(eccv) Package eccv Warning: Package ‘hyperref’ is loaded with option ‘pagebackref’, which is *not* recommended for camera-ready version
Shanghai AI Laboratory
https://caraj7.github.io/comat/
CoMat: Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching
Abstract
Diffusion models have demonstrated great success in the field of text-to-image generation. However, alleviating the misalignment between the text prompts and images is still challenging. The root reason behind the misalignment has not been extensively investigated. We observe that the misalignment is caused by inadequate token attention activation. We further attribute this phenomenon to the diffusion model’s insufficient condition utilization, which is caused by its training paradigm. To address the issue, we propose CoMat, an end-to-end diffusion model fine-tuning strategy with an image-to-text concept matching mechanism. We leverage an image captioning model to measure image-to-text alignment and guide the diffusion model to revisit ignored tokens. A novel attribute concentration module is also proposed to address the attribute binding problem. Without any image or human preference data, we use only 20K text prompts to fine-tune SDXL to obtain CoMat-SDXL. Extensive experiments show that CoMat-SDXL significantly outperforms the baseline model SDXL in two text-to-image alignment benchmarks and achieves start-of-the-art performance.
Keywords:
Text-to-Image Generation Diffusion model Text-Image Alignment
1 Introduction
The area of text-to-image generation has witnessed considerable progress with the introduction of diffusion models [17, 39, 38, 42, 44] recently. These models have demonstrated remarkable performance in creating high-fidelity and diverse images based on textual prompts. However, it still remains challenging for these models to faithfully align with the prompts, especially for the complex ones. For example, as shown in Fig. 1, current state-of-the-art open-sourced model SDXL [36] fails to generate entities or attributes mentioned in the prompts, e.g., the feathers made of lace and dwarfs in the top row. Additionally, it fails to understand the relationship in the prompt. In the middle row of Fig. 1, it mistakenly generates a Victorian gentleman and a quilt with a river on it.
Recently, various works propose to incorporate external knowledge from linguistics prior [40, 34] or Large Language Model (LLM) [30, 54, 59] to address the problem. However, there still exists a lack of reasonable explanations for the misalignment problem. To further explore the reason for the problem, we design a pilot experiment and study the cross-attention activation value of text tokens. As the example shown in Fig. 2(a), the gown and diploma do not appear in the image. At the same time, the activation values of these two tokens are also at a low level, compared with the concepts shown in the image (i.e., owl and cap). Besides, we also visualize the overall distribution of the token activation in Fig. 2(b). Specifically, we simulate the training process, where the pre-trained UNet [43] of SDXL [36] is used to denoise a noisy image conditioned with its text caption. We record the activation value of each text token and take the mean value across spatial dimensions.
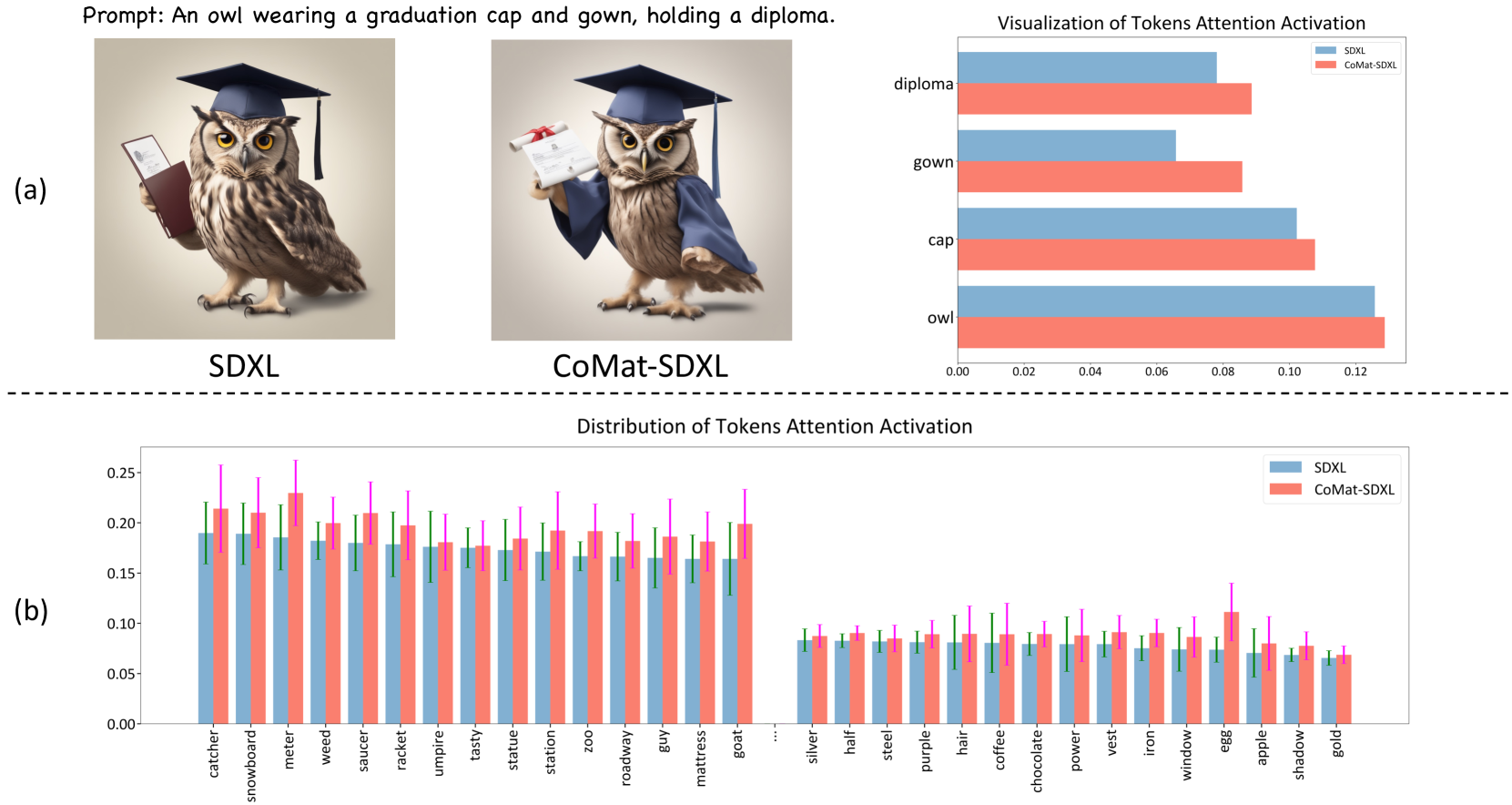
The distribution suggests that the activation remains at a low level during generation. Hence, we identify that the misalignment issue is caused by insufficient attention to certain text tokens. This behavior originally stems from the training paradigm of the text-to-image diffusion models: Given the text condition and the paired image , the training process aims to learn the conditional distribution . However, the text condition only serves as additional information for the denoising loss. Without explicit guidance in learning each concept in the text, the diffusion model could easily overlook the condition information of text tokens.
