gradients can be very small, leading to slow convergence in the fine-tuning process. We also observe this phenomenon empirically, where LoRA often wastes much time around the initial point.
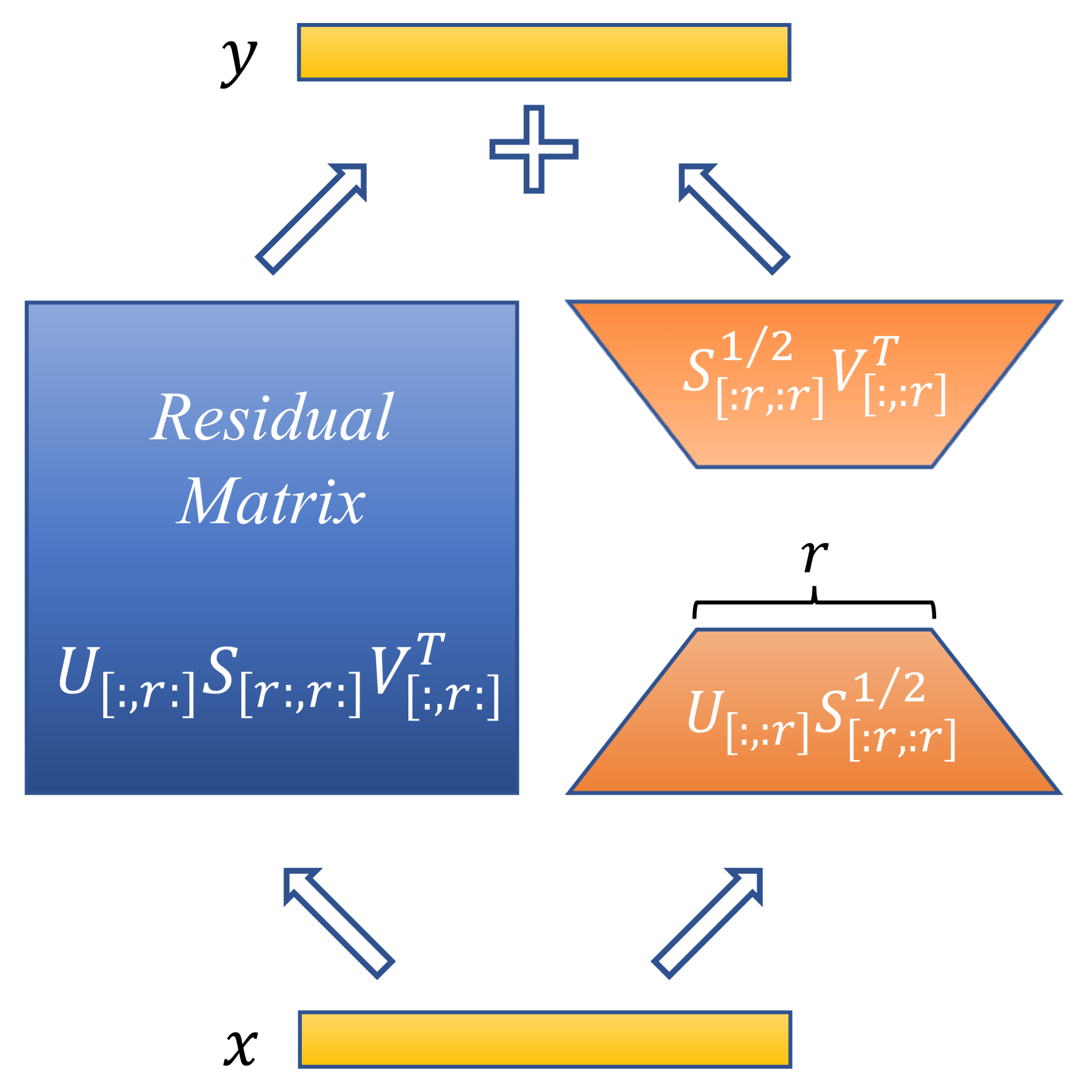
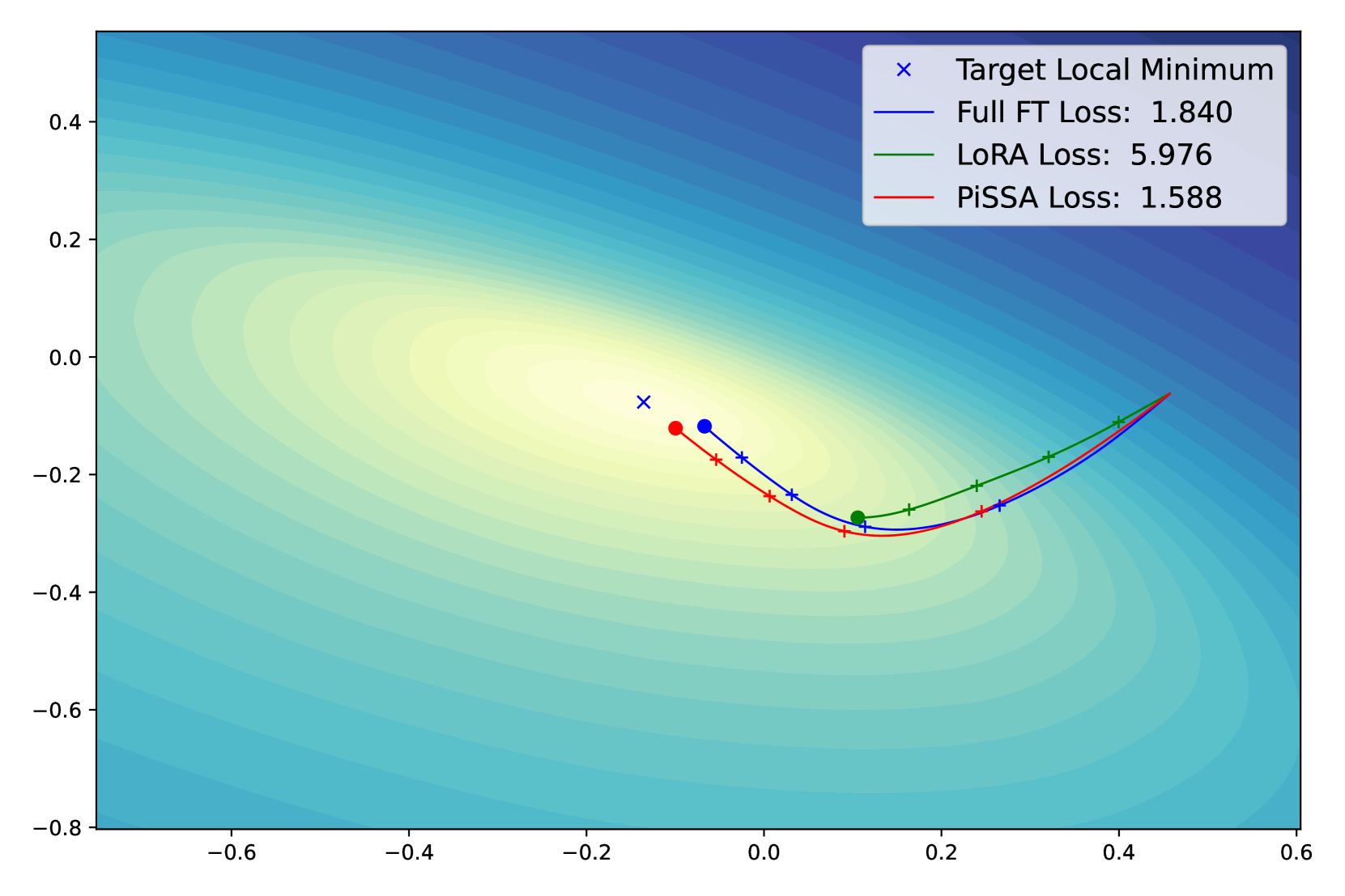
Our Principal Singular values and Singular vectors Adapter (PiSSA) diverges from LoRA and its successors by focusing not on approximating , but . We apply singular value decomposition (SVD) to matrix . Based on the magnitude of the singular values, we partition into two parts: the principal low-rank matrix , comprising a few largest singular values, and the residual matrix , which possesses the remaining smaller singular values (with a larger quantity, representing a possible long-tail distribution). The principal matrix can be represented by the product of and , where . As depicted in Figure 1(c), and are initialized based on the principal singular values and singular vectors and are trainable. Conversely, is initialized with the product of the residual singular values and singular vectors and remains frozen during fine-tuning. Since the principal singular vectors represent the directions in which the matrix has the most significant stretching or impact, by directly tuning these principal components, PiSSA is able to fit the training data faster and better (as demonstrated in Figure 2(a)). Moreover, the loss and gradient norm curves of PiSSA often demonstrate a similar trend to those of full parameter fine-tuning in our experiments (Figure 4), indicating that fine-tuning the principal components matches the behavior of fine-tuning the full matrix to some degree.
Since the principal components are preserved in the adapter and are of full precision, another benefit of PiSSA is that when applying quantization to the frozen part , we can significantly reduce the quantization error compared to QLoRA (which quantizes the whole ), as illustrated in Figure 2(b). Therefore, PiSSA is perfectly compatible with quantization, making it a plug-and-play substitution for LoRA.
2 Related Works
The vast complexity and computational needs of large language models (LLMs) with billions of parameters present significant hurdles in adapting them for specific downstream tasks. Parameter Efficient Fine-Tuning (PEFT) [12, 13] emerges as a compelling solution by minimizing the fine-tuning parameters and memory requirements while achieving comparable performance to full fine-tuning. PEFT encompasses strategies like partial fine-tuning [14, 15, 16, 17, 18, 19, 20, 21], soft prompt fine-tuning [22, 23, 24, 25, 26, 27, 28], non-linear adapter fine-tuning [29, 30, 31, 32, 33, 34, 35, 36, 37, 38], and low rank adapter based fine-tuning [39, 40, 11, 41].
LoRA [11] inject trainable adapters to the linear layers. After fine-tuning, these adaptations can be re-parameterized into the standard model structure, thus gaining widespread adoption due to their ability to maintain the model’s original architecture while enabling efficient fine-tuning. Following LoRA, AdaLoRA [42, 41, 43] dynamically learns the rank size needed for LoRA in each layer of the model. DeltaLoRA [44, 45] updates the original weights of the model using parameters from adapter layers, enhancing LoRA’s representational capacity. LoSparse [46] incorporates LoRA to prevent pruning from eliminating too many expressive neurons. DoRA [47] introduces a magnitude component to learn the scale of while utilizing the original AB as a direction component of . Unlike LoRA and its successors, which focus on learning low-rank approximations of weight updates, our PiSSA approach directly tunes the essential but low-rank parts of the model while keeping the noisier, high-rank, and nonessential parts frozen. Although our approach differs in philosophy from LoRA, it shares most of LoRA’s structural benefits and can be extended by these methods to enhance its performance.
QLoRA [10] integrates LoRA with 4-bit NormalFloat (NF4) quantization, along with Double Quantization and Paged Optimizers, enabling the fine-tuning of a 65B parameter model on a single 48GB GPU while preserving the performance of full 16-bit fine-tuning tasks. QA-LoRA [48] introduces group-wise operators to increase the degree of freedom in low-bit quantization. LoftQ [49] reduces quantization error by decomposing the quantization error matrix of QLoRA and retaining the principal components with an adapter. Our PiSSA approach can also be combined with quantization techniques, and we have found that PiSSA significantly reduces quantization error compared to QLoRA and LoftQ.
3 PiSSA: Principal Singular Values and Singular Vectors Adaptation
This section formally presents our Principal Singular values and Singular vectors Adaptation method. PiSSA computes the singular value decomposition (SVD) of matrices within the self-attention and multilayer perceptron (MLP) layers. The (economy size) SVD of a matrix is given by , where are the singular vectors with orthonormal columns, and is the transpose of . , where the operation transforms to a diagonal matrix , and represents the singular values arranged in descending order. When the top singular values are significantly larger than the remaining singular values , we denote the intrinsic rank of as . Consequently, , along with and , can be divided into two groups: the principal singular values and vectors—, and the residual singular values and vectors—, where the matrix slicing notations are the same as those in PyTorch and denotes the first dimensions. The principal singular values and vectors are utilized to initialize the injected adapter consisting of and :
| (2) | ||||
| (3) |
The residual singular values and vectors are used to build the residual matrix which is frozen during fine-tuning:
| (4) |
As indicated by Equation 5, the integration of with the residual matrix also preserves the full capability of the pre-trained model in the beginning of fine-tuning:
| (5) |
Similar to LoRA, the gradients of and are also given by and . Since elements of elements of , the trainable adapter contains the most essential directions of . In the ideal case, training mirrors the process of fine-tuning the entire model despite using fewer parameters. The ability to directly fine-tune the most essential part of a model enables PiSSA to converge faster and better. In contrast, LoRA initializes the adapters and with Gaussian noise and zeros while keeping frozen. Consequently, the gradients are small or in random directions during the early stages of fine-tuning, possibly introducing much waste of gradient descent steps. Moreover, an inferior initialization might lead to suboptimal local minimum points found, causing worse generalization performance.
Since PiSSA shares the identical architecture with LoRA, it inherits most of LoRA’s benefits. These include but are not limited to the capability of fine-tuning a model with a reduced number of trainable parameters, quantizing the residual model to decrease memory consumption during forward propagation in training, and easy deployment. The adapter’s straightforward linear structure facilitates the integration of trainable matrices with the pre-trained weights upon deployment, thereby maintaining the original inference speed of a fully fine-tuned model. Employing the Fast SVD technique [50] allowed PiSSA to finish initialization in several seconds (Appendix B), which is a negligible cost.
For storage efficiency, we can choose not to store the dense parameter matrix , but to store the low-rank matrices, and instead. As shown in Appendix C, leveraging solely the and facilitates their seamless integration with the original pre-trained models. Finally, one pre-trained model can accommodate multiple , fine-tuned by diverse PiSSA or LoRA procedures, which enables fast adaptation of the pre-trained model to different downstream applications.
