Improve Knowledge Distillation via Label Revision and Data Selection
Abstract
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher’s inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
Knowledge distillation has significance and potential implications in the field of machine learning and model compression, making it a powerful technique for model optimization and deployment in real-world scenarios. It enables the transfer of knowledge from a large, highly accurate teacher model to a smaller, computationally efficient student model. This process not only reduces the model size but also improves its generalization capabilities. However, in knowledge distillation, despite performing well on specific tasks, the teacher model may make incorrect predictions which can potentially mislead the training of the student model. In this paper, the proposed method aims to address the issue of erroneous predictions from the teacher model. By incorporating two key aspects, label revision and data selection, these approaches seeks to minimize the impact of incorrect supervision, with the potential to enhance the accuracy and reliability of knowledge distillation.
Knowledge Distillation, Lightweight Model, Image Classification
1 Introduction
In recent years, lightweight models have attracted more and more attention for deploying deep neural networks (DNNs) on resource-constrained devices due to their property of being less parameterized [1, 2, 3]. Among the various approaches used to build and train lightweight models, knowledge distillation (KD) has been proven to be a highly effective method for achieving model compression, and promoting the performance of lightweight models in various applications [4, 5, 6, 7]. KD works by transferring knowledge from a high-capacity network (the teacher) to a smaller one (the student) [8, 9, 10]. Typically, the teacher is a large neural network or network set with a large number of parameters, whereas the student network is compact and lightweight. Given a powerful teacher network, it is used to supervise the training of the student by utilizing the information (referred to as “knowledge”) such as final predictions [8, 11], intermediate feature maps [12, 13], or the relationships between different layers or samples [14, 15]. Under the teacher’s supervision, the accuracy of the student network will be significantly improved, with much less storage and computation cost.
The seminal work of [8] trains the student using the logits of the teacher, which provides additional knowledge of inter-class probabilities and similarities. Specifically, the student is trained to mimic the predictions of teacher by minimizing the Kullback-Leibler (KL) divergence. In addition to the classical supervision of ground-truth labels, an extra logit loss is introduced as a powerful regularization, where the teacher’s predictions are regarded as the soft labels to supervise the training of student. One drawback of this vanilla KD method is that the knowledge of the teacher is only represented by the final layer, ignoring the enriched intermediate-level information that has been proven to be crucial for learning representations [12, 16]. Recent works are built upon the theoretical basis of vanilla KD, aiming at further capturing the wealth of knowledge contained in intermediate feature maps by exploiting auxiliary loss functions to overcome this limitation [17, 18, 19, 20]. For instance, Yang et al. [21] introduced additional feature matching and regression losses to optimize the penultimate layer feature of the student. SemCKD [19] uses an attention mechanism to minimize the calibration loss in cross-layer knowledge distillation. There are also some methods that focus on extending different training strategy to improve transfer efficiency [14, 22]. Through these approaches, the performance of the student models has been constantly enhanced.
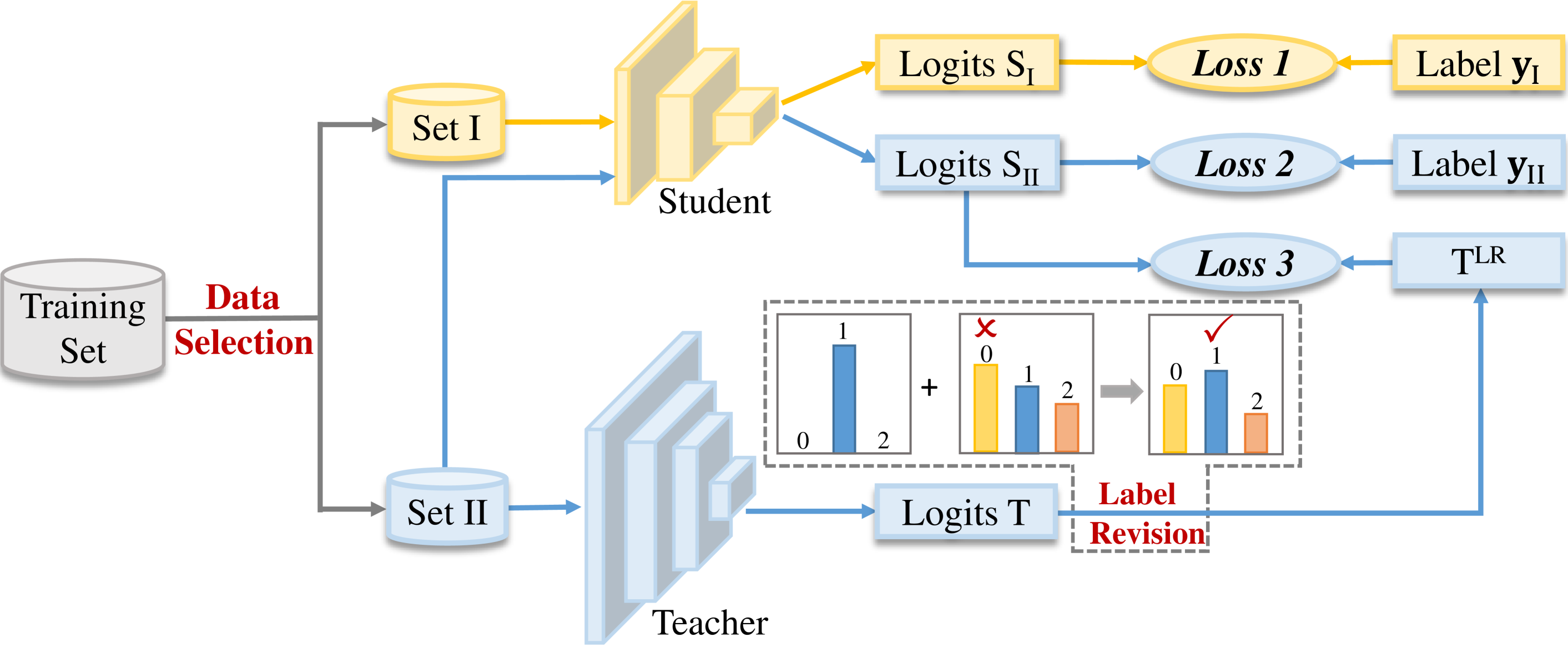
However, most of the algorithms are developed based on the vanilla KD framework, under the supervision of teacher models. Although the teacher usually has been trained well on specific tasks, it still contains incorrect knowledge such as wrong predictions. The previous works have not given much consideration to the reliability of the teacher models. Since the ground truth labels (hard labels) and teacher predictions (soft labels) are both utilized to supervise the student in vanilla KD, two problems will arise naturally during the learning process. The first problem is that the teacher will also assign probabilities to incorrect classes. Although this kind of “dark knowledge” typically contains information on relative probabilities that has been shown to be beneficial for generalization, it is not fully trustworthy and some incorrect knowledge such as wrong predictions will also be transferred to student, misleading the direction of learning [22]. Additionally, wrong predictions will contradict ground truth that may cause confusion. Analogous to real-life learning in classes, the students will not be able to make correct judgments if they receive inconsistent information from different teachers for the same task. Therefore, to alleviate the negative impact of such incorrect supervision from the teacher and contradictions with ground truth, we first propose Label Revision (LR) to rectify the wrong predictions from the teacher via ground truth. Specifically, the ground-truth label is first reformulated as one-hot label, and then the soft labels of teacher are combined with the one-hot label based on meticulously designed rules. In this way, the wrong probabilities in teacher predictions can be revised, while the relative information among different classes can also be maintained.