To tackle the limitation, we propose CoMat, a novel end-to-end fine-tuning strategy for text-to-image diffusion models by incorporating image-to-text concept matching. We first generate image according to prompt . In order to activate each concept present in the prompt, we seek to optimize the posterior probability given by a pre-trained image captioning model. Thanks to the image-to-text concept matching ability of the captioning model, whenever a certain concept is missing from the generated image, the diffusion model would be steered to generate it in the image. The guidance forces the diffusion model to revisit the ignored tokens and attend more to them. As shown in Fig. 2(a), our method largely enhances the token activation of ‘gown’ and ‘diploma’, and makes them present in the image. Moreover, Fig. 2(b) suggests that our method raises activation in the entire distribution. Additionally, due to the insensitivity of the captioning model in identifying and distinguishing attributes, we find that the attribute alignment still remains unsatisfactory. Hence, we introduce an entity attribute concentration module, where the attributes are enforced to be activated within the entity’s area to boost attribute alignment. Finally, a fidelity preservation part is added to preserve the generation capability of the diffusion model. Notably, our training data only includes text prompts, without the requirement of any image-text pairs or human preference data. Moreover, as an end-to-end method, we introduce no extra overheads during inference. We also show that our method is composable with methods leveraging external knowledge.
Our contributions are summarized as follows:
-
•
We propose CoMat, a diffusion model fine-tuning strategy with an image-to-text concept matching mechanism.
-
•
We introduce the concept matching module and entity attribute concentration module to promote concepts and attribute generation.
-
•
Extensive quantitative and qualitative comparisons with baseline models indicate the proposed method’s superior text-to-image generation capability.
2 Related Works
2.1 Text-to-Image Alignment
Text-to-image alignment is the problem of enhancing coherence between the prompts and the generated images, which involves multiple aspects including existence, attribute binding, relationship, etc. Recent methods address the problem mainly in three ways.
Attention-based methods [6, 40, 34, 52, 2, 29] aim to modify or add restrictions on the attention map in the attention module in the UNet. This type of method often requires a specific design for each misalignment problem. For example, Attend-and-Excite [6] improves object existence by exciting the attention score of each object, while SynGen [40] boosts attribute binding by modulating distances of attention maps between modifiers and entities.
Planning-based methods first obtain the image layouts, either from the input of the user [28, 8, 23, 56, 12] or the generation of the Large Language Models (LLM) [35, 59, 51], and then produce aligned images conditioned on the layout. In addition, a few works propose to further refine the image with other vision expert models like grounded-sam [41], multimodal LLM[53], or image editing models [54, 53, 59]. Although such integration splits a compositional prompt into single objects, it does not resolve the inaccuracy of the downstream diffusion model and still suffers from incorrect attribute binding problems. Besides, it exerts nonnegligible costs during inference.
Moreover, some works aim to enhance the alignment using feedback from image understanding models. [21, 46] fine-tune the diffusion model with well-aligned generated images chosen by the VQA model [25] to strategically bias the generation distribution. Other works propose to optimize the diffusion models in an online manner. For generic rewards, [13, 4] introduce RL fine-tuning. While for differentiable reward, [11, 57, 55] propose to directly backpropagate the reward function gradient through the denoising process. Our concept matching module can be viewed as utilizing a captioner directly as a differentiable reward model. Similar to our work, [14] proposes to caption the generated images and optimize the coherence between the produced captions and text prompts. Although image captioning models are also involved, they fail to provide detailed guidance. The probable omission of key concepts and undesired added features in the generated captions both lead the optimization target to be suboptimal [20].

2.2 Image Captioning Model