4 QPiSSA: PiSSA with Quantization
Quantization divides the value range of a matrix into several continuous regions, and maps all values falling inside a region into the same “quantized” value. It is an effective technique to reduce the memory consumption of forward propagation, but breaks down during backpropagation. At the same time, LoRA greatly reduces the backward memory requirement, making it highly suitable to use LoRA and quantization together, where the base model is quantized for memory-efficient forward propagation, and the LoRA adaptors are kept in full precision for accurate backward parameter updates. One representative previous work, QLoRA, quantizes the base model to Normal Float 4-bit (NF4) and initializes the full-precision and with Gaussian-Zero initialization. Therefore, the overall error is given by:
| (6) |
where denotes the nuclear norm (also known as the trace norm) [51], defined as:
| (7) |
where is the singular value of . As we can see, the quantization error of QLoRA is the same as that of directly quantizing the base model. Our QPiSSA, however, does not quantize the base model but the residual model. Therefore, its error is given by:
| (8) |
Since the residual model has removed the large-singular-value components, has a narrower distribution than that of , as can be seen in Figures 3(a) and 3(b) (comparing the singular value distributions of and ), as well as Figures 3(c) and 3(f) (comparing the value distributions of and ), which is beneficial for reducing the quantization error. Furthermore, since NF4 is optimized for normally distributed data [10], we fit a Gaussian for the values of and , respectively. As can be seen in Figures 3(c) and 3(f), is much more Gaussian-like and has a smaller standard deviation, making it more suitable to apply NF4 to instead of . Both the above lead QPiSSA to achieve a significantly lower quantization error than QLoRA, shown in Figures 3(d) and 3(e).
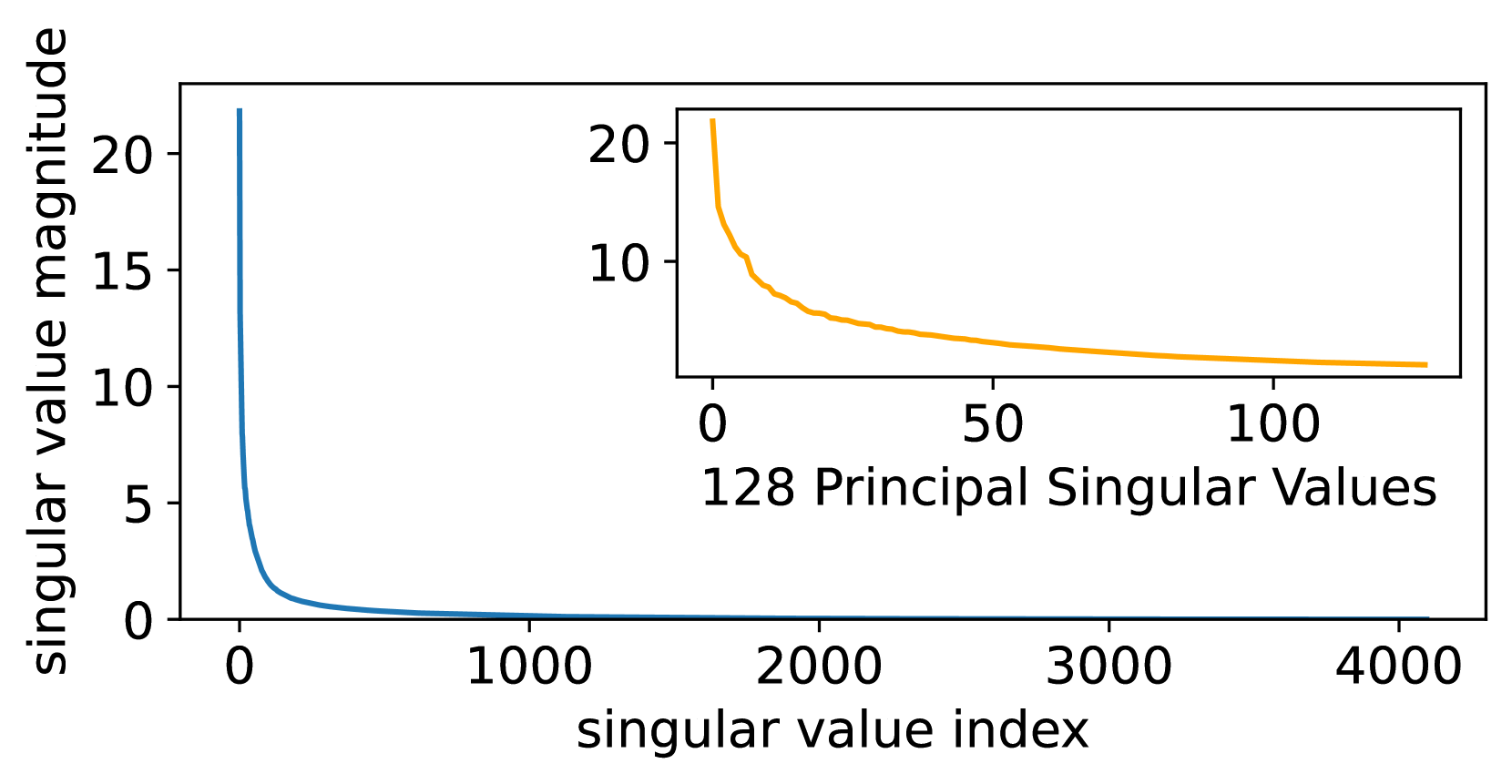
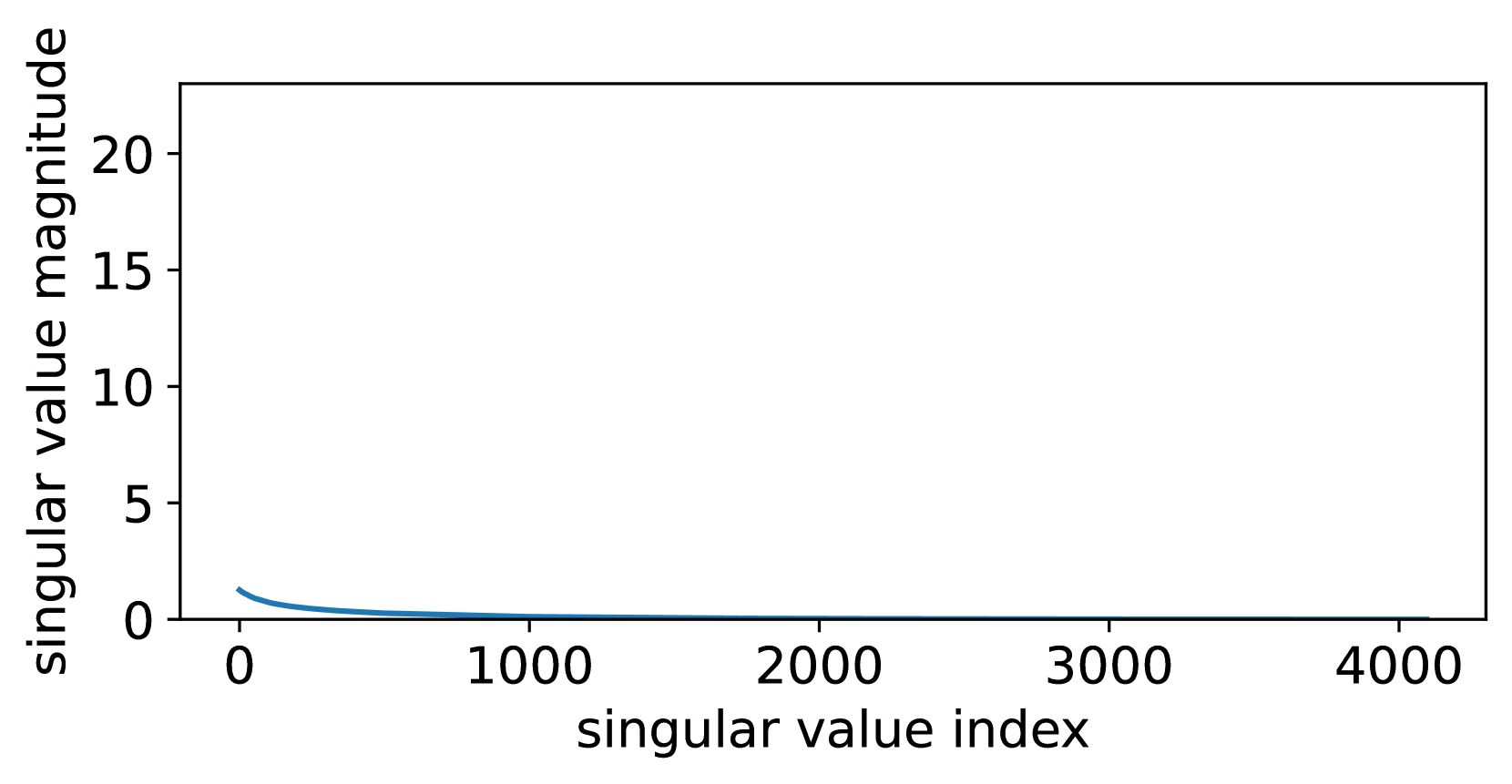
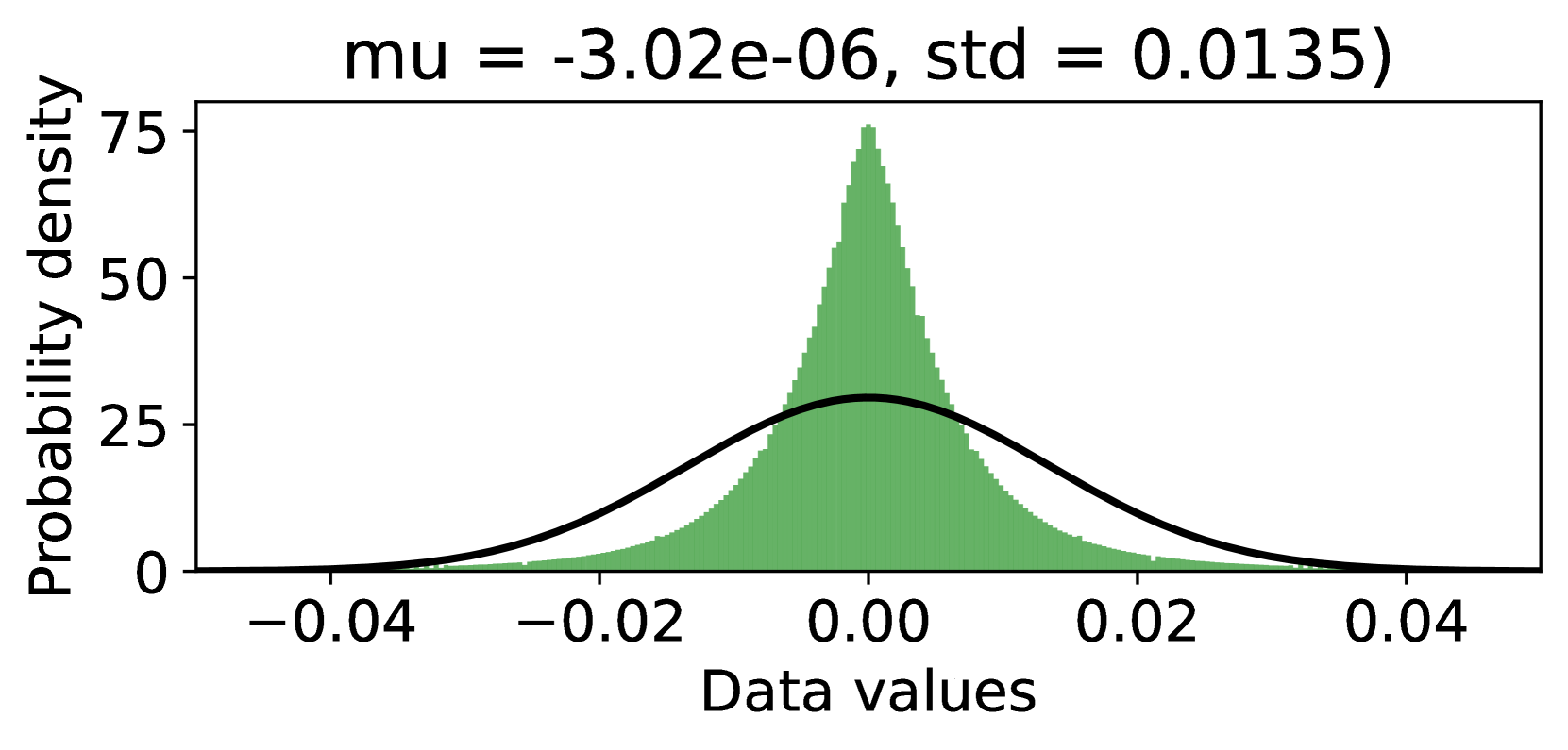
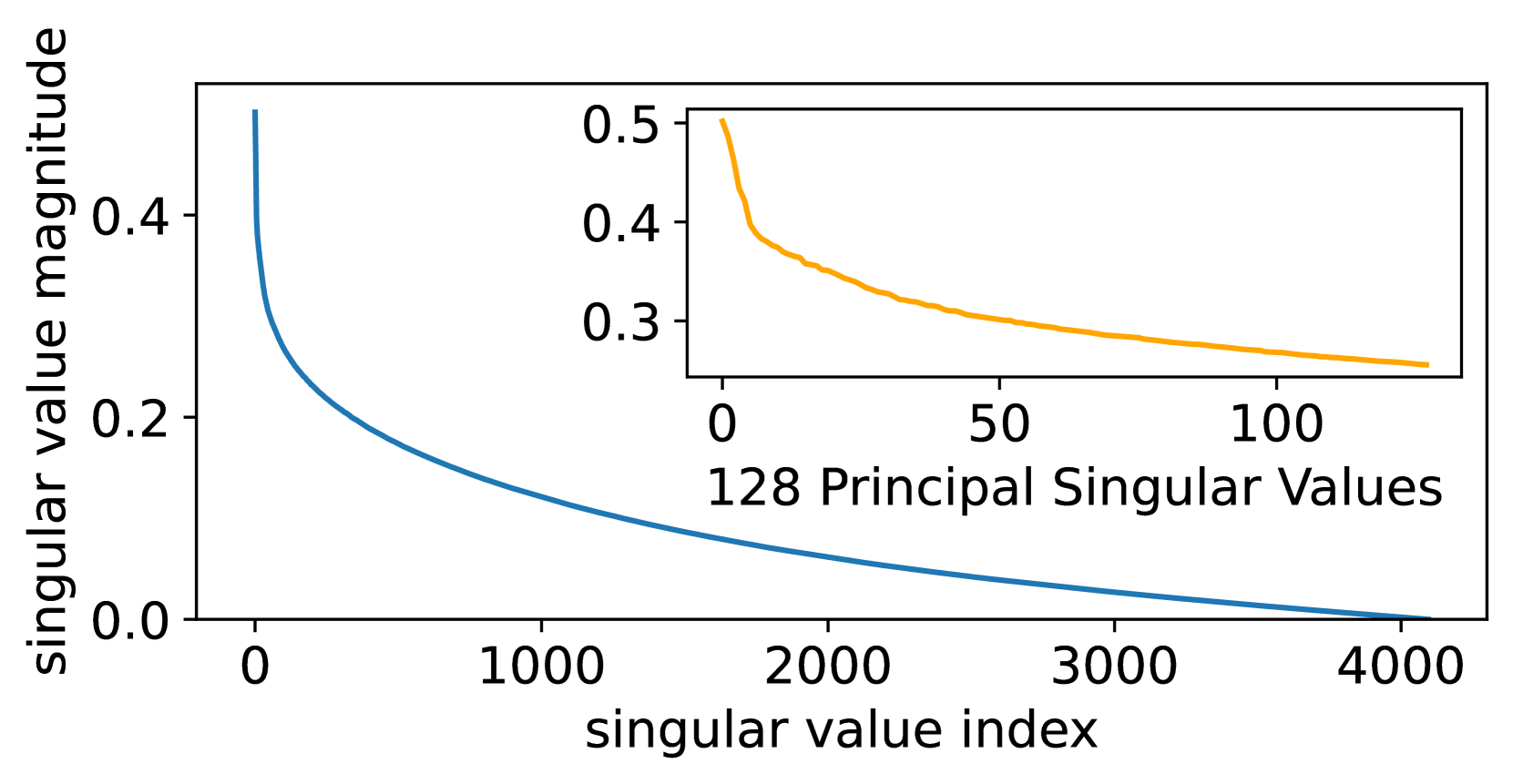
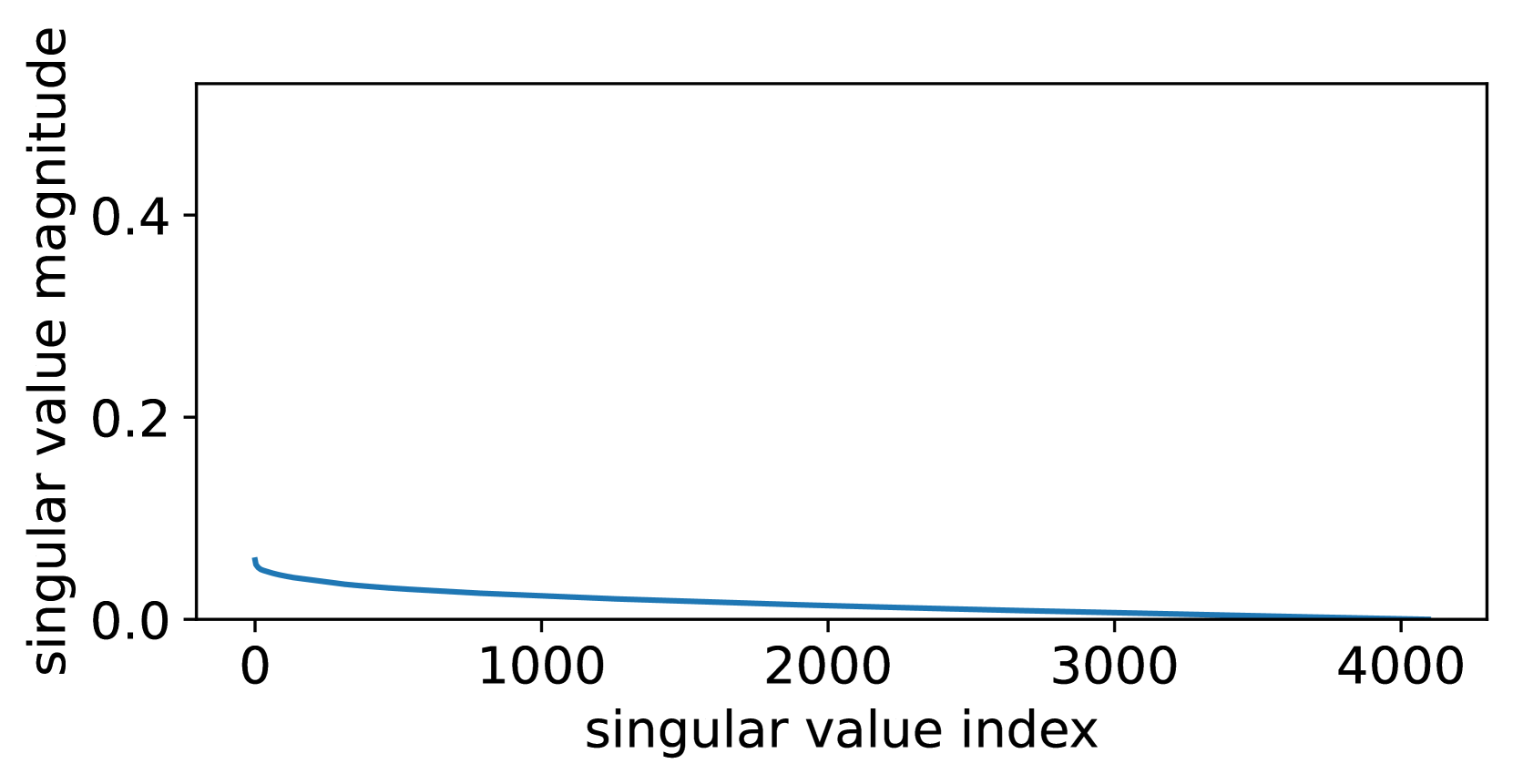
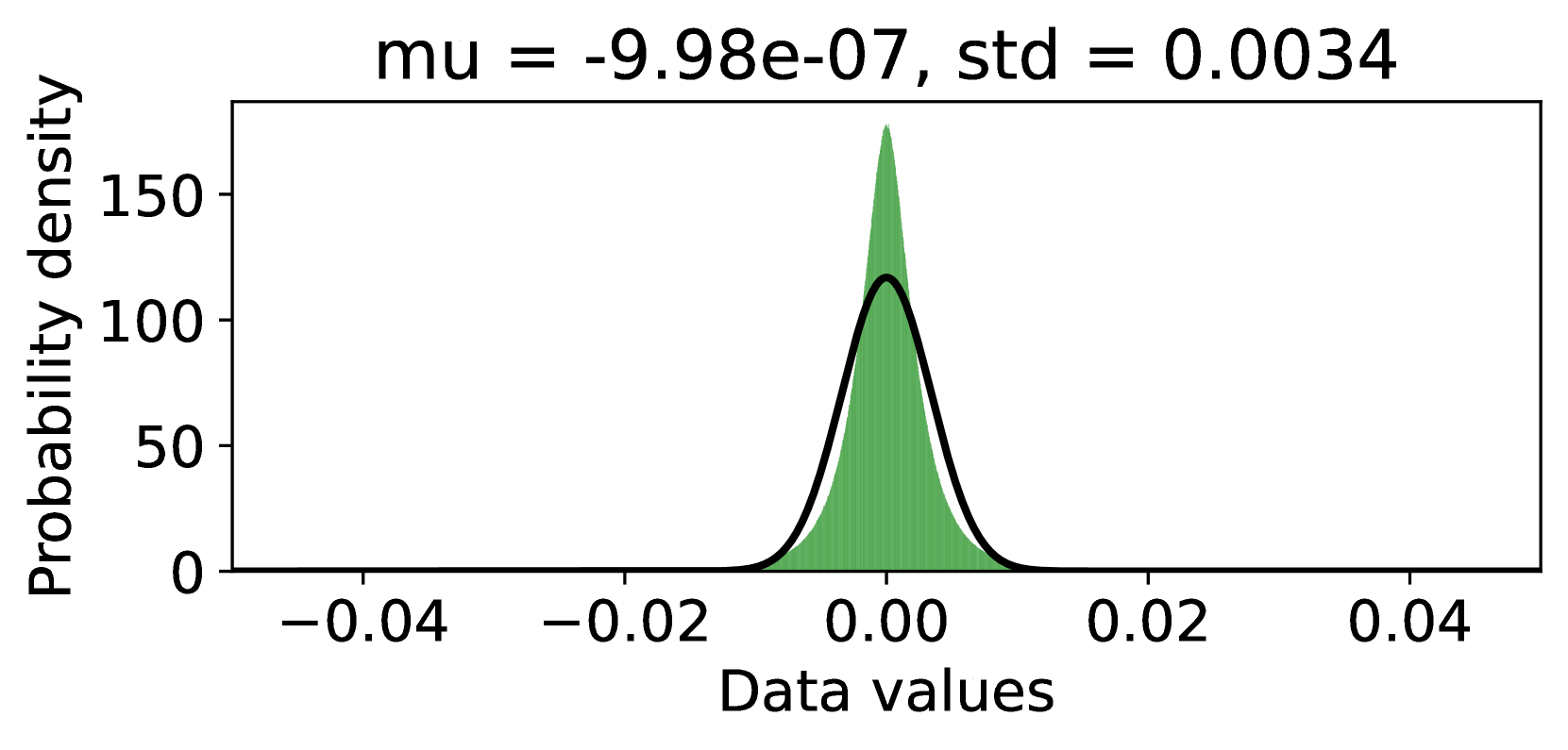
Besides the advantage of reducing quantization error, QPiSSA’s gradient direction is similar to that of PiSSA, resulting in significantly better fine-tuning performance compared to QLoRA.
5 Experiments
The experiments were conducted on the NVIDIA A800-SXM4(80G) GPU. In our experiments, we adopt the Alpaca [52] implementation strategy, using the AdamW optimizer with a batch size of 128, a learning rate of 2e-5, cosine annealing schedules, and a warmup ratio of 0.03, without any weight decay. As discussed in Section B.3 of QLoRA [10], we compute the loss using only the responses from the instruction-following datasets. We ensure lora_alpha is always equal to lora_r, set lora_dropout to 0, and incorporate the adapters into all linear layers of the base model. We utilize the Float32 computation type for both the base model and the adapter in LoRA and PiSSA. For QLoRA, LoftQ, and QPiSSA, we use 4-bit NormalFloat [10] for the base model and Float32 for the adapter. BFloat16 [53] is used for full parameter fine-tuning to save the resources (see Appendix D).
5.1 Evaluating the Performance of PiSSA on both NLG and NLU Tasks
Table 1 presents a comparative evaluation of fine-tuning strategies PiSSA, LoRA, and full parameter fine-tuning on natural language generation (NLG) tasks. We fine-tuned LLaMA 2-7B [54], Mistral-7B-v0.1 [55], and Gemma-7B [56] on the MetaMathQA dataset [2] to assess their mathematical problem-solving capabilities on the GSM8K [57] and MATH [2] validation sets. Additionally, the models were fine-tuned on the CodeFeedback dataset [58] and evaluated for coding proficiency using the HumanEval [59] and MBPP [60] datasets. Furthermore, the models were trained on the WizardLM-Evol-Instruct dataset [7] and tested for conversational abilities on the MT-Bench dataset [6]. All experiments were conducted using subsets containing 100K data points and were trained for only one epoch to reduce training overhead.
| Model | Strategy | Trainable | GSM8K | MATH | HumanEval | MBPP | MT-Bench |
|---|---|---|---|---|---|---|---|
| Parameters | |||||||
| LLaMA 2-7B | Full FT | 6738M | 49.05 | 7.22 | 21.34 | 35.59 | 4.91 |
| LoRA | 320M | 42.30 | 5.50 | 18.29 | 35.34 | 4.58 | |
| PiSSA | 320M | 53.07 | 7.44 | 21.95 | 37.09 | 4.87 | |
| Mistral-7B | Full FT | 7242M | 67.02 | 18.6 | 45.12 | 51.38 | 4.95 |
| LoRA | 168M | 67.70 | 19.68 | 43.90 | 58.39 | 4.90 | |
| PiSSA | 168M | 72.86 | 21.54 | 46.95 | 62.66 | 5.34 | |
| Gemma-7B | Full FT | 8538M | 71.34 | 22.74 | 46.95 | 55.64 | 5.40 |
| LoRA | 200M | 74.90 | 31.28 | 53.66 | 65.41 | 4.98 | |
| PiSSA | 200M | 77.94 | 31.94 | 54.27 | 66.17 | 5.64 |
As shown in Table 1, across all models and tasks, fine-tuning with PiSSA consistently surpasses the performance of fine-tuning with LoRA. For instance, fine-tuning the LLaMA, Mistral, and Gemma with PiSSA results in performance improvements of 10.77%, 5.26%, and 3.04% respectively in mathematical tasks. In coding tasks, the improvements are 20%, 6.95%, and 1.14% respectively. In MT-Bench, we observe enhancements of 6.33%, 8.98%, and 13.25%. Notably, using PiSSA with only 2.3% of Gemma’s trainable parameters outperforms full parameter fine-tuning by 15.59% in coding tasks. Further experiments demonstrated that this improvement is robust across various amounts of training data and epochs (Section 5.2), including both 4-bit and full precision (Section 5.3), different model sizes and types (Section 5.4), and varying proportions of trainable parameters (Section 5.5).
| Method | Parameters | MNLI | SST-2 | MRPC | CoLA | QNLI | QQP | RTE | STS-B |
|---|---|---|---|---|---|---|---|---|---|
| RoBERTa-large (355M) | |||||||||
| Full FT | 355M | 90.2 | 96.4 | 90.9 | 68.0 | 94.7 | 92.2 | 86.6 | 91.5 |
| LoRA | 1.84M | 90.6 | 96.2 | 90.9 | 68.2 | 94.9 | 91.6 | 87.4 | 92.6 |
| PiSSA | 1.84M | 90.7 | 96.7 | 91.9 | 69.0 | 95.1 | 91.6 | 91.0 | 92.9 |
| DeBERTa-v3-base (184M) | |||||||||
| Full FT | 184M | 89.90 | 95.63 | 89.46 | 69.19 | 94.03 | 92.40 | 83.75 | 91.60 |
| LoRA | 1.33M | 90.65 | 94.95 | 89.95 | 69.82 | 93.87 | 91.99 | 85.20 | 91.60 |
| PiSSA | 1.33M | 90.43 | 95.87 | 91.67 | 72.64 | 94.29 | 92.26 | 87.00 | 91.88 |
We also evaluate PiSSA’s natural language understanding (NLU) capability on the GLUE benchmark [61] with RoBERTa-large [62] and DeBERTa-v3-base [63]. Table 2 presents the results across 8 tasks conducted with the two base models. PiSSA outperforms LoRA on 14 out of 16 experimental settings, and achieves the same performance on QQP + RoBERTa. The single exception arises from the DeBERTa-based model on the MNLI dataset. Upon reviewing the training loss, we observed that PiSSA’s average loss of was lower than LoRA’s in the final epoch. This indicates that the fitting ability of PiSSA remains stronger than that of LoRA.
5.2 Experiments using Full Data and More Epochs
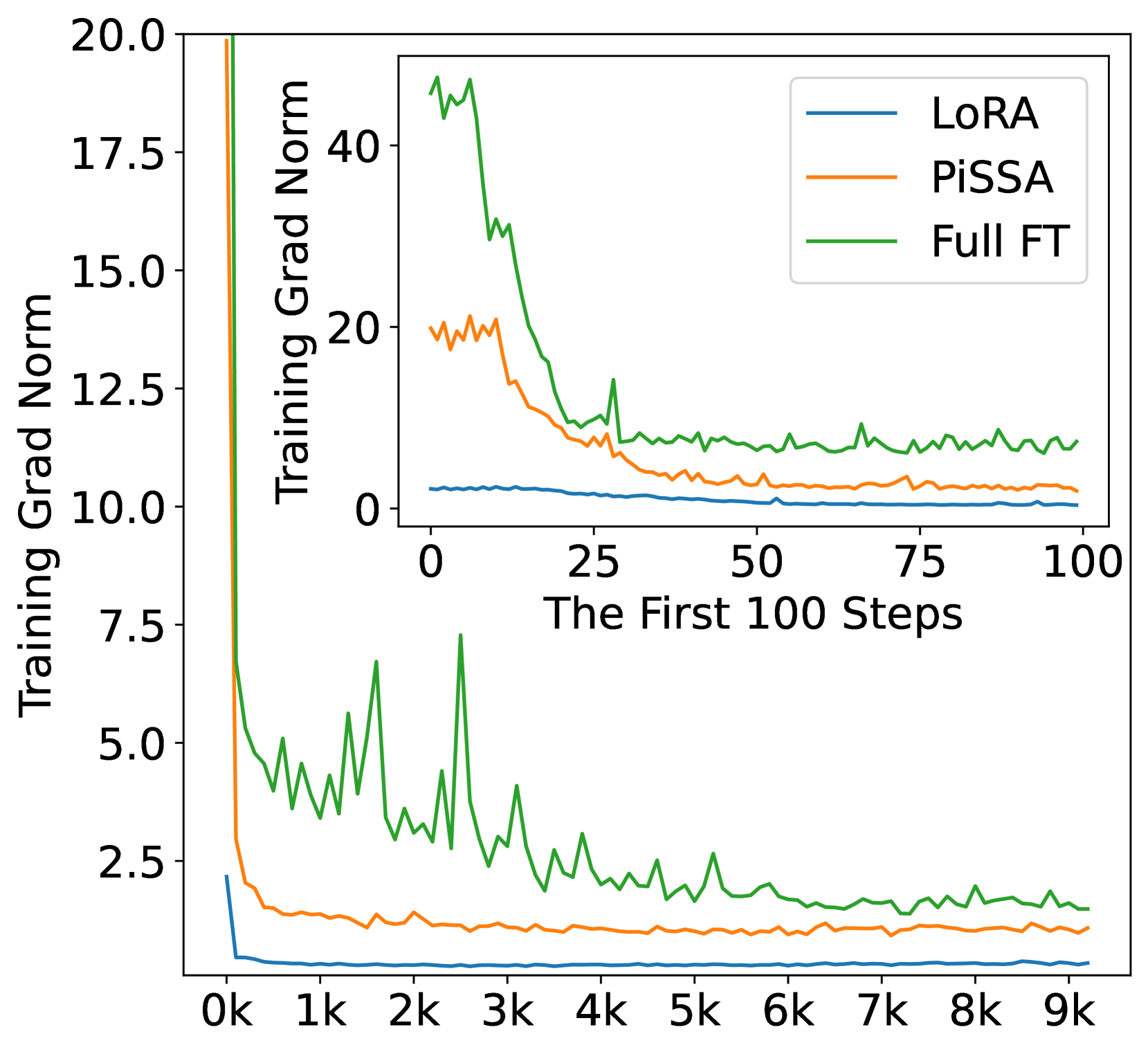
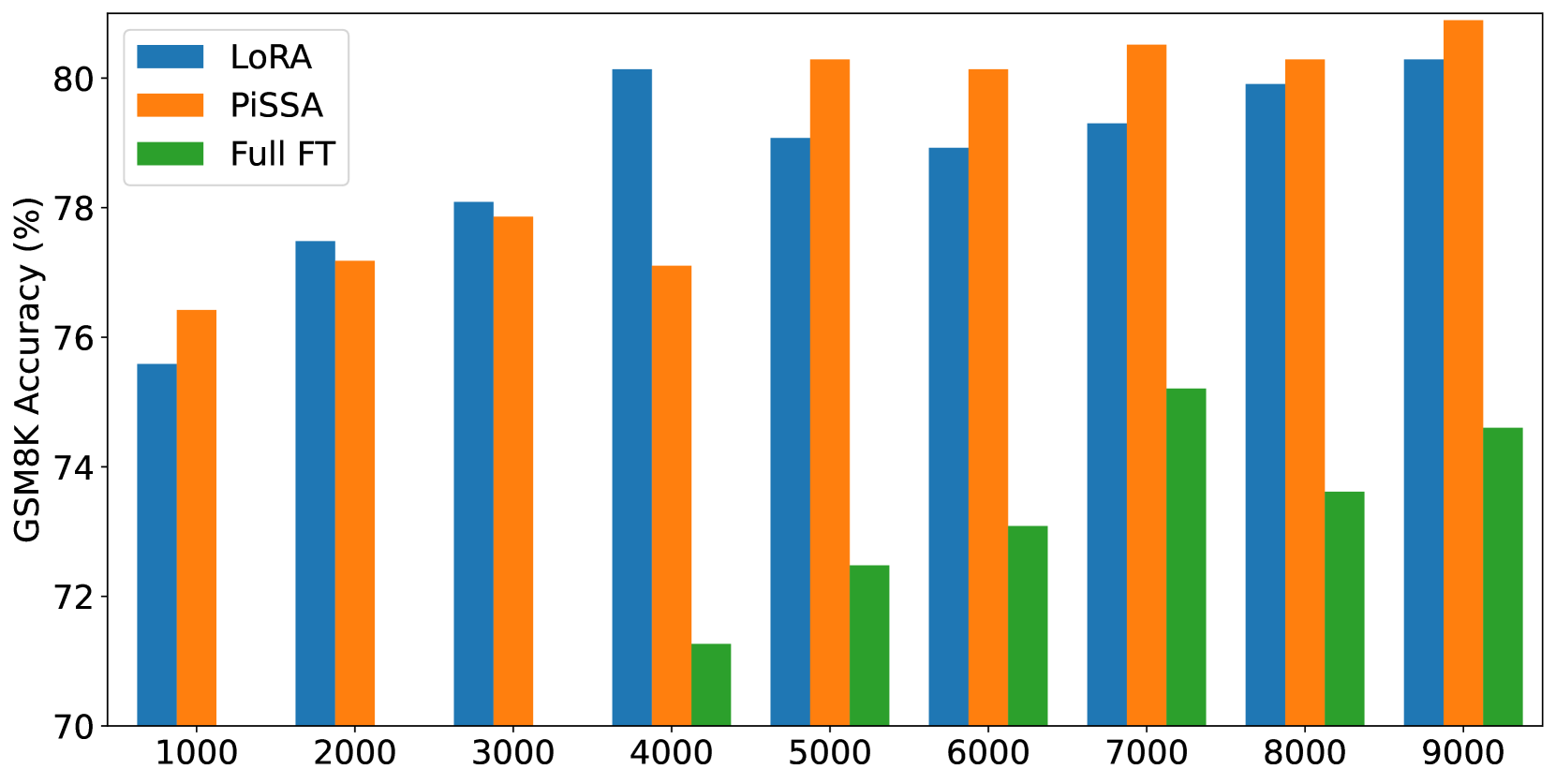
In this section, we finetune LLaMA 2-7B model on the complete MetaMathQA-395K dataset for 3 epochs to ensure thorough saturation. The training loss and gradient norms is visualized to demonstrate quicker convergence and evaluated on the GSM8K dataset every 1000 steps to demonstrate superior performance of PiSSA compared to LoRA. The results are depicted in Figure 4. Additionally, similar comparisons on Mistral-7B and Gemma-7B are detailed in Appendix G.