The other concern is whether the student needs the supervision from teacher on the entire dataset. Intuitively, the more guidance provided by the teacher, the greater the probability of containing wrong predictions. Therefore, we further introduce a Data Selection (DS) technique to select appropriate data for distillation, thereby reducing the impact of incorrect supervision to some extent. During the training of the student model with a whole training set, only a portion of the training samples are selected to be supervised by the teacher with logits loss, while the remaining samples are directly supervised by ground-truth using a single cross-entropy loss. The entire procedure of the proposed method, including LR and DS, is illustrated in Figure 1. First, the entire training set is split into two parts (i.e., Set I and Set II) based on a certain criterion. Next, Set I is input to both the teacher and student models to obtain the logits loss, where the teacher’s predictions are revised by LR before calculating the loss. For Set II, it is only input to the student and the loss is computed as the cross-entropy loss between student’s logits and ground truth. We summarize our main contributions as follows:
-
1)
To obtain more reliable supervision from the teacher model, we propose to rectify the incorrect predictions contained in teacher’s soft labels using the ground truth. Without destroying hidden knowledge, the revised soft labels still maintain the relative information among different classes.
-
2)
We also introduce a data selection technique to select appropriate training samples for distillation from the teacher to the student, which further decreases the impact of wrong supervision.
-
3)
Extensive experiments with different datasets and network architectures are conducted to illustrate the effectiveness of our proposed method. It is also demonstrated that our method can be applied to other distillation approaches and bring improvements on their performance.
2 Related Work
2.1 Knowledge Distillation
The concept of knowledge distillation was first introduced in the pioneering work of Hinton et al. [8]. This technique leverages the knowledge contained in a larger teacher model to train a smaller student model. Initially, the method regards the output of the softmax layer of the teacher network, which is referred to as logits, as soft labels to supervise the training of the student. Building upon this idea, subsequent works have introduced various knowledge representations to achieve more accurate and efficient learning. These methods can be roughly divided into three categories according to the type of knowledge: logits-based distillation, feature-based distillation, and relation-based distillation [16].
Logits-based Distillation As used in [8], logits refer to the final predictions of models. The vanilla method converts the logits into soft probability through a softmax function, where a temperature parameter is introduced for scaling small probabilities that contain valuable information and play an important role in supervision. To further improve accuracy, numerous methods have explored the potential of soft labels and made better use of logits. Zhou et al. [23] analyzed the impact of soft labels on the bias-variance trade-off during training and proposed to dynamically distribute weights to different samples for balance. Mirzadeh et al. observed that the performance of student network will greatly degrade when the gap between the student and teacher is large. Thus, they introduced a small assistant network to distill the knowledge step by step. Kim et al. [24] explored mean squared error (MSE) to replace the original KL divergence loss in vanilla KD and achieved superior distillation performance. In SimKD [10], the classifier of teacher model is reused to make predictions for student model, where the output of the student is scaled by additional layers to match the dimensions of the teacher’s output. However, the deployment cost will also increase due to the additional layers and teacher’s classifier. Instead of introducing extra components, Zhao et al. [25] directly reformulated the loss of vanilla KD, which identified the target class and non-target classes in classification tasks to balance the contributions of training samples more effectively.
Feature-based Distillation Since the performance gap between the student and teacher models is still large after logits-based distillation, new representations of knowledge have been explored by leveraging the information of features. The intermediate layers play an important role, especially when the neural network is deep, and the information contained in these layers can also be utilized as knowledge to train the student. FitNets [12] first forces the student to mimic the corresponding intermediate features of teacher. Rather than utilizing the feature information, [26] further fitted the attention maps of the student and teacher. Besides, [27] extended the attention map by neuron selectivity transfer. To make it easier to transfer the knowledge from the teacher to student, Kim et al. [28] introduced several factors to represent the features in a more understandable format. Jin et al. [13] proposed hint learning with a constraint on the route, which supervised the student by the outputs of hint layers in the teacher. VID [18] transfers knowledge by maximizing variational information. Inspired by contrastive learning, CRD [29] utilizes the representational knowledge in the teacher to capture the relationship among each dimension. CTKD [30] applies collaborative teaching and trains the student using two teachers synchronously. SRRL [21] focuses on training the student’s penultimate layer by using teacher’s classifier. SemCKD [19] introduces an attention mechanism that can automatically assign the most semantically related layer in the teacher model for each student layer, and the work is further extended to different scenarios [31]. Kao et al. [6] proposed SEL that enables the student to obtain various expertise knowledge from different networks.
Compared with logits-based distillation, feature-based methods can capture richer information, while the computation cost will also increase due to heavy feature transformation.
Relation-based Distillation: Relation-based distillation methods focus on the relationship between different data samples or network layers. Lee et al. [14] proposed to use the correlation between feature graphs as knowledge and extract the key information via singular value decomposition. RKD [32] transfers the structured relationship between the outputs of the teacher to student. Passalis et al. [15] explored the hint information, which utilizes the mutual information flow from pairs of hint layers in the teacher to train the student. In addition to the relationship among different layers, data samples also contain rich knowledge. For example, Passalis et al. [33] modeled the relationship of data samples as a probability distribution via the feature representation of the data, where the teacher and student can be matched by transferring the probability distribution. MASCKD [34] explores more powerful relation knowledge and introduce attention maps to build correlations between samples.
2.2 Data Selection
When training a model, different training samples will have varying contributions to specific behaviors of model. Measuring the effect of different samples and selecting more appropriate ones for training can help improve the performance of model to some extent [35, 36]. In fact, data selection technique has been explored in many fields such as active learning [37, 38], adversarial learning [39, 40], transfer learning [41, 42] and reinforcement learning [43]. To quantify the value of data samples for further selection, various algorithms have been explored. Koh et al. [44] estimated the effect of individual data through influence function [45], which perturbs each training sample and measures changes in the model’s output. Data Shapley [46] regards the improvement of marginal performance as data values, where all the possible subsets of the whole training set are considered. TracIn [47] tracks the gradient information during training and monitors the changes in model predictions as each training sample is accessed. By quantifying the contributions of training data, more appropriate samples can be selected to further improve the performance or efficiency of model training.
3 Proposed Method
In this section, we first provide a brief introduction to the vanilla KD method including some essential notations. Then, we introduce the proposed method to revise soft labels of the teacher and describe the data selection technique applied before distillation in detail. For reference, the main notations are listed in Table 1.
| The entire training set, where . and are samples and labels, respectively. | |
| Training subsets, where . | |
| Model parameter set. | |
| Optimal model parameters, where . | |
| The logits of the teacher and student, respectively. | |
| The right and wrong part of student’s logits, respectively, which are split according to teacher’s prediction. | |
| Perturbation added on sample . | |
| Softmax probabilities of the teacher. | |
| The softmax function. | |
| Risk of model with parameter on sample . | |
| The loss of right and wrong part, respectively. | |
| Hyper-parameters. |
3.1 Preliminaries
Vanilla Knowledge Distillation. The fundamental concept behind vanilla KD is to train the student model to mimic the outputs of the teacher model, by minimizing the difference between their predictions for a given set of input data. This is accomplished by combining the original loss function (i.e., cross-entropy loss) with an additional distillation loss term. Suppose the logits of the teacher and student model are and , respectively. Then, the total loss function of vanilla KD can be expressed as:
| (1) |
where donates the distillation loss and is the cross-entropy loss between model predictions and ground-truth label y in classification. refers to the softmax function. Here, a hyperparameter is introduced as a weight to balance the two losses.