The image captioning models here refer to those pre-trained on various vision and language tasks (e.g., image-text matching, (masked) language modeling) [27, 33, 22, 47], then fine-tuned with image captioning tasks [9]. Various model architectures have been proposed [50, 60, 26, 25, 49]. BLIP [25] takes a fused encoder architecture, while GIT [49] adopts a unified transformer architecture. Recently, multimodel large language models have been flourishing [32, 66, 62, 1, 63]. For example, LLaVA [32] leverages LLM as the text decoder and obtain impressive results.
3 Preliminaries
We implement our method on the leading text-to-image diffusion model, Stable Diffusion [42], which belongs to the family of latent diffusion models (LDM). In the training process, a normally distributed noise is added to the original latent code with a variable extent based on a timestep sampling from . Then, a denoising function , parameterized by a UNet backbone, is trained to predict the noise added to with the text prompt and the current latent as the input. Specifically, the text prompt is first encoded by the CLIP [37] text encoder , then incorporated into the denoising function by the cross-attention mechanism. Concretely, for each cross-attention layer, the latent and text embedding is linearly projected to query and key , respectively. The cross-attention map is calculated as , where is the index of head. and are the resolution of the latent, is the token length for the text embedding, and is the feature dimension. denotes the attention score of the token index at the position . The denoising loss in diffusion models’ training is formally expressed as:
| (1) |
For inference, one draws a noise sample , and then iteratively uses to estimate the noise and compute the next latent sample.
4 Method
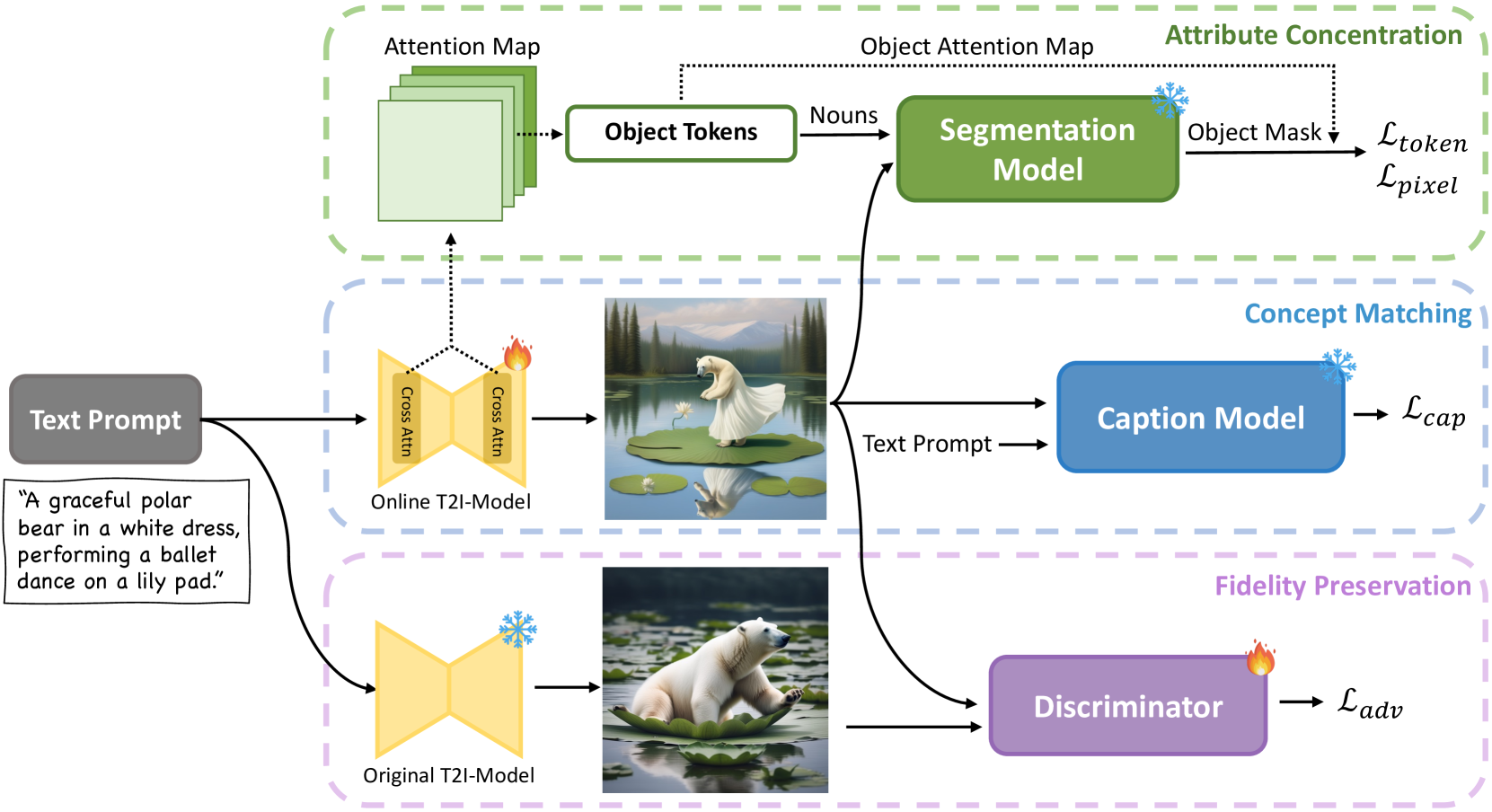
The overall framework of our method is shown in Fig. 4, which consists of three modules: Concept Matching, Attribute Concentration, and Fidelity Preservation. In Section 4.1, we illustrate the image-to-text concept matching mechanism with the image captioning model. Then, we detail the attribute concentration module for promoting attribute binding in Section 4.2. Subsequently, we introduce how to preserve the generation ability of the diffusion model in Section 4.3. Finally, we combine the three parts for joint learning, as illustrated in Section 4.4
4.1 Concept Matching
As noted in Section 1, we posit that the fundamental reason behind the misalignment issue lies in the incomplete utilization of contextual information. As a result, even though all the text conditions are presented, the diffusion model exhibits little attention on certain tokens and the corresponding concept is therefore missing in the generated image. To address this problem. our key insight is to add supervision on the generated image to detect the missing concepts. We achieve this by leveraging the image understanding capability of the image captioning model, which can accurately identify concepts not present in the generated image based on the given text prompt. With the caption model’s supervision, the diffusion model is compelled to revisit text tokens to search for ignored condition information and would assign significance to the previously overlooked text concepts for better text-image alignment.
Concretely, given a prompt with word tokens , we first generate an image with the denoising function after denoising steps. Then, a frozen image captioning model is used to score the alignment between the prompt and the image in the form of log-likelihood. Therefore, our training objective aims to minimize the negative of the score, denoted as :
| (2) |
Actually, the score from the caption model could be viewed as a differential reward for fine-tuning the diffusion model. To conduct the gradient update through the whole iterative denoising process, we follow [55] to fine-tune the denoising network , which ensures the training effectiveness and efficiency by simply stopping the gradient of the denoising network input. In addition, noting that the concepts in the image include a broad field, a variety of misalignment problems like object existence and complex relationships could be alleviated by our concept matching module.
4.2 Attribute Concentration
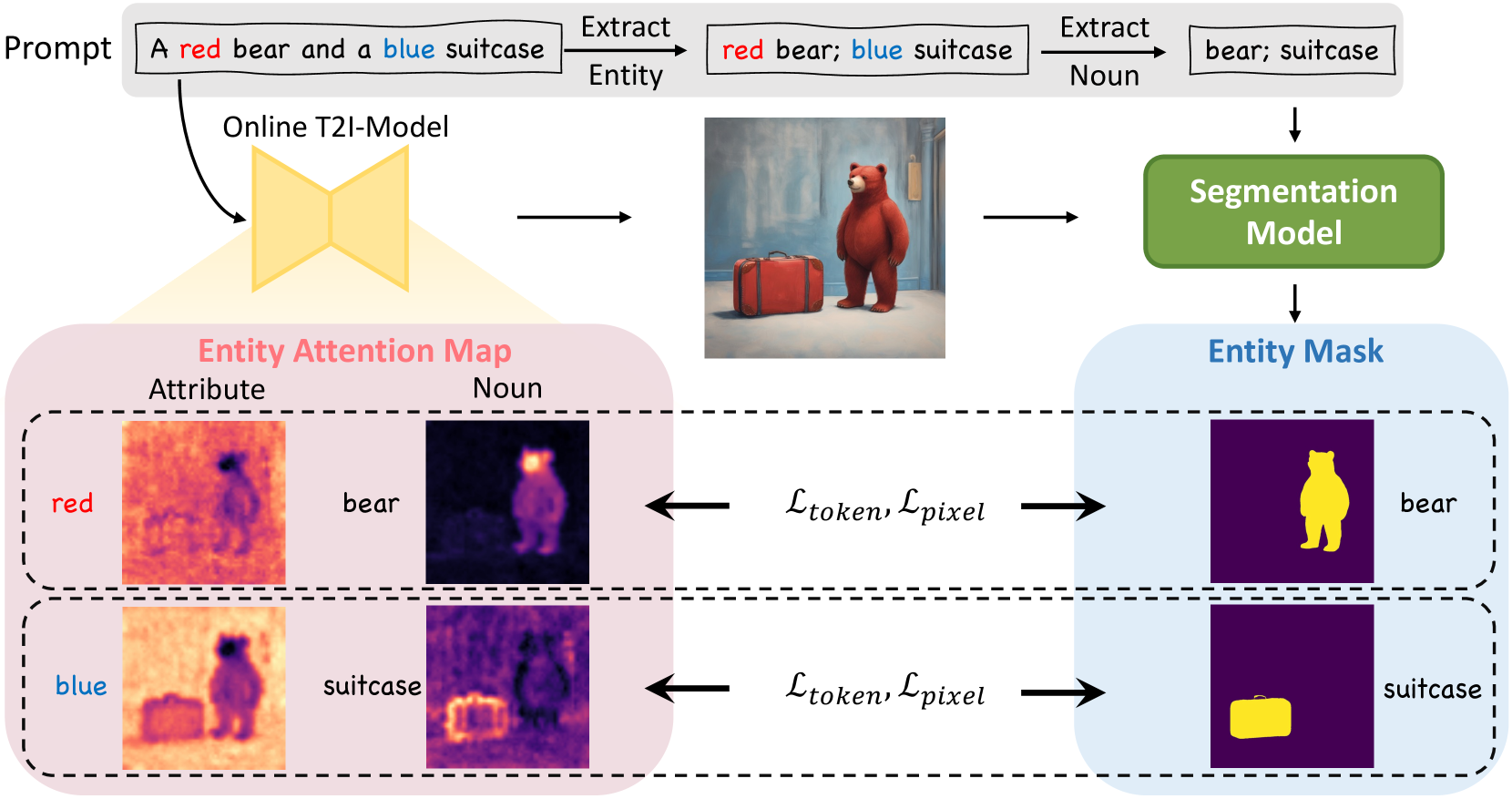
It has been well-reported that attribution binding is a challenging problem in text-to-image diffusion models [40]. As the example in Fig. 5 shows, which is based on the SDXL model, the attention of the word ‘red’ and ‘blue’ is mostly activated in the background, with little alignment of its corresponding object. Our concept matching module can alleviate this problem to some extent. However, bounded by the caption model’s insensitivity to object attributes, the performance improvement is limited. Here, to align the entities with their attributes from a more fine-grained view, we introduce attribute concentration to direct the attention of the entities’ textual description to focus on its area in the image.