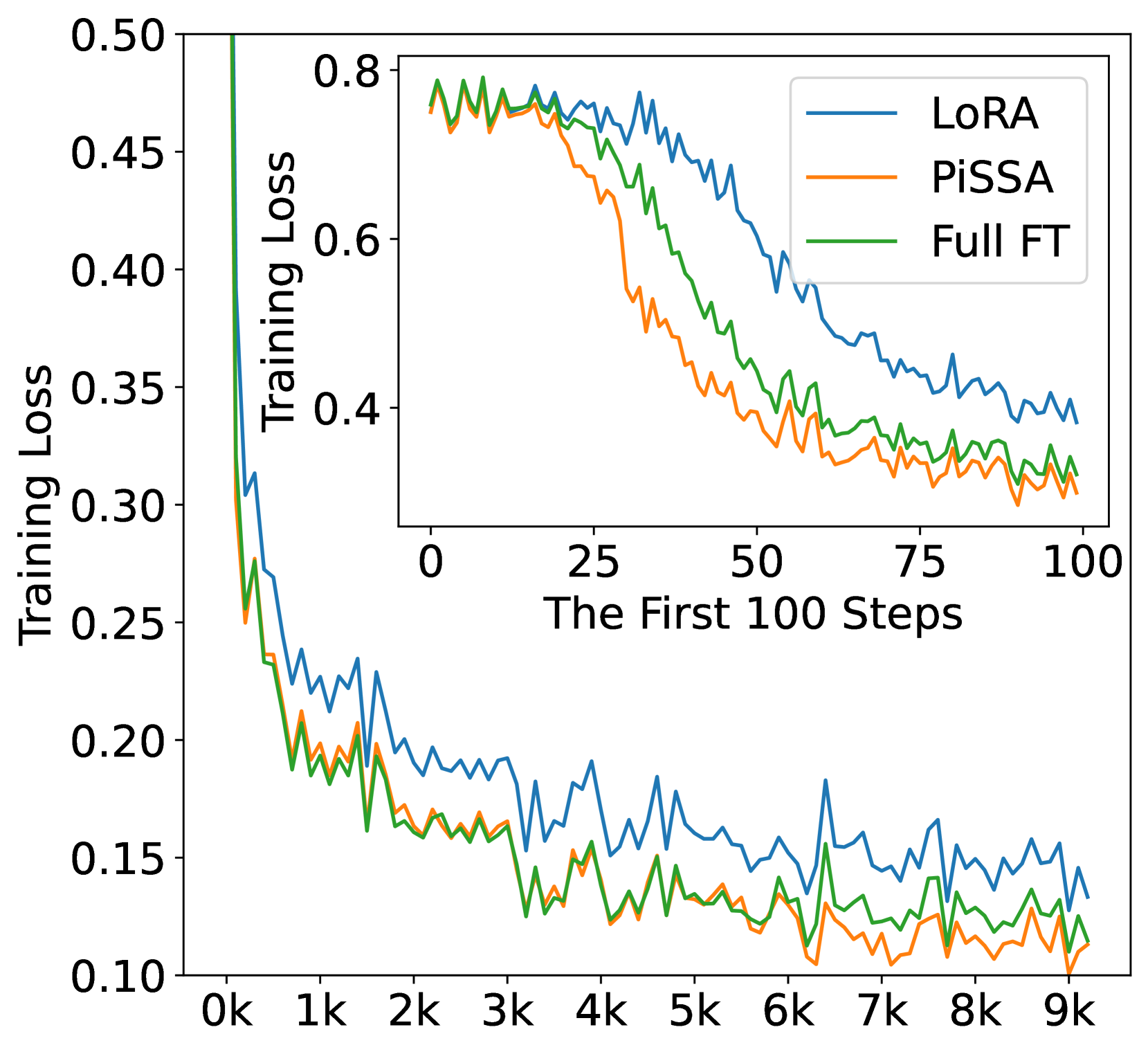
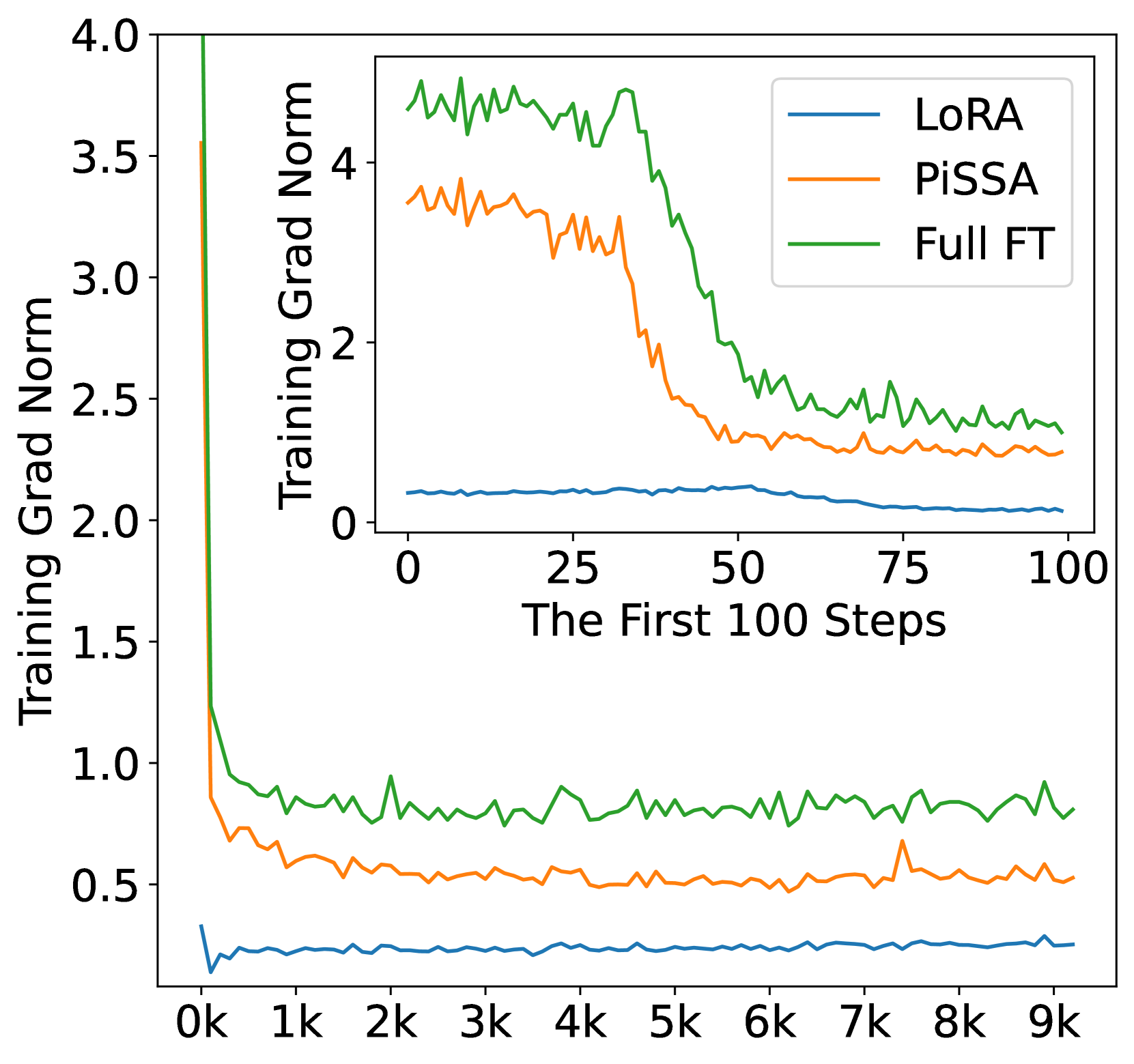
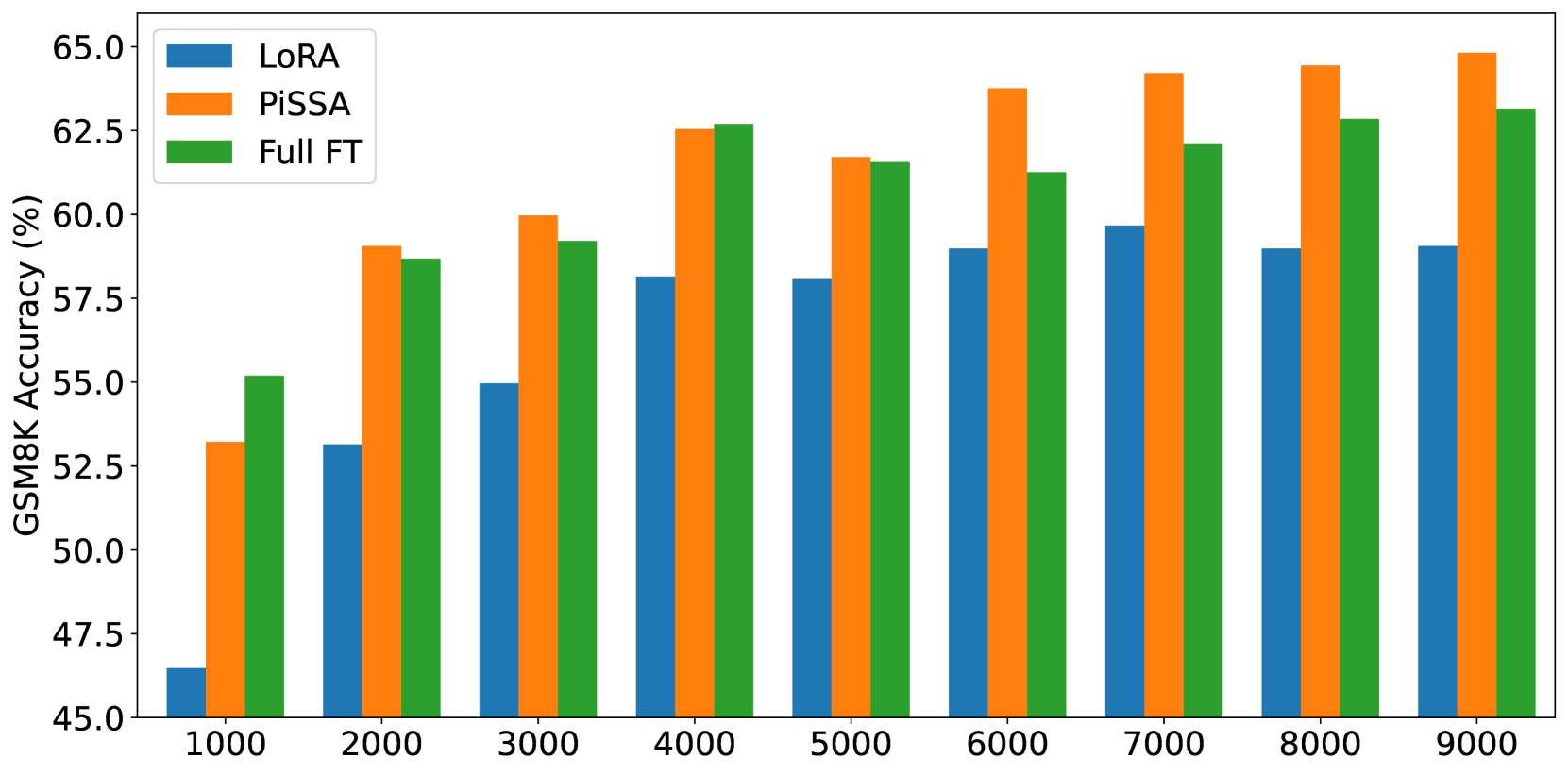
According to Figure 4(a), the loss of PiSSA reduces rapidly during the first 100 steps, and the grad norm (shown in Figure 4(b)) of PiSSA is significantly higher than that of LoRA, with a trend similar to full fine-tuning. Throughout the process, the loss of PiSSA remains lower than that of LoRA, indicating that PiSSA converges to a better local optimum. As shown in Figure 4(c), PiSSA consistently achieves higher accuracy compared to LoRA, and in most cases also surpasses full parameters fine-tuning. We hypothesize that this is because PiSSA is a denoised version of full fine-tuning. Comparing the grad norm and loss curves of PiSSA and full fine-tuning, we can see that the larger grad norm of full fine-tuning does not bring lower loss, indicating that a portion of the grad norm is spent on noisy directions not beneficial for loss reduction. This phenomenon is consistent with Figure 2(a).
5.3 Conducting 4-bit Quantization Experiments
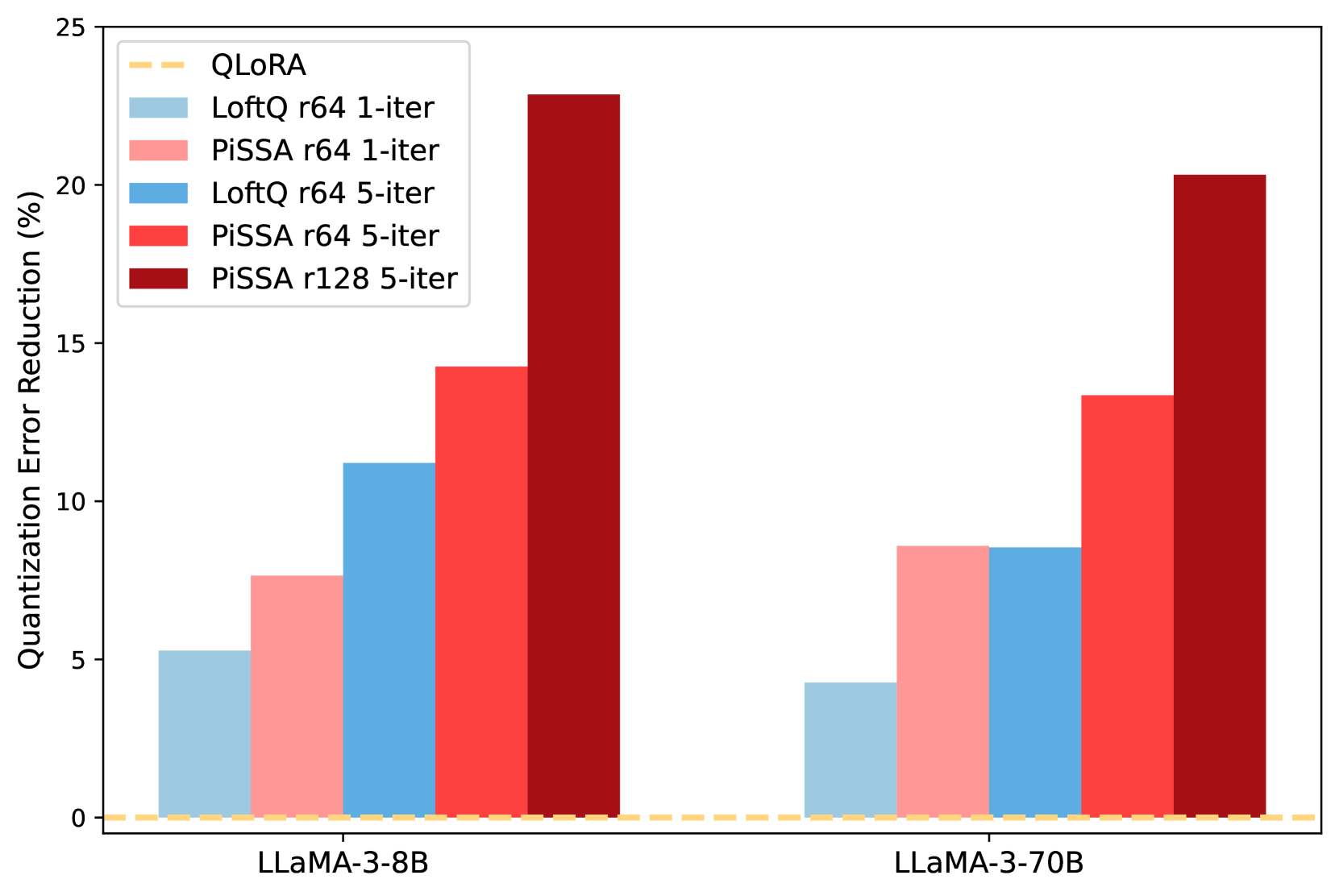
In this section, we first compare the initial quantization error reduction ratio of PiSSA, QLoRA, and LoftQ. This ratio is defined as , measuring the relative error decrease achieved by each mehod compared to directly quantizing the base model. The partial results are presented in Table 3, and the complete results can be found in Table 6 in Appendix E.
| Method | Rank | Q | K | V | O | Gate | Up | Down | AVG | |
|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA 2-7B | QLoRA | – | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| loftQ | 128 | 16.5 | 16.5 | 15.9 | 16.0 | 12.4 | 12.4 | 12.3 | 14.6 | |
| PiSSA | 128 | 27.9 | 27.2 | 18.7 | 18.6 | 15.8 | 13.6 | 13.6 | 19.4 | |
| LLaMA 3-8B | QLoRA | – | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| loftQ | 128 | 16.4 | 29.8 | 28.8 | 16.1 | 11.9 | 11.7 | 11.7 | 18.1 | |
| PiSSA | 128 | 26.3 | 41.7 | 32.3 | 20.1 | 14.4 | 12.5 | 12.9 | 22.9 | |
| LLaMA 3-70B | QLoRA | – | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LoftQ | 64 | 6.1 | 17.8 | 17.0 | 6.0 | 4.3 | 4.4 | 4.2 | 8.5 | |
| PiSSA | 64 | 15.7 | 34.2 | 18.9 | 7.5 | 6.7 | 5.7 | 4.7 | 13.4 | |
| PiSSA | 128 | 23.2 | 49.0 | 30.5 | 12.5 | 10.1 | 8.8 | 8.2 | 20.3 |
In Table 3, PiSSA reduces the quantization error by about 20% compared to directly quantizing the base model. The reduction is more significant for lower-rank matrices. For instance, in the LLaMA-3-70B [64], all “Key” projection layers see a reduction of 49%. The results in Table 3 validate that QLoRA, discussed in Section 4, does not reduce quantization error. In contrast, PiSSA significantly outperforms LoftQ in reducing quantization error, as further discussed in Appendix F.
Besides reducing the quantization error, we expect QPiSSA to also converge faster than QLoRA and LoftQ. We train LLaMA 3-8B with LoRA/QLoRA, PiSSA/QPiSSA, LoftQ, and full fine-tuning on MetaMathQA-395K for 3 epochs and record the loss, grad norm, and accuracy on GSM8K.