In general, the distillation loss is typically a soft version of the original loss function, which encourages the student to learn the same underlying information as the teacher model. As used in [8], it is defined as the KL divergence between the logits of student and teacher. In the original softmax function, the output values are transformed into a probability distribution over the set of possible classes. To allow the student to capture more knowledge contained in teacher, the distillation loss involves a temperature parameter to the softmax function. Thus, the distillation loss can be reformulated as:
| (2) |
A higher temperature will result in a softer and more diffuse probability distribution. This softer distribution encourages student to learn from the decision-making process of teacher rather than simply mimicking its outputs.
Data Impact Estimation. There has been various algorithms to estimate the impact of different training samples that can help select data, such as influence-based methods and shapley-based methods. Among these methods, the influence function is one of the most popular tools for data selection due to the advantage of low complexity without retraining models [48, 49]. The influence function is first developed in the field of statistics [45, 50], and has been applied to measure the influence of data samples [44]. Without retraining the model, it provides an efficient way to estimate the change on model predictions or parameters if a sample is perturbed slightly. Let donate a set of data pairs, and model parameter set is , where the optimal parameter after convergence is,
| (3) |
When the i-th training sample is perturbed by an infinitesimal step , the new optimal parameters will change to
| (4) |
Using influence function [45], the change on model parameters can be roughly estimated as:
| (5) |
where is the Hessian matrix and is the loss at point .
We can also approximate the change in model predictions at a test sample based on the chain rule [44], that is,
| (6) |
3.2 Revise Soft Labels of Teacher
The loss function in Equation (1) shows that the student model is supervised by the logits of teacher and hard labels (i.e., y) simultaneously. However, even if the teacher model is pre-trained well, it can still make incorrect predictions, which may conflict with the guidance provided by the hard labels, leading to decline on accuracy of the student model. The vanilla KD method utilizes an extra cross-entropy loss to decrease the impact of wrong predictions, but the revision is insufficient to make reliable supervision and there remains noteworthy wrong information. To address this issue, we propose to improve the reliability of the teacher’s supervision by revising its soft labels. Specifically, we focus on the wrong soft labels provided by the teacher and propose to revise them via hard labels, where the revised label is a linear combination of hard labels in one-hot form and teacher’s soft labels. Assuming that the finally predicted probabilities of teacher after softmax is , where is the number of classes. Then, the new revised soft label can be computed as:
| (7) |
We donate as the corresponding probability of the predicted class, that is, the maximum probability, and as the corresponding probability of the true target class. To rectify the probability so that the maximum probability is consistent with the hard label, the choice of weight parameter needs to meet the constraint, that is,
| (8) |
The constraint can be reformulated as,
| (9) |
where is a coefficient that is smaller than 1. Instead of directly swapping the predicted probability of the target class and incorrect class, as applied in [51], our proposed strategy can maintain the relative probabilities between similar classes from the perspective of feature representation, which has been proved to be beneficial to generalization of networks [22].
Considering a simple case of a four-class classification, suppose that there is a sample belonging to Class 3 and the one-hot hard label is y = [0, 0, 0, 1]. However, the teacher model makes a wrong prediction as Class 2 with probabilities of = [0.1, 0.1, 0.5, 0.3]. According to the proposed strategy of Eq. (7), the soft label with be rectified as = [0.075, 0.075, 0.375, 0.475] if is set as 0.9. As shown in Figure 2, the target class obtains the maximum probability after revising.
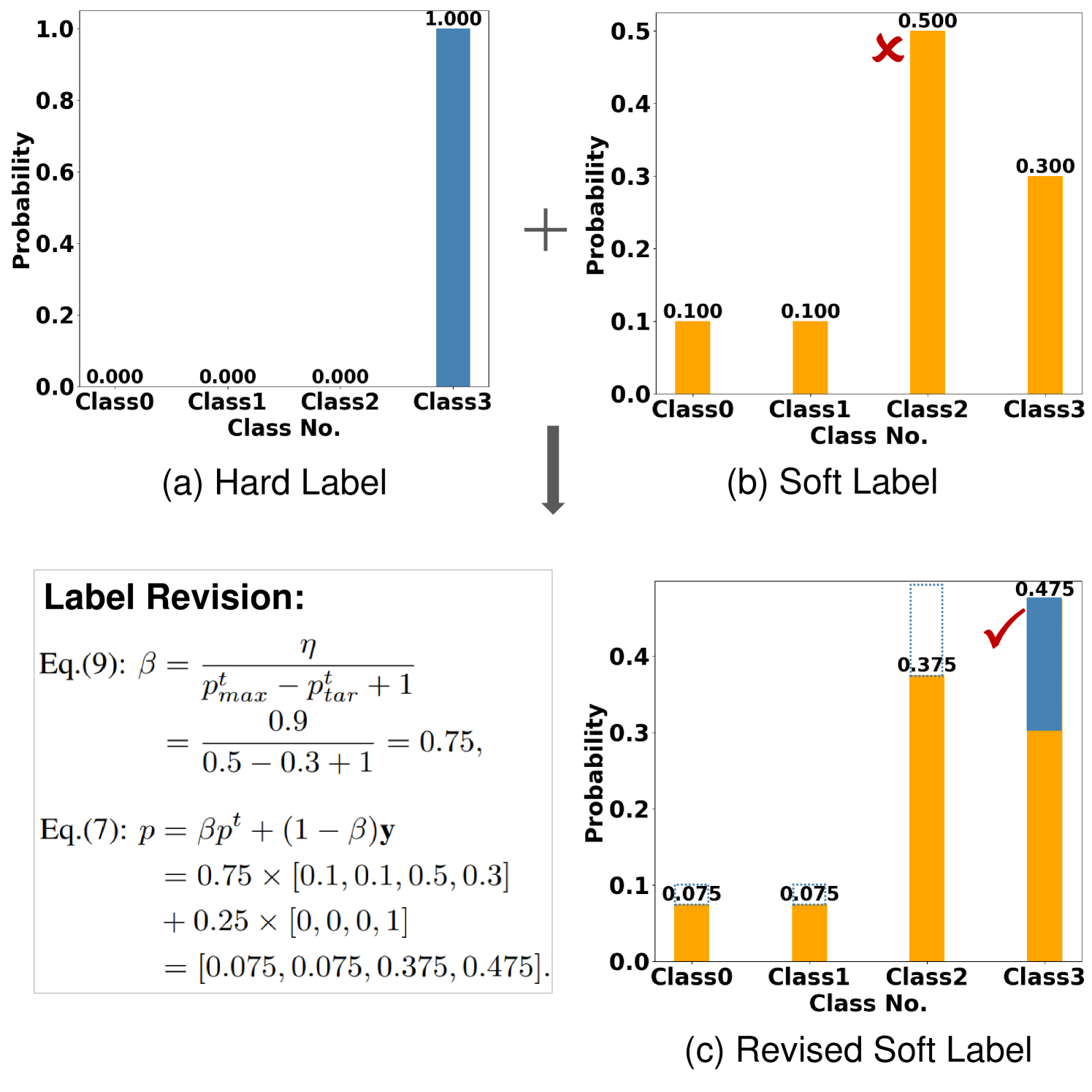
After obtaining the new soft labels, we can then compute the loss between student and teacher. To take full advantage of logits information, we replace the original KL loss with Mean Square Error (MSE) as suggested in [12, 24]. Thus, the new loss of wrong predictions will be:
| (10) |
The cross-entropy loss between ground truth and wrong predictions is not considered here, because has already contained the correct information from the true labels. The logits of the student are also normalized using the softmax function to match . For the remaining right predictions that do not require revision, the loss is calculated by Eq. (1). By integrating the wrong and right parts, we can then obtain the total new loss as:
| (11) |
where {} are the coefficients to balance each term, which can be adjusted flexibly. The revised soft label of the wrong part is calculated by Eq. (7).