Specifically, we first extract all the entities in the prompts. An entity can be defined as a tuple of a noun and its attributes , i.e., , where both and are the sets of one or multiple tokens. We employ spaCy’s transformer-based dependency parser [18] to parse the prompt to find all entity nouns, and then collect all modifiers for each noun. We manually filter nouns that are abstract (e.g., scene, atmosphere, language), difficult to identify their area (e.g., sunlight, noise, place), or describe the background (e.g., morning, bathroom, party). Given all the filtered nouns, we use them to prompt an open vocabulary segmentation model, Grounded-SAM [41], to find their corresponding regions as a binary mask . It is worth emphasizing that we only use the nouns of entities, excluding their associated attributes, as prompts for segmentation, considering the diffusion model could likely assign a wrong attribute to the object. Taking the ‘suitcase’ object in Fig 5 as an example, the model mistakenly generates a red one even with the prompt ‘blue suitcase’. Consequently, if the prompt ’blue suitcase’ is given to the segmentor, it will fail to identify the entity’s region. These inaccuracies can lead to a cascade of errors in the following process.
Then, we aim to focus the attention of both the noun and attributes of each entity in the same region, which is denoted by a binary mask matrix . We achieve this alignment by adding the training supervision with two objectives, i.e., token-level attention loss and pixel-level attention loss [52]. Specifically, for each entity , the token-level attention loss forces the model to activate the attention of the object tokens only inside the region , i.e.,:
| (3) |
where denotes element-wise multiplication.
The pixel-level attention loss is to further force every pixel in the region to attend only to the object tokens by a binary cross-entropy loss:
| (4) |
where is the number of pixels on the attention map. Different from [52], certain objects in the prompt may not appear in the generated image due to misalignment. In this case, the pixel-level attention loss is still valid. When the mask is entirely zero, it signifies that none of the pixels should be attending to the missing object tokens in the current image. Besides, on account of the computational cost, we only compute the above two losses on randomly selected timesteps during the image generation process of the online model.
4.3 Fidelity Preservation
Since the current fine-tuning process is purely piloted by the image captioning model and prior knowledge of relationship between attributes and entities, the diffusion model could quickly overfit the reward, lose its original capability, and produce deteriorated images, as shown in Fig. 6. To address this reward hacking issue, we introduce a novel adversarial loss by using a discriminator that differentiates between images generated from pre-trained and fine-tuning diffusion models. For the discriminator , we follow [58] and initialize it with the pre-trained UNet in Stable Diffusion model, which shares similar knowledge with the online training model and is expected to preserve its capability better. In our practice, this also enables the adversarial loss to be directly calculated in the latent space instead of the image space. In addition, it is important to note that our fine-tuning model does not utilize real-world images but instead the output of the original model. This choice is motivated by our goal of preserving the original generation distribution and ensuring a more stable training process.
Finally, given a single text prompt, we employ the original diffusion model and the online training model to respectively generate image latent and . The adversarial loss is then computed as follows:
| (5) |
We aim to fine-tune the online model to minimize this adversarial loss, while concurrently training the discriminator to maximize it.
4.4 Joint Learning
Here, we combine the captioning model loss, attribute concentration loss, and adversarial loss to build up our training objectives for the online diffusion model as follows:
| (6) |
where , , and are scaling factors to balance different loss terms.
5 Experiment
5.1 Experimental Setup
Base Model Settings. We mainly implement our method on SDXL [42] for all experiments, which is the state-of-the-art open-source text-to-image model. In addition, we also evaluate our method on Stable Diffusion v1.5 [42] (SD1.5) for more complete comparisons in certain experiments. For the captioning model, we choose BLIP [25] fine-tuned on COCO [31] image-caption data. As for the discriminator in fidelity preservation, we directly adopt the pre-trained UNet of SD1.5.
Dataset. Since the prompt to the diffusion model needs to be challenging enough to lead to concepts missing, we directly utilize the training data or text prompts provided in several benchmarks on text-to-image alignment. Specifically, the training data includes the training set provided in T2I-CompBench [21], all the data from HRS-Bench [3], and 5,000 prompts randomly chosen from ABC-6K [15]. Altogether, these amount to around 20,000 text prompts. Note that the training set composition can be freely adjusted according to the ability targeted to improve.
| Model | Attribute Binding | Object Relationship | Complex | |||
| Color | Shape | Texture | Spatial | Non-Spatial | ||
| PixArt- [7] | 0.6690 | 0.4927 | 0.6477 | 0.2064 | 0.3197 | 0.3433 |
| Playground-v2 [24] | 0.6208 | 0.5087 | 0.6125 | 0.2372 | 0.3098 | 0.3613 |
| SD1.5 [42] | 0.3758 | 0.3713 | 0.4186 | 0.1165 | 0.3112 | 0.3047 |
| CoMat-SD1.5 (Ours) | 0.6561 | 0.4975 | 0.6190 | 0.2002 | 0.3150 | 0.3476 |
| (+0.2983) | (+0.1262) | (+0.2004) | (+0.0837) | (+0.0038) | (+0.0429) | |
| SDXL [36] | 0.5879 | 0.4687 | 0.5299 | 0.2131 | 0.3119 | 0.3237 |
| CoMat-SDXL (Ours) | 0.7774 | 0.5262 | 0.6591 | 0.2431 | 0.3183 | 0.3696 |
| (+0.1895) | (+0.0575) | (+0.1292) | (+0.03) | (+0.0064) | (+0.0459) | |
Training Details. In our method, we inject LoRA [19] layers into the UNet of the online training model and discriminator and keep all other components frozen. For both SDXL and SD1.5, we train 2,000 iters on 8 NVIDIA A100 GPUS. We use a local batch size of 6 for SDXL and 4 for SD1.5. We choose Grounded-SAM [41] from other open-vocabulary segmentation models [64, 67]. The DDPM [17] sampler with 50 steps is used to generate the image for both the online training model and the original model. In particular, we follow [55] and only enable gradients in 5 steps out of those 50 steps, where the attribute concentration module would also be operated. Besides, to speed up training, we use training prompts to generate and save the generated latents of the pre-trained model in advance, which are later input to the discriminator during fine-tuning. More training details is shown in Appendix 0.B.1.