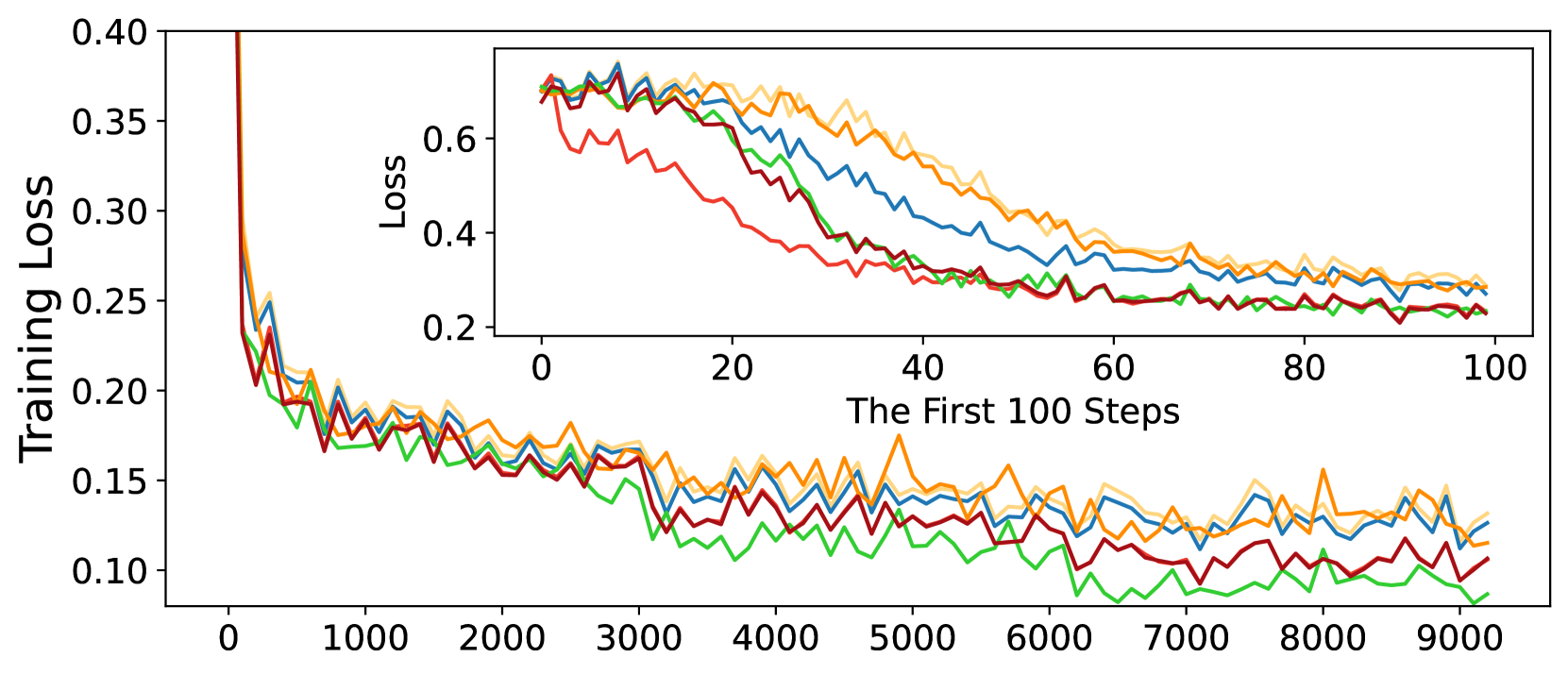
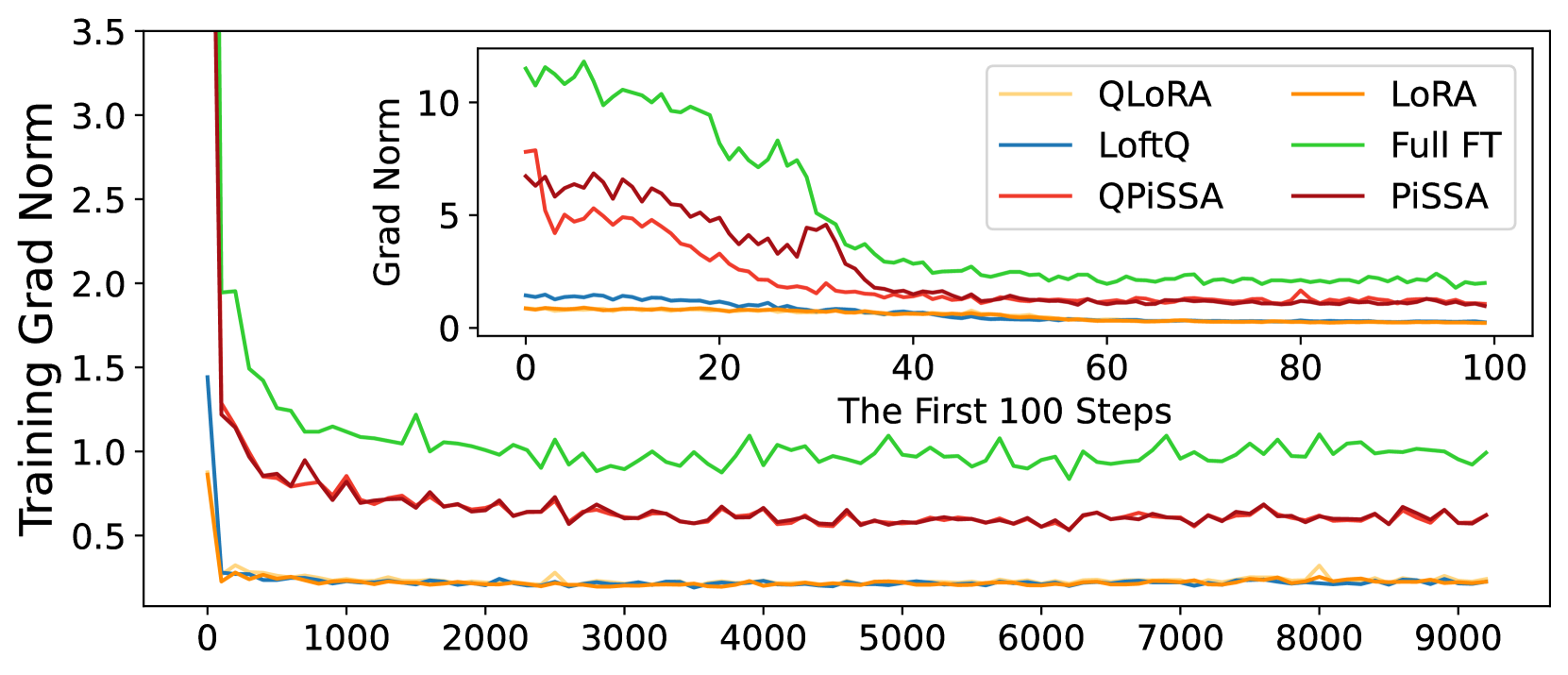
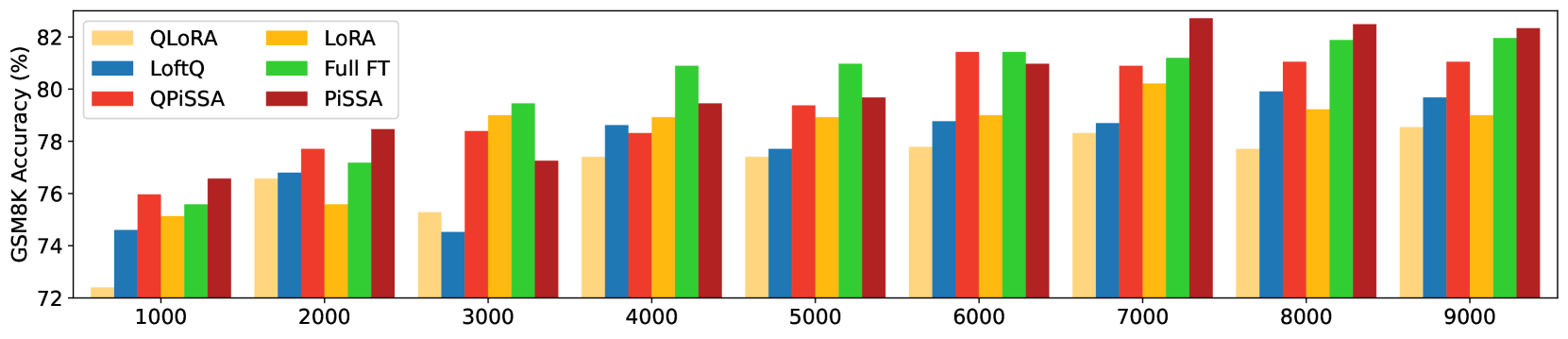
According to Figure 5, QPiSSA’s loss reduction speed in the first 100 steps is even faster than PiSSA and full fine-tuning. Although LoftQ can reduce the quantization error, its loss convergence speed is not faster than LoRA and QLoRA, indicating that QPiSSA’s ability to reduce the quantization error and its fast convergence might also be orthogonal capabilities. After sufficient training, QPiSSA’s loss is also much lower than that of LoRA/QLoRA and LoftQ. The grad norm is significantly larger than those of LoRA/QLoRA and LoftQ. In terms of fine-tuning performance, QPiSSA’s accuracy is higher than that of QLoRA and LoftQ and even better than that of full-precision LoRA.
5.4 Experiments Across Various Sizes and Types of Models
In this section, we compare (Q)PiSSA and (Q)LoRA across 9 models, ranging from 7-70B parameters, including LLaMA 2-7/13B [54], LLaMA-3-8/70B [64], Mistral-7B [55], Gemma-7B [56], and Qwen1.5-7B [65], Yi-1.5-34B [66] and MoE models: DeepSeek-MoE-16B [67] and Mixtral-8x7B [68]. These models were fine-tuned on the MetaMathQA-100K and CodeFeedback-100K dataset and evaluated on the GSM8K and HumanEval. DeepSeek-MoE-16B, Mixtral-8x7B, Yi-1.5-34B, and LLaMA-3-70B were fine-tuned with QPiSSA and QLoRA, while the other models were using PiSSA and LoRA. From Figure 6, it can be observed that (Q)PiSSA, compared to (Q)LoRA, shows improved accuracy across various sizes and types of models, demonstrating its consistent advantage over (Q)LoRA.
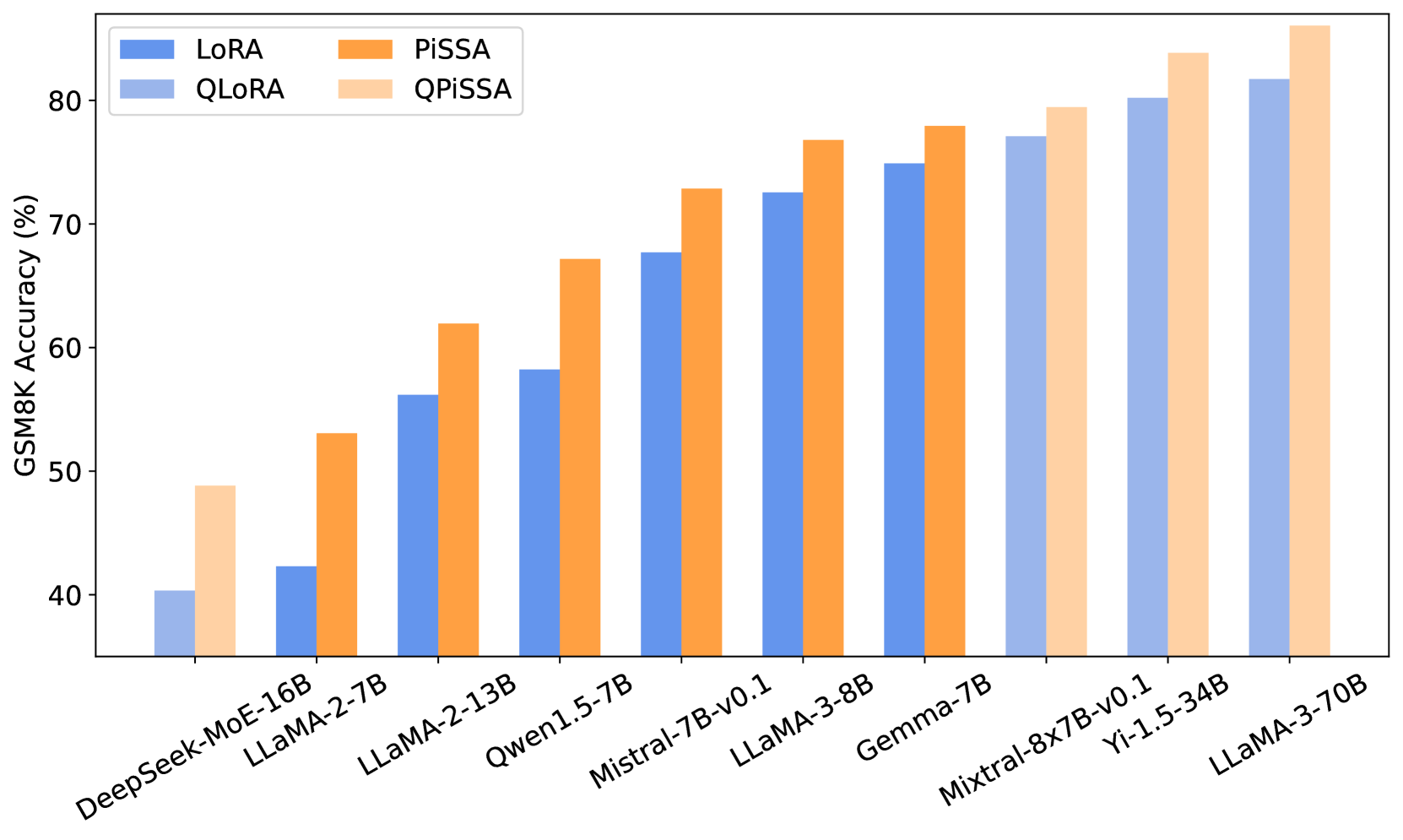
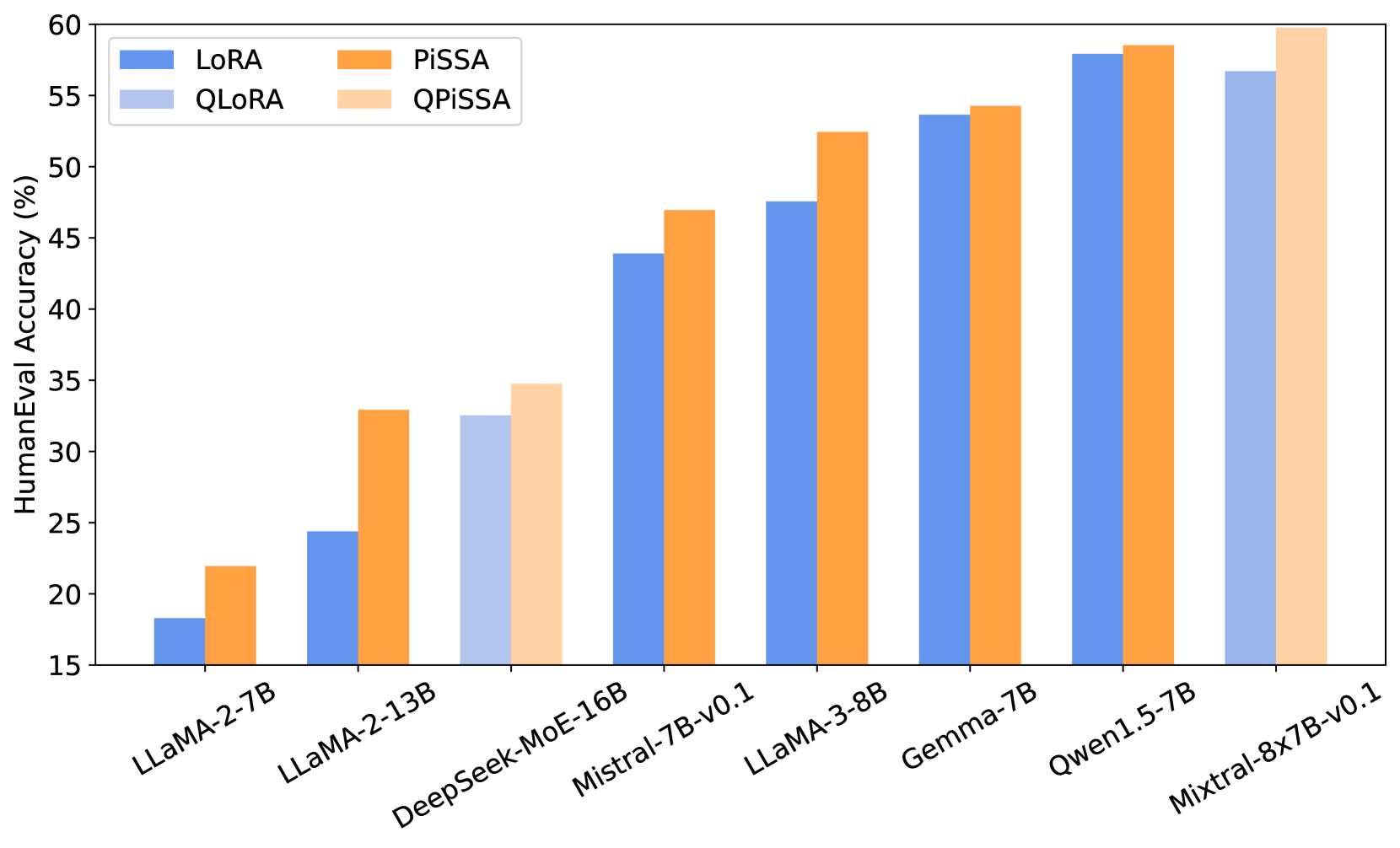
5.5 Experiments on Various Ranks
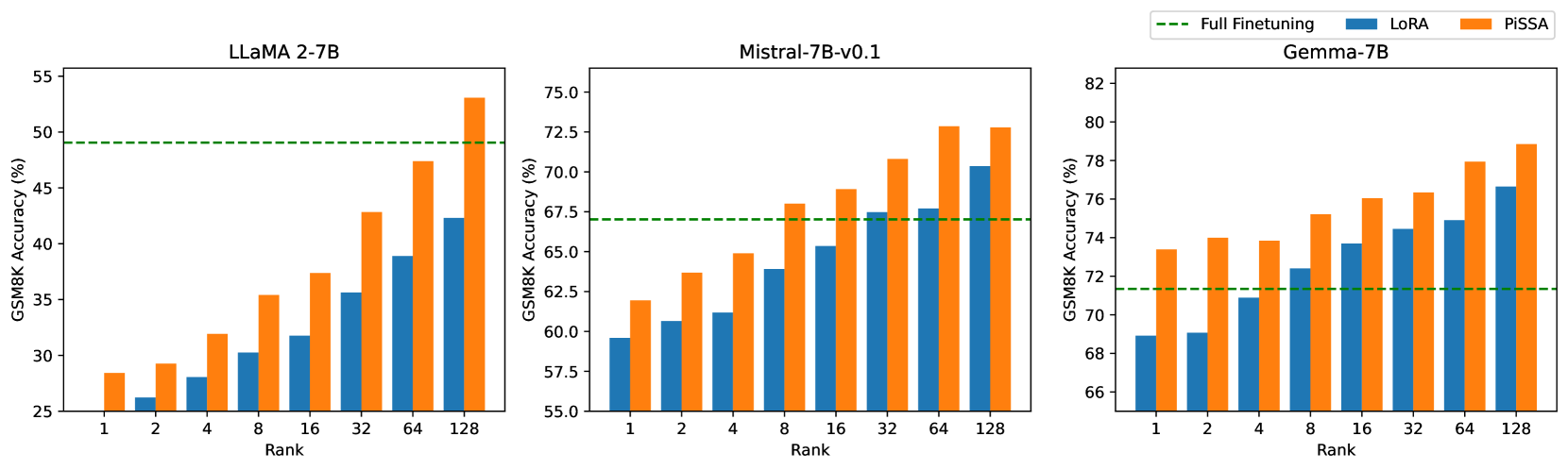
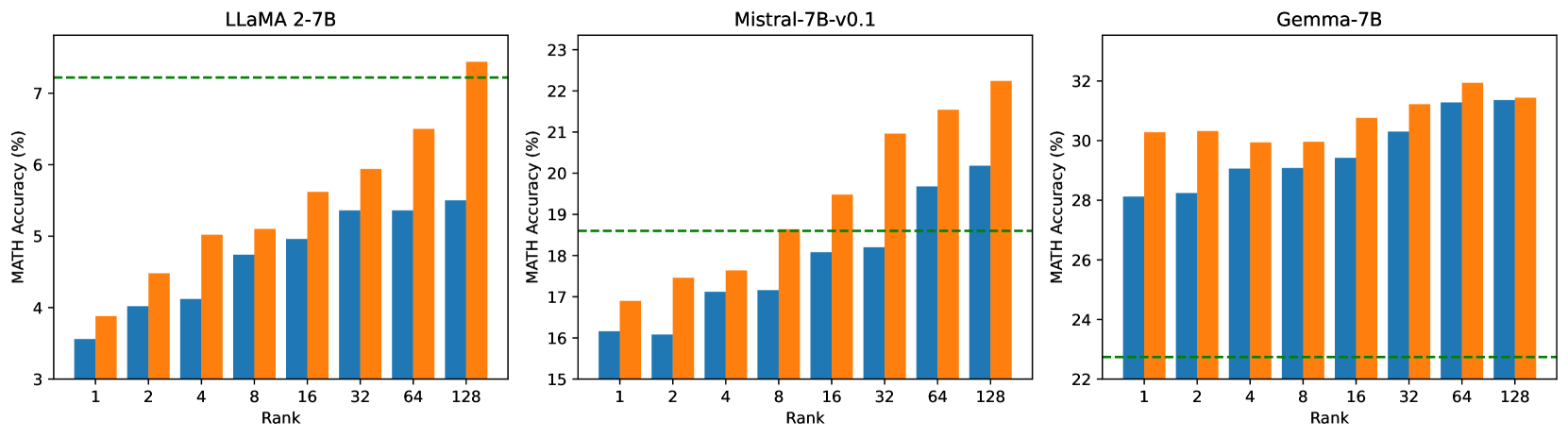
This section explores the impact of incrementally increasing the rank of PiSSA/QPiSSA and LoRA/QLoRA from 1 to 128, aiming to determine whether PiSSA/QPiSSA consistently outperforms LoRA/QLoRA under different ranks. The training is conducted using the MetaMathQA-100K dataset for 1 epoch, while the validation is performed on the GSM8K and MATH datasets. The outcomes of these experiments are depicted in Figure 7, with additional results presented in Appendix H.