3.3 Select Appropriate Data to Distill
Most previous KD methods concentrate on extracting more information from the teacher to improve the accuracy of the student, but few of them consider the impact of training data, which has a significant effect on the performance of supervised learning. To alleviate the wrong supervision from teacher, we have proposed to revise the soft labels in the previous section. From a different perspective of training data, it is also worth considering whether the supervision of the teacher is necessary to be applied to the entire training set. Therefore, we introduce a data selection technique to further decrease the risk of incorrect supervision.
To train a student model, we select only a portion of the training samples to transfer the knowledge from the teacher, the remaining samples are directly supervised by ground-truth. Specifically, for a pre-trained teacher model, we first calculate the influence score of each sample in training set using Eq. (5) and sort the samples based on these scores to form a new set . Then, we split into two subsets and , where is supervised by the teacher with revised soft labels while is only supervised by ground-truth. The loss on subset is calculated using Eq. (11), while the loss on subset is the original cross-entropy loss between the student’s prediction and ground-truth. Finally, the overall loss is the summation of these two losses. It is worth noting that the split of is flexible, for example, we can select the top 50% (or 20%, 80% and so on) of the samples as and the remaining portion as . In the experimental section, we conduct an ablation study to evaluate the performance of different split strategies.
To make a comprehensive view of our proposed method of LR and DS, we summarize the whole process to train the student model in Algorithm 1.
4 Experiments
To demonstrate the effectiveness of our proposed method, we conduct various experiments on image classification tasks. Firstly, we present the results of using or not using LR and DS, compared with vanilla KD. Next, we compare the performance our method with state-of-the-art distillation approaches. We also apply our method to other approaches to show that our method is compatible with them and can help improve their performance. Finally, ablation studies are also conducted to illustrate the sensitivity of our method to different settings of hyper-parameters.
4.1 Experiment Setup
4.1.1 Dataset and Network Architectures
The experiments involve three popular datasets on classification tasks.
CIFAR-100 [52]. The CIFAR-100 dataset consists of 100 classes with a total of 60K colorful images, where each class has 50K training images and 10K test samples.
ImageNet-2012 [53]. ImageNet-2012 is a large-scale dataset that contains around 1.2M training images and 50K validation samples from 1,000 different classes. The sizes of images in ImageNet are various so that they are often cropped as 224x224 for uniform.
With respect to the network architectures, different combinations of teacher-student model are applied for evaluation. The selected architectures are all widely-used in classification, that are, VGG [54], ResNet [55], ShuffleNet [56, 57] and MobileNet [2, 58].
4.1.2 Compared Methods
We compare our proposed method with both logit-based and feature-based methods. We also combine our method with other distillation approaches to illustrate that the proposed method is compatible and can help improve their performance. The experimental settings of the compared methods follow their original papers.
Logit-based distillation: Vanilla KD [8], VBD [59], DTD-LA [51], DKD [25], CTKD [60].
Feature-based distillation: FitNet [12], PKT [61], VID [18], SRRL [21] and SemCKD [31]
4.1.3 Training Details
To ensure fair comparison, we follow the same training settings as in the previous works [29, 19]. In all experiments, stochastic gradient descent (SGD) with momentum 0.9 is adopted as the parameter optimizer. For CIFAR-100, the initial learning rate is set to 0.05 except for ShuffleNet and MobileNet, whose initial learning rate is 0.01 instead. The learning rate is divided by 10 at the 150, 180 and 210 epoch during the whole training process of 240 epochs. The batch size for both training and test sets is 64. For ImageNet, the model is trained 120 epochs, with an initial learning rate of 0.1, which is divided by 10 every 30 epochs. The batch size on ImageNet is set to 256.
Throughout the experiments, we set the temperature of vanilla KD loss to 4, which is consistent with [29, 19]. In terms of DS, we select 80% samples with higher influence scores as to be supervised by the teacher and the remaining 20% samples as to be directly supervised by ground-truth labels. When conducting LR, the hyper-parameter is set as 0.8. We further explore the impact of hyper-parameters in the ablation study. The results on CIFAR-100 are reported as the mean of three trials, while the results on ImageNet are obtained from a single trial. As for hardware, the experiments on CIFAR-100 are conducted on a single NVIDIA Tesla P40, which three Tesla V100S are used for ImageNet.
| Baseline Acc: 74.12% | ||
| PCT(%) | Strategy | Acc(%) |
| 20 | Random | 70.54 |
![[Uncaptioned image]](x3.png)
|
70.10 | |
![[Uncaptioned image]](x4.png)
|
71.13 | |
| 50 | Random | 73.05 |
![[Uncaptioned image]](DS3.png)
|
73.60 | |
![[Uncaptioned image]](DS4.png)
|
73.69 | |
| 80 | Random | 74.70 |
![[Uncaptioned image]](DS5.png)
|
74.59 | |
![[Uncaptioned image]](DS6.png)
|
74.81 | |
-
•
1. The entire dataset is represented as a rectangle, where the samples are arranged in ascending order of influence score.
-
•
2. The gray part represents and the white part is . For example, the icon
![[Uncaptioned image]](x5.png) means that contains 20% samples with lower score and contains the remaining 80% samples with higher score.
means that contains 20% samples with lower score and contains the remaining 80% samples with higher score.