Benchmarks. We evaluate our method on two benchmarks:
-
•
T2I-CompBench [21] is a benchmark for compositional text-to-image generation. It comprises 6,000 compositional text prompts from 3 categories (attribute binding, object relationships, and complex compositions) and 6 sub-categories (color binding, shape binding, texture binding, spatial relationships, non-spatial relationships, and complex compositions). It adopts the BLIP-VQA model [25], CLIP [37], and UniDet [65] to automatically evaluate the generation results. Each sub-category contains 700 prompts for training and 300 prompts for testing.
-
•
TIFA [20] is a benchmark to evaluate text-to-image faithfulness. It uses pre-generated question-answer pairs and a VQA model to evaluate the generation results. The benchmark contains 4,000 diverse text prompts and 25,000 questions across 12 categories.
We follow the default evaluation setting of these two benchmarks.
| Model | TIFA |
| PixArt- [7] | 82.9 |
| Playground-v2 [24] | 86.2 |
| SD1.5 [42] | 78.4 |
| CoMat-SD1.5 (Ours) | 85.7 |
| (+7.3) | |
| SDXL [36] | 85.9 |
| CoMat-SDXL (Ours) | 87.7 |
| (+1.8) |
| Model | Discriminator | FID-10K |
| SD1.5 [42] | - | 16.69 |
| CoMat-SD1.5 | N/A | 19.02 |
| CoMat-SD1.5 | DINO [5] | 23.86 |
| CoMat-SD1.5 | UNet [43] | 16.69 |
5.2 Quantitative Results
We compare our methods with our baseline models: SD1.5 and SDXL, and two state-of-the-art open-sourced text-to-image models: PixArt- [7] and Playground-v2 [24]. PixArt- adopts the transformer [48] architecture and leverages dense pseudo-captions auto-labeled by a large Vision-Language model to assist text-image alignment learning. Playground-v2 follows a similar structure to SDXL but is preferred 2.5x more on the generated images [24].
| Caption Model | Attribute Binding | Object Relationship | Complex | |||
| Color | Shape | Texture | Spatial | Non-Spatial | ||
| BLIP [25] | 0.7774 | 0.5262 | 0.6591 | 0.2431 | 0.3183 | 0.3696 |
| GIT [49] | 0.7451 | 0.4881 | 0.5893 | 0.1880 | 0.3120 | 0.3375 |
| LLaVA [32] | 0.6550 | 0.4713 | 0.5490 | 0.1835 | 0.3112 | 0.3349 |
| N/A | 0.5879 | 0.4687 | 0.5299 | 0.2131 | 0.3119 | 0.3237 |
T2I-CompBench. The evaluation result is shown in Table 1. It is important to note that we cannot reproduce results reported in some relevant works [7, 21] due to the evolution of the evaluation code. All our shown results are based on the latest code released in GitHub111https://github.com/Karine-Huang/T2I-CompBench. We observe significant gains in all six sub-categories compared with our baseline models. Specifically, SD1.5 increases , , and for color, shape, and texture attributes. In terms of object relationship and complex reasoning, CoMat-SD1.5 also obtains large improvement with over improvement in the spatial relationship. With our methods, SD1.5 can even achieve better or comparable results compared with PixArt- and Playground-v2. When applying our method on the larger base model SDXL, we can still witness great improvement. Our CoMat-SDXL demonstrates the best performance regarding attribute binding, spatial relationships, and complex compositions. We find our method fails to obtain the best result in non-spatial relationships. We assume this is due to the training distribution in our text prompts, where a majority of prompts are descriptive phrases aiming to confuse the diffusion model. The type of prompts in non-spatial relationships may only take a little part.
TIFA. We show the results in TIFA in Table 3. Our CoMat-SDXL achieves the best performance with an improvement of 1.8 scores compared to SDXL. Besides, CoMat significantly enhances SD1.5 by 7.3 scores, which largely surpasses PixArt-.
5.3 Qualitative Results
Fig. 3 presents a side-by-side comparison between CoMat-SDXL and other state-of-the-art diffusion models. We observe these models exhibit inferior condition utilization ability compared with CoMat-SDXL. Prompts in Fig. 3 all possess concepts that are contradictory to real-world phenomena. All the three compared models stick to the original bias and choose to ignore the unrealistic content (e.g., waterfall cascading from a teapot, transparent violin, robot penguin, and waterfall of liquid gold), which causes misalignment. However, by training to faithfully align with the conditions in the prompt, CoMat-SDXL follows the unrealistic conditions and provides well-aligned images.
5.4 Ablation Study
Here, we aim to evaluate the importance of each component and model setting in our framework and attempt to answer three questions: 1) Are both two main modules, i.e., Concept Matching and Attribute Concentration, necessary and effective? 2) Is the Fidelity Preservation module necessary, and how to choose the discriminator? 3) How to choose the base model for the image captioning models?
| Model | CM | AC | Attribute Binding | Object Relationship | Complex | |||
| Color | Shape | Texture | Spatial | Non-Spatial | ||||
| SDXL | 0.5879 | 0.4687 | 0.5299 | 0.2131 | 0.3119 | 0.3237 | ||
| SDXL | ✓ | 0.7593 | 0.5124 | 0.6362 | 0.2247 | 0.3164 | 0.3671 | |
| SDXL | ✓ | ✓ | 0.7774 | 0.5262 | 0.6591 | 0.2431 | 0.3183 | 0.3696 |
Concept Matching and Attribute Concentration. In Table 5, we show the T2I-CompBench result aiming to identify the effectiveness of the concept matching and attribute concentration modules. We find that the concept matching module accounts for major gains to the baseline model. On top of that, the attribute concentration module brings further improvement on all six sub-categories in T2I-CompBench.
Different Discriminators. We ablate the choice of discriminator here. We randomly sample 10K text-image pairs from the COCO validation set. We calculate the FID [16] score on it to quantitatively evaluate the photorealism of the generated images. As shown in Table 3, the second row shows that without the discriminator, i.e. no fidelity perception module, the generation ability of the model greatly deteriorates with an increase of FID score from 16.69 to 19.02. We also visualize the generated images in Fig. 6. As shown in the figure, without fidelity preservation, the diffusion model generates misshaped envelops and swans. This is because the diffusion model only tries to hack the captioner and loses its original generation ability. Besides, inspired by [45], we also experiment with a pre-trained DINO [5] to distinguish the images generated by the original model and online training model in the image space. However, we find that DINO fails to provide valid guidance, and severely interferes with the training process, leading to a FID score even higher than not applying a discriminator. Using pre-trained UNet yields the best preservation. The FID score remains the same as the original model and no obvious degradation can be observed in the generated images.

Different Image Captioning Models. We show the T2I-CompBench results with different image captioning models in Table 4, where the bottom line corresponds to the baseline diffusion model without concept matching optimization. We can find that all three captioning models can boost the performance of the diffusion model with our framework, where BLIP achieves the best performance. In particular, it is interesting to note that the LLaVA [32] model, a general multimedia large language model, cannot capture the comparative performance with the other two captioning models, which are trained on the image caption task. We provide a detailed analysis in Appendix 0.A.3.
6 Limitation
How to effectively incorporate Multimodal Large Language Models (MLLMs) into text-to-image diffusion models by our proposed method remains under-explored. Given their state-of-the-art image-text understanding capability, we will focus on leveraging MLLMs to enable finer-grained alignment and generation fidelity. In addition, we also observe the potential of CoMat for adapting to 3D domains, promoting the text-to-3D generation with stronger alignment.