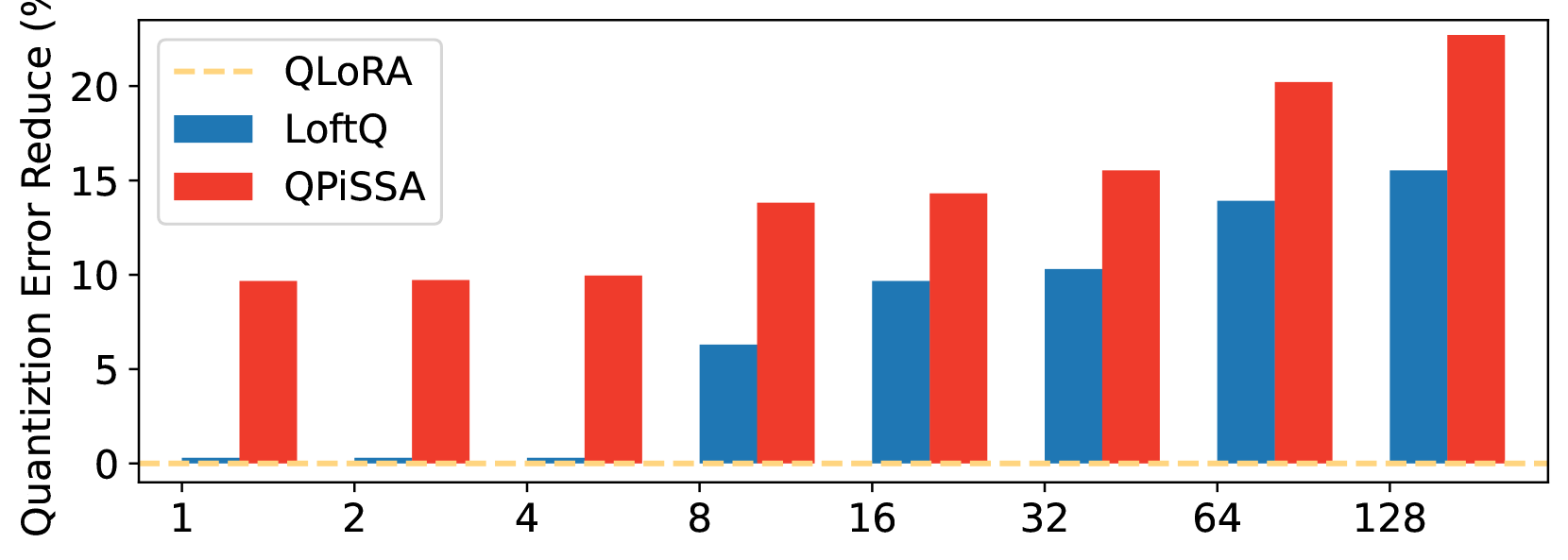
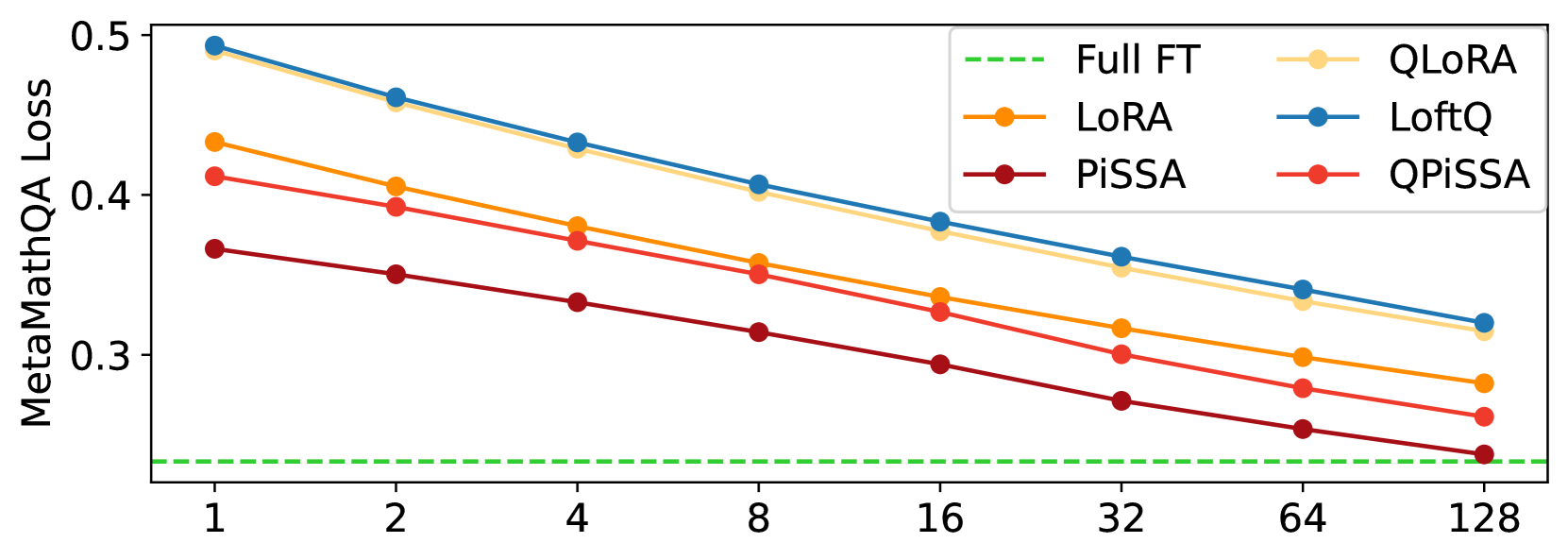
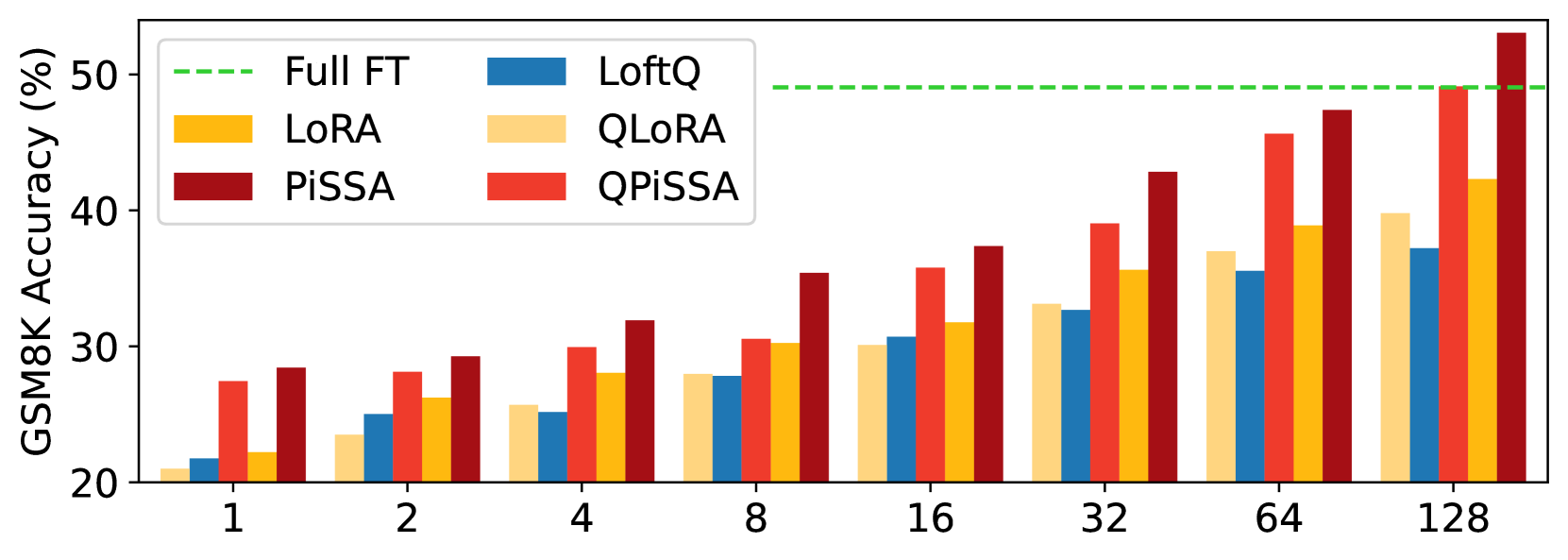
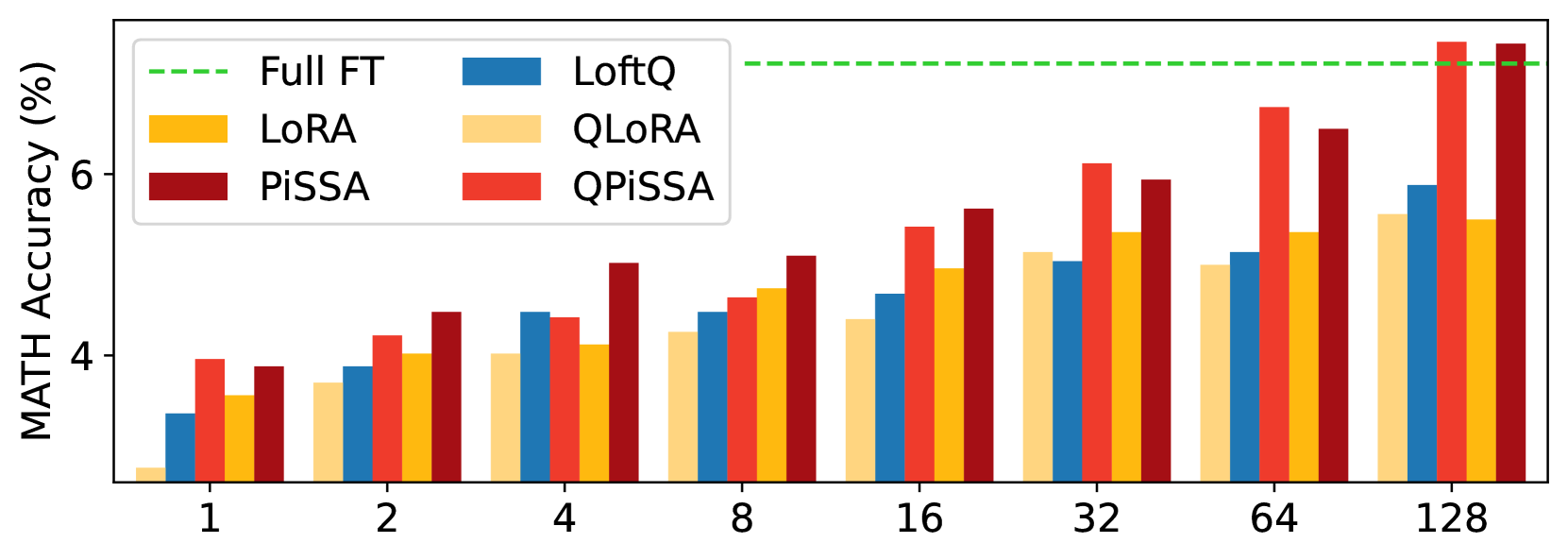
Figure 7(a) illustrates the quantization error reduction ratio across various ranks. In this figure, QLoRA shows no reduction in quantization error, while QPiSSA consistently outperforms LoftQ in reducing quantization error across all ranks, with a particularly notable advantage at lower ranks. In Figure 7(b), the final loss on the training set is shown for models trained with ranks ranging from 1 to 128. The results indicate that PiSSA and QPiSSA achieve a better fit to the training data compared to LoRA, QLoRA, and LoftQ. In Figures 7(c) and Figures 7(d), we compare the accuracy of the fine-tuned models on the GSM8K and MATH validation sets under various ranks, finding that PiSSA consistently outperforms LoRA with the same amount of trainable parameters. Furthermore, as the rank increases, PiSSA will reach and surpass the performance of full-parameter fine-tuning.
6 Conclusion
This paper presents a PEFT technique that applies singular value decomposition (SVD) to the weight matrix of pre-trained models. The principal components obtained from the SVD are used to initialize a low-rank adapter named PiSSA, while the residual components are kept frozen, in order to achieve effective fine-tuning and parameter efficiency at the same time. Through extensive experiments, we found that PiSSA and its 4-bit quantization version QPiSSA significantly outperform LoRA and QLoRA in both NLG and NLU tasks, across different training steps, various model sizes and types, and under various amount of trainable parameters. PiSSA provides a novel direction for research in PEFT by identifying and fine-tuning the principal components within the model, analogous to slicing and re-baking the richest slice of a pizza. As PiSSA shares the same architecture as LoRA, it can be seamlessly used in existing LoRA pipelines as an efficient alternative initialization method.
7 Limitation
There are still some questions with PiSSA not addressed in this paper: 1) Besides language models, can PiSSA also be adapted to convolutional layers and enhance the performance of vision tasks? 2) Can PiSSA also benefit from some improvements to LoRA, such as AdaLoRA [69] and DyLoRA [42] which adaptively adjust the rank? 3) Can we provide more theoretical explanations for the advantages of PiSSA over LoRA? We are actively exploring these questions. Nevertheless, we are excited to see the huge potential of PiSSA already demonstrated in existing experiments and look forward to more tests and suggestions from the community.
References
- [1] Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583, 2023.
- [2] Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023.
- [3] Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568, 2023.
- [4] Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161, 2023.
- [5] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- [6] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36, 2024.
- [7] Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qingwei Lin, and Daxin Jiang. Wizardlm: Empowering large pre-trained language models to follow complex instructions. In The Twelfth International Conference on Learning Representations, 2023.
- [8] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- [9] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36, 2024.
- [10] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36, 2024.
- [11] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- [12] Lingling Xu, Haoran Xie, Si-Zhao Joe Qin, Xiaohui Tao, and Fu Lee Wang. Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment. arXiv preprint arXiv:2312.12148, 2023.
- [13] Zeyu Han, Chao Gao, Jinyang Liu, Sai Qian Zhang, et al. Parameter-efficient fine-tuning for large models: A comprehensive survey. arXiv preprint arXiv:2403.14608, 2024.
- [14] Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv preprint arXiv:2106.10199, 2021.
- [15] Neal Lawton, Anoop Kumar, Govind Thattai, Aram Galstyan, and Greg Ver Steeg. Neural architecture search for parameter-efficient fine-tuning of large pre-trained language models. arXiv preprint arXiv:2305.16597, 2023.
- [16] Mengjie Zhao, Tao Lin, Fei Mi, Martin Jaggi, and Hinrich Schütze. Masking as an efficient alternative to finetuning for pretrained language models. arXiv preprint arXiv:2004.12406, 2020.
- [17] Yi-Lin Sung, Varun Nair, and Colin A Raffel. Training neural networks with fixed sparse masks. Advances in Neural Information Processing Systems, 34:24193–24205, 2021.
- [18] Alan Ansell, Edoardo Maria Ponti, Anna Korhonen, and Ivan Vulić. Composable sparse fine-tuning for cross-lingual transfer. arXiv preprint arXiv:2110.07560, 2021.
- [19] Runxin Xu, Fuli Luo, Zhiyuan Zhang, Chuanqi Tan, Baobao Chang, Songfang Huang, and Fei Huang. Raise a child in large language model: Towards effective and generalizable fine-tuning. arXiv preprint arXiv:2109.05687, 2021.
- [20] Demi Guo, Alexander M Rush, and Yoon Kim. Parameter-efficient transfer learning with diff pruning. arXiv preprint arXiv:2012.07463, 2020.
- [21] Zihao Fu, Haoran Yang, Anthony Man-Cho So, Wai Lam, Lidong Bing, and Nigel Collier. On the effectiveness of parameter-efficient fine-tuning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 12799–12807, 2023.
- [22] Karen Hambardzumyan, Hrant Khachatrian, and Jonathan May. Warp: Word-level adversarial reprogramming. arXiv preprint arXiv:2101.00121, 2021.
- [23] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021.
- [24] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190, 2021.
- [25] Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. Gpt understands, too. AI Open, 2023.
- [26] Tu Vu, Brian Lester, Noah Constant, Rami Al-Rfou, and Daniel Cer. Spot: Better frozen model adaptation through soft prompt transfer. arXiv preprint arXiv:2110.07904, 2021.
- [27] Akari Asai, Mohammadreza Salehi, Matthew E Peters, and Hannaneh Hajishirzi. Attempt: Parameter-efficient multi-task tuning via attentional mixtures of soft prompts. arXiv preprint arXiv:2205.11961, 2022.
- [28] Zhen Wang, Rameswar Panda, Leonid Karlinsky, Rogerio Feris, Huan Sun, and Yoon Kim. Multitask prompt tuning enables parameter-efficient transfer learning. arXiv preprint arXiv:2303.02861, 2023.
- [29] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In International conference on machine learning, pages 2790–2799. PMLR, 2019.
- [30] Zhaojiang Lin, Andrea Madotto, and Pascale Fung. Exploring versatile generative language model via parameter-efficient transfer learning. arXiv preprint arXiv:2004.03829, 2020.
- [31] Tao Lei, Junwen Bai, Siddhartha Brahma, Joshua Ainslie, Kenton Lee, Yanqi Zhou, Nan Du, Vincent Zhao, Yuexin Wu, Bo Li, et al. Conditional adapters: Parameter-efficient transfer learning with fast inference. Advances in Neural Information Processing Systems, 36, 2024.
- [32] Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. Towards a unified view of parameter-efficient transfer learning. arXiv preprint arXiv:2110.04366, 2021.
- [33] Andreas Rücklé, Gregor Geigle, Max Glockner, Tilman Beck, Jonas Pfeiffer, Nils Reimers, and Iryna Gurevych. Adapterdrop: On the efficiency of adapters in transformers. arXiv preprint arXiv:2010.11918, 2020.
- [34] Hongyu Zhao, Hao Tan, and Hongyuan Mei. Tiny-attention adapter: Contexts are more important than the number of parameters. arXiv preprint arXiv:2211.01979, 2022.
- [35] Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. Adapterfusion: Non-destructive task composition for transfer learning. arXiv preprint arXiv:2005.00247, 2020.
- [36] Shwai He, Run-Ze Fan, Liang Ding, Li Shen, Tianyi Zhou, and Dacheng Tao. Mera: Merging pretrained adapters for few-shot learning. arXiv preprint arXiv:2308.15982, 2023.
- [37] Rabeeh Karimi Mahabadi, Sebastian Ruder, Mostafa Dehghani, and James Henderson. Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks. arXiv preprint arXiv:2106.04489, 2021.
- [38] Alexandra Chronopoulou, Matthew E Peters, Alexander Fraser, and Jesse Dodge. Adaptersoup: Weight averaging to improve generalization of pretrained language models. arXiv preprint arXiv:2302.07027, 2023.
- [39] Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objective landscapes. arXiv preprint arXiv:1804.08838, 2018.
- [40] Armen Aghajanyan, Luke Zettlemoyer, and Sonal Gupta. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. arXiv preprint arXiv:2012.13255, 2020.
- [41] Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adaptive budget allocation for parameter-efficient fine-tuning. In The Eleventh International Conference on Learning Representations, 2022.
- [42] Mojtaba Valipour, Mehdi Rezagholizadeh, Ivan Kobyzev, and Ali Ghodsi. Dylora: Parameter efficient tuning of pre-trained models using dynamic search-free low-rank adaptation. arXiv preprint arXiv:2210.07558, 2022.
- [43] Feiyu Zhang, Liangzhi Li, Junhao Chen, Zhouqiang Jiang, Bowen Wang, and Yiming Qian. Increlora: Incremental parameter allocation method for parameter-efficient fine-tuning. arXiv preprint arXiv:2308.12043, 2023.
- [44] Bojia Zi, Xianbiao Qi, Lingzhi Wang, Jianan Wang, Kam-Fai Wong, and Lei Zhang. Delta-lora: Fine-tuning high-rank parameters with the delta of low-rank matrices. arXiv preprint arXiv:2309.02411, 2023.
- [45] Mingyang Zhang, Chunhua Shen, Zhen Yang, Linlin Ou, Xinyi Yu, Bohan Zhuang, et al. Pruning meets low-rank parameter-efficient fine-tuning. arXiv preprint arXiv:2305.18403, 2023.
- [46] Yixiao Li, Yifan Yu, Qingru Zhang, Chen Liang, Pengcheng He, Weizhu Chen, and Tuo Zhao. Losparse: Structured compression of large language models based on low-rank and sparse approximation. In International Conference on Machine Learning, pages 20336–20350. PMLR, 2023.
- [47] Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. arXiv preprint arXiv:2402.09353, 2024.
- [48] Yuhui Xu, Lingxi Xie, Xiaotao Gu, Xin Chen, Heng Chang, Hengheng Zhang, Zhensu Chen, Xiaopeng Zhang, and Qi Tian. Qa-lora: Quantization-aware low-rank adaptation of large language models. arXiv preprint arXiv:2309.14717, 2023.
- [49] Yixiao Li, Yifan Yu, Chen Liang, Pengcheng He, Nikos Karampatziakis, Weizhu Chen, and Tuo Zhao. Loftq: Lora-fine-tuning-aware quantization for large language models. arXiv preprint arXiv:2310.08659, 2023.
- [50] Nathan Halko, Per-Gunnar Martinsson, and Joel A Tropp. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. SIAM review, 53(2):217–288, 2011.
- [51] Ky Fan. Maximum properties and inequalities for the eigenvalues of completely continuous operators. Proceedings of the National Academy of Sciences, 37(11):760–766, 1951.
- [52] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- [53] Shibo Wang and Pankaj Kanwar. Bfloat16: The secret to high performance on cloud tpus. Google Cloud Blog, 4, 2019.
- [54] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [55] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- [56] Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- [57] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [58] Tianyu Zheng, Ge Zhang, Tianhao Shen, Xueling Liu, Bill Yuchen Lin, Jie Fu, Wenhu Chen, and Xiang Yue. Opencodeinterpreter: Integrating code generation with execution and refinement. arXiv preprint arXiv:2402.14658, 2024.
- [59] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code, 2021.
- [60] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- [61] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. In International Conference on Learning Representations, 2018.
- [62] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- [63] Pengcheng He, Jianfeng Gao, and Weizhu Chen. Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing, 2021.
- [64] AI@Meta. Llama 3 model card. 2024.
- [65] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- [66] Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Heng Li, Jiangcheng Zhu, Jianqun Chen, Jing Chang, et al. Yi: Open foundation models by 01. ai. arXiv preprint arXiv:2403.04652, 2024.
- [67] Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y Wu, et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. arXiv preprint arXiv:2401.06066, 2024.
- [68] Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088, 2024.
- [69] Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adaptive budget allocation for parameter-efficient fine-tuning. arXiv preprint arXiv:2303.10512, 2023.
- [70] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
The Supplementary Material for The Paper
“PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models.”
-
•
In Section A, we compare the use of high, medium, and low singular values and vectors to initialize adapters. The experimental results show that initializing adapters with principal singular values and vectors yields the best fine-tuning performance.
-
•
In Section B, we use fast singular value decomposition to initialize PiSSA. The results indicate that the performance of fast singular value decomposition approaches that of SVD decomposition in just several seconds. This ensures that the cost of converting from LoRA/QLoRA to PiSSA/QPiSSA is negligible.
-
•
In Section C, we demonstrate that the trained PiSSA adapter can be losslessly converted to LoRA, allowing for integration with the original model, facilitating sharing, and enabling the use of multiple PiSSA adapters.
-
•
In Section D, we explore the experimental effects of using different precisions.
-
•
In Section E, we discuss the effects of QPiSSA during multiple rounds of SVD decomposition, which can significantly reduce quantization errors without increasing training or inference costs.
-
•
In Section F, we provide a comprehensive comparison of quantization errors among QLoRA, LoftQ, and QPiSSA, theoretically explaining why QPiSSA reduce quantization errors.
-
•
In Section G, we trained Mistral-7B and Gemma-7B for a sufficient number of steps. The results indicate that PiSSA and LoRA are less prone to overfitting compared to full parameter fine-tuning.
-
•
In Section H, we offer a more detailed comparison of PiSSA and LoRA at different ranks. It is evident that PiSSA consistently outperforms LoRA in terms of loss convergence, quantization error reduction, and final performance across different ranks.
-
•
In Section I, we describe the detail setting for NLU task.
Appendix A Conductive Experiments on Various SVD Components
To investigate the influence of singular values and vectors of varying magnitudes on the fine-tuning performance, we initialize the adapters injected into LLaMA 2-7B, Mistral-7B-v0.1, and Gemma-7B with principal, medium, and minor singular values and vectors. These models are then fine-tuned on the MetaMathQA dataset [2] and evaluated against the GSM8K [57] and MATH datasets [70], with the outcomes depicted in Figures 8.