| Method | DS | LR | Acc (%) | |
| KD [8] | (KL) | 74.12 | - | |
| (MSE) | 74.34 | 0.22 | ||
| ✓ | 75.33 | 1.21 | ||
| ✓ | 74.81 | 0.69 | ||
| ✓ | ✓ | 75.76 | 1.64 | |
| PKT [61] | 74.81 | - | ||
| ✓ | 75.15 | 0.34 | ||
| ✓ | 74.93 | 0.12 | ||
| ✓ | ✓ | 75.53 | 0.72 |
| Teacher | ResNet324 | WRN-40-2 | WRN-40-2 | ResNet56 | VGG13 | ResNet324 | ResNet324 | ResNet324 | WRN-40-2 | WRN-40-2 |
| 79.42 | 76.31 | 76.31 | 72.41 | 74.64 | 79.42 | 79.42 | 79.42 | 76.31 | 76.31 | |
| Student | ResNet84 | WRN-40-1 | WRN-16-2 | ResNet20 | VGG8 | VGG8 | ShuffleNetV1 | ShuffleNetV2 | MobileNetV2 | ShuffleNetV1 |
| 73.09 | 71.92 | 73.51 | 69.06 | 70.36 | 73.09 | 71.92 | 73.51 | 69.06 | 70.36 | |
| Vanilla KD [8] | 74.12 | 73.42 | 74.92 | 70.66 | 72.66 | 72.73 | 74.07 | 74.45 | 69.07 | 74.83 |
| Our | 76.60 | 74.53 | 75.99 | 71.61 | 74.31 | 74.08 | 75.26 | 76.78 | 69.39 | 76.90 |
| 2.48 | 1.11 | 1.07 | 0.95 | 1.65 | 1.35 | 1.19 | 2.33 | 0.32 | 2.07 |
| Type | Teacher | ResNet324 | WRN-40-2 | WRN-40-2 | ResNet56 | VGG13 | ||||||||||
| 79.42 | 76.31 | 76.31 | 72.41 | 74.64 | ||||||||||||
| Student | ResNet84 | WRN-40-1 | WRN-16-2 | ResNet20 | VGG8 | |||||||||||
| 73.09 | 71.92 | 73.51 | 69.06 | 70.36 | ||||||||||||
| - | OA | LDA | OA | LDA | OA | LDA | OA | LDA | OA | LDA | ||||||
| Logits | Vanilla KD [8] | 74.12 | 74.81 | 0.69 | 73.42 | 74.25 | 0.83 | 74.92 | 75.39 | 0.47 | 70.66 | 71.32 | 0.66 | 72.66 | 73.49 | 0.83 |
| DTD-LA [51] | 73.78 | 75.15 | 1.37 | 73.49 | 73.76 | 0.27 | 74.73 | 75.54 | 0.81 | 70.99 | 71.24 | 0.25 | 72.98 | 73.87 | 0.89 | |
| DKD [25] | 76.02 | 76.49 | 0.47 | 76.11 | 76.23 | 0.12 | 76.55 | 76.75 | 0.20 | 71.79 | 71.90 | 0.11 | 74.68 | 74.88 | 0.20 | |
| CTKD [60] | 74.49 | 75.24 | 0.75 | 73.84 | 74.21 | 0.37 | 75.51 | 75.72 | 0.21 | 71.13 | 71.99 | 0.86 | 73.36 | 73.84 | 0.48 | |
| Features | FitNet [12] | 74.32 | 75.72 | 1.40 | 74.12 | 74.56 | 0.44 | 75.04 | 75.68 | 0.64 | 71.52 | 71.96 | 0.44 | 73.54 | 73.86 | 0.32 |
| PKT [61] | 74.81 | 75.53 | 0.72 | 73.51 | 73.78 | 0.27 | 75.60 | 75.76 | 0.16 | 70.92 | 71.35 | 0.43 | 73.40 | 74.16 | 0.76 | |
| VID [18] | 74.49 | 75.90 | 1.41 | 74.20 | 74.79 | 0.59 | 74.79 | 75.14 | 0.35 | 71.71 | 72.01 | 0.30 | 73.96 | 73.61 | -0.35 | |
| SRRL [21] | 75.39 | 76.15 | 0.76 | 74.98 | 75.16 | 0.18 | 75.55 | 76.20 | 0.65 | 72.01 | 71.79 | -0.22 | 74.68 | 74.81 | 0.13 | |
| SemCKD [31] | 75.58 | 76.35 | 0.77 | 74.78 | 74.57 | -0.21 | 75.42 | 75.52 | 0.10 | 71.98 | 72.31 | 0.33 | 74.42 | 74.75 | 0.33 | |
| Type | Teacher | ResNet324 | ResNet324 | ResNet324 | WRN-40-2 | WRN-40-2 | ||||||||||
| 79.42 | 79.42 | 79.42 | 76.31 | 76.31 | ||||||||||||
| Student | VGG8 | ShuffleNetV1 | ShuffleNetV2 | MobileNetV2 | ShuffleNetV1 | |||||||||||
| 73.09 | 71.92 | 73.51 | 69.06 | 70.36 | ||||||||||||
| - | OA | LDA | OA | LDA | OA | LDA | OA | LDA | OA | LDA | ||||||
| Logits | Vanilla KD [8] | 72.73 | 72.92 | 0.19 | 74.07 | 74.21 | 0.14 | 74.45 | 75.45 | 1.00 | 69.07 | 69.54 | 0.47 | 74.83 | 75.50 | 0.67 |
| DTD-LA [51] | 72.67 | 73.00 | 0.33 | 73.99 | 74.88 | 0.89 | 75.05 | 76.24 | 1.19 | 68.99 | 69.57 | 0.58 | 74.90 | 75.87 | 0.97 | |
| DKD [25] | 74.10 | 74.55 | 0.45 | 75.88 | 75.71 | -0.17 | 76.87 | 77.06 | 0.19 | 69.47 | 69.58 | 0.11 | 76.41 | 76.52 | 0.11 | |
| CTKD [60] | 73.54 | 74.27 | 0.73 | 74.37 | 75.49 | 1.12 | 75.42 | 75.51 | 0.09 | 69.21 | 69.45 | 0.24 | 75.80 | 76.14 | 0.34 | |
| Features | FitNet [12] | 72.91 | 73.53 | 0.62 | 74.52 | 74.64 | 0.12 | 74.23 | 75.42 | 1.19 | 68.71 | 68.77 | 0.06 | 74.11 | 76.11 | 2.00 |
| PKT [61] | 73.08 | 73.82 | 0.74 | 74.05 | 74.94 | 0.89 | 74.69 | 75.84 | 1.15 | 68.80 | 69.06 | 0.26 | 75.68 | 75.87 | 0.19 | |
| VID [18] | 73.19 | 74.04 | 0.85 | 74.28 | 75.58 | 1.30 | 75.22 | 76.01 | 0.79 | 68.91 | 68.33 | -0.58 | 74.41 | 75.88 | 1.47 | |
| SRRL [21] | 74.06 | 74.57 | 0.51 | 75.38 | 76.04 | 0.66 | 76.19 | 77.07 | 0.88 | 69.34 | 69.56 | 0.22 | 75.22 | 76.23 | 1.01 | |
| SemCKD [31] | 75.27 | 75.51 | 0.24 | 75.41 | 76.45 | 1.04 | 77.63 | 77.85 | 0.22 | 69.88 | 69.98 | 0.10 | 76.83 | 77.46 | 0.63 | |
4.2 Effect of LR and DS
Influenced-based selection v.s. Random selection. When conducting DS, we propose to select appropriate samples according to certain criterion (e.g., influence score), where the entire dataset is split into two parts and . is input to both the teacher and student models at the same time, while is only applied to the student. To investigate the effect of this kind of specific selection and random selection, which is the simplest way to realize DS, we evaluate the performance on CIFAR-100. For detailed illustration, we also set different selection percentages of (i.e., 20%, 50% and 80%), and the baseline is vanilla KD.
Table 2 presents the results of our experiments on the impact of the amount of data input to the teacher on the distillation accuracy. The results indicate that, when the amount of data input to the teacher is relatively small, the distillation accuracy is worse than vanilla KD. This finding highlights the necessity of the guidance from the teacher model. For instance, when only 20% samples are used for the teacher, the accuracy is only around 71%, which is significantly lower than vanilla KD. When there are enough samples to receive supervision from the teacher, the performance of selecting data based on influence score is relatively better than random selection. Furthermore, the accuracy gain of selecting data with higher scores is more significant. We ascribe this kind of phenomenon to an hypothesis that the samples with higher scores may be more difficult to be classified, so that they need supervision from teacher model to provide more information for classification. Thus, based on these observations, we follow the strategy of selecting 80% samples with higher influence score to be supervised by teacher in the following experiments.