7 Conclusion
In this paper, we propose CoMat, an end-to-end diffusion model fine-tuning strategy equipped with image-to-text concept matching. We utilize an image captioning model to perceive the concepts missing in the image and steer the diffusion model to review the text tokens to find out the ignored condition information. This concept matching mechanism significantly enhances the condition utilization of the diffusion model. Besides, we also introduce the attribute concentration module to further promote attribute binding. Our method only needs text prompts for training, without any images or human-labeled data. Through extensive experiments, we have demonstrated that CoMat largely outperforms its baseline model and even surpasses commercial products in multiple aspects. We hope our work can inspire future work of the cause of the misalignment and the solution to it.
References
- [1] Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
- [2] Agarwal, A., Karanam, S., Joseph, K., Saxena, A., Goswami, K., Srinivasan, B.V.: A-star: Test-time attention segregation and retention for text-to-image synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2283–2293 (2023)
- [3] Bakr, E.M., Sun, P., Shen, X., Khan, F.F., Li, L.E., Elhoseiny, M.: Hrs-bench: Holistic, reliable and scalable benchmark for text-to-image models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20041–20053 (2023)
- [4] Black, K., Janner, M., Du, Y., Kostrikov, I., Levine, S.: Training diffusion models with reinforcement learning. arXiv preprint arXiv:2305.13301 (2023)
- [5] Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
- [6] Chefer, H., Alaluf, Y., Vinker, Y., Wolf, L., Cohen-Or, D.: Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. ACM Transactions on Graphics (TOG) 42(4), 1–10 (2023)
- [7] Chen, J., Yu, J., Ge, C., Yao, L., Xie, E., Wu, Y., Wang, Z., Kwok, J., Luo, P., Lu, H., Li, Z.: Pixart-: Fast training of diffusion transformer for photorealistic text-to-image synthesis (2023)
- [8] Chen, M., Laina, I., Vedaldi, A.: Training-free layout control with cross-attention guidance. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 5343–5353 (2024)
- [9] Chen, X., Fang, H., Lin, T.Y., Vedantam, R., Gupta, S., Dollár, P., Zitnick, C.L.: Microsoft coco captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325 (2015)
- [10] Cho, J., Hu, Y., Baldridge, J., Garg, R., Anderson, P., Krishna, R., Bansal, M., Pont-Tuset, J., Wang, S.: Davidsonian scene graph: Improving reliability in fine-grained evaluation for text-to-image generation. In: ICLR (2024)
- [11] Clark, K., Vicol, P., Swersky, K., Fleet, D.J.: Directly fine-tuning diffusion models on differentiable rewards. arXiv preprint arXiv:2309.17400 (2023)
- [12] Dahary, O., Patashnik, O., Aberman, K., Cohen-Or, D.: Be yourself: Bounded attention for multi-subject text-to-image generation. arXiv preprint arXiv:2403.16990 (2024)
- [13] Fan, Y., Watkins, O., Du, Y., Liu, H., Ryu, M., Boutilier, C., Abbeel, P., Ghavamzadeh, M., Lee, K., Lee, K.: Reinforcement learning for fine-tuning text-to-image diffusion models. Advances in Neural Information Processing Systems 36 (2024)
- [14] Fang, G., Jiang, Z., Han, J., Lu, G., Xu, H., Liang, X.: Boosting text-to-image diffusion models with fine-grained semantic rewards. arXiv preprint arXiv:2305.19599 (2023)
- [15] Feng, W., He, X., Fu, T.J., Jampani, V., Akula, A., Narayana, P., Basu, S., Wang, X.E., Wang, W.Y.: Training-free structured diffusion guidance for compositional text-to-image synthesis. arXiv preprint arXiv:2212.05032 (2022)
- [16] Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems 30 (2017)
- [17] Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems 33, 6840–6851 (2020)
- [18] Honnibal, M., Montani, I.: spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing (2017), to appear
- [19] Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021)
- [20] Hu, Y., Liu, B., Kasai, J., Wang, Y., Ostendorf, M., Krishna, R., Smith, N.A.: Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20406–20417 (2023)
- [21] Huang, K., Sun, K., Xie, E., Li, Z., Liu, X.: T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. Advances in Neural Information Processing Systems 36, 78723–78747 (2023)
- [22] Kim, W., Son, B., Kim, I.: Vilt: Vision-and-language transformer without convolution or region supervision. In: International conference on machine learning. pp. 5583–5594. PMLR (2021)
- [23] Kim, Y., Lee, J., Kim, J.H., Ha, J.W., Zhu, J.Y.: Dense text-to-image generation with attention modulation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7701–7711 (2023)
- [24] Li, D., Kamko, A., Sabet, A., Akhgari, E., Xu, L., Doshi, S.: Playground v2, [https://huggingface.co/playgroundai/playground-v2-1024px-aesthetic](https://huggingface.co/playgroundai/playground-v2-1024px-aesthetic)
- [25] Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: International conference on machine learning. pp. 12888–12900. PMLR (2022)
- [26] Li, J., Selvaraju, R., Gotmare, A., Joty, S., Xiong, C., Hoi, S.C.H.: Align before fuse: Vision and language representation learning with momentum distillation. Advances in neural information processing systems 34, 9694–9705 (2021)
- [27] Li, X., Yin, X., Li, C., Zhang, P., Hu, X., Zhang, L., Wang, L., Hu, H., Dong, L., Wei, F., et al.: Oscar: Object-semantics aligned pre-training for vision-language tasks. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX 16. pp. 121–137. Springer (2020)
- [28] Li, Y., Liu, H., Wu, Q., Mu, F., Yang, J., Gao, J., Li, C., Lee, Y.J.: Gligen: Open-set grounded text-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22511–22521 (2023)
- [29] Li, Y., Keuper, M., Zhang, D., Khoreva, A.: Divide & bind your attention for improved generative semantic nursing. arXiv preprint arXiv:2307.10864 (2023)
- [30] Lian, L., Li, B., Yala, A., Darrell, T.: Llm-grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models. arXiv preprint arXiv:2305.13655 (2023)
- [31] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. pp. 740–755. Springer (2014)