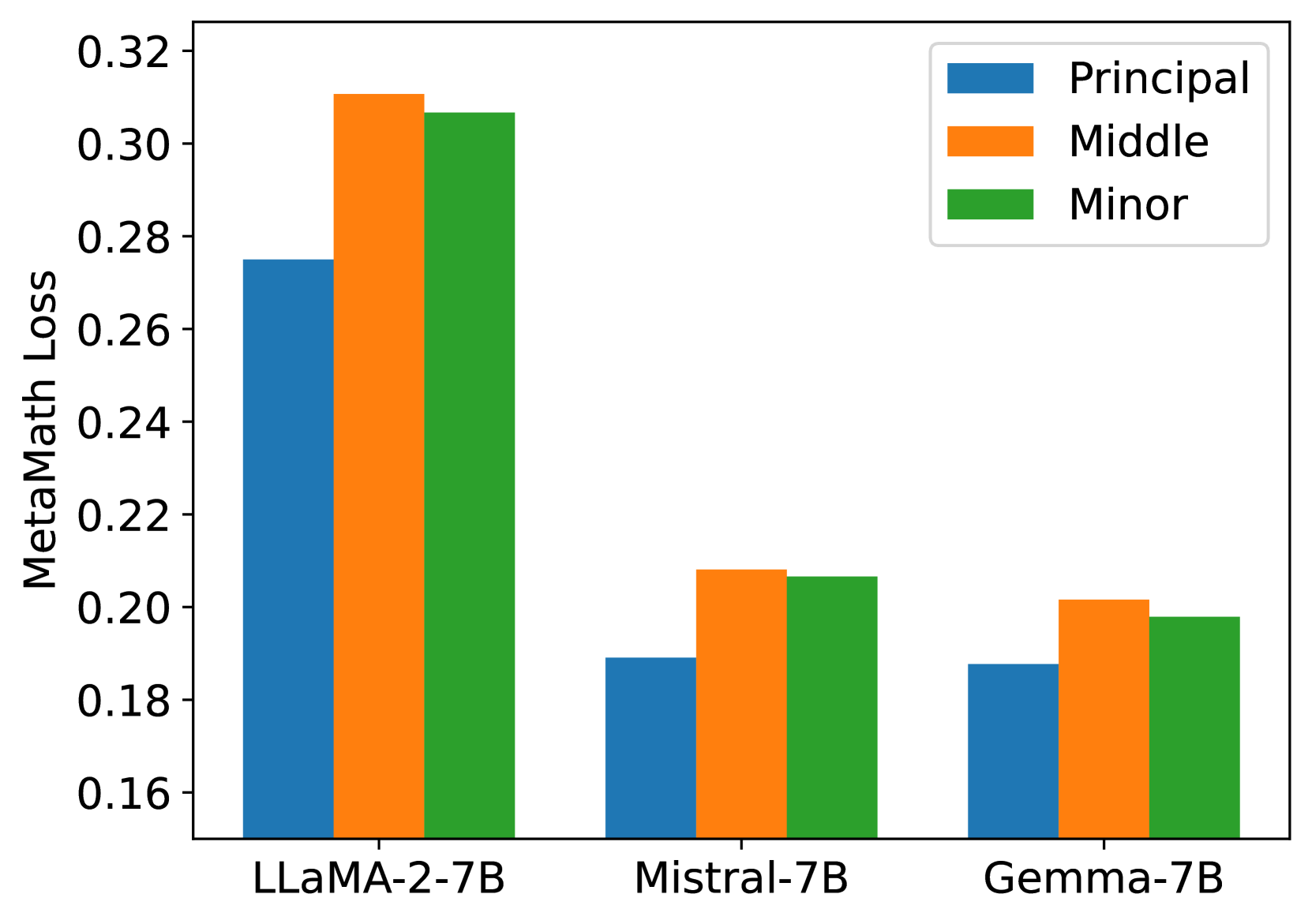
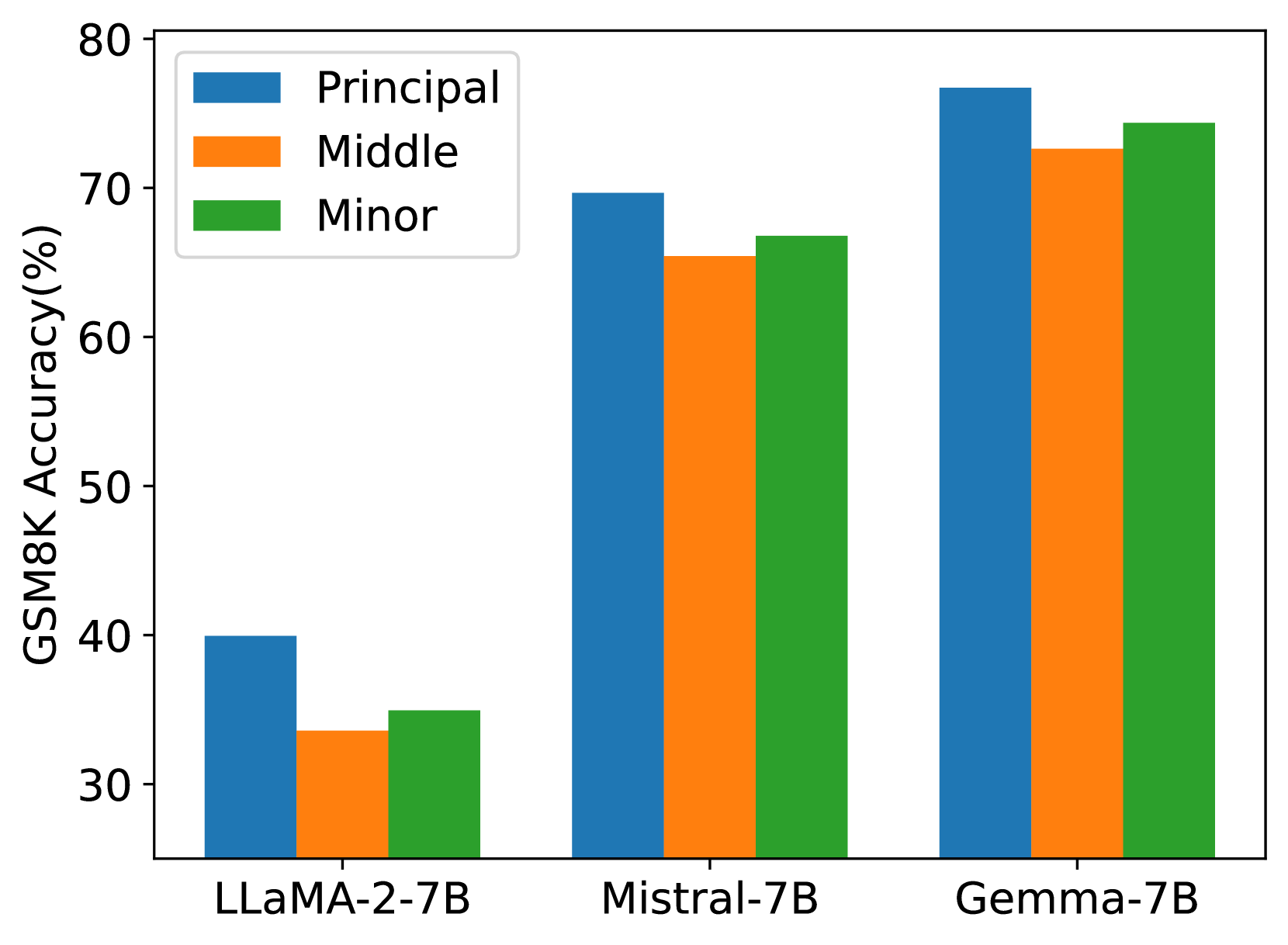
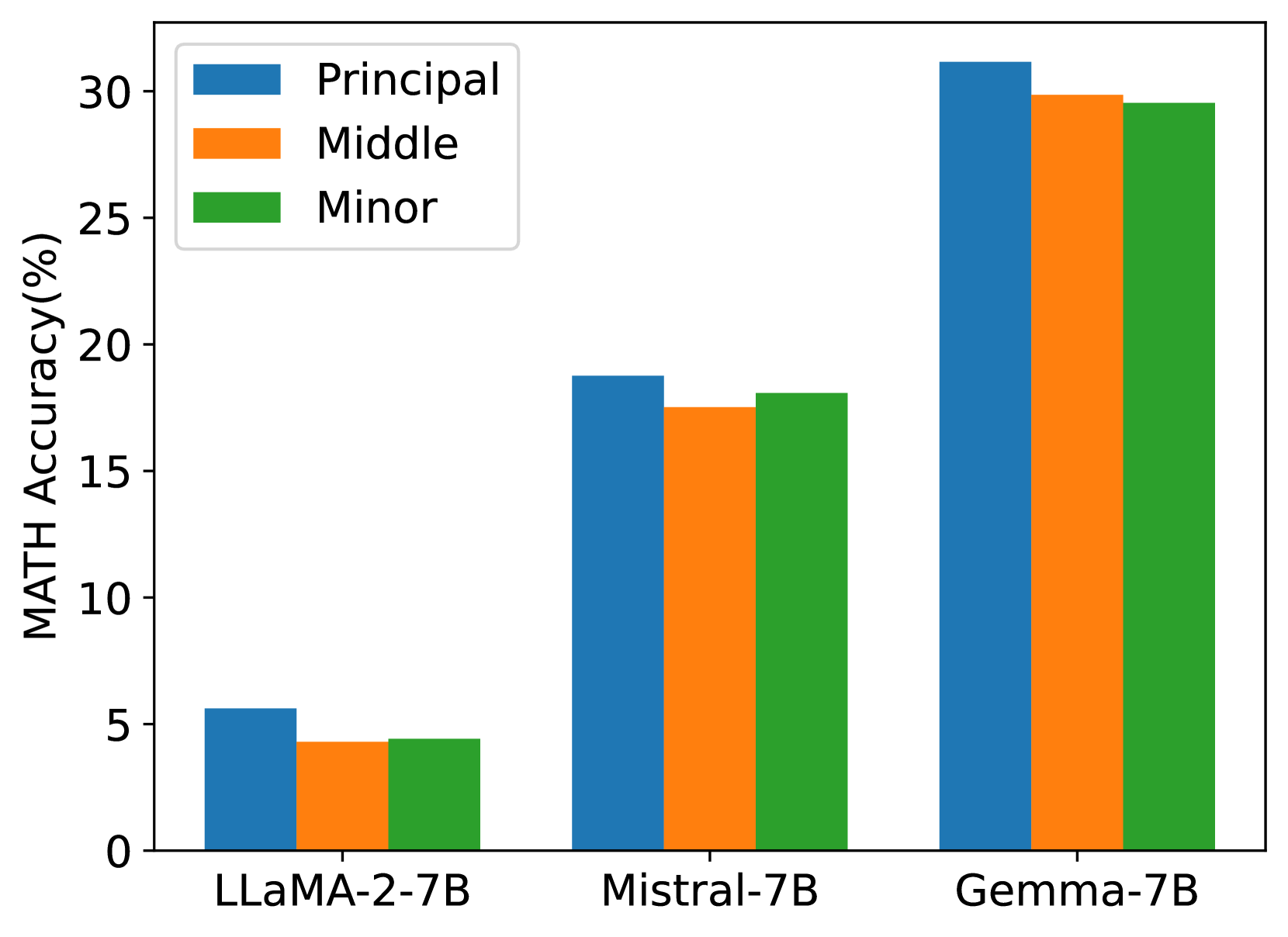
The results highlight that initializing adapters with principal singular values and vectors consistently leads to reduced training loss and enhanced accuracy on both the GSM8K and MATH validation datasets across all three models. This underscores the efficacy of our strategy in fine-tuning the model parameters based on the principal singular values.
Appendix B Fast Singular Value Decomposition
In order to speed up the decomposition of the pre-trained matrix , we adopted the algorithm proposed by Halko et.al [50] (denoted as Fast SVD), which introduces randomness to achieve an approximate matrix decomposition. We compare the initialization time, error, and training loss between SVD and Fast SVD, with the results shown in Table B. Initialization time refers to the computation time taken to decompose the pre-trained parameter matrix , measured in seconds. Initialization error indicates the magnitude of the discrepancy introduced by Fast SVD compared to SVD after decomposing the matrix. Specifically, the error is the sum of the absolute differences between the matrices decomposed by original SVD and Fast SVD. For the error, we report the results of the self-attention module in the table. Loss refers to the loss value at the end of training. In Fast SVD, the parameter niter refers to the number of subspace iterations to conduct. A larger niter leads to increased decomposition time but results in smaller decomposition error. The symbol represents the experimental results with the SVD method.
| Metric | Niter | Rank | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | ||
| Initialize Time | 1 | 5.05 | 8.75 | 5.07 | 8.42 | 5.55 | 8.47 | 6.80 | 11.89 |
| 2 | 4.38 | 4.71 | 4.79 | 4.84 | 5.06 | 5.79 | 7.70 | 16.75 | |
| 4 | 5.16 | 4.73 | 5.09 | 5.16 | 5.60 | 7.01 | 7.90 | 11.41 | |
| 8 | 4.72 | 5.11 | 5.14 | 5.40 | 5.94 | 7.80 | 10.09 | 14.81 | |
| 16 | 6.24 | 6.57 | 6.80 | 7.04 | 7.66 | 9.99 | 14.59 | 22.67 | |
| 434.92 | 434.15 | 434.30 | 435.42 | 435.25 | 437.22 | 434.48 | 435.84 | ||
| Initialize Error | 1 | 1.30E-3 | 1.33E-3 | 1.55E-3 | 1.9E-3 | 1.98E-3 | 1.97E-3 | 2.00E-3 | 1.93E-3 |
| 2 | 5.84E-4 | 1.25E-3 | 1.45E-3 | 1.43E-3 | 1.48E-3 | 1.55E-3 | 1.48E-3 | 1.33E-3 | |
| 4 | 6.01E-4 | 8.75E-4 | 6.75E-4 | 1.10E-3 | 1.05E-3 | 1.03E-3 | 1.08E-3 | 9.75E-4 | |
| 8 | 1.26E-4 | 2.34E-4 | 5.25E-4 | 7.25E-4 | 5.75E-4 | 8.25E-4 | 8.25E-4 | 7.75E-4 | |
| 16 | 7.93E-5 | 2.25E-4 | 1.28E-4 | 6.50E-4 | 4.25E-4 | 6.50E-4 | 6.00E-4 | 4.75E-4 | |
| – | – | – | – | – | – | – | – | ||
| Training Loss | 1 | 0.3629 | 0.3420 | 0.3237 | 0.3044 | 0.2855 | 0.2657 | 0.2468 | 0.2301 |
| 2 | 0.3467 | 0.3337 | 0.3172 | 0.2984 | 0.2795 | 0.2610 | 0.2435 | 0.2282 | |
| 4 | 0.3445 | 0.3294 | 0.3134 | 0.2958 | 0.2761 | 0.2581 | 0.2414 | 0.2271 | |
| 8 | 0.3425 | 0.3279 | 0.3122 | 0.2950 | 0.2753 | 0.2571 | 0.2406 | 0.2267 | |
| 16 | 0.3413 | 0.3275 | 0.3116 | 0.2946 | 0.2762 | 0.2565 | 0.2405 | 0.2266 | |
| 0.3412 | 0.3269 | 0.3116 | 0.2945 | 0.2762 | 0.2564 | 0.2403 | 0.2264 | ||
It can be observed that the computation time of the SVD is tens of times that of Fast SVD. In addition, SVD exhibits consistently high time consumption with minimal variation as the rank increases, while Fast SVD, although experiencing a slight increase in computation time with higher ranks, remains significantly lower compared to SVD throughout. As the rank increases, the initialization error initially rises gradually, with a slight decrease observed when the rank reaches 128. And at the same rank, increasing the niter in Fast SVD leads to a gradual reduction in error. For training loss, we observed that as the rank increases, the training loss decreases gradually. At the same rank, with the increase of niter, the training loss of models initialized based on Fast SVD approaches that of models initialized based on SVD.
Appendix C Equivalently Converting PiSSA into LoRA
The advantage of PiSSA lies in its ability to significantly enhance training outcomes during the fine-tuning phase. After training, it allows for the direct sharing of the trained matrices and . However, if we directly save , users need to perform singular value decomposition on the original model to get , which requires additional time. When employing fast singular value decomposition, there can be slight inaccuracies too. More importantly, such a way necessitates altering the parameters of the original model, which can be inconvenient when using multiple adapters, especially when some adapters might be disabled or activated. Therefore, we recommend converting the trained PiSSA module equivalently into a LoRA module, thereby eliminating the need to modify the original model’s parameters during sharing and usage. In the initialization phase, PiSSA decomposes the original matrix into principal components and a residual matrix: . Upon completion of training, the model adjusts the weights as follows: . Thus, the modification of the model weights by PiSSA is given by:
| (9) | ||||
| (10) |
where and . Therefore, we can store and share the new adaptor and instead of , which allows directly inserting the adaptor to the original matrix and avoids breaking . Since is typically small, the twice storage overhead is still acceptable. This modification allows for plug-and-play usage without the need for singular value decomposition, saving time and avoiding computational errors associated with the SVD, without necessitating changes to the original model parameters.
Appendix D Comparison of Fine-Tuning in BF16 and FP32 Precision
In this section, we compare the effects of training with BFloat16 and Float32 precision. The comparing include four models: LLaMA-2-7B, Mistral-7B, Gemma-7B, and LLaMA-3-8B, each fine-tuned with all parameters in both BFloat16 and Float32 precision on the MetaMathQA-395K dataset. The validation results conducted on the GSM8K dataset are shown in Figure 5.
| Model | Training Loss | GSM8K ACC (%) | MATH ACC (%) | |||
|---|---|---|---|---|---|---|
| BF16 | FP32 | BF16 | FP32 | BF16 | FP32 | |
| LLaMA-2-7B | 0.1532 | 0.1316 | 63.15 | 68.31 | 13.14 | 20.38 |
| Mistral-7B | 0.1145 | 0.1306 | 73.09 | 65.88 | 26.44 | 23.66 |
| Gemma-7B | 0.1331 | 0.1382 | 75.21 | 75.97 | 29.18 | 28.64 |
| LLaMA-3-8B | 0.1271 | 0.1317 | 81.96 | 75.44 | 33.16 | 28.72 |
From Table 5, it is evident that the choice of precision greatly affects the experimental results. For example, the LLaMA-2-7B model shows a 5.16% higher performance on the GSM8K dataset when using FP32 compared to BF16. Conversely, the Mistral-7B and LLaMA-3-8B on GSM8K are 7.21% and 6.52% lower with FP32 than with BF16 separately. The Gemma-7B model shows similar performance with both precisions. Unfortunately, the experiments did not prove which precision is better. To reduce training costs, we use BF16 precision when fine-tuning all parameters. For methods with lower training costs, such as LoRA, PiSSA, we use FP32 precision. For QLoRA, QPiSSA and LoftQ, the base model was used NF4 precision, while the adapter layers used FP32 precision.
Appendix E Reducing Quantization Error through QPiSSA with Multiple Iteration of SVD
Table 6 provides a supplementary explanation of the results in Table 3. When number of iterations , LoftQ uses an -bit quantized weight and low-rank approximations and to minimize the following objective by alternating between quantization and singular value decomposition:
| (11) |
where denotes the Frobenius norm, and are set to zero. Inspired by LoftQ, our QPiSSA -iter alternately minimize the following objective:
| (12) |
where and are initialized by the principal singular values and singular vectors. The process is summarized in Algorithm 1:
| Method | Rank | niter | Q | K | V | O | Gate | Up | Down | AVG | |
| LLaMA -2-7B | QLoRA | – | – | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| loftQ | 128 | 1 | 8.1 | 8.1 | 7.2 | 7.3 | 5.3 | 5.1 | 5.1 | 6.6 | |
| PiSSA | 128 | 1 | 19.0 | 18.1 | 8.9 | 8.9 | 8.2 | 5.9 | 6.0 | 10.7 | |
| loftQ | 128 | 5 | 16.5 | 16.5 | 15.9 | 16.0 | 12.4 | 12.4 | 12.3 | 14.6 | |
| PiSSA | 128 | 5 | 27.9 | 27.2 | 18.7 | 18.6 | 15.8 | 13.6 | 13.6 | 19.4 | |
| LLaMA -3-8B | QLoRA | – | – | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LoftQ | 64 | 1 | 4.3 | 11.0 | 9.9 | 3.9 | 2.7 | 2.5 | 2.6 | 5.3 | |
| PiSSA | 64 | 1 | 11.3 | 16.4 | 8.8 | 6.3 | 4.5 | 2.9 | 3.3 | 7.7 | |
| loftQ | 64 | 5 | 10.1 | 18.8 | 18.2 | 9.9 | 7.1 | 7.1 | 7.1 | 11.2 | |
| PiSSA | 64 | 5 | 17.1 | 27.3 | 19.5 | 12.1 | 8.9 | 7.2 | 7.6 | 14.3 | |
| loftQ | 128 | 1 | 8.2 | 20.7 | 18.8 | 7.5 | 5.2 | 4.8 | 4.9 | 10.0 | |
| PiSSA | 128 | 1 | 17.1 | 26.5 | 10.7 | 10.7 | 7.0 | 5.0 | 5.6 | 11.8 | |
| loftQ | 128 | 5 | 16.4 | 29.8 | 28.8 | 16.1 | 11.9 | 11.7 | 11.7 | 18.1 | |
| PiSSA | 128 | 5 | 26.3 | 41.7 | 32.3 | 20.1 | 14.4 | 12.5 | 12.9 | 22.9 | |
| LLaMA -3-70B | QLoRA | – | – | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LoftQ | 64 | 1 | 2.4 | 11.6 | 9.2 | 1.9 | 1.8 | 1.7 | 1.3 | 4.3 | |
| PiSSA | 64 | 1 | 12.3 | 25.0 | 9.0 | 4.1 | 4.2 | 3.2 | 2.2 | 8.6 | |
| LoftQ | 64 | 5 | 6.1 | 17.8 | 17.0 | 6.0 | 4.3 | 4.4 | 4.2 | 8.5 | |
| PiSSA | 64 | 5 | 15.7 | 34.2 | 18.9 | 7.5 | 6.7 | 5.7 | 4.7 | 13.4 | |
| PiSSA | 128 | 1 | 17.7 | 36.6 | 15.7 | 6.7 | 5.8 | 4.5 | 3.8 | 13.0 | |
| PiSSA | 128 | 5 | 23.2 | 49.0 | 30.5 | 12.5 | 10.1 | 8.8 | 8.2 | 20.3 |
According to Table 6, multiple iterations can significantly reduce quantization error. For instance, using QPiSSA-r64 with 5-iter on LLaMA-3-8B reduces the quantization error nearly twice as much as with 1-iter. In the main paper, we used 5 iterations in Section 5.3 and Section 5.4, while 1 iteration was used in Section 5.5.