Performance gain of each part. We also conduct a simple comparison on CIFAR-100 to evaluate the contribution brought by the proposed LR and DS. The results are presented in Table 3. To explore the effect of LR and DS, we individually apply them on vanilla KD [8] and PKT [61]. The results show that both DS and LR are helpful to improve the distillation performance, but the gain from individually applying one of them is limited (e.g., 0.12% of DS and 0.34% of LR on PKT). Therefore, the results suggest that the combination of DS and LR is necessary to achieve better performance. Besides, to eliminate the influence of MSE, we also compare the performance of directly replacing KL divergence with MSE for calculating the KD loss. It can be noted that the performance gain is still lower than using LR and DS, showing the effectiveness of the proposed method. Furthermore, it is initially illustrated that DS and LR are compatible with other distillation methods to improve their performance. More combination results will be provided in the following section.
4.3 Main Results
CIFAR-100. In Table 4-6, we provide a comprehensive comparison of our method with other distillation approaches, including both logits-based and feature-based methods. We also choose various combinations of the teacher and student models, where the architectures of models are either similar (Table 5) or quite different (Table 6).
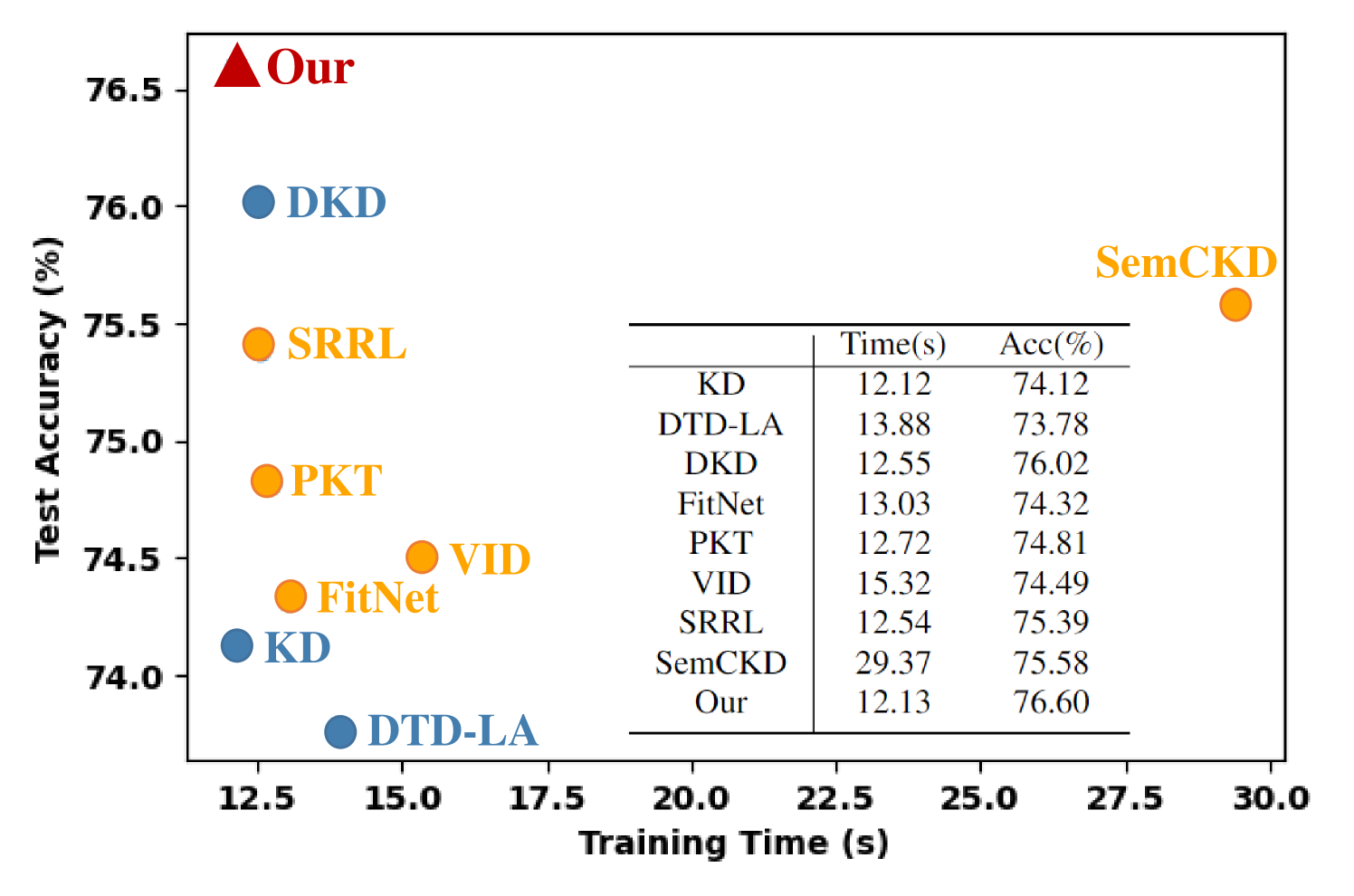
In Table 4, the accuracy of our proposed method can be improved on all combinations of teacher and student compared with vanilla KD, and the improvement are significant in some cases. It is also inspired that our method can achieve comparable or even better performance than some of feature-based distillation. For example, for “WRN-40-2” and “WRN-16-2” pair, our method achieves 75.99% accuracy, which is higher than other feature-based approaches. For the pair of “ResNet32x4_ResNet8x4” and “WRN-40-2_ShuffleNetV1”, our method outperforms all competitors. Moreover, our method incurs a lower computation cost than feature-based methods, as the latter often requires tedious computation to transform intermediate feature maps that may hinder their application on resource-constrained devices. We assess the training time of different methods on CIFAR-100 in Figure 3, and the results demonstrate that our method achieves a better trade-off between the training efficiency and accuracy than feature-based approaches.
To further evaluate the effectiveness of the proposed LR and DS, we also apply them to other distillation approaches, where the hyper-parameters are set as the same as original papers. For logits-based methods, only DS technique is combined because the logits loss has already been modified. For feature-based methods, both LR and DS are applied. The results show that in most cases, the distillation performance can be further boosted through applying DS and LR. For instance, the original accuracy of VID [18] on the pair of “WRN-40-2” and “ShuffleNetV1” is only 74.41%, which is even lower than 74.83% of vanilla KD. However, the accuracy is increased by 1.47% after applying DS and LR, outperforming the vanilla KD by 1.05%. These results strongly demonstrate the effectiveness of our proposed LR and DS, and also illustrate an encouraging property that LR and DS are highly compatible with the state-of-the-art distillation methods.
| Teacher | ResNet34 | ResNet50 |
| 73.31 | 76.26 | |
| Student | ResNet18 | ResNet18 |
| 70.04 | 70.04 | |
| Vanilla KD [8] | 70.66 | 71.29 |
| LR | 70.83 | 71.36 |
| CTKD [60] | 71.22 | 71.31 |
| VID [18] | 70.30 | 71.11 |
| SRRL [21] | 70.95 | 71.46 |
| SemCKD [31] | 70.87 | 71.41 |
| SRRL+LR | 71.10 | 71.58 |
| CTKD+LR | 71.30 | 71.43 |
ImageNet. We evaluate the performance of our proposed LR technique on ImageNet using two popular teacher-student model pairs, i.e., “ResNet34-ResNet18” and “ResNet50-ResNet18”. The results are presented in Table 7. Compared to vanilla KD, our LR achieves encouraging improvement on Top-1 accuracy, further narrowing the gap between the student and teacher models. This also validates that our method is effective on large-scale datasets. Additionally, we apply LR on other approachs such as SRRL and CTKD, and it obtains more favourable performance compared to other competitors, verifying the compatibility of our proposed method again.