- [32] Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems 36 (2024)
- [33] Lu, J., Batra, D., Parikh, D., Lee, S.: Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Advances in neural information processing systems 32 (2019)
- [34] Meral, T.H.S., Simsar, E., Tombari, F., Yanardag, P.: Conform: Contrast is all you need for high-fidelity text-to-image diffusion models. arXiv preprint arXiv:2312.06059 (2023)
- [35] Phung, Q., Ge, S., Huang, J.B.: Grounded text-to-image synthesis with attention refocusing. arXiv preprint arXiv:2306.05427 (2023)
- [36] Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
- [37] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021)
- [38] Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text-conditional image generation with clip latents. arxiv 2022. arXiv preprint arXiv:2204.06125 (2022)
- [39] Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., Sutskever, I.: Zero-shot text-to-image generation. In: International conference on machine learning. pp. 8821–8831. Pmlr (2021)
- [40] Rassin, R., Hirsch, E., Glickman, D., Ravfogel, S., Goldberg, Y., Chechik, G.: Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment. Advances in Neural Information Processing Systems 36 (2024)
- [41] Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., et al.: Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159 (2024)
- [42] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
- [43] Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. pp. 234–241. Springer (2015)
- [44] Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems 35, 36479–36494 (2022)
- [45] Sauer, A., Lorenz, D., Blattmann, A., Rombach, R.: Adversarial diffusion distillation. arXiv preprint arXiv:2311.17042 (2023)
- [46] Sun, J., Fu, D., Hu, Y., Wang, S., Rassin, R., Juan, D.C., Alon, D., Herrmann, C., van Steenkiste, S., Krishna, R., et al.: Dreamsync: Aligning text-to-image generation with image understanding feedback. arXiv preprint arXiv:2311.17946 (2023)
- [47] Tan, H., Bansal, M.: Lxmert: Learning cross-modality encoder representations from transformers. arXiv preprint arXiv:1908.07490 (2019)
- [48] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30 (2017)
- [49] Wang, J., Yang, Z., Hu, X., Li, L., Lin, K., Gan, Z., Liu, Z., Liu, C., Wang, L.: Git: A generative image-to-text transformer for vision and language. arXiv preprint arXiv:2205.14100 (2022)
- [50] Wang, W., Bao, H., Dong, L., Bjorck, J., Peng, Z., Liu, Q., Aggarwal, K., Mohammed, O.K., Singhal, S., Som, S., et al.: Image as a foreign language: Beit pretraining for all vision and vision-language tasks. arXiv preprint arXiv:2208.10442 (2022)
- [51] Wang, Z., Xie, E., Li, A., Wang, Z., Liu, X., Li, Z.: Divide and conquer: Language models can plan and self-correct for compositional text-to-image generation. arXiv preprint arXiv:2401.15688 (2024)
- [52] Wang, Z., Sha, Z., Ding, Z., Wang, Y., Tu, Z.: Tokencompose: Grounding diffusion with token-level supervision. arXiv preprint arXiv:2312.03626 (2023)
- [53] Wen, S., Fang, G., Zhang, R., Gao, P., Dong, H., Metaxas, D.: Improving compositional text-to-image generation with large vision-language models. arXiv preprint arXiv:2310.06311 (2023)
- [54] Wu, T.H., Lian, L., Gonzalez, J.E., Li, B., Darrell, T.: Self-correcting llm-controlled diffusion models. arXiv preprint arXiv:2311.16090 (2023)
- [55] Wu, X., Hao, Y., Zhang, M., Sun, K., Song, G., Liu, Y., Li, H.: Deep reward supervisions for tuning text-to-image diffusion models (2024)
- [56] Xie, J., Li, Y., Huang, Y., Liu, H., Zhang, W., Zheng, Y., Shou, M.Z.: Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7452–7461 (2023)
- [57] Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems 36 (2024)
- [58] Xu, Y., Zhao, Y., Xiao, Z., Hou, T.: Ufogen: You forward once large scale text-to-image generation via diffusion gans. arXiv preprint arXiv:2311.09257 (2023)
- [59] Yang, L., Yu, Z., Meng, C., Xu, M., Ermon, S., Cui, B.: Mastering text-to-image diffusion: Recaptioning, planning, and generating with multimodal llms. arXiv preprint arXiv:2401.11708 (2024)
- [60] Yu, J., Wang, Z., Vasudevan, V., Yeung, L., Seyedhosseini, M., Wu, Y.: Coca: Contrastive captioners are image-text foundation models. arXiv preprint arXiv:2205.01917 (2022)
- [61] Yuksekgonul, M., Bianchi, F., Kalluri, P., Jurafsky, D., Zou, J.: When and why vision-language models behave like bags-of-words, and what to do about it? In: The Eleventh International Conference on Learning Representations (2022)
- [62] Zhang, R., Han, J., Zhou, A., Hu, X., Yan, S., Lu, P., Li, H., Gao, P., Qiao, Y.: Llama-adapter: Efficient fine-tuning of language models with zero-init attention. ICLR 2024 (2023)
- [63] Zhang, R., Jiang, D., Zhang, Y., Lin, H., Guo, Z., Qiu, P., Zhou, A., Lu, P., Chang, K.W., Gao, P., et al.: Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? arXiv preprint arXiv:2403.14624 (2024)
- [64] Zhang, R., Jiang, Z., Guo, Z., Yan, S., Pan, J., Dong, H., Gao, P., Li, H.: Personalize segment anything model with one shot. ICLR 2024 (2023)
- [65] Zhou, X., Koltun, V., Krähenbühl, P.: Simple multi-dataset detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7571–7580 (2022)
- [66] Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023)
- [67] Zou, X., Yang, J., Zhang, H., Li, F., Li, L., Wang, J., Wang, L., Gao, J., Lee, Y.J.: Segment everything everywhere all at once. Advances in Neural Information Processing Systems 36 (2024)
Appendix 0.A Additional Results and Analysis
0.A.1 User preference study

We randomly select 100 prompts from DSG1K [10] and use them to generate images with SDXL [42] and our method (CoMat-SDXL). We ask 5 participants to assess both the image quality and text-image alignment. Human raters are asked to select the superior respectively from the given two synthesized images, one from SDXL, and another from our CoMat-SDXL. For fairness, we use the same random seed for generating both images. The voting results are summarised in Fig. 7. Our CoMat-SDXL greatly enhances the alignment between the prompt and the image without sacrificing the image quality.