Appendix F Comparing the Quantization Error of QLoRA, LoftQ and QPiSSA
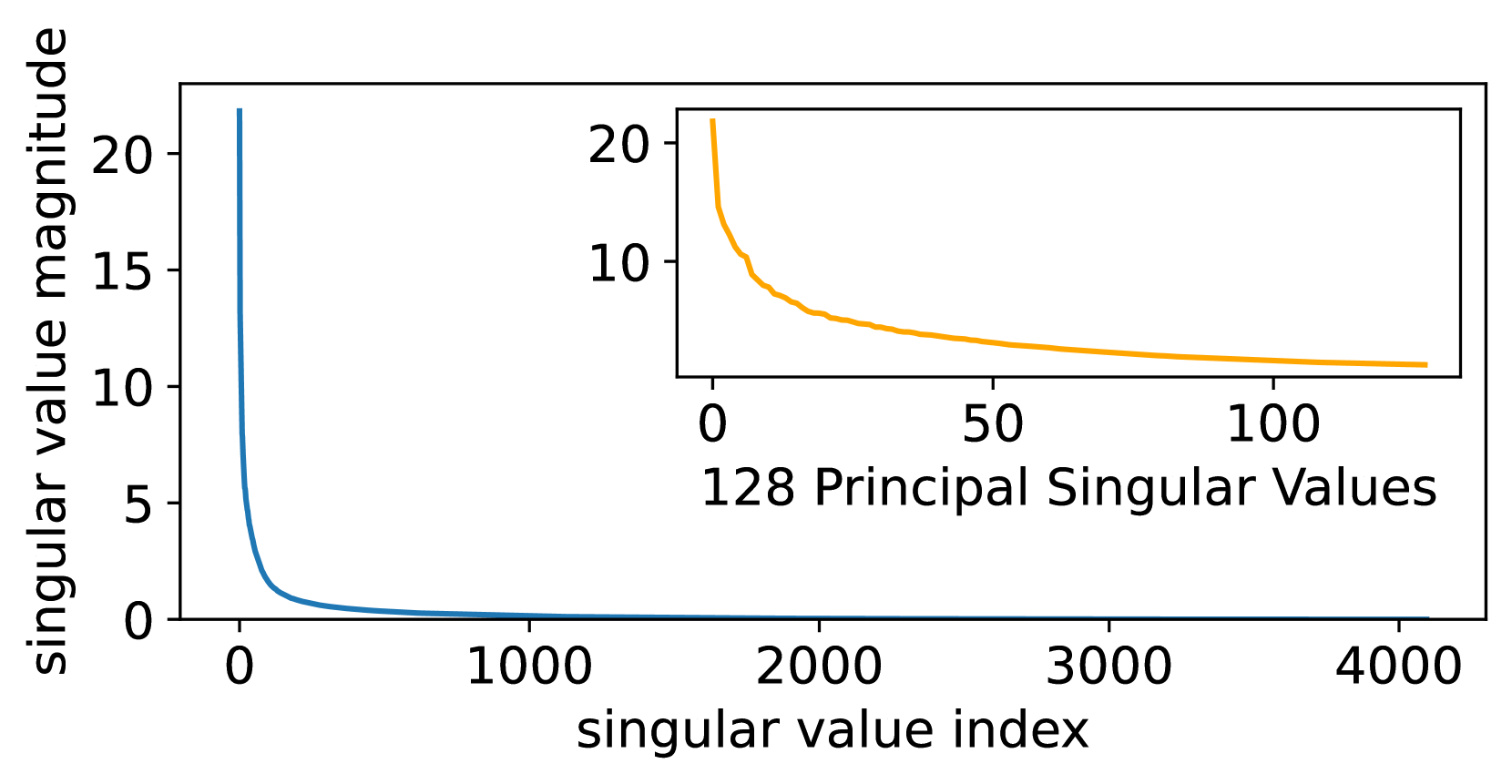
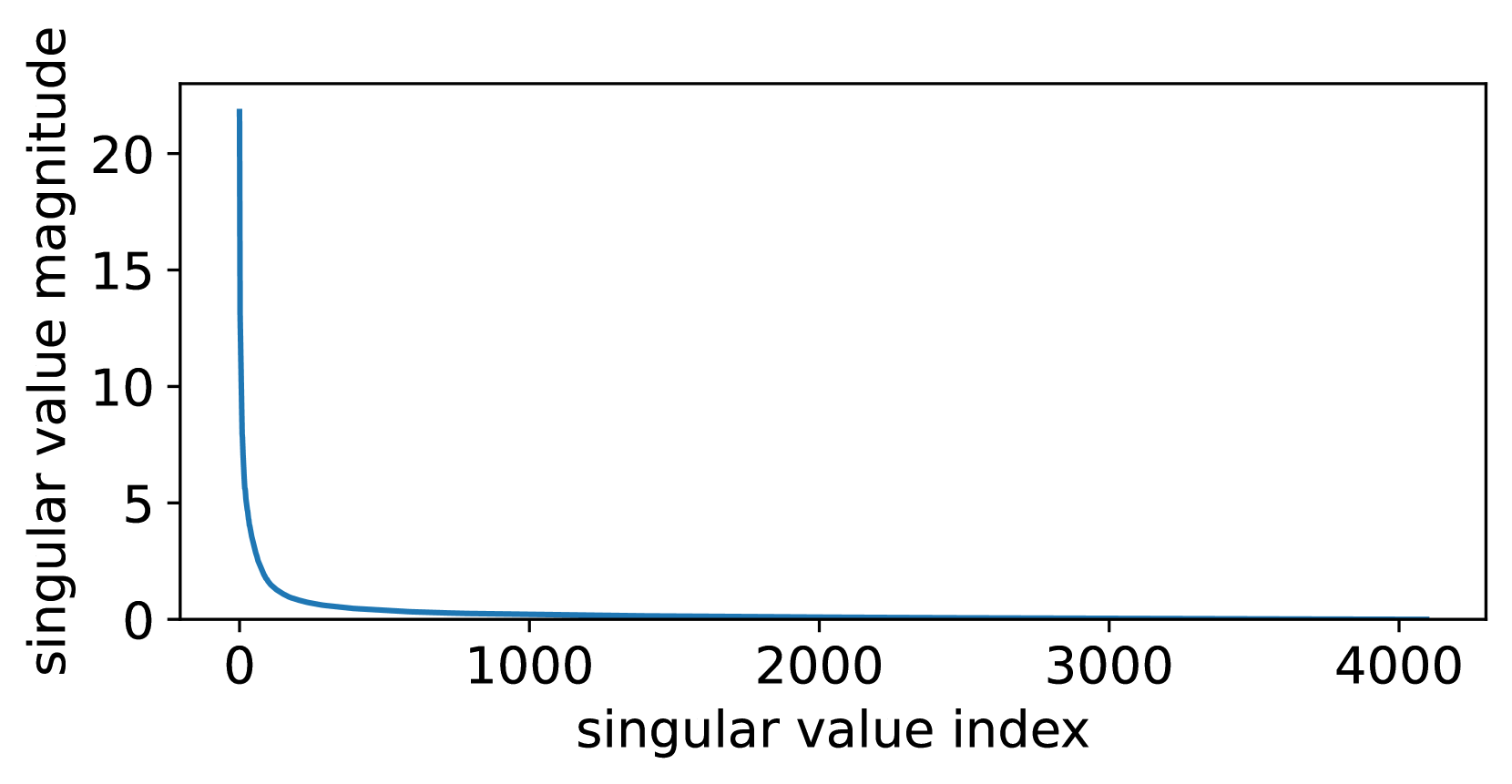
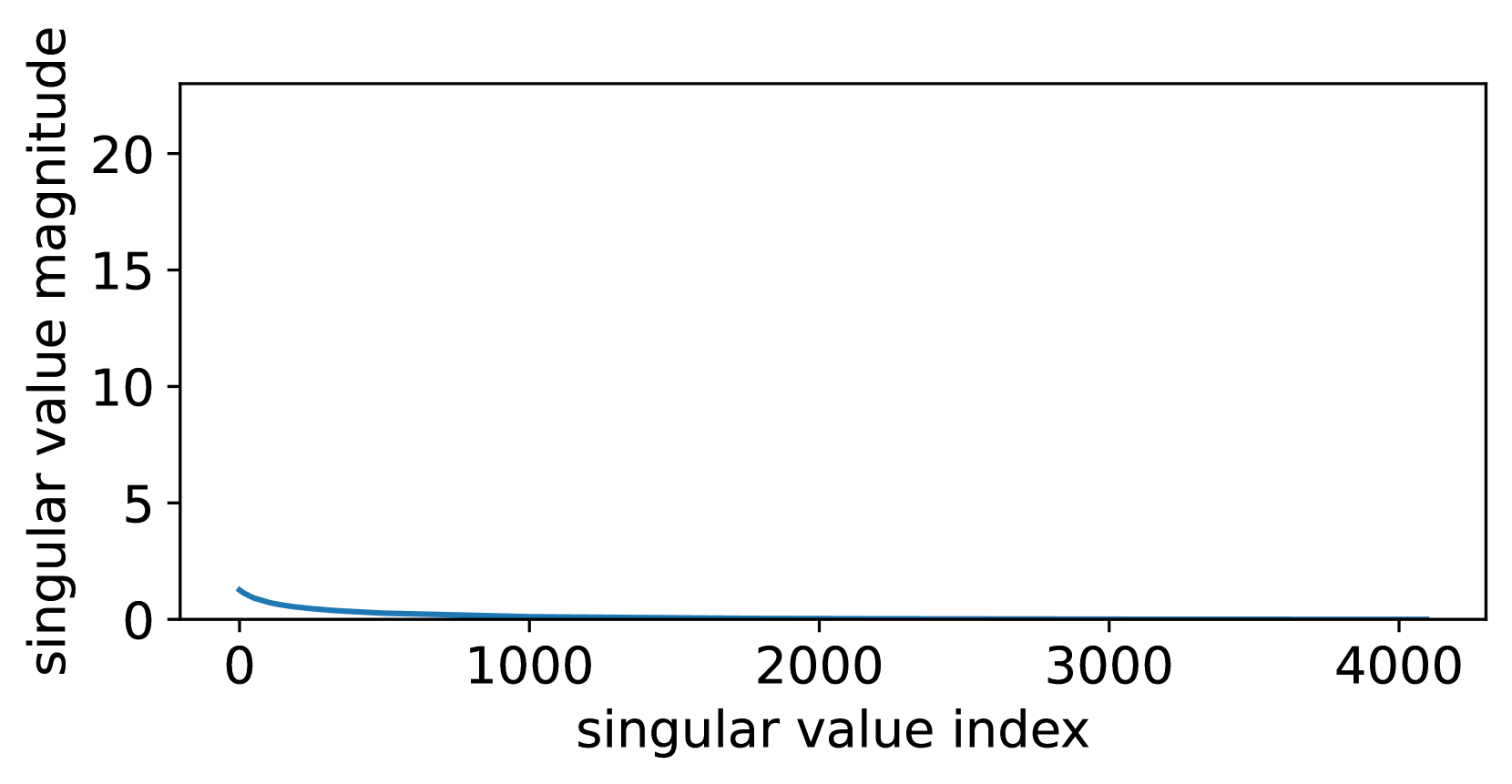
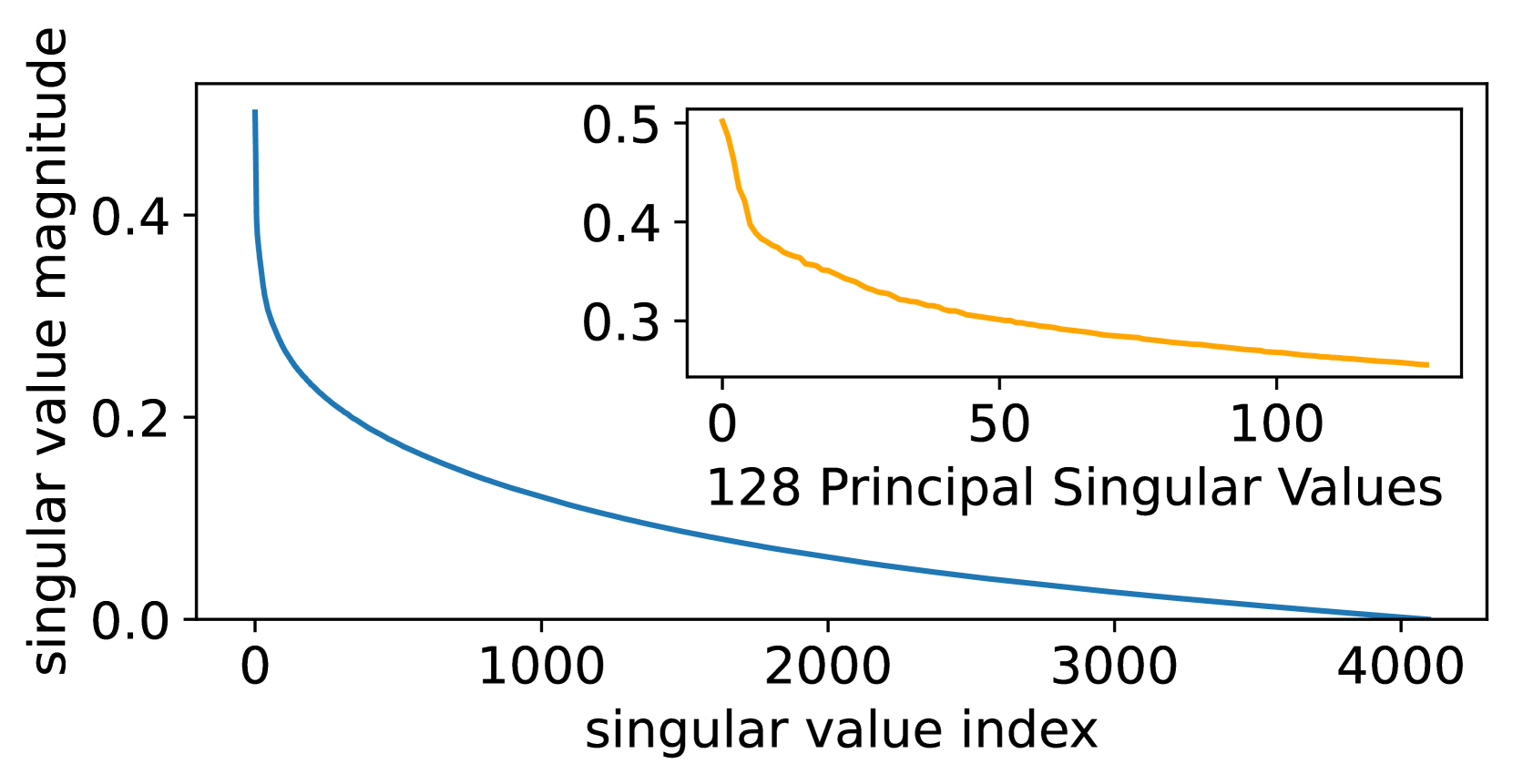
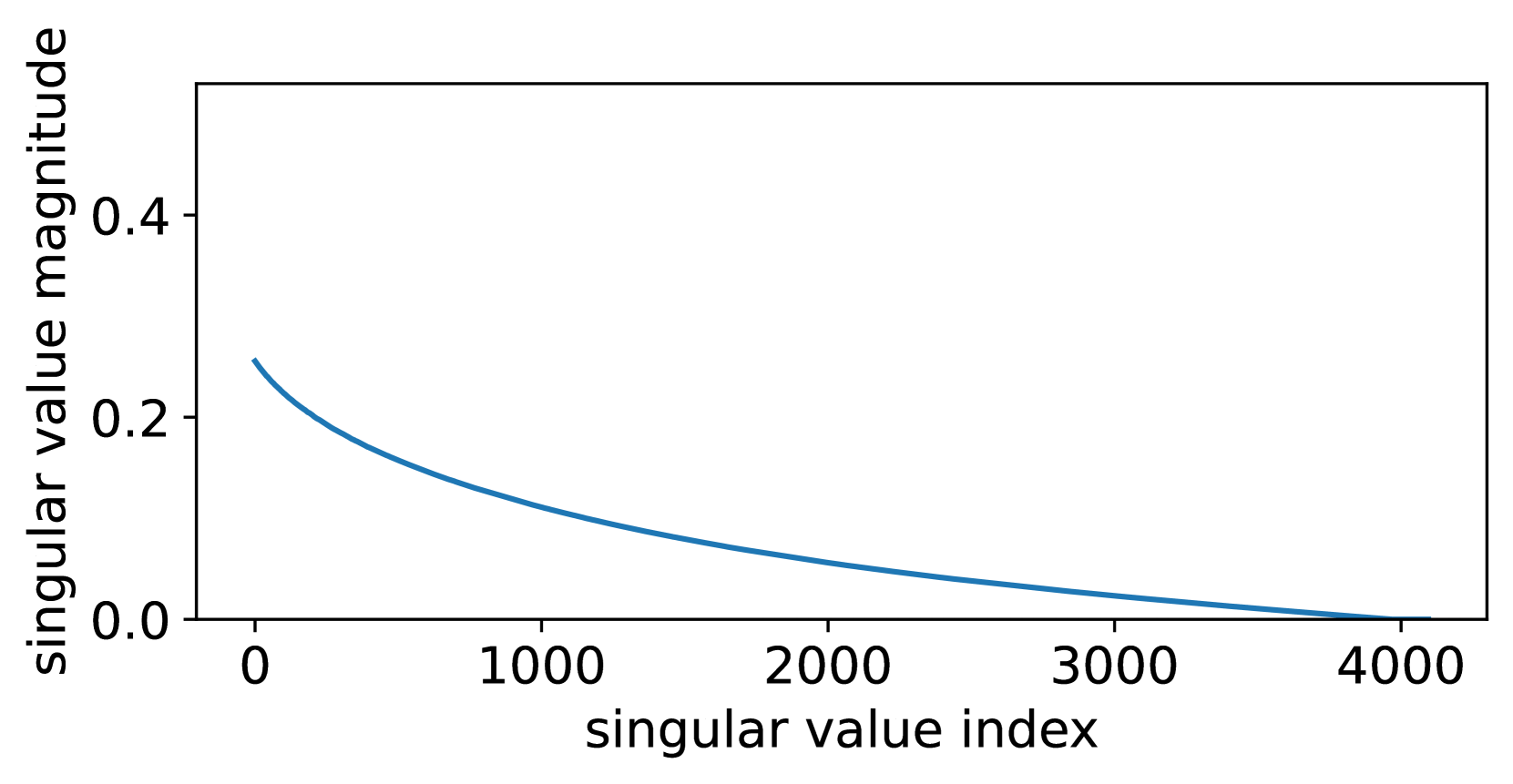
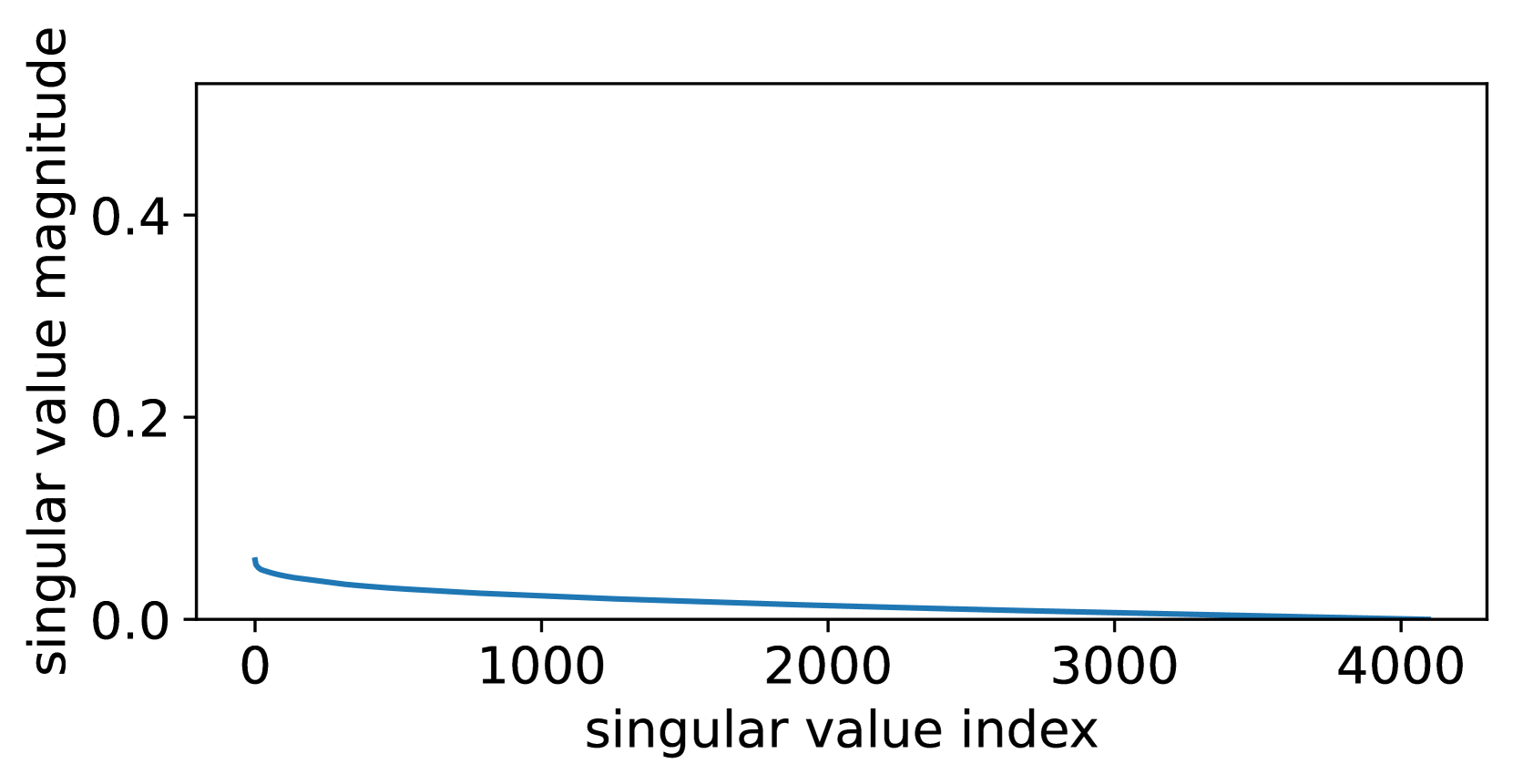
This section extends the discussion in Section 4 by providing a comprehensive comparison of the quantization errors associated with QLoRA, LoftQ, and QPiSSA. Using the “layers[0].self_attn.q_proj” of LLaMA 2-7B as an example, we illustrate the singular values of critical matrices during the quantization process with QLoRA, LoftQ, and PiSSA in Figure 9. A larger sum of the singular values (nuclear norm) of the error matrix indicates a greater quantization error.
The quantization error of QLoRA, which quantizes the base model to Normal Float 4-bit (NF4) and initializes and with Gaussian-Zero initialization, is:
| (13) |
As shown in Equation 13, QLoRA decomposes the original matrix in Figure 8(a) into the sum of a quantized matrix (Figure 8(b)) and an error matrix (Figure 8(d)). By comparing Figure 8(a) and Figure 8(d), we can see that the magnitude of the error matrix is much smaller than that of the original matrix. Therefore, the benefit of preserving the principal components of the matrix with the adapter is greater than that of preserving the principal components of the error matrix with the adapter.
LoftQ [49], designed to preserve the principal components of the error matrix using the adapter, first performs singular value decomposition on the quantization error matrix of QLoRA:
| (14) |
then uses the larger singular values to initialize and , thereby reducing the quantization error to:
| (15) |
LoftQ eliminates only the largest singular values (see Figure 8(e)) from the QLoRA error matrix (Figure 8(d)).
Our PiSSA, however, does not quantify the base model but the residual model:
| (16) |
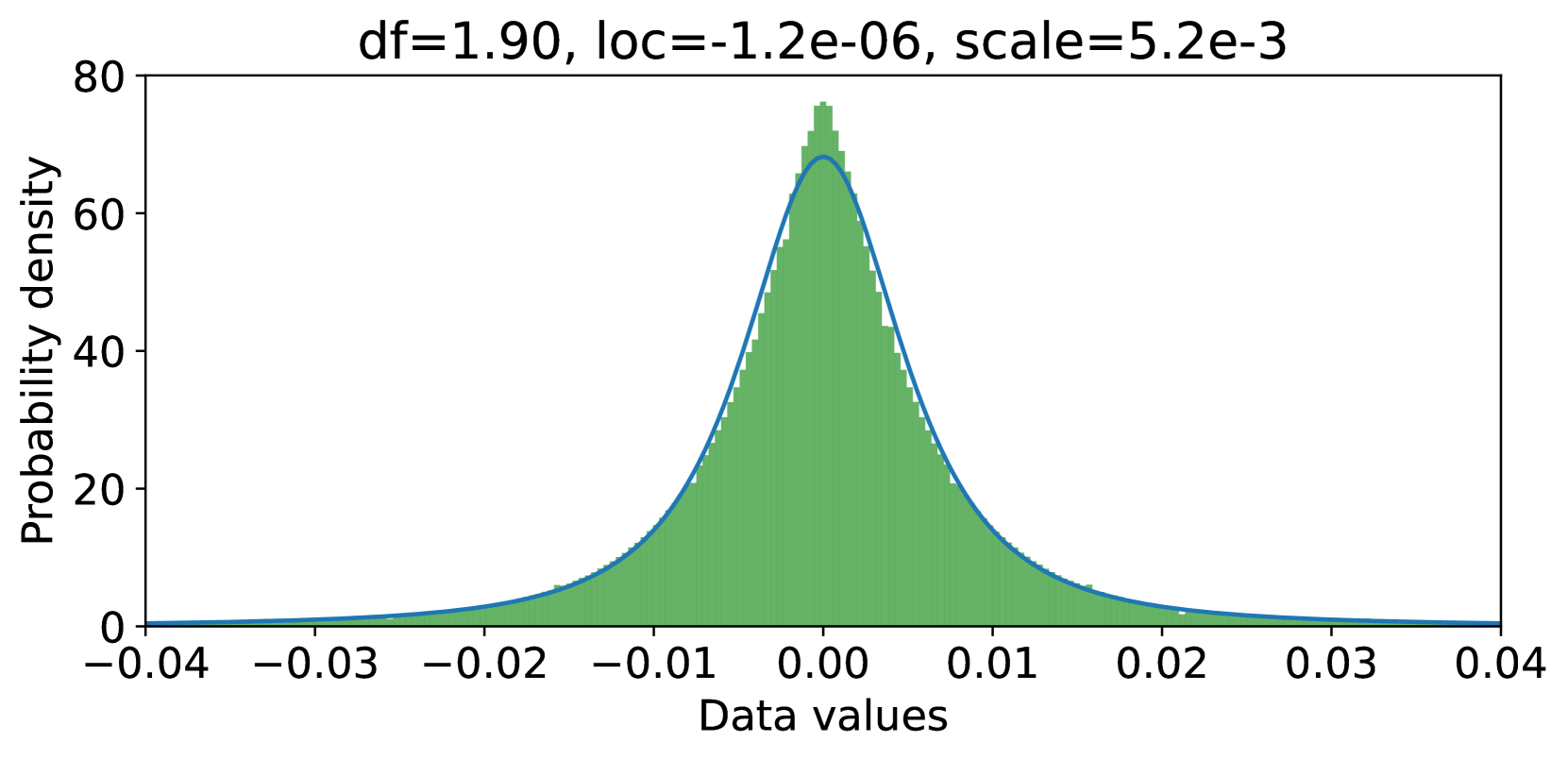
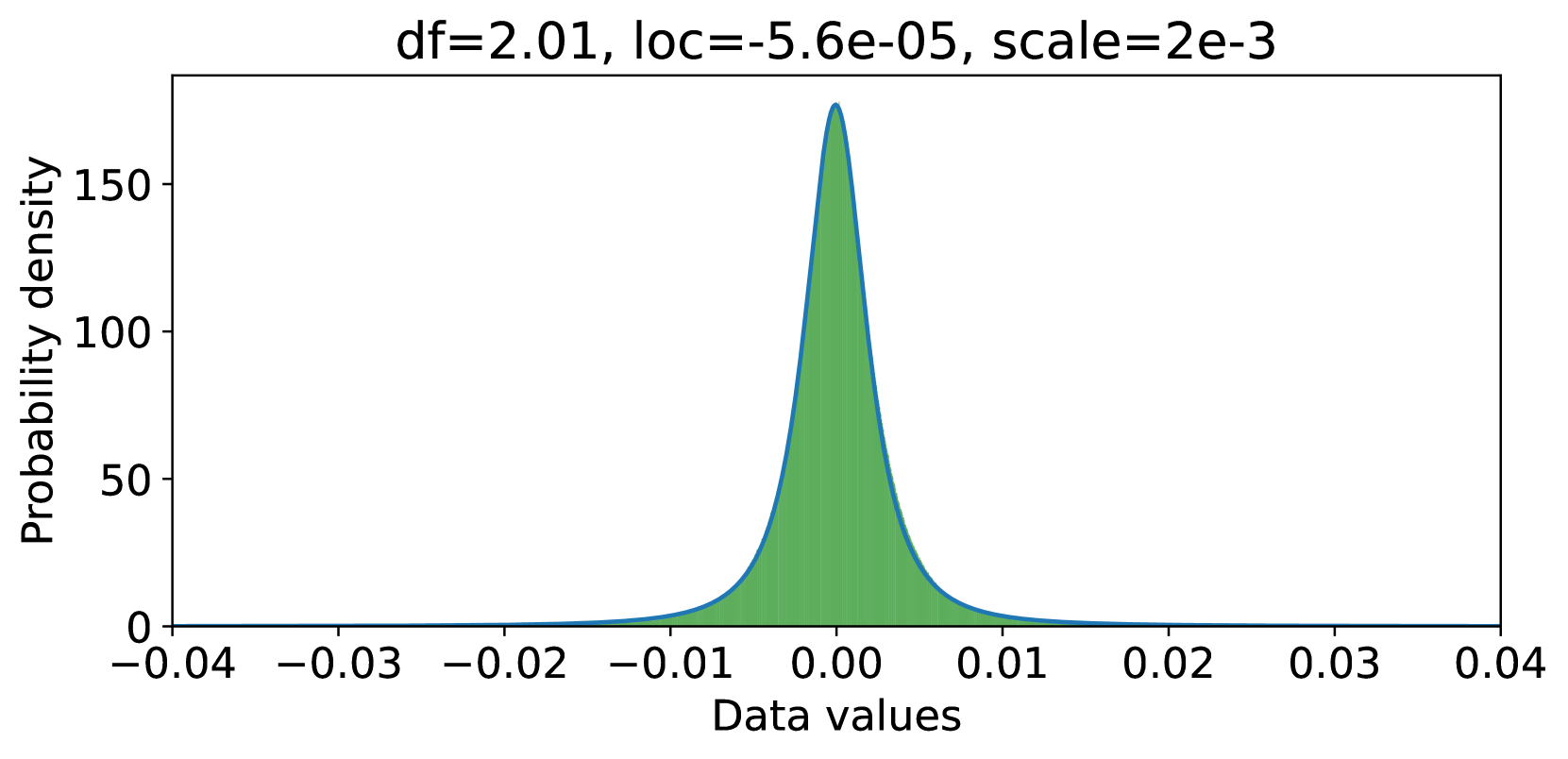
where and are initialized following Equation 2 and 3. Since the residual model has removed the large-singular-value components, the value distribution of can be better fitted by a Student’s t-distribution with higher degrees of freedom compared to (as can be seen in Figure 10) and thus quantizing results in lower error using 4-bit NormalFloat (shown in Figure 8(f)).