| Baseline: 74.81% | |||||||||
| 0 | 0.1 | 0.5 | 0.8 | 1 | 2 | 4 | 8 | 10 | |
| Acc(%) | 72.96 | 73.73 | 75.02 | 75.30 | 75.76 | 75.75 | 76.60 | 76.54 | 76.46 |
| 0 | 0.1 | 0.5 | 0.8 | 1 | 2 | 4 | 8 | 10 | |
| Acc(%) | 75.01 | 76.31 | 75.09 | 75.34 | 75.76 | 75.54 | 75.20 | 75.07 | 75.45 |
| Baseline: 74.81% | ||||||||
| Fixed | Learnable | |||||||
| 0.5 | 0.7 | 0.8 | 0.85 | 0.9 | 0.95 | |||
| Acc(%) | 75.45 | 75.58 | 75.76 | 75.59 | 75.18 | 75.03 | 75.34 | 75.6 |
-
•
1. For learnable values, we set and , that is, the probability of predicted class and target class in teacher’s prediction, respectively.
4.4 Additional Analysis
Analysis of Coefficients and . We also evaluate the impact of coefficients and in Eq. (11), which are introduced to balance each loss term. For evaluation, we set various values of and ranging from 0 to 10, that is . The results are showed in Table 8. Our method outperforms baseline in most of the cases, showing the effectiveness again. It is also indicated that both the logits loss of the right and wrong parts are indispensable, the absence of either will result in a sharp decline of accuracy, especially when . As rises from 0 to 10, the accuracy first increases gradually and reaches a maximum at the point of . As for , the performance gain are relatively stable with different around 1.
Analysis of Coefficient . We explore the sensitivity of the hyper-parameter in Eq. (9). Table 9 reports the performance with different on CIFAR-100. Since is a coefficient between 0 and 1, we first choose some fixed values as {0.5, 0.7, 0.8, 0.85, 0.9, 0.95}. In addition to these fixed values, we also set as a learnable parameter that varies for different input samples. For example, we directly regard the probabilities of predicted class () and target class () in teacher’s prediction as , whose value ranges are also 0-1. Here, other hyper-parameters and are set as 1. It can be observed that our method shows its superiority to baseline under varying , where the performance gain ranging from 0.22% to 0.95%, and it achieves the best performance when is set to around 0.8. From another perspective, the fluctuation of accuracy is relatively small, demonstrating the robustness of our method to hyper-parameter .
5 Conclusion
Conclusions. Knowledge distillation has been hampered by the issue of incorrect supervision from the teacher model. In this paper, we have proposed to alleviate the impact of such incorrect supervision from two aspects, which are simple but effective. Firstly, we have proposed LR to rectify the wrong predictions of the teacher according to the ground truth. Secondly, we have also introduced DS to select appropriate samples to be supervised by the teacher. Experiments on both small and large-scale datasets have been conducted to justify the effectiveness of the proposed LR and DS. The statistical results have demonstrated that our proposed method achieves better performance than vanilla KD or even feature-based methods, and is more efficient for training without tedious computation to transfer features. Furthermore, as a plug-in technique, our method can be easily combined with other distillation approaches that can further improve their performance.
Limitations and Future Work. For LR, we rectify incorrect predictions by combining the correct information contained in the ground truth, with an assumption that the training samples are labeled correctly. However, in real-world applications, ground truth labels are sometimes incomplete or missing, which limits the effectiveness of LR. Therefore, revising wrong supervision without relying on ground truth deserves further exploration.
Regarding DS, this paper only uses the influence function to estimate the values of each sample. Other estimation methods are also worth investigating in the future, as they may help select more appropriate samples for distillation to further enhance performance. Additionally, the current method of estimating values needs to work on each sample, which would be time-consuming for large-scale datasets. Designing more efficient approaches is also a direction of future work.
References
- [1] S. Han, H. Mao, and W. J. Dally, “Deep Compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” arXiv preprint arXiv:1510.00149, 2015.
- [2] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “MobileNets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
- [3] M. Zawish, S. Davy, and L. Abraham, “Complexity-driven model compression for resource-constrained deep learning on edge,” IEEE Transactions on Artificial Intelligence, pp. 1–15, 2024.
- [4] L. Wang and K.-J. Yoon, “Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 6, pp. 3048–3068, 2022.
- [5] Q. Xu, K. Wu, M. Wu, K. Mao, X. Li, and Z. Chen, “Reinforced knowledge distillation for time series regression,” IEEE Transactions on Artificial Intelligence, pp. 1–11, 2023.
- [6] W.-C. Kao, H.-X. Xie, C.-Y. Lin, and W.-H. Cheng, “Specific expert learning: Enriching ensemble diversity via knowledge distillation,” IEEE Transactions on Cybernetics, vol. 53, no. 4, pp. 2494–2505, 2023.
- [7] Z. Wang, Y. Ren, X. Zhang, and Y. Wang, “Generating long financial report using conditional variational autoencoders with knowledge distillation,” IEEE Transactions on Artificial Intelligence, pp. 1–12, 2024.
- [8] G. Hinton, O. Vinyals, J. Dean et al., “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015.
- [9] L. Wang and K.-J. Yoon, “Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 06, 2021.
- [10] D. Chen, J.-P. Mei, H. Zhang, C. Wang, Y. Feng, and C. Chen, “Knowledge distillation with the reused teacher classifier,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 11 933–11 942.
- [11] S. I. Mirzadeh, M. Farajtabar, A. Li, N. Levine, A. Matsukawa, and H. Ghasemzadeh, “Improved knowledge distillation via teacher assistant,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, 2020, pp. 5191–5198.
- [12] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio, “FitNets: Hints for thin deep nets,” arXiv preprint arXiv:1412.6550, 2014.
- [13] X. Jin, B. Peng, Y. Wu, Y. Liu, J. Liu, D. Liang, J. Yan, and X. Hu, “Knowledge distillation via route constrained optimization,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 1345–1354.
- [14] S. H. Lee, D. H. Kim, and B. C. Song, “Self-supervised knowledge distillation using singular value decomposition,” in Proceedings of the European Conference on Computer Vision, 2018, pp. 339–354.
- [15] N. Passalis, M. Tzelepi, and A. Tefas, “Heterogeneous knowledge distillation using information flow modeling,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 2339–2348.
- [16] J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,” International Journal of Computer Vision, vol. 129, no. 6, pp. 1789–1819, 2021.
- [17] F. Tung and G. Mori, “Similarity-preserving knowledge distillation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 1365–1374.
- [18] S. Ahn, S. X. Hu, A. Damianou, N. D. Lawrence, and Z. Dai, “Variational information distillation for knowledge transfer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 9163–9171.
- [19] D. Chen, J.-P. Mei, Y. Zhang, C. Wang, Z. Wang, Y. Feng, and C. Chen, “Cross-layer distillation with semantic calibration,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 8, 2021, pp. 7028–7036.