0.A.2 Composability with planning-based methods
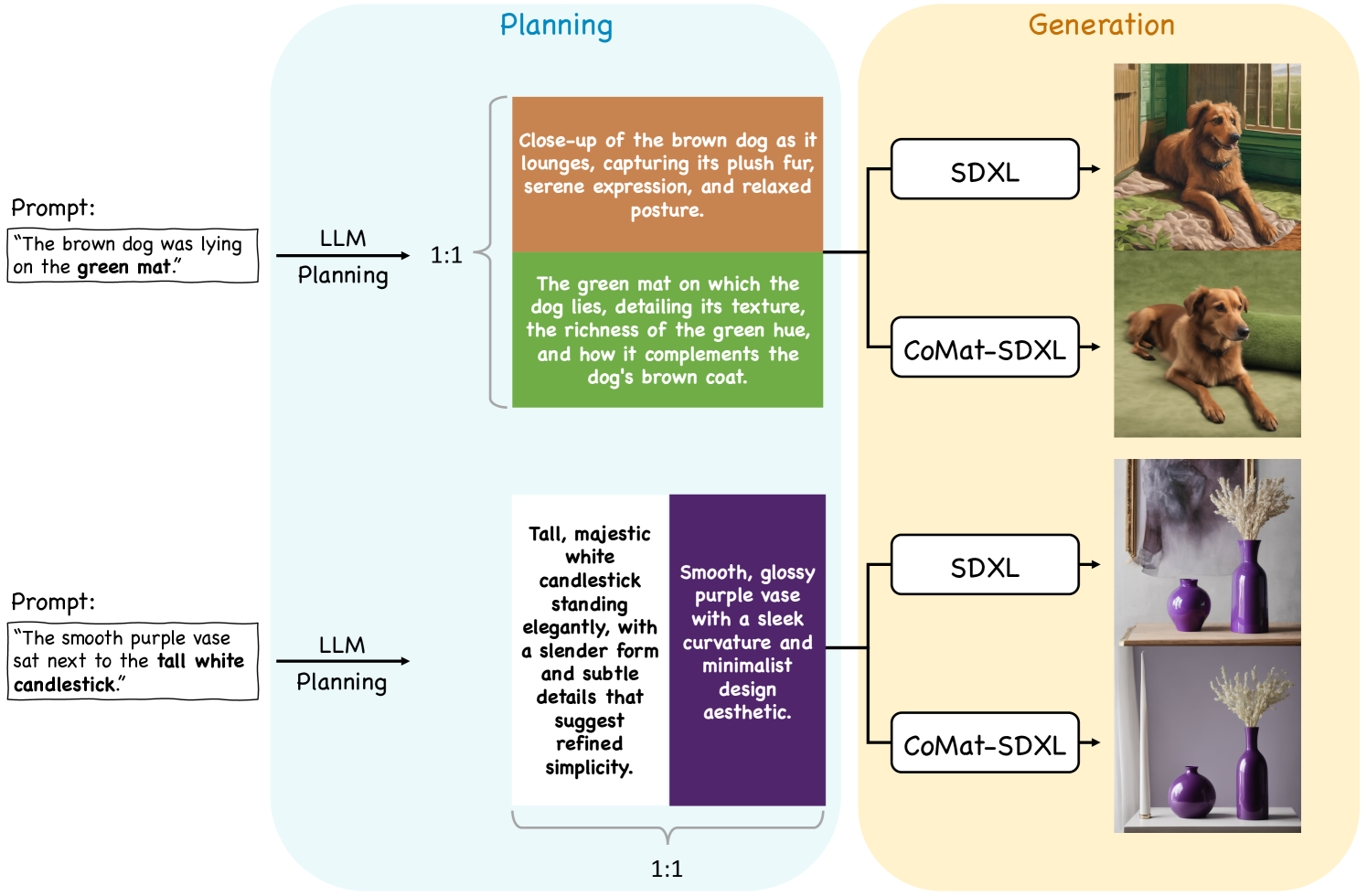
Since our method is an end-to-end fine-tuning strategy, we demonstrate its flexibility in the integration with other planning-based methods, where combining our method also yields superior performance. RPG [59] is a planning-based method utilizing Large Language Model (LLM) to generate the description and subregion for each object in the prompt. We refer the reader to the original paper for details. We employ SDXL and our CoMat-SDXL as the base model used in [59] respectively. As shown in Fig. 8, even though the layout for the generated image is designed by LLM, SDXL still fails to faithfully generate the single object aligned with its description, e.g., the wrong mat color and the missing candle. Although the planning-based method generates the layout for each object, it is still bounded by the base model’s condition following capability. Combining our method can therefore perfectly address this issue and further enhance alignment.
0.A.3 How to choose an image captioning model?
We provide a further analysis of the varied performance improvements observed with different image captioning models, as shown in Table 5 of the main text.

For an image captioning model to be valid for the concept matching module, it should be able to tell whether each concept in the prompt appears and appears correctly. We construct a test set to evaluate this capability of the captioner. Intuitively, given an image, a qualified captioner should be sensitive enough to the prompts that faithfully describe it against those that are incorrect in certain aspects. We study three core demands for a captioner:
-
•
Attribute sensitivity. The captioner should distinguish the noun and its corresponding attribute. The corrupted caption is constructed by switching the attributes of the two nouns in the prompt.
-
•
Relation sensitivity. The captioner should distinguish the subject and object of a relation. The corrupted caption is constructed by switching the subject and object.
-
•
Quantity sensitivity. The captioner should distinguish the quantity of an object. Here we only evaluate the model’s ability to tell one from many. The corrupted caption is constructed by turning singular nouns into plural or otherwise.
We assume that they are the basic requirements for a captioning model to provide valid guidance for the diffusion model. Besides, we also choose images from two domains: real-world images and synthetic images. For real-world images, we randomly sample 100 images from the ARO benchmark [61]. As for the synthetic images, we use the pre-trained SD1.5 [42] and SDXL [36] to generate 100 images according to the prompts in T2ICompBench [21]. These selections make up for the 200 images in our test data. We show the examples in Fig. 9.
For the sensitivity score, we compare the difference between the alignment score (i.e., log-likelihood) of the correct and corrupted captions for an image. Given the correct caption and corrupted caption corresponding to image , we compute the sensitivity score as follows:
| (7) |
Then we take the mean value of all the images in the test set. The result is shown in Table 6. The rank of the sensitivity score aligns with the rank of the gains brought by the captioning model shown in the main text. Hence, except for the parameters, we argue that sensitivity is also a must for an image captioning model to function in the concept matching module.
| Caption Model | Parameters | Sensitivity Score |
| BLIP [25] | 469M | 0.1987 |
| GIT [49] | 394M | 0.1728 |
| LLaVA [32] | 7.2B | 0.1483 |
Appendix 0.B Experimental Setup
0.B.1 Implementation Details
Training Resolutions. We observe that training SDXL is very slow due to the large memory overhead at . However, SDXL is known to generate low-quality images at resolution . This largely affects the image understanding of the caption model. So we first equip the training model with better image generation capability at . We use our training prompts to generate images with pre-trained SDXL. Then we resize these images to and use them to fine-tune the UNet of SDXL for 100 steps, after which the model can already generate high-quality images. We continue to implement our method on the fine-tuned UNet.
Training Layers for Attribute Concentration. We follow the default setting in [52]. Only cross-attention maps in the middle blocks and decoder blocks are used to compute the loss.
Hyperparameters Settings. We provide the detailed training hyperparameters in Table 7.
| Name | SD1.5 | SDXL |
| Online training model | ||
| Learning rate | 5e-5 | 2e-5 |
| Learning rate scheduler | Constant | Constant |
| LR warmup steps | 0 | 0 |
| Optimizer | AdamW | AdamW |
| AdamW - | 0.9 | 0.9 |
| AdamW - | 0.999 | 0.999 |
| Gradient clipping | ||
| Discriminator | ||
| Learning rate | 5e-5 | 5e-5 |
| Optimizer | AdamW | AdamW |
| AdamW - | ||
| AdamW - | ||
| Gradient clipping | ||
| Token loss weight | 1e-3 | 1e-3 |
| Pixel loss weight | 5e-5 | 5e-5 |
| Adversarial loss weight | 1 | 5e-1 |
| Gradient enable steps | ||
| Attribute concentration steps | ||
| LoRA rank | 128 | 128 |
| Classifier-free guidance scale | 7.5 | 7.5 |
| Resolution | ||
| Training steps | 2,000 | 2,000 |
| Local batch size | ||
| Mixed Precision | FP16 | FP16 |
| GPUs for Training | 8 NVIDIA A100 | 8 NVIDIA A100 |
| Training Time | 10 Hours | 24 Hours |
Appendix 0.C More Qualitative Results