Appendix G Evaluating PiSSA on Mixtral and Gemma with More Training Steps
This is the supplement for Section 5.2. We applied PiSSA, LoRA, and full parameter fine-tuning on the full MetaMathQA-395K dataset using Mistral-7B and Gemma-7B models, training for 3 epochs. Figures 11 and 12 display the training loss, gradient norm, and evaluation accuracy on GSM8K.
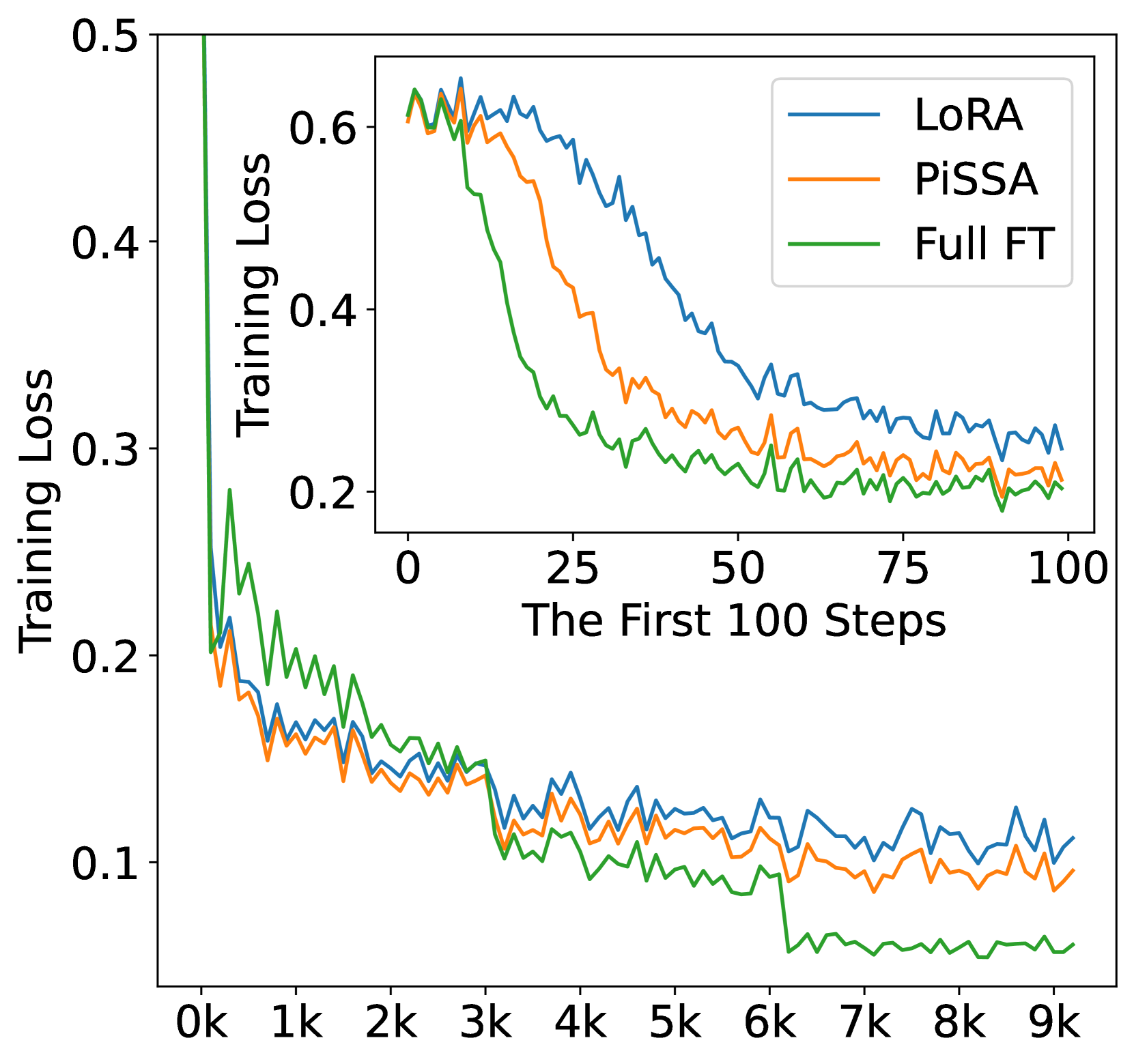
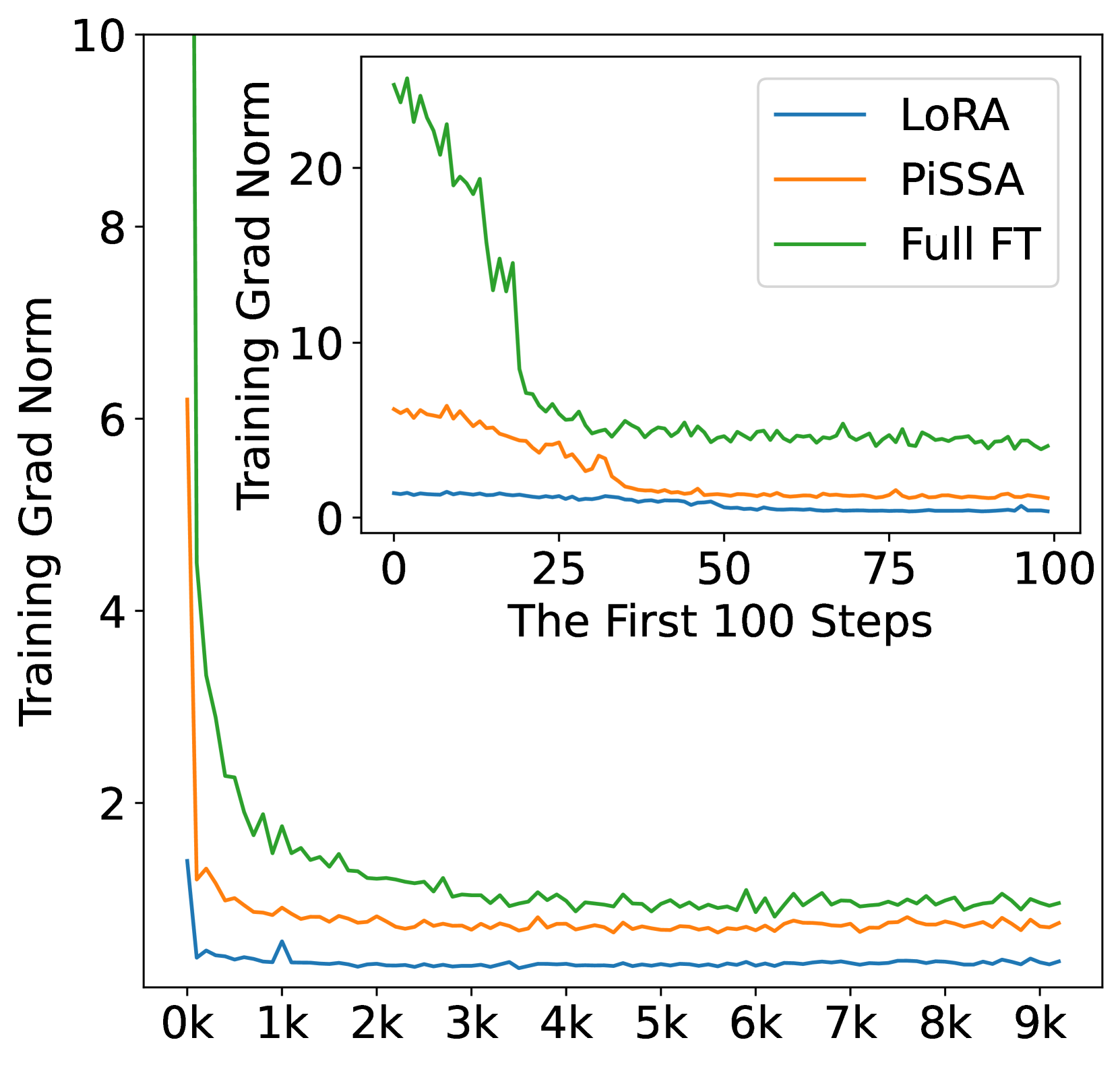
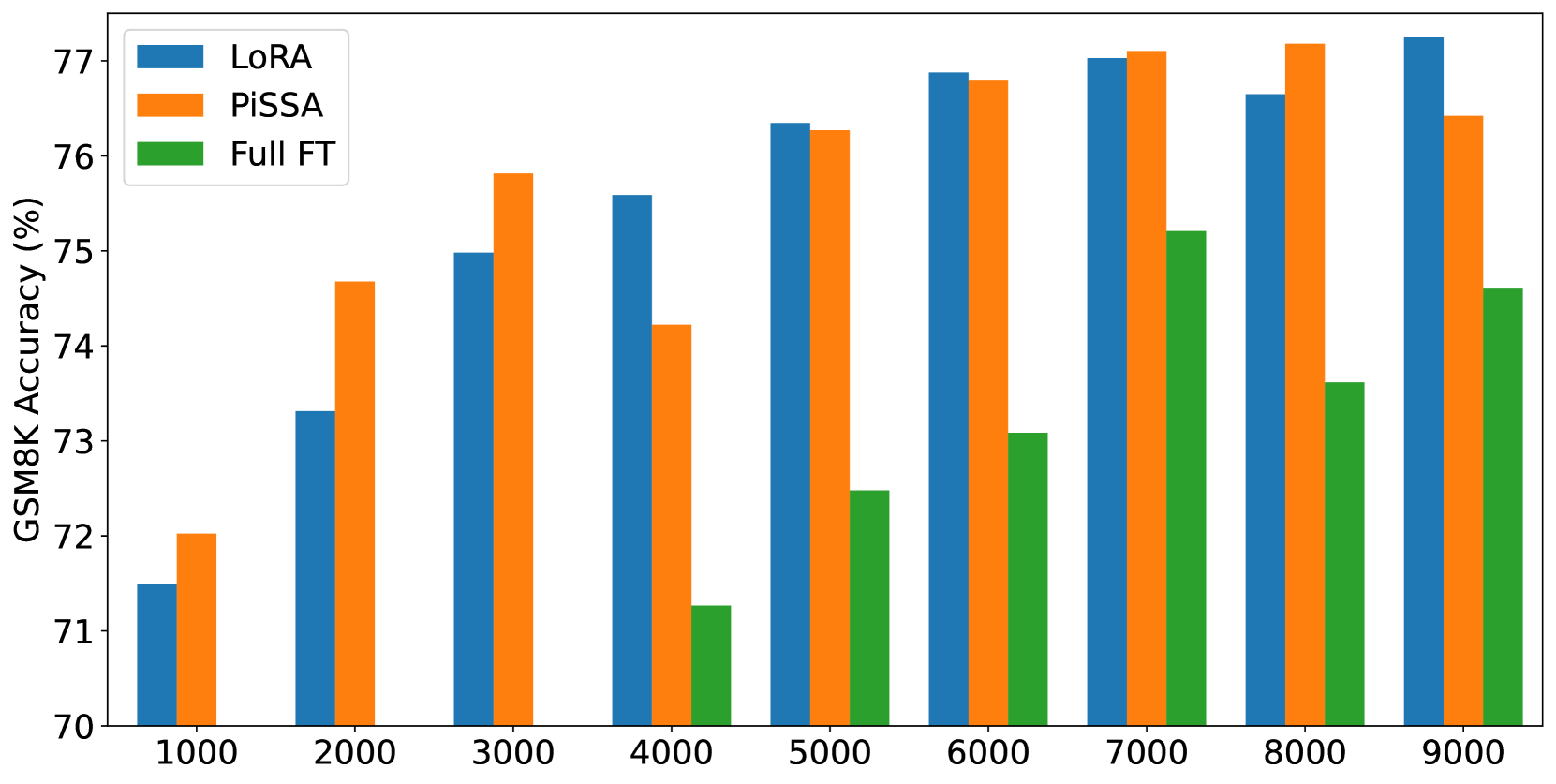

As shown in Figure 10(a) and 11(a), the loss for full parameter fine-tuning decreases sharply with each epoch, indicating overfitting to the training data. Notably, during the entire first epoch, the loss for full parameter fine-tuning on Mistral and Gemma is significantly higher than for LoRA and PiSSA, suggesting that full parameter fine-tuning has weaker generalization capabilities compared to LoRA and PiSSA on Mistral-7B and Gemma-7B models. The gradient norm for the first epoch in Figure 11(b) fluctuates dramatically with each step, further indicating instability in the training process for full parameter fine-tuning. Consequently, as illustrated in Figures 10(c) and 11(c), the performance of full parameter fine-tuning is markedly inferior to that of LoRA and PiSSA. These experiments demonstrate that using parameter-efficient fine-tuning can prevent the over-fitting issue caused by over-parameters.
Appendix H Supplementary Experiments on Various Ranks
H.1 Quantization Error for More Type of Layers
Figure 7(a) only shows the reduction ratio of quantization error for “q_proj” layers. In Figure 13, we present the error reduction ratios for the remaining types of linear layers under different ranks.
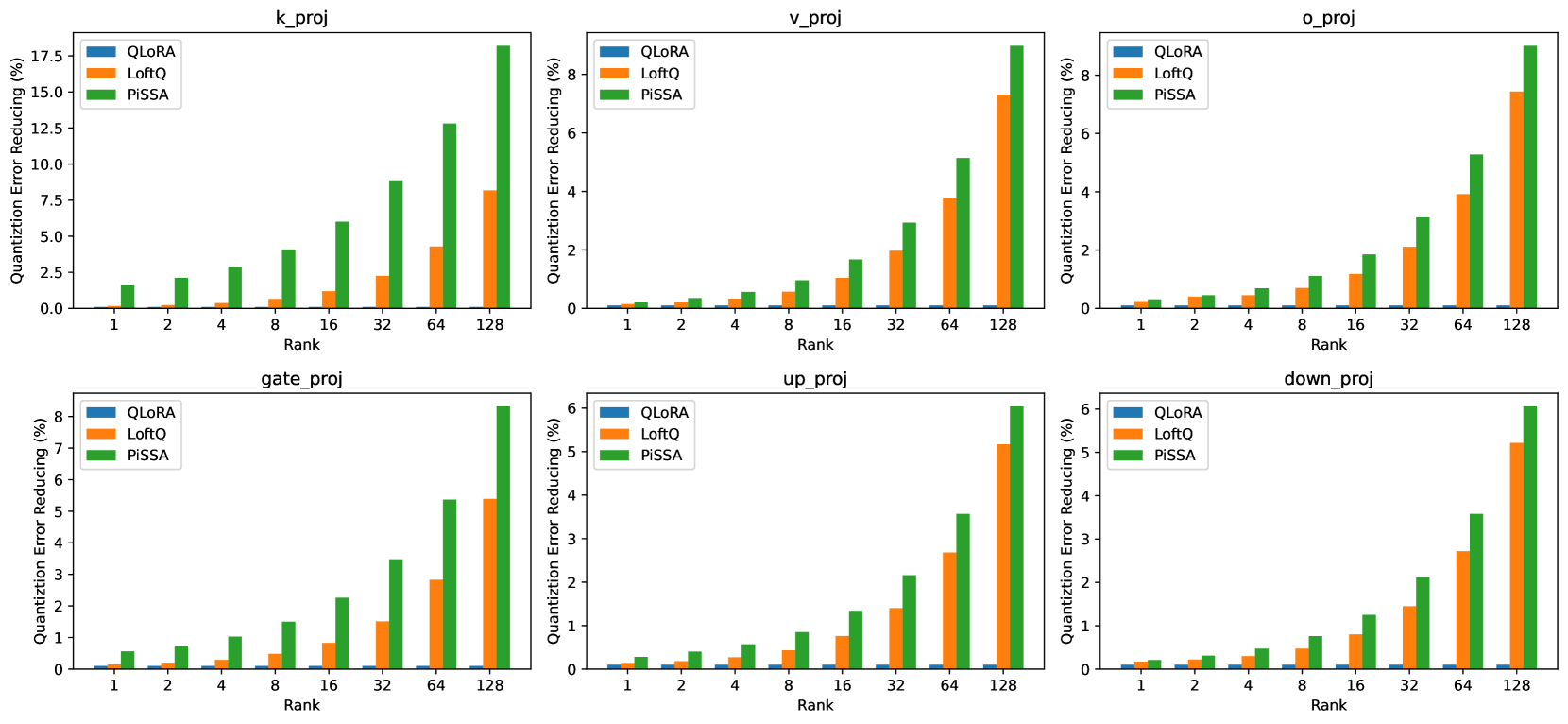
From Figure 13 it can be observed that under different ranks, the reduction ratio of quantization error for various linear layers in LLaMA-2-7B, including “k_proj”, “v_proj”, “o_proj”, “gate_proj”, “up_proj”, and “down_proj” layers, is consistently lower with PiSSA compared to LotfQ.
H.2 Evaluation Performance for More Model on Various Ranks
Section 5.5 only validated the effectiveness of LLaMA-2-7B. In Figure 14, we also present the comparative results of Mistral-7B-v0.1, and Gemma-7B under different ranks.
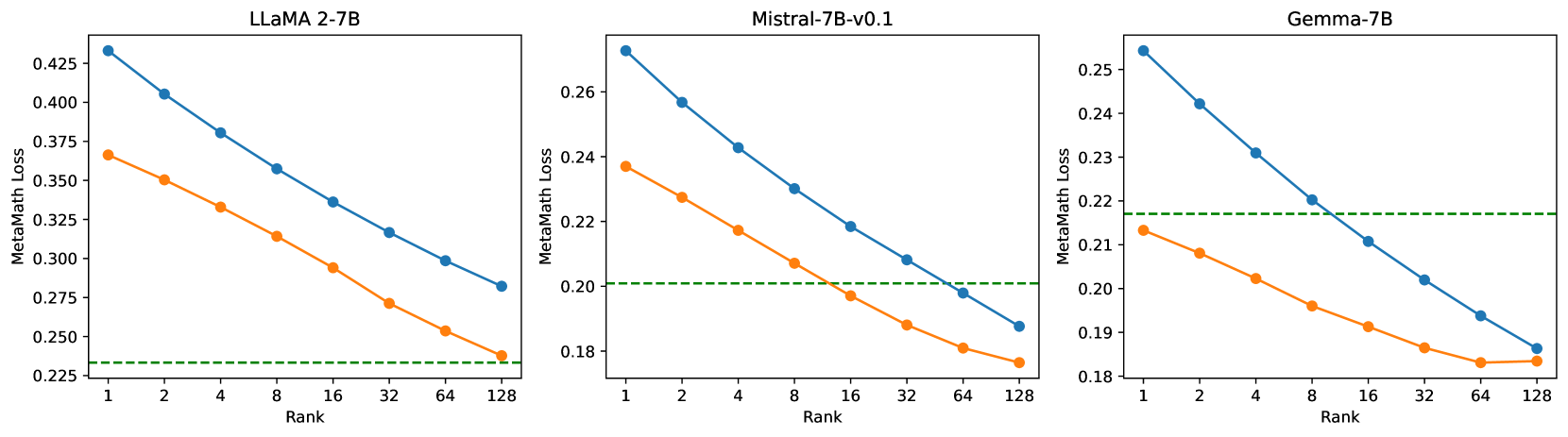
From Figure 14, PiSSA uses fewer trainable parameters compared to LoRA while achieving or even surpassing full-parameter fine-tuning on LLaMA-2-7B and Mistral-7B. Remarkably, on Gemma-7B, PiSSA exceeds full-parameter fine-tuning performance even at rank=1. However, as the rank increases to 128, the performance of PiSSA begins to decline, indicating that PiSSA over-parameterizes earlier than LoRA. This over-parameterization phenomenon does not occur on LLaMA-2-7B, suggesting that increasing the rank further might enable PiSSA to achieve even higher performance on LLaMA-2-7B.
H.3 More Training Loss and Grad Norm under Various Ranks
In Figure 15 and 16, we examining the loss and gradient norm during the training process of PiSSA and LoRA on LLaMA 2-7B, Mistral-7B-v0.1, and Gemma-7B using different ranks.






From Figure 15, PiSSA consistently shows a faster initial loss reduction compared to LoRA across various ranks. Additionally, the final loss remains lower than that of LoRA. This advantage is particularly pronounced when the rank is smaller. From Figure 16, the gradient norm of PiSSA remains consistently higher than that of LoRA throughout the training process, indicating its efficient fitting of the training data. A closer look at the first few steps of LoRA’s gradient norm reveals a trend of rising and then falling. According to Section 3, LoRA’s gradients are initially close to zero, leading to very slow model updates. This requires several steps to elevate LoRA’s weights to a higher level before subsequent updates. This phenomenon validates our assertion that LoRA wastes some training steps and therefore converges more slowly. It demonstrates the robustness of the faster convergence property of PiSSA across various ranks.
Appendix I Experimental Settings on NLU
Datasets
We evaluate the performance of PiSSA on GLUE benchmark, including 2 single-sentence classification tasks (CoLA, SST), 5 pairwise text classification tasks (MNLI, RTE, QQP, MRPC and QNLI) and 1 text similarity prediction task (STS-B). We report overall matched and mismatched accuracy on MNLI, Matthew’s correlation on CoLA, Pearson correlation on STS-B, and accuracy on the other datasets.
Implementation Details
To evaluate the performance of PiSSA intuitively, we compared PiSSA and LoRA with the same number of trainable parameters. RoBERTa-large has trainable parameters. PiSSA was applied to and , resulting in a total of trainable parameters. DeBERTa-v3-base has trainable parameters. PiSSA and LoRA were applied to , and respectively, resulting in a total of trainable parameters.
Experiments on NLU are based on the publicly available LoftQ [49] code-base. On RoBERTa-large, we initialize the model with pretrained MNLI checkpoint for the task of MRPC, RTE and STS-B. We set the rank of PiSSA in this experiment as and selecte lora alpha in 8, 16. We utilize AdamW with linear learning rate schedule to optimize and tune learning rate (LR) from 1e-4,2e-4,3e-4,4e-4,5e-4, 6e-4, 5e-5, 3e-5. Batch sizes (BS) are selected from . Table 7 presents the hyperparmeters we utilized on the glue benchmark.
| Dataset | Roberta-large | Deberta-v3-base | ||||||
|---|---|---|---|---|---|---|---|---|
| Epoch | BS | LR | Lora alpha | Epoch | BS | LR | Lora alpha | |
| MNLI | 10 | 32 | 1e-4 | 16 | 5 | 16 | 5e-5 | 8 |
| SST-2 | 10 | 32 | 2e-4 | 16 | 20 | 16 | 3e-5 | 8 |
| MRPC | 20 | 16 | 6e-4 | 8 | 20 | 32 | 2e-4 | 8 |
| CoLA | 20 | 16 | 4e-4 | 8 | 20 | 16 | 1e-4 | 8 |
| QNLI | 10 | 6 | 1e-4 | 8 | 10 | 32 | 1e-4 | 16 |
| QQP | 20 | 32 | 3e-4 | 8 | 10 | 16 | 1e-4 | 8 |
| RTE | 20 | 16 | 3e-4 | 16 | 50 | 16 | 1e-4 | 8 |
| STS-B | 30 | 16 | 3e-4 | 16 | 20 | 8 | 3e-4 | 8 |