- [20] Y. Tian, D. Krishnan, and P. Isola, “Contrastive representation distillation,” arXiv preprint arXiv:1910.10699, 2019.
- [21] J. Yang, B. Martinez, A. Bulat, G. Tzimiropoulos et al., “Knowledge distillation via softmax regression representation learning,” in Proceedings of International Conference on Learning Representations, 2021.
- [22] G. Xu, Z. Liu, X. Li, and C. C. Loy, “Knowledge distillation meets self-supervision,” in Proceedings of the European Conference on Computer Vision, 2020, pp. 588–604.
- [23] H. Zhou and L. Song, “Rethinking soft labels for knowledge distillation: A bias–variance tradeoff perspective,” in Proceedings of International Conference on Learning Representations, 2021.
- [24] T. Kim, J. Oh, N. Y. Kim, S. Cho, and S.-Y. Yun, “Comparing kullback-leibler divergence and mean squared error loss in knowledge distillation,” in Proceedings of International Joint Conference on Artificial Intelligence, 2021, pp. 2628–2635.
- [25] B. Zhao, Q. Cui, R. Song, Y. Qiu, and J. Liang, “Decoupled knowledge distillation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 11 953–11 962.
- [26] S. Zagoruyko and N. Komodakis, “Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer,” arXiv preprint arXiv:1612.03928, 2016.
- [27] Z. Huang and N. Wang, “Like what you like: Knowledge distill via neuron selectivity transfer,” arXiv preprint arXiv:1707.01219, 2017.
- [28] J. Kim, S. Park, and N. Kwak, “Paraphrasing complex network: Network compression via factor transfer,” Advances in Neural Information Processing Systems, pp. 2760–2769, 2018.
- [29] Y. Tian, D. Krishnan, and P. Isola, “Contrastive representation distillation,” in Proceedings of International Conference on Learning Representations, 2020, pp. 1–13.
- [30] H. Zhao, X. Sun, J. Dong, C. Chen, and Z. Dong, “Highlight every step: Knowledge distillation via collaborative teaching,” IEEE Transactions on Cybernetics, vol. 52, no. 4, pp. 2070–2081, 2020.
- [31] C. Wang, D. Chen, J.-P. Mei, Y. Zhang, Y. Feng, and C. Chen, “Semckd: semantic calibration for cross-layer knowledge distillation,” IEEE Transactions on Knowledge and Data Engineering, 2022.
- [32] W. Park, D. Kim, Y. Lu, and M. Cho, “Relational knowledge distillation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 3967–3976.
- [33] N. Passalis, M. Tzelepi, and A. Tefas, “Probabilistic knowledge transfer for lightweight deep representation learning,” IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 5, pp. 2030–2039, 2020.
- [34] J. Gou, L. Sun, B. Yu, S. Wan, W. Ou, and Z. Yi, “Multilevel attention-based sample correlations for knowledge distillation,” IEEE Transactions on Industrial Informatics, vol. 19, no. 5, pp. 7099–7109, 2022.
- [35] M. Toneva, A. Sordoni, R. T. des Combes, A. Trischler, Y. Bengio, and G. J. Gordon, “An empirical study of example forgetting during deep neural network learning,” in Proceedings of International Conference on Learning Representations, 2019, pp. 1–12.
- [36] J. Lin, A. Zhang, M. Lécuyer, J. Li, A. Panda, and S. Sen, “Measuring the effect of training data on deep learning predictions via randomized experiments,” in Proceedings of International Conference on Machine Learning, 2022, pp. 13 468–13 504.
- [37] S. Paul, J. H. Bappy, and A. K. Roy-Chowdhury, “Non-uniform subset selection for active learning in structured data,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2017, pp. 6846–6855.
- [38] Z. Liu, H. Ding, H. Zhong, W. Li, J. Dai, and C. He, “Influence selection for active learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9274–9283.
- [39] S. Sinha, S. Ebrahimi, and T. Darrell, “Variational adversarial active learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 5972–5981.
- [40] S. Wang, Y. Li, K. Ma, R. Ma, H. Guan, and Y. Zheng, “Dual adversarial network for deep active learning,” in Proceedings of the European Conference on Computer Vision, 2020, pp. 680–696.
- [41] S. Ruder and B. Plank, “Learning to select data for transfer learning with bayesian optimization,” arXiv preprint arXiv:1707.05246, 2017.
- [42] F. Xiong, J. Barker, Z. Yue, and H. Christensen, “Source domain data selection for improved transfer learning targeting dysarthric speech recognition,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2020, pp. 7424–7428.
- [43] J. Yoon, S. Arik, and T. Pfister, “Data valuation using reinforcement learning,” in Proceedings of International Conference on Machine Learning, 2020, pp. 10 842–10 851.
- [44] P. W. Koh and P. Liang, “Understanding black-box predictions via influence functions,” in Proceedings of International Conference on Machine Learning, 2017, pp. 1885–1894.
- [45] R. D. Cook and S. Weisberg, Residuals and influence in regression. New York: Chapman and Hall, 1982.
- [46] A. Ghorbani and J. Zou, “Data shapley: Equitable valuation of data for machine learning,” in Proceedings of International Conference on Machine Learning, 2019, pp. 2242–2251.
- [47] G. Pruthi, F. Liu, S. Kale, and M. Sundararajan, “Estimating training data influence by tracing gradient descent,” Advances in Neural Information Processing Systems, vol. 33, pp. 19 920–19 930, 2020.
- [48] Z. Hammoudeh and D. Lowd, “Training data influence analysis and estimation: A survey,” arXiv preprint arXiv:2212.04612, 2022.
- [49] A. Li, L. Zhang, J. Wang, F. Han, and X.-Y. Li, “Privacy-preserving efficient federated-learning model debugging,” IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 10, pp. 2291–2303, 2021.
- [50] P. J. Huber, “Robust statistics,” in International Encyclopedia of Statistical Science, 2011, pp. 1248–1251.
- [51] T. Wen, S. Lai, and X. Qian, “Preparing lessons: Improve knowledge distillation with better supervision,” Neurocomputing, vol. 454, pp. 25–33, 2021.
- [52] A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” Technical Report, CIFAR, 2009.
- [53] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Ieee, 2009, pp. 248–255.
- [54] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [55] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [56] N. Ma, X. Zhang, H.-T. Zheng, and J. Sun, “ShuffleNet V2: Practical guidelines for efficient cnn architecture design,” in Proceedings of the European Conference on Computer Vision, 2018, pp. 116–131.
- [57] X. Zhang, X. Zhou, M. Lin, and J. Sun, “ShuffleNet: An extremely efficient convolutional neural network for mobile devices,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 6848–6856.
- [58] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 4510–4520.
- [59] S. Hegde, R. Prasad, R. Hebbalaguppe, and V. Kumar, “Variational student: Learning compact and sparser networks in knowledge distillation framework,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2020, pp. 3247–3251.
- [60] Z. Li, X. Li, L. Yang, B. Zhao, R. Song, L. Luo, J. Li, and J. Yang, “Curriculum temperature for knowledge distillation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 2, 2023, pp. 1504–1512.
- [61] N. Passalis and A. Tefas, “Learning deep representations with probabilistic knowledge transfer,” in Proceedings of the European Conference on Computer Vision, 2018, pp. 268–284